Coded Alternating Least Squares for Straggler Mitigation in Distributed Recommendations
Abstract
Matrix factorization is an important representation learning algorithm, e.g., recommender systems, where a large matrix can be factorized into the product of two low dimensional matrices termed as latent representations. This paper investigates the problem of matrix factorization in distributed computing systems with stragglers, those compute nodes that are slow to return computation results. A computation procedure, called coded Alternative Least Square (ALS), is proposed for mitigating the effect of stragglers in such systems. The coded ALS algorithm iteratively computes two low dimensional latent matrices by solving various linear equations, with the Entangled Polynomial Code (EPC) as a building block. We theoretically characterize the maximum number of stragglers that the algorithm can tolerate (or the recovery threshold) in relation to the redundancy of coding (or the code rate). In addition, we theoretically show the computation complexity for the coded ALS algorithm and conduct numerical experiments to validate our design.
I Introduction
Matrix factorization is one of the most successful algorithms for many machine learning tasks [1]. For example, recommender systems have played an increasingly important role in the field of Internet business in recent years. Companies such as Amazon and Alibaba have used recommender systems to promote sales. Netflix, HBO, and YouTube have also used video recommender systems to recommend videos to target users. Since the Netfilx Prize competition held by Netflix [2], the accuracy of recommendations have been greatly improved by matrix factorization algorithms.
With large amounts of data available nowadays, distributed computation is an important approach to deal with large scale data computations. Straggler nodes are one of the most prominent problem in distributed computing systems [3, 4, 5, 6, 7, 8]. Straggler is a node that runs much slower than others, which may be caused by various software or hardware issues such as hardware reliability, or network congestion. As a result, straggler mitigation in distributed matrix multiplication - a basic building block for many machine learning algorithms - is crucial and has been extensively studied in the literature. Among them, coding techniques have attracted more attention recently in the information theory community, for example, Entangled Polynomial Code (EPC) [9].
In this paper, we investigate the problem of large scale matrix factorization through distributed computation systems. Consider a data matrix of size , where the dimensions and are typically very large so that each individual computing node can only deal with computations over matrices with dimensions much smaller than . We aim to factorize approximately into the product , where the dimensions of and are and respectively for some latent dimension . The factorization of can be formalized as minimizing for some , where is the Frobenius norm.
Alternating Least Squares (ALS) is an efficient iterative algorithm to find out a solution by updaing and alternatively, where in each iteration, the algorithm updates with the current estimate of and then updates with the updated estimate of . We propose a distributed implementation of the ALS algorithm, with the ability to tolerate straggler nodes. In distributed ALS, matrix multiplication is a key building block and we adopt the EPC as a means to realize matrix multiplication, however, making special tailoring to the ALS algorithms where multiple matrix multiplications are involved at each iteration. To speed up the iteration, we first obtain the formulas that update from the current estimate of or update from the current estimate of . Based on the new update formulas, we only need to update either or , since the estimates of and are connected by the original ALS formulas.
Therefore, we propose a coded ALS framework as follows:
-
1.
Pre-computation: computing the transformed data matrix (or ) through the distributed computing system;
-
2.
Iterative computation: update (or ) through the distributed computing system;
-
3.
Post-computation: compute the estimate of (or ) from the estimate of (or ).
In this computation framework, the bottleneck happens in the iterative computation phase, as the pre- and post- computations only need to be carried out once. In the iterative computations, both and are partitioned into submatrices along the larger dimension (i.e., or ), and the transformed data matrix or is partitioned in both row and column dimensions and stored at the workers in coded form. We show that, with given partition parameters, the recovery threshold to compute matrix multiplications using EPC code is optimal among all linear codes (for matrix multiplication). We characterize the relationship between the coding redundancy and the recovery threshold. In addition, we provide the computation complexity analysis for the proposed coded ALS algorithm. Finally, we conduct numerical experiments to validate our proposed design.
I-A Related Work
The slow machine problem has been existed in distributed machine learning for a long time[10]. To tackle this, many different approaches have been proposed.In synchronous machine learning problems, solutions using speculative executions [11, 12]. However, this types of methods need much more communication time and thus perform poor.
Adding redundancy is another effective way to cope with straggler problems. With each worker bear more information than it was supposed to, the final result could be recovered by these newly added extra information. In [13], the idea of using coded to solve straggler problems in distributed learning tasks. However, this work only focus on matrix multiplication and data shuffling. Then more and more research have been put into this area. One typical type of approach is data encoding, where the encoded data is stored in different workers. Works like [13, 4, 3] encodes data as the linear combination of original data and recover the result according to the encoding matrix.
Another type is to encode the intermediate parameter of this code. A typical type of this coding is the gradient coding[14]. Many gradient based methods have been proposed within these years like [15, 16, 8]. However, these works focus only on gradient based distributed learning tasks.
[17] Using coding in iterative matrix multiplication, which shares a similar application scenario with this paper.
I-B Statement of Contributions
In this work, we make the following contributions. 1) Propose a coding scheme for large scale matrix decomposition problem to help with the recommender system. 2) Analysis of the complexity of this scheme and the running time of the coded distributed computation. 3) Solve the problem that the data partitions are too big when the numbers of columns and rows of the data matrix are both large.
Notation
Throughout the paper, we use to denote the set , where is a positive integer. We denote by the Frobenius norm of the matrix . For easy of presentation, we will simply write as when there is no confusion.
II Problem Formulation
II-A Matrix Factorization via ALS
Given a data matrix and a latent dimension , we consider the matrix factorization problem to learn the dimensional representations and as follows:
| (1) |
For example, the matrix factorization can be used for the recommendation problem, where represents the number of users; represents the number of items; entry of the data matrix represents the rating (or preference) of user to item . This rating can be approximated by the inner product of the latent vector of user and the latent vector of item , where and are the -th row of and the -th row of , respectively. The problem is to find these representations and , so as to minimize the differences . Note that parameters are often large and the latent dimension .
Since this matrix factorization problem is non-convex, it is in general not easy to find the optimal solution. A well known iterative algorithm to solve this problem is the ALS algorithm, which iterates between optimizing for given and optimizing for given . The update formulas for and are given as follows:
| (2) | |||||
| (3) |
where and are the estimates of and in the -th iteration. In (2) is fixed, is updated and fixed to be used in (3), updating alternatively.
II-B Distributed Matrix Factorization with Stragglers
For large dimensions , the updates in (2) and (3) are unpractical in a single computation node. We consider solving the matrix factorization problem via a ‘master-worker’ distributed computing system with a master and workers. There may be some straggling workers (i.e., stragglers) among these workers which may perform the calculations slow and affect the system performance.
We consider a coding aided framework to solve this matrix factorization problem.
Data matrix encoding and distribution: we first encode the data matrix to another matrix via some encoding function and the encoded data matrix will be distributed among workers. For worker , the encoding and data distribution can be represented as via some function .
Iterative calculation and model aggregation: the calculation is carried out in an iterative manner. At each round , each worker aims to calculate the model parameters and send model parameters to the master, namely, , where is the local computation function of worker at round . However, there are a set of stragglers among these workers that either cannot calculate the result in time or cannot make successful transmissions. The server aggregates these model parameters from non-straggling workers in to get a new model, namely, , where is the decoding and aggregation function at round . After that, the server returns the updated parameter to all workers via a lossless broadcast channel.
Our aim is to design a coded ALS scheme to solve the distributed matrix factorization problem111Here, we mean the coded ALS scheme achieves the same computation result as the centralized counterpart in Eqs. (2) and (3). when there are no more than stragglers among the workers ().
Moreover, we would like to study how the coding scheme performs and the computation complexity with respect to the straggler mitigation capability . In particular, let denotes the the number of elements in matrix . We define the redundancy of coding (coding rate) as the ratio between the coded matrix size and the original data matrix size .
We then ask what is the relationship between and and how this further affects the computation complexity.
III Distributed Computation of ALS Algorithm
In this section, we will present our framework to implement the ALS algorithm in distributed computing systems.
III-A Preliminary: Entangled Polynomial Code
Entangled Polynomial Code (EPC) [9] is an efficient linear code [9, Definition 1] to compute the large scale matrix multiplication in distributed computation systems with stragglers.
The entangled polynomial code computes via distributed worker nodes. Each worker node stores a coded sub-matrix based on the polynomials
| (4) | |||||
| (5) |
Specially, let be distinct numbers in . Each worker stores and , and computes and returns . It was shown in [9] that all the sub-matrices of the product , i.e.,
| (6) |
are enclosed in the polynimal , which has degree . As a result, the master can decode via interpolation from any responses of worker nodes, where
| (7) |
Given the parameters , the of responses that the master needs to decode is called recovery theoreshold. It was showed in [9, Theorem 2] that, when or , the EPC achieves best recovery threshold among all linear code.
III-B Direct Update Formulas
Unlike the traditional way (2) and (3) to update and , here we choose to update either and only based on the following new update formulas. Note that here each iteration consists of several rounds.
Lemma 1.
In ALS algorithm, let be the estimates of and in the -th iteration, for each ,
| (8) | |||
| (9) |
Proof:
E.q. (8) can be obtained by plugging E.q. (2) into E.q. (3), and E.q. (9) can be obtained by plugging E.q. (3) (with the subscript replaced by ) into E.q. (2). For detailed proof, please refer appendix B
∎
The main computation iterations either update the estimate of according to (8) or update the estimate of according to (9) instead of both in traditional ALS. Before the iteration, the matrix or is computed as a pre-computation to update or . After obtaining the estimate of or , a post-computation is used to compute the other factor via the relations (2) or (3).
III-C Distribute ALS Algorithm
In this subsection, we describe our algorithm in detail. The whole computation consists of three phases.
III-C1 Pre-computation
If , the master aims to compute in order to update the estimate of according to (8); or else, the master aims to compute according to the estimate of according to (9). This can be done by using the standard EPC code, with appropriate parameters . For clarity, in the following, we will denote matrix to be computed by , and the factor that to be updated by i.e.,
| (12) | |||||
| (15) |
To have to smaller size of data to compute, we choose to be smaller one within and . We choose in a similar way. Notice that, by (8) and (9), let be the estimate in the -th iteration, then the update formula is
| (16) |
where is an symmetric matrix given by (12), , and is of size .
III-C2 Iterative Computation of
To implement the ALS algorithm in the distributed computing system, the matrix is partitioned into equal-size submatrices, each of size for some positive integer , i.e.,
| (21) |
In accordance with the partition in (21), is partitioned into equal-size sub-matrices of size , i.e.,
| (25) |
The bottleneck of updating the estimate of according to (16) is three matrix product computations: , and , and the product operation between the matrics and , which need to be computed at the distributed worker nodes222Notice that, as the dimensions of the matrix and are both , the inverse operation in and the product operation between and can be calculated at the master..
For clarity, we define the following polynomials:
| (26) |
where represents the encoded version of matrix .
For any , partition in the same manner as in (25), i.e., where , define
| (27) | |||||
| (28) |
Let be distinct real numbers. The system operates as follows:
Initially, is generated randomly according to some continuous distribution. The master sends , and to the worker for each .
In each iteration
-
1.
Each worker computes and , then responds the results to the master;
-
2.
By EPC, receiving any results among
(29) the master can decode the matrix
(30) Receiving any results among
(31) the master can decode the matrix
(32) The master then sends to worker for each ;
-
3.
Each worker replace the matrix with the matrix . Then it computes and sends the result to the master.
-
4.
Receiving any responses among
(33) the master decodes , and then the master computes
(34) and sends to all the worker nodes.
-
5.
Each worker computes
(35) and response to the master.
-
6.
With any responses among
(36) the master decodes
(37) Then the master sends and to worker for each .
-
7.
Each worker updates and with and respectively, and then starts the -th iteration.
The procedure iterates until converges. Now, we claim that the above iterative procedure is correct.
In fact, it is easy to verify (16) by (30), (32), (34) and (37). We only need to show the following facts:
-
a)
With any responses in (29), the master can decode . Notice that, the polynomials and are created according the and respectively, with parameters . Thus, it directly follows from the result of EPC.
- b)
- c)
The whole process can be represented in Figure 1.
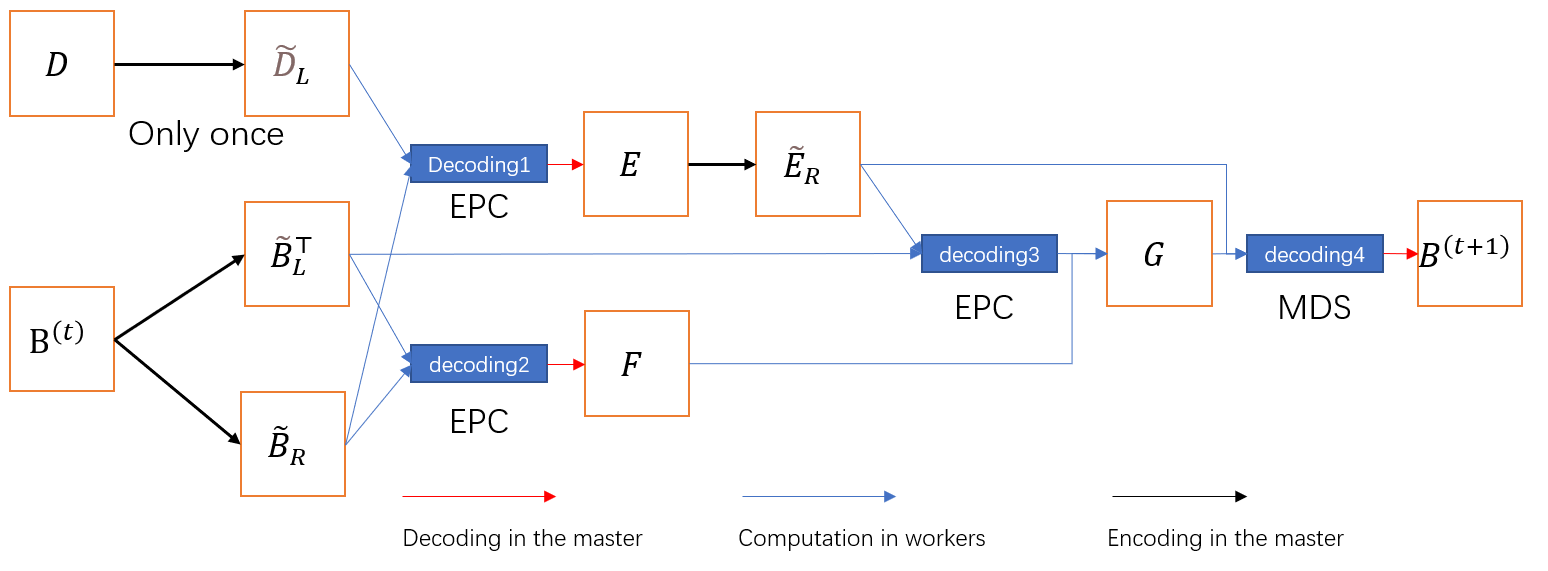
Lemma 2.
(Recovery threshold) The recovery threshold of the algorithm is given by
| (38) |
Proof: From the above descriptions a), b), c), the iteration involves four distributed matrix multiplication. The recovery threshold is given by the maximum recovery threshold of those updates, i.e.,
| (39) |
Remark 1 (Optimality of the Recovery Thresholds).
Notice that, with the given parameter , from the results of EPC in [9, Theorem 2], all the EPC code in a) and b) achieves the optimal recovery threshold among all linear code for the corresponding matrix multiplication problems. For the calculation in c), it also achieves the optimal recovery threshold by simple cut-set bound.
III-C3 Post-Computation
The master has obtained the final estimate of , denoted by . The master first computes as follows:
-
1.
The master sends and to worker for each ;
-
2.
Each worker computes and sends the results to the master;
-
3.
With any responses, the master decode
(40) by EPC decoding. Then, it computes and sends to all the worker nodes;
-
4.
Each worker computes
(41) and sends it back to the master;
-
5.
With any responses, the master decodes by interpolating the polynomial .
Then the master continue to obtain the estimates of and as follows:
-
1.
If , the estimate of is given by . The estimate of is given by
(42a) which computed with standard EPC code with appropriate parameters. -
2.
If , the estimate of is given by , the estimate is given by
(42b) which can be computed by standard EPC code with appropriate parameters.
Remark 2.
Since the main computation load is in the iterative computation of , we omit the details of computation of in (12) and the computations in (42). One convenient choice of the partition parameters is partition (if ) or (if ) into equal-size sub-matrices for some , and partition in the same form as in (25), so that the result of has the form (21). Under such partitions, the EPC computation of (42) also achieves the optimal recovery threshold among all linear code since by [9, Theorem 2].
IV Main Results
The following theorem characterizes the maximum number of stragglers that the algorithm can tolerate in relation to the coding redundancy.
Theorem 1.
The relation between the recovery threshold (or the maximum number of stragglers that the coded ALS algorithm can tolerate ) and coding redundancy is given by
| (43) |
where .
Proof:
Suppose each worker have a same size of data partitions of with elements. According to (21) and the fact that each worker holds one partition of , and there are partitions in , and the number of elements in is . So that could be represented as
| (44) |
Theorem 2.
(Computation Complexity Analysis) Given a distributed matrix factorization problem with workers, matrix , latent dimension , and coding redundancy , the computation complexity of the proposed coded ALS algorithm can be calculated as follows.
-
1.
The pre-computation complexity (at master) is (one time).
-
2.
The computation complexity at each worker is at each iteration333Each iteration involves both updates of and .
-
3.
The encoding and decoding complexities are and at the master at each iteration.
-
4.
The decoding complexity, donotes the decoding procedure happened in the master, is
For the whole process proposed in this algorithm depicted in Fig.1, where we use to represent the number of iterations, and to represent the number of columns and rows of 444Here we assume that for R. The complexity for each stage of the algorithm can be represented as the following form:
Proof:
Consider the size of matrix multiplication, we can measure the computation complexity of different procedure of this proposed algorithm. In the pre-computation stage, we only have a computation task of or , and thus the the complexity is . In each worker, we only consider the first stage that is . The two matrices involved in the computation have size that are and . Replace by , we will get the complexity of each worker. For the encoding and decoding complexity, it is an weighted sum of matrices from each workers and data partitions. We consider the number of workers and number of data partitions . Finally, we could get the encoding and decoding complexity respectively. ∎
Remark 3.
(Number of partitions) In the proposed algorithm, to get a better partition method, in common configurations, e.g., when . When , we will achieve a relatively less expected computation time when workers doing their computation task.
By the definition of stragglers and the fact that , we could find the largest that could be tolerated by the algorithm, which will therefore save a large amount of time in practical.
According to the definition of stragglers
| (45) |
There are 4 decoding procedure in the algorithm, shown in figure 1, the recovery threshold for the first step to get is the largest which is
| (46) |
In Remark 4, we have discussed that the computation time decreases as grows. Therefore, to get smaller , we need to make greater.
It’s easly known that monotonously increased when , which is upper bounded by (45). Therefore, (45) and (46) can be written as
| (47) |
and therefore the best is got to make to make the computation time less.
Remark 4.
In worker’s computation stage, when doing the multiplication of matrices, the computation time decreases as grows.
We consider two impacts of this algorithm. The first impact is more partitions makes each worker share less proportion of data which speeds up the computation. The second impact is more partitions require more usable worker, which will make us get an bigger order statistics. See Appendix A for full explanation.
and are determined by the performance of the computer, which is hard to measure in this setup.Intuitively, with larger , each worker has smaller data to process, the total computation time could be less.
V Simulations
In this section, we design a simulation experiment to measure the running time of our algorithm.
We conduct our simulations on synthetic data by adding noise into the product of two randomly initiated matrices and . In the simulation, we set the parameters , , and run the simulations when the number of non-stragglers . We tested the computation time of the proposed algorithm of different number of data partitions and record the result in Table I.
| 7.59468 | - | - | - | - | |
| 7.376128 | 3.952123 | 2.856271 | - | - | |
| 6.581517 | 3.7818 | 2.729829 | 0.113088 | - | |
| 6.860791 | 3.744443 | 1.285898 | 0.008618 | - | |
| 6.852958 | 3.778484 | 0.937565 | 0.003492 | 0.000598 |
In Table I, we could easily see the relationship between the computation time in workers and the number of partitions in data matrix for different number of non-straggling workers . The minus sign in the table means there is no data, because the condition is not met. Intuitively, smaller partitions result in a faster computation time in workers although smaller partitions will lead to more workers involved in the computation and therefore increase the computation time. For the same , larger could make the computation faster on the whole. That’s because more workers in total bring more workers that are faster. Given the same number of workers, we can also see that when the coding redundancy increases ( decreases), we need less computation time, indicating a tradeoff of straggler mitigation ability and computation complexity in the simulation results.
VI Conclusion
We presented a distributed implementation of the ALS algorithm, which solves the matrix factorization problem in a distributed computation system. The procedure takes the advantage of the entangled polynomial code as a building block, which can resist stragglers. The relationship between the recovery threshold and the storage load is characterized. The simulation result indicates that with more workers and partitions of data matrix, we could obtain a shorter computation time, and thereby fully implemented the role of distributed learning.
Appendix A
Let represents the total time consuming in the encoding process, and thus
| (48) |
where represents the -th computation stage. Because , and have the same size of matrix to do the multiplication, so the
| (49) |
So that the expected encoding time can be represented as
| (50) |
where , in which represents the -th iteration of the algorithm and represents the total time consumed of stage at -th iteration.
For each worker, The primary task is to compute , whose computation time is denoted as . The computation time for it is for each worker at each iteration. To compute , and ,denoted as ,, , where each worker needs at each iteration, where represents the time to do a element-wise multiplication in one worker.
The computation time at each iteration can be represented as the following form.
| (51) |
where denotes the -th shortest time taken by the workers to return the result.
The multiplication of matrices can be seen as element-wise operation in each worker. According to the Central Limit Theorem, the can be represented as
| (52) |
where represents the time taken by worker in -th iteration in stage 1.
The expected computation time can be represented as
| (53) |
Similarly, the can be represented as same form, and
| (54) |
According to the [18], the approximation of expected value of the -th order statistic can be represented as
| (55) |
where and is the inverse function of the cumulative distribution function of standart normal distribution.
so that the computation time in (48) could be written as
| (56) | |||
| (57) |
Let represents the right hand side term in (57) and then can be written as
| (58) |
where denotes the probability density function of standard normal distribution.
Dividing both sides by , we could get
| (59) |
| (60) |
So that we only need to (60) to determine whether it’s positive or negative.
In (60), let’s use to represent and use to represent . is a decreaseing function after . When , reaches its maximum , which is less than 0.398 when ; When , where denotes the max such that , reaches its minimum which is greater than 0.246 when .
Let’s use to represent . Then is increasing when . So the reaches its maximum when
| (64) |
when
| (65) |
Therefore, . In other words, the second and third term in (60) are all bounded. If we can guarantee
| (66) |
such that , which suggests decrease monotonously when , resulting in a less time of computation with a greater .
Appendix B
| (67) |
in which could be writen as
| (68) |
Because , and that is a symmetric matrix, (68) could be With (68) and (67), we will get that
| (69) |
Now we know that is invertible. So that the items within the rightmost bracket is invertible. From the fact that , the RHS of 69 could be
| (70) |
and 69 becomes
| (71) |
Simplify (71) we will finally get (8). Similarly, we can do the same procedure and then get (9)
References
- [1] Y. Koren, R. Bell, and C. Volinsky, “Matrix factorization techniques for recommender systems,” Computer, no. 8, pp. 30–37, 2009.
- [2] J. Bennett, S. Lanning et al., “The netflix prize,” in Proceedings of KDD cup and workshop, vol. 2007. New York, NY, USA., 2007, p. 35.
- [3] C. Karakus, Y. Sun, S. Diggavi, and W. Yin, “Straggler mitigation in distributed optimization through data encoding,” in Advances in Neural Information Processing Systems, 2017, pp. 5434–5442.
- [4] D. Data, L. Song, and S. Diggavi, “Data encoding for byzantine-resilient distributed gradient descent,” in 2018 56th Annual Allerton Conference on Communication, Control, and Computing (Allerton). IEEE, 2018, pp. 863–870.
- [5] S. Li, S. M. M. Kalan, Q. Yu, M. Soltanolkotabi, and A. S. Avestimehr, “Polynomially coded regression: Optimal straggler mitigation via data encoding,” arXiv preprint arXiv:1805.09934, 2018.
- [6] R. Bitar, M. Wootters, and S. E. Rouayheb, “Stochastic gradient coding for straggler mitigation in distributed learning,” arXiv preprint arXiv:1905.05383, 2019.
- [7] E. Ozfatura, D. Gündüz, and S. Ulukus, “Speeding up distributed gradient descent by utilizing non-persistent stragglers,” in 2019 IEEE International Symposium on Information Theory (ISIT). IEEE, 2019, pp. 2729–2733.
- [8] R. K. Maity, A. S. Rawa, and A. Mazumdar, “Robust gradient descent via moment encoding and ldpc codes,” in 2019 IEEE International Symposium on Information Theory (ISIT). IEEE, 2019, pp. 2734–2738.
- [9] Q. Yu, M. A. Maddah-Ali, and A. S. Avestimehr, “Straggler mitigation in distributed matrix multiplication: Fundamental limits and optimal coding,” IEEE Transactions on Information Theory, vol. 66, no. 3, pp. 1920–1933, 2020.
- [10] Q. Ho, J. Cipar, H. Cui, S. Lee, J. K. Kim, P. B. Gibbons, G. A. Gibson, G. Ganger, and E. P. Xing, “More effective distributed ml via a stale synchronous parallel parameter server,” in Advances in neural information processing systems, 2013, pp. 1223–1231.
- [11] J. Dean and S. Ghemawat, “Mapreduce: simplified data processing on large clusters,” Communications of the ACM, vol. 51, no. 1, pp. 107–113, 2008.
- [12] M. Zaharia, A. Konwinski, A. D. Joseph, R. H. Katz, and I. Stoica, “Improving mapreduce performance in heterogeneous environments.” in Osdi, vol. 8, no. 4, 2008, p. 7.
- [13] K. Lee, M. Lam, R. Pedarsani, D. Papailiopoulos, and K. Ramchandran, “Speeding up distributed machine learning using codes,” IEEE Transactions on Information Theory, vol. 64, no. 3, pp. 1514–1529, 2017.
- [14] R. Tandon, Q. Lei, A. G. Dimakis, and N. Karampatziakis, “Gradient coding: Avoiding stragglers in distributed learning,” in International Conference on Machine Learning, 2017, pp. 3368–3376.
- [15] J. M. Neighbors, “The draco approach to constructing software from reusable components,” IEEE Transactions on Software Engineering, no. 5, pp. 564–574, 1984.
- [16] W. Halbawi, N. Azizan, F. Salehi, and B. Hassibi, “Improving distributed gradient descent using reed-solomon codes,” in 2018 IEEE International Symposium on Information Theory (ISIT). IEEE, 2018, pp. 2027–2031.
- [17] S. Dutta, Z. Bai, H. Jeong, T. M. Low, and P. Grover, “A unified coded deep neural network training strategy based on generalized polydot codes,” in 2018 IEEE International Symposium on Information Theory (ISIT). IEEE, 2018, pp. 1585–1589.
- [18] J. Royston, “Algorithm as 177: Expected normal order statistics (exact and approximate),” Journal of the royal statistical society. Series C (Applied statistics), vol. 31, no. 2, pp. 161–165, 1982.