CIM: Class-Irrelevant Mapping for Few-Shot Classification
Abstract
Few-shot classification (FSC) is one of the most concerned hot issues in recent years. The general setting consists of two phases: (1) Pre-train a feature extraction model (FEM) with base data (has large amounts of labeled samples). (2) Use the FEM to extract the features of novel data (with few labeled samples and totally different categories from base data), then classify them with the to-be-designed classifier. The adaptability of pre-trained FEM to novel data determines the accuracy of novel features, thereby affecting the final classification performances. To this end, how to appraise the pre-trained FEM is the most crucial focus in the FSC community. It sounds like traditional Class Activate Mapping (CAM) based methods can achieve this by overlaying weighted feature maps. However, due to the particularity of FSC (e.g., there is no backpropagation when using the pre-trained FEM to extract novel features), we cannot activate the feature map with the novel classes. To address this challenge, we propose a simple, flexible method, dubbed as Class-Irrelevant Mapping (CIM). Specifically, first, we introduce dictionary learning theory and view the channels of the feature map as the bases in a dictionary. Then we utilize the feature map to fit the feature vector of an image to achieve the corresponding channel weights. Finally, we overlap the weighted feature map for visualization to appraise the ability of pre-trained FEM on novel data. For fair use of CIM in evaluating different models, we propose a new measurement index, called Feature Localization Accuracy (FLA). In experiments, we first compare our CIM with CAM in regular tasks and achieve outstanding performances. Next, we use our CIM to appraise several classical FSC frameworks without considering the classification results and discuss them.


I Introduction
The great strides in deep learning have enabled unprecedented breakthroughs in image classification tasks. The success is partially attributed to a large number of labeled data. However, annotating data is expensive or infeasible, leading to a novel hot issue – Few-Shot Classification (FSC). FSC targets to help machines achieve or even surpass human beings’ level with scarce labeled samples. A general FSC setting includes two components: (1) Pre-train. Employ the base data (with large amounts of labeled samples) to train a convolutional neural network (CNN) based Feature Extraction Model (FEM). (2) Meta-test. Extract the features of novel data (with only a few labeled samples and totally different categories from base data) by using the trained FEM, then design a classifier (such as support vector machine, logistic regression) to predict their labels.
[1] pointed out that a fundamental problem prevents the development of FSC, e.g., regardless of how well the pre-trained FEM performs on base data, it will be enormously challenging to fit into the novel data due to the limitation of Cross-Domain. The extracted novel features can not describe the novel samples accurately, which causes trouble for the classification. Therefore, how to evaluate whether a pre-trained FEM is applicable in novel classes is an essential issue of concern to the FSC community.
Of course, the final classification result is a crucial measurement index. But there exist multiple factors that influence the classification performance, such as the qualities of pre-trained FEM and the to-be-designed classifier. Perhaps a weak FEM with a strong classifier will still yield high classification accuracy. Thus, it is one-sided to evaluate an existing FEM only by the classification accuracy. Besides, this strategy lacks interpretability to the model.
Inspired by the development of Explainable Deep Learning, researchers attempt to appraise the pre-trained FEM by visualizing the feature map of novel samples by employing Class Activation Map (CAM) based methods. CAM was first proposed by [2]. Following, Grad-CAM [3], Grad-CAM++ [4], Score-CAM [5] et.al. contributed a lot for this community. In essence, all these visualization methods attempt to overlay weighted feature map to model the salient part of an image. They design different structures to calculate channel weights, but all of them are based on the class (to which the sample belongs) activation. That is, they rely on the feedback of the deep neural network to update the weights. However, in most of existed FSC frameworks, there is no backpropagation process in the meta-test phase. It means that we cannot activate the feature map with the novel class to obtain the corresponding weights, contrary to the basic principle of CAM-based methods. We illustrate an example in Figure 1.
It sounds like all we need to do is to fine-tune the FEM and drive it to generate class-activated weights for the feature map to tackle this problem. However, as the scarce of labeled novel data (as an example, for the typically -shot and -shot case, each category only has or labeled samples), fine-tuning only has a limited promotion for FSC (has been proved in [6]) and is abandoned by the vast majority of FSC approaches. To this end, the existing CAM-based methods cannot be well applied to the FSC models.
To address this challenge, we propose Class-Irrelevant Mapping (CIM) to explain and appraise the ability of pre-trained FEM on a novel set. The essence of a feature map is the description of an image on the same level (e.g., CNN layer) but different focus, which correlates with dictionary learning theory [7] (e.g., a channel of feature map is similar to a base of dictionary).
Inspired by this find, we first design a flexible specific dictionary fully connected layer (SDFC layer) and make the dimension equal to the product of the width and height of the to-be-visualized feature map. Then, we use the feature map as a reconstructed dictionary to fit the feature vector of an image (e.g., the SDFC layer) and introduce a sparse constraint for calculating channel weights. Finally, we overlap the weighted feature map to visualize the pre-trained model on novel data and appraise it. We illustrate the flowchart in Figure 2. In addition, to quantify metrics for visualization, we propose new evaluation criteria as Feature Localization Accuracy (FLA), please refer to Figure 3. Notably, our CIM not only performs well on the FSC task, but also is suitable for regular tasks.
In summary, the main contributions focus on:
-
•
Based on the characteristics of the few-shot classification (FSC) architecture, we propose a Class-Irrelevant Mapping (CIM) method, which can be used to measure the quality of the pre-trained feature extraction model (FEM) on novel data.
-
•
In order to better apply our CIM in the FSC community, we propose a visual quantitative metric, called Feature Localization Accuracy (FLA).
-
•
Our CIM refers to the dictionary learning theory to calculate channel weights by fitting the feature vector of an image. It is a simple, flexible method, which is adequate for most of the existed classification tasks.
-
•
In experiments, we first compare our CIM with CAM to evaluate the efficiency in regular classification tasks, then use CIM to appraise several current classical FSC frameworks. Note that, we merely evaluate the model from the perspective of whether it fits into a new class or not. Our purpose in designing CIM is to help researchers in the FSC community to construct more robust and effective networks.
II Related Work
II-A Few-Shot Classification
In recent years, Few-shot classification (FSC) has attracted a lot of attention. As described above, a high-quality pre-trained feature extraction model (FEM) is crucial to promote the final performances. Therefore, researchers focus on developing novel technologies for designing FEMs. ICI [8], CovaMNet [9] et.al. referred to the standard classification model to design the FEM. MetaOpt [10], Feat [11] et.al. introduced meta-learning strategy to split the base data to different tasks for pre-training. GFL [12], KGTN [13] et.al. considered graph structure when constructing the FEM. S2M2 [14], MHFC [15] et.al. fused self-supervised methods to strengthen the FEM. RFS [16], IER [17] integrated knowledge distillation technology to optimize the FEMs.
II-B Class Activation Mapping
Recently, why deep learning achieves outstanding performance has attracted a lot of attention, which leads to a novel hot issue – Explainable Deep Learning. There exist two perspectives to explain the network. The first one is dubbed as Salience Map, which focused on the pixel of original images, and many related works were proposed, such as [18, 19, 20, 21]. In the year , zhou et al. proposed the explainable deep learning from another perspective, i.e., Class Activation Map (CAM) [2]. Following, some improved methods were proposed, including [3, 4, 5, 22]. All these methods have various structures, but one indispensable point is the class activation. However, this hard need leads to a limitation for some special tasks, such as Few-Shot Classification (FSC).
II-C Dictionary Learning
Dictionary learning is one of the most popular machine learning theories, which was first proposed by [7]. It is capable of mapping samples’ original feature embeddings to the dictionary space. Using the reconstructive dictionary bases to represent samples is helpful to reduce the redundant information of samples. Dictionary learning was widely applied in various fields, such as image classification [23, 24], person re-identification [25, 26], image denoising [27, 28], etc. In this paper, we apply it to visualize and explain the deep models.

III Methodology
In this section, we first describe our Class-Irrelevant Mapping (CIM) in detail; then introduce the optimization method for the mapping weight; finally, show the details of how to employ CIM to evaluate FSC models.
III-A Class-Irrelevant Mapping
This section shows the details of our Class Irrelevant Mapping (CIM). We view the feature maps as the reconstructive dictionary to model the raw sample. Take an image as an example, we input the image into a convolutional neural network , and obtain the feature map on the layer, which is denoted as , where represents the channel, indicates the spatial location. Then pull each channel of feature map to a vector, and construct a matrix as , where , , denote the height, width, and channel of the feature map, an example is shown in Figure 2; indicates the vector in .
The feature map can be seen as the subspace representation of an image, which is similar to the principle of dictionary learning. Each channel corresponds to a base vector of the dictionary. To obtain reasonable and robust weights independent of the category of the sample, we use the feature map as a reconstructed dictionary to fit the feature vector of the sample, which is defined as . In our task, if we use the feature map on the layer to complete the visualization operation, we need to guarantee the length of this vector equal to the product of the height and width of the feature map on the layer (e.g., ). Therefore, we need to adjust the network structure to add an additional fully connected (FC) layer with neurons, which is dubbed as specific dictionary FC (SDFC) layer. The position is shown in Figure 2. Actually, we do not expect this layer to significantly affect the outcome, as it would disfavor our objective judgment of an already existing FSC network. Fortunately, our ablation study has demonstrated that adding this layer will generate little difference in network performance.
Following, we formulate our objective function to calculate the weights as:
| (1) |
where , represent ’s -norm, -norm. is used to adjust sparsity of . , denotes the feature vector of the sample. , indicates the one layer’s feature map of the sample. . is the to-be-learned weight vector. indicates the element in , corresponds to the weight of channel of feature map (the optimization process, please refer to Section Optimization). Thus, we define the objective function of our class-irrelevant mapping as:
| (2) |
where reflects the key spatial grid.
III-B Optimization for Mapping Weight
Observe Equation 1, is a constant matrix. We introduce the Alternating Direction Method of Multipliers (ADMM) [29] to solve the optimization problem.
(1) Introduce an auxiliary variable and reformulate Equation 1 as:
| (3) |
(2) Introduce the Lagrangian operator and rewrite Equation 3 as:
| (4) |
where is the augmented lagrangian multiplier, and denotes the penalty parameter.
(3) Alternative update , , until Equation 4 convergence, the solutions are formulated as follows:
| (5) |
where denotes the identity matrix; and indicate the one vector and zero vector; denotes the gradient degree.





III-C CIM for Few-Shot Classification
III-C1 Problem Setup of Few-Shot Classification
The General few-shot classification setting (FSC) includes two stages, e.g., pre-train and meta-test. (1) In pre-train stage, we use base set to train a standard classification model , where and denote the sample and corresponding label, respectively; indicates the base category set; denotes the parameters of the network. (2) In the meta-test stage, we use the trained model as the feature extraction model to extract the feature of novel data, then recognize them. The novel data is denoted as , where denotes the novel category set. Note that, .
Due to the scarce of labeled novel samples, fine-tuning is not appliable for the few-shot task. Besides the difference between and , the network parameters cannot be well applied to the novel data, making it impossible to activate feature mapping with novel classes. Therefore, we use our class-irrelevant mapping (CIM) to model the heat map and reveal if this network is suitable for new classes.
III-C2 FSC Network
In the FSC community, researchers have designed lots of strategies to improve the robustness of the FEM. In this article, four representative model structures are selected to evaluate. (1) ICI [8] designed a standard classification model as the pre-trained model. (2) Metaopt [10] introduced meta-learning strategy to make the network learning to learn. (3) MHFC-R [15] introduced rotation based auxiliary loss to a standard classification model, the rotated degrees include . (4) MHFC-M [15] introduced mirror based auxiliary loss to a standard classification model, the mirrored ways consist of .
III-C3 Feature Localization Accuracy
To evaluate the quality of the pre-trained model, we propose a new evaluation criterion as Feature Localization Accuracy (FLA). It aims to reveal if the pre-trained model pays attention to the crucial and correct visual cues on the novel image. Specifically, we first collect bounding boxes for images from [30], just like Figure 3(a). Then we utilise the visualization methods, such as CAM, CIM, to generate hot map through Equation 2, see Figure 3(b). The darker the red, the more attention of the network. Next, we pick the region of the hot map with pixel values larger than as the feature localization area, e.g., the area inside the black box in Figure 3(c). Finally, we define the Feature Localization Accuracy (FLA), which consists of two components, FLA-1 and FLA-2. FLA-1 indicates the proportion of information that we focus on within the bounding box, see Figure 3(d). FLA-2 indicates that the information we focus on in the bounding box accounts for the proportion of all the information we follow with interest, see Figure 3(e). Note that, the larger the two values, the better the model.
IV Experiments
In this section, we first introduce the employed datasets, then compare our CIM technology with classical CAM method on the regular task to evaluate the efficiency of CIM, next design ablation studies to analyse the factors that influence our CIM. Finally, we use our CIM to appraise several existed classical FSC networks and discuss them. We conduct our experiments on a Tesla- GPU with memory. All the source codes will be made available to the public.
IV-A Dataset
This paper evaluates our CIM on two benchmark datasets of FSC field, e.g., mini-ImageNet [31], tiered-ImageNet [32]. Both of them are the subsets of ImageNet dataset [33]. mini-ImageNet includes classes, and we select classes as the base set, classes as the validation set, classes as the novel set. Each class include images with the size of . tiered-ImageNet is composed of classes with images per class. We select classes as the base set, classes as the validation set, classes as the novel set. All the image size is . We collect the bounding box from [30].
| Method | mini-ImageNet | ||
|---|---|---|---|
| -way -shot | -way -shot | ||
| ICI | |||
| +SDFC | |||
| MetaOpt | |||
| +SDFC | |||
| MHFC-R | |||
| +SDFC | |||
| MHFC-M | |||
| +SDFC | |||
| Method | mini-ImgaeNet | tiered-ImgaeNet | ||
|---|---|---|---|---|
| FLA-1 | FLA-2 | FLA-1 | FLA-2 | |
| ICI | ||||
| MetaOpt | ||||
| MHFC-R | ||||
| MHFC-M | ||||
IV-B Evaluate Our CIM
IV-B1 Compare with CAM
To evaluate FSC by CIM, it needs to be guaranteed that CIM itself can achieve good results. Therefore, let’s start by comparing the performance of CIM with classical CAM [2] in regular tasks. We conduct the experiments on mini-ImageNet and tiered-ImageNet. Specifically, we view the base data of the two datasets as the training data to train a network with a fixed ResNet-12 backbone (e.g., pre-trained ICI network). Then use our proposed Feature Localization Accuracy (FLA) to evaluate the performance. The visualization results and FLA based results on base data are separately shown in Figure 4, 5. We can see that, different methods (CIM and CAM) are suitable to different images and they achieve similar performance as a whole. Thus, we can safely use it to evaluate FSC networks.
IV-B2 Ablation Study
From Figure 2, we know that our CIM is adaptive for all kinds of existed networks if we add an extra specific dictionary FC (SDFC) layer. This step does not require us to retrain a model, just need to fine-tune the model with extremely few resource consumption. And next, we have to discuss whether this extra layer will have a large impact on the final FSC results (what we expect is no). Therefore, we design ablation studies to look at the influence of SDFC layer. Specifically, we use mini-ImageNet to compare the final classification results with or without it. The results are listed in Table I. ICI, MetaOpt, MHFC-R, MHFC-M are the classical few-shot classification networks. Obviously, we see that the additional SDFC layer has little effect on the network, and further demonstrates the generalizability of our CIM.
From Equation 1, we know that parameter maybe affect the performance of our CIM. To evaluate it, we make ablation studies on mini-ImageNet and tiered-ImageNet to see the change of FLA. Figure 7 lists the influence. From the results, we conclude that our method is not sensitive to this parameter, and it is helpful to the stability of visualization.
IV-C New Appraised Criterion for FSC
IV-C1 Appraise FSC Network
The above section has proved that CIM is a good choose to visualize the pre-trained FSC model on novel set. In this section, we use our CIM to appraise the existed FSC networks on novel data. All of them are based on the ResNet-12 backbone. Some visualization results are shown in Figure 6, and the FLA of all images are listed in Table II. We list some observations.
(1) We rank the four models from our perspective (rank the sum value of each model), that is, MHFC-R () MHFC-M () ICI () MetaOpt (). (2) ICI based model adopts a regular classification network, while MetaOpt introduces meta-learning strategy. Compared to the results of ICI and Metaopt, we find that ICI achieves similar performance to Metaopt or even surpasses it. It demonstrates that using a meta-learning strategy alone seems to have limited help for FSC in our perspective. (3) Compared the two self-supervised models (MHFC-R and MHFC-M) with ICI, they both achieve better performances. It demonstrates the efficiency of self-supervised auxiliary loss for the FSC task. Besides, MHFC-R performs better than MHFC-M, implying that rotation loss may be better suited for FSC than mirror loss.



IV-C2 What Factors Influence the Pre-trained Model?
In FSC based network, we know that some factors influence the final classification results, such as the backbone, dropout, smoothing loss function. Thus, it is interesting to see how they influence the pre-trained model on novel data from our CIM-based view. Specifically, we employ the ICI network as the example to look at the FLA on mini-ImageNet and tiered-ImageNet.
For the backbones, we select four kinds of popular ones (e.g., ResNet-10, ResNet-12, ResNet-18, ResNet-34) to observe the results, which is listed in Figure 8. We are surprised to find that the structure based on ResNet-12 can achieve much higher performances than other backbones in our evaluation indicators. Actually, this phenomenon coincides with a view of [34]: In this particular area of few-shot classification, the depth of the network can affect the performance of classification, but it is not the case that the deeper the network, the better the outcome. Or there is another possibility: Our testing network is based on improvements of ICI. It is possible that some parameters (tricks) in the ICI network structure highly match the Resnet-12 architecture.
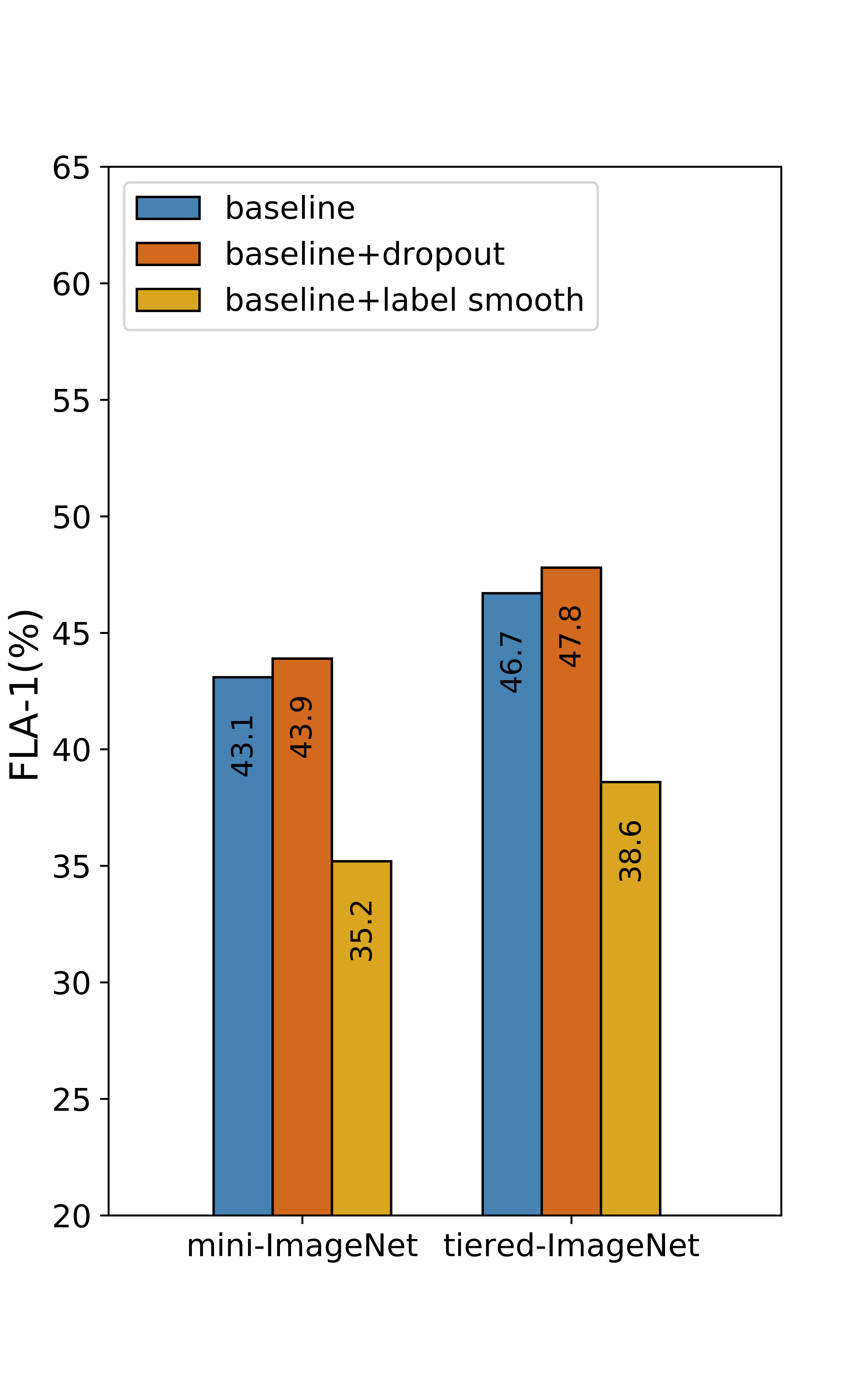
For the other factors, we list the comparison results in Figure 9. All the results are based on the ResNet-12 backbone. As we all know, dropout is not generally used in normal CNN architectures due to the presence of batch normalization. However, in the special field of FSC, adding dropout to the network can help improve performance. In addition, label smoothing is a common strategy in CNN, which has been used in MetaOpt. But when we introduce it into the generic ResNet architecture, we find that it has a serious negative impact on the results. Of course, it may just be an accident, just not suitable for the ICI based network, but we hope that researchers are more careful when using this trick when designing FSC model.
IV-D Discussion
In this section, we first verify the validity of CIM, then use CIM to evaluate the FSC structure. Several FSC methods may not perform well on our metrics, but the performance of the final classification is satisfactory. Because we mentioned earlier that there are many factors affect the final classification results, our evaluation criteria are only used to assess whether the pre-trained model can adapt to the novel class, that is, how well it performs on cross-domain with limited labeled samples. Our ultimate goal is to help researchers design model structures that are more suitable for FSC tasks.
V Conclusion
According to the characteristics of the FSC task, this paper designs Class Irrelevant Mapping (CIM) as a new measurement method to evaluate the FSC framework. It uses the feature maps as dictionary base vectors to calculate the weights without relying on the class activation. This method is not only suitable for FSC tasks but also suitable for traditional architecture. In the experimental section, we evaluate some classical FSC methods through CIM and analyze them. In future work, we’d like to introduce the graph regularization method to fit dictionary bases and achieve more robust weights for feature maps.
Acknowledgment
The paper was supported by the National Natural Science Foundation of China (Grant No. 62072468), the Natural Science Foundation of Shandong Province, China (Grant No. ZR2019MF073), the Fundamental Research Funds for the Central Universities, China University of Petroleum (East China) (Grant No. 20CX05001A), the Graduate Innovation Project of China University of Petroleum (East China) YCX2021117, and the Graduate Innovation Project of China University of Petroleum (East China) YCX2021123, the Qingdao Science and Technology Project (No. 17-1-1-8-jch).
References
- [1] N. Dvornik, C. Schmid, and J. Mairal, “Selecting relevant features from a multi-domain representation for few-shot classification,” in ECCV. Springer, 2020, pp. 769–786.
- [2] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” in CVPR, 2016, pp. 2921–2929.
- [3] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in ICCV, 2017, pp. 618–626.
- [4] A. Chattopadhay, A. Sarkar, P. Howlader, and V. N. Balasubramanian, “Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks,” in WACV. IEEE, 2018.
- [5] H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, P. Mardziel, and X. Hu, “Score-cam: Score-weighted visual explanations for convolutional neural networks,” in CVPRW, 2020, pp. 24–25.
- [6] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in ICML, 2017, pp. 1126–1135.
- [7] S. G. Mallat and Z. Zhang, “Matching pursuit with time-frequency dictionaries,” TSP, vol. 41, no. 12, pp. 3397–3415, 1993.
- [8] Y. Wang, C. Xu, C. Liu, L. Zhang, and Y. Fu, “Instance credibility inference for few-shot learning,” in CVPR, 2020, pp. 12 836–12 845.
- [9] W. Li, J. Xu, J. Huo, L. Wang, Y. Gao, and J. Luo, “Distribution consistency based covariance metric networks for few-shot learning,” in AAAI, vol. 33, no. 01, 2019, pp. 8642–8649.
- [10] K. Lee, S. Maji, A. Ravichandran, and S. Soatto, “Meta-learning with differentiable convex optimization,” in CVPR, 2019, pp. 10 657–10 665.
- [11] H.-J. Ye, H. Hu, D.-C. Zhan, and F. Sha, “Few-shot learning via embedding adaptation with set-to-set functions,” in CVPR, 2020, pp. 8808–8817.
- [12] H. Yao, C. Zhang, Y. Wei, M. Jiang, S. Wang, J. Huang, N. Chawla, and Z. Li, “Graph few-shot learning via knowledge transfer,” in AAAI, vol. 34, no. 04, 2020, pp. 6656–6663.
- [13] R. Chen, T. Chen, X. Hui, H. Wu, G. Li, and L. Lin, “Knowledge graph transfer network for few-shot recognition,” in AAAI, vol. 34, no. 07, 2020, pp. 10 575–10 582.
- [14] P. Mangla, N. Kumari, A. Sinha, M. Singh, B. Krishnamurthy, and V. N. Balasubramanian, “Charting the right manifold: Manifold mixup for few-shot learning,” in WACV, 2020, pp. 2218–2227.
- [15] S. Shao, L. Xing, Y. Wang, R. Xu, C. Zhao, Y.-J. Wang, and B.-D. Liu, “Mhfc: Multi-head feature collaboration for few-shot learning,” in ACMMM, 2021.
- [16] Y. Tian, Y. Wang, D. Krishnan, J. B. Tenenbaum, and P. Isola, “Rethinking few-shot image classification: a good embedding is all you need?” in ECCV. Springer, 2020, pp. 266–282.
- [17] M. N. Rizve, S. Khan, F. S. Khan, and M. Shah, “Exploring complementary strengths of invariant and equivariant representations for few-shot learning,” in CVPR, 2021.
- [18] M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” in ECCV. Springer, 2014, pp. 818–833.
- [19] K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep inside convolutional networks: Visualising image classification models and saliency maps,” in ICLRW, 2014.
- [20] D. Smilkov, N. Thorat, B. Kim, F. Viégas, and M. Wattenberg, “Smoothgrad: removing noise by adding noise,” in ICMLW, 2017.
- [21] A. Kapishnikov, S. Venugopalan, B. Avci, B. Wedin, M. Terry, and T. Bolukbasi, “Guided integrated gradients: An adaptive path method for removing noise,” in CVPR, 2021, pp. 5050–5058.
- [22] H. G. Ramaswamy et al., “Ablation-cam: Visual explanations for deep convolutional network via gradient-free localization,” in WACV, 2020, pp. 983–991.
- [23] S. Shao, R. Xu, W. Liu, B.-D. Liu, and Y.-J. Wang, “Label embedded dictionary learning for image classification,” Neurocomputing, vol. 385, pp. 122–131, 2020.
- [24] Y.-J. Wang, S. Shao, R. Xu, W. Liu, and B.-D. Liu, “Class specific or shared? a cascaded dictionary learning framework for image classification,” Signal Processing, vol. 176, p. 107697, 2020.
- [25] K. Li, Z. Ding, S. Li, and Y. Fu, “Discriminative semi-coupled projective dictionary learning for low-resolution person re-identification,” in AAAI, vol. 32, no. 1, 2018.
- [26] H. Li, J. Xu, J. Zhu, D. Tao, and Z. Yu, “Top distance regularized projection and dictionary learning for person re-identification,” Information Sciences, vol. 502, pp. 472–491, 2019.
- [27] H. Zhu and M. K. Ng, “Structured dictionary learning for image denoising under mixed gaussian and impulse noise,” TIP, vol. 29, pp. 6680–6693, 2020.
- [28] X. Gong, W. Chen, and J. Chen, “A low-rank tensor dictionary learning method for hyperspectral image denoising,” TSP, vol. 68, pp. 1168–1180, 2020.
- [29] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed optimization and statistical learning via the alternating direction method of multipliers,” Foundations and Trends® in Machine learning, vol. 3, no. 1, pp. 1–122, 2011.
- [30] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet Large Scale Visual Recognition Challenge,” IJCV, vol. 115, no. 3, pp. 211–252, 2015.
- [31] O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra et al., “Matching networks for one shot learning,” in NeurIPS, vol. 29, 2016, pp. 3630–3638.
- [32] M. Ren, E. Triantafillou, S. Ravi, J. Snell, K. Swersky, J. B. Tenenbaum, H. Larochelle, and R. S. Zemel, “Meta-learning for semi-supervised few-shot classification,” in ICLR, 2018.
- [33] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognition challenge,” IJCV, vol. 115, no. 3, pp. 211–252, 2015.
- [34] W.-Y. Chen, Y.-C. Liu, Z. Kira, Y.-C. F. Wang, and J.-B. Huang, “A closer look at few-shot classification,” in ICLR, 2019.