Cluster detection in networks using percolation
Abstract
We consider the task of detecting a salient cluster in a sensor network, that is, an undirected graph with a random variable attached to each node. Motivated by recent research in environmental statistics and the drive to compete with the reigning scan statistic, we explore alternatives based on the percolative properties of the network. The first method is based on the size of the largest connected component after removing the nodes in the network with a value below a given threshold. The second method is the upper level set scan test introduced by Patil and Taillie [Statist. Sci. 18 (2003) 457–465]. We establish the performance of these methods in an asymptotic decision- theoretic framework in which the network size increases. These tests have two advantages over the more conventional scan statistic: they do not require previous information about cluster shape, and they are computationally more feasible. We make abundant use of percolation theory to derive our theoretical results, and complement our theory with some numerical experiments.
doi:
10.3150/11-BEJ412keywords:
and
1 Introduction
We consider the problem of cluster detection in a network. The network is modeled as a graph, and we assume that a random variable is observed at each node. The task is then to detect a cluster, that is, a connected subset of nodes with values that are larger than usual. There are a multitude of applications for which this model is relevant; examples include detection of hazardous materials (Hills [25]) and target tracking (Li et al. [35]) in sensor networks (Culler, Estrin and Srivastava [12]), and detection of disease outbreaks (Heffernan et al. [24]; Rotz and Hughes [49]; Wagner et al. [53]). Pixels in digital images are also sensors, and thus many other applications are found in the rich literature on image processing, for example, road tracking (Geman and Jedynak [20]) and fire prevention using satellite imagery (Pozo, Olmo and Alados-Arboledas [47]), and the detection of cancerous tumors in medical imaging (McInerney and Terzopoulos [36]).
After specifying a distributional model for the observations at the nodes and a class of clusters to be detected, the generalized likelihood ratio (GLR) test is the first method that comes to mind. Indeed, this is by far the most popular method in practice, and as such, is given different names in different fields. The likelihood ratio is known as the scan statistic in spatial statistics (Kulldorff [29, 30]) and the corresponding test as the method of matched filters in engineering (Jain, Zhong and Dubuisson-Jolly [27]; McInerney and Terzopoulos [36]). Here we use the former, where scanning a given cluster means computing the likelihood ratio for the simple alternative where is the anomalous cluster. Various forms of scan statistic have been proposed, differing mainly by the assumptions made on the shape of the clusters. Most methods assume that the clusters are in some parametric family (e.g., circular (Kulldorff and Nagarwalla [33]), elliptical (Hobolth, Pedersen and Jensen [26]; Kulldorff et al. [32])) or, more generally, deformable templates (Jain, Zhong and Dubuisson-Jolly [27]). Sometimes no explicit shape is assumed, leading to nonparametric models (Duczmal and Assunção [16]; Kulldorff, Fang and Walsh [31]; Tango and Takahashi [51]).
We consider two alternative nonparametric methods, both based on the percolative properties of the network, that is, based on the connected components of the graph after removing the nodes with values below a given threshold. The simplest is based on the size of the largest connected component after thresholding – the threshold is the only parameter of this method. If the graph is a one-dimensional lattice, then after thresholding, this corresponds to the test based on the longest run (Balakrishnan and Koutras [4]), which Chen and Huo [9] adapt for path detection in a thin band. This test has been studied in a similar context in a series of papers111The authors were not aware of this unpublished line of work until M. Langovoy contacted them in the final stages manuscript preparation. (Davies, Langovoy and Wittich [14]; Langovoy and Wittich [34]) under the name of maximum cluster test. The idea behind this method is simple. When an anomalous cluster is indeed present, the values at the nodes belonging to this cluster are larger than usual and thus more likely to survive the threshold, and because these nodes are also likely to clump together – because the cluster is connected in the graph – the size of the statistic will be (stochastically) larger than when no anomalous cluster is present.
More sophisticated, and also parameter-free, is the method based on the upper level set scan statistic of Patil and Taillie [41], subsequently developed in the context of ecological and environmental applications (Patil, Joshi and Koli [38]; Patil and Taillie [42]; Patil et al. [37, 39]). It is the result of scanning over the connected components of the graph after thresholding, which is repeated at all thresholds. This method obviously is closely related to the scan statistic. It can be seen as attempting to approximate the scan statistic over all possible connected components of the graph by restricting the class of subsets to be scanned to those surviving a threshold. Our results indicate that this method is in fact more closely related to the previous one (based on the size of the largest connected component at a given threshold), and in some sense provides a way to automatically choose the threshold.
These two percolation-based methods have two significant advantages over the scan statistic. First, they do not need to be provided with the shape of the clusters to be detected. Thus they are valuable in settings with less previous spatial information. The second advantage is computational. The scan statistic tends to be computationally demanding, even in parametric settings, or even outright intractable, particularly in nonparametric settings. In contrast, these two methods are computationally feasible, and their implementation is fairly straightforward, even for irregular networks. On the other hand, the scan statistic often relies on the fast Fourier transform in the square lattice to scan clusters of known shape over all locations in that network.
In terms of detection performance, we compare these percolation-based methods to the scan statistic in a standard asymptotic decision theoretic framework where the network is a square lattice of growing size and the variables at the nodes are assumed i.i.d. for nodes inside (resp., outside) the anomalous cluster. The performance of the scan statistic in such a framework is well understood and known to be (near-) optimal, which makes it the gold standard in detection (Arias-Castro, Candès and Durand [1]; Arias-Castro, Donoho and Huo [3]; Perone Pacifico et al. [45]; Walther [54]). We find that these two methods are suboptimal for the detection of hypercubes, an emblematic parametric class, but are near-optimal for the detection of self-avoiding paths, an emblematic nonparametric class. The main weakness of these percolation-based methods is that when the per-node signal-to-noise ratio is weak, the connected components after thresholding are heavily influenced by the whimsical behavior of the values at the nodes. The scan statistic is very effective in such situations. Although this rationale seems to apply particularly well in the case of self-avoiding paths, what makes these methods competitive in this case is that the problem of detecting such objects is intrinsically very hard.
The study of the connected components after thresholding is intrinsically connected to percolation theory (Grimmett [21]), an important branch in probability theory. In fact, when the node values are i.i.d. – which is the case when no anomalous cluster is present – the only dependence on the distribution at the nodes is the probability of surviving the threshold, and after thresholding, the network is a site percolation model. (We introduce and discuss these notions in detail later in the article.) Our contribution is a careful analysis of these two nonparametric methods using percolation theory (Grimmett [21]) in a substantial way, thus applying percolation theory in a sophisticated fashion to shed light on an important problem in statistics.
The rest of the paper is organized as follows. In Section 2 we formally introduce the framework and state some fundamental detection bounds. In Section 3 we describe the standard scan statistic and present some results on its performance, showing that it is essentially optimal. In Section 4, we consider the size of the largest connected component after thresholding. In Section 5, we consider the upper level set scan statistic. We briefly discuss implementation issues and present some numerical experiments in Section 6. Finally, Section 7 is a discussion section where, in particular, we mention extensions. We provide proofs in the Appendix.
2 Mathematical framework and fundamental detection bounds
For concreteness, and also for its relevance to signal and image processing, we model the network as a finite subgrid of the regular square lattice in dimension , denoted . Our analysis is asymptotic in the sense that the network is assumed to be large, that is, . To each node , we attach a random variable, . For example, in the context of a sensor network, the nodes represent the sensors and the variables represent the information that they transmit. The random variables are assumed to be independent with common distribution in a certain one-parameter exponential family , defined as follows. Let , let be a distribution function with finite non-zero variance , and assume the that moment-generating function is finite for . Then is the distribution function with density with respect to . We assume further regularity of at later points in this paper. Note that our results apply to other distributional models as well, as discussed in Section 7.
Examples of such a family include the following:
-
•
Bernoulli model: , , relevant in sensor arrays where each sensor transmits one bit (i.e., makes a binary decision)
-
•
Poisson model: , popular with count data, for example, arising in infectious disease surveillance systems
-
•
Exponential model: (e.g., to model response times)
-
•
Normal location model: , standard in signal and image processing, where noise is often assumed to be Gaussian.
Let be a class of clusters, with a cluster defined as a subset of nodes connected in the graph. Under the null hypothesis, all of the variables at the nodes have distribution , that is,
Under the particular alternative where is anomalous, the variables indexed by have distribution for some , that is,
We are interested in the situation where the anomalous cluster is unknown, namely in testing against . We illustrate the setting in Figure 1 in the context of the two-dimensional square grid.

Let denote a cluster class for . As usual, a test is a function of the data, , that takes values in , with corresponding to a rejection, meaning a decision in favor of . For a test , we define its worst-case risk as the sum of its probability of type I error and its probability of type II maximized over the anomalous clusters in the class
A method is formally defined as a sequence of tests for testing versus . We say that a method is asymptotically powerless if
This amounts to saying that as the size of the network increases, the method is not substantially better than random guessing. Conversely, a method is asymptotically powerful if
The minimax risk is defined as , and we say that a method is (asymptotically) optimal if whenever . Everything else fixed, the latter depends on the behavior of when becomes large. We say that is optimal up to a multiplicative constant if under whenever under . We say that is near-optimal if the same is true with replaced by with . (This occurs here only when polynomially fast and poly-logarithmically fast.)
We focus on situations where the clusters in the class are of same size, increasing with but negligible compared with the size of the entire network. We do so for the sake of simplicity; more general results could be obtained as in Arias-Castro, Candès and Durand [1], Arias-Castro, Donoho and Huo [3], Perone Pacifico et al. [45], Walther [54] without additional difficulty. Assuming a large anomalous cluster allows us to state general results applying to a wide range of one-parameter exponential families (via the central limit theorem). In addition, note that on the one hand, reliably detecting a cluster of bounded size is impossible in the Bernoulli model or any other model where has finite support, whereas on the other hand, detecting a cluster of size comparable to that of the entire network is in some sense trivial, given that the simple test based on the total sum is optimal up to a multiplicative constant.
We consider two emblematic classes of clusters, in some sense at the opposite extremes:
-
•
Hypercube detection. Let denote the class of hypercubes within of sidelength with . This class is parametric, with the location of the hypercube the only parameter.
-
•
Path detection. Let denote the class of loopless paths within of length with . This class is nonparametric, in the sense that its cardinality is exponential in the length of the paths.
See Figure 1 for an illustration. (Note that a hypercube of side length may be seen as a loopless path of length .) Although we obtain results for both, our main focus is in the setting of hypercube detection, which is relevant to a wider range of applications, in fact any situation where the task is to detect a shape that is not filamentary. The situation exemplified in the setting of path detection may be relevant in target tracking from video, or the detection of cracks in materials in non-destructive testing. Note that the two settings coincide in dimension one.
We state fundamental detection bounds for each setting. The following result is standard (see, e.g., Arias-Castro, Candès and Durand [1]; Arias-Castro, Donoho and Huo [3]). Remember that denotes the variance of .
Lemma 0
In hypercube detection, all methods are asymptotically powerless if
In fact, the conclusions of Lemma 1 apply for a wide variety of parametric classes, such as discs, a popular model in disease outbreak detection (Kulldorff and Nagarwalla [33]), as well as to nonparametric classes of blob-like clusters (see Arias-Castro, Candès and Durand [1]; Arias-Castro, Donoho and Huo [3]).
The following result is taken from Arias-Castro et al. [2].
Lemma 0
In path detection, all methods are asymptotically powerless if , in dimension , and the same is true in dimension if , where depends only on .
In dimension , may be taken to be the unique solution to
where is the return probability of a symmetric random walk in dimension .
3 The scan statistic
For a subset of nodes , let denote its size and define
Given a cluster class , we define the (simple) scan statistic as
| (1) |
where is the mean of . If is not available, we may use the grand mean instead. In Appendix B, we derive this form of the scan statistic as an approximation to the scan statistic of Kulldorff [29], which is, strictly speaking, the GLR and arguably the most popular version, particularly in spatial statistics. We use this simpler form to streamline our theoretical analysis.
The test that rejects for large values of the scan statistic (1), which we call the scan test, is near-optimal in a wide range of settings (Arias-Castro, Candès and Durand [1]; Arias-Castro, Donoho and Huo [3]; Walther [54]). In particular, in the context of a class of hypercubes, and in fact many other parametric classes, this test is asymptotically optimal to the exact multiplicative constant.
Lemma 0
In hypercube detection, the scan test is asymptotically powerful if
In the context of a class of paths, the following result states that the scan test detects if is bounded away from 0 and sufficiently large. Note that this does not match the order of magnitude of the lower bound given in dimension . Let and ( is the rate function of when .) The following result is established in Arias-Castro et al. [2].
Lemma 0
In path detection, the scan test is asymptotically powerful if
4 Size of the largest open cluster
We study the test based on the size of the largest connected component after thresholding the values at the nodes. This test was independently considered in a series of papers (Davies, Langovoy and Wittich [14]; Langovoy and Wittich [34]). Our results are seen to sharpen and elaborate on these results. In particular, we study this test under all three regimes (subcritical, supercritical, and critical).
Adapting terminology from percolation theory (Grimmett [21]), for a threshold , we say that a subset is open (at threshold ) if for all . Let (resp., ) denote the size of the largest open cluster within (resp., within ). The analysis of the test based on , which we call the largest open cluster (LOC) test, boils down to bounding the size of from above, under , and, because , bounding the size of from below, under . Define , which is Bernoulli with parameter . The process is a site percolation model (Grimmett [21]). In general, consider a process i.i.d. Bernoulli with parameter , and let denote the size of the largest open cluster within . In dimension , this process may be seen as a sequence of coin tosses, and viewed as the longest heads run in that sequence. In this context, the Erdős–Rényi Law (Erdős and Rényi [17]) says that
| (2) |
In higher dimensions , the situation is much more involved. Let denote the critical probability for site percolation in , defined as the supremum over all such that the size of the open cluster at the origin, denoted by , is finite with probability 1. (The dependency in is left implicit.) We consider the subcritical (), supercritical (), and near-critical () cases separately.
4.1 Subcritical percolation
In the subcritical case, where is such that , we are able to obtain precise, rigorous results on the performance of the test based on in terms of the function , implicitly defined as
| (3) |
(see Grimmett [21], Section 6.3). Again, the dependency in is left implicit. As a function of , is continuous and strictly decreasing, with limits at and 0 at (see Lemma 8), whereas for . In the Appendix, we include a proof that
| (4) |
for a subcritical threshold .
The convergence result in (4) may be used to bound under the null by taking . Under the alternative, if we consider a class of hypercubes, then (4) also may be used to bound , because is a scaled version of .
Theorem 1
In hypercube detection, the test based on , with fixed such that , is asymptotically powerful if , and asymptotically powerless if , where is the unique solution to .
Note that when is fixed, as a function of is continuous and strictly strictly decreasing, by the fact that is continuous and strictly increasing in (Brown [7], Cor. 2.6, 2.22) and is continuous and strictly decreasing in (Lemma 8). Therefore, in the theorem is well defined.
If instead, we consider a class of paths, then (2) may be used to bound , because is a scaled version of the lattice in dimension 1. In congruence with (2), we define .
Theorem 2
In path detection, the test based on , with fixed such that , is asymptotically powerful if , and asymptotically powerless if , where (resp., ) is the unique solution to (resp., ).
Note that in dimension , the result is not sharp, because we always have . We believe that sharper forms of this result may be substantially more involved, and for this reason we have not pursued this.
Qualitatively, the message is that for both hypercube detection and path detection, the subcritical LOC test requires that be larger than a constant to be effective. Compared with the scan statistic, this makes it grossly suboptimal when detecting hypercubes and comparable (up to a multiplicative constant in ) when detecting self-avoiding paths.
What if we let , so that ? Then the test based on is powerless under some additional conditions on . For , consider the following class of approximately exponential power () distributions, sometimes called Subbotin distributions:
( is the survival distribution function of .) For example, and , whereas behaves roughly as a distribution in .
Proposition 1
Assume that for some and . In hypercube detection, the test based on is asymptotically powerless when , unless .
4.2 Supercritical percolation
Here we consider the supercritical regime, where . (Note that necessarily for in dimension 1.) In this setting, too, the size of the largest cluster is well understood. Let be the probability that the open cluster at the origin is infinite, and note that for , by the definition of . We have with probability 1 that
(see Falconer and Grimmett [18], Lemma 2 and proof, Penrose and Pisztora [44], Theorem 4, Pisztora [46]). In fact (with probability ), the largest open cluster within is unique, and the foregoing statement says that it occupies a non-negligible fraction of . With a supercritical choice of threshold, the LOC test is powerless for any if the anomalous cluster is too small, specifically if in the setting of hypercube detection. Indeed, we have the following result.
Theorem 3
In hypercube detection, the test based on , with fixed such that , is asymptotically powerful if and , and asymptotically powerless if or if .
Thus, for the detection of small clusters, a supercritical LOC test is potentially worthless, whereas for larger clusters it improves substantially on the performance of a subcritical LOC test, although it is still suboptimal compared with the scan statistic. (Indeed, comparing the exponents when , we have , because .) We mention that in the context of path detection, the same arguments show that the LOC test for any choice of supercritical threshold is asymptotically powerless.
4.3 Critical percolation
If our goal is to choose a threshold so as to maximize the difference in size for the largest open cluster under the null and under an alternative, then we are necessarily in the neighborhood of the percolation phase transition, which is to say that is small. (Again, here we assume .) The percolation model is not fully understood in the critical regime, which poses a serious obstacle to a rigorous statistical analysis. (See Grimmett [21], Chapter 9, for a general discussion of this percolation regime.) We base our discussion on the work of Borgs et al. [6]. Let denote the probability that the open cluster at the origin reaches outside the box , and let denote the correlation length, defined as
Note that, with thus defined, if and only if . The critical exponent for (subcritical) correlation length is postulated to be
It is not known whether the limit exists for all dimensions, but it is known that whenever it exists. It is shown in Borgs et al. [6] that, subject to the existence of this limit together with other scaling assumptions, when varies with ,
| (5) |
where means that there exists a constant such that in probability. The scaling assumptions of Borgs et al. [6] are believed to hold if and only if the number of dimensions satisfies , and they are proved for . The work of Borgs et al. [6] was directed at bond percolation only, but similar results are expected for site percolation.
It is known that for site percolation on the triangular lattice (see Smirnov and Werner [50]), and it is believed that this holds for percolation on any two-dimensional lattice. As described in Grimmett [21], Section 10.4, it is believed that for , and this has been proved for and for the so-called “spread-out model” in and more dimensions (Hara, van der Hofstad and Slade [23]).
Subject to the assumption that (5) holds, we establish the power of the test based on when choosing near criticality. We assume that there exists such that , and that is a continuous function of in a neighborhood of .
Theorem 4
Let be such that for some . In hypercube detection, assuming that (5) holds, the test based on is asymptotically powerful if is sufficiently large.
Compared with a subcritical choice of threshold, which requires that be bounded away from 0 for the test to have any power, as seen in Theorem 1, with a near-critical choice of threshold, the test is able to detect at polynomially small . In particular, with a proper choice of threshold, the test is powerful for of order with . Note that, by Lemma 1, all methods are asymptotically powerless if is of order , implying that . We thus obtain the inequality . This may be compared with the scaling relation (Grimmett [21], Equation (9.23)) stating that , where () is the percolation critical exponent for the number of clusters per vertex. It is believed that when and when . Compared with the performance at supercriticality, the test at near-criticality (with a proper choice of threshold) is superior if , which is equivalent to . For example, with , the near-critical LOC test is superior when .
5 The upper level set scan statistic
For a threshold , let denote the (random) class of clusters within open at , and let , which is also random. Patil and Taillie [41] suggested scanning the clusters in . To facilitate a rigorous mathematical analysis of its performance, we consider the upper level set () scan at a given threshold , and use the simple scan described in Section 3. Specifically, in correspondence with (1), we define the (simple) scan statistic at threshold as
| (6) |
where (resp., ) is the the mean (resp., variance) of when , and is a non-decreasing sequence of positive integers. The scan statistic of Patil and Taillie [41] corresponds (in its simple form) to
| (7) |
If and/or are not available, we may use their empirical versions based on the that survive the threshold . We restrict the scan to clusters of size at least to increase power, because the behavior of is, as we show later, completely driven by the smallest open clusters that are scanned, at least when is subcritical. We present the rest of our discussion in terms of subcritical, supercritical, and near-critical choices of threshold. We then conclude with a result on the performance of the scan test across all thresholds.
5.1 Subcritical threshold
We start by describing the behavior of under the null. Let denote the distribution of under , and let and denote its mean and rate function, respectively. Also, when , or and for some and , let , where is the function defined in Lemma 16. Note that can be computed explicitly in some cases, like the normal location model, and when , defined (when it exists) as the solution to .
Lemma 0
Assume that and is fixed such that and that for some . Then, under on , the following holds in probability:
-
1.
If , then for large enough.
-
2.
If , then
-
3.
If and for some and , then
-
[(b)]
-
(a)
If , the convergence in Part 2 applies;
-
(b)
If ,
-
In the last case, where , the behavior of is influenced by the very large deviations of for . (The symbol denotes convolution.) We choose to state a result for distributions, for which the very large deviations resemble the large deviations.
Based on Lemma 5, we establish the performance of the scan statistic. We start by arguing that choosing such that leads to a test that may potentially have less power than the test based on the largest cluster after thresholding. Indeed, the behavior of the scan statistic does not depend on as long as .
Proposition 2
Assume that for some and . In hypercube detection, the test based on , with fixed such that and , is asymptotically powerless if .
For example, in the setting just described with , the scan test has (asymptotically) no power unless , whereas the test based on the size of the largest cluster after thresholding is, by Theorem 1, asymptotically powerful if is large enough. We therefore choose a sequence comparable in magnitude to and state the performance of the scan test in this case.
Theorem 5
In hypercube detection, the test based on , with fixed such that and with , is asymptotically powerful if and asymptotically powerless if , where is the unique solution to .
Note that is well defined by Lemma 17 and that as long as . In any case, the test based on with a subcritical threshold is, in the setting of hypercube detection, asymptotically powerless when , just like the LOC test. In essence, the two tests are qualitatively comparable in this setting. This is also true in the context of path detection. Let denote in dimension 1.
Theorem 6
In path detection, the test based on , with fixed such that and with , is asymptotically powerful if , and asymptotically powerless if , where (resp., ) is the unique solution to (resp., ).
As in Theorem 2, the result is not as sharp.
Qualitatively, we see that the performance of the subcritical scan and LOC tests are comparable for both hypercube detection and path detection.
5.2 Supercritical threshold
Here we consider the choice of a supercritical threshold, where is fixed such that . We already saw in Section 4.2 that the largest open cluster is unique and occupies a non-negligible fraction of the entire network. This is actually true both under the null and under an alternative. The scan test based solely on the largest open cluster is comparable to the test based on the grand mean after thresholding. In turn, assuming is fixed, this test is asymptotically powerful when , and asymptotically powerless if and is bounded. (This is easily seen using Chebyshev’s inequality.) This is comparable to the LOC test at supercriticality.
In general, the scan statistic includes other (smaller) open clusters. The story of the second-largest cluster of supercritical percolation in a box is not yet complete, and for this reason the behavior of the scan statistic remains incompletely understood. The difficulty arises from the possibility that the second-largest cluster in might lie at its boundary. Whether or not this occurs depends on the outcome of a calculation (yet to be done) of energy/entropy type involving so-called “droplets” near the boundary of (see, e.g., Bodineau, Ioffe and Velenik [5]). To simplify the discussion, we finesse this problem by working where necessary on with toroidal boundary conditions. That is, whenever we make statements concerning supercritical percolation on the graph , we may add edges connecting sites on its boundary as follows: when , for , an additional edge is placed between site and site , and similarly between and .
In proving exact asymptotics for test statistics under the null, we assume toroidal boundary conditions. Our results on asymptotic power do not require such exact results but require only orders of magnitude, which do not need the toroidal assumption. We emphasize that similar results are expected to hold with “free” (i.e., without the extra edges) rather than toroidal boundary conditions. Once the percolation picture is better understood, such results will follow in the same manner as those presented in this paper. Our results for the torus are also valid if instead we discount open clusters that touch the boundary of . Details of this are omitted, and the proofs are essentially the same.
When working on the torus, the second-largest cluster is controlled through the following calculation. Cerf [8] proved that the limit
| (8) |
exists, with for all fixed . The dependency on is left implicit.
A result similar to Lemma 5 holds with playing the role of and the exponent of changed in places. It turns out that we need this result only when . For and a supercritical , let , defined in Lemma 16.
Lemma 0
Assume that is fixed such that and that and for some . Then, under the null, the following holds in probability on the torus :
-
1.
If , then .
-
2.
If and , then
where .
-
3.
If , then the conclusions of Lemma 5 apply. (Note that .)
Based on Lemma 6, we obtain the following result on the performance of the scan test at supercriticality. As before, we restrict ourselves to the case where is of order . We also chose to state a simple result instead of a more precise result with multiple subcases. This result holds irrespective of the type of boundary condition assumed on .
Theorem 7
In hypercube detection, the test based on , with fixed such that and and , is asymptotically powerful (resp., powerless) if
We also mention that the equivalent of Theorem 6 holds here as well.
The improvement of the supercritical scan test compared with the supercritical LOC test is a weaker requirement on by a logarithmic factor. Thus, this test’s performance is still much worse than that of the scan statistic when detecting hypercubes.
5.3 Critical threshold
If we choose a threshold as described in Section 4.3, and if (5) is true, then the power of the scan statistic is greatly improved, as in the case of the LOC test. In fact, it can be proven that Theorem 4 remains valid with replaced with , as long as so that the largest open cluster under the alternative is scanned. This boils down to showing that under the null, the scan statistic is at most a power of , which we do in Lemma 7 below. However, the scan test does not seem to offer any substantial gain in power over the LOC test, given that is still required to be large enough to change the regime of the percolation process within an alternative from subcritical to supercritical. That said, actually proving this would require information on the smaller open clusters near criticality, which is scarce and very difficult to obtain (see Borgs et al. [6] for some partial results and postulates).
5.4 Across all thresholds
Finally, we discuss the (simple) scan test across all thresholds, as suggested in Patil and Taillie [41]. To take advantage of a phase transition near criticality, we assume, as in Section 4.3, that there exists such that and that is a continuous function of in a neighborhood of . We also assume that (5) holds. In Proposition 2, we showed that scanning small clusters may lead to a decrease in power. For this reason, and also to facilitate the analysis, we limit ourselves to clusters of size at least ; that is, we consider the test based on
| (9) |
where, for definiteness, is calculated on the torus when .
Let , where, in congruence with Sections 5.1 and 5.2,
with being the function defined in Lemma 16. We first establish the behavior of under the null.
Lemma 0
Let where , and let be such that . Define . With probability tending to 1, under ,
If in addition, either is non-decreasing in or has no atoms on , then, in probability under ,
In fact, a result as precise as Lemma 7 is superfluous, given the behavior of the scan statistic under the alternative at supercriticality and near-criticality, which is polynomial in . The next theorem does not require the use of toroidal boundary conditions.
Theorem 8
In hypercube detection and assuming that (5) holds, the test based on , with for some , is asymptotically powerful if , for some satisfying if .
Thus, scanning all thresholds elicits the best performance of the LOC tests. Nevertheless, the overall test is still suboptimal when detecting hypercubes compared with the scan statistic. We mention in passing that the same result holds for the simpler test that scans only the largest open cluster at each threshold.
6 Implementation and numerical experiments
The scan test has been shown to be near-optimal in a wide variety of settings, differing in terms of both network structure and cluster class (Arias-Castro, Candès and Durand [1]; Arias-Castro, Donoho and Huo [3]). It is computationally demanding, however. For the simple situation of detecting a hypercube, the scan statistic can be computed in flops, where is the network size if the size of the hypercube is known. If one scans over all possible hypercubes, then computing the scan statistic requires flops. For nonparametric shapes, the computational cost is even higher; in fact, for the problem of detecting a loopless path, computing the scan statistic corresponds to the reward-budget problem of DasGupta et al. [13], shown there to be NP-hard. Because the scan statistic is so computationally burdensome, the cluster class is most often taken to be parametric in practice, even though the underlying clusters may take a much wider range of shapes. For instance, discs are the prevalent shape used in disease outbreak detection (Kulldorff and Nagarwalla [33]), with variants such as ellipses (Hobolth, Pedersen and Jensen [26]; Kulldorff et al. [32]). For a wide range of parametric shapes, Arias-Castro, Donoho and Huo [3] recommended a multiscale approximation to the scan statistic. Efforts to move beyond parametric models include tree-based approaches (Kulldorff, Fang and Walsh [31]), simulated annealing (Duczmal and Assunção [16]) and an exhaustive search among arbitrarily shaped clusters of small size (Tango and Takahashi [51]).
The LOC test does not assume any parametric form for the anomalous cluster, and in that sense is nonparametric. Its computational complexity at a given threshold is of order the number of nodes plus the number of edges in the network (Cormen et al. [10]), and so of order flops for the square lattice.
The scan statistic is nonparametric as well. Computing requires determining , which takes flops, and then scanning over . Because the clusters in do not intersect, scanning over them takes order flops. Therefore, computing can be done in flops, where is the number of distinct values at the nodes. Patil and Taillie [42] argued that this can be done faster by using the tree structure of , where the root is the entire network and a cluster is the parent of any cluster such that , where denote the distinct values at the nodes.
We complement our theoretical analysis with some small-scale numerical experiments. Specifically, we explore the power properties of the LOC test of Section 4 and the scan test of Section 5 in the context of detecting a hypercube in the two-dimensional square lattice. Patil, Modarres and Patankar [40] are developing sophisticated software implementing the scan statistic for use in real-life situations, with more recent variations Patil, Joshi and Koli [38]. However, this software is not yet available, so we implemented our own (basic) routines.
We used the statistical software R (R Core Team [48]) with the package igraph (Csardi [11]). Our (basic) implementation of the scan statistic for a given threshold is much slower than both the scan statistic with a given mask and the LOC statistic, especially when there is no constraint on the size of the open clusters to be scanned, that is, when . In all of our experiments, we chose the square lattice in dimension with side length for a total of 250,000 nodes, and we considered three alternatives: squares of side length , corresponding roughly to . The squares were fixed away from the boundary of the lattice, given that the methods are essentially location-independent. (This is rigorously true of the scan statistic.) We assessed the performance of a method in a given situation by estimating its risk, which we define as the sum of the probabilities of type I and type II errors optimized over all rejection regions.
We first ran some experiments to quickly assess the power of the scan test. We found that the test agrees very well with the theory (i.e., Lemma 3), which we already knew from previous experience. Specifically, we assumed a normal location model and simulated 100 realizations of the null and each of the three alternatives with (see Figure 2).
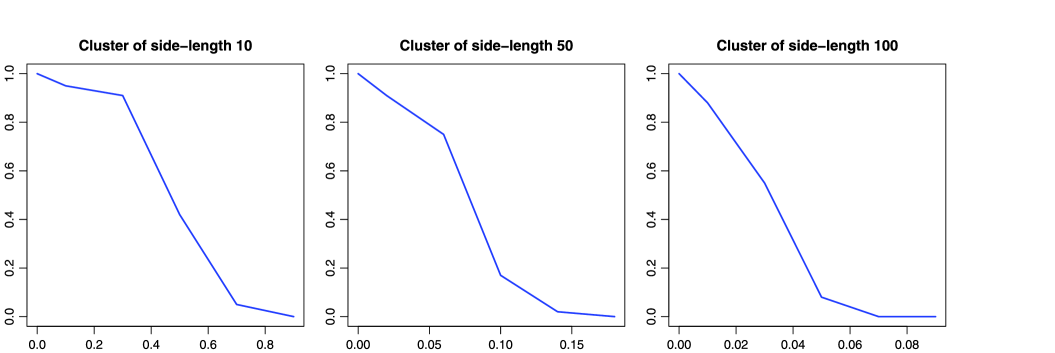
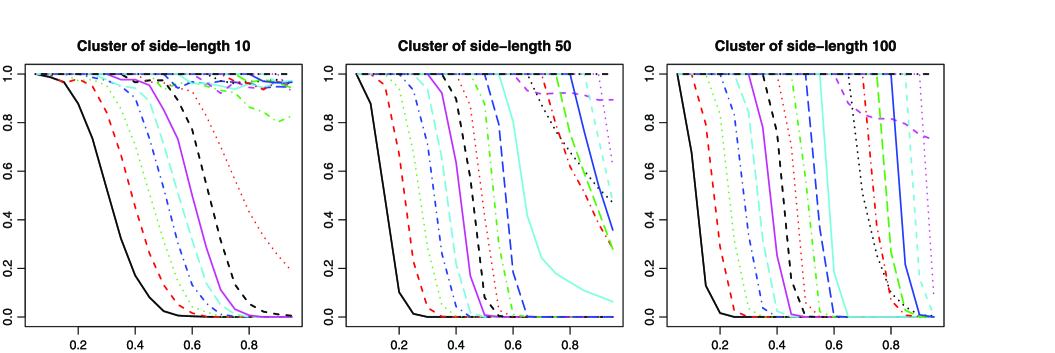
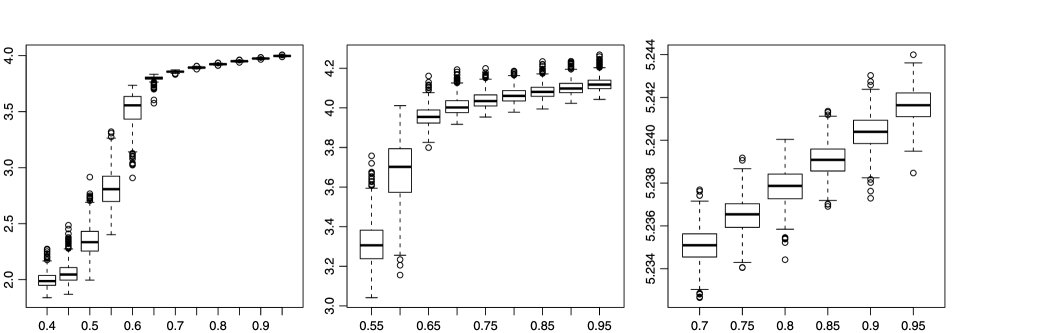
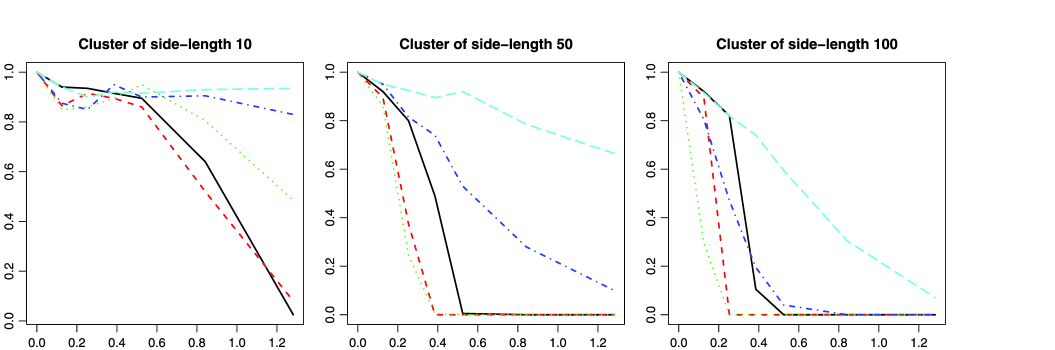
Next, we performed some larger experiments to assess the power of the LOC test. We simply assumed a site percolation model with probability . Note that is not known for site percolation in the square lattice, although from extensive numerical experiments (Feng, Deng and Blöte [19]). We simulated the null and each of the three alternatives with within the anomalous cluster. We replicated each situation 1000 times. The risk curves are shown in Figure 3. The test seems to behave similarly above and below criticality. At near-criticality, the test is rather erratic. However, when the size of the anomalous cluster is large enough, , the risk curve is steepest just under , at in our experiments, with full power against . Figure 4 shows boxplots of the test statistic for the case where and (subcritical), (near-critical), and (supercritical).
If we were to use this test in the context of a normal location model, then the correspondence would be (the threshold) and , where denotes the normal survival distribution function. Figure 5 plots the risk curves in this context for . In particular, the test at near-criticality with has full power against the alternative with and .
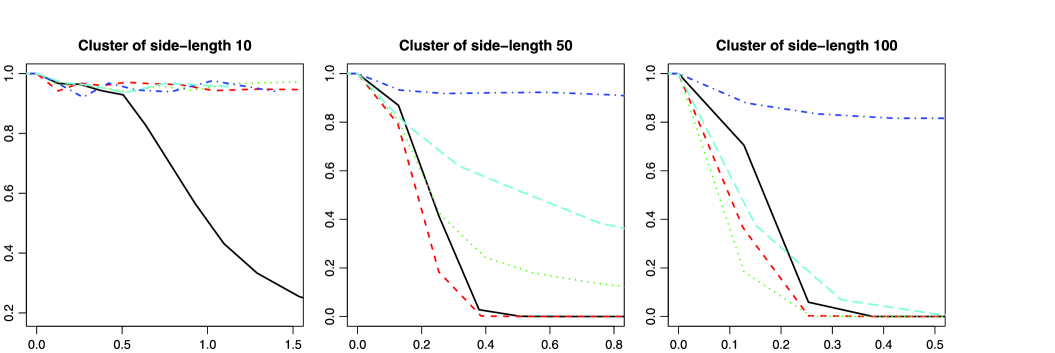
Finally, we experimented with the scan test. To limit the size of our simulations, we considered alternatives with with and chose with as thresholds. We restricted scanning to open clusters of size not smaller than of the size of largest open cluster, essentially falling in the regime of Part 2 of Lemma 5, and also making the computation much faster. We used 200 replicates. We again see that the risk curve is sharpest near criticality when the size of the anomalous cluster is sufficiently large, here for . Compared with the LOC test, the scan test has more power at large when the cluster is small (as predicted) and, more interestingly, slightly more power when the cluster is larger. Compared with the scan statistic, which knows the size and shape of the anomalous cluster, the scan test with the best choice of threshold (corresponding to ) requires approximately threefold greater signal amplitude.
7 Discussion
The contribution of this paper is a rigorous mathematical analysis of the performance of the LOC test independent of, and more extensively than Davies, Langovoy and Wittich [14] and Langovoy and Wittich [34], and of the scan test, both nonparametric and computationally tractable methods. We made abundant use of percolation theory to establish these results. We compared the power of these tests with that of the scan statistic, which is known to be near-optimal in a wide array of settings. Although these tests are comparable in power with the scan statistic for the detection of a path, they may be substantially less powerful for the detection of a hypercube. Note, however, that the scan statistic is provided with knowledge about the shape and size of the anomalous cluster. In theory, we argued that this was the case based on some heuristics and conjectures from percolation theory. Numerically, this appears to be the case when the anomalous cluster is large enough. In our experiments, the scan test was slightly more powerful than the LOC test, and required a three to four times larger than the scan statistic, which has the advantage of knowing the shape and size of the cluster. This result is promising, and further numerical experiments are needed to evaluate the power of these tests in truly nonparametric settings, because they do not require previous information about cluster shape, and are computationally more feasible in general.
Our theoretical results generalize to other networks that resemble the lattice, with a different critical percolation probability and different functions and . In particular, we used the self-similarity property of the square lattice and the fact that it has polynomial growth. Our results also generalize to other cluster classes; in the setting of the square lattice, they extend immediately to any class of clusters that includes a hypercube of comparable size (e.g., the class of clusters of size ), such that there is a hypercube with , where more slowly than any negative power of . In addition, the class might contain clusters of different sizes, although in that case the worst-case risk would be driven by the smallest clusters. Implementation of the scan statistic may be much more demanding in this case. The main results of Section 4 require only that be twice differentiable in , with for all , which is the case, for example, for location models and scale models if is twice differentiable with a strictly positive first derivate. With some additional work, we also can obtain results for classes of “thin” clusters as defined in Arias-Castro, Candès and Durand [1]. The key is to understand the percolation behavior within and near such clusters. Some results are available for slabs (Grimmett [21], Theorem 7.2) and more general subgraphs of lattices including “wedges,” and these appear to be transferable to other “curved” slabs.
Appendix A: Proofs
We write as if . Similarly, we use and and write as if and vice versa. We also use their random counterparts, , , , and . For example, means that in probability, and means that is bounded in probability, which is to say that as for any satisfying . We use to denote the indicator function of the set . The maximum of and is denoted by .
.1 On the size of percolation clusters
Here we state and prove some results on the sizes of percolation clusters in . We start by proving some properties of . Recall that denotes the size of the open cluster at the origin. Besides the limit in (3), the following bound holds for and all :
| (1) |
by Grimmett [21], Equation (6.80), adapted to site percolation.
Lemma A.0
The function defined in (3) is continuous and strictly decreasing over , and satisfies and .
Proof.
Let . By coupling and in the usual way,
so that . Applying Grimmett [21], Theorem 2.38, to the event , we find that, as in the proof of Grimmett [21], Equation (6.16), . In summary,
| (2) |
Therefore, is continuous and strictly decreasing on . Moreover, by fixing and letting , we have
Finally, by Grimmett [21], Equations (6.83), (6.56), as . ∎
Next, we prove (4). We do this by standard means, and the claim may be strengthened (see also Grimmett [22]; Hofstad and Redig [52]).
Lemma A.0
Consider site percolation on with parameter , and let denote the size of the largest open cluster within . Then (4) holds, namely
Proof.
Fix . Let be the size of the open cluster at a node , which has the same distribution as . We start with the upper bound. By the union bound,
| (3) |
Thus, using (3), for and large enough,
and the term on the right-hand side converges to .
For the lower bound, consider nodes separated from each other and the boundary of by at least . Let . For sufficiently large , the events are independent. Therefore, using (3), for large ,
and the last term on the right-hand side tends to 0 as . ∎
The following result describes the behavior of size of the open cluster at the origin when is small. It may be made more precise, but we do not pursue this here.
Lemma A.0
There exists depending only on such that, for ,
Proof.
An animal is a connected subgraph of containing the origin. The lower bound comes from considering the probability that any given animal of size is open. For the upper bound, by the union bound, we have , where is the set of animals with vertices. There is a constant such that , so that
when . ∎
We next present a result on the number of open clusters of a given size that is valid for all .
Lemma A.0
Consider site percolation on with parameter , and let denote the number of open clusters of size within . Then, for ,
In addition, for ,
Thus, for ,
Proof.
Let be the size of the open cluster at within the box . Then
| (5) |
where . We immediately have
For the lower bound, we count only nodes away from the boundary, obtaining
where .
We turn now to the covariances. By (5),
because and are independent if , where denotes -norm. Now,
so that
and the second claim of the lemma follows. ∎
We now describe some properties of the open clusters within in the supercritical regime. In this regime, it is known that, with probability 1, there is a unique infinite open cluster in , denoted by (see, e.g., Grimmett [21], Section 8.2). With high probability, the largest open cluster within is a subgraph of this infinite open cluster. Next, we present some additional information on its size, .
Lemma A.0
Suppose that . There is a constant such that, with probability at least , there is a unique largest open cluster within , and it is a subgraph of . Moreover, as , its size satisfies
with and for some depending on .
Proof.
We next describe some properties of the smaller open clusters. Let be the size of the largest open cluster of that is contained entirely within .
Lemma A.0
Suppose that . There exists a positive constant such that
For any , there exists such that the following holds: With probability tending to 1, there exist at least open clusters of size of lying within .
Our results on exact asymptotics in the supercritical phase concern with toroidal boundary conditions. One effect of removing the boundary from is that the asymptotics of the largest cluster coincide with those of , as well as for the second-largest cluster . In the proof of Theorem 7, we need an upper bound on the size of the second-largest cluster inside a box with “free” boundary conditions. We do not explore this in detail here, because it relies on extensions of arguments of Kesten and Zhang [28] (see also Grimmett [21], Proof of Theorem 8.65), which have not yet been not fully explored in the literature. Instead, we note that the the second-largest open cluster in a supercritical percolation model on with free boundary conditions has size of order . {pf*}Proof of Lemma 13 It was proven by Cerf [8] that the limit
| (6) |
exists and is strictly positive and finite when . It is elementary that thus defined is equal to that of (8) (see also Grimmett [21], Section 8.6). The first part of the lemma follows by the same proof as used in Lemma 9.
As in the proof of Lemma 11, the mean number of clusters of size satisfies
for positive constants . The number of such clusters has variance no larger than for some . The claim follows by Chebyshev’s inequality.
.2 Some distributional properties
Here we present some results for and exponential families of distributions. Our first result is on the size of the maximum of an i.i.d. sample from an distribution.
Lemma A.0
Let for some and . Then, for ,
Proof.
Fix and define . For large enough, we have, by independence,
Now redefine . For large enough, we have, by the union bound,
∎
We next describe the behavior at infinity of the logarithmic moment-generating function and rate function of an distribution.
Lemma A.0
Let for some and , with logarithmic moment-generating function and rate function . Then, as ,
| (7) | |||||
| (8) |
and, as ,
| (9) |
Proof.
Let be the moment-generating function of . We focus on the upper bound in (7) – obtaining the bound in (8) is analogous – and deduce the lower bound in (9). Let , , and let be such that for all . We start from the following bound:
We again divide the integral into and , where . For , we bound by its maximum over . For , . Letting , and assuming that is large enough such that , we get
Thus, when ,
| (10) |
Taking logs and letting , we get
Then letting tend to , we obtain the upper bound in (7).
We now define , first appearing in Section 5.1. Our function depends on certain quantities listed in the following lemma. It also depends on the quantity , which we take as that defined in (3). It is only through its dependence on that is affected by the geometry of .
Lemma A.0
Consider a distribution on the real line, possibly discrete but not a point mass, with finite mean and finite moment-generating function at some positive , and let denote its rate function. Let , and fix .
-
1.
Assume that . If , or and for some and , then there is a unique solution to the following equation
-
2.
Assume that . The foregoing holds as long as (and with interpreted as ).
Proof.
Let . Because is not a point mass, . Define
Note that is finite (resp., infinite) if (resp., ). In addition, , and its derivatives are continuous wherever is finite, and thus are uniformly continuous on any compact subset of on which is finite. Furthermore, is strictly increasing in on the interval . Let
| (11) |
Thus is finite if , and infinite when is replaced by . Furthermore, for , the infimum is achieved at some value of in a neighborhood where .
Assume first that . It may be seen that is continuous and strictly increasing in on the interval . Let . Then
| (12) |
and continuity follows from the properties of noted earlier. Similarly,
| (13) |
and strict monotonicity follows similarly.
It suffices to prove that takes values 1 and finite values 1. The first claim follows from the fact that, with ,
We now turn to the second claim, and make use of two general properties of rate functions that follow from Dembo and Zeitouni [15], Equation (2.2.10), Lemma 2.2.20. It is standard that as , where is the variance of . Therefore,
| (14) |
With thus chosen, by convexity,
| (15) |
Assume first that and . By (15), for sufficiently large ,
Suppose next that and . Let . Because if ,
The limit of this, as , is strictly greater than .
Now let and , and note that for all . Suppose that and . By dividing the infimum in (11) according to whether or not , we find that
When , some of the arguments fail, because might not be continuous at . Assume that for some and . Note that by Lemma 15. If , when is fixed and , by Lemma 15, and taking this limit as an extension at , the same arguments used in the case apply. If , we need slightly different arguments. As before, let be a minimizer of . We have that is well defined for all and strictly positive, because is uniformly continuous on any compact of and when . Thus we may proceed as before in (12)–(13), obtaining that is strictly increasing and continuous. As before, we turn to proving that takes values 1 and finite values 1. First, with and ,
Next, showing that takes finite values above 1 is done exactly as before, except that (14) is replaced by
by Lemma 15. ∎
The following result describes the variations of (defined in Lemma 16) with the parameter of an exponential family.
Lemma A.0
Consider a natural exponential family of distributions and let and denote the mean and the rate function of , respectively. Let be a continuous and decreasing function of . Then, for any fixed , is continuous and strictly increasing in . Moreover, if when , then when .
Proof.
First, note that (Brown [7], Cor. 2.22) so that is well-defined. That is strictly increasing comes from the fact that both and ( fixed) are decreasing. The latter can be seen from
where is the average of the sample of size from Brown [7], Cor. 2.22, and the fact that the distribution of as varies forms a natural exponential family with parameter . That is continuous comes from the continuity of and (in ).
For the behavior near , note that for , so that for any . Combine this with the fact that is strictly increasing in to see that is of order at least . In fact, it is easy to see that when . ∎
.3 Main proofs
.3.1 Proof of Theorem 1
By monotonicity, it is sufficient to assume that for all . Fix and, for short, let and . First, assume that , so that . Fix such that and consider the test with rejection region . Under , we have by (4), so that . Under , , so that . Thus this test is asymptotically powerful.
Now assume that , so that and there is such that . Let . It is sufficient to show that under both and , with probability tending to 1, so that the values at the nodes in have no influence on . Indeed, let be a hypercube within of sidelength which does not intersect . Then , and the distribution of is the same under both and . In addition, by (4). Now, let be the set of nodes within (supnorm) distance from , so that is a hypercube of side length containing in its interior. In the event that , only when . The distribution of under the null is stochastically bounded by its distribution under , which is itself bounded by its distribution under . Even under the latter, by (4). We then conclude the proof using the fact that , again by (4).
.3.2 Proof of Theorem 2
Here we use the notation and follow the arguments of Section .3.1. In addition, let , that is, the function in dimension one. When , we consider . Under , we still have . Under , , because is isomorphic to a subinterval of the one-dimensional lattice. We conclude as before that the test with rejection region is asymptotically powerful.
When , we consider . As before, let be the set of nodes within (supnorm) distance from , so that is now a band. As before, it suffices to prove that under . Although (4) cannot be applied, because is not isomorphic to a square lattice, its proof via the union bound and (3) applies. Indeed, fix small enough that . Then, for large enough, we have
.3.3 Proof of Proposition 1
Let with fixed. We first show that with probability tending to 1 under . We use the notation and arguments provided in the proof of Lemma 9. As in (.1),
where the second inequality holds for large enough by Lemma 10.
Assume that for all . Proceeding as in Section .3.1 and using the slightly larger region , it is sufficient to show that for small enough, when for all . Using the union bound and the fact that , we have
| (17) |
where the last inequality is due to Lemma 10 (and is the constant that appears there). Through integration by parts, for and fixed, we have for sufficiently large . Indeed, for large enough,
where we used the fact that in line 3 and the fact that as (because ) in lines 2 and 4. The last property also implies that for large . Thus, for large enough, , so that taking logs in (17), we get
when . (Remember that and that , so the middle term is small.)
.3.4 Proof of Theorem 3
We consider the alternative with anomalous cluster as a two-stage percolation process, where the first stage is percolation on with probability , as under the null, and the second stage is percolation on the closed nodes within , that is, , with (conditional) probability . An open cluster at the first stage is called small if it is not a largest open cluster.
We may assume, except where noted below, that . Because
which is positive at by choice of , there exists such that
| (19) |
Let be the difference between the sizes of the largest clusters under the null and the alternative. For , let be the sum of the sizes of all small clusters of the entire lattice that contain some neighbor of . Note that , where is the set of that are closed at the first stage and open at the second stage. Therefore, has expectation bounded above by
| (20) |
where is the mean size of a finite open cluster in the infinite lattice.
By (19) and the foregoing, for some . By Markov’s inequality, .
Thus, if , then , implying that the same central limit law as (18) holds under the alternative, so that the test based on the largest open cluster is asymptotically powerless. We also must consider the case where , for which a similar argument is valid.
Now assume that and . By Grimmett [21], Theorem 8.99, and standard properties of the largest cluster in a box (to be found in, e.g., Falconer and Grimmett [18]), with probability tending to 1, the largest open cluster increases in size by at least for some . By (19), this has order . Because
for some , the test based on the largest open cluster is asymptotically powerful.
.3.5 Proof of Theorem 4
We may assume without loss of generality that as . By (5) and the assumption on , we have that under the null. Now is infinitely differentiable in , with each derivative continuous in and with
uniformly for in a neighborhood of . Therefore, there exists such that
for in some neighborhood of . Thus,
on such a neighborhood. Let and be such that and , and assume that , based on the statement of the theorem. Because and ,
for and sufficiently large . By (5) applied to , it follows that under the alternative. Consequently, the test with rejection region is asymptotically powerful.
.3.6 Proof of Lemma 5
Part 1. This follows immediately from Lemma 9.
Therefore, we focus on the remaining two parts. We use the abbreviated notation , , , , , , and write . Let . As in Lemma 11, let denote the number of open cluster of size within , and define
where and is the average of an i.i.d. sample of size from . By the independence of and for distinct, we have
where
Thus, we turn to bounding .
Part 2. Define and fix . For the lower bound, let be the closest integer to between and , where
| (21) |
We have
and we show that for fixed, in probability. Fix . On the one hand, we use Lemma 11 and (3), to get
for large enough. On the other hand, we use Cramér’s theorem (Dembo and Zeitouni [15], Theorem 2.2.3) to get
for large enough. By the definition of , , and thus for small enough,
by strict monotonicity, as in the proof of Lemma 16. Thus, for small enough,
It follows that
To bound the corresponding variance, we use Lemma 11 to obtain
and it follows by Chebyshev’s inequality that indeed in probability.
Because , in , and thus
We next show that , which will imply the claim of Part 2. Fix . We have that
| (22) |
where
and is the number of clusters of size exceeding . We first note that, as in the proof of Lemma 11, for large ,
| (23) |
We next turn to , and show that for fixed and small enough, . On the one hand, we use Lemma 11 and (3) to get
for large enough. On the other hand, by Chernoff’s bound,
Taken together, we obtain
where
| (24) |
As in the proof of Lemma 16, is continuous in and strictly increasing in . Because by definition of , for fixed, for small enough, in which case as increases.
Part 3. We build on the arguments provided so far, which apply essentially unchanged, except in two places. In the lower bound, instead of Cramér’s theorem, we use
combined with the asymptotic behavior for . In the upper bound, defined in (24) is evaluated differently when .
Part 3(a). When , we have in (21) (with ), because
for fixed and , by Lemma 15. When , we take small enough if the minimum is at . Then the other arguments in Part 2 apply unchanged.
Part 3(b). By the same calculations, in (21), because for all , and when , because . This would make in (24) for any , making the arguments for the upper bound collapse. Instead, redefine . Because uniformly over , for fixed, we have
for large enough, by Lemma 15. Then the term on the right-hand side takes its minimum over at , and from here, the remaining arguments apply.
.3.7 Proof of Proposition 2
Assume, for simplicity, that for all . The key point is that . Indeed, we have , where the denominator is constant in and, integrating by parts,
From here, we reason as in the proof of Proposition 1, using the fact that when , with . Thus and have same (first-order) asymptotics, and so nothing distinguishes the asymptotic behavior of under the null and under an alternative. In detail, we proceed as in Section .3.1, with the enlarged hypercube , and show that in probability under ,
where is the scan statistic restricted to open clusters within . Because is a scaled version of , and , Lemma 5 applies to yield
We then conclude with the fact that .
.3.8 Proof of Theorem 5 and Theorem 6
The proof of Theorem 5 is parallel to that of Theorem 1 in Section .3.1, but using Lemma 5 in place of Lemma 9. Note that we use the fact that for and fixed, is continuous and strictly increasing in . This comes from Lemma 17 and the fact that when is fixed, is also a natural exponential family with parameter . Similarly, the proof of Theorem 6 is parallel to that of Theorem 2 in Section .3.2. Further details are omitted.
.3.9 Proof of Lemma 6
The proof is parallel to that of Lemma 5. In particular, we use the notation introduced there and only note where the arguments differ (although never substantially).
Part 1. In this case, by Lemma 12 and Lemma 13, there is only one open cluster with size or larger, and the result follows from, for example, Chebyshev’s inequality.
Part 2. Define and fix . For the lower bound, we have
Fix . By Lemma 11 (still valid) and (8),
for large enough. By Cramér’s theorem and the fact that when is small,
for large enough. Thus,
for large enough and small enough. For the variance, we use Lemma 11 to get
We then conclude by Chebyshev’s inequality.
We now show that in probability. Equation (22) holds with . As before,
for large enough. The absence of a boundary to is being used here. The tail behavior of percolation clusters near the boundary of a box is not yet fully understood (see the remark in Section 5.2). By Chernoff’s bound and the behavior of near the origin,
for any . Thus,
for large enough and small enough.
Part 3. This part is even more similar to what we did in the proof of Lemma 5. The behavior of is driven by the open clusters of size of order , with the only difference being that the term in from the bounds on is negligible. Details are omitted.
.3.10 Proof of Theorem 7
Without loss of generality, we assume that is bounded. By Lemma 6 and our assumptions on , under the null, for a finite constant . We now consider the alternative, where the anomalous cluster is .
The contribution of the largest open cluster, , is
On the right-hand side, the first term is of order , and the second term is of order , by Chebyshev’s inequality and the fact that, with probability tending to 1, and , by Lemma 12. The last term is of (exact) order , by the fact that is differentiable at with derivative equal to . Therefore, the scan test is asymptotically powerful when is large enough. (Note that this requires .) If instead, we have , then the scan over may be ignored, and we need to consider smaller clusters.
By Lemma 13 and the upper bound on , the second-largest cluster entirely within is scanned and its contribution is of order , by the same arguments that established the contribution of the largest open cluster. Thus, the scan test is asymptotically powerful when is large enough. If instead, , the test is asymptotically powerless. Indeed, let be the set of nodes within distance from , and let be the result of scanning the open clusters of size at least and entirely within . As argued in the proof of Proposition 2, this time using Lemma 13, it is sufficient to show that with probability tending to 1 under . For any open cluster entirely within ,
so that
where the maximum is over open clusters of size at least and entirely within , and the second term is by Lemma 13 and the size of . Although varies, this maximum may be handled exactly as in Lemma 6, so that it is , and we conclude.
.3.11 Proof of Lemma 7
We prove only the more refined part. We use abbreviated notation as before, in particular, we omit the subscript 0, using , , and so on. The lower bound is obtained via , where defines , and applying Lemmas 5 or 6 to depending on whether or . For simplicity, we assume that . If , then we consider a nearby threshold and argue by continuity. For the upper bound, we prove that , where and .
As increases, clusters are created and then destroyed in the coupled percolation processes. Suppose the removal at time from the percolation process of vertex creates some cluster at some neighbor of . If , there must exist a vertex and a neighbor such that the cluster formed at at time contributes at some future time an amount at least to . By conditioning on , , and , one obtains that
| (25) |
where the term covers the probability that the cluster at time , namely , determines , or that a cluster at threshold is of size at least ; is the neighbor set of ; and is the event that:
-
1.
satisfies ,
-
2.
there exists a time such that still exists at time and
-
3.
, where is the sum of a -sample from .
Assume (briefly) that is non-decreasing, and note that is automatically non-decreasing. Then as in the proofs of Lemmas 5 and 6, and using similar notation,
where is the number of -open clusters of size and
Therefore, by (25),
for any . We bound as we did in the proofs of Lemmas 5 and 6. Explicitly, when , we use Lemma 11 and (1), to get
We use Chernoff’s Bound on , to obtain
where ,
as in (24), and the last term is the probability that a there is a -open of size exceeding . Note that for all because . By continuity of , . Hence, we have the following bound for all ,
When , we simply use the fact that
and bound in the same way. We get
where
Again, for and as . Hence, by continuity of , , so that
valid for all . Hence, the two integrals in (.3.11) tend to zero with . We then let so that , because is continuous at .
Assume now that has no atoms on . Then is continuous on , and in fact, is uniformly continuous because when , because it is positive on that interval (because implies that is a point mass), . Because we can find such that , and also such that
| (27) |
Let . We say that a cluster scores at time if it exists at time and in addition
Without loss of generality, assume that is not an integer multiple of . Fix two neighbors , and a time . If occurs then either:
-
[(b)]
-
(a)
scores at some time , where satisfies , or
-
(b)
there exists and such that scores at time .
The latter possibility arises when scores at some time not belonging to the interval . Writing for the interval containing , must exist at the start of this interval, which is to say that .
The probability of (a) is no larger than
| (28) |
By (27) and the fact that is non-decreasing,
| (29) |
so that (28) is no greater than
| (30) |
Arguing similarly, part (b) has probability no greater than
| (31) |
We divide the integral in (25) as follows
The first integral is bounded by and the third integral by , both terms vanishing as . For the second and fourth integrals, we do exactly as before, separately for (30) and (31) – for the latter, the sum has at most terms in the second integral and at most terms in the fourth integral.
.3.12 Proof of Theorem 8
By Lemma 7, is of order at most under the null. Now consider the alternative with anomalous cluster . If , consider the contribution of the largest open cluster at supercritical threshold and reason as in the proof of Theorem 7. Otherwise, consider the contribution of the largest open cluster at a threshold such that . As in Theorem 4, the largest open cluster will be comparable in size to, and occupy a substantial portion of . Reasoning again as in the proof of Theorem 7, the contribution is of order , which increases as a positive power of .
Appendix B: The scan statistic as the GLR
We show that the simple scan statistic defined in (1) approximates the scan statistic of Kulldorff [29], which is strictly speaking the GLR, defined as follows. The log-likelihood under is given by
Assuming and are both unknown, the log GLR is defined as
which is equal to
| (B.1) |
(The subscript + denotes the positive part.)
Under the normal location model, and (B.1) is equal to
(We used the fact that .) If satisfies , which is the case in our examples, the fraction above is equal to . Moreover, knowing that there is always a cluster such that , we get that the square root of (B.1) is approximately equal to
| (B.2) |
which is the version of (1) when is unknown. (Note that , by the central limit theorem, so that (B.2) is within from (1).) This approximation is actually valid more generally, at least in a way that suffices for the asymptotic analysis that we perform in this work. Indeed, with , we have in the neighborhood of . Assuming that satisfies , which is the case in our examples, the approximation of the square root of (B.1) by (B.2) is valid under the null, because and , by the central limit theorem and the fact that and . The same applies under the alternative if , so that , and therefore, for any . When is bounded away from 0, the two statistics, square root of (B.1) and (B.2), are both of order , where denotes the cluster under the alternative (or in the case of the scan, the largest open cluster within the anomalous cluster). Taken together, these findings are sufficient to allow us to conclude that the tests based on (B.1) and (1) behave similarly.
Acknowledgements
The authors thank Ganapati Patil for providing additional references on the upper level set scan statistic, and Mikhail Langovoy for alerting the authors of his work on the LOC test. They are grateful to Thierry Bodineau and Raphaël Cerf for their remarks on the second-largest cluster in supercritical percolation, and to anonymous referees for helping them improve the presentation of the paper. EAC was partially supported by grants from the National Science Foundation (DMS-06-03890) and the Office of Naval Research (N00014-09-1-0258), as well as a Hellman Fellowship. GRG was partially supported by the Engineering and Physical Sciences Research Council under Grant EP/103372X/1.
References
- [1] {barticle}[mr] \bauthor\bsnmArias-Castro, \bfnmEry\binitsE., \bauthor\bsnmCandès, \bfnmEmmanuel J.\binitsE.J. &\bauthor\bsnmDurand, \bfnmArnaud\binitsA. (\byear2011). \btitleDetection of an anomalous cluster in a network. \bjournalAnn. Statist. \bvolume39 \bpages278–304. \biddoi=10.1214/10-AOS839, issn=0090-5364, mr=2797847 \bptokimsref \endbibitem
- [2] {barticle}[mr] \bauthor\bsnmArias-Castro, \bfnmEry\binitsE., \bauthor\bsnmCandès, \bfnmEmmanuel J.\binitsE.J., \bauthor\bsnmHelgason, \bfnmHannes\binitsH. &\bauthor\bsnmZeitouni, \bfnmOfer\binitsO. (\byear2008). \btitleSearching for a trail of evidence in a maze. \bjournalAnn. Statist. \bvolume36 \bpages1726–1757. \biddoi=10.1214/07-AOS526, issn=0090-5364, mr=2435454 \bptokimsref \endbibitem
- [3] {barticle}[mr] \bauthor\bsnmArias-Castro, \bfnmEry\binitsE., \bauthor\bsnmDonoho, \bfnmDavid L.\binitsD.L. &\bauthor\bsnmHuo, \bfnmXiaoming\binitsX. (\byear2005). \btitleNear-optimal detection of geometric objects by fast multiscale methods. \bjournalIEEE Trans. Inform. Theory \bvolume51 \bpages2402–2425. \biddoi=10.1109/TIT.2005.850056, issn=0018-9448, mr=2246369 \bptokimsref \endbibitem
- [4] {bbook}[mr] \bauthor\bsnmBalakrishnan, \bfnmN.\binitsN. &\bauthor\bsnmKoutras, \bfnmMarkos V.\binitsM.V. (\byear2002). \btitleRuns and Scans with Applications. \bseriesWiley Series in Probability and Statistics. \baddressNew York: \bpublisherWiley-Interscience. \bidmr=1882476 \bptokimsref \endbibitem
- [5] {barticle}[mr] \bauthor\bsnmBodineau, \bfnmT.\binitsT., \bauthor\bsnmIoffe, \bfnmD.\binitsD. &\bauthor\bsnmVelenik, \bfnmY.\binitsY. (\byear2001). \btitleWinterbottom construction for finite range ferromagnetic models: An -approach. \bjournalJ. Stat. Phys. \bvolume105 \bpages93–131. \biddoi=10.1023/A:1012277926007, issn=0022-4715, mr=1861201 \bptokimsref \endbibitem
- [6] {barticle}[mr] \bauthor\bsnmBorgs, \bfnmC.\binitsC., \bauthor\bsnmChayes, \bfnmJ. T.\binitsJ.T., \bauthor\bsnmKesten, \bfnmH.\binitsH. &\bauthor\bsnmSpencer, \bfnmJ.\binitsJ. (\byear2001). \btitleThe birth of the infinite cluster: Finite-size scaling in percolation. \bjournalComm. Math. Phys. \bvolume224 \bpages153–204. \bnoteDedicated to Joel L. Lebowitz. \biddoi=10.1007/s002200100521, issn=0010-3616, mr=1868996 \bptokimsref \endbibitem
- [7] {bbook}[mr] \bauthor\bsnmBrown, \bfnmLawrence D.\binitsL.D. (\byear1986). \btitleFundamentals of Statistical Exponential Families with Applications in Statistical Decision Theory. \bseriesInstitute of Mathematical Statistics Lecture Notes—Monograph Series \bvolume9. \baddressHayward, CA: \bpublisherIMS. \bidmr=0882001 \bptokimsref \endbibitem
- [8] {bbook}[mr] \bauthor\bsnmCerf, \bfnmR.\binitsR. (\byear2006). \btitleThe Wulff Crystal in Ising and Percolation Models. \bseriesLecture Notes in Math. \bvolume1878. \baddressBerlin: \bpublisherSpringer. \bnoteLectures from the 34th Summer School on Probability Theory held in Saint-Flour, July 6–24, 2004, with a foreword by Jean Picard. \bidmr=2241754 \bptokimsref \endbibitem
- [9] {barticle}[mr] \bauthor\bsnmChen, \bfnmJihong\binitsJ. &\bauthor\bsnmHuo, \bfnmXiaoming\binitsX. (\byear2006). \btitleDistribution of the length of the longest significance run on a Bernoulli net and its applications. \bjournalJ. Amer. Statist. Assoc. \bvolume101 \bpages321–331. \biddoi=10.1198/016214505000000574, issn=0162-1459, mr=2268049 \bptokimsref \endbibitem
- [10] {bbook}[mr] \bauthor\bsnmCormen, \bfnmThomas H.\binitsT.H., \bauthor\bsnmLeiserson, \bfnmCharles E.\binitsC.E., \bauthor\bsnmRivest, \bfnmRonald L.\binitsR.L. &\bauthor\bsnmStein, \bfnmClifford\binitsC. (\byear2009). \btitleIntroduction to Algorithms, \bedition3rd ed. \baddressCambridge, MA: \bpublisherMIT Press. \bidmr=2572804 \bptokimsref \endbibitem
- [11] {bmisc}[author] \bauthor\bsnmCsardi, \bfnmG.\binitsG. \btitleThe igraph library. \bhowpublishedAvailable at http://igraph.sourceforge.net. \bptokimsref \endbibitem
- [12] {barticle}[author] \bauthor\bsnmCuller, \bfnmD.\binitsD., \bauthor\bsnmEstrin, \bfnmD.\binitsD. &\bauthor\bsnmSrivastava, \bfnmM.\binitsM. (\byear2004). \btitleOverview of sensor networks. \bjournalIEEE Computer \bvolume37 \bpages41–49. \bptokimsref \endbibitem
- [13] {barticle}[mr] \bauthor\bsnmDasGupta, \bfnmBhaskar\binitsB., \bauthor\bsnmHespanha, \bfnmJoão P.\binitsJ.P., \bauthor\bsnmRiehl, \bfnmJames\binitsJ. &\bauthor\bsnmSontag, \bfnmEduardo\binitsE. (\byear2006). \btitleHoney-pot constrained searching with local sensory information. \bjournalNonlinear Anal. \bvolume65 \bpages1773–1793. \biddoi=10.1016/j.na.2005.10.049, issn=0362-546X, mr=2252129 \bptokimsref \endbibitem
- [14] {bmisc}[author] \bauthor\bsnmDavies, \bfnmP. L.\binitsP.L., \bauthor\bsnmLangovoy, \bfnmM.\binitsM. &\bauthor\bsnmWittich, \bfnmO.\binitsO. (\byear2010). \bhowpublishedDetection of objects in noisy images based on percolation theory. Unpublished manuscript. \bptokimsref \endbibitem
- [15] {bbook}[mr] \bauthor\bsnmDembo, \bfnmAmir\binitsA. &\bauthor\bsnmZeitouni, \bfnmOfer\binitsO. (\byear2010). \btitleLarge Deviations Techniques and Applications. \bseriesStochastic Modelling and Applied Probability \bvolume38. \baddressBerlin: \bpublisherSpringer. \bnoteCorrected reprint of the second (1998) edition. \biddoi=10.1007/978-3-642-03311-7, mr=2571413 \bptokimsref \endbibitem
- [16] {barticle}[mr] \bauthor\bsnmDuczmal, \bfnmLuiz\binitsL. &\bauthor\bsnmAssunção, \bfnmRenato\binitsR. (\byear2004). \btitleA simulated annealing strategy for the detection of arbitrarily shaped spatial clusters. \bjournalComput. Statist. Data Anal. \bvolume45 \bpages269–286. \biddoi=10.1016/S0167-9473(02)00302-X, issn=0167-9473, mr=2045632 \bptokimsref \endbibitem
- [17] {barticle}[mr] \bauthor\bsnmErdős, \bfnmPaul\binitsP. &\bauthor\bsnmRényi, \bfnmAlfréd\binitsA. (\byear1970). \btitleOn a new law of large numbers. \bjournalJ. Analyse Math. \bvolume23 \bpages103–111. \bidissn=0021-7670, mr=0272026 \bptokimsref \endbibitem
- [18] {barticle}[mr] \bauthor\bsnmFalconer, \bfnmK. J.\binitsK.J. &\bauthor\bsnmGrimmett, \bfnmG. R.\binitsG.R. (\byear1992). \btitleOn the geometry of random Cantor sets and fractal percolation. \bjournalJ. Theoret. Probab. \bvolume5 \bpages465–485. \biddoi=10.1007/BF01060430, issn=0894-9840, mr=1176432 \bptokimsref \endbibitem
- [19] {barticle}[author] \bauthor\bsnmFeng, \bfnmXiaomei\binitsX., \bauthor\bsnmDeng, \bfnmYoujin\binitsY. &\bauthor\bsnmBlöte, \bfnmHenk W. J.\binitsH.W.J. (\byear2008). \btitlePercolation transitions in two dimensions. \bjournalPhys. Rev. E \bvolume78 \bpages031136. \bptokimsref \endbibitem
- [20] {barticle}[author] \bauthor\bsnmGeman, \bfnmD.\binitsD. &\bauthor\bsnmJedynak, \bfnmB.\binitsB. (\byear1996). \btitleAn active testing model for tracking roads in satellite images. \bjournalIEEE Trans. Pattern Anal. Mach. Intell. \bvolume18 \bpages1–14. \bptokimsref \endbibitem
- [21] {bbook}[mr] \bauthor\bsnmGrimmett, \bfnmGeoffrey\binitsG. (\byear1999). \btitlePercolation, \bedition2nd ed. \bseriesGrundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences] \bvolume321. \baddressBerlin: \bpublisherSpringer. \bidmr=1707339 \bptokimsref \endbibitem
- [22] {barticle}[mr] \bauthor\bsnmGrimmett, \bfnmG. R.\binitsG.R. (\byear1985). \btitleThe largest components in a random lattice. \bjournalStudia Sci. Math. Hungar. \bvolume20 \bpages325–331. \bidissn=0081-6906, mr=0886037 \bptokimsref \endbibitem
- [23] {barticle}[mr] \bauthor\bsnmHara, \bfnmTakashi\binitsT., \bauthor\bparticlevan der \bsnmHofstad, \bfnmRemco\binitsR. &\bauthor\bsnmSlade, \bfnmGordon\binitsG. (\byear2003). \btitleCritical two-point functions and the lace expansion for spread-out high-dimensional percolation and related models. \bjournalAnn. Probab. \bvolume31 \bpages349–408. \biddoi=10.1214/aop/1046294314, issn=0091-1798, mr=1959796 \bptokimsref \endbibitem
- [24] {barticle}[pbm] \bauthor\bsnmHeffernan, \bfnmRichard\binitsR., \bauthor\bsnmMostashari, \bfnmFarzad\binitsF., \bauthor\bsnmDas, \bfnmDebjani\binitsD., \bauthor\bsnmKarpati, \bfnmAdam\binitsA., \bauthor\bsnmKulldorff, \bfnmMartin\binitsM. &\bauthor\bsnmWeiss, \bfnmDon\binitsD. (\byear2004). \btitleSyndromic surveillance in public health practice, New York City. \bjournalEmerging Infect. Dis. \bvolume10 \bpages858–864. \bidissn=1080-6040, pmid=15200820 \bptokimsref \endbibitem
- [25] {bmisc}[author] \bauthor\bsnmHills, \bfnmR.\binitsR. (\byear2001). \bhowpublishedSensing for danger. Science & Technology Review 11–17. \bptokimsref \endbibitem
- [26] {barticle}[mr] \bauthor\bsnmHobolth, \bfnmAsger\binitsA., \bauthor\bsnmPedersen, \bfnmJan\binitsJ. &\bauthor\bsnmJensen, \bfnmEva B. Vedel\binitsE.B.V. (\byear2002). \btitleA deformable template model, with special reference to elliptical templates. \bjournalJ. Math. Imaging Vision \bvolume17 \bpages131–137. \bnoteSpecial issue on statistics of shapes and textures. \biddoi=10.1023/A:1020681419750, issn=0924-9907, mr=1950865 \bptokimsref \endbibitem
- [27] {barticle}[author] \bauthor\bsnmJain, \bfnmA. K.\binitsA.K., \bauthor\bsnmZhong, \bfnmY.\binitsY. &\bauthor\bsnmDubuisson-Jolly, \bfnmM. P.\binitsM.P. (\byear1998). \btitleDeformable template models: A review. \bjournalSignal Processing \bvolume71 \bpages109–129. \bptokimsref \endbibitem
- [28] {barticle}[mr] \bauthor\bsnmKesten, \bfnmHarry\binitsH. &\bauthor\bsnmZhang, \bfnmYu\binitsY. (\byear1990). \btitleThe probability of a large finite cluster in supercritical Bernoulli percolation. \bjournalAnn. Probab. \bvolume18 \bpages537–555. \bidissn=0091-1798, mr=1055419 \bptokimsref \endbibitem
- [29] {barticle}[mr] \bauthor\bsnmKulldorff, \bfnmMartin\binitsM. (\byear1997). \btitleA spatial scan statistic. \bjournalComm. Statist. Theory Methods \bvolume26 \bpages1481–1496. \biddoi=10.1080/03610929708831995, issn=0361-0926, mr=1456844 \bptokimsref \endbibitem
- [30] {barticle}[mr] \bauthor\bsnmKulldorff, \bfnmMartin\binitsM. (\byear2001). \btitleProspective time periodic geographical disease surveillance using a scan statistic. \bjournalJ. Roy. Statist. Soc. Ser. A \bvolume164 \bpages61–72. \biddoi=10.1111/1467-985X.00186, issn=0964-1998, mr=1819022 \bptokimsref \endbibitem
- [31] {barticle}[mr] \bauthor\bsnmKulldorff, \bfnmMartin\binitsM., \bauthor\bsnmFang, \bfnmZixing\binitsZ. &\bauthor\bsnmWalsh, \bfnmStephen J.\binitsS.J. (\byear2003). \btitleA tree-based scan statistic for database disease surveillance. \bjournalBiometrics \bvolume59 \bpages323–331. \biddoi=10.1111/1541-0420.00039, issn=0006-341X, mr=1987399 \bptokimsref \endbibitem
- [32] {barticle}[mr] \bauthor\bsnmKulldorff, \bfnmMartin\binitsM., \bauthor\bsnmHuang, \bfnmLan\binitsL., \bauthor\bsnmPickle, \bfnmLinda\binitsL. &\bauthor\bsnmDuczmal, \bfnmLuiz\binitsL. (\byear2006). \btitleAn elliptic spatial scan statistic. \bjournalStat. Med. \bvolume25 \bpages3929–3943. \biddoi=10.1002/sim.2490, issn=0277-6715, mr=2297401 \bptokimsref \endbibitem
- [33] {barticle}[pbm] \bauthor\bsnmKulldorff, \bfnmM.\binitsM. &\bauthor\bsnmNagarwalla, \bfnmN.\binitsN. (\byear1995). \btitleSpatial disease clusters: Detection and inference. \bjournalStat. Med. \bvolume14 \bpages799–810. \bidissn=0277-6715, pmid=7644860 \bptokimsref \endbibitem
- [34] {btechreport}[author] \bauthor\bsnmLangovoy, \bfnmM.\binitsM. &\bauthor\bsnmWittich, \bfnmO.\binitsO. (\byear2011). \btitleMultiple testing, uncertainty and realistic pictures. \btypeTechnical report, \binstitutionEURANDOM. \bptokimsref \endbibitem
- [35] {barticle}[author] \bauthor\bsnmLi, \bfnmDan\binitsD., \bauthor\bsnmWong, \bfnmK. D.\binitsK.D., \bauthor\bsnmHu, \bfnmYu Hen\binitsY.H. &\bauthor\bsnmSayeed, \bfnmA. M.\binitsA.M. (\byear2002). \btitleDetection, classification, and tracking of targets. \bjournalSignal Processing Magazine, IEEE \bvolume19 \bpages17–29. \bptokimsref \endbibitem
- [36] {barticle}[pbm] \bauthor\bsnmMcInerney, \bfnmT.\binitsT. &\bauthor\bsnmTerzopoulos, \bfnmD.\binitsD. (\byear1996). \btitleDeformable models in medical image analysis: A survey. \bjournalMed. Image Anal. \bvolume1 \bpages91–108. \bidissn=1361-8415, pii=S1361-8415(96)80007-7, pmid=9873923 \bptokimsref \endbibitem
- [37] {barticle}[mr] \bauthor\bsnmPatil, \bfnmG. P.\binitsG.P., \bauthor\bsnmBalbus, \bfnmJ.\binitsJ., \bauthor\bsnmBiging, \bfnmG.\binitsG., \bauthor\bsnmJaja, \bfnmJ.\binitsJ., \bauthor\bsnmMyers, \bfnmW. L.\binitsW.L. &\bauthor\bsnmTaillie, \bfnmC.\binitsC. (\byear2004). \btitleMultiscale advanced raster map analysis system: Definition, design and development. \bjournalEnviron. Ecol. Stat. \bvolume11 \bpages113–138. \biddoi=10.1023/B:EEST.0000027205.77490.8c, issn=1352-8505, mr=2086391 \bptokimsref \endbibitem
- [38] {barticle}[mr] \bauthor\bsnmPatil, \bfnmG. P.\binitsG.P., \bauthor\bsnmJoshi, \bfnmS. W.\binitsS.W. &\bauthor\bsnmKoli, \bfnmR. E.\binitsR.E. (\byear2010). \btitlePULSE, progressive upper level set scan statistic for geospatial hotspot detection. \bjournalEnviron. Ecol. Stat. \bvolume17 \bpages149–182. \biddoi=10.1007/s10651-010-0140-1, issn=1352-8505, mr=2725778 \bptokimsref \endbibitem
- [39] {barticle}[mr] \bauthor\bsnmPatil, \bfnmG. P.\binitsG.P., \bauthor\bsnmModarres, \bfnmR.\binitsR., \bauthor\bsnmMyers, \bfnmW. L.\binitsW.L. &\bauthor\bsnmPatankar, \bfnmP.\binitsP. (\byear2006). \btitleSpatially constrained clustering and upper level set scan hotspot detection in surveillance geoinformatics. \bjournalEnviron. Ecol. Stat. \bvolume13 \bpages365–377. \biddoi=10.1007/s10651-006-0017-5, issn=1352-8505, mr=2297368 \bptokimsref \endbibitem
- [40] {bunpublished}[author] \bauthor\bsnmPatil, \bfnmG. P.\binitsG.P., \bauthor\bsnmModarres, \bfnmR.\binitsR. &\bauthor\bsnmPatankar, \bfnmP.\binitsP. (\byear2005). \btitleThe ULS software, version 1.0. \bnoteCenter for Statistical Ecology and Environmental Statistics, Dept. Statistics, Pennsylvania State Univ. \bptokimsref \endbibitem
- [41] {barticle}[mr] \bauthor\bsnmPatil, \bfnmG. P.\binitsG.P. &\bauthor\bsnmTaillie, \bfnmC.\binitsC. (\byear2003). \btitleGeographic and network surveillance via scan statistics for critical area detection. \bjournalStatist. Sci. \bvolume18 \bpages457–465. \biddoi=10.1214/ss/1081443229, issn=0883-4237, mr=2109372 \bptokimsref \endbibitem
- [42] {barticle}[mr] \bauthor\bsnmPatil, \bfnmG. P.\binitsG.P. &\bauthor\bsnmTaillie, \bfnmC.\binitsC. (\byear2004). \btitleUpper level set scan statistic for detecting arbitrarily shaped hotspots. \bjournalEnviron. Ecol. Stat. \bvolume11 \bpages183–197. \biddoi=10.1023/B:EEST.0000027208.48919.7e, issn=1352-8505, mr=2086394 \bptokimsref \endbibitem
- [43] {barticle}[mr] \bauthor\bsnmPenrose, \bfnmMathew D.\binitsM.D. (\byear2001). \btitleA central limit theorem with applications to percolation, epidemics and Boolean models. \bjournalAnn. Probab. \bvolume29 \bpages1515–1546. \biddoi=10.1214/aop/1015345760, issn=0091-1798, mr=1880230 \bptokimsref \endbibitem
- [44] {barticle}[mr] \bauthor\bsnmPenrose, \bfnmMathew D.\binitsM.D. &\bauthor\bsnmPisztora, \bfnmAgoston\binitsA. (\byear1996). \btitleLarge deviations for discrete and continuous percolation. \bjournalAdv. in Appl. Probab. \bvolume28 \bpages29–52. \biddoi=10.2307/1427912, issn=0001-8678, mr=1372330 \bptokimsref \endbibitem
- [45] {barticle}[mr] \bauthor\bsnmPerone Pacifico, \bfnmM.\binitsM., \bauthor\bsnmGenovese, \bfnmC.\binitsC., \bauthor\bsnmVerdinelli, \bfnmI.\binitsI. &\bauthor\bsnmWasserman, \bfnmL.\binitsL. (\byear2004). \btitleFalse discovery control for random fields. \bjournalJ. Amer. Statist. Assoc. \bvolume99 \bpages1002–1014. \biddoi=10.1198/0162145000001655, issn=0162-1459, mr=2109490 \bptokimsref \endbibitem
- [46] {barticle}[mr] \bauthor\bsnmPisztora, \bfnmAgoston\binitsA. (\byear1996). \btitleSurface order large deviations for Ising, Potts and percolation models. \bjournalProbab. Theory Related Fields \bvolume104 \bpages427–466. \biddoi=10.1007/BF01198161, issn=0178-8051, mr=1384040 \bptnotecheck year \bptokimsref \endbibitem
- [47] {barticle}[author] \bauthor\bsnmPozo, \bfnmD.\binitsD., \bauthor\bsnmOlmo, \bfnmF. J.\binitsF.J. &\bauthor\bsnmAlados-Arboledas, \bfnmL.\binitsL. (\byear1997). \btitleFire detection and growth monitoring using a multitemporal technique on AVHRR mid-infrared and thermal channels. \bjournalRemote Sensing of Environment \bvolume60 \bpages111–120. \bptokimsref \endbibitem
- [48] {bmisc}[author] \borganizationR Core Team. \bhowpublishedThe R project for statistical computing. Available at http://www.r-project.org. \bptokimsref \endbibitem
- [49] {barticle}[pbm] \bauthor\bsnmRotz, \bfnmLisa D.\binitsL.D. &\bauthor\bsnmHughes, \bfnmJames M.\binitsJ.M. (\byear2004). \btitleAdvances in detecting and responding to threats from bioterrorism and emerging infectious disease. \bjournalNat. Med. \bvolume10 \bpagesS130–S136. \biddoi=10.1038/nm1152, issn=1078-8956, pii=nm1152, pmid=15577931 \bptokimsref \endbibitem
- [50] {barticle}[mr] \bauthor\bsnmSmirnov, \bfnmStanislav\binitsS. &\bauthor\bsnmWerner, \bfnmWendelin\binitsW. (\byear2001). \btitleCritical exponents for two-dimensional percolation. \bjournalMath. Res. Lett. \bvolume8 \bpages729–744. \bidissn=1073-2780, mr=1879816 \bptokimsref \endbibitem
- [51] {barticle}[pbm] \bauthor\bsnmTango, \bfnmToshiro\binitsT. &\bauthor\bsnmTakahashi, \bfnmKunihiko\binitsK. (\byear2005). \btitleA flexibly shaped spatial scan statistic for detecting clusters. \bjournalInt. J. Health Geogr. \bvolume4 \bpages11. \biddoi=10.1186/1476-072X-4-11, issn=1476-072X, pii=1476-072X-4-11, pmcid=1173134, pmid=15904524 \bptokimsref \endbibitem
- [52] {barticle}[mr] \bauthor\bparticlevan der \bsnmHofstad, \bfnmRemco\binitsR. &\bauthor\bsnmRedig, \bfnmFrank\binitsF. (\byear2006). \btitleMaximal clusters in non-critical percolation and related models. \bjournalJ. Stat. Phys. \bvolume122 \bpages671–703. \biddoi=10.1007/s10955-005-8012-z, issn=0022-4715, mr=2213947 \bptokimsref \endbibitem
- [53] {barticle}[pbm] \bauthor\bsnmWagner, \bfnmM. M.\binitsM.M., \bauthor\bsnmTsui, \bfnmF. C.\binitsF.C., \bauthor\bsnmEspino, \bfnmJ. U.\binitsJ.U., \bauthor\bsnmDato, \bfnmV. M.\binitsV.M., \bauthor\bsnmSittig, \bfnmD. F.\binitsD.F., \bauthor\bsnmCaruana, \bfnmR. A.\binitsR.A., \bauthor\bsnmMcGinnis, \bfnmL. F.\binitsL.F., \bauthor\bsnmDeerfield, \bfnmD. W.\binitsD.W., \bauthor\bsnmDruzdzel, \bfnmM. J.\binitsM.J. &\bauthor\bsnmFridsma, \bfnmD. B.\binitsD.B. (\byear2001). \btitleThe emerging science of very early detection of disease outbreaks. \bjournalJ. Public Health Manag. Pract. \bvolume7 \bpages51–59. \bidissn=1078-4659, pmid=11710168 \bptokimsref \endbibitem
- [54] {barticle}[mr] \bauthor\bsnmWalther, \bfnmGuenther\binitsG. (\byear2010). \btitleOptimal and fast detection of spatial clusters with scan statistics. \bjournalAnn. Statist. \bvolume38 \bpages1010–1033. \biddoi=10.1214/09-AOS732, issn=0090-5364, mr=2604703 \bptokimsref \endbibitem