Communication-Efficient and Privacy-Preserving Decentralized Meta-Learning
Abstract
Distributed learning, which does not require gathering training data in a central location, has become increasingly important in the big-data era. In particular, random-walk-based decentralized algorithms are flexible in that they do not need a central server trusted by all clients and do not require all clients to be active in all iterations. However, existing distributed learning algorithms assume that all learning clients share the same task. In this paper, we consider the more difficult meta-learning setting, in which different clients perform different (but related) tasks with limited training data. To reduce communication cost and allow better privacy protection, we propose LDMeta (Local Decentralized Meta-learning) with the use of local auxiliary optimization parameters and random perturbations on the model parameter. Theoretical results are provided on both convergence and privacy analysis. Empirical results on a number of few-shot learning data sets demonstrate that LDMeta has similar meta-learning accuracy as centralized meta-learning algorithms, but does not require gathering data from each client and is able to better protect data privacy for each client.
1 Introduction
Modern machine learning relies on increasingly large models trained on increasingly large amount of data. However, real-world data often come from diverse sources, and collecting these data to a central server can lead to large communication cost and high privacy risks. As such, distributed learning Balcan et al. (2012); Yuan et al. (2022), which does not require gathering training data together, has received increasing attention in recent years. Existing methods for distributed learning can be classified as (i) centralized distributed learning Predd et al. (2009); Balcan et al. (2012), which assumes the presence of a central server to coordinate the computation and communication for model training, and (ii) decentralized learning Mao et al. (2020); Lu and De Sa (2021); Yuan et al. (2021); Sun et al. (2022), which does not involve a central server, thus is more preferable when it is hard to find a central server trusted by all clients. Decentralized learning methods can be further subdivided as: (i) gossip methods Koloskova et al. (2020); Yuan et al. (2021), which let all clients communicate with their neighbors to jointly learn models; and (ii) random-walk (or incremental) methods Mao et al. (2020); Sun et al. (2022); Triastcyn et al. (2022), which activate only one client in each round. While many works consider gossip methods, it requires most clients to be active during training, which can be difficult in practice. For example, in IoT applications (especially when clients are placed in the wild), clients can be offline due to energy or communication issues. In such cases, random-walk methods may be more preferable.
Most distributed learning methods assume all clients perform the same task and share a global model. However, in many applications, different clients may have different (but related) tasks. For example, consider bird classification in the wild, different clients (camera sensors) at different locations may target different kinds of birds. On the other hand, the naive approach of training a separate model for each client is not practical, as each client typically has only very limited data, and directly training a model can lead to bad generalization performance.
In a centralized setting, meta-learning Hospedales et al. (2022) has been a popular approach for efficient learning of a diverse set of related tasks with limited training data. It has been successfully used in many applications, such as few-shot learning Ravi and Larochelle (2017); Finn et al. (2017) and learning with label noise Shu et al. (2019). Recently, meta-learning is extended to the centralized distributed setting in the context of personalized federated learning (PFL) Marfoq et al. (2022); Pillutla et al. (2022); Collins et al. (2021); Singhal et al. (2021). The central server updates the meta-model, while each client obtains its own personalized model from the meta-model. However, PFL, as in standard federated learning, still requires the use of a central server to coordinate learning. Some works have also considered generalizing meta-learning to decentralized settings. For example, Dif-MAML Kayaalp et al. (2020) combines gossip algorithm with MAML Finn et al. (2017), and DRML Zhang et al. (2022) combines gossip algorithm with Reptile Nichol et al. (2018). Another example is L2C Li et al. (2022a), which also uses gossip algorithm and proposes to dynamically update the mixing weights for different clients. Also, methods based on decentralized bi-level optimization Yang et al. (2022); Liu et al. (2023); Chen et al. (2023); Yang et al. (2023) may also be used to solve the meta-learning problem. Nevertheless, these works are all based on gossip algorithm, and share a common disadvantage that they need most clients to be always active during the learning process to achieve good performances. Furthermore, these methods only learn a model that can be used for all training clients, and the final model cannot be adapted to unseen clients that are not present during training.
Motivated by the above limitations, we propose a novel decentralized learning algorithm for the setting where each client has limited data for different tasks. Based on random-walk decentralized optimization methods, the proposed method removes additional communication cost of directly using adaptive optimizers. We also introduce random perturbations to protect data privacy for each client. We prove that the proposed method achieves the same convergence rate as existing centralized meta-learning methods, and provide theoretical justifications on how it can protect data privacy for each client. Empirical results demonstrate that the proposed method achieves similar performances with centralized settings. Our contributions are listed as follows:
-
•
We propose a novel decentralized meta-learning algorithm based on random walk. Compared with existing decentralized learning algorithms, it has a smaller communication cost and can protect client privacy.
-
•
Theoretically, we prove that the proposed method achieves the same asymptotic convergence rate with existing decentralized learning algorithms, and analyze how the perturbation variance affects privacy protection.
-
•
Extensive empirical results on various data sets and communication networks demonstrate that the proposed method can reduce the communication cost and protect client privacy, without sacrificing model performance.
2 Related works
2.1 Random-Walk Decentralized Optimization
Given a set of clients, random-walk (incremental) decentralized optimization algorithms Mao et al. (2019, 2020); Sun et al. (2022); Triastcyn et al. (2022) aim to minimize the total loss over all clients:
| (1) |
in a decentralized manner by performing random walk in the communication network. Here, is the model parameter, is the training data on client , and is client ’s loss on its local data. In each iteration, one client is activated, receives the current model from the previously activated client, updates the model parameter with its own training data, and then sends the updated model to the next client. The active client is selected from a Markov chain with transition probability matrix , where is the probability that the next client is given that the current client is .
The pioneering work on random-walk decentralized optimization is in Bertsekas (1997), which focuses only on the least squares problem. A more general algorithm is proposed in Johansson et al. (2010), which uses (sub)gradient descent with Markov chain sampling. More recently, the Walkman algorithm Mao et al. (2020) formulates problem (1) as a linearly-constrained optimization problem, which is then solved by the alternating direction method of multipliers (ADMM) Boyd et al. (2011). However, these works are all based on the simple SGD for decentralized optimization. Very recently, adaptive optimizers are also used in random-walk decentralized optimization Sun et al. (2022). However, its communication cost is three times that of SGD, as both the momentum and preconditioner (which are of the same size as the model parameter) need to be transmitted. Moreover, existing works in random-walk decentralized learning assume that all clients perform the same task, which is not the case in many real-world applications.
2.2 Privacy in Distributed Learning
Privacy is a core issue in distributed machine learning. Among various notations for privacy, one of the most well-known is differential privacy (DP) Dwork et al. (2014). The idea is to add noise to the model updates so that the algorithm output does not reveal sensitive information about any individual data sample. Although it is originally proposed for centralized machine learning algorithms McMahan et al. (2018), DP has also found wide applications in centralized distributed learning, particularly the federated learning setting where a central server coordinates model training on distributed data sources without data ever leaving each client. An example is FedDP Wei et al. (2020), where DP is directly combined with the FedAvg algorithm McMahan et al. (2017). Later, Hu et al. (2020) generalizes DP to the personalized federated learning, where different clients have non-i.i.d. training data.
There have been limited progress on privacy in decentralized learning without a central server. One prominent work is Cyffers and Bellet (2022), which considers random-walk algorithms on rings and fully-connected graphs, but not communication networks with diverse topological structures as is often encountered in the real world. Another decentralized learning algorithm with privacy guarantees is Muffliato Cyffers et al. (2022), which is based on gossip methods but not random walk. Moreover, both cannot be used for decentralized meta-learning, in which different clients perform different tasks.
3 Proposed Method
3.1 Problem Formulation
Following the formulation in (1), we consider the setting where each client has its own task, and new clients may join the network with limited data. We propose to use meta-learning Hospedales et al. (2022) to jointly learn from different tasks. Denote the set of all tasks (which also corresponds to all clients) as , we have the following bi-level optimization problem:
where is the meta-parameter shared by all tasks, is the parameter specific to task , and (resp. ) is task ’s meta-training or support (resp. meta-validation or query) data. is the loss of task ’s model on data , where is the loss on a stochastic sample . As in most works on meta-learning Finn et al. (2017); Nichol et al. (2018); Zhou and Bassily (2022), we use the meta-parameter as meta-initialization. This can be used on both training clients and unseen clients, as any new client can simply use the learned meta-parameter to initialize its model . The outer loop finds a suitable meta-initialization , while the inner loop adapts it to each client as . An example algorithm for such adaptation is shown in Algorithm 3 of Appendix B.
While existing works on random-walk decentralized optimization Sun et al. (2022); Triastcyn et al. (2022) can also be easily extended to the meta-learning setting (an example is shown in Algorithm 1), they often have high communication cost as the adaptive optimizer’s auxiliary parameters (momentum and pre-conditioner ) need to be passed to the next client. Moreover, sending more auxiliary parameters can possibly lead to high privacy risk, as adversarial clients have more information to attack.
3.2 Reducing Communication Cost
Since the high communication cost and privacy leakage both come from sending auxiliary parameters to the other clients, we propose to use localized auxiliary parameters for each client. Specifically, the meta-learner of each client keeps its own momentum and pre-conditioner . They are no longer sent to the next client, and only the model parameter needs to be transmitted. The proposed algorithm, called LoDMeta (Local Decentralized Meta-learning), is shown in Algorithm 2. At step 2, we initialize the local auxiliary parameters for each client . During learning, each client then uses its local auxiliary parameters and . Without the need to transmit auxiliary parameters, its communication cost is reduced to only one-third of that in Algorithm 1. Moreover, as will be shown theoretically in the next section, Algorithm 2 can achieve the same asymptotic convergence rate as Algorithm 1 even only with localized auxiliary parameters.
While LoDMeta in Algorithm 2 is based on the MAML algorithm and Adam optimizer, it can be easily used with other meta-learning algorithms (e.g., ANIL Raghu et al. (2020) or BMG Flennerhag et al. (2022)) by simply replacing the update step with steps in the corresponding meta-learning algorithm. Similarly, LoDMeta can also be easily used with other adaptive optimizers that need transmission of auxiliary parameters (e.g., AdaGrad Duchi et al. (2011), AdaBelief Zhuang et al. (2020) and Adai Xie et al. (2022)) by again replacing the global auxiliary parameters with local copies.
3.3 Protecting Privacy
Sharing the model parameter can still incur privacy leakage. For privacy protection, we propose to add random Gaussian perturbations to the model parameters Dwork et al. (2014); Cyffers and Bellet (2022). There have been works on privacy-preserving adaptive optimizers Li et al. (2022b, 2023). While they achieve remarkable performance under the centralized setting, they cannot be directly generalized to the decentralized setting. For example, AdaDPS Li et al. (2022b) requires additional side information (e.g., public training data without privacy concerns) to estimate the momentum or preconditioner, which is hard to obtain in practice even in the centralized setting. DP2-RMSprop Li et al. (2023) requires accumulating gradients across different clients. This needs additional communication and computation in the decentralized setting.
In contrast, as in Algorithm 2, the proposed method protects privacy by first removing communication of the auxiliary parameters. We then only need to add random perturbations to the model parameters, which is the only source of privacy leakage.
4 Theoretical Analysis
4.1 Analysis on Convergence Rate and Communication Cost
Denote the total communication cost as , which can be expressed by , where denotes the per-iteration communication cost and denotes the number of iterations. Then to compare the total communication cost for different methods, we need to consider their per-iteration communication costs and the total number of iterations. For comparison fairness, we consider the relative per-iteration communication cost, which can neglect other affecting factors such as model size and parameter compression techniques. We take the per-iteration communication cost of LoDMeta as 1 unit, as the active client only sends model parameters to another client. LoDMeta(basic) then requires three times the communication cost of LoDMeta in each iteration, as it needs to also transmit momentum and preconditioner to the next client. Centralized methods (i.e., MAML and FedAlt) require twice the communication cost for each active client, as each client requires downloading and uploading the current meta-parameter to the central server.
| MAML/FedAlt | L2C/LoDMeta(basic) | LoDMeta (SGD)/LoDMeta |
|---|---|---|
| (Centralized, denotes number of active clients) | (Decentralized) | (Decentralized) |
| 2 | 3 | 1 |
Then we compare the number of iterations by deriving the convergence rate for LoDMeta. Under the meta-learning setting, the objective in (1) takes the following form:
| (2) |
where , the local model parameter for client computed from , is computed in the inner loop of Algorithm 2:
The meta-gradient for client is then computed as Ji et al. (2020): , where is the identity matrix.
We make the following assumptions, which are commonly used in the convergence analysis of meta-learning Fallah et al. (2020b); Ji et al. (2020); Yang and Kwok (2022) and random-walk decentralized optimization Sun et al. (2022); Triastcyn et al. (2022).
Assumption 4.1.
For data , the loss satisfies: (i) bounded loss: ; (ii) Lipschitz gradient: For any ; (iii) Lipschitz Hessian: for any , where is the spectral norm; (iv) bounded gradient variance: For any , ; (v) bounded differences for support/query data: for each , there exists a constant such that for any .
The following Proposition shows that the expected meta-gradient is also Lipschitz. This is useful in analyzing the convergence and privacy properties of Algorithm 2.
Proposition 4.2.
For any , we have , where , and .
Theorem 4.3.
Set the inner- and outer-loop learning rates in Algorithm 2 to , and , respectively. For any , with , where is the second largest eigenvalue of the transition probability matrix , we have .
Proof is in Appendix E.1, where we need to make different bounds with local auxiliary parameters. Compared with the convergence of MAML in centralized setting Ji et al. (2020), Theorem 4.3 has the same dependency on . This also agrees with previous work on random-walk algorithms Sun et al. (2022); Triastcyn et al. (2022), though their analysis requires auxiliary parameters to be synchronized across all clients, while Algorithm 2 uses localized ones. The impact of communication network is reflected by the , which also matches previous analysis on random-walk algorithms Sun et al. (2022); Triastcyn et al. (2022). Then since LoDMeta has the same convergence rate (same number of iterations ) but significantly smaller per-iteration communication cost (as in Table 1), it has much smaller communication cost than existing methods.
4.2 Privacy Analysis
Let the (private) data on client be , and the union of all client data be . For two such unions and , we use to indicate that and have the same number of clients and differ only on client ’s data, which defines a neighboring relation over these unions. Following existing works on privacy in decentralized algorithms Cyffers and Bellet (2022), we consider any decentralized algorithm as a (randomized) mapping that takes the union of client data as input and outputs all messages exchanged between two clients over the network. We denote all these messages as . A key difference between centralized and decentralized algorithms is that in the decentralized setting, a given client does not have access to all messages in , but only to the messages it is involved in. As such, to analyze the privacy property of a decentralized algorithm, we need to consider separate view of each client. Mathematically, we denote client ’s view of algorithm as: .
Definition 4.4 (Network Differential Privacy Cyffers and Bellet (2022)).
A decentralized algorithm satisfies -network DP if for all pairs of distinct clients and all neighboring unions of data , we have: .
In other words, network DP requires that for any two users and , the information gathered by user from algorithm should not depend too much on user ’s data. Under this definition, we can now prove
Theorem 4.5.
Algorithm 2 have similar dependencies on and as in Cyffers and Bellet (2022). As is proportional to , a smaller leads to better protection of privacy. Recall that a smaller leads to a larger perturbation in Algorithm 2 (step 12). Thus, a larger perturbation leads to better privacy protection, which agrees with our intuition. Compared with Cyffers and Bellet (2022), our analysis is applicable to networks of any topology, while the analysis in Cyffers and Bellet (2022) is only applicable to rings and fully-connected networks. Moreover, Cyffers and Bellet (2022) only considers learning a single specific task (namely, mean estimation or stochastic gradient descent on convex objectives), while we consider the more sophisticated and general meta-learning setting.
The recent work MetaNSGD Zhou and Bassily (2022) also considers private meta-learning. However, we consider a decentralized setting while MetaNSGD assumes all the data to be stored in a centralized server. Moreover, MetaNSGD assumes that the loss for each task/client is convex (which does not hold for deep networks), while our analysis does not require such strong assumption.
5 Experiments
5.1 Setup
Datasets. We conduct experiments on few-shot learning using two standard benchmark data sets: (i) mini-ImageNet, which is a coarse-grained image classification data set popularly used in meta-learning Finn et al. (2017); Nichol et al. (2018); (ii) Meta-Dataset Triantafillou et al. (2020), which is a collection of fine-grained image classification data sets. As in Yao et al. (2019), we use four data sets in Meta-Dataset: (i) Bird, (ii) Texture, (iii) Aircraft, and (iv) Fungi. We consider two few-shot settings: 5-way 1-shot and 5-way 5-shot. 111-way -shot refers to doing classification with classes, and each client has samples for each class samples in total. The number of query samples is always set to 15. Following standard practice in meta-learning Finn et al. (2017); Yao et al. (2019), some classes are used for meta-training, while the rest is for meta-testing.
Baselines. Our proposed method LoDMeta is compared with the following baselines: (i) two popular methods from personalized federated learning, including MAML under the federated learning setting Fallah et al. (2020a) and FedAlt Marfoq et al. (2022) (ii) L2C Li et al. (2022a), which is the only known decentralized meta-learning algorithm and uses the gossip algorithm instead of the random-walk algorithm, and (iii) the basic MAML extension to decentralized learning in Algorithm 1, denoted as LoDMeta(SGD) and LoDMeta(basic). Both of them do not perform communication cost reduction. For MAML, since its communication cost depends on the number of clients, we consider two settings: the original setting Finn et al. (2017) where it samples 4 clients in each iteration, referred as MAML, and another setting where it only samples 1 client to reduce communication cost, referred as MAML (1 client).
Communication network. For centralized methods (MAML and FedAlt), the communication network is essentially a star, with the server at the center. For decentralized methods (L2C, LoDMeta(basic) and LoDMeta), we use two networks: the popular Watts-Strogatz small-world network Watts and Strogatz (1998), and the 3-regular expander network, in which each client has 3 neighbors. The number of clients for each data set is in Table 4 in Appendix C.
The clients in the network are divided into two types: (i) training clients, with data coming from the meta-training classes; and (ii) unseen clients, which join the network after meta-training. Their data are from the meta-testing classes, and they use the trained meta-model for adaptation.
| 49.8 | 49.8 | 49.7 | 49.4 | 48.2 | 47.3 | |
| 49.7 | 49.7 | 49.6 | 49.3 | 47.6 | 46.4 | |
| 49.7 | 49.6 | 49.5 | 49.1 | 47.1 | 45.2 | |
| 49.6 | 49.6 | 49.4 | 48.8 | 46.7 | 44.6 |
| 48.0 | 48.0 | 47.8 | 47.2 | 46.6 | 45.9 | |
| 48.0 | 48.0 | 47.6 | 47.0 | 45.5 | 44.6 | |
| 48.0 | 47.9 | 47.4 | 46.7 | 44.7 | 43.2 | |
| 48.0 | 47.9 | 47.1 | 46.3 | 43.8 | 42.3 |
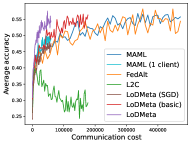
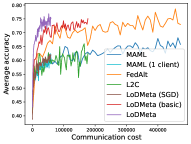
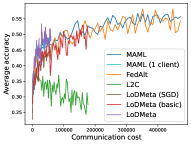
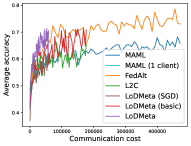
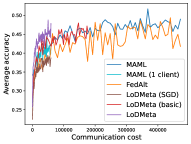
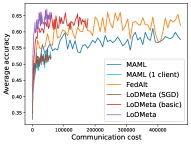
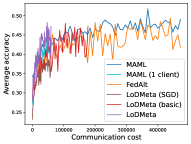
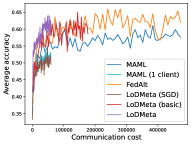
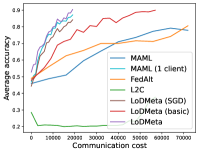
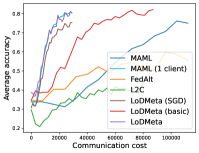
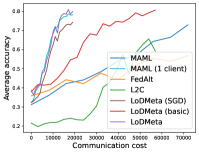
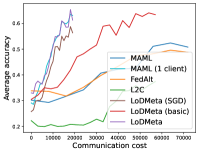
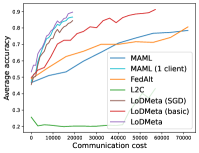
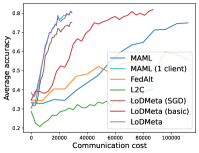
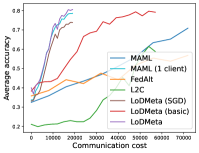
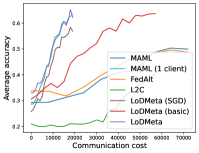
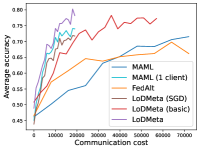
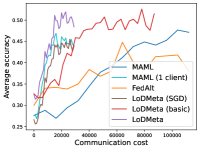
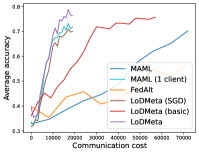
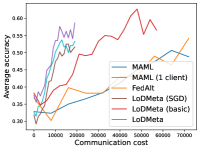
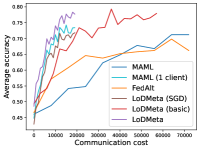
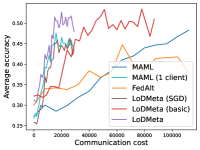
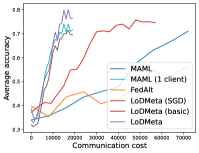
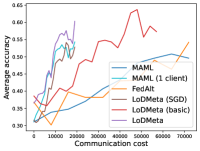
5.2 Results
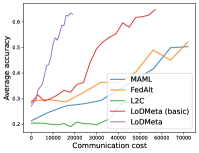
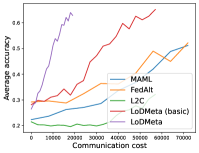
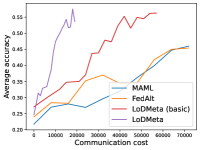
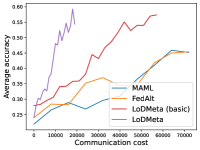
Mini-ImageNet. Figure 1 compares the testing accuracies of training clients with communication cost for different methods. We use the relative communication cost as in Table 1. Among random-walk methods, while LoDMeta(SGD) performs a bit worse, LoDMeta(basic) and LoDMeta achieve comparable performances with the centralized learning methods (MAML and FedAlt), and do not need additional central server to coordinate the learning process. This agrees with Theorem 4.3, which shows Algorithm 2 has the same asymptotic convergence rate as centralized methods. It also demonstrates the necessity of using adaptive optimizers for meta-learning problems. Moreover, L2C has worse performance than reported in Li et al. (2022a). This may be due to that we use fewer training samples and smaller number of neighbors, and L2C overfits.222For the mini-ImageNet experiment, Li et al. (2022a) use 500 samples for each client (50 samples per class), and each client has 10 neighbors. Here, we use 100 samples for each client (20 samples per class), and the maximum number of neighbors is 5. LoDMeta is also more preferable than LoDMeta(basic) in the decentralized setting due to its smaller communication cost.
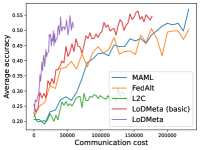
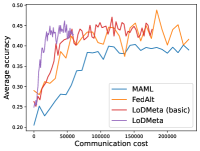
Figure 2 compares the testing accuracy of unseen clients with communication cost for different methods and communication networks. L2C is not compared on the unseen clients as it can only produce models for the training clients. Similar to the testing accuracies for training clients, LoDMeta (basic) and LoDMeta both achieve comparable or even better performance than the centralized learning methods (MAML and FedAlt), and LoDMeta has significantly smaller communication cost compared with LoDMeta (basic).
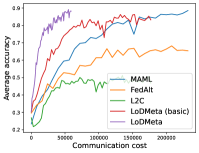
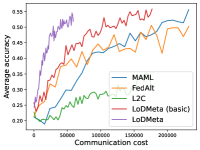
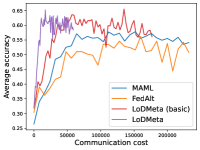
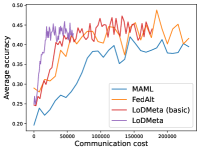
Meta-Datasets. Figure 3 compares the testing accuracies of training clients with communication cost for different methods and communication networks. Within limited communication resources, LoDMeta achieves the best performances, which comes from its significantly smaller per-iteration communication cost (1/3 of L2C/LoDMeta(basic) as in Table 1). Among all the baseline methods, L2C still has poorer performances than both centralized methods (MAML and FedAlt) and random-walk methods (LoDMeta(SGD), LoDMeta(basic) and LoDMeta).
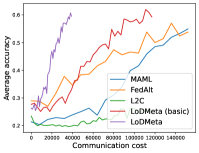
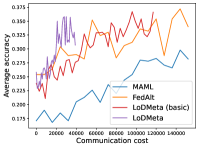
Figure 4 compares the testing accuracy of unseen clients with communication cost for different methods and communication networks. LoDMeta(basic) and LoDMeta achieve much better performances than the centralized learning methods (MAML and FedAlt). Compared with LoDMeta(basic), LoDMeta further reduces the communication cost, and achieves the best performance.
Effect of Random Perturbations for Privacy. Since there are limited works on privacy protection for decentralized meta-learning, here we study the performance of LoDMeta at different amounts of privacy perturbation, which is controlled by the two hyper-parameters used to generate the random perturbation . Table 2 (resp. Table 3) compares the testing accuracies on training (resp. unseen) clients with different and ’s in Algorithm 2. As is shown in Theorem 4.5, a larger perturbation (which corresponds to a smaller or ) leads to better privacy protection. From both Tables 2 and 3, a smaller or leads to worse testing accuracies. Hence, there is a trade-off between privacy protection and model performance, which agrees with studies on other settings Hu et al. (2020); Cyffers and Bellet (2022).
6 Conclusion
In this paper, we proposed a novel random-walk-based decentralized meta-learning algorithm (LoDMeta) in which the learning clients perform different tasks with limited data. It uses local auxiliary parameters to remove the communication overhead associated with adaptive optimizers. To better protect data privacy for each client, LoDMeta also introduces random perturbations to the model parameter. Theoretical analysis demonstrates that LoDMeta achieves the same convergence rate as centralized meta-learning algorithms. Empirical few-shot learning results demonstrate that LoDMeta has similar accuracy as centralized meta-learning algorithms, but does not require gathering data from each client and is able to protect data privacy for each client.
References
- Balcan et al. (2012) Maria Florina Balcan, Avrim Blum, Shai Fine, and Yishay Mansour. Distributed learning, communication complexity and privacy. In Conference on Learning Theory, 2012.
- Bertsekas (1997) Dimitris P. Bertsekas. A new class of incremental gradient methods for least squares problems. SIAM Journal on Optimization, 7(4):913–926, 1997.
- Boyd et al. (2011) Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends® in Machine learning, 3(1):1–122, 2011.
- Chen et al. (2023) Xuxing Chen, Minhui Huang, Shiqian Ma, and Krishna Balasubramanian. Decentralized stochastic bilevel optimization with improved per-iteration complexity. In Proceedings of the 40th International Conference on Machine Learning, pages 4641–4671, 2023.
- Collins et al. (2021) Liam Collins, Hamed Hassani, Aryan Mokhtari, and Sanjay Shakkottai. Exploiting Shared Representations for Personalized Federated Learning. In International Conference on Machine Learning, 2021.
- Cyffers and Bellet (2022) Edwige Cyffers and Aurélien Bellet. Privacy amplification by decentralization. In International Conference on Artificial Intelligence and Statistics, 2022.
- Cyffers et al. (2022) Edwige Cyffers, Mathieu Even, Aurélien Bellet, and Laurent Massoulié. Muffliato: Peer-to-peer privacy amplification for decentralized optimization and averaging. Neural Information Processing Systems, 2022.
- Duchi et al. (2011) John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. In Journal of machine learning research, volume 12, pages 2121–2159, 2011.
- Dwork et al. (2014) Cynthia Dwork, Aaron Roth, et al. The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science, 9(3–4):211–407, 2014.
- Fallah et al. (2020a) Alireza Fallah, Aryan Mokhtari, and Asuman Ozdaglar. On the convergence theory of gradient-based model-agnostic meta-learning algorithms. In International Conference on Artificial Intelligence and Statistics, 2020a.
- Fallah et al. (2020b) Alireza Fallah, Aryan Mokhtari, and Asuman Ozdaglar. On the convergence theory of gradient-based model-agnostic meta-learning algorithms. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics, pages 1082–1092, 2020b.
- Feldman et al. (2018) Vitaly Feldman, Ilya Mironov, Kunal Talwar, and Abhradeep Thakurta. Privacy amplification by iteration. In 2018 IEEE 59th Annual Symposium on Foundations of Computer Science, 2018.
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In International Conference on Machine Learning, 2017.
- Flennerhag et al. (2022) Sebastian Flennerhag, Yannick Schroecker, Tom Zahavy, Hado van Hasselt, David Silver, and Satinder Singh. Bootstrapped Meta-Learning. In International Conference on Learning Representations, 2022.
- Hospedales et al. (2022) Timothy Hospedales, Antreas Antoniou, Paul Micaelli, and Amos Storkey. Meta-learning in neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(9):5149–5169, 2022.
- Hu et al. (2020) Rui Hu, Yuanxiong Guo, Hongning Li, Qingqi Pei, and Yanmin Gong. Personalized federated learning with differential privacy. IEEE Internet of Things Journal, 7(10):9530–9539, 2020.
- Ji et al. (2020) Kaiyi Ji, Junjie Yang, and Yingbin Liang. Theoretical Convergence of Multi-Step Model-Agnostic Meta-Learning. Technical Report arXiv:2002.07836, 2020.
- Johansson et al. (2010) Björn Johansson, Maben Rabi, and Mikael Johansson. A randomized incremental subgradient method for distributed optimization in networked systems. SIAM Journal on Optimization, 20(3):1157–1170, 2010.
- Kayaalp et al. (2020) Mert Kayaalp, Stefan Vlaski, and Ali H. Sayed. Dif-maml: Decentralized multi-agent meta-learning. IEEE Open Journal of Signal Processing, 3:71–93, 2020.
- Koloskova et al. (2020) Anastasia Koloskova, Nicolas Loizou, Sadra Boreiri, Martin Jaggi, and Sebastian Stich. A Unified Theory of Decentralized SGD with Changing Topology and Local Updates. In International Conference on Machine Learning, 2020.
- Li et al. (2022a) Shuangtong Li, Tianyi Zhou, Xinmei Tian, and Dacheng Tao. Learning to collaborate in decentralized learning of personalized models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022a.
- Li et al. (2022b) Tian Li, Manzil Zaheer, Sashank Reddi, and Virginia Smith. Private adaptive optimization with side information. In International Conference on Machine Learning, 2022b.
- Li et al. (2023) Tian Li, Manzil Zaheer, Ken Liu, Sashank J Reddi, Hugh Brendan McMahan, and Virginia Smith. Differentially private adaptive optimization with delayed preconditioners. In International Conference on Learning Representations, 2023.
- Liu et al. (2023) Zhuqing Liu, Xin Zhang, Prashant Khanduri, Songtao Lu, and Jia Liu. Prometheus: Taming sample and communication complexities in constrained decentralized stochastic bilevel learning. In Proceedings of the 40th International Conference on Machine Learning, pages 22420–22453, 2023.
- Lu and De Sa (2021) Yucheng Lu and Christopher De Sa. Optimal Complexity in Decentralized Training. In International Conference on Machine Learning, 2021.
- Mao et al. (2019) Xianghui Mao, Yuantao Gu, and Wotao Yin. Walk Proximal Gradient: An Energy-Efficient Algorithm for Consensus Optimization. IEEE Internet of Things Journal, 6(2):2048–2060, 2019.
- Mao et al. (2020) Xianghui Mao, Kun Yuan, Yubin Hu, Yuantao Gu, Ali H. Sayed, and Wotao Yin. Walkman: A Communication-Efficient Random-Walk Algorithm for Decentralized Optimization. IEEE Transactions on Signal Processing, 68:2513–2528, 2020.
- Marfoq et al. (2022) Othmane Marfoq, Giovanni Neglia, Richard Vidal, and Laetitia Kameni. Personalized Federated Learning through Local Memorization. In International Conference on Machine Learning, 2022.
- McMahan et al. (2017) Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In International Conference on Artificial Intelligence and Statistics, 2017.
- McMahan et al. (2018) H Brendan McMahan, Daniel Ramage, Kunal Talwar, and Li Zhang. Learning differentially private recurrent language models. In International Conference on Learning Representations, 2018.
- Mironov (2017) Ilya Mironov. Rényi differential privacy. In IEEE 30th Computer Security Foundations Symposium, 2017.
- Nichol et al. (2018) Alex Nichol, Joshua Achiam, and John Schulman. On First-Order Meta-Learning Algorithms. Technical Report arXiv:1803.02999, 2018.
- Pillutla et al. (2022) Krishna Pillutla, Kshitiz Malik, Abdel-Rahman Mohamed, Mike Rabbat, Maziar Sanjabi, and Lin Xiao. Federated Learning with Partial Model Personalization. In International Conference on Machine Learning, 2022.
- Predd et al. (2009) Joel B Predd, Sanjeev R Kulkarni, and H Vincent Poor. A collaborative training algorithm for distributed learning. IEEE Transactions on Information Theory, 55(4):1856–1871, 2009.
- Raghu et al. (2020) Aniruddh Raghu, Maithra Raghu, Samy Bengio, and Oriol Vinyals. Rapid learning or feature reuse? Towards understanding the effectiveness of MAML. In International Conference on Learning Representations, 2020.
- Ravi and Larochelle (2017) Sachin Ravi and Hugo Larochelle. Optimization as a model for few-shot learning. In International Conference on Learning Representations, 2017.
- Rényi (1961) Alfréd Rényi. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, 1961.
- Shu et al. (2019) Jun Shu, Qi Xie, Lixuan Yi, Qian Zhao, Sanping Zhou, Zongben Xu, and Deyu Meng. Meta-weight-net: Learning an explicit mapping for sample weighting. In Neural Information Processing Systems, 2019.
- Singhal et al. (2021) Karan Singhal, Hakim Sidahmed, Zachary Garrett, Shanshan Wu, John Rush, and Sushant Prakash. Federated Reconstruction: Partially Local Federated Learning. In Neural Information Processing Systems, 2021.
- Sun et al. (2022) Tao Sun, Dongsheng Li, and Bao Wang. Adaptive Random Walk Gradient Descent for Decentralized Optimization. In International Conference on Machine Learning, 2022.
- Triantafillou et al. (2020) Eleni Triantafillou, Tyler Zhu, Vincent Dumoulin, Pascal Lamblin, Utku Evci, Kelvin Xu, Ross Goroshin, Carles Gelada, Kevin Swersky, Pierre-Antoine Manzagol, and Hugo Larochelle. Meta-dataset: A dataset of datasets for learning to learn from few examples. In International Conference on Learning Representations, 2020.
- Triastcyn et al. (2022) Aleksei Triastcyn, Matthias Reisser, and Christos Louizos. Decentralized Learning with Random Walks and Communication-Efficient Adaptive Optimization. In Workshop on Federated Learning: Recent Advances and New Challenges (in Conjunction with NeurIPS 2022), 2022. URL https://openreview.net/forum?id=QwL8ZGl_QGG.
- Watts and Strogatz (1998) Duncan J Watts and Steven H Strogatz. Collective dynamics of ‘small-world’networks. Nature, 393(6684):440–442, 1998.
- Wei et al. (2020) Kang Wei, Jun Li, Ming Ding, Chuan Ma, Howard H Yang, Farhad Farokhi, Shi Jin, Tony QS Quek, and H Vincent Poor. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Transactions on Information Forensics and Security, 15:3454–3469, 2020.
- Xie et al. (2022) Zeke Xie, Xinrui Wang, Huishuai Zhang, Issei Sato, and Masashi Sugiyama. Adaptive inertia: Disentangling the effects of adaptive learning rate and momentum. In Proceedings of the 39th International Conference on Machine Learning, pages 24430–24459, 2022.
- Yang and Kwok (2022) Hansi Yang and James Kwok. Efficient variance reduction for meta-learning. In Proceedings of the 39th International Conference on Machine Learning, pages 25070–25095, 2022.
- Yang et al. (2022) Shuoguang Yang, Xuezhou Zhang, and Mengdi Wang. Decentralized gossip-based stochastic bilevel optimization over communication networks. In Advances in Neural Information Processing Systems, volume 35, pages 238–252, 2022.
- Yang et al. (2023) Yifan Yang, Peiyao Xiao, and Kaiyi Ji. Simfbo: Towards simple, flexible and communication-efficient federated bilevel learning. In Advances in Neural Information Processing Systems, volume 36, pages 33027–33040, 2023.
- Yao et al. (2019) Huaxiu Yao, Ying Wei, Junzhou Huang, and Zhenhui Li. Hierarchically structured meta-learning. In International Conference on Machine Learning, 2019.
- Yuan et al. (2022) Binhang Yuan, Yongjun He, Jared Quincy Davis, Tianyi Zhang, Tri Dao, Beidi Chen, Percy Liang, Christopher Re, and Ce Zhang. Decentralized training of foundation models in heterogeneous environments. In Neural Information Processing Systems, 2022.
- Yuan et al. (2021) Kun Yuan, Yiming Chen, Xinmeng Huang, Yingya Zhang, Pan Pan, Yinghui Xu, and Wotao Yin. DecentLaM: Decentralized Momentum SGD for Large-Batch Deep Training. In IEEE/CVF International Conference on Computer Vision, 2021.
- Zhang et al. (2022) Xianyang Zhang, Chen Hu, Bing He, and Zhiguo Han. Distributed reptile algorithm for meta-learning over multi-agent systems. IEEE Transactions on Signal Processing, 70:5443–5456, 2022.
- Zhou and Bassily (2022) Xinyu Zhou and Raef Bassily. Task-level differentially private meta learning. In Neural Information Processing Systems, 2022.
- Zhuang et al. (2020) Juntang Zhuang, Tommy Tang, Yifan Ding, Sekhar C Tatikonda, Nicha Dvornek, Xenophon Papademetris, and James Duncan. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients. Advances in neural information processing systems, 33:18795–18806, 2020.
NeurIPS Paper Checklist
-
1.
Claims
-
Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope?
-
Answer: [Yes]
-
Justification: the claims made in abstract and introduction (section 1) clearly reflects the paper’s contributions and scope.
-
Guidelines:
-
•
The answer NA means that the abstract and introduction do not include the claims made in the paper.
-
•
The abstract and/or introduction should clearly state the claims made, including the contributions made in the paper and important assumptions and limitations. A No or NA answer to this question will not be perceived well by the reviewers.
-
•
The claims made should match theoretical and experimental results, and reflect how much the results can be expected to generalize to other settings.
-
•
It is fine to include aspirational goals as motivation as long as it is clear that these goals are not attained by the paper.
-
•
-
2.
Limitations
-
Question: Does the paper discuss the limitations of the work performed by the authors?
-
Answer: [Yes]
-
Justification: we have discussed possible limitations in in Appendix A.
-
Guidelines:
-
•
The answer NA means that the paper has no limitation while the answer No means that the paper has limitations, but those are not discussed in the paper.
-
•
The authors are encouraged to create a separate "Limitations" section in their paper.
-
•
The paper should point out any strong assumptions and how robust the results are to violations of these assumptions (e.g., independence assumptions, noiseless settings, model well-specification, asymptotic approximations only holding locally). The authors should reflect on how these assumptions might be violated in practice and what the implications would be.
-
•
The authors should reflect on the scope of the claims made, e.g., if the approach was only tested on a few datasets or with a few runs. In general, empirical results often depend on implicit assumptions, which should be articulated.
-
•
The authors should reflect on the factors that influence the performance of the approach. For example, a facial recognition algorithm may perform poorly when image resolution is low or images are taken in low lighting. Or a speech-to-text system might not be used reliably to provide closed captions for online lectures because it fails to handle technical jargon.
-
•
The authors should discuss the computational efficiency of the proposed algorithms and how they scale with dataset size.
-
•
If applicable, the authors should discuss possible limitations of their approach to address problems of privacy and fairness.
-
•
While the authors might fear that complete honesty about limitations might be used by reviewers as grounds for rejection, a worse outcome might be that reviewers discover limitations that aren’t acknowledged in the paper. The authors should use their best judgment and recognize that individual actions in favor of transparency play an important role in developing norms that preserve the integrity of the community. Reviewers will be specifically instructed to not penalize honesty concerning limitations.
-
•
-
3.
Theory Assumptions and Proofs
-
Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof?
-
Answer: [Yes]
-
Guidelines:
-
•
The answer NA means that the paper does not include theoretical results.
-
•
All the theorems, formulas, and proofs in the paper should be numbered and cross-referenced.
-
•
All assumptions should be clearly stated or referenced in the statement of any theorems.
-
•
The proofs can either appear in the main paper or the supplemental material, but if they appear in the supplemental material, the authors are encouraged to provide a short proof sketch to provide intuition.
-
•
Inversely, any informal proof provided in the core of the paper should be complemented by formal proofs provided in appendix or supplemental material.
-
•
Theorems and Lemmas that the proof relies upon should be properly referenced.
-
•
-
4.
Experimental Result Reproducibility
-
Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)?
-
Answer: [Yes]
-
Justification: we have mentioned necessary experimental settings in Appendix C to reproduce our experimental results.
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
If the paper includes experiments, a No answer to this question will not be perceived well by the reviewers: Making the paper reproducible is important, regardless of whether the code and data are provided or not.
-
•
If the contribution is a dataset and/or model, the authors should describe the steps taken to make their results reproducible or verifiable.
-
•
Depending on the contribution, reproducibility can be accomplished in various ways. For example, if the contribution is a novel architecture, describing the architecture fully might suffice, or if the contribution is a specific model and empirical evaluation, it may be necessary to either make it possible for others to replicate the model with the same dataset, or provide access to the model. In general. releasing code and data is often one good way to accomplish this, but reproducibility can also be provided via detailed instructions for how to replicate the results, access to a hosted model (e.g., in the case of a large language model), releasing of a model checkpoint, or other means that are appropriate to the research performed.
-
•
While NeurIPS does not require releasing code, the conference does require all submissions to provide some reasonable avenue for reproducibility, which may depend on the nature of the contribution. For example
-
(a)
If the contribution is primarily a new algorithm, the paper should make it clear how to reproduce that algorithm.
-
(b)
If the contribution is primarily a new model architecture, the paper should describe the architecture clearly and fully.
-
(c)
If the contribution is a new model (e.g., a large language model), then there should either be a way to access this model for reproducing the results or a way to reproduce the model (e.g., with an open-source dataset or instructions for how to construct the dataset).
-
(d)
We recognize that reproducibility may be tricky in some cases, in which case authors are welcome to describe the particular way they provide for reproducibility. In the case of closed-source models, it may be that access to the model is limited in some way (e.g., to registered users), but it should be possible for other researchers to have some path to reproducing or verifying the results.
-
(a)
-
•
-
5.
Open access to data and code
-
Question: Does the paper provide open access to the data and code, with sufficient instructions to faithfully reproduce the main experimental results, as described in supplemental material?
-
Answer: [No]
-
Justification: since our code also includes scripts from other open-source packages, it takes more time to arrange our code. We will release our code along with camera-ready version if our submission is accepted.
-
Guidelines:
-
•
The answer NA means that paper does not include experiments requiring code.
-
•
Please see the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
-
•
While we encourage the release of code and data, we understand that this might not be possible, so “No” is an acceptable answer. Papers cannot be rejected simply for not including code, unless this is central to the contribution (e.g., for a new open-source benchmark).
-
•
The instructions should contain the exact command and environment needed to run to reproduce the results. See the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
-
•
The authors should provide instructions on data access and preparation, including how to access the raw data, preprocessed data, intermediate data, and generated data, etc.
-
•
The authors should provide scripts to reproduce all experimental results for the new proposed method and baselines. If only a subset of experiments are reproducible, they should state which ones are omitted from the script and why.
-
•
At submission time, to preserve anonymity, the authors should release anonymized versions (if applicable).
-
•
Providing as much information as possible in supplemental material (appended to the paper) is recommended, but including URLs to data and code is permitted.
-
•
-
6.
Experimental Setting/Details
-
Question: Does the paper specify all the training and test details (e.g., data splits, hyperparameters, how they were chosen, type of optimizer, etc.) necessary to understand the results?
-
Answer: [Yes]
-
Justification: we have mentioned necessary experimental settings (including data splits, hyper-parameters and how they were chosen, type of optimizer) in Appendix C.
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
The experimental setting should be presented in the core of the paper to a level of detail that is necessary to appreciate the results and make sense of them.
-
•
The full details can be provided either with the code, in appendix, or as supplemental material.
-
•
-
7.
Experiment Statistical Significance
-
Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments?
-
Answer: [No]
-
Justification: we do not report error bars in our experimental results.
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
The authors should answer "Yes" if the results are accompanied by error bars, confidence intervals, or statistical significance tests, at least for the experiments that support the main claims of the paper.
-
•
The factors of variability that the error bars are capturing should be clearly stated (for example, train/test split, initialization, random drawing of some parameter, or overall run with given experimental conditions).
-
•
The method for calculating the error bars should be explained (closed form formula, call to a library function, bootstrap, etc.)
-
•
The assumptions made should be given (e.g., Normally distributed errors).
-
•
It should be clear whether the error bar is the standard deviation or the standard error of the mean.
-
•
It is OK to report 1-sigma error bars, but one should state it. The authors should preferably report a 2-sigma error bar than state that they have a 96% CI, if the hypothesis of Normality of errors is not verified.
-
•
For asymmetric distributions, the authors should be careful not to show in tables or figures symmetric error bars that would yield results that are out of range (e.g. negative error rates).
-
•
If error bars are reported in tables or plots, The authors should explain in the text how they were calculated and reference the corresponding figures or tables in the text.
-
•
-
8.
Experiments Compute Resources
-
Question: For each experiment, does the paper provide sufficient information on the computer resources (type of compute workers, memory, time of execution) needed to reproduce the experiments?
-
Answer: [Yes]
-
Justification: we mentioned compute resources used in our experiments in Appendix C.
-
Guidelines:
-
•
The answer NA means that the paper does not include experiments.
-
•
The paper should indicate the type of compute workers CPU or GPU, internal cluster, or cloud provider, including relevant memory and storage.
-
•
The paper should provide the amount of compute required for each of the individual experimental runs as well as estimate the total compute.
-
•
The paper should disclose whether the full research project required more compute than the experiments reported in the paper (e.g., preliminary or failed experiments that didn’t make it into the paper).
-
•
-
9.
Code Of Ethics
-
Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines?
-
Answer: [Yes]
-
Justification: we have thoroughly checked the code of ethics and found no conflict.
-
Guidelines:
-
•
The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics.
-
•
If the authors answer No, they should explain the special circumstances that require a deviation from the Code of Ethics.
-
•
The authors should make sure to preserve anonymity (e.g., if there is a special consideration due to laws or regulations in their jurisdiction).
-
•
-
10.
Broader Impacts
-
Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed?
-
Answer: [Yes]
-
Justification: we have discussed possible societal impacts of our proposed method in Appendix A.
-
Guidelines:
-
•
The answer NA means that there is no societal impact of the work performed.
-
•
If the authors answer NA or No, they should explain why their work has no societal impact or why the paper does not address societal impact.
-
•
Examples of negative societal impacts include potential malicious or unintended uses (e.g., disinformation, generating fake profiles, surveillance), fairness considerations (e.g., deployment of technologies that could make decisions that unfairly impact specific groups), privacy considerations, and security considerations.
-
•
The conference expects that many papers will be foundational research and not tied to particular applications, let alone deployments. However, if there is a direct path to any negative applications, the authors should point it out. For example, it is legitimate to point out that an improvement in the quality of generative models could be used to generate deepfakes for disinformation. On the other hand, it is not needed to point out that a generic algorithm for optimizing neural networks could enable people to train models that generate Deepfakes faster.
-
•
The authors should consider possible harms that could arise when the technology is being used as intended and functioning correctly, harms that could arise when the technology is being used as intended but gives incorrect results, and harms following from (intentional or unintentional) misuse of the technology.
-
•
If there are negative societal impacts, the authors could also discuss possible mitigation strategies (e.g., gated release of models, providing defenses in addition to attacks, mechanisms for monitoring misuse, mechanisms to monitor how a system learns from feedback over time, improving the efficiency and accessibility of ML).
-
•
-
11.
Safeguards
-
Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pretrained language models, image generators, or scraped datasets)?
-
Answer: [N/A]
-
Justification: this paper does not involve releasing any data or models that may have risk for misuse.
-
Guidelines:
-
•
The answer NA means that the paper poses no such risks.
-
•
Released models that have a high risk for misuse or dual-use should be released with necessary safeguards to allow for controlled use of the model, for example by requiring that users adhere to usage guidelines or restrictions to access the model or implementing safety filters.
-
•
Datasets that have been scraped from the Internet could pose safety risks. The authors should describe how they avoided releasing unsafe images.
-
•
We recognize that providing effective safeguards is challenging, and many papers do not require this, but we encourage authors to take this into account and make a best faith effort.
-
•
-
12.
Licenses for existing assets
-
Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected?
-
Answer: [Yes]
-
Justification: we mentioned licenses for data sets used in our work in Appendix C.
-
Guidelines:
-
•
The answer NA means that the paper does not use existing assets.
-
•
The authors should cite the original paper that produced the code package or dataset.
-
•
The authors should state which version of the asset is used and, if possible, include a URL.
-
•
The name of the license (e.g., CC-BY 4.0) should be included for each asset.
-
•
For scraped data from a particular source (e.g., website), the copyright and terms of service of that source should be provided.
-
•
If assets are released, the license, copyright information, and terms of use in the package should be provided. For popular datasets, paperswithcode.com/datasets has curated licenses for some datasets. Their licensing guide can help determine the license of a dataset.
-
•
For existing datasets that are re-packaged, both the original license and the license of the derived asset (if it has changed) should be provided.
-
•
If this information is not available online, the authors are encouraged to reach out to the asset’s creators.
-
•
-
13.
New Assets
-
Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets?
-
Answer: [N/A]
-
Justification: this paper does not release any new assets.
-
Guidelines:
-
•
The answer NA means that the paper does not release new assets.
-
•
Researchers should communicate the details of the dataset/code/model as part of their submissions via structured templates. This includes details about training, license, limitations, etc.
-
•
The paper should discuss whether and how consent was obtained from people whose asset is used.
-
•
At submission time, remember to anonymize your assets (if applicable). You can either create an anonymized URL or include an anonymized zip file.
-
•
-
14.
Crowdsourcing and Research with Human Subjects
-
Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)?
-
Answer: [N/A]
-
Justification: this paper does not involve crowdsourcing nor research with human subjects.
-
Guidelines:
-
•
The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
-
•
Including this information in the supplemental material is fine, but if the main contribution of the paper involves human subjects, then as much detail as possible should be included in the main paper.
-
•
According to the NeurIPS Code of Ethics, workers involved in data collection, curation, or other labor should be paid at least the minimum wage in the country of the data collector.
-
•
-
15.
Institutional Review Board (IRB) Approvals or Equivalent for Research with Human Subjects
-
Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or institution) were obtained?
-
Answer: [N/A]
-
Justification: this paper does not involve crowdsourcing nor research with human subjects.
-
Guidelines:
-
•
The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
-
•
Depending on the country in which research is conducted, IRB approval (or equivalent) may be required for any human subjects research. If you obtained IRB approval, you should clearly state this in the paper.
-
•
We recognize that the procedures for this may vary significantly between institutions and locations, and we expect authors to adhere to the NeurIPS Code of Ethics and the guidelines for their institution.
-
•
For initial submissions, do not include any information that would break anonymity (if applicable), such as the institution conducting the review.
-
•
Appendix A Possible Limitations and Broader Impacts
Limitations. One possible limitation of this work is that we only consider network DP for privacy protection. We will consider other privacy metric as future works.
Broader Impacts. As a paper on pure machine learning algorithms, there should be no direct societal impact of this work. Our proposed algorithm is not about generative models and there is no concern on generating fake contents.
Appendix B Algorithms
Appendix C Details for Experiments
Some statistics for data sets used in experiments are in Table 4. All data sets used in our experiments are released under Apache 2.0 license. Figure 5(a) gives an example for small-world network, while Figure 5(b) gives an example for 3-regular expander network. These two network types are used in our experiments (with different number of clients).
| number of classes | #clients for 1-shot/5-shot setting | |||||
|---|---|---|---|---|---|---|
| meta-training | meta-testing | #samples per class | training clients | unseen clients | ||
| Meta-Dataset | Bird | 80 | 20 | 60 | 38/38 | 12/12 |
| Texture | 37 | 10 | 120 | 42/36 | 14/12 | |
| Aircraft | 80 | 20 | 100 | 76/64 | 24/20 | |
| Fungi | 80 | 20 | 150 | 115/89 | 36/28 | |
| mini-Imagenet | 80 | 20 | 600 | 380/380 | 120/120 | |
All experiments are run on a single RTX2080 Ti GPU. Following [13, 32], we use the CONV4333The CONV4 model is a 4-layer CNN. Each layer contains 64 convolutional filters, followed by batch normalization, ReLU activation, and max-pooling. as base learner. The hyper-parameter settings for all data sets also follow MAML [13]: learning rate is , first-order momentum weight is , and the second-order momentum weight is . The number of gradient descent steps () in the inner loop is 5. Unless otherwise specified, we set and for the privacy perturbation.
Appendix D Additional Experimental Results
D.1 Experiments on 1-shot Meta-Datasets with small-world network
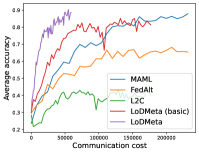
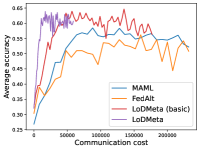
Figure 6 compares the average testing accuracy across different clients during training on these four data sets under the 1-shot setting with the number of training iterations. Similar to the 5-shot learning setting, the two random-walk algorithms (DMAML and LDMeta) achieve slightly worse performance than MAML, but better performance than FedAlt. Compared to the 5-shot setting (Figure 7), the gossip-based algorithm L2C performs even worse in this 1-shot setting because each client has even fewer samples.
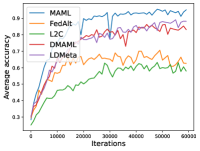
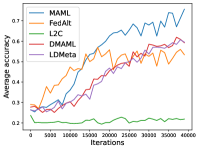
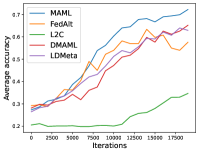
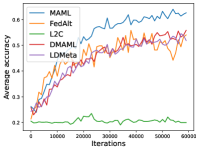
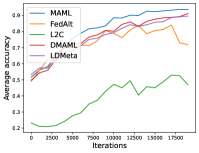
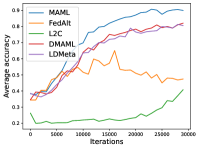
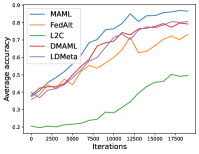
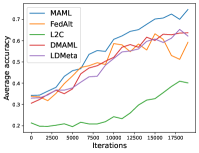
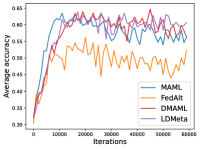
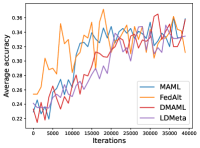
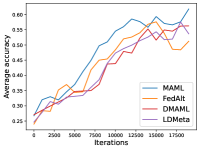
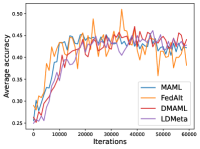
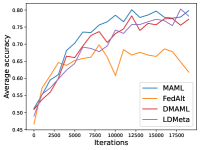
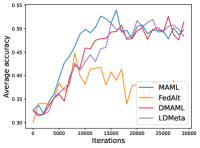
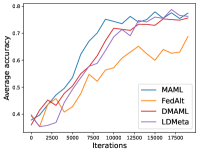
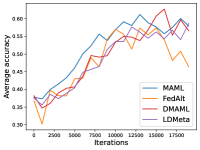
Figure 8 compares the average testing accuracy across different clients during training on these four data sets under the 1-shot setting with communication cost. Similar to the 5-shot learning setting (Figure 3), LDMeta has a much smaller communication cost than DMAML, and is more preferable when we require communication to be efficient.
D.2 Experiments with 3-regular network
Here, we perform experiments on the 3-regular expander graph, in which all clients have 3 neighbors. The other settings are the same as experiments in the main text.
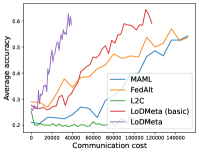
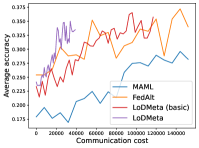
Figure 9 compares the average testing accuracy across different clients during training on four data sets in Meta-Datasets with the number of training iterations. As can be seen, the two random-walk algorithms (DMAML and LDMeta) have slightly worse performance than MAML, but better performance than FedAlt, and significantly outperform the gossip-based algorithm L2C. This is because in the random-walk setting, only one client needs to update the meta-model in each iteration, while personalized federated learning methods require multiple clients to update the meta-model.
Appendix E Proofs
E.1 Proof of Proposition 4.2
By the definition of , we have
| (4) |
We next upper-bound in the above inequality. Specifically, we have
| (5) |
Combining (E.1) and (E.1) yields
| (6) |
To upper-bound in (6), using the mean value theorem, we have
| (7) |
For , we have:
| (8) |
Combining (6), (E.1) and (8) yields
which yields
Based on the above inequality and Jensen’s inequality, we finish the proof.
E.2 Proof for Theorem 4.3
Despite Proposition 4.2, we also need to upper-bound the expectation of , as follows:
Lemma E.1.
Set . we have for any ,
where , and .
Proof.
Conditioning on , we have
Using an approach similar to (E.1), we have:
| (9) |
Noting that and using the definitions of , we finish the proof. ∎
Apart from these propositions, we also need some auxiliary lemmas to prove Theorem 4.3. In the sequel, for any vector , define as the vector whose elements are the squares of elements in .
Lemma E.2.
Suppose function is a non-increasing function. Then for any sequence , we have:
Proof.
Let . Since any for , obviously we have , and . Therefore, we have:
Summing from to gives the result. ∎
Lemma E.3.
Let be the sequence of model weights generated from Algorithm 2 with . Then for , we have:
Proof for Lemma E.3.
We first define for each client . Intuitively, this set counts the iterations where client is visited, and obviously we have
For each iteration , consider set . We can express as , and we have:
Using Cauchy’s inequality , from
we can bound it as:
Since , we always have for any . Then we have:
Note that by definition, and each element of is non-decreasing with since for all . As such, we have:
| 0 | |||||
| 0 | 0 | ||||
| 0 | 0 | 0 | |||
| 0 | 0 |
∎
Lemma E.4.
Let be generated from Algorithm 2. Define
Further, define to be the last iteration before iteration when worker is visited. Specifically, for all . We have:
Proof for Lemma E.4.
We first consider bounding a related term . We have:
Then,
The second term can be bounded using Proposition 4.2 as:
| (10) |
With Cauchy’s inequality, we have
where is arbitrary. Combining it with (10), we have:
Now choose , we have:
The third term can be bounded as:
The bound for the last term is very similar to the second term, and we have:
which is exactly the same as (10). Hence, we have:
Combining them together gives:
| (11) |
Now for , consider the expectation conditioned on , we have:
The first term has been bounded by (11), and the third term can be bounded from Proposition 4.2 as:
Finally, the last term can be bounded by Proposition E.1 as:
Now taking expectation on both sides gives:
Rearranging these terms gives:
which is exactly Lemma E.4. ∎
Now we are ready to present the proof for the main theorem:
Proof for Theorem 4.3.
First from Lemma E.4, we have:
Summing all the above gives us:
| (12) |
where we note that all terms on the right hand side must have a correspondence on left hand. Then from Proposition E.1, for any client , we have:
Since the loss function is smooth (Proposition 4.2), we have:
Taking expectation on both sides gives . Then summing from to gives:
For the last term, we have:
Combined with (12), we have:
For , first from Lemma, we have
Then using Lemma E.2 with , we have:
Combine it with, we have
Finally, note that
We introduce the following auxiliary variables:
We have:
Let , we obtain:
Let and gives:
which completes our proof. ∎
E.3 Proof of Theorem 4.5
Proof.
The proof is similar to the proof in [6], which tracks privacy loss using Rényi Differential Privacy (RDP) [31] and leverages results on amplification by iteration [12]. We first recall the definition of RDP and the main theorems that we will use. Then, we apply these tools to our setting and conclude by translating the resulting RDP bounds into -DP.
Definition E.5 (Rényi divergence [37, 31]).
Let and be measures such that for all measurable set , implies . The Rényi divergence of order between and is defined as
Definition E.6 (Rényi DP [31]).
For and , a randomized algorithm satisfies -Rényi differential privacy, or -RDP, if for all neighboring data sets and we have
Similar to network DP, the definition of Network-RDP [6] can also be introduced as follows:
Definition E.7 (Network Rényi DP [6]).
For and , a randomized algorithm satisfies -network Rényi differential privacy, or -NRDP, if for all pairs of distinct users and all pairs of neighboring datasets , we have
This proposition will be used in later proofs to analyze the privacy properties for the composition of different messages:
Proposition E.8 (Composition of RDP [31]).
If are randomized algorithms satisfying -RDP respectively, then their composition satisfies -RDP. Each algorithm can be chosen adaptively, i.e., based on the outputs of algorithms that come before it.
We can also translate the result of the RDP by the following proposition [31].
Proposition E.9 (Conversion from RDP to DP [31]).
If satisfies -Rényi differential privacy, then for all it also satisfies differential privacy.
In our context, we aim to leverage this result to capture the privacy amplification since a given user will only observe information about the update of another user after some steps of the random walk. To account for the fact that this number of steps will itself be random, we will use the so-called weak convexity property of the Rényi divergence [12].
Proposition E.10 (Weak convexity of Rényi divergence [12]).
Let and be probability distributions over some domain such that for all for some . Let be a probability distribution over and denote by (resp. ) the probability distribution over obtained by sampling i from and then outputting a random sample from (resp. ). Then we have:
We now have all the technical tools needed to prove our result. Let us denote by the variance of the Gaussian noise added at each gradient step in Algorithm 2. Let us fix two distinct users and . We aim to quantify how much information about the private data of user is leaked to from the visits of the token. Let us fix a contribution of user at some time . Note that the token values observed before do not depend on the contribution of at time . Let be the first time that receives the token posterior to . It is sufficient to bound the privacy loss induced by the observation of the token at : indeed, by the post-processing property of DP, no additional privacy loss with respect to will occur for observations posterior to . If there is no time (which can be seen as ), then no privacy loss occurs. Let and be the distribution followed by the token when observed by at time for two neighboring datasets which only differ in the dataset of user . For any , let also and be the distribution followed by the token at time for two neighboring datasets . Then, we can apply Proposition E.10 to with , which is ensured when , and we have:
We can now bound for each and obtain:
Denote as the maximum number of contributions for user . Using the composition property of RDP, we can then prove that Algorithm 2 satisfies -Network Rényi DP, which can then be converted into an -DP statement using Proposition E.9. This proposition calls for minimizing the function for . However, recall that from our use of the weak convexity property we have the additional constraint on requiring that . This creates two regimes: for small (i.e, large and small ), the minimum is not reachable, so we take the best possible within the interval, whereas we have an optimal regime for larger . This minimization can be done numerically, but for simplicity of exposition we can derive a suboptimal closed form which is the one given in Theorem 4.5.
To obtain this closed form, we reuse Theorem 32 of [12]. In particular, for , and , the conditions and are satisfied. Thus, we have a bound on the privacy loss which holds the two regimes thanks to the definition of .
Finally, we bound by with probability as done in the previous proofs for real summation and discrete histograms. Setting and concludes the proof. ∎