Choosing the in loss: rate adaptivity on the symmetric location problem
Abstract
Given univariate random variables distributed uniformly on , the sample midrange is the MLE for the location parameter and has estimation error of order , which is much smaller compared with the error rate of the usual sample mean estimator. However, the sample midrange performs poorly when the data has say the Gaussian distribution, with an error rate of . In this paper, we propose an estimator of the location with a rate of convergence that can, in many settings, adapt to the underlying distribution which we assume to be symmetric around but is otherwise unknown. When the underlying distribution is compactly supported, we show that our estimator attains a rate of convergence of up to polylog factors, where the rate parameter can take on any value in and depends on the moments of the underlying distribution. Our estimator is formed by minimizing the -loss with respect to the data, for a power chosen in a data-driven way – by minimizing a criterion motivated by the asymptotic variance. Our approach can be directly applied to the regression setting where is a function of observed features and motivates the use of loss function with a data-driven in certain settings.
1 Introduction
Given random variables , the optimal estimator for the center is not the usual sample mean but rather the sample midrange , which is also the MLE. Indeed, we have that
which is far smaller than the error of the sample mean; a two points argument in Le Cam (1973) shows that the rate is optimal in this case. One may also show via the Lehman–Scheffe Theorem that sample midrange is the uniformly minimum variance unbiased (UMVU) estimator. However, sample midrange is a poor choice when , where we have that is of order . These observations naturally motivate the following question: let be a univariate density symmetric around and suppose has the distribution which is the location shift of , can we construct an estimator of the location whose rate of convergence adapts to the unknown underlying distribution ?
This question has not yet been addressed by the wealth of existing knowledge, dating back to at least Stein (1956), on symmetric location estimation, which focuses on semiparametric efficiency for asymptotically Normal estimators. The classical theory states that when the underlying density is regular in the sense of being differentiable in quadratic mean (DQM), there exists -consistent estimator which has the same asymptotic variance as the best estimator when one does know the underlying density ; in other words, under the regular regime and in terms of asymptotic efficiency, one can perfectly adapt to the unknown distribution. The adaptive estimators rely on being able to consistently estimate the unknown density at an appropriate rate.
In contrast, the setting where can be estimated at a rate faster than is irregular in that the Fisher information is infinity and any -asymptotically Normal estimator is suboptimal; the underlying distribution is not DQM and is difficult to estimate. Even the problem of choosing between only the sample mean and the sample midrange is nontrivial, as we show in this paper that tried-and-true method of cross-validation fails in this setting (see Remark 2.1 for the detailed discussion).
If the underlying density is known, the optimal rate in estimating the location is governed by how quickly the function decreases as goes to zero, where is the Hellinger distance. To be precise, for any estimator , we have
where the supremum can be taken in a local ball of shrinking radius around any point in ; see for example Theorem 6.1 of Chapter I of Ibragimov and Has’ Minskii (2013) for an exact statement. Le Cam (1973) also showed that the MLE attains this convergence rate under mild conditions. Therefore, if is of order for some , then the optimal rate of the error is . If the underlying density is DQM, then we have that which yields the usual rate of . But, if is the uniform density on , we have which gives an optimal rate of .
The behavior of the function depends on the smoothness of the underlying density . In the extreme case where has a Dirac delta point mass at 0 for instance, is bounded away from 0 for any . This is expected since, in this case, we can estimate perfectly by localizing the discrete point mass. More generally, discontinuities in the density function or singularities in its first derivative anywhere can increase and thus lead to a faster rate in estimating the location . Interested readers can find a detailed discussion and a large class of examples in Chapter VI of Ibragimov and Has’ Minskii (2013).
When the underlying density is unknown, it becomes unclear how to design a rate adaptive location estimator. One possible approach is to nonparametrically estimate , but we would need our density estimator to be able to accurately recover the points of discontinuities in or singularities in – this goes beyond the scope of existing theory on nonparametric density estimation which largely deals with estimating a smooth density . Because of the clear difficulty in analyzing rate adaptive location estimation problem in its fullest generality, we focus on rate adaptivity among compactly supported densities which exhibit discontinuity or singularity at the boundary points of the support; the uniform density on for instance has discontinuity at the boundary points and .
With the more precise goal in mind, we study a simple class of estimators of the form where the power is selected in a data-driven way. Estimators of this form encompass both the sample mean , with , and the sample midrange, with . These estimators are easy to interpret, easy to compute, and can be extended in a straightforward way to the regression setting where is a linear function of some observed covariates.
The key step is selecting the optimal power from the data; in particular, must be allowed to diverge with in order for the resulting estimator to have an adaptive rate. Since is unbiased for any , the ideal selection criterion is to minimize the variance. In this work, we approximate the variance of by its asymptotic variance, which has a finite sample empirical analog that can be computed from the empirical central moments of the data. We then select by minimizing the empirical asymptotic variance, using Lepski’s method to ensure that we consider only those ’s for which the empirical asymptotic variance is a good estimate of the population version. For any distribution with a finite second moment, the resulting estimator has rate of convergence at least as fast as , where we use the notation to suppress log-factors. Moreover, for any compacted supported density that satisfies a moment condition of the form for some , our estimator attains an adaptive rate of .
Our estimation procedure can be easily adapted to the linear regression setting where we have where has a distribution symmetric around 0. It is computationally fast using second order methods and can be directly applied on real data. Importantly, it is robust to violation of the symmetry assumption. More precisely, if and the noise has a distribution that is asymmetric around 0 but still has mean zero, then our estimator will converge to nevertheless.
The rest of our paper is organized as follows: we finish Section 1 reviewing existing work and defining commonly used notation. In Section 2, we formally define the problem and our proposed method; we also show that our proposed method has a rate of convergence that is at least (Theorem 2.1). In Section 3, we prove that our proposed estimator has an adaptive rate of convergence where is determined by a moment condition on the noise distribution. We perform empirical studies in Section 4 and conclude with a discussion of open problems in Section 5.
1.1 Literature review
Starting from the seminal paper by Stein (1956), a long series of work, for example Stone (1975), Beran (1978), and many others (Van Eeden, 1970; Bickel, 1982; Schick, 1986; Mammen and Park, 1997; Dalalyan et al., 2006) showed, under the regular DQM setting, we can attain an asymptotically efficient estimator by taking a pilot estimator , applying a density estimation method on the residues to obtain a density estimate , and then construct either by maximizing the estimated log-likelihood, by taking one Newton step using an estimate of the Fisher information, or by various other related schemes; see Bickel et al. (1993) for more discussion on adaptive efficiency. Interestingly, Laha (2021) recently showed that the smoothness assumption can be substituted by a log-concavity condition instead.
Also motivated in part by the contrast between sample midrange and sample mean, Baraud et al. (2017) and Baraud and Birgé (2018) propose the -estimator. When the underlying density is known, the -estimator has optimal rate in estimating the location. When is unknown, the -estimator would need to estimate nonparametrically; it is not clear under what conditions it would attain adaptive rate. Moreover, computing the -estimator in practice is often difficult.
Our estimator is related to methods in robust statistics (Huber, 2011), although our aim is different. Our asymptotic variance based selector can be seen as a generalization of a procedure proposed by Lai et al. (1983), which uses the asymptotic variance to select between the sample mean and the median. Another somewhat related line of work is that of Chierichetti et al. (2014) and Pensia et al. (2019), which study location estimation when are allowed to have different distributions, all of which are still symmetric around 0, and construct robust estimators that interestingly adapt to the heterogeneity of the distributions of the ’s.
1.2 Notation
We write . We write , , and . For two functions , we write if there exists a universal constant such that ; we write or if and . We use to denote a positive universal constants whose value may be different from instance to instance. We use the notation to represent rate of convergence ignoring poly-log factors.
2 Method
We observe random variables such that
where is the unknown location and where is an unknown distribution with density symmetric around zero. Our goal is to estimate from the observations .
2.1 A simple class of estimators
Our approach is motivated by the fact that both the sample mean and the sample midrange minimize the norm of the residual for different values of . More precisely,
This suggests an estimation scheme where we first select the power in a data-driven way and then output the empirical center with respect to the norm:
It is clear that and that approaches as increases, that is, . We in fact have a deterministic bound of in the following lemma:
Lemma 1.
Let be arbitrary points on , then
We prove Lemma 1 in Section S1 of the appendix. It is important to note that, by Lemma 1, we need to consider as large as to approximate with error that is of order . Therefore, in settings where is optimal, we need to be able to diverge with .
Estimators of form is simple, easy to compute via Newton’s method (see Section S1.4 of the appendix), and interpretable even for asymmetric distributions. The key question is of course, how do we select the power ? It is necessary to allow to increase with to attain adaptive rate but selecting a power that is too large can introduce tremendous excess variance. As is often said, ”with great power comes great responsibility”.
Before describing our approach in the next subsection, we give some remarks on two approaches that seem reasonable but in fact have significant limitations.
Remark 2.1.
(Suboptimality of Cross-validation)
Cross-validation is a natural method for choosing the best estimator among some family, but this fails in our problem. To illustrate why, we consider the simpler problem where we choose between only the sample mean and the sample midrange . We consider held-out validation where we divide our data into training data and test data each with data points. We compute on training data, evaluate test data MSE
| (1) |
for and also for the midrange estimator. Since the first term on the right hand side of (1) is constant, we select if .
Now assume that the data follows the uniform distribution on , so that the optimal estimator is the sample midrange . We observe that and whereas in probability. Hence, by the Portmanteau Theorem,
where and are independent random variables. In other words, held-out validation has a non-vanishing probability of incorrectly selecting over even as and thus has an error of order , which is far larger than the optimal rate. It is straightforward to extend the argument to the setting of -fold cross-validation for any fixed .
Remark 2.2.
(Suboptimality of MLE with respect to the generalized Gaussian family)
We observe that is the maximum likelihood estimator for the center when the data follow the Generalized Normal GN distribution, which is also known as the Subbotin distribution (Subbotin, 1923), whose density is of the form
where denotes the Gamma function. This suggests a potential approach where we determine by fitting the data to the potentially misspecified Generalized Gaussian family via likelihood maximization:
This approach works well if the underlying density of the noise belongs in the Generalized Gaussian family. Otherwise, it may be suboptimal: it may select a that is too small when the optimal is large and it may select a that is too large when the optimal is small. We give a precise and detailed discussion of the drawbacks of the generalized Gaussian MLE in Section 3.2.
2.2 Asymptotic variance
Under the assumption that the noise has a distribution symmetric around , it is easy to see by symmetry that for any fixed . We thus propose a selection scheme based on minimizing the variance. The finite sample variance of is intractable to compute, but for any fixed , assuming , we have that as , where
| (2) |
is the asymptotic variance of . Thus, from an asymptotic perspective, is a better estimator of if is small. When is allowed to depend on , may not be a good approximation of the finite sample variance of , but the next example suggests that is still a sensible selection criterion.
Example 1.
When , straightforward calculation yields that for any and thus, we have . We see that is minimized when , in accordance with the fact that the sample midrange is the optimal estimator among the class of estimators . More generally, if has a density supported on which is symmetric around and satisfies the property that is bounded away from 0 and for all , then one may show that . On the other hand, if , then, using the fact that , we can directly calculate that that , which goes to infinity as as expected. Using the fact that is the MLE, we have that is minimized at in the Gaussian case.
2.3 Proposed procedure
We thus propose to select by minimizing an estimate of the asymptotic variance . For simplicity, we restrict our attention to in the main paper and discuss how to select in Remark 2.6. A natural estimator of is
| (3) |
Although has pointwise consistency in that it is a consistent estimator of for any fixed (see Lemma 2 in Section S1.2 of the appendix), we require uniform consistency since our goal is to minimize as a surrogate of . This unfortunately does not hold; if we allow to diverge with , the error can be arbitrarily large. This occurs because, if we fix and increase , the finite average does not approximate the population mean and behaves closer to instead. Indeed, for any fixed and any deterministic set of points , we have
| (4) |
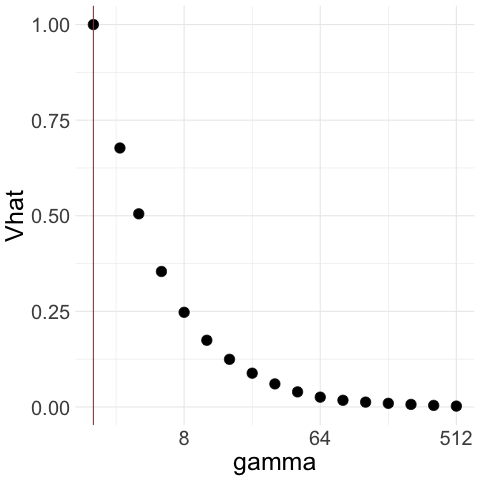
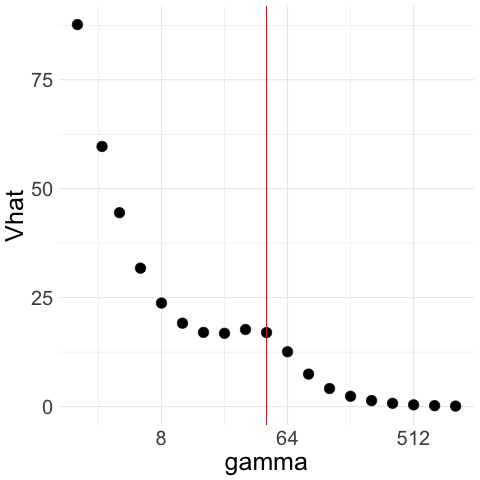
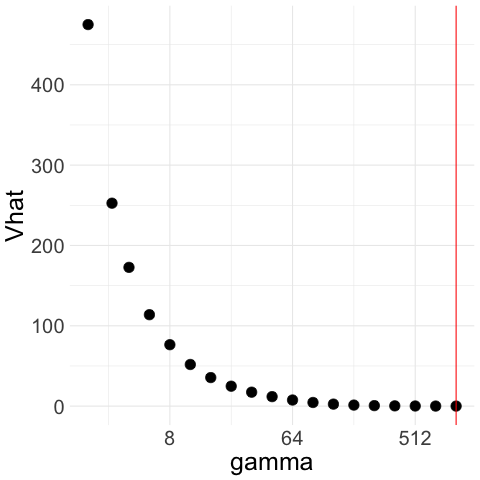
Therefore, unconstrained minimization of over all would select . See for example Figure 1(a), where we generate Gaussian noise and plot for a range of ’s; although the population tends to infinity when is large, the empirical increases for moderately large but then, as further increases, decreases and tends to .
Luckily, we can overcome this issue by restricting our attention to ’s that are not too large. To be precise, we add an upper bound and minimize only among . We select using Lepski’s method, which is typically used to select smoothing parameters in nonparametric estimation problems (Lepskii, 1990, 1991) but can be readily adapted to our setting. The idea is to construct confidence intervals for a set of ’s, starting with , and take to be the largest such that the confidence intervals all intersect. We would thus exclude for which is far from and is too small.
This leads to our full estimation procedure below, which we refer to as CAVS (Constrained Asymptotic Variance Selector):
Let be a tuning parameter and let be the set of candidate ’s. Define as (3) for and define .
-
1.
Define as the largest such that
-
2.
Select
-
3.
Output
(5)
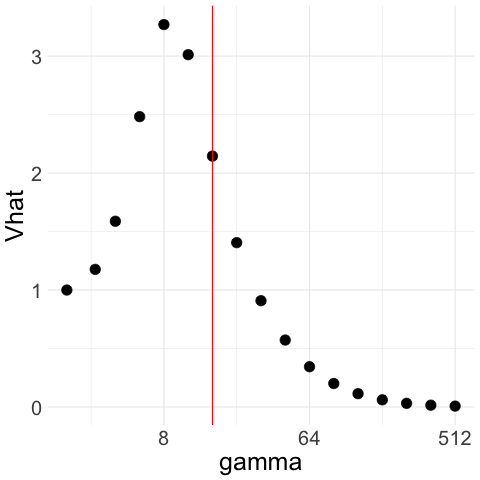
The candidate set can be the entire half-line . In practice, we take to be a finite set so that we are able to compute the minimizer of . A convenient and computationally efficient choice is .
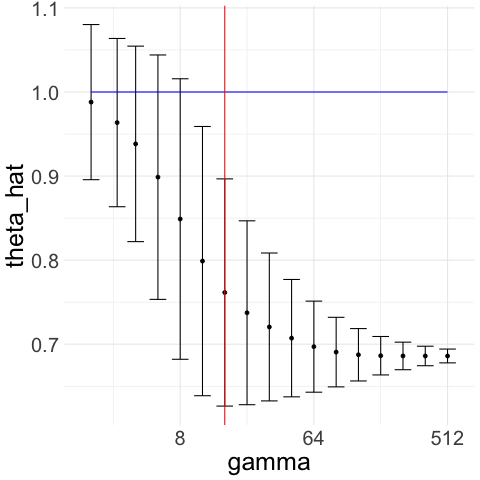
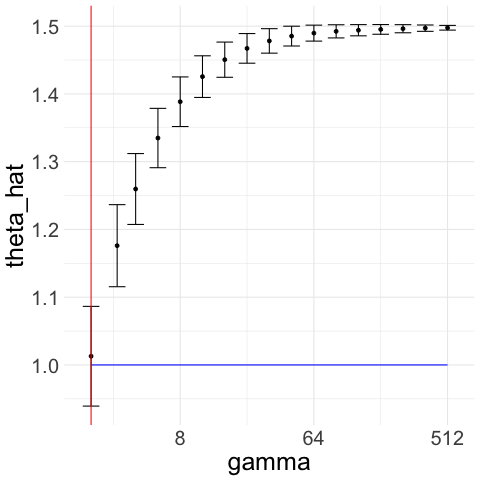
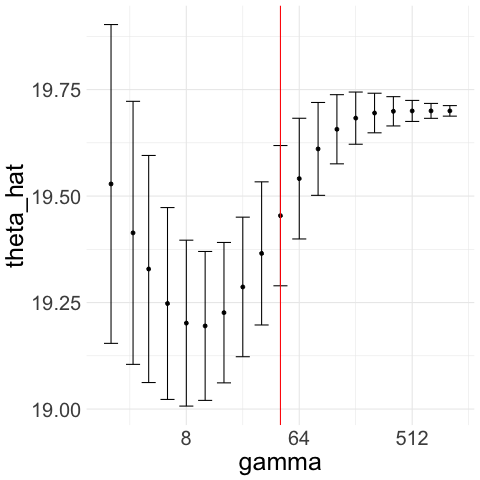
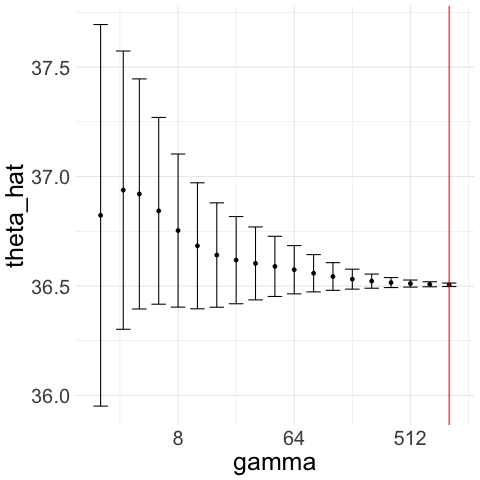
We illustrate how the CAVS procedure works with two examples in Figure 1. In Figure 1(a), we generate Gaussian noise ; we plot for a exponentially increasing sequence of ’s ranging from 2 to 512. The constraint upper bound is given by the red line in the figure. Unconstrained minimization of leads to . Figure 1(b) illustrates the Lepski method that we use to choose upper bound : we compute confidence intervals of width around for the whole range of ’s. To get , we pick the largest such that the intersection of all the confidence intervals to the left of is non-empty.
This allows us to avoid the region where is very small but the actual asymptotic variance is very large. Indeed, if is much larger than the variance , then likely to be quite far from the sample mean and thus, if is also small, then is unlikely to overlap with the confidence interval around the sample mean.
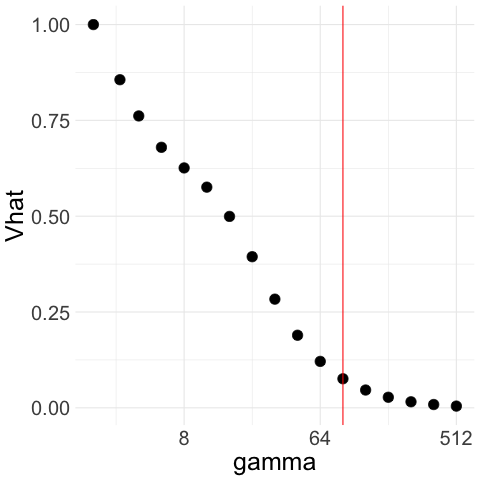
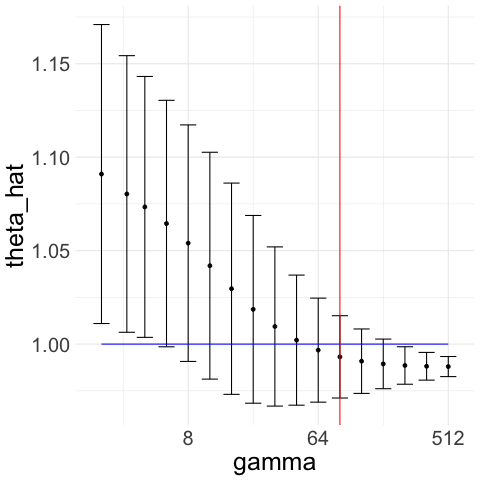
Therefore, with Gaussian noise, CAVS selects by minimizing only to the left of (red line) in Figure 1(a). In contrast, if decreases as increases, then remains close to the sample mean and the confidence interval overlaps with that of the sample mean even when is large, which means we would select a large as desired. We illustrate this in Figure 1(c) and 1(d), where we generate truncated Gaussian noise by truncating at ; that is, we generate Gaussian samples and keep only those that lie in the interval . In this case, the optimal is and the optimal rate is . From Figure 1(c), we see that our procedure picks a large .
Remark 2.3.
(Selecting parameter)
Our proposed CAVS procedure has a tuning parameter which governs the strictness of the constraint. Smaller will in general result in a smaller and hence a stronger constraint. For our theoretical results, namely Theorem 3.1, it suffices to choose to be very slowly growing so that . For practical data analysis applications, we recommend as a conservative choice based on simulation studies in Section 4.1
Remark 2.4.
(Robustness to asymmetry)
One important aspect of CAVS is that it is robust to violations of the symmetry assumption. If the density of the noise has mean zero but is asymmetric (so that is the mean of ), then, for various ’s that are greater than 2, the -th center of may be different from ; that is so that is a biased estimator of . In such cases however, the confidence interval will, for large enough , be concentrated around and thus not overlap with the confidence interval about the sample mean , which will concentrated around . Therefore, we would have and the constraint would thus exclude any biased . We illustrate an example in Figure 2 where because is biased, we have that and thus, we select and the resulting estimator still converges to . Indeed, our basic convergence guarantee–formalized in Theorem 2.1–does not require the noise distribution to be symmetric around , it only requires the noise to have mean zero.
Remark 2.5.
(Extension to the regression setting)
We can directly extend our estimation procedure to the linear regression setting. Suppose we observe for where is a random vector on , , and is an independent noise with a distribution symmetric around .
Then, we would compute, for each in a set ,
We define . Using Taylor expansion, it is straightforward to show that . Thus, for a given , our estimation procedure first computes as the largest such that
where we use the notation to denote the Cartesian product. Then, we select the minimizer and output .
Remark 2.6.
(Selecting )
When the noise is heavy-tailed, it is desirable to allow consideration of ; note that corresponds to the sample median . For , the estimator given in (3) is not appropriate. In particular, if has a density and population median 0 and that , then the asymptotic variance of sample median is instead of (2). For , expression (2) holds but the estimator may behave poorly because of the negative power in the denominator. We do not have a general way of estimating for . In the specific case of the sample median , there are various good estimators of the variance. For instance, Bloch and Gastwirth (1968) proposed an approach based on density estimation and Lai et al. (1983) proposed an approach based on the bootstrap. The general idea of selecting an estimator using asymptotic variance is not specific to the -centers; one can also add say Huber loss minimizers into the set of candidate estimators provided that there is a good way to estimate the asymptotic variance.
2.4 Basic properties of the estimator
Using the definition of , we can directly show that must be close to the sample mean and that the error of is at most where .
Theorem 2.1.
Let be the empirical variance of . For any , it holds surely that
Therefore, if we additionally have that , then, writing ,
Proof.
Since , we have by the definition of that
Since by definition of and since and , the first claim immediately follows. The second claim directly follows from the first claim. ∎
It is important to note that Theorem 2.1 does not require symmetry of the noise distribution . If has a distribution asymmetric around but , then Theorem 2.1 implies that converges to as might be desired.
Remark 2.7.
An important property of is that it is shift and scale invariant in the following sense: if we scale our data with the transformation where and and then compute on , then . This follows from the fact that is shift and scale invariant. Likewise, we see that is shift and scale equivariant in that if we compute on , then .
3 Adaptive rate of convergence
Theorem 2.1 shows that, so long as is chosen to be not too large and the noise has finite variance, then our proposed estimator has an error that is at most . In this section, we show that if the noise has a density that is in a class of compactly supported densities, then our estimator can attain an adaptive rate of convergence of for any , depending on a moment property of the noise distribution.
Theorem 3.1.
Suppose are independent and identically distributed with a distribution symmetric around . Suppose there exists , and such that for all . Let be a subset of with and suppose contains for all integer .
Let be a constant that depends only on ; let be defined as (5). The following then hold:
-
1.
If , then
-
2.
If , then
Therefore, we can choose and , without any knowledge of , so that our estimator has an adaptive rate of convergence
where can take on any value in depending on the underlying noise distribution. The adaptive rate is, up to log-factors, minimax optimal for the class of densities satisfying ; see Remark 3.2 for more details.
We relegate the proof of Theorem 3.1 to Section S2.1 of the appendix, but give a sketch of the proof ideas here. First, by using the moment condition as well as Talagrand’s inequality, we give the following uniform bound to : that for all . Using this bound in conjunction with another uniform bound on , we then can guarantee that is large enough in that . These results in turn yields the key fact that is also sufficiently large in that . We then bound the error of by the inequality
where is the sample midrange. We control the first term through Lemma 1 and the second term using the moment condition. The resulting bound gives the desired conclusion of Theorem 3.1.
Remark 3.1.
The condition that for all implies that is supported on . This is not as restrictive as it appears: using the fact that is scale equivariant, it is straightforward to show that if takes value on for any and satisfies , then we have that .
3.1 On the moment condition in Theorem 3.1
The moment condition constrains the behavior of the density around the boundary of the support . The following Proposition formalizes this intuition.
Proposition 1.
Let and suppose is a random variable with density satisfying
for dependent only on . Then, there exists , dependent only on , such that, for all ,
Example 2.
Using Proposition 1, we immediately obtain examples of noise distributions where the rates of convergence of our location estimator vary over a wide range.
-
1.
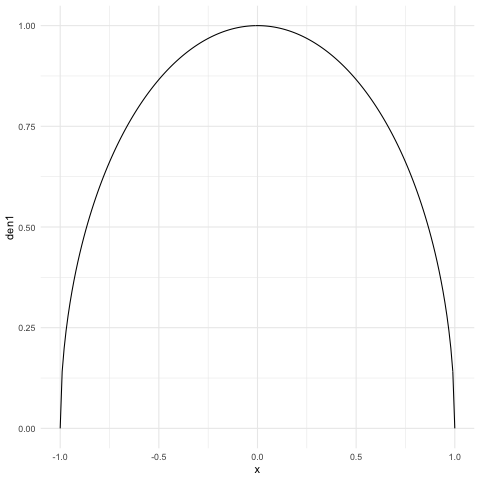
When has the semicircle density (see Figure 3(a)), then so that has rate , where we use the notation to indicate that we have ignored polylog terms.
-
2.
When , we have that so that has rate .
-
3.
More generally, let be a symmetric continuous density on and let be a density that results from truncating , that is, . If , then where depend on . In particular, if is a truncated Gaussian, then also has rate.
-
4.
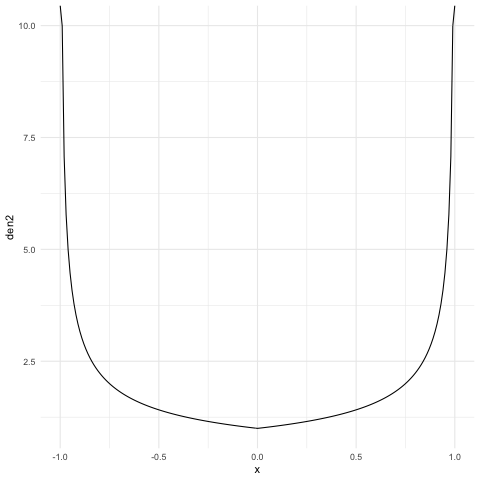
Suppose has a U-shaped density of the form (Figure 3(b)), then so that has rate .
Remark 3.2.
By Proposition 6 and the subsequent Remark S2.1 in Section S2.2 of the Appendix, we have that if a density is of the form for , then we have that, writing ,
for and dependent only on . From Le Cam (1973, Proposition 1), any estimator has a rate lower bounded by the fact that so that among the class of densities
| (6) |
our proposed estimator has a rate of convergence that is minimax optimal up to poly-log factors.
3.2 Comparison with the MLE
Recall from Remark 2.2 that for and , the generalized Gaussian distribution (also known as the Subbotin distribution) has a density of the form . We note that the uniform distribution on is a limit point of the generalized Gaussian class where we let .
Using univariate observations , we may then compute the MLE of with respect to the generalized Gaussian family:
For any fixed , we may minimize over and to obtain that
where
A natural question then is how good is as a selection procedure? Would the resulting location estimator have good properties? If the density of belongs to the generalized Gaussian class, then we expect to perform well. But when there is model misspecification, we show in this section that performs suboptimally compared to the CAVS estimator that we propose in Section 2.3.
To start, let us define the population level likelihood function for every
We define and . We note that if , then and if is supported on the real line, then . Moreover, by Lemma 2 (in Section S1.2 of the appendix), we have that, for any fixed , we have that .
Define as the minimizer of . We show in the next Proposition that when the noise is supported on with a small but positive density value at the boundary, then even though the optimal selection of is to take since the sample midrange would have a rate of convergence that is at least as fast as .
Proposition 2.
Suppose where has a distribution symmetric around . Define .
-
1.
If is supported on all of , then .
-
2.
Suppose has a density supported and continuous on . Let be the Euler–Mascheroni constant. If the density value at the boundary satisfies , then .
-
3.
Suppose has a density supported and continuous on . If the density value at the boundary satisfies , then is a local minimum of .
If the noise density is continuous and has boundary value , then Proposition 2 suggests that we would not expect . More precisely, we have that and thus, by Lemma 2, when is large enough, we also have almost surely. Therefore, selecting by minimizing would always favor a finite over . As a result, selecting based on MLE yields a suboptimal rate of .
In contrast, Theorem 3.1 shows that under the same setting, our proposed CAVS estimator selects a divergent which can yield an error that is smaller than for . In fact, there are settings in which the density at the boundary is equal to zero, that is, , where our proposed estimator can have a rate of convergence that is faster than ; for example, we see in that is when the noise has the semicircle density.
We note that although Proposition 2 is stated for supported on , by scale invariance of , Proposition 2 holds for support of the form , where the the condition on the density generalizes to .
Remark 3.3.
Another drawback, one that is perhaps more alarming, of selecting based on the Generalized Gaussian likelihood is that the resulting location estimator may have a standard deviation (and hence error) that is larger than .
Consider the following example: let be the density of , where follows the standard Cauchy distribution, let , and let the noise have a mixture density for some . We let as usual.
If so that , then is minimized at . It also holds, when is sufficiently small (see Lemma 8), the likelihood is also minimized at so that the likelihood based selector would likely output . However, for any , we have that , the asymptotic variance of , is . In contrast, our proposed procedure would output the sample mean , which has finite asymptotic variance. Intuitively, the CAVS procedure behaves better because it takes into account the higher moment whereas the likelihood selector is based only on .
4 Empirical studies
We perform empirical studies on simulated data to verify our theoretical results in Section 3. We also analyze a dataset of NBA player statistics for the 2020-2021 season to show that our proposed CAVS estimator can be directly applied to real data.
4.1 Simulations
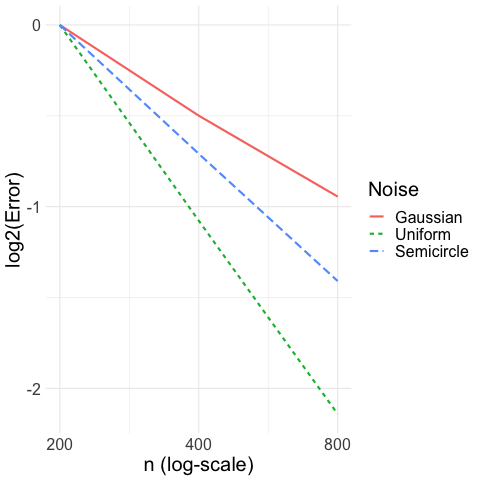
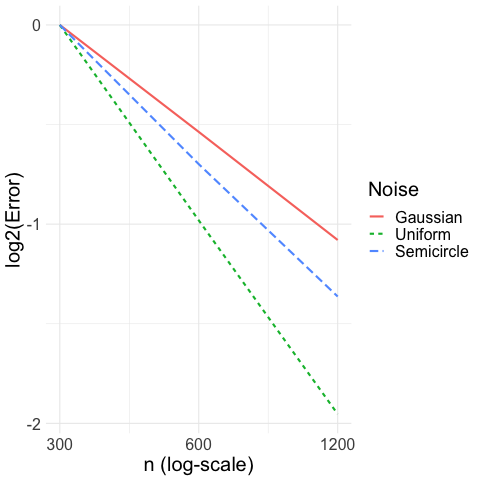
Convergence rate for location estimation: Our first simulation takes the location estimation setting where for . We let the distribution of the noise be either Gaussian , uniform , or semicircle (see Example 2). We let the sample size vary between . We compute our proposed CAVS estimator (with ) and plot, in Figure 4(a), log-error versus the sample size , where is plotted on a logarithmic scale. Hence, a rate of convergence of would yield an error line of slope in Figure 4(a). We normalize the errors so that all the lines have the same intercept. We see that error under uniform noise has a slope of , error under semicircle noise has a slope of , and error under Gaussian noise has a slope of exactly as predicted by Theorem 2.1 and Theorem 3.1.
Convergence rate for regression: Then, we study the regression setting where for . We let the distribution of the noise be either Gaussian , uniform , or the semicircle density given in Example 2. We let the sample size vary between . We apply the regression version of the CAVS estimate as described in Remark 2.5 (with ), and plot, in Figure 4(a), log-error versus the sample size , where is plotted on a logarithmic scale. We see that CAVS also has adaptive rate of convergence; the uniform noise yields a rate of , the semicircle noise yields a rate of , and the Gaussian noise yields a rate of as increases, as predicted by our theory.
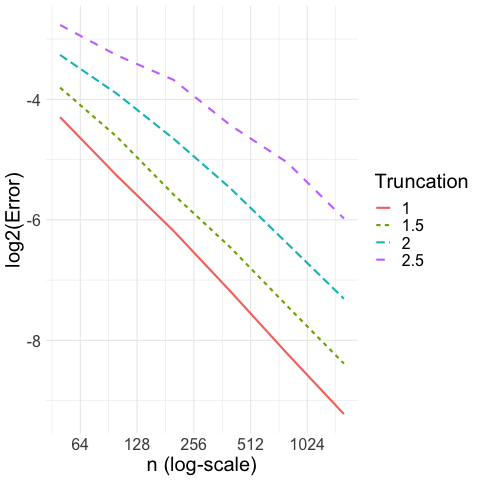
Convergence rate for truncated Gaussian at different truncation levels: In Figure 5(a), we take the location model where has the density for some and where is chosen so that always has unit variance. In other words, we sample by first generating , keep only if , and then take where is chosen so that . We use four different truncation levels ; we let the sample size vary from to and compute our CAVS estimate (with ). We plot in Figure 5(a), the log-error versus the sample size , where is plotted on a logarithmic scale. We observe that when the truncation level is or or , the error is of order . When the truncation level is , the error behaves like for small but transitions to when becomes large. This is not surprising since, when is small, it is difficult to know whether the ’s are drawn from or drawn from truncated Gaussian with a large truncation level.
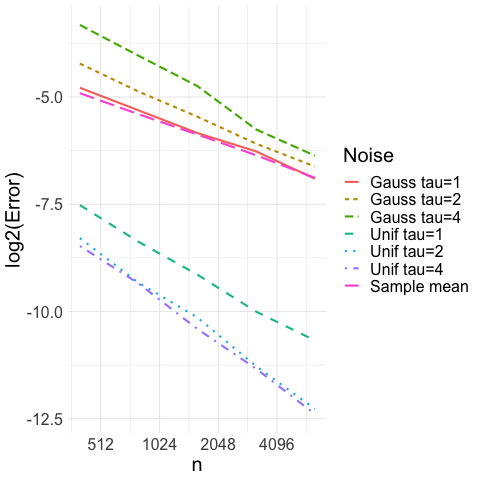
Convergence rate for different : In Figure 5(b), we take the location model and take to be either Gaussian or uniform where is chosen so that has unit variance. We then apply our proposed CAVS procedure for different levels of , ranging from . We let the sample size vary from to and plot the log-error versus the sample size , where is plotted on a logarithmic scale. For comparison, we also plot the error of the sample mean , which does not depend on the distribution of since we scale to have unit variance in both settings. We observe in Figure 5(b) that when , the CAVS estimate basically coincides with the sample mean if but has much less error when is uniform. As we increase , CAVS estimator has increased error under the Gaussian setting when since we select more often; under the uniform setting, it has less error. Based on these studies, we recommend in practice as a conservative choice.
4.2 Real data experiments
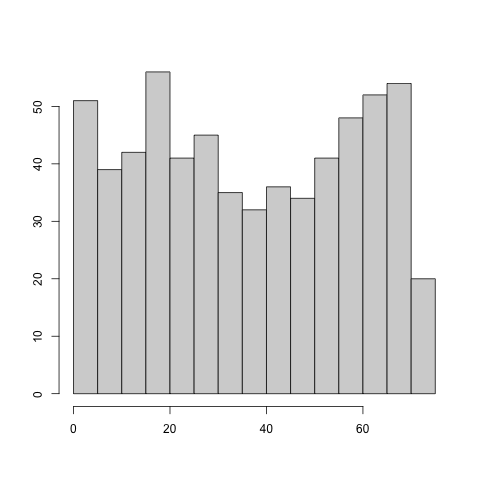
Uniform or truncated Gaussian data are not ubiquitous but they do appear in real world datasets. In this section, we use the CAVS location estimation and regression procedure to analyze a dataset of 626 NBA players in the 2020–2021 season. We consider variables AGE, MPG (average minutes played per game), and GP (games played).
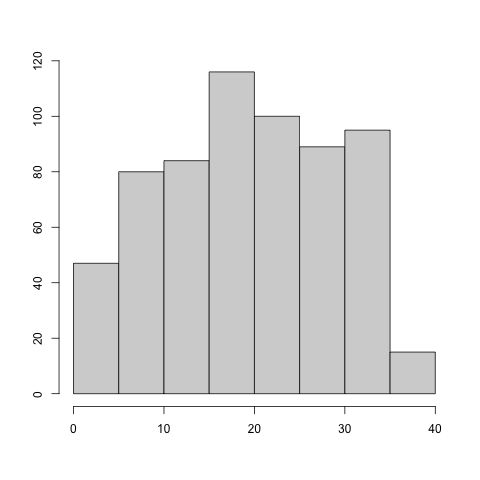
Both MPG and GP variables are compactly supported. They also do not exhibit clear signs of asymmetry; MPG has an empirical skewness of and GP has an empirical skewness of . We apply the CAVS procedure to both with and we obtain for MPG variable and for the GP variable. In contrast, the AGE variable has a skewness of and when we apply CAVS procedure (still with ), we obtain . These results suggest that CAVS can be useful for practical data analysis.
Moreover, we also study the CAVS regression method by considering two regression models:
where W is an independent Gaussian feature add so that we can assess how close the estimated coefficient is to zero to gauge the estimation error. We estimate on 100 randomly chosen training data points and report the predictive error on the remaining test data points; we also report the average value of , which we would like to be as close to 0 as possible. We perform 1000 trials of this experiment (choosing random training set in each trial) and report the performance of CAVS versus OLS estimator in Table 1.
| Model 1 Pred. Error | Model 1 | Model 2 Pred. Error | Model 2 | |
|---|---|---|---|---|
| CAVS | 0.686 | 0.045 | 0.95 | 0.082 |
| OLS | 0.689 | 0.140 | 1.04 | 0.205 |
5 Discussion
In this paper, we give an estimator of the location of a symmetric distribution whose rate of convergence can be faster than the usual and can adapt to the unknown underlying density. There are a number of interesting open questions that remain:
-
•
It is unclear whether the excess log-factors in our adaptive rate result is an artifact of the analysis or an unavoidable cost of adaptivity.
-
•
We emphasize that it is the discontinuity of the noise density (or the singularities of the derivative ) on the boundary of the support that allows our estimator to have rates of convergence faster than . Any discontinuities of the noise density (or the singularities of the density derivative) in the interior of the support will also lead to an infinite Fisher information (for the location parameter) and open the possibility of faster-than-root-n rate. Our estimator unfortunately cannot adapt to discontinuities in the interior. For example, if the noise density is a mixture of Uniform and Gaussian , the tail of the Gaussian component would imply that our estimator cannot have a rate faster than root-n. On the other hand, an oracle with knowledge of the discontinuity points at could still estimate at rate with the estimator . One potential approach for adapting to discontinuities in the interior is to first estimate the position of these discontinuity points. However, the position must be estimated with a high degree of accuracy as any error would percolate to the down-stream location estimator. We leave a formal investigation of this line of inquiry to future work.
-
•
It would be nontrivial to extend our rate adaptivity result to the multivariate setting, for instance, if where and is uniformly distributed on a convex body that is balanced in that so that . When is known, it would be natural to study estimators of the form where is the gauge function (Minkowski functional) associated with . In general, it would be necessary to simultaneously estimate and . Xu and Samworth (2021) studies an approach where one first estimates via the sample mean and then compute using the convex hull of the directional quantiles of the data. This however cannot achieve a rate faster than root-n.
-
•
When applied in the linear regression setting, our CAVS procedure performs well empirically on both synthetic and real data. It would thus be interesting to rigorously establish a rate adaptivity result in the linear regression model. More generally, in a nonparametric regression model where the noise has a noise distribution symmetric around and the regression function lies in some nonparametric function class , we can still use our procedure to select amongst estimators of the form . Understanding the statistical properties of this procedure would motivate the use of loss functions, for , in general regression problems.
Acknowledgement
The first and second authors are supported by NSF grant DMS-2113671. The authors are very grateful to Richard Samworth for suggesting the use of Lepski’s method. The authors further thank Jason Klusowski for many insightful discussions.
References
- (1)
- Baraud and Birgé (2018) Baraud, Y. and Birgé, L. (2018). Rho-estimators revisited: General theory and applications, The Annals of Statistics 46(6B): 3767–3804.
- Baraud et al. (2017) Baraud, Y., Birgé, L. and Sart, M. (2017). A new method for estimation and model selection: -estimation, Inventiones mathematicae 207(2): 425–517.
- Beran (1978) Beran, R. (1978). An efficient and robust adaptive estimator of location, The Annals of Statistics pp. 292–313.
- Bickel (1982) Bickel, P. J. (1982). On adaptive estimation, The Annals of Statistics pp. 647–671.
- Bickel et al. (1993) Bickel, P. J., Klaassen, C. A., Ritov, Y. and Wellner, J. A. (1993). Efficient and adaptive estimation for semiparametric models, Vol. 4, Springer.
- Bloch and Gastwirth (1968) Bloch, D. A. and Gastwirth, J. L. (1968). On a simple estimate of the reciprocal of the density function, The Annals of Mathematical Statistics 39(3): 1083–1085.
- Chierichetti et al. (2014) Chierichetti, F., Dasgupta, A., Kumar, R. and Lattanzi, S. (2014). Learning entangled single-sample gaussians, Proceedings of the twenty-fifth annual ACM-SIAM symposium on Discrete algorithms, SIAM, pp. 511–522.
- Dalalyan et al. (2006) Dalalyan, A., Golubev, G. and Tsybakov, A. (2006). Penalized maximum likelihood and semiparametric second-order efficiency, The Annals of Statistics 34(1): 169–201.
- Giné and Nickl (2016) Giné, E. and Nickl, R. (2016). Mathematical foundations of infinite-dimensional statistical models, Cambridge university press.
- Huber (2011) Huber, P. J. (2011). Robust statistics, International encyclopedia of statistical science, Springer, pp. 1248–1251.
- Ibragimov and Has’ Minskii (2013) Ibragimov, I. A. and Has’ Minskii, R. Z. (2013). Statistical estimation: asymptotic theory, Vol. 16, Springer Science & Business Media.
- Laha (2021) Laha, N. (2021). Adaptive estimation in symmetric location model under log-concavity constraint, Electronic Journal of Statistics 15(1): 2939–3014.
- Lai et al. (1983) Lai, T., Robbins, H. and Yu, K. (1983). Adaptive choice of mean or median in estimating the center of a symmetric distribution, Proceedings of the National Academy of Sciences 80(18): 5803–5806.
- Le Cam (1973) Le Cam, L. (1973). Convergence of estimates under dimensionality restrictions, Annals of Statistics 1(1): 38–53.
- Lepskii (1990) Lepskii, O. (1990). On a problem of adaptive estimation in gaussian white noise, Theory of Probability & Its Applications 35(3): 454–466.
- Lepskii (1991) Lepskii, O. (1991). Asymptotically minimax adaptive estimation. i: Upper bounds. optimally adaptive estimates, Theory of Probability & Its Applications 36(4): 682–697.
- Mammen and Park (1997) Mammen, E. and Park, B. U. (1997). Optimal smoothing in adaptive location estimation, Journal of statistical planning and inference 58(2): 333–348.
- Pensia et al. (2019) Pensia, A., Jog, V. and Loh, P.-L. (2019). Estimating location parameters in entangled single-sample distributions, arXiv preprint arXiv:1907.03087 .
- Schick (1986) Schick, A. (1986). On asymptotically efficient estimation in semiparametric models, The Annals of Statistics pp. 1139–1151.
- Stein (1956) Stein, C. (1956). Efficient nonparametric testing and estimation, Proceedings of the third Berkeley symposium on mathematical statistics and probability, Vol. 1, pp. 187–195.
- Stone (1975) Stone, C. J. (1975). Adaptive maximum likelihood estimators of a location parameter, The Annals of Statistics pp. 267–284.
- Subbotin (1923) Subbotin, M. T. (1923). On the law of frequency of error, Matematicheskii Sbornik 31(2): 296–301.
- Van Der Vaart and Wellner (1996) Van Der Vaart, A. W. and Wellner, J. (1996). Weak convergence and empirical processes: with applications to statistics, Springer Science & Business Media.
- Van Der Vaart and Wellner (2011) Van Der Vaart, A. and Wellner, J. A. (2011). A local maximal inequality under uniform entropy, Electronic Journal of Statistics 5(2011): 192.
- Van Eeden (1970) Van Eeden, C. (1970). Efficiency-robust estimation of location, The Annals of Mathematical Statistics 41(1): 172–181.
- Xu and Samworth (2021) Xu, M. and Samworth, R. J. (2021). High-dimensional nonparametric density estimation via symmetry and shape constraints, The Annals of Statistics 49(2): 650–672.
Supplementary material to “Rate optimal and adaptive estimation of the center of a symmetric distribution”
Yu-Chun Kao, Min Xu, and Cun-Hui Zhang
S1 Supplementary material for Section 2
S1.1 Proof of Lemma 1
Proof.
(of Lemma 1)
First, we observe that if , then, by the fact that , we have that
Therefore, we assume that .
We apply Lemma 3 with and so that and . Fix any . We observe that
Therefore, for , we have that . On the other hand, by the fact that
we have that
| (S1.1) |
Therefore, for , we have that
Using our assumption that , we have that for any and any ,
The Lemma thus immediately follows from Lemma 3. ∎
S1.2 Lemma 2 on the convergence of
The following lemma implies that, for a fixed such that is well-defined, our asymptotic variance estimator is consistent. For a random variable , we define its essential supremum to be
where the infimum of an empty set is taken to be infinity. Note that if and only if is compacted supported and that .
We may define is the same way. For an infinite sequence of independent and identically distributed random variables, it is straightforward to show that and regardless of whether the essential supremum and infimum are finite or not.
Lemma 2.
Let be a sequence of independent and identically distributed random variables and let . The following hold:
-
1.
If , then .
-
2.
If , then .
-
3.
If is compactly supported, then we have that .
-
4.
If , then .
As a direct consequence, for any such that , we have , even when .
Proof.
(of Lemma 2)
For the first claim, we apply Proposition 3 with and and immediately obtain the desired conclusion.
We now prove the second claim by a truncation argument. Suppose so that . Fix arbitrarily. We claim there then exists such that
To see this, for any , define . The argmin is well-defined since is strongly convex and goes to infinity as . If is bounded, then the claim follows because . If is unbounded, then there exists a sub-sequence such that say. For any such that , we have . Therefore, in either cases, our claim holds.
Using Proposition 3 again with , we have that
In other words, there exists an event with probability 1 such that, for any , there exists such that for all ,
Thus, on , we have that
Thus, on the event , we have that . Since has probability 1, the second claim follows. For the third claim, without loss of generality, we can assume that and . Define , then we have and
where, as , the right hand side tends to for every . thus converges to in probability. Since the collection is defined on the same infinite sequence of independent and identically distributed random variables, we have that so that by the monotone convergence theorem.
For the forth claim, suppose without loss of generality that and that . Let as with the proof of the third claim. Then,
Since the right hand side tends to for every , we have that converges to infinity almost surely. The Lemma follows as desired. ∎
S1.3 Bound on
The following lower bound on holds regardless of whether is symmetric around or not. We have
where the first inequality follows from the fact that . In particular, we have that . Equality is attained when is a Rademacher random variable.
S1.4 Optimization algorithm
We give the Newton’s method algorithm for computing . It is important to note that to avoid numerical precision issues when is large, we have to transform the input so that they are supported on the unit interval .
INPUT: observations and .
OUTPUT: .
To compute for a collection of , we can warm start our optimization of by initializing with . In the regression setting where is large, we find that it improves numerical stability to to apply a quasi-Newton’s method where we add a an identity to the Hessian for a small .
S1.5 Supporting Lemmas
Lemma 3.
Let and suppose is convex. Let and . Suppose there exists such that
Then, we have that
Proof.
Let and suppose satisfies the condition of the Lemma. Fix such that . Define so that . Note by convexity of that .
Therefore, we have that
under the condition of the Theorem. Therefore, we have for any such that . The conclusion of the Theorem follows as desired. ∎
S1.5.1 LLN for minimum of a convex function
Proposition 3.
Suppose is convex on for all . Define and suppose is finite on an open subset of and .
Then, we have that
and
where and
Proof.
Define and observe that is a convex function on . We also observe that is a closed bounded interval on and we define to be its midpoint.
Fix arbitrarily. We may then choose and such that
-
1.
and ,
-
2.
,
-
3.
,
-
4.
and .
Define and note that by our choice of and . By LLN, there exists an event with probability 1 such that, for every , there exists where for all ,
Fix any and fix , we have that and likewise for . Thus, must attain its minimum in the interval , i.e., . We then have by Lemma 4 that
On the other hand,
Therefore, for all , we have that
and
We then define and observe that has probability 1 and that on ,
and
The Proposition follows as desired.
∎
Lemma 4.
Let be a convex function. For any , and , we have
As a direct consequence, if , then we have that for all ,
and that for all ,
Proof.
Let ; using the fact that , we have
Likewise, for , we have and hence,
∎
S2 Supplementary material for Section 3
S2.1 Proof of Theorem 3.1
Structure of intermediate results: The proof is long and uses various intermediate technical results. The key intermediate theorems are (1) Theorem S2.1 which is essentially a corollary of Proposition 4 and (2) Theorem S2.2 which follow from Proposition 5 as well as Theorem S2.1.
Notation for constants: For all the proofs in this section, we let indicate a generic universal constant whose value could change from instance to instance. We let be specific universal constants where are defined in the proof of Proposition 4 and where are defined in Theorem S2.2.
Proof.
(of Theorem 3.1)
We first prove the following: assume that is large enough such that
| (S2.2) |
where are universal constants and are constants depending only on – the value of these are specified in Theorem S2.1 and Theorem S2.2.
We claim that
| (S2.3) |
This immediately proves the first claim of the theorem. To see that the second claim of the theorem also holds, note that if (S2.3) holds and if , then, by inflating the constant if necessary, we have that, for all ,
where the first inequality uses the fact that . The desired conclusion would then immediately follow.
We thus prove (S2.3) under assumption (S2.2). To that end, let and define and note that under assumption (S2.2).
Let be a sufficiently large universal constant as defined in Theorem S2.2 and define the event
| (S2.4) |
It holds by Theorem S2.2 that .
Now define and note that under assumption (S2.2). Define the event
| (S2.5) |
Then we have by Theorem S2.1 that
On the event , we have that, for all ,
Therefore, we have that
Since contains , either or there exists such that . In either case, it holds by the definition of that . Write . For any , we have
Since and since so that there exists such that , it must be that
where we define .
Now define as the event that . We have by Corollary 1 that . Therefore, on the event , we have by Lemma 1 that
where, in the final inequality, we define .
Since , the desired conclusion (S2.3) follows. Hence, the Theorem follows as well.
∎
Theorem S2.1.
Let be independent and identically distributed random variables on with a distribution symmetric around and write . Suppose there exists and and such that for all .
Let be universal constants and be a constant depending only on , as defined in Proposition 4. Let , let , and let .
Suppose is large enough so that . Then, we have that
| (S2.6) |
Moreover, if is large enough such that and that . Then, we also have
| (S2.7) |
Proof.
Since for any is location equivariant, we assume without loss of generality that so that .
Define and note that since , , and . We further note that with our definition of and assumptions, the conditions in Proposition 4 (i) and (ii) are all satisfied.
Let be a collection of positive numbers. For any , we have by the second claim of Lemma 7 that, for ,
| (S2.8) |
To prove the first claim of the theorem, we let . We use Proposition 4 (noting that the probability bound in (S2.9) is less than under our definition of ) and (S2.8) to obtain that, with probability at least , the following holds simultaneously for all :
where, in the last inequality, we use the fact that the function is strongly convex for all and minimized at .
Likewise, we have that
By the strong convexity of the function therefore, we have that . The first claim thus follows as desired.
To prove the second claim, we let and follow exactly the same argument. The only difference is that the probability bound of Proposition 4 in this case becomes, under our assumptions on ,
The entire theorem then follows. ∎
Proposition 4.
Let be independent and identically distributed random variables on with a distribution symmetric around and write . Suppose there exists and and such that for all .
For and , define . Let and let be a collection of positive numbers; define the event
Let be universal constants and be a constant depending only on (the values of these are specified in the proof). Then, the following holds:
-
(i)
Suppose for some and suppose that and , then, we have that
(S2.9) -
(ii)
Let and suppose . Suppose also and . Then, we have that
Proof.
We define the function class
| (S2.10) |
We now use Talagrand’s inequality (Theorem S3.1) to prove the Proposition. To this end, we derive upper bounds on various quantities involved in Talagrand’s inequality.
Step 1: bounding and .
Using the fact in both cases, we observe that for any , if and , then . Therefore, we have that,
Thus, it follows that
| (S2.11) |
Therefore, we have that
| (S2.12) |
When , we also see that
| (S2.13) |
Step 2: bounding the envelope function.
Define . Since, for any ,
we have that
| (S2.14) |
Using the fact that the distribution of is symmetric around 0, and defining ,
| (S2.15) |
Case 1: suppose . In this case, we have that
where the second inequality follows from the third claim of Lemma 7.
Case 2: suppose . In this case,
| (S2.16) |
where, in the second inequality, we use Lemma 7 again.
Step 3: bounding the VC-dimension of .
We first note that the class of univariate functions has VC dimension at most 4. This holds because consists of functions of the form
and thus lies in a subspace of dimension 2. It then follows from Lemma 2.6.15 and 2.6.18 (viii) of Van Der Vaart and Wellner (1996) that has VC-dimension at most 4.
It then follows from Lemma 2.6.18 (vi) that has VC-dimension at most 8.
Step 4: bounding the expected supremum.
Let us define
| (S2.17) |
Case 1: suppose . Then, using the second claim of Theorem S3.2, we have that
| (S2.18) |
Case 2: suppose now that .
Define the entropy integral as (S3.29) and note that is decreasing for . By Corollary 2 and our bound on the VC-dimension of , we have that
Therefore, using our upper and lower bounds on , upper bound on and upper bound on , we have, by the first claim of Theorem S3.2, that
where, in the second inequality, we used the fact that , and in the last inequality, we used the hypothesis that (with as a sufficiently large universal constant).
Step 5: bounding the tail probability.
Using our assumption that and (with as a sufficiently large universal constant), we have that in both the case where and the case where .
Case 1: when , we have that, writing ,
Case 2: when , we have
∎
Theorem S2.2.
Let be independent and identically distributed random variables on with a distribution symmetric around and write . Suppose there exists and and such that for all .
We note that, in Theorem S2.2, by choosing arbitrarily close to 0, we can have be arbitrarily close to 1.
Proof.
By Theorem S2.1, with probability at least , we have that, simultaneously for all ,
On this event, we have that
Then, by Proposition 5, with probability at least , simultaneously for all ,
Therefore,
Likewise, we have that . Using our assumption that , the first claim of the theorem directly follows.
The second claim of the theorem follows then from Lemma 6.
∎
Proposition 5.
Let be independent and identically distributed random variables on with a distribution symmetric around and write . Suppose there exists and and such that for all .
Let and . Define the event
| (S2.20) |
Let be a constant depending only on (its value is specified in the proof). Suppose . Then, we have that
Proof.
First, we claim that, for all , , , and , it holds that
| (S2.21) |
Now define and and observe that . Suppose without loss of generality that . Then, using (S2.21), we have that, for any ,
We also trivially have that . Therefore, writing and , we have that, for any ,
| (S2.22) |
Therefore, we have that
| (S2.23) |
Bounding Term 2:
Since , by setting , we have
| Term 2 | |||
Bounding Term 1:
To bound Term 1, we define the function class
so that we have .
We observe that
Moreover, defining and , we have that
| (S2.24) | ||||
| (S2.25) | ||||
| (S2.26) |
We note that is a subset of a linear subspace of dimension 2 (see Step 3 in the proof of Proposition 4). By Lemma 2.6.15 and 2.6.18 (viii) of Van Der Vaart and Wellner (1996), we know that the VC dimension of is at most 4.
Therefore, using our hypothesis that where is chosen to be sufficiently large, then . Then,
Therefore, by (S2.23), it holds that
By inflating the value of if necessary, the Proposition follows as desired. ∎
Lemma 5.
Let be a random variable on with a distribution symmetric around . If there exists and such that for all , then we have that
Proof.
As a short-hand, write and ; note that . Then,
∎
Corollary 1.
Let be independent and identically distributed random variables on with a distribution symmetric around and let . If there exists and such that for all , then we have that
Proof.
As a short-hand, write . By the fact that is symmetric around and Lemma 5, we have
The desired conclusion thus follows. ∎
S2.2 Proof of Examples
Proof.
(of Proposition 1)
It suffices to show that there exists constants such that
Indeed, we have by Stirling’s approximation that
The conclusion of the Proposition then directly follows from the fact that for all .
∎
For a given density , we define
for any .
Proposition 6.
Let and suppose is a random variable with density satisfying
for dependent only on . Suppose also that for some .
Suppose is symmetric around 0. Then, there exist dependent only on and such that
for all .
Proof.
Since , it suffices to bound for .
For the lower bound, we observe that
To establish the upper bound, observe that, by symmetry of ,
| (S2.27) |
We upper bound the two terms of (S2.27) separately. To bound the first term,
If , then and
On the other hand, if , then and . Hence, we have that
We now turn to the second term of (S2.27). Write and note that . Then, by mean value theorem, there exists depending on such that
where the second inequality follows because . The desired conclusion immediately follows. ∎
Remark S2.1.
We observe that if a density is of the form
for a normalization constant , then as required in Proposition 6. Therefore, we immediately see that for such a density, it holds that .
S2.3 Proof of Proposition 2
Proof.
We first note that if where has a density symmetric around , then, for ,
To prove the first claim, suppose that is supported on all of . We observe that
We thus need only show that . Let be arbitrary, then, for any ,
Since for all by assumption, we see that . Since is arbitrary, the claim follows.
Now consider the second claim of the Proposition and assume that ; write as the density of . Writing , we have that
Differentiating with respect to , we have
We make a change of variable by letting to obtain
Therefore, using the fact that , we have that
Therefore, if , then and hence, is a local minimum of . On the other hand, if , then and is not a local minimum. The Proposition follows as desired.
∎
S3 Other material
S3.1 Technical Lemmas
Lemma 6.
Let be a random variable supported on . For , define and suppose there exists , , and such that for all .
Define . Then, for some universal constant , for all ,
Proof.
First suppose . Then we have that
where the second inequality follows because , the third inequality follows from Jensen’s inequality. Therefore, we have that
The upper bound on follows similarly.
Now suppose , then,
The upper bound on follows in an identical manner. The conclusion of the Lemma then follows as desired.
∎
Lemma 7.
Let be a random variable on with a distribution symmetric around and write for . Suppose for all and for some , and . Then, for any and any , we have
Moreover, we have that for any and any ,
Lastly, for any and any (allowed to depend on ) such that , we have
Proof.
Consider the first claim. Observe that
To bound Term 1, we have that
where, in the last inequality, we use the fact that and that for all . It is clear then that Term 1 is bounded by . To bound Term 2, we have that
where in the second inequality, we use the fact that . Therefore, we have that
Combining the bounds on the two terms, we have that as desired.
We now turn to the second claim. Without loss of generality, assume that so that, by symmetry of the distribution of , we have .
Since ,
For , it holds that since is supported on . For , it holds that . Therefore, we have that
Thus, for all , we have that
Finally, we consider the third claim. The argument is similar to that of the first claim. We observe that
| (S3.28) |
To bound the first term of (S3.28), we use the fact that and that to obtain
To bound the second term of (S3.28), we have
The third claim of the lemma thus follows as desired. ∎
Lemma 8.
Define for every . Given , being the unique minimizer of , and , we have that is the unique minimizer of for all small positive .
Proof.
We first show that . Given , there exists a such that for every , and thus
For a fixed , we have
∎
S3.2 Reference results
We use the following statement of Talagrand’s inequality:
Theorem S3.1.
(Talagrand’s Inequality; see e.g. Giné and Nickl (2016, Theorem 3.3.9)) Let be independent and identically distributed random objects taking value on some measurable space . Let be a class of real-valued Borel measurable functions on .
Define . Let be a scalar that almost surely; let . Then, for any ,
We use the following bound on the expected supremum of the empirical process. For a class of real-valued functions on some measurable domain , we write as its envelope function. For , define the entropy integral
| (S3.29) |
where the supremum is taken over all finitely discrete probability measures.
Lemma 9.
(Van Der Vaart and Wellner; 1996, Theorem 2.6.7) If has finite VC dimension , then, for any ,
Corollary 2.
If has finite VC dimension , then, for any ,
Proof.
Theorem S3.2 (Van Der Vaart and Wellner (2011)).
Let , , and . Then the following two bounds hold:
as well as