Classifier Guidance Enhances Diffusion-based Adversarial Purification by Preserving Predictive Information
Abstract
Adversarial purification is one of the promising approaches to defend neural networks against adversarial attacks. Recently, methods utilizing diffusion probabilistic models have achieved great success for adversarial purification in image classification tasks. However, such methods fall into the dilemma of balancing the needs for noise removal and information preservation. This paper points out that existing adversarial purification methods based on diffusion models gradually lose sample information during the core denoising process, causing occasional label shift in subsequent classification tasks. As a remedy, we suggest to suppress such information loss by introducing guidance from the classifier confidence. Specifically, we propose Classifier-cOnfidence gUided Purification (COUP) algorithm, which purifies adversarial examples while keeping away from the classifier decision boundary. Experimental results show that COUP can achieve better adversarial robustness under strong attack methods.
1260
1 Introduction
Extensive research has shown that neural networks are vulnerable to well-designed adversarial examples, which are created by adding imperceptible perturbations on benign samples [12, 28, 3, 6]. Various approaches have been explored to improve model robustness, including model training enhancement [28, 49, 14] and input data preprocessing [33, 26]. While these works have significantly improved adversarial robustness, there is still a clear gap in the classification accuracy between clean and adversarial data.
In recent years, adversarial purification with diffusion probabilistic models [29, 46, 4, 45, 41] has become an effective approach to defend against adversarial attacks in image classification tasks. The key idea is to preprocess the input image using an auxiliary diffusion model before feeding it into the downstream classifier. Leveraging the strong ability of generative models to fit data distributions, adversarial purification methods are able to purify the adversarial examples by pushing them toward the manifold of benign data. Such a process is essentially a denoising process, which gradually removes possible noise from input data.
Though achieved advanced performance on robust image classification tasks, adversarial purification methods rely solely on the denoising function during purification, thus inevitably fall into the dilemma of balancing the need for noise removal and information preservation [29]. While stronger purification may destroy the image details that are necessary for classification, weaker purification may not be sufficient to remove the adversarial perturbations completely. The passive strategy to balance this, i.e. controlling the global purification steps [29], is limited in its effect, in the sense that data information monotonically loses as the purification steps grow. The existing method to mitigate the loss of information is to constrain the distance between the input adversarial example and the purified image [41, 45]. However, such constraint may inhibit the purified example from escaping the adversarial region effectively.
In this paper, we aim to propose a method that directly takes into consideration the need for information preservation. We borrow the idea of classifier guidance for diffusion models [39, 17, 8, 21], using the classifier confidence on the current class label given data as an indicator of the degree of preservation and try to maintain high confidence during the purification process. Staying away from low-confidence areas is beneficial to successful purification since such areas are close to the decision boundary and are more sensitive to small perturbations. Approaching a low confidence area can result in a potential label shift problem, i.e. a sample that initially has the correct label is misclassified after purification, especially when combined with stochastic defense strategies.
Specifically, we propose a Classifier-cOnfidence gUided Purification algorithm (COUP) with diffusion models to match the requirement of information preservation. The key idea is to gradually push input data towards high probability density regions while keeping relatively high confidence for classification. This process is realized by applying the denoising process together with a regularization term which improves the confidence score of the downstream classifier. This guidance discourages the purification process from moving toward decision boundaries, where the classifier becomes confused, and the confidence decreases.
We empirically evaluate our algorithm using strong adversarial attack methods, including AutoAttack [6], which contains both white-box and black-box attacks, Backward Pass Differentiable Approximation (BPDA) [1], as well as EOT [1] to tackle the randomness in defense strategy. Results show that COUP outperforms purification method without classifier guidance, e.g., DiffPure [29] in terms of robustness on CIFAR-10 and CIFAR-100 datasets.
Our work has the following main contributions:
-
•
We propose a new adversarial purification algorithm COUP. By leveraging the confidence score from the downstream classifier, COUP is able to preserve the predictive information while removing the malicious perturbation.
-
•
We provide both theoretical and empirical analysis for the effect of confidence guidance, showing that keeping away from the decision boundary can preserve predictive information and alleviate the label shift problem which are beneficial for classification. Though classifier guidance has been proven to be useful for better generation quality in previous works [17], we are the first to demonstrate its necessity for adversarial purification to the best of our knowledge.
-
•
Experiments demonstrate that COUP can achieve significantly higher adversarial robustness against strong attack methods, reaching a robustness score of for and for under AutoAttack method on CIFAR-10 dataset.

2 Related Work
Adversarial Training Adversarial training consolidates the discriminative model by enriching trained data [28]. Such methods include generating adversarial examples during model training [28, 49, 30, 20], or using an auxiliary generation model for data augmentation [14, 31, 42]. Though effective, such methods still face adversarial vulnerability for unseen threats [24] and suffer from computational complexity [43] during training. These works are orthogonal to ours and can be combined with our purification method.
Adversarial Purification Adversarial purification is another effective approach to defense. The idea is to use a generative model to purify the adversarial examples before feeding them into the discriminative model for classification. Based on different generative models [11, 22, 25, 18, 39], corresponding purification methods are proposed [33, 26, 10, 15, 16, 4] to convert the perturbed sample into a benign one. Recently, adversarial purification methods based on diffusion models have been proposed and achieved better performance [48, 46, 29, 45, 41]. Among these works, DiffPure [29] achieves the most remarkable result, which is the focus of our comparison.
Classifier Guided Diffusion Models Diffusion models [35, 18, 36, 39] are recently proposed generation models, achieving high generation quality on images. Some works further leverage the guidance of the classifier to achieve controllable generation and improve the image synthesis ability [17, 39, 8, 21]. Although the idea of classifier guidance has been proven to be beneficial for better image generation quality, whether the guided diffusion is helpful for adversarial purification is not yet verified. In our work, we utilize the classifier guidance to mitigate the loss of predictive information, so as to strike a balance between information preservation and purification.
3 Objective of Adversarial Purification
In this section, we present an objective of adversarial purification from the perspective of classification tasks and discuss how to achieve such an objective. The analysis results indicate the importance of considering the need for information preservation directly, which can be achieved by introducing guidance from classifier confidence during the purification process.
The concept of adversarial examples is first proposed by Szegedy et al. [40], showing that neural networks are vulnerable to imperceptible perturbations. Data is called an adversarial example w.r.t. if it is close enough and belongs to the same class under ground truth classifier , but has a different label under model , such that
| (1) |
with the constraint that .
The idea of adversarial purification is to introduce a purification process before feeding data into the classifier. Though the optimal purification result would be converting back to , it is almost impossible and not necessary. For the task of classification, it is sufficient as long as shares the same label with . Therefore, the objective of adversarial purification from the classification perspective can be formulated as
| (2) |
where is the purification function.
In practice, the above objective cannot be optimized directly since the ground truth label is in general unknown, and so is the clean data . A substitute idea may be using the label of a nearby but not too close data with high likelihood instead. The reasons include two aspects: first, the classification model is more trustworthy in high-density areas, thus can eliminate the effect of adversarial perturbation; second, compared with far-away data, a data with moderate distance from is more likely to share the same label with the clean data . The search for such nearby data is non-trivial, therefore as an alternative, we can use itself as the nearby data and take as an approximation of .
According to this idea, the ideal for solving Eq.(2) should balance the following requirements:
-
1.
Maximizing the likelihood . This helps to remove the adversarial noise.
-
2.
Maximizing the classifier confidence . This helps to preserve the essential information for classification.
-
3.
Controlling the distance . This helps to avoid significant semantic changes.
Discussion of existing works. Existing adversarial purification methods usually utilize a generative model to approximate , and try to maximize while keeping the distance small enough. We show a few examples here. DefenseGAN [33] is an early work for such purification, it uses generative adversarial nets as a generative model and optimizes for purification. The norm is used for controlling the distance, and is guaranteed to have a high likelihood with the generator . DiffPure [29] is a recently proposed adversarial purification method, it uses diffusion probabilistic models as a generative model. The purification process is a stochastic differential equation, whose main part includes a score function update which essentially increases the likelihood of . Meanwhile, it has been shown that the distance is implicitly controlled by the global update steps.
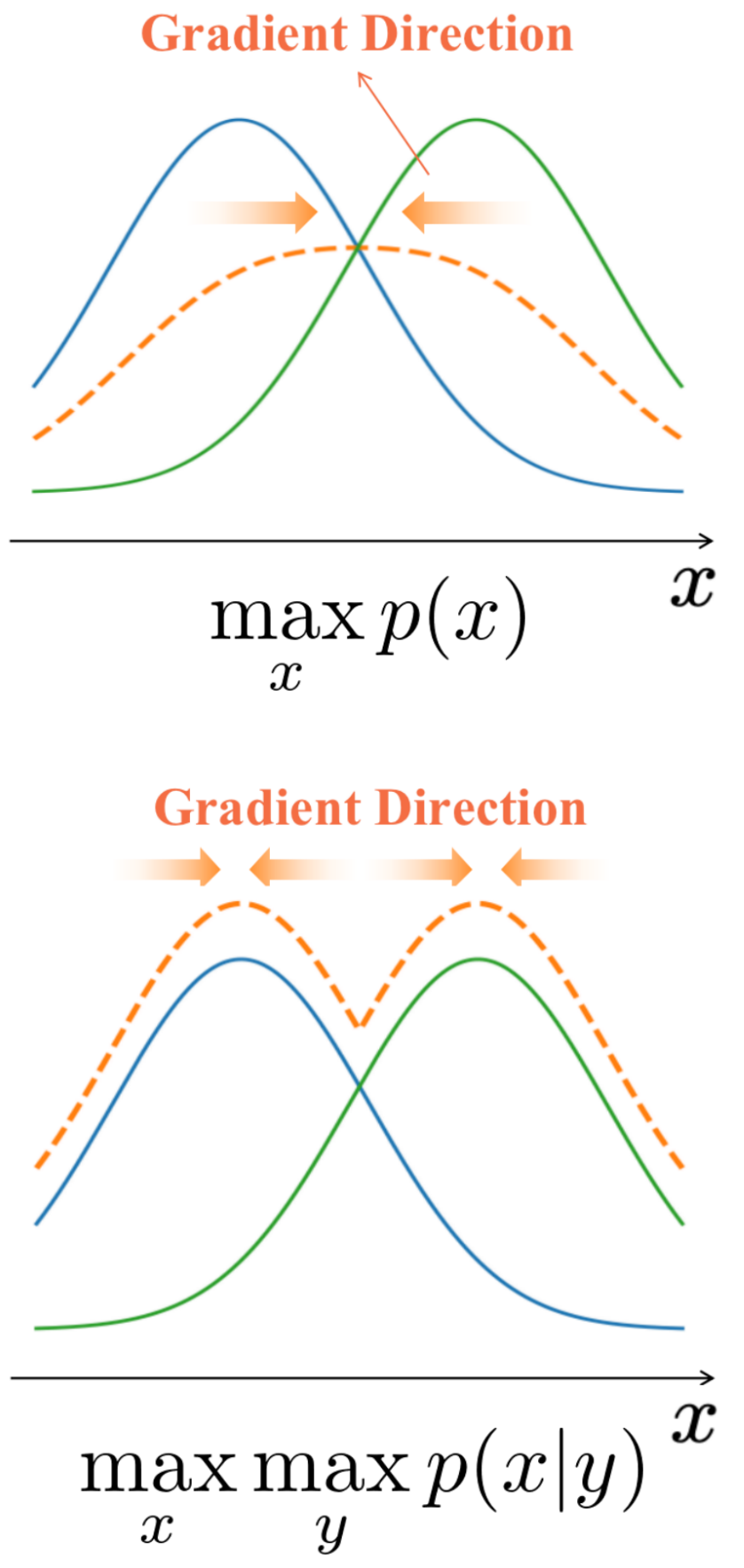
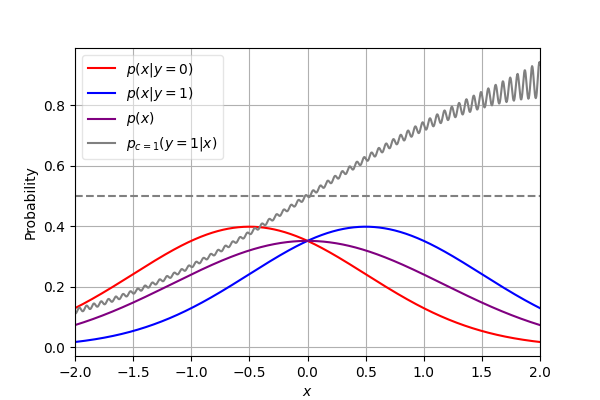
We find that the requirement of classifier confidence maximization is widely overlooked in existing works. A possible explanation might be that this requirement is partially addressed through density maximization. This is the case when there is little overlap between different classes of data, such that high likelihood generally means high classifier confidence. However, when such overlap exists, i.e. the decision boundary crosses high probability density areas, maximizing likelihood alone can be problematic. Consider the case where areas around the decision boundary have the highest density, the purification process without classifier confidence guidance will drive nearby samples towards the boundary, causing potential label shift especially when combined with stochastic defense strategies. A specific example is shown in Fig. 1. As a result, we suggest directly addressing the need for information preservation by maximizing the classifier confidence simultaneously.
4 Classifier-Confidence Guided Purification
Motivated by the objective of adversarial purification discussed in Section 3, we propose a Classifier-cOnfidence gUided Purification (COUP) method with score-based diffusion models to achieve the objective of adversarial purification.
4.1 Methodology
In order to meet the three requirements in Section 3, we address each of them separately: we use a score-based diffusion model and apply the denoising process to maximize the likelihood of purified image (i.e. ); we query the classifier during purification and maximize the classifier confidence (i.e. ); we control the distance by choosing appropriate global update steps . We will first introduce the diffusion model used for denoising, and then explain how we utilize the classifier confidence for adversarial purification.
Input: Perturbed example .
Output: Purified example , predicted label .
Required: Trained classifier score function of fully trained diffusion model, optimal timestep ,
and a regularization parameter .
Set up drift function:
Set up diffusion function:
Solve SDE for purification according to Eq. 5:
Classification:
return predicted label
4.1.1 Score-based Diffusion Models
Diffusion probabilistic models are deep generative models that have recently shown remarkable generation ability. Among existing diffusion models, Score SDE is a unified architecture that models the diffusion process by a stochastic differential equation (SDE) and the denoising process by a corresponding reverse-time SDE. Specifically, the forward SDE is formalized as
| (3) |
where is the time, is the drift function, is the diffusion coefficient, is a standard Wiener process (Brownian motion). The effect of forward SDE is to progressively inject Gaussian noise into the input, and eventually transfer the original data to a Gaussian distribution. The corresponding reverse-time SDE is
| (4) |
where is a standard reverse-time Wiener process. is parameterized by a neural model , which is also called the score function. The score function is the core of the reverse process, driving data towards higher likelihood by improving , where can be viewed as an approximation of .
4.1.2 Purification with Guidance of Classifier Confidence
The reverse-time SDE has been used for adversarial purification in previous diffusion-based purification methods. Our key idea is to introduce the guidance signal into the reverse-time SDE, such that we use to replace in the score function . Therefore, the purification update rule becomes
| (5) | ||||
where is the classifier confidence estimated by a fully trained classifier. The coefficient is determined by how much we can trust the classifier. The more accurate the classifier is, the larger value we can take for . More discussions on the choice of can be found in section 5.4.
In practice, we use VP-SDE [39], such that the drift function and diffusion coefficient are
| (6) |
where is a linear interpolation from to . The purification process starts from at time and ends at time to get . The global purification steps controls the distance between and , which we will later explain in section 4.3.
4.2 The COUP Algorithm
According to the purification rule of Eq. 5, we design our Classifier-cOnfidence gUided Purification (COUP) algorithm in Algo. 1. Our algorithm first set up the drift function and diffusion scale of guided reverse-time SDE according to Eq. 6. Then, we adopt an SDE process from to to get the purified image , where the input is adversarial example . Finally, we can use the trained classifier to predict the label of the purified image . We omit the forward diffusion process since it yields no positive impact on the objectives of adversarial purification discussed in Section 3, and may cause a potential semantic shift. A detailed discussion can be found in Appendix C.1.
Note that COUP can use the off-the-shelf diffusion model and the fully trained classifier. In other words, we combine the off-the-shelf generative model and the trained classifier to achieve higher robustness.
4.2.1 Adaptive Attack
In order to evaluate our defense method against strong attacks, we propose an augmented SDE to compute the gradient of COUP for gradient-based attacks. In other words, we expose our purification strategy to the attacker to obtain strict robustness evaluation. In this way, we can make a fair comparison with other adversarial defense methods. In Section 4.3, we discuss the key idea of adaptive attack. Suppose is the input of classifier, can be obtained easily obtained. Then we can get the full gradient according to the augmented SDE. According to the SDE in Eq. 5 with input and output , the augmented SDE is
where is the gradient of the objective w.r.t. the output of the SDE, defined in Eq. 5, and
with and representing the -dimensional vectors of all ones and all zeros, respectively. Empirically, we use the stochastic adjoint method [27] to compute the pathwise gradients of Score SDE.
4.3 Analysis of COUP
In this section, we further analyze the effectiveness of our method. First, we show that under the guidance of classifier confidence, our method can better preserve information for classification. Second, under the guided reverse-time VP-SDE, the distance can be bounded through controlling .
To show that our proposed confidence guidance helps to preserve data information, we give theoretical analysis on a simple case where such guidance can be proved to alleviate the label shift problem. Consider a 1-dimension SDE with starting point and final solution , which is simulated using the Euler method with step size . Denote as the label flip probability such that there exist satisfying , we have the following proposition:
Proposition 1.
If for any and , there is and is strictly monotonically increasing w.r.t. , then
| (7) |
Proposition 1 supports the claim that forces pushing the data away from the decision boundary are helpful to avoid the label shift problem. Consider the case where the data is composed of two classes: one distribution follows and another follows , the conditions in Proposition 1 would be satisfied using a VP-SDE (as ) and a corresponding SDE with guidance (as ), since the added gradient of classifier confidence is always positive on . In this case, Proposition 1 shows that with the guidance from the ground-truth classifier, it is less likely for a sample to change its label during the purification process. We provide the proof of proposition 1 in Appendix A.1.
Next, we show that the distance between the input sample and the purified sample can be bounded under our proposed method, thus can avoid severe semantic changes during purification. The result of proposition 2 indicates that for an an adversarial example , the distance has an upper bound, which is monotonically increasing w.r.t. . As a result, the maximal distance can be controlled by adjusting .
Proposition 2.
Under the assumption that , , and , the denoising error of our guided reverse variance preserving SDE (VP-SDE) can be bounded as
| (8) | ||||
, is the noise added by the reverse-time Wiener process.
5 Experiments
In this section, we mainly evaluate the adversarial robustness of COUP against AutoAttack [6], including both black-box and white-box attacks. Furthermore, we analyze the mechanism of the classifier confidence guidance through a case study and ablation study to verify the effectiveness of COUP. Besides, we combine our work with the state-of-the-art adversarial training method for further promotion.
| Defense | Accuracy (%) | Robustness (%) |
| - | 96.09 | 0.00 |
| AWP - w/o Aug [44] | 85.36 | 59.18 |
| GAIRAT [50] | 89.36 | 59.96 |
| Adv. Train - Aug [31] | 87.33 | 61.72 |
| AWP - Aug [44] | 88.25 | 62.11 |
| Adv. Train - Tricks [13] | 89.48 | 62.70 |
| Adv. Train - Aug [14] | 87.50 | 65.24 |
| DiffPure [29] | 89.02 | 70.64 |
| Our COUP | 90.04 | 73.05 |
5.1 Experimental Settings
Dataset and Models We evaluate our method on CIFAR-10 and CIFAR-100 [23] dataset. To make a fair comparison with other diffusion-based purification methods, we follow the settings of DiffPure [29], evaluating the robustness on randomly sampled 512 images. As for the purification model, we use variance preserving SDE (VP-SDE) of Score SDE [39] with for threat model and for . We select two backbones of the classifier, including WRN-28-10 (WideResNet-28-10) and WRN-70-16 (WideResNet-70-16).
Baselines We compare our method with (1) robust optimization methods, that is the adversarial defense based on discriminative models, also including using generative models for data augmentation; (2) adversarial purification methods based on generative models before classification. Since some diffusion-based adversarial purification methods do not support gradient computation and do not design an adaptive attack, we compare the SOTA method [29] supported by AutoAttack [6].
Evaluation Method We evaluate our method against the AutoAttack [6] against the and threat models and Backward Pass Differentiable Approximation (BPDA) [1]. Since our method contains Brownian motion, we use both standard (including three white-box attacks APGD-ce, APGD-t, FAB-t, and one black-box attack Square) and rand mode (including two white-box attack APGD-ce, APGD-dlr with EOT=20) of AutoAttack, choosing the worse one to eliminate the ’fake robustness’ brought by randomness. Since the white-box plays stronger attack behavior, we evaluate our algorithm across different classifier backbones and other analysis experiments against APGD-ce, one of the white-box in AutoAttack.
| Defense | Accuracy (%) | Robustness (%) |
| - | 96.09 | 0.00 |
| Adv. Train - DDN [32] | 89.05 | 66.41 |
| Adv. Train - MMA [9] | 88.02 | 67.77 |
| AWP [44] | 88.51 | 72.85 |
| PORT [34] | 90.31 | 75.39 |
| RATIO [2] | 92.23 | 77.93 |
| Adv. Train - Aug[31] | 91.79 | 78.32 |
| DiffPure [29] | 91.03 | 78.58 |
| Our COUP | 92.58 | 83.13 |
| Defense | Accuracy (%) | Robustness (%) |
| - | 96.09 | 0.00 |
| PixelDefend [37] | 95.00 | 9.00 |
| ME-Net [47] | 94.00 | 15.00 |
| Purification - EBM[16] | 84.12 | 54.90 |
| ADP [48] | 86.14 | 70.01 |
| GDMP [41] | 93.50 | 76.22 |
| DiffPure [29] | 89.02 | 81.40 |
| Our COUP | 90.04 | 83.20 |
5.2 Comparison with Related Work
5.2.1 AutoAttack
We evaluate our COUP against AutoAttack and compare the robustness with other advanced defense methods on CIFAR-10 according to the results proposed in robustbench [7]. DiffPure [29] is the most related work to ours. According to the results in Table 1 and Table 2, our COUP achieves better robustness (+2.41% for and +4.55% for ) as well as better accuracy (+1.02% for and +1.55% for ), showing the effectiveness of classifier guidance enhancing the adversarial robustness through better purification.
Moreover, we also adapt our COUP to the DDPM architecture [18] in consideration of the inference efficiency and evaluate the adversarial robustness against APGD-ce on CIFAR-100. We employ the purification method suggested by Chen et al. [5] and add classifier confidence guidance during likelihood maximization. Our results indicate that COUP attains a 40.55% robustness under the threat model with , surpassing the 38.67% achieved by likelihood maximization without classifier guidance.
Besides, owing to the adaptive attack, we can make a fair comparison with other purification algorithms as well as robust optimization methods based on discriminative models. The state-of-the-art method of robust optimization is an improved adversarial training using generated data by diffusion models. COUP is orthogonal to those. We will further discuss the comparison and combination with the SOTA work among them in Section 5.3.
5.2.2 BPDA
We also evaluate the robustness against BPDA + EOT [1] in order to make a comparison with other guided diffusion-based purification methods [45, 41] (since they do not support adaptive attack). The results are represented in Table 3. Considering both Wu et al. [45] and Wang et al. [41] utilize adversarial samples as guidance, we compare with the more proficient GDMP [41] of the two (according to the results from Table 1 of Wu et al. [45]). We test our method on the CIFAR-10 dataset against PGD-20, employing a setting of , . The experimental robustness of GDMP achieves 76.22%, DiffPure achieves 81.40%, while our COUP achieves the best of 83.20%. These results verify the effectiveness of our method against BPDA except for adaptive attack and obtain better performance than the adversarial examples guided diffusion-based purification algorithm.
5.3 Experimental Analysis
5.3.1 Case Study
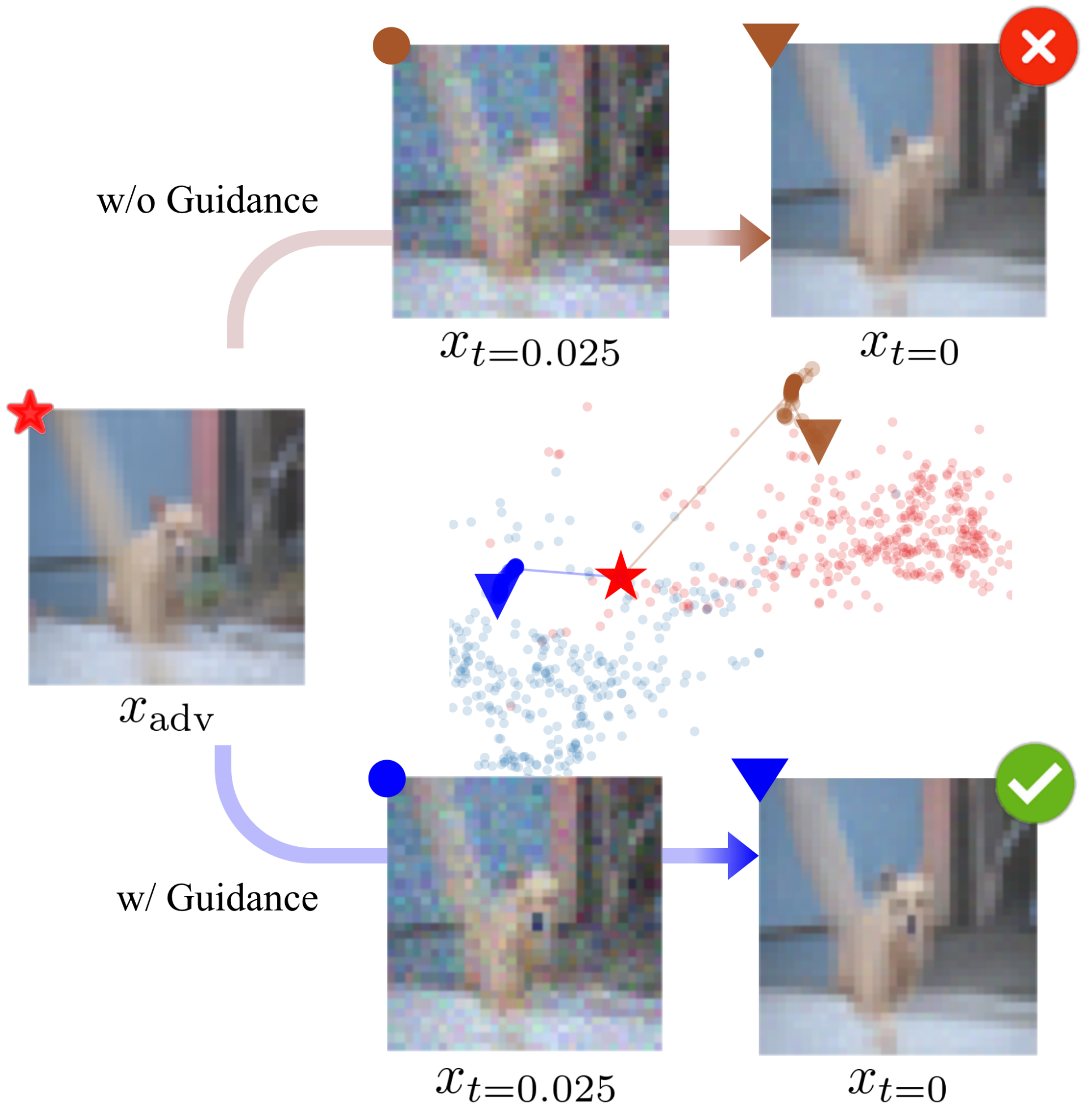
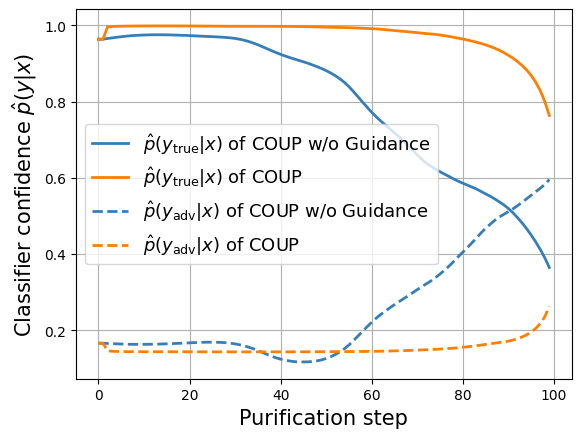
In this part, we plot the curve of and to show what happens from the view of classifier during purification, where the is the predict confidence by the classifier of label . Moreover, we analyze the mechanism of the classifier guidance. To obtain the adversarial examples, we use APGD-ce under the threat model to attack the reverse-time SDE (COUP without Guidance) to get bad cases for COUP w/o Guidance. To focus on the purification process, we do not consider Brownian motion at inference time.
According to the analysis in Section 3, we use the predict confidence for ground truth label to evaluate the information preservation degree of the image during purification. Then we plot the curve as shown in Fig. 2a. The rise of is the reason for successful attack. Meanwhile, the decrease of shows that, during purification, predictive information keeps losing. After 90 steps of purification, suddenly declines to a very low level due to "over purification" and dominates the prediction confidence, which leads to vulnerability. Next, we further explore the mechanism of classifier guidance. After adding classifier guidance, obtains a rapid rise under the guidance of the classifier at the very beginning. Besides, the guidance of the classifier alleviates the information loss (also weakens the influence of adversarial perturbation) during purification and finally results in correct classification.
5.3.2 Analysis of Information Preservation on Toy Data
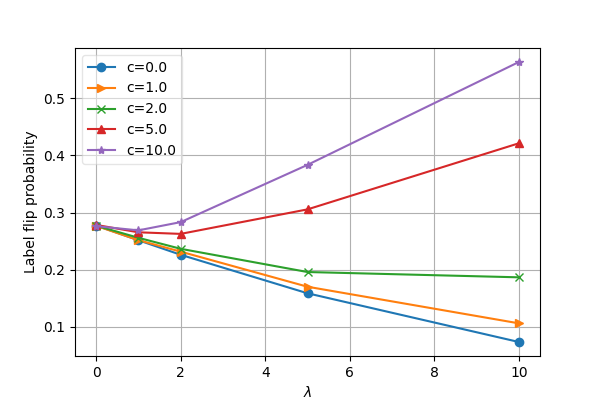
To verify the effectiveness of our method for information preservation, we use 2-Gaussian toy data and run a simulation of pure SDE and COUP to show that COUP can alleviate the label shift problem. The data distribution is a 1-dimension uniform mixture of 2 symmetric Gaussian distributions and , the data from which we label as and , respectively. Starting from the point , we apply the COUP algorithm with guidance weight ranging from to . To simulate the adversarial vulnerability of the classifier, we use a noisy classifier , where is the density function of class , is the noise and is the noise level. We apply the Euler method for SDE simulation, using step size and . We run times and estimate the label flip probability, i.e. . The result in Fig. 3b shows that the guidance signal is overall helpful to keep the label unchanged under small or no noise. When the noise level is high, the classifier becomes untrustworthy. Thus, an appropriate should be chosen.
5.3.3 Analysis on Different Classifier Architectures
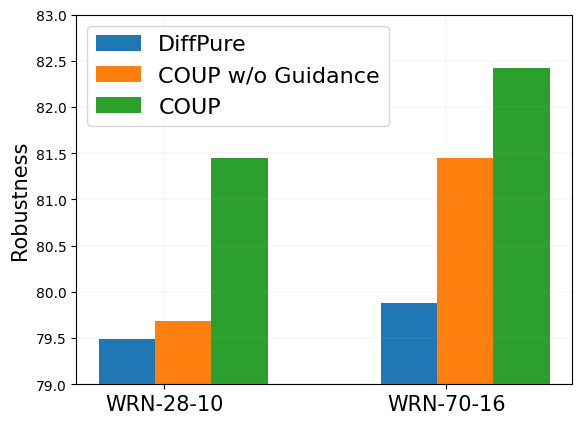
In order to evaluate the effectiveness of our guidance method for different architectures of classifiers, we adapt our purification method to both WRN-28-10 and WRN-70-16 against APGD-ce attack (under ). The results in Fig. 2b show that COUP achieves better robustness on both two classifier backbones. In other words, our method is effective across different classifier architectures.
5.3.4 Ablation Study
In order to demonstrate the effectiveness of classifier guidance, we evaluate the robustness of COUP and COUP w/o Guidance (i.e. reverse-time SDE) against APGD-ce attack (under ) as an ablation. Results in Fig. 2b support that the robustness promotion in Table 1 and Table 2 of our COUP is mainly caused by the classifier guidance instead of the structure of diffusion model (since we remove the forward process from DiffPure).
5.4 Hyperparameters
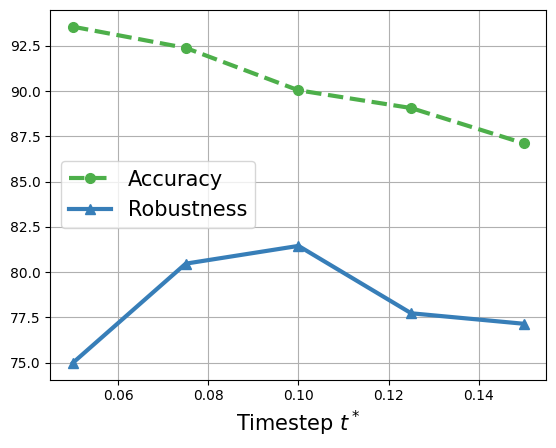
Analysis on Purification Timestep Since the purification timestep is a critical hyperparameter deciding the degree of denoising, we evaluate the robustness against APGD-ce across different and find it performs the best at . The experimental result in Fig. 4a shows that insufficient purification step or "over purification" both leads to lower robustness. This phenomenon strongly supports that balancing denoising and information preservation is very important. Besides, it is intuitive that accuracy decreases as timestep grows.
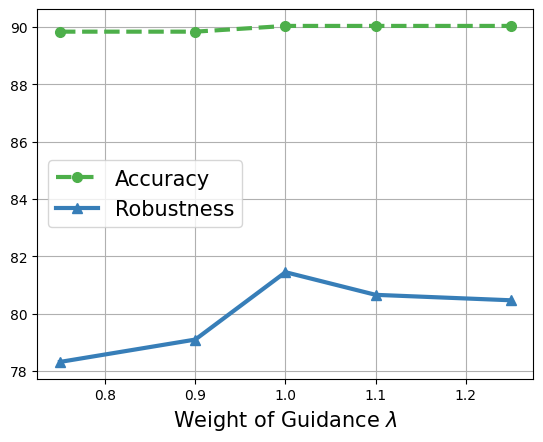
Analysis on Guidance Weight We experimentally find that COUP obtains the highest robustness against APGD-ce under . That is, the diffusion model and the classifier have equal weight. Note that it implements the same effect as a conditional generative model (according to the Bayes formula: since the prior probability of category is considered as uniform).
5.4.1 Comparison and Combination with SOTA of Adversarial Training
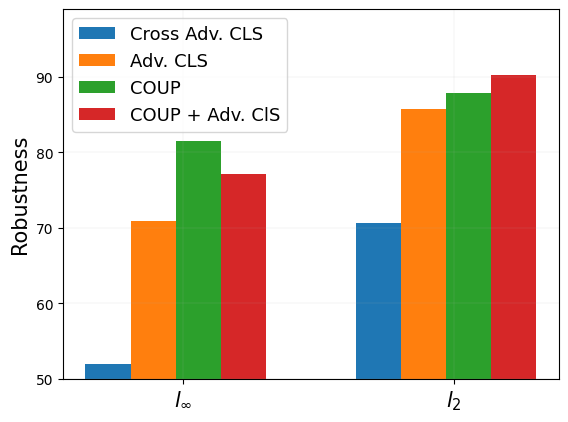
Considering the settings of robust evaluation, we argue that it is unfair to compare our COUP with the adversarial training algorithm. The reason is we do not make any assumption about the attack, while the adversarial training methods are specifically trained for the evaluation attack. Therefore, we additionally evaluate the SOTA [42] of adversarial training under both cross and non-cross settings. Specifically, in the cross-setting, we use the model trained for () to defend the attack under (). The results in Table 2c show that it [42] suffers a severe robustness drop under the cross-setting. In other words, its robustness becomes poor when defending against unseen attacks.
Besides, to take advantage of their work [42], we combine our purification method with the adversarially trained classifier. When the classifier has better clean accuracy (95.16% under ), it can further improve the robustness against APGD-ce attack. However, worse accuracy under (92.44%) may provide inappropriate guidance for purification. Note that, in that case, our purification method COUP further improves their robustness from 70.90% to 77.15%.
6 Conclusion
To address the principal challenge in purification, i.e., achieving a balance between noise removal and information preservation, we employ the concept of the classifier-guided purification method. We discover that classifier-confidence guidance aids in preserving predictive information, which facilitates the purification of adversarial examples towards the category center. Specifically, we introduce Classifier-cOnfidence gUided Purification (COUP) and have assessed its performance against AutoAttack and BPDA, comparing it with other advanced defense algorithms under the RobustBench benchmark. The results demonstrated that our COUP achieved superior adversarial robustness.
This work is supported by the Strategic Priority Research Program of the Chinese Academy of Sciences, Grant No. XDB0680101, CAS Project for Young Scientists in Basic Research under Grant No. YSBR-034, Innovation Project of ICT CAS under Grant No. E261090, and the project under Grant No. JCKY2022130C039. This paper acknowledges the valuable assistance of Xiaojie Sun in the experiment execution.
References
- Athalye et al. [2018] A. Athalye, N. Carlini, and D. Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In International conference on machine learning, pages 274–283. PMLR, 2018.
- Augustin et al. [2020] M. Augustin, A. Meinke, and M. Hein. Adversarial robustness on in-and out-distribution improves explainability. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVI 16, pages 228–245. Springer, 2020.
- Brendel et al. [2017] W. Brendel, J. Rauber, and M. Bethge. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. arXiv preprint arXiv:1712.04248, 2017.
- Carlini et al. [2022] N. Carlini, F. Tramer, J. Z. Kolter, et al. (certified!!) adversarial robustness for free! arXiv preprint arXiv:2206.10550, 2022.
- Chen et al. [2023] H. Chen, Y. Dong, Z. Wang, X. Yang, C. Duan, H. Su, and J. Zhu. Robust classification via a single diffusion model. arXiv preprint arXiv:2305.15241, 2023.
- Croce and Hein [2020] F. Croce and M. Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In International conference on machine learning, pages 2206–2216. PMLR, 2020.
- Croce et al. [2020] F. Croce, M. Andriushchenko, V. Sehwag, E. Debenedetti, N. Flammarion, M. Chiang, P. Mittal, and M. Hein. Robustbench: a standardized adversarial robustness benchmark. arXiv preprint arXiv:2010.09670, 2020.
- Dhariwal and Nichol [2021] P. Dhariwal and A. Nichol. Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems, 34:8780–8794, 2021.
- Ding et al. [2018] G. W. Ding, Y. Sharma, K. Y. C. Lui, and R. Huang. Mma training: Direct input space margin maximization through adversarial training. arXiv preprint arXiv:1812.02637, 2018.
- Du and Mordatch [2019] Y. Du and I. Mordatch. Implicit generation and modeling with energy based models. Advances in Neural Information Processing Systems, 32, 2019.
- Goodfellow et al. [2020] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial networks. Communications of the ACM, 63(11):139–144, 2020.
- Goodfellow et al. [2014] I. J. Goodfellow, J. Shlens, and C. Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- Gowal et al. [2020] S. Gowal, C. Qin, J. Uesato, T. Mann, and P. Kohli. Uncovering the limits of adversarial training against norm-bounded adversarial examples. arXiv preprint arXiv:2010.03593, 2020.
- Gowal et al. [2021] S. Gowal, S.-A. Rebuffi, O. Wiles, F. Stimberg, D. A. Calian, and T. A. Mann. Improving robustness using generated data. Advances in Neural Information Processing Systems, 34:4218–4233, 2021.
- Grathwohl et al. [2019] W. Grathwohl, K.-C. Wang, J.-H. Jacobsen, D. Duvenaud, M. Norouzi, and K. Swersky. Your classifier is secretly an energy based model and you should treat it like one. arXiv preprint arXiv:1912.03263, 2019.
- Hill et al. [2020] M. Hill, J. Mitchell, and S.-C. Zhu. Stochastic security: Adversarial defense using long-run dynamics of energy-based models. arXiv preprint arXiv:2005.13525, 2020.
- Ho and Salimans [2022] J. Ho and T. Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- Ho et al. [2020] J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- Hyvärinen and Dayan [2005] A. Hyvärinen and P. Dayan. Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 6(4), 2005.
- Jiang et al. [2019] H. Jiang, P. He, W. Chen, X. Liu, J. Gao, and T. Zhao. Smart: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization. arXiv preprint arXiv:1911.03437, 2019.
- Kawar et al. [2022] B. Kawar, R. Ganz, and M. Elad. Enhancing diffusion-based image synthesis with robust classifier guidance. arXiv preprint arXiv:2208.08664, 2022.
- Kingma and Welling [2013] D. P. Kingma and M. Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Krizhevsky et al. [2009] A. Krizhevsky, G. Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- Laidlaw et al. [2020] C. Laidlaw, S. Singla, and S. Feizi. Perceptual adversarial robustness: Defense against unseen threat models. arXiv preprint arXiv:2006.12655, 2020.
- LeCun et al. [2006] Y. LeCun, S. Chopra, R. Hadsell, M. Ranzato, and F. Huang. A tutorial on energy-based learning. Predicting structured data, 1(0), 2006.
- Li and Ji [2019] X. Li and S. Ji. Defense-vae: A fast and accurate defense against adversarial attacks. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 191–207. Springer, 2019.
- Li et al. [2020] X. Li, T.-K. L. Wong, R. T. Chen, and D. K. Duvenaud. Scalable gradients and variational inference for stochastic differential equations. In Symposium on Advances in Approximate Bayesian Inference, pages 1–28. PMLR, 2020.
- Madry et al. [2017] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017.
- Nie et al. [2022] W. Nie, B. Guo, Y. Huang, C. Xiao, A. Vahdat, and A. Anandkumar. Diffusion models for adversarial purification. arXiv preprint arXiv:2205.07460, 2022.
- Qin et al. [2019] C. Qin, J. Martens, S. Gowal, D. Krishnan, K. Dvijotham, A. Fawzi, S. De, R. Stanforth, and P. Kohli. Adversarial robustness through local linearization. Advances in Neural Information Processing Systems, 32, 2019.
- Rebuffi et al. [2021] S.-A. Rebuffi, S. Gowal, D. A. Calian, F. Stimberg, O. Wiles, and T. Mann. Fixing data augmentation to improve adversarial robustness. arXiv preprint arXiv:2103.01946, 2021.
- Rony et al. [2019] J. Rony, L. G. Hafemann, L. S. Oliveira, I. B. Ayed, R. Sabourin, and E. Granger. Decoupling direction and norm for efficient gradient-based l2 adversarial attacks and defenses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4322–4330, 2019.
- Samangouei et al. [2018] P. Samangouei, M. Kabkab, and R. Chellappa. Defense-gan: Protecting classifiers against adversarial attacks using generative models. arXiv preprint arXiv:1805.06605, 2018.
- Sehwag et al. [2021] V. Sehwag, S. Mahloujifar, T. Handina, S. Dai, C. Xiang, M. Chiang, and P. Mittal. Robust learning meets generative models: Can proxy distributions improve adversarial robustness? arXiv preprint arXiv:2104.09425, 2021.
- Sohl-Dickstein et al. [2015] J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256–2265. PMLR, 2015.
- Song and Ermon [2019] Y. Song and S. Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019.
- Song et al. [2017] Y. Song, T. Kim, S. Nowozin, S. Ermon, and N. Kushman. Pixeldefend: Leveraging generative models to understand and defend against adversarial examples. arXiv preprint arXiv:1710.10766, 2017.
- Song et al. [2020a] Y. Song, S. Garg, J. Shi, and S. Ermon. Sliced score matching: A scalable approach to density and score estimation. In Uncertainty in Artificial Intelligence, pages 574–584. PMLR, 2020a.
- Song et al. [2020b] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020b.
- Szegedy et al. [2013] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
- Wang et al. [2022] J. Wang, Z. Lyu, D. Lin, B. Dai, and H. Fu. Guided diffusion model for adversarial purification. arXiv preprint arXiv:2205.14969, 2022.
- Wang et al. [2023] Z. Wang, T. Pang, C. Du, M. Lin, W. Liu, and S. Yan. Better diffusion models further improve adversarial training. arXiv preprint arXiv:2302.04638, 2023.
- Wong et al. [2020] E. Wong, L. Rice, and J. Z. Kolter. Fast is better than free: Revisiting adversarial training. arXiv preprint arXiv:2001.03994, 2020.
- Wu et al. [2020] D. Wu, S.-T. Xia, and Y. Wang. Adversarial weight perturbation helps robust generalization. Advances in Neural Information Processing Systems, 33:2958–2969, 2020.
- Wu et al. [2022] Q. Wu, H. Ye, and Y. Gu. Guided diffusion model for adversarial purification from random noise. arXiv preprint arXiv:2206.10875, 2022.
- Xiao et al. [2022] C. Xiao, Z. Chen, K. Jin, J. Wang, W. Nie, M. Liu, A. Anandkumar, B. Li, and D. Song. Densepure: Understanding diffusion models towards adversarial robustness. arXiv preprint arXiv:2211.00322, 2022.
- Yang et al. [2019] Y. Yang, G. Zhang, D. Katabi, and Z. Xu. Me-net: Towards effective adversarial robustness with matrix estimation. arXiv preprint arXiv:1905.11971, 2019.
- Yoon et al. [2021] J. Yoon, S. J. Hwang, and J. Lee. Adversarial purification with score-based generative models. In International Conference on Machine Learning, pages 12062–12072. PMLR, 2021.
- Zhang et al. [2019] H. Zhang, Y. Yu, J. Jiao, E. Xing, L. El Ghaoui, and M. Jordan. Theoretically principled trade-off between robustness and accuracy. In International conference on machine learning, pages 7472–7482. PMLR, 2019.
- Zhang et al. [2020] J. Zhang, J. Zhu, G. Niu, B. Han, M. Sugiyama, and M. Kankanhalli. Geometry-aware instance-reweighted adversarial training. arXiv preprint arXiv:2010.01736, 2020.
In Appendix A, we give the proofs of proposition 1 and proposition 2. In Appendix B, we provide supplementary analysis to show the necessity for introducing the guidance of classifier confidence, stated in the second requirement in Section 3. In Appendix C we further discuss the evidence of omitting the forward process and why the first requirement in Section 3 "Maximizing the probability density of purified image helps to remove the adversarial noise" is valid. In Appendix D we show more details for implementation. In Appendix E we provide more experimental results including the robustness against salt-and-pepper noise, and the speed test. Moreover, we further discuss the effectiveness of our method through the purified images and find that the semantic drift and information loss caused by DiffPure and COUP w/o Guidance, respectively. Finally, we analyze the limitations in Appendix F and broader impacts in Appendix G.
Appendix A Proofs of Propositions
A.1 Proof of Proposition 1
Porposition 1 (restated) If for any and , there is and is strictly monotonically increasing w.r.t. , then
| (9) |
Proof: Define the noise term in update step as , where is a standard Gaussian noise so that each update by Euler method is
Define an auxiliary function
then whether there exist such that can be written as
where is the indicator function. Therefore, the label flip probability will be
Since there is for any , so that . The equivalence holds only when . Considering is strictly monotonically increasing in , there is
By parity of reasoning, we get
so that
thus
The above equivalence holds only when , which will not be possible due to the random nature of Gaussian noise, since there is always a positive probability such that is kept during each update. So that
A.2 Proof of Proposition 2 :
Proposition 2 (restated) Under the assumption that , , and , the denoising error of our guided reverse variance preserving SDE (VP-SDE) can be bounded as
| (10) | ||||
, is the noise added by the reverse-time Wiener process.
Proof: Suppose given an example , the COUP purification function is a guided reverse-time SDE (depicted in Section 4.1.2) from to . Thus, the distance between and the purified example is
| (11) | ||||
Under the assumption that and , we have
| (12) | ||||
where and is an linear interpolation with , . Since is an integration of linear SDE, the solution follows a Gaussian distribution with and satisfies
| (13) | ||||
The initial value is and , thus, the result of solving Eq. 13 is and . Therefore, the conditional probability , the predicted of the linear SDE from to can be represented as
| (14) |
where .
Thus, we have
| (15) |
Under the assumption that , we have
| (16) |
Therefore, we have
| (17) | ||||
So far, the result in proposition 2 has been proved. It supports that under our purification method, the distance between the input and the purified sample can be upper bounded to avoid unexpected semantic changes.
Appendix B Additional Analysis on the Objective of Adversarial Purification
In this section, We provide supplementary explanations for the content in Section 3.
B.1 The Relation between Probability Density and Classifier Credibility
We give an analysis of a simple case to show that the classification model is more trustworthy in high-density areas. Consider a binary classification problem with label space the ground truth classifier is and the learned classification model is . Assume the total numbers of training data is and all data are equally divided into each class. The value of is determined by the proportion of sampled data in class over total samples in the neighborhood of , i.e. . Consider the points on the ground truth class boundary, i.e. , there is
| (18) |
According to the central limit theorem, as long as is large enough, the number of samples in class would be following a Gaussian distribution with mean and variance as
| (19) | ||||
Applying Eq. 18, we get
| (20) | ||||
Therefore the estimated model would be
| (21) | ||||
where and are independent variables following a standard normal distribution. To estimate the approximate variance of , we consider the value of and are limited within a range such that . Under such assumption, there is
| (22) |
So that the larger is, the smaller variance of would be. As a result, it is necessary to seek high density areas where the classification boundary would be more stable.
B.2 The Relation between Probability Density and Classifier Confidence
We claimed in section 3 that optimizing the likelihood is sometimes consistent with optimizing the classifier confidence. We will explain here when such relation exists and when it does not.
Still consider a binary classification task for 1-dimension data and uniformly distributed , there is
| (23) |
Consider how changes as changes:
| (24) |
Assuming
| (25) |
then whether is also positive may not be sure. If data from different classes are well-separated, such that and , there would be . Otherwise, if and , there would be .
In conclusion, for most cases in a dataset with well-separated classes, optimizing has similar effect as optimizing . However, there are exceptions that such objectives are opposite.
Appendix C Additional Analysis of Our Methodology
C.1 Effect of Forward Process for Adversarial Purification
Motivation of removing forward process The objective of the forward process (injecting random noise) is to guide the training procedure for the reverse process. During adversarial purification, the model aims to recover the true label by maximizing likelihood, utilizing the score function of the backward process. Our method exclusively employs the reverse process, avoiding the forward process due to concerns over potential semantic changes induced by the random noise injection.
Existing adversarial purification methods [29, 46, 4, 45, 41, 48], follow the forward-reverse process of image generation tasks. However, they neither offer ablation studies nor provide theoretical evidence for the necessity of incorporating the forward process when the backward process is already in use. The habitual combination of forward and backward processes in applying diffusion models may not be a deliberate choice, warranting further consideration and evaluation.
Better performance (see Fig. 2b) after removing the forward process does not conflict with the existing works. To put it more rigorously, the conclusion drawn from existing works [29, 46, 4, 45, 41, 48] is that including random noise is necessary for successful purification. Note that both the forward and backward processes contain a noise-adding operation, retaining either process can introduce considerable random noise. Yoon et al. [48] is an example, which applied the forward process but removed the noise term in the backward process. Our work applies the backward process with noise term by the Brownian motion, which is empirically sufficient to submerge the adversarial perturbation.
Evidence Therefore, we choose to discard the forward process since it could potentially lead to unexpected category drift, increasing the risk of misclassification. The case study in Fig. 5 in Appendix E.3 illustrates such a difference, where DiffPure causes more of a semantic change than COUP w/o guidance. For numerical evidence, we empirically find that after removing the forward process, "COUP w/o guidance" (i.e., DiffPure w/o forward process) achieves better robustness, as shown in Fig. 2b. For theoretical support, we refer to Proposition 2, where introducing the forward noise causes the term to double, leading to a larger upper bound of distance (between purified image and input image).
C.2 Score Function Plays a Role as Denoiser
In this section, we will introduce the reason why maximizing the likelihood can remove adversarial noise. Then we will discuss the effect of the score function.
Specifically, the training objective [39] of score function is to mimic by score matching [19, 38]
| (26) | ||||
As for VP-SDE there has , where . Since the gradient of the density given a Gaussian distribution is , thus we have
| (27) | ||||
where corresponds to the predicted noise contained in , and is the scaling factor. Therefore, the effect of score function is to denoise the image meanwhile increase the data likelihood.
Appendix D More Implementation Details
Our code is available in an anonymous Github repository: https://anonymous.4open.science/r/COUP-3D8C/README.md.
D.1 Off-the-shelf Models
We develop our method on the basis of DiffPure: https://github.com/NVlabs/DiffPure/tree/master. As for the checkpoint of the off-the-shelf generative model, we use vp/cifar10_ddpmpp_deep_continuous pre-trained from Score SDE: https://github.com/yang-song/score_sde. As for the robustness of baselines and the checkpoint of the classifier, it is provided in RobustBench: https://github.com/RobustBench/robustbench.
D.2 Key Consideration for Reproduction
In Table 1 and Table 2, we experiment with our method on an NVIDIA A100 GPU, while other experiments are tested on an NVIDIA V100 GPU.
Random Seed Consider the setting of DiffPure [29], we use seed = 121 and data seed = 0.
Automatic Mixed Precision (AMP) In our experiments, we use torch.cuda.amp.autocast (enabled=False) to alleviate the loss of precision caused by A100 GPU’s automatic use of fp16 for acceleration. The reason is our guidance is small in the integral drift function of each step of SDE. Empirically, we found our method performs even well on V100 GPU, however, it is too computationally expensive. In other words, we may gain better performance than proposed in Table 1 and Table 2 if avoiding accelerating strategies e.g. tested on V100 GPU.
D.3 Resources and Running Time
To evaluate the robustness of COUP against AutoAttack, we use 2 NVIDIA A100 GPUs and run analysis experiments against APGD-ce attack on 2 NVIDIA V100 GPUs. It takes about 18 days to test our COUP for AutoAttack once (8 days for "rand" mode + 10 days for "standard" mode). For this reason, we do not provide error bars.
Appendix E More Experimental Results
E.1 Robustness against Salt-and-Pepper Noise Attack
Thanks to the powerful capability of the diffusion model, modeling the data distribution serves as a defensive measure against not only adversarial attacks but also corruptions. Though this is not the main proposal of our main paper, we conduct a preliminary assessment experiment focused on mitigating salt-and-pepper noise.
In detail, we randomly select 500 examples from the CIFAR-10 dataset for evaluation and adopt against salt-and-pepper noise attack with . In this context, the robustness of WideResNet-28-10, without purification, stands at 87.80%. Conversely, COUP, without guidance, exhibits a robustness of 92.60%. Remarkably, our implementation of COUP attains a robustness of 93.00%. The outcomes indicate that our COUP is capable of defending against salt-and-pepper noise attacks, demonstrating enhanced performance regarding classifier-confidence guidance.
E.2 Speed Test of Inference Time
We do the speed test of the inference time of DiffPure, reverse-time SDE, and COUP on variant . The results in Table 4 are tested on an NVIDIA V100 GPU. They show that with larger timestep , the inference time will obviously increase. The larger inference time of COUP is caused by computing the gradient of classifier confidence at each diffusion timestep.
| Method | |||||
| DiffPure | 0.006 | 0.140 | 3.056 | 5.770 | 8.648 |
| COUP w/o Guidance | 0.006 | 0.148 | 3.032 | 6.930 | 8.732 |
| our COUP | 0.006 | 0.170 | 3.894 | 7.662 | 11.134 |
E.3 Purified Images
We plot the purified images by different purification methods including DiffPure, COUP without Guidance, and our COUP. We follow the setting of 2b and use WRN-28-10 as the classifier.
As shown in Fig. 5, the purified images of DiffPure suffer from unexpected distortion caused by the forward diffusion process and it of COUP w/o Guidance has lost some details e.g. texture due to its denoising process. Specifically, the 2nd example purified by DiffPure suffers a significant semantic drift from a "frog" to a "bird", and the 3rd example occurs some unexpected feature, which is not beneficial for classification. Moreover, the 3rd image purified by COUP w/o Guidance lost a wing of the airplane and buffed the ears of the cat in the 4th image. However, our COUP has augmented some classification-related features while removing the malicious perturbation.
We further focus on the purification effectiveness of COUP compared with the method without guidance.
In Fig. 6, we plot the bad cases of COUP w/o Guidance which are correctly classified after adding classifier guidance. It shows that reverse-time SDE does destroy the image details (e.g. the body of the ship in 1st example and the texture of the dog and the details of the track have been destroyed) which is viewed as "over-purification". However, our COUP alleviates this phenomenon (maintaining the predictive information which leads to correct classification).
In conclusion, the results of the example show that
-
•
DiffPure sometimes tends to cause semantic changes due to the diffusion process.
-
•
Using only reverse-time SDE (i.e. COUP w/o Guidance) can avoid semantic drift, however, it faces the problem of information loss in the process of denoising.
-
•
Our method tackles the above problems by removing the forward diffusion process and enhancing the classification-related features.
Appendix F Limitations
Despite the effectiveness, our method suffers from high computational costs at inference time. Besides, the hyperparameter timestep and guidance weight need to be searched empirically, which further increases the calculation overhead.
Appendix G Broader Impacts
Our method does not create new models, instead, we take advantage of the off-the-shelf generative models and discriminative models. Besides, we design a method for purifying adversarial perturbations, one of the adversarial defenses to improve model robustness. It would not bring risks for misuse. However, our purification method helps eliminate the impact of malicious attacks by removing adversarial perturbation.

