Comprehensive Saliency Fusion for Object Co-segmentation
Abstract
Object co-segmentation has drawn significant attention in recent years, thanks to its clarity on the expected foreground, the shared object in a group of images. Saliency fusion has been one of the promising ways to carry it out. However, prior works either fuse saliency maps of the same image or saliency maps of different images to extract the expected foregrounds. Also, they rely on hand-crafted saliency extraction and correspondence processes in most cases. This paper revisits the problem and proposes fusing saliency maps of both the same image and different images. It also leverages advances in deep learning for the saliency extraction and correspondence processes. Hence, we call it comprehensive saliency fusion. Our experiments reveal that our approach achieves much-improved object co-segmentation results compared to prior works on important benchmark datasets such as iCoseg, MSRC, and Internet Images.
I Introduction
Object co-segmentation is the task of extracting common objects as foregrounds in a group of images. Compared to the single image segmentation, where it’s difficult to ascertain what’s foreground, we have a clear-cut definition of what foreground we wish to extract in the object co-segmentation task. Rother [1] first introduced the concept of co-segmentation by developing a histogram matching method to extract common parts from a pair of images. However, Vicente [2] were the first to propose that co-segmentation should be about things (or objects) and there is a need to incorporate a measure of objectness in the models. They proposed a Random Forest classifier to find the similarity between a pair of proposed segmentation of objects in each image of a group followed by the A* search algorithm [3] to find the segmented objects with maximum similarity score. The major applications of object co-segmentation include image grouping[4], object recognition[5], and object tracking[6] which are among the fundamental tasks of Computer Vision .
The problem of object co-segmentation is highly correlated to finding the common regions of interest in a group of images. [7, 8] approach the problem of co-segmentation by trying to highlight these common regions of interest. [9] proposed a shortest path algorithm between the salient regions of images, [10] found saliency maps and the computed dense correspondence for all the similar images for obtaining matching scores for pixels across the images. Geometric Mean Saliency (GMS) [7] uses dense SIFT Correspondence [11] for each pair of images to align saliency maps and fuses them. [8] extended [7] by making it more efficient through introducing the key image concept. [12] use saliency prior and superpixels to partition images into foreground and background. They calculate several feature level descriptors on superpixel level and organized in Bag of Words (BoW) to perform clustering of common foregrounds. All of these use single saliency source. Rather than going through the same trend, we propose the usage of multiple saliency sources to benefit from all of them.
In the last decade, there has been a immensely growing interest towards deep learning in the computer vision coomunity, thanks to better availability of computational resources and platforms for large-scale annotations. A large variety of deep neural networks have been proposed for the task of object co-segmentation. [13, 14] use deep siamese networks to perform object co-segmentation. [13] use a pre-trained VGG16 network for feature extraction and pass them to a correlation layer to find the similarities among a pair of images as inspired by Flownet [15]. The features from the encoder are combined with the correspondence obtained from the correlation layer and passed to the siamese decoder to obtain the output co-segmentation masks. [14] developed a similar architecture to perform deep object co-segmentation by passing the global image features obtained from pre-trained VGG16 model to a channel-wise attention model which trains a fully connected network. The output features are then upsampled and sent to a convolution network which acts as a siamese decoder and generates the cosegmentation mask for the input images. Recently, [16] developed a unique deep learning architecture which uses HRNet[17] pre-trained on ImageNet as a backbone to extract image features and then capture the correlation between features using a spatial modulator to generate a mask which can localize the common foreground object. They also developed a semantic modulator which acts as a supervised image classification model. The combined outputs of both modulators is able to co-segment common objects by using the multi-resolution image features.
However, it is well-known that deep learning based co-segmentation methods require training which can make these approaches class specific. The performance of these models on unseen data will largely depend on the similarity between the seen and unseen classes. In such a scenario, saliency based co-segmentation methods might give superior performance because they are based on generic saliency methods. In the proposed approach, we exploit the inherent genericness of deep learning based saliency methods to identify common salient objects. An important aspect in a co-segmentation method is finding the correspondence between the images in a group. Usually, it’s done through hand-crafted feature descriptors like SIFT [11], GSS [18], etc. However these traditional methods do not work well when there are large viewpoint or illumination changes. In the proposed approach we use deep ResNet features and pre-trained DGC Net[19] to establish global and local correspondences, respectively.
We make two contributions: (1) using multiple saliency sources and (2) using learning based saliency extraction and correspondence processes for effective object co-segmentation.
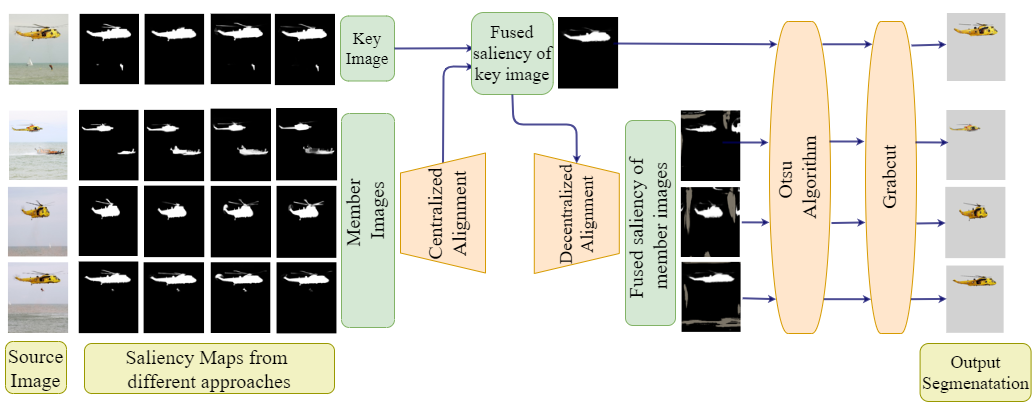
II Methodology
Notations and Overview: Let’s consider a group of images , which is divided into sub-groups, following [7]. If denotes the sub-group label of , we can define sub-group of images as , where . Let’s denote the cluster representative of cluster with the notation .
As far as saliency maps are concerned, let’s denote saliency map of image as , where , if we consider saliency sources. Let the warping function between two images, say , be denoted as .
In Fig. 1, we show how different fused saliency maps are generated in a sub-group and eventual object co-segmentation masks are obtained. The core idea is to fuse the saliency maps available in a sub-group through appropriate alignments, which are of two types: centralized and decentralized. The centralized and decentralized alignments lead to fused saliency maps for the key image and member images, respectively. Let’s discuss all this in detail.
Sub-group Formation: In a given group of images, there may be lot of shape and pose variance across the images, which is not ideal for saliency fusion. Also, we need not process all of them together. We must note that an image needs only a couple of other neighboring images to carry out object co-segmentation. Hence, we divide the group into sub-groups via k-means clustering on global features extracted using ResNet50 pre-trained model (on ImageNet dataset[21]). We perform silhouette analysis [22] to find the best . We also identify the images nearest to the cluster centers as key images.
Saliency Map Generation: Current saliency fusion-based co-segmentation approaches mostly utilize a single saliency source. In contrast, we extract four saliency maps (which means ) using different deep saliency detection methods, namely PoolNet [23], EGNet [24], BASNet [25], U2Net [26]. The main motivation behind using multiple methods is to benefit from all the sources, instead of just one.
Saliency Fusion: Our proposed framework has two stages: (i) centralized alignment, and (ii) decentralized alignment.
For generating fused saliency map of the key image, we align all the available saliency maps in the sub group to the key image. We call this centralized alignment. For making alignments, we use the pre-trained DGC-Net [19] model throughout our work. Such learning-based models provide us excellent correspondences between the pixels from two different images, which can be used to align saliency maps as well, not just images. First let’s collect all the candidate saliency maps for the key-image in a sub-group after proper alignment, as given below:
| (1) |
where denotes the collection. There will be a total of candidate saliency maps in the sub-group for the key image . Here denotes cardinality. Since all these candidate saliency maps will be of same size, because of aligning to one image, the key-image, we can denote the collection of candidate saliency values of a pixel as . We fuse all these candidate values to generate fused saliency map for the key image in the following way:
| (2) |
where we are basically finding the median of all the candidate saliency values for any pixel . Having obtained the fused saliency map for the key-images, to obtain such map for sub-group members, we perform what we call decentralized alignment, i.e., aligning fused saliency map of key image to the member images. Note here that, in the centralized alignment discussed earlier, the alignment was opposite, i.e. aligning saliency maps of member images to the key image. Once we know the key-image to member image correspondences, we can align the fused saliency obtained for the key image to the member images. For instance, we can obtain fused saliency map for a member image in the following way:
| (3) |
where denotes the fused saliency map for image .
Object Co-segmentation Masks: Having obtained fused saliency map for every image, we now need to generate their object co-segmentation masks. For that, we first apply the Otsu algorithm on those maps to generate foreground and background seeds. These seeds are then passed along with the image to Grabcut [27] algorithm to extract our expected foreground, the shared object.
III Experimental Results
We conduct all our experiments on three standard benchmark datasets of object co-segmentation research, namely MSRC, iCoseg and Internet Images. The most common evaluation metrics used for this task in literature are Jaccard Similarity Score () and Precision Score (). We use both of them. Jaccard Similarity is defined as the intersection over union (IoU) of the resultant co-segmentation mask and groundtruth mask whereas Precision is used to measure the percentage of correctly labeled foreground and background pixels.
We use the standard subset [10] of MSRC with classes cat, bird, dog, sheep, car, plane and cow, where each class contains 10 images. It can be seen from Table I that our proposed approach obtains the best score and the second best score. We provide our sample qualitative results on this dataset in Fig. 5.
| Methodology | MSRC Dataset | iCoseg Dataset | ||
|---|---|---|---|---|
| Rubenstein 2013[10] | 92.2 | 0.75 | 89.6 | 0.68 |
| Faktor 2013[28] | 92.0 | 0.77 | - | 0.78 |
| Jerripothula 2016[29] | 88.7 | 0.71 | 91.9 | 0.72 |
| Ren 2018[30] | - | 0.72 | - | 0.74 |
| Jerripothula 2018[31] | 89.7 | 0.74 | 91.8 | 0.72 |
| Tsai 2019[32] | 86.5 | 0.68 | 90.8 | 0.72 |
| Tao 2019[33] | 89.8 | 0.72 | 93.2 | 0.76 |
| Jerripothula 2021[34] | - | 0.79 | - | 0.81 |
| Proposed Approach | 92.1 | 0.84 | 94.4 | 0.88 |
| Methodology | Airplane | Car | Horse | Average | ||||
|---|---|---|---|---|---|---|---|---|
| Rubenstein 2013[10] | 88.0 | 0.56 | 85.4 | 0.64 | 82.8 | 0.52 | 82.7 | 0.43 |
| Jerripothula 2016[29] | 90.5 | 0.61 | 88.0 | 0.71 | 88.3 | 0.61 | 88.9 | 0.64 |
| Quan 2016[35] | 91.0 | 0.56 | 88.5 | 0.67 | 89.3 | 0.58 | 89.6 | 0.60 |
| Tao 2017[12] | 79.8 | 0.43 | 84.8 | 0.66 | 85.7 | 0.55 | 83.4 | 0.55 |
| Ren 2018[30] | 88.3 | 0.48 | 83.5 | 0.62 | 83.2 | 0.49 | 85.0 | 0.53 |
| Tao 2019[33] | 92.4 | 0.63 | 91.9 | 0.78 | 90.1 | 0.62 | 91.4 | 0.68 |
| Zhang 2020[16] | 94.8 | 0.70 | 91.6 | 0.82 | 94.4 | 0.70 | 93.6 | 0.74 |
| Proposed Approach | 93.4 | 0.85 | 92.1 | 0.81 | 89.1 | 0.77 | 91.5 | 0.81 |




The iCoseg dataset [36] was proposed initially for the task of interactive co-segmentation but is often used to analyze the performance of automatic co-segmentation approaches as well. It contains 643 images belonging to 38 classes and is sufficiently challenging due to multiple objects and varying camera angles. It can be seen from Table I that our proposed approach gives the best and scores among all the methods. We provide a few sample qualitative results of our method on this dataset in Fig. 5.
Internet Images dataset [10] is a very challenging dataset because it comprises of a few noise images as well, meaning they do not contain the shared object. The standard subset of this dataset used for object co-segmentation contains 100 images for each class. Table II gives a detailed analysis of class-wise and average performance for various methods on this subset of Internet Images dataset. It can be seen that our approach obtains the best average and second best average scores. Our method obtained at least second rank in almost all the cases except of Horse category. We provide a few sample qualitative results of our method on this dataset in Fig. 5.
| Approach | MSRC [37] | Internet [10] | iCoseg[36] | ||||
|---|---|---|---|---|---|---|---|
| Single Saliency | BASNet [25] | 89.7 | 0.79 | 89.8 | 0.79 | 93.2 | 0.86 |
| U2Net [26] | 90.1 | 0.79 | 90.0 | 0.80 | 92.7 | 0.85 | |
| PoolNet [23] | 90.6 | 0.80 | 91.1 | 0.80 | 93.0 | 0.85 | |
| EGNet [24] | 90.4 | 0.80 | 90.5 | 0.80 | 93.3 | 0.86 | |
| Multiple Saliency | Proposed Approach | 92.1 | 0.84 | 91.5 | 0.81 | 94.4 | 0.88 |
Discussion: In Table III, we show the efficacy of using multiple saliency sources by comparing with the cases when there is only single saliency source available, i.e. . It can be seen that our proposed approach performs better than all the cases involving just one saliency source. It clearly demonstrates that using multiple saliency sources is indeed beneficial. In Fig. 5, we also demonstrate how the proposed method performs better than individual saliency methods, if we were to simply apply Otsu algorithm followed by GrabCut on them, without performing any type of fusion.
IV Conclusion
We propose a comprehensive saliency fusion framework for performing object co-segmentation. In this framework, unlike previous saliency fusion-based methods, we rely on multiple saliency sources and use deep learning based saliency extraction and fusion processes. Our experimental analysis indicates that we are able to perform better than several state-of-the-art methods.
Acknowledgements
This work was supported by Infosys Centre for Artificial Intelligence, IIIT-Delhi, and IIIT-Delhi PDA Grant.
References
- [1] C. Rother, T. Minka, A. Blake, and V. Kolmogorov, “Cosegmentation of image pairs by histogram matching-incorporating a global constraint into mrfs,” in CVPR 2006, vol. 1. IEEE, pp. 993–1000.
- [2] S. Vicente, C. Rother, and V. Kolmogorov, “Object cosegmentation,” in CVPR 2011. IEEE, 2011, pp. 2217–2224.
- [3] B. Andres, J. H. Kappes, U. Köthe, C. Schnörr, and F. A. Hamprecht, “An empirical comparison of inference algorithms for graphical models with higher order factors using opengm,” in Joint Pattern Recognition Symposium. Springer, 2010, pp. 353–362.
- [4] E. Kim, H. Li, and X. Huang, “A hierarchical image clustering cosegmentation framework,” in 2012 IEEE CVPR. Ieee, 2012, pp. 686–693.
- [5] A. C. Gallagher and T. Chen, “Clothing cosegmentation for recognizing people,” in 2008 IEEE CVPR. IEEE, 2008, pp. 1–8.
- [6] Y.-H. Tsai, G. Zhong, and M.-H. Yang, “Semantic co-segmentation in videos,” in ECCV. Springer, 2016, pp. 760–775.
- [7] K. R. Jerripothula, J. Cai, F. Meng, and J. Yuan, “Automatic image co-segmentation using geometric mean saliency,” in IEEE International Conference on Image Processing (ICIP). IEEE, 2014, pp. 3277–3281.
- [8] K. R. Jerripothula, J. Cai, and J. Yuan, “Group saliency propagation for large scale and quick image co-segmentation,” in IEEE International Conference on Image Processing (ICIP). IEEE, 2015, pp. 4639–4643.
- [9] F. Meng, H. Li, G. Liu, and K. N. Ngan, “Object co-segmentation based on shortest path algorithm and saliency model,” IEEE transactions on multimedia, vol. 14, no. 5, pp. 1429–1441, 2012.
- [10] M. Rubinstein, A. Joulin, J. Kopf, and C. Liu, “Unsupervised joint object discovery and segmentation in internet images,” in IEEE conference on computer vision and pattern recognition, 2013, pp. 1939–1946.
- [11] C. Liu, J. Yuen, and A. Torralba, “Sift flow: Dense correspondence across scenes and its applications,” IEEE transactions on pattern analysis and machine intelligence, vol. 33, no. 5, pp. 978–994, 2010.
- [12] Z. Tao, H. Liu, H. Fu, and Y. Fu, “Image cosegmentation via saliency-guided constrained clustering with cosine similarity,” in AAAI Conference on Artificial Intelligence, vol. 31, no. 1, 2017.
- [13] W. Li, O. H. Jafari, and C. Rother, “Deep object co-segmentation,” in Asian Conference on Computer Vision. Springer, 2018, pp. 638–653.
- [14] H. Chen, Y. Huang, and H. Nakayama, “Semantic aware attention based deep object co-segmentation,” in ACCV. Springer, 2018, pp. 435–450.
- [15] A. Dosovitskiy, P. Fischer, E. Ilg, P. Hausser, C. Hazirbas, V. Golkov, P. Van Der Smagt, D. Cremers, and T. Brox, “Flownet: Learning optical flow with convolutional networks,” in ICCV, 2015, pp. 2758–2766.
- [16] K. Zhang, J. Chen, B. Liu, and Q. Liu, “Deep object co-segmentation via spatial-semantic network modulation,” in AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 12 813–12 820.
- [17] K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution representation learning for human pose estimation,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5693–5703.
- [18] T. Deselaers and V. Ferrari, “Global and efficient self-similarity for object classification and detection,” in CVPR, 2010, pp. 1633–1640.
- [19] I. Melekhov, A. Tiulpin, T. Sattler, M. Pollefeys, E. Rahtu, and J. Kannala, “Dgc-net: Dense geometric correspondence network,” in WACV, 2019, pp. 1034–1042.
- [20] H. S. Chhabra and K. Rao Jerripothula, “Comprehensive saliency fusion for object co-segmentation,” in 2021 IEEE International Symposium on Multimedia (ISM), 2021, pp. 107–110.
- [21] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [22] P. J. Rousseeuw, “Silhouettes: a graphical aid to the interpretation and validation of cluster analysis,” Journal of computational and applied mathematics, vol. 20, pp. 53–65, 1987.
- [23] J.-J. Liu, Q. Hou, M.-M. Cheng, J. Feng, and J. Jiang, “A simple pooling-based design for real-time salient object detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 3917–3926.
- [24] J.-X. Zhao, J.-J. Liu, D.-P. Fan, Y. Cao, J. Yang, and M.-M. Cheng, “Egnet: Edge guidance network for salient object detection,” in IEEE/CVF International Conference on Computer Vision, 2019, pp. 8779–8788.
- [25] X. Qin, Z. Zhang, C. Huang, C. Gao, M. Dehghan, and M. Jagersand, “Basnet: Boundary-aware salient object detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 7479–7489.
- [26] X. Qin, Z. Zhang, C. Huang, M. Dehghan, O. R. Zaiane, and M. Jagersand, “U2-net: Going deeper with nested u-structure for salient object detection,” Pattern Recognition, vol. 106, p. 107404, 2020.
- [27] C. Rother, V. Kolmogorov, and A. Blake, “” grabcut” interactive foreground extraction using iterated graph cuts,” ACM transactions on graphics (TOG), vol. 23, no. 3, pp. 309–314, 2004.
- [28] A. Faktor and M. Irani, “Co-segmentation by composition,” in IEEE international conference on computer vision, 2013, pp. 1297–1304.
- [29] K. R. Jerripothula, J. Cai, and J. Yuan, “Image co-segmentation via saliency co-fusion,” IEEE Transactions on Multimedia, vol. 18, no. 9, pp. 1896–1909, 2016.
- [30] Y. Ren, L. Jiao, S. Yang, and S. Wang, “Mutual learning between saliency and similarity: Image cosegmentation via tree structured sparsity and tree graph matching,” IEEE Transactions on Image Processing, vol. 27, no. 9, pp. 4690–4704, 2018.
- [31] K. R. Jerripothula, J. Cai, and J. Yuan, “Quality-guided fusion-based co-saliency estimation for image co-segmentation and colocalization,” IEEE Transactions on Multimedia, vol. 20, no. 9, pp. 2466–2477, 2018.
- [32] C. C. Tsai, W. Li, K. J. Hsu, X. Qian, and Y. Y. Lin, “Image co-saliency detection and co-segmentation via progressive joint optimization,” IEEE Transactions on Image Processing, vol. 28, no. 1, pp. 56–71, 2019.
- [33] Z. Tao, H. Liu, H. Fu, and Y. Fu, “Multi-view saliency-guided clustering for image cosegmentation,” IEEE Transactions on Image Processing, vol. 28, no. 9, pp. 4634–4645, 2019.
- [34] K. R. Jerripothula, J. Cai, J. Lu, and J. Yuan, “Image co-skeletonization via co-segmentation,” IEEE Transactions on Image Processing, vol. 30, pp. 2784–2797, 2021.
- [35] R. Quan, J. Han, D. Zhang, and F. Nie, “Object co-segmentation via graph optimized-flexible manifold ranking,” in CVPR’16, pp. 687–695.
- [36] D. Batra, A. Kowdle, D. Parikh, J. Luo, and T. Chen, “icoseg: Interactive co-segmentation with intelligent scribble guidance,” in IEEE Computer Vision and Pattern Recognition, 2010, pp. 3169–3176.
- [37] J. Shotton, J. Winn, C. Rother, and A. Criminisi, “Textonboost: Joint appearance, shape and context modeling for multi-class object recognition and segmentation,” in ECCV. Springer, 2006, pp. 1–15.