Coarse reduced model selection for nonlinear state estimation
Abstract
State estimation is the task of approximately reconstructing a solution of a parametric partial differential equation when the parameter vector is unknown and the only information is linear measurements of . In [3] the authors proposed a method to use a family of linear reduced spaces as a generalised nonlinear reduced model for state estimation. A computable surrogate distance is used to evaluate which linear estimate lies closest to a true solution of the PDE problem.
In this paper we propose a strategy of coarse computation of the surrogate distance while maintaining a fine mesh reduced model, as the computational cost of the surrogate distance is large relative to the reduced modelling task. We demonstrate numerically that the error induced by the coarse distance is dominated by other approximation errors.
1 Introduction
Complex physical systems are often modelled by a parametric partial differential equation (PDE). We consider the general problem of the form
| (1) |
where is an elliptic second order operator, is an appropriate Hilbert space. The problem is defined on a physical domain , and the parameter is within a parameter domain , typically a subset of where might be large. Each parameter is assumed to result in a unique solution but we mostly suppress the spatial dependence and write . We denote all -norms by and inner-products , and use an explicit subscript if they are from a different space.
In practical modelling applications it is often computationally expensive to produce a high precision numerical solution to the PDE problem (1). To our advantage however, the mapping is typically smooth and compact, hence the set of solutions over all parameter values will be a smooth manifold, possibly of finite intrinsic dimension. We define the solution manifold as follows, assuming from here that it is compact,
The methods proposed in this paper extend on reduced basis approximations. A reduced basis is a linear subspace of moderate dimension . We use the worst-case error as a benchmark, defined as
| (2) |
where is the orthogonal projection operator on to . There are a variety of methods to construct a reduced basis with desirable worst-case error performance, and here we concentrate on greedy methods that select points in which become the basis for . We discuss these methods further in §1.1.
A reduced basis can be used to accelerate the forward problem. One can numerically solve the PDE problem for a given parameter by using directly in the Galerkin method, making the numerical problem vastly smaller while retaining a high level of accuracy. A thorough treatment of the development of reduced basis approximations is given in [5].
In this paper we are concerned with inverse problems. In this setting it is assumed that there is some unknown true state (which could correspond to the state of some physical system), and we do not know the parameter vector that gives this solution. Instead, we make do with a handful of linear measurements . These measurements are used to make some kind of accurate reconstruction of (state estimation) or a guess of the true parameter (parameter estimation).
The Parametrized Background Data Weak (PBDW) approach introduced in [6] gives a straightforward procedure for finding an estimator of the true state , using only the linear measurement information and a reduced basis . One limitation however is that the estimator error is bounded from below by the Kolmogorov -width given by
| (3) |
where the infimum is taken over all dimensional linear spaces in . The -width is known to converge slowly for many parametric PDE problems.
We will review methods for constructing a family of local linear reduced models and a nonlinear estimator using a surrogate distance model selection procedure. We propose the use of coarser finite element meshes to perform this selection. This coarse selection strategy is motivated by the observation in [3] that the model selection is by far the most computationally costly component in the nonlinear estimation routine. Finally in §4 we examine numerical examples of surrogate distances over different mesh widths, and see that they make insubstantial impacts to the nonlinear estimator.
1.1 Linear reduced models
A reduced basis is a linear space of the form , where the . The parameter values are typically chosen in some iterative greedy procedure to try and minimise at each step.
We can define a greedy procedure follows: given of dimension and a finite subset of , to produce an -dimensional reduced space we find the parameter which gives us the largest . We then augment the space with . This simple strategy, in some cases [1], yields a reduced basis that is optimal with regards to the Kolmogorov -width of . In this setting the quantity
| (4) |
serves as a reasonable and calculable estimate of , as shown in [4].
In practice, we also allow to be an affine space, with an offset , such that
Typically we take to be an approximate barycenter of . From here we will use the term reduced space or model rather than basis.
With chosen, we now consider the state estimation problem. We have pieces of linear data for of the unknown state , and the . We assume we know the form of the functionals and hence the Riesz representers for which . These define a measurement space and the measurement vector of :
Note here that we assume no noise in our measurements, but allowing for random noise is straightforward and has been considered in [6, 2].
The PBDW approach, developed in [6], seeks a reconstruction candidate or estimator that is close to , but that agrees with the measurement data, that is . They define an estimator
which can be calculated through a set of normal equations of size , using the cross-Grammian matrix of the bases of and . Given only the measurement information , the measurement space , and the reduced space , this estimator is an optimal choice [2]. The estimator lies in the subspace .
We require that for this reconstruction algorithm to be well posed (otherwise there are infinitely many candidates for ), which in turn requires that . This dimensionality requirement is reflected in the error analysis. We define an inf-sup constant
| (5) |
which is the inverse of the cosine of the angle between and and we have . For to be finite, we require . The inf-sup constant plays the role of a stability constant for our linear estimator as we have the well known bound
as deomstrated in [2]. From the definitions we have , hence this reconstruction error can at best be the -width of .
2 Nonlinear reduced models
A fundamental drawback of linear reduced models is the slow decay of the Kolmogorov -width for a wide variety of PDE problems. To circumvent this limitation, a framework for non-linear reduced models and their use for state estimation was presented in [3]. The proposal involves determining a partition of the manifold
and producing a family of affine reduced space approximations to each portion . Each space has dimension , requiring for well-posedness.
Given any target and it is possible with large enough to determine a partition and family of reduced spaces that satisfies
| (6) |
in which case we say the family is -admissible. A slightly looser criteria on the partition can also be satisfied: given some , we say the family is -admissible if for all . The existence of both and -admissible families follow from the compactness of , and a full demonstration can be found in [3].
In practice one may construct a -admissible family in the following way. Say we are given a partition of the parameter space with , and the associated partition of the manifold . We have a reduced space , produced by a greedy algorithm on each . With each we have an associated error estimate . We can pick the the largest , with index say, and we split the cell in half for each parameter coordinate direction , resulting in two reduced spaces and for each split direction. We take the split direction to be the one with the smallest maximum error , and we enrich the family with the two new reduced spaces, making sure to remove from the collection. More details of the splitting procedure can be found in [3].
2.1 Surrogate reduced model selection
Based on a measurement , each affine reduced space has an associated reconstruction candidate that is found through the PBDW method,
| (7) |
If we happen to know which that the true state originates from some , then we would best use as our estimator. In this scenario we would have an error bound of . This information about the true state is not available in practice, so we require some other method to determine which candidate to choose.
Consider a surrogate distance from to that satisfies the uniform bound for ,
| (8) |
If this surrogate distance is computable, then we can use it to find a surrogate selected estimator by choosing
| (9) |
noting that as there is a dependence on we can write . We define an error benchmark
This quantity can take in to account errors from model bias, and we have the following result.
Theorem 2.1.
Given a -admissible family of affine reduced spaces , the estimator based on the surrogate selection (9) has worst-case error bounded above by
| (10) |
where depends only on the uniform bounds of the surrogate distance.
The proof is detailed in Theorem 3.2 of [3]. Note that even given some optimal nonlinear reconstruction algorithm, our best possible error would be , and it is not bounded from below by . We remark also that .
3 Affine elliptic operators
Say the operator in (1) is uniformly bounded in with uniformly bounded inverse, that is for some we have
| (11) |
Then we can show that for any the residual of the PDE,
satisfies the uniform bound . If we define the following,
then we have arrived at a surrogate distance that satisfies the uniform bounds of (8). Using this surrogate in the selection (9) to define , we have a nonlinear reconstruction algorithm with the error guarantees of (10).
We now make the further assumption that the operator and source term have affine dependence on , that is
The residual can be calculated using representers in . We define as member of that satisfies
| (12) |
and now write to denote the representer of the overall residual problem. The residual is equal to , and determining the surrogate distance is a quadratic minimisation problem
This leads to a constrained least squares problem that can be solved using standard optimisation routines, using the values for .
3.1 Finite element residual evaluation
In practice these calculations take place in a finite element space that is the span of polynomial elements on a triangulation of width . In this setting the residual is where and the satisfy the variational problem
| (13) |
Naturally we define . Note that when we subtract (12) from (13) we obtain for all , meaning that .
We write to be the minimiser selected in , and the equivalent for . In general , but we have
| (14) |
where in the last step we have used the fact that
Thus the convergence of to depends on the finite element convergence of solutions to . This convergence is determined by the regularity of , which depends on the smoothness of the data and the so called Riesz lift implied in the variational problem (12).
Recall that in (1) is a second order symmetric elliptic operator. If we assume homogeneous Dirichlet boundary conditions on and that , then a natural choice for our ambient space is the Sobolev space , with . In this setting the solutions of (12) are the weak solutions of the Poisson problem with homogeneous Dirichlet boundary conditions,
| (15) |
where we have written to denote the Laplacian in the spatial variables, recalling that we have the unwritten spatial dependence in .
In our surrogate model selection, depends on . This estimator lies in . As is the span of some solutions selected from , the smoothness of will depend on the smoothness of all solutions of the PDE problem and of the measurement functionals .
The convergence of to in the weak form of (15) is well known in a wide variety of settings, for example we have the classical result
which would be applicable in a wide variety of situations. Under these circumstances we thus have that .
3.2 Coarse surrogate evaluation
Say we construct a family of reduced spaces, , where each family , and the solutions are numerically calculated with respect to a triangulation with mesh-width . Our estimators will be in .
We may consider to be our fine mesh, and nominate another triangulation with to be a coarse mesh. We can use this coarse mesh to compute the surrogate distance, noting that may be orders of magnitude faster to compute than the fine mesh equivalent. This will necessarily introduce an inaccuracy in the surrogate selection, however we maintain the high fidelity of the fine mesh reduced space approximations .
If is a fine mesh that contains in the sense that , then the variational problem (13) straightforward as we can calculate the inner-product based on the known relationships between the basis elements of and . Furthermore the size of the error , and hence , is bounded above by a constant times through the same reasoning as in (14).
4 Numerical tests
We present two separate studies of the surrogate as evaluated in finite element spaces. On the unit square we consider the PDE
where our parametric diffusivity field is given by . Here the denote squares of side length that subdivide the unit square in to 16 portions, and is the indicator function on . The parameter range is the unit hypercube , and the coefficients are or , meaning that , but when the can become closer to 0 hence the PDE problem can lose ellipticity.
We perform space discretisation by the Galerkin method using finite elements to produce solutions , with a fine triangulation on a regular grid of mesh size . In the tests that follow, we will evaluate with coarse meshes of size with .
We generate training sets to compute the reduced models, and test sets on which we test the reconstruction algorithms. The training set is taken to be the collection of PDE solutions for random samples drawn independently and uniformly on . The test set is created from independent parameter samples that are distinct from the training set samples.
In our test the measurement space is given by a collection of measurement functionals that are local averages in a small area which are boxes of width , each placed randomly in the unit square.
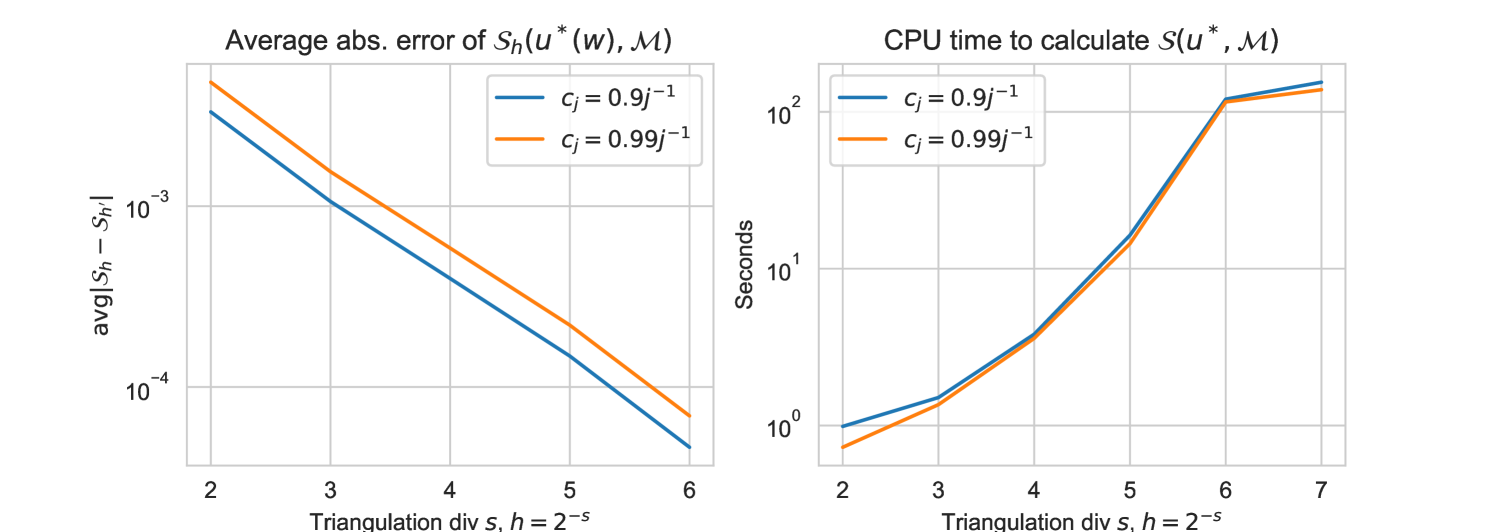
In our first test we compute a single reduced space using the greedy procedure on . For each test candidate we calculate . In Figure 2 we plot the difference between the coarse and fine surrogate distances . We note that this error is significantly dominated by the calculated value of the estimator error (4), as we found for and for . This dominates the errors presented in Figure 2 significantly.
Furthermore, we see a linear relationship in the right hand in Figure 2. The linear best fit of and has slope , which implies that on average
For the second test we examine the impact of using the coarse surrogate for model selection. We build the -admissible families as outlined in §2 using the greedy splitting of . Note that at each point the cells are rectangular, which we can split in half in coordinate directions. We split the parameter space 7 times, resulting in local reduced spaces.
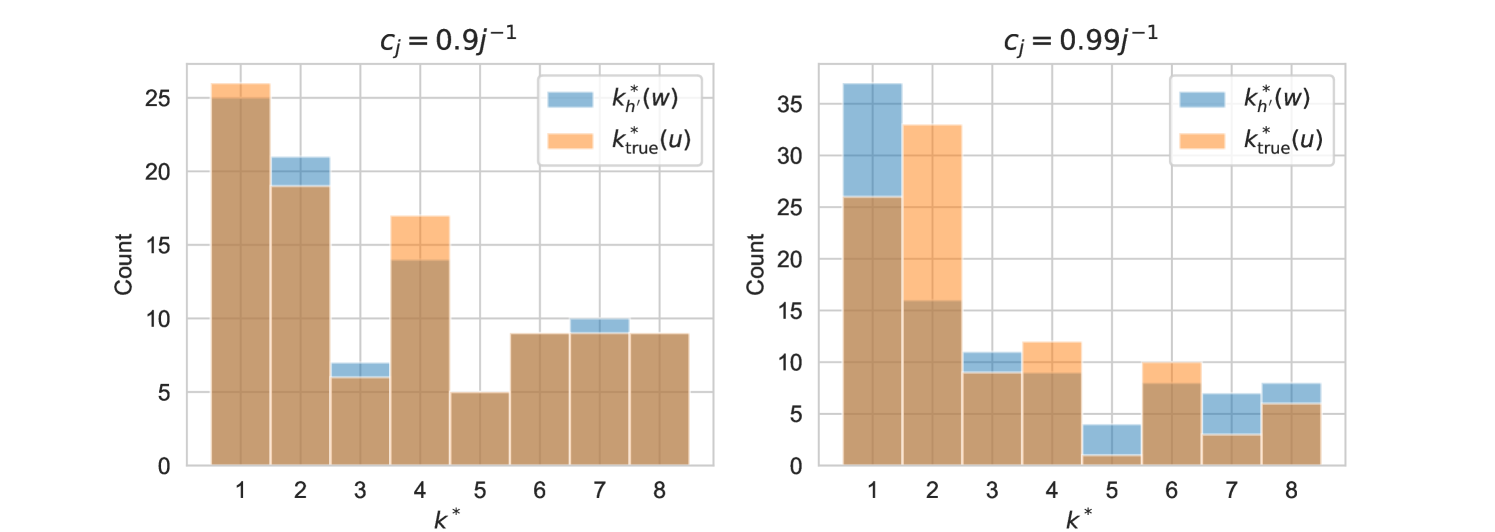
For each test candidate we have possible reconstructions . We use the coarse surrogate in the model selection (9), writing to make the dependence on and clear, and we inspect how often it agrees with the fine selection for all test points . We can also compare compare this to and the “true” selection for which .
Table 1 demonstrates that agrees with the vast majority of the time from onwards, in both cases for . We also see that the fine selection agrees with the true selection 77 times out of 100 for and 64 times for , that is, it picks the estimator that is trained on the portion of manifold that originated from. Out of interest we also plot the histogram of selections and , recalling that they are a number in . We see broadly similar patterns in the reduced model selection. Given the CPU time savings that we see in Figure 2, we conclude that model selection through a coarse surrogate distance is a worthwhile numerical strategy.
| Mesh width | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 97 | 100 | 100 | 100 | 100 | 88 | 94 | 96 | 98 | 100 | |
| 74 | 77 | 77 | 77 | 77 | 58 | 59 | 61 | 65 | 64 | |
References
- [1] Peter Binev, Albert Cohen, Wolfgang Dahmen, Ronald DeVore, Guergana Petrova, and Przemyslaw Wojtaszczyk. Convergence Rates for Greedy Algorithms in Reduced Basis Methods. SIAM Journal on Mathematical Analysis, 43(3):1457–1472, January 2011. Publisher: Society for Industrial and Applied Mathematics.
- [2] Peter Binev, Albert Cohen, Wolfgang Dahmen, Ronald DeVore, Guergana Petrova, and Przemyslaw Wojtaszczyk. Data assimilation in reduced modeling. SIAM/ASA Journal on Uncertainty Quantification, 5(1):1–29, 2017.
- [3] Albert Cohen, Wolfgang Dahmen, Olga Mula, and James Nichols. Nonlinear reduced models for state and parameter estimation. arXiv:2009.02687 [cs, math], November 2020. arXiv: 2009.02687.
- [4] Albert Cohen, Dahmen Wolfgang, Ronald DeVore, and James Nichols. Reduced basis greedy selection using random training sets. ESAIM: Mathematical Modelling and Numerical Analysis, January 2020.
- [5] Jan S. Hesthaven, Gianluigi Rozza, and Benjamin Stamm. Certified Reduced Basis Methods for Parametrized Partial Differential Equations. SpringerBriefs in Mathematics. Springer International Publishing, 2016.
- [6] Yvon Maday, Anthony T. Patera, James D. Penn, and Masayuki Yano. A parameterized-background data-weak approach to variational data assimilation: formulation, analysis, and application to acoustics. International Journal for Numerical Methods in Engineering, 102(5):933–965, May 2015.