CO-SNE: Dimensionality Reduction and Visualization for Hyperbolic Data
Abstract
Hyperbolic space can naturally embed hierarchies that often exist in real-world data and semantics. While high-dimensional hyperbolic embeddings lead to better representations, most hyperbolic models utilize low-dimensional embeddings, due to non-trivial optimization and visualization of high-dimensional hyperbolic data.
We propose CO-SNE, which extends the Euclidean space visualization tool, t-SNE, to hyperbolic space. Like t-SNE, it converts distances between data points to joint probabilities and tries to minimize the Kullback-Leibler divergence between the joint probabilities of high-dimensional data and low-dimensional embedding . However, unlike Euclidean space, hyperbolic space is inhomogeneous: A volume could contain a lot more points at a location far from the origin. CO-SNE thus uses hyperbolic normal distributions for and hyperbolic Cauchy instead of t-SNE’s Student’s t-distribution for , and it additionally seeks to preserve ’s individual distances to the Origin in .
We apply CO-SNE to naturally hyperbolic data and supervisedly learned hyperbolic features. Our results demonstrate that CO-SNE deflates high-dimensional hyperbolic data into a low-dimensional space without losing their hyperbolic characteristics, significantly outperforming popular visualization tools such as PCA, t-SNE, UMAP, and HoroPCA which is also designed for hyperbolic data.
1 Introduction
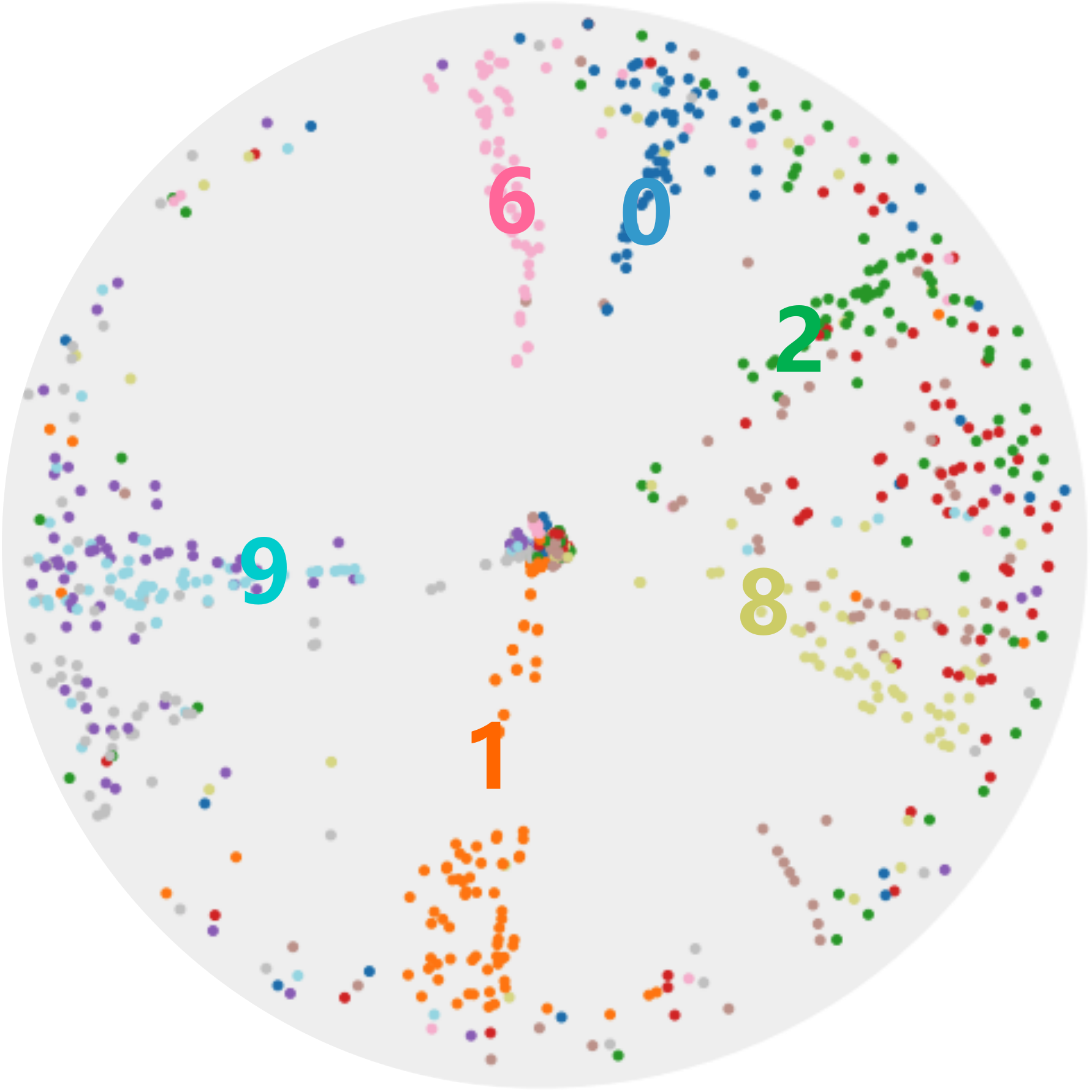
Datasets with hierarchical structures are ubiquitous. Social networks [10] and complex networks [1] are representative examples of hierarchical data. Euclidean space cannot embed entities in such hierarchical datasets without distortion. Hyperbolic space, a non-Euclidean space with constant negative curvature, has been widely used for embedding hierarchical data since hyperbolic metric can closely approximate the tree metric. Hyperbolic space has thus been used in the representation learning of word embeddings [23] (Figure 1) and visual inputs [13, 18]. Several algorithms also directly operate on hyperbolic space [7, 6, 32].
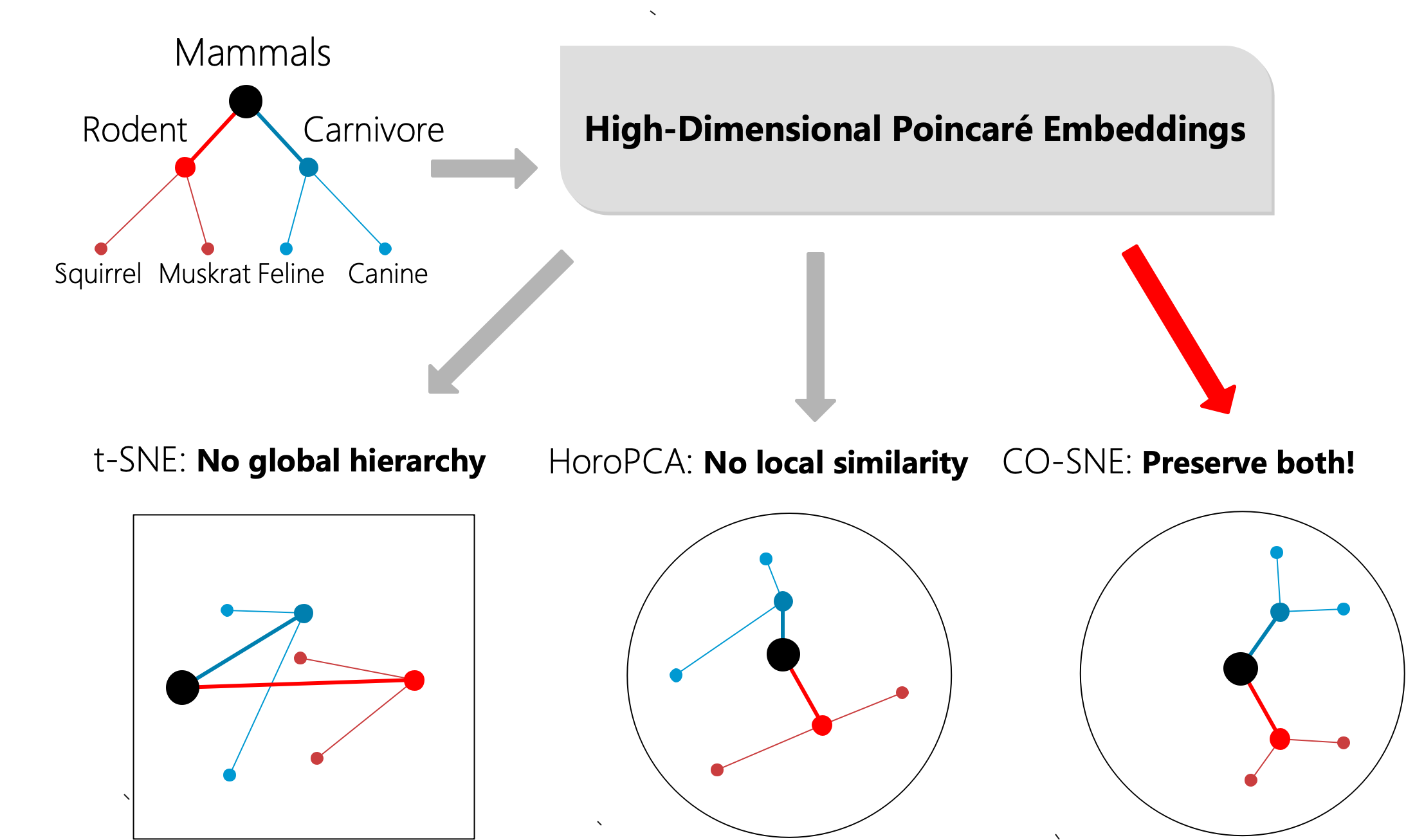
Higher embedding dimension can generally lead to better hyperbolic representation quality [23, 11]. However, learning with two-dimensional hyperbolic space is prevalent [23, 11]. One of the reasons is the ease of visualization. There are several isometrically equivalent models for representing hyperbolic space. The Poincaré ball model is arguably the most widely used model in hyperbolic representation learning [23, 11, 9]. With the Poincaré ball model, we can easily visualize two-dimensional hyperbolic embeddings within a unit Euclidean circle. However, to visualize high-dimensional hyperbolic data is not easy, as most visualization methods assume the data exist in Euclidean space.
Embeddings in Poincaré ball have two notable properties: 1) The embeddings have a global hierarchical structure. Root nodes are in the center of the ball and leaf nodes are close to the boundary of the ball. 2) The embeddings possess a local similarity structure. Sibling nodes should be close in the embedding space.
t-SNE [31] is a popular visualization tool for visualizing high-dimensional Euclidean data. However, t-SNE cannot preserve the global hierarchy of the hyperbolic embeddings. HoroPCA [5] is recently proposed as an extension of PCA on hyperbolic space. However, HoroPCA cannot preserve the local similarity of the hyperbolic embeddings. In this paper, we propose CO-SNE which can preserve both the global hierarchy and local similarity of high-dimensional hyperbolic embeddings in a low- dimensional hyperbolic space (1). In Figure 1, the subtree from WordNet [21] is embedded in a five-dimensional hyperbolic space via Poincaré embeddings [23]. We use t-SNE [31], HoroPCA [5] and CO-SNE to visualize the embeddings in a two-dimensional space. CO-SNE can preserve the structure of the data well.
In CO-SNE, for maintaining local similarity structure, we adopt the same idea as in the standard t-SNE to minimize the KL-divergence between the high-dimensional similarities and the low-dimensional similarities. We adopt hyperbolic versions of the normal distribution and Cauchy distribution to compute the similarities. To maintain the global hierarchical structure, we adopt a distance loss function which seeks to preserve the individual distances of high-dimensional hyperbolic embeddings to the Origin in low-dimensional hyperbolic space.
In summary, we make the following contributions,
-
•
We propose CO-SNE which can represent high-dimensional hyperbolic datapoints in a low-dimensional hyperbolic space while maintaining the local similarity and the global hierarchical structure.
-
•
We propose to use hyperbolic Cauchy distribution for computing low-dimensional similarities which is crucial for producing good visualization in hyperbolic space.
-
•
We apply CO-SNE to visualize synthetic hyperbolic data, hierarchical biological datasets and hyperbolic embeddings learned by supervised and unsupervised learning methods to better understand high-dimensional hyperbolic data. Across all the cases, CO-SNE produces much better visualization than the baselines.
2 Related Work
Large-margin Classification [6] in hyperbolic space was proposed by changing the distance function from Euclidean to hyperbolic. Robust large-margin classification [32] in hyperbolic space is also proposed and has the first theoretical guarantees for learning a hyperbolic classifier.
Hyperbolic Neural Networks (HNNs) [7] rewrite multinomial logistic regression (MLR), fully connected layers and Recurrent Neural Networks for hyperbolic embeddings via gyrovector space operations [30]. In a follow-up work, Hyperbolic Neural Networks++ [28] introduces hyperbolic convolutional layers. Hyperbolic attention networks [8] are proposed by extending attention operations to hyperbolic space in a manner similar to [7]. Hyperbolic graph neural networks [17] are further proposed by altering the geometry of Graph Neural Networks (GNNs) [34] to hyperbolic space. Hyperbolic neural networks have also been used for visual inputs and achieve better results than Euclidean neural networks on tasks such as few-shot classification and person re-identification [13].
Unsupervised Learning Methods in Hyperbolic Space are also proposed recently. Poincaré embeddings are proposed to embed words and relations in hyperbolic space [23]. [22] proposed a generalized version of the normal distribution on hyperbolic space called wrapped normal distribution. The proposed wrapped normal distribution is used as the latent space for constructing hyperbolic variational autoencoders (VAEs) [14]. A similar idea is also adopted in [18] to construct Poincaré VAEs. Unsupervised 3D segmentation [11] and instance segmentation [33] are achieved in hyperbolic space via hierarchical triplet loss.
Data Visualization is the process of generating low-dimensional representation of each high-dimensional datapoint. A good visualization should maintain the interesting structure of the data presented in high-dimensional space. t-distributed stochastic neighbor embedding (t-SNE) [31] is arguably the most widely used tool for data visualization. t-SNE attempts to maintain the local similarities of the high-dimensional datapoints in the low-dimensional space. More recently, UMAP [19] is proposed as a manifold learning technique for dimensionality reduction and visualization. Compared with t-SNE, UMAP can better preserve the global structure of the high-dimensional data.
Dimensionality Reduction methods also can be used for data visualization. Principal Component Analysis (PCA [12] is a commonly used dimensionality reduction technique. PCA aims at maintaining the maximum amount of variation of information in the low-dimensional space. Isomap [29] is a non-linear dimensionality reduction method which attempts to preserve local structures. LLE [27] is another popular non-linear dimensionality reduction method that can produce neighborhood preserving embeddings of high-dimensional data.
Notably, no existing data visualization methods are designed for visualizing high-dimensional hyperbolic data. Our proposed CO-SNE method can be used to visualize high-dimensional hyperbolic embeddings.
3 CO-SNE
We present the proposed CO-SNE method which can faithfully represent high-dimensional hyperbolic data in a low-dimensional hyperbolic space. In Section 3.1, we review the basics of Poincaré ball model for hyperbolic space. In Section 3.2, we review t-distributed Stochastic neighbor embedding (t-SNE). In Section 3.3 and 3.4, we introduce the hyperbolic version of normal distribution and Student’s t-distribution. In Section 3.5, we discuss the issue of using hyperbolic Student’s t-distribution for computing low-dimensional similarities and propose to use hyperbolic Cauchy distribution. In Section 3.6, we present the distance loss for maintaining global hierarchy. In Section 3.7, we present the optimization details of CO-SNE.
3.1 Poincaré Ball Model for Hyperbolic Space
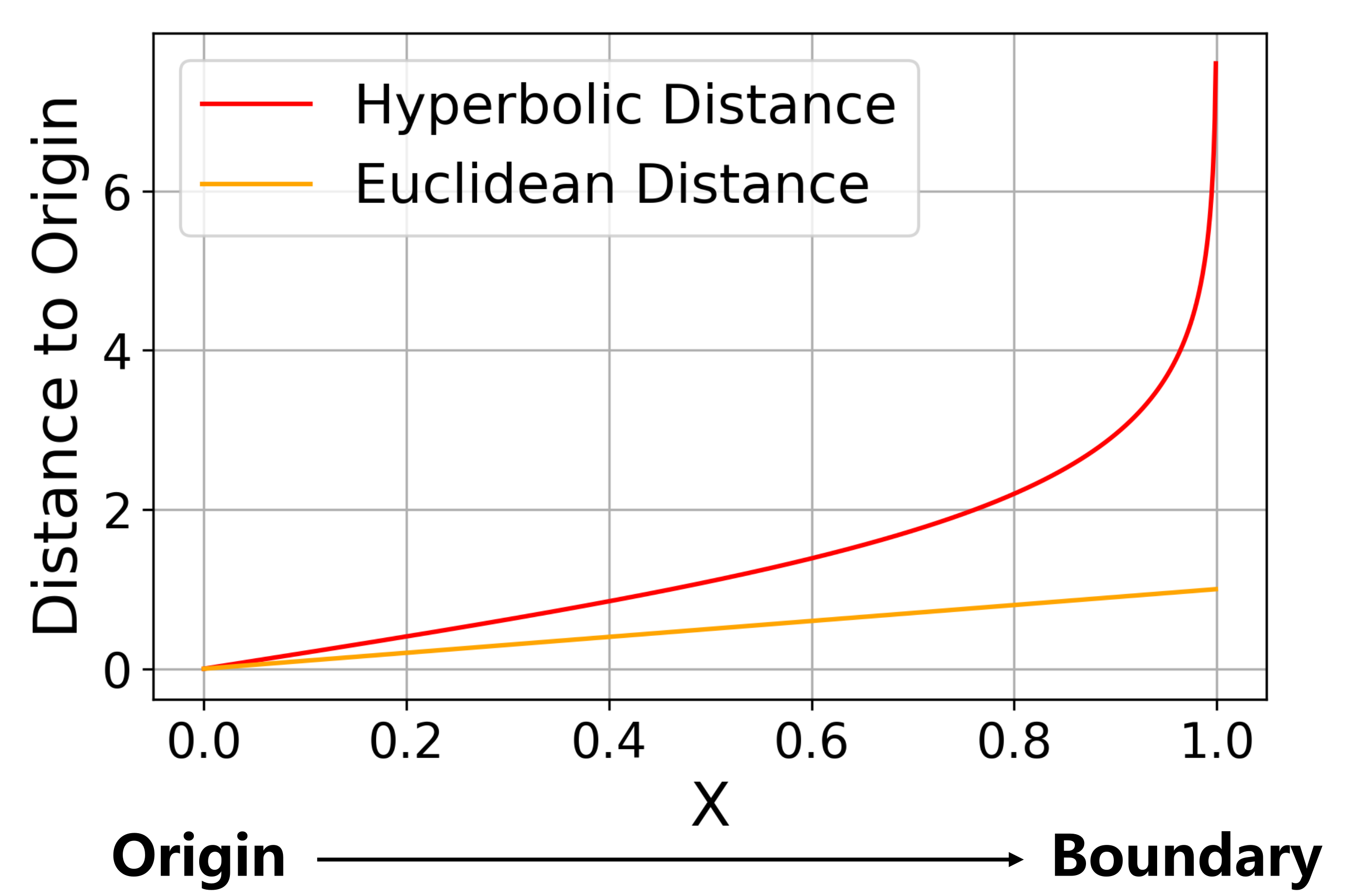
A hyperbolic space is a Riemannian manifold with a constant negative curvature. There are several isometrically equivalent models for representing hyperbolic space. The Poincaré ball model is the most commonly used one in hyperbolic representation learning [23, 7]. The -dimensional Poincaré ball model is defined as , where = and is the Riemannian metric tensor. is the conformal factor and is the Euclidean metric tensor. Given two points and , the hyperbolic distance between them is defined as,
| (1) |
where is the inverse hyperbolic cosine function and is the usual Euclidean norm. Different from Euclidean distance, hyperbolic distance grows exponentially fast as we move the points towards the boundary of the Poincaré ball as in Figure 2.
3.2 t-SNE
t-SNE [31] begins by mapping high-dimensional distances between datapoints to similarity values. The similarity values are either conditional or joint probabilities based on the probability a point will pick another as its neighbor if neighbors are picked in proportion to the probability density of a distribution centered at that point. t-SNE defines the conditional probability , the probability that the point will pick a point as its neighbor, using a normal distribution centered at the point . t-SNE then defines the joint probability distribution , by setting as a way to increase the cost contribution of outlier points, where is the number of high-dimensional datapoints. The conditional probability density is,
| (2) |
where is the distance between and . In the low-dimensional space, Student’s t-distribution is used for modeling the joint probability distribution between embeddings, and is defined as,
| (3) |
where is the corresponding low-dimensional embedding of . In t-SNE, to maintain the local similarities, the cost function to minimize is the Kullback-Leibler divergence between the probability distributions and :
| (4) |
One direct extension of t-SNE is to replace Euclidean version of normal distribution and Student’s t-distribution with hyperbolic normal distribution and hyperbolic Student’s t-distribution. We call such a direct extension as HT-SNE. In Section 3.3 and Section 3.4, we show how to generalize the distributions to hyperbolic space.
 |
 |
 |
 |
| a) Normal and Cauchy Dist. | b) t-SNE | c) HT-SNE | d) CO-SNE |
3.3 Hyperbolic Normal Distribution
To define the conditional probability in the high-dimensional hyperbolic space, we need to generalize the normal distribution to hyperbolic space. One natural generalization is called the Riemannian normal distribution which is the maximum entropy probability distribution given an expectation and a variance [26]. Given the Fréchet mean and a dispersion parameter , the Riemannian normal distribution is defined as,
| (5) |
where is the normalization constant. There are other generalizations of the normal distribution in hyperbolic space [18]. We use the Riemannian normal distribution for simplicity. Thereafter, we refer to Riemannian normal distribution as hyperbolic normal distribution.
3.4 Hyperbolic Student’s t-Distribution
One way to define the Student’s t-distribution is to express the random variable as,
| (6) |
where is a random variable sampled from a standard normal distribution and is a random variable sampled from a -distribution of degrees of freedom. In particular, t-SNE adopts a Student’s t-distribution with one degree of freedom and the probability density function is defined as,
| (7) |
To extend the Student’s t-distribution to hyperbolic space, we derive the probability density function as,
| (8) |
The details can be found in the Supplementary.
3.5 Hyperbolic t-Distribution is Not Enough
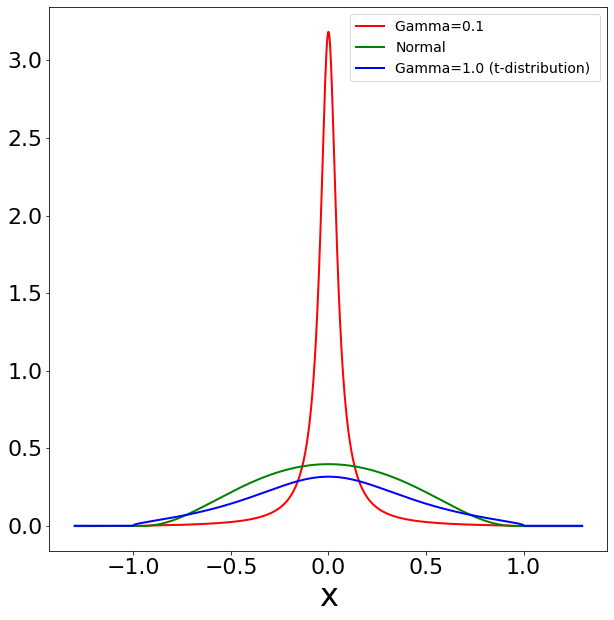
The motivation to use Student’s t-distribution in the standard t-SNE is that Student’s t-distribution has heavier tails than the normal distribution. This causes a repulsion force between dissimilar high-dimensional datapoints which helps mitigate the “Crowding Problem” [31]. However, hyperbolic Student’s t-distribution is not heavy-tailed since the hyperbolic distance grows exponentially fast.
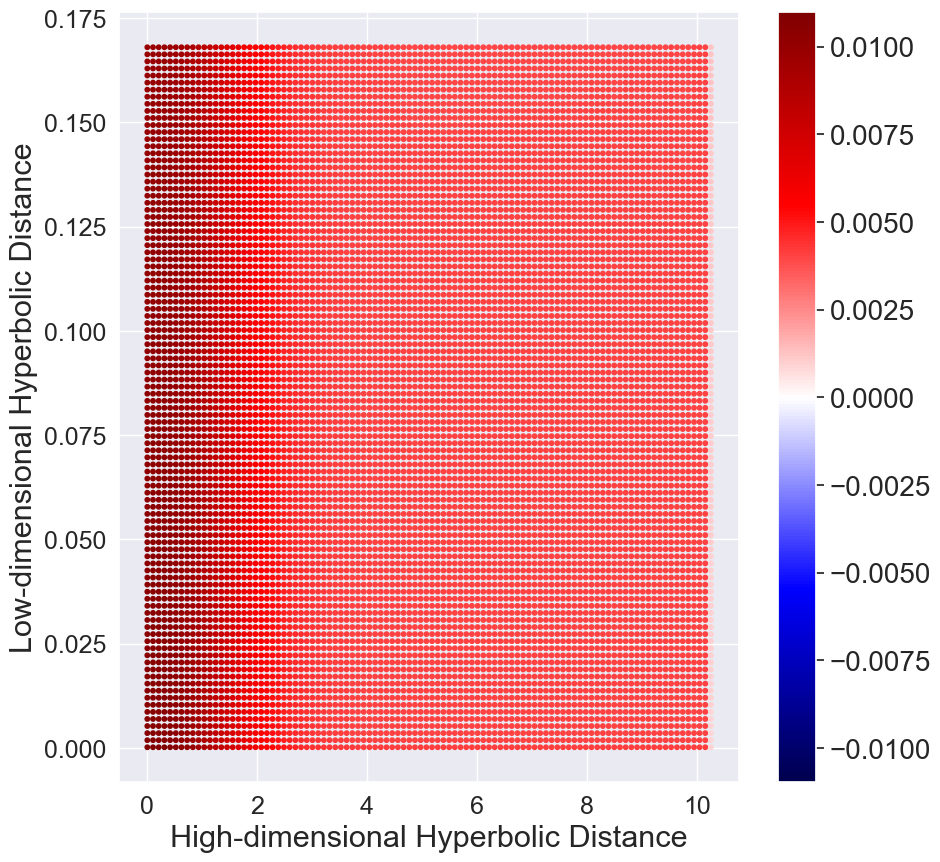
Figure 3 plots the hyperbolic normal distribution and hyperbolic Student’s t-distribution. It can be noted that the tails of hyperbolic Student’s t-distribution diminish as fast as hyperbolic normal distribution. In contrast, the standard Euclidean Student’s t-distribution has heavier tails than the normal distribution. The consequence is that the repulsion force and the attraction force with hyperbolic Student’s t-distribution behave drastically different from that of using Euclidean Student’s t-distribution.
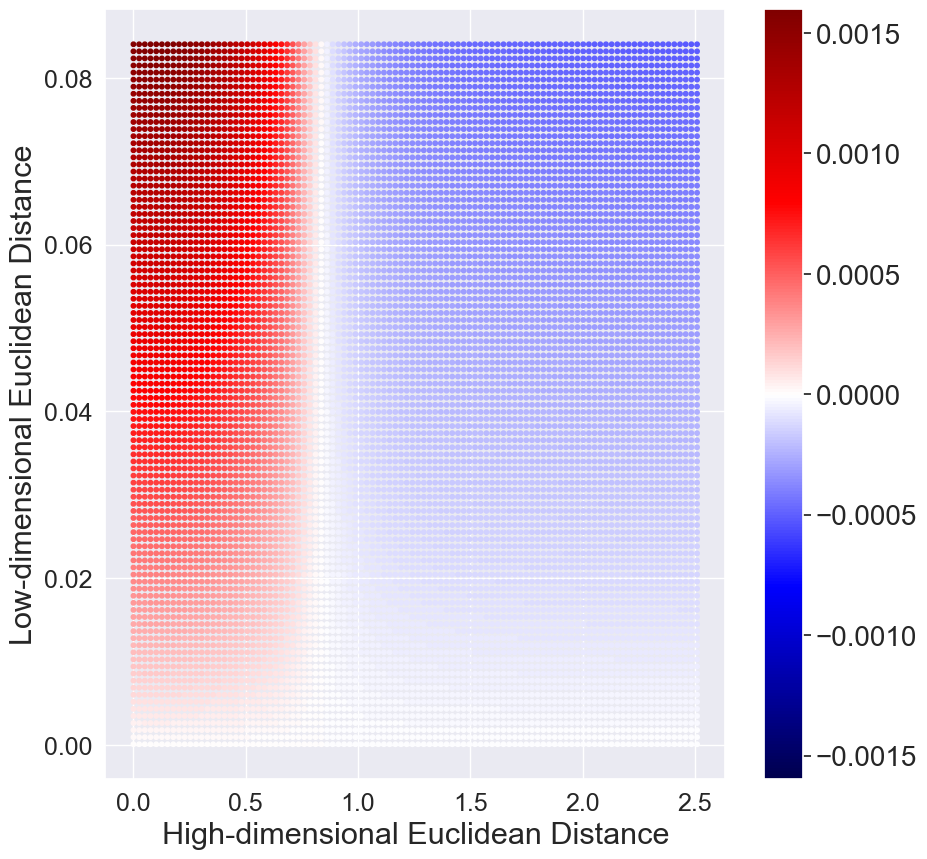
Similar to [31], we plot the gradients between two low-dimensional embeddings and as a function of their pairwise Euclidean (hyperbolic) distance in the low-dimensional Euclidean (hyperbolic) and the pairwise Euclidean (hyperbolic) distance of the corresponding datapoints in the high-dimensional Euclidean (hyperbolic) space. Positive values indicate attraction and negative values indicate repulsion between the embeddings and respectively. Here we only consider the initial stage when all the low-dimensional embeddings are close. The results are shown in Figure 3. We have two observations. First, for the standard t-SNE, there is strong repulsion when dissimilar high-dimensional datapoints are projected closely. Second, with the hyperbolic Student’s t-distribution in HT-SNE, there is little or no repulsion force which causes the low-dimensional embeddings tend to cluster together.
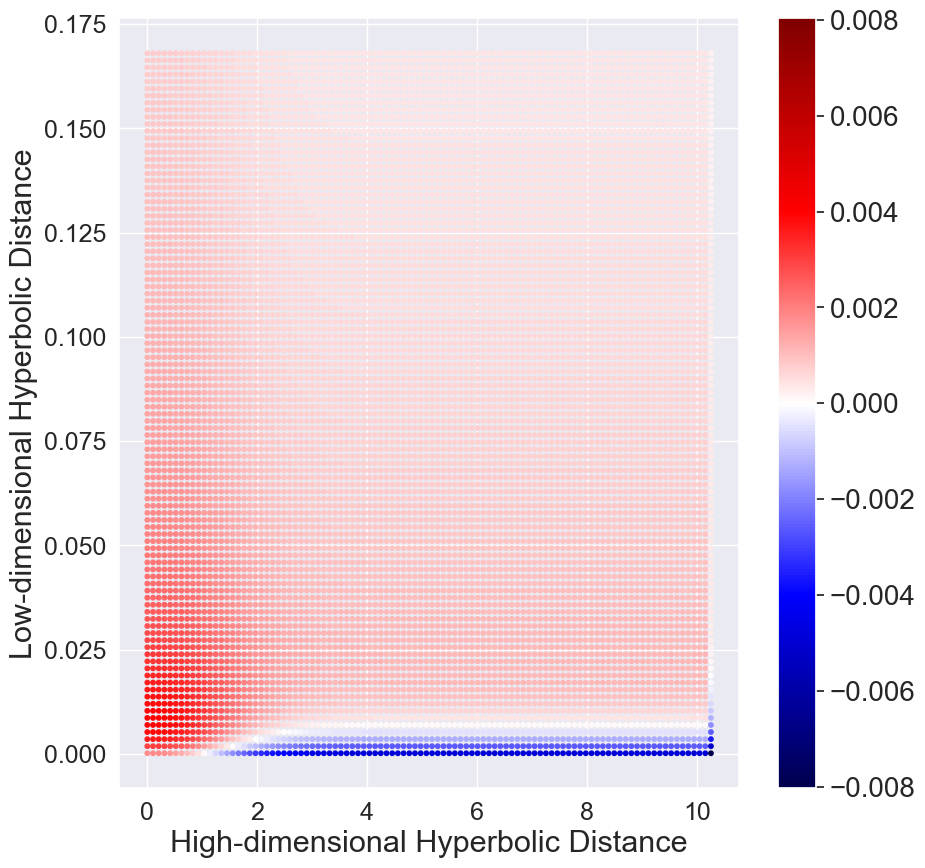
To remedy this issue, we seek to replace the hyperbolic Student’s t-distribution to create more repulsion forces between dissimilar high-dimensional datapoints. Consider the hyperbolic Cauchy distribution which has the probability density function,
| (9) |
where is the scale parameter. Notice that the Student’s t-distribution is a special case of Cauchy distribution with . With a small , Cauchy distribution has a higher peak (Figure 3 (a)). Thus, if the high-dimensional datapoints are modeled with close low-dimensional embeddings, the density value is much larger than the corresponding density in the high-dimensional space. This produces a strong repulsion when dissimilar high-dimensional datapoints are modeled with close low-dimensional embeddings. More details can be found in the Supplementary. We show the corresponding gradients in Figure 3 (d). We can observe that there is a strong repulsion force when high-dimensional dissimilar datapoints are projected closely in CO-SNE. Such repulsion is particularly important in the initial stage of training since all the low-dimensional embeddings are close.
3.6 Distance Loss
Hyperbolic space can be naturally used for embedding tree structured data. The datapoint which is close to the center of the Poincaré ball can be viewed as the root node and datapoints which are close to the boundary of the Poincaré ball can be viewed as leaf nodes. The criterion of t-SNE cannot preserve the tree-structure of the high-dimensional datapoints in the low-dimensional space. One natural way to characterize the level of the datapoint in the underlying tree is the norm of the datapoint. Thus, we attempt to keep the norm invariant after the high-dimensional datapoint is projected. This leads to the following loss function which minimizes the difference between the norms of the high-dimensional datapoint and the corresponding low-dimensional embedding ,
| (10) |
With the distance loss, we can preserve the global hierarchy of the high-dimensional hyperbolic embeddings.
| Metric | High/low-dimensional Dist. | Losses | |
|---|---|---|---|
| t-SNE | Euclidean | Normal/t-distribution | KL-div |
| HT-SNE | Hyperbolic | Normal/t-distribution | KL-div |
| CO-SNE | Hyperbolic | Normal/Cauchy | KL-div + Distance |
3.7 Optimization of CO-SNE
Criterion. The criterion of CO-SNE is composed of the KL-divergence for maintaining local similarity and the distance loss for maintaining the global hierarchy,
| (11) |
where and are hyperparameters. Table 1 shows a comparison of t-SNE, HT-SNE and CO-SNE.
Gradients. The cost function is optimized by gradient descent with respect to the low-dimensional embeddings. The gradient of the KL-divergence with respect to is given by,
| (12) |
The partial gradient of the distance with respect to the low dimensional embedding is given by
| (13) |
where , , . We use the Riemannian stochastic gradient descent [3] for the KL-divergence . The gradient of the distance loss with respect to is computed as,
| (14) |
We constrain the embeddings to the Poincaré ball after each update as in [23].
Stagewise Training. We found the following training strategy is useful for producing better visualization in practice. We train the low-dimensional embeddings only with the local similarity loss for the first 500 iterations. Then we add the distance loss. The stopping criterion is the same as in t-SNE [31]. The reason of the strategy is that it is hard to move the points when they are approaching the boundary of the Poincaré ball.
4 Experiments and Results
Baselines. We compare CO-SNE with 4 baselines,
-
•
The standard t-SNE [31]: this is the standard t-SNE which adopts Euclidean distance for computing the similarities in the high-dimensional space and the low-dimensional space.
- •
-
•
HoroPCA [5]: HoroPCA is a recently proposed extension of PCA on hyperbolic space. HoroPCA proposed to parameterize geodesic subspaces by ideal points in the Poincaré ball. HoroPCA also generalized the notion of projection and the objective function of PCA to hyperbolic space. HoroPCA can be used as a data whitening method for hyperbolic data and as a visualization method as well.
-
•
UMAP [19]: UMAP is a recently proposed dimensionality reduction and visualization method based on the ideas from Riemannian geometry and topology. UMAP is competitive with t-SNE and can better preserve the global structure of the data.
Tasks. We consider 4 datasets to validate the effectiveness of CO-SNE: 1) synthetic datasets sampled from a mixture of hyperbolic normal distributions, 2) cellular differentiation data, 3) supervised hyperbolic embeddings and 4) unsupervised hyperbolic embeddings.
Implementation Details. For PCA and the standard t-SNE, we use the implementation from [25]. For UMAP, we use the implementation from [20]. For HoroPCA, we use the implementation from https://github.com/HazyResearch/HoroPCA which is provided by the original authors. We implement CO-SNE based on t-SNE by modifying the way of computing similarities and the optimization procedure.
Hyperparameters. For PCA, UMAP and HoroPCA, we use the default hyperparameters. For SNE-based methods, we initialize the low-dimensional embedding using a normal distribution with mean 0.01 and unit variance. The training follows the standard setups as in [25]. For CO-SNE, the scaling parameter is set to 0.1. The hyperparameter is usually set to 10.0 and the hyperparameter is usually set to 0.01.
 |
 |
 |
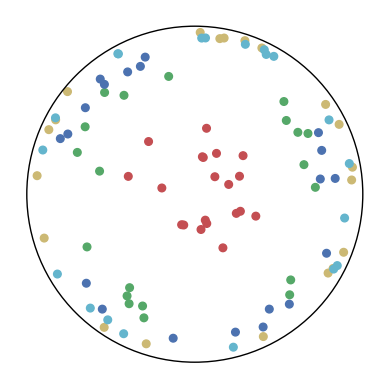
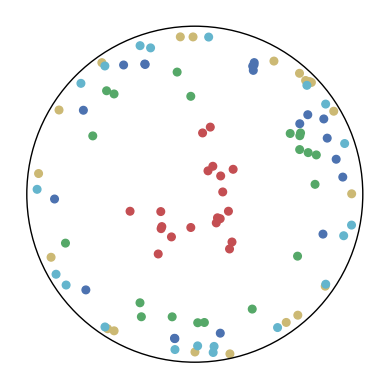
| UMAP | PCA | t-SNE |
 |
 |
 |
| HoroPCA | HT-SNE | CO-SNE |
4.1 Synthetic Point Clusters
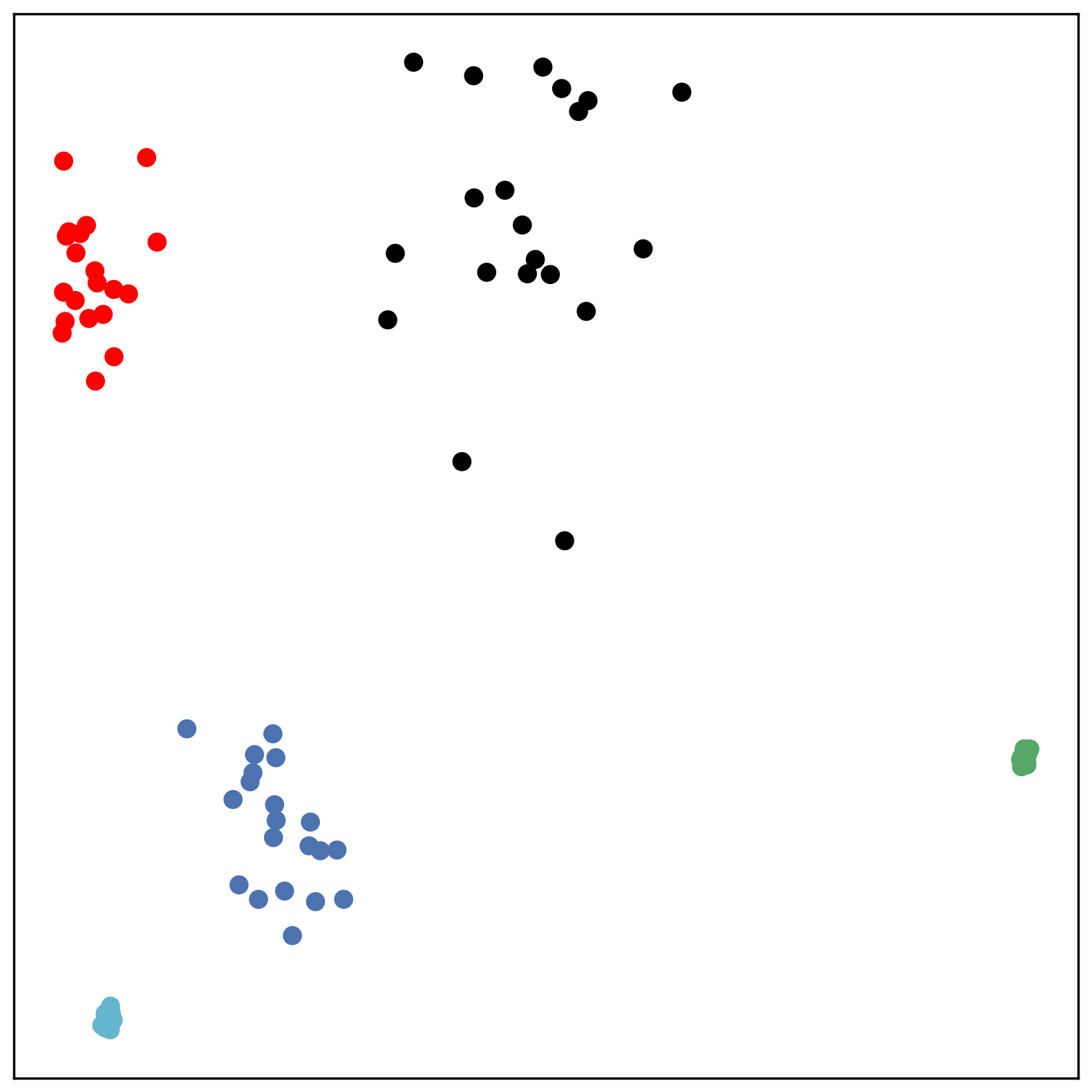
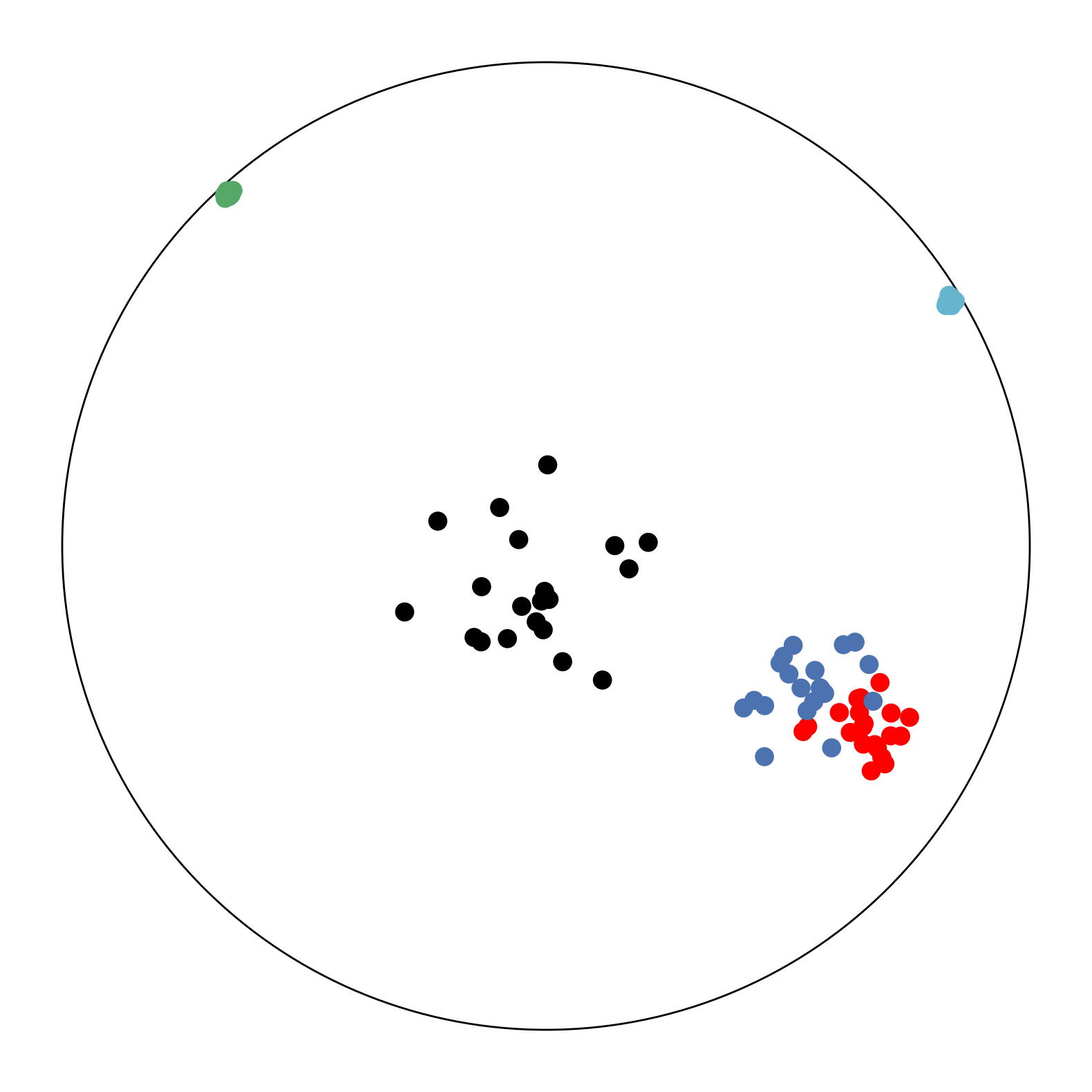
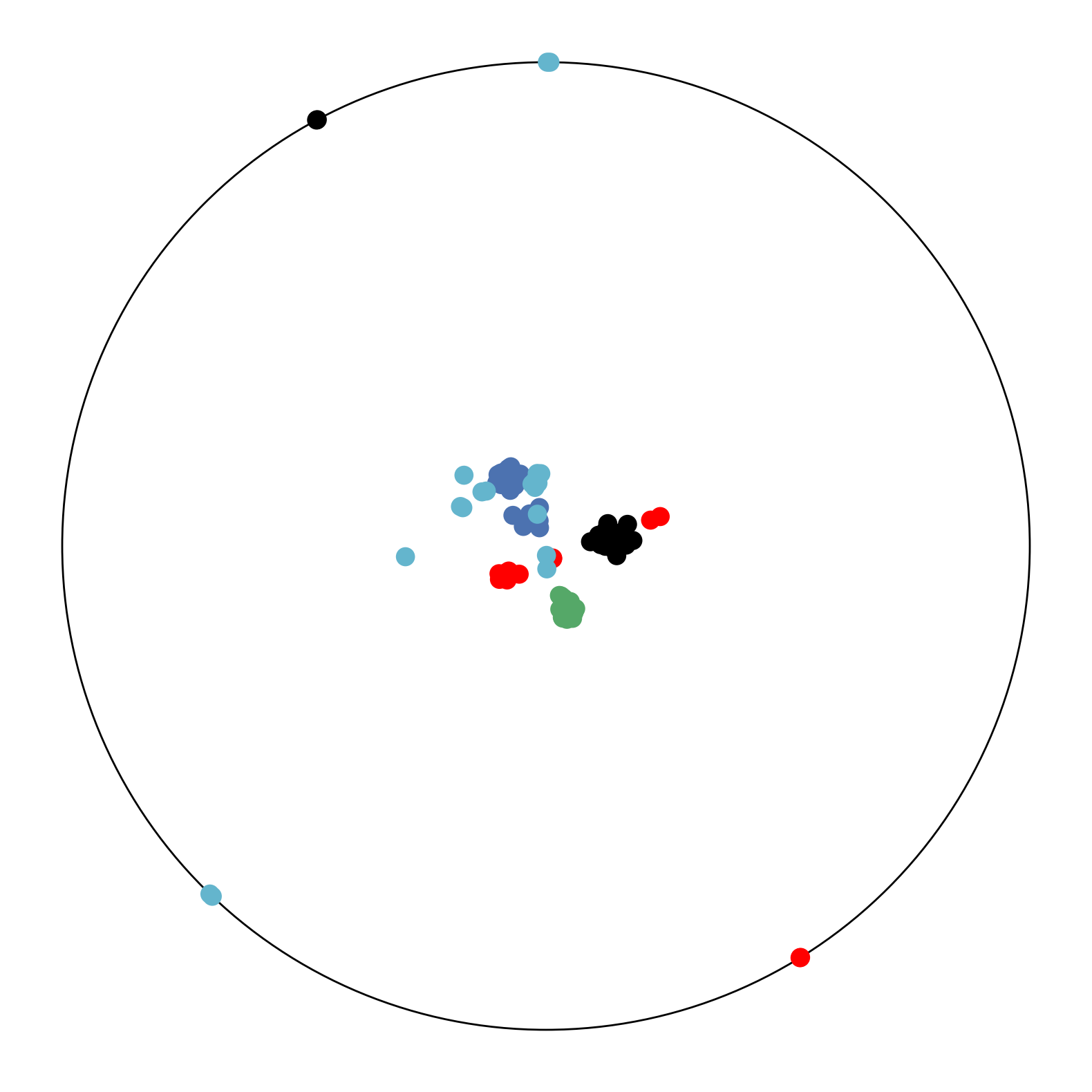
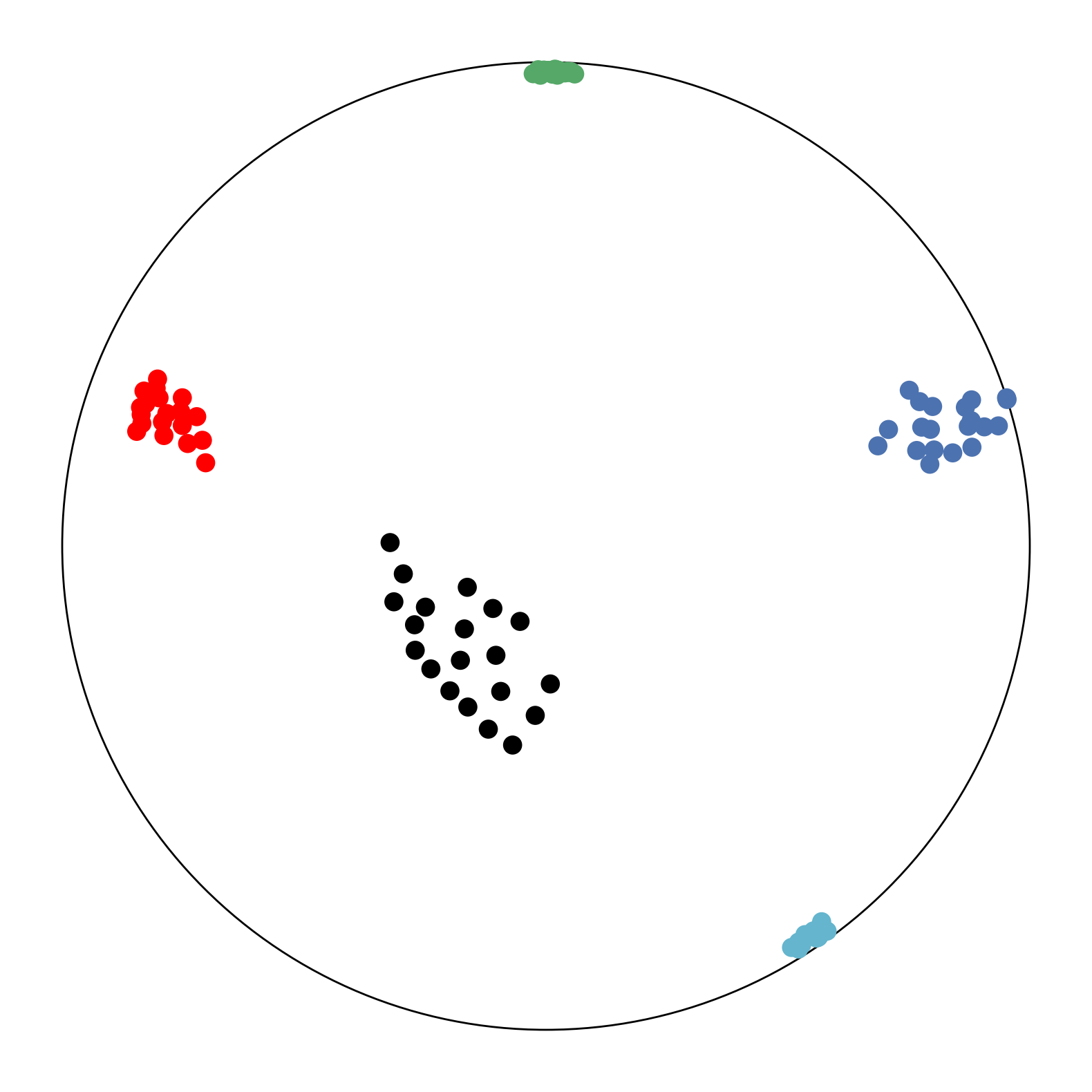
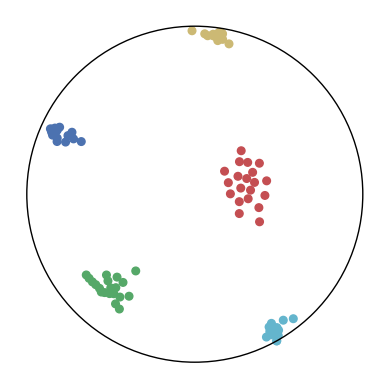
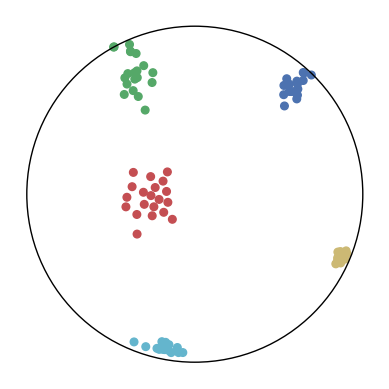
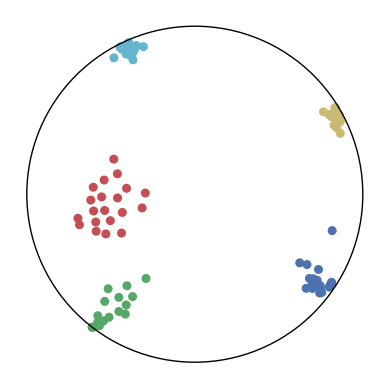
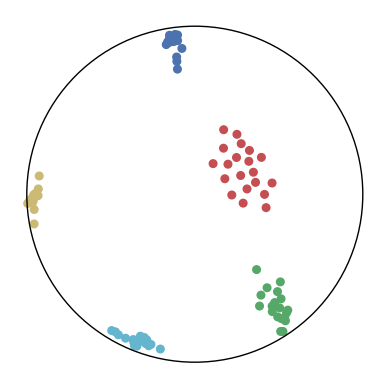
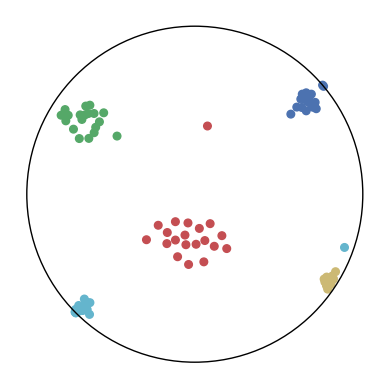
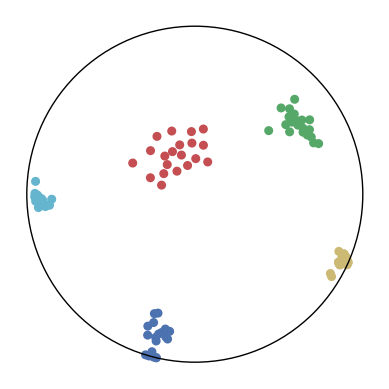
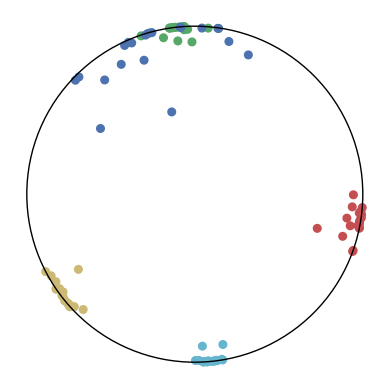
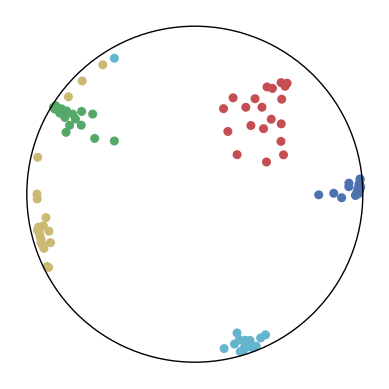
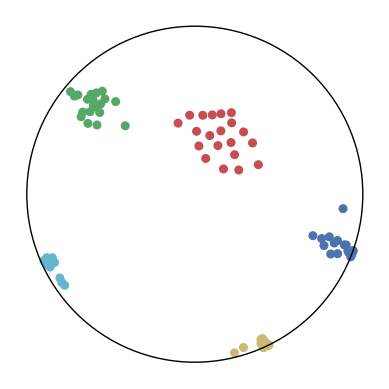
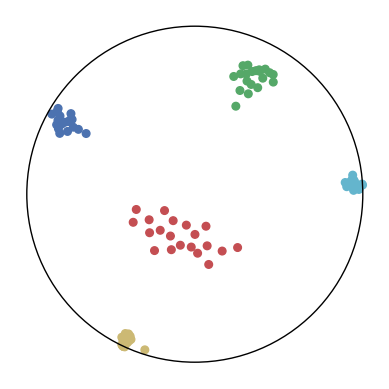
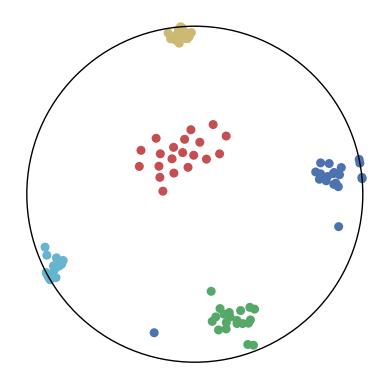
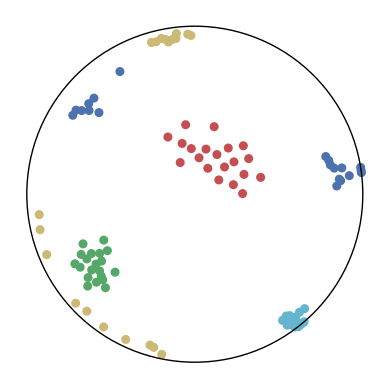
We first use a synthetic dataset to validate the efficacy of CO-SNE. We randomly generate five point clusters of 20 points each in the 5D hyperbolic space. Each follows a hyperbolic normal distribution with the unit variance and the mean located on a different axis. The first and second means are close to the origin, at [0.1, 0, 0, 0, 0] and [0, -0.2, 0, 0, 0] respectively, whereas the third and fourth means are far from and equi-distance to the origin, at [0, 0, 0.9, 0, 0] and [0, 0, 0, -0.9, 0] respectively. The last mean is right at the origin [0, 0, 0, 0, 0]. Figure 4 shows the 2D visualization results of these 5D points by different methods.
CO-SNE produces a much better visualization compared with the baselines. With CO-SNE, the projected two-dimensional hyperbolic embeddings can preserve the local similarity structure and the global hierarchical structure of high-dimensional datapoints well. Also, CO-SNE can prevent the high-dimensional datapoints from being projected too close which usually happens with Euclidean distance based methods. Note that HT-SNE does not have not enough repulsion to push close low-dimensional embeddings apart. We provide a detailed analysis on the drawbacks of each baseline for visualizing high-dimensional hyperbolic datapoints.
-
•
Standard t-SNE: Euclidean distances are used for computing similarities in the high-dimensional space. Hyperbolic distances grow much faster than Euclidean distances. For high-dimensional hyperbolic datapoints which are close to boundary of the Poincaré ball, the standard t-SNE wrongly underestimates the distance between them. As a consequence, the standard t-SNE would take dissimilar high-dimensional data points as neighbors. The resulting low-dimensional embeddings would collapse into one point which leads to poor visualization. In summary, t-SNE cannot preserve the global hierarchy of the hyperbolic data.
-
•
PCA and HoroPCA: as mentioned above, PCA and HoroPCA are linear dimensionality reduction methods which are not generally suitable for visualization in a two-dimensional space. Both PCA and HoroPCA cannot preserve local similarity of the hyperbolic data.
-
•
UMAP: UMAP suffers from the same issue as t-SNE since Euclidean distance is used for computing high-dimensional similarities.
We mainly compare CO-SNE with HoroPCA since HoroPCA is specifically designed for hyperbolic data.
 |
||||
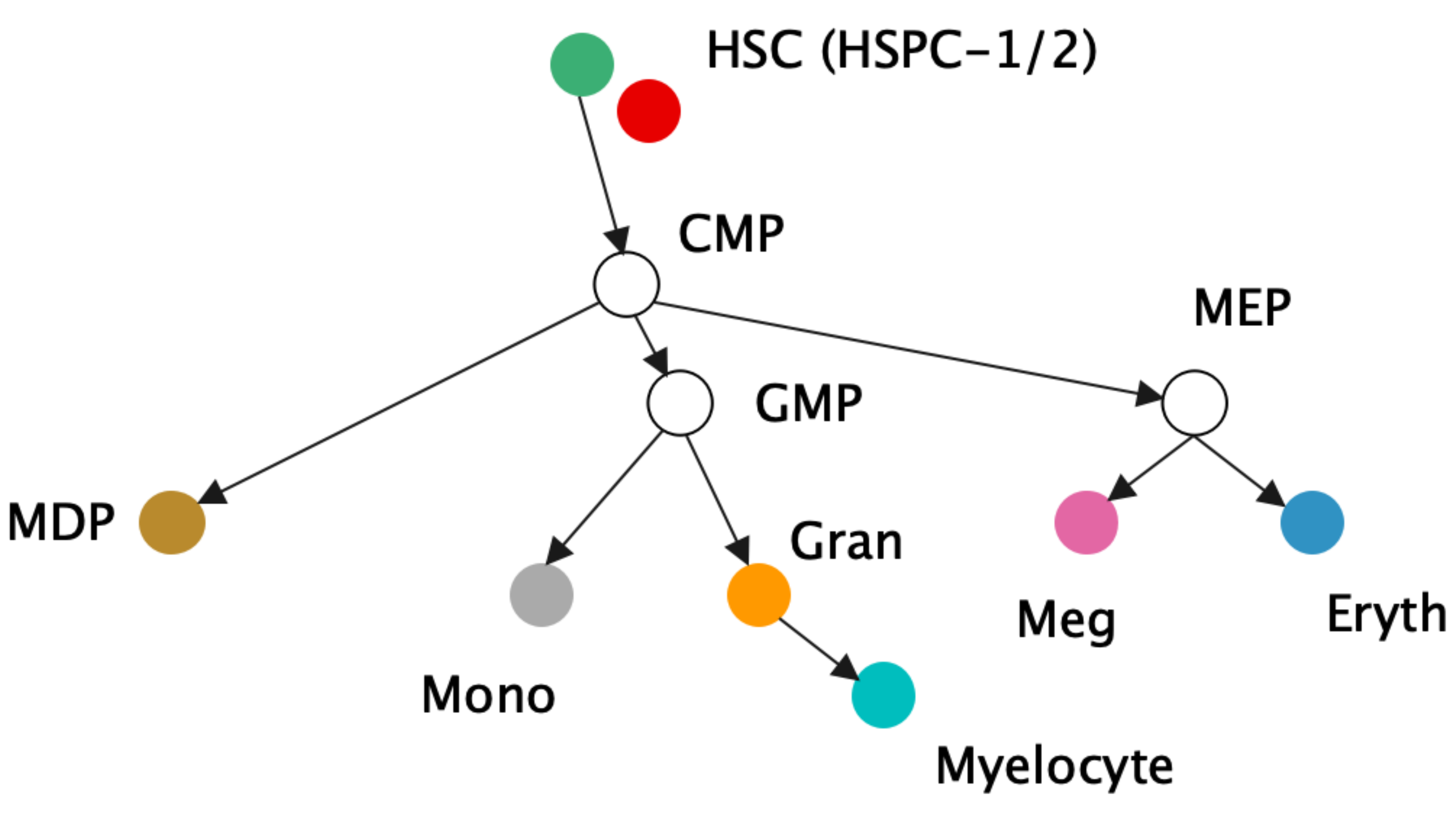
| a) Canonical hematopoetic cell lineage tree [15] | ||||
|

4.2 Biological Dataset
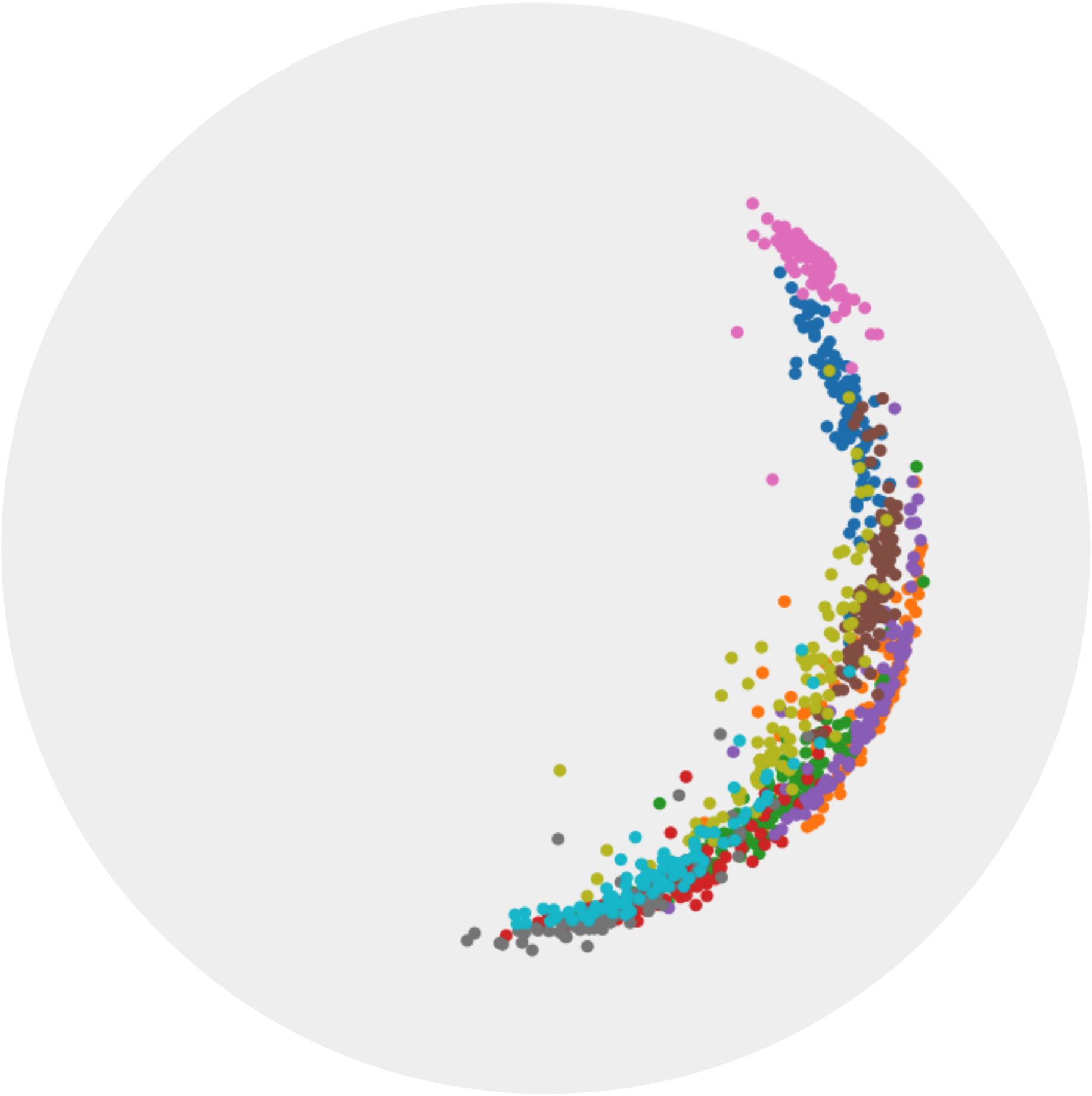
Biological data can reveal naturally occurring hierarchies, such as in single cell RNA sequencing data [15]. In [15], they analyze cellular differentiation data, the transition of immature cells to specialized types. The immature cells can be viewed as the root of the tree and can branch off into several different types of cells, creating hierarchical data of cells in different states of progress in the transition process. One dataset we adapt from [15] is the mouse myelopoiesis dataset presented by [24], where there are 532 cells of 9 types. Two of the types, HSPC-1 and HSPC-2, form the root of the hierarchy, while megakaryocytic (Meg), erythrocytic (Eryth), monocyte-dendritic cell precursor (MDP), monocytic (Mono), and myelocyte (myelocytes and metamyelocytes) type cells are states father from the root. Granulocytic (Gran) cells are a precursor to myelocytes and multi-lineage primed (Multi-Lin) cells are in an intermediate state.
The data has originally 382 dimensions (noisy) and like [15] we first reduce it to 20 dimensions via PCA to reduce the noises. We then scale the data to fit within the Poincaré ball and run CO-SNE and HoroPCA to produce two-dimensional hyperbolic embeddings. Noted that this dataset is not centered. The results are shown in Figure 5. The proposed low-embeddings by CO-SNE capture the hierarchical structure in the original data.
 |
 |
| a) HoroPCA | b) CO-SNE |
4.3 Hierarchical Word Embeddings
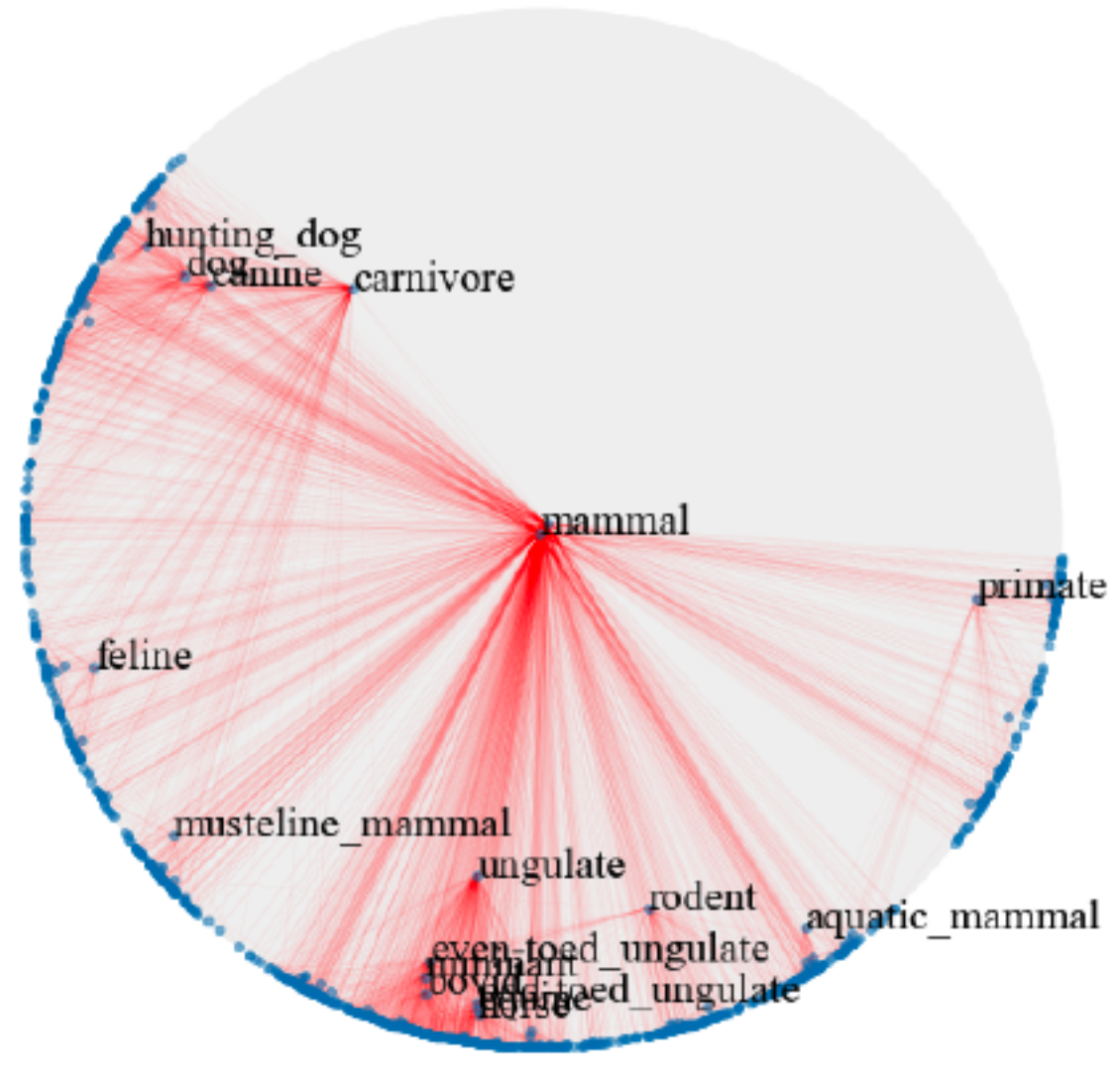
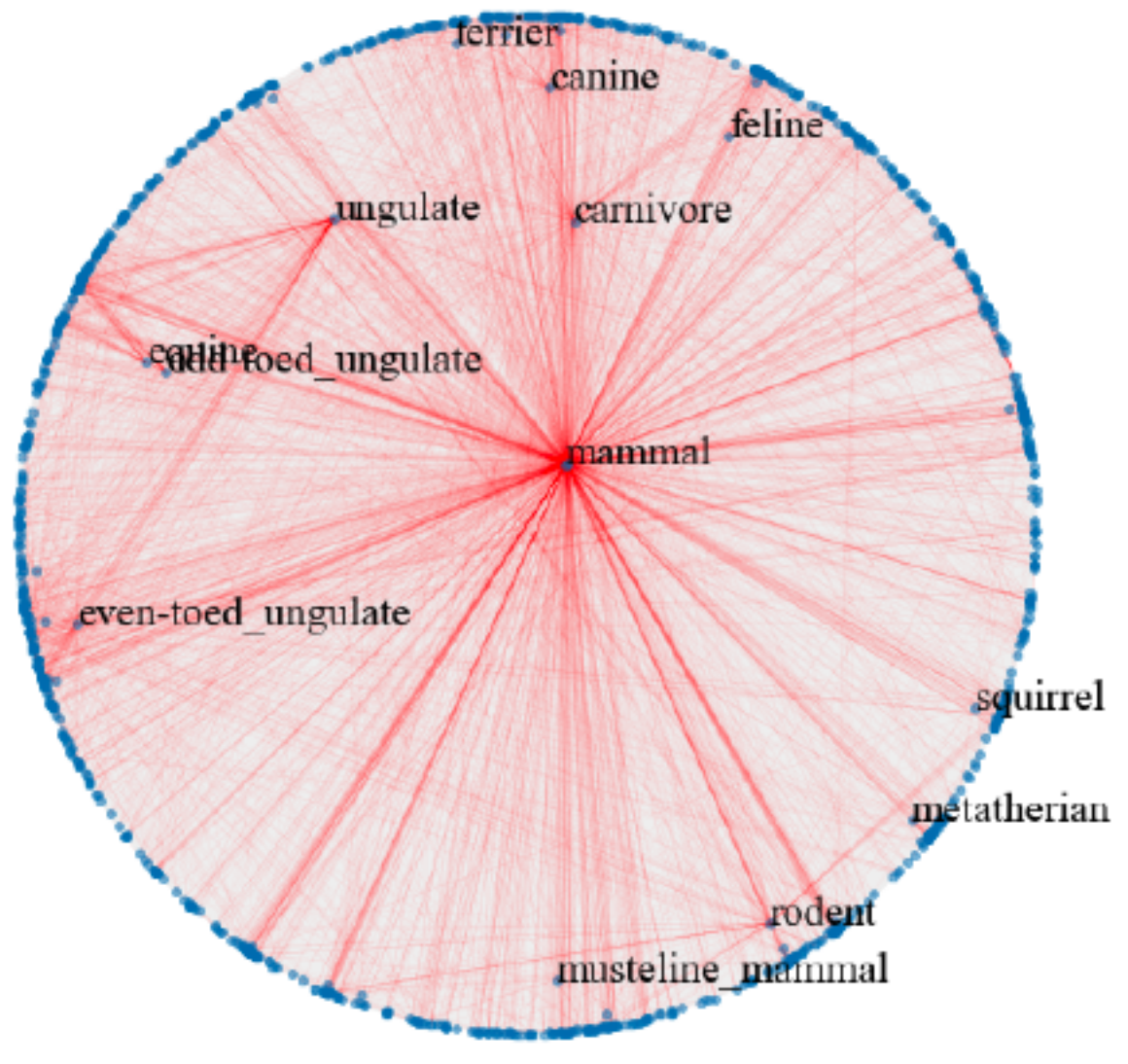
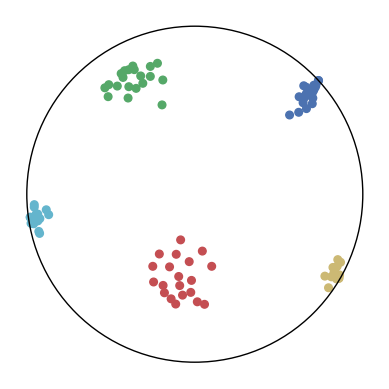
Hyperbolic space has been used to embed hierarchical representations of symbolic data. In [23], the authors adopt hyperbolic space for embedding taxonomies, in particular, the transitive closure of WordNet noun hierarchy [21]. As shown in [23], higher-dimensional hyperbolic embeddings often lead to better representations, but they are harder to visualize. Following [23], we embed the hypernymy relations of the mammals subtree of WordNet in hyperbolic space. We use the open source implementation provided by [23] to train the ten-dimensional embeddings. We use HoroPCA and CO-SNE to visualize the learned embeddings in a two-dimensional hyperbolic space.
Figure 6 shows that compared with HoroPCA, CO-SNE can better preserve the hierarchical and similarity structure of the high-dimensional datapoints. For example, the word and are close to in the CO-SNE embeddings, which is not the case in HoroPCA. The embeddings produced by CO-SNE also more resemble the two-dimensional embeddings as shown in Figure 2b of [23].
 |
 |
| a) HoroPCA | b) CO-SNE |
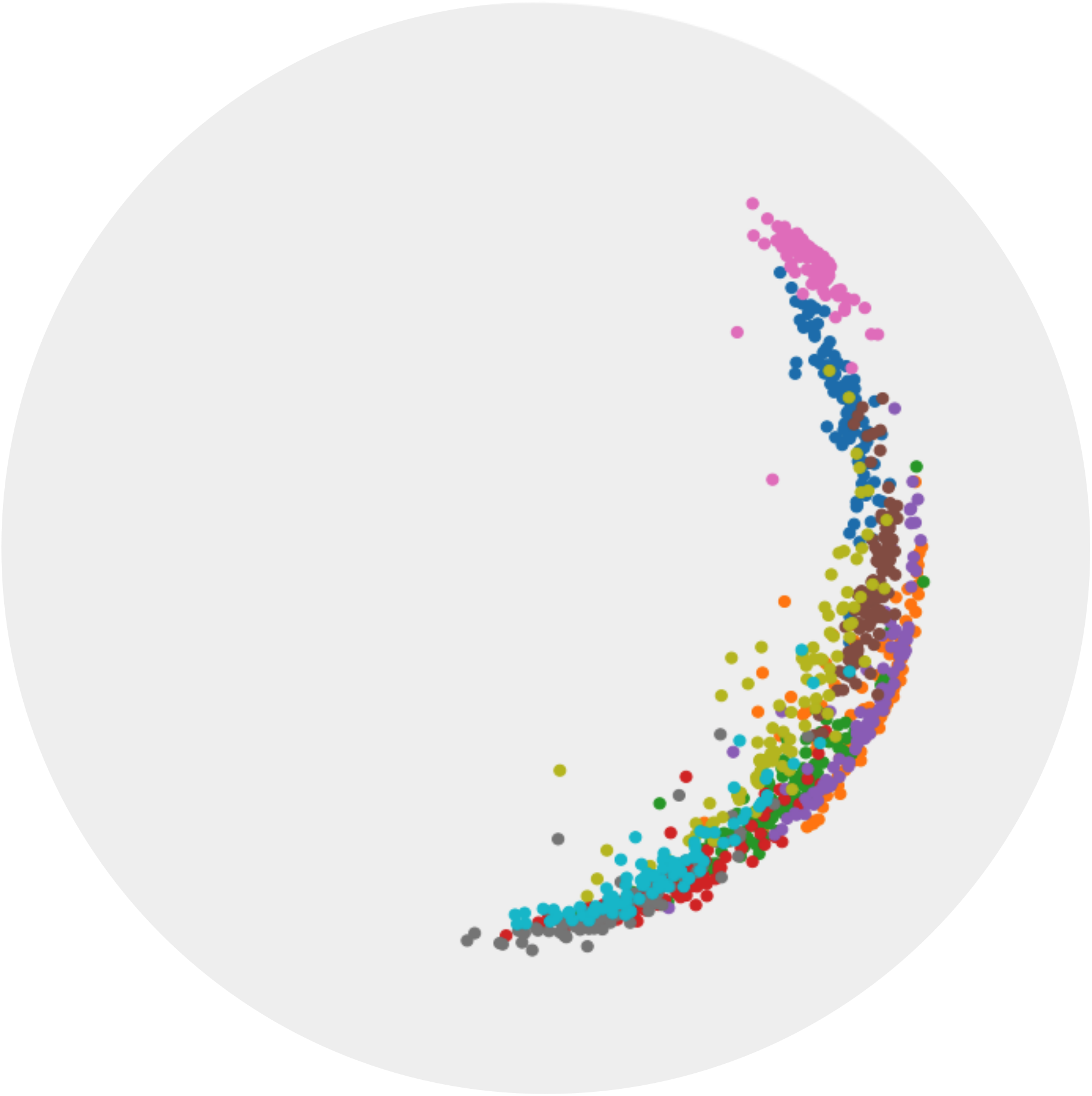
4.4 Features of Hyperbolic Neural Networks
We apply CO-SNE to visualize the embeddings produced by hyperbolic neural networks for supervised image classification. We train a hyperbolic neural network (HNN) [7] with feature clipping [9] on MNIST. The clipping value is 1.0 and the feature dimension is 64. We use HoroPCA and CO-SNE to reduce the dimensionality of the features to two. The full test set of MNIST cannot be used due to the out-of-memory issue of HoroPCA. So for each class, we randomly sample 100 images.
Figure 7 shows the two-dimensional embeddings generated by HoroPCA and CO-SNE. The visualization produced by CO-SNE is significantly better the visualization produced by HoroPCA. In CO-SNE, the classes are well separated and have a clear hierarchical structure. We further train hyperbolic classifiers [7] on the frozen two-dimensional features. We use a learning rate of 0.001 and the number of epoch is 10. The accuracy of the features generated by HoroPCA is 30.2% while the accuracy of the features generated by CO-SNE is 61.2%. This implies that low-dimensional features generated by CO-SNE are more separated and respect the structure of original high-dimensional embeddings.
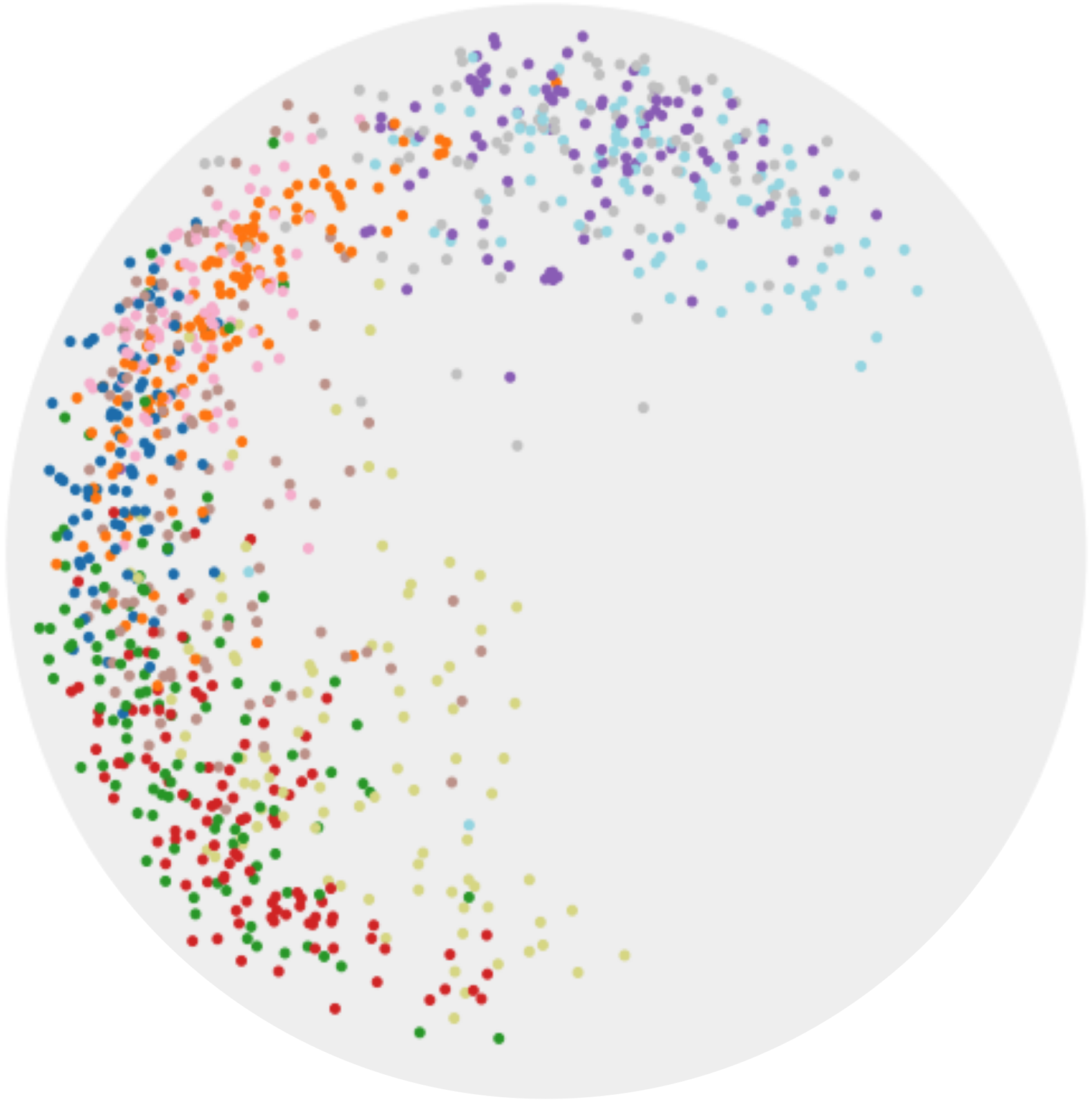 |
 |
| a) HoroPCA | b) CO-SNE |
5 Latent Space of Poincaré VAE
Variational autoencoders (VAEs) [14] is a popular unsupervised learning method. Standard VAEs assume the latent space is Euclidean. [18] extends VAEs by assuming the latent space is hyperbolic. Different from the standard VAEs, Poincaré VAEs can embed tree-like structures more efficiently. For using CO-SNE to visualize the latent space of Poincaré VAEs, we train a Poincaré VAE with a latent dimension of five on MNIST [16] following from [18]. We further generate the latent space representations of 1000 randomly sampled images with the encoder.
Figure 8 shows the visualizations produced by HoroPCA and CO-SNE. Clearly, CO-SNE produces much better visualization than HoroPCA. In particular, we can easily observe the hierarchical and clustering structures in the latent space which are totally distorted in the visualization produced by HoroPCA. Thus, CO-SNE can be used to understand the latent space of Poincaré VAEs and facilitate the development of better unsupervised hyperbolic learning methods.
5.1 Discussion
CO-SNE can be used to visualize hyperbolic datapoints in a two-dimensional hyperbolic space while maintaining the local similarities and hierarchical structure. CO-SNE still suffers from the same weaknesses as t-SNE. In particular, as a general method for dimensionality reduction, the curse of intrinsic dimensionality and the non-convexity, please see [31] for more details. More ablations and results can be found in the Supplementary. In particular, we investigate the effect of hyperparameters for balancing the KL-divergence and the distance loss.
6 Summary
We propose CO-SNE which can be used to visualize hyperbolic data in a two-dimensional hyperbolic space. We use the generalized versions of the normal and Cauchy distributions in hyperbolic space to compute the high-dimensional and the low-dimensional similarities, respectively. We apply CO-SNE to visualize synthetic hyperbolic data, biological data and embeddings learned by supervised and unsupervised representation learning methods. CO-SNE produces much better visualizations than several popular visualization methods.
Acknowledgements. This work was supported, in part, by Berkeley Deep Drive and the National Science Foundation (NSF) under Grant No. 2131111. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the NSF.
7 Supplementary
7.1 Riemannian Geometry
We give a brief overview of Riemannian geometry, for more details please refer to [4]. A Riemannian manifold is a real smooth manifold with a Riemannian metric . The Riemannian metric is a smoothly varying inner product which is defined on the tangent space of . Given and two vectors , we can use the Riemannian metric to compute the inner product as . The norm of is defined as . A geodesic generalizes the notion of straight line in the manifold which is defined as a curve of constant speed that is everywhere locally a distance minimizer. The exponential map and the inverse exponential map are defined as follows: given , and a geodesic of length such that , the exponential map satisfies and the inverse exponential map satisfies .
7.2 Hyperbolic Student’s t-Distribution
Recall the way to define the the Student’s t-distribution which expresses the random variable as,
| (15) |
where is a random variable sampled from a standard normal distribution and is a random variable sampled from a -distribution of degrees of freedom. The -distribution can also be derived from normal distribution. Let , , …, be independent standard normal random variables, then the sum of the squares,
| (16) |
is a -distribution with degrees of freedom. Thus, the probability density function of the -distribution can be derived from the probability density function of the normal distribution which is,
| (17) |
Using Equation 15, we can further derive the probability density function of the Student’s t-distribution,
| (18) |
where is the Beta function.
The probability density function of hyperbolic Cauchy distribution can be derived in a similar way using hyperbolic normal distribution.
| = 0.0 | = 0.01 | = 0.05 | = 0.1 | = 0.2 | |
| = 0 | 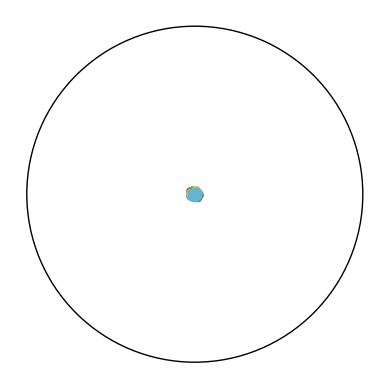 |
 |
 |
 |
 |
| = 5 | 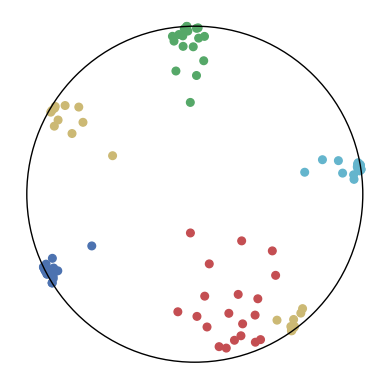 |
 |
 |
 |
 |
| = 10 | 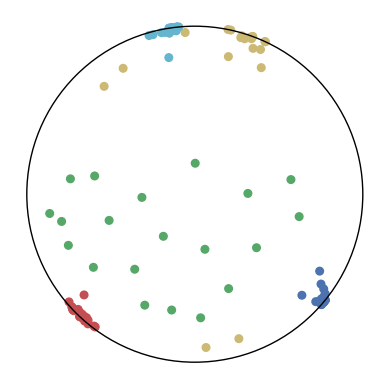 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
| = 20 | 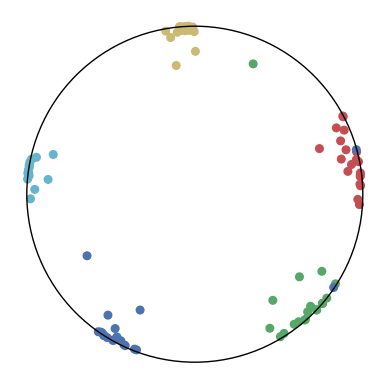 |
 |
 |
 |
 |
7.3 Hyperbolic Cauchy Distribution
Similar to the Student’s t-Distribution, the probability density function of Cauchy distribution can derived from the probability density function of the normal distribution. In particular, let and be independent standard normal random variables, then is a Cauchy random variable. The probability density function of Cauchy distribution can be written as,
| (19) |
The probability density function of hyperbolic Cauchy distribution can be derived in a similar way using hyperbolic normal distribution.
The repulsion and attraction forces in CO-SNE depend on the term in Equation 12 of the main text. is fixed during training which depends on the distribution of the high-dimensional datapoints. To create more repulsion forces between two close low-dimensional embeddings and , we aim at increasing the probability that the point would select the point as its neighbor (i.e., ). By using a small in hyperbolic Cauchy distribution, the distance between and is scaled up. When the point is fixed, the probability of selecting as a neighbor (i.e., ) is scaled up relatively to some point which is far away from . As a result, can potentially become negative. This creates additional repulsion forces to push the low-dimensional points apart.
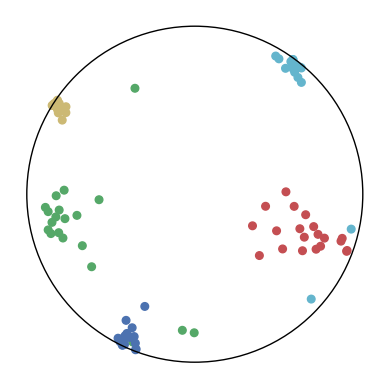
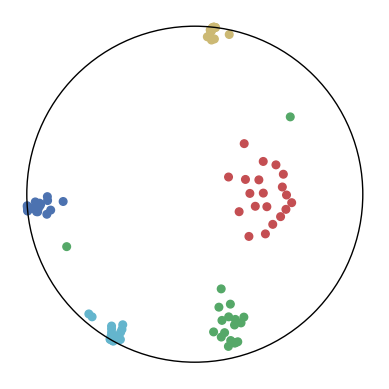
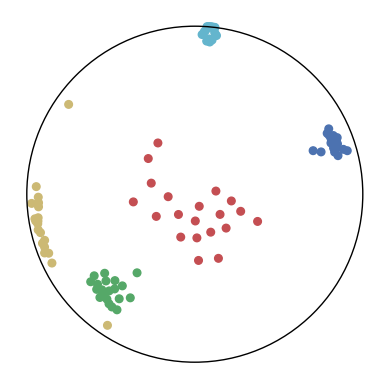
7.4 The Effect of and
Recall the objective function of CO-SNE,
| (20) |
and are used to balance the KL-divergence and the distance loss and can be regarded as the learning rates. For ablation studies on the effect of and , we reuse the settings in Section 4.1 of the main text.
We consider different settings of and to investigate the effect of the KL-divergence and the distance loss. The results are shown in Figure 9. We have several observations from the results.
-
1.
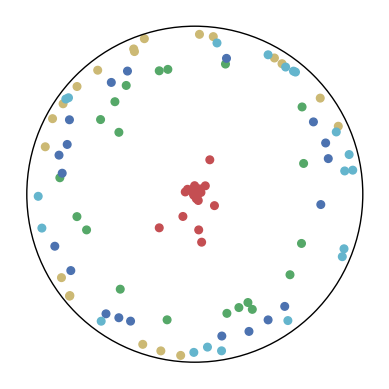
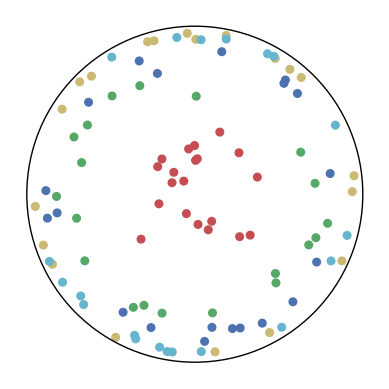
In the first row, . This means that only the distance loss is presented. We can observe that the low-dimensional embeddings can only approximate the magnitude of the high-dimensional datapoints but not the similarity structure.
-
2.
In the first column, . This means that only the KL-divergence is presented. We can observe that the low-dimensional embeddings can only preserve the similarity structure in the high-dimensional datapoints but not the hierarchical information.
-
3.
In other cases, we can observe that a larger can better preserve the hierarchical structure in the high-dimensional datapoints but may distort the similarity structure. A larger may also lead to a bad visualization of the similarity structure since the KL-divergence might diverge. Nevertheless, CO-SNE is robust to wide choices of and . Both the KL-divergence and the distance loss are important for producing good visualization.
References
- [1] Gregorio Alanis-Lobato, Pablo Mier, and Miguel A Andrade-Navarro. Efficient embedding of complex networks to hyperbolic space via their laplacian. Scientific reports, 6(1):1–10, 2016.
- [2] Sanjeev Arora, Wei Hu, and Pravesh K Kothari. An analysis of the t-sne algorithm for data visualization. In Conference On Learning Theory, pages 1455–1462. PMLR, 2018.
- [3] Silvere Bonnabel. Stochastic gradient descent on riemannian manifolds. IEEE Transactions on Automatic Control, 58(9):2217–2229, 2013.
- [4] Manfredo Perdigao do Carmo. Riemannian geometry. Birkhäuser, 1992.
- [5] Ines Chami, Albert Gu, Dat P Nguyen, and Christopher Ré. Horopca: Hyperbolic dimensionality reduction via horospherical projections. In International Conference on Machine Learning, pages 1419–1429. PMLR, 2021.
- [6] Hyunghoon Cho, Benjamin DeMeo, Jian Peng, and Bonnie Berger. Large-margin classification in hyperbolic space. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 1832–1840. PMLR, 2019.
- [7] Octavian-Eugen Ganea, Gary Bécigneul, and Thomas Hofmann. Hyperbolic neural networks. arXiv preprint arXiv:1805.09112, 2018.
- [8] Caglar Gulcehre, Misha Denil, Mateusz Malinowski, Ali Razavi, Razvan Pascanu, Karl Moritz Hermann, Peter Battaglia, Victor Bapst, David Raposo, Adam Santoro, et al. Hyperbolic attention networks. arXiv preprint arXiv:1805.09786, 2018.
- [9] Yunhui Guo, Xudong Wang, Yubei Chen, and Stella X Yu. Free hyperbolic neural networks with limited radii. arXiv preprint arXiv:2107.11472, 2021.
- [10] Mangesh Gupte, Pravin Shankar, Jing Li, Shanmugauelayut Muthukrishnan, and Liviu Iftode. Finding hierarchy in directed online social networks. In Proceedings of the 20th international conference on World wide web, pages 557–566, 2011.
- [11] Joy Hsu, Jeffrey Gu, Gong-Her Wu, Wah Chiu, and Serena Yeung. Learning hyperbolic representations for unsupervised 3d segmentation. arXiv preprint arXiv:2012.01644, 2020.
- [12] Ian T Jolliffe and Jorge Cadima. Principal component analysis: a review and recent developments. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 374(2065):20150202, 2016.
- [13] Valentin Khrulkov, Leyla Mirvakhabova, Evgeniya Ustinova, Ivan Oseledets, and Victor Lempitsky. Hyperbolic image embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6418–6428, 2020.
- [14] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- [15] Anna Klimovskaia, David Lopez-Paz, Léon Bottou, and Maximilian Nickel. Poincaré maps for analyzing complex hierarchies in single-cell data. Nature communications, 11(1):1–9, 2020.
- [16] Yann LeCun. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/.
- [17] Qi Liu, Maximilian Nickel, and Douwe Kiela. Hyperbolic graph neural networks. arXiv preprint arXiv:1910.12892, 2019.
- [18] Emile Mathieu, Charline Le Lan, Chris J Maddison, Ryota Tomioka, and Yee Whye Teh. Continuous hierarchical representations with poincar’e variational auto-encoders. arXiv preprint arXiv:1901.06033, 2019.
- [19] Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426, 2018.
- [20] Leland McInnes, John Healy, Nathaniel Saul, and Lukas Grossberger. Umap: Uniform manifold approximation and projection. The Journal of Open Source Software, 3(29):861, 2018.
- [21] George A Miller. Wordnet: a lexical database for english. Communications of the ACM, 38(11):39–41, 1995.
- [22] Yoshihiro Nagano, Shoichiro Yamaguchi, Yasuhiro Fujita, and Masanori Koyama. A wrapped normal distribution on hyperbolic space for gradient-based learning. In International Conference on Machine Learning, pages 4693–4702. PMLR, 2019.
- [23] Maximilian Nickel and Douwe Kiela. Poincar’e embeddings for learning hierarchical representations. arXiv preprint arXiv:1705.08039, 2017.
- [24] Andre Olsson, Meenakshi Venkatasubramanian, Viren K Chaudhri, Bruce J Aronow, Nathan Salomonis, Harinder 1 Singh, and H. Leighton Grimes. Single-cell analysis of mixed-lineage states leading to a binary cell fate choice. Nature, 2016.
- [25] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
- [26] Xavier Pennec. Intrinsic statistics on riemannian manifolds: Basic tools for geometric measurements. Journal of Mathematical Imaging and Vision, 25(1):127–154, 2006.
- [27] Sam T Roweis and Lawrence K Saul. Nonlinear dimensionality reduction by locally linear embedding. science, 290(5500):2323–2326, 2000.
- [28] Ryohei Shimizu, Yusuke Mukuta, and Tatsuya Harada. Hyperbolic neural networks++. arXiv preprint arXiv:2006.08210, 2020.
- [29] Joshua B Tenenbaum, Vin De Silva, and John C Langford. A global geometric framework for nonlinear dimensionality reduction. science, 290(5500):2319–2323, 2000.
- [30] Abraham Albert Ungar. A gyrovector space approach to hyperbolic geometry. Synthesis Lectures on Mathematics and Statistics, 1(1):1–194, 2008.
- [31] Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine learning research, 9(11), 2008.
- [32] Melanie Weber, Manzil Zaheer, Ankit Singh Rawat, Aditya Menon, and Sanjiv Kumar. Robust large-margin learning in hyperbolic space. arXiv preprint arXiv:2004.05465, 2020.
- [33] Zhenzhen Weng, Mehmet Giray Ogut, Shai Limonchik, and Serena Yeung. Unsupervised discovery of the long-tail in instance segmentation using hierarchical self-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2603–2612, 2021.
- [34] Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun. Graph neural networks: A review of methods and applications. AI Open, 1:57–81, 2020.