Compact Binary Systems Waveform Generation with Generative Pre-trained Transformer
Abstract
Space-based gravitational wave (GW) detection is one of the most anticipated GW detection projects in the next decade, which promises to detect abundant compact binary systems. At present, deep learning methods have not been widely explored for GW waveform generation and extrapolation. To solve the data processing difficulty and the increasing waveform complexity caused by the detector’s response and second-generation time-delay interferometry (TDI 2.0), an interpretable pre-trained large model named CBS-GPT (Compact Binary Systems Waveform Generation with Generative Pre-trained Transformer) is proposed. For compact binary system waveforms, three models were trained to predict the waveforms of massive black hole binaries (MBHB), extreme mass-ratio inspirals (EMRIs), and galactic binaries (GB), achieving prediction accuracies of at most 99%, 91%, and 99%, respectively. The CBS-GPT model exhibits notable generalization and interpretability, with its hidden parameters effectively capturing the intricate information of waveforms, even with the complex instrument response and a wide parameter range. Our research demonstrates the potential of large models in the GW realm, opening up new opportunities and guidance for future researches such as complex waveforms generation, gap completion, and deep learning model design for GW science.
I Introduction
The first direct detection of a binary black hole merger (GW150914) [1, 2] by the Laser Interferometer Gravitational-Wave Observatory (LIGO) has opened an innovative window to understand the universe, which provides direct evidence for the validity of Einstein’s General Relativity. Gravitational wave (GW) observations will clarify many questions in astrophysics, cosmology, and fundamental physics [3, 4, 5, 6, 7, 8, 9, 10]. So far, the ground-based GW detectors have reported over a hundred compact binary coalesces (CBC) events [11], and recently Pulsar Timing Array (PTA) has also successfully detected sound evidence of the existence of Stochastic GW Background [12, 13, 14, 15]. To gain a deeper understanding and an overall picture of GW cosmology [16], the field of low-frequency GWs needs to be widely covered.
The space-based GW detection avoids terrestrial noise [17] and makes the detection of low-frequency () GW signals more promising. Spaced-based GW detectors like Laser Interferometer Space Antenna (LISA) [18], Taiji [19, 20] and Tianqin [21] have been planned and are scheduled for the 2030s. In particular, future space-based GW detection is expected to detect a richer variety of GW sources including massive black hole binaries (MBHB), extreme mass-ratio inspirals (EMRIs), and galactic binaries (GB) [18].
GW signals are extremely weak and usually buried in instrumental noise. With the improvement of detector sensitivity and the increasing amount of data, the computational complexity and timeliness demands for detection and parameter estimation are growing, which are challenging problems for traditional methods that based on computing power of central processing unit (CPU). With the rapid developing of graphics processing unit (GPU) computing power, Artificial Intelligence (AI) methods have shed some new light on this issue. Specifically, AI techniques have been successfully applied in various subjects such as GW signal detection [22, 23, 24, 25, 26, 27], parameter estimation [28, 29, 30], signal extraction and noise reduction [31, 32, 33, 34, 35, 36, 37, 38] with promising results. Additionally, the target of space GW detectors is also one type of complex and multi-scale waveforms (such as MBHB, EMRIs, and GB). Some previous studies focused on generating binary black hole (BBH) waveforms. Lee et al. [39] employed a Recurrent Neural Network (RNN) that is capable of generating BBH waveforms during the merging and ringdown phases of non-spinning binary black hole coalescence. Khan et al. [40] demonstrated that a vanilla transformer can learn quasi-circular and non-precessing BBH waveforms. Similarly, Chua et al. [41] used a greedy algorithm to build a reduced basis, enabling the rapid generation of BBH waveforms. Recently, large-scale language models (LLM) based on attention mechanism have shown their tremendous power in computer vision (CV) and natural language processing (NLP) [42, 43, 44]. Some studies indicate that similar architectures can be applied to the GW data analysis [36, 35]. Space-based GW detectors will observe more signals along with complex difficulties such as source confusion, gaps, and glitches [45]. It is critical to provide a set of data processing tools to address these issues. Deep learning holds promise for meeting these challenges.
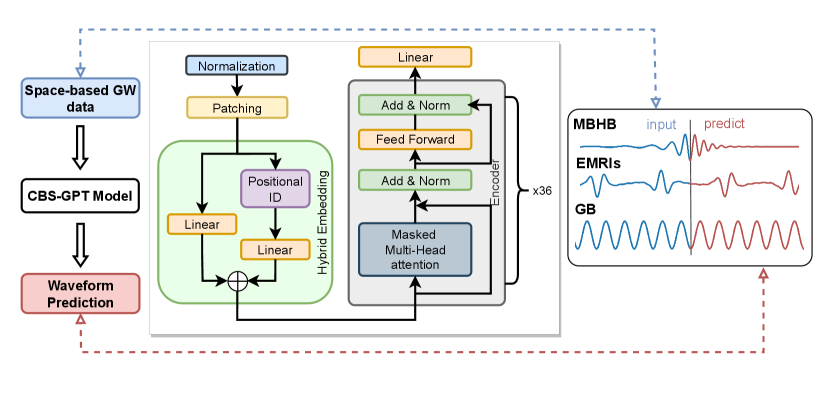
In contrast to previous studies on AI waveform generation, which had limitations in considering the second-generation time-delay interferometry (TDI 2.0) responses, our paper takes a step further. Moreover, the parameter range of waveforms in prior investigations was relatively narrow. In our paper, we are committed to further investigation on more complex waveforms and train a model to facilitate solving downstream problems. We introduce CBS-GPT (Compact Binary Systems Waveform Generation with Generative Pre-trained Transformer) model, which is an interpretable, transformer-based, and self-supervised large model for prediction of compact binary sources (MBHB, EMRIs, and GB). In CBS-GPT (Figure 1), patching and hybrid embedding mechanisms are proposed for full extraction of waveform features. By utilizing the self-attention mechanism and mean square error loss, CBS-GPT is trained for each GW waveform source. The experiment results illustrate that CBS-GPT can accurately predict the subsequent waveform based on the input waveform. In this study, two models were trained to achieve extrapolation with different input-to-prediction length ratios. In the 20:1 extrapolation, the average overlap between the predicted and target waveforms of MBHB, EMRIs, and GB reaches 0.981, 0.912, and 0.991, respectively. In the 1:1 extrapolation, the average overlaps reached 0.990, 0.807, and 0.992 for MBHB, EMRIs, and GB, respectively. We have also discovered that waveform complexity can significantly influence the model’s prediction performance, and CBS-GPT can match the key frequencies effectively. Finally, through attention map visualization and correlation calculation, we discover that the attention map and its corresponding waveform present similar periodic distribution, which illustrates that CBS-GPT is able to learn waveform features even under the complex instrument response and a wide parameter range.
The rest of this paper is organized as follows. Section II describes data generation and the CBS-GPT model architecture. In Section III, we present our overlap and attention map results, and discuss interpretability outcomes as well as potential applications. Finally, Section IV highlights our findings based on the results.
II Methodology
II.1 Data
Space-based GW detectors’ targets are GW signals at frequencies of . We focus on three compact binary sources that are of major interest for LISA: MBHB, EMRIs, and GB. Figure 2 displays data examples. Detailed information of the data generation process is given below.
II.1.1 MBHB
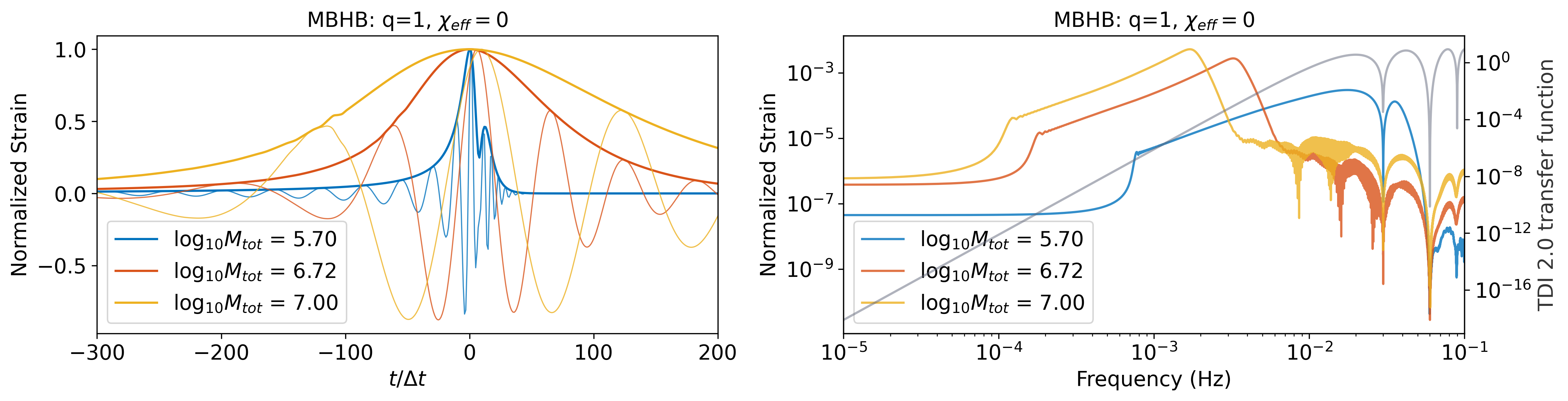
MBHB are one of the space-based GW detector’s main detection targets [18]. In this paper, SEOBNRv4_opt [46] ( mode) is used to generate the MBHB waveforms. The parameter space of the MBHB dataset is shown in Table 2(a). In Figure 2(a), the TDI 2.0 transfer function significantly affects high-frequency transmissions due to the lower total mass of MBHB. Firstly, we generate MBHB time-series waveforms with a length of 20,000 points with a sampling rate of 5 seconds. We train two models with different input-to-prediction token length ratios. The two scenarios are referred to as 20:1 and 1:1 extrapolation in the subsequent sections. Table 2 summarizes token information for each source. The 20:1 extrapolation involved predicting the subsequent 200 points after merging with an input sequence of the preceding 4000 points. The 1:1 extrapolation predicted the same 200 points after merging, but with an input sequence limited to the preceding 200 points. During the inference phase, the 4,000 valid points (or 200 valid points) before the merge time are fed into CBS-GPT to predict the succeeding 200 points, hence achieving a 20:1 extrapolation (or 1:1 extrapolation) prediction of the MBHB waveforms.
| Parameter | Description | Parameter distribution |
|---|---|---|
| Total mass of massive black hole binaries | log-Uniform | |
| Mass ratio | Uniform | |
| Spin parameters of two black holes | Uniform | |
| , | The inclination angle and polarization angle | Uniform |
| Coalescence phase. | Uniform | |
| Ecliptic longitude | Uniform | |
| Ecliptic latitude | Uniform |
| Parameter | Description | Parameter distribution |
|---|---|---|
| The mass of MBH | Uniform | |
| The mass of stellar-mass compact | Fix | |
| Spin parameter of MBH | Uniform | |
| Semi-latus rectum | Uniform | |
| Eccentricity | Uniform | |
| The cosine of the orbit’s inclination angle from the equatorial plane | Uniform | |
| , | The polar angles describing the sky location and the orientation of the spin angular momentum vector of the MBH | Uniform |
| , | The azimuthal angles describing the sky location and the orientation of the spin angular momentum vector of the MBH | Uniform |
| The phase of azimuthal, polar, and radial modes | Fix |
| Parameter | Description | Parameter distribution |
|---|---|---|
| Frequency | log-Uniform Hz | |
| The derivative of | Fix | |
| Amplitude | Uniform | |
| , , | The inclination angle, polarization angle and initial phase | Uniform |
| Ecliptic longitude | Uniform | |
| Ecliptic latitude | Uniform |
| 20:1 extrapolation | 1:1 extrapolation | |
| Input tokens | 1000 | 50 |
| Prediction tokens | 50 | 50 |
| MBHB | 4 points/token | 4 points/token |
| EMRIs | 4 points/token | 16 points/token |
| GB | 4 points/token | 32 points/token |
II.1.2 EMRIs
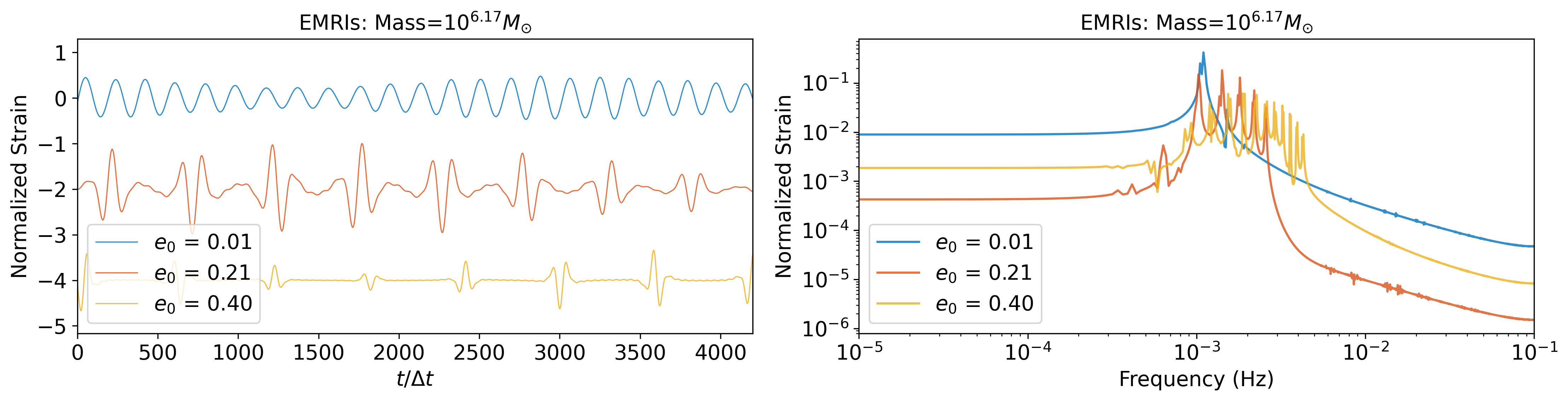
EMRIs are a kind of black hole binary system with a mass ratio of and massive black holes (MBH) that have a mass range of . EMRIs waveforms are able to encapsulate the properties of space-time near a massive black hole. EMRIs are among the primary detection targets for the space-based GW detectors, possessing the potential to unveil new physical phenomena [47, 48, 49]. We employ FastEMRIsWaveforms (FEW) package [50] to generate EMRIs waveforms with a sampling rate of 5s. The EMRIs signals with a duration of 1 year are randomly sliced into five waveform segments containing 4,200 points for 20:1 extrapolation (or 1600 points for 1:1 extrapolation). For continuous GWs, the random slice can simulate variations in the phase and amplitude domain of the same signal, enhancing the model’s generalization capability. The parameter space of the EMRIs dataset is shown in Table 2(b). The complexity of the EMRIs waveform is visible in Figure 2(b). As the eccentricity increases, there is a corresponding increase in its complexity, which becomes particularly prominent in the frequency domain.
II.1.3 Galactic binary
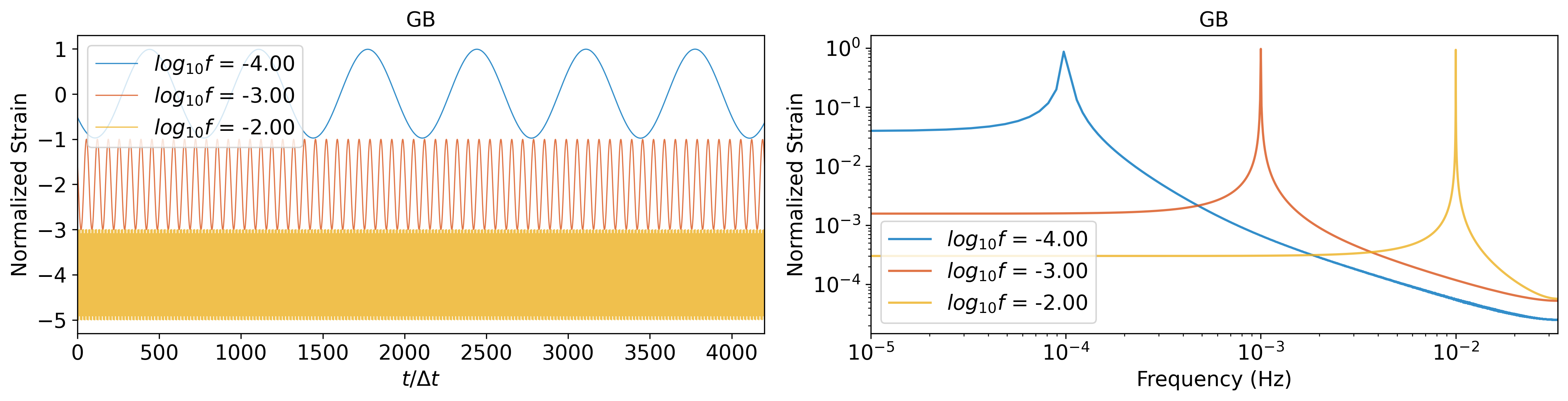
Within the Milky Way galaxy, a substantial population of binary white dwarf systems exists, posing foreground noise challenges for space-based GW detectors. We use the following GB model to generate GB waveforms [51]:
| (1) | ||||
Similar to EMRIs, GB waveforms are generated with a duration of 1 year and a sampling rate of 1/15 Hz. Five slices of 4,200 points for 20:1 extrapolation (or 3200 points for 1:1 extrapolation) is randomly truncated for training and inference. The parameter space of the GB dataset is shown in Table 2(c).
II.1.4 Detector response and TDI 2.0
After generating the waveform, we project it into the LISA detector [52]. For LISA, the signals will be processed with TDI combination to suppress the overpowering laser noise. The response of space-based GW detectors is more intricate compared to ground-based detectors, accounting for factors such as satellite orbits and arm-length delays. The strain induced on link 12 is:
| (2) | |||
The refers to the antenna pattern:
| (3) | ||||||
where is the link unit vector, and represent polarization vectors defined as the opposite direction of the polar and azimuthal angles in the Solar System Barycenter (SSB) frame respectively. Due to the longer arm lengths of space-based GW detectors, the influence of arm length needs to be taken into consideration. The time of transmission from spacecraft 2 is denoted as , and after propagating over the arm length distance to reach spacecraft 1, the reception time is ,
| (4) |
where represents the arm length of the detector. The variable describes the path of the photon. and we approximate to the first order as Due to the slow motion of the space-based GW detector, the frequency shift is given by
| (5) | ||||
where represents the propagation vector of the wave source.
Space-based GW detectors have unequal arm lengths, which results in significant laser frequency noise. To mitigate this issue, TDI techniques are commonly employed to suppress laser frequency noise [53, 54]. The first and second generation Michelson combinations, X1 and X2, are defined by [53],
| (6) | ||||
| (7) | ||||
where the delay operators are defined by,
| (8) |
The detector response and TDI 2.0 response of GW are calculated using Fastlisaresponse [52]. TDI 2.0 generates three channels X, Y, and Z. The variables Y and Z may be produced via cyclic permutation of the indices in Eq. 7. A more detailed derivation can be found in Section IV of the reference [52]. By combining X, Y, and Z, three independent channels A, E, and T are obtained,
| (9) | ||||
The incorporation of response functions and TDI 2.0 combination introduces increased complexity to the waveform, especially in the high-frequency part. As depicted in Figure 2, MBHB waveforms exhibit significant differences at various parameter values.
II.2 CBS-GPT Model
Transformers [55] are a class of deep learning models that have exhibited excellent performance in various tasks, such as NLP [43] and CV [44]. We incorporate the masked self-attention mechanism and feed-forward neural network to build our CBS-GPT model.
Patching. Firstly, the input waveform is preprocessed by standardization, which facilitates the model in capturing waveform information more effectively:
| (10) |
where represents the input waveform, and represent the mean and standard deviation of the waveform, respectively. The standardization centers the original data to a mean of 0 and a standard deviation of 1, which makes features have equal weight in various analyses and is more suitable for machine learning algorithms that are sensitive to feature scales. Then, is divided into non-overlapping patches, and we refer to each patch as a "token" here. In our 20:1 extrapolation experiment for example, we have an input waveform with sampling points, which is segmented into tokens, and each token contains points. Each token is treated as a vector, after patching, the standardized waveform is processed into the input matrix .
Hybrid Embedding. The hybrid embedding module is utilized in our model, because each token contains richer physical information and cannot be tokenized by simple tokenizers as in NLP. As Figure 1 shows, it is combined with a token embedding layer and a positional embedding layer (Eq. 11). The token embedding layer performs linear projection to achieve dimension-matching with following encoder blocks, which meanwhile preserves the entire information of the input waveform. The positional embedding is also a linear layer that encodes positional relationships between tokens, which is rather important in improving prediction accuracy [55].
| (11) | ||||
where , and are both learnable parameters, and represents an identity matrix with shape .
Encoder block. The encoder contains blocks. Each block mainly consists of an attention module and a feed-forward neural network. As for the attention module, masked multi-heads self-attention (MMHSA) is adopted in our work, which enables information to be projected into matrices in different ways, thereby enhancing the expressive capacity of the model. The computation process of the attention module is as follows:
| (12) | ||||
| (13) |
| (14) |
| (15) |
In each encoder block, there is heads. represent learnable query, key, and value parameters of -th attention head and -th encoder block, respectively, and is a lower triangular standard matrix.
| (16) |
where represents the hybrid embedding or the output of the previous encoder block. The feed-forward network (FFN) is composed of two dense layers and is connected to each attention module.
We employ the residual connection (Eq. 18), which is helpful to alleviate the gradient-vanishing problem.
| (17) |
| (18) |
where are both learnable parameters and is an activation function. Finally, the output of the last encoder block is inversely projected to the same shape of .
| (19) |
Loss Function. Next-token-prediction error is adopted to train CBS-GPT, which means that the predicted token is designed to match the input token () at position . Hence, only tokens are taken into account when calculating the training loss. Specifically, the mean squared error (MSE) loss is used to measure the difference between the predictions:
| (20) |
II.3 Training and Inference
During training, the Adam [56] optimizer with , is used, and the initial learning rate is 2e-4. There are 1.6 millions waveforms in the training dataset of each model, and the parameter of each waveform is randomly selected from its correponding parameter space. After passing through the LISA response, each waveform is divided into three TDI channels (A, E, and T). In this study, the E channel is selected to train the model. The model was trained on two NVIDIA V100 GPUs for approximately 30 hours. During inference, for each signal source, 10,000 waveforms are generated to test CBS-GPT’s performance. For each waveform, the initial input contains 1,000/50 valid tokens and 50 masked tokens that are masked with zero, whose corresponding value in the mask matrix also equals zero, which guarantees that no attention is paid to the to-be-extrapolated token. In the first step, the 1,001-st/51-st token is predicted and replaces the previous 1,001-st/51-st token, and so forth, 50 successive tokens are predicted based on 1,000/50 valid input tokens.
III Results and discussion
During inference, overlap is defined to evaluate the extrapolation accuracy of the predicted waveform. Overlap is calculated between the target waveform and the predicted waveform generated by CBS-GPT as stated in Eq. 21. The overlap ranges between , with values closer to 1 indicating that the predicted waveform is more similar to the target waveform.
| (21) |
with
| (22) | ||||
where represents time-shifted, and we set .
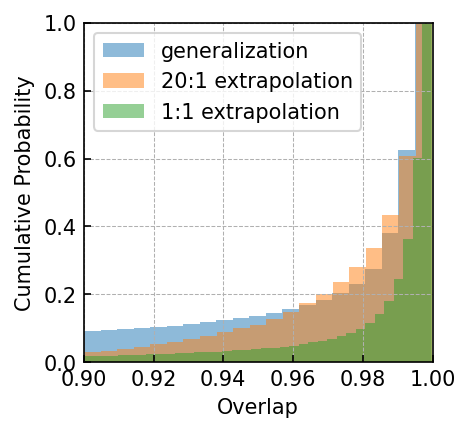
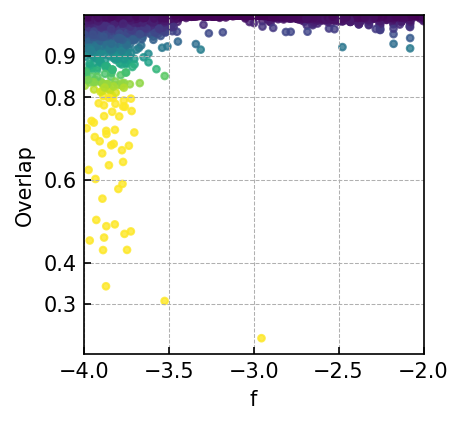
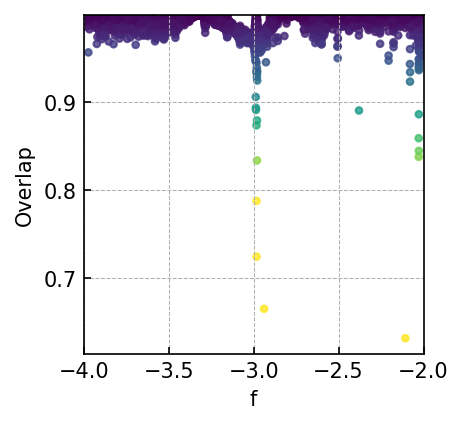
Overall, in the context of 20:1 extrapolation tasks targeting MBHB, GB, and EMRIs signals, CBS-GPT has demonstrated remarkable efficacy, with over 50% of the overlaps exceeding 0.99. Figure 3 and 4 showcase the prediction performance of each waveform under varying parameter conditions, revealing that the CBS-GPT model can learn waveform features with a wide range of parameters. Figure 5 and 6 demonstrate the generalization and potent interpretability of CBS-GPT.
III.1 Results of MBHB
The results of MBHB overlap are shown in Table 4(a). The CBS-GPT model is sensitive to total mass, mass ratio, and spin parameters. Here we use to represent the spin parameter [57]:
| (23) |
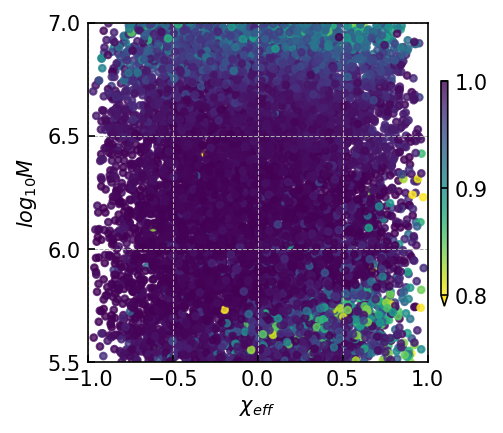
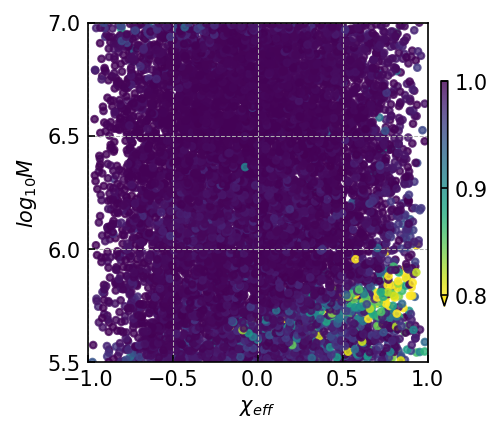
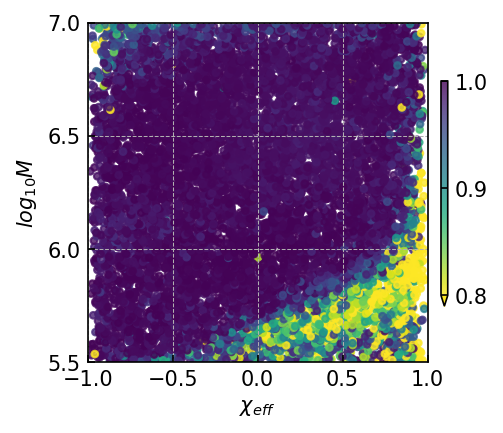
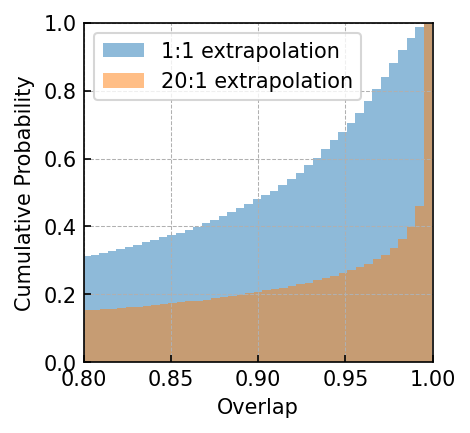
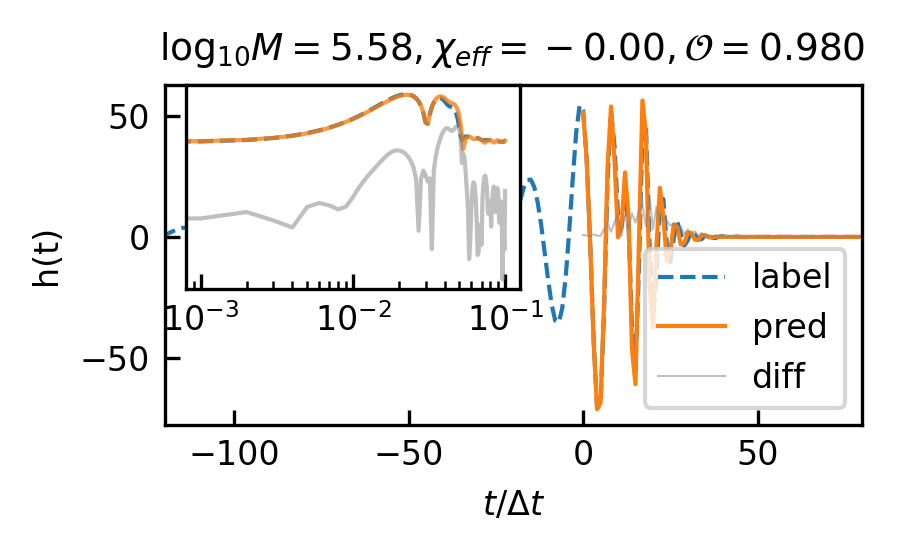
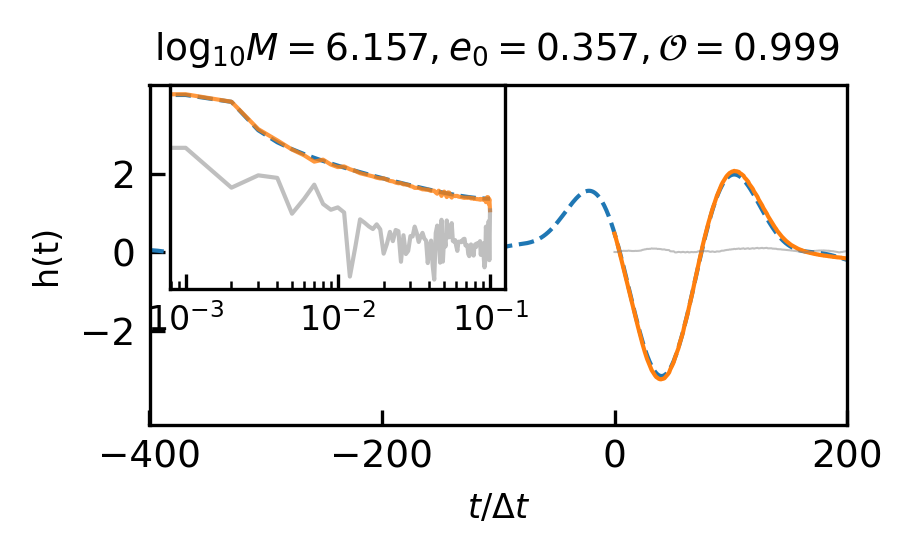
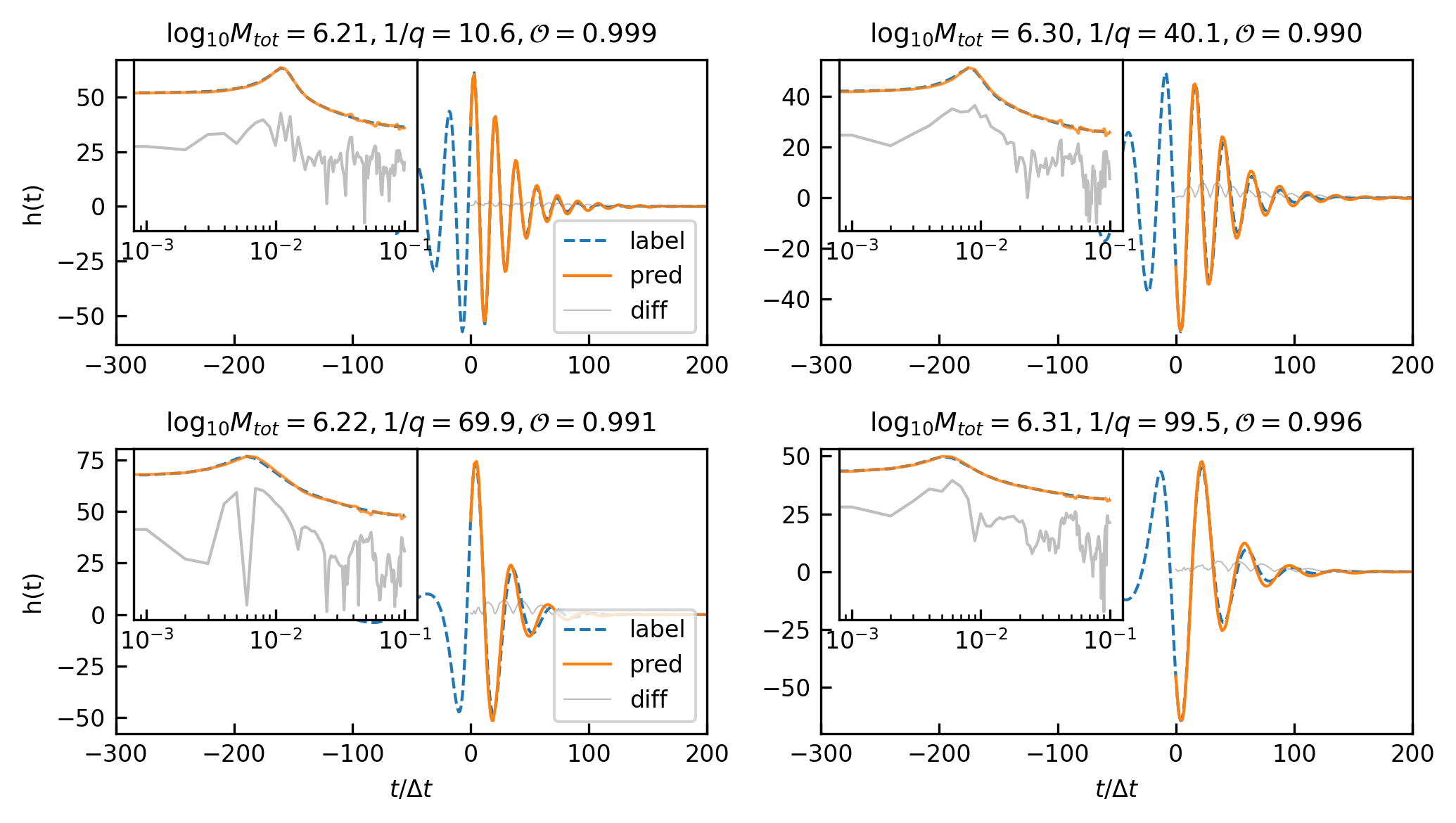
20:1 extrapolation. The overlap distribution and waveform examples are shown in Figure 3(a) and Figure 5(a), with mean and median overlaps equal 0.981 and 0.992, respectively. The overlap results reveal that CBS-GPT can forecast the waveform of the merge-ringdown phase based on the inspiral phase characteristics. CBS-GPT exhibits optimal inference performance when the total mass is approximately as shown in Figure 3(b). This phenomenon has also been observed in other signal sources. The overlap is lower for for waveforms with low total mass and high effective spin . Comparing low and high-mass situations to those involving intermediate masses, the performance of mid-frequency band prediction is the best. Since TDI 2.0 transfer functions in the high-frequency part are more complex [58, 59], the waveform is also more complex. Consequently, the model’s performance experiences a slight decrease. But even under such less ideal circumstances, CBS-GPT can still successfully recover a significant portion of the signals.
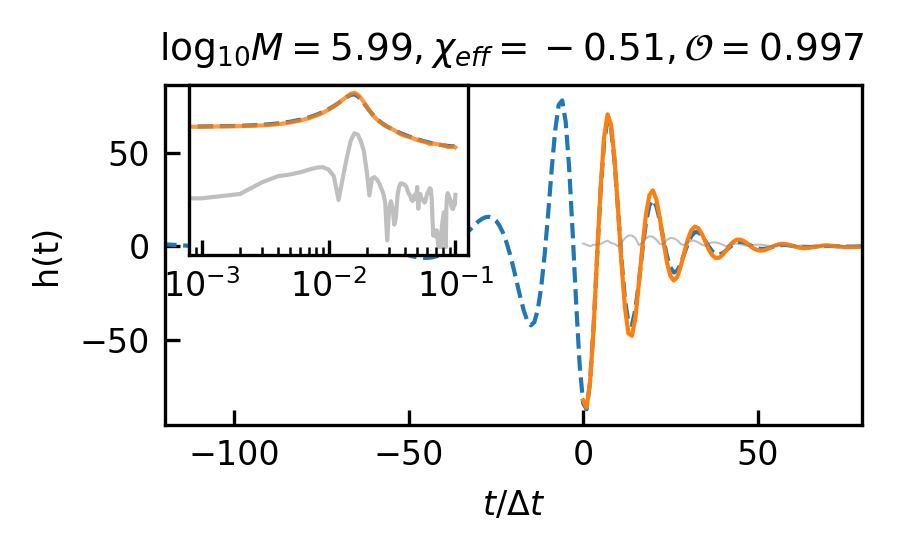
1:1 extrapolation. We find that the model pays little attention to the early-stage waveform and mainly concentrates on the late-stage inspiral waveform when forecasting the merging waveform of an MBHB (detailed explanation is in Section III.3). This demonstrates the marginal contribution of early-stage inspiral waveforms to subsequent waveforms generation. Hence we retrained a model, whose input only contains 200 points before merge time and predicted the subsequent 200 points, thus achieving a 1:1 extrapolation. The average and median overlap achieved 0.990 and 0.996, respectively. The results are slightly better than the previous 20:1 extrapolation, which validates our former conclusion. In Table 4(a), we observe a noticeable improvement in overlap for cases with masses greater than , which illustrates that shorter input waveforms allow the model’s attention to be more focused, leading to improved inference performance. In Figure 5(b), we showcase the predictive performance of CBS-GPT in the 1:1 extrapolation scenario.
Generalization ability refers to the performance of a model when applied to data that has not seen before. To evaluate the generalization capability of CBS-GPT, we selected MBHB signals with mass ratios ranging from 1:10 to 1:100 in the 1:1 extrapolation model. Figure 5(g) showcases the waveform examples of generalization ability. The average overlap achieved 0.970, with more than half of the overlaps surpassing 0.993, which demonstrated the strong generalization ability of our method. The model’s performance on generalization experiment also illustrates its ability to learn the essence of the data.
| MBHB | 20:1 | 1:1 | generalization |
|---|---|---|---|
| i. mean | 0.981 | 0.990 | 0.970 |
| ii. median | 0.992 | 0.996 | 0.993 |
| iii. mass | 0.980 | 0.979 | 0.938 |
| iv. mass | 0.982 | 0.995 | 0.986 |
| EMRIs | 20:1 | 1:1 |
|---|---|---|
| i.mean | 0.912 | 0.807 |
| ii. median | 0.997 | 0.910 |
| iii. | 0.962 | 0.905 |
| iv. | 0.896 | 0.778 |
| GB | 20:1 | 1:1 |
|---|---|---|
| i. mean | 0.991 | 0.992 |
| ii. median | 0.996 | 0.994 |
| iii. | 0.987 | 0.990 |
| iv. | 0.995 | 0.993 |
III.2 Results of Continous Waveform: EMRIs and GB
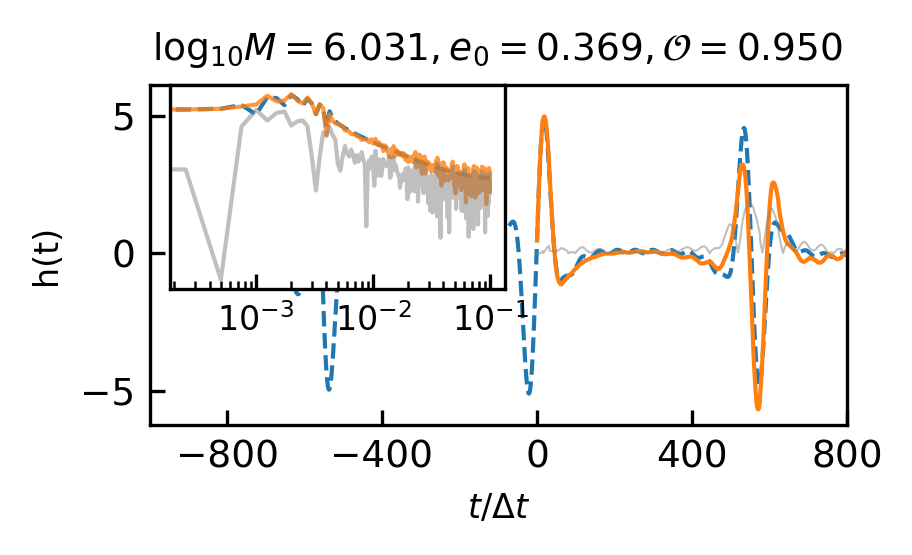
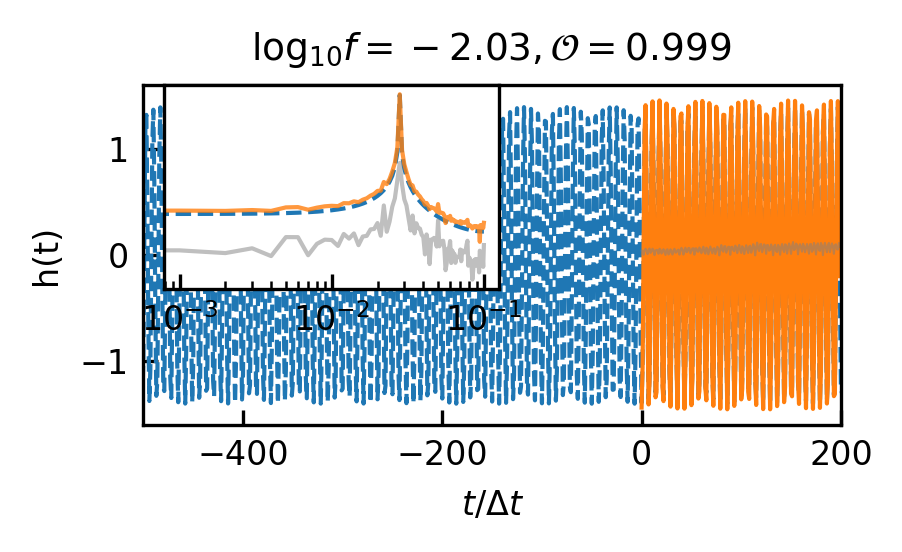
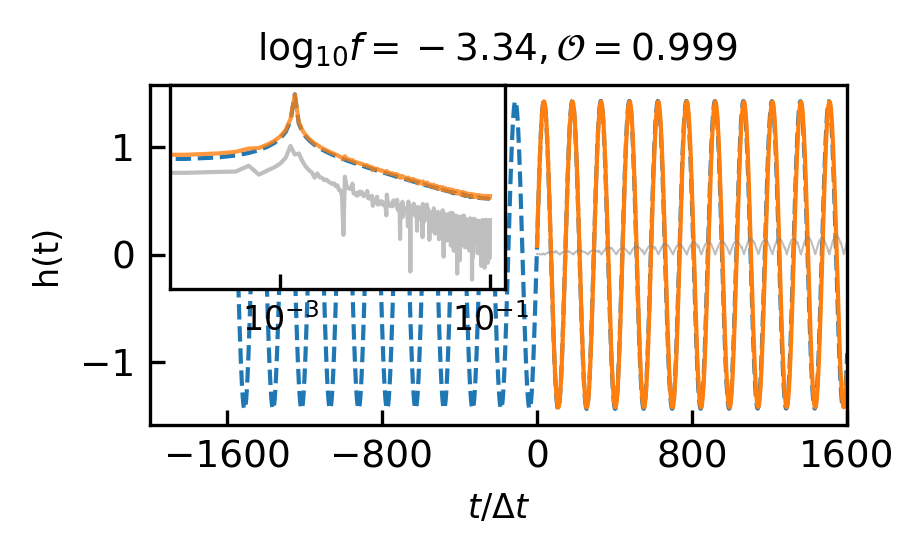
The overlap distributions of the EMRIs and GB are shown in Figure 4 and their mean and median values are displayed in Table 4(b) and Table 4(c). Examples of predicted EMRIs and GB waveforms are shown in Figure 5(c)-5(f).
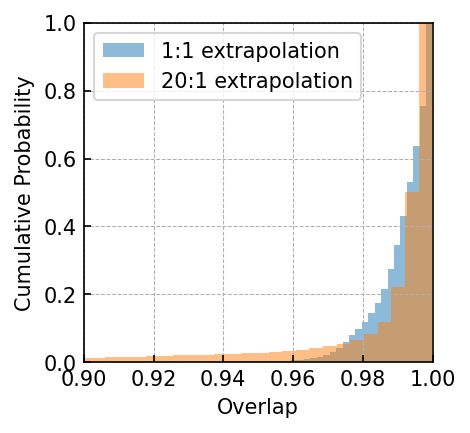
20:1 extrapolation. Regarding GB, its mean and median overlap both exceed 0.99. The mean and median overlap of EMRIs are equal to 0.912 and 0.997, respectively. While the mean overlap of EMRIs is slightly lower, its median overlap aligns with that observed in MBHB and GB waveforms.
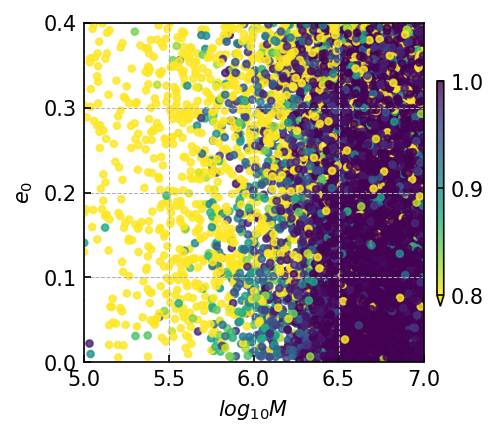
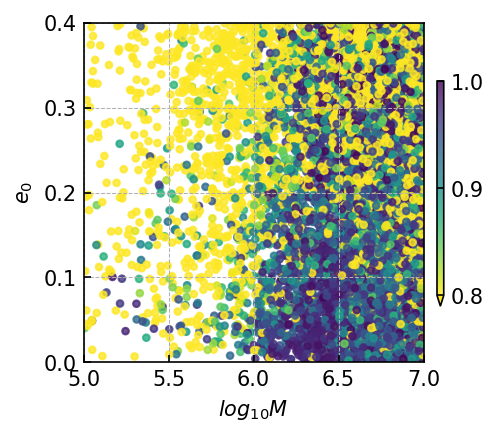
Specifically, the overlap distribution of EMRIs significantly influenced by the mass parameters and eccentricity parameters. As depicted in Table LABEL:tab:emri_overlap, when is less than , the majority of overlaps remain below 0.9. As the eccentricity increases, the waveform features become more complex in waveform amplitude. Therefore, when the eccentricity is higher, the corresponding overlap tends to decrease.
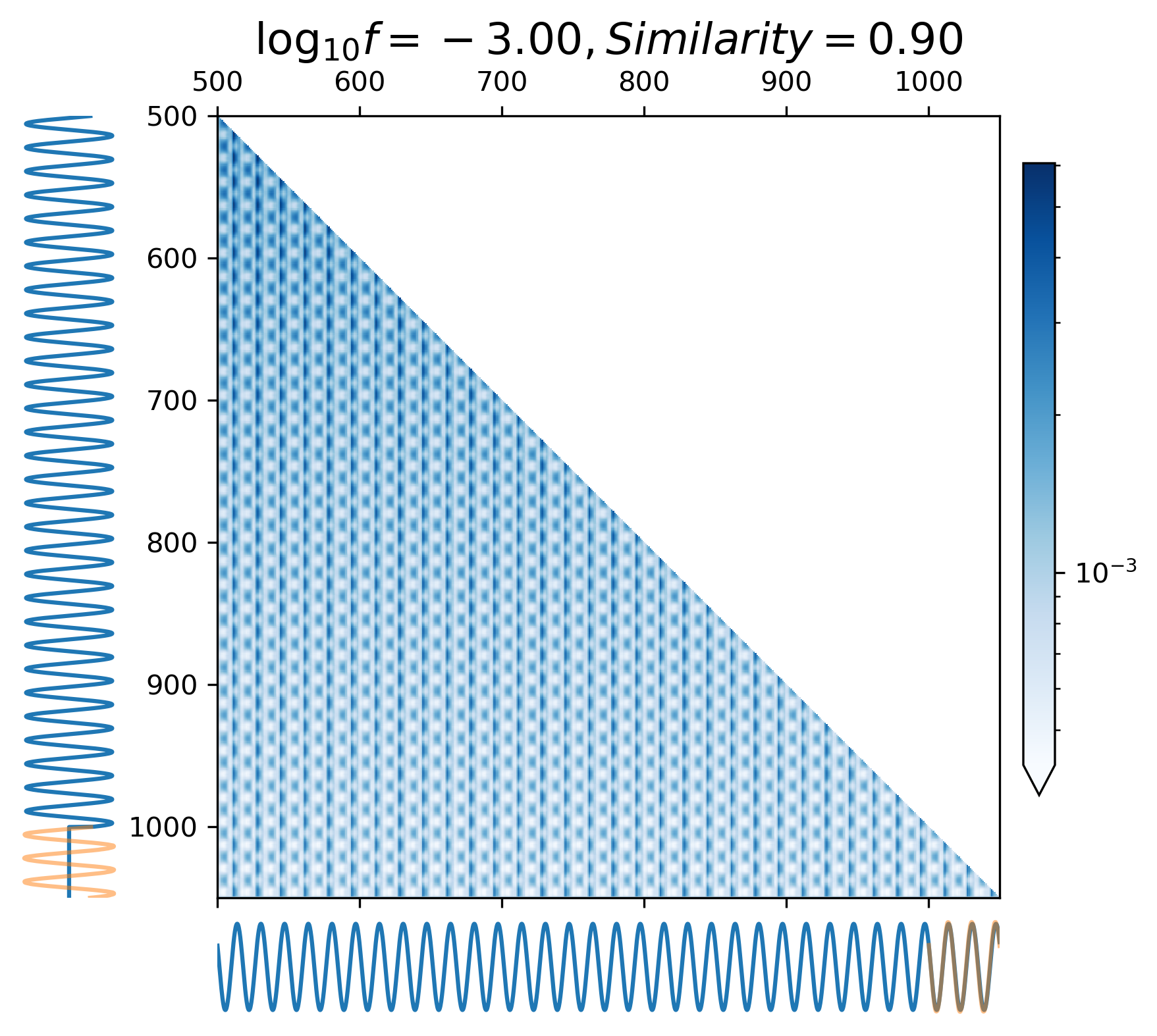
In contrast to MBHB and EMRIs signals, the GB signal presents a comparatively straightforward, single-frequency waveform. As for GB, the frequency parameter has the greatest impact on the waveform. When the frequency is larger than Hz, the overlap is basically higher than 0.9. The result of GB signals demonstrates the model’s sensitivity over frequency, with the distinct preference for learning the characteristics associated with intermediate frequency signals.
1:1 extrapolation. In this scenario, the mean and median overlaps for EMRIs were found to be 0.807 and 0.910, while for GB, the mean and median overlaps were 0.992 and 0.994 respectively.
The performance impact was negligible for GB, but there was a significant decrease in EMRIs waveforms. This can be attributed to the larger eccentricity and wider range of scales exhibited by EMRIs, as well as their continuous periodic transitions. Due to the high complexity of EMRI waveforms, shorter waveforms fail to capture the waveform features. Therefore, in the case of complex waveforms, CBS-GPT requires longer input waveforms to learn more distinctive features.
III.3 Interpretability
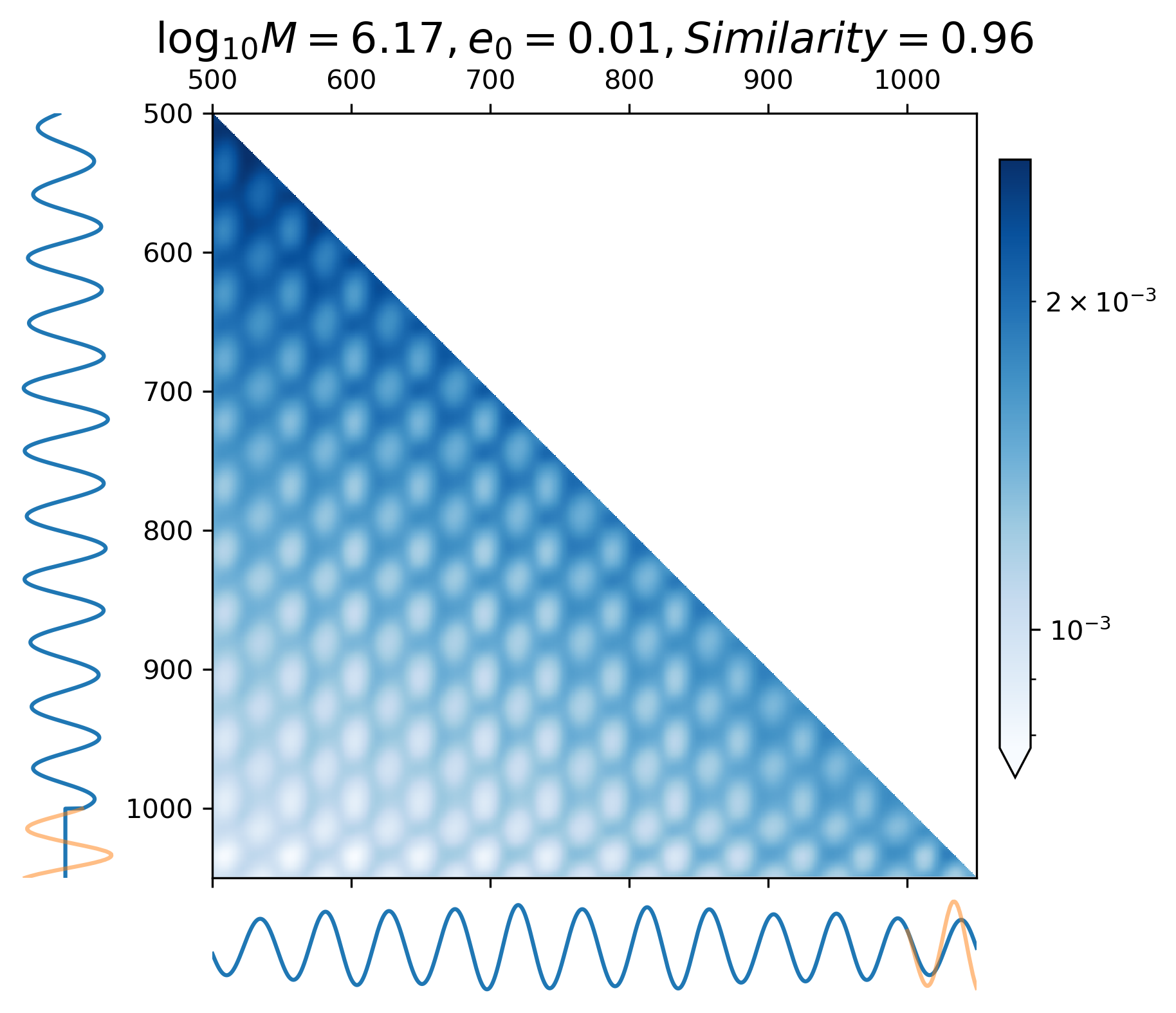
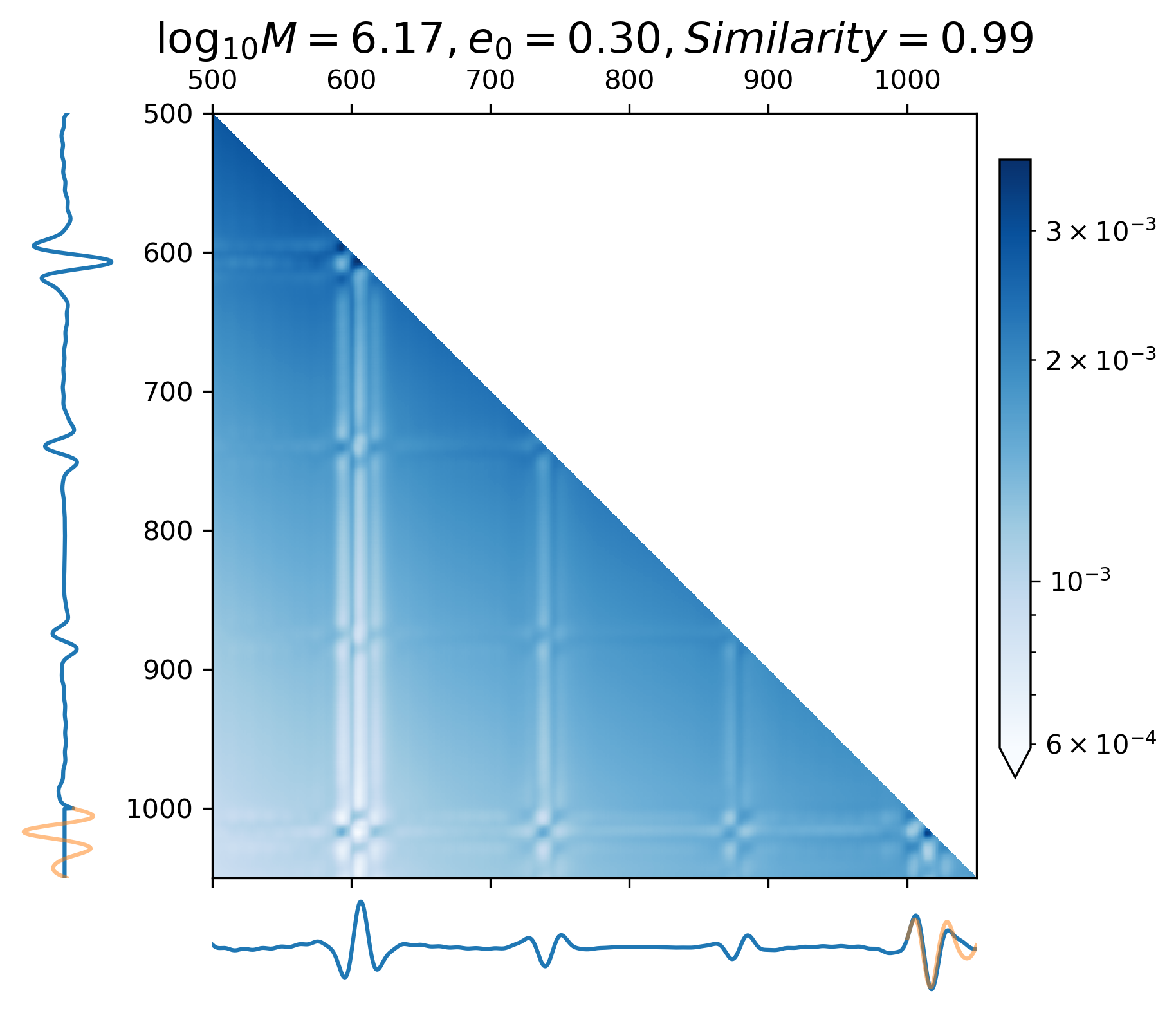
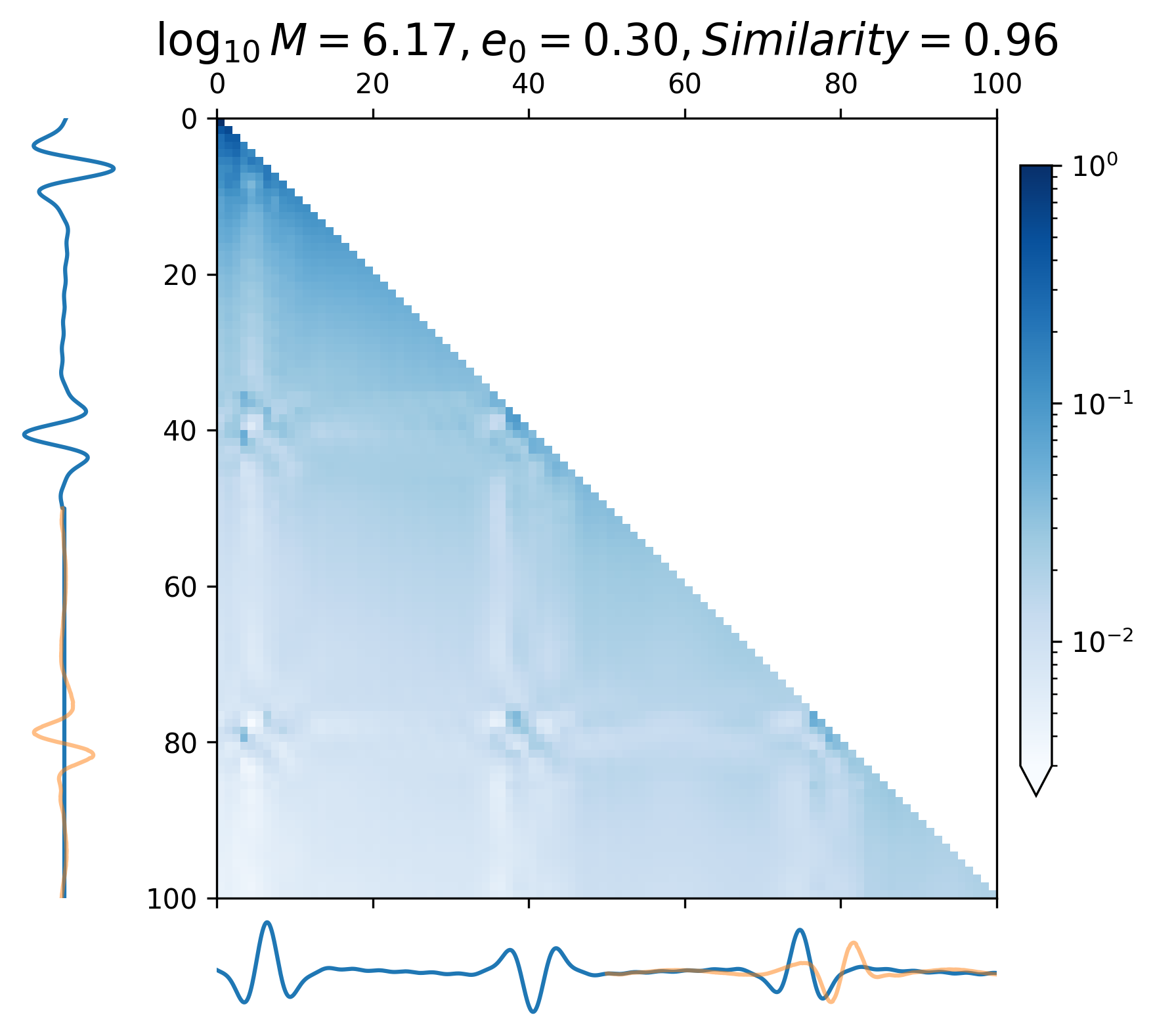
The attention map (Eq. 24) allows us to understand the extrapolation process and attention mechanism while forecasting waveforms, making it easier to gain insight into how CBS-GPT interpret GW data.
| (24) |
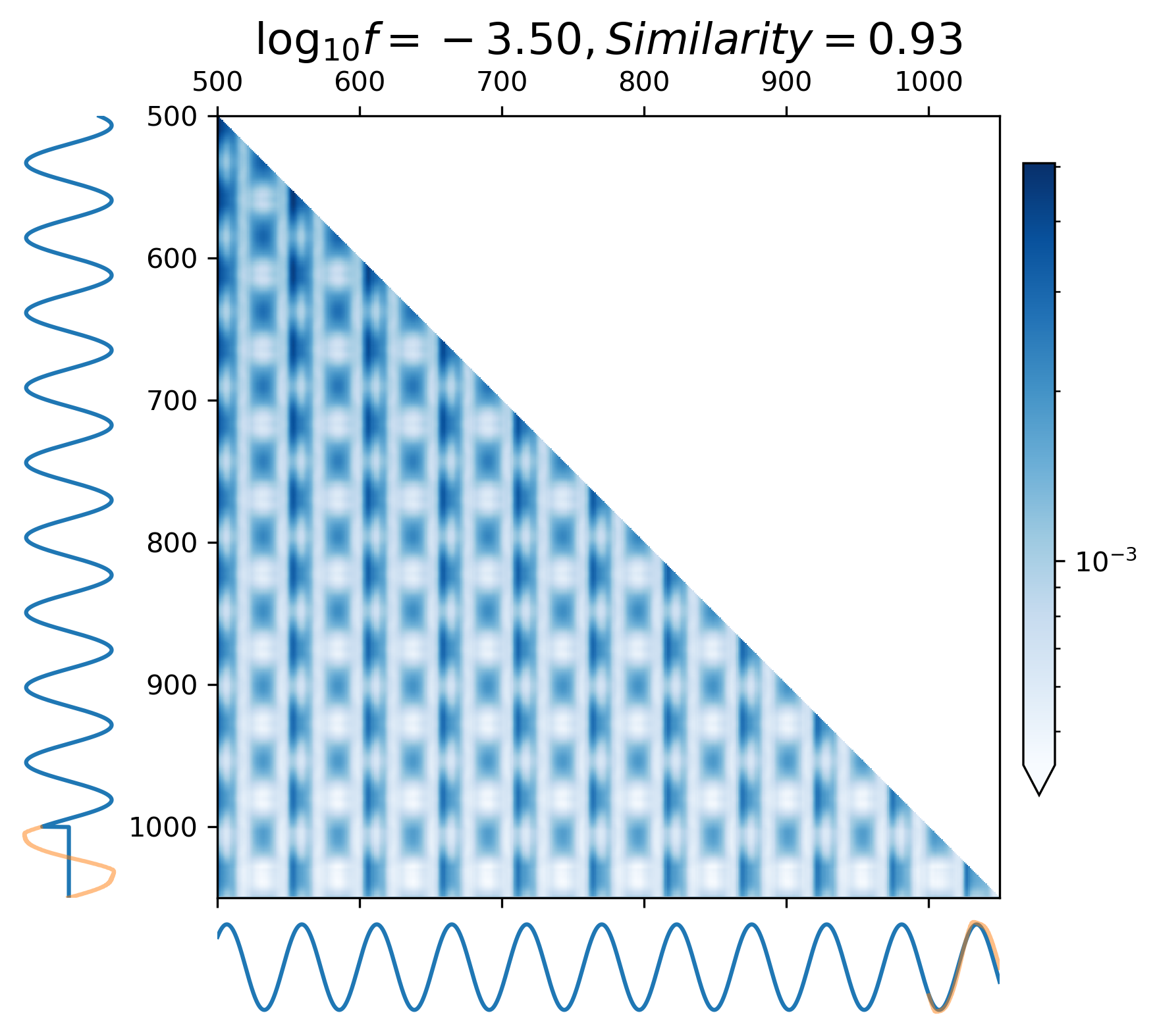
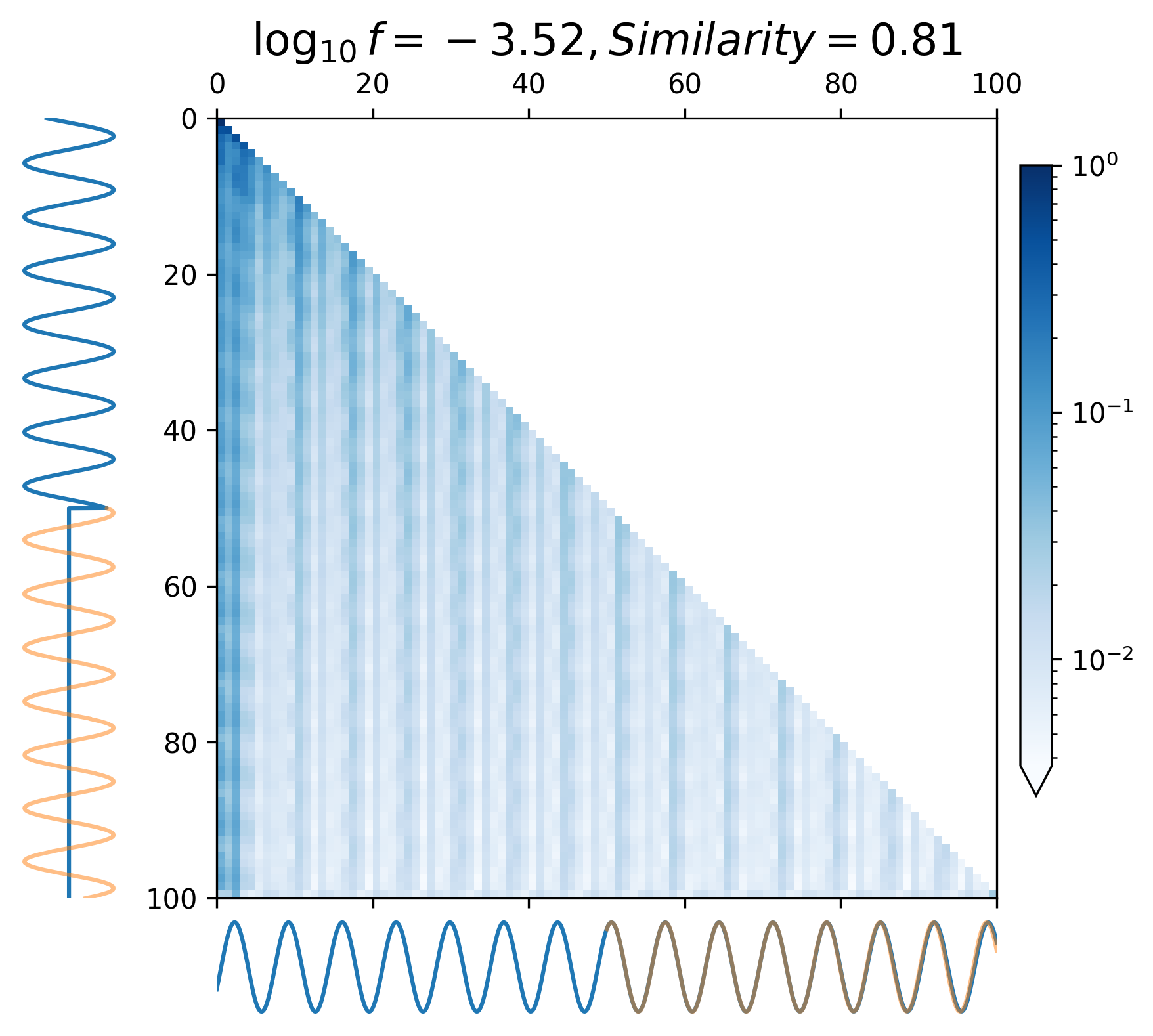
where represents all attention heads of the last encoder block. In Figure 6, the vertical axis represents the model input waveform, and the horizontal axis represents the predicted waveform.
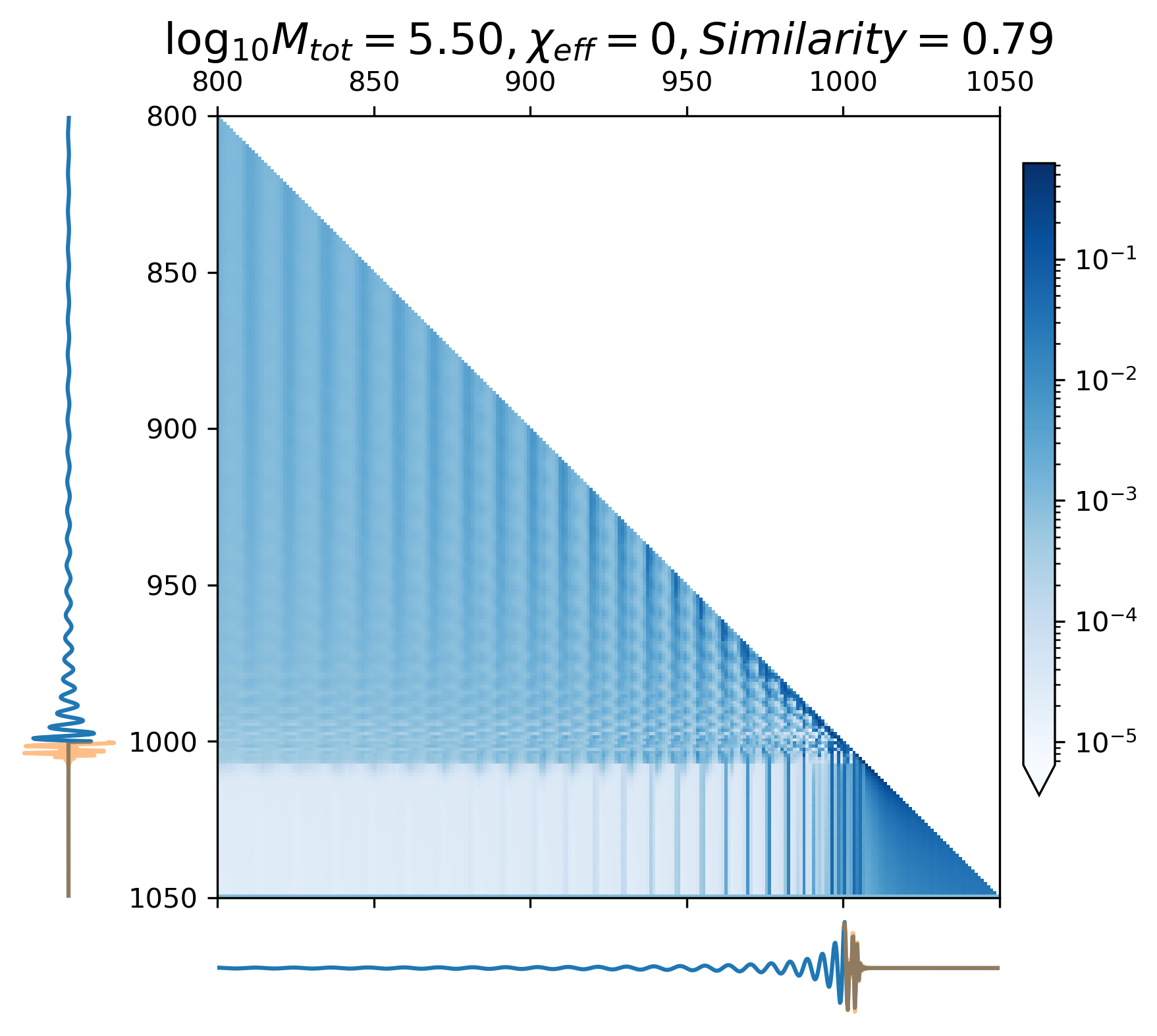
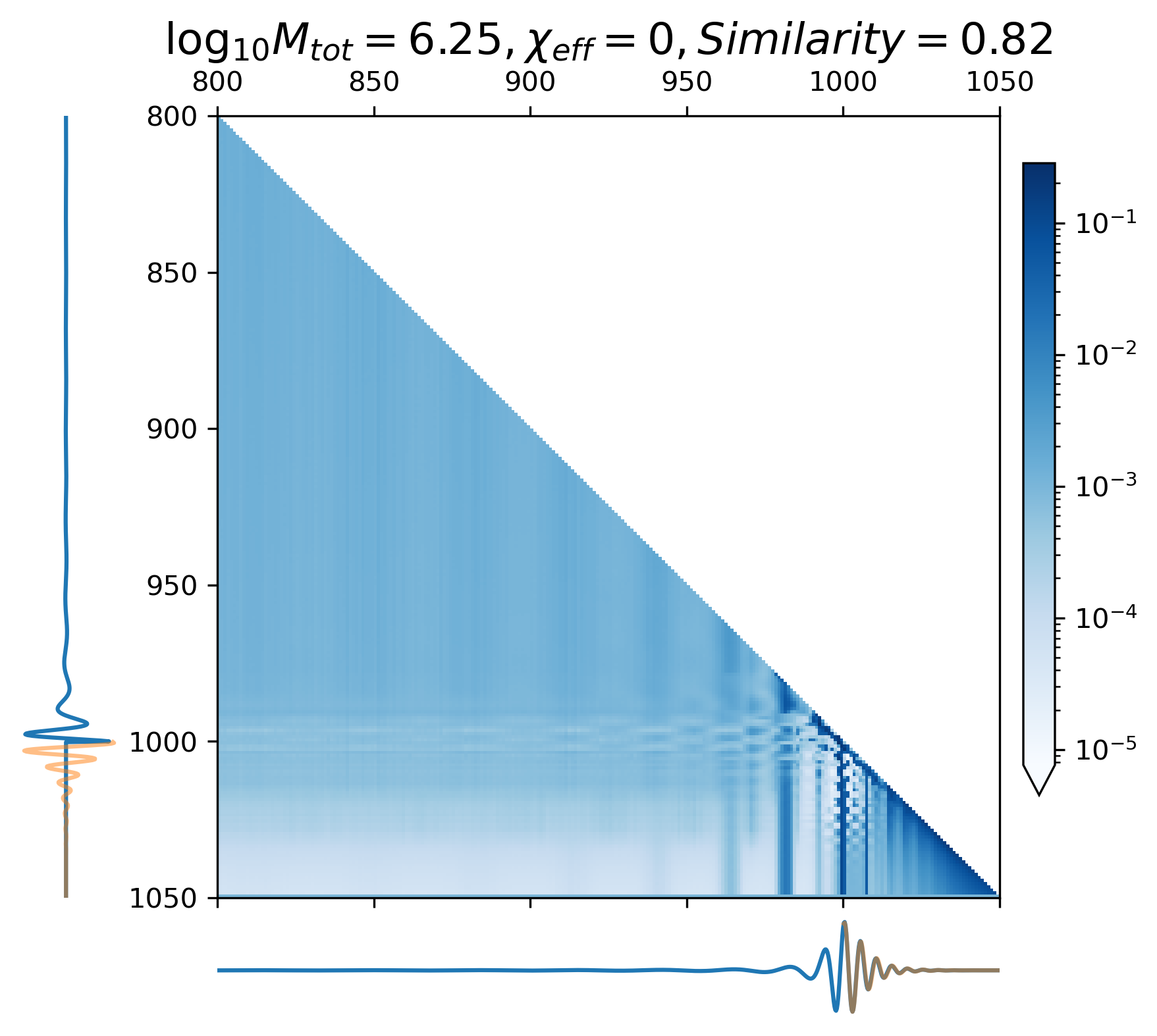
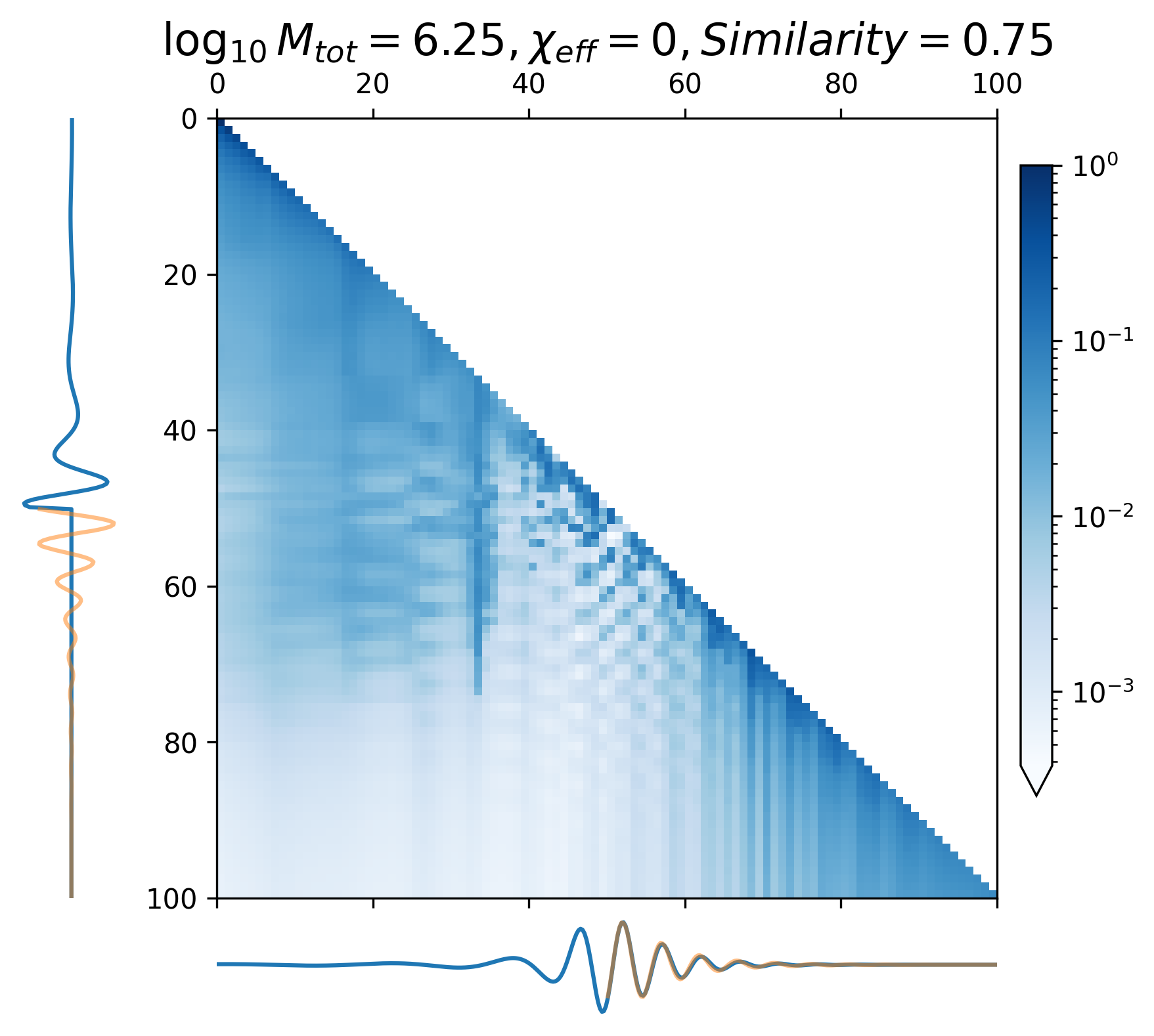
When predicting continuous gravitational waveforms (EMRIs and GB), the attention maps (Figure 6(d) - 6(i)) exhibit grid-like patterns that are closely related to the phase of the waveforms, with the scale of the grid expanding as the frequency decreases. In order to measure the similarity between the attention map and the input waveform, we introduce the correlation coefficient (with details described in Appendix A). Overall, the average correlation coefficient of continuous waveform exceeds 0.8, which demonstrates that the model can accurately match the waveform’s frequency and phase information. This mode assists CBS-GPT in successfully extrapolating waveforms.
As showcased in Figure 6(a) - 6(c), during the prediction of the merge-ringdown phase of MBHB waveforms, attention primarily focuses on near-diagonal elements. In contrast to continuous GW signals, the amplitude of MBHB reaches zero after the merge-ringdown, and the main focus of attention mechanism lies in the merging stage and the stage after the merge, with relatively less attention payed to inspiral phase.
III.4 Potential Applications
Complex waveforms generation. Currently, waveform generation for high mass ratio binary black holes remains a challenging problem because of high computational cost. Our approach can partially alleviate this problem since CBS-GPT that trained on low mass ratio waveforms with relatively low computational cost can be applied to high mass ratio waveform generation. This generalization characteristic, as shown in Figure 5(g), demonstrates that the model can learn intrinsic features and can be applied to waveform extrapolation of a broader parameter space. By incorporating simulations based on numerical relativity, we may build a waveform template bank by extrapolating more complex and computation-intensive waveforms. For burst wave sources such as MBHB, waveform generation time of CBS-GPT for a single waveform is less than 100ms on a single NVIDIA V100 GPU. With the rapid development of GPU computing power, CBS-GPT presents the potential for high-speed template waveform generation.
Gap imputation. In space-based GW detectors, the presence of data gaps due to data transmission, satellite attitude adjustments, and unidentified glitches can significantly impact the precision of waveform parameter estimation. Our waveform extrapolation method is promising to accomplish the task of waveform imputation, and by integrating with successive denoising models [33, 37, 34, 35, 36, 37, 38, 60], parameter estimation accuracy can be further enhanced [61].
Model Design Guidance. We established a more convenient method for visualizing and quantifying attention maps, offering guidance for transformer-based models design in the GW research realm. Our results also demonstrate that attention mechanism can be leveraged to establish more robust deep learning models that are specifically tailored for GW astronomy.
IV Conclusion
In this paper, we introduce the CBS-GPT model, consisting of hybrid embedding and encoder blocks. The CBS-GPT is applied to predict GW waveforms after the TDI 2.0 response. We investigated two scenarios of different extrapolation ratios between input and predicted waveform length. Different models are trained for MBHB, EMRIs, and GB. In the 20:1 and 1:1 extrapolation scenarios, the average overlaps between the predicted waveform and the target waveform of MBHB, EMRIs, and GB reach 0.981, 0.912, 0.991, and 0.990, 0.807, 0.991, respectively. EMRIs exhibited poorer performance in the 1:1 extrapolation due to their complex waveform patterns and rich amplitude variations caused by eccentricity. We also proved the strong generalization of CBS-GPT on MBHB waveforms.
Moreover, we introduced a correlation coefficient and found that the correlation between hidden parameters of CBS-GPT and waveform was relatively high, which indicated that the model could learn waveform’s phase information extremely well. Overall, our results show that CBS-GPT has the ability to comprehend detailed waveform properties and make predictions over varied frequencies. We are confident that in the future, large AI models such as CBS-GPT can be applied to GW data processing tasks including complex waveforms generation and gap imputation.
Acknowledgements.
This research was supported by the Peng Cheng Laboratory and Peng Cheng Cloud-Brain. This work was also supported in part by the National Key Research and Development Program of China Grant No. 2021YFC2203001 and in part by the NSFC (No. 11920101003 and No. 12021003). Z.C. was supported by the “Interdisciplinary Research Funds of Beijing Normal University" and CAS Project for Young Scientists in Basic Research YSBR-006.Appendix A Correlation coefficient between waveform and hidden parameters
To evaluate the correlation between the attention map’s grid-like pattern and the waveform, we introduce the correlation coefficient between the waveform and hidden parameters (or attention map). This coefficient assesses the level of correlation and demonstrates the attention map’s ability to capture phase information. Firstly, we compute the mean value of each token of the patched waveform to get the sequence . Subsequently, the outer product of is computed, resulting in the auto-correlation matrix. As the attention map (Eq. 24) is processed by masking and normalization, we do a similar adjustment to the auto-correlation matrix:
| (25) | ||||
where denotes the normalization of each row of the matrix and is consistent with the mask method of Section II.3.
To assess the correlation between the two matrices, we calculate the Pearson correlation coefficient between the flattened attention map and flattened :
| (26) | ||||
where denotes flattening the matrix into one dimension, and represent the flattened vector of and respectively, and represents the length after flattening. Finally, is defined as the correlation coefficient between waveform and hidden parameters.
References
- Abbott et al. [2016a] B. P. Abbott, R. Abbott, T. D. Abbott, M. R. Abernathy, F. Acernese, K. Ackley, C. Adams, T. Adams, P. Addesso, R. X. Adhikari, et al., Physical Review Letters 116, 061102 (2016a).
- Abbott et al. [2016b] B. P. Abbott, R. Abbott, T. D. Abbott, M. R. Abernathy, F. Acernese, K. Ackley, C. Adams, T. Adams, P. Addesso, R. X. Adhikari, et al., Physical Review D 93, 122003 (2016b).
- Schutz [1986] B. F. Schutz, Nature 323, 310 (1986).
- Sathyaprakash and Schutz [2009] B. S. Sathyaprakash and B. F. Schutz, Living Reviews in Relativity 12, 2 (2009).
- Klein et al. [2016] A. Klein, E. Barausse, A. Sesana, A. Petiteau, E. Berti, S. Babak, J. Gair, S. Aoudia, I. Hinder, F. Ohme, et al., Physical Review D 93, 024003 (2016), arxiv:1511.05581 [astro-ph, physics:gr-qc].
- Tamanini et al. [2016] N. Tamanini, C. Caprini, E. Barausse, A. Sesana, A. Klein, and A. Petiteau, Journal of Cosmology and Astroparticle Physics 2016, 002 (2016), arxiv:1601.07112 [astro-ph, physics:gr-qc].
- Bartolo et al. [2016] N. Bartolo, C. Caprini, V. Domcke, D. G. Figueroa, J. Garcia-Bellido, M. C. Guzzetti, M. Liguori, S. Matarrese, M. Peloso, A. Petiteau, et al., Journal of Cosmology and Astroparticle Physics 2016, 026 (2016), arxiv:1610.06481 [astro-ph, physics:gr-qc, physics:hep-ph].
- Caprini et al. [2016] C. Caprini, M. Hindmarsh, S. Huber, T. Konstandin, J. Kozaczuk, G. Nardini, J. M. No, A. Petiteau, P. Schwaller, G. Servant, et al., Journal of Cosmology and Astroparticle Physics 2016, 001 (2016), arxiv:1512.06239 [astro-ph, physics:gr-qc, physics:hep-ph].
- Babak et al. [2017a] S. Babak, J. Gair, A. Sesana, E. Barausse, C. F. Sopuerta, C. P. L. Berry, E. Berti, P. Amaro-Seoane, A. Petiteau, and A. Klein, Physical Review D 95, 103012 (2017a), arxiv:1703.09722 [astro-ph, physics:gr-qc].
- Arun et al. [2022] K. G. Arun, E. Belgacem, R. Benkel, L. Bernard, E. Berti, G. Bertone, M. Besancon, D. Blas, C. G. Böhmer, R. Brito, et al., Living Reviews in Relativity 25, 4 (2022), arxiv:2205.01597 [gr-qc].
- Collaboration et al. [2021] T. L. S. Collaboration, the Virgo Collaboration, the KAGRA Collaboration, R. Abbott, T. D. Abbott, F. Acernese, K. Ackley, C. Adams, N. Adhikari, R. X. Adhikari, et al., “GWTC-3: Compact Binary Coalescences Observed by LIGO and Virgo During the Second Part of the Third Observing Run,” (2021), arxiv:2111.03606 [astro-ph, physics:gr-qc].
- Agazie et al. [2023] G. Agazie, A. Anumarlapudi, A. M. Archibald, Z. Arzoumanian, P. T. Baker, B. Bécsy, L. Blecha, A. Brazier, P. R. Brook, S. Burke-Spolaor, et al., The Astrophysical Journal Letters 951, L8 (2023).
- Xu et al. [2023] H. Xu, S. Chen, Y. Guo, J. Jiang, B. Wang, J. Xu, Z. Xue, R. N. Caballero, J. Yuan, Y. Xu, et al., Research in Astronomy and Astrophysics 23, 075024 (2023), arxiv:2306.16216 [astro-ph, physics:gr-qc].
- EPTA Collaboration and InPTA Collaboration: et al. [2023] EPTA Collaboration and InPTA Collaboration:, J. Antoniadis, P. Arumugam, S. Arumugam, S. Babak, M. Bagchi, A.-S. Bak Nielsen, C. G. Bassa, A. Bathula, A. Berthereau, et al., Astronomy & Astrophysics 678, A50 (2023).
- Reardon et al. [2023] D. J. Reardon, A. Zic, R. M. Shannon, G. B. Hobbs, M. Bailes, V. Di Marco, A. Kapur, A. F. Rogers, E. Thrane, J. Askew, et al., The Astrophysical Journal Letters 951, L6 (2023).
- Bailes et al. [2021] M. Bailes, B. K. Berger, P. R. Brady, M. Branchesi, K. Danzmann, M. Evans, K. Holley-Bockelmann, B. R. Iyer, T. Kajita, S. Katsanevas, et al., Nature Reviews Physics 3, 344 (2021).
- Matichard et al. [2015] F. Matichard, B. Lantz, R. Mittleman, K. Mason, J. Kissel, B. Abbott, S. Biscans, J. McIver, R. Abbott, S. Abbott, et al., Classical and Quantum Gravity 32, 185003 (2015).
- Amaro-Seoane et al. [2017] P. Amaro-Seoane, H. Audley, S. Babak, J. Baker, E. Barausse, P. Bender, E. Berti, P. Binetruy, M. Born, D. Bortoluzzi, et al., “Laser Interferometer Space Antenna,” (2017), arxiv:1702.00786 [astro-ph].
- Hu and Wu [2017] W.-R. Hu and Y.-L. Wu, National Science Review 4, 685 (2017).
- Ren et al. [2023] Z. Ren, T. Zhao, Z. Cao, Z.-K. Guo, W.-B. Han, H.-B. Jin, and Y.-L. Wu, Frontiers of Physics 18, 64302 (2023).
- Luo et al. [2016] J. Luo, L.-S. Chen, H.-Z. Duan, Y.-G. Gong, S. Hu, J. Ji, Q. Liu, J. Mei, V. Milyukov, M. Sazhin, et al., Classical and Quantum Gravity 33, 035010 (2016), arxiv:1512.02076 [astro-ph, physics:gr-qc].
- Wang et al. [2020] H. Wang, S. Wu, Z. Cao, X. Liu, and J.-Y. Zhu, Physical Review D 101, 104003 (2020).
- George and Huerta [2018a] D. George and E. Huerta, Physics Letters B 778, 64 (2018a).
- George and Huerta [2018b] D. George and E. A. Huerta, Physical Review D 97, 044039 (2018b).
- Gabbard et al. [2018] H. Gabbard, M. Williams, F. Hayes, and C. Messenger, Physical Review Letters 120, 141103 (2018).
- Badger et al. [2023] C. Badger, K. Martinovic, A. Torres-Forné, M. Sakellariadou, and J. A. Font, Physical Review Letters 130, 091401 (2023).
- Zhang et al. [2022a] X.-T. Zhang, C. Messenger, N. Korsakova, M. L. Chan, Y.-M. Hu, and J.-d. Zhang, Physical Review D 105, 123027 (2022a), arxiv:2202.07158 [astro-ph, physics:gr-qc].
- Dax et al. [2021] M. Dax, S. R. Green, J. Gair, J. H. Macke, A. Buonanno, and B. Schölkopf, Physical Review Letters 127, 241103 (2021).
- Gabbard et al. [2022] H. Gabbard, C. Messenger, I. S. Heng, F. Tonolini, and R. Murray-Smith, Nature Physics 18, 112 (2022).
- Wang et al. [2022] H. Wang, Z. Cao, Y. Zhou, Z.-K. Guo, and Z. Ren, Big Data Mining and Analytics 5, 53 (2022).
- Wei and Huerta [2020a] W. Wei and E. Huerta, Physics Letters B 800, 135081 (2020a).
- Colgan et al. [2020] R. E. Colgan, K. R. Corley, Y. Lau, I. Bartos, J. N. Wright, Z. Márka, and S. Márka, Physical Review D 101, 102003 (2020).
- Torres-Forné et al. [2016] A. Torres-Forné, A. Marquina, J. A. Font, and J. M. Ibáñez, Physical Review D 94, 124040 (2016).
- Akhshi et al. [2021] A. Akhshi, H. Alimohammadi, S. Baghram, S. Rahvar, M. R. R. Tabar, and H. Arfaei, Scientific Reports 11, 20507 (2021).
- Ren et al. [2022] Z. Ren, H. Wang, Y. Zhou, Z.-K. Guo, and Z. Cao, “Intelligent noise suppression for gravitational wave observational data,” (2022), arxiv:2212.14283 [astro-ph, physics:gr-qc].
- Zhao et al. [2023] T. Zhao, R. Lyu, H. Wang, Z. Cao, and Z. Ren, Communications Physics 6, 212 (2023).
- Wei and Huerta [2020b] W. Wei and E. Huerta, Physics Letters B 800, 135081 (2020b).
- Chatterjee et al. [2021] C. Chatterjee, L. Wen, F. Diakogiannis, and K. Vinsen, Physical Review D 104, 064046 (2021).
- Lee et al. [2021] J. Lee, S. H. Oh, K. Kim, G. Cho, J. J. Oh, E. J. Son, and H. M. Lee, Physical Review D 103, 123023 (2021), arxiv:2101.05685 [astro-ph, physics:gr-qc].
- Khan et al. [2022] A. Khan, E. A. Huerta, and H. Zheng, Physical Review D 105, 024024 (2022), arxiv:2110.06968 [astro-ph, physics:gr-qc].
- Chua et al. [2019] A. J. K. Chua, C. R. Galley, and M. Vallisneri, Physical Review Letters 122, 211101 (2019), arxiv:1811.05491 [astro-ph, physics:gr-qc, stat].
- Devlin et al. [2019] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” (2019), arxiv:1810.04805 [cs].
- Brown et al. [2020] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., “Language Models are Few-Shot Learners,” (2020), arxiv:2005.14165 [cs].
- Liu et al. [2021] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows,” (2021), arxiv:2103.14030 [cs].
- Collaboration [2022] L. P. Collaboration, Physical Review D 106, 062001 (2022), arxiv:2205.11938 [astro-ph].
- Bohé et al. [2017] A. Bohé, L. Shao, A. Taracchini, A. Buonanno, S. Babak, I. W. Harry, I. Hinder, S. Ossokine, M. Pürrer, V. Raymond, et al., Physical Review D 95, 044028 (2017), arxiv:1611.03703 [gr-qc].
- Babak et al. [2017b] S. Babak, J. Gair, A. Sesana, E. Barausse, C. F. Sopuerta, C. P. L. Berry, E. Berti, P. Amaro-Seoane, A. Petiteau, and A. Klein, Physical Review D 95, 103012 (2017b).
- Maselli et al. [2022] A. Maselli, N. Franchini, L. Gualtieri, T. P. Sotiriou, S. Barsanti, and P. Pani, Nature Astronomy 6, 464 (2022).
- Amaro-Seoane et al. [2023] P. Amaro-Seoane, J. Andrews, M. Arca Sedda, A. Askar, Q. Baghi, R. Balasov, I. Bartos, S. S. Bavera, J. Bellovary, C. P. L. Berry, et al., Living Reviews in Relativity 26, 2 (2023).
- Katz et al. [2021] M. L. Katz, A. J. K. Chua, L. Speri, N. Warburton, and S. A. Hughes, Physical Review D 104, 064047 (2021).
- Zhang et al. [2022b] X.-H. Zhang, S.-D. Zhao, S. D. Mohanty, and Y.-X. Liu, Physical Review D 106, 102004 (2022b), arxiv:2206.12083 [gr-qc].
- Katz et al. [2022] M. L. Katz, J.-B. Bayle, A. J. K. Chua, and M. Vallisneri, Physical Review D 106, 103001 (2022), arxiv:2204.06633 [astro-ph, physics:gr-qc].
- Tinto et al. [2004] M. Tinto, F. B. Estabrook, and J. W. Armstrong, Physical Review D 69, 082001 (2004).
- Tinto and Dhurandhar [2014] M. Tinto and S. V. Dhurandhar, Living Reviews in Relativity 17, 6 (2014).
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” (2017).
- Kingma and Ba [2017] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” (2017), arxiv:1412.6980 [cs].
- Barack et al. [2019] L. Barack, V. Cardoso, S. Nissanke, T. P. Sotiriou, A. Askar, C. Belczynski, G. Bertone, E. Bon, D. Blas, R. Brito, et al., Classical and Quantum Gravity 36, 143001 (2019).
- Larson et al. [2000] S. L. Larson, W. A. Hiscock, and R. W. Hellings, Physical Review D 62, 062001 (2000), arxiv:gr-qc/9909080.
- Babak et al. [2021] S. Babak, M. Hewitson, and A. Petiteau, “LISA Sensitivity and SNR Calculations,” (2021), arxiv:2108.01167 [astro-ph, physics:gr-qc].
- Ormiston et al. [2020] R. Ormiston, T. Nguyen, M. Coughlin, R. X. Adhikari, and E. Katsavounidis, Physical Review Research 2, 033066 (2020).
- Dey et al. [2021] K. Dey, N. Karnesis, A. Toubiana, E. Barausse, N. Korsakova, Q. Baghi, and S. Basak, Physical Review D 104, 044035 (2021), arxiv:2104.12646 [gr-qc].