∎
22email: {akortyl1,qingliu,angtianwang,ysun86,ayuille1}@jhu.edu
Compositional Convolutional Neural Networks:
A Robust and Interpretable Model for Object Recognition under Occlusion
Abstract
Computer vision systems in real-world applications need to be robust to partial occlusion while also being explainable. In this work, we show that black-box deep convolutional neural networks (DCNNs) have only limited robustness to partial occlusion. We overcome these limitations by unifying DCNNs with part-based models into Compositional Convolutional Neural Networks (CompositionalNets) - an interpretable deep architecture with innate robustness to partial occlusion. Specifically, we propose to replace the fully connected classification head of DCNNs with a differentiable compositional model that can be trained end-to-end. The structure of the compositional model enables CompositionalNets to decompose images into objects and context, as well as to further decompose object representations in terms of individual parts and the objects’ pose. The generative nature of our compositional model enables it to localize occluders and to recognize objects based on their non-occluded parts. We conduct extensive experiments in terms of image classification and object detection on images of artificially occluded objects from the PASCAL3D+ and ImageNet dataset, and real images of partially occluded vehicles from the MS-COCO dataset. Our experiments show that CompositionalNets made from several popular DCNN backbones (VGG-16, ResNet50, ResNext) improve by a large margin over their non-compositional counterparts at classifying and detecting partially occluded objects. Furthermore, they can localize occluders accurately despite being trained with class-level supervision only. Finally, we demonstrate that CompositionalNets provide human interpretable predictions as their individual components can be understood as detecting parts and estimating an objects’ viewpoint.
Keywords:
Compositional models Robustness to partial occlusion Image classification Object detection Out-of-distribution generalization


1 Introduction
Advances in the architecture design of deep convolutional neural networks (DCNNs) krizhevsky2012imagenet ; simonyan2014very ; he2016deep increased the performance of computer vision systems at object recognition enormously. This led to the deployment of computer vision models in safety-critical real-world applications, such as self-driving cars and security systems. In these application areas, we expect models to reliably generalize to previously unseen visual stimuli. However, in practice we observe that deep models do not generalize as well as humans in scenarios that are different from what has been observed during training, e.g., unseen partial occlusion, rare object pose, changes in the environment, etc.. This lack of generalization may lead to fatal consequences in real-world applications, e.g. when driver-assistant systems fail to detect partially occluded pedestrians economist2017uber .
In particular, a key problem for computer vision systems is how to deal with partial occlusion. In natural environments, objects are often surrounded and partially occluded by each other. The large variability of occluders in terms of their shape, appearance and position introduces an exponential complexity in the data distribution yuille2018deep that is unfeasible to be exhaustively represented in finite training data. Recent works hongru ; kortylewski2019compositional have shown that deep vision systems are not as robust as humans at recognizing partially occluded objects. Moreover, our experiments show that this limitation persists even when deep networks have been exposed to large amounts of partial occlusion during training. Hence, this reveals a fundamental limitation of current approaches to computer vision that needs to be addressed.
While robustness to partial occlusion is crucial, safety-critical applications also require AI systems to provide human interpretable explanations of their prediction. Such explanations can help to understand failures and enable the further advancement of the performance of the models, while potentially also supporting the scientific understanding of the vision process. This insight motivated recent work to focus on developing interpretable vision models ross2017right ; hu2016harnessing ; stone2017teaching ; zhang2018interpretable ; zhang2018visual . However, most often interpretable models do not perform as well as black-box DCNNs and can only be applied in a very specific domain.
In this work, we propose a general deep architecture that recognizes partially occluded objects robustly even when it has not been exposed to partial occlusion during training, while also being able to provide human interpretable explanations of its prediction. Here, we refer to interpretability in terms of the definition provided by Montavon et al. montavon2018methods as the mapping of an abstract concept (e.g. a predicted class) into a domain that the human can make sense of (e.g. in the image space instead of an abstract neural feature space) and an explanation as a collection of features from the interpretable domain that have contributed to the decision (e.g. object part detections and occluder locations in the image space).
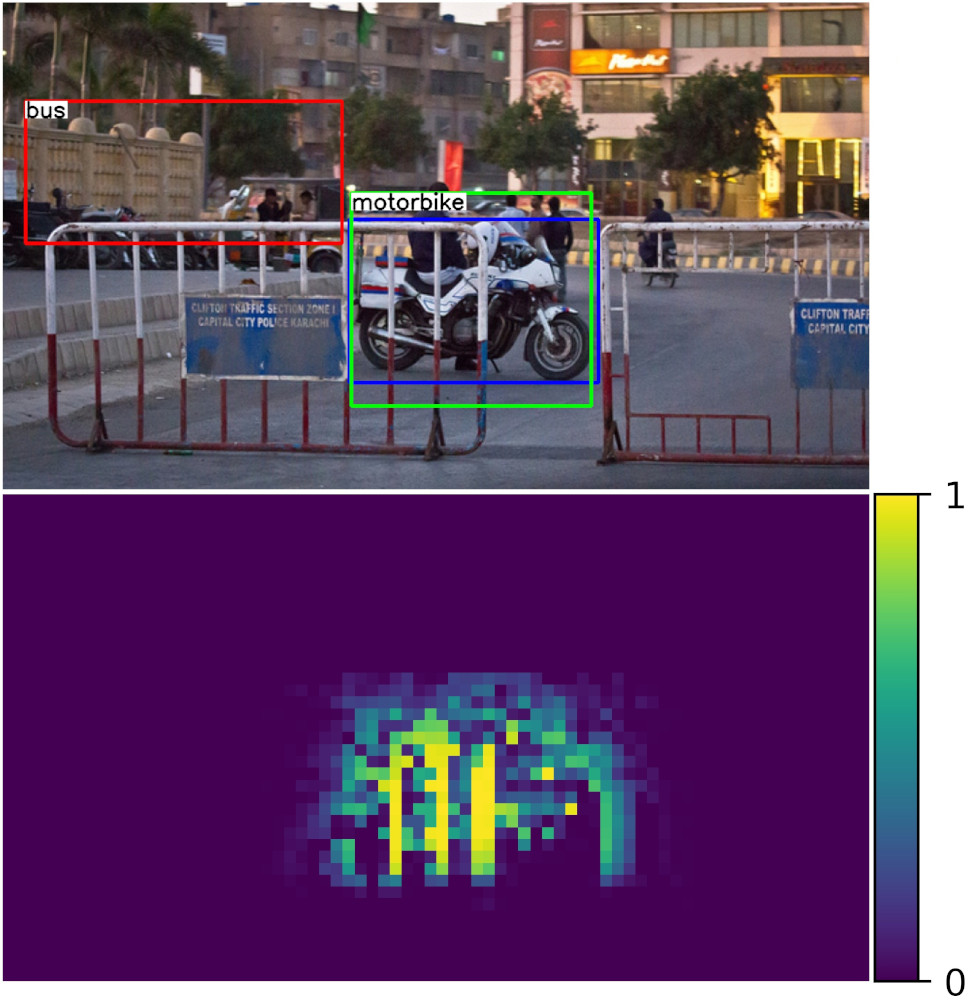
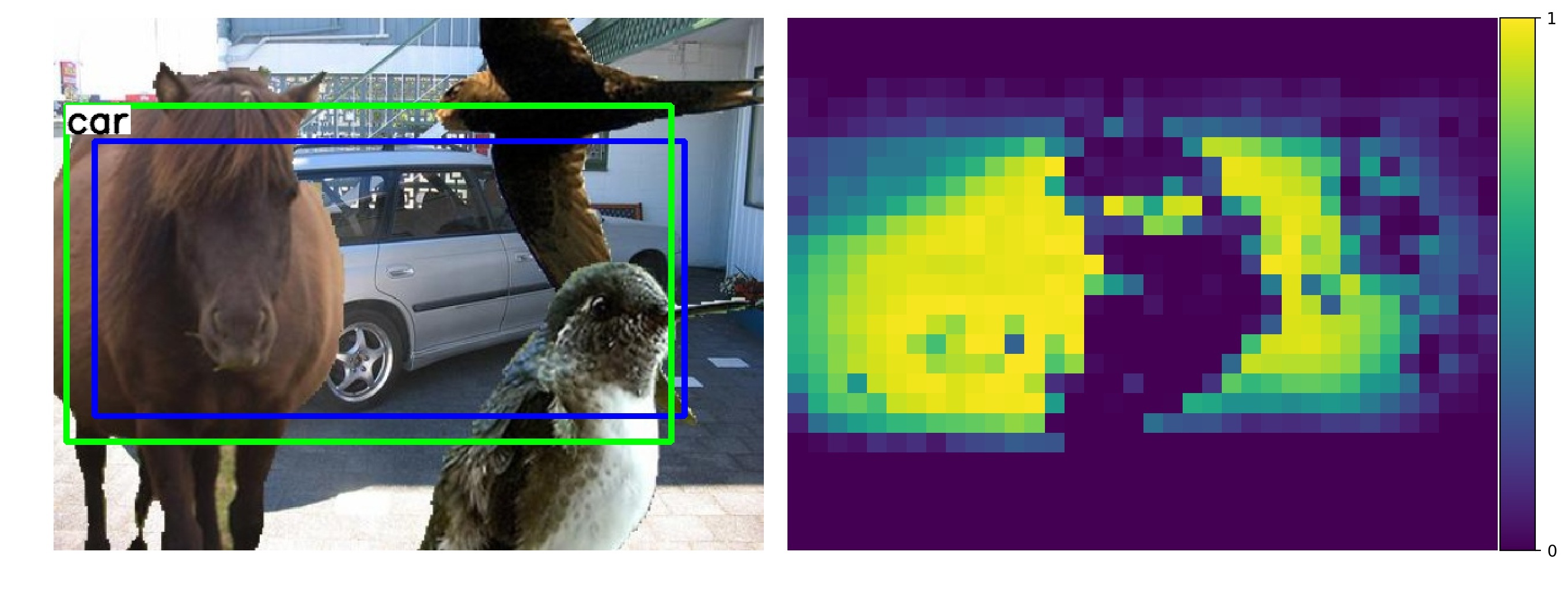
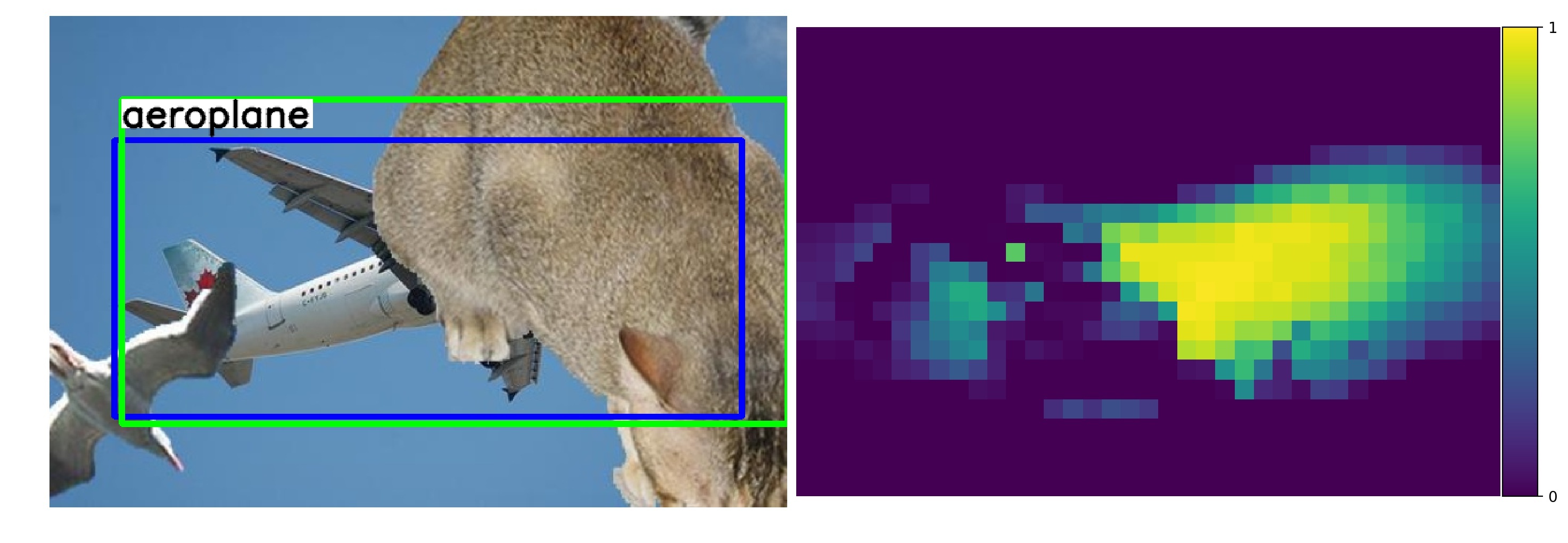
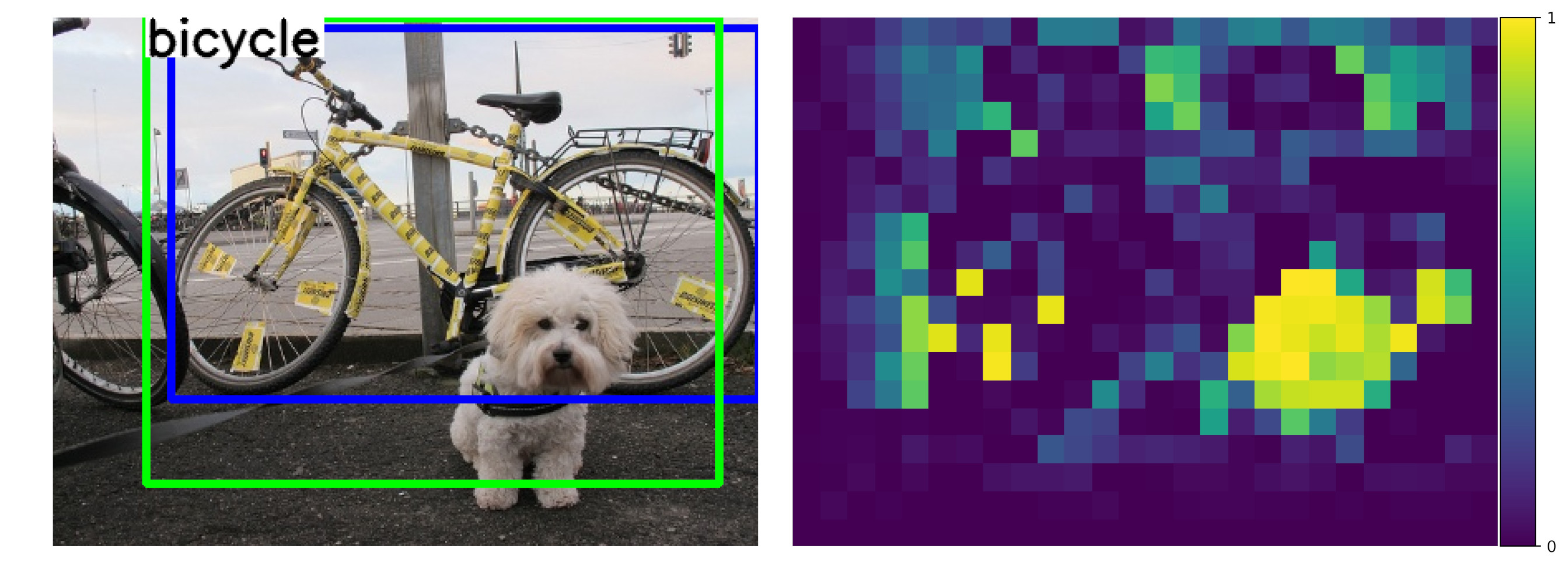
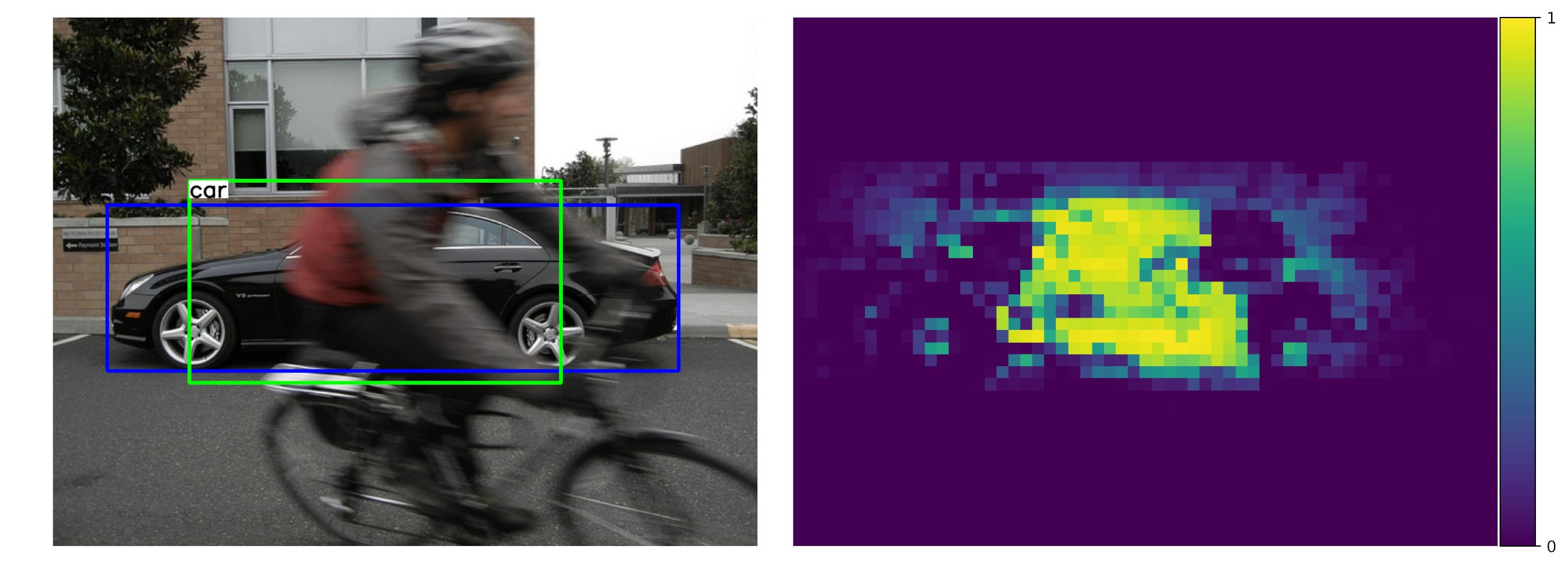
Our key contribution is that we unify compositional models and DCNNs into an architecture that we term Compositional Convolutional Neural Network. Our model is inspired by a number of works that demonstrated how the modularity of compositional representations enables efficient learning jin2006context , interpretability george2017generative and strong generalization at classifying partially occluded 2D patterns george2017generative ; kortylewski2017model ; wang2017detecting ; zhang2018deepvoting and 3D objects kortylewski2019compositional . In particular, we propose to replace the fully-connected classification head of a DCNN with a differentiable compositional model that can be trained end-to-end. The compositional model represents objects as a set of parts that are composed spatially. This enables a robust classification based on the spatial configuration of a few visible parts. The compositional model is regularized to be fully generative in terms of the neural feature activations of the last convolutional layer. The generative nature of the model enables the network to localize occluders in an image and subsequently focus on the non-occluded parts of the object for recognition. In addition, the structure of our compositional model enforces the decomposition of the image representation as a mixture of the context and object representation. This context-aware image representation enables us to control the influence of the context on the models’ prediction, which turns out to be important for the detection of partially occluded objects. Figure 1 illustrates the robustness of CompositionalNets at classifying and detecting partially occluded objects, while also being able to localize occluders in an image. In particular, it shows several images of partially occluded objects from the MS-COCO dataset lin2014microsoft . Next to these images, we show occlusion scores that illustrate the position of occluders as estimated by the CompositionalNets. Note how the occluders are accurately localized and provide a human interpretable explanation of the models’ perception of the image.
Our work on CompositionalNets includes several important contributions:
-
1.
We propose a differentiable compositional model that can be trained end-to-end and that is regularized to be generative in terms of the feature activations of a DCNN. This enables us to integrate compositional models with popular deep network architectures into compositional convolutional neural networks, a unified deep model with innate robustness to partial occlusion.
-
2.
We evaluate the robustness to partial occlusion on images of artificially occluded objects from the PASCAL3D+ and ImageNet datasets, as well as real images of partially occluded vehicles from the MS-COCO dataset. Our extensive experiments with popular DCNN backbones (VGG-16 simonyan2014very , ResNet50 he2016deep , ResNext xie2017aggregated ) demonstrate that CompositionalNets consistently outperform their non-com- positional counterparts by a large margin at the classification and detection of partially occluded objects.
-
3.
We propose to decompose the image representation in CompositionalNets as a mixture model of context and object representations. We demonstrate that such context-aware CompositionalNets allow for fine-grained control of the influence of the object context on the model prediction, which increases the robustness when detecting strongly occluded objects.
-
4.
We show that CompositionalNets are human interpretable, because their predictions can be understood in terms of object part detection, occluder localization and object viewpoint estimation. We perform qualitative and quantitative experiments that demonstrate the ability of CompositionalNets to localize occluders accurately, despite being trained with class labels only.
Finally, we note that this article extends the conference papers kortylewski2020compositional ; wang2020compositional in multiple ways: (1) We present the models of both papers coherently in a common theoretical framework and perform a number additional experiments, including ablation studies. (2) We show that a bad generalization to out-of-distribution examples in terms of partial occlusion is not just a limitation of the VGG-16 network. Instead, our experiments show that it is a general challenge for a variety of advanced deep architectures. (3) We find that CompositionalNets learned from residual backbones can use two fundamentally different approaches to achieve robustness to partial occlusion: Invariance to occlusion and localization of occluders. We observe that the combination of both approaches enables these models to achieve the highest robustness. (4) We study the interpretability of CompositionalNets quantitatively and show that the predictions of CompositionalNets are highly interpretable in terms of part detection, occluder localization and pose estimation. (5) We study large-scale classification of non-vehicle objects with CompositionalNets and achieve very promising results.
In summary, this article shows that the recognition of partially occluded objects poses a general and fundamental challenge to deep models. We give important insights into how this limitation can be overcome by unifying deep models with compositional models, and we show that the resulting CompositionalNets are not just more robust but also much more interpretable compared to their non-compositional counterparts.
2 Related Work
2.1 Object Recognition Under Occlusion
Many recent studies hongru ; kortylewski2019compositional have shown that, current deep neural networks are much less robust to partial occlusion compared with humans at object classification. Fawzi et al. fawzi2016measuring show that DCNNs are vulnerable to partial occlusions simulated by masking small patches of the input image. Several following works devries2017improved ; yun2019cutmix propose to augment the training data by masking out patches from the image. Our experimental results in Section 6.2 show that such data augmentation approaches only have limited beneficial effects. Moreover, data augmentation increases the amount of training data and thus the training time and cost. Therefore, it is desirable to develop novel neural network architectures that are inherently robust to partial occlusion. Xiao et al. xiao2019tdapnet propose TDAPNet, a deep network with an attention mechanism that masks out occluded features in lower layers to increase the robustness of the model against occlusion. Though it can work reliably on artificial occlusion, our results show that this model does not perform well on images with real occlusion.
Compared to image classification, object detection additionally involves the estimation of the object location and bounding box. While a search over the image can be implemented efficiently, e.g. using a scanning window lampert2008beyond , the number of potential bounding boxes is combinatorial in the number of pixels. Currently, the most widely used approach for solving this problem is to use region proposal networks (RPNs) girshick2014rich which enable the training of fast approaches for object detection girshick2015fast ; ren2015faster ; cai2018cascade . However, our experiments in Section 6.3 demonstrate that RPNs do not estimate the location and bounding box of an object correctly under occlusion, which consequentially deteriorates the performance of these approaches.
To resolve this problem, a boosted cascade-based method for detecting partially visible objects has been proposed by InferenOccDetect . However, this approach is based on hand-crafted features and can only be applied to images which are artificially occluded by cutting out patches. A number of deep learning based approaches have also been proposed for detecting occluded objects OR-CNN ; OccNet , but they require detailed part level annotation to reconstruct the occluded objects. The work of 3DAspectlets proposes to use 3D models and treat occlusion as a multi-label classification problem. However, in real-world scenarios, the classes of the occluders can be difficult to model and are often not known a-priori. Other approaches focus on videos or stereo images SymmNet ; Symmetricstereo . In this work, we consider the problem of partial occlusion in still images.
In contrast to deep learning approaches, generative compositional models jin2006context ; zhu2008 ; fidler2014 ; dai2014unsupervised ; kortylewski2017greedy have been shown to be inherently robust to partial occlusion. Such models have been successfully applied for detecting object parts wang2017detecting ; zhang2018deepvoting and recognizing 2D patterns george2017generative ; kortylewski2016probabilistic under partial occlusion. Such part-based voting approaches wang2017detecting ; zhang2018deepvoting perform reliably for semantic part detection under occlusion, but they assume a fixed size bounding box and are viewpoint specific, which limits their applicability in the context of object detection.
2.2 Relation of CompositionalNets to And-Or Graphs
And-Or graphs (AOG) nilsson1980principles ; jin2006context ; dechter2007and have been investigated e.g. to build hierarchical part-based models for human parsing and for object detection.
Intuitively, the or-nodes allow the model to learn different object/part configurations, while the and-node decomposes them into smaller components.
Early works in this direction chen2008rapid ; zhu2008max ; li2013vehicle relied on pre-defined parts and pre-defined graph structures.
To learn the AOG model with less supervision, Zhu et al. zhu2008 use recursive compositional clustering. However, this method may lead to unexplainable parts and structures.
Song et al. song2013discriminatively used an over-complete set of shape primitives to quantize the image lattices and then organized them into an AOG by exploiting their compositional relations through iterative cutting.
Xia et al. xia2016pose explicitly defined parts and part compositions, which correspond to the leaf node and non-leaf node in the AOG respectively. Then they used a score function with pre-defined adjacent part pairs to learn the structure of the AOG, which still required considerable amount of human input.
Wu et al. wu2015learning made use of a large number of synthetic images generated by CAD simulations, on which 17 semantic parts were manually labeled. They enumerated all configurations observed from the synthetic data and then used a graph compression algorithm to get the refined AOG structure. All these models learned the AOG in two steps: after the graph structure was decided, variants of latent structural SVM was used to learn model parameters. In a different approach, Lin et al. lin2014discriminatively learned AOG by joint optimization of both model structures and parameters. The resulting model worked on object shape detection with moderate performance and may not be easily applied to general object detection.
Most of the works on AOGs used low-level features (e.g., HOG features) to model the part appearance, which may limit their capacity and discriminative power. Furthermore, none of these works modeled occluders explicitly or tested their method on images with different level of occlusions, therefore it is unclear how those models can be made robust to occlusion. CompositionalNets can be considered to be complementary to and-or-graphs. In fact, our mixture model can be interpreted as simple two-layered and-or-graph, where each mixture components combines parts (vMF kernels) for a certain object pose, and the final class score is an “or”-combination over the different object poses (mixture components). While our model could be generalized to have multiple layers with and-or-nodes to introduce more flexibility in the representation, the focus of this work is robustness to partial occlusion. Furthermore, our experiments show that a two-layered and-or graph seems to be good enough to achieve high performance at image classification and detection on popular datasets such as PASCAL3D+, MS-COCO and ImageNet. Moreover, and-or-graphs often require considerable amounts of supervision for the graph structure chen2008rapid ; zhu2008max ; li2013vehicle or are not well interpretable zhu2008 ; song2013discriminatively , whereas our graph is learned from class supervision only and still learns a meaningful human-interpretable representation.
2.3 Deep Compositional Models in Computer Vision
An early work from Liao et al. liao2016learning proposes to integrate compositionality into DCNNs by regularizing the feature representations of DCNNs to cluster during learning. Their qualitative results show that the resulting feature clusters resemble part-like detectors. Zhang et al. zhang2018interpretable also demonstrate that part detectors emerge in DCNNs by restricting the activations in feature maps to have a localized distribution. However, these approaches have not been shown to enhance the robustness of deep models to partial occlusion. Other related works propose to regularize the convolution kernels to be sparse tabernik2016towards , or to force feature activations to be disentangled for different objects stone2017teaching . As the compositional model is not explicitly incorporated but rather implicitly encoded within the parameters of the DCNNs, the resulting models remain black-box and not expedcted to be robust to partial occlusion. A number of works li2019aognets ; tang2018deeply ; tang2017towards use differentiable graphical models to integrate part-whole compositions into DCNNs. However, these models are purely discriminative and thus are also deep networks with no internal mechanism to account for partial occlusion. Girshick et al. girshick2015deformable discussed that compositional deformable part models can be formulated as neural networks. However, they do not evaluate their models’ robustness to partial occlusion nor its explainability. Kortylewski et al. kortylewski2019compositional propose to learn a generative dictionary-based compositional model using the features of a DCNN. Instead of merging the compositional model into the DCNN, they use it as a “backup” for an independently trained DCNN. Only when the DCNN classification score falls below a certain threshold, the prediction will be substituted by the output of the compositional model.
2.4 Explainable Computer Vision Models
Many post-hoc methods have been proposed to explain what has been encoded in the intermediate layers of DCNNs. Several works le2013building ; zhou2015object visualize a real or generated input that activates a filter most to study the roles of individual units inside neural networks. Similarly, Nguyen et al. nguyen2016synthesizing synthesize prototypical images for individual units by learning a feature inversion mapping, while Bau et al. bau2017network visualize segmentation masks extracted from filter activations and assign concept labels automatically. On the other hand, the works of mahendran2015understanding ; simonyan2013deep ; zeiler2014visualizing use variants of back-propagation to identify or generate salient image features. Moving beyond studying individual hidden units, Wang et al. wang2015unsupervised use clusters of activations from all units in a layer and shows that the cluster centers yield better part detectors. Alain and Bengio alain2016understanding probe mid-layer filters by training linear classifiers on the intermediate activations. They also analyze the information dynamics among layers and its effect on the final prediction. The work of Fong et al. fong2018net2vec shows that filter embeddings better characterize the meaning of a representation and its relationship to other concepts. Most of these works evaluate their results using human judgments.
Unlike the post-hoc methods that focus on visualizing/analyzing pre-trained DCNNs, other approaches aim to learn more meaningful representations during the network training stage. The work of ross2017right explains and regularizes differentiable models by examining and selectively penalizing their input gradients, but this method requires extra annotation from human experts. Hu et al. hu2016harnessing regularize the learning process by introducing an iterative distillation method that transfers the structured information of logic rules into the weights of neural networks. Stone et al. stone2017teaching encourage networks to form representations that disentangle objects from their surroundings and from each other, but they do not obtain part-level semantics explicitly. Sabour et al. sabour2017dynamic propose a capsule model, which used a dynamic routing mechanism to parse the entire object into a parsing tree of capsules, and each capsule may encode a specific meaning. The work of Zhang et al. zhang2018interpretable invents a generic loss to regularize the representation of a filter to improve its interpretability.
In this work, we unify generative compositional models and deep convolutional neural networks into a joint architecture with innate robustness to partial occlusion.
The generative nature of the model enables it to localize occluders and to recognize objects based on the spatial configuration of visible object parts.
CompositionalNets are naturally interpretable as their predictions can be understood in terms of part detection, occluder localization and viewpoint estimation.
3 CompositionalNets for Image Classification
In this section, we introduce CompositionalNets, a neural architecture design that replaces the fully-connected classification head of deep networks with a differentiable generative compositional model. We extend CompositionalNets to object detection in Section 4 and discuss how CompositionalNets can be trained in an end-to-end manner in Section 5.










3.1 A Generative Compositional Model of Neural Feature Activations
We denote a feature map as the output of a layer in a DCNN, with being the number of channels. is a feature vector in at position on the 2D lattice of the feature map. In the remainder of this section we omit the superscript for notational simplicity because this is fixed a-priori in our experiments.
Our goal is to learn a generative model of the real-valued feature activations for an object class . In the following, we assume the viewpoint of the object to be known. Later, we generalize the model to 3D objects with varying viewpoints. We define the probabilistic model to be a mixture of von-Mises-Fisher (vMF) distributions:
| (1) | ||||
| (2) |
where are the model parameters and are the parameters of the mixture models at every position on the 2D lattice of the feature map . Note that the probabilistic model defined in Equation 1 has a tree-like independence structure and therefore enables efficient inference kortylewski2017greedy . Moreover,
| (3) |
are the mixture coefficients, is the number of mixture components and are the variance and mean of the vMF distribution:
| (4) |
where is the normalization constant. As is difficult to compute for high-dimensional data banerjee2005clustering , we assume to be fixed a-priori. Hence, the normalization constant is the same for each mixture component and does not need to be computed explicitly when optimizing the parameters. After learning the vMF cluster centers with maximum likelihood optimization, they resemble feature activation patterns that frequently occur in the training data. Interestingly, feature vectors that are similar to one of the vMF cluster centers, are often induced by image patches that are similar in appearance and often even share semantic meanings (see Figure 2). This property was also observed in a number of related works that used clustering in the neural feature space wang2015unsupervised ; liao2016learning ; wang2017detecting . Subsequently, we learn the mixture coefficients with maximum likelihood estimation from the training images. Intuitively, describes the expected activation of a cluster center at a position in a feature map for a class .
3.2 Viewpoint Modeling
An important property of convolutional networks is that the spatial information from the image is preserved in the feature maps. Hence, the set of mixture coefficients intuitively can be thought of as being a 2D template that describes the expected spatial activation pattern of parts in an image for a given class - e.g. where the tires of a car are expected to be located in an image. Therefore, our proposed vMF model intuitively accumulates the part detections spatially into a hypothesis about the objects’ presence. Note that this implements a part-based voting mechanism.
As the spatial pattern of parts varies significantly with the 3D pose of the object, we represent 3D objects as a mixture of compositional models:
| (5) |
with and . Here is the number of compositional models in the mixture distribution and is a binary assignment variable that indicates which mixture component is active. Intuitively, each mixture component will represent a different viewpoint of an object (see Experiments in Section 6.4.3).
The parameters of the mixture components need to be learned in an EM-type manner by iterating between estimating the assignment variables and maximum likelihood estimation of . We discuss how this process can be performed in a neural network in Section 5.2.
3.3 Occlusion modeling
Following the approach presented in kortylewski2017model , compositional models can be augmented with an occlusion model. The intuition behind an occlusion model is that at each position in the image either the object model or an occluder model is active (note that this is closely related to robust statistics huber2011robust ):
| (6) | |||
| (7) | |||
| (8) |
The binary variables indicate if the object is occluded at position for mixture component . The occlusion prior is fixed a-priori. We use a mixture of several occluder models that are learned in an unsupervised manner:
| (9) | ||||
| (10) |
where { indicates which occluder model explains the data best. Note that the model parameters are independent of the position in the feature map and thus the model has no spatial structure.
The parameters of the occluder models are learned from clustered features of random natural images that do not contain any object of interest (see Figure 4(a)). Hence, the mixture coefficients intuitively describe the expected activation of in regions of natural images. While it is possible to use just a single occluder model kortylewski2019compositional , we found that having a mixture model slightly increases the classification performance and the occluder localization performance. The reason is that different occluder models can focus at explaining part distributions for different typical regions in images e.g. uniform colored image patches or textured regions. We illustrate this in Figure 4(b) by visualizing patches from the training data in Figure 4(a) that have the highest likelihood for five different occluder models. Note that the purpose of the occluder models is not to be purely specific to one particular texture type, they also need to be general enough to explain a variety of local image patterns which the object model (Eq. 1) is not able to explain well. Therefore, there is a trade-off between specificity and generality of the occluder models. We found that using five models balances this trade-off well.










4 Object Detection with CompositionalNets
Object detection involves the estimation of the object class, the object center, and the object scale (a bounding box around the object). We find that partial occlusion can have significant negative effects on all three tasks. In the following section, we generalize CompositionalNets to enable robust object detection under partial occlusion. We first discuss how CompositionalNets can be generalized to locate objects in images by introducing a detection layer (Section 4.1). Subsequently, we show how robust bounding box estimates can be obtained with an advanced compositional voting mechanism in Section 4.2. Finally, we discuss the importance of separating the representations of objects and their context in object detection, and show how this can be achieved with CompositionalNets in Section 4.3.
4.1 CompositionalNets for Object Localization
A natural way of generalizing CompositionalNets to object detection is to combine them with region proposal networks (RPNs). However, RPNs are typically trained end-to-end and therefore cannot predict the bounding box of strongly occluded objects reliably (see our experiments in Section 6.3). Figure 5 illustrates this limitation by depicting the detection results of Faster R-CNN trained with CutOut devries2017improved (red box) and a combination of RPN and CompositionalNet (yellow box). We address this limitation by generalizing CompositionalNets to object localization. In particular, we introduce a detection layer that accumulates votes for the object center for all mixtures over the positions in the feature map . In order to achieve this, we compute the object likelihood in a scanning window manner. Thus, we shift the feature map, w.r.t. the object model along all points from the 2D lattice of the feature map. This process will generate a spatial likelihood map:
| (11) |
where denotes the feature map centered at the position . Using this simple generalization we can perform object localization by selecting all maxima in above a threshold after non-maximum suppression. Our proposed detection layer can be implemented efficiently on modern hardware using convolution-like operations (see Section 6.3 for more details).

4.2 Robust Compositional Bounding-Box Voting
While CompositionalNets can be generalized to localize partially occluded objects using our proposed detection layer, estimating the bounding box of an object under occlusion is more difficult because a significant amount of the object might not be visible (Figure 5). We solve this problem by generalizing the part-based voting mechanism in CompositionalNets to vote for the bounding box corners in addition to voting for the object center. In this way, we can leverage the viewpoint-specific spatial distribution of part activations for bounding-box estimation. This makes the process highly robust to missing parts. In particular, we learn additional mixture components that model the expected feature activations around bounding box corners , where are the object center and two opposite bounding box corners . Figure 5 illustrates the spatial likelihood maps of all three models. We generate a bounding box using the two points that have maximal likelihood. Note how in Figure 5 the bounding box can be localized accurately, despite the partial occlusion of the object. We discuss how the model can be learned in an end-to-end manner in Section 5.3.
4.3 Context-aware CompositionalNets
While in image classification, the object of interest often dominates a large part of the image, in object detection the object is embedded in a larger context that is often biased in the training data (e.g. airplanes often have blue background). This gives rise to a critical problem when aiming to detect partially occluded objects. Intuitively, the objects’ context can be useful for recognizing objects due to biases in the data. However, relying too strongly on context can be misleading, because if objects are strongly occluded (Figure 6) the detection thresholds must be lowered. This, in turn, increases the influence of the objects context and leads to false-positive detections in regions with no object. Hence, it is important to have control over the influence of contextual cues on the detection result.

We overcome this issue by explicitly separating the representation of the context from that of the object, to control the influence of the contextual information on the detection result. In particular, we represent the feature map as a mixture of two models:
| (12) |
Here are the parameters of the context-aware model that is defined to be a mixture of vMF likelihoods (Equation 2). The parameter controls the trade-off between context and object, and is fixed a-priori at test time. Note that setting retains the CompositionalNet as proposed in Section 3 as the context and object would be weighted equally. Figure 6 illustrates the benefits of reducing the influence of the context on the detection result under partial occlusion. The context parameters and object parameters can be learned from the training data using maximum likelihood estimation, assuming a binary assignment of the feature vectors in the training data to either the context or the object. To obtain this binary assignment, we need to segment the training images into context and object based on the available bounding box annotation. We do so, by assuming that any feature vector with a receptive field outside of the scope of the bounding boxes can be considered to be context. Based on this assumption, we cluster the context features using K-means++ k-means++ to generate a dictionary of context feature centers . We apply a threshold on the cosine similarity to segment the context and the object in any given training image (Figure 7).

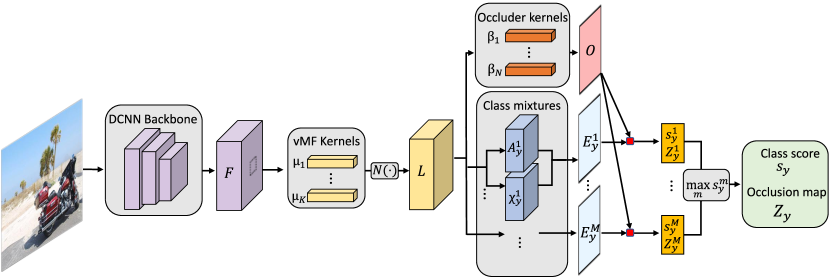
5 End-to-End Training of CompositionalNets
In the following, we show how inference in CompositionalNets can be formulated as feed-forward neural network (Section 5.1) and discuss how CompositionalNets can be trained end-to-end for image classification (Section 5.2) and object detection (Section 5.3).
5.1 Inference as Feed-Forward Neural Network
The computational graph of our proposed fully generative compositional model is acyclic.
Hence, we can perform inference in a single forward pass as illustrated in Figure 8. We use a standard DCNN backbone to extract a feature representation from the input image , where are the parameters of the feature extractor (purple tensor in Figure 8). The pipeline after the feature extractor illustrates the computation of the model likelihood when the model is centered at position in the feature map (illustrated by the dotted black square on the feature tensor ). For image classification, the model will always be positioned at the image center, whereas for object detection, the model will be evaluated at every position in (as defined in Equation 11). We omit the subscript in in the following for notational clarity.
After feature extraction the model computes the vMF likelihood function (Equation 4). The function is composed of two operations: An inner product and a non-linear transformation . Since is independent of the position , computing is equivalent to a convolution of with . Hence, the vMF likelihood (Figure 8 yellow tensor) can be computed by :
| (13) |
The mixture likelihoods (Equation 4.3) are computed for every position as a dot-product between the mixture coefficients and the corresponding vector from the vMF likelihood tensor :
| (14) |
(Figure 8 blue planes). Similarly, the occlusion likelihood can be computed as (Figure 8 red plane). Together, the occlusion likelihood and the mixture likelihoods are used to estimate the overall likelihood of the individual mixtures as . The final model likelihood is computed as and the final occlusion map is selected accordingly as where .
5.2 End-to-end Training for Image Classification
Our model is fully differentiable and can be trained end-to-end using backpropagation. In our image classification experiments, context-awareness does not have a significant influence as the background is largely cropped out. Therefore, we use CompositionalNets as defined in Section 3 for image classification. Hence, the trainable parameters of a CompositionalNet are . We optimize those parameters jointly using stochastic gradient descent. The loss function is composed of three terms:
| (15) | ||||
| (16) |
is the cross-entropy loss between the network output and the true class label . We use a temperature in the softmax classifier: , with . and regularize the parameters of the compositional model to have maximal likelihood for the features in . The parameters control the trade-off between the loss terms.
The vMF cluster centers are learned by maximizing the vMF-likelihoods (Equation 4) for the feature vectors in the training images. We keep the vMF variance constant, which also reduces the normalization term to a constant. We assume a hard assignment of the feature vectors to the vMF clusters during training. Hence, the free energy to be minimized for maximizing the vMF likelihood wang2017visual is:
| (17) | ||||
| (18) |
where is a constant. Intuitively, this loss encourages the cluster centers to be similar to the feature vectors .
In order to learn the mixture coefficients we need to maximize the model likelihood (Equation 5). We can avoid an iterative EM-type learning procedure by making use of the fact that the the mixture assignment and the occlusion variables have been inferred in the forward inference process. Furthermore, the parameters of the occluder model are learned a-priori and then fixed. Hence the energy to be minimized for learning the mixture coefficients is:
| (19) |
Here, and denote the variables that were inferred in the forward process (Figure 8).
5.3 Training CompositionalNets for Object Detection
For object detection, we train context-aware CompositionalNets as proposed in Section 4. The trainable parameters of the model are where . The loss function has three main objectives. The model should explain data with maximal likelihood (), while also localizing () and classifying () the object accurately in the training images. :
| (20) | ||||
| (21) |
where control the trade-off between the loss terms. While is learned from images with feature maps that are centered at , the other losses are learned from unaligned training images with feature maps .
Generative Regularization. The model is regularized to be generative in terms of the neural feature activations by optimizing:
| (22) | ||||
| (23) |
where is defined in Equation 17 and the parameters of the context-aware model and are learned by optimizing the context loss:
| (24) | ||||
| (25) |
Here, is a context assignment variable that indicates if a feature vector belongs to the context or to the object model and is defined in Equation 19. We estimate the context assignments a-priori using a simple binary segmentation as described in Section 4.3.























Localization and Bounding Box Estimation. We denote the normalized response map of the ground truth class as and the ground truth annotation as . The elements of the response map are computed as:
| (26) |
The ground truth map is a binary map where the ground truth position is set to and all other entries are set to zero. The detection loss is then defined as:
| (27) |
6 Experiments
We give an overview of the datasets used for evaluation and the training setup in Section 6.1. Subsequently, we extensively evaluate our model at image classification and object detection of partially occluded objects in Sections 6.2 & 6.3. Finally, we show that CompositionalNets are human interpretable, as their predictions can be understood in terms of occluder localization (Section 6.4.1), object part detection (Section 6.4.2) and object pose estimation (Section 6.4.3).
6.1 Datasets and Training Setup
Datasets for image classification. We evaluate our model on the Occluded-P3D+-Vehicles dataset as proposed in wang2017detecting and extended in kortylewski2019compositional . The dataset is based on images of vehicles from the PASCAL3D+ dataset xiang2014beyond that were synthetically occluded with four different types of occluders: segmented objects as well as patches with constant white color, random noise and textures (see Figure 10(a) for examples). The amount of partial occlusion of the object varies in four different levels: (L0), - (L1), - (L2), - (L3).
Furthermore, we introduce a dataset with images of real occlusions which we term Occluded-COCO-Vehicles. It contains the same classes as the Occluded-P3D+-Vehicles dataset. The dataset was generated by categorizing objects from the MS-COCO lin2014microsoft into the four occlusion levels as defined in the Occluded-P3D+-Vehicles dataset. To achieve this, we relate the amount of object that is visible in the MS-COCO images to the one from the Occluded-P3D+-Vehicles based on the segmentation masks that are available in both datasets. The numbers of test images for each occlusion level are: (L0), (L1), (L2), (L3). For training purpose, we define a separate training dataset of images from level L0. Figure 10(b) illustrates some example images from this dataset.
While the current generation of CompositionalNets has been primarily developed for recognizing a smaller number of vehicle-type objects, we also want to study if CompositionalNets retain their robustness to partial occlusion even when tested at a larger scale with non-vehicle type objects. For this, we introduce the Occluded-ImageNet dataset. In particular, we randomly select different numbers of classes from the ImageNet dataset deng2009imagenet to study the influence of the dataset scale on the performance. We crop the objects from the training images with available annotation to make our results comparable to the Occluded-P3D+-Vehicles and Occluded-COCO-Vehicles data. We randomly split the data into test images per class and assign the remaining images to the training data. This results in training and test images for the different sized subsets. We artificially occlude the test images by using segmented objects from the MS-COCO dataset. Note that to simulate occlusion, we only use those object classes from MS-COCO that do not overlap with the ImageNet classes. The amount of partial occlusion of the object varies in four different levels (L0, L1, L2, L3) as in the Occluded-P3D+-Vehicles dataset.
| PASCAL3D+ Vehicles Classification under Occlusion | ||||||||||||||
| Occ. Area | L0: 0% | L1: 20-40% | L2: 40-60% | L3: 60-80% | Mean | |||||||||
| Occ. Type | - | w | n | t | o | w | n | t | o | w | n | t | o | |
| VGG | 99.2 | 96.9 | 97.0 | 96.5 | 93.8 | 92.0 | 90.3 | 89.9 | 79.6 | 67.9 | 62.1 | 59.5 | 62.2 | 83.6 |
| Resnet50 | 99.1 | 96.8 | 96.8 | 96.8 | 91.0 | 91.6 | 91.5 | 91.8 | 73.4 | 66.1 | 69.2 | 71.4 | 58.3 | 84.1 |
| ResNext | 99.7 | 98.7 | 98.5 | 98.4 | 94.5 | 94.5 | 93.4 | 92.3 | 76.7 | 68.0 | 62.8 | 51.2 | 55.9 | 83.4 |
| CoDkortylewski2019compositional | 92.1 | 92.7 | 92.3 | 91.7 | 92.3 | 87.4 | 89.5 | 88.7 | 90.6 | 70.2 | 80.3 | 76.9 | 87.1 | 87.1 |
| TDAPNet xiao2019tdapnet | 99.3 | 98.4 | 98.9 | 98.5 | 97.4 | 96.1 | 97.5 | 96.6 | 91.6 | 82.1 | 88.1 | 82.7 | 79.8 | 92.8 |
| CompNet-VGG-p4 | 97.4 | 96.7 | 96.0 | 95.9 | 95.5 | 95.8 | 94.3 | 93.8 | 92.5 | 86.3 | 84.4 | 82.1 | 88.1 | 92.2 |
| CompNet-VGG-p5 | 99.3 | 98.4 | 98.6 | 98.4 | 96.9 | 98.2 | 98.3 | 97.3 | 88.1 | 90.1 | 89.1 | 83.0 | 72.8 | 93.0 |
| CompNet-Res50-RB4 | 99.3 | 98.7 | 98.7 | 98.5 | 96.9 | 96.9 | 97.2 | 96.9 | 88.7 | 86.1 | 83.6 | 79.4 | 72.9 | 91.8 |
| CompNet-RXT-RB3 | 98.1 | 95.9 | 96.3 | 96.3 | 94.6 | 92.1 | 93.5 | 92.7 | 87.4 | 76.1 | 80.1 | 75.2 | 76.4 | 88.8 |
| CompNet-RXT-RB4 | 99.7 | 99.3 | 99.0 | 99.2 | 98.0 | 98.2 | 97.0 | 97.5 | 93.0 | 90.3 | 83.8 | 84.7 | 83.3 | 94.1 |
Datasets for Object Detection. The object detection datasets are defined in a similar way as the classification data. We synthesize an Occluded-P3D+-Vehicles-Detection dataset, which contains vehicles at a certain scale and various levels of occlusion. The occluders, which include humans, animals and plants, are cropped from the MS-COCO dataset lin2014microsoft . In an effort to accurately depict real-world occlusions, we superimpose the occluders onto the object, such that the occluders are placed not only inside the bounding box of the objects but also on the background. We generate the dataset in a total of 9 occlusion levels along two occlusion dimensions: We define three levels of occlusion of the object (FG-L1: 20-40%, FG-L2:40-60% and FG-L3:60-80% of the object area is occluded). Furthermore, we define three levels of occlusion of the context around the object (BG-L1: 0-20%, BG-L2:20-40% and BG-L3:40-60% of the context area is occluded). Example images are shown in Figure 10(c). In order to evaluate the tested models on real-world occlusions, we test them on the subset of the MS-COCO dataset as defined for classification (Figure 10(d)).
Model initialization. We initialize the vMF kernels and the mixture components by maximum likelihood estimation after clustering the training data. We compute the mixture assignments using spectral clustering with the hamming distance between vMF kernel activations in the pool4 layer in VGG-16 of all training images. The intuition is that objects with a similar viewpoint and 3D structure will have similar vMF activation patterns, and thus should be assigned to the same mixture component.
| MS-COCO Vehicles Classification under Occlusion | |||||||||||||||
| Train Data | PASCAL3D+ | MS-COCO | MS-COCO + CutPaste | ||||||||||||
| Occ. Area | L0 | L1 | L2 | L3 | Avg | L0 | L1 | L2 | L3 | Avg | L0 | L1 | L2 | L3 | Avg |
| VGG | 97.8 | 86.8 | 79.1 | 60.3 | 81.0 | 99.1 | 88.7 | 78.8 | 63.0 | 82.4 | 99.3 | 92.3 | 89.9 | 80.8 | 90.6 |
| ResNet50 | 98.5 | 89.6 | 84.9 | 71.2 | 86.1 | 99.6 | 92.7 | 86.9 | 67.1 | 86.6 | 99.6 | 94.1 | 92.5 | 84.9 | 92.8 |
| ResNext | 98.7 | 90.7 | 85.9 | 75.3 | 87.7 | 99.5 | 92.9 | 87.6 | 73.9 | 88.5 | 99.6 | 94.5 | 93.1 | 89.0 | 94.1 |
| CoD | 91.8 | 82.7 | 83.3 | 76.7 | 83.6 | - | - | - | - | - | - | - | - | - | - |
| TDAPNet | 98.0 | 88.5 | 85.0 | 74.0 | 86.4 | 99.4 | 88.8 | 87.9 | 69.9 | 86.5 | 98.1 | 89.2 | 90.5 | 79.5 | 89.3 |
| CompNet-VGG-p4 | 96.6 | 91.8 | 85.6 | 76.7 | 87.7 | 97.7 | 92.2 | 86.6 | 82.2 | 89.7 | 98.3 | 93.8 | 88.6 | 84.9 | 91.4 |
| CompNet-VGG-p5 | 98.2 | 89.1 | 84.3 | 78.1 | 87.5 | 99.1 | 92.5 | 87.3 | 82.2 | 90.3 | 99.4 | 93.9 | 90.6 | 90.4 | 93.5 |
| CompNet-Res50-RB4 | 98.5 | 92.6 | 88.9 | 83.6 | 90.9 | 99.2 | 95.2 | 91.8 | 89.0 | 93.8 | 99.0 | 95.2 | 93.4 | 89.0 | 94.2 |
| CompNet-RXT-RB3 | 97.5 | 91.7 | 82.3 | 73.2 | 86.2 | 98.2 | 93.1 | 84.1 | 83.6 | 89.8 | 98.7 | 93.8 | 87.3 | 84.9 | 91.2 |
| CompNet-RXT-RB4 | 98.8 | 94.0 | 93.5 | 87.7 | 93.5 | 99.0 | 94.8 | 93.5 | 91.8 | 94.8 | 99.0 | 95.0 | 94.1 | 91.8 | 95.0 |
Training setup for classification. We train CompositionalNets from the feature activations of the layer before the classifier for several popular DCNNs: VGG-16 simonyan2014very , ResNet50 he2016deep and ResNext xie2017aggregated . All models were pretrained on ImageNetdeng2009imagenet . We set the vMF variance to . We train the parameters of the generative model using backpropagation and keep the parameters of the backbone fixed (training did not have significant effects on the results). We learn the parameters of occluder models in an unsupervised manner as described in Section 3.1 and keep them fixed throughout the experiments. We set the number of mixture components to . The mixing weights of the loss are set to: , . We train for epochs using stochastic gradient descent with momentum and a learning rate of . Our reported parameter settings are very general as they are fixed in all our experiments even for different datasets.
Training setup for object detection. We optimize the loss described in Equation 20, with and . We apply the Adam Optimizer kingma2014adam with different learning rates on different parts of CompositionalNets: , . The model is trained for a total of 2 epochs with 10600 iteration per epoch. The training takes three hours in total on a machine with 4 NVIDIA TITAN Xp GPUs.
6.2 Image Classification under Occlusion
Occluded-P3D+. Table 1 reports the results of VGG-16, ResNet50 and ResNext that were fine-tuned with the respective training data. Furthermore, we show the results of dictionary-based compositional models (CoD) kortylewski2019compositional and TDAPNet xiao2019tdapnet . We also report CompositionalNets learned from the pool4 and pool5 layer of the VGG-16 network respectively (CompNet-VGG-[p4 & p5]) and CompositionalNets learned from features of the last residual block (RB4) of ResNet50 (CompNet-Res50) and both the last (RB4) and second last (RB3) residual block of ResNext (CompNet-RXT). In this setup, all models are trained with non-occluded images (), while at test time the models are exposed to images with different amount of partial occlusion (-).
Overall, we observe that DCNNs do not generalize well to out-of-distribution examples in terms of partial occlusion. They perform well on the type of data that they were exposed to during training (L0) and generalize to a limited extent away from it (L1). However, their performance collapses when objects are strongly occluded (L3).
In contrast, we observe that CompositionalNets generalize very well even under strong occlusion. Moreover, using the higher layers of more powerful residual backbones also significantly increases the performance of CompositionalNets. We also observe that CompNets learned from the RB3 layer of ResNext perform significantly worse, compared to those learned from RB4 ( on average). In contrast, CompNets learned from pool4 of VGG still give comparable results pool5. We conjecture from this observation that the additional convolutional and residual layers in RB4 are of critical importance for the ResNext backbone.
| ImageNet Classification under Occlusion | |||||||||||||||
| Number of classes | 25 | 50 | 100 | ||||||||||||
| Occ. Area | L0 | L1 | L2 | L3 | Avg | L0 | L1 | L2 | L3 | Avg | L0 | L1 | L2 | L3 | Avg |
| ResNext + CutOut | 98.6 | 69.2 | 40.8 | 20.7 | 57.3 | 97.7 | 58.6 | 28.4 | 13.5 | 49.6 | 97.1 | 53.0 | 25.5 | 10.5 | 46.5 |
| CompNet-ResNext-RB4-512 | 98.1 | 70.6 | 46.9 | 31.3 | 61.7 | 95.1 | 60.7 | 36.5 | 19.8 | 53.0 | 92.9 | 53.7 | 30.1 | 14.7 | 47.9 |
| CompNet-ResNext-RB4-1024 | 97.2 | 69.8 | 45.9 | 29.1 | 60.5 | 95.4 | 61.3 | 37.0 | 21.2 | 53.7 | 94.2 | 56.1 | 32.6 | 16.0 | 49.7 |
Occluded MS-COCO. Table 2 shows classification results under a realistic occlusion scenario by testing on the Occluded-COCO-Vehicles dataset. The models in the first part of the Table (PASCAL3D+) are trained solely on non-occluded images of the PASCAL3D+ data. We can observe that from all standard DCNNs VGG-16 transfers the worst to the MS-COCO data, while ResNet50 and ResNext generalize better, in particular to strongly occluded objects. ResNext even outperforms the recently proposed TDAPNet that was specifically designed for image classification under occlusion. CompositionalNets consistently outperform non- compositional DCNNs by a large margin, highlighting the generality of our approach. In particular, CompNet-ResNext-RB4 can generalize very strongly from training on non-occluded PASCAL3D+ data to strongly occluded objects from MS-COCO.
The second part of the table (MS-COCO) shows the classification performance after fine-tuning on the non-occluded training set of the Occluded-COCO-Vehicles dataset. A common pattern of all three standard DCNNs is that their performance increases for low occlusion () while it decreases for stronger occlusion (). In contrast, the performance of the CompositionalNets increases substantially after fine-tuning for all occlusion levels.
The third part of Table 2 (MS-COCO-CutPaste) shows classification results after training with strong data augmentation in terms of partial occlusion. In particular, we artificially occlude the non-occluded training images used in the previous experiment with all four types of artificial occluders used in the Occluded-P3D+-Vehicles dataset. This data augmentation increases the dataset by a factor of . From the classification results, we can observe that data augmentation increases the performance of the DCNNs significantly. VGG-16 still suffers from strong occlusions. However, ResNet50 and particularly ResNext become significantly more robust to occlusion. The performance of the CompositionalNets learned from VGG-16 increases further when trained with augmented data, whereas the ones learned from ResNet50 and ResNext only benefit slightly, while still outperforming their non-compositional counterparts. Similar to the results in Table 1, CompNet-ResNext-RB3 performs significantly worse compared to CompNet-ResNext-RB4, highlighting the importance of the last layers in the backbone of ResNext. Interestingly, CompNet-ResNext-RB3 performs on par to CompNet-ResNext-p4 under real occlusion, whereas it is less robust to the artificial occluders (Table 1). This suggests that the ResNext features have developed an invariance to partial occlusion from the ImageNet pre-training that does not transfer as well to artificial occlusion. We discuss this in more detail in Section 6.4.1.
| Ablation Study on PASCAL3D+ Vehicles Classification under Occlusion | ||||||||||||||
| Occ. Area | L0: 0% | L1: 20-40% | L2: 40-60% | L3: 60-80% | Mean | |||||||||
| Occ. Type | - | w | n | t | o | w | n | t | o | w | n | t | o | |
| CompNet-ResNext initialization | 98.1 | 95.8 | 96.0 | 95.6 | 91.3 | 91.7 | 91.8 | 91.7 | 80.8 | 75.7 | 77.2 | 77.1 | 67.9 | 87.0 |
| CompNet-ResNext | 99.5 | 98.3 | 97.8 | 98.0 | 95.0 | 94.5 | 92.9 | 92.6 | 81.7 | 71.0 | 59.0 | 59.0 | 58.3 | 84.4 |
| CompNet-ResNext | 99.6 | 97.7 | 96.5 | 97.4 | 93.6 | 95.0 | 91.4 | 93.8 | 86.8 | 87.0 | 75.3 | 80.0 | 77.6 | 90.1 |
| CompNet-ResNext | 99.9 | 99.2 | 98.8 | 98.9 | 97.5 | 97.5 | 95.6 | 96.5 | 92.8 | 87.8 | 78.4 | 81.9 | 83.9 | 93.0 |
| CompNet-ResNext | 99.7 | 99.3 | 99.0 | 99.2 | 98.0 | 98.2 | 97.0 | 97.5 | 93.0 | 90.3 | 83.8 | 84.7 | 83.3 | 94.1 |
Occluded ImageNet. Table 3 shows classification results for larger scale experiments with non-vehicle objects on the Occluded-ImageNet dataset. We compare a standard ResNext model trained with strong data augmentation using CutOut devries2017improved with CompositionalNets learned from a ResNext backbone that were trained with non-augmented images only. We also test CompositionalNets with and vMF kernels. We observe that CompositionalNets are more robust under strong occlusion in all experiments and stay competitive in low occlusion scenarios. The CompositionalNet performance decreases slightly on non-occluded images in the 100 class experiment (ResNext+CutOut: 97.1; CompNet-ResNext-1024: 94.2). However, CompositionalNets perform better under any amount of partial occlusion even for this large set of non-vehicle objects.
Furthermore, we observe that the number of vMF kernels does not have a critical influence on the performance. This highlights the advantage of the compositional representation which enables an efficient sharing of the vMF kernels among the different classes. Nevertheless, we can observe that increasing the number of vMF kernels has a positive effect on the performance for higher number classes, because the model can represent the objects more accurately when more parts are available.
Overall, we can observe that CompositionalNets are already capable to generalize to large amounts of non-vehicle classes, while retaining their robustness to partial occlusion. This is a very promising result considering that our model was mainly tested at the robust analysis of a smaller set of vehicle objects. Therefore, we expect improvements by investigating how CompositionalNets could better model articulated objects such as animals.
Summary of classification experiments. All classification experiments clearly highlight the robustness of CompositionalNets at classifying partially occluded objects, while also being highly discriminative when objects are not occluded. Overall, CompositionalNets learned from several popular DCNNs show a significantly improved generalization performance compared to non-compositional DCNNs under artificial as well as real occlusion. Notably, CompNet-ResNext trained from non-occluded PASCAL3D+ data performs essentially on par with the best DCNN (ResNext) trained from strongly augmented MS-COCO images. This highlights the data efficiency and strong generalization ability of CompositionalNets. Furthermore, we observe that CompositionalNets have a lot of potential for large-scale classification tasks with non-vehicle type objects.
| PASCAL3D+ Vehicles Detection under Occlusion | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Occ. Area Foreground | FG L0 | FG L1 | FG L2 | FG L3 | Mean | ||||||
| Occ. Area Background | BG L0 | BG L1 | BG L2 | BG L3 | BG L1 | BG L2 | BG L3 | BG L1 | BG L2 | BG L3 | – |
| Faster R-CNN | 98.0 | 88.8 | 85.8 | 83.6 | 72.9 | 66.0 | 60.7 | 46.3 | 36.1 | 27.0 | 66.5 |
| Faster R-CNN with reg. | 97.4 | 89.5 | 86.3 | 89.2 | 76.7 | 70.6 | 67.8 | 54.2 | 45.0 | 37.5 | 71.1 |
| CompNet-VGG-p4-RPN | 74.2 | 68.2 | 67.6 | 67.2 | 61.4 | 60.3 | 59.6 | 46.2 | 48.0 | 46.9 | 60.0 |
| CompNet-VGG-p4-RPN | 73.1 | 67.0 | 66.3 | 66.1 | 59.4 | 60.6 | 58.6 | 47.9 | 49.9 | 46.5 | 59.6 |
| CompNet-VGG-p4 | 91.7 | 85.8 | 86.5 | 86.5 | 78 | 77.2 | 77.9 | 61.8 | 61.2 | 59.8 | 76.6 |
| CompNet-VGG-p4 | 92.6 | 87.9 | 88.5 | 88.6 | 82.2 | 82.2 | 81.1 | 71.5 | 69.9 | 68.2 | 81.3 |
| CompNet-VGG-p4 | 94.0 | 89.2 | 89.0 | 88.4 | 82.5 | 81.6 | 80.7 | 72.0 | 69.8 | 66.8 | 81.4 |
| CompNet-ResNext-RB3 | 94.6 | 85.5 | 85.3 | 85.4 | 76.4 | 74.7 | 74.7 | 62.4 | 60.7 | 58.0 | 75.8 |
6.2.1 Ablation Study
In Table 4 we show the results of an ablation study using a CompositionalNet learned from a ResNext backbone. After initialization, the CompositionalNet achieves an average performance of and hence already outperforms a standard ResNext architecture by on average. Note that the CompositionalNet at this point is not as discriminative at and performs on par at , while significantly outperforming ResNext at and .
When the parameters of the vMF kernels and mixture components are not regularized () the overall performance decreases. In particular, the CompositionalNet becomes more discriminative for the type of data it has observed at training time () and cannot generalize well to stronger occlusion. Hence, it behaves as one would expect from a standard DCNN.
Regularizing only the mixture components to maximize the likelihood of the vMF kernel activations () increases the performance in all experiments. In particular, the end-to-end training makes CompositionalNets highly discriminative for the within-distribution-data () while preserving strong generalization performance for out-of-distribution data (). Similarly, regularizing only the vMF kernels to maximize the likelihood of the ResNext features () also increases performance for all experiments significantly for non-occluded as well as strongly occluded data. The best performance is achieved with a joint regularization of the vMF kernels and mixture components ().
| MS-COCO Vehicles Detection under Occlusion | |||||
|---|---|---|---|---|---|
| Occ. Area | L0 | L1 | L2 | L3 | Avg |
| Faster R-CNN | 77.2 | 59.0 | 40.8 | 24.6 | 50.4 |
| Faster R-CNN with reg. | 80.7 | 63.3 | 45.0 | 33.3 | 55.6 |
| Faster R-CNN with occ. | 82.5 | 66.0 | 50.7 | 45.6 | 61.2 |
| CompNet-VGG-p4-RPN | 60.0 | 49.7 | 45.4 | 38.6 | 48.4 |
| CompNet-VGG-p4 = | 81.6 | 70.8 | 51.7 | 40.4 | 61.1 |
| CompNet-VGG-p4 = | 86.8 | 77.8 | 65.4 | 59.6 | 72.4 |
| CompNet-VGG-p4 = | 89.4 | 76.2 | 61.1 | 54.4 | 70.3 |
| CompNet-RXT-RB3 = | 85.7 | 72.5 | 65.9 | 59.6 | 70.9 |


6.3 Object Detection under Occlusion
In this Section, we evaluate CompositionalNets at the task of object detection. In the experiments, we use a context-aware CompNet-VGG16-pool4 and a CompNet-ResNext-RB3 because of their higher resolution compared to the other types of backbones tested in image classification.
Occluded-P3D+. In Table 5, we report the results of Faster-RCNN and CompositionalNets on the Occluded-P3D+-Vehicles-Detection dataset. The models are trained on the images from the original PASCAL3D+ dataset with non-occluded objects. Qualitative detection results are illustrated in Figure 11.
We observe that Faster R-CNN fails to detect strongly occluded objects reliably, while it performs well under low levels of occlusion. When trained with strong data augmentation in terms of partial occlusion using CutOut devries2017improved , the detection performance increases under strong occlusion. However, the model still suffers from a drop in performance on strong occlusion, compared to the non-occlusion setup. We suspect that the inaccurate prediction is because of two major factors. 1) The Region Proposal Network (RPN) in the Faster R-CNN is not able to predict accurate proposals of objects that are heavily occluded. 2) The VGG-16 classifier cannot successfully classify valid object regions under heavy occlusion.
We proceed to investigate the performance of the region proposals on occluded images. We conduct this experiment by replacing the VGG-16 classifier in the Faster R-CNN with a CompositionalNet classifier that is learned from the pool4 layer of VGG, which is expected to be more robust to occlusion. Based on the results in Table 1, we observe two phenomena. 1) In high levels of occlusion, the performance is better than Faster R-CNN. Thus, the CompositionalNet generalizes to heavy occlusions better than the VGG-16 classifier. 2) In low levels of occlusion, the performance is worse than Faster R-CNN.
The importance of spatial alignment in CompositionalNets. Recall that in the classification experiments, we observed that CompositionalNets are robust to occlusion because they can roughly localize occluders and subsequently focus on the non-occluded object parts for classification. They can localize occluders because the different components in the mixture models explicitly represent the spatial distribution of features of an object in a certain pose. To be successful, the localization process requires the features of the object in the image to be roughly aligned with the mixture models. Therefore, CompositionalNets require bounding box proposals in which the center of the object is roughly aligned to the center of the bounding box, independent of whether the object is occluded or not. In this sense, CompositionalNets are rather high precision models which require spatial alignment between image and model. This is in contrast to standard deep networks, which are observed to not use spatial information extensively and behave more like bag-of-words type models brendel2019approximating . The results in Section 6.2 and Section 6.4.1 show that the spatial distribution of object parts in an image is very important for computer vision models, because it enables the rough localization of occluders and thus a robust classification and detection under occlusion. One problem with the RPN proposals is that they mostly cover the visible part of the object only and often do not align the object center to the center of the bounding box.
Effect of robust bounding box voting. Our approach of accurately estimating the corners of the bounding box substantially improves the performance of the CompositionalNet, in comparison with the RPN. This further validates our conclusion that the CompositionalNet classifier requires precise proposals to classify objects correctly with partial occlusions.
Effect of context-aware representation. We observe that models with a reduced influence of the context () outperform models with equal weight on context and object representation (). Hence, context-aware CompositionalNets are more robust to partial occlusion than unaware models. Furthermore, the performance of all models follows a similar trend over all three levels of foreground occlusions: the performance decreases as the level of background occlusion increases from BG-L1 to BG-L3. This further confirms our understanding of the effects of the context as a valuable source of information in object detection.
Occluded-MS-COCO. As show in Table 6 and Figure 11, the context-aware CompositionalNet with robust bounding box voting outperforms Faster R-CNN and CompNet+RPN significantly. Furthermore, the quantitative results clearly show the benefit of the context-awareness () over unaware CompositionalNets (). While fully deactivating the context () slightly decreases the performance, controlling the prior of the context model to reaches a sweet spot where the context is helpful but does not have an overwhelming influence as the in the original CompositionalNet. Similar as observed in the classification experiments, CompNet-RXT-RB3 performs significantly worse compared to its pool4 variant for artificial occluders (Table 5), whereas it performs similarly under real occlusion (Table 6). We will discuss this phenomenon in more detail in Section 6.4.1.
6.4 Model Interpretability
While it is important that computer vision systems can robustly generalize to out-of-distribution examples in terms of partial occlusion, in real-world applications it is equally important that their prediction result is human interpretable. In this section, we show that CompositionalNets are highly interpretable models. We demonstrate that they can localize occluders accurately in image classification and object detection (Section 6.4.1), while being trained with class-level supervision only. Furthermore, we show that the predictions of CompositionalNets can be understood in terms of detecting object parts (Section 6.4.2) and estimating the objects’ viewpoint (Section 6.4.3).
6.4.1 Occluder Localization
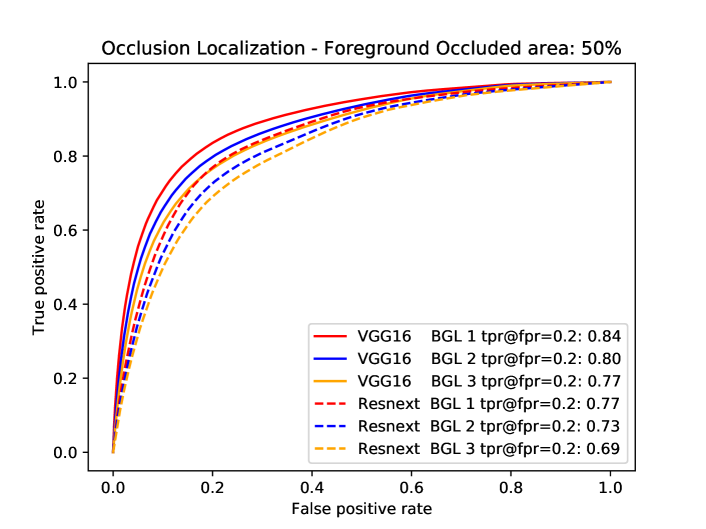
A successful localization of occluders increases the robustness of a model to partial occlusion and also enables a human observer to better understand a models’ underlying reasoning process. In the following, we test the ability of CompositionalNets at occluder localization. We compute the occlusion score as the log-likelihood ratio between the occluder model and the object model: , where is the mixture component that explains the feature activations of the DCNN backbone the best.
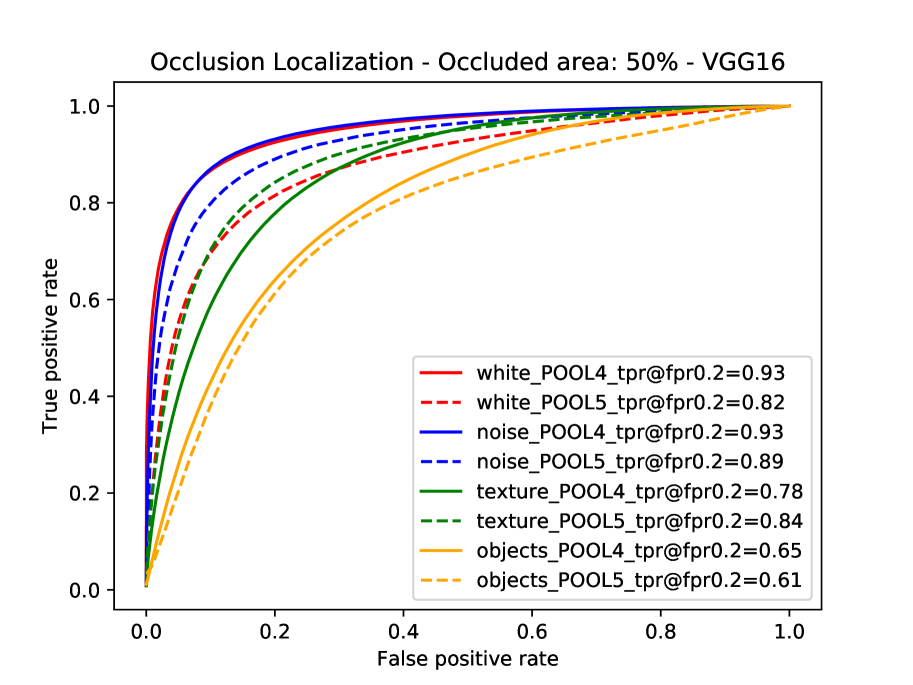
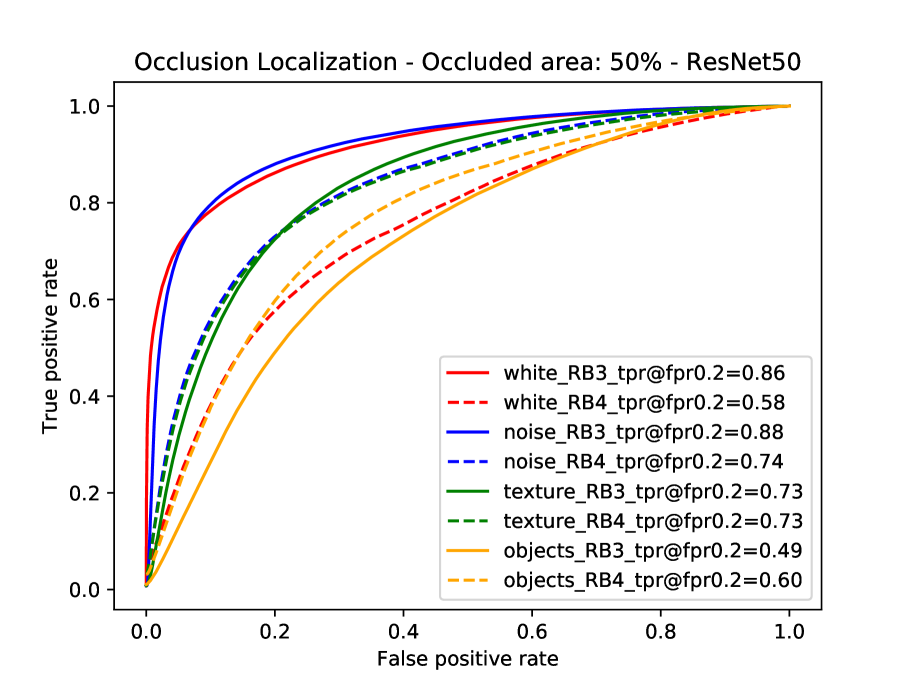
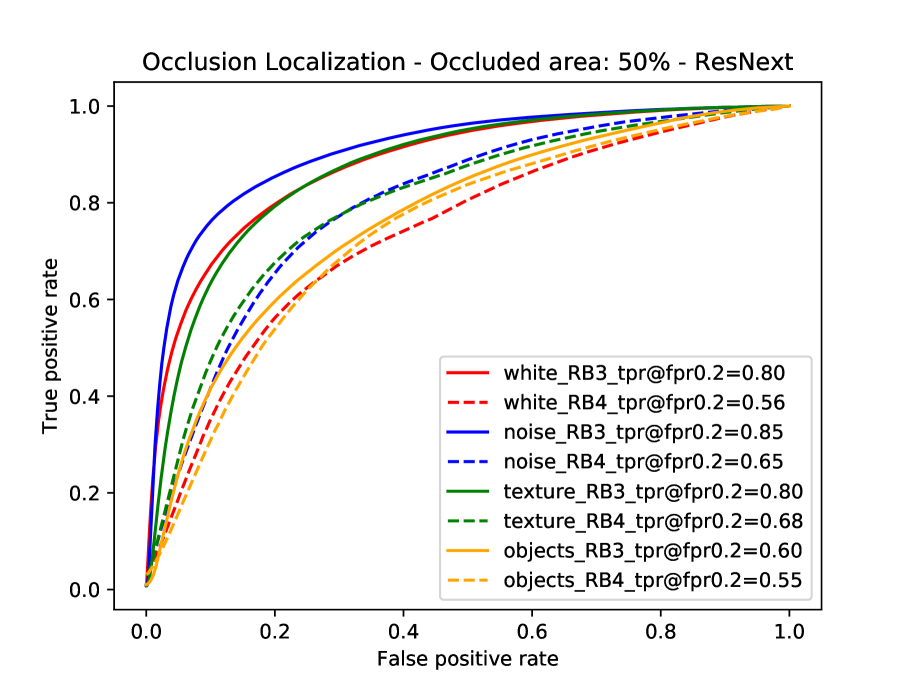
Occluder localization in image classification. We study occluder localization quantitatively (Figure 12) for correctly classified images from the Occluded-P3D+-Vehicles dataset using the ground truth segmentation masks of the occluders and the objects. We show qualitative results in Figure 14b. The evaluation is done on the occlusion level , hence a pixel on the object will be occluded with chance. We evaluate CompositionalNets learned from different DCNN backbones (VGG-16, ResNet50, ResNext) from the last and second-last layer before the classifier. All models were trained for classifying non-occluded vehicles of the PASCAL3D+ dataset (classification performance can be seen in Table 1).
In general, we can observe from the ROC curves in Figure 12 that CompositionalNets can localize occluders accurately, although there are differences in terms of their performance. Furthermore, we observe that it is more difficult for the models to localize natural object occluders compared to box-shaped occluders, probably because of the fine-grained irregular shape of objects.
Insights into robustness to partial occlusion in neural networks. When comparing our experimental results at image classification and occluder localization in more detail, we make four interesting observations:
-
1.
CompositionalNets learned from the lower layers of a backbone (pool4 and RB3) can consistently localize occluders more accurately when compared to models learned from higher layers of the same backbone.
- 2.
-
3.
The performance of CompositionalNets with residual backbones is higher on images with real occlusion, compared to those with artificial object occluders. In contrast, we observe the opposite for CompositionalNets learned from the VGG backbone.
-
4.
The ability to localize occluders more accurately does not directly translate into a superior performance at classifying partially occluded objects (Table 1). For example all three high-level models perform similarly at localizing “object“ occluders, nevertheless CompNet-ResNext-RB4 performs more than better at classifying images with these types of occluders at level compared to the other models. This phenomenon can also be observed for the “white box“ occluders, which CompNet-ResNext cannot localize as accurately as CompNet-VGG16-pool5, while their performance is on par at level .
In general, neural networks can exploit two complementary approaches to achieve robustness to occlusion, depending on the backbone architecture: (A1) When the backbone is powerful enough, the features can become robust to occlusion, in a similar way as they are robust to illumination or viewpoint changes. Hence, by using a powerful feature extractor, residual models can achieve a very high classification performance even when using a rather simple classifier (global average pooling and one fully-connected layer. (A2) When the backbone cannot learn features that are robust to occlusion, then a more complex classifier is required, such as the multiple fully-connected layers in the VGG network.
Based on this intuition, our experimental results for occluder localization and object recognition lead us to the following conjecture: Using powerful residual backbones, CompositionalNets achieve high classification performance, because of the highly discriminative features. However, they cannot localize the occluders as accurately, because the robustness to occlusion makes it difficult to distinguish between occluded and non-occluded features. In contrast, CompositionalNets based on the VGG backbone can localize the occluders well, because the features are not robust to occlusion. However, those CompositionalNets do not achieve the highest classification performance because the features are less discriminative compared to those of the residual backbones. Furthermore, the lower layers in neural networks typically exhibit less invariance. Therefore, CompositionalNets learned from those layer can consistently achieve better localization performance compared to those learned from higher layers of the same backbone. Finally, CompositionalNets with residual backbones rely more on invariance then on occluder localization. They perform better on real data, because the they rely on invariant features that were learned during ImageNet pre-training. This invariance does do not generalize well to the artificial occluders, therefore their performance is lower compared to the real occlusion scenario. In contrast, CompositionalNets learned from VGG rely less on invariance to occlusion and more on occluder localization. As the artificial occluders are easier to localize, their performance is higher on artificially generated occlusions compared to the real data.
In general, replacing the standard classifiers with compositional models increases the classification performance under occlusion for all models and also enables them to localize occluders. However, the ability to localize occluders and the final classification performance are at odds with each other, depending on the extent to which the features are invariant to occlusion.
Occluder localization in object detection. Figure 13 illustrates the ROC curve of a context-aware CompNet-VGG16-pool4 and CompNet-RXT-RB3 for successfully detected objects. We can observe that they can predict occluded regions accurately. Furthermore, the performance increases compared to the classification experiments as the context-awareness reduces false-positive detections in the background regions. In Figure 14a, we show qualitative results of a context-aware CompNet-VGG16-pool4 at occluder localization in object detection. We illustrate results for artificially occluded objects and real occlusions from the MS-COCO dataset, in which the CompositionalNet could successfully locate the objects. Overall, the model can locate occluders with high accuracy, despite their large variability in terms of appearance and shape. Note how the shape of the occluders is outlined accurately, although the localization is done for each pixel in the feature map independently. In summary, we observe that the occluder localization results for object detection are consistent with those for image classification, in that they confirm the ability of CompositionalNets at localizing occluders accurately.














6.4.2 Interpretation of vMF Kernels




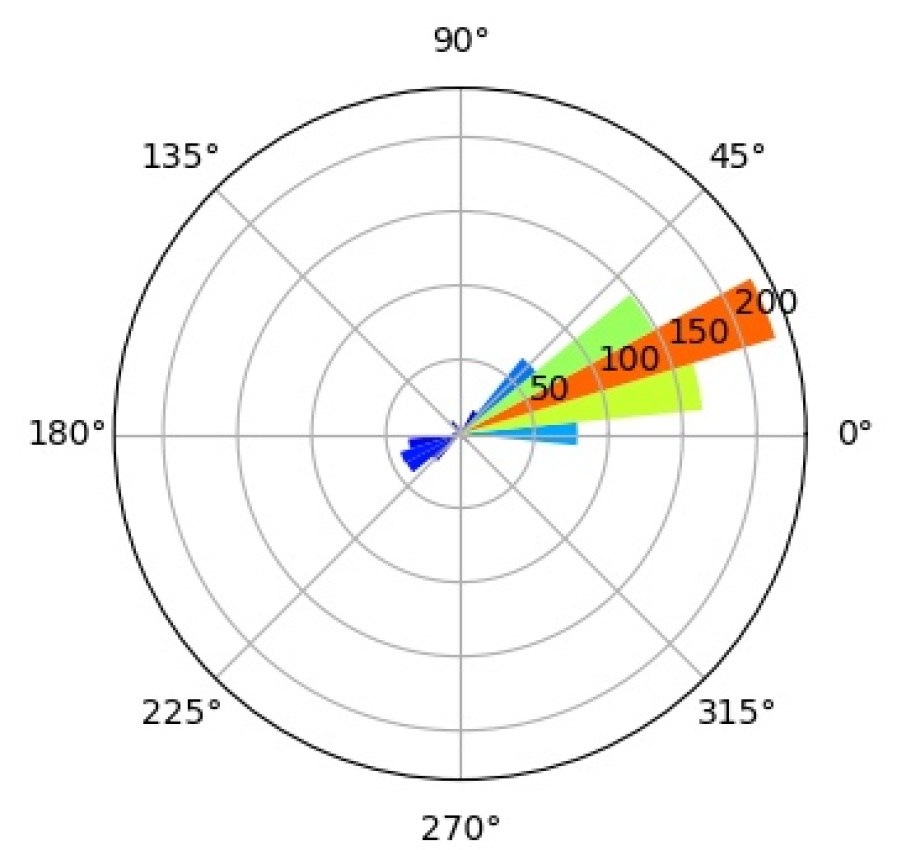
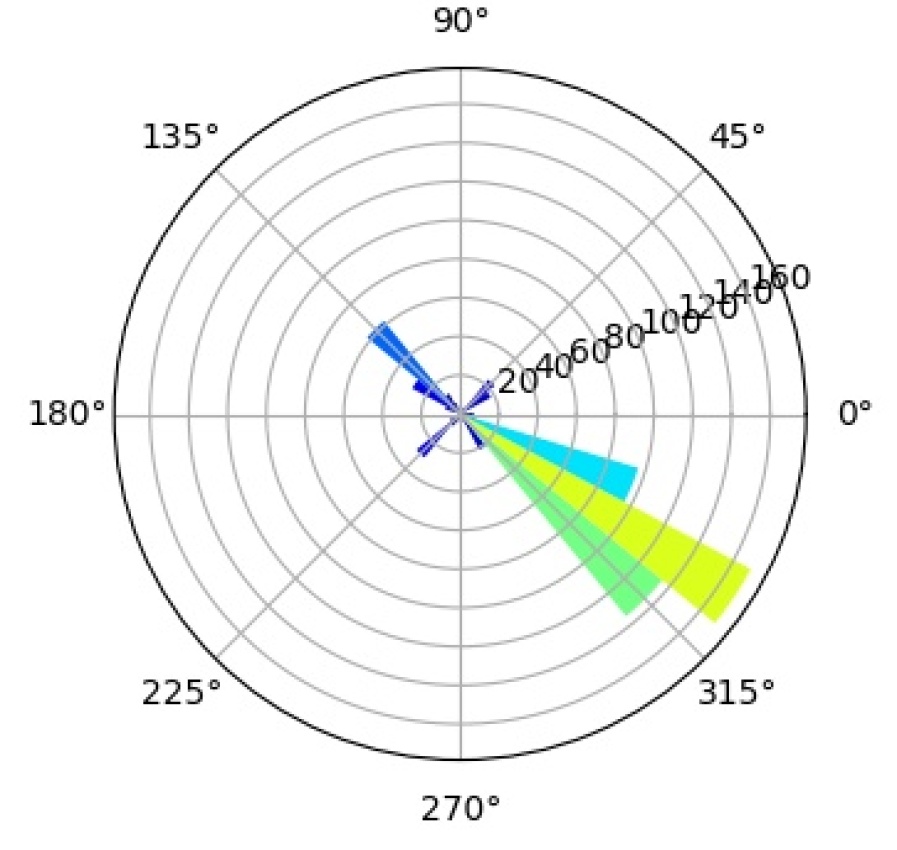




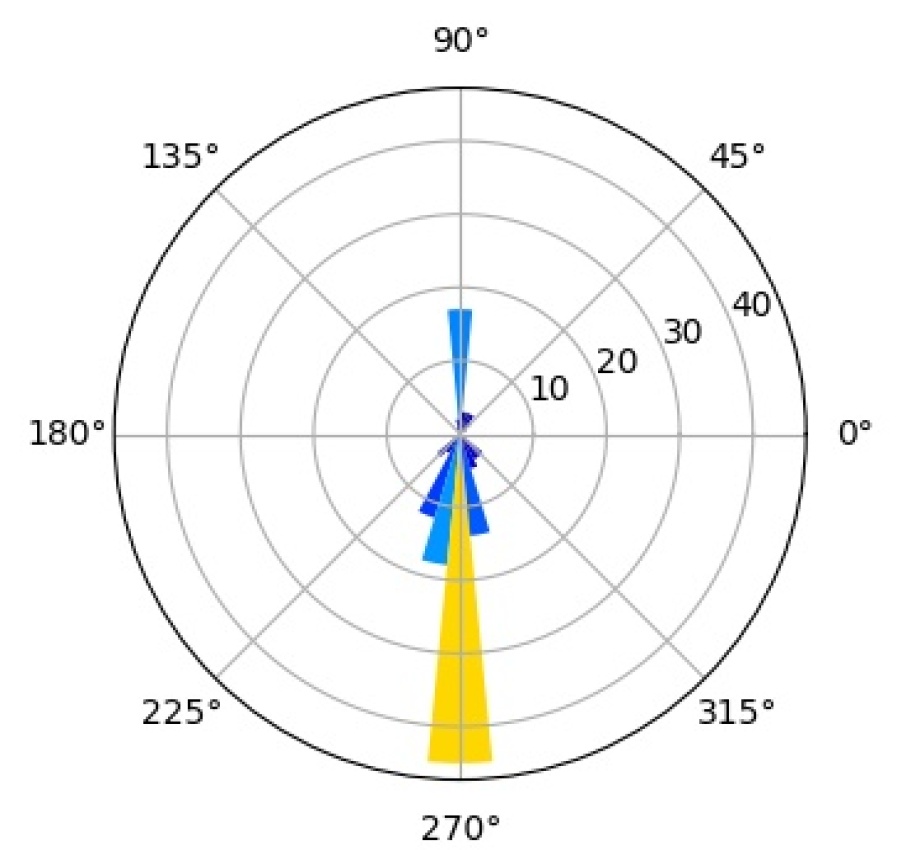
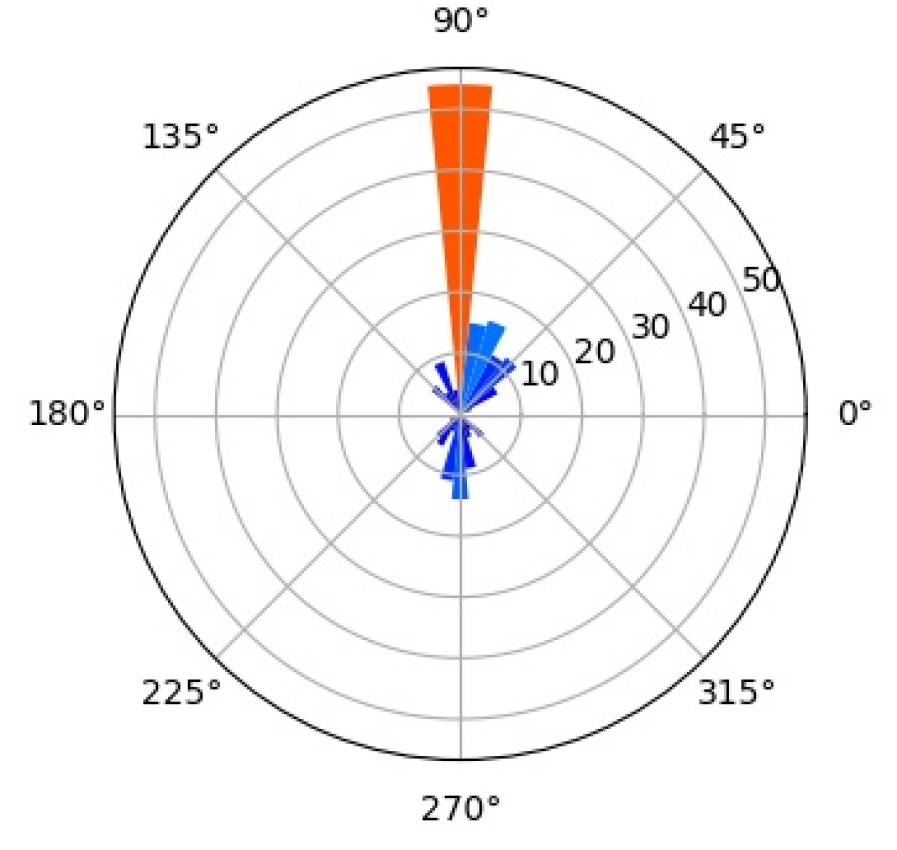
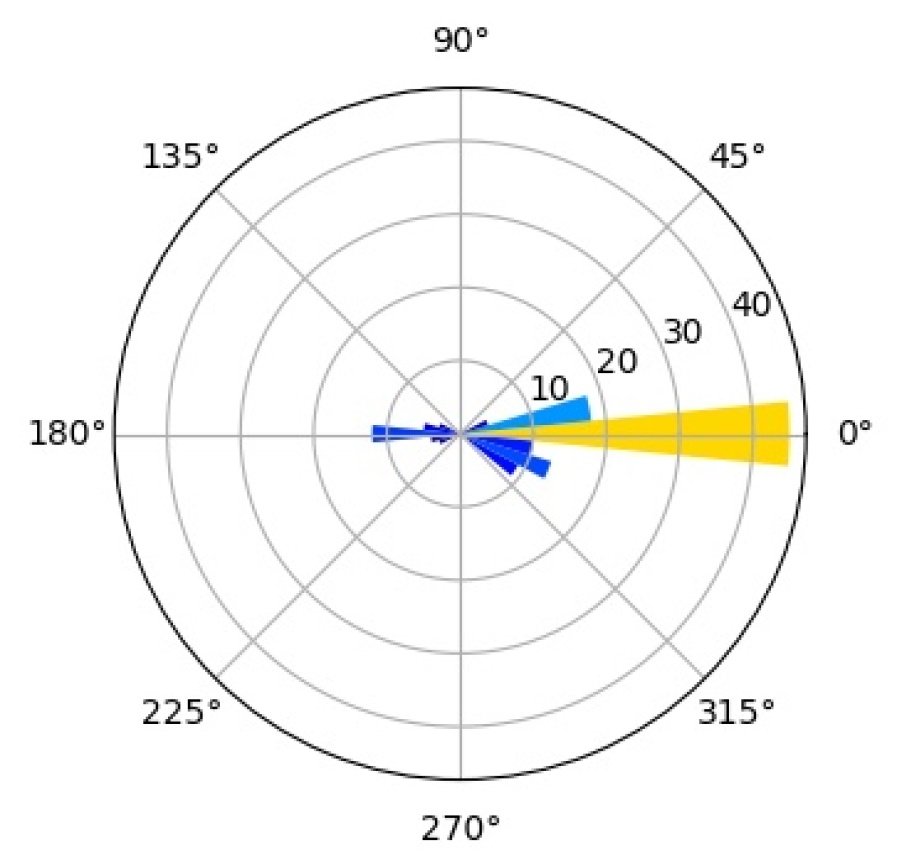
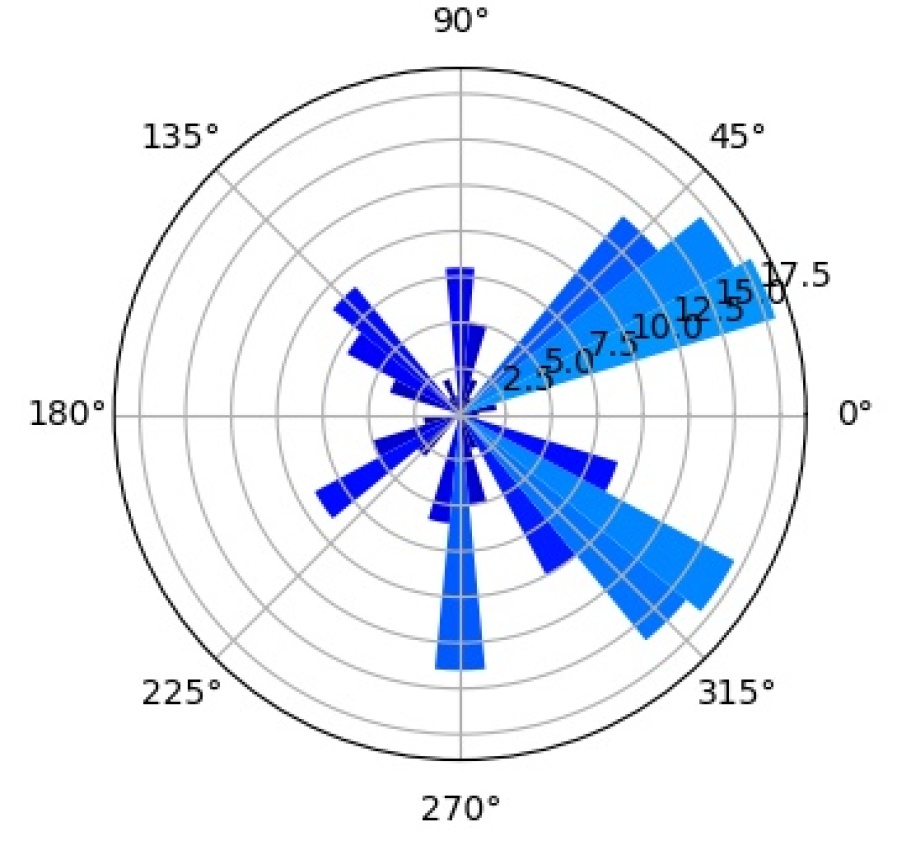




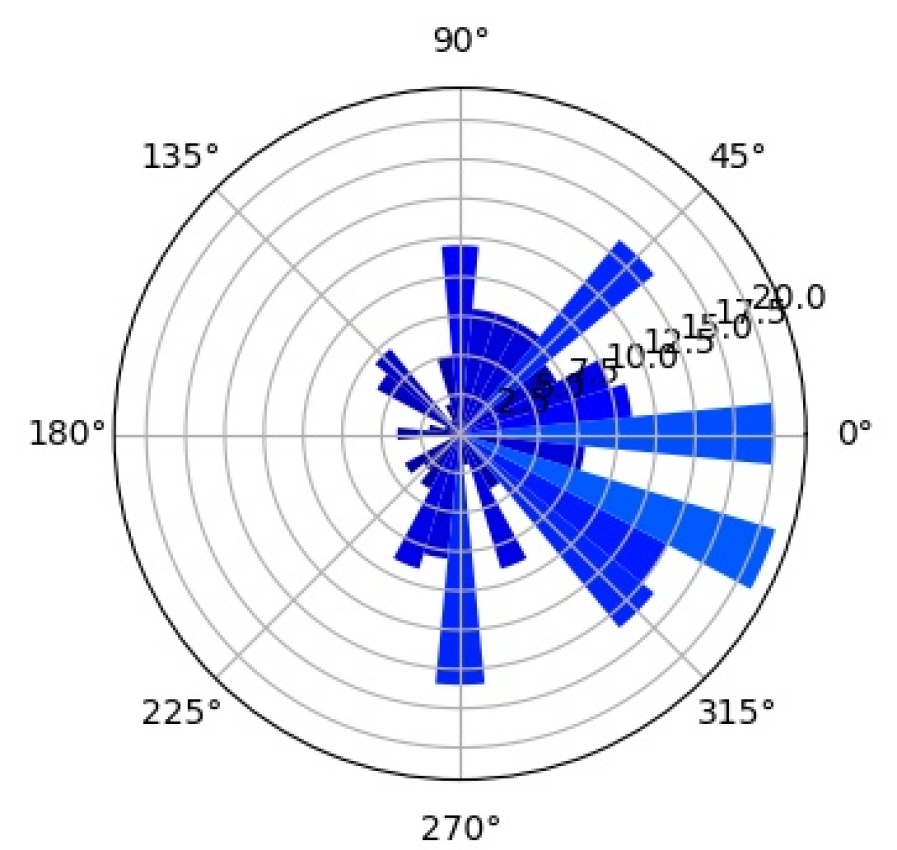
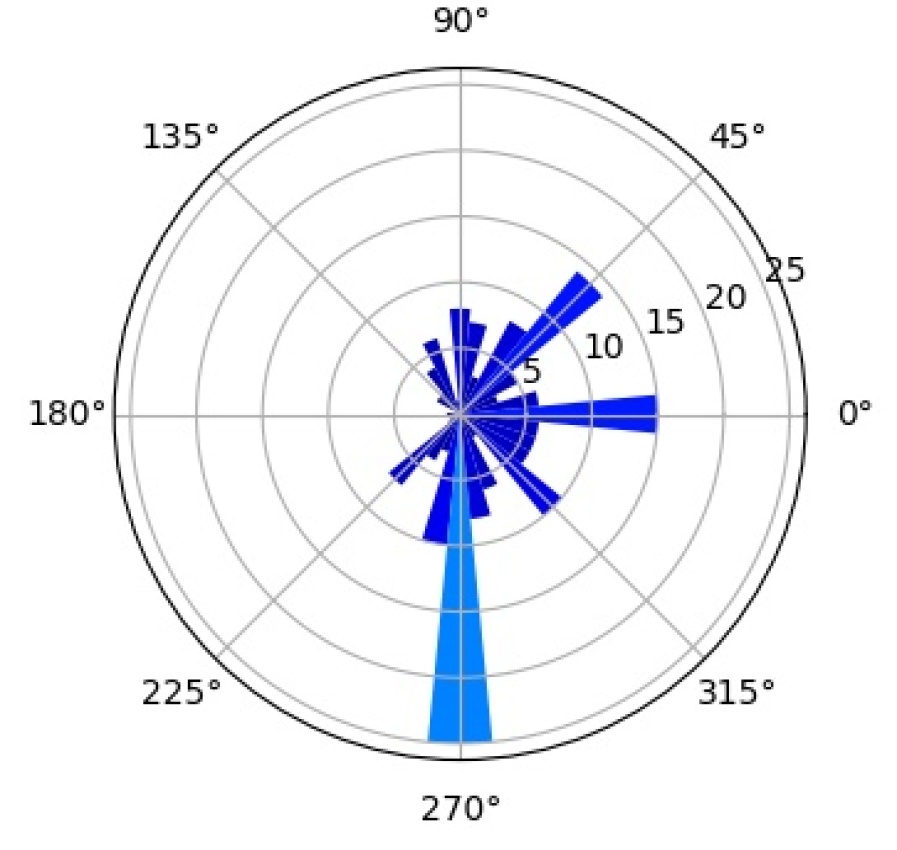




We further investigate the interpretability of our CompositionalNets using network dissection as proposed by bau2017network . In short, network dissection looks at the top activation of the hidden units and correlates them with a large range of human labeled visual concepts in the Broden dataset. Most of the concepts are annotated as segmentation mask with input resolution and the activation maps are up-scaled to the same size to calculate the intersection over union (IoU) scores. By setting a threshold for the best matched score, Network Dissection studies the latent representations of various layers in a network. Since CompositionalNets are unifying part-based compositional models with deep neural networks, intuitively we expect to see the hidden units in CompositionalNets to be more correlated with visual concepts of parts, since the models evaluated are trained for classifying vehicles in PASCAL3D+, we expect to see more vehicle related parts emerge.
For the experiment, we adopt the code from the authors of bau2017network and use most default settings, except that we change the testing categories into “part” only. This means that during the hidden unit and visual concepts correlation test, only classes from the part category are involved. Note that these classes include both vehicle parts (e.g., windowpane, wheel, stern, etc.) and non-vehicle ones (e.g., hair, torso, muzzle, etc.).
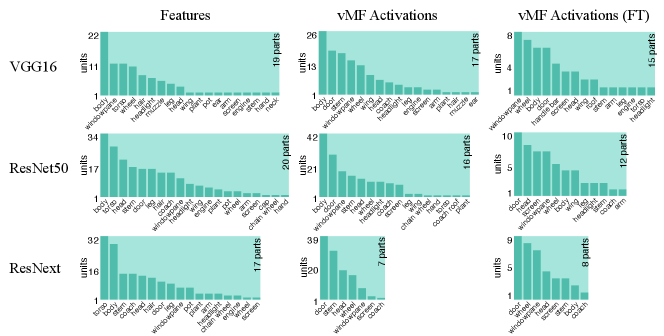
As aforementioned, we expect to see the hidden units in CompositionalNets to be highly correlated with vehicle related parts. More specifically, we are interested in studying (1) what part concepts are correlated with the units before and after vMF kernels, and (2) how the end-to-end training affects these correlations. In Figure 15, we examine three different backbone architectures, one in each row, and three different types of hidden units, one in each column. “Features” are the hidden units from the layer before the vMF kernel, which is pool5 for VGG16 and the residual block four (RB4) layer for ResNet50 and ResNext, all with weights initialized from ImageNet pretrained models. “vMF Activations” are the units right after the vMF kernel, where the kernel weights are initialized by clustering as described in Section 3. “vMF Activations (FT)” shows the same units after the end-to-end fine-tuning. In the barplots, the horizontal axis lists the parts with scores above the threshold, while the vertical axis shows the number of hidden units that are correlated with a specific part.
Comparing the “Features” versus the “vMF Activations”, we observe that the vMF kernels indeed help the hidden units to be more concentrated on the vehicle related parts. The non-vehicle parts, such as “pot” and “cap”, are removed while more units become correlated with vehicle ones, like “door” and “stern”. However, this might also introduce a lot of redundancy in the representation and hence a waste of computational resources. When comparing “vMF Activations” with “vMF Activations (FT)”, we find that not only some non-vehicle parts are further removed, the number of units correlated to each vehicle part is also reduced. This indicates the training may help the vMF kernels to recognize more diverse part representations and reduce the redundancy in the representation.
It is worth mentioning that the annotation of parts in the Broden dataset is coarse and not specific for different object classes, e.g., windowpane is shared for car, airplane, and house, etc.. Therefore, it may not match the internal representations learned by the CompositionalNets. Nevertheless, the results support our conjecture observed in Figure 2 that the vMF kernels work as part detectors and CompositionalNets learn part representations without supervision.
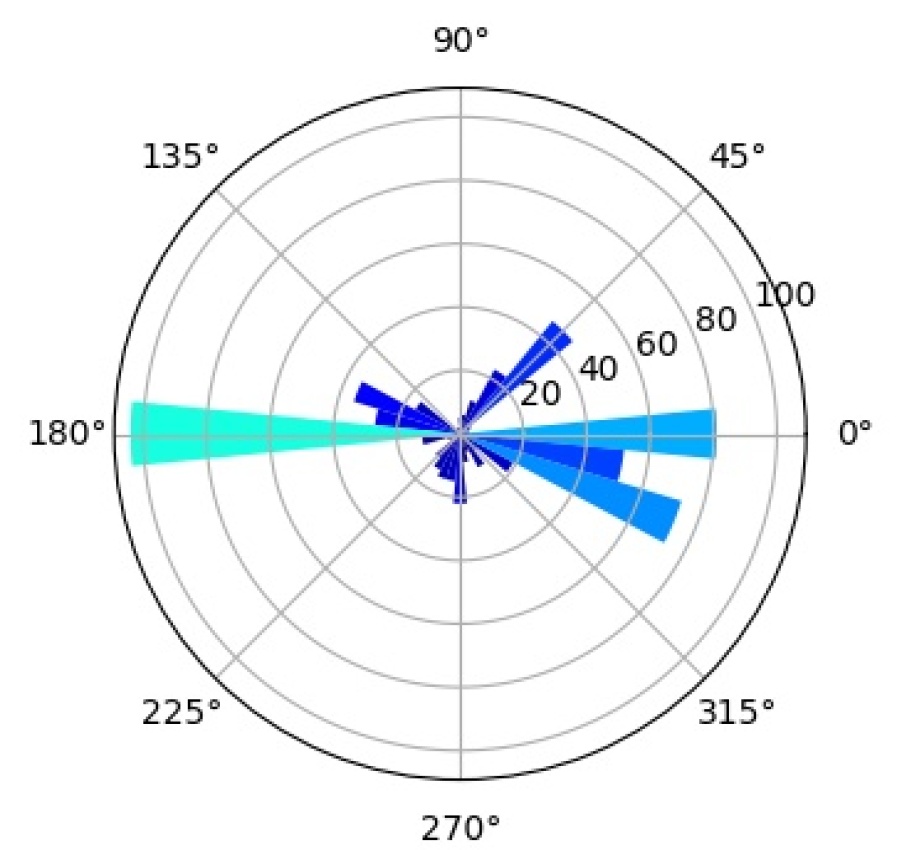
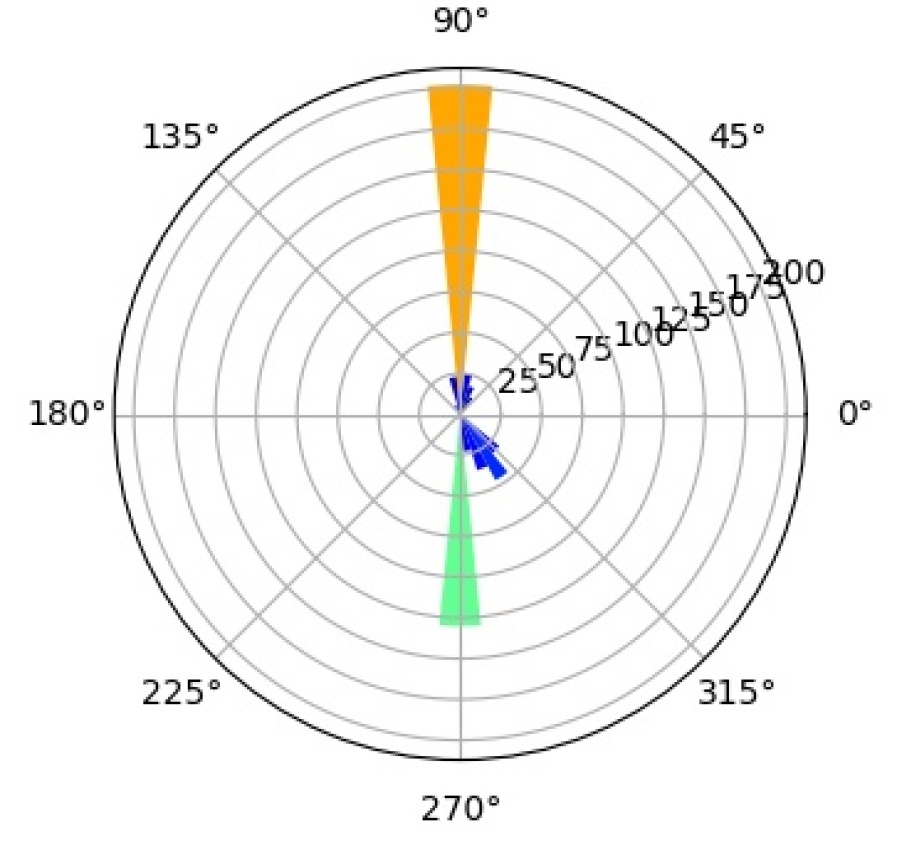
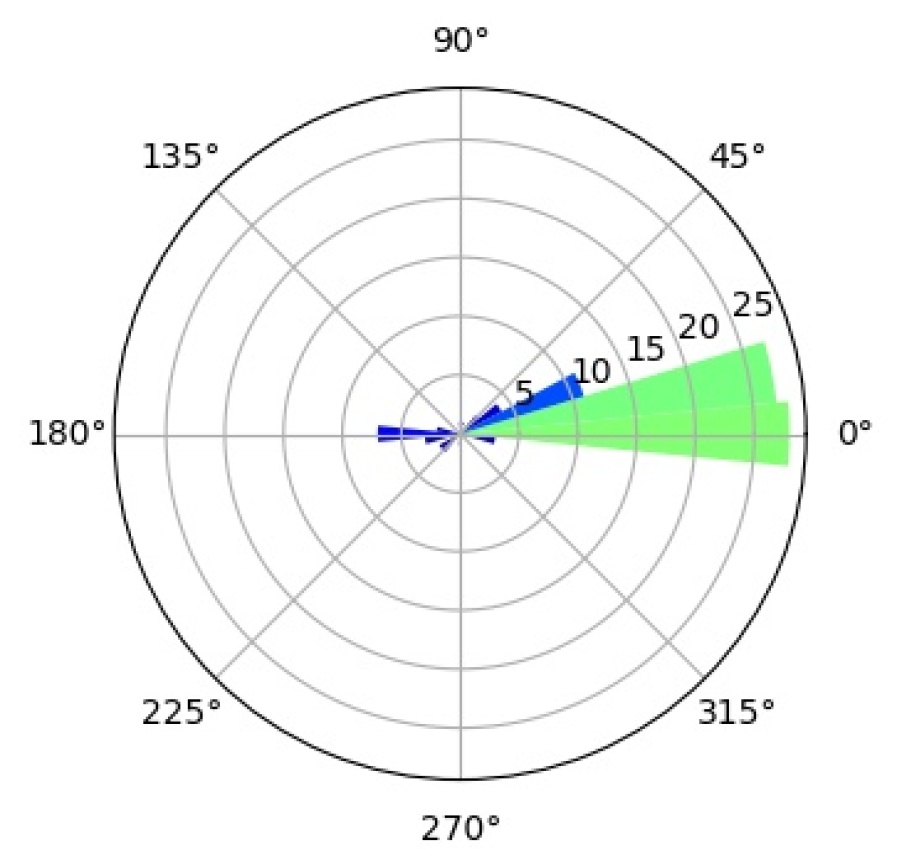
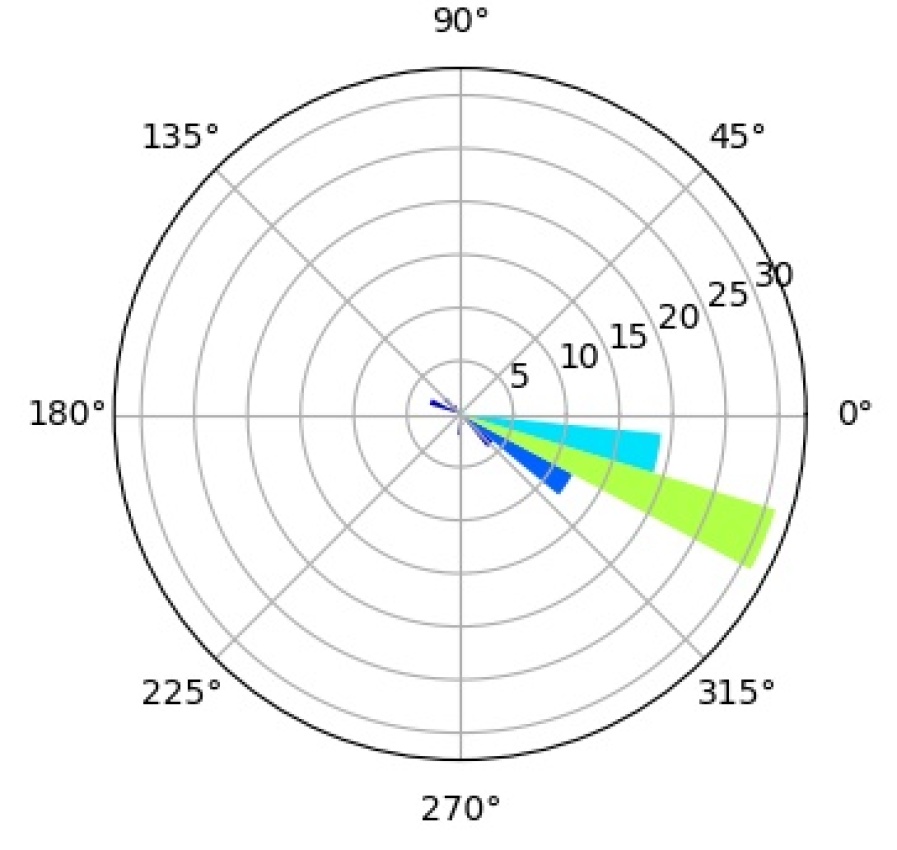
6.4.3 Interpretation of Mixture Components
In an effort to better understand the inner workings of CompositionalNets we study what the individual mixture components have learned to represent during training. We study a CompNet-VGG16-pool5 with mixture components, but the following analysis gives very similar results for other CompositionalNet architectures.
Each mixture component is by design of the training process specific to a particular object class. We have already shown that the vMF kernels are responsive to individual object parts (see Section 6.4.2 and Figure 2). During training the mixture components are learned by clustering of the spatial activation patterns of vMF kernel activations. As the spatial distribution of parts of an object varies significantly with changes in the object pose, the mixture components become specific to certain viewpoints of the objects. We illustrate this property of CompositionalNets in Figure 16 by showing the training images with highest likelihood in each mixture. Furthermore, we illustrate the histogram of poses for all training images in each mixture components as bar plots (using the pose annotations in the PASCAL3D+ dataset). As vehicles in natural images mostly vary in terms of their azimuth angle, we restrict the plots to this angle only. Each bar plot shows the distributions of azimuth angles in the range of degrees. The length of the bars is normalized such that the longest bar indicates the most frequent azimuth angle within each mixture. The color of the bar is selected from the colormap “jet“ and normalized such that the maximal value (dark red) is equivalent to more than of the total number of training images for a particular class. We can observe from Figure 16 that for the classes “car“, “bicycle“ and “bus“ the mixture components are very specific to objects in a certain azimuth angle. Note that this happens despite a significant variability in the objects’ appearance and backgrounds.
In contrast, for the class “airplane“ the pose distribution is less viewpoint specific. We think that the reason is that airplanes naturally vary in terms of several pose angles, in contrast to vehicles on the street which vary mostly in terms of their azimuth angle w.r.t. the camera. As the number of mixture components is fixed a-priori it is difficult for the model to become specific to a certain pose during maximum likelihood learning from the data. In future work, it would therefore be useful to explore unsupervised strategies for determining the number of mixture components per class based on the training data.
7 Conclusion
In this work, we studied the problem of generalizing beyond the training data in terms of partial occlusion. We showed that current approaches to computer vision based on deep learning fail to generalize to out-of-distribution examples in terms of partial occlusion. In an effort to overcome this fundamental limitation we made several important contributions:
-
•
We introduced Compositional Convolutional Neural Networks - a deep model that unifies compositional part-based representations and deep convolutional neural networks (DCNNs). In particular we replace the fully connected classification head of DCNNs with a differentiable generative compositional model.
-
•
We demonstrated that CompositionalNets built from a variety of popular DCNN architectures (VGG16, ResNet50 and ResNext) have a significantly increased ability to robustly classify out-of-distribution data in terms of partial occlusion compared to their non-compositional counterparts.
-
•
We found that a robust detection of partially occluded objects requires a separation of the representation of the objects’ context from that of the object itself. We proposed context-aware CompositionalNets that are learned from image segmentations obtained using bounding box annotations and showed that context-awareness increases robustness to partial occlusion in object detection.
-
•
We found that CompositionalNets can exploit two complementary approaches to achieve robustness to partial occlusion: learning features that are invariant to occlusion, or localizing and discarding occluders during classification. We showed that CompositionalNets that combine both approaches achieve the highest robustness to partial occlusion.
Furthermore, we showed that CompositionalNets learned from class-label supervision only develop a number of intriguing properties in terms of model interpretability:
-
•
We showed that CompositionalNets can localize occluders accurately and that the DCNN backbone has a significant influence on this ability.
-
•
Qualitative and quantitative results show that CompositionalNets learn meaningful par representations. This enables them to recognize objects based on the spatial configuration of a few visible parts.
-
•
Qualitative and quantitative results show that the mixture components in CompositionalNets are viewpoint specific.
-
•
In summary, the predictions of CompositionalNets are highly interpretable in terms of where the model thinks the object is occluded and where the model perceives the individual object parts as well as the objects viewpoint.
Our experimental results also hint at important future research directions. We observed that a good occluder localization is add odds with classification performance, because classification benefits from features that are invariant to occlusion, whereas occluder localization requires features to be sensitive to occlusion. We believe that it is important to resolve this trade-off wit new types of models that achieve high classification performance while also being able to localize occluders accurately. Furthermore, we observed that defining the number of mixture components a-priori fails to account for the fact that different objects can have significantly different pose variability. We think unsupervised approaches for determining the number of mixture components are needed to enable the adaptive adjustment of the complexity of the object representation in CompositionalNets.
References
- (1) Alain, G., Bengio, Y.: Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644 (2016)
- (2) Arthur, D., Vassilvitskii, S.: k-means++: The advantages of careful seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms (2007)
- (3) Banerjee, A., Dhillon, I.S., Ghosh, J., Sra, S.: Clustering on the unit hypersphere using von mises-fisher distributions. Journal of Machine Learning Research 6(Sep), 1345–1382 (2005)
- (4) Bau, D., Zhou, B., Khosla, A., Oliva, A., Torralba, A.: Network dissection: Quantifying interpretability of deep visual representations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6541–6549 (2017)
- (5) Brendel, W., Bethge, M.: Approximating cnns with bag-of-local-features models works surprisingly well on imagenet. arXiv preprint arXiv:1904.00760 (2019)
- (6) Cai, Z., Vasconcelos, N.: Cascade r-cnn: Delving into high quality object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6154–6162 (2018)
- (7) Chen, Y., Zhu, L., Lin, C., Zhang, H., Yuille, A.L.: Rapid inference on a novel and/or graph for object detection, segmentation and parsing. In: Advances in neural information processing systems, pp. 289–296 (2008)
- (8) Dai, J., Hong, Y., Hu, W., Zhu, S.C., Nian Wu, Y.: Unsupervised learning of dictionaries of hierarchical compositional models. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2505–2512 (2014)
- (9) Dechter, R., Mateescu, R.: And/or search spaces for graphical models. Artificial intelligence 171(2-3), 73–106 (2007)
- (10) Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee (2009)
- (11) DeVries, T., Taylor, G.W.: Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552 (2017)
- (12) Economist, T.: Why uber’s self-driving car killed a pedestrian (2017)
- (13) Fawzi, A., Frossard, P.: Measuring the effect of nuisance variables on classifiers. Tech. rep. (2016)
- (14) Fidler, S., Boben, M., Leonardis, A.: Learning a hierarchical compositional shape vocabulary for multi-class object representation. arXiv preprint arXiv:1408.5516 (2014)
- (15) Fong, R., Vedaldi, A.: Net2vec: Quantifying and explaining how concepts are encoded by filters in deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8730–8738 (2018)
- (16) George, D., Lehrach, W., Kansky, K., Lázaro-Gredilla, M., Laan, C., Marthi, B., Lou, X., Meng, Z., Liu, Y., Wang, H., et al.: A generative vision model that trains with high data efficiency and breaks text-based captchas. Science 358(6368), eaag2612 (2017)
- (17) Girshick, R.: Fast r-cnn. In: Proceedings of the IEEE international conference on computer vision, pp. 1440–1448 (2015)
- (18) Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 580–587 (2014)
- (19) Girshick, R., Iandola, F., Darrell, T., Malik, J.: Deformable part models are convolutional neural networks. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 437–446 (2015)
- (20) He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778 (2016)
- (21) Hu, Z., Ma, X., Liu, Z., Hovy, E., Xing, E.: Harnessing deep neural networks with logic rules. arXiv preprint arXiv:1603.06318 (2016)
- (22) Huber, P.J.: Robust statistics. Springer (2011)
- (23) Jian Sun, Y.L., Kang, S.B.: Symmetric stereo matching for occlusion handling. IEEE Conference on Computer Vision and Pattern Recognition (2018)
- (24) Jin, Y., Geman, S.: Context and hierarchy in a probabilistic image model. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), vol. 2, pp. 2145–2152. IEEE (2006)
- (25) Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
- (26) Kortylewski, A.: Model-based image analysis for forensic shoe print recognition. Ph.D. thesis, University_of_Basel (2017)
- (27) Kortylewski, A., He, J., Liu, Q., Yuille, A.: Compositional convolutional neural networks: A deep architecture with innate robustness to partial occlusion. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2020)
- (28) Kortylewski, A., Liu, Q., Wang, H., Zhang, Z., Yuille, A.: Combining compositional models and deep networks for robust object classification under occlusion. arXiv preprint arXiv:1905.11826 (2019)
- (29) Kortylewski, A., Vetter, T.: Probabilistic compositional active basis models for robust pattern recognition. In: British Machine Vision Conference (2016)
- (30) Kortylewski, A., Wieczorek, A., Wieser, M., Blumer, C., Parbhoo, S., Morel-Forster, A., Roth, V., Vetter, T.: Greedy structure learning of hierarchical compositional models. arXiv preprint arXiv:1701.06171 (2017)
- (31) Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, pp. 1097–1105 (2012)
- (32) Lampert, C.H., Blaschko, M.B., Hofmann, T.: Beyond sliding windows: Object localization by efficient subwindow search. In: 2008 IEEE conference on computer vision and pattern recognition, pp. 1–8. IEEE (2008)
- (33) Le, Q.V.: Building high-level features using large scale unsupervised learning. In: 2013 IEEE international conference on acoustics, speech and signal processing, pp. 8595–8598. IEEE (2013)
- (34) Li, A., Yuan, Z.: Symmnet: A symmetric convolutional neural network for occlusion detection. British Machine Vision Conference (2018)
- (35) Li, X., Song, X., Wu, T.: Aognets: Compositional grammatical architectures for deep learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6220–6230 (2019)
- (36) Li, Y., Li, B., Tian, B., Yao, Q.: Vehicle detection based on the and–or graph for congested traffic conditions. IEEE Transactions on Intelligent Transportation Systems 14(2), 984–993 (2013)
- (37) Liao, R., Schwing, A., Zemel, R., Urtasun, R.: Learning deep parsimonious representations. In: Advances in Neural Information Processing Systems, pp. 5076–5084 (2016)
- (38) Lin, L., Wang, X., Yang, W., Lai, J.H.: Discriminatively trained and-or graph models for object shape detection. IEEE Transactions on pattern analysis and machine intelligence 37(5), 959–972 (2014)
- (39) Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision, pp. 740–755. Springer (2014)
- (40) Mahendran, A., Vedaldi, A.: Understanding deep image representations by inverting them. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5188–5196 (2015)
- (41) Montavon, G., Samek, W., Müller, K.R.: Methods for interpreting and understanding deep neural networks. Digital Signal Processing 73, 1–15 (2018)
- (42) Narasimhan, N.D.R.M.V.S.G.: Occlusion-net: 2d/3d occluded keypoint localization using graph networks. IEEE Conference on Computer Vision and Pattern Recognition (2019)
- (43) Nguyen, A., Dosovitskiy, A., Yosinski, J., Brox, T., Clune, J.: Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. In: Advances in Neural Information Processing Systems, pp. 3387–3395 (2016)
- (44) Nilsson, N.J., et al.: Principles of artificial intelligence (1980)
- (45) Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. In: Advances in neural information processing systems, pp. 91–99 (2015)
- (46) Ross, A.S., Hughes, M.C., Doshi-Velez, F.: Right for the right reasons: Training differentiable models by constraining their explanations. arXiv preprint arXiv:1703.03717 (2017)
- (47) Sabour, S., Frosst, N., Hinton, G.E.: Dynamic routing between capsules. In: Advances in neural information processing systems, pp. 3856–3866 (2017)
- (48) Simonyan, K., Vedaldi, A., Zisserman, A.: Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034 (2013)
- (49) Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
- (50) Song, X., Wu, T., Jia, Y., Zhu, S.C.: Discriminatively trained and-or tree models for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3278–3285 (2013)
- (51) Stone, A., Wang, H., Stark, M., Liu, Y., Scott Phoenix, D., George, D.: Teaching compositionality to cnns. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5058–5067 (2017)
- (52) Tabernik, D., Kristan, M., Wyatt, J.L., Leonardis, A.: Towards deep compositional networks. In: 2016 23rd International Conference on Pattern Recognition (ICPR), pp. 3470–3475. IEEE (2016)
- (53) Tang, W., Yu, P., Wu, Y.: Deeply learned compositional models for human pose estimation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 190–206 (2018)
- (54) Tang, W., Yu, P., Zhou, J., Wu, Y.: Towards a unified compositional model for visual pattern modeling. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2784–2793 (2017)
- (55) Wang, A., Sun, Y., Kortylewski, A., Yuille, A.: Robust object detection under occlusion with context-aware compositionalnets. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2020)
- (56) Wang, J., Xie, C., Zhang, Z., Zhu, J., Xie, L., Yuille, A.: Detecting semantic parts on partially occluded objects. arXiv preprint arXiv:1707.07819 (2017)
- (57) Wang, J., Zhang, Z., Xie, C., Premachandran, V., Yuille, A.: Unsupervised learning of object semantic parts from internal states of cnns by population encoding. arXiv preprint arXiv:1511.06855 (2015)
- (58) Wang, J., Zhang, Z., Xie, C., Zhou, Y., Premachandran, V., Zhu, J., Xie, L., Yuille, A.: Visual concepts and compositional voting. arXiv preprint arXiv:1711.04451 (2017)
- (59) Wu, T., Li, B., Zhu, S.C.: Learning and-or model to represent context and occlusion for car detection and viewpoint estimation. IEEE transactions on pattern analysis and machine intelligence 38(9), 1829–1843 (2015)
- (60) Xia, F., Zhu, J., Wang, P., Yuille, A.L.: Pose-guided human parsing by an and/or graph using pose-context features. In: Thirtieth AAAI Conference on Artificial Intelligence (2016)
- (61) Xiang, Y., Mottaghi, R., Savarese, S.: Beyond pascal: A benchmark for 3d object detection in the wild. In: IEEE Winter Conference on Applications of Computer Vision, pp. 75–82. IEEE (2014)
- (62) Xiang, Y., Savarese, S.: Object detection by 3d aspectlets and occlusion reasoning. IEEE International Conference on Computer Vision (2013)
- (63) Xiao, M., Kortylewski, A., Wu, R., Qiao, S., Shen, W., Yuille, A.: Tdapnet: Prototype network with recurrent top-down attention for robust object classification under partial occlusion. arXiv preprint arXiv:1909.03879 (2019)
- (64) Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1492–1500 (2017)
- (65) Yan, S., Liu, Q.: Inferring occluded features for fast object detection. Signal Processing, Volume 110 (2015)
- (66) Yuille, A.L., Liu, C.: Deep nets: What have they ever done for vision? arXiv preprint arXiv:1805.04025 (2018)
- (67) Yun, S., Han, D., Oh, S.J., Chun, S., Choe, J., Yoo, Y.: Cutmix: Regularization strategy to train strong classifiers with localizable features. arXiv preprint arXiv:1905.04899 (2019)
- (68) Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks. In: European conference on computer vision, pp. 818–833. Springer (2014)
- (69) Zhang, Q., Nian Wu, Y., Zhu, S.C.: Interpretable convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8827–8836 (2018)
- (70) Zhang, Q.s., Zhu, S.C.: Visual interpretability for deep learning: a survey. Frontiers of Information Technology & Electronic Engineering 19(1), 27–39 (2018)
- (71) Zhang, S., Wen, L., Bian, X., Lei, Z., Li, S.Z.: Occlusion-aware r-cnn: detecting pedestrians in a crowd pp. 637–653 (2018)
- (72) Zhang, Z., Xie, C., Wang, J., Xie, L., Yuille, A.L.: Deepvoting: A robust and explainable deep network for semantic part detection under partial occlusion. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1372–1380 (2018)
- (73) Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Object detectors emerge in deep scene cnns. In: ICLR (2015)
- (74) Zhu, H., Tang, P., Park, J., Park, S., Yuille, A.: Robustness of object recognition under extreme occlusion in humans and computational models. CogSci Conference (2019)
- (75) Zhu, L., Chen, Y., Lu, Y., Lin, C., Yuille, A.: Max margin and/or graph learning for parsing the human body. In: 2008 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE (2008)
- (76) Zhu, L.L., Lin, C., Huang, H., Chen, Y., Yuille, A.: Unsupervised structure learning: Hierarchical recursive composition, suspicious coincidence and competitive exclusion. In: Computer vision–eccv 2008, pp. 759–773. Springer (2008)