CMLFormer: A Dual Decoder Transformer with Switching Point Learning for Code-Mixed Language Modeling
Abstract
Code-mixed languages, characterized by frequent within-sentence language transitions, present structural challenges that standard language models fail to address. In this work, we propose CMLFormer, an enhanced multi-layer dual-decoder Transformer with a shared encoder and synchronized decoder cross-attention, designed to model the linguistic and semantic dynamics of code-mixed text. CMLFormer is pre-trained on an augmented Hinglish corpus with switching point and translation annotations with multiple new objectives specifically aimed at capturing switching behavior, cross-lingual structure, and code-mixing complexity. Our experiments show that CMLFormer improves F1 score, precision, and accuracy over other approaches on the HASOC-2021 benchmark under selected pre-training setups. Attention analyses further show that it can identify and attend to switching points, validating its sensitivity to code-mixed structure. These results demonstrate the effectiveness of CMLFormer’s architecture and multi-task pre-training strategy for modeling code-mixed languages.
1 Introduction
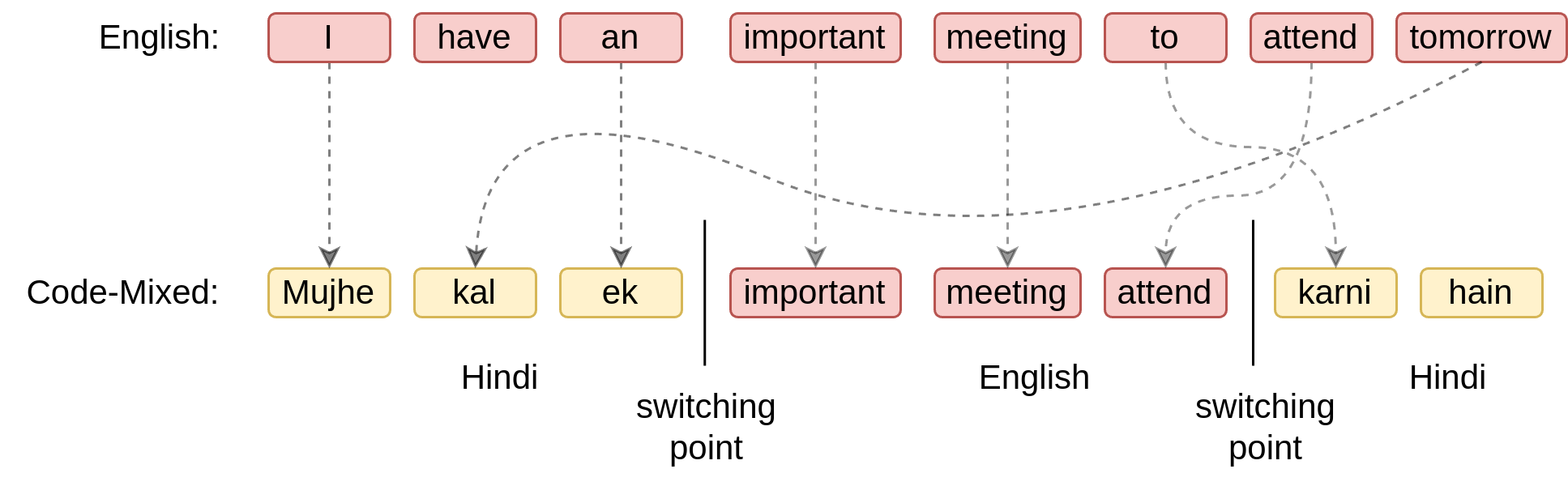
Globalization and cultural adaptation have fostered the growth of multilingualism in the modern world. This has led to a widespread phenomenon of code-mixing (CM), where multiple languages are juxtaposed within a single utterance, with the transition points being known as switching points (SP). In multilingual countries like India, the fusion of Hindi and English (popularly termed Hinglish) has become increasingly prevalent in conversational usage both online and offline. In code-mixed languages, the base language provides the grammatical structure, while the mixing language contributes loan words or phrases. For example, for the CM sentence , Hindi serves as the base language, while the words important, meeting, and attend from English are mixed in.
As Large Language Models (LLMs) become increasingly integrated into our daily lives, recent years have seen the development of multiple LLMs for a range of diverse languages, including high-resource ones such as English Anil et al. (2024) and French Faysse et al. (2024). Despite the steady increase in CM speakers, most LLMs still fail to serve CM needs Srivastava (2025); Venkatesh et al. (2024). This is evidenced by the subpar performance on real-world tasks requiring encoder-only models, such as classification, semantic search and information retrieval. Their limitations can be traced back to their inadequate and poor neural representations of these languages Mazumder et al. (2024); Jagdale et al. (2024). The unique linguistic structure of CM languages makes it a challenge to represent them effectively, limiting their efficacy in multilingual contexts.
Addressing these limitations requires a richer modeling of CM structure, particularly the role of switching points in transitional contexts. Since prior studies suggest that current pre-training approaches are insufficient to model CM languages, we propose CMLFormer, a novel dual-decoder Transformer architecture with switching point learning, specifically for code-mixed language modeling. Additionally, we introduce new supervised and unsupervised pre-training objectives such as Switching Point Prediction and Bilingual Language Translation Modeling to learn richer representations of CM languages and encourage cross-lingual learning and alignment.
The main contributions of this work are summarized as follows,
-
•
An enhanced multi-layer Transformer with a shared encoder and synchronized coupling between of two decoders for CM language modeling.
-
•
Multiple new pre-training objectives to capture syntactic and semantic dynamics of language transitions in CM text.
-
•
Augmentation of the L3Cube-HingCorpus dataset with labels for switching points and translations of CM sentences.
-
•
Extrinsic and intrinsic evaluation of our work against baseline models on recognised CM classification benchmarks.
2 Related Work
Previous approaches have used multilingual models to bridge the gap between the languages in a CM language. However, studies have shown that CM languages being inherently multilingual cannot be effectively modeled by multilingual models since they are not natural code-mixers Zhang et al. (2023) of monolingual languages. The lack of formal grammar, frequent occurrence of switching points, spelling variants and contextual nuances are some of the problems posed by CM languages. Additionally, models pre-trained on CM data have surprisingly shown inadequate improvements over multilingual models despite increasing the number of parameters Patil et al. (2023); Santy et al. (2021). Since scaling up both data and parameters has only yielded marginal improvements, recent studies have moved away from the former and established the necessity of specialised pre-training techniques for CM languages.
Li and Murray (2022) introduce a language-agnostic approach that shows that masking the loan words from a CM sequence allows multilingual models to generalize better to downstream tasks. The effectiveness of cross-lingual representations using approaches like Translation Language Modeling Lample and Conneau (2019) has also been extensively studied in MuRIL Khanuja et al. (2021) and IndicBERT Doddapaneni et al. (2023), both of which demonstrate significant improvements over multilingual BERT Devlin et al. (2019) on Indian languages. However, these approaches still failed to sufficiently capture the linguistic nuances of CM text. Moving towards architectural modifications, Sengupta et al. (2021) introduce a Hierarchical Transformer with a new outer-product attention mechanism to effectively capture the syntactic and structural characteristics of CM sentences. Ali et al. (2021) was one of the first to introduce a new positional encoding approach that assigned weights to words near switching points, enabling the model to capture language transitions in a CM sentence better. Building upon this, Ali et al. (2023) introduce an improved switching point based rotary matrix by combining it with rotatory positional encodings Su et al. (2023), which rotate at switching points to denote language transitions.
3 CMLFormer
This section introduces our proposed model, the CMLFormer, and includes details about the architecture, pre-training tasks, data, and other details.
3.1 Problem Definition
We formally represent a sequence of tokens in the CM language as , a sequence of translated tokens in the base language as , and a sequence of translated tokens in the mixing language as . We also define the set of language labels with and language transitions with a bit vector , where is a 0-1 bit that indicates a language transition before token , that is, if , and otherwise. The vector always starts with a at the beginning since there is no transition on the first token.
For example, for an input CM sentence : , we denote the language labels and transitions . The input to CMLFormer’s encoder is the sequence , with and being passed to the base and mixing language decoder, respectively.
3.2 Architecture
We build the backbone of the CMLFormer (Fig. 2) using an enhanced multi-layer Transformer Vaswani et al. (2017) with both the encoder and decoder layers. We propose two significant modifications to the vanilla Transformer architecture. First, we explore a novel multi-target pre-training setup where two fully synchronous decoders sharing the same encoder are coupled through an attention layer. Considering the usually significant syntactical and semantic differences between the base and mixing language, this allows the model to decouple the two languages and handle their specific nuances effectively while still learning cross-lingual representations. We further explore two variations of this enhancement through our ablations (Appendix A.2).
Second, to help the architecture capture language transitions and learn richer representations of code-mixed inputs, we introduce additional pre-training objectives focused on code-mixing that teach the encoder to recognize where and how language transitions occur within a sentence. These tasks are built directly into the model through auxiliary prediction layers on top of the encoder, allowing it to learn not just from the main language modeling and translation tasks, but also from signals about language identity, switching points, and mixing patterns, enabling the encoder to learn richer representations of the structure of code-mixed text during training.
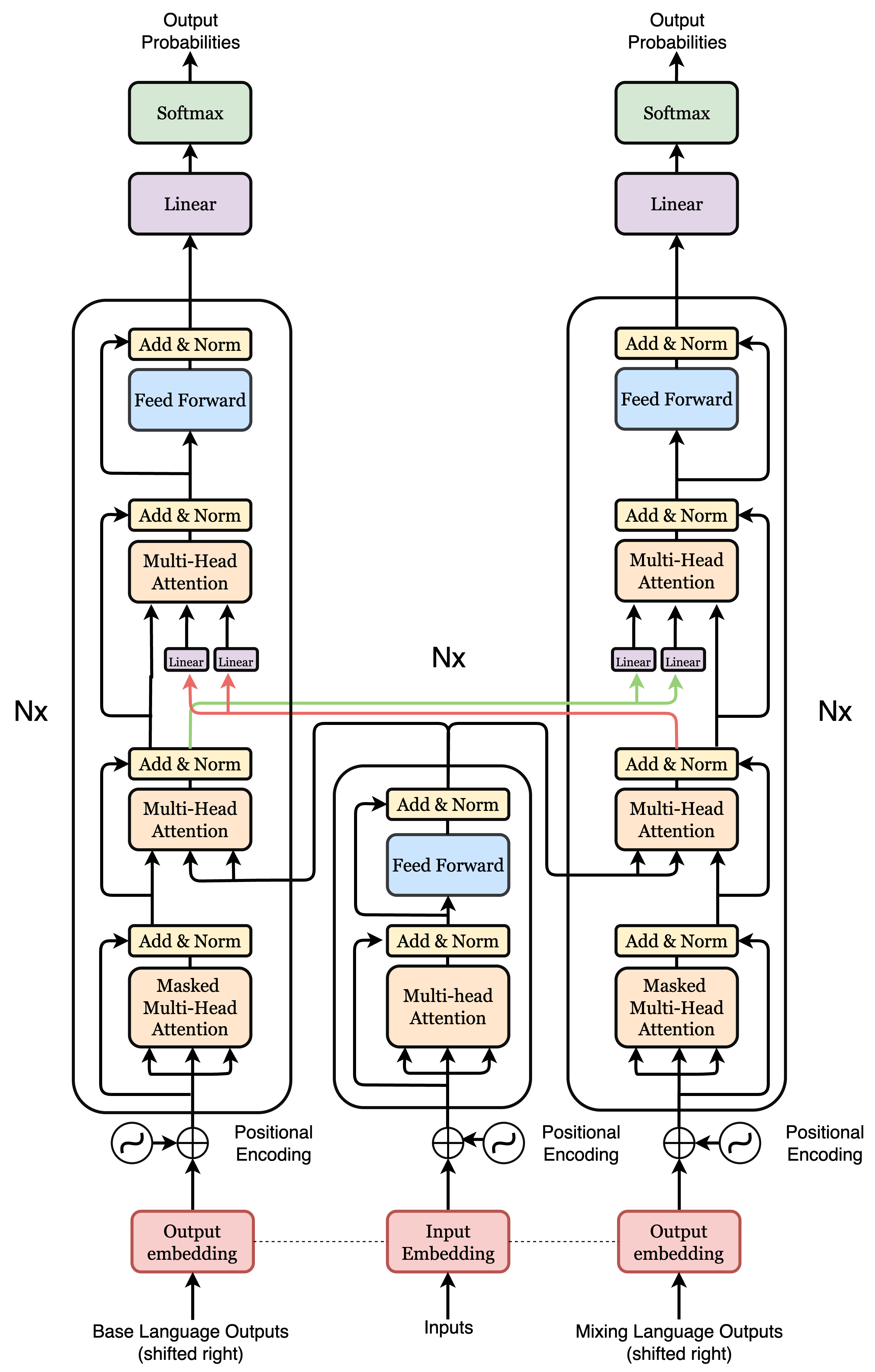
3.2.1 Dual Decoder with Cross Attention
We introduce a synchronous coupling of two decoders with the same shared encoder. In contrast to the vanilla Transformer architecture, we add a third attention layer to introduce inter-decoder cross-attention in each decoder block to mutually share the latent characteristics of each constituent language. Denoting the output hidden states from layer normalization after the encoder-decoder attention sub-layer of the base and mixing language decoder as and respectively, the decoder-decoder cross-attention is computed as,
| (1) |
The corresponding output attention scores and are then passed as input to the feed-forward and layer normalization sub-layers as in the vanilla Transformer. This allows each decoder to attend to and "peek" at the other decoder’s hidden states while decoding the input CM sentence into their corresponding language, helping it capture inter-block interactions and driving cross-lingual learning and alignment. The two decoders are thus fully synchronized as each requires the hidden states of the other in each block to compute its own.
3.3 Cross-Decoder Linear Projections
To facilitate effective cross-attention between the base and mixing decoders, we introduce cross-decoder linear projections. Before applying decoder-decoder cross-attention, each decoder’s hidden states are linearly projected into the latent space of the other decoder. This allows the base decoder to attend to representations expressed in the mixing decoder’s feature space, and vice versa. By adapting the representations across decoders, the projections account for structural and semantic asymmetries between the two languages, enabling more coherent cross-lingual interaction during decoding.
3.4 Pre-Training Tasks
CMLFormer is expected to learn rich representations of the CM language, including cross-lingual representations for the base and mixing language, and the relationship between tokens at switching points. To achieve this, we introduce multiple supervised and unsupervised pre-training tasks to learn rich contextual representations.
3.4.1 Masked Language Modeling
We incorporate the widely used Masked Language Modeling Devlin et al. (2019) task as the base pre-training objective. Masked Language Modelling (MLM) was first introduced in BERT to mitigate the problem of traditional bidirectional language modelling, allowing the model to "see" the tokens being predicted. Given a token sequence , a subset of tokens are randomly sampled denoted by , typically 15% of which 80% are replaced by token, 10% are replaced by a random token, and 10% remain unchanged. The objective of MLM is to predict the masked tokens by using the surrounding unmasked tokens in the input sequence as context. We pre-train on the MLM objective using all three , and language sequences and average over the three cross-entropy losses , and .
3.4.2 Bilingual Translated Sentence Prediction
The multilingual setting of CM languages enables concepts to be represented by words from the base or mixing languages. It is necessary to model cross-lingual relationships between these word variants by learning rich contextual representations of the CM, base and mixing languages. We propose a new Bilingual Translated Sentence Prediction (BTSP) objective to capture these cross-lingual relationships. Given a CM token sequence , we randomly sample another token sequence with 50% positive examples (25% of the time is , 25% of the time it is ) and 50% negative examples (25% of the time it is a randomly selected sequence and the remaining 25% of the time it is a randomly selected sequence from the dataset). The objective of BTSP, formulated using binary cross-entropy as , is to predict whether sequence is equivalent to the sampled sequence .
3.4.3 Bilingual Language Translation Modeling
To capture the inherent multilingual characteristics of CM languages, it is crucial to not only learn rich contextual representations for the CM, base and mixing languages but also model a three-way alignment among them. Given a CM token sequence , and its corresponding translations in the base and mixing language translations and respectively, we introduce a multi-target Bilingual Language Translation (BiLTM) objective. The base and mixed language decoders are tasked to simultaneously generate translations of the CM sequence into its equivalent base language and mixing language forms and , respectively. The objective of BiLTM can be formulated as the average over the autoregressive modeling losses and for each decoder.
3.4.4 Token Language Classification
Code-mixing enables words to be shared from its constituent languages, also known as lexical borrowing. These loan words can thus occur within the context of a base or mixing language sentence, with each having a different syntactic and lexical structure within its local language’s context. CM representations must capture this phenomenon to effectively represent the mixing of two languages and thus, be able to identify the language in which a word occurs from a given local context window.
We propose a Token Language Classification (TLC) objective using binary cross-entropy to predict the language in which each token occurs from its given local context. We construct a concatenated sequence comprising , and in a randomly shuffled order. This concatenation allows loan words to concurrently occur in two out of the three segments of . Consequently, the model must rely solely on local context while predicting, enabling it to learn the usage of loan words across different languages and linguistic structures.
3.4.5 Switching Point Prediction
Switching points mark the locations where a language transition occurs between consecutive tokens in a code-mixed sequence. Modeling these transitions explicitly allows the encoder to capture the structural dynamics of language alternation, which are often critical to understanding the syntactic and semantic properties of code-mixed text.
Given a code-mixed sequence and a corresponding switching point label sequence , where if a switch occurs between and and otherwise, the task is to predict the probability of a switch occurring at each token position. We treat the SPP objective as a token-level binary classification task, where the loss is computed using binary cross-entropy between the predicted switching probabilities and the ground truth labels .
3.4.6 Code-Mixing Index Prediction
The Code Mixing Index (CMI) is a commonly used metric that quantifies the degree of code-mixing in a sentence by measuring the relative proportion of tokens across its constituent languages Das and Gambäck (2014). Given a sequence of tokens, with switching points and tokens from the base language, we adapt the CMI formulation for our objective as,
| (2) |
where and are weighting factors. This extension balances the contribution of language distribution and the frequency of transitions in the code-mixed sentence.
To encourage the encoder to model these sentence-level code-mixing dynamics, we introduce CMI Prediction as a regression objective. The encoder is tasked with predicting a scalar for each input sequence , with the ground truth computed directly from the labels, which is then optimized using Mean Squared Error (MSE). This task complements local objectives such as Switching Point Prediction and Token Language Classification by providing a global signal for code-mixing complexity, capturing both global mixing and local switching behavior.
3.4.7 Overall Loss Objective
CMLFormer is jointly trained on all the above pre-training objectives to minimise the overall training loss . This can be formulated as,
| (3) |
where , , , , , and are scaling constants.
3.5 Datasets
3.5.1 Pre-training
CMLFormer is pre-trained on the L3Cube-HingCorpus Nayak and Joshi (2022), a large-scale Hindi-English code-mixed corpus in Roman script. It comprises 52.93M111Due to computational limitations and time constraints, it was not possible to augment and pre-train on all 52.3M sentences. Instead, we sampled 10,000 sentences for pre-training. sentences and 1.04B tokens from Twitter and reflects real-world code-mixing patterns. To support our auxiliary pre-training objectives, we augment the dataset by generating parallel translations of code-mixed Hinglish sentences into pure Hindi and English in Roman script and annotate each code-mixed sentence with its corresponding switching points. More details about the data augmentation can be found in Appendix A.1.
3.5.2 Fine-tuning and Evaluation
CMLFormer is evaluated on downstream tasks by detaching the decoders and fine-tuning just the encoder on an established Hinglish CM language classification benchmark, the HASOC 2021 Mandl et al. (2021) dataset for hate speech detection. It comprises 7,000 code-mixed Hinglish tweets distributed across 5,740 train and 1,348 test examples. We compare its performance against HingBERT, a code-mixed model for Hinglish with MLM as its only pre-training objective.222We pre-trained on our sample of the dataset to produce a comparable HingBERT to benchmark against.
4 Pre-training 333For our base model, we restricted the encoder size to match , which can be found in Table 2. This ensures that the number of parameters in the encoder remains consistent with the BERT-based model we will benchmark against.
4.1 Training a Tokenizer
To support our pre-training objectives, we trained a custom WordPiece tokenizer using the combined augmented dataset, i.e, parallel sequences in code-mixed Hinglish, base Hindi, and mixing English. Rather than training separate tokenizers for each language, we use a single tokenizer with a shared vocabulary across all three. This design choice ensures consistent subword segmentation across the languages and simplifies the overall architecture. Our trained tokenizer can be found on HuggingFace555https://huggingface.co/cmlformer/L3Cube-HingCorpus10K.
4.2 Multi-task Pre-training and Optimization
We pre-train CMLFormer with all pre-training objectives jointly enabled, allowing the encoder to optimize across multiple linguistic and structural tasks simultaneously. During training, we monitor the loss behavior of each objective individually to ensure stable multi-task optimization. The full model configuration and pre-training hyperparameters are provided in Appendix A.4.
5 Fine-tuning
During fine-tuning, we detach the dual decoders and attach a task-specific classification head to the encoder. We perform full fine-tuning, i.e, both the encoder and classification head parameters are updated jointly666We repeat the same for the model pre-trained on our dataset. Our fine-tuning hyperparameters are provided in Appendix A.7. CMLFormer’s implementation with its pre-training and fine-tuning scripts can be found here777https://github.com/cmlformer/cmlformer.
6 Results
| Model | MLM | BiLTM | SPP | BTSP | TLC | CMI | Precision | Recall | Accuracy | F1 | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 0.189 | – | 0.367 | – | 0.496 | – | 0.249 | – | ||||||
| ✓ | ✓ | 0.327 | 0.633 | 0.504 | 0.431 | |||||||||
| ✓ | ✓ | ✓ | 0.223 | 0.433 | 0.498 | 0.295 | ||||||||
| ✓ | ✓ | ✓ | ✓ | 0.086 | 0.167 | 0.490 | 0.113 | |||||||
| ✓ | ✓ | ✓ | ✓ | ✓ | 0.120 | 0.233 | 0.492 | 0.159 | ||||||
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 0.155 | 0.300 | 0.494 | 0.204 |
6.1 Pre-training
6.1.1 Complexity of Pre-training Tasks and Role of Encoder
Pre-training Complexity. We observe that CMLFormer converges quickly on most tasks before reaching a long stagnating tail. The lack of improvement beyond the first epoch could be attributed to the large number of pre-training objectives, increasing the complexity of the overall pre-training stage. The small size of the pre-training dataset also contributes to a lack of robust generalization across training examples.
We observe a steady decrease in the decoder-based losses and before stagnating while the encoder-based losses , and do not show much convergence before stagnating. This could hint towards the higher overall complexity of the encoder-based objectives compared to decoder-based ones. Additionally, the encoder is responsible for not only generalizing well to its own tasks but also learning rich representations that aid the decoder in autoregressively generating sequences.
Encoder Optimization. Since the encoder is optimized for multiple training objectives, it bears a heavier representational burden and faces a greater optimization challenge than each decoder, which is trained for a single task. Consequently, the encoder’s loss exhibits slower convergence during training. Due to its involvement in multiple training objectives, the base variant’s encoder might not be robust enough and could benefit from a larger model with a higher number of parameters. We will explore this in our future experiments, where we restrict our encoder to match the parameters in while retaining the same size of the decoder.
6.2 Fine-tuning
Our fine-tuning results (Table 1) show the efficacy of our auxiliary CM-focused pre-training objectives on a downstream classification task. We observe that additional pre-training tasks such as Bilingual Translation Language Modeling and Switching Point Prediction significantly outperform the model pre-trained on the same dataset with an improvement of 0.18 and 0.05 on the F1 metric, respectively. This enforces our hypothesis that learning cross-lingual aligned representations of the constituent languages and understanding the structural dynamics of switching points helps CMLFormer model code-mixed inputs more effectively than other approaches.
However, contrary to our intuition, we see that further adding other pre-training objectives like BTSP, TLC and CMI degrade the overall performance of the model. This decline may be attributed to conflicting learning signals introduced by these additional objectives during pre-training, which could make optimization harder and reduce the model’s ability to generalize effectively. We hypothesize that increasing the size of the encoder to handle the representational burden from the large number of pre-training tasks, along with pre-training on a larger dataset to generalize to more code-mixed texts, could help the model perform better on downstream tasks.
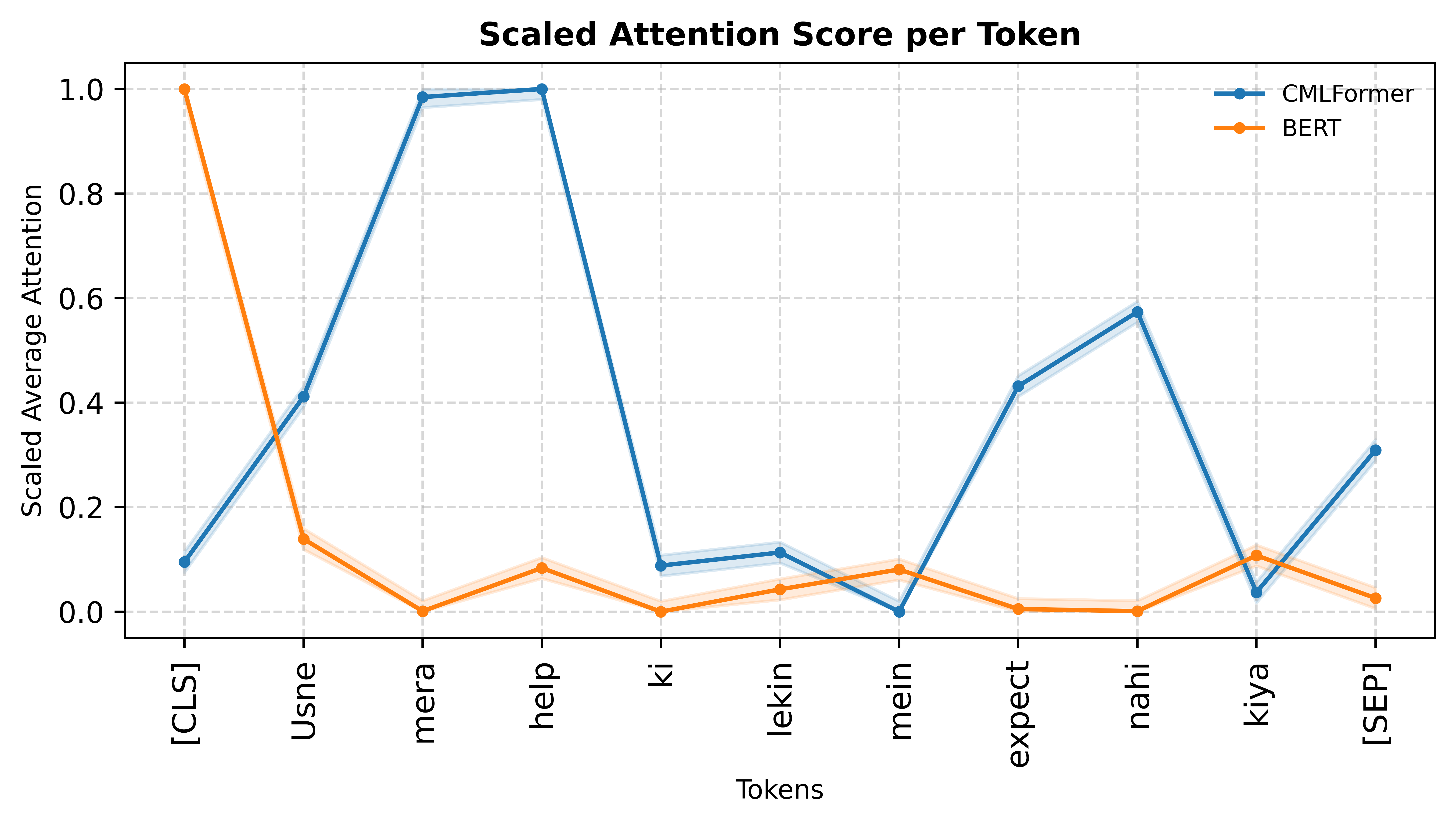
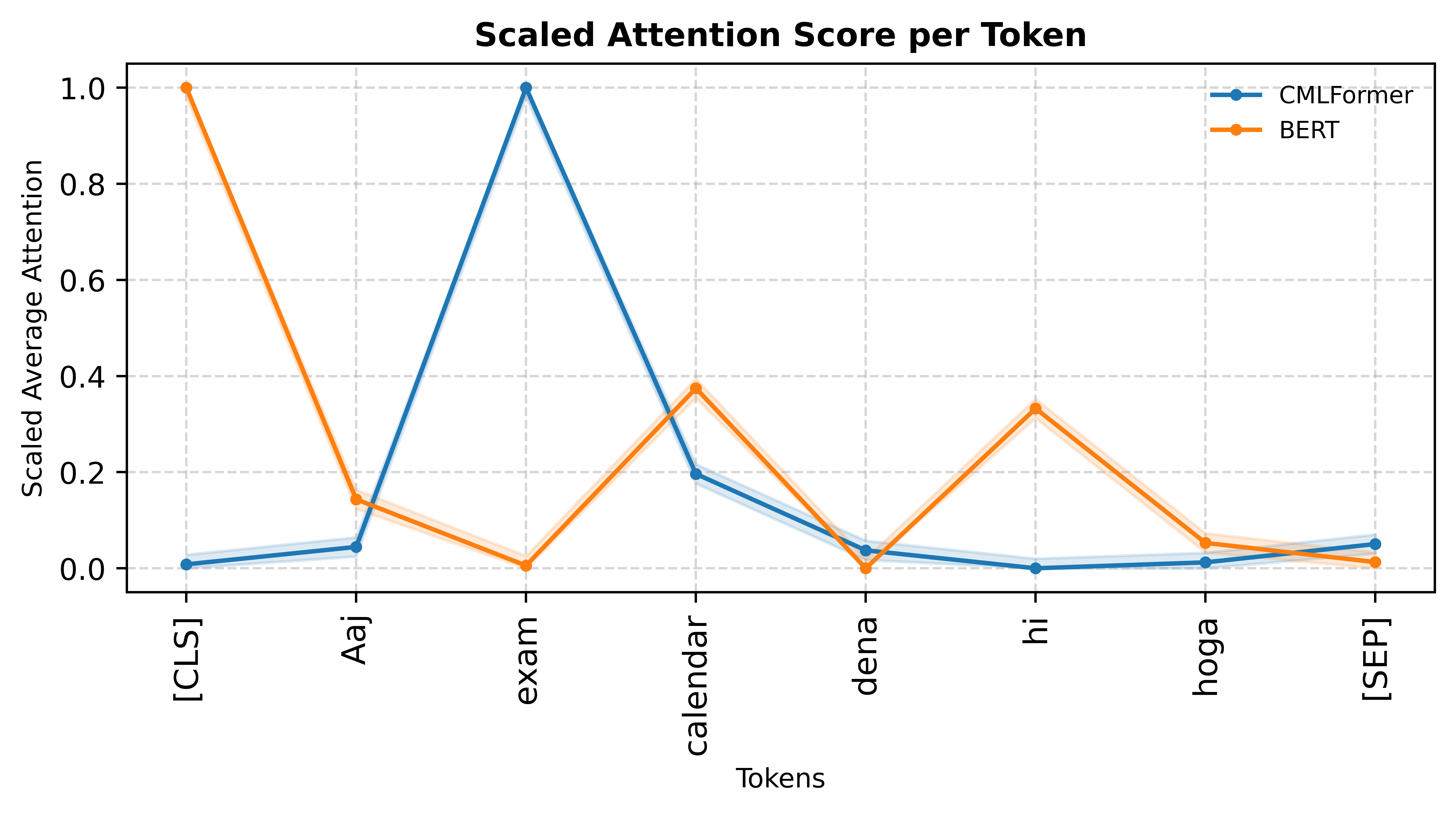
6.3 Learning Switching Point Dynamics
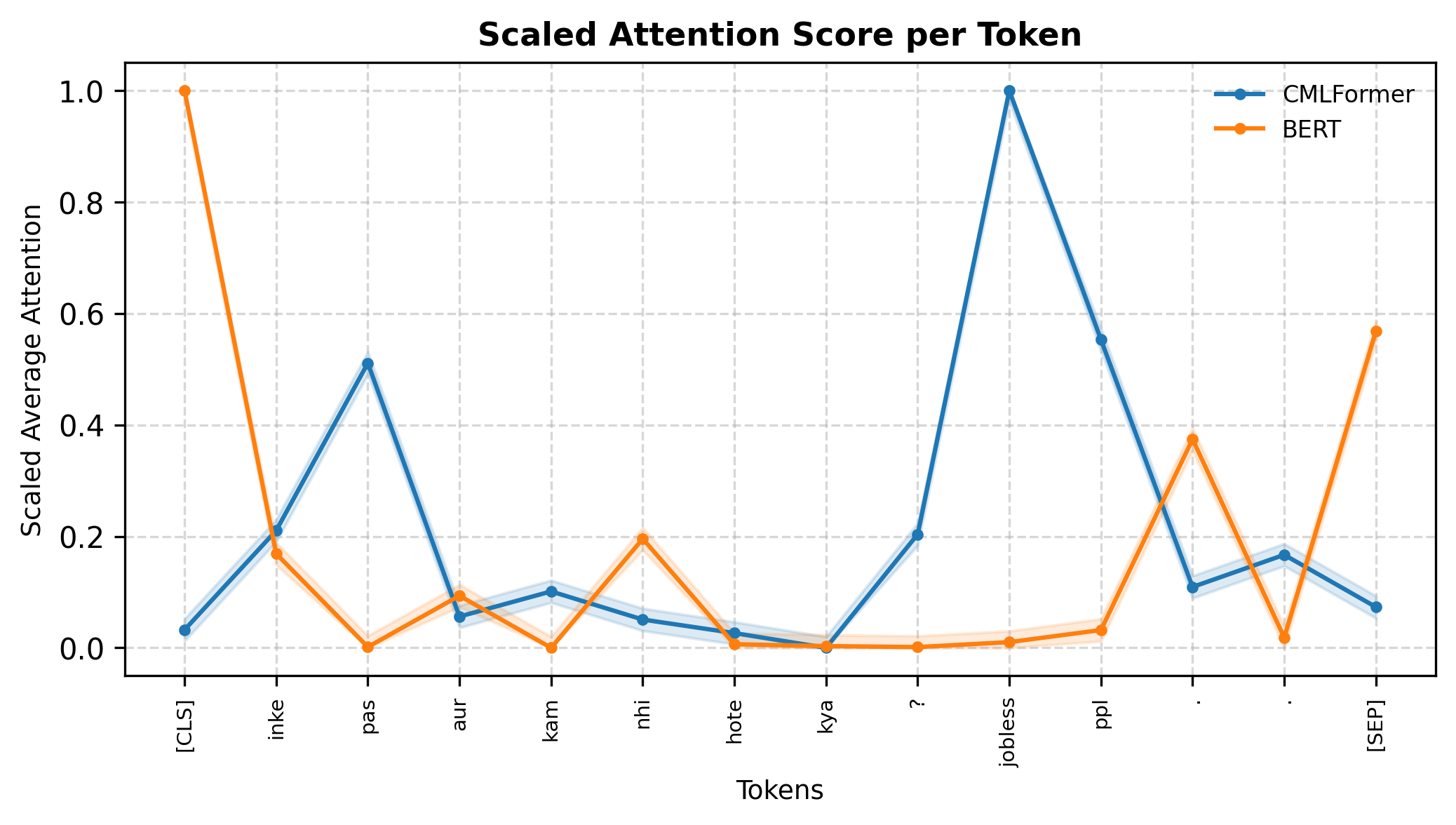
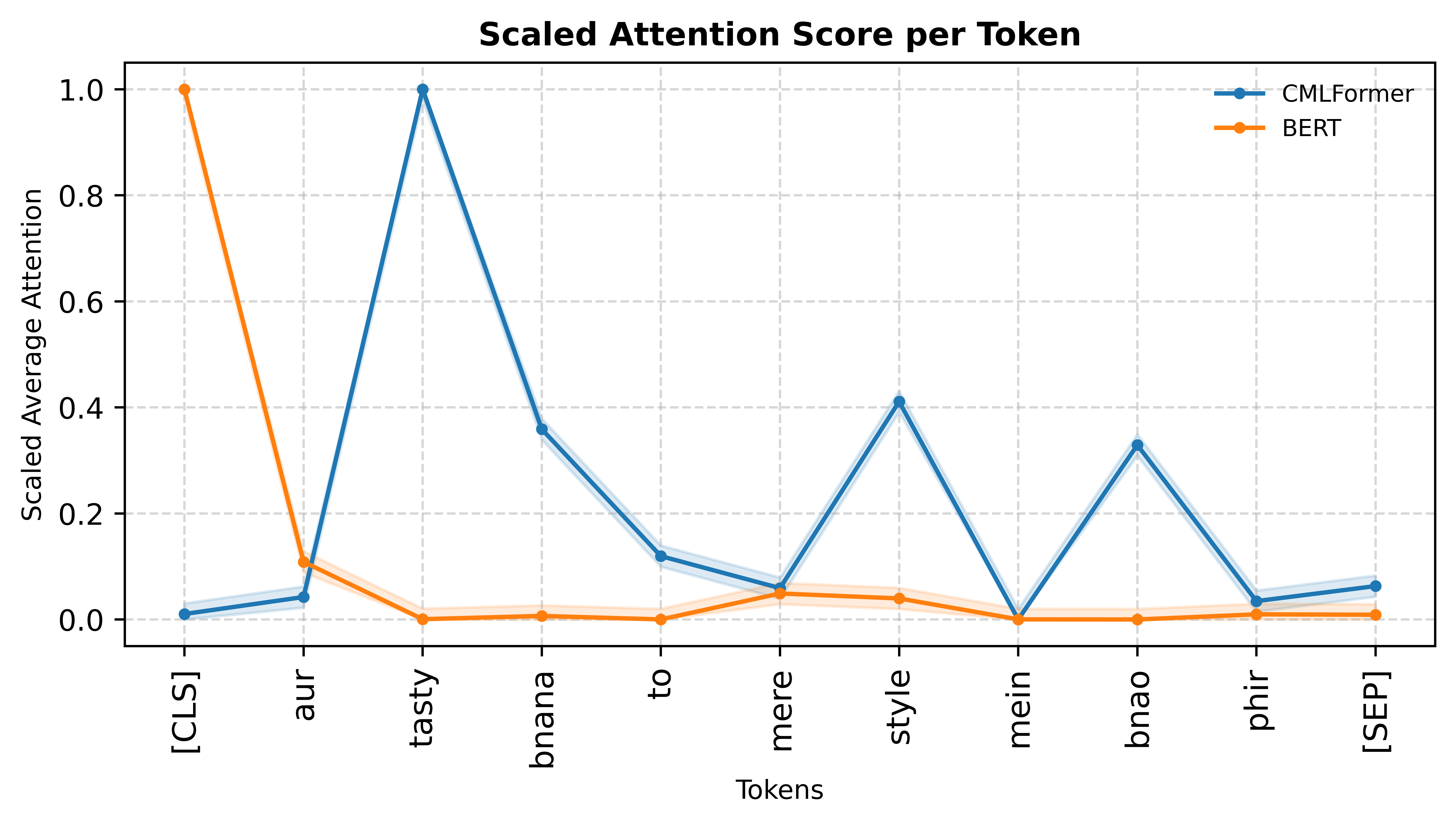
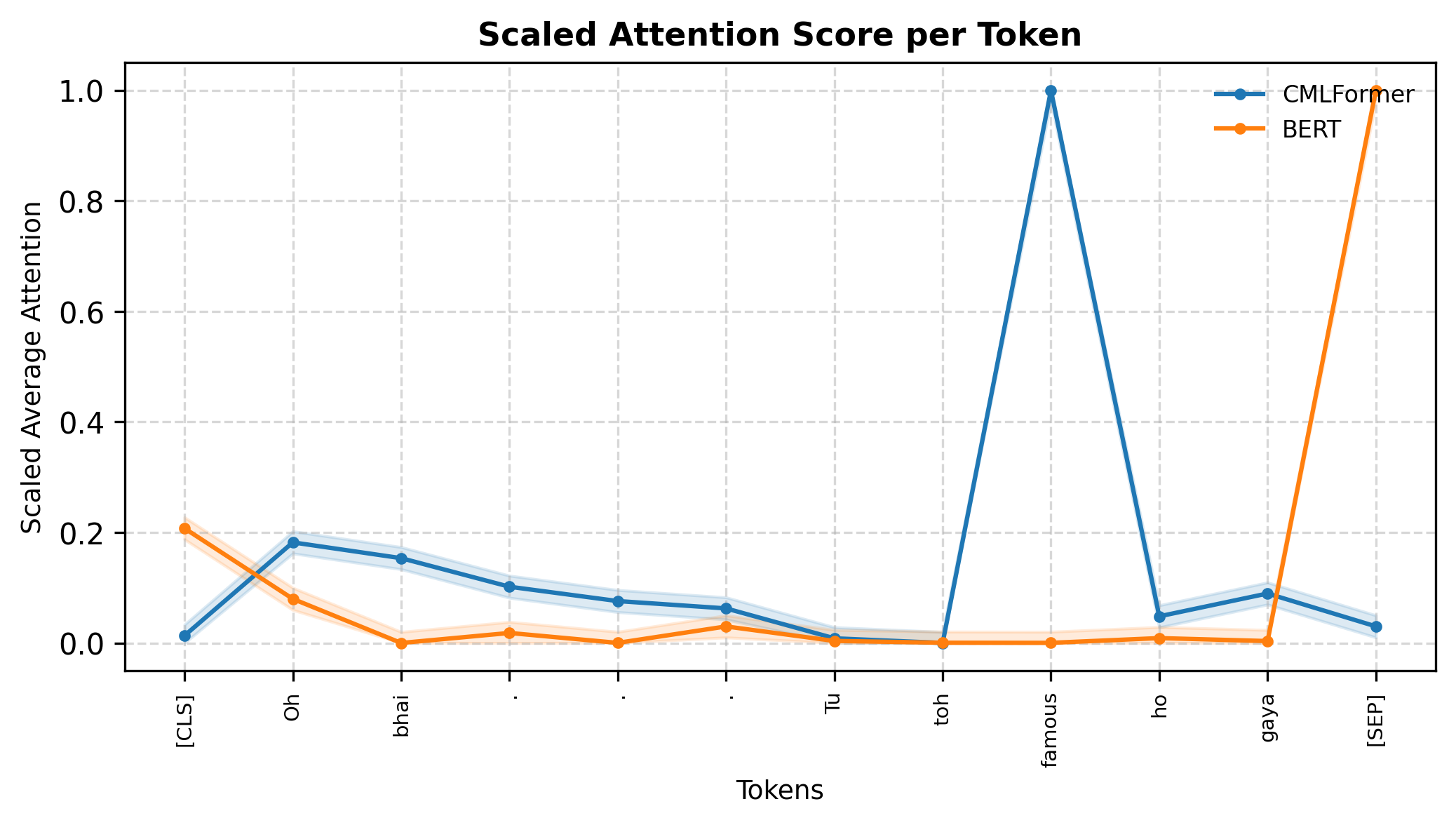
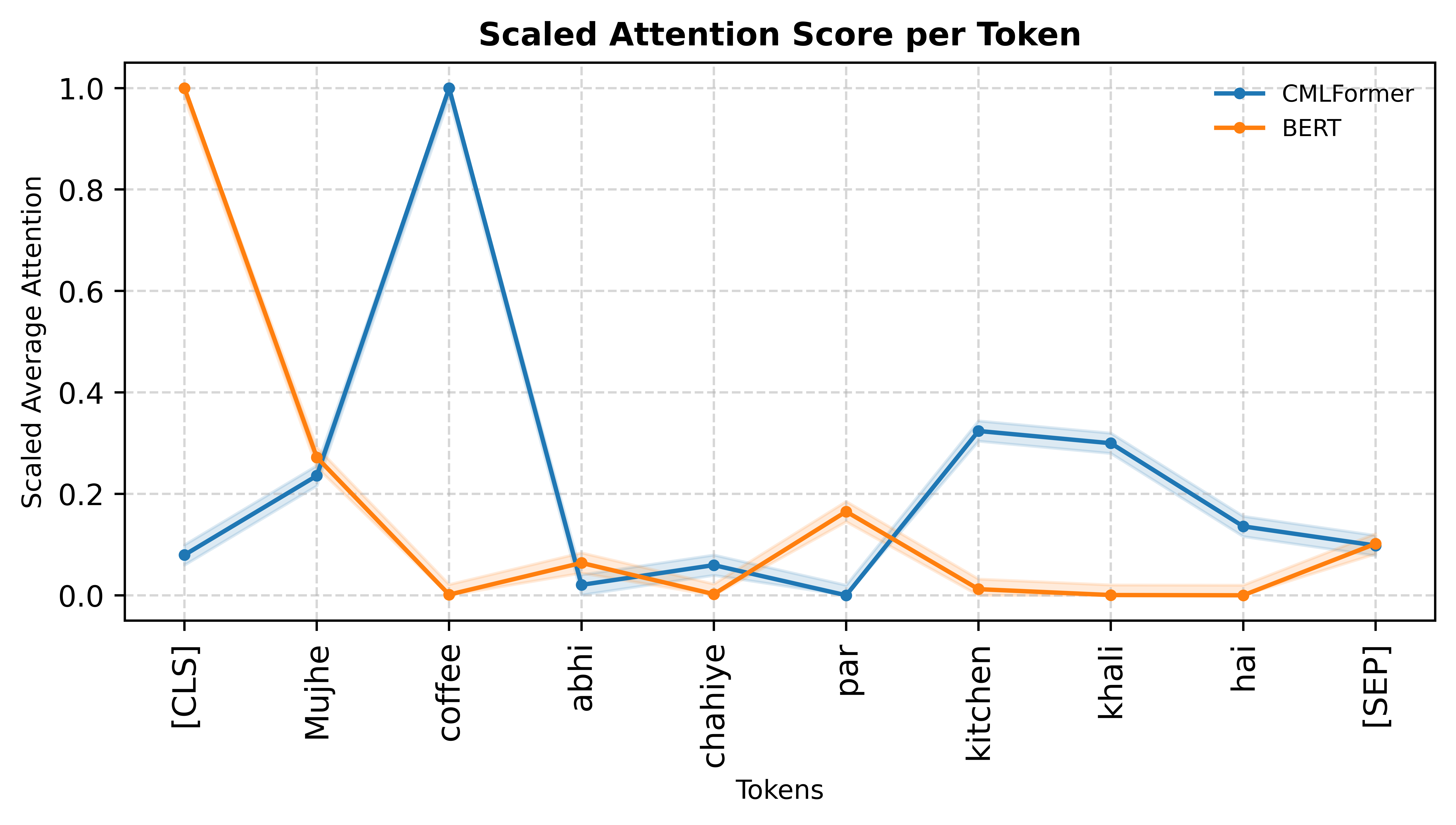
We visualize attention scores generated by CMLFormer on different code-mixed examples to understand the model’s focus on switching points and language transitions. Selected examples are shown in Figure 3, with additional visualizations provided in Appendix A.8. We plot the scaled average attention score per token from CMLFormer’s encoder’s first self-attention layer and compare the corresponding scores from BERT. Choosing the first attention head and the early layers allows us to investigate the sensitivity of each model to local linguistic patterns, like language transitions at switching points.
Our results show that CMLFormer far exceeds ’s capability at identifying switching points in code-mixed inputs. Our switching point focused pre-training objectives enable it to consistently attend to language transitions, giving it significantly higher weights compared to other tokens. We also observe that CMLFormer is agnostic to the number as well as the nature of switching points (base-to-mix or mix-to-base), being confidently able to scale up attention around these tokens while BERT fails to identify any kind of switching point in the input.
These results reinforce that by explicitly modeling switching behavior, our model can learn to internalize patterns that traditional models like BERT overlook. The consistency of attention alignment around transition points, regardless of directionality or position, highlights both the effectiveness of the multi-task objectives and the representational advantages of CMLFormer’s design.
7 Limitations
Despite the architectural innovations introduced by CMLFormer, our current work is subject to several limitations. The primary constraint was the size of the pre-training dataset; due to computational resource and time restrictions, we were only able to pre-train on a small subset of 10,000 augmented samples from the L3Cube-HingCorpus. The limited data availability invites concerns of overfitted pre-training, potentially leading to a substantial loss of robust generalization abilities in CMLFormer. This likely led to an imbalance where the downstream evaluation dataset (HASOC 2021, with over 5,000 examples) could overpower the learned representations, potentially resulting in overfitting to the evaluation task, rather than specializing from pre-training.
Additionally, while our architecture employs a dual-decoder setup with a shared encoder, the encoder in this work was relatively underparameterized compared to the size of the dual decoders and the complexity of the pre-training tasks. This mismatch may have restricted the encoder’s capacity to fully leverage the multi-task supervision and handle the representational burden required for effective cross-lingual alignment. We hypothesize that for effective multi-task learning involving a shared encoder and multiple decoders, the size of the encoder must be approximately times the size of each decoder.
8 Future Work
In our future work, we plan to pre-train CMLFormer on the full L3Cube-HingCorpus dataset with 52.9M sentences, along with higher-quality augmentations. Scaling up the dataset would provide more diverse switching patterns and lexical variations, improving the model’s ability to generalize. We will also integrate Rotary Positional Encodings that can explicitly incorporate switching point information into token representations. This enhancement could allow the model to structurally internalize language transitions, providing stronger inductive bias toward code-mixed syntactic patterns. Future work will also explore scaling up the encoder’s parameter count to match the dual decoders. Given that the encoder bears the majority of the representational and optimization load across multiple objectives, an asymmetric architecture with a larger encoder could significantly improve learning stability and downstream performance.
9 Conclusion
In this work, we introduce CMLFormer, an enhanced dual–decoder Transformer that explicitly targets the linguistic structure of code–mixed text. We also introduce new pre-training objectives with a focused set of supervised and unsupervised tasks targeted at code-mixed language modeling - Masked Language Modeling (MLM), Bilingual Language Translation Modeling (BiLTM), Switching Point Prediction (SPP), Bilingual Translated Sentence Prediction (BTSP), Token Language Classification (TLC) and Code–Mix Index Regression (CMI). Through a combination of pre-training tasks, we aim to learn rich contextualized representations of code-mixing that are sensitive to both cross-lingual semantics and local language transitions.
CMLFormer outperforms known baselines like BERTbase on the HASOC-2021 Hinglish benchmark for hate-speech detection by yielding an absolute F1 gain of 0.18 and 0.05 through its BiLTM and SPP tasks, respectively. Attention-map analysis further shows that CMLFormer is far more capable than other approaches at effectively learning switching point dynamics in code-mixed inputs, indicated by higher attention scores obtained by attending higher to switching points caused by language transitions. Our extrinsic and intrinsic evaluations confirm our hypothesis and reinforce our claims that CMLFormer’s architectural novelties and design make it powerful at code-mixed language modeling, enabling it to learn richer and more informative representations that internalize the syntactic and semantic nuances of code-mixed text and language transition cues.
References
- Ali et al. (2023) Mohsin Ali, Kandukuri Sai Teja, Neeharika Gupta, Parth Patwa, Anubhab Chatterjee, Vinija Jain, Aman Chadha, and Amitava Das. 2023. Conflator: Incorporating switching point based rotatory positional encodings for code-mixed language modeling.
- Ali et al. (2021) Mohsin Ali, Kandukuri Sai Teja, Sumanth Manduru, Parth Patwa, and Amitava Das. 2021. Pesto: Switching point based dynamic and relative positional encoding for code-mixed languages.
- Anil et al. (2024) Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Gemini Team, Jiahui Yu, and Radu Soricut et. al. 2024. Gemini: A family of highly capable multimodal models.
- Das and Gambäck (2014) Amitava Das and Björn Gambäck. 2014. Identifying languages at the word level in code-mixed indian social media text. In Proceedings of the 11th International Conference on Natural Language Processing (ICON-2014), pages 169–178.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding.
- Doddapaneni et al. (2023) Sumanth Doddapaneni, Rahul Aralikatte, Gowtham Ramesh, Shreya Goyal, Mitesh M. Khapra, Anoop Kunchukuttan, and Pratyush Kumar. 2023. Towards leaving no indic language behind: Building monolingual corpora, benchmark and models for indic languages.
- Faysse et al. (2024) Manuel Faysse, Patrick Fernandes, Nuno M. Guerreiro, António Loison, Duarte M. Alves, Caio Corro, Nicolas Boizard, João Alves, Ricardo Rei, Pedro H. Martins, Antoni Bigata Casademunt, François Yvon, André F. T. Martins, Gautier Viaud, Céline Hudelot, and Pierre Colombo. 2024. Croissantllm: A truly bilingual french-english language model.
- Jagdale et al. (2024) Shruti Jagdale, Omkar Khade, Gauri Takalikar, Mihir Inamdar, and Raviraj Joshi. 2024. On importance of code-mixed embeddings for hate speech identification.
- Khanuja et al. (2021) Simran Khanuja, Diksha Bansal, Sarvesh Mehtani, Savya Khosla, Atreyee Dey, Balaji Gopalan, Dilip Kumar Margam, Pooja Aggarwal, Rajiv Teja Nagipogu, Shachi Dave, Shruti Gupta, Subhash Chandra Bose Gali, Vish Subramanian, and Partha Talukdar. 2021. Muril: Multilingual representations for indian languages.
- Lample and Conneau (2019) Guillaume Lample and Alexis Conneau. 2019. Cross-lingual language model pretraining.
- Li and Murray (2022) Shuyue Stella Li and Kenton Murray. 2022. Language agnostic code-mixing data augmentation by predicting linguistic patterns.
- Mandl et al. (2021) Thomas Mandl, Sandip Modha, Gautam Kishore Shahi, Hiren Madhu, Shrey Satapara, Prasenjit Majumder, Johannes Schaefer, Tharindu Ranasinghe, Marcos Zampieri, Durgesh Nandini, and Amit Kumar Jaiswal. 2021. Overview of the hasoc subtrack at fire 2021: Hate speech and offensive content identification in english and indo-aryan languages.
- Mazumder et al. (2024) Debajyoti Mazumder, Aakash Kumar, and Jasabanta Patro. 2024. Revealing the impact of synthetic native samples and multi-tasking strategies in hindi-english code-mixed humour and sarcasm detection.
- Nayak and Joshi (2022) Ravindra Nayak and Raviraj Joshi. 2022. L3Cube-HingCorpus and HingBERT: A code mixed Hindi-English dataset and BERT language models. In Proceedings of the WILDRE-6 Workshop within the 13th Language Resources and Evaluation Conference, pages 7–12, Marseille, France. European Language Resources Association.
- Patil et al. (2023) Aryan Patil, Varad Patwardhan, Abhishek Phaltankar, Gauri Takawane, and Raviraj Joshi. 2023. Comparative study of pre-trained bert models for code-mixed hindi-english data. In 2023 IEEE 8th International Conference for Convergence in Technology (I2CT), page 1–7. IEEE.
- Santy et al. (2021) Sebastin Santy, Anirudh Srinivasan, and Monojit Choudhury. 2021. BERTologiCoMix: How does code-mixing interact with multilingual BERT? In Proceedings of the Second Workshop on Domain Adaptation for NLP, pages 111–121, Kyiv, Ukraine. Association for Computational Linguistics.
- Sengupta et al. (2021) Ayan Sengupta, Sourabh Kumar Bhattacharjee, Tanmoy Chakraborty, and Md. Shad Akhtar. 2021. HIT - a hierarchically fused deep attention network for robust code-mixed language representation. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4625–4639, Online. Association for Computational Linguistics.
- Srivastava (2025) Varad Srivastava. 2025. DweshVaani: An LLM for detecting religious hate speech in code-mixed Hindi-English. In Proceedings of the First Workshop on Challenges in Processing South Asian Languages (CHiPSAL 2025), pages 46–60, Abu Dhabi, UAE. International Committee on Computational Linguistics.
- Su et al. (2023) Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2023. Roformer: Enhanced transformer with rotary position embedding.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, pages 5998–6008.
- Venkatesh et al. (2024) Dilip Venkatesh, Pasunti Prasanjith, and Yashvardhan Sharma. 2024. BITS pilani at SemEval-2024 task 10: Fine-tuning BERT and llama 2 for emotion recognition in conversation. In Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), pages 811–815, Mexico City, Mexico. Association for Computational Linguistics.
- Zhang et al. (2023) Ruochen Zhang, Samuel Cahyawijaya, Jan Christian Blaise Cruz, Genta Indra Winata, and Alham Fikri Aji. 2023. Multilingual large language models are not (yet) code-switchers.
Appendix A Appendix
A.1 Dataset Augmentation and Curation
A.1.1 Generating a Parallel Hinglish-English-Hindi Corpus
To support the pre-training objectives, we proceeded with the data augmentation process with an initial sample of 10,000 Hinglish lines selected from the L3Cube-HingCorpus as a first milestone. The augmentation pipeline involved various stages applied to these 10,000 lines. First, the data was cleaned to remove emojis, special Unicode characters, and extra whitespace. Then, they were fed into Gemini 2.0 Flash to generate parallel translations in English and Hindi (Roman script).
A.1.2 Augmentation Details and Example Transformations
Below is an example from our augmented dataset showing Hinglish sentences alongside their English and Hindi (Roman) translations:
Example 1:
-
•
Hinglish: aapki logo ki help krne ki soch bhut acchi h …manav seva bhut hi accha kary krte ho di.
-
•
English: Your thought of helping people is very good… you do a very good deed of human service, sister.
-
•
Hindi (Roman): Aapki logo ki madad karne ki soch bahut achchhi hai… manav seva bahut hi achchha karya karte ho di.
-
•
Labels: [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0]
-
•
Switching Points: [0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0]
Example 2:
-
•
Hinglish: Tum abhi Twitter use kr rhi ho :)
-
•
English: Are you currently using Twitter? :)
-
•
Hindi (Roman): Tum abhi Twitter use kar rahi ho? :)
-
•
Labels: [0, 0, 1, 1, 0, 0, 0, 0]
-
•
Switching Points: [0, 0, 1, 0, 1, 0, 0, 0]
A.1.3 Switching Point Labels Generation
To facilitate the Switching Point Prediction (SPP) objective, we generated fine-grained switching point labels for each tokenized Hinglish sentence in our augmented dataset. We approached this task by developing a semi-automatic labeling pipeline using Gemini 2.0 Flash, prompted to perform token-level language annotation with strict rules for tagging each token as either Hindi (hi) or English (en).
Each Hinglish sentence was first tokenized into whitespace-separated tokens. Then, Gemini was instructed to annotate every token individually without modifying their original structure, preserving punctuation and special symbols. Tokens were labeled as [en] for English or uncertain words and [hi] for Hindi, Urdu, or Punjabi words. Ambiguous cases defaulted to the previous token’s language following a consistency-first principle.
After obtaining the annotated sentences, we parsed the labeled outputs to derive two sequences:
-
•
Token Language Labels: A sequence of 0s and 1s, where 1 denotes an English token and 0 denotes a Hindi token.
-
•
Switching Points Array: A binary array computed by scanning the token labels and marking 1 whenever a language switch occurred between adjacent tokens, and 0 otherwise.
For example, a labeled sequence like Phone[en] ko[hi] charge[en] karo[hi] results in a token language array [1, 0, 1, 0] and a switching points array [0, 1, 1, 1]. This allows CMLFormer to directly supervise on detecting fine-grained language transitions.
To ensure data quality, we applied post-processing filters to discard entries where the annotated labels were incomplete, ambiguous, or invalid (e.g., containing unexpected tags or lacking parallel translations). The final curated dataset contains the Hinglish sentence, its parallel English and Hindi translations (in Roman script), the token-level language labels, and the switching point labels, stored in JSONL format for pretraining. This process produced high-quality supervision data to explicitly teach the model to recognize and anticipate language switching points..
A.1.4 Data Curation and Pre-processing
During augmentation, we conducted a manual review of several hundred samples to ensure the quality of translation. However, we observed examples where producing a valid translation could not be generated because of unintelligible text or highly ambiguous phrasing. Such training examples were omitted from the dataset.
A.1.5 LLM Prompts and Configuration
We used the Gemini-2.0-Flash888https://ai.google.dev/gemini-api/docs/models#gemini-2.0-flash model from Google’s Generative AI suite via the official Python SDK. The model was configured with output type set to application/json to ensure structured output for easier parsing and sentence extraction. To make sure the model adheres to our request, we prompted it with a few-shot examples.
The prompt we use is:
Task: Translate the given Hinglish text into both formal English and standardized Hindi (written in Roman script).
Input Hinglish: "{hinglish_text}"
Requirements:
1. English translation should be grammatically correct and natural.
2. Hindi translation must use ONLY Roman script (Latin alphabet), not Devanagari.
3. Maintain the original meaning and tone in both translations.
4. Use standard transliteration conventions for Hindi.
5. Preserve context from the original text.Important:
- DO NOT include any explanations, notes, or additional text.
- Respond ONLY with the exact JSON format shown below.
- Both translations should be complete sentences with proper punctuation.
- If the input text is not in Hinglish, English, or Hindi, return "NULL"
- If the input is Hindi, return the Hindi as is in the "hindi_roman" field.
- If the input is English, return the English as is in the "english" field.Return this exact JSON structure:
{ "english": "Your English translation here",
"hindi_roman": "Your Hindi translation in Roman script here" }Examples:
Input: "Main kal movie dekhne jaa raha hoon"
Output: {"english": "I am going to watch a movie tomorrow", "hindi_roman": "Main kal film dekhne ja raha hoon"}Input: "Office ke baad hum coffee shop par milenge"
Output: {"english": "We will meet at the coffee shop after office", "hindi_roman": "Karyalay ke baad hum coffee shop par milenge"}
We chose a default temperature of 0.7 for generating translations to ensure translations are natural yet accurate. We also added a retry logic of 3 requests, with a delay of 2 seconds to avoid rate limiting.
A.2 Architecture Ablations
A.2.1 Dual Decoder without Decoder-level Cross Attention
To isolate and measure the impact of the proposed decoder cross-attention sub-layer in each layer, we will decouple the two decoders by removing cross-attention from both branches. This would degenerate both decoders to the vanilla architecture and remove the need for synchronous decoding since the overall architecture would function as two independent decoders with a shared encoder. While the model retains the multi-target training setup, this approach prevents each decoder from learning from the other, inhibiting cross-lingual alignment and learning inter-language relationships.
A.2.2 Ablating with Cross-Attention Inputs
We will investigate the effect of swapping the inputs to the cross-attention sub-layer with the final output hidden state from the previous layer of the other decoder after being passed through all its sub-layers. We hypothesize that this will ensure that each layer’s cross-attention is based on a stable and richer representation from the other decoder branch. Denoting the output hidden states of the previous layer of the base and mixing language decoder as and respectively, this can be formulated as,
| (4) |
Output attention scores and are then passed as input to the feed-forward and layer normalization sub-layers as done previously. After each layer in the decoder, we store the final output hidden states and so they can be used in the cross-attention sub-layer of the decoder’s layer.
A.3 Synchronous Dual-Decoder Cross Attention Outperforms other Setups
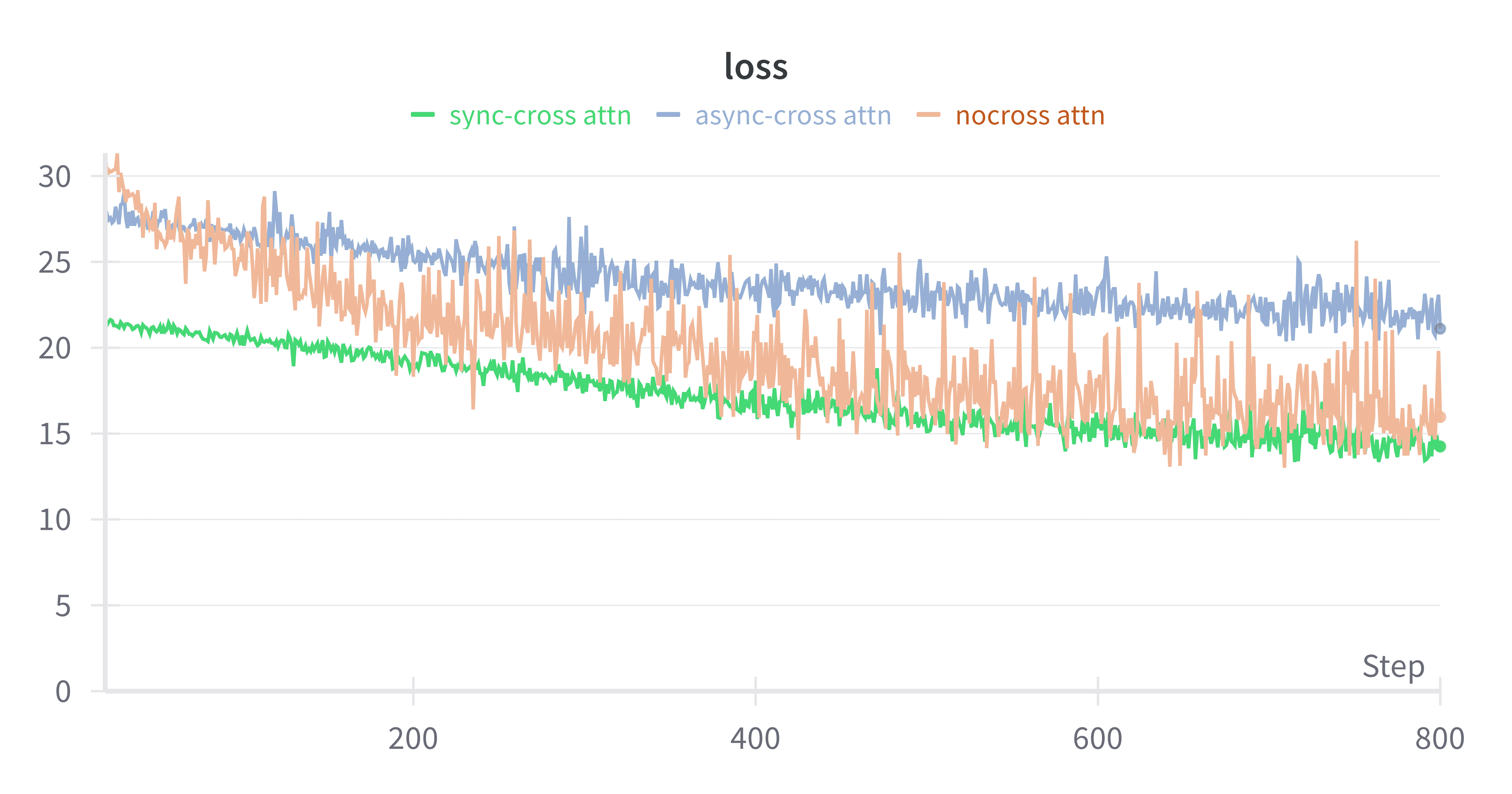
We explored the three variants of decoder-level cross-attention through different pre-training runs. The synchronous variant, where each decoder attends to the current layer’s hidden state from the other decoder, shows the smoothest and lowest loss trajectory consistently across our preliminary experiments. This exhibits effective mutual learning between the base and mixing language decoders and supports our hypothesis that fully synchronized decoders facilitate stronger cross-lingual alignment.
The no cross-attention setup initially decreases in loss but exhibits high variance and noisy training throughout. Despite almost matching the synchronous cross-attention variant and consistently outperforming the asynchronous cross-attention setup, the instability implies poor generalization and inconsistent learning.
In contrast to our hypothesis, asynchronous cross-attention, which uses the previous layer’s representations, leads to higher and much slower-converging loss, possibly due to delayed exchange of information leading to weaker inter-decoder interaction and suboptimal alignment.
A.4 Pre-training Details
A.4.1 Tokenizer
The tokenizer was trained using standard WordPiece preprocessing and vocabulary construction techniques, with a vocabulary size of 32,000, following conventions established in models like BERT. This size offers a good trade-off between vocabulary coverage and computational efficiency and is especially well-suited for code-mixed data where subword-level generalization is important.
A.4.2 Model Configuration
The model configuration for pre-training , which matches the number of parameters in is given in Table 2.
| Metric | Value |
| Source vocabulary size | 32,000 |
| Base target vocabulary size | 32,000 |
| Mixed target vocabulary size | 32,000 |
| Number of layers | 12 |
| Hidden dimension | 768 |
| Feed-forward network dimension | 3,072 |
| Number of attention heads | 12 |
| Dropout rate | 0.1 |
| Maximum sequence length | 512 |
| Decoder cross-attention | ✓ |
| Decoder cross-attention type | synchronous |
A.4.3 Pre-training Hyperparameters
The best pre-training hyperparameters, including the loss weights assigned to each pre-training objective, are provided in Table 3.
| Parameter | Value |
|---|---|
| Epochs | 20 |
| Learning Rate (initial) | 1e-5 |
| Learning Rate Scheduler | Exponential Decay |
| Learning Rate Decay Factor | 0.9 |
| weight () | 1.0 |
| weight () | 1.0 |
| weight () | 10.0 |
| weight () | 1.0 |
| weight () | 10.0 |
| weight () | 1.0 |
A.5 Pre-Training Tasks and Training Losses
A.6 Switching Point Prediction Implementation Details
The switching point labels are provided at the word level, while the model operates on subword token sequences produced by the tokenizer. To ensure correct supervision, we align the switching labels to the tokenized inputs by assigning each switching label only to the first subword token of its corresponding word. All other subword tokens within the same word, as well as special tokens (e.g., padding), are masked out using a label of (ignored index in PyTorch).
The alignment is performed by tracking token-to-word mappings provided by the tokenizer and applying switching labels only when a new word boundary at the first token of a word is encountered. This prevents duplicated supervision across subwords and ensures that loss computation reflects the original word-level switching annotations accurately.
A.7 Fine-tuning Hyperparameters
The best fine-tuning hyperparameters are provided below.
| Parameter | Value |
|---|---|
| Epochs | 30 |
| Learning Rate (initial) | 1e-5 |
| Learning Rate Scheduler | Exponential Decay |
| Learning Rate Decay Factor | 0.9 |
A.8 Additional Attention Visualizations
Additional attention maps generated by CMLFormer are shown in Figure 5, complementing the examples provided in Section 6.3. These plots further illustrate the model’s sensitivity to language transitions within code-mixed text.