Complex fractal trainability boundary can arise from trivial non-convexity
Abstract
Training neural networks involves optimizing parameters to minimize a loss function, where the nature of the loss function and the optimization strategy are crucial for effective training. Hyperparameter choices, such as the learning rate in gradient descent (GD), significantly affect the success and speed of convergence. Recent studies indicate that the boundary between bounded and divergent hyperparameters can be fractal, complicating reliable hyperparameter selection. However, the nature of this fractal boundary and methods to avoid it remain unclear. In this study, we focus on GD to investigate the loss landscape properties that might lead to fractal trainability boundaries. We discovered that fractal boundaries can emerge from simple non-convex perturbations, i.e., adding or multiplying cosine type perturbations to quadratic functions. The observed fractal dimensions are influenced by factors like parameter dimension, type of non-convexity, perturbation wavelength, and perturbation amplitude. Our analysis identifies “roughness of perturbation”, which measures the gradient’s sensitivity to parameter changes, as the factor controlling fractal dimensions of trainability boundaries. We observed a clear transition from non-fractal to fractal trainability boundaries as roughness increases, with the critical roughness causing the perturbed loss function non-convex. Thus, we conclude that fractal trainability boundaries can arise from very simple non-convexity. We anticipate that our findings will enhance the understanding of complex behaviors during neural network training, leading to more consistent and predictable training strategies.
Introduction
Machine learning has become a cornerstone of modern technology. When training a machine learning model, we need to update the model parameters towards optimizing a loss function (usually based on the loss gradient) to attain desired performance. To better understand and achieve successful training, researchers have tried to capture shapes of the loss landscapes [1, 2, 3] and dynamics that arise from optimization algorithms [4, 5, 6, 7, 8]. In general, despite the considerable empirical success and broad application of these optimization techniques in training models, our theoretical understanding of the training processes remains limited.
Recent empirical evidence suggests that whether a model is trainable can be extremely sensitive to choices in optimization. A model is said to be not trainable here if the optimization applied leads to divergent loss function value. By convention, we call model parameters to be optimized as parameters and other parameters in the optimizer controlling the optimization process as hyperparameters. One of the most important hyperparameters is learning rate, which affects the size of the steps taken during optimization. On a simple two layer neural network, gradient descent (GD) was recently found to have a fractal boundary between learning rates that lead to bounded and divergent loss (fractal trainability boundary for short) [9]. Consequently, a slight change in hyperparameters can change the training result qualitatively with little hope to choose good hyperparameters in advance.
Here, we aim to explore the mechanisms underlying the fractal trainability boundary and the key factors influencing its fractal dimension. Guided by the intuition that non-convexity renders the gradient sensitive to parameter, which makes GD sensitive to varying learning rates, we tried to quantify the relation between non-convexity and fractal trainability. Given the difficulties in describing and controlling the loss functions of real neural networks, our approach involves constructing simple non-convex loss functions and testing GD on these to examine the boundary between learning rates that lead to bounded versus divergent losses. We discover that even a simple quadratic function, when perturbed by adding or multiplying a regular perturbation function (specifically a cosine function), exhibits a fractal trainability boundary. A parameter specific to the form of the perturbation, defined as roughness, appears to govern the fractal dimension of the trainability boundary, describing the gradient sensitivity to the parameter. A notable difference emerges between the fractal behaviors of trainability in quadratic functions perturbed by additive perturbation versus those altered by multiplicative perturbation: fractal behavior disappears at a finite roughness (when the perturbed loss becomes convex) for additive cases but persists for multiplicative perturbations (where the perturbed loss is always non-convex). We therefore offer a perspective to explain the fractal trainability boundaries observed in real neural networks as a result of non-convexity, emphasizing “roughness” as the factor controlling fractal dimensions.
Results
We first elaborate the key intuition of why certain non-convexity may lead to the fractal trainability boundary. Common ways to generate fractals involve iterating a function sensitive to hyperparameters in the function (e.g., Mandelbrot and quadratic Julia sets [10, 9]). We denote the loss function as where is the parameter to optimize to minimize . GD can be described as iterating the function
| (1) |
Here, is the parameter obtained at the th step and is the learning rate (hyperparameter). If non-convexity can make the gradient sensitive to parameter , after we shift learning rate a little at the th step (this is another training process to be compared with the original one), will be a little different from the one obtained with the unchanged learning rate. However, the gradient at the new will be very different, leading to very different subsequent iterations. The sensitivity of gradient’s dependence on parameter can therefore be transformed to the sensitive dependence of optimization process on the learning rate (hyperparameter), which is the key to generate fractals. Notably, this sensitive dependence on learning rate is sufficient to generate chaos while is not obvious to yield divergent training.
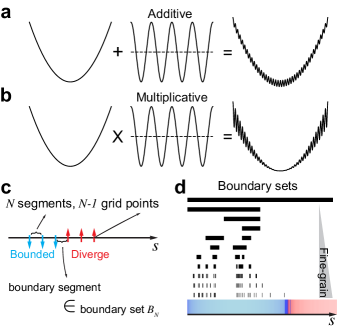
We thus need to do experiments on specific functions to test if non-convexity with sensitive gradients can lead to fractal trainability boundaries. We started by looking at one dimensional parameters (, ) and chose to construct our loss landscape by perturbing the convex quadratic function . One way of perturbation is to add a non-convex function (Fig. 1a). We used the simplest regular perturbation , where is the wavelength of the perturbation, and the amplitude of the perturbation. We therefore defined the additive perturbation case in our context as
| (2) |
An alternative way to introduce non-convexity is via multiplying a perturbation function (Fig. 1b), which will be referred to as multiplicative perturbation case:
| (3) |
The two cases are qualitatively different as when , the additive perturbation will become small comparing to while the multiplicative perturbation is always comparable to the unperturbed . Our test functions have simple analytic forms and represent different forms of non-convexity.
We next explain the idea of investigating fractal trainability boundaries numerically. The boundary points separating learning rates leading to finite and divergent loss are not accessible directly. So, we need to use finite but many grid points to locate the boundary learning rates. On a given range of learning rate (), we can evenly put grid points, with which GD can be tested to diverge or not. If two neighboring learning rate grid point values lead to the same divergent/bounded loss behavior, at this coarse-grain level (quantified by ), we say there is no boundary between the two grid points. Otherwise, we say the segment between this two grid points is a boundary segment. We define a set as the set containing all boundary segments when we have grid points (Fig. 1c). Heuristically, we expect each boundary segment to cover one boundary accurately when the segment length goes to zero (i.e., ), and thus becomes the set of boundary learning rates when . If the number of boundary segments, denoted by , increases with respect to as a scaling law asymptotically
| (4) |
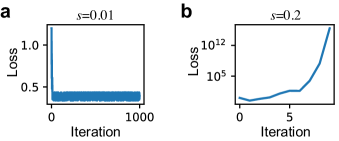
we say the trainability boundary has a fractal dimension (by convention, the fractal dimension defined in this way is called box dimension [11]). We observed that the number of boundary segments (black segments in Fig. 1d) indeed increases when we do tests on the multiplicative case and put more and more testing grid points in a fixed learning rate range (Fig. 1d). The colored bar at the bottom visualizes loss values for bounded (blue) and divergent (red) training evaluated at grid points in (Fig. 1d). And the color intensity is determined by for bounded training and for divergent training, respectively [9], where is the loss value at th step (totally 1000 steps). Once we zoom in, we see more boundaries between blue and red (the original vector image can be found online). We therefore are ready for further exploration with the numerical tool identifying fractals.
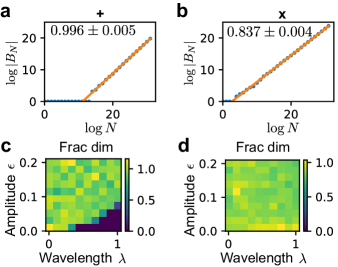
We investigated the trainability boundaries using GD on specifically constructed loss functions. For our experiments, we applied GD to the loss function with additive perturbation, , starting from with parameters and . We conducted 1000 steps of GD and defined a training session as divergent (untrainable) if the sum of losses at the 1000 steps exceeded . This upper loss threshold affects misclassifying slowly diverging training into bounded training; although varying it between and did not alter the observed fractal dimension. We adjusted the learning rate within the range of and increased the number of intervals, , up to (see Methods). Our findings reveal that the trainability boundary for this simple function displays fractal behaviors, meaning the number of boundary segments, , increases following a scaling law with at large values (Fig. 2a). The fractal dimension, , calculated via least squares as the slope of against ( base is throughout this paper), is approximately (error is standard deviation). A similar analysis on another loss function with multiplicative perturbation, , yielded a fractal dimension of (Fig. 2b). This suggests that fractal boundaries are more densely packed in a narrower range for the additive perturbation scenario, indicating a potentially less erratic behavior. Nonetheless, the emergence of fractal trainability boundaries in these trivially simple loss functions is remarkable.
We next sought to examine factors affecting the fractal dimension of trainability boundaries. We evaluated the fractal dimension of the trainability boundary with ten different amplitudes evenly picked from and ten different wavelengths evenly picked from . Least square fitting is used to obtain the fractal dimensions. We found that for the additive perturbation case, the fractal dimension increases with decreasing wavelength and increasing amplitude (Fig. 2c), while for the multiplicative perturbation case, the fractal dimension has no clear dependence on amplitude or wavelength (Fig. 2d). The fractal dimension therefore depends on the type, wavelength, and amplitude of the non-convex perturbation in a complicated manner.
We next tried to analyze how the perturbation wavelength and amplitude change the fractal dimension of trainability boundary. We can rescale the parameter, , and renormalize the loss, , such that we map a GD process starting at to another one starting at and updating with respect to
| (5) |
By choosing , we can show that and has the same function form (i.e., with additive perturbation or multiplicative perturbation) as while with different function parameters and (see Methods). This means a GD process on our constructed loss given , , and will have the same divergence property with the same learning rate as another GD process on our constructed loss with , , and . Therefore, trainability boundaries are the same for the two sets of conditions, and . If we further assume the fractal dimension depends mainly on loss properties rather than initial conditions (seems to be true, see SI), we conclude that fractal dimensions of the trainability boundaries for and are the same.
More specifically, for the additive perturbation case, the renormalization flow not changing the fractal dimension should be given by (see Methods)
| (6) |
Note there is only one independent combination of and , i.e.,
| (7) |
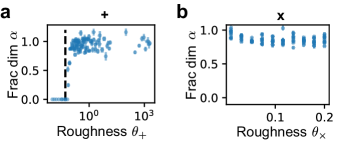
is invariant under the renormalization transformation, we claim the fractal dimension can only depends on since it only depends on and is invariant under the renormalization transformations. We would call the quantity “roughness” as it is in the pre-factor of the second derivative of the additive perturbation, measuring the sensitivity of gradient’s dependence on parameter. We plotted the fractal dimension as a function of roughness (the same set of data as Fig. 2c) and found the fractal dimension shows a clear and sharp transition from zero (i.e., no fractal behavior) to non-zero when increasing roughness (Fig. 3a). We found that the critical roughness is near (dashed line in Fig. 3a), which corresponds to the critical situation begin to be non-convex ( such that ). The simple renormalization analysis yields roughness of the additive perturbation, which determines the fractal dimension and shows that fractal behaviors show up when the perturbed loss is non-convex.
Following the same renormalization procedure, we found the roughness determining fractal dimension for the multiplicative perturbation case is
| (8) |
This quantity also shows up in the second derivative of and contributes to the sensitive dependence of gradient on parameter , while it is not the only one (there are also and ) and thus just looking at the second derivative does not suffice. For the multiplicative perturbation case, we found the fractal dimension decreases a little with increasing roughness (Fig. 3b; same data as Fig. 2d). The multiplicative case is always non-convex and always has fractal trainability boundary, which is consistent with the previous finding that fractal behaviors emerges when the perturbed loss becomes non-convex. Note that the non-convex part of the multiplicative case (where the second derivatives begin to be non-positive) has loss value around and above the order of magnitude , if we have too small while our numerical upper bound to classify bounded and divergent training is not large enough, the classification will solely depends on the convex part of the loss. In this case, if non-convexity is necessary for fractal behaviors, we would expect no fractal behaviors as a numerical artifact, which is proved to be true (see SI). We therefore conclude that roughness found through simple renormalization determines fractal dimension of trainability boundaries and the transition to non-zero fractal dimensions corresponds to the loss function becoming non-convex.
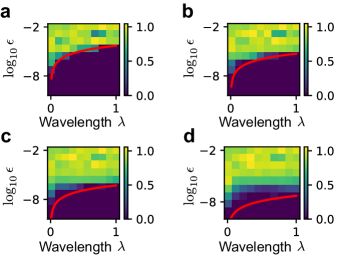
Beyond simple cases we can analyze, we next studied a slightly more complicated loss landscapes. As a first step towards perturbations with multiple length scales, we considered additive perturbations with two cosine functions,
| (9) |
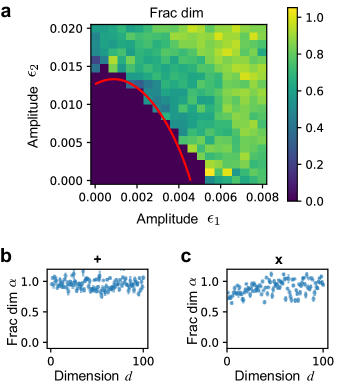
The renormalization can only say and determine the fractal dimension and cannot yield a single variable controlling the fractal behavior. In numerical tests, we fixed and , while changed amplitudes and . We found the fractal dimension depends non-monotonically on each of the amplitudes (Fig. 4a). However, the claim that fractal behaviors arise when the loss becomes non-convex is still valid, as the boundary between convex and non-convex losses (red curve in Fig. 4a, solved numerically) also separates zero and non-zero fractal dimensions.
We next explored how the dimension of parameters affect the trainability boundary. For the additive perturbation case, we generalize the function for as
| (10) |
Following similar numerical methods as before (see detailed parameter setting in SI), we studied the fractal dimension of trainability boundary for varying from to . The results suggest that the fractal dimension does not change much with respect to in the additive perturbation scenario (Fig. 4b). For the multiplicative perturbation case, we can define a class of functions
| (11) |
We found the fractal dimension slowly increases in this case with respect to increasing (Fig. 4c), which makes sense as high-dimensional optimization should be more complicated. Our renormalization procedure cannot connect two functions with different dimensions , and therefore roughness values for functions with different dimensions are not comparable. Future works are needed to analyze the impact of parameter dimensions , e.g., defining a generalized roughness that can determine fractal dimension of trainability boundaries across different .
Discussion
In this study, we have demonstrated that fractal trainability boundaries can arise from relatively simple non-convex modifications to loss functions. Specifically, our results show that the sensitivity of the loss gradient to parameter changes—a consequence of non-convexity introduced either through additive or multiplicative cosine perturbation—plays a crucial role in the emergence of fractal trainability. The fractal dimensions we observed are influenced by several factors, including the parameter dimension, the type of non-convexity, perturbation wavelength, and amplitude. Notably, our use of renormalization techniques in one-dimensional optimization cases has linked various loss functions to corresponding fractal dimensions of their trainability boundaries. Therefore, we have identified “roughness of perturbation” as a key property that quantifies this sensitivity and dictates the fractal behavior. We observed a clear transition from non-fractal to fractal trainability boundaries as roughness increases, with the critical roughness causing the perturbed loss to be non-convex. These findings not only validate our hypothesis about the impact of non-convexity on trainability but also open up new avenues for understanding the dynamics of learning in complex models.
While our method effectively characterizes fractal behaviors, it may not fully capture the complexity inherent in the trainability boundary. We computed the box dimension of these boundaries as a more feasible alternative to direct, uniform sampling from the trainability boundary set, which remains impractical. However, the box dimension is not without its limitations; for example, it is known that all rational numbers between 0 and 1 technically have a box dimension of [11, 12]. Consequently, while the relative magnitudes of our computed box dimensions can be informative in assessing the degree of complexity, the absolute values themselves may not be entirely reliable.
Beyond mathematical limitations, constraints in our numerical implementation also impact the accuracy of the fractal dimensions we obtained. For instance, computational resources cap the largest feasible , limiting the number of data points available for accurately fitting the fractal dimension. If a fractal boundary is densely packed within a very narrow range, a significantly large is required to discern its fractal nature, potentially causing us to overlook certain fractal behaviors when is limited. Interestingly, the practical significance of these fractal boundaries also comes into question; narrowly distributed boundaries are unlikely to be encountered in most applications, thus posing minimal risk. This observation led to a new insight: fractal dimension alone may not suffice to assess the risk posed by fractal boundaries. It also becomes essential to understand the distribution breadth of these boundary points. In our experiments, the maximum tested did not vary widely, suggesting that we may have consistently overlooked very narrow fractal boundaries. However, this might not be detrimental, as such boundaries are less likely to impact practical applications.
Our renormalization analysis, while effective in identifying roughness as a key parameter, exhibits limited generalizability. This analysis is restricted to simple functions with explicitly defined parameters, making our conclusions highly specific to the cases studied. Additionally, we cannot answer with this analysis why non-convexity of the loss function leads to the emergence of fractal behaviors. My initial concept was to establish a mapping that links different loss landscapes and learning rates, thereby preserving unchanged trainability. This mapping would ideally define an updating flow for function parameters and the learning rate. If successful, we could potentially transform the question of trainability into an investigation of where this updating flow stabilizes, using familiar functions such as the quadratic function as endpoints. However, the renormalization flow falls short in achieving this, as it cannot eliminate the perturbations. The first time I viewed the figures in [9], they reminded me of images of Jupiter, whose fractal-like surface arises from some fluid dynamics. This analogy suggests a future possibility where we might develop an updating flow for hyperparameters that mirrors principles from fluid dynamics.
In conclusion, substantial future research is necessary to more accurately capture the fractal behaviors of trainability boundaries. As we have discussed, developing a theory that can predict both the critical emergence of fractal trainability boundaries and their fractal dimensions is essential. Moreover, establishing connections to realistic loss functions from contemporary machine learning models is needed, particularly finding methods to characterize roughness in general loss functions lacking simple explicit formulas. Further exploration into the mechanisms that contribute to rough non-convexity is also required. With a deeper understanding of these phenomena, we could potentially develop strategies associated to model construction, dataset management, and optimizers that mitigate the risks associated with dangerous fractal trainability boundaries. By continuing to build on this foundation, we pave the way for more robust and predictable machine learning methodologies.
Methods
We conducted large scale numerical experiments with Julia 1.8.4 on CPUs or with Python 3.9 on GPUs of MIT Supercloud [13]. The results have no notable difference. We ran small scale tests and analyze data with Python 3.10.9 on a laptop. All codes are available online. In practice, we set number of segments for integer , and ran tests on learning rates evenly distributed in . Given hyperparameters and the loss function, we ran GD for 1000 steps, and classify bounded or divergent training based on the sum of loss values of the 1000 steps. We also classified bounded or divergent training based on whether GD cannot or can hit an upper bound. The latter classification may mistake some cases where GD first diverge but then converge. However, in the tests reported in the main text, the two classification methods do not have notable difference. When analyzing data, we can choose () evenly spaced points from the points to analyze boundary segments at a coarse-grained level, which can give with . The largest we tested is . Most times, is sufficient to yield a good fitting of fractal dimensions. We ran all numerical tests with data type float64, which is accurate enough for our choices of .
The choice of learning rate range tested relies on the facts has one trainability boundary at and we observe a lot of trainability boundaries when in practice (Fig. 1d). We prove has one trainability boundary as follows. By the definition of GD, on , we have
| (12) |
Convergence requires , which gives and thus completes the proof. We applied our numerical method to for a rational check and found indeed there is no fractal trainability boundary for (SI).
Details of the renormalization procedure are given as follows. For both additive and multiplicative perturbation cases, we can write the loss function in a form
| (13) |
By substituting and into the original GD, we have
| (14) |
with and
| (15) |
Since we want the new function to have the same function form as , we need the pre-factor of , i.e., , to be one. Consequently, we have and the learning rate unchanged. And for the additive perturbation case, where , if we want to write the transformed , we will arrive the results and . Similarly, for the multiplicative perturbation case, since and , we will have and . Since is a one-to-one mapping, we know that changing the set of conditions to will only yield a rescaled GD trajectory but not change whether the trajectory diverge or not. In other words, the conditions have the same trainability boundary as .
acknowledgments
It is a pleasure to thank Weijie Su for introducing this problem and highlighting the importance, Ziming Liu for discussions on the intuitions, Jörn Dunkel for valuable discussions on aspects to explore, Jeff Gore for the support and inspiring discussions, and Jascha Sohl-Dickstein for valuable suggestions.
References
- Choromanska et al. [2015] A. Choromanska, M. Henaff, M. Mathieu, G. Ben Arous, and Y. LeCun, The Loss Surfaces of Multilayer Networks, in Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research, Vol. 38, edited by G. Lebanon and S. V. N. Vishwanathan (PMLR, San Diego, California, USA, 2015) pp. 192–204.
- Jin et al. [2018] C. Jin, L. T. Liu, R. Ge, and M. I. Jordan, On the local minima of the empirical risk, in Neural Information Processing Systems (2018).
- Zhang et al. [2022] Y. Zhang, Q. Qu, and J. Wright, From symmetry to geometry: Tractable nonconvex problems (2022), arXiv:2007.06753 [cs.LG] .
- Su et al. [2016] W. Su, S. Boyd, and E. J. Candès, A differential equation for modeling nesterov’s accelerated gradient method: Theory and insights, Journal of Machine Learning Research 17, 1 (2016).
- Wibisono et al. [2016] A. Wibisono, A. C. Wilson, and M. I. Jordan, A variational perspective on accelerated methods in optimization, Proceedings of the National Academy of Sciences 113, E7351 (2016), https://www.pnas.org/doi/pdf/10.1073/pnas.1614734113 .
- Kong and Tao [2020] L. Kong and M. Tao, Stochasticity of deterministic gradient descent: Large learning rate for multiscale objective function, in Advances in Neural Information Processing Systems, Vol. 33, edited by H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin (Curran Associates, Inc., 2020) pp. 2625–2638.
- Shi et al. [2023] B. Shi, W. Su, and M. I. Jordan, On Learning Rates and Schrödinger Operators, Journal of Machine Learning Research 24, 1 (2023).
- Chen et al. [2023] X. Chen, K. Balasubramanian, P. Ghosal, and B. Agrawalla, From stability to chaos: Analyzing gradient descent dynamics in quadratic regression (2023), arXiv:2310.01687 [cs.LG] .
- Sohl-Dickstein [2024] J. Sohl-Dickstein, The boundary of neural network trainability is fractal (2024), arXiv:2402.06184 [cs.LG] .
- Mandelbrot [1982] B. B. Mandelbrot, The fractal geometry of nature, Vol. 1 (WH freeman New York, 1982).
- Strogatz [2018] S. H. Strogatz, Nonlinear dynamics and chaos: with applications to physics, biology, chemistry, and engineering (CRC press, 2018).
- Falconer [2007] K. Falconer, Fractal geometry: mathematical foundations and applications (John Wiley & Sons, 2007).
- Reuther et al. [2018] A. Reuther, J. Kepner, C. Byun, S. Samsi, W. Arcand, D. Bestor, B. Bergeron, V. Gadepally, M. Houle, M. Hubbell, M. Jones, A. Klein, L. Milechin, J. Mullen, A. Prout, A. Rosa, C. Yee, and P. Michaleas, Interactive Supercomputing on 40,000 Cores for Machine Learning and Data Analysis, in 2018 IEEE High Performance Extreme Computing Conference (HPEC) (2018) pp. 1–6.
Supplementary Information
All the raw data and comparison between fitted line and raw data points are available online.
We show two examples of training loss updating on our constructed loss landscapes in Fig. S1. The sanity check of our method on the quadratic function is presented in Fig. S2.
The multiplicative case is always non-convex and should always display fractal trainability boundary. But if we study the second derivative,
| (S1) |
we find that in a region is small enough. If we set an upper bound to tell whether training is classified to be bounded or divergent and do not care the dynamics once it goes beyond , GD actually only sees the loss within the region roughly. And if is too small, in the region , the loss may be convex and we may not see any fractal behaviors, which is a numerical artifact. To test the idea, we set different values and stop GD and regard it as divergent once the loss reaches . We found too small indeed will make fractal behaviors vanish and the transition to fractal behaviors differs for different upper bounds (Fig. S3). We next analyze when the loss within can be non-convex and see if this case corresponds to the emergence of fractal behaviors. The critical situation is that becomes zero near . Since is very large, the quadratic term dominants among terms having , we have the minimum second derivative near being
| (S2) |
By setting the above estimation to be zero, we reach the boundary of non-convexity for loss within as
| (S3) |
These estimated boundaries are plotted in the plane for different values (red curves in Fig. S3). Note greater means non-convexity, we found it is true that fractal behaviors only show up when the part of loss function GD can see becomes non-convex (non-zero fractal dimensions are all above the red curves). We also note that with increasing upper bound , the boundary of non-convexity (red curves) tend to be smaller and smaller than the boundary of fractal behaviors. This might due to the fact the region is expanding with larger and near critical for non-convexity, it is more difficult to see the non-convex part near . In conclusion, the numerical artifact help to further prove the idea that loss becoming non-convex leads to the emergence of fractal behaviors in training.
We checked the dependence of fractal dimension on the initial condition of parameter in Fig. S4 and S5, which suggest initial parameter may not affect fractal dimension.