22email: jliu85@ncsu.edu, 22email: csymons@lirio.com, 22email: rrvatsav@ncsu.edu
CoMAC: Conversational Agent for Multi-Source Auxiliary Context with Sparse and Symmetric Latent Interactions
Abstract
Recent advancements in AI-driven conversational agents have exhibited immense potential of AI applications. Effective response generation is crucial to the success of these agents. While extensive research has focused on leveraging multiple auxiliary data sources (e.g., knowledge bases and personas) to enhance response generation, existing methods often struggle to efficiently extract relevant information from these sources. There are still clear limitations in the ability to combine versatile conversational capabilities with adherence to known facts and adaptation to large variations in user preferences and belief systems, which continues to hinder the wide adoption of conversational AI tools. This paper introduces a novel method, Conversational Agent for Multi-Source Auxiliary Context with Sparse and Symmetric Latent Interactions (CoMAC), for conversation generation, which employs specialized encoding streams and post-fusion grounding networks for multiple data sources to identify relevant persona and knowledge information for the conversation. CoMAC also leverages a novel text similarity metric that allows bi-directional information sharing among multiple sources and focuses on a selective subset of meaningful words. Our experiments show that CoMAC improves the relevant persona and knowledge prediction accuracies and response generation quality significantly over two state-of-the-art methods.
1 Introduction
Recent advancements in deep learning and large language models (LLMs) are facilitating widespread application of Conversational AI. Many real-world applications demand human-level performance and additional enhancements tailored to specific use cases. Achieving these objectives typically requires carefully curated data, including auxiliary data that provides implicit or explicit context for models to generate better responses [1, 17, 13]. Many applications require conversational agents to provide answers that adhere to known facts. Therefore, it is crucial to effectively utilize auxiliary knowledge bases and extract relevant information when generating responses. There is also growing demand for conversational systems that can enhance the user experience via personalization, improving engagement and aiding users in achieving personal goals. This requires models to better understand auxiliary user information that captures meaningful context, such as demographics, preferences, and beliefs. For instance, to support different patients from different backgrounds and in different states of health in attaining particular behavioral objectives tied to improved health, an agent must accurately reflect knowledge and facts about specific health conditions, and employ customized persuasive strategies aligned with each individual patient’s beliefs and medical history.
Despite the potential to offer valuable insights that can enhance a conversational agent’s understanding of context, auxiliary data also has the potential to introduce noise that can hinder comprehension. It still remains a challenge to effectively and efficiently extracting relevant information while filtering out irrelevant data for response generation. For this reason, addressing these issues remains a vital area of research in conversational AI.
To address these challenges, we present a novel conversational method, CoMAC, that can jointly leverage different types of auxiliary data to enhance the quality of generated responses. Specifically, CoMAC encodes the conversational history, as well as each form of auxiliary data (persona/knowledge) in individual, specialized encoding streams, and adopts separate post-fusion persona and knowledge grounding networks (denoted PG and KG) that effectively utilizes each stream to identify relevant information. Meanwhile, a novel text similarity metric, , is developed to exploit low-level word-to-word similarities among multiple sources of auxiliary contexts by introducing normalization, symmetry, and sparsity.
CoMAC can be easily extended to other applications with additional auxiliary data sources due to the flexibility of the post-fusion framework. We evaluate CoMAC against two state-of-the-art (SOTA) methods, PK-FoCus [6] and PK-NCLI [10], and adopt a new training setup that addresses the inherent data imbalance issues overlooked by previous work. Our experiments demonstrated that CoMAC significantly outperforms the best SOTA PK-NCLI, in terms of both PG/KG grounding accuracies by 45.74% and 6.76%, respectively. In addition, it enhances response generation quality by 5.26%, 5.54%, 7.84%, and 11.64% in F1, ROUGE-L, BLEU, and PPL scores.
2 Related Work
2.1 Neural-Based Conversational Models
Deep neural network (DNN) based conversational systems have recently become prevalent due to superior scalability and applicability [2] compared to traditional systems. Neural networks can extract signals directly from end-to-end training driven by data without human intervention. With the ever-increasing learning capabilities of LLMs, especially pre-trained Transformer-based LLMs [16], DNN-based agents are being continually developed for new applications. Retrieval methods [5, 12] and Generative methods [18, 9] are two common categories of DNN-based conversational methods. Many document retrieval solutions [7] can also be easily adapted to solve conversational challenges.
2.2 Auxiliary Data-Enhanced Models
Knowledge-based models [1, 3] are focused on better utilizing auxiliary facts to enhance the accuracy of responses. Knowledge and facts are crucial for many conversational tasks since providing accurate responses that avoid hallucinations and adhere to known facts is often a minimum requirement.
Persona-based models [12, 5, 17, 9] customize responses using auxiliary data that can represent the values, beliefs, characteristics, and/or history of a specific user. Models without persona information often fail to align responses with the user’s preferences, which can be problematic when personalization is an expectation [11]. Many pre-fusion-based methods [5] concatenate personas with input queries as long text inputs to the model. These approaches have been shown to be sub-optimal because they process heterogeneous data from multiple sources in a homogeneous way, which might ignore the critical source-specific signals and increase the learning complexity of the model. Liu et al. [12] recently proposed a retrieval model in a post-fusion framework that handles heterogeneous persona and query data in specialized encoding streams.
2.3 Persona and Knowledge-based Models
The above methods are limited to a single source of auxiliary data, while many real applications contain multiple auxiliary sources that can provide valuable perspectives of the conversation. Jang et al. [6] proposed a pre-fusion-based method, PK-FoCus, that identifies relevant persona and knowledge data based on a single highly summarized context embedding. This type of pre-fusion approach can ignore important signals in low-level word interactions. Consequently, it is unable to effectively extract useful information for response generation.
Liu et al. [10] used low-level word similarities in the PK-NCLI method, which leverages a variation of ColBERT [7] similarity in grounding networks. However, ColBERT is designed particularly for one-to-many document retrieval problems, where there is only one query and many documents. PK-NCLI failed to address critical issues of ColBERT when used for many-to-many context retrieval when it involves multiple sources, each with multiple entries. First, ColBERT has a bias based on query length. While this bias is harmless when only one query is involved, it can favor longer, but potentially irrelevant, context entries in multi-source, multi-entry scenarios. Second, it is an asymmetric metric that finds “one-way” relevance from the query to the documents. It ignores the critical reverse relevance from the documents to the queries when multiple auxiliary sources are involved. Third, it considers all word pairs equally, which makes it sensitive to frequent but mostly irrelevant words and suppresses subtle yet critical relevance among meaningful notional words.
3 Method
In this paper, we consider a response generation problem grounded by auxiliary persona and knowledge data. Given a set of user persona entries =, a set of knowledge entries related to the conversation =, and the conversation history or utterance (concluding with a question), we aim to train an end-to-end model that can a response or answer, , that is both personalized to the user and grounded in relevant knowledge. / are the numbers of entries in /. A persona entry, , describes specific personal information about the user, while a knowledge entry, , pertains to the conversation topic. Importantly, , , and the and entries are all in textual format.
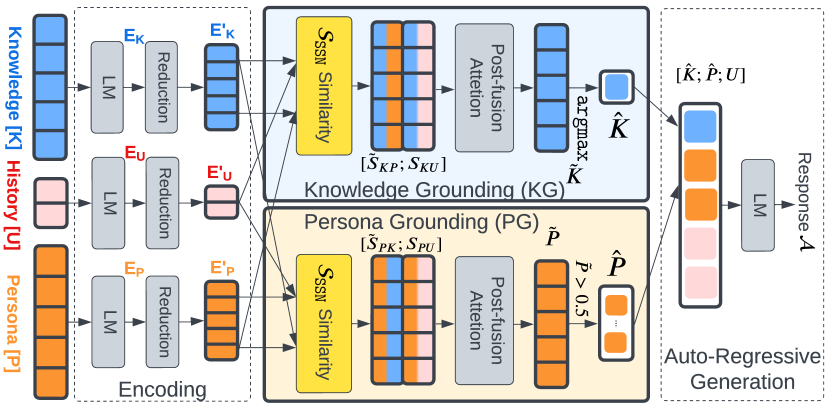
Figure 1 demonstrates the three stages of the CoMAC method. In the Encoding Stage (Section 3.1), all inputs // are embedded by a fine-tuned language model, . In the Post-Fusion Grounding Stage (Section 3.3), two subsets of relevant persona and knowledge entries / are selected in two separate post-fusion-based grounding networks, PG and KG, using the novel metric (Section 3.2). In the Generation Stage (Section 3.4), the utterance, , is supplemented with and to generate the response, , using (i.e., ).
3.1 Input Embedding
The inputs, , , and , are first embedded separately by as , , and , where // are the padded sequence lengths (i.e., number of tokens) of the // entries, and is the embedding size. Here, each source of data is encoded in a separate stream to preserve low-level authentic information of the corresponding source, instead of using a single highly summarized embedding for all sources as in [6].
3.2 Sparse, Symmetric, Normalized ColBERT Similarity
Identifying the relevant auxiliary entries starts with a metric that evaluates the relevance of an entry (e.g., ) to the rest of the conversational context (e.g., and ). We first review the ColBERT similarity [7]. measures the token-level latent interaction similarity between a query, , and a document, , in document retrieval, computed as , where / are the embeddings of the -th/-th token of /, respectively. can be generalized to any two texts, and .
In our problem, the vanilla suffers from several issues mentioned in Section 2.3. Here, we develop a novel metric, denoted as , that introduces normalization, symmetry and sparsity in ColBERT-style latent interactions.
Normalization To eliminate the dominating bias of longer but potentially less relevant ’s in a batch (e.g., longer vs. shorter paragraphs in the auxiliary knowledge base), is normalized by , the number of tokens in . That is,
Symmetry Both and are asymmetric metrics that exchange information from only to . In a multi-source auxiliary setup, it is critical to allow information to flow bi-directionally among all sources. A simple yet effective approach is to combine the asymmetric similarities obtained in both directions, i.e., .
Sparsity Another common issue of existing ColBERT-style similarities is that, when measuring pairwise token similarity, certain frequent tokens (such as function words) can dominate overall similarities, diminishing the subtle but critical signals from informative tokens (like notional words). To mitigate the potential adverse effects of such language noise, we introduce sparsity and selectivity into the similarity measure, using only a subset of tokens chosen through specific sampling strategies, denoted as , where / are the tokens sampled from /, respectively, following the sampling strategies.
The main assumption of sparsity and selectivity is that frequent tokens are less informative than those appearing sparsely in the dataset. TF-IDF [15] is a common solution that fits the assumption. We propose a sampling strategy that selects tokens with highest TF-IDF weights for , referred to as “CoMAC (TF-IDF)”. We denote the percentage of selected tokens as . In Section 5.2, we also discuss an alternative sampling strategy which learns the token weights by a feed-forward network using //, referred to as “CoMAC (FF)”.
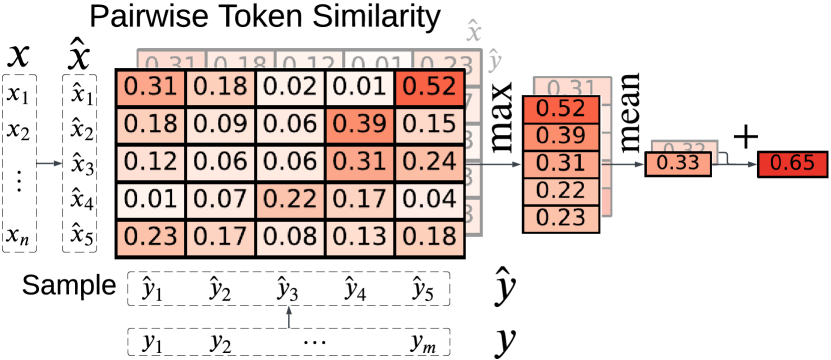
Figure 2 demonstrates the computation of similarity by using token-level similarities. Calculating a similarity matrix for a large set of text entries, and , incurs an exponentially growing computational cost. To improve efficiency, we reduce to () by a dimension reduction layer prior to .
3.3 Post-Fusion Grounding Networks
In this section, we aim to identify two subsets of relevant persona and knowledge entries, , and knowledge entries, , that are helpful for response generation in the PG and KG networks with .
Persona Grounding In PG, we consider as the “query” set and / as two distinct sets of “documents.” We construct two similarity matrices for: (I) persona and utterance entry pairs (), and (ii) persona and knowledge entry pairs (). The elements in and are calculated as follows:
| (1) |
where / is a reduced embedding of an entry token-by-token. We further calculate the similarities between each persona entry and the overall knowledge by taking the average entry-wise similarity, i.e., .
A post-fusion strategy scores each persona entry by fusing and in an attention layer with sigmoid activation, i.e., , where // are the attentions and bias, and . Persona entries are considered relevant when .
Knowledge Grounding KG is similarly constructed by calculating the relevance scores of each knowledge entry with the utterance and persona, and , respectively, followed by the post-fusion strategy . The knowledge candidate with the highest score is considered relevant, i.e., . Here softmax and argmax are used, following the dataset assumption [6] that a response is based on only one knowledge entry, while multiple persona entries could contribute to it.
3.4 Response Generation
With estimated relevant persona and knowledge entries ( and ), a new input is formed by combining , and the original input for language model , i.e., ==. A probability distribution over the vocabulary space is estimated based on by a projection layer.
For inference, follows the auto-regressive framework [4] to generate a sequence of tokens as the response. For training, we train the model with loss function , where is the cross-entropy loss over for knowledge grounding, is the cross-entropy loss over for persona grounding, is the cross-entropy loss over , and // are the weighting hyper-parameters. The loss term addresses an extreme imbalance issue overlooked by the baselines [6, 10] that nearly 87% of persona entries are irrelevant. First, we apply weights / to positive/negative persona labels, respectively, to emphasize the importance of relevant persona entries. Second, we randomly discard with probability of if an utterance has all negative persona labels. However, and are not affected by the persona labels.
4 Experiments
4.1 Dataset
| Train. | Valid. | |
| # Dialogs | 12484 | 1,000 |
| # Average Rounds | 5.63 | 5.64 |
| Avg. Length of Human’s Utt. | 40.70 | 40.21 |
| Avg. Length of Machine’s Utt. | 138.16 | 138.60 |
| # Knowledge-only Answer | 37,488 | 3,007 |
| # Persona-Knowledge Answer | 32,855 | 2,630 |
| # Landmarks | 5,152 | 923 |
We train CoMAC models on the FoCus dataset [6], which is a conversational dataset powered by persona and knowledge. Each conversation includes five text-based persona entries describing the user’s personal profile, such as demographic data or hobbies (e.g., “I find heritage-listed buildings interesting”), and several knowledge entries extracted from a Wikipedia page about a landmark (e.g., “Thorps Building is a heritage-listed commercial building at Macrossan Street…”). For each round, zero or more persona entries are relevant to the conversation, while only one knowledge entry is relevant. Table 1 shows some basic statistics of dataset. For more detailed information and examples, please refer to [6].
4.2 Experimental Setup
We compare CoMAC with two baseline methods, PK-FoCus [6] and PK-NCLI [10]. The source code of CoMAC is available online 111https://github.com/jliu-v/CoMAC. All models are initialized with pre-trained BART [8] weights, trained on NVIDIA RTX2080-Ti GPUs over the training set for two epochs and evaluated on the validation set. For TF-IDF, the IDF weights are pre-computed offline for efficiency, and the TF and final TF-IDF weights are computed on the fly. It is worth noting that, theoretically, CoMAC could use any existing language model . GPT-2 [14] is sub-optimal compared to BART (encoder-decoder architecture) for all methods, as GPT-2’s decoder-only architecture is not suitable for the PG/KG tasks which require advanced capabilities on comprehension and summarization.
Hyper-parameters Besides the default setup of =1/1/10 in [6], we conduct additional hyper-parameter search, limiting ++=10 to avoid arbitrary optimization solutions. In our experiments, the optimal values of other hyper-parameters are =, = and =. The / values roughly match the persona label distribution in the dataset.
Evaluation Metrics We evaluate CoMAC in terms of both the quality of generated responses and the grounding accuracies. For response quality, we use the perplexity (PPL), ROUGE and BLEU, and F1 scores. For grounding, we use PG/KG accuracies. Due to the imbalanced persona label distribution, we also report F1, precision, and recall for PG (PG-F1/PG-PR/PG-RC). All reported metrics are based on the validation dataset. Lower PPL values indicate better performance, while the other metrics are the higher the better.
5 Results
Table 2 compares the experimental results of CoMAC models with the baselines. The comparison demonstrates that our method, CoMAC, surpasses both baselines in terms of both language generation and KG/PG qualities. Specifically, CoMAC outperforms the best baseline PK-NCLI by 5.26%, 9.31%, 7.84% and 11.64% in F1, ROUGE-L, BLEU, and PPL scores, respectively. It also enhanced PG accuracy (PG) and F1 (PG-F1) by 45.75% and 27.41% , respectively, and KG accuracy (KG) by 6.76%. CoMAC outperforms PK-FoCus even more significantly. This comparison indicates on a high level that CoMAC can better leverage the sparsity and symmetry to identify the relevancy among various conversational contexts, which further assists language modeling and response generation.
| Method | F1 | ROUGE1 | ROUGE2 | ROUGEL | BLEU | PPL↓ | PG(%) | PG-F1(%) | PG-PR(%) | PG-RC(%) | KG(%) |
| PK-FoCus0 | 0.291 | 0.353 | 0.186 | 0.311 | 11.364 | 25.23 | 86.70 | - | - | 0.00 | 68.61 |
| PK-FoCus | 0.304 | 0.377 | 0.214 | 0.335 | 12.966 | 11.863 | 13.40 | 23.46 | 13.30 | 99.70 | 70.76 |
| PK-NCLI0 | 0.317 | 0.382 | 0.213 | 0.337 | 12.882 | 13.17 | 86.69 | - | - | 0.00 | 89.61 |
| PK-NCLI | 0.342 | 0.409 | 0.241 | 0.361 | 14.622 | 9.021 | 44.75 | 30.46 | 18.30 | 90.90 | 90.25 |
| CoMAC- | 0.348 | 0.410 | 0.243 | 0.361 | 14.632 | 9.19 | 51.82 | 32.60 | 20.05 | 87.73 | 90.42 |
| CoMAC (FF) | 0.354 | 0.420 | 0.254 | 0.372 | 15.386 | 9.07 | 72.70 | 43.70 | 30.11 | 79.68 | 92.48 |
| CoMAC (TF-IDF)∗ | 0.360 | 0.429 | 0.263 | 0.381 | 15.768 | 7.97 | 65.22 | 38.81 | 25.33 | 82.93 | 96.35 |
| Improvement | 5.26% | 4.89% | 9.13% | 5.54% | 7.84% | 11.64% | 45.74% | 27.41% | 38.42% | -8.77% | 6.76% |
-
•
PK-FoCus0 and PK-NCLI0 represent the baseline methods from the original publications where and were not used. PG performance of PK-FoCus0 and PK-NCLI0 are discarded as due to over-fitting issue mentioned in Section 3.4. PK-NCLI is equivalent to CoMAC with only . CoMAC- is CoMAC with only (no token sampling). Metrics with “↓” mean that lower values are more desirable. Values in bold represent the best performance of the corresponding metric among all methods from both default setup and hyper-parameter search experiments. “Improvement” measures the percentage improvement of the best CoMAC model (denoted by “∗”) over the best baseline PK-NCLI.
5.1 Symmetric Information Flow
Asymmetric similarities like or learn one-way information flow from the “queries” (e.g., in PG network) to the “documents” (e.g., / as the context in PG network). They are not suitable for the purpose of the grounding networks in conversational problems, where all sources of inputs (whether “query” or “documents”) will contribute to the final output.
To demonstrate that the supplemental two-way signals are critical among multiple auxiliary data, we compare the CoMAC method with the two-way (no sparsity, denoted as CoMAC-) against the baseline PK-NCLI with the one-way . Table 2 shows that CoMAC- has significant improvements over the baseline PK-NCLI on PG accuracy (51.82% vs 44.75%), and provides minor improvements on KG accuracy (90.42% vs 90.25%) and other language generation metrics. For PG tasks with extremely imbalanced and sparse data, it is especially important to exploit symmetry and leverage other context data. The KG task benefits less from the symmetry, primarily because most contexts in the dataset are highly correlated with knowledge entries. Most questions are related to information from the knowledge, making them more similar to traditional document retrieval tasks. Therefore, the asymmetric already captured most of the useful signal, and the symmetric only provides marginal improvement.
| Persona () | I hope to move to Adelaide this year . |
| Knowledge () | The National War Memorial is a monument on the north edge of the city centre of Adelaide , South Australia , commemorating those who served in the First World War . |
| Utterance () | Where is this memorial ? |
| Response () | This memorial is located on the north edge of the city centre of Adelaide , South Australia , where you hope to move to this year . |
-
•
Tokens with underscores and bold fonts are the sampled tokens from the original full text.
5.2 Sparse Token Sampling
The baselines failed to reduce the extra noise brought into the grounding networks from less informative tokens. Such noise not only dilutes the overall information in texts but could also obscure the importance of meaningful words. We conduct two sets of CoMAC experiments with two different strategies (TF-IDF and FF) to sample tokens in the PG/KG networks.
Table 2 shows that both strategies can significantly improve the PG/KG and generation performance over the two baselines and CoMAC-. TF-IDF/FF improved PG over the best baseline PK-NCLI by 45.74%/62.46% (65.22/72.70 vs 44.75), PG-F1 by 27.41%/43.47% and KG by 6.76%/2.47%, respectively. They also improved the generation quality, e.g., F1 by 5.26%/3.51%. Table 3 shows an example of the tokens sampled by the CoMAC (TF-IDF). For efficiency, CoMAC outperforms the baseline by 9.77% (2872 vs 3183 sec.) in terms of inference time. In real applications, further efficiency and scalability can be achieved through pre-sampling of persona and knowledge fully offline.
An interesting observation is that TF-IDF is better for KG and generation performances, while FF is better for PG performance. This is probably because many conversations in the dataset are highly correlated with knowledge, and personas do not have as much influence as knowledge on the responses, as observed in [10]. The FF strategy is a fully trained layer directly driven by the loss of the PG network. In contrast, the token distribution and contribution to the PG training target is disconnected. Therefore, FF performs well on PG accuracy. However, this doesn’t make TF-IDF a sub-optimal choice overall, as it is directly tied to the token distributions in the dataset, which can preserve rare but informative tokens in the grounding stage for response generation later.
5.3 Human Evaluation
To evaluate the quality of generated responses, we randomly selected 75 conversations (408 rounds) from the validation set for human evaluation. We presented to human volunteers the original utterance, ground truth and predicted knowledge, as well as the persona entries, reference response and two predicted responses from CoMAC and PK-FoCus (denoted as and , respectively). In order to compare the performance of CoMAC with the baseline, each volunteer was asked to answer three questions: Q1. do they prefer or , Q2. did successfully address the original question, and Q3. did successfully address the original question. For Q1, 46.81% of were rated as better than , 42.40% were similar to , and only 10.78% were worse than . For Q2 and Q3, 90.44% and 75.98% of and , respectively, addressed the original question. These results demonstrate that CoMAC is better than PK-FoCus at addressing questions and producing higher quality responses.
6 Ablation Study
Previous work [10] showed that, among the three sub-tasks (KG, PG, LM), good learning on one can benefit the other two. However, the optimization objective prioritizes one task at the expense of the others when assigning weights. An ablation study is necessary to investigate how each hyper-parameter affects CoMAC ’s performance and find the optimal balance. In this study, we test the model’s sensitivity to ///. Except for the hyper-parameter being tested, other values are fixed to the optimal combination from the main experiments, that is, ///=1/1/10/0.35, TF-IDF for sampling, and /=0.9/0.1 for loss.
Knowledge Grounding () Figure 4 shows how affects the performance of CoMAC. When =0, the model performs poorly in KG and response generation, because the model fails to learn the KG network, and irrelevant knowledge entries are selected for generation. When =1, the performance improves significantly due to learning knowledge entries relevant to the conversation. As increases, it diminishes the learning objectives for the PG and LM. Without a well-learned LM, it becomes difficult to extract signals from text-based knowledge. Therefore KG and generation performance declines despite increases.
Persona Grounding () Figure 4 demonstrates how affects the PG and generation performance of the CoMAC model. We observe that a non-zero value is critical for improving the performance of the PG and LM tasks, but too much emphasis on the PG task can be detrimental.
Fig. 3(c) and 3(d) show that the optimal values are 6/1 for PG/LM tasks, respectively. This aligns with the observation that conversations are less correlated with personas than with knowledge. A common example in the dataset is questions, , like “Where is this place?”. A positive-labeled persona entry matches the reference answer “This is [place], a place you like to visit”. However, the core part of (“[place]”) might already be extracted from the conversation context (e.g., knowledge or history). In these cases, the labeled persona entry provides little new insight for the rest of the answer. Consequently, higher leads to higher PG performance, but lower performance on KG and generation. However, when is very high (>6), an insufficiently trained LM will no longer adequately support the learning of the PG network due to weights competition.
Language Modeling () Figure 5 shows how impacts on the LM generation. We experiment with various values between 120. The best performance is achieved with =10. When <10, generation performance increases with as the LM is able to model the language better. With higher , competition among the three sub-tasks takes effect, suppressing the learning of PG and KG. As a result, the LM is unable to learn effectively without the assistance of persona/knowledge data from well-trained PG/KG networks.
| F1 | ROUGE1 | BLEU | PPL↓ | PG | KG | |
| 0.25 | 0.359 | 0.427 | 15.744 | 8.02 | 71.75 | 95.69 |
| 0.35 | 0.360 | 0.429 | 15.768 | 7.97 | 65.22 | 96.35 |
| 0.50 | 0.359 | 0.428 | 15.854 | 8.12 | 67.83 | 96.15 |
| 0.75 | 0.355 | 0.425 | 15.480 | 8.02 | 72.23 | 96.33 |
| 1.00 | 0.348 | 0.410 | 14.642 | 9.19 | 51.82 | 90.42 |
Sampling Rate () Table 4 summarizes performance of CoMAC with values of [0.25, 0.5, 0.75, 1.0], in addition to the 0.35 reported in the main experiments. We notice that, as long as the sampling is in place (<1.0), has a very minor effect on the overall performance, while =0.35 is slightly better than the other values in most evaluation metrics. Without sampling (=1.0), equivalent to CoMAC-, the model’s performance drops significantly due to its inability to mitigate the impact of noisy tokens. This stresses the significance of the sampling strategy in preserving useful signals, but more importantly, in reducing noise in the data.
7 Conclusions
Conversational agents built on DNNs and LLMs are playing increasingly critical roles in numerous real-world applications. For increased adoption in the future, it is crucial that these agents consistently provide truthful responses and tailor them to users’ personal preferences. By leveraging auxiliary data like external knowledge and user personas, these agents are becoming increasingly powerful and versatile. However, effectively and efficiently retaining relevant information while filtering out irrelevant data remains a challenging problem.
In this paper, we presented a novel method, CoMAC, that is able to (i) encode multiple auxiliary data sources and preserve source-specific signals in specialized streams, (ii) accurately identify relevant persona and knowledge entries in two post-fusion grounding networks via a novel text similarity measure () at the word-level with normalization, symmetry and sparsity, and (iii) generate high-quality responses that respect provided facts and that are personalized to a user. Our experiments demonstrated that CoMAC significantly outperforms the SOTA methods, PK-FoCus and PK-NCLI, in terms of both PG/KG accuracies and language generation quality. We also conducted a comprehensive study on specific choices within CoMAC, including the weights of various components in the model, the choice of language model, and sparse sampling strategies. This paper demonstrated the importance of leveraging normalization, sparsity and symmetry among multiple auxiliary sources to effectively extract useful information and provide supplementary view for the conversational context.
Our method, CoMAC, still faces challenges. A major challenge observed in both the baselines and CoMAC is hallucination, where generated responses contain inaccuracies and misinformation despite appearing genuine. Another issue with CoMAC is that its efficiency is limited by the online calculation of TF-IDF weights, particularly when novel tokens are present in the query in real-world applications. Furthermore, CoMAC was only evaluated on the FoCus dataset due to the lack of appropriate publicly available evaluation datasets. We will focus future research efforts on addressing these challenges.
7.0.1 Acknowledgements
We would like to thank Joongyeub Yeo (Lirio) and Seoyeong Park (NCSU) for their valuable suggestions on an early version of this paper.
Disclosure: This paper has been accepted to The 29th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD2025) and will be published in the conference proceedings by Springer. DOI will provided once available.
References
- [1] Dinan, E., Roller, S., Shuster, K., Fan, A., Auli, M., Weston, J.: Wizard of wikipedia: Knowledge-powered conversational agents. arXiv preprint arXiv:1811.01241 (2018)
- [2] Gao, J., Galley, M., Li, L.: Neural approaches to conversational ai. In: The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. pp. 1371–1374 (2018)
- [3] Ghazvininejad, M., Brockett, C., Chang, M.W., Dolan, B., Gao, J., Yih, W.t., Galley, M.: A knowledge-grounded neural conversation model. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 32 (2018)
- [4] Hoogeboom, E., Gritsenko, A.A., Bastings, J., Poole, B., Berg, R.v.d., Salimans, T.: Autoregressive diffusion models. arXiv preprint arXiv:2110.02037 (2021)
- [5] Humeau, S., Shuster, K., Lachaux, M.A., Weston, J.: Poly-encoders: Transformer architectures and pre-training strategies for fast and accurate multi-sentence scoring. arXiv preprint arXiv:1905.01969 (2019)
- [6] Jang, Y., Lim, J., Hur, Y., Oh, D., Son, S., Lee, Y., Shin, D., Kim, S., Lim, H.: Call for customized conversation: Customized conversation grounding persona and knowledge. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 36, pp. 10803–10812 (2022)
- [7] Khattab, O., Zaharia, M.: Colbert: Efficient and effective passage search via contextualized late interaction over bert. In: Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. pp. 39–48 (2020)
- [8] Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., Stoyanov, V., Zettlemoyer, L.: Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461 (2019)
- [9] Li, J., Galley, M., Brockett, C., Spithourakis, G.P., Gao, J., Dolan, B.: A persona-based neural conversation model. arXiv preprint arXiv:1603.06155 (2016)
- [10] Liu, J., Mei, Z., Peng, K., Vatsavai, R.R.: Context retrieval via normalized contextual latent interaction for conversational agent. In: 2023 IEEE International Conference on Data Mining Workshops (ICDMW). pp. 1543–1550. IEEE (2023)
- [11] Liu, J., Symons, C., Vatsavai, R.R.: Persona-based conversational ai: State of the art and challenges. In: 2022 IEEE International Conference on Data Mining Workshops (ICDMW). pp. 993–1001. IEEE (2022)
- [12] Liu, J., Symons, C., Vatsavai, R.R.: Persona-coded poly-encoder: Persona-guided multi-stream conversational sentence scoring. In: 2023 IEEE 35th International Conference on Tools with Artificial Intelligence (ICTAI). pp. 250–257. IEEE (2023)
- [13] Mostafazadeh, N., Brockett, C., Dolan, B., Galley, M., Gao, J., Spithourakis, G.P., Vanderwende, L.: Image-grounded conversations: Multimodal context for natural question and response generation. arXiv preprint arXiv:1701.08251 (2017)
- [14] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al.: Language models are unsupervised multitask learners. OpenAI blog 1(8), 9 (2019)
- [15] Salton, G., Buckley, C.: Term-weighting approaches in automatic text retrieval. Information processing & management 24(5), 513–523 (1988)
- [16] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems. pp. 5998–6008 (2017)
- [17] Zhang, S., Dinan, E., Urbanek, J., Szlam, A., Kiela, D., Weston, J.: Personalizing dialogue agents: I have a dog, do you have pets too? arXiv preprint arXiv:1801.07243 (2018)
- [18] Zhang, Y., Sun, S., Galley, M., Chen, Y.C., Brockett, C., Gao, X., Gao, J., Liu, J., Dolan, B.: Dialogpt: Large-scale generative pre-training for conversational response generation. arXiv:1911.00536 (2019)