0 \vgtccategoryResearch \vgtcinsertpkg
Classifying In-Place Gestures with End-to-End Point Cloud Learning
Abstract
Walking in place for moving through virtual environments has attracted noticeable attention recently. Recent attempts focused on training a classifier to recognize certain patterns of gestures (e.g., standing, walking, etc) with the use of neural networks like CNN or LSTM. Nevertheless, they often consider very few types of gestures and/or induce less desired latency in virtual environments. In this paper, we propose a novel framework for accurate and efficient classification of in-place gestures. Our key idea is to treat several consecutive frames as a “point cloud”. The HMD and two VIVE trackers provide three points in each frame, with each point consisting of 12-dimensional features (i.e., three-dimensional position coordinates, velocity, rotation, angular velocity). We create a dataset consisting of 9 gesture classes for virtual in-place locomotion. In addition to the supervised point-based network, we also take unsupervised domain adaptation into account due to inter-person variations. To this end, we develop an end-to-end joint framework involving both a supervised loss for supervised point learning and an unsupervised loss for unsupervised domain adaptation. Experiments demonstrate that our approach generates very promising outcomes, in terms of high overall classification accuracy (95.0%) and real-time performance (192ms latency). Our code will be publicly available at: https://github.com/ZhaoLizz/PCT-MCD.
Human-centered computingHuman computer interaction (HCI)Interaction techniquesGestural input; \CCScatTwelveHuman-centered computing—Human computer interaction (HCI)Interaction paradigmsVirtual reality
Introduction
Locomotion in the virtual environment is an important function in virtual reality (VR) applications [25]. An ideal, immersive and natural approach to virtual locomotion is real walking [50]; however the limitation of physical space often makes this approach difficult to implement [49]. Joystick-based movement is a common method in video games, but this method can cause motion sickness in virtual reality environments [17]. The Walking-in-place (WIP) method allows the user to navigate the virtual environment with walking-in-place gestures, which provides kinesthetic feedback similar to real walking and provides high immersion and naturalness [25].
Although the WIP technique has the advantages mentioned above, it is still not widely used mainly due to several challenges. The first challenge is to classify gesture patterns that map the user’s specific gestures in the real world to virtual locomotion with low latency [7]. There are many proposed WIP methods to recognize specific WIP gestures of users and then to transform them into virtual movements. For instance, LLCM-WIP [5], GUD-WIP [47] and SAS-WIP [3] implemented low-latency WIP gestures detection by manually designing features. Hansen et al. [14] used a convolutional neural network to classify whether the user is standing or WIP. VR-STEP [40] utilized a dynamic threshold method proposed in [56] to detect WIP gait. However, many existing methods suffer from manually designing features such as threshold parameters, or introducing high classification latency, or focusing on classifying only two types of gestures (standing and walking) while ignoring other common in-place gestures (e.g., jogging or jumping). Moreover, due to the inter-person variations which represent different characteristics of users such as height, weight, gender and locomotion habits, domain gaps do exist between users. So the method designed may be accurate for some users, but may not work for others. DCTC [36] is based on improved Long Short-Term Memory (LSTM) network for classifying 7 types of foot patterns and can be generalized across different sensors and individuals, but it induces a relatively high latency (i.e., 500ms for 95% accuracy).
To address the above challenges in virtual locomotion, we propose an effective method that can accurately classify the user’s in-place gestures in the real world with low latency and can bridge the domain gap between users so that the model is generalizable across persons. Our key idea is to use the head-mounted display (HMD) and two VIVE trackers attached to the thighs to collect the user’s head and legs position, velocity, rotation angle and angular velocity data in each frame, and treat the data of several consecutive frames as a point cloud. Thus each point in the point cloud consists of 12-dimensional features which provide rich geometric, trajectory shape and scale information of user’s WIP gestures [12, 11]. We then design an end-to-end point-based classification network that takes both supervised learning and unsupervised domain adaptation into account, with a supervised loss and an unsupervised loss for joint training.
As for creating the dataset, we first collect 9 classes of locomotion data from 14 participants using the HMD and two VIVE trackers mentioned above. Then, using the sliding window method, the data is partitioned into samples, with each sample representing a point cloud. Then we label each sample with the gesture that appears most number of times in that sample. For a particular user, we first collect the locomotion data of the user, and define the unlabeled data of the user as the target domain and the labeled data in the dataset as the source domain. Inspired by Maximum Classifier Discrepancy (MCD) [34] from image processing and Point Cloud Transformer (PCT) [10] from point cloud learning, we design an end-to-end framework by fusing MCD with PCT. With the adversarial training strategy proposed in MCD, the encoder from PCT is used as a feature generator, and two task-specific classifiers are used as the discriminator which takes features from the generator as input. Two classifiers are trained to simultaneously classify source samples and detect target samples that are not clearly categorized into some classes. The generator is trained to fool the discriminator by generating target features close to the two classifiers’ decision boundaries.
In summary, this paper makes the following main contributions.
-
•
We propose a novel gesture classification framework for virtual locomotion, by regarding several consecutive frames as a point cloud in which the HMD and two VIVE trackers provide three points in each frame and each point consists of 12-dimensional features. To our knowledge, it is the first work for in-place gestures classification context with considering consecutive frames as a point cloud.
-
•
We take both supervised learning and unsupervised domain adaptation into account and develop an aggregated architecture for joint training.
-
•
We create a dataset that involves 9 classes of gestures. To our knowledge, this is the first dataset that includes the largest number of in-place gesture classes. We will release it and our source code to the community.
-
•
We conduct experiments on our dataset with the proposed method. Results show that our method is able to generate high overall classification accuracy (95.0%) with real-time latency (192ms).
1 Related Work
1.1 Walking-in-Place for Virtual Locomotion
Virtual locomotion is a technique by which the user controls the virtual avatar to travel in a 3D virtual environment. It has a significant impact on the users’ sense of presence [36]. Real walking is an immersive and natural approach to navigate in the virtual environment [32, 42], but this method requires the same large physical space as the virtual environment for users to move, which in most cases can not be satisfied because the virtual space can be infinite and the room space is limited [2, 5].
WIP is a natural way of virtual locomotion using leg motions while remaining in place, which makes it easy to be applied in limited physical space. WIP is easy to control the direction and distance of movement [50, 42, 37] and it can also reduce simulation sickness [40].
WIP motion is usually detected by wearable sensors, such as inertial measurement units (IMUs) embedded in HMD, smartphones, and trackers, etc. We can get the information of leg position, linear velocity, acceleration, angular velocity etc by attaching the wearable sensors to the user’s body [14]. Tregillus et al. [40] used the smartphone’s inertial sensors which include a 3-axis accelerometer and 3-axis gyroscope to collect the acceleration signal from the HMD in real-time and used Zhao’s proposed pedometry algorithm [56] to implement VR-Step. Wendt et al. [46] built a model that uses only the bobbing head-track position data to estimate the walking speed, step frequency and direction. Paris et al. [27] used the IMU of the smartphone for Samsung Gear VR to detect whether the user is stepping by setting threshold values of the acceleration signal. Feasel et al. [5] proposed a LLCM-WIP System to reduce the system latency by using a chest-orientation tracker and foot trackers. Lee et al. [20] used the vertical position of the HMD to detect the jogging in place step and considered eliminating the impact of the HMD’s pitch angle on the vertical position. Wendt et al. [47] implemented a Gait Understanding-Driven(GUD) WIP model with a fairly low start-stop latency by attaching two 6-DoF trackers to the user’s shins. With prior knowledge of biomechanics, they implemented a state machine with manual-tuning of parameters, then walking speed was estimated by the proposed GUD WIP model from step frequency and foot position.
Most of the aforementioned methods rely greatly on empirical experience and require the experimenter to be familiar with the biomechanical characteristics of the gait in order to manually adjust the parameters of the WIP model such as threshold values. Moreover, as suggested by [36], there are inter-person and intra-person variations. The intra-person variation refers to the fact that the sensor signal of the same person may change significantly for multiple repetitions of the same experiment due to physical exertion, and the inter-person variation refers to the fact that the sensor signal of the same gesture may vary significantly for different users, due to the differences in height, weight, gender and movement habits among users. These factors lead to significant differences in the effectiveness of manually setting model parameters for different users [14].
1.2 Machine Learning for Walking In Place
Previous data-driven approaches for WIP were usually used to recognize certain patterns of motion. Slater et al. [31] used the position of the HMD as input to a simple neural network to identify whether the user is walking in place or not. Hanson et al. [14] utilized the linear acceleration of the x, y, z axes of the HMD as input and fed it into a convolutional neural network to predict whether the user is currently walking or standing in real-time. Their approach improves the generalization of the WIP model and reduces the impact of inter-person variation across different users on the model. Lee et al. [22] used the position values of the x-axis and z-axis of the HMD labeled with the torso direction of the user to train a model based on the LSTM network to predict the current WIP direction of the user. Lee et al. [21] attached the VIVE tracker to the user’s left ankle and used the continuous x-y-z coordinates and yaw angles of the HMD and tracker labeled with the user’s posture in the gait cycle to train a convolutional neural network for predicting the gait state of the user’s WIP posture. Maghoumi et al. [24] proposed an end-to-end gesture recognition network consisting of an encoder network of stacked gated recurrent units, attention module and classification layers. It directly took as input a sequence of raw 3D gesture vector features collected by sensors to predict gesture labels.
Shi et al. [36] attached a microchip and three pressure sensors to the insole, which were then used to collect pressure signals from users under seven different gait patterns to create a dataset. This dataset was used to train a pattern classifier for real-time classification of user’s gait, which is based on the LSTM. Shi et al. then proposed a Dual-Check Till Consensus (DCTC) method, which dynamically adjusted the segment length of the input data according to the classifier’s probability, to improve the classification accuracy of the LSTM and to reduce the system latency. Their approach can achieve excellent generalization across sensors and individuals.
1.3 Deep Learning on Point Clouds
A point cloud is a set of unordered 3D points, which is the most direct way to represent 3D geometric information [13]. PointNet [28] was pioneer in directly consuming raw point cloud representation without either voxelization or projection. It obtains permutation invariance by a symmetric function. Qi et al. further proposed PointNet++ [29], a hierarchical network that extracts the geometric features of each point’s neighborhood. DGCNN [45] is a graph-based method which creates a dynamic graph in the feature space and uses the EdgeConv layer to learn the edge features of the graph. Guo et al. [10] proposed Point Cloud Transformer (PCT) to apply the traditional Transformer [43] to the field of point cloud learning. They constructed an attention mechanism based on the Transformer for the learning of point cloud features. The Transformer has the order-invariant property, which is favorable for processing point clouds. Zhang et al. proposed to filter 3D point clouds with a point-based network [55]. Vatavu et al. [44] proposed to consider the two-dimensional strokes generated by gestural input as a disordered set of points, and introduced a $P recognizer, a member of the $-family, to recognize the input stroke gestures.
1.4 Unsupervised Domain Adaptation (UDA) for Point Clouds
Qin et al.[30] proposed PointDAN, which aligns the local and global features of point clouds together using a Self-Adaptive (SA) node module with an adjusted receptive field. They also used an adversarial training strategy to learn and align features across domains. Achituve et al. [1] applied self-supervised learning(SSL) to point cloud processing. They came up with a multi-task architecture with a multi-head network, where one head is used to train the classifier and one head is trained using the loss caused by the self-supervised Deformation Reconstruction (DefRec) task. SqueezeSetV2 [52] used geodesic correlation alignment and progressive domain calibration to bridge the domain gap between synthetic and real point clouds.
2 Method
The goal of our research is to build a model that can quickly and accurately identify the user’s in-place gestures for virtual locomotion. To this end, we first collect locomotion data using the HTC VIVE Pro HMD and two VIVE trackers attached to the user’s thighs, in which each device provides a point at each frame. Each point involves the 3D position coordinates, velocity, rotation and angular velocity of the user’s head or legs. We treat the data of several consecutive frames as a point cloud sample and build a point cloud dataset by labeling all samples. To consider the inter-person variations, we design a point-based classification network by fusing unsupervised domain adaptation with a point cloud backbone for joint supervised and unsupervised training. A general overview of our approach is shown in Figure 1.
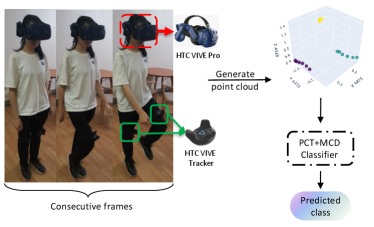
2.1 Dataset
2.1.1 Participants
To collect the dataset for training the in-place gesture classification model, we recruit 14 volunteers, all of whom are students from our university, with a mean age of 24.3 and a standard deviation of 2.1. In them, 5 are female and 9 are male. Before data collection begins, we ask the volunteers about their familiarity with virtual reality using a questionnaire from [36]. The average familiarity score is 2.9 and the standard deviation is 0.87. According to [36], these numbers represent a moderate level of familiarity with virtual reality for this group of participants. Each participant is informed of the methodology and purpose of the study before the experiments.
2.1.2 Selection of Gestures
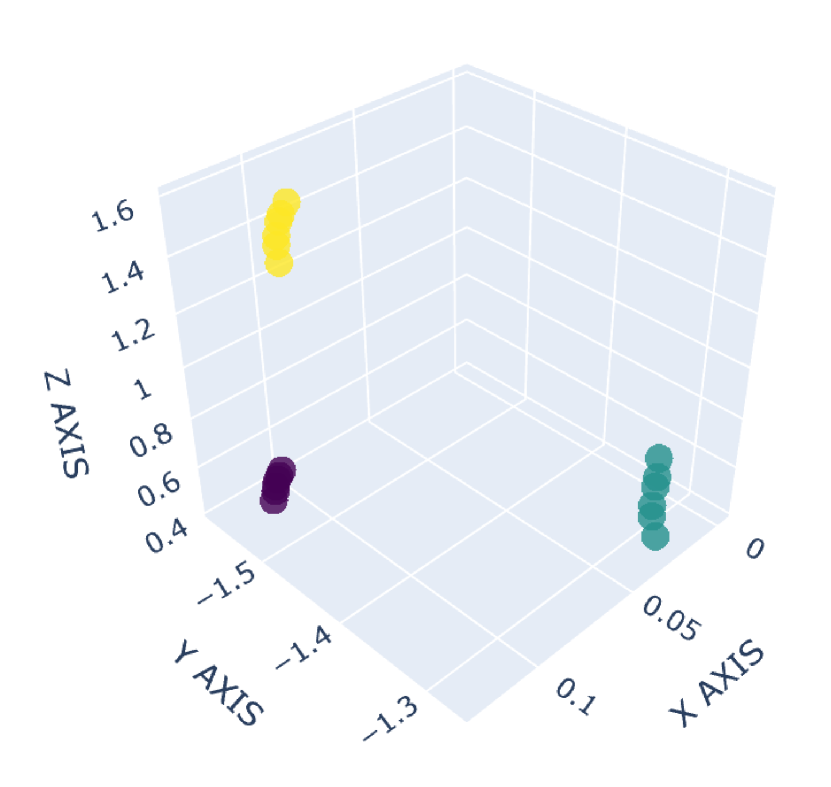
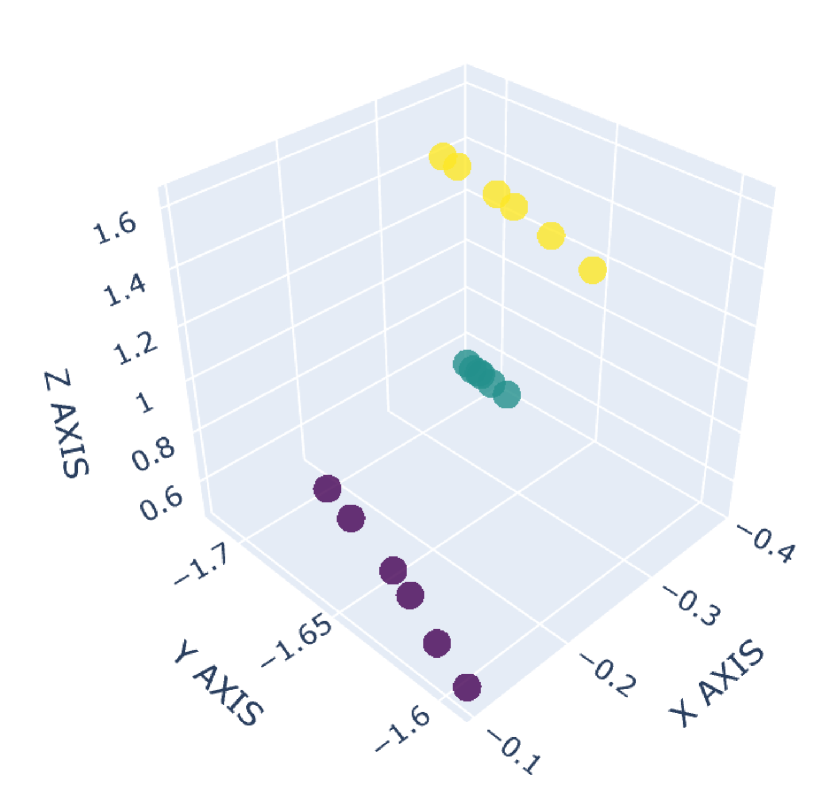
There are many common forms of body movement in virtual reality games or applications [8, 53, 16, 33, 51]. Referring to previous work [40, 48, 6], we choose walking in place as the basic way to navigate through the virtual environment while keeping users in a limited horizontal space. In order to allow the user to control the speed [14] and move quickly in the virtual environment, we also consider the “jog-in-place” motion [20]. Furthermore, we use real steps forward or backward as triggers to control whether the direction of walking or jogging in place is forward or backward. In the existing work [33], jumping is a form of movement with high presence, creativity and immersion, so we also add jumping as a form of locomotion in our dataset. VR exergames have been shown to be effective in engaging and motivating sedentary users to exercise [35], and squatting is a common gesture in exergames [54]. Therefore, we add three labels to our dataset to identify squat-related gestures: squatting down, keeping squatting, and squatting up. Finally, with considering standing, our dataset involves a total of 9 labels: walking in place, jogging in place, jumping, stepping forward, stepping backward, squatting down, keeping squatting, squatting up and standing. To our knowledge, our dataset has the largest number of classes for virtual locomotion. The normalized point cloud visualization of these gestures is shown in Figure 2, where each subplot represents a gesture and each point is provided by the HMD or VIVE tracker. Different devices are indicated by different point colors. (a)standing,(b)walking in place,(c)jogging in place,(d)jumping,(e)squatting down,(f)keeping squatting,(g)squatting up,(h)stepping forward,(i)stepping backward
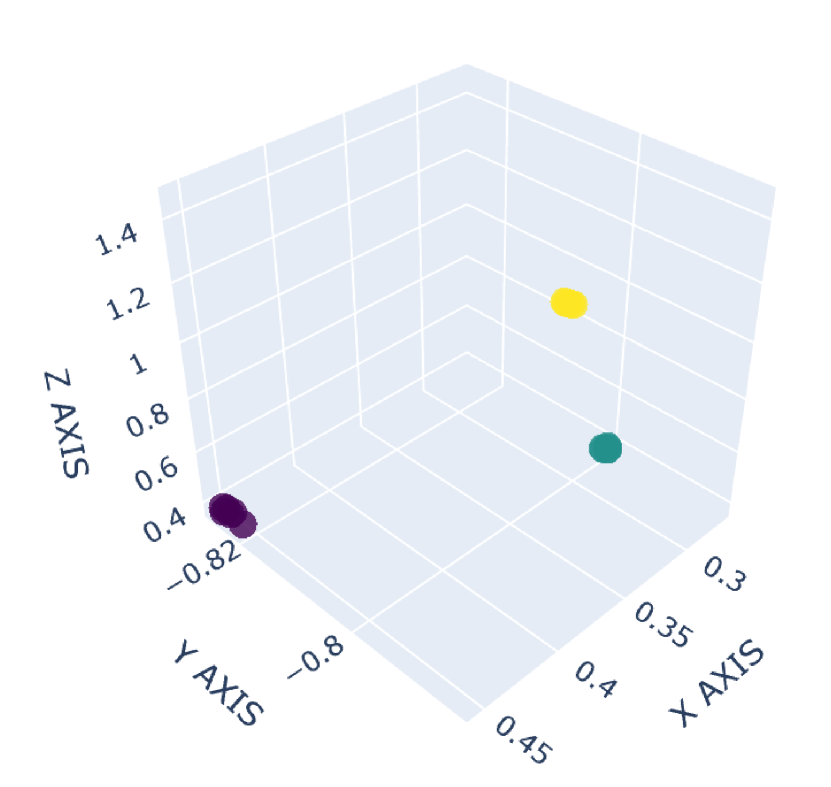
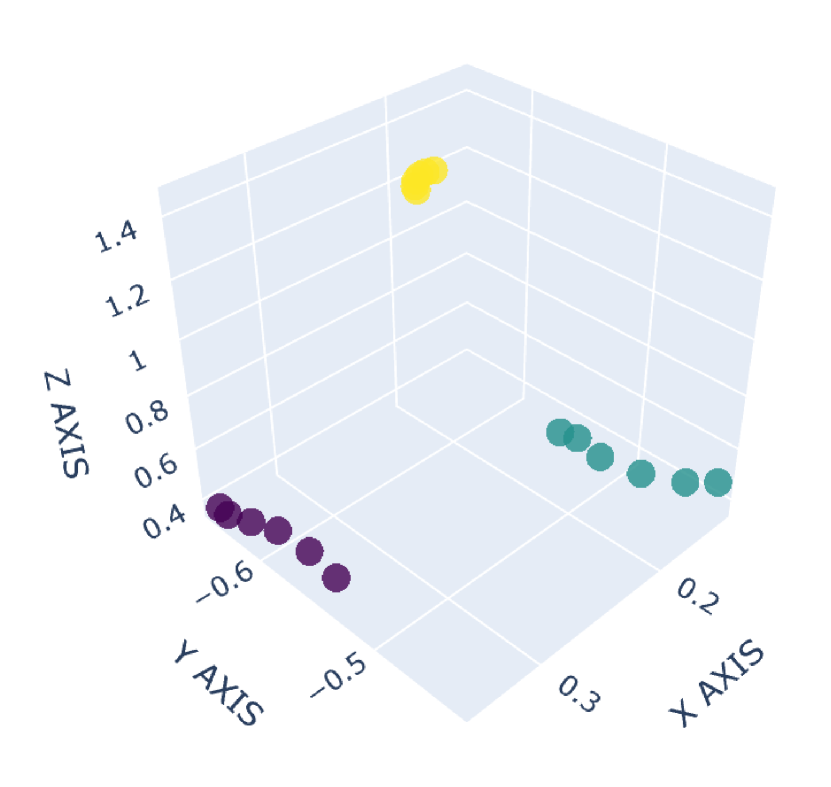
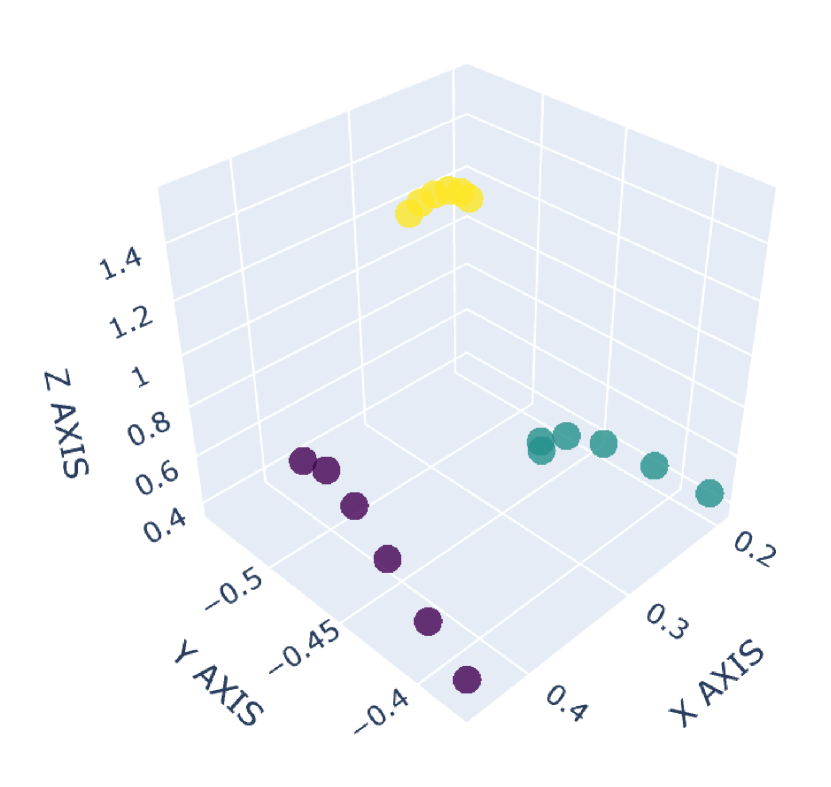
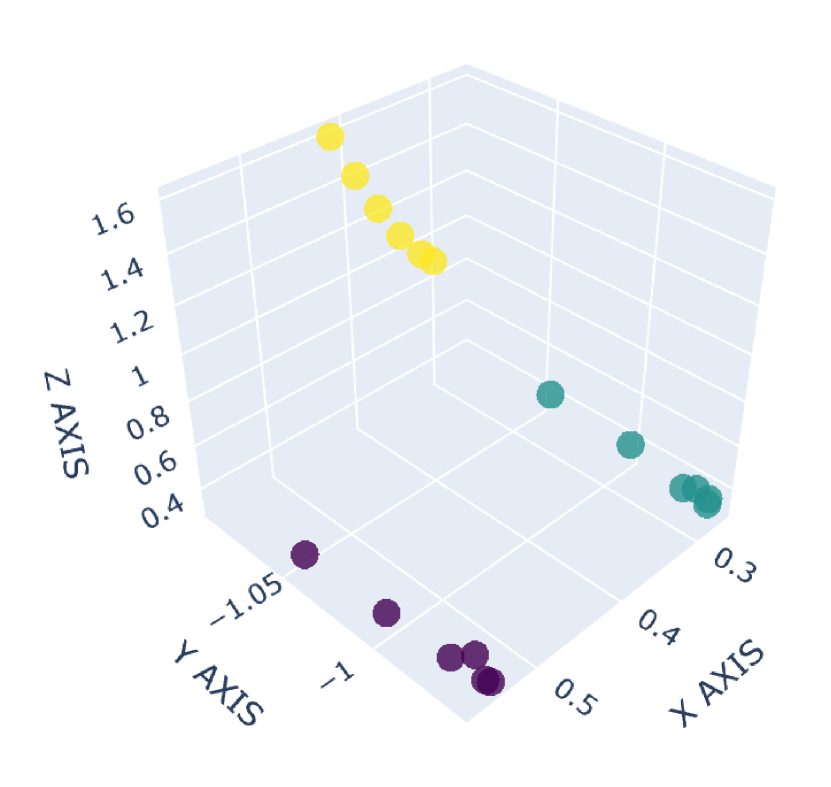
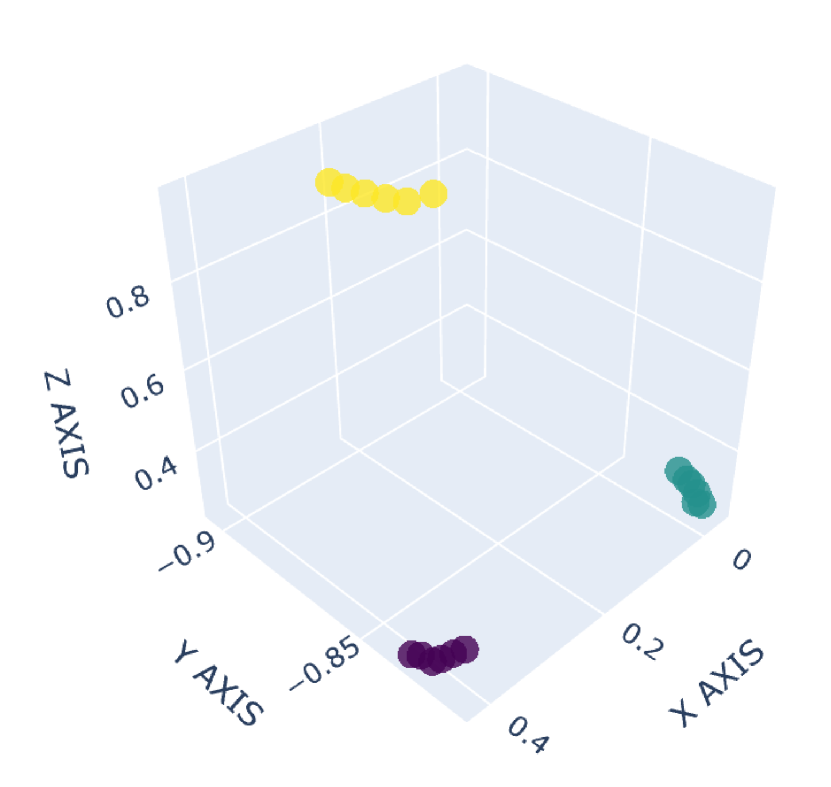
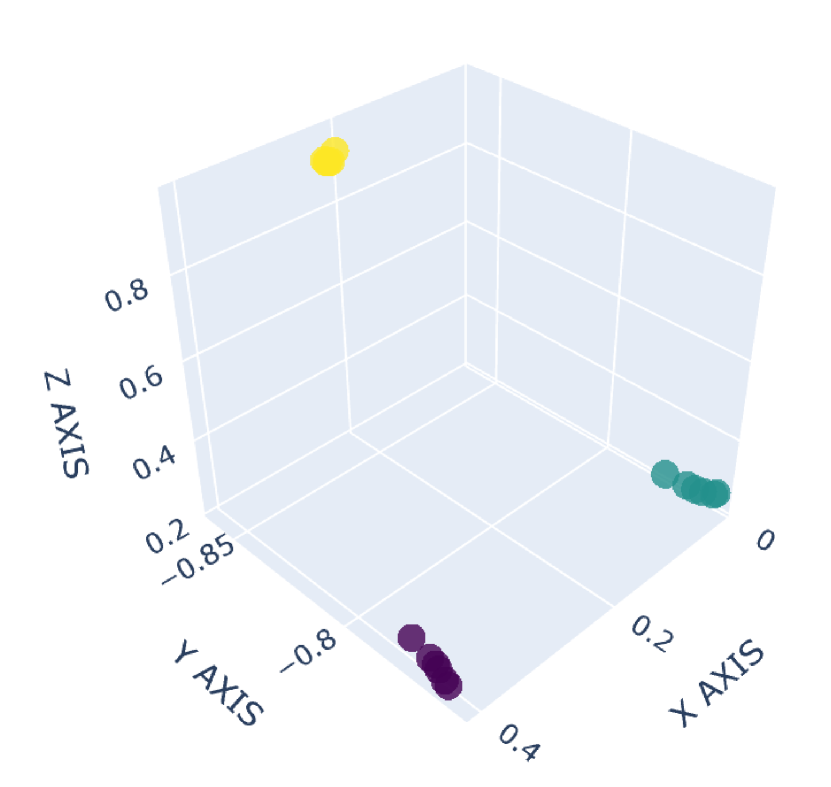
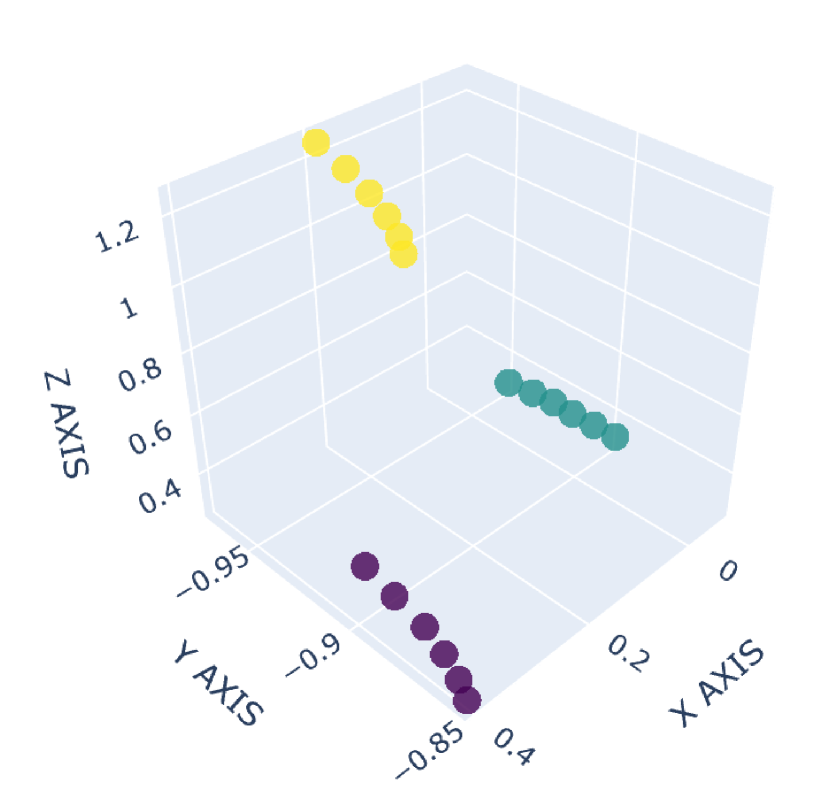
2.1.3 Collection Procedure
We used the HTC VIVE Pro HMD111https://business.vive.com/us/product/vive-pro-eye-office/ and two VIVE trackers222https://www.vive.com/us/accessory/vive-tracker/ attached to the front of the participant’s thighs to collect 6 DoF head and leg motion tracking data from the participants. We developed a Unity3D application to collect 3D spatial position coordinates, velocity, rotation angle and angular velocity information from the HMD and VIVE trackers at a frequency of 30 Hz. The HMD rendered a virtual scene of a beautiful mountain village with the participants positioned on the flat ground of the village.
After the experimenter helped the participants to put on the HMD and VIVE trackers, the participants followed the experimenter’s instructions and performed the aforementioned 9 gestures as described in Section 2.1.2 sequentially, and each gesture lasted for about two minutes. The participants could see the current gesture name and duration timer in the HMD. Before data were formally recorded for each gesture, the experimenter instructed participants to familiarize themselves with the corresponding gesture, and this step lasted approximately one minute per gesture. The experiment can be paused at any time when the participant feels fatigued until the participant is well-rested and feels ready to continue.
We recorded the participants’ data collection experiments on video, which was used as a reference to manually label the dataset. The total experiment time for each participant was approximately 40 minutes.
2.2 Gesture Classification
2.2.1 Data pre-processing
We propose to transform the collected data into a point cloud dataset for in-place gesture recognition. Since we collect data from the HMD and the two VIVE trackers at 30Hz, we can acquire 3 points at each sampling frame, with each point containing its 3D position coordinates, velocity, rotation angle and angular velocity, i.e., a total of dimensional features.
We use the sliding window method as mentioned in [26] to segment the whole dataset into point clouds. The fixed window size is 180ms, which means 6 consecutive samples at a frequency of 30Hz, and the window step size is 90ms. Each point cloud contains points, where 3 refers to three sensors and the shape of the point cloud is .
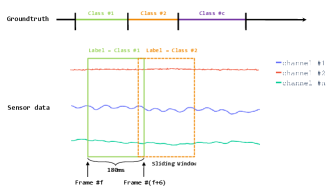
The label of the point cloud indicates the ground truth of the pose contained in the corresponding window. Suppose there are classes of gestures in the window, we choose the class that appears the most number of times in this window as the label of the window, as illustrated in Figure 3. The number of point cloud samples in the collected dataset is presented in Table 1.
| Gestures | Number of samples |
|---|---|
| standing | 31790 |
| walking in place | 18409 |
| jogging in place | 16857 |
| jumping | 12200 |
| squatting down | 5205 |
| keeping squatting | 2278 |
| squatting up | 4688 |
| stepping forward | 4522 |
| stepping backward | 4457 |
| total | 100406 |
We apply data augmentation methods for point clouds as mentioned in [41], including adding Gaussian noise to jitter point clouds, randomly rotating point clouds, shifting and scaling point clouds. Then we normalize the point clouds into using the min-max normalization [26]. Data augmentation and normalization are applied to all feature channels.
We train a model for each user, by using the current user data for unsupervised domain adaptation (target domain) and all other users’ data for supervised learning (source domain). We divide the entire dataset into two parts, the labeled source domain and the unlabeled target domain , and fuse unsupervised domain adaptation in image learning [23] with a point cloud backbone to train an end-to-end classifier on the target domain. Inspired by the Leave-One-Subject-Out Cross-Validation method [9], given a specific user, we use the unlabeled data of this user in the dataset as the target domain, then we remove this user’s data from the dataset and use the remaining labeled data as the source domain. We select all the data in the source domain as the source training set. For the data in the target domain, we select 80% of the data as the target training set (unsupervised) and the remaining 20% of the data as the target test set. Both source training set and target training set are used to train an end-to-end gesture classification model. The target test set is used to evaluate the performance of the model. Separating the training and testing data at the individual level allows evaluating the generalization performance of the model for users without labeled data [36].
2.2.2 Network Architecture
We apply point cloud transformer (PCT) [10] as the backbone and fuse unsupervised domain adaptation in image learning (MCD - Maximum Classifier Discrepancy) [34]. Our model is dubbed as PCT+MCD. PCT is a Transformer-based model for learning point clouds, achieving state-of-the-art results for point cloud classification and semantic segmentation tasks. PCT uses the neighborhood embedding module to capture the local geometric features of the point clouds and the optimized offset-attention module to learn the global features. PCT employs the neighbor embedding module combined with 4 offset-attention modules and Linear, BatchNorm, and ReLU layers as encoder, and uses three Linear layers with BatchNorm and ReLU layers as a decoder, for classification tasks. Inspired by the novel adversarial training strategy proposed by MCD, we use the encoder from PCT as the feature generator, and two task-specific classifiers as the discriminator which take features from the generator as input. The two classifiers are trained to correctly classify samples in the source domain while detecting target samples that are not clearly categorized into some classes. The feature generator is trained to fool the two classifiers by generating target features close to the two classifiers’ decision boundary. After fusing them, we achieve the network architecture in our work, as shown in Figure 4.
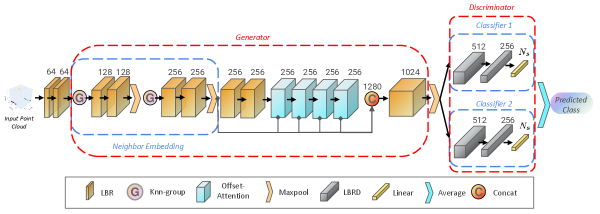
We use the encoder from PCT as the feature generator to extract the global features of the point clouds, and we adopt two classifiers and consisting mainly of multiple linear layers as the discriminator. is the point cloud in the labeled source domain , and is the point cloud in the unlabeled target domain . Both and contain points, each point with a -dimensional feature (here ). We first feed and to to extract the global feature , where represents -th sample of and , denotes the global features of . Then we feed to classifiers and to obtain -dimensional probabilistic outputs and which classify into classes (9 kinds of gestures), respectively.
Inspired by [34], our total loss function consists of a classification loss and a discrepancy loss. We adopt the cross-entropy loss function as the classification loss, which is used to train two classifiers and and generator to classify samples from the source domain :
The discrepancy loss is defined by the distance of the outputs of the two classifiers and :
2.2.3 Training
As suggested by [34], we also implement three steps in each epoch to realize the end-to-end training in an adversarial manner.
Step 1. We train both classifiers and generator simultaneously by minimizing the classification loss , so as to make the network correctly classify the point clouds in the source domain.
Step 2. We fix the parameters of the generator and train two classifiers and by maximizing the discrepancy loss to better detect the target samples. Classification loss is also added empirically to update the model more stably.
Step 3. We fix the parameters of the two classifiers, and train the generator by minimizing the discrepancy loss.
3 Discussion
3.1 Model Evaluation
We implement our method on PyTorch. We choose Adam [19] as the optimizer and train the model on an Nvidia TITAN RTX GPU. The learning rate is set to 0.001 and the weight decay is assigned to 0.0001. The batch size is set to 64. Similar to [38], we train an individual model for each selected user in the dataset. Each model is trained for 250 epochs. Note that for a given user, we first remove his/her data from the dataset and use his/her unlabeled data as target and the remaining labeled data as source.
We selected 10 subjects from the dataset marked as S1 to S10. 4 subjects in the dataset were not selected because of missing data for the squatting gesture due to a systematic error during data collection. For these subjects, we evaluated the classification results after training the individual models separately, including the classification accuracy of each class, the mean class accuracy (the average of each accuracy per class), and the overall accuracy (the number of correctly predicted samples divided by the number of total samples to predict). The classification results obtained for each selected subject are listed in Table 2. The results show that the average classification accuracy of keeping squatting is the lowest (85.9%), which is caused by the relatively small amount of data of keeping squatting. During the data collection phase, subjects tended to get up immediately after squatting down, resulting in a relatively short period to maintain the keeping squatting posture. Except for keeping squatting, the average classification accuracy of all other classes is greater than 92.5%. Jogging has the highest mean classification accuracy of 97.7%. Note that a window size of only 180ms enables an accuracy of 94.4% with 12ms model inference time (192ms in total), which satisfies the requirement of real-time applications.
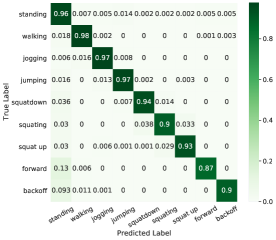
The average confusion matrix normalized over the true (rows) condition for all the 10 selected classification models is shown in Figure 5. The figure shows that stepping forward achieves the lowest recall of 87%, and stepping backward is the second-lowest recall of 90%, and these two postures are easily misclassified as standing. This is probably because users are allowed to do some relaxing actions such as turning in place or resting when standing to better observe the virtual environment. These unintentional relaxed turns are sort of similar to forward movements or backward movements, which leads to relatively low recall of these two gestures. The recall of squatting is also relatively low (90%) due to the relatively small sample number in the dataset.
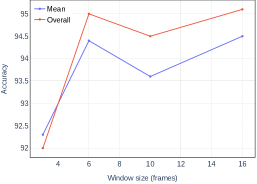
The results of the model (mean class accuracy and overall accuracy) for different sliding window sizes (number of consecutive frames) are shown in Figure 6. The sequence duration time for generating a sample with a window size of 3 is 90ms, but the corresponding model has the lowest mean class accuracy and overall accuracy, which are only 92.3% and 92.0%, respectively. This is probably because a sample contains only 9 points which represent little spatial information in making gesture classification. When the window size is 6, the mean class accuracy and overall accuracy reach 94.4% and 95.0%, respectively, inducing a moderate sequence duration time (180ms). When the window size is increased to 10 and 16, we do not observe any remarkable improvement in the classification accuracy. Therefore, we choose a window size of 6 in this work.
For latency, we experimentally examine the inference time of PointNet, PointNet++, DGCNN, and PCT+MCD networks on the same sample, and the results show that they all consume around 10ms. Shi et al. [36] also mentioned that the maximum inference time of DCTC is around 15ms. This means the networks have very similar inference time. To achieve an accuracy of about 95%, our method requires a sequence duration of 180ms, while DCTC requires 500ms. The inference time of these networks is significantly smaller than the sequence duration time, which indicates that the delay of ours and other machine learning methods mainly arises from the sequence duration time rather than the inference time. In short, to achieve similar accuracy, our method induces a much smaller delay compared to CNN and LSTM. This is mainly because our method only requires the collection of a few data points in a sample.
| Standing | Walking | Jogging | Jumping | Squatting down | Keeping squatting | Squatting up | Forward | Backward | Mean | Overall | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| S1 | 97.2 | 96.3 | 100.0 | 93.6 | 100.0 | 84.8 | 100.0 | 100.0 | 100.0 | 96.9 | 97.4 |
| S2 | 91.2 | 97.8 | 100.0 | 74.5 | 100.0 | 76.9 | 100.0 | 100.0 | 94.9 | 92.8 | 93.0 |
| S3 | 96.6 | 100.0 | 100.0 | 99.5 | 96.4 | 90.3 | 92.6 | 94.7 | 97.2 | 96.4 | 97.9 |
| S4 | 97.3 | 95.6 | 99.0 | 67.6 | 90.2 | 89.2 | 96.4 | 96.1 | 100.0 | 92.4 | 94.5 |
| S5 | 93.8 | 97.2 | 95.2 | 97.4 | 94.9 | 94.7 | 98.4 | 92.9 | 92.5 | 95.2 | 95.3 |
| S6 | 91.8 | 95.2 | 94.4 | 100.0 | 89.2 | 87.5 | 92.8 | 91.2 | 96.7 | 93.2 | 93.6 |
| S7 | 95.4 | 92.2 | 98.0 | 97.3 | 91.5 | 96.4 | 87.5 | 98.4 | 90.6 | 94.2 | 95.0 |
| S8 | 87.7 | 97.1 | 100.0 | 100.0 | 100.0 | 66.7 | 97.8 | 97.5 | 97.4 | 93.8 | 95.7 |
| S9 | 85.9 | 97.9 | 94.4 | 98.9 | 91.4 | 96.3 | 94.8 | 96.4 | 98.1 | 94.9 | 93.2 |
| S10 | 87.9 | 97.7 | 96.3 | 99.6 | 100.0 | 75.8 | 98.6 | 98.0 | 93.2 | 94.1 | 94.8 |
| average | 92.5 | 96.7 | 97.7 | 92.8 | 95.3 | 85.9 | 95.9 | 96.5 | 96.0 | 94.4 | 95.0 |
3.2 Comparison with Existing WIP Methods
Hanson et al. [15] applied convolutional neural networks to WIP research. They classify walking or standing using a simple CNN structure and achieved 98.6% accuracy on the test set with a latency of 680ms (a sample is composed of 40 consecutive triaxial data and data is polled every 0.017 seconds) for the Oculus Go and 92.6% accuracy with a latency of 1020ms (60 consecutive triaxial data) for the Samsung Gear VR. For comparison purpose, we trained a binary classification model using only the samples of walking and standing in the dataset. In contrast, our method is more accurate for classifying standing and walking, with a mean class accuracy of 99.2%, and our method significantly shortens the latency (taking only about 192ms).
LLCM-WIP [5] achieves a start latency of 138ms and a stop latency of 96ms, which is faster than our method. However, LLCM-WIP requires manual adjustment of thresholds for the model, such as the speed-offset threshold. Due to inter-person variations, the threshold of the model needs to be adjusted across users [36] which actually consumes time. In comparison, our approach avoids the need for manual setting of threshold parameters and can personalize the model using only the user’s unlabeled data, which is more flexible and automatic.
DCTC [36] can classify 7 foot patterns based on the LSTM model using the pressure sensor data. They achieve 95% accuracy at 500ms delay and 85.3% accuracy at 300ms delay. In contrast, our method can achieve 94.4% mean class accuracy and 95.0% overall accuracy at 192ms latency, which has overall better performance than DCTC with considering the latency. Moreover, DCTC provides different general models according to the shoe size. By contrast, our method needs to collect unlabeled data for each user to train an individual model.
3.3 Comparison with Existing Point Cloud Classification Methods
We compare our method (PCT + MCD) with a series of point cloud classification methods, including PointNet [28], PointNet++ [29], DGCNN [45] and PointDan [30]. PointDan also involves unsupervised domain adaptation. These experiments are all using Adam as the optimization strategy, with a learning rate of 0.001 and a batch size of 64. The cosine annealing schedule is adopted to adjust the learning rate for each epoch. The models are trained using the same 10 subjects’ posture data as shown in Table 2 and the train-test splitting method as described in Section 2.2.1. All models are evaluated on the test set of the target domain. The comparison results are summarized in Table 3.
As illustrated in Table 3, our method achieves the best result of 95.0% overall accuracy and 94.4% mean class accuracy. Compared to PointNet, our method achieves a 3.7% improvement in mean class accuracy and 2.0% improvement in overall accuracy, respectively. Compared with PointDAN which also uses the unsupervised domain adaptation, our method achieves 4.7% gain on mean class accuracy and 3.1% gain on overall accuracy, respectively. We also perform an ablation experiment, eliminating MCD and using only PCT for classification, and obtains a mean class accuracy of 92.2% and an overall accuracy of 93.7%, which are lower than PCT+MCD. This demonstrates the necessity of MCD.
To verify the significance of the improvement of our introduced PCT+MCD, we perform two-tailed t-tests for mean class accuracy of different methods. The t-test results show that the mean class accuracy of PCT+MCD is significantly higher than that of PointNet (, ), PointNet++ (, ), DGCNN (, ), PointDAN (, ) and PCT (, ).
| Method | Mean | Overall |
|---|---|---|
| PointNet[28] | 90.7 | 93.0 |
| PointNet++[29] | 88.5 | 91.5 |
| DGCNN[45] | 91.1 | 91.7 |
| PointDAN[30] | 89.7 | 91.9 |
| PCT[10] | 92.2 | 93.7 |
| PCT+MCD(ours) | 94.4 | 95.0 |
4 User Study
In this section, we conducted user study using the evaluation testbed proposed by [4] to evaluate the straight-line walking and directional control performance, agility, and user experience of our model for locomotion in the virtual environment.
4.1 Participants
15 volunteers participated in this experiment, each of them use their individual model trained by labeled dataset and their unlabeled data to perform the virtual locomotion experiment. Note that if the participant participated in the dataset collection experiment as mentioned in Section 2.1, we remove his/her data from the dataset before training. There are 4 female volunteers and 11 male volunteers, and their mean age is 25.6 and the standard deviation is 2.8. The mean value of their familiarity with VR was 2.8, and the standard deviation was 0.82. None of these volunteers suffered from severe motion sickness.
4.2 Experimental Setup
We utilize 1 square meter of space in the center of the room for moving in place and install two SteamVR Base Stations around the space. Participants wear HTC VIVE Pro HMD and are attached two VIVE trackers to their left and right thighs respectively. Participants then performed a series of movements in place as described in Section 2.1.2.
We develop the virtual locomotion system in Unity3D. Our model is deployed to the server through the torchserve333https://pytorch.org/serve/ framework, which allows Unity clients to call the prediction model via HTTP requests. We sample the user’s motion data at 30Hz and input samples to the model every 180ms to predict the user’s gesture class. The user’s forward direction is defined as the average value of the z-axis rotation of the two VIVE trackers. When a backward step is detected, we reverse the forward direction, and when a forward step is detected, we reset the forward direction. When detecting a user walking in place or jogging in place, we calculate the time between steps (), which is defined as:
where refers to the time corresponding to the last maximum peak of the vertical position of the HMD, and refers to the time corresponding to the last minimum peak of the vertical position of the HMD. A large means that the user is walking slowly and vice versa. Then we calculate the virtual locomotion speed of walking () and jogging ( ) with the equation proposed by [40]:
where are respectively the upper and lower bounds of , and are respectively the maximum and minimum values of velocity. is a constant greater than 1. When is less than , we set to , and when the user is detected to be standing, we set to 0. When a user is detected to be jumping, we apply a forward and upward force to the rigid body of the user’s virtual avatar, so that the avatar jumps forward. Finally, when the user is detected to be squatting down or keeping squatting , we lower the avatar’s view and collision body, and when the user is detected to be squatting up, we reset the avatar’s view and collision body.
We selected several scenarios and tasks from the testbed [4] which are relevant to our locomotion gestures for experiments. The first scenario is called Straight Line Movement and consists of 4 tasks. Task 1 requires the user to walk towards the target spot, following the green straight line on the ground as closely as possible. Task 2 requires the user to walk through three progressively smaller circular areas in sequence. Task 3 requires the user to follow a circle, staying inside the circle as much as possible, which moves forward at a variable speed. Task 4 requires the user to dash through a straight corridor as fast as possible. The second direction control scenario is used to evaluate the directional control performance of the locomotion method and includes 5 tasks. First, the user walks along the folded lines marked on the ground to reach several targets, then the user must walk backward through a door while gazing at the target ahead, after that, the user adjusts the appropriate direction through a narrow and curved tunnel, without hitting the walls as much as possible. Next, the user jumps through a staircase and walks across a ramp. Finally, the user crosses a dangerous area on the edge of the roof of a tall building and avoids falling from the roof. The third agility scenario is used to evaluate the agility of the locomotion method. This scenario requires the user to cross a corridor with blocks of various shapes moving towards the user. The user has to control the direction of movement and squat to avoid the oncoming blocks.
Following the instructions [4], we collect some objective metrics which focus on accuracy and latency for each task during the experiment, which are classified as the Accuracy (AC) and the Error-proneness (EP). We recommend that readers refer to [4] for detailed explanation of these objective metrics. The questionnaire provided by the testbed [4] is used to investigate user’s subjective feelings, including Input sensitivity, Input responsiveness, Ease of use, Perceived errors, Appropriateness and Satisfaction, and so on. Then we use the SSQ tool [18] to assess the symptoms of motion sickness caused by our experiment (if any).
For comparison, we choose the improved LLCM-WIP [5] method embedded in the testbed [4]. This method attaches two VIVE trackers to the back of the user’s left and right calves. To be fair, we set its forward direction to be the average of the z-axis value of rotation of the two trackers, which is the same as our method. We also trained a model of DGCNN [45] for comparison purpose. Before the experiment, participants will be assigned one of these three methods without knowing which one it is.
4.3 Results
4.3.1 Error-proneness
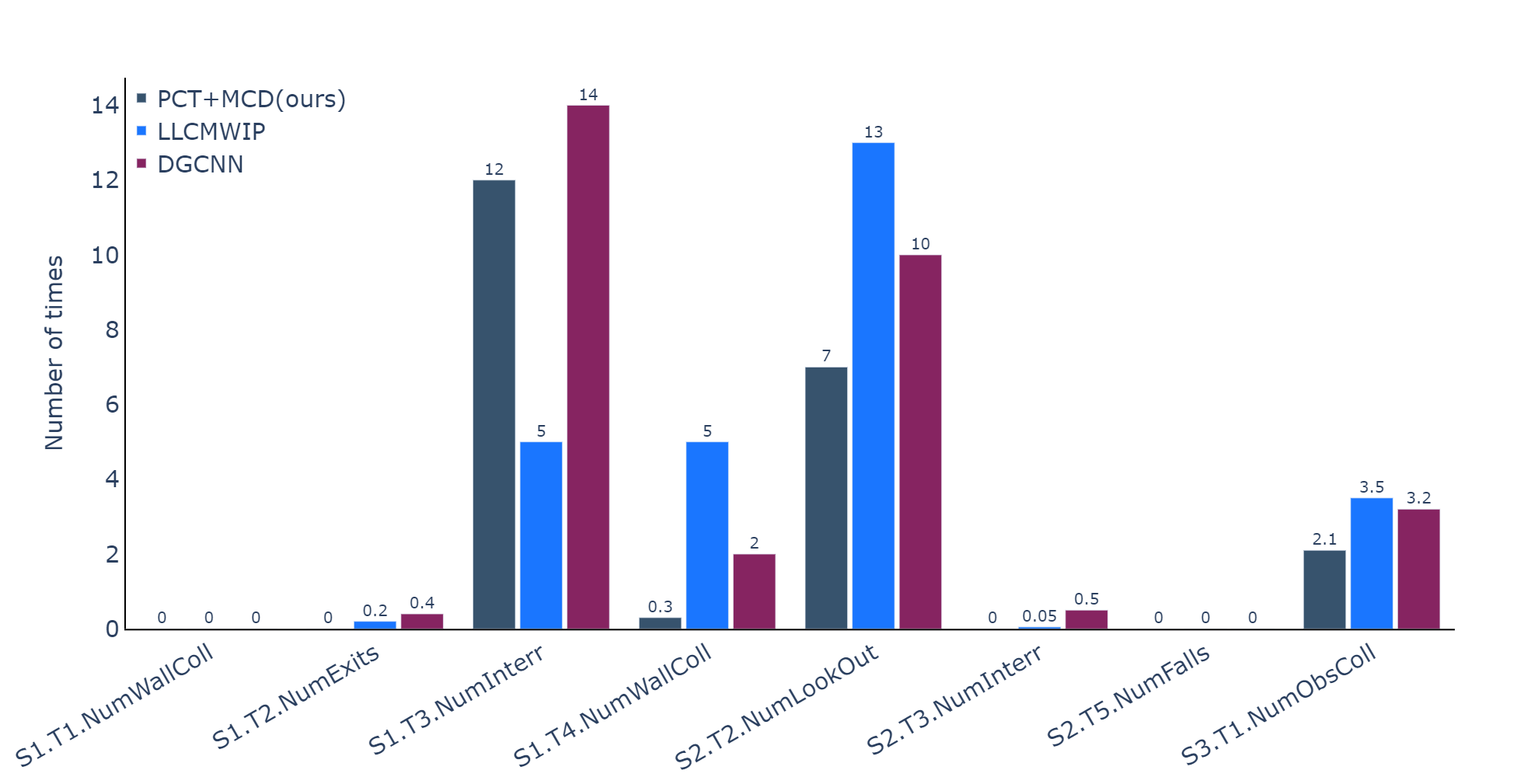
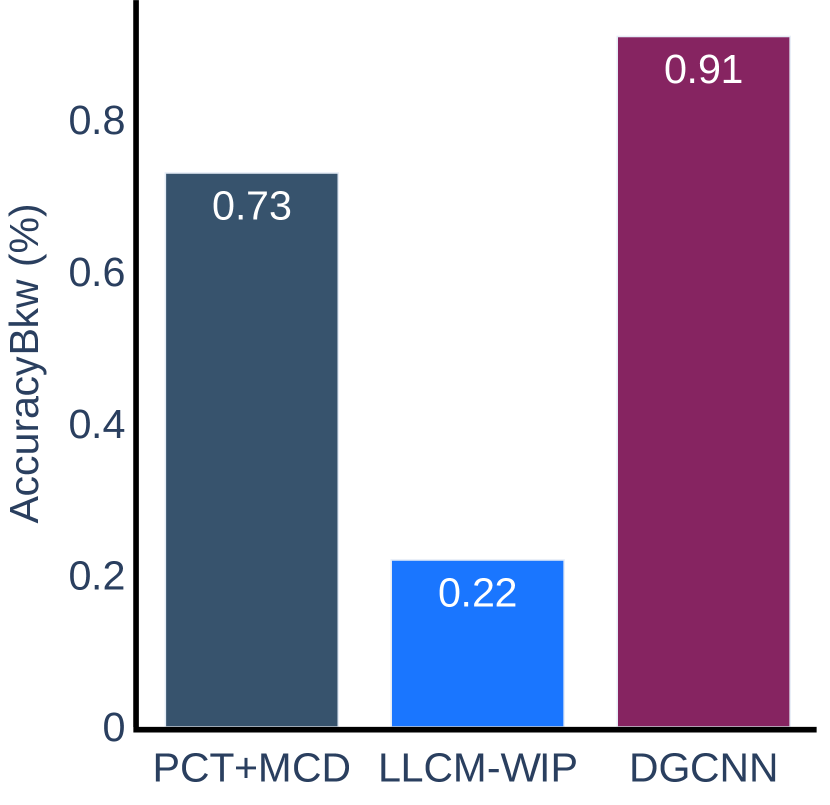
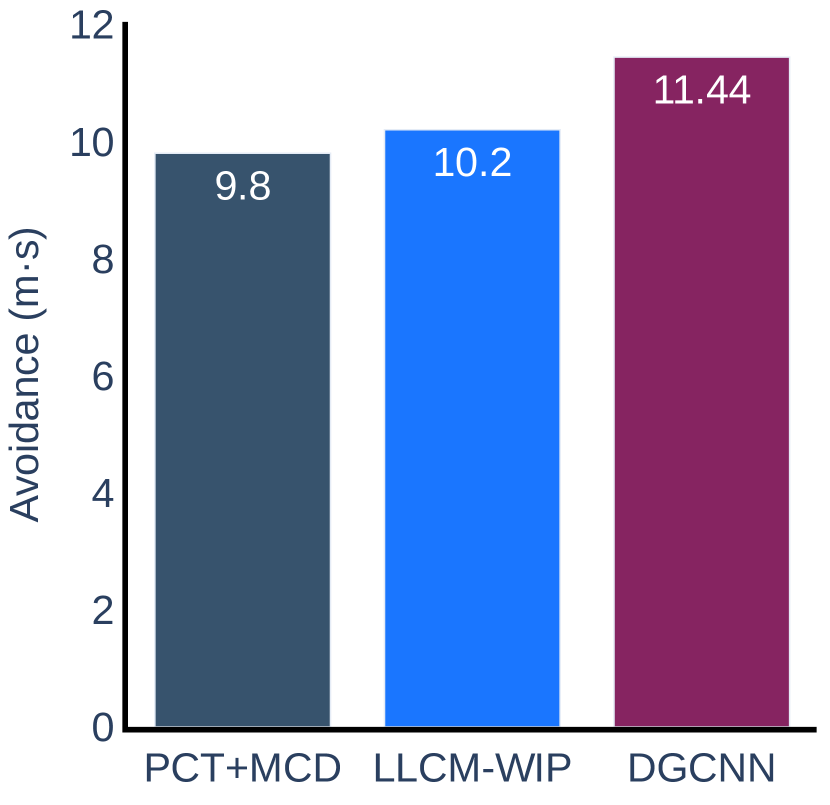
The results of the error proneness collected during the experiment are presented in Figure 7. The results show that our method has significantly fewer errors than the LLCM-WIP method in Task 4 of Scenario 1 and Task 2 of Scenario 2. This is because our method is easy to toggle the forward or backward direction of movements and has a relatively low start-stop delay. The LLCM-WIP method does not have a backward mechanism, and the user has to turn his body and turn his/her head backward, which leads to lower performance in the backward task. However, our method has more errors than LLCM-WIP in Task 3 of Scenario 1. In this task, the circle that the user is chasing will suddenly accelerate at a moment and the user tends to toggle from walking to jogging at this moment, so the walking speed will increase suddenly from to instead of increasing smoothly, resulting in the user having difficulty in controlling the speed and then drifting out of the circle. In other tasks, both our method and the LLCM-WIP method show a small error proneness, and there is no significant difference between them. We also found a slight increase in user error-proneness when using the DGCNN model due to a decrease in classification accuracy compared to the PCT+MCD model.
4.3.2 Accuracy
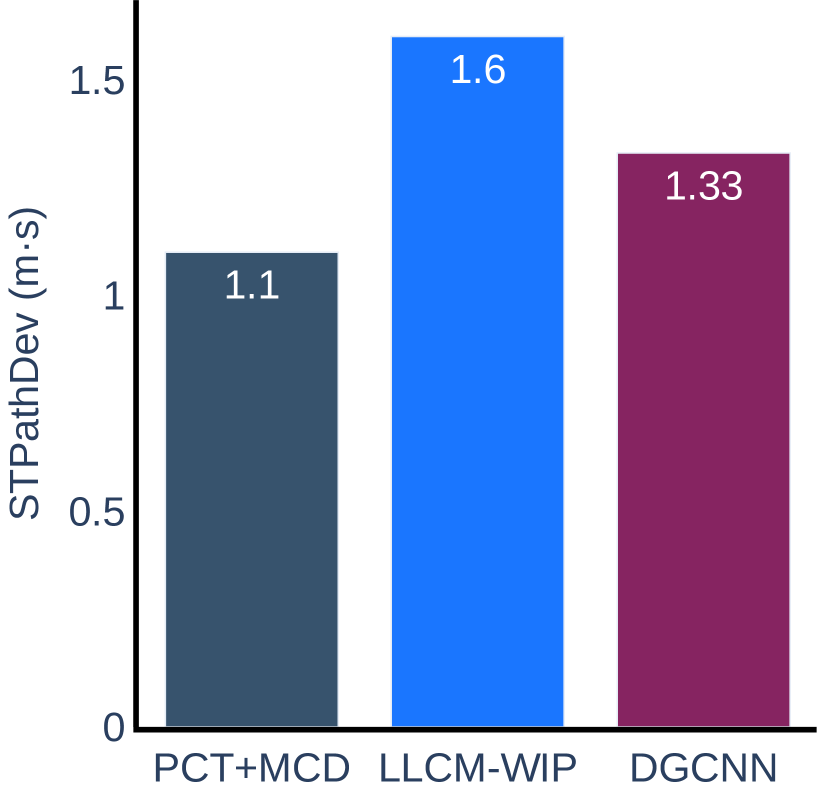
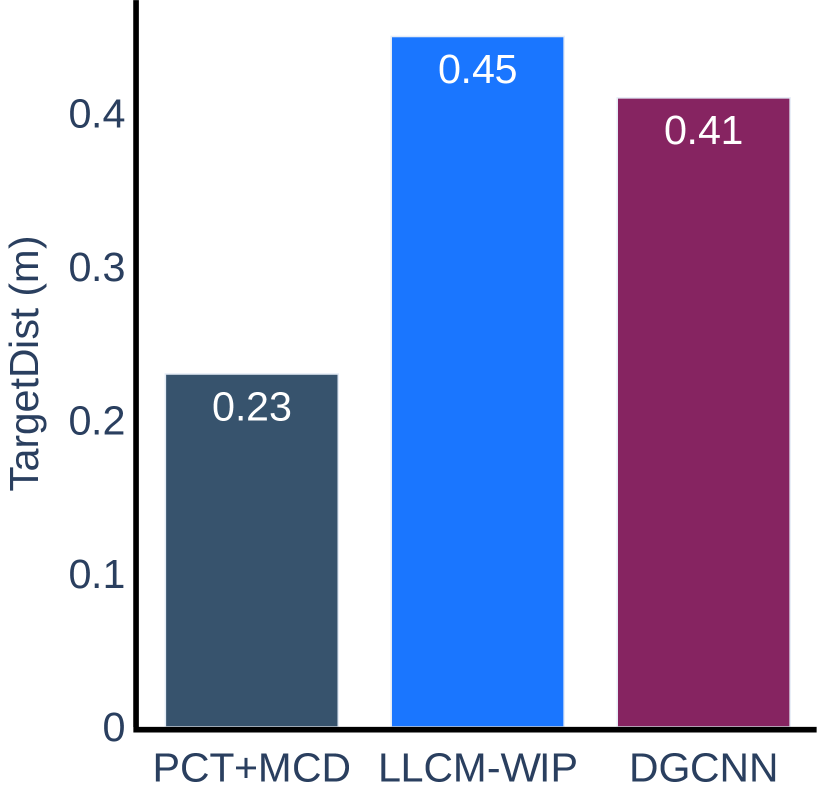
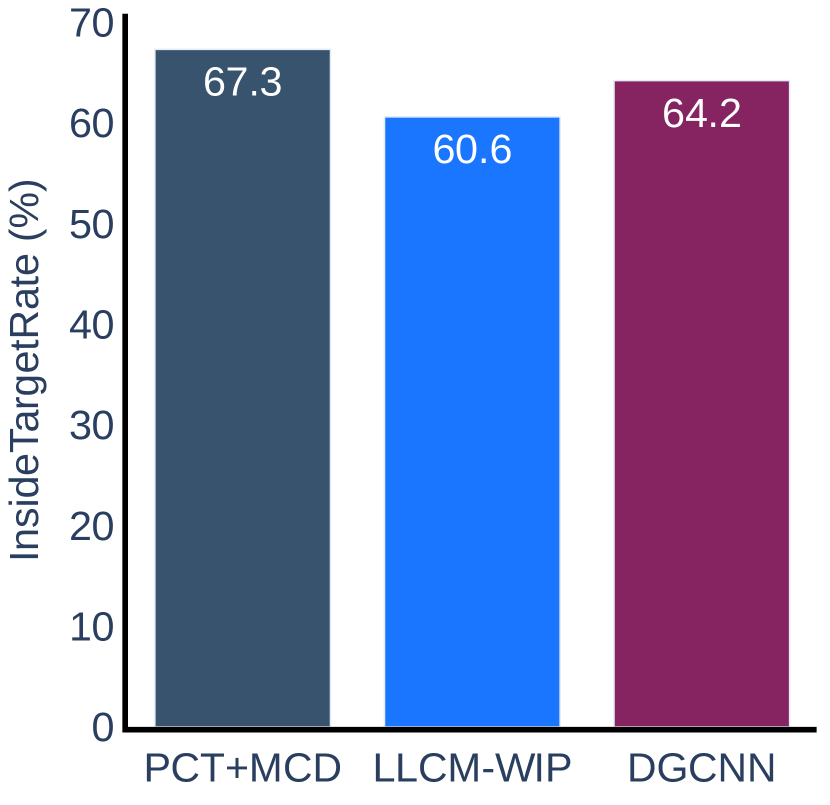
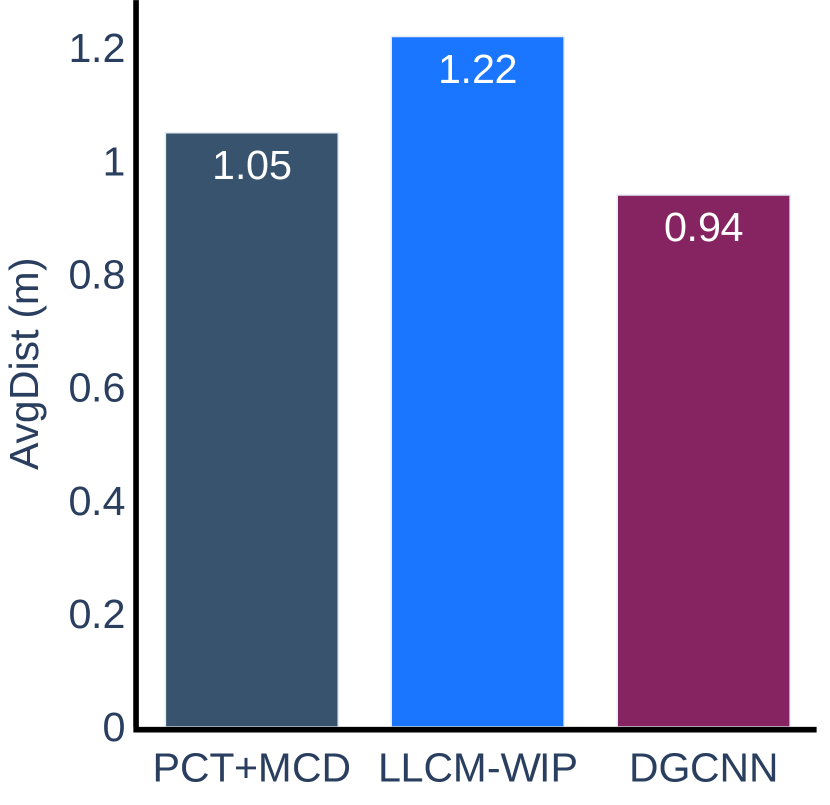
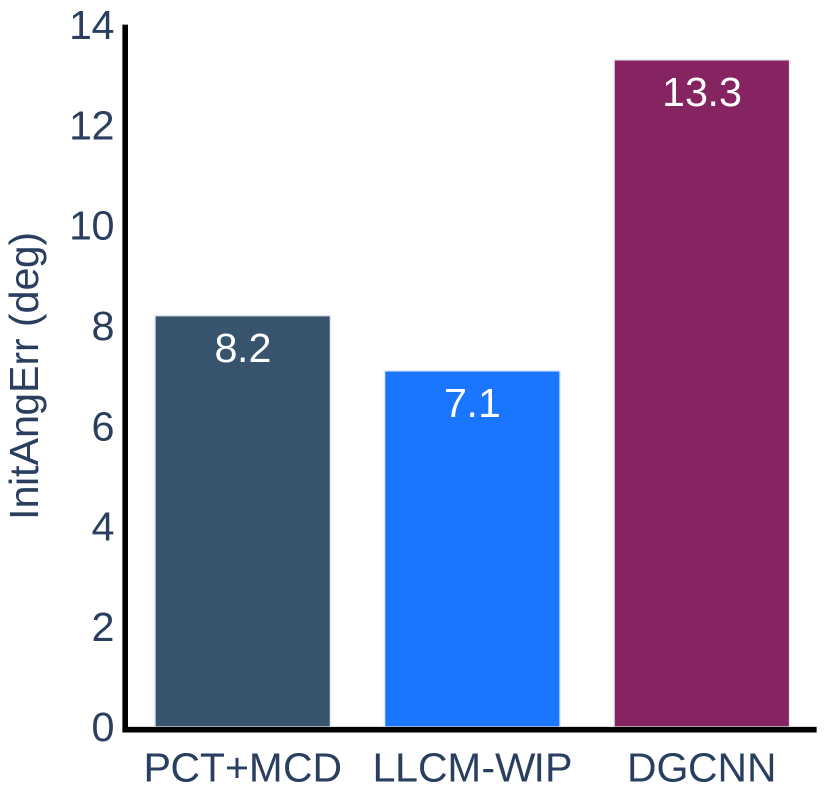
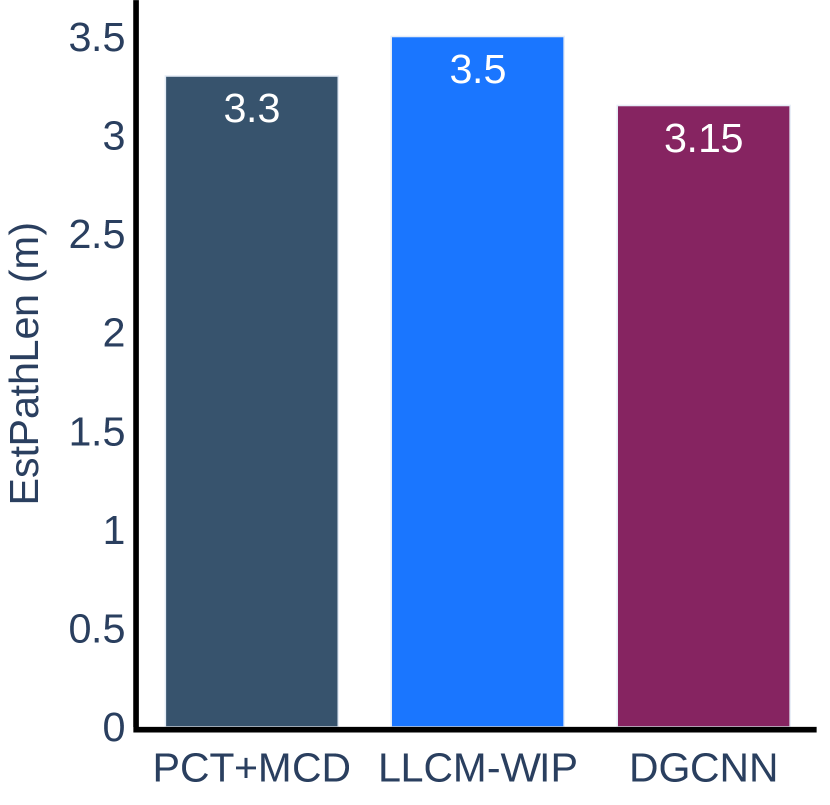
The experimental results for the accuracy metric are presented in Figure 8. We can conclude that our method is more accurate than LLCM-WIP for Task 1 and Task 2 in Scenario 1 and Task 2 in Scenario 2. When using our method, the user can walk closer to the target straight line indicated on the ground and can stop more accurately within the target range. The results on other tasks do not show any significant difference between our method and LLCM-WIP. When compared with DGCNN, our method is more accurate on tasks of Scenario 2, but slightly less accurate than DGCNN on tasks of Scenario 1.
4.3.3 Subjective Evaluation
We conducted a simulator sickness questionnaire before and after the experiment, and we found that the experiment did not induce motion sickness symptoms.
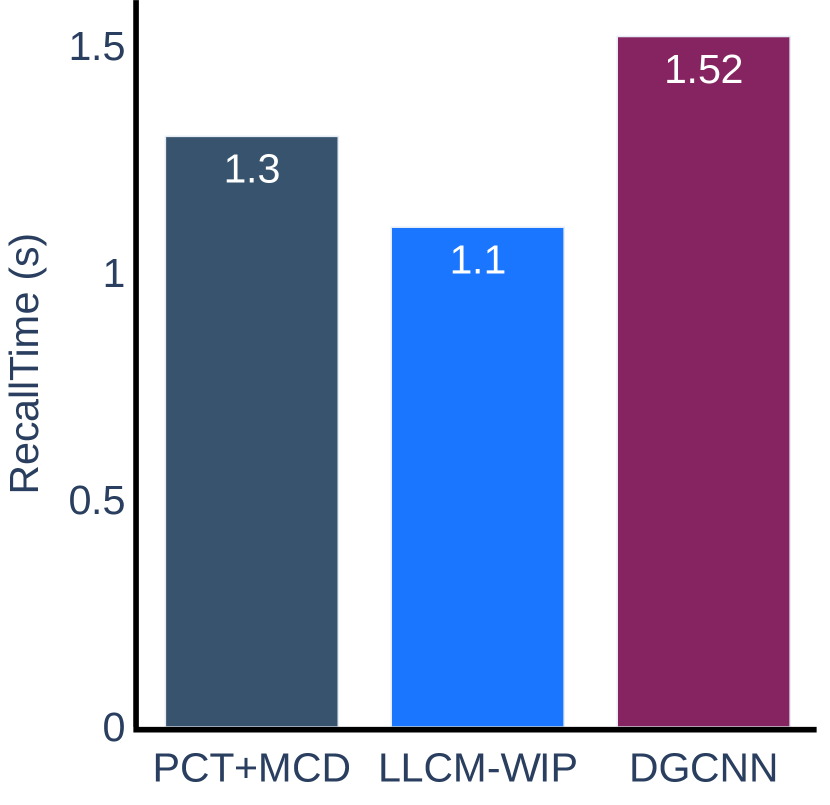
For latency, we asked users to respectively evaluate the input responsiveness questionnaire at the end of each scenario experiment and at the end of the full experiment. Users are asked to rate two statements in a scale from 1 (Strongly Disagree) to 5 (Strongly Agree), with the first statement being “The response to user input was acceptable” and the second being “The response time did not affect my performance”. The results show that the average rating of PCT+MCD and LLCM-WIP are 4.7 (SD: 0.48) and 4.9 (SD: 0.32), respectively. We then perform the two-tailed t-test at the 5% significance level and did not find a statistically significant difference in the rating of PCT+MCD and LLCM-WIP delays (, ).
5 Conclusion
We presented an effective classification framework for classifying 9 in-place gestures for virtual locomotion. We propose to treat several consecutive frames as a point cloud in which the HMD and two VIVE trackers provide three points in each frame. We design an end-to-end method by fusing supervised learning with unsupervised domain adaptation. Experiments show that our method achieves very promising outcomes, i.e., 95.0% overall accuracy and a latency of 192ms. We also conducted user study to further verify the effectiveness of our method.
However, the manual labeling of the dataset is time-consuming and tedious, which limits us to build a larger dataset. In future, we would like to speed up this with the aid of other techniques like pose estimation[39]. We also plan to increase the number of IMUs, and fuse deep learning methods with traditional biomechanics-based methods to improve accuracy.
Acknowledgements.
This work was partially funded by 2021 Science and Technology Innovation Program of Shaanxi Academy of Forestry Science (SXLK2021-0214), Key Laboratory of Agricultural Internet of Things, Ministry of Agriculture and Rural Affairs, Yangling,Shaanxi 712100, China (2018AIOT-09). National Natural Science Foundation of China(61702433). The Key Research and Development Project of Shaanxi Province (2019NY-167).References
- [1] I. Achituve, H. Maron, and G. Chechik. Self-supervised learning for domain adaptation on point clouds. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 123–133, 2021.
- [2] J. Bhandari, S. Tregillus, and E. Folmer. Legomotion: Scalable walking-based virtual locomotion. In Proceedings of the 23rd ACM Symposium on Virtual Reality Software and Technology, VRST ’17. Association for Computing Machinery, New York, NY, USA, 2017. doi: 10 . 1145/3139131 . 3139133
- [3] L. Bruno, J. Pereira, and J. Jorge. A new approach to walking in place. In IFIP Conference on Human-Computer Interaction, pp. 370–387. Springer, 2013.
- [4] A. Cannavò, D. Calandra, F. G. Pratticò, V. Gatteschi, and F. Lamberti. An evaluation testbed for locomotion in virtual reality. IEEE Transactions on Visualization and Computer Graphics, 27(3):1871–1889, 2020.
- [5] J. Feasel, M. C. Whitton, and J. D. Wendt. Llcm-wip: Low-latency, continuous-motion walking-in-place. In 2008 IEEE Symposium on 3D User Interfaces, pp. 97–104, 2008. doi: 10 . 1109/3DUI . 2008 . 4476598
- [6] J. Feasel, M. C. Whitton, and J. D. Wendt. Llcm-wip: Low-latency, continuous-motion walking-in-place. In 2008 IEEE Symposium on 3D User Interfaces, pp. 97–104, 2008. doi: 10 . 1109/3DUI . 2008 . 4476598
- [7] Y. Felberbaum and J. Lanir. Better understanding of foot gestures: An elicitation study. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, pp. 1–12, 2018.
- [8] Y. Felberbaum and J. Lanir. Better understanding of foot gestures: An elicitation study. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, CHI ’18, p. 1–12. Association for Computing Machinery, New York, NY, USA, 2018. doi: 10 . 1145/3173574 . 3173908
- [9] D. Gholamiangonabadi, N. Kiselov, and K. Grolinger. Deep neural networks for human activity recognition with wearable sensors: Leave-one-subject-out cross-validation for model selection. IEEE Access, 8:133982–133994, 2020.
- [10] M.-H. Guo, J.-X. Cai, Z.-N. Liu, T.-J. Mu, R. R. Martin, and S.-M. Hu. Pct: Point cloud transformer, 2021.
- [11] Y. Guo, M. Bennamoun, F. Sohel, M. Lu, and J. Wan. 3d object recognition in cluttered scenes with local surface features: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(11):2270–2287, 2014.
- [12] Y. Guo, F. Sohel, M. Bennamoun, M. Lu, and J. Wan. Rotational projection statistics for 3d local surface description and object recognition. International journal of computer vision, 105(1):63–86, 2013.
- [13] Y. Guo, H. Wang, Q. Hu, H. Liu, L. Liu, and M. Bennamoun. Deep learning for 3d point clouds: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–1, 2020. doi: 10 . 1109/TPAMI . 2020 . 3005434
- [14] S. Hanson, R. A. Paris, H. A. Adams, and B. Bodenheimer. Improving walking in place methods with individualization and deep networks. In 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pp. 367–376. IEEE, 2019.
- [15] S. Hanson, R. A. Paris, H. A. Adams, and B. Bodenheimer. Improving walking in place methods with individualization and deep networks. In 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pp. 367–376, 2019. doi: 10 . 1109/VR . 2019 . 8797751
- [16] D. Hayashi, K. Fujita, K. Takashima, R. W. Lindeman, and Y. Kitamura. Redirected jumping: Imperceptibly manipulating jump motions in virtual reality. In 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pp. 386–394. IEEE, 2019.
- [17] B. K. Jaeger and R. R. Mourant. Comparison of simulator sickness using static and dynamic walking simulators. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, vol. 45, pp. 1896–1900. SAGE Publications Sage CA: Los Angeles, CA, 2001.
- [18] R. S. Kennedy, N. E. Lane, K. S. Berbaum, and M. G. Lilienthal. Simulator sickness questionnaire: An enhanced method for quantifying simulator sickness. The international journal of aviation psychology, 3(3):203–220, 1993.
- [19] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization, 2017.
- [20] J. Lee, S. C. Ahn, and J.-I. Hwang. A walking-in-place method for virtual reality using position and orientation tracking. Sensors, 18(9):2832, 2018.
- [21] J. Lee, M. Lee, G. J. Kim, and J.-I. Hwang. Effects of synchronized leg motion in walk-in-place utilizing deep neural networks for enhanced body ownership and sense of presence in vr. In 26th ACM Symposium on Virtual Reality Software and Technology, pp. 1–10, 2020.
- [22] J. Lee, A. Pastor, J.-I. Hwang, and G. J. Kim. Predicting the torso direction from hmd movements for walk-in-place navigation through deep learning. In 25th ACM Symposium on Virtual Reality Software and Technology, pp. 1–2, 2019.
- [23] M. Long, H. Zhu, J. Wang, and M. I. Jordan. Unsupervised domain adaptation with residual transfer networks. arXiv preprint arXiv:1602.04433, 2016.
- [24] M. Maghoumi and J. J. LaViola. Deepgru: Deep gesture recognition utility. In International Symposium on Visual Computing, pp. 16–31. Springer, 2019.
- [25] N. C. Nilsson, S. Serafin, and R. Nordahl. Walking in place through virtual worlds. In International Conference on Human-Computer Interaction, pp. 37–48. Springer, 2016.
- [26] F. J. Ordóñez and D. Roggen. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors, 16(1):115, 2016.
- [27] R. Paris, M. Joshi, Q. He, G. Narasimham, T. P. McNamara, and B. Bodenheimer. Acquisition of survey knowledge using walking in place and resetting methods in immersive virtual environments. In Proceedings of the ACM Symposium on Applied Perception, SAP ’17. Association for Computing Machinery, New York, NY, USA, 2017. doi: 10 . 1145/3119881 . 3119889
- [28] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation, 2017.
- [29] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space, 2017.
- [30] C. Qin, H. You, L. Wang, C. C. J. Kuo, and Y. Fu. Pointdan: A multi-scale 3d domain adaption network for point cloud representation, 2019.
- [31] S. Razzaque, D. Swapp, M. Slater, M. C. Whitton, and A. Steed. Redirected walking in place. In EGVE, vol. 2, pp. 123–130, 2002.
- [32] B. E. Riecke, B. Bodenheimer, T. P. McNamara, B. Williams, P. Peng, and D. Feuereissen. Do we need to walk for effective virtual reality navigation? physical rotations alone may suffice. In International Conference on Spatial Cognition, pp. 234–247. Springer, 2010.
- [33] M. Rietzler, M. Deubzer, T. Dreja, and E. Rukzio. Telewalk: Towards free and endless walking in room-scale virtual reality. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, CHI ’20, p. 1–9. Association for Computing Machinery, New York, NY, USA, 2020. doi: 10 . 1145/3313831 . 3376821
- [34] K. Saito, K. Watanabe, Y. Ushiku, and T. Harada. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3723–3732, 2018.
- [35] L. A. Shaw, B. C. Wünsche, C. Lutteroth, S. Marks, J. Buckley, and P. Corballis. Development and evaluation of an exercycle game using immersive technologies. 2015.
- [36] X. Shi, J. Pan, Z. Hu, J. Lin, S. Guo, M. Liao, Y. Pan, and L. Liu. Accurate and fast classification of foot gestures for virtual locomotion. In 2019 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pp. 178–189. IEEE, 2019.
- [37] M. Slater, M. Usoh, and A. Steed. Taking steps: the influence of a walking technique on presence in virtual reality. ACM Transactions on Computer-Human Interaction (TOCHI), 2(3):201–219, 1995.
- [38] A. Subasi, M. Radhwan, R. Kurdi, and K. Khateeb. Iot based mobile healthcare system for human activity recognition. In 2018 15th learning and technology conference (L&T), pp. 29–34. IEEE, 2018.
- [39] A. Toshev and C. Szegedy. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014.
- [40] S. Tregillus and E. Folmer. Vr-step: Walking-in-place using inertial sensing for hands free navigation in mobile vr environments. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, pp. 1250–1255, 2016.
- [41] T. T. Um, F. M. Pfister, D. Pichler, S. Endo, M. Lang, S. Hirche, U. Fietzek, and D. Kulić. Data augmentation of wearable sensor data for parkinson’s disease monitoring using convolutional neural networks. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, pp. 216–220, 2017.
- [42] M. Usoh, K. Arthur, M. C. Whitton, R. Bastos, A. Steed, M. Slater, and F. P. Brooks Jr. Walking¿ walking-in-place¿ flying, in virtual environments. In Proceedings of the 26th annual conference on Computer graphics and interactive techniques, pp. 359–364, 1999.
- [43] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need, 2017.
- [44] R.-D. Vatavu, L. Anthony, and J. O. Wobbrock. Gestures as point clouds: a $ p recognizer for user interface prototypes. In Proceedings of the 14th ACM international conference on Multimodal interaction, pp. 273–280, 2012.
- [45] Y. Wang, Y. Sun, Z. Liu, S. E. Sarma, M. M. Bronstein, and J. M. Solomon. Dynamic graph cnn for learning on point clouds, 2019.
- [46] J. D. Wendt, M. C. Whitton, D. Adalsteinsson, and F. P. Brooks. Reliable forward walking parameters from head-track data alone. In 2012 IEEE Virtual Reality Workshops (VRW), pp. 81–82, 2012. doi: 10 . 1109/VR . 2012 . 6180892
- [47] J. D. Wendt, M. C. Whitton, and F. P. Brooks. Gud wip: Gait-understanding-driven walking-in-place. In 2010 IEEE Virtual Reality Conference (VR), pp. 51–58, 2010. doi: 10 . 1109/VR . 2010 . 5444812
- [48] J. D. Wendt, M. C. Whitton, and F. P. Brooks. Gud wip: Gait-understanding-driven walking-in-place. In 2010 IEEE Virtual Reality Conference (VR), pp. 51–58, 2010. doi: 10 . 1109/VR . 2010 . 5444812
- [49] B. Williams, G. Narasimham, B. Rump, T. P. McNamara, T. H. Carr, J. Rieser, and B. Bodenheimer. Exploring large virtual environments with an hmd when physical space is limited. In Proceedings of the 4th symposium on Applied perception in graphics and visualization, pp. 41–48, 2007.
- [50] P. T. Wilson, W. Kalescky, A. MacLaughlin, and B. Williams. Vr locomotion: walking>walking in place>arm swinging. In Proceedings of the 15th ACM SIGGRAPH Conference on Virtual-Reality Continuum and Its Applications in Industry - Volume 1, VRCAI ’16, p. 243–249. Association for Computing Machinery, New York, NY, USA, 2016. doi: 10 . 1145/3013971 . 3014010
- [51] D. Wolf, K. Rogers, C. Kunder, and E. Rukzio. Jumpvr: Jump-based locomotion augmentation for virtual reality. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, CHI ’20, p. 1–12. Association for Computing Machinery, New York, NY, USA, 2020. doi: 10 . 1145/3313831 . 3376243
- [52] B. Wu, X. Zhou, S. Zhao, X. Yue, and K. Keutzer. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In 2019 International Conference on Robotics and Automation (ICRA), pp. 4376–4382. IEEE, 2019.
- [53] S. Yoo, C. Ackad, T. Heywood, and J. Kay. Evaluating the actual and perceived exertion provided by virtual reality games. In Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems, CHI EA ’17, p. 3050–3057. Association for Computing Machinery, New York, NY, USA, 2017. doi: 10 . 1145/3027063 . 3053203
- [54] S. Yoo, C. Ackad, T. Heywood, and J. Kay. Evaluating the actual and perceived exertion provided by virtual reality games. In Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems, pp. 3050–3057, 2017.
- [55] D. Zhang, X. Lu, H. Qin, and Y. He. Pointfilter: Point cloud filtering via encoder-decoder modeling. IEEE Transactions on Visualization and Computer Graphics, 27(3):2015–2027, 2021. doi: 10 . 1109/TVCG . 2020 . 3027069
- [56] N. Zhao. Full-featured pedometer design realized with 3-axis digital accelerometer. Analog Dialogue, 44(06):1–5, 2010.