Common Sense Knowledge Learning for Open Vocabulary Neural Reasoning: A First View into Chronic Disease Literature
Abstract
In this paper, we address reasoning tasks from open vocabulary Knowledge Bases (openKBs) using state-of-the-art Neural Language Models (NLMs) with applications in scientific literature. For this purpose, self-attention based NLMs are trained using a common sense KB as a source task. The NLMs are then tested on a target KB for open vocabulary reasoning tasks involving scientific knowledge related to the most prevalent chronic diseases (also known as non-communicable diseases, NCDs). Our results identified NLMs that performed consistently and with significance in knowledge inference for both source and target tasks. Furthermore, in our analysis by inspection we discussed the semantic regularities and reasoning capabilities learned by the models, while showing a first insight into the potential benefits of our approach to aid NCD research.
keywords:
elsarticle.cls, LaTeX, Elsevier , templateMSC:
[2010] 00-01, 99-001 Introduction
The scientific community in multiple areas is now proactive in generating knowledge aimed at addressing the needs to improve public health and quality of life of the world population. Evidently, this knowledge is generated with the main aim of being persistent and reusable [1]. Ironically, its evolution and volume makes it even more difficult to access, share and interpret it. We believe that generalizing access to knowledge of scientific domains relevant to societal challenges using Natural Language Processing (NLP) and Deep Learning (DL) methods is a promising approach to advance the aforementioned problem.
Nowadays, Knowledge Bases (KBs) are important pieces of technology that organize knowledge in a way that scientists from different areas can navigate the structure and meaning of the documented empiricism. KBs are commonly applied in organizing knowledge generated for different levels of specificity in different areas of Health Care and Biomedicine [2]. On the one hand, there is a well known set of NLP techniques, called Information Extraction (IE, [3, 4]), that have been applied to automatically generate KBs and Knowledge Graphs (KGs). On the other hand, Neural Network-Based Language Models (NLMs) are becoming a very useful set of methods that can take these KBs as training data and use them to perform semantic reasoning tasks such as Common Sense Reasoning (CSR) and Knowledge Base Completion (KBC) [5, 6].
The goal of the trained NLM in the KBC task is to infer the missing parts of semantic structures, i.e. the NLM learns from training samples of the form {Subject, Predicate, Object} (i.e. SPO triples, e.g. {music, is a, form of communication}). This includes the training triples edited by the model. For instance, given an incomplete SPO triple, i.e. the subject and the predicate phrases, {music, is a, __}, the goal of the trained model is to infer the missing object phrase: form of communication. open vocabulary KBs (openKBs, for short) are generalizations of KBs, whose entries (SPO triples) are built from natural language phrases, rather than from fixed inventories of entities and relations.
The mentioned models and reasoning tasks compose a well-known methodology for knowledge processing. Nonetheless, its effectiveness is currently limited by (i) the method used to build the KB, and (ii) the generalization ability of the NLM in reasoning. IE methods, in particular Relation Extraction (RE), are the building blocks of KBs and KGs. However, they are currently limited by their low recall [7], which is important because it directly affects the expressiveness and contextual information (very controlled syntactic structure and vocabulary) provided by the resulting KB [8, 9, 10, 11, 12]. The low recall of simple RE methods is due to the fact that the subject and object of a triple are limited to a predefined set of named entities, which are very special cases of noun phrases, and the predicate to a small set of predefined attributional or defining verbs.
NLMs based on Recurrent Neural Networks (RNNs) have shown limitations in reasoning tasks [13, 14], particularly encoder-decoder architectures [15, 16]. These models have been improved with contextual alignment (i.e. attention) between source and target sequences [17, 18], but recent developments have shown even better improvements, i.e. the Transformer encoder-decoder architecture [19], which is a self-attention-based Neural Language Model. From these developments, pre-trained Transformer-based NLMs are becoming ubiquitous in multiple IE and reasoning tasks [20, 21, 22], however the need to prune and tweak them to make more efficient and specialized applications is also becoming apparent [23, 24, 25, 26]. Moreover, they only consider general purpose vocabulary, which makes difficult their transferability to open domains. Openness for new domains allows selecting an arbitrary specific target (application) domain.
In this work, we address the limited flexibility of the current reasoning methodology based on KBs. We apply the obtained improvements to a reasoning task in the context of the research literature on Chronic Diseases (also known as Non-Communicable Diseases, NCDs). For this, we use an open vocabulary chronic disease KB, that we call OpenNCDKB, built using a state-of-the-art OpenIE on abstracts of articles retrieved from PubMed. Consequently, we trained a Transformer-based NLM to solve a set of similar source reasoning tasks (KBC) that involve general purpose vocabulary: the ConceptNet knowledge Graph and an openKB we built from multiple sources of Open Information Extractions (OpenIE [27, 28]). Using the models obtained for the source tasks, we observed their reasoning performance and capabilities on our OpenNCDKB. Our results showed that a significant number of SPO structures used as ground truth were predicted by the NLM. Other predictions were incorrect from the point of view of loss function and accuracy. However, we note that, rather than being due to ground-truth errors, from the point of view of language meaning, the view of these metrics could be biased towards accuracy (which is not peculiar to natural language), although this was effective in learning. We subsequently confirmed this using an STS-based hypothesis test of the predicted and true object sentence embeddings in the source and target tasks [29, 30]. This helped us to analyze by inspection the semantic regularities of some predictions taken at random. The apparent robustness of these regularities showed the potential benefits of the new knowledge inferred by the model from our OpenNCDKB, which suggested that such knowledge (not in the training data) needs to be validated through further research, rather than being directly discarded as a set of senseless predictions.
The rest of this paper is organized as follows. In Section 2 we expose our methodology. In Section 3 we show the theoretical background. In Section 4 we describe the data and the experimental setup. In Section 5 we report our results, together with the corresponding discussion. In Section 6 we describe prior work related to ours, and in Section 7 we present our conclusions.
2 Methodology
DL and NLP researchers recently tested Transformer-Based NLMs in general purpose CSR tasks [31, 32]. In sight of this progress, our research uses a methodological approach that can be especially useful for the semantic analysis of documents dealing with arbitrary but specialized topics, such as open domain scientific literature. Figure 1 shows the general methodology used in this work.
First, we trained Transformer-based encoder-decoder NLMs to solve combinations of two similar source reasoning tasks that involve general purpose domains: the ConceptNet KG in its Common Sense KB version, and an openKB we built from multiple sources using OpenIE. The target specialized domains were included in an open vocabulary Chronic Disease KB (OpenNCDKB) we built using a state-of-the-art OpenIE method that extracts open vocabulary triples from a dataset of paper abstracts retrieved from the PubMed.
Although this open vocabulary approach can add complexity to the modeling of semantic relationships (and therefore to the learning problem), it also adds expressiveness to the resulting KBs. Such expressiveness can improve the contextual informativeness of semantic structures and thus allow the NLM to discriminate useful patterns from those that are not for the target reasoning task [33]. To show the effectiveness of our approach in the target reasoning task from multiple points of view, we evaluated and analyzed the results in terms of:
-
1.
Performance metrics in source tasks. Accuracy considers the reasoning quality as an exact prediction, with respect to the predicted and ground truth tokens. Cross Entropy quantify the degree of dissimilarity between the probability distribution predicted by the model and the ground truth one. These are effective at learning time because the inner representations of the NLM acquire knowledge on what are the specific words (the object phrase) that probably should be next to the input ones (the subject and predicate).
-
2.
STS-based hipothesis testing. When it comes to reasoning, specificity of performance metrics may not be characteristic of natural language, especially from the point of view of the open vocabulary inherent in natural language and semantic change (probably due to logical inference and/or synonymy). To account for these points of view, we performed hypothesis testing based on Semantic Textual Similarity (STS) in source and target tasks, which measures reasoning quality in the sense of semantic relatedness [34, 29]. We compared to the distribution of STS measurements between predicted and shuffled ground truth object phrases (a random baseline that simulates perturbation of the actual correspondence between subject-predicate and object).
-
3.
Inspection of the inferences in the source and target tasks, which has the aim of showing the semantic regularities learned by the NLMs and how it holds from source to target tasks.
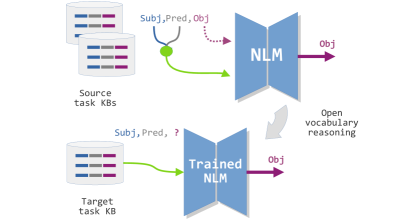
Note that from the point of view of the ConceptNet KB as a source task, this has been mostly compiled by hand, and therefore, the task represents a distantly supervised learning problem. The target task represented by the OpenNCDKB was built unsupervised, so this task represents the target domain of a transfer learning problem.
3 Theoretical Background
3.1 Open Information Extraction for openKBs
Open Information Extraction (OpenIE) is a set of IE methods that generalize semantic relations to open vocabulary semantic structures. The latter allow for a much broader coverage of the ideas expressed in natural language, even when the classic methods are rule-based [27, 28].
OpenIE works in such a way that given the example sentence “habitat loss is recognized as the driving force in biodiversity loss”, it generates semantic relations in the form of SPO triples, e.g. { ‘‘habitat loss’’, ‘‘is recognized as driving’’, ‘‘biodiversity loss’’}. In this triple, in the sense of Dependency Grammars [35],888Unlike to Dependency Grammars, Phrase Structure Grammars (the classic approach), in that the predicate includes the verb and the object phrase. Instead, Dependency Grammars assumes the verbal form as the center (or highest hierarchy) of the sentence, linking the subject and the object. This latter is a convenient approach in building KBs, and therefore for OpenIE. ‘‘habitat loss’’ is the subject phrase, ‘‘is recognized as driving’’ is the predicate phrase, and ‘‘biodiversity loss’’ is the object phrase. In semantics, the subject is the thing that performs actions on the object, which is another thing affected by the action expressed in the predicate. Predicates, therefore, relate things (the subject and the object) in a directed way from the former to the latter.
OpenIE takes a sentence as input and outputs different versions of its SPO structure. Normally these versions are “sub-SPO” structures contained in the same sentence, e.g. { ‘‘habitat loss’’, ‘‘is recognized as’’, ‘‘driving biodiversity’’}, and { ‘‘habitat loss’’, ‘‘recognized as’’, ‘‘driving’’}. Notice that the last extraction (triplet) may not be factual at all and, depending on the downstream task this kind of output is used for, it may be considered purposeless.
We use the obtained OpenIE triples to build an openKB that organizes knowledge from NCD-related paper abstracts (Section 4.2). In addition we used already existent extractions to build a general purpose openKB (with no specific topics, see Section 4.1). A KB is a special case of a database that uses a structured schema to store both structured and unstructured data. In our case, the structured data constitute the identified elements of semantic triples, i.e. {subject, predicate, object}, while the unstructured part is the open vocabulary text (natural language phrases) of each of these elements.
3.2 Neural Semantic Reasoning Modeling
Let be a semantic triple, where are subject, predicate and object phrases, respectively, and is the training openKB. The KBC task here is to predict given , which gives place to the conditional probability distribution implemented using a Neural Network model:
where is the Random Variable (RV) that takes values on the set of object phrases , and is the RV that takes values on the set of concatenated subject-predicate phrases . The Neural Network has learnable parameters , which can be interpreted as phrase embeddings of and , respectively. From the point of view of NMT, the probability mass function can be used as a sequence prediction model. In this setting, each word of the target sequence (the object phrase) has a temporal dependency on prior words of the same phrase , and on the source sequence embedding (the concatenated subject-predicate phrases):
| (1) |
where is the decoder activation (a softmax function) that computes the probability of decoding the th (current) word of the object phrase from both, the current hidden state embedding and the prior state embedding , as well as from the source embedding. Notice that in the case of modeling this sequence prediction problem using Recurrent Neural Networks (RNNs), the index represents time. Otherwise, it is simply the position of a word within the phrase.
3.3 Transformers
As first introduced for attention RNNs [18, 17], we use the encoder-decoder Transformer as an NLM intended to generate object phrases (output) given the concatenated subject-predicate phrases (input) .999Notice that in this case we have sequences of the same length, , in the input and in the output. The input Transformer encoder block takes as input the dimensional (learnable) word embeddings of each item of the input sequence in parallel. Therefore, such input to the encoder is a matrix (whose rows are word embeddings ) accepted by the th attention head of the headed multi-head self-attention layer [36]:
| (2) |
where is the context matrix resulting from the th attention head, with , and is the element-wise softmax activation. The attention matrix is given by
| (3) |
where are fully connected layers with linear activations (simple linear transformation layers), each entry of is the attention weight, from to each other .
The multi-head self-attention layer builds its output by concatenating the context matrices:
where then is fed to another linear output fully connected layer, i.e. , whose output is in turn fed to the normalization layer given by:
where is applied both, to , therefore , and to the output of the block, i.e. , where is an dimensional linear output fully connected layer ( is the dimension of the latent space of the encoder-decoder model, i.e. the number of outputs of the encoder. In most cases ). The user defined parameters and of are the sample-wise mean and variance, i.e. over each input embedding of the layer.
To build the decoder, a second Transformer block is stacked to an input one, just after the first normalization layer of the latter (thus does not operate for the first block). This way, the output of the first decoder block is taken as the query of the second block, whose key and value are the output of the encoder. As in the case of any encoder-decoder configuration, the decoder takes the target sequence as input and output. The Transformer architecture allows the stacking of multiple blocks (layers), which also extends to the encoder and decoder. In this work we used block Transformer encoder-decoder NLMs.
4 Data and Experimental Setup
4.1 The OIE-GP Knowledge Base
In this work, we created a dataset called OIE-GP by using manually annotated and artificially annotated OpenIE extractions. The main criterion for selecting the sources of the extractions was that they had some human annotation, either for the identification of the elements of the structure or for their factual validity. We considered factual validity as an important criterion because it is important to train the NLM to reason with factual validity.
ClausIE was used to generate a large amount of triples that were manually annotated according to their factual validity [37].101010https://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/ambiverse-nlu/clausie The resulting dataset provides annotations indicating if the triples are either too general or senseless (correct/incorrect), which recent datasets have adopted in some way. For example it is common to find negative samples (incorrect triples) like, e.g., {"he"; "states"; "such thing"}, {"he"; "states"; "he"}. From this dataset, we took the 3374 OpenIE triples annotated as correct (or positive) samples.
MinIE-C111111MinIE-C is the less strict version of MinIE system, and we selected it as it is not restricted in the length of the slots of the triples: https://github.com/uma-pi1/minie provided artificially annotated triples that are specially useful to our purposes because they are as natural as possible in the sense of open vocabulary [38]. These are generated by the ClausIE algorithm (as part of MinIE) and are annotated as positive/negative according to the same criterion used by ClausIE. From this dataset, we took the 33216 OpenIE triples annotated as positive samples.
CaRB is a dataset of triples whose structure have been manually annotated (supervised) with n-ary relations [39]. From this dataset, we took the 2235 triples annotated as positive samples.
WiRe57 contains supervised extractions along with anaphora resolution [40]. The 341 hand-made extractions of the dataset are 100% useful as positive samples because they include anaphora resolution.
4.2 The OpenNCDKB
A noncommunicable disease (NCD) is a medical condition or disease that is considered to be non-infectious. NCDs can refer to Chronic Diseases, which last long periods of time and progress slowly. We created a dataset of scientific paper abstracts related to nine different NCD domains: Breast Cancer, Lung Cancer, Prostate Cancer, Colorectal Cancer, Gastric Cancer, Cardiovascular Disease, Chronic Respiratory Diseases, Type 1 Diabetes Mellitus, and Type 2 Diabetes Mellitus. These are the most prevalent world-wide NCDs, according to the World Health Organization [41].
We used the names of the diseases as search terms to retrieve the most relevant abstracts from the PubMed.121212National Library of Medicine, National Center for Biotechnology Information (NCBI): https://pubmed.ncbi.nlm.nih.gov The resulting set of abstracts constituted our NCD dataset. To generate our Open vocabulary Chronic Disease Knowledge Base (OpenNCDKB), we retrieved a total of 1,200 article abstracts that correspond to the NCD-related domains mentioned above.
To obtain OpenIE triples (and therefore an open vocabulary KB), we used the CoreNLP and OpenIE-5 libraries [42, 43]. First, we took each abstract from the NCD dataset and split it into sentences using the coreNLP library. Afterwards, we took each sentence and extracted the corresponding OpenIE triples using the OpenIE-5 library. By doing so, we obtained a total of 22,776 triples. These triples were filtered to remove the ones that contain only stop words in the subject or object phrases. After this preprocessing, we were left with 18,616 triples that were considered valid for our purposes.
In addition to the valid triples, we also generated semantically incorrect negative samples (triples). These were generated using the same methods for Artificial Semantic Perturbations and were preprocessed in the same way as the positive ones, giving 45,032 semantically invalid triples. These negative samples can be used for training factual validity detection models, which resemble the plausibility score included in the ConceptNet Common Sense Knowledge Base [44].
4.3 The Source Reasoning Tasks
To perform training, we first used a compact version of the ConceptNet KG converted into a KB (the ConceptNet Common Sense Knowledge Base [44]) 131313https://home.ttic.edu/~kgimpel/commonsense.html consisting of 600k triples. We also used our OIE-GP Knowledge Base (Section 4.1) containing 39166 triples, i.e. only the (semantically) positive samples of the whole data described in Section 4.
From these KBs, we constructed mixed KBs that include the source task vocabulary and also include, as much possible, missing vocabulary needed to validate the model on the target task, related to NCDs. In this way, we obtained our source KBs:
-
1.
OpenNCDKB. We split the 18.6k triples of the OpenNCDKB into 70% (13.03k) for training, and 30% for testing (5.58k). We included the OpenNCDKB here because in the context of source and target task, we simply split the whole KB into train, test and validation data. Validation data was considered the target task in this case.
-
2.
ConceptNet+NCD. By merging the triples collected from the ConceptNet Knowledge Graph and those from OpenNCDKB, we obtained our ConceptNet+NCD KB containing 429.12k training triples and 183.91k test triples.
-
3.
OIE-GP+NCD. We obtained our OIE-GP+NCD KB by merging 39.17k OIE-GP and 13.03k NCD triples to obtain a total of 52.20k triples. These were split into 70% (36.54k) for training and 30% (15.66k) for testing.
-
4.
ConceptNet+OIE-GP+NCD. We obtained this large KB that included ConceptNet, general purpose OpenIE (the OIE-GP KB) and NCD OpenIE triples (the OpenNCDKB) by taking the union between ConceptNet+NCD and OIE-GP+NCD. This source training task constitutes 600k + 39.17k + 13.03k = 652.20 total triples. These were split into 70% (456.54k) for training and 30% (195.66k) for testing.
All the mentioned quantities consider that we filtered out the triples whose subject or object phrases were only stopwords.
5 Results and Discussion
5.1 Experimental Setup
For our experiments we used a previously validated Transformer encoder-decoder model to evaluate its performance on our open vocabulary KBC task. Due to the fact that our KBs are smaller than the datasets used for NMT by the authors of [19], we decided to use the smallest model architecture they reported. The Base Model defined by these authors used a sequence length of (the maximum subject-predicate concatenation and object lengths in word-based tokens), a model dimension of (the input positional word embeddings), an output fully connected layer dimension of (denoted in the original paper), a number of attention heads of , attention key and value embedding dimensions of , and a number of transformer blocks of . In addition, we considered the possibility that such “small” model is still too big for our KBs (the largest one has k triples), compared to the 4.5 million sentence pairs this model consumed in the original paper for NMT tasks. Therefore, we also included an alternative version of the Base Model using only one Transformer block () in both the encoder and decoder,141414In the case of the decoder, single Transformer block refers to two self-attention layers (), whereas refers to three of these layers (i.e. the decoder’s number of blocks is w.r.t the encoder). while keeping all other hyperparameters.
The training of the models was performed using different KBs constructed from different sources to select the task and the model that best transfers to our target task, the OpenNCDKB (see Section 4.3). Using the four source KBs and the OpenNCDKB we obtained the four mixed KBs used for training: ConceptNet+NCD (CN+NCD, for short), IOE-GP+NCD, Concepnet+IOE-GP+NCD (CN+OIE-GP+NCD, for short). Using these, we obtained a total of eight models, four with and four with .
We presented a comparison of the source task performance metrics of the eight models (training and test). We also performed an STS-based hypothesis test on the source and target tasks. STS is based on the cosine similarity between phrase embeddings. During the source tasks, and for each of the eight trained models, we first computed the STSs between the predicted and ground-truth object phrases (actual STS measurements). Then, we computed the STSs between the predicted phrases and a shuffled version of the ground-truth object phrases to obtain a random baseline that simulated the perturbation of the actual correspondence between subject-predicate and object. Therefore, hypothesis testing was first performed for the actual STS measurements and then for the randomized baseline. Next, the same computations were performed on the target tasks. The overall outcome of this experiment was to demonstrate whether the null hypothesis, i.e., that the means of the actual STS measurements and the random baselines come from the same distribution, could be rejected with confidence, and whether this held from the source to target tasks.
The neural word embeddings we used for STS-based hypothesis testing were trained on the Wikipedia corpus in order to obtain a good coverage of the set difference between the vocabulary of the source and target tasks (paper abstracts contain simpler vocabulary than the paper itself, while Wikipedia contains a relatively technical vocabulary). The embedding algorithm used was FastText as it has showed better performance in representing short texts [45]. The phrase embedding method used to represent object phrases was simple embedding summation, this was because at the phrase level, even functional words (e.g. prepositions, copulative and auxiliary verbs) can change the meaning of the represented linguistic sample [29].
Finally, we analyzed by inspection the natural language predictions of the best models with N=1 and N=2, in both source and target tasks. For this purpose, five input samples were randomly chosen from the source tasks, and the NLMs that showed the highest confidence during our STS hypothesis testing were fed with them. The obtained predictions were analyzed from the point of view of their meaning, and semantic regularities they showed. Next, in the target task (OpenNCDKB), we performed the same inspection on a random sample of five subject-predicate inputs not seen by the trained models. This was to verify whether the semantic regularities previously identified in the source task predictions were reproduced in the target task.
5.2 Results
5.2.1 Performance Metrics
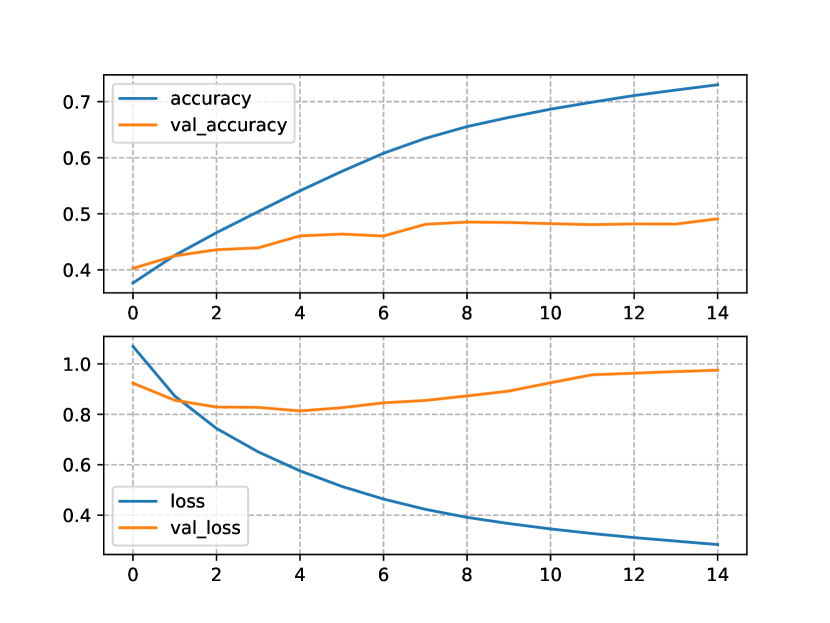
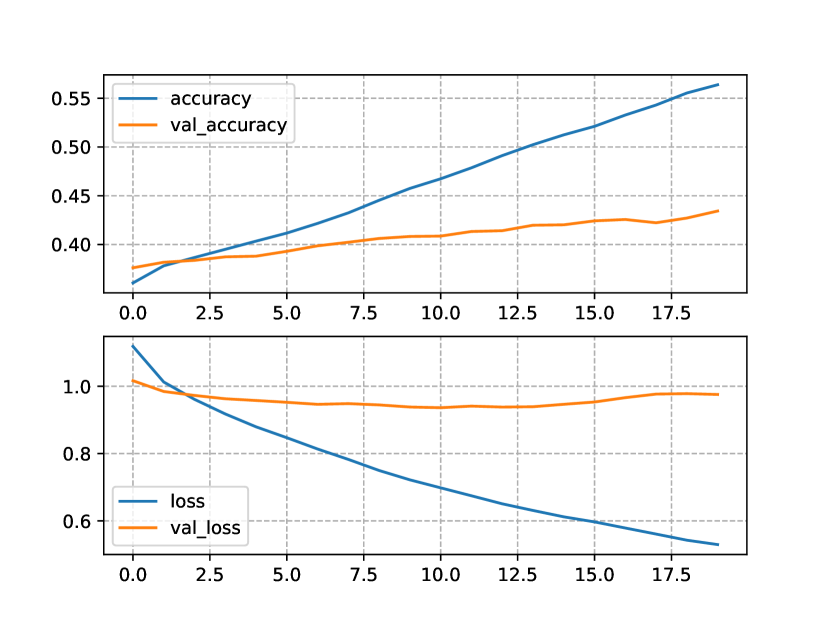
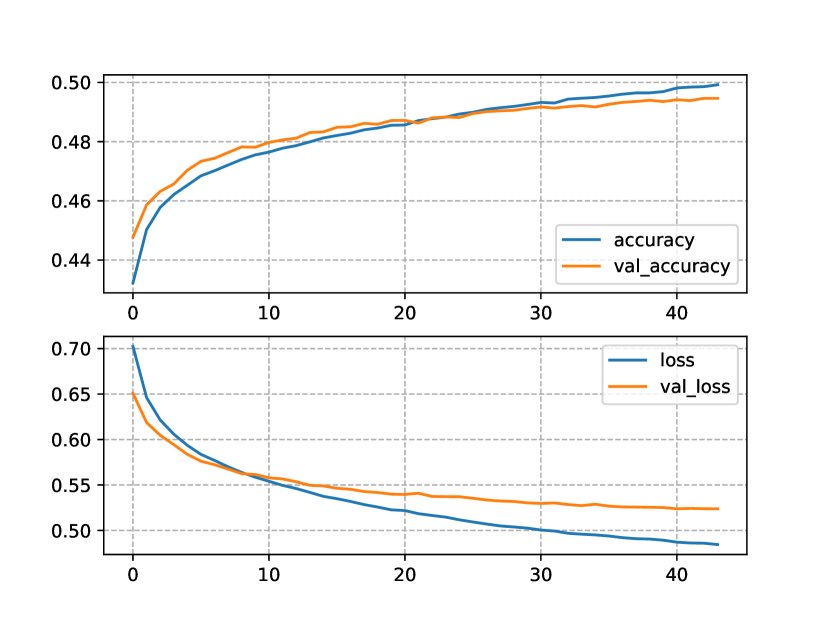
In Figure 2, we show the progress of the performance metrics of the Transformers trained and tested only on the OpenNCDKB. Figure 2(a) shows the accuracy and the loss for the one-block Transformer NLM. Notice that the difference between train and test accuracy (accuracy=80% and val_accuracy=48%, respectively) is relatively large. The same occurred for the loss function (loss=1.28bits and val_loss=0.25bits). This can be the manifestation of overfitting, although the NLM showed to be relatively stable through the fourteen epochs allowed by the patience hyperparameter.
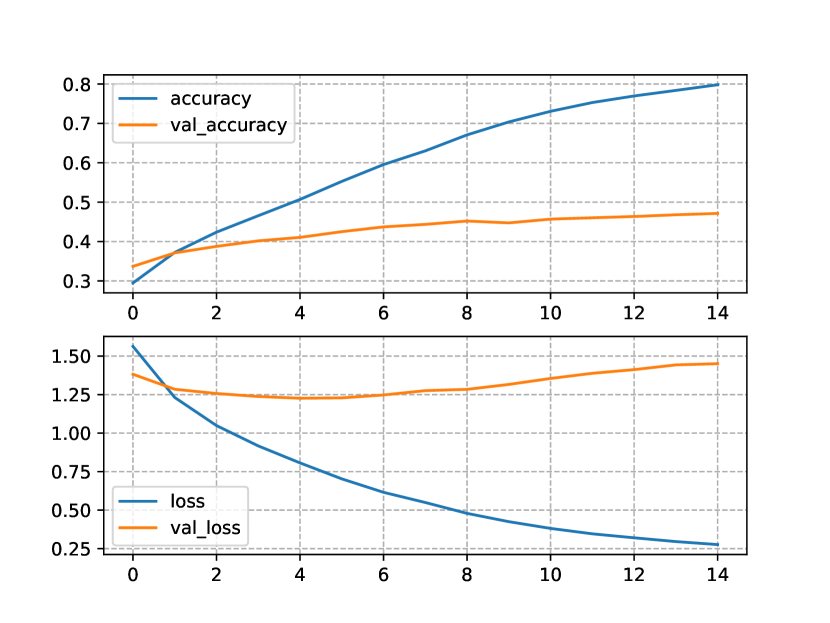
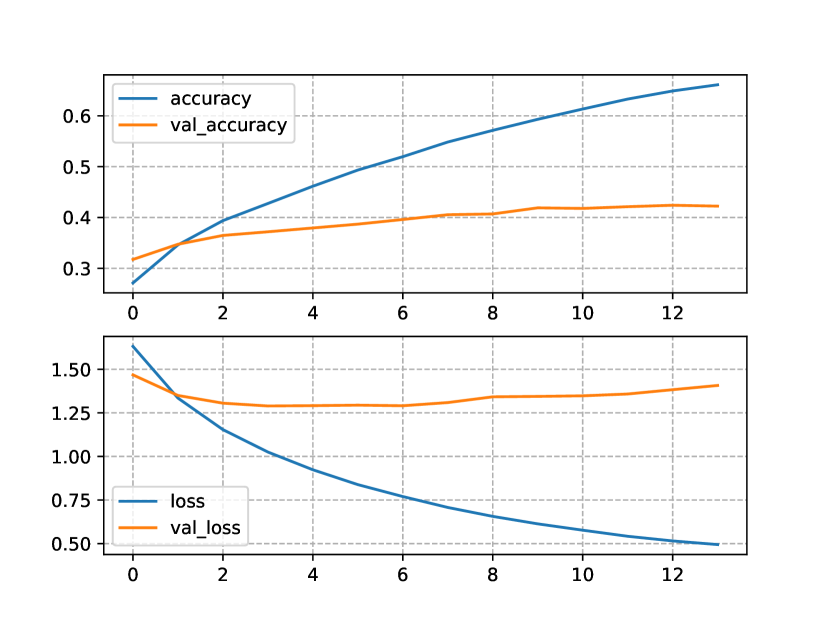
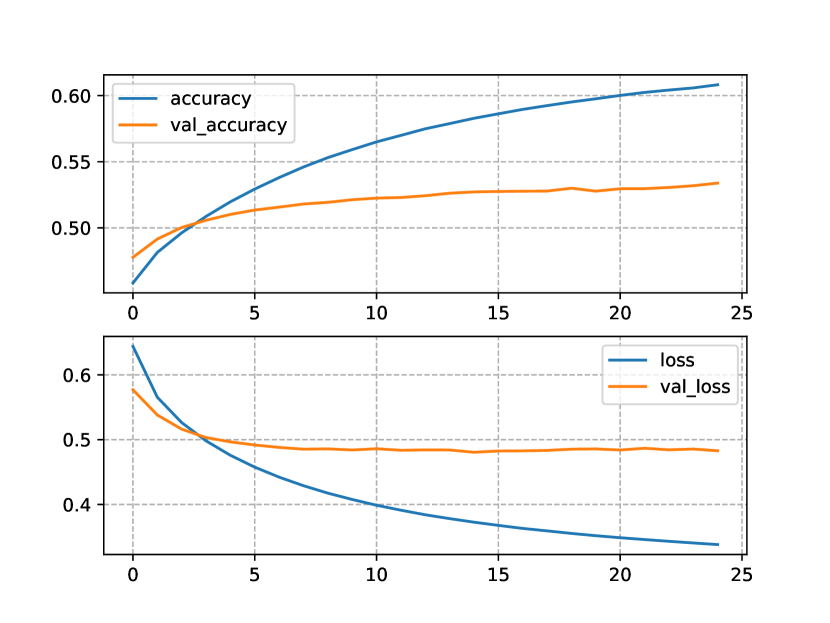
Similarly to the one-block model, the accuracy and the loss (Figure 2(b)) for the two-block Trasformer NLM shows a manifestation of overfitting. Also, the two-block NLM converged two epochs earlier than the one-block NLM. The models trained with the CN+NCD KB were provided with much more data than the models only using the OpenNCDKB. The accuracy and loss for these models are shown in Figure 3. Figure 3(a) shows a clear improvement in the test loss, reaching a minimum near to 0.48bits. On the other hand, the training loss was about 0.13bits apart from the test loss, which is less than the same comparison made for the two-block NLM trained only with the OpenNCDKB. Regarding accuracy, the maximum on test data was about 53%, showing similar train and test curves with respect to OpenNCDKB.
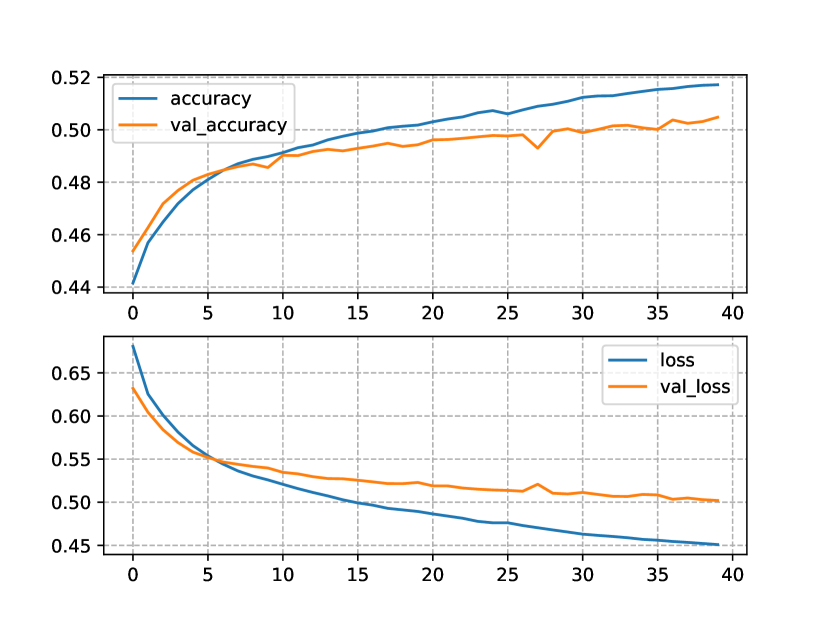
In the case of the two-block NLM trained with the CN+NCD KB (Figure 3(b)), the training and test losses developed with lower divergence, the same can be said for the accuracies, possibly indicating stability and low variability of the model when it is exposed to unseen data (generalization). In addition, the test loss reached a minimum of 0.5bits, and did not diverge as much as in the one-block NLM. The maximum test accuracy surpassed 50%, and the training accuracy behaved in a similar way. It is worth noting that the model improved throughout the 40 epochs we set as maximum, which suggests that the results could be improved by increasing the total number of epochs.
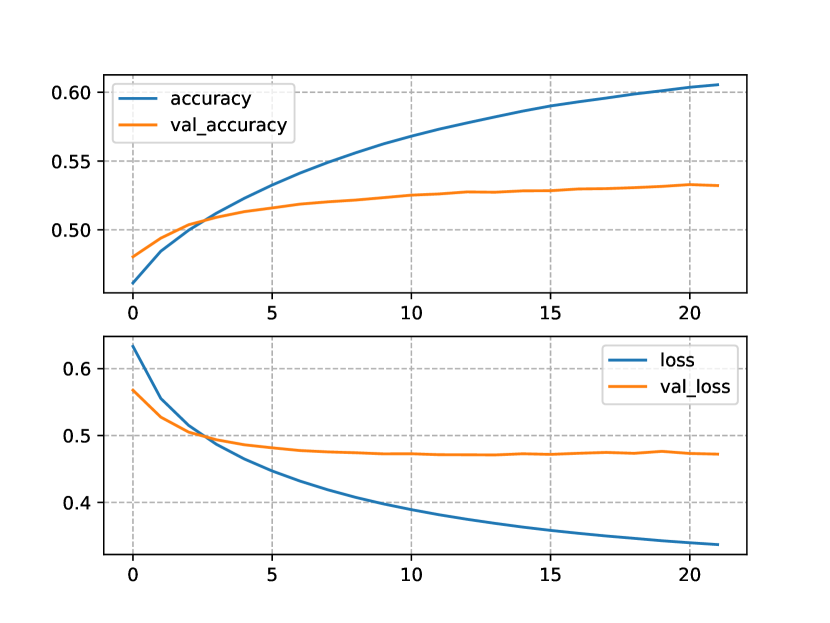
The apparent lack of data of our smaller KBs was again highlighted by the results obtained from the NLM trained with the OIE-GP+NCD KB (see Figure 4). Although the OIE-GP KB is twice as large as OpenNCDKB, its barely one tenth the size of ConceptNet. The losses and accuracies shown in Figures 4(a) and 4(b) indicate that there are no clear improvements of using this KB over the OpenNCDKB.
Finally, the NLMs trained using the ConceptNet+OIE-GP+NCD KB show similar results to the ones obtained with the ConceptNet+NCD KB (see Figure 5). The one-block NLM (Figure 5(a)) required two less epochs, compared to the same architecture trained on the ConceptNet+NCD KB. Training the two-block NLM (Figure 5(b)) with the ConceptNet+OIE-GP+NCD KB caused a decrease in performance, compared to training the model with the ConceptNet+NCD KB, i.e. 0.03bits in the case of the loss and 0.01% in the case of accuracy. Despite this decrease, the model showed a greater stability, as the train and test curves were less divergent when the ConceptNet+OIE-GP+NCD KB was used.
5.2.2 Semantic Textual Similarity
We compared predictions with respect to random baselines using STSs between the predicted and ground truth object phrases (pred), and between the predicted and randomized ground truth object phrases (rdn). See Table 1. Our most significant model resulted when using the CN+NCD KB for training (the null hypothesis can be safely rejected). Its mean similarity with respect to the ground truth in the source task (-Src pred) was 0.551 (), while in the target task (-Trg pred) it was 0.414 (). Such model required one Transformer block (encoder/decoder) and 20 training epochs. The performance of this model was followed by the NLM constituted by one-block Transformer trained with the CN+OIE-GP+NCD KB ( in the target task).
| N | KB | -Src (pred/rdn) | Source | -Trg (pred/rdn) | Target |
| 1 | CN+OIE-GP+NCD | 0.506 / 0.468 | 0.0 | 0.414 / 0.309 | |
| 1 | CN+NCD | 0.551 / 0.511 | 0.0 | 0.414 / 0.315 | |
| 1 | OIE-GP+NCD | 0.584 / 0.569 | 0.459 / 0.404 | ||
| 1 | OpenNCDKB | 0.613 / 0.596 | 0.610 / 0.595 | ||
| 2 | CN+OIE-GP+NCD | 0.424 / 0.418 | 0.0 | 0.342 / 0.298 | 0.0708 |
| 2 | CN+NCD | 0.500 / 0.492 | 0.0 | 0.367 / 0.310 | 0.0468 |
| 2 | OIE-GP+NCD | 0.308 / 0.308 | 1.0 | 0.284 / 0.284 | 1.0 |
| 2 | OpenNCDKB | 0.607 / 0.607 | 1.0 | 0.604 / 0.604 | 1.0 |
In the case of the two-block NLMs, most of their predictions on the NCD-related target task can be confidently regarded as random (the null hypothesis holds), even those of the model trained with our largest KB (CN+OIE-GP+NCD). Only the two-block model trained with CN+NCD proved to be significantly reliable, but with relatively low mean STS on the target task (-Trg pred of 0.367, ). Based on our performance analysis, in which we had observed that the two-block models generalized well, but underperformed on the source task (), we believe that this low confidence of the STS measurements in the target predictions may be due to an overfitting of the models to the task level on the source task, which in turn can be attributed to model size. Despite this, the predictions of the one-block models trained with CN+OIE-GP+NCD and CN+NCD were the most confident in distinguishing from the random baseline in the source task. The only two-block model that resulted significant barely reached , which was trained with the CN+NCD KB. These models trained with the smaller KBs (OIE-GP+NCD and OpenNCDKB) evidenced their poor performance (which initially appeared to be generalization), as their predictions can be reliably discarded as random in both the source and target task ().
Overall, according to our STS-based hypothesis tests, all source tasks provided the needed knowledge to the one-block NLMs to consistently and confidently be distinguished from the random baseline in both source and target tasks. This means that the models did not generate random meanings for the object phrases and that the generated meanings are in fact correlated with those of the ground truth.
Notice also that most differences between the actual STSs and the random baselines (pred-rdn) were relatively small and the maximum resulted from the second most significant model (the one-block NLM trained with CN+OIE-GP+NCD), i.e. . However, very small p-values also indicated low variability and high isolation between randomness and predictions, and thus high stability in the decisions the model made to generate meanings.
5.2.3 Inspection of Predictions
In Table 2 we show the predictions for five subject-predicate concatenations randomly sampled from the ConceptNet KB. In the case of “music is a” (1), the NLMs predict, on the one hand, the exact object phrase “a form of communication” (CN+OIE-GP+NCD), and on the other hand it predicted a synonymous phrase, “a form of expression” (CN+NCD, N=1 and N=2), which sounds even more appropriate considering the context (arts), i.e. replacing “communication” by “expression”. The predictions of the one-block NLMs for the second input (2) can be seen as an “objectification” of the ground truth. The models replace the subjective idea of “enjoying” an activity (riding a bicycle) with the objective, and therefore simpler, idea of the purpose for which the activity is conceived (its functional definition). In this case, there is no logical implication from the ground truth, but from the subject-predicate to the objective benefits that someone can obtain by doing the activity with respect to not doing it. The two-block NLM, however, tried to learn subjectivity but with an imprecise semantic change (“you like to play”). A similar pattern could be observed again in the following sample (3), “car receives action”, which focused on the action that cars are most likely to receive: being driven, rather than being propelled. This is called predicate-subject semantic agreement. We believe that these two interesting semantic regularities that the NLM learned can most likely be thought of as common sense (what the source task taught the model), rather than what the ground truth indicated. The two-block model attempted to attribute an abstract application to cars, rather than paying attention to the semantic and grammatical agreements between predicate and subject (“receives action”).
The case of the next sample (4), “an Indian restaurant used for”, the NLMs to exhibit the above regularities and also show an additional manifestation of performance generalization in language generation. The input specifies the type of restaurant, and implicitly the country of origin of the food it sells, but the NLM probably could not learn to pay attention to such specific information. At the level of semantics, these manifestations of generalization of the model can also explain its preference for the more probable arguments of the predicate over the more specific ones in (3).
| 1 | music is a [start] form of communication [end] | |
|---|---|---|
| CN+OIE-GP+NCD | [start] a form of communication [end] | |
| CN+NCD | [start] a form of expression [end] | |
| CN+NCD (N=2) | [start] a form of expression [end] | |
| 2 | ride a bicycle motivated by goal [start] enjoy riding a bicycle [end] | |
| CN+OIE-GP+NCD | [start] you are tired [end] | |
| CN+NCD | [start] you need to get somewhere [end] | |
| CN+NCD (N=2) | [start] you like to play [end] | |
| 3 | car receives action [start] propel by gasoline or electricity [end] | |
| CN+OIE-GP+NCD | [start] drive by car [end] | |
| CN+NCD | [start] drive by car [end] | |
| CN+NCD (N=2) | [start] find in car [end] | |
| 4 | an indian restaurant used for [start] selling indian meals [end] | |
| CN+OIE-GP+NCD | [start] eat a meal [end] | |
| CN+NCD | [start] eating [end] | |
| CN+NCD (N=2) | [start] eating [end] | |
| 5 | mediators capable of [start] settle a disagreement [end] | |
| CN+OIE-GP+NCD | [start] eat cat food [end] | |
| CN+NCD | [start] be [UNK] [end] | |
| CN+NCD (N=2) | [start] be [UNK] [end] | |
The case of entry number five was atypical with respect to the objectivity that the NLMs try to induce in their predictions so far. From a general point of view of the meaning of the word “mediator”, there is no relation to cats (see the prediction made by the NLM trained on the CN+OIE-GP+NCD KB). However, there is a sense of that word related to animal welfare organizations, for which “mediators” are representatives who are concerned with the prevention of animal abuse. So, was it just the addition of some general purpose knowledge (OIE-GP) to CN+NCD that allowed the NLM to infer a (rare) capability for “mediators”? And, therefore allowing the (rare) prediction of “mediators eat cat food”. The model trained with the KB CN+NCD (N=1 and N=2) did not find things that mediators can do (so the [UNK] output token). Note that, in general, the random samples analyzed so far showed that the two-block models did not learn semantic agreement between the elements of the semantic structures, even when they managed to distinguish themselves from the random baseline in the source task. This suggests that to be more confident about the knowledge acquired by the NLM, it must pass the STS-based hypothesis test with high significance in both the source and target task (from CSR to an arbitrary but specialized domain KBC, in our case).
| 1 | these subtypes are closely correlated [start] to clinical variables [end] | |
|---|---|---|
| CN+OIE-GP+NCD | [start] with a [UNK] [end] | |
| CN+NCD | [start] with cardiovascular disease [end] | |
| CN+NCD (N=2) | [start]with the development of the management of the disease[end] | |
| 2 | Immune - based interventions are opening up [start] entirely novel therapeutic avenues [end] | |
| CN+OIE-GP+NCD | [start] to treat the disease [end] | |
| CN+NCD | [start] [UNK] to cure individuals [end] | |
| CN+NCD (N=2) | [start] to the development of the disease [end] | |
| 3 | glycemic targets should reflect [start] presence of comorbid conditions [end] | |
| CN+OIE-GP+NCD | [start] the risk of gastric cancer [end] | |
| CN+NCD | [start] the risk of microvascular complications such as retinopathy in patients with type 2 diabetes mellitus [end] | |
| CN+NCD (N=2) | [start] the [UNK] of the [UNK] of the [UNK] [end] | |
| 4 | these factors may provide [start] an opportunity to reduce deaths [end] | |
| CN+OIE-GP+NCD | [start] the risk of lung cancer [end] | |
| CN+NCD | [start] more effective in treatment options in lung cancer [end] | |
| CN+NCD (N=2) | [start] the [UNK] of the [UNK] [end] | |
| 5 | Ethnic minorities to have [start] worse control of their diabetes [end] | |
| CN+OIE-GP+NCD | [start] the risk of lung cancer [end] | |
| CN+NCD | [start] more likely to be high among patients [end] | |
| CN+NCD (N=2) | [start] the treatment of gastric cancer [end] | |
The best models obtained from source tasks were used to obtain predictions on validation samples obtained from the OpenNCDKB as a target task. To compare these models using these samples, we performed predictions on 5 randomly selected triples and listed them in Table 3. The case of the triples randomly selected from the OpenNCDKB showed some very general inputs. This is the case of the inputs (1) and (4). For example, in the case of the model trained with CN+NCD (N=1), it gives what may be the most likely, grammatically well-formed prediction: “cardivascular disease” given “subtypes closely correlated”, which is not factual at all as there is no a concrete subject in the input. The two-block model generated much more free constructions in this case.
The second input, “Immune-based interventions are opening up” (2), causes the models to reason with very similar but much simpler meanings (“to treat the disease”, and “to cure individuals”) than the ground truth (“entirely novel therapeutic avenues”). This was a reasoning behavior consistently observed during the inspection of the source task. In the case of the input “glycemic targets should reflect” (3) provides a concrete subject (“glycemic targets”) which is related to “comorbid conditions” in the ground truth sentence. Here the model (trained with the CN+OIE-GP+NCD KB) proposed that “glycemic targets” also should be reflected in “the risk of gastric cancer”, which can be verified as a valid fact in [46]. The prediction made by the model trained with the CN+NCD KB could also be confirmed in [47]. Last, the fifth input “Ethnic minorities to have” (5), is interesting because the models seemed to learn more abstract meaning than ground truth. While the ground truth focuses on a specific disease (“Ethnic minorities to have worse control of their diabetes”), the models reason that this is not only true for diabetes, but also for lung cancer, and that in general any sick person is more likely to be a minority.
Since the OpenNCDKB was made from abstracts, we had the opportunity to see some sentences that are not so specialized at all. This allowed us to confirm the replication of the behavior shown by NLMs from source to the target NCD-related task. This statement may be more difficult to make for the case of more specific knowledge. For example, it might require specialized boimedical knowledge to know whether the risk of gastric cancer and the risk microvascular complications are more likely and concrete conditions that can be affected or controlled by glycemic targets than any comorbid condition.
6 Related Work
Regarding systems with IE, and semantic reasoning capabilities, we found common traits shared with the seminal work in Chronic Disease KGs [48]. The authors proposed a data model to organize and integrate the knowledge extracted from text into graphs (ontologies, in fact), and a set of rules to perform reasoning via first-order predicate logic over a predefined dictionary of entities and relations [49]. More recently, [50] proposed association rule learning for relation extraction for KG construction, and neural network-based graph embedding for entity clustering from EMRs. In [51], the authors constructed a KG of gene-disease interactions from the literature on co-morbid diseases. They predicted new interactions using embeddings obtained from a tensor decomposition method. The authors of [52] proposed a KG of drug combinations used to treat cancer, which was built from OpenIE triples filtered using different thesaurus [53, 54]. The drug combinations were inferred directly from the co-occurrence of different individual drugs with fixed predicate and disease. The authors created their resource from the conclusions of clinical trial reports and clinical practice guidelines related with antineoplastic agents.
An EMR-based KG was used as part of a feature selection method for a support vector machine to successfully diagnose chronic obstructive pulmonary disease [55]. Deep Learning has been used in recent work to predict heart failure risks [56]. The authors used a medical KG to guide the attentional mechanism of a Recurrent Neural Network trained with event sequences extracted from EMRs. Previously the authors of [57] also predicted disease risk, but for a broader spectrum of NCDs, and using Convolutional Neural Networks in a KG of EMR events. Medical entity disambiguation is an NLP task aimed at normalizing KG entity nodes, and the authors of [58] approached this problem as one of classification using Graph Neural Network. Overall, multiple classical NLP methods have been applied to biomedical KGs, including biomedical KG forecasting from the point of view of link prediction (also known as literature-based discovery) [59].
7 Conclusions
We trained different Transformer-based encoder-decoder NLMs to perform general-purpose reasoning as source task, including one-block and two-block NLMs. On the one hand, the performance results provided that one-block models showed the best metrics (accuracy and loss), however the divergence between train and test measurements was interpreted as overfitting at first glance. The two-block models, on the other hand, showed much more stable and less divergent (although decreasing) performance measurements, which was interpreted as higher generalization at first glance.
Nevertheless, hypothesis testing based on STS revealed with high confidence, on the one hand, that one-block models showed high generalization in source tasks, and from source to target tasks. These models managed to successfully distinguish themselves from simulated adversarial perturbation (the random baseline) without even learning directly from it (). On the other hand, two-block models ended by memorizing the source task, thus generating nearly random object phrases in the target task (only one two-block model barely reached ). This also confirmed that the NLMs’ reasoning generalization may be manifested in semantic displacements and logical implications (as well as the abstraction and simplification of meanings), rather than in the ground truth distribution of output tokens.
We analyzed by inspection the semantic regularities shown by NLMs during source tasks and the NCD-related target task. The main behaviors observed as transferred were: the model generally takes concrete subjects and predicates, and associates with them the (semantically) most probable object, i.e. it learned semantic agreement; the model “objectifies” and/or simplifies those meanings that could be considered subjective and/or complex (i.e., in terms of generalization, it is more likely to construct simpler than abstract and/or complex ideas). The two-block NLMs failed to acquire these skills, even the one that barely reached in the STS-based hypothesis testing.
Finally, our results suggest with significance that the predictions obtained by the proposed method can help answer research questions whose answers give rise to potential new knowledge, as we demonstrated for NCDs.
Acknowledgements
We thank to PRODEP-SEP (project number UTMIX-PTC-069) for the support given. Also thanks to Dr. J. Anibal Arias Aguilar (Postgraduate Studies Division, UTM) for giving access to his computing nodes.
References
- [1] L. Harper, J. Campbell, E. K. Cannon, S. Jung, M. Poelchau, R. Walls, C. Andorf, E. Arnaud, T. Z. Berardini, C. Birkett, et al., Agbiodata consortium recommendations for sustainable genomics and genetics databases for agriculture, Database 2018 (2018).
- [2] L. E. Hunter, Knowledge-based biomedical data science, Data Science 1 (1-2) (2017) 19–25.
- [3] S. Sheikhalishahi, R. Miotto, J. T. Dudley, A. Lavelli, F. Rinaldi, V. Osmani, Natural language processing of clinical notes on chronic diseases: systematic review, JMIR medical informatics 7 (2) (2019) e12239.
- [4] K.-H. Yu, A. L. Beam, I. S. Kohane, Artificial intelligence in healthcare, Nature biomedical engineering 2 (10) (2018) 719–731.
- [5] E. Davis, G. Marcus, Commonsense reasoning and commonsense knowledge in artificial intelligence, Communications of the ACM 58 (9) (2015) 92–103.
- [6] R. Socher, D. Chen, C. D. Manning, A. Ng, Reasoning with neural tensor networks for knowledge base completion, in: Advances in neural information processing systems, 2013, pp. 926–934.
-
[7]
Y. Xu, M.-Y. Kim, K. Quinn, R. Goebel, D. Barbosa,
Open information extraction with
tree kernels, in: Proceedings of the 2013 Conference of the North American
Chapter of the Association for Computational Linguistics: Human Language
Technologies, Association for Computational Linguistics, Atlanta, Georgia,
2013, pp. 868–877.
URL https://aclanthology.org/N13-1107 -
[8]
M. Cetto, C. Niklaus, A. Freitas, S. Handschuh,
Graphene: a context-preserving
open information extraction system, in: Proceedings of the 27th
International Conference on Computational Linguistics: System Demonstrations,
Association for Computational Linguistics, Santa Fe, New Mexico, 2018, pp.
94–98.
URL https://aclanthology.org/C18-2021 - [9] J. Shin, S. Wu, F. Wang, C. De Sa, C. Zhang, C. Ré, Incremental knowledge base construction using deepdive, in: Proceedings of the VLDB Endowment International Conference on Very Large Data Bases, Vol. 8, NIH Public Access, 2015, p. 1310.
- [10] A. Popescul, L. H. Ungar, S. Lawrence, D. M. Pennock, Statistical relational learning for document mining, in: Third IEEE International Conference on Data Mining, IEEE, 2003, pp. 275–282.
- [11] D. Koller, N. Friedman, S. Džeroski, C. Sutton, A. McCallum, A. Pfeffer, P. Abbeel, M.-F. Wong, D. Heckerman, C. Meek, et al., Introduction to statistical relational learning, MIT press, 2007.
- [12] L. Getoor, L. Mihalkova, Learning statistical models from relational data, in: Proceedings of the 2011 ACM SIGMOD International Conference on Management of data, 2011, pp. 1195–1198.
- [13] S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural computation 9 (8) (1997) 1735–1780.
- [14] J. Zhou, W. Xu, End-to-end learning of semantic role labeling using recurrent neural networks, in: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2015, pp. 1127–1137.
- [15] K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, Y. Bengio, Learning phrase representations using rnn encoder-decoder for statistical machine translation, arXiv preprint arXiv:1406.1078 (2014).
- [16] S. Chaudhari, V. Mithal, G. Polatkan, R. Ramanath, An attentive survey of attention models, ACM Transactions on Intelligent Systems and Technology (TIST) 12 (5) (2021) 1–32.
- [17] D. Bahdanau, K. Cho, Y. Bengio, Neural machine translation by jointly learning to align and translate, in: ICLR 2015 : International Conference on Learning Representations 2015, 2015.
-
[18]
T. Luong, H. Pham, C. D. Manning,
Effective approaches to
attention-based neural machine translation, in: Proceedings of the 2015
Conference on Empirical Methods in Natural Language Processing, Association
for Computational Linguistics, Lisbon, Portugal, 2015, pp. 1412–1421.
doi:10.18653/v1/D15-1166.
URL https://aclanthology.org/D15-1166 - [19] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, in: Advances in neural information processing systems, 2017, pp. 5998–6008.
- [20] J. D. M.-W. C. Kenton, L. K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of NAACL-HLT, 2019, pp. 4171–4186.
- [21] Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. R. Salakhutdinov, Q. V. Le, Xlnet: Generalized autoregressive pretraining for language understanding, Advances in neural information processing systems 32 (2019).
- [22] L. Floridi, M. Chiriatti, Gpt-3: Its nature, scope, limits, and consequences, Minds and Machines 30 (4) (2020) 681–694.
-
[23]
W. Han, B. Pang, Y. N. Wu,
Robust transfer learning
with pretrained language models through adapters, in: Proceedings of the
59th Annual Meeting of the Association for Computational Linguistics and the
11th International Joint Conference on Natural Language Processing (Volume 2:
Short Papers), Association for Computational Linguistics, Online, 2021, pp.
854–861.
doi:10.18653/v1/2021.acl-short.108.
URL https://aclanthology.org/2021.acl-short.108 - [24] J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, J. Kang, Biobert: a pre-trained biomedical language representation model for biomedical text mining, Bioinformatics 36 (4) (2020) 1234–1240.
- [25] Z. Meng, F. Liu, T. H. Clark, E. Shareghi, N. Collier, Mixture-of-partitions: Infusing large biomedical knowledge graphs into bert, arXiv preprint arXiv:2109.04810 (2021).
- [26] J. Pfeiffer, A. Rücklé, C. Poth, A. Kamath, I. Vulić, S. Ruder, K. Cho, I. Gurevych, Adapterhub: A framework for adapting transformers, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2020, pp. 46–54.
- [27] O. Etzioni, M. Banko, S. Soderland, D. S. Weld, Open information extraction from the web, Communications of the ACM 51 (12) (2008) 68–74.
- [28] A. Fader, S. Soderland, O. Etzioni, Identifying relations for open information extraction, in: Proceedings of the Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, 2011, pp. 1535–1545.
- [29] I. Arroyo-Fernández, C.-F. Méndez-Cruz, G. Sierra, J.-M. Torres-Moreno, G. Sidorov, Unsupervised sentence representations as word information series: Revisiting tf–idf, Computer Speech & Language 56 (2019) 107–129.
- [30] H. Wang, H. Mai, Z.-h. Deng, C. Yang, L. Zhang, H.-y. Wang, Distributed representations of diseases based on co-occurrence relationship, Expert Systems with Applications (2021) 115418.
- [31] A. Bosselut, H. Rashkin, M. Sap, C. Malaviya, A. Celikyilmaz, Y. Choi, Comet: Commonsense transformers for automatic knowledge graph construction, in: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 4762–4779.
- [32] B. Y. Lin, X. Chen, J. Chen, X. Ren, Kagnet: Knowledge-aware graph networks for commonsense reasoning, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pp. 2829–2839.
- [33] B. Dhingra, M. Zaheer, V. Balachandran, G. Neubig, R. Salakhutdinov, W. W. Cohen, Differentiable reasoning over a virtual knowledge base, arXiv preprint arXiv:2002.10640 (2020).
- [34] I. Arroyo-Fernández, I. Meza-Ruiz, Lipn-iimas at semeval-2017 task 1: Subword embeddings, attention recurrent neural networks and cross word alignment for semantic textual similarity, in: Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), 2017, pp. 208–212.
-
[35]
D. G. Hays, Dependency theory: A
formalism and some observations, Language 40 (4) (1964) 511–525.
URL http://www.jstor.org/stable/411934 - [36] S. Dutta, T. Gautam, S. Chakrabarti, T. Chakraborty, Redesigning the transformer architecture with insights from multi-particle dynamical systems, arXiv preprint arXiv:2109.15142 (2021).
-
[37]
L. Del Corro, R. Gemulla,
Clausie: Clause-based open
information extraction, in: Proceedings of the 22nd International Conference
on World Wide Web, WWW ’13, Association for Computing Machinery, New York,
NY, USA, 2013, p. 355–366.
doi:10.1145/2488388.2488420.
URL https://doi.org/10.1145/2488388.2488420 -
[38]
K. Gashteovski, R. Gemulla, L. del Corro,
MinIE: Minimizing facts in open
information extraction, in: Proceedings of the 2017 Conference on Empirical
Methods in Natural Language Processing, Association for Computational
Linguistics, Copenhagen, Denmark, 2017, pp. 2630–2640.
doi:10.18653/v1/D17-1278.
URL https://aclanthology.org/D17-1278 -
[39]
S. Bhardwaj, S. Aggarwal, M. Mausam,
CaRB: A crowdsourced benchmark
for open IE, in: Proceedings of the 2019 Conference on Empirical Methods
in Natural Language Processing and the 9th International Joint Conference on
Natural Language Processing (EMNLP-IJCNLP), Association for Computational
Linguistics, Hong Kong, China, 2019, pp. 6262–6267.
doi:10.18653/v1/D19-1651.
URL https://aclanthology.org/D19-1651 -
[40]
W. Lechelle, F. Gotti, P. Langlais,
WiRe57 : A fine-grained
benchmark for open information extraction, in: Proceedings of the 13th
Linguistic Annotation Workshop, Association for Computational Linguistics,
Florence, Italy, 2019, pp. 6–15.
doi:10.18653/v1/W19-4002.
URL https://aclanthology.org/W19-4002 - [41] W. H. Organization, et al., Noncommunicable diseases country profiles 2018 (2018).
- [42] C. D. Manning, M. Surdeanu, J. Bauer, J. R. Finkel, S. Bethard, D. McClosky, The stanford corenlp natural language processing toolkit, in: Proceedings of 52nd annual meeting of the association for computational linguistics: system demonstrations, 2014, pp. 55–60.
-
[43]
S. Saha, H. Pal, Mausam,
Bootstrapping for numerical open
IE, in: Proceedings of the 55th Annual Meeting of the Association for
Computational Linguistics (Volume 2: Short Papers), Association for
Computational Linguistics, Vancouver, Canada, 2017, pp. 317–323.
doi:10.18653/v1/P17-2050.
URL https://aclanthology.org/P17-2050 - [44] X. Li, A. Taheri, L. Tu, K. Gimpel, Commonsense knowledge base completion, in: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016, pp. 1445–1455.
- [45] P. Bojanowski, E. Grave, A. Joulin, T. Mikolov, Enriching word vectors with subword information, Transactions of the Association for Computational Linguistics 5 (2017) 135–146.
- [46] L. Augustin, S. Gallus, E. Negri, C. La Vecchia, Glycemic index, glycemic load and risk of gastric cancer, Annals of oncology 15 (4) (2004) 581–584.
- [47] J. M. Lachin, S. Genuth, D. M. Nathan, B. Zinman, B. N. Rutledge, et al., Effect of glycemic exposure on the risk of microvascular complications in the diabetes control and complications trial—revisited, Diabetes 57 (4) (2008) 995–1001.
- [48] L. Shi, S. Li, X. Yang, J. Qi, G. Pan, B. Zhou, Semantic health knowledge graph: semantic integration of heterogeneous medical knowledge and services, BioMed research international 2017 (2017).
- [49] C. Bizon, S. Cox, J. Balhoff, Y. Kebede, P. Wang, K. Morton, K. Fecho, A. Tropsha, Robokop kg and kgb: integrated knowledge graphs from federated sources, Journal of chemical information and modeling 59 (12) (2019) 4968–4973.
- [50] L. Li, P. Wang, J. Yan, Y. Wang, S. Li, J. Jiang, Z. Sun, B. Tang, T.-H. Chang, S. Wang, et al., Real-world data medical knowledge graph: construction and applications, Artificial intelligence in medicine 103 (2020) 101817.
- [51] S. Biswas, P. Mitra, K. S. Rao, Relation prediction of co-morbid diseases using knowledge graph completion, IEEE/ACM Transactions on Computational Biology and Bioinformatics 18 (2) (2021) 708–717. doi:10.1109/TCBB.2019.2927310.
- [52] J. Du, X. Li, A knowledge graph of combined drug therapies using semantic predications from biomedical literature: Algorithm development, JMIR medical informatics 8 (4) (2020) e18323.
-
[53]
T. C. Rindflesch, M. Fiszman,
The
interaction of domain knowledge and linguistic structure in natural language
processing: interpreting hypernymic propositions in biomedical text, Journal
of Biomedical Informatics 36 (6) (2003) 462–477, unified Medical Language
System.
doi:https://doi.org/10.1016/j.jbi.2003.11.003.
URL https://www.sciencedirect.com/science/article/pii/S1532046403001175 - [54] C.-H. Wei, H.-Y. Kao, Z. Lu, Pubtator: a web-based text mining tool for assisting biocuration, Nucleic Acids Research 41 (2013) W518 – W522.
- [55] Y. Fang, H. Wang, L. Wang, R. Di, Y. Song, Diagnosis of copd based on a knowledge graph and integrated model, IEEE Access 7 (2019) 46004–46013. doi:10.1109/ACCESS.2019.2909069.
-
[56]
R. Li, C. Yin, S. Yang, B. Qian, P. Zhang,
Marrying medical domain knowledge
with deep learning on electronic health records: A deep visual analytics
approach, J Med Internet Res 22 (9) (2020) e20645.
doi:10.2196/20645.
URL http://www.jmir.org/2020/9/e20645/ - [57] J. Zhang, J. Gong, L. Barnes, Hcnn: Heterogeneous convolutional neural networks for comorbid risk prediction with electronic health records, in: 2017 IEEE/ACM International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), IEEE, 2017, pp. 214–221.
-
[58]
A. Vretinaris, C. Lei, V. Efthymiou, X. Qin, F. Özcan,
Medical entity disambiguation
using graph neural networks, in: Proceedings of the 2021 International
Conference on Management of Data, SIGMOD/PODS ’21, Association for Computing
Machinery, New York, NY, USA, 2021, p. 2310–2318.
doi:10.1145/3448016.3457328.
URL https://doi.org/10.1145/3448016.3457328 - [59] G. K. O. Crichton, Improving automated literature-based discovery with neural networks: neural biomedical named entity recognition, link prediction and discovery, Ph.D. thesis, University of Cambridge (2019).