Competition over data: how does data purchase affect users?
Abstract
As the competition among machine learning (ML) predictors is widespread in practice, it becomes increasingly important to understand the impact and biases arising from such competition. One critical aspect of ML competition is that ML predictors are constantly updated by acquiring additional data during the competition. Although this active data acquisition can largely affect the overall competition environment, it has not been well-studied before. In this paper, we study what happens when ML predictors can purchase additional data during the competition. We introduce a new environment in which ML predictors use active learning algorithms to effectively acquire labeled data within their budgets while competing against each other. We empirically show that the overall performance of an ML predictor improves when predictors can purchase additional labeled data. Surprisingly, however, the quality that users experience—i.e., the accuracy of the predictor selected by each user—can decrease even as the individual predictors get better. We demonstrate that this phenomenon naturally arises due to a trade-off whereby competition pushes each predictor to specialize in a subset of the population while data purchase has the effect of making predictors more uniform. With comprehensive experiments, we show that our findings are robust against different modeling assumptions.
1 Introduction
When there are several companies on a marketplace offering similar services, a customer usually chooses the one that offers the best options or functionalities, leading to competition among the companies. Accordingly, companies are motivated to offer high-quality services without raising price too much, as their ultimate goal is to attract more customers and make more profits. When it comes to machine learning (ML)-based services, high-quality services are often achieved by a regular re-training after buying more data from customers or data vendors (Meierhofer et al., 2019). In this paper, we consider a competition situation where multiple companies offer ML-based services while constantly improving their predictions by acquiring labeled data.
For instance, we consider the U.S. auto insurance market (Jin & Vasserman, 2019; Sennaar, 2019). The auto insurance companies including State Farm, Progressive, and AllState use ML models to analyze customer data, assess risk, and adjust actual premiums. These companies also offer insurance called the Pay-How-You-Drive, which is usually cheaper than regular auto insurances on the condition that the insurer monitors driving patterns, such as rapid acceleration or oscillations in speed (Arumugam & Bhargavi, 2019; Jin & Vasserman, 2019). That is, the companies essentially provide financial benefits to customers, collecting customers’ driving pattern data. With these user data, they can regularly update their ML models, improving model performance while competing with each other.
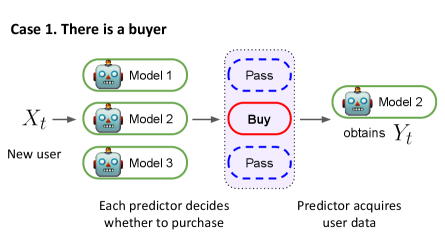
Analyzing the effects of data purchase in competitions could have practical implications, but it has not been studied much in the ML literature. The effects of data acquisition have been investigated in active learning (AL) literature (Settles, 2009; Ren et al., 2020), but it is not straightforward to establish competition in AL settings because it considers the single-agent situation. Recently, Ginart et al. (2021) studied implications of competitions by modeling an environment where ML predictors compete against each other for user data. They showed that competition pushes competing predictors to focus on a small subset of the population and helps users find high-quality predictions. Although this work describes an interesting phenomenon, it is limited to describe the data purchase system due to the simplicity of its model. The impact of data purchases on competition has not been studied much in the literature, which is the main focus of our work. Our environment is able to model situations where competing companies actively acquire user data by providing a financial benefit to users, and influence the way users choose service providers (See Figure 1). Related works are further discussed in Section 5.
Contributions
In this paper, we propose a general competition environment and study what happens when competing ML predictors can actively acquire user data. Our main contributions are as follows.
-
•
We propose a novel environment that can simulate various real-world competitions. Our environment allows ML predictors to use AL algorithms to purchase labeled data within a finite budget while competing against each other (Section 2).
-
•
Surprisingly, our results show that when competing ML predictors purchase data, the quality of the predictions selected by each user can decrease even as competing ML predictors get better (Section 3.1).
- •
-
•
We theoretically analyze how the diversity of a user’s available options can affect the user experience to support our empirical findings. (Section 4).
2 A general environment for competition and data purchase
This section formally introduces a new and general competition environment. In our environment, competition is represented by a series of interactions between a sequence of users and fixed competing ML predictors. Here the interaction is modeled by supervised learning tasks. To be more specific, we define some notations.
Notations
At each round , we denote a user query by and its associated user label by . We focus on classification problems, i.e., is finite, while our environment can easily extend to regression settings. We denote a sequence of users by and assume users are independent and identically distributed (i.i.d.) by some distribution . We call the user distribution.
As for the ML predictor side, we suppose there are competing predictors in a market. For , each ML predictor is described as a tuple , where is the number of i.i.d. seed data points from , is a budget, is an ML model, and is a buying strategy. We consider the following setting. A predictor initially owns data points and can additionally purchase user data within budgets. We set the price of one data point is one, i.e., a predictor can purchase up to data points from a sequence of users. A predictor produces a prediction using the ML model and determines whether to buy the user data with the buying strategy . We consider the utility function for is the classification accuracy of with respect to the user distribution . Lastly, and are allowed to be updated throughout the competition rounds. That is, companies keep improving their ML models with newly collected data points.
Competition dynamics
Before the first competition round, all the competing predictors independently train their model using the seed data points. After this initialization, at each round , a user sends a query to all the predictors , and each predictor determines whether to buy the user data. We describe this decision by using the buying strategy . If the predictor thinks that the labeled data would be worth one unit of budget, we denote this by . Otherwise, if thinks that it is not worth one unit of budget, then . As for the , ML predictors can use any stream-based AL algorithm (Freund et al., 1997; Žliobaitė et al., 2013). For instance, a predictor can use the uncertainty-based AL rule (Settles & Craven, 2008)—i.e., attempts to purchase user data if the current prediction is not confident (e.g., the Shannon’s entropy of is higher than some predefined threshold value where is the probability estimate at the -th round). In brief, we suppose a predictor shows purchase intent if the remaining budget is greater than zero and . If the remaining budget is zero or , then does not show purchase intent and provides a prediction to the user. To analyze the complicated real-world competition, we simplify the competition environment and assume that the service price is the same for all companies. This allows users to primarily compare the quality of ML predictions. Given that users select one company within their desired price range, this assumption describes that the options competing companies provide are within this range.
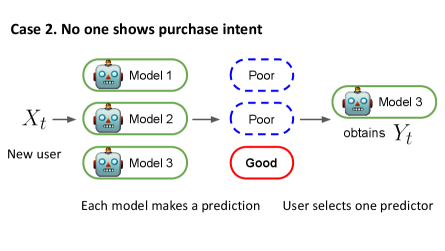
We now elaborate on how a user selects one predictor. At every round , the user selects only one predictor based on both purchase intents and prediction information received from . If there is a buyer, then we assume that a user prefers the company with purchase intent to others. We can think of this as a bargain in that the company offers a financial advantage (e.g., discounts or coupons) and the user selects it even if the quality might not be the best. When there is more than one buyer, we assume a user selects one of them uniformly at random. Once selected, the only selected predictor’s budget is reduced by one; all other predictor’s budget stays the same because they are not selected and do not have to provide financial benefits. If no predictor shows purchase intent, then a user receives prediction information and chooses the predictor with the following probability.
| (1) |
where denotes a temperature parameter and denotes the index of selected predictor. Here, is a predefined quality function that measures similarity between the user label and the prediction (e.g., ). With the softmax function in Equation (1), users are more likely to select high-quality predictions, describing the rationality of the user selection. Here, the temperature parameter indicates how selective users are. For instance, is close to , users are very confident in their selection and choose the best company. Afterwards, the selected predictor gets the user label and updates the model by training on the new datum . The other predictors stay the same for . We describe our competition system in Environment 1.
Characteristics of our environment
Our environment simplifies real-world competition and data purchases, which usually exist in much more complicated forms, yet it captures key characteristics. First, our environment reflects the rationality of customers. Customers are likely to choose the best service within their budget, but they can select a company that is not necessarily the best if it offers financial benefits, such as promotional coupons, discounts, or free services (Rowley, 1998; Familmaleki et al., 2015; Reimers & Shiller, 2019). Such a user selection represents that a user can prioritize financial advantages and change her selection, which has not been considered in the ML literature. Second, our environment realistically models a company’s data acquisition. Competing companies strive to attract more users, constantly purchasing user data to improve their ML predictions. Since the data buying process could be costly for the companies, data should be carefully chosen, and this is why we incorporate AL algorithms. Our environment allows companies to use AL algorithms within finite budgets and to selectively acquire user data. Third, our environment is flexible and takes into account various competition situations in practice. Note that we make no assumptions about the number of competing predictors or budgets , algorithms for predictors or buying strategies , and the user distribution .
Example 1 (Auto insurance in Section 1).
includes the -th driver’s demographic information, driving or insurance claim history, and is the driver’s preferred insurance plan within the user’s budget constraints. Each predictor is one insurance company (e.g., State Farm, Progressive, or AllState), offering an auto insurance plan based on what it predicts to be most suitable for this driver. The driver chooses one company whose offered plan is the closest to . If a company believes that in its database there are infrequent data from a particular group of drivers -th driver belongs to (e.g., new drivers in their 30s), it can attempt to collect more data. Accordingly, the company offers discounts to attract her, and the acquired data is used to improve the company’s future ML predictions.
3 Experiments
Using the proposed Environment 1, we investigate the impacts of the data purchase in ML competition. Our experiments show an interesting phenomenon that data purchase can decrease the quality of the predictor selected by a user, even when the quality of the predictors gets improved on average (Section 3.1). In addition, we demonstrate that data purchase makes ML predictors similar to each other. Data purchase reduces the effective variety of options, and predictors can avoid specializing to a small subset of the population (Section 3.2). Lastly, we show our results are robust against different modeling assumptions (Section 3.3).
Metrics
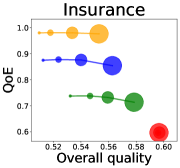
To quantitatively measure the effects of data purchase, we introduce three population-level evaluation metrics. First, we define the overall quality as follows.
| (Overall quality) |
where the expectation is taken over the user distribution . The overall quality represents the average quality that competing predictors provide in the market. Second is the quality of experience (QoE), the quality of the predictor selected by a user. The QoE is defined as
| (QoE) |
Here, the expectation is over the random variables and a conditional distribution of a selected index is considered as Equation (1). Given that a user selects one predictor based on Equation (1) when there is no buyer, QoE can be considered as the key utility of users. Note that the overall quality and QoE capture different aspects of prediction qualities, and they are only equal when users select one predictor uniformly at random, i.e., when (See Lemma 1).
Next, we define the diversity to quantify how variable the ML predictions are. To be more specific, for , we define the proportion of predictors whose prediction is as . Then the diversity is defined as
| (Diversity) |
where the expectation is taken over the marginal distribution and we use the convention when . Note that the diversity is defined as the expected Shannon’s entropy of competing ML predictions. When there are various different options that a user can choose from, the diversity is more likely to be large.
Implementation protocol
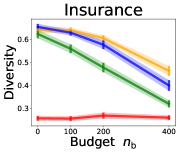
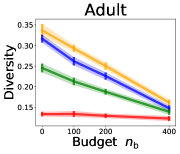
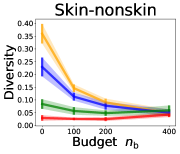
Our experiments consider the seven real datasets to describe various user distributions , namely Insurance (Van Der Putten & van Someren, 2000), Adult (Dua & Graff, 2017), Postures (Gardner et al., 2014), Skin-nonskin (Chang & Lin, 2011), MNIST (LeCun et al., 2010), Fashion-MNIST (Xiao et al., 2017), and CIFAR10 (Krizhevsky et al., 2009) datasets. To minimize the variance caused by other factors, we first consider a homogeneous setting in Sections 3.1 and 3.2: for each competition, all predictors have the same number of seed data and budgets , the same classification algorithm for , and the same AL algorithm for . As for heterogeneous settings in Section 3.3, competitors are allowed to have different configurations of parameters.
Throughout the paper, we set the total number of competition rounds to , the number of predictors to , and a quality function to the correctness function, i.e., for all . We set a small number for seed data points , which is between 50 and 200 depending on a dataset. We use either a logistic model or a neural network model with one hidden layer for . As for the buying policy, we use a standard entropy-based AL rule for (Settles & Craven, 2008). We consider various competition situations by varying the budget 111In Section 3, for notational convenience, we often suppress the predictor index in the superscript if the context is clear. For example, we use instead of . and the temperature parameter . Note that a pair generates one competition environment. We repeat experiments 30 times to obtain stable estimates for each pair . We provide the full implementation details in Appendix A.
As the evaluation time, we do not perform data buying procedures in order to directly compare the predictability of ML models. As the evaluation metrics are defined as the population-level quantity, it is difficult to compute the expectation exactly. To handle this, we consider the sample averages using the i.i.d. held-out test data that are not used during the competition rounds.
3.1 Effects of data purchase on quality
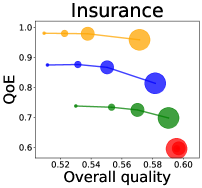
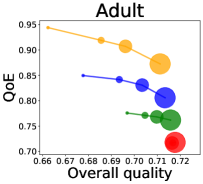
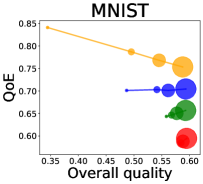
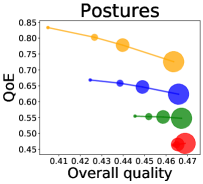
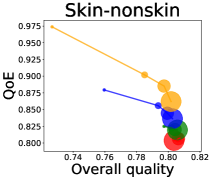
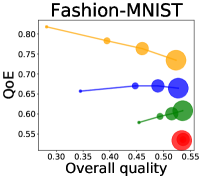
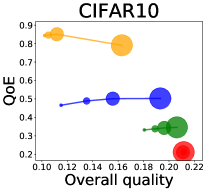
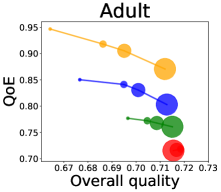
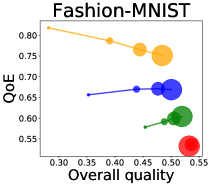
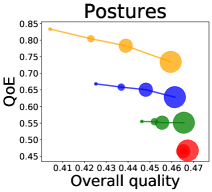
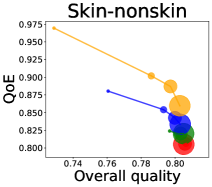
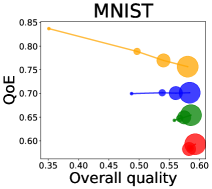
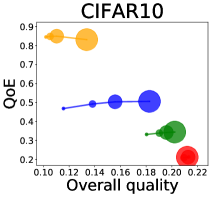
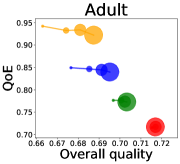
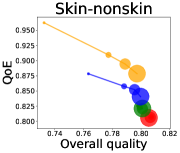
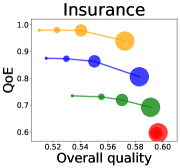
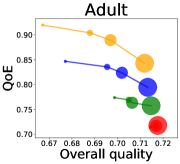
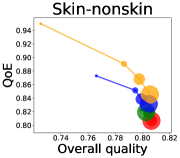
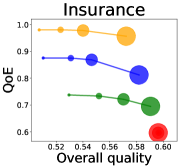
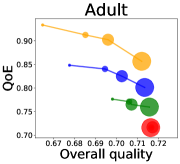
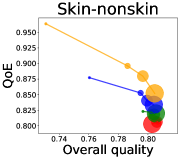
We first study how data purchase affects the overall quality and the QoE in various competition settings. As Figure 2 illustrates, data purchase increases the overall quality as increases across all datasets. For instance, when and the dataset is Postures, the overall quality is on average when , but it increases to and when and , which correspond to and increases, respectively. As for the QoE, however, data purchase mostly decreases QoE as increases. For example, when the user distribution is Insurance and , QoE is when , but it reduces to and when and , which correspond to 1% and 7% reduction, respectively. For MNIST or Fashion-MNIST, although there are small increases when , QoE decreases when .
This can be explained as follows. Given that an ML predictor attempts to collect user data when its prediction is highly uncertain, this active data acquisition increases the predictability of the individual model and reduces the model’s uncertainty. Similar to AL, data purchase effectively increases a model’s predictability, and so does the overall quality.
In most cases, surprisingly, QoE decreases even when the overall quality increases. In other words, the quality that competing predictors provide is generally improved, but it does not necessarily mean that users will be more satisfied with the ML predictions. Although this result might sound counterintuitive, we demonstrate that it happens when the data purchase makes users experience fewer options, increasing the probability of finding low-quality predictions. To verify our hypothesis, we examine how data purchase affects diversity in the next section.
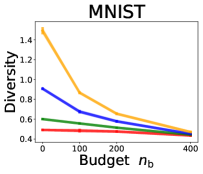
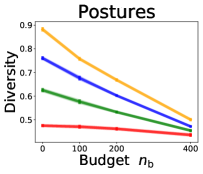
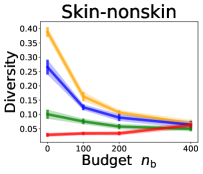
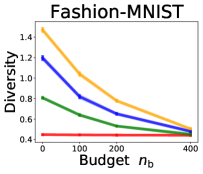
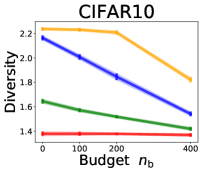

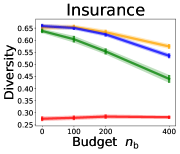
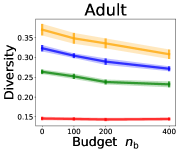
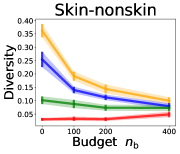
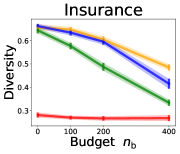
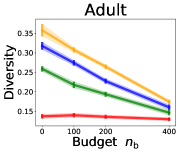
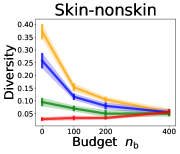
3.2 Effects of data purchase on diversity
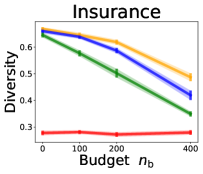
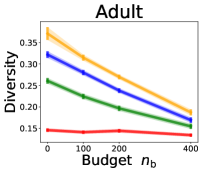
We investigate the effect of data purchase on the diversity. Figure 3 illustrates the diversity as a function of the budget in various competition settings. In general, the diversity monotonically decreases as increases across all datasets. That is, the competing predictors get similar as more budgets are allowed, and users get essentially fewer options when increases. In particular, when and the dataset is Adult, the diversity is on average when , but it reduces to and , which correspond to and reduction, when and , respectively.
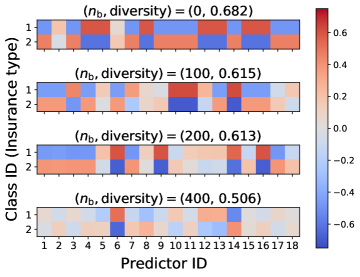
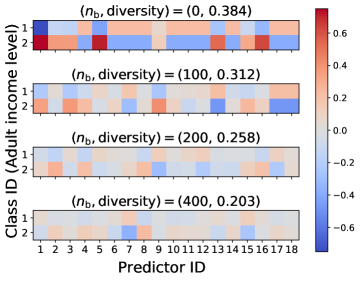
We also compare the class-specific qualities of competing predictors. In Figure 4, we illustrate heatmaps of the difference where is the class-specific quality defined as for and , and for is defined as . This difference measures the class-specific quality of a company, showing how specialized its ML model is. We use the Insurance and Adult datasets. When , the Adult heatmap shows that predictor 1 and predictor 5 so specialize to class 2 prediction that they sacrifice their prediction power for class 1 compared to other predictors. In other words, the competition encourages each ML model to be very specialized in a small subgroup. However, when , all predictors have similar levels of class-specific quality. The data purchase makes competing ML predictors similar and helps predictors not too much focus on a subgroup of the population. Similar results are shown in Ginart et al. (2021), but one finding that the previous works have not shown is that this specialization can be alleviated when predictors purchase user data.
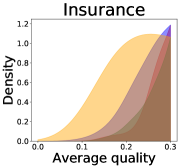
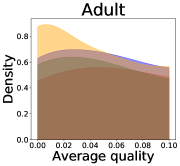
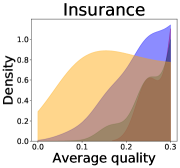
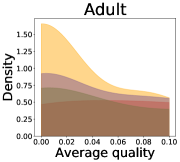
Implications of decreases in diversity
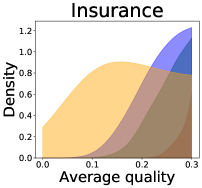
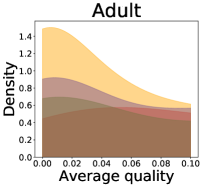
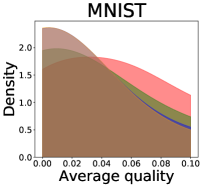
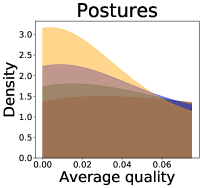
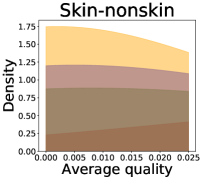
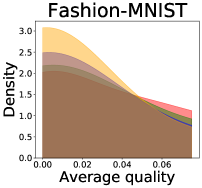
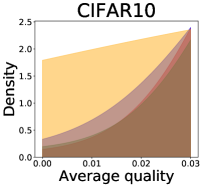
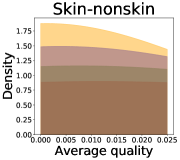
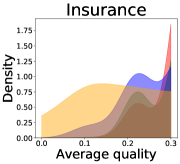
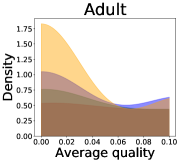
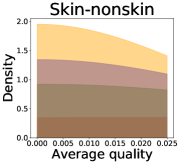
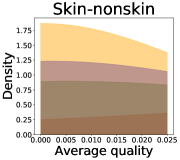
We now examine the connection between the diversity and the quality of the predictor selected by a user. We demonstrate that the probability of finding low-quality predictions can increase due to the reduction in diversity, explaining how diversity affects QoE. Figure 5 illustrates the probability density functions of the average quality near zero. It clearly shows that the probability that the average quality is near zero increases as more budgets are used: the areas for (colored in yellow) are clearly larger than those for (colored in red). That is, as predictions become similar, it is more likely that all ML predictions have a low quality simultaneously. Hence, the probability that users are not satisfied with the predictions increases, and leading to decreases in QoE even when the overall quality increases.
3.3 Robustness to modeling assumptions
We further demonstrate that our findings are robust against different modeling assumptions. We consider the same situation used in the previous sections but ML predictors now can have different buying strategies . To be more specific, we consider the three different types of buying strategies by varying the threshold of the uncertainty-based AL method. For , we consider the following buying strategy models , where is the Shannon’s entropy function and is the probability estimate given . We assume there are predictors for each buying strategy , , and . This modeling assumption considers the situation where there are three groups with different levels of sensitivity to data purchases. For instance, in our setting, is the most conservative data buyer and is less likely to buy new data.
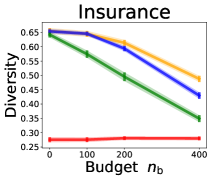
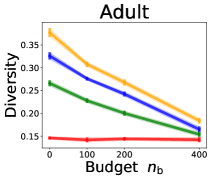
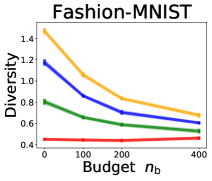
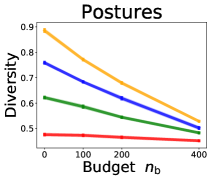
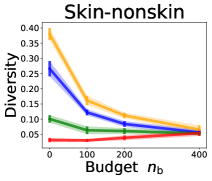
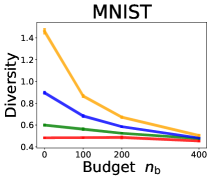
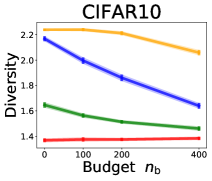
Figure 6 shows the relationship between the QoE and the overall quality when there are heterogeneous ML predictors with different buying strategies. Similar to Figure 2, the overall quality increases but QoE generally decreases as the budget increases across all datasets. As for the diversity, as anticipated, Figure 7 shows that the diversity decreases as the budget increases. It demonstrates that our findings are robustly observed against different environment settings. We also conduct more experiments (i) when budgets are different across companies or (ii) when there are different number of predictors . All these additional results are provided in Appendix B.
4 Theoretical analysis on competition
In this section, we establish a simple representation for QoE when a quality function is the correctness function. Based on this finding, we theoretically analyze how the diversity-like quantity can affect QoE. Proofs are provided in Appendix C.
Lemma 1 (A simple representation for QoE).
Suppose there is a set of predictors and a quality function is the correctness function, i.e., for all . Let be the average quality for a user . For any , we have
| (2) |
where the inequality holds when and the expectation is considered over .
Lemma 1 presents a relationship between QoE and the overall quality—QoE is always greater than the overall quality if . In addition, it shows that QoE can be simplified as a function of the average quality over competitors when a quality function is the correctness function. When is not the correctness function, QoE does not have such a comprehensible representation. We present upper and lower bounds for QoE in Appendix C.2. Using the relationship shown in Lemma 1, we provide a sufficient condition for the overall quality to be greater but the QoE to be less in the following theorem.
Theorem 1 (Comparison of two competition dynamics).
Suppose there are two sets of predictors, and . Without loss of generality, the overall quality for is larger than that of . For the correctness function , we define and as Lemma 1. If and for some explicit constants and , then QoE for is smaller than that for .
Theorem 1 compares two competition dynamics, and , providing a sufficient condition for when QoE for is smaller than that for whereas the associated overall quality is larger. For ease of understanding, we can regard (resp. ) as a set of ML predictors when (resp. when ). Theorem 1 implies that QoE can decrease when is large enough compared to . Considering our results in Figures 3, 4, and 5 that data purchase makes competing predictors similar when is large enough, the average quality is more likely to become zero or one. As a result, it increases variance because the variance is maximized when random variables spread over . Theorem 1 explains why QoE decreases when ML predictors can actively acquire user data through the data purchase system, supporting our main findings in experiments.
5 Related works
This work builds off and extends the recent paper, Ginart et al. (2021), which studied the impacts of the competition. We extend this setting by incorporating the data purchase system into competition systems. Note that the setting by Ginart et al. (2021) is a special case of ours when for all . Our environment enables us to study the impacts of data acquisition in competition, which is not considered in the previous work. Compared to the previous work, which showed competing predictors become too focused on sub-populations, our work suggests that this can be a good thing in the sense that it provides a variety of different options and better quality of the predictors selected by users.
A related field of our work is the stream-based AL, the problem of learning an algorithm that effectively finds data points to label from a stream of data points. (Settles, 2009; Ren et al., 2020). AL has been shown to have better sample complexity than passive learning algorithms (Kanamori, 2007; Hanneke et al., 2011; El-Yaniv & Wiener, 2012), and it is practically effective when the training sample size is small (Konyushkova et al., 2017; Gal et al., 2017; Sener & Savarese, 2018). However, our competition environment is significantly different from AL. In AL, since there is only one agent, competition cannot be established. In addition, while an agent in AL collects data only from label queries, competing predictors in our environment can obtain data from data purchase as well as regular competition. These differences create a unique competition environment, and this work studies the impacts of data purchase in competitive systems.
Competition has been studied in multi-agent reinforcement learning (MARL), which is a problem of optimizing goals in a setting where a group of agents in a common environment interact with each other and with the environment (Lowe et al., 2017; Foerster et al., 2017). Competing agents in MARL maximize their own objective goals that could conflict with others. This setting is often characterized by zero-sum Markov games and is applied to video games such as Pong or Starcraft II (Littman, 1994; Tampuu et al., 2017; Vinyals et al., 2019). We refer to Zhang et al. (2019) for a complementary literature survey of MARL.
Although MARL and our environment have some similarities, the user selection and the data purchase in our environment uniquely define the interactions between users and ML predictors. In MARL, it is assumed that all agents observe information drawn from the shared environment. Different agents may observe different statuses and rewards, but all agents receive information and use them to update the policy function. In contrast, in our environment, the only selected predictor obtains the label and updates the predictor, which might be more realistic. In addition, ML predictors can collect data points through the data purchase. These settings have not been considered in the field of MARL.
6 Conclusion
In this paper, characterizing the nature of competition and data purchase, we propose a new competition environment in which ML predictors are allowed to actively acquire user labels and improve their models. Our results show that even though the data purchase improves the quality that predictors provide, it can decrease the quality that users experience. We explain this counterintuitive finding by demonstrating that data purchase makes competing predictors similar to each other in various situations.
Broader impact statement
Our findings can broadly benefit the ML communities by providing insights into how competition over datasets and data acquisitions can affect a user’s experiences. In order to derive tractable analysis and experiments, we have to make some modeling simplifications. Similar simplifications are commonly used in ML and multi-agent literature and are necessary here, especially because there lacks systematic previous analysis of data purchase in competition. For example, one assumption in our environment for simplicity is that the user distribution does not change over time. In practice, customer behavior can change or evolve over time (Jin & Vasserman, 2019; Reimers & Shiller, 2019). It is therefore important to expand this direction of research with other models in future works.
References
- Arumugam & Bhargavi (2019) Subramanian Arumugam and R Bhargavi. A survey on driving behavior analysis in usage based insurance using big data. Journal of Big Data, 6(1):1–21, 2019.
- Chang & Lin (2011) Chih-Chung Chang and Chih-Jen Lin. Libsvm: A library for support vector machines. ACM transactions on intelligent systems and technology (TIST), 2(3):1–27, 2011.
- Dua & Graff (2017) Dheeru Dua and Casey Graff. Uci machine learning repository, 2017. URL http://archive.ics.uci.edu/ml.
- El-Yaniv & Wiener (2012) Ran El-Yaniv and Yair Wiener. Active learning via perfect selective classification. The Journal of Machine Learning Research, 13(1):255–279, 2012.
- Familmaleki et al. (2015) Mahsa Familmaleki, Alireza Aghighi, and Kambiz Hamidi. Analyzing the influence of sales promotion on customer purchasing behavior. International Journal of Economics & management sciences, 4(4):1–6, 2015.
- Foerster et al. (2017) Jakob Foerster, Nantas Nardelli, Gregory Farquhar, Triantafyllos Afouras, Philip HS Torr, Pushmeet Kohli, and Shimon Whiteson. Stabilising experience replay for deep multi-agent reinforcement learning. In International Conference on Machine Learning, pp. 1146–1155. PMLR, 2017.
- Freund et al. (1997) Yoav Freund, H Sebastian Seung, Eli Shamir, and Naftali Tishby. Selective sampling using the query by committee algorithm. Machine learning, 28(2):133–168, 1997.
- Gal et al. (2017) Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learning with image data. In International Conference on Machine Learning, pp. 1183–1192, 2017.
- Gardner et al. (2014) Andrew Gardner, Christian A Duncan, Jinko Kanno, and Rastko Selmic. 3d hand posture recognition from small unlabeled point sets. In 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 164–169. IEEE, 2014.
- Ginart et al. (2021) Tony Ginart, Eva Zhang, Yongchan Kwon, and James Zou. Competing ai: How does competition feedback affect machine learning? In International Conference on Artificial Intelligence and Statistics, pp. 1693–1701. PMLR, 2021.
- Hanneke et al. (2011) Steve Hanneke et al. Rates of convergence in active learning. The Annals of Statistics, 39(1):333–361, 2011.
- Jin & Vasserman (2019) Yizhou Jin and Shoshana Vasserman. Buying data from consumers: The impact of monitoring programs in us auto insurance. Unpublished manuscript. Harvard University, Department of Economics, Cambridge, MA, 2019.
- Kanamori (2007) Takafumi Kanamori. Pool-based active learning with optimal sampling distribution and its information geometrical interpretation. Neurocomputing, 71(1-3):353–362, 2007.
- Kingma & Ba (2014) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Konyushkova et al. (2017) Ksenia Konyushkova, Raphael Sznitman, and Pascal Fua. Learning active learning from data. In Advances in Neural Information Processing Systems, pp. 4225–4235, 2017.
- Krizhevsky et al. (2009) Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- LeCun et al. (2010) Yann LeCun, Corinna Cortes, and CJ Burges. Mnist handwritten digit database. ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010.
- Littman (1994) Michael L Littman. Markov games as a framework for multi-agent reinforcement learning. In Machine learning proceedings 1994, pp. 157–163. Elsevier, 1994.
- Lowe et al. (2017) Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. In Advances in Neural Information Processing Systems, pp. 6379–6390, 2017.
- Meierhofer et al. (2019) Jürg Meierhofer, Thilo Stadelmann, and Mark Cieliebak. Data products. In Applied Data Science, pp. 47–61. Springer, 2019.
- Reimers & Shiller (2019) Imke Reimers and Benjamin R Shiller. The impacts of telematics on competition and consumer behavior in insurance. The Journal of Law and Economics, 62(4):613–632, 2019.
- Ren et al. (2020) Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Xiaojiang Chen, and Xin Wang. A survey of deep active learning. arXiv preprint arXiv:2009.00236, 2020.
- Rowley (1998) Jennifer Rowley. Promotion and marketing communications in the information marketplace. Library review, 1998.
- Sener & Savarese (2018) Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. In International Conference on Learning Representations, 2018.
- Sennaar (2019) Kumba Sennaar. How america’s top 4 insurance companies are using machine learning. https://emerj.com/ai-sector-overviews/machine-learning-at-insurance-companies, 2019. Posted February 26, 2020; Retrieved May 19, 2021.
- Settles (2009) Burr Settles. Active learning literature survey. Technical report, University of Wisconsin-Madison Department of Computer Sciences, 2009.
- Settles & Craven (2008) Burr Settles and Mark Craven. An analysis of active learning strategies for sequence labeling tasks. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, pp. 1070–1079, 2008.
- Tampuu et al. (2017) Ardi Tampuu, Tambet Matiisen, Dorian Kodelja, Ilya Kuzovkin, Kristjan Korjus, Juhan Aru, Jaan Aru, and Raul Vicente. Multiagent cooperation and competition with deep reinforcement learning. PloS one, 12(4):e0172395, 2017.
- Van Der Putten & van Someren (2000) Peter Van Der Putten and Maarten van Someren. Coil challenge 2000: The insurance company case. Technical report, Technical Report 2000–09, Leiden Institute of Advanced Computer Science, 2000.
- Vinyals et al. (2019) Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature, 575(7782):350–354, 2019.
- Xiao et al. (2017) Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
- Zhang et al. (2019) Kaiqing Zhang, Zhuoran Yang, and Tamer Başar. Multi-agent reinforcement learning: A selective overview of theories and algorithms. arXiv preprint arXiv:1911.10635, 2019.
- Žliobaitė et al. (2013) Indrė Žliobaitė, Albert Bifet, Bernhard Pfahringer, and Geoffrey Holmes. Active learning with drifting streaming data. IEEE transactions on neural networks and learning systems, 25(1):27–39, 2013.
Appendix
Appendix A Implementation details
In this section, we provide implementation details. We explain the user distribution, ML predictors, and the proposed environment.
Datasets (user distribution)
As for the datasets (user distribution ), we used the following seven datasets for our experiments: Insurance (Van Der Putten & van Someren, 2000), Adult (Dua & Graff, 2017), Postures (Gardner et al., 2014), Skin-nonskin (Chang & Lin, 2011), FashionMNIST (Xiao et al., 2017), MNIST (LeCun et al., 2010), and CIFAR10 (Krizhevsky et al., 2009). For all datasets, we first split a dataset into competition and evaluation datasets: the competition dataset is used during the competition rounds and the evaluation dataset is used for evaluate metrics after the competition. For FashionMNIST, MNIST, and CIFAR10, we use the original training and test datasets for competition and evaluation datasets, respectively. For Insurance, Adult, Postures, and Skin-nonskin, we randomly sample data points from the original dataset to make the evaluation dataset and use the remaining data points as the competition dataset. At each round of competition, we randomly sample one data point from the competition dataset. After the competition rounds, we randomly sample points from the evaluation dataset and evaluate the metrics (the overall quality, QoE, and diversity). Note that all of experiment results are based on the evaluation dataset. Table 1 shows a summary of the seven datasets used in our experiments.
| Dataset | The size of | The size of | Input dimension | # of classes |
|---|---|---|---|---|
| competition dataset | evaluation dataset | |||
| Insurance | 13823 | 5000 | 16 | 2 |
| Adult | 43842 | 5000 | 108 | 2 |
| Postures | 69975 | 5000 | 15 | 5 |
| Skin-nonskin | 239057 | 5000 | 3 | 2 |
| Fashion-MNIST | 60000 | 10000 | 784 | 10 |
| MNIST | 60000 | 10000 | 784 | 10 |
| CIFAR10 | 50000 | 10000 | 3072 | 10 |
As for the preprocessing, we apply the standardization to have zero mean and one standard deviation for Skin-nonskin. For the two image datasets, MNIST and CIFAR10 we apply the channel-wise standardization. Other than the three datasets, we do not apply any other preprocessing. To reflect the customers’ randomness in their selection, we apply a random noise on the original label. We assign a random label with 30% for every dataset. This random perturbation is applied to both the competition and evaluation datasets.
ML predictors
We fix the number of predictors to throughout our experiments. For each dataset, which makes one competition environment, we consider a homogeneous setting, i.e., all predictors have the same number of seed data , a budget , a model , and a buying strategy . As for the buying strategy, we fix , where is the Shannon’s entropy of , and is the corresponding probability estimate for . That is, if the entropy is higher than the pre-defined threshold , a predictor decides to buy the user data. Note that is the Shannon’s entropy of the uniform distribution on .
Table 2 shows a summary information for the seed data and the model for each dataset. Every ML predictor initially trains with the seed data points. For all experiments, we use the Adam optimization (Kingma & Ba, 2014) with the specified learning rate and epochs. The batch size is fixed to . If an predictor is selected, then its ML model is updated with one iteration with the newly obtained data point, and we retrain the model whenever the ‘retrain period’ new samples are obtained.
| Dataset | Seed data | ML predictor | ||||
|---|---|---|---|---|---|---|
| Model | # of hidden nodes | Epoch | Learning rate | Retrain period | ||
| Insurance | 100 | Logistic | - | 10 | 50 | |
| Adult | 100 | Logistic | - | 10 | 50 | |
| Postures | 200 | Logistic | - | 10 | 50 | |
| Skin-nonskin | 50 | Logistic | - | 10 | 50 | |
| Fashion-MNIST | 50 | NN | 400 | 30 | 150 | |
| MNIST | 50 | NN | 400 | 30 | 150 | |
| CIFAR10 | 100 | NN | 400 | 30 | 150 | |
Appendix B Additional numerical experiments
In this section, we provide additional experimental results to demonstrate the robustness of our findings against different modeling assumptions in the heterogeneous setting. As for the heterogeneous settings, we consider different budgets in the subsection B.1 and different number of competing predictors in the subsection B.2. All additional results again show the robustness of our experimental findings against different modeling assumptions.
B.1 Different budgets
We use the same setting used in the homogeneous setting but with different budgets. We use the Insurance, Adult, and Skin-nonskin datasets. For , we assume that the first predictors have budgets, but the last predictors have budgets. That is, half of the predictors have half the budget compared to the other group. This situation can be considered as some groups of companies have a larger amount of capital than others. Figure 8 shows that the main findings appear again even when different budgets are used (QoE generally decreases, overall quality increases, and diversity decreases).


B.2 Different number of competing predictors
We also show that our findings are consistent for the different number of competing predictors in the market. All the experiments in Section 3 of the manuscript consider . Here, we consider the homogeneous setting but a different number of competing predictors or . As Figures 9 and 10 show, the main findings are captured again when the number of predictors are used.




Appendix C Proofs and additional theoretical results
We provide proofs for Lemma 1 and Theorem 1 in the subsection C.1. We also present an additional theoretical result, QoE for a general quality function, in the subsection C.2.
C.1 Proofs
Proof of Lemma 1.
For notational convenience, we set for .
| (3) |
where for ,
Since , for , we have
and
Since and is an increasing function, it concludes a proof. ∎
Proof of Theorem 1.
For and , let , , and . Note that
Thus, we have
For , we have
Therefore, since , we have
| (4) |
Let and . From the inequalities (4), we have
The last equality is due to . Therefore, QoE is decreased if
where
Therefore, if there is a constant such that , then it concludes a proof.
By definition of , it is positive when .
By setting , it concludes a proof.
∎
C.2 QoE for a general quality function
The following theorem shows the upper and lower bounds of QoE for a general quality function.
Theorem 2.
Suppose there is a set of prediction models . For any non-negative function and , we have the following upper and lower bounds.
where denotes the selected index.
Proof of Theorem 2.
We use the same notations in the proof of Lemma 1. We first show QoE is an increasing function as . From the representation (3), we have
where . From the last equality, we have
Note the non-negativity is from Cauchy-Schwarz inequality. We now prove an upper bound. Note that
and the equality holds when . Therefore, taking expectations on both sides provides an upper bound. As for the lower bound. Due to the representation (3), it is enough to show that
Since QoE is an increasing function, by plugging in , it gives . It concludes a proof. ∎