Compressive Imaging using Approximate Message Passing and a Markov-Tree Prior
Abstract
We propose a novel algorithm for compressive imaging that exploits both the sparsity and persistence across scales found in the 2D wavelet transform coefficients of natural images. Like other recent works, we model wavelet structure using a hidden Markov tree (HMT) but, unlike other works, ours is based on loopy belief propagation (LBP). For LBP, we adopt a recently proposed “turbo” message passing schedule that alternates between exploitation of HMT structure and exploitation of compressive-measurement structure. For the latter, we leverage Donoho, Maleki, and Montanari’s recently proposed approximate message passing (AMP) algorithm. Experiments with a large image database suggest that, relative to existing schemes, our turbo LBP approach yields state-of-the-art reconstruction performance with substantial reduction in complexity.
I Introduction
In compressive imaging [1], we aim to estimate an image from noisy linear observations ,
| (1) |
assuming that the image has a representation in some wavelet basis (i.e., ) containing only a few () large coefficients (i.e., ). In (1), is a known measurement matrix and is additive white Gaussian noise. Though makes the problem ill-posed, it has been shown that can be recovered from when is adequately small and is incoherent with [1]. The wavelet coefficients of natural images are known to have an additional structure known as persistence across scales (PAS) [2], which we now describe. For 2D images, the wavelet coefficients are naturally organized into quad-trees, where each coefficient at level acts as a parent for four child coefficients at level . The PAS property says that, if a parent is very small, then all of its children are likely to be very small; similarly, if a parent is large, then it is likely that some (but not necessarily all) of its children will also be large.
Several authors have exploited the PAS property for compressive imaging [3, 4, 5, 6]. The so-called “model-based” approach [3] is a deterministic incarnation of PAS that leverages a restricted union-of-subspaces and manifests as a modified CoSaMP [7] algorithm. Most approaches are Bayesian in nature, exploiting the fact that PAS is readily modeled by a hidden Markov tree (HMT) [8]. The first work in this direction appears to be [4], where an iteratively re-weighted algorithm, generating an estimate of , was alternated with a Viterbi algorithm, generating an estimate of the HMT states. More recently, HMT-based compressive imaging has been attacked using modern Bayesian tools [9]. For example, [5] used Markov-chain Monte-Carlo (MCMC), which is known to yield correct posteriors after convergence. For practical image sizes, however, convergence takes an impractically long time, and so MCMC must be terminated early, at which point its performance may suffer. Variational Bayes (VB) can sometimes offer a better performance/complexity tradeoff, motivating the approach in [6]. Our experiments indicate that, while [6] indeed offers a good performance/complexity tradeoff, it is possible to do significantly better.
In this paper, we propose a novel approach to HMT-based compressive imaging based on loopy belief propagation [10]. For this, we model the coefficients in as conditionally Gaussian with variances that depend on the values of HMT states, and we propagate beliefs (about both coefficients and states) on the corresponding factor graph. A recently proposed “turbo” messaging schedule [11] suggests to iterate between exploitation of HMT structure and exploitation of observation structure from (1). For the former we use the standard sum-product algorithm [12, 13], and for the latter we use the recently proposed approximate message passing (AMP) approach [14]. The remarkable properties of AMP are 1) a rigorous analysis (as with fixed, under i.i.d Gaussian ) [15] establishing that its solutions are governed by a state-evolution whose fixed points—when unique—yield the true posterior means, and 2) very low implementational complexity (e.g., AMP requires one forward and one inverse fast-wavelet-transform per iteration, and very few iterations).
We consider two types of conditional-Gaussian coefficient models: a Bernoulli-Gaussian (BG) model and a two-state Gaussian-mixture (GM) model. The BG model assumes that the coefficients are either generated from a large-variance Gaussian distribution or are exactly zero (i.e., the coefficients are exactly sparse), whereas the GM model assumes that the coefficients are generated from either a large-variance or a small-variance Gaussian distribution. Both models have been previously applied for imaging, e.g., the BG model was used in [6, 5], whereas the GM model was used in [8, 4].
Although our models for the coefficients and the corresponding HMT states involve statistical parameters like variance and transition probability, we learn those parameters directly from the data. To do so, we take a hierarchical Bayesian approach—similar to [6, 5]—where these statistical parameters are treated as random variables with suitable hyperpriors. Experiments on a large image database show that our turbo-AMP approach yields state-of-the-art reconstruction performance with substantial reduction in complexity.
The remainder of the paper is organized as follows. Section II describes the signal model, Section III describes the proposed algorithm, Section IV gives numerical results and comparisons with other algorithms, and Section V concludes.
Notation: Above and in the sequel, we use lowercase boldface quantities to denote vectors, uppercase boldface quantities to denote matrices, to denote the identity matrix, to denote transpose, and . We use to denote the probability density111 or the probability mass function (pmf), as will be clear from the context. function (pdf) of random variable given the event , where often the subscript “” is omitted when there is no danger of confusion. We use to denote the -dimensional Gaussian pdf with argument , mean , and covariance matrix , and we write to indicate that random vector has this pdf. We use to denote expectation, to denote the probability of event , and to denote the Dirac delta. Finally, we use to denote equality up to a multiplicative constant.
II Signal Model


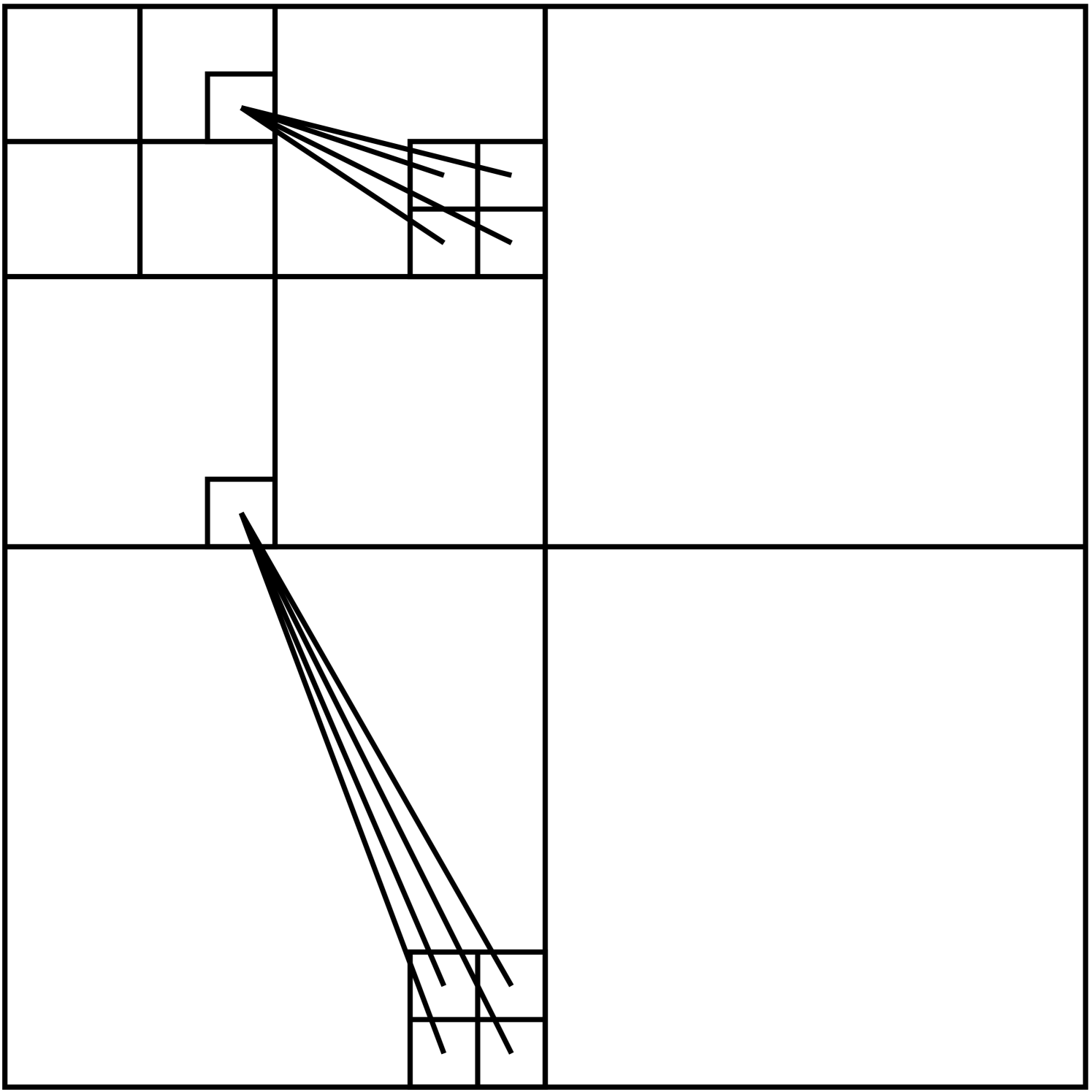
Throughout, we assume that represents a 2D wavelet transform [2], so that the transform coefficients can be partitioned into so-called “wavelet” coefficients (at indices ) and “approximation” coefficients (at indices ). The wavelet coefficients can be further partitioned into several quad-trees, each with levels (see Fig. 1). We denote the indices of all coefficients at level of these wavelet trees by , where refers to the root. In the interest of brevity, and with a slight abuse of notation, we refer to the approximation coefficients as level “” of the wavelet tree (i.e., ).
As discussed earlier, two coefficient models are considered in this paper: Bernoulli-Gaussian (BG) and two-state Gaussian mixture (GM). For ease of exposition, we focus on the BG model until Section III-E, at which point the GM case is detailed. In the BG model, each transform coefficient is modeled using the (conditionally independent) prior pdf
| (2) |
where is a hidden binary state. The approximation states are assigned the apriori activity rate , which is discussed further below. Meanwhile, the root wavelet states are assigned . Within each quad-tree, the states have a Markov structure. In particular, the activity of a state at level is determined by its parent’s activity (at level ) and the transition probabilities , where denotes the probability that the child’s state equals given that his parent’s state also equals , and denotes the probability that the child’s state equals given given that his parent’s state also equals . The corresponding factor graph is shown in Fig. 2.
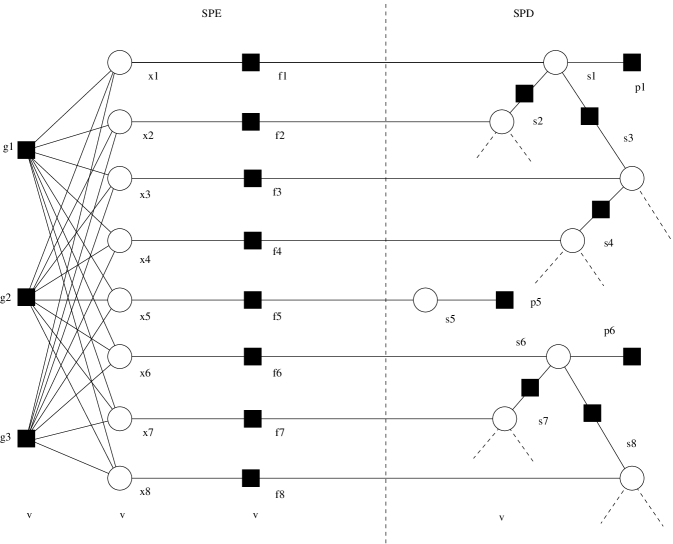
We take a hierarchical Bayesian approach, modeling the statistical parameters as random variables and assigning them appropriate hyperpriors. Rather than working directly with variances, we find it more convenient to work with precisions (i.e., inverse-variances) such as . We then assume that all coefficients at the same level have the same precision, so that for all . To these precisions, we assign conjugate priors [16], which in this case take the form
| (3) | |||||
| (4) |
where for , and where are hyperparameters. (Recall that the mean and variance of are given by and , respectively [16].) For the activity rates and transition parameters, we assume
| (5) | |||||
| (6) | |||||
| (7) | |||||
| (8) |
where , and where are hyperparameters. (Recall that the mean and variance of are given by and , respectively [16].) Our hyperparameter choices are detailed in Section IV.
III Image Reconstruction
To infer the wavelet coefficients , we would ideally like to compute the posterior pdf
| (9) | |||||
| (10) |
where denotes equality up to a multiplicative constant. For the BG coefficient model, is specified by (2). Due to the white Gaussian noise model (1), we have , where denotes the row of the matrix .
III-A Loopy Belief Propagation
While exact computation of is computationally prohibitive, the marginal posteriors can be efficiently approximated using loopy belief propagation (LBP) [10] on the factor graph of Fig. 2, which uses round nodes to denote variables and square nodes to denote the factors in (10). In doing so, we also obtain the marginal posteriors . For now, we treat statistical parameters , as if they were fixed and known, and we detail the procedure by which they are learned in Section III-D.
In LBP, messages are exchanged between the nodes of the factor graph until they converge. Messages take the form of pdfs (or pmfs), and the message flowing to/from a variable node can be interpreted as a local belief about that variable. According to the sum-product algorithm [12, 13] the message emitted by a variable node along a given edge is (an appropriate scaling of) the product of the incoming messages on all other edges. Meanwhile, the message emitted by a function node along a given edge is (an appropriate scaling of) the integral (or sum) of the product of the node’s constraint function and the incoming messages on all other edges, where the integration (or summation) is performed over all variables other than the one directly connected to the edge along which the message travels. When the factor graph has no loops, exact marginal posteriors result from two (i.e., forward and backward) passes of the sum-product algorithm [12, 13]. When the factor graph has loops, however, exact inference is known to be NP hard [17] and so LBP is not guaranteed to produce correct posteriors. Still, LBP has shown state-of-the-art performance in many applications, such as inference on Markov random fields [18], turbo decoding [19], LDPC decoding [20], multiuser detection [21], and compressive sensing [22, 14, 23, 15].
III-B Message Scheduling: The Turbo Approach
With loopy belief propagation, there exists some freedom in how messages are scheduled. In this work, we adopt the “turbo” approach recently proposed in [11]. For this, we split the factor graph in Fig. 2 along the dashed line and obtain the two decoupled subgraphs in Fig. 3. We then alternate between belief propagation on each of these two subgraphs, treating the likelihoods on generated from belief propagation on one subgraph as priors for subsequent belief propagation on the other subgraph. We now give a more precise description of this turbo scheme, referring to one full round of alternation as a “turbo iteration.” In the sequel, we use to denote the message passed from node to node during the turbo iteration.
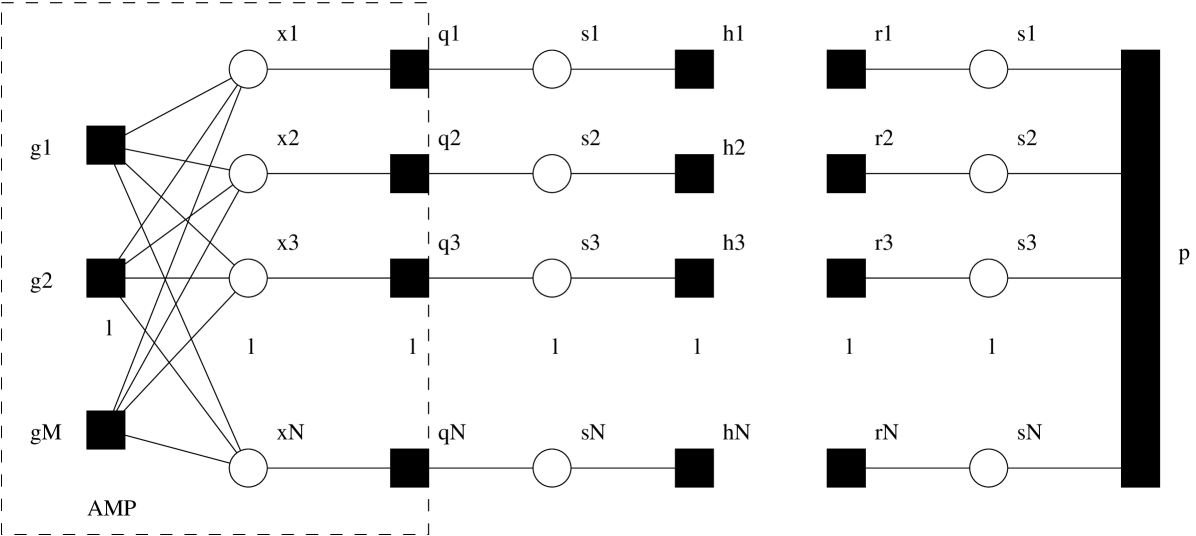
The procedure starts at by setting the “prior” pmfs in accordance with the apriori activity rates described in Section II. LBP is then iterated (to convergence) on the left subgraph in Fig. 3, finally yielding the messages . We note that the message can be interpreted as the current estimate of the likelihood222 In turbo decoding parlance, the likelihood would be referred to as the “extrinsic” information about produced by the left “decoder”, since it does not directly involve the corresponding prior . Similarly, the message would be referred to as the extrinsic information about produced by the right decoder. on , i.e., as a function of . These likelihoods are then treated as priors for belief propagation on the right subgraph, as facilitated by the assignment for each . Due to the tree structure of HMT, there are no loops in right subgraph (i.e., inside the “” super-node in Fig. 3), and thus it suffices to perform only one forward-backward pass of the sum-product algorithm [12, 13]. The resulting leftward messages are subsequently treated as priors for belief propagation on the left subgraph at the next turbo iteration, as facilitated by the assignment . The process then continues for turbo iterations , until the likelihoods converge or a maximum number of turbo iterations has elapsed. Formally, the turbo schedule is summarized by
| (11) | |||||
| (12) |
In the sequel, we refer to inference of using compressive-measurement structure (i.e., inference on the left subgraph of Fig. 3) as soft support-recovery (SSR) and inference of using HMT structure (i.e., inference on the right subgraph of Fig. 3) as soft support-decoding (SSD). SSR details are described in the next subsection.
III-C Soft Support-Recovery via AMP
We now discuss our implementation of SSR during a single turbo iteration . Because the operations are invariant to , we suppress the -notation. As described above, SSR performs several iterations of loopy belief propagation per turbo iteration using the fixed priors . This implies that, over SSR’s LBP iterations, the message is fixed at
| (13) |
The dashed box in Fig. 3 shows the region of the factor graph on which messages are updated during SSR’s LBP iterations. This subgraph can be recognized as the one that Donoho, Maleki, and Montanari used to derive their so-called approximate message passing (AMP) algorithm [14]. While [14] assumed an i.i.d Laplacian prior for , the approach for generic i.i.d priors was outlined in [23]. Below, we extend the approach of [23] to independent non-identical priors (as analyzed in [24]) and we detail the Bernoulli-Gaussian case. In the sequel, we use a superscript- to index SSR’s LBP iterations.
According to the sum-product algorithm, the fact that is non-Gaussian implies that is also non-Gaussian, which complicates the exact calculation of the subsequent messages as defined by the sum-product algorithm. However, for large , the combined effect of at the nodes can be approximated as Gaussian using central-limit theorem (CLT) arguments, after which it becomes sufficient to parameterize each message by only its mean and variance:
| (14) | |||||
| (15) |
Combining
| (16) |
with , the CLT then implies that
| (17) | |||||
| (18) | |||||
| (19) |
The updates and can then be calculated from
| (20) |
where, using (16), the product term in (20) is
| (21) |
Assuming that the values satisfy
| (22) |
which occurs, e.g., when is large and are generated i.i.d with variance , we have , and thus (20) is well approximated by
| (23) | |||||
| (24) |
In this case, the mean and variance of become
| (25) | |||||
| (26) | |||||
| (27) |
where
According to the sum-product algorithm, , the posterior on after SSR’s -LBP iteration, obeys
| (28) |
whose mean and variance determine the -iteration MMSE estimate of and its variance, respectively. Noting that the difference between (28) and (20) is only the inclusion of the product term, these MMSE quantities become
| (29) | |||||
| (30) | |||||
| (31) | |||||
| (32) |
Similarly, the posterior on after the iteration obeys
| (33) |
where
| (34) |
Since , it can be seen that the corresponding log-likelihood ratio (LLR) is
| (35) |
Clearly, the LLR and the likelihood function express the same information, but in different ways.
The procedure described thus far updates variables per LBP iteration, which is impractical since can be very large. In [23], Donoho, Maleki, and Montanari proposed, for the i.i.d case, further approximations that yield a “first-order” approximate message passing (AMP) algorithm that allows the update of only variables per LBP iteration, essentially by approximating the differences among the outgoing means/variances of the nodes (i.e., and ) as well as the differences among the outgoing means/variances of the nodes (i.e., and ). These resulting algorithm was then rigorously analyzed by Bayati and Montanari in [15]. We now summarize a straightforward extension of the i.i.d AMP algorithm from [23] to the case of an independent but non-identical Bernoulli-Gaussian prior (13):
| (36) | |||||
| (37) | |||||
| (38) | |||||
| (39) | |||||
| (40) |
where , and are defined as
| (41) | |||||
| (42) | |||||
| (43) | |||||
| (44) |
For the first turbo iteration (i.e., ), we initialize AMP using , , and for all . For subsequent turbo iterations (i.e., ), we initialize AMP by setting equal to the final values of generated by AMP at the previous turbo iteration. We terminate the AMP iterations as soon as either or a maximum of AMP iterations have elapsed. Similarly, we terminate the turbo iterations as soon as either a maximum of turbo iterations have elapsed. The final value of is output at the signal estimate .
III-D Learning the Statistical Parameters
We now describe how the precisions are learned. First, we recall that describes the apriori precision on the active coefficients at the level, i.e., on , where the corresponding index set is of size . Furthermore, we recall that the prior on was chosen as in (4). Thus, if we had access to the true values , then (2) implies that
| (45) |
which implies333 This posterior results because the chosen prior is conjugate [16] for the likelihood in (45). that the posterior on would take the form of where and . In practice, we don’t have access to the true values nor to the set , and thus we propose to build surrogates from the SSR outputs. In particular, to update after the turbo iteration, we employ
| (46) | |||||
| (47) |
and , where and denote the final LLR on and the final MMSE estimate of , respectively, at the turbo iteration. These choices imply the hyperparameters
| (48) | |||||
| (49) |
Finally, to perform SSR at turbo iteration , we set the variances equal to the inverse of the expected precisions, i.e., . The noise variance is learned similarly from the SSR-estimated residual.
Next, we describe how the transition probabilities are learned. First, we recall that describes the probability that a child at level is active (i.e., ) given that his parent (at level ) is active. Furthermore, we recall that the prior on was chosen as in (7). Thus if we knew that there were active coefficients at level , of which had active children, then444 This posterior results because the chosen prior is conjugate to the Bernoulli likelihood [16]. the posterior on would take the form of , where and . In practice, we don’t have access to the true values of and , and thus we build surrogates from the SSR outputs. In particular, to update after the turbo iteration, we approximate by the event , and based on this approximation set (as in (47)) and . The corresponding hyperparameters are then updated as
| (50) | |||||
| (51) |
Finally, to perform SSR at turbo iteration , we set the transition probabilities equal to the expected value . The parameters , , and are learned similarly.
III-E The Two-State Gaussian-Mixture Model
Until now, we have focused on the Bernoulli-Gaussian (BG) signal model (2). In this section, we describe the modifications needed to handle the Gaussian mixture (GM) model
where denotes the variance of “large” coefficients and denotes the variance of “small” ones. For either the BG or GM prior, AMP is performed using the steps (36)-(40). For the BG case, the functions , , , and are given in (41)–(44), whereas for the GM case, they take the form
| (53) | |||||
| (55) | |||||
| (56) |
where
| (57) | |||||
| (58) | |||||
| (59) | |||||
| (60) |
Likewise, for the BG case, the extrinsic LLR is given by (35), whereas for the GM case, it becomes
| (61) |
IV Numerical Results
IV-A Setup
The proposed turbo555An implementation of our algorithm can be downloaded from http://www.ece.osu.edu/~schniter/turboAMPimaging approach to compressive imaging was compared to several other tree-sparse reconstruction algorithms: ModelCS [3], HMT+IRWL1 [4], MCMC [5], variational Bayes (VB) [6]; and to several simple-sparse reconstruction algorithms: CoSaMP [7], SPGL1 [25], and Bernoulli-Gaussian (BG) AMP. All numerical experiments were performed on (i.e., ) grayscale images using a -level 2D Haar wavelet decomposition, yielding approximation coefficients and individual Markov trees. In all cases, the measurement matrix had i.i.d Gaussian entries. Unless otherwise specified, noiseless measurements were used. We used normalized mean squared error (NMSE) as the performance metric.
We now describe how the hyperparameters were chosen for the proposed Turbo schemes. Below, we use to denote the total number of wavelet coefficients at level , and to denote the total number of approximation coefficients. For both Turbo-BG and Turbo-GM, the Beta hyperparameters were chosen so that , and with , , , and . These informative hyperparameters are similar to the “universal” recommendations in [26] and, in fact, identical to the ones suggested in the MCMC work [5]. For Turbo-BG, the hyperparameters for the signal precisions were set to and . This choice is motivated by the fact that wavelet coefficient magnitudes are known to decay exponentially with scale (e.g., [26]). Meanwhile, the hyperparameters for the noise precision were set to . Although the measurements were noiseless, we allow Turbo-BG a nonzero noise variance in order to make up for the fact that the wavelet coefficients are not exactly sparse, as assumed by the BG signal model. (We note that the same was done in the BG-based work [6, 5].) For Turbo-GM, the hyperparameters for the signal precisions were set at the values of for the BG case, while the hyperparameters for were set as and . Meanwhile, the noise variance was assumed to be exactly zero, because the GM signal prior is capable of modeling non-sparse wavelet coefficients.
For MCMC [5], the hyperparameters were set in accordance with the values described in [5]; the values of are same as the ones used for the proposed Turbo-BG scheme, while . For VB, the same hyperparameters as MCMC were used except for and , which were the default values of hyperparameters used in the publicly available code.666http://people.ee.duke.edu/~lcarin/BCS.html We experimented with the values for both MCMC and VB and found that the default values indeed seem to work best. For example, if one swaps the hyperparameters between VB and MCMC, then the average performance of VB and MCMC degrade by dB and dB, respectively, relative to the values reported in Table I.
For both the CoSaMP and ModelCS algorithms, the principal tuning parameter is the assumed number of non-zero coefficients. For both ModelCS (which is based on CoSaMP) and CoSaMP itself, we used the Rice University codes,777http://dsp.rice.edu/software/model-based-compressive-sensing-toolbox which include a genie-aided mechanism to compute the number of active coefficients from the original image. However, since we observed that the algorithms perform somewhat poorly under that tuning mechanism, we instead ran (for each image) multiple reconstructions with the number of active coefficients varying from to in steps of , and reported the result with the best NMSE. The number of active coefficients chosen in this manner was usually much smaller than that chosen by the genie-aided mechanism.
To implement BG-AMP, we used the AMP scheme described in Section III-C with the hyperparameter learning scheme described in Section III-D; HMT structure was not exploited. For this, we assumed that the priors on variance and activity were identical over the coefficient index , and assigned Gamma and Beta hyperpriors of and , respectively.
For HMT+IRWL1, we ran code provided by the authors with default settings. For SPGL1,888http://www.cs.ubc.ca/labs/scl/spgl1/index.html the residual variance was set to , and all parameters were set at their defaults.
IV-B Results
Fig. 4 shows a section of the “cameraman” image along with the images recovered by the various algorithms. Qualitatively, we see that CoSaMP, which leverages only simple sparsity, and ModelCS, which models persistence-across-scales (PAS) through a deterministic tree structure, both perform relatively poorly. HMT+IRWL1 also performs relatively poorly, due to (we believe) the ad-hoc manner in which the HMT structure was exploited via iteratively re-weighted . The BG-AMP and SPGL1 algorithms, neither of which attempt to exploit PAS, perform better. The HMT-based schemes (VB, MCMC, Turbo-GM, and Turbo-GM) all perform significantly better, with the Turbo schemes performing best.

| Algorithm | NMSE (dB) | Computation Time (sec) |
|---|---|---|
| HMT+IRWL1 | -14.37 | 363 |
| CoSaMP | -16.90 | 25 |
| ModelCS | -17.45 | 117 |
| BG-AMP | -17.84 | 68 |
| SPGL1 | -18.06 | 536 |
| VB | -19.04 | 107 |
| MCMC | -20.10 | 742 |
| Turbo-BG | -20.49 | 51 |
| Turbo-GM | -20.74 | 51 |
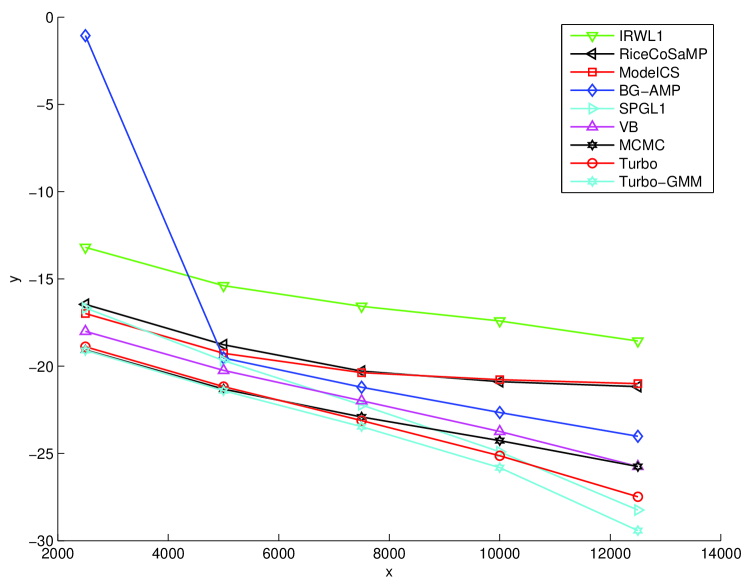
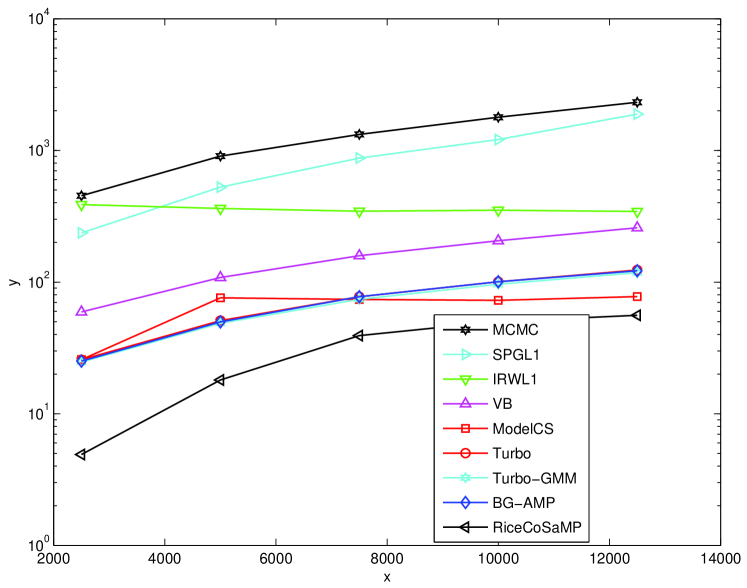
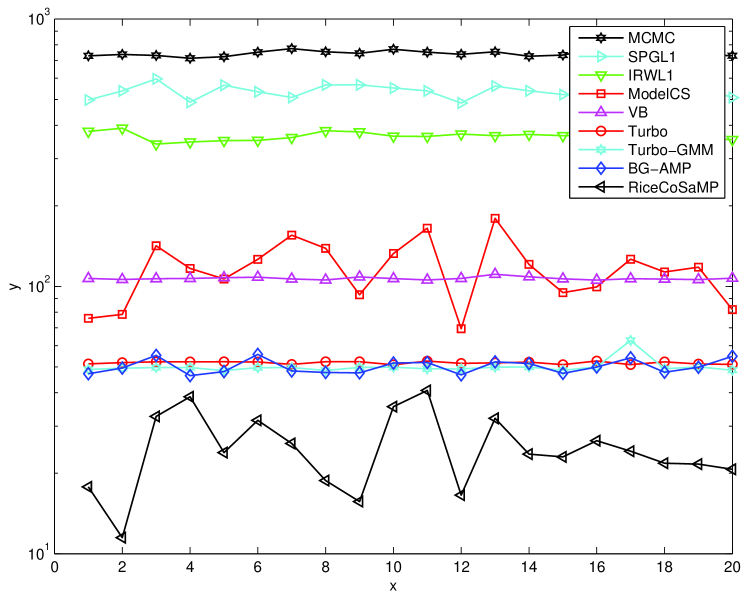
For a quantitative comparison, we measured average performance over a suite of images in a Microsoft Research Object Class Recognition database999 We used images extracted from the “Pixel-wise labelled image database v2” at http://research.microsoft.com/en-us/projects/objectclassrecognition. What we refer to as an “image type” is a “row” in this database. that contains types of images (see Fig. 5) with roughly images of each type. In particular, we computed the average NMSE and average runtime on a 2.5 GHz PC, for each image type. These results are reported in Figures 6 and 7, and the global averages (over all images) are reported in Table I. From the table, we observe that the proposed Turbo algorithms outperform all the other tested algorithms in terms of reconstruction NMSE, but are beaten only by CoSaMP in speed.101010 The CoSaMP runtimes must be interpreted with caution, because the reported runtimes correspond to a single reconstruction, whereas in practice multiple reconstructions may be needed to determined the best value of the tuning parameter. Between the two Turbo algorithms, we observe that Turbo-GM slightly outperforms Turbo-BG in terms of reconstruction NMSE, while taking the same runtime. In terms of NMSE performance, the closest competitor to the Turbo schemes is MCMC,111111 The MCMC results reported here are for the defaults settings: 100 MCMC iterations and 200 burn-in iterations. Using 500 MCMC iterations and 200 burn-in iterations, we obtained an average NMSE of dB (i.e., dB better) at an average runtime of sec (i.e., slower). whose NMSE is dB worse than Turbo-BG and dB worse than Turbo-GM. The good NMSE performance of MCMC comes at the cost of complexity, though: MCMC is times slower than the Turbo schemes. The second closest NMSE-competitor is VB, showing performance dB worse than Turbo-BG and dB worse than Turbo-GM. Even with this sacrifice in performance, VB is still twice as slow as the Turbo schemes. Among the algorithms that do not exploit PAS, we see that SPGL1 offers the best NMSE performance, but is by far the slowest (e.g., times slower than CoSaMP). Meanwhile, CoSaMP is the fastest, but shows the worst NMSE performance (e.g., dB worse than SPGL1). BG-AMP strikes an excellent balance between the two: its NMSE is only dB away from SPGL1, whereas it takes only times as long as CoSaMP. However, by combining the AMP algorithm with HMT structure via the turbo approach, it is possible to significantly improve NMSE while simultaneously decreasing the runtime. The reason for the complexity decrease is twofold. First, the HMT structure helps the AMP and parameter-learning iterations to converge faster. Second, the HMT steps are computationally negligible relative to the AMP steps: when, e.g., , the AMP portion of the turbo iteration takes approximately sec while the HMT portion takes sec.
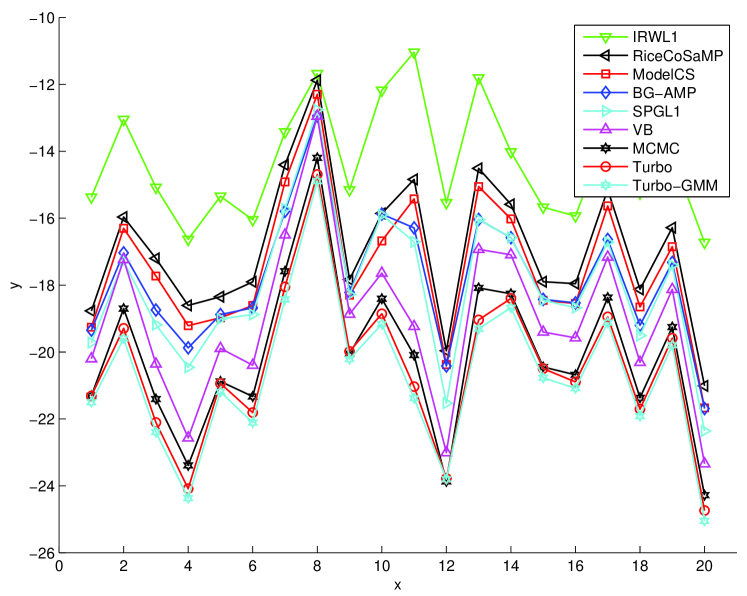
We also studied NMSE and compute time as a function of the number of measurements, . For this study, we examined images of Type 1 at . In Figure 8, we see that Turbo-GM offers the uniformly best NMSE performance across . However, as decreases, there is little difference between the NMSEs of Turbo-GM, Turbo-CS, and MCMC. As increases, though, we see that the NMSEs of MCMC and VB converge, but that they are significantly outperformed by Turbo-GM, Turbo-CS, and—somewhat surprisingly—SPGL1. In fact, at , SPGL1 outperforms Turbo-BG, but not Turbo-GM. However, the excellent performance of SPGL1 at these comes at the cost of very high complexity, as evident in Figure 9.
V Conclusion
We proposed a new approach to HMT-based compressive imaging based on loopy belief propagation, leveraging a turbo message passing schedule and the AMP algorithm of Donoho, Maleki, and Montanari. We then tested our algorithm on a suite of natural images and found that it outperformed the state-of-the-art approach (i.e., variational Bayes) while halving its runtime.
References
- [1] J. Romberg, “Imaging via compressive sampling,” IEEE Signal Process. Mag., vol. 25, no. 2, pp. 14–20, Mar. 2008.
- [2] S. Mallat, A Wavelet Tour of Signal Processing, 3rd ed. San Diego, CA: Academic Press, 2008.
- [3] R. G. Baraniuk, V. Cevher, M. F. Duarte, and C. Hegde, “Model-based compressive sensing,” IEEE Trans. Inform. Theory, vol. 56, no. 4, pp. 1982–2001, Apr. 2010.
- [4] M. F. Duarte, M. B. Wakin, and R. G. Baraniuk, “Wavelet-domain compressive signal reconstruction using a hidden Markov tree model,” in Proc. IEEE Int. Conf. Acoust. Speech & Signal Process., Las Vegas, NV, Apr. 2008, pp. 5137–5140.
- [5] L. He and L. Carin, “Exploiting structure in wavelet-based Bayesian compressive sensing,” IEEE Trans. Signal Process., vol. 57, no. 9, pp. 3488–3497, Sep. 2009.
- [6] L. He, H. Chen, and L. Carin, “Tree-structured compressive sensing with variational Bayesian analysis,” IEEE Signal Process. Lett., vol. 17, no. 3, pp. 233–236, Mar. 2010.
- [7] D. Needell and J. A. Tropp, “CoSaMP: Iterative signal recovery from incomplete and inaccurate samples,” Appl. Computational Harmonic Anal., vol. 26, no. 3, pp. 301–321, 2009.
- [8] M. S. Crouse, R. D. Nowak, and R. G. Baraniuk, “Wavelet-based statistical signal processing using hidden Markov models,” IEEE Trans. Signal Process., vol. 46, no. 4, pp. 886–902, Apr. 1998.
- [9] C. P. Robert and G. Casella, Monte Carlo Statistical Methods, 2nd ed. New York: Springer, 2004.
- [10] B. J. Frey and D. J. C. MacKay, “A revolution: Belief propagation in graphs with cycles,” in Adv. in Neural Inform. Processing Syst., M. Jordan, M. S. Kearns, and S. A. Solla, Eds. MIT Press, 1998.
- [11] P. Schniter, “Turbo reconstruction of structured sparse signals,” in Proc. Conf. Inform. Science & Syst., Princeton, NJ, Mar. 2010.
- [12] J. Pearl, Probabilistic Reasoning in Intelligent Systems. San Mateo, CA: Morgan Kaufman, 1988.
- [13] F. R. Kschischang, B. J. Frey, and H.-A. Loeliger, “Factor graphs and the sum-product algorithm,” IEEE Trans. Inform. Theory, vol. 47, pp. 498–519, Feb. 2001.
- [14] D. L. Donoho, A. Maleki, and A. Montanari, “Message passing algorithms for compressed sensing,” Proc. National Academy of Sciences, vol. 106, no. 45, pp. 18 914–18 919, Nov. 2009.
- [15] M. Bayati and A. Montanari, “The dynamics of message passing on dense graphs, with applications to compressed sensing,” IEEE Trans. Inform. Theory, vol. 57, no. 2, pp. 764–785, Feb. 2011.
- [16] A. Gelman, J. B. Carlin, H. S. Stern, and D. B. Rubin, Eds., Bayesian Data Analysis, 2nd ed. CRC Press, 2003.
- [17] G. F. Cooper, “The computational complexity of probabilistic inference using Bayesian belief networks,” Artificial Intelligence, vol. 42, 1990.
- [18] W. T. Freeman, E. C. Pasztor, and O. T. Carmichael, “Learning low-level vision,” Intl. J. Computer Vision, vol. 40, no. 1, pp. 25–47, Oct. 2000.
- [19] R. J. McEliece, D. J. C. MacKay, and J.-F. Cheng, “Turbo decoding as an instance of Pearl’s ‘belief propagation’ algorithm,” IEEE J. Sel. Areas Commun., vol. 16, no. 2, pp. 140–152, Feb. 1998.
- [20] D. J. C. MacKay, Information Theory, Inference, and Learning Algorithms. New York: Cambridge University Press, 2003.
- [21] J. Boutros and G. Caire, “Iterative multiuser joint decoding: Unified framework and asymptotic analysis,” IEEE Trans. Inform. Theory, vol. 48, no. 7, pp. 1772–1793, Jul. 2002.
- [22] D. Baron, S. Sarvotham, and R. G. Baraniuk, “Bayesian compressive sensing via belief propagation,” IEEE Trans. Signal Process., vol. 58, no. 1, pp. 2269–280, Jan. 2010.
- [23] D. L. Donoho, A. Maleki, and A. Montanari, “Message passing algorithms for compressed sensing: I. Motivation and construction,” in Proc. Inform. Theory Workshop, Cairo, Egypt, Jan. 2010.
- [24] S. Som, L. C. Potter, and P. Schniter, “On approximate message passing for reconstruction of non-uniformly sparse signals,” in Proc. National Aerospace and Electronics Conf., Dayton, OH, Jul. 2010.
- [25] E. van den Berg and M. P. Friedlander, “Probing the Pareto frontier for basis pursuit solutions,” SIAM J. Scientific Comput., vol. 31, no. 2, pp. 890–912, 2008.
- [26] J. K. Romberg, H. Choi, and R. G. Baraniuk, “Bayesian tree-structured image modeling using wavelet-domain hidden Markov models,” IEEE Trans. Image Process., vol. 10, no. 7, pp. 1056–1068, Jul. 2001.
- [27] S. Som, L. C. Potter, and P. Schniter, “Compressive Imaging using Approximate Message Passing and a Markov-Tree Prior,” in Proc. Asilomar Conf. Signals Syst. Comput., Pacific Grove, CA, Nov. 2010.