Computational Attention System for Children, Adults and Elderly
Abstract.
The existing computational visual attention systems have focused on the objective to basically simulate and understand the concept of visual attention system in adults. Consequently, the impact of observer’s age in scene viewing behavior has rarely been considered. This study quantitatively analyzed the age-related differences in gaze landings during scene viewing for three different class of images: naturals, man-made, and fractals. Observer’s of different age-group have shown different scene viewing tendencies independent to the class of the image viewed. Several interesting observations are drawn from the results. First, gaze landings for man-made dataset showed that whereas child observers focus more on the scene foreground, i.e., locations that are near, elderly observers tend to explore the scene background, i.e., locations farther in the scene. Considering this result a framework is proposed in this paper to quantitatively measure the depth bias tendency across age groups. Second, the quantitative analysis results showed that children exhibit the lowest exploratory behavior level but the highest central bias tendency among the age groups and across the different scene categories. Third, inter-individual similarity metrics reveal that an adult had significantly lower gaze consistency with children and elderly compared to other adults for all the scene categories. Finally, these analysis results were consequently leveraged to develop a more accurate age-adapted saliency model independent to the image type. The prediction accuracy suggests that our model fits better to the collected eye-gaze data of the observers belonging to different age groups than the existing models do.
1. Introduction
The human visual system has the ability to filter out the most relevant part within the large amount of visual data, which is determined by the mechanism of selective attention of the human brain. In order to mimic this mechanism of human’s selective attention in computational systems, researchers in computer vision have developed computational attention systems during last 15-20 years. These computational systems attempts to predict the most salienct location for the given input image similar to human observers. However, these systems (Erdem and Erdem, 2013; Itti et al., 1998; Zhang et al., 2016; Harel et al., 2007) fail to predict gaze accurately when compared with an actual human gaze.
The factors that drive a human’s attention can be either related to the scene being observed or to the observer viewing the scene. In a sense, we can also think of fixation as either being ‘pulled’ to a specific location by the visual properties of the fixated region i.e. scene related factors or ‘pushed’ to a certain location by cognitive factors i.e. observer related factors such as task to be accomplished and the knowledge structure. Most of the research in developing computational attention system has been devoted to the scene related factors, as the bottom-up image features such as color, intensity and orientation are easier to model than the cognitive factors related to observers. However, there are a few studies where they investigated the role of observer related factors and also attempted to model them in computational system. The observer related factors are mainly studies for the cognitive factors such as given task (Tatler et al., 2010; Hayhoe and Ballard, 2005), human tendency (Koffka, 2013), habituation and conditioning (Balkenius, 2000), and emotions (Taylor and Fragopanagos, 2005), while the impact of physical factors over scene viewing behavior which are predominately related to the external state of human observers, such as observer’s age, eye sight, visual disparity, and gender are least explored. In this paper, we focus on the age-impact on fixation tendencies while viewing natural scenes.


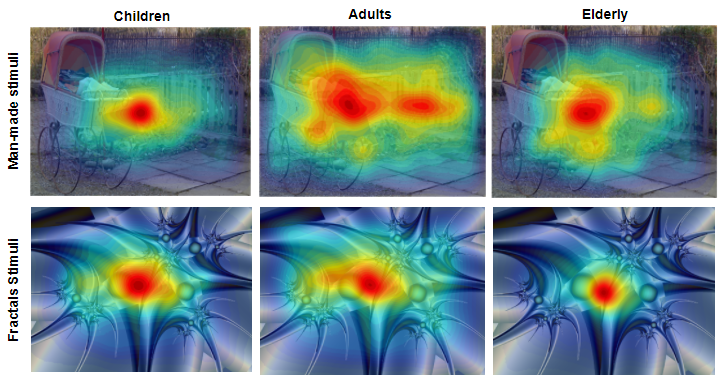
In recent years, vision research studies (Açık et al., 2010; Helo et al., 2014) have shown that age-related changes in scene-viewing behavior exist by measuring the age-impact on gaze attributes, such as total number of fixations per image, inter-fixation distance, fixation duration, and image feature related viewing across different age groups. To date, however, most of the existing computational models predict salient locations pertaining to young adults (Itti et al., 1998; Harel et al., 2007) and ignore the variations that comes with age. In this study, we discovered that observers belonging to the same age group and looking at the same scene have differences in gaze landings that become more prominent when the observers belong to different age groups, as shown in Figure 1, children, adults, and the elderly age groups have different spread of fixations while exploring the scene and this stands valid for different scene categories. Similarly, it can be seen in Figure 2 that children and elderly visualize different level of depth in a scene.
In this study we have not only investigated the age-related differences scene viewing behavior but also the differences in gaze pattern across the images belonging to three different categories; ”man-made”, ”nature”, and ”fractals”. This investigation is triggered by the fact that human gaze is not only driven by visual input but also the knowledge structure associated with the input (Navalpakkam and Itti, 2006). It has been known for few decades that the gist of a scene can be grasped very rapidly, within the duration of only a fixation (Unema et al., 2005). Given the fast gist understanding, the category of the image such as natural, man-made, and fractals are known in very beginning of the scene viewing (Wu et al., 2014), later the prior knowledge about image category guide the gaze together with the bottom-up features associated with the specific image currently in view. Our main aim of including different scene categories was to analyze that age-related differences in scene viewing behavior is independent of the class of the scene in observation.
In this paper, quantitative analysis of the age-related differences of fixation tendencies are performed by using four objective measures including depth bias, center bias, explorativeness, and inter-individual similarity. Consequently, the analysis results provided us some recommendations that we incorporated in the general framework of learning based saliency model to make it age-adapted. This involve choosing suitable scale of features in accordance with the level of detail in a scene to which observers of different age groups explored. And including differently weighted depth map as a new feature based on different tendencies of children and elderly toward fixating on foreground and background. Similarly inter-individual similarity and center bias are used in the proposed model to tune it further to observers age. We demonstrate that our new model yields better prediction accuracy compared with those which do not consider age-related factors. In this study, we observed the explicit tendency of foreground bias in children observers, and developed a framework to quantify this tendency.
The following are the three main contributions of our study. First, we extended the study reported in (Krishna et al., 2017; Luna et al., 2008) to exploration of the differences in the scene-viewing behavior of observers in three different age groups: children, adults, and the elderly during inspection of ”natural”, ”man-made” and ”fractal” stimulus. Second, we developed new parameters, depth bias, inter-individual similarity and upper performance limit to analyze the age impact on scene viewing behavior. Depth bias examined weather observers of different ages have different tendencies toward fixating on foreground and background. Finally, we incorporated the analysis results in the development of an age-adapted computational attention system.
2. Background
We first review the available literature on developmental changes in scene viewing behavior and specify the developmental factors that missed in the existing studies that need to be quantified in order to develop an age-adapted saliency model. We then briefly review works on computational model of visual attention system for adult observers and discuss the scope of upgrading them to an age-adapted saliency model for complex image belonging to different scene categories.
2.1. Developmental Literature
In this section we present the evidences of age-impact on scene viewing behavior from developmental literature in order to establish the need for quantifying the age-impact on scene viewing to develop an age-adapted saliency model. There are many studies in psychology and neuroscience investigating the aging effect on eye-movement controls (Luna et al., 2008; Aring et al., 2007; Irving et al., 2006; Fukushima et al., 2006; Klein, 2001) such as focusing on target, maintaining focus on object, moving eyes effectively, coordinating both eyes and eye-hand coordination. These developmental aspects of eye-movement control have been studied mainly by using scene viewing behavior with the use of artificial stimuli. However, there are only a few studies employed natural stimuli to reveal developmental changes in free viewing behavior (Açık et al., 2010). Most of the developmental studies has either focused on developmental changes during early stage in life (childhood) or during late stage in life (elderly) (Aring et al., 2007; Ygge et al., 2005; Fioravanti et al., 1995; Luna et al., 2004), and their are only a few investigating the age-related changes for whole life span (children, adult, and elderly) (Irving et al., 2006; Açık et al., 2010) .
The studies reporting development of fixation system suggests that ability to fixate on target is present since early in childhood but the more complex aspect of fixation system such as stability and control of fixation increases with increasing age between 4 to 15 years of age (Aring et al., 2007; Ygge et al., 2005). Further, the studies about development of saccadic control system found that saccade velocity increases during childhood with peak value between 10-15 years of age group and then followed by decay until 86 years of age (Irving et al., 2006; Fioravanti et al., 1995). Findings about saccade latency i.e. reaction time to initiate an eye-movement have showed that the voluntary eye-movement decreases exponentially from birth to 14-15 years of age (Fischer et al., 1997; Fukushima et al., 2006; Klein, 2001; Luna et al., 2004). A study (Fischer et al., 1997) about anti-saccade (AS) task (which helps to understand the developmental changes in the cognitive ability to inhibit the reflexive saccade) in 300 participants of 8-65 years age has observed strong developmental effect in AS performance. The participants of age 40-65 years of age demonstrated a moderate deterioration in AS performance. These results are also replicated in several other studies where they found the relationship between age and anti-saccade is curvliner from childhood to adulthood (Klein and Feige, 2005; Luna et al., 2004) and from adulthood to elderly stage it has been found to be linear (Nelson et al., 2000; Fukushima et al., 2000; Klein and Feige, 2005). Even though this selection of the developmental literature briefly discuss the age-impact on eye-movement control but the neglected aspect of these works is that these findings are gathered by using artificial stimulus.
There are only a few studies employed the naturalsitic stimuls to understand the age-impact on scene viewing behavior (Açık et al., 2010). The study (Açık et al., 2010) found that bottom-up features of a scene such as color, luminance, contrast, etc. guided viewing during early stage in life (7-9 years) whereas in later stage (more than 72) dominated by more top-down processing. This result can be helpful in upgrading those saliency models based on guided search theory (Wolfe et al., 1989; Cave and Wolfe, 1990) to make them age-adapted, by tuning the bottom-up and top-down maps according to the oberver’s age-group, before combining them into a final saliency map. In this study, total number of fixation landed, inter-fixation distance, and performance in patch matching task has been used as other metrics to quantify the age-impact over scene viewing behavior.
The developmental literature presents several evidences that the age-related difference in natural scene viewing behavior is significant across children, adult, and elderly participants. Further, these findings motivates us to investigate the age-related differences in scene viewing with aim of reflecting them in development of an age-adapted computational model of saliency prediction. In order to develop and age-adapted saliency model it gets important to understand the age-impact on gaze distribution (fixation locations distribution) across different age groups, however, the studies reported in developmental literature has mainly focused on revealing the age-impact by analyzing the gaze attributes such as fixation duration, saccade amplitude, blinks, etc.
2.2. Saliency Models
The computational models of saliency prediction which are reviewed in this section have in common that they are build on the psychophysical theories of visual attention system. Treisman’s Feature Integration Theory (FIT) (Treisman, 1993) and Wolfe’s Guided Search Model (Wolfe et al., 1989) has been among the most influential theories of psychological attention system. The main idea of the computational systems based on these theories is to compute different features maps in parallel and then fuse them together to get the final saliency map.
Most of the Bottom-up feature based saliency models have a very similar general structure to compute saliency. In these models we observe following basic structure: (a) Bottom-up features such as color, intensity, and orientation are extracted over multiple scales. (b) All these features are processed in parallel, to obtain the feature maps. (c) Finally, these features are integrated to obtain the final saliency map. Itti et al.’s model (Itti et al., 1998) is one of the most well-known model based on this general structure of saliency prediction. The Graph Based Visual Saliency Model (GBVS) (Harel et al., 2007) follows the similar general structure, where the maps are represented as fully connected graph and the distribution in Markov chain is treated as the saliency map.
Recent studies attempted to incorporate additional cues with bottom-up features such as human intention, given task, and cognitive states of mind which are also known as top-down features. Torralba et al. (Torralba, 2003; Torralba et al., 2006) proposed models for attention guidance which integrates the bottom-up features with the scene-context by using a Bayesian framework. Similarly, the SUN model of saliency prediction (Zhang et al., 2008) combines bottom-up feature maps with top-down information represented as Difference of Gaussian (DoG) and Independent Component Analysis (ICA) in order to predict the salient locations in imgaes. In very recent studies supervised learning based saliency models using eye-tracking data collected over young-adults are getting popular. Judd et al. (Judd et al., 2009) proposed a model which learn to predict saliency by learning feature (bottom-up and top-down) weights in a supervised manner over 1003 images viewed by 15 young adults. In light of the recent popularity of learning based saliency models there are many eye-gaze data introduced as shown in Table 1. It can be clearly seen form the Table 1 that participants of these experiments were mostly adults across all the dataset. Thus, all the computational models of visual attention learned on these dataset are inclined to reflect the scene exploration behavior of adults only.
3. Dataset
3.1. Participants, stimuli, and apparatus
The dataset used in this study was collected by Açiket al. (Açık et al., 2010) and the data can be retrieved from (Wilming et al., 2017). Fifty-eight participants participated in this study, comprising children (18 participants, age-range 7 to 9 years, mean age 7.6), adults (23 participants, age-range 19 to 27 years, mean age 22.1), and the elderly (17 participants, age-range 72 to 88 years, mean age 80.6) groups. All participatns reported normal or corrected-to-normal vision, including the elderly participants. Acik et al. (Açık et al., 2010) declared that all participants or their parents signed a written consent to participate in the experiment. The experiment was conducted in compliance with the Declaration of Helsinki as well as national and institutional guidelines for experiments with human participants.
In this study, we used 192 color images belonging to 3 different categories; “naturals”, “man-made” and “fractals” (64 in each categories). “Naturals” image category is representing natural scenes having trees, flowers, and bushes, this image category did not contain any artificial objects. “Man-made” category includes urban scenes such as street, road, building and construction sites, and the “fractals” are the computer generated shapes taken from the different web database such as Elena’s Fractal Gallery. Stimulus randomizations were balanced across pairs of participants. All images had a resolution of . EyeLink 1000 was used to record the gaze in its remote and hand-free mode.
3.2. Eye movement recording
Eye gaze was recorded while the observers viewed the images displayed for 5 seconds. The scene was subsequently replaced by a circular patch and participants had to determine if the patch was part of the previous scene or not. The patch recognition task was included to maintain the motivation of participants; thus the recognition results were not used in this study. Target stickers were placed on each observer’s head to compensate for head movements. Observers viewed the stimuli from a distance of 65 cm on a 20-inch LCD monitor display (width: 40 cm). All observers were instructed to explore the scene. Fixation and saccade were identified via a fixation detection algorithm supplied by EyeLink.
3.3. Data representation
We generated human fixation maps, human saliency maps and heat maps from the gaze data. For each age group the human fixation map for an image stimuls was generated by combining the fixation landings of all observers of that age group. Further, the human saliency maps were generated from human fixation maps by convolving a Gaussian, similar to Velichkovsky et al. (Velichkovsky et al., 1996). The heat map was obtained from the human saliency maps to visualize the age differences in the region of interest.
4. Analysis Method
In this section, we discuss various measures developed for quantitative analysis of age-related changes in scene-viewing behavior of images belonging to “naturals”, “man-made” and “fractals” categories. Human saliency maps across age groups served as a basis for all the metrics developed for this purpose. We also propose a framework that measures age-impact over the depth bias tendency, explorativeness, inter-individual similarity, and center bias tendency for images belonging to the different categories. The details of each measure are presented in the following subsections. Fixation location was selected as prime attribute in this study to quantify the age-impact on scene viewing behavior. The reason for this selection was based on the fact that the end goal of analysis was to develop a saliency model which can predict gaze locations accurately for different age groups.
4.1. Depth bias
The human visual system has the tendency of focusing earlier on the objects placed in the foreground than the objects in the background of the scene (Jansen et al., 2009). Gautier and Le Meur (Gautier and Le Meur, 2012) investigated the influence of disparity on saliency for 3D conditions. Their results indicate that foreground features play an important role in attention deployment. Itti and Koch (Itti and Koch, 2001) suggested that stereo disparity could be used as additional cue in saliency detection. However, this tendency of the human visual system was mainly explored for three-dimensional media but there is no study investigating the role of depth bias for two-dimensional media. Most importantly, to the best of our knowledge, for the first time we reported the role of scene depth in gaze landings across different age groups.
In the presented study, we visualized the age-related differences in gaze landings to the most salient foreground and the background regions in the scene. However, it is important to develop a framework to quantify this tendency across age groups. This tendency was observed in all those images in which some interesting item was placed in the foreground and the background of the scene, there was 20 such images in man-made category.
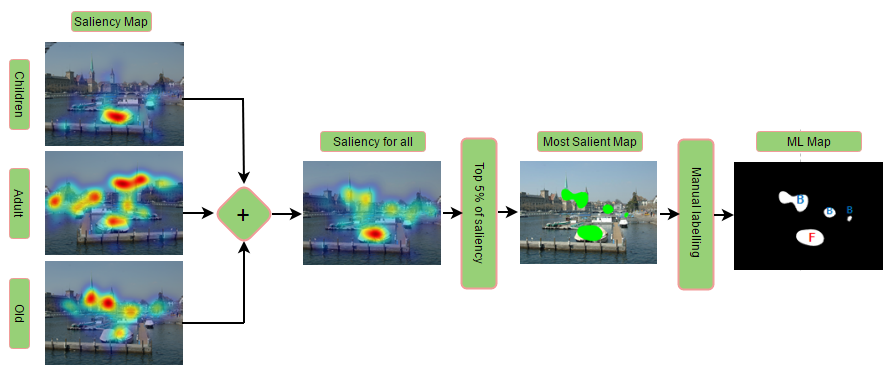
We propose a novel framework to quantify the depth bias tendency across age groups (Figure 3). As a first step a combined saliency map for each image is generated by linearly integrating the human saliency map of children, adults, and the elderly groups. The combined saliency map is generated to find the most salient locations independent of an observer’s age group. In the second step, we threshold the combined saliency map to get and percentage of the most salient locations of the scene. We fix and to five and ten, respectively, as we discovered that a small percentage of the most salient locations is sufficient to represent most of the fixation landings in the scene. In the third step, the most salient locations of the thresholded maps are manually labelled to foreground and background based on the near and far places in the scene. As shown in Figure 3, the thresholded map gives the most salient regions of the image (four different regions). Further, these regions are labelled as ”F” or ”B” according to their respective locations in the foreground or background of the scene (as shown in the ML map in Figure 3). Finally, the percentage of the fixations landing on the most salient foreground and background locations is calculated for each image to obtain an average score for individual age groups from the two thresholded maps. In summary, to measure the depth bias across age groups, we labelled most salient locations as foreground and background and then calculated average of the percentage of fixations landed on the foregrounds and backgrounds across all the images.
4.2. Explorativeness
Explorativeness study is conducted to evaluate the age-related changes in eye-movement behavior across different image categories. We found that the observers belonging to different age-groups viewing the same set of images, have differences in explored regions, and this age-impact was present independent of the image categories used in the study. We used the explorativeness metric (Krishna et al., 2017) introduced previously to quantify gaze distribution of observers belonging to children, adults and elderly age groups. Explorativeness is quantified by measuring the first-order entropy of the human saliency map of an images, further, the entropy value defines the spread of fixations for different age groups. For an image, explorativeness is computed as follows:
| (1) |
where is the human saliency map of the image from all observers in group for which entropy is calculated and is the histogram entry of intensity value in image , and is the total number of pixels in .
A higher entropy correspond to more exploratory viewing behavior of the observers belonging to an age group as their gaze points are more scattered, similarly a lower entropy correspond to less exploratory behavior of the observers.
4.3. Inter-Individual Similarity
Inter-individual similarity test was performed to understand the level of consistency between explored regions i.e. fixation locations among observers of the same or different age groups for all the image categories. Explorativeness analysis revealed that adults were more explorative than children and elderly participants; however, it is not clear whether the explored region by children and elderly observers was a subset of the explored region by adults (i.e. higher inter-individual similarity between children and adults age group). If that is the case, then adults can perform similarly in predicting the gaze landings of children observers to the children predicting others of the same age group. The inter-individual similarity aimed to answer this question in order to understand the need for development of an age-adapted computational attention system. We also aims to understand how the age impact differently to inter-individual similarity for the images belonging to ”nature”, ”man-made” and ”fractal” categories.
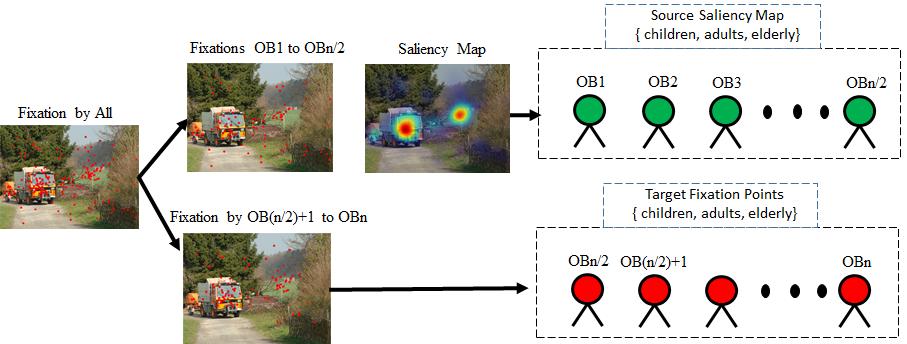
To evaluate the inter-individual similarity of an observer’s explored locations with rest of the observers of same and different age groups, we used source saliency map of one participant as a predictor to predict the target fixation of other observers (as in Figure 4). Thus under the intra-individual similarity the observer of source saliency map and target fixation points belongs to the same age group and for the inter-individual similarity the observer of source saliency map was different from target group. The formulation of this inter-individual similarity is as follows.
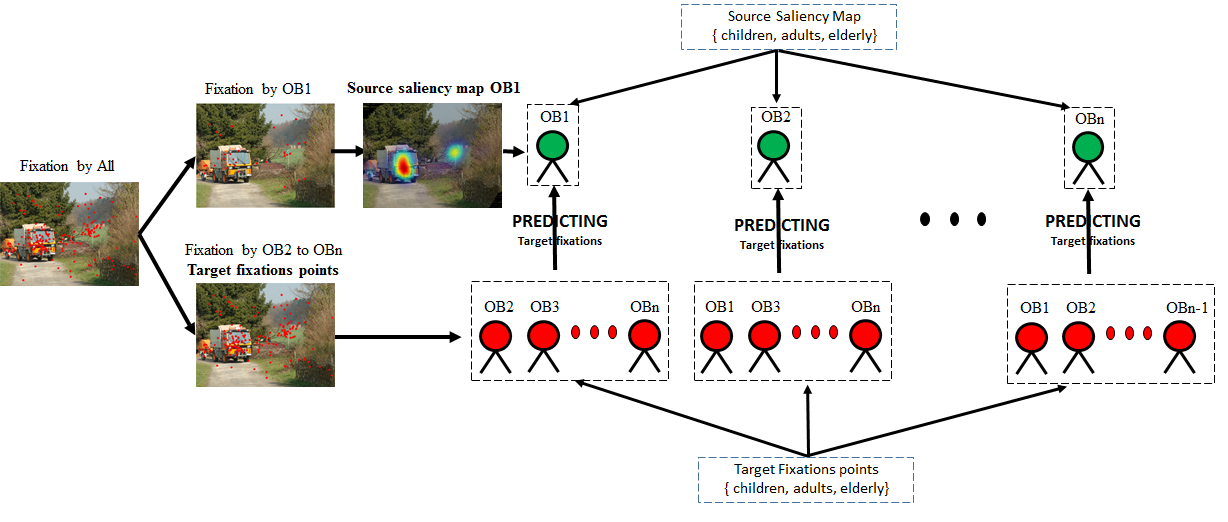
= The prediction score of the observer of group (source saliency map) in predicting others of a group (target fixations) for the image.
To measure the predictibilty of an oberver’s source saliency for target fixation points () we made use of area under the curve (AUC) metrics as explained in (Le Meur and Baccino, 2013). The AUC-score measures how well the source saliency map of an observer could be used to find the pooled fixation locations of the rest of the observers of the same or different age group i.e. inter-individual similarity of the observer for an image with rest of observers. Final inter and intra-individual similarity score of observer is obtained by taking average over all the images () as shown in following equation.
| (2) |
Where is inter-individual similarity of observer, is the total number of images.
4.4. Center bias
Center bias is the tendency of fixating around the center locations in a scene while viewing the scene. This is one of the strongest bias reported in many eye tracking studies (Tatler, 2007; Zhang et al., 2008). The prediction accuracy of many computational models of visual attention (Zhang et al., 2008; Judd et al., 2009) have been seen to improve when center bias is included in their prediction framework. For example, a Gaussian blob centered at the middle of the image, considerably improved prediction performance of the learning-based saliency model (Judd et al., 2009).
To include the center bias tendency in the proposed age-adapted computational attention system, we first analyzed the age-related changes in this tendency. Then based on the analysis results we introduced a weighting factor for tuning the strength of the center-map in our proposed age-adapted model. To measure the center bias across age groups, we, first, generated a center-map for each age group by taking the average of all the maps for each age group. The heat map representation of the center-map over a sample image. Finally, the center bias for each age group is measured by measuring the euclidean distance between the centroid of the center-map and the center pixel of the image.
5. Analysis Results
5.1. Depth Bias
The results are shown in Figure 5, which show that:
-
•
Average of the fixations percentage landed on the most salient foreground locations in the images is significantly higher for child observers than for adults and the elderly (Figure 5(a)). The one-way ANOVA analysis suggest a significant influence of age over gaze landings in the foreground regions of the scene (), Further, a post-hoc analysis confirms that the foreground bias tendency in children is significantly different from that of adult and elderly observers ().
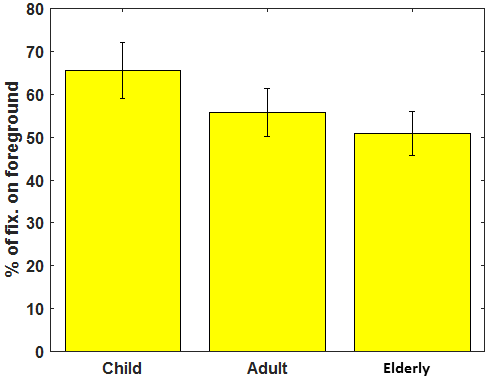
(a) 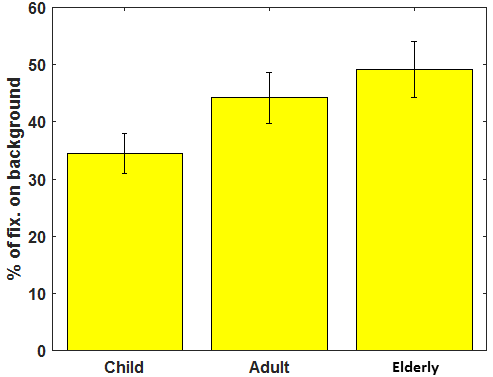
(b) Figure 5. (a) Percentage of the gaze landed on foreground. (b) Percentage of the gaze landed on background -
•
The percentage of fixation landings on most salient background places (Figure 5(b)) gives an interesting observation for the gaze behavior of elderly observers. It was found that elderly observers have a significantly higher tendency for fixating over items placed in the scene background than children and adult observers. The one-way ANOVA analysis confirmed the age-impact over the background bias (), and post-hoc analysis revealed the behavior of elderly observers is significantly different to adults () and children ().
5.2. Explorativeness
The explorativeness result suggests following tendency for children, adults, and elderly observers:
-
•
Result showed significant impact of age over explorativeness tendency across all the image categories (). Post-hoc results across all the image categories showed that the child observers possess the lowest exploratory tendency compared to adults (), who are highly explorative for the same set of images. Elderly observers showed less exploratory tendency than adults but higher than that of children () (Figure 6).
-
•
Explorativeness tendency reflects the level of details an observer visualizes in a scene. With the highest exploratory behavior, young adults have a tendency to visualize finer to coarser details in the scene, as inferred from (Judd et al., 2011), which states that a decrease in spatial scale results in a decrease in the exploratory behavior of the observers.
The age-related differences in explorativeness tendency on three different class of images (see Figure 6) show that this exploratory behavior is independent of the type of stimuli being observed.
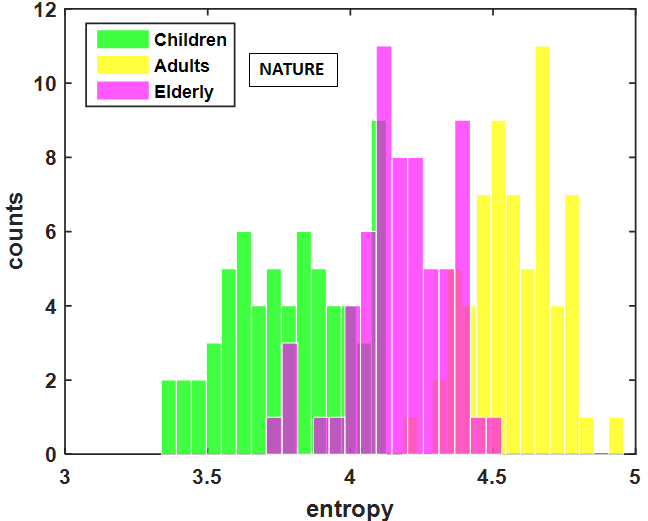
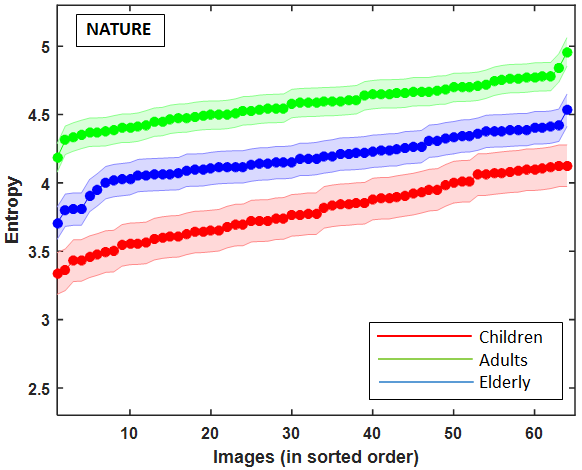
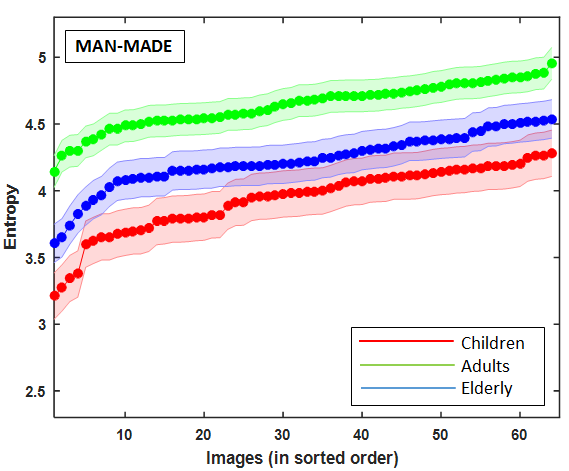
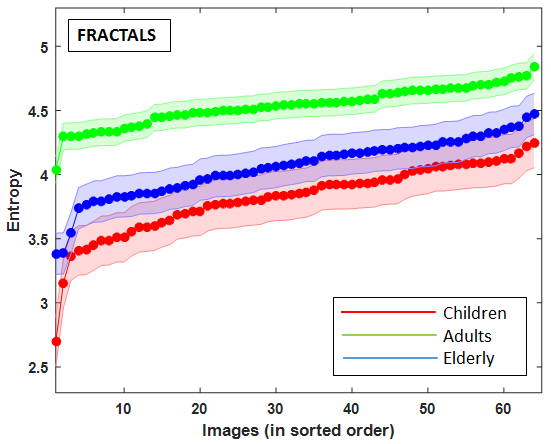
5.3. Inter-individual similarity
The inter and intra-individual similarity results are shown in Table 1 and Figure 7.
-
•
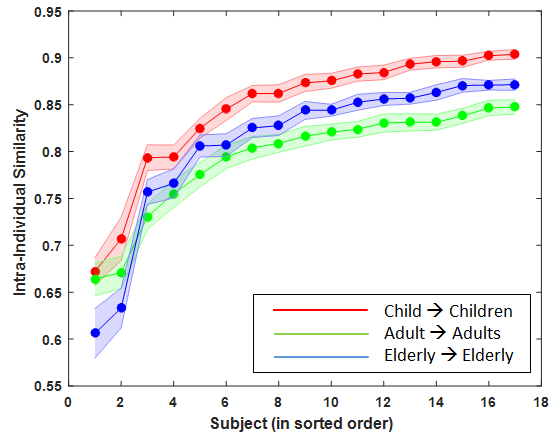
One-way ANOVA confirmed the age influence over intra-age-group agreement between observers independent of the class of the image (). Further, post-hoc revealed that the children are in better agreement with each other for explored locations than adults and elderly observers for all the image categories, (Figure 7(a) and Table 1).
-
•
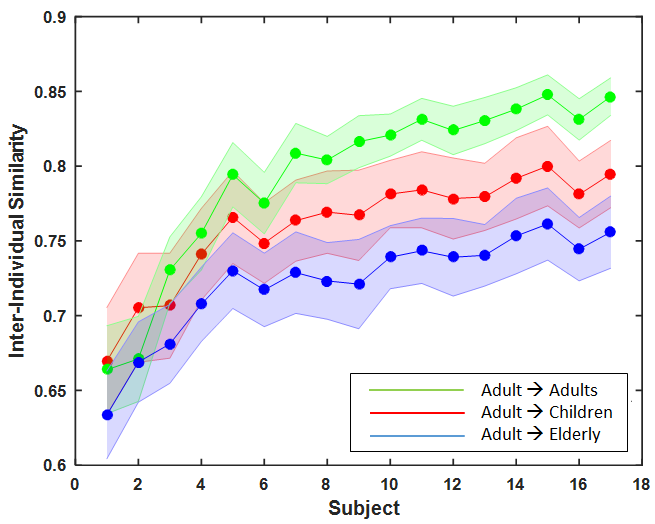
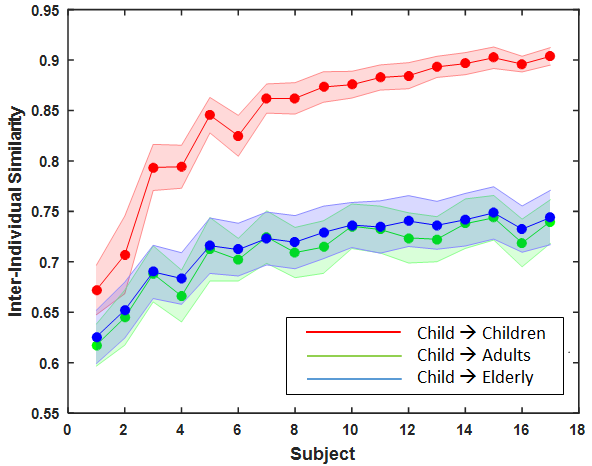
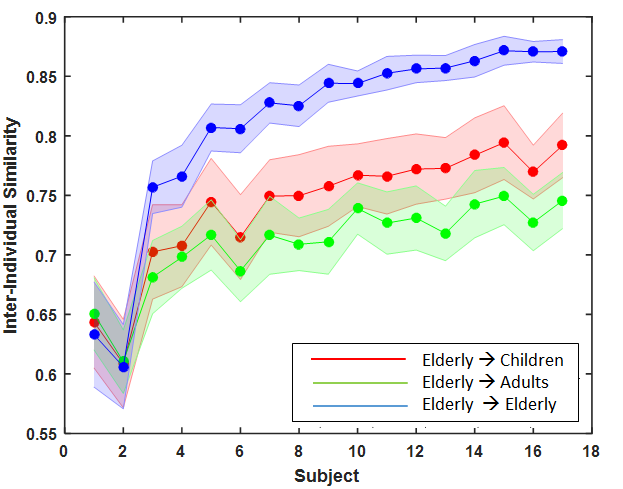
Inter-age-group agreement analysis suggests that fixations of an specific age group can be best predicted by an observer of the same age group. As highlighted in table 1, the diagonal entries in each image class are highest compared to other elements in the same row, which suggest a fixation is well predicted by an observer of the same age-group than the observer of different age-group. For instance, as shown in Figure 7(c) for natural images, a child can predict well the fixations of other children better than an adult can predict children observers ().
This result suggest that the prediction accuracy of learning-based saliency models can be optimized only when the training weights are learned over the age-specific fixation data.
| Class | Nature | Man-made | Fractals | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Children | Adults | Elderly | Children | Adults | Elderly | Children | Adults | Elderly | |
| Children | \cellcolor[HTML]FFCCC90.8390 | 0.6937 | 0.7253 | \cellcolor[HTML]9AFF990.8483 | 0.7093 | 0.7172 | \cellcolor[HTML]CBCEFB0.8579 | 0.7257 | 0.7559 |
| Adults | 0.7548 | \cellcolor[HTML]FFCCC90.7874 | 0.7193 | 0.7693 | \cellcolor[HTML]9AFF990.8085 | 0.7310 | 0.7870 | \cellcolor[HTML]CBCEFB0.8037 | 0.7507 |
| Elderly | 0.7432 | 0.6860 | \cellcolor[HTML]FFCCC90.8063 | 0.7410 | 0.7094 | \cellcolor[HTML]9AFF990.8093 | 0.7693 | 0.7173 | \cellcolor[HTML]CBCEFB0.8326 |
5.4. Center Bias
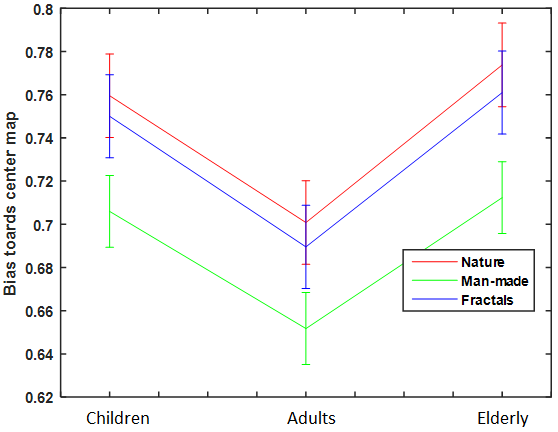
We can visualize different tendency of gaze landings towards center of scene for different age groups as shown in center map of different age groups (Figure 8). Agreement score (AUC score) of fixations of different age groups towards their center map revealed the age-impact over this tendency independent of the image categories (see Figure 9). The post-hoc analysis revealed that children have significantly different tendency towards center map that adults for all the scene categories ().
Further, the result of Euclidean distance from the centriod of the explored region by different age group and center pixel of the scene showed that children have highest center bias but elderly participants showed similar tendency. (Nature- 150, 210, and 184 are the euclidean distance in pixels for children, adult and elderly participants, man-made- 203, 267, and 244, and fractals- 189, 214, and 202).
5.5. Recommendations for age-adapted saliency model
The analysis results recommended five major findings that we use to develop an age-adapted computational model of visual attention. These recommendations are as follows: .
-
•
Depth object bias tendency showed that child observers are focused more towards the objects in foreground compared to adult and old observers. This can be incorporated in age-adapted model by including a depth map at different spatial scales for children and old age groups.
-
•
Explorativeness result showed that children were least explorative among the three age groups i.e. they are mostly focused on the coarser details of the scene, whereas being highly explorative adults evaluated finer detail too. This can be included in age-adapted model by selecting different spatial scale for different age groups.
-
•
Inter age group agreement analysis suggests that the saliency maps of adults fail to appropriately predict fixation landings of child and old observers. Thus it is advisable to train the learning based models over the age-specific gaze data to optimize the prediction performance for different age groups.
-
•
Analysis result of age-related changes in central bias tendency motivated us to investigate the scope of reflecting these change in computational model of visual attention by tuning the center feature map of existing algorithms.
6. Upper performance limit
The final goal of our study is to reflect the age-related changes reported in the eye gaze-data analysis into the proposed age-adapted model of saliency prediction. Keeping that in mind, prior to developing any model, we have used the metrics reported in (Stankiewicz et al., 2011) to estimate the upper performance limit (UPL) of an age-adapted saliency model developed for children, adults, and elderly. The UPL score also gives us an idea that how well a saliency model can predict fixations for images belonging to ”natural”, ”man-made” and ”fractals” image categories. Making it more clear, in this section we presented a robust metric UPL to measure the upper performance limit of a computational model of visual attention developed for these age groups.
The upper performance limit of an age group is defined as the ability of fixations over half of the observers in predicting fixations of other half of the observers. In order to do that first we generate human saliency map over fixations of first half of the observers by following the similar procedure mentioned in data representation section. Further, the human saliency map obtained after this step used to predict the fixation points of rest of the observers. The area under the curve (AUC) based metrics are used for this purpose. The framework to measure upper performance limit is shown in Figure 10.
Higher UPL score of an age group suggests higher agreement among fixations of a group of observers with rest of the observers of same age group. Similarly the lower UPL score of an age group, suggests the lower agreement between two group of observers.
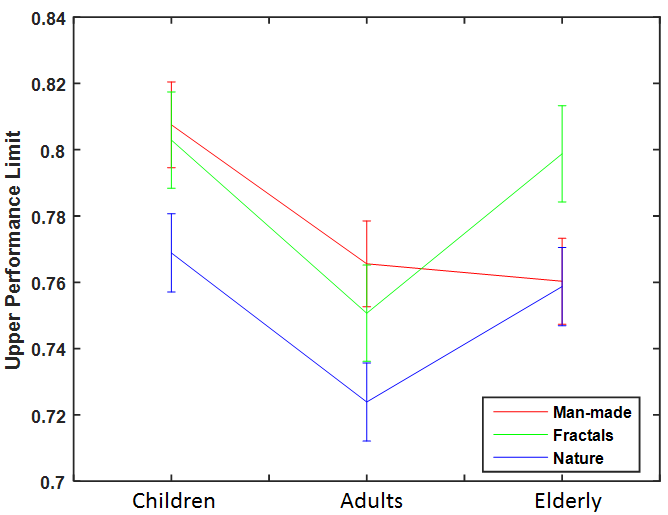
The Upper Performance Limit results are shown in Figure 11.
-
•
One-way ANOVA confirmed the age influence over UPL for all the image categories, for the man-made category . Further, post-hoc revealed that the UPL of children were highest and significantly different to adults and elderly participants for man-made images ().
-
•
Similarly, for the natural and man-made categories the UPL was significantly higher for children and elderly participants than the adults (). The UPL results presents a very important finding that the prediction accuracy of a computational model developed for children will always be higher than a model developed for adults in all the image categories.
The prior knowledge about the upper-bound of the proposed age-adapted saliency model will help in optimizing the prediction accuracy for each age groups.
7. Age-adapted learning based saliency model
In the previous section we laid some recommendations from our analysis results for developing an age-adapted computational attention system. The general structure of our proposed model is similar to learning based saliency algorithmes (Judd et al., 2009) in which the final saliency map is the weighted sum of the features extracted from the input image, where the weights are learned adults gaze data. We modified learning based algorithms to reflect the age-related changes in saliency prediction following the below mentioned steps: (a) Depth bias: We include an extra feature map for depth information at different spatial scale and orientation, generated by steerable pyramid (Simoncelli and Freeman, 1995). (b)Center bias: Instead of using the center map independent of the observers age group and image category, we use a weighted mechanism for tuning them in accordance with age-related changes in center bias tendency. (c) Explorativeness: Age-related differences in explorativeness tendency was incorporated by selecting different scales of features for different age groups. (d) Individual Similarity: Finally, the model weights are learned over the age-specific gaze data instead of using adults gaze data.
7.1. Feature used in machine learning
We use a learning approach to train a classifier directly from age-adapted eye tracking data. The general structure is that the proposed model learns the weight for combining different features extracted from a input image to generate the final saliency map.
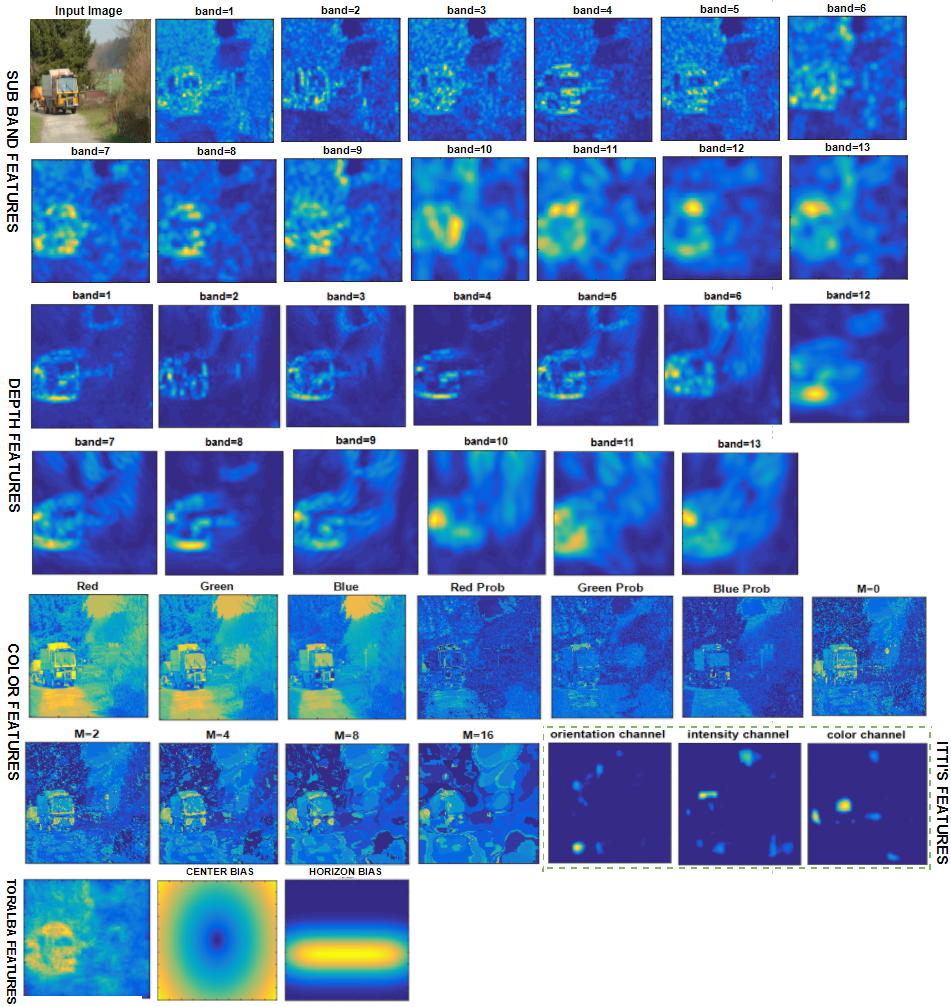
Features that we used for training and testing can be categorized in low-level, mid-level, and high-level features. Low-level feature includes, color features, itti’s saliency map (intensity, color, and orientation channel) (Itti et al., 1998), Torralba’s saliency map (Torralba, 2003), and the local energy of steerable pyramid (Simoncelli and Freeman, 1995). In mid-level features horizon feature is extracted similar to (Judd et al., 2009), as the human’s have tendency of naturally directing their gaze on horizon locations in a scene viewing. For high-level features, object and car detection algorithms were applied in the proposed model. Figure 12 shows the feature maps extracted from a sample image.
The center bias is included by a adding center map generated by Gaussian blob placed at center of the scene as in (Judd et al., 2009). The most important contribution of this work is that for the first time we included a depth feature maps extracted from input 2D scenes in context of the age-related diffrences in depth bias tendecies. The depth maps from single images are estimated using a method proposed in (Liu et al., 2015) as shown in Figure 11.


| Dataset | Age | Itti | GBVS | Patch | Judd | Age-adapted | UPL |
| Manmade | Children | 0.7140 | 0.7322 | 0.6765 | 0.7365 | 0.7456 | 0.8075 |
| Adults | 0.6723 | 0.6681 | 0.6083 | 0.6627 | 0.6960 | 0.7656 | |
| Elderly | 0.6956 | 0.7160 | 0.6679 | 0.7211 | 0.7402 | 0.7603 | |
| Nature | Children | 0.6224 | 0.7427 | 0.7359 | 0.7657 | 0.7648 | 0.7689 |
| Adults | 0.6021 | 0.6807 | 0.6513 | 0.6774 | 0.6991 | 0.7239 | |
| Elderly | 0.6150 | 0.7267 | 0.7186 | 0.7433 | 0.7498 | 0.7587 | |
| Fractals | Children | 0.6903 | 0.7610 | 0.7111 | 0.7627 | 0.7831 | 0.8029 |
| Adults | 0.6582 | 0.6998 | 0.6439 | 0.6855 | 0.6960 | 0.7507 | |
| Elderly | 0.6758 | 0.7485 | 0.7139 | 0.7562 | 0.7708 | 0.7988 |
7.2. Training and Testing: age-adapted model
We used Liblinear support vector machine to train our model over different features extracted from the scene. The model he model of Judd et al. (Judd et al., 2009) was not well suited for the age-adapted mechanism as the depth bias features maps were not included in the proposed model. To fit the training and testing in our age-adapted framework, we follow the recommendations of our analysis results. We can see in Figure 12 different features are extracted at several spatial scales (finer to coarser), where band 2 to 4 is scale 1 (finer), band 5 to 8 is scale 2 and band 9 to 12 is scale 3 (coarser). Further, based on the results of explorativeness study, first we focus on feature scale selection, where we found that being less explorative only a few scales are required to represent the level of details explored by children and old observers, conversely, for adults, all the scales are used to represent the level of details they explored in a scene. From our experiments we found that optimal scale for children was 3, whereas scale 2 and 3 for old and scale 1, 2, and 3 for adult observers.
We split the dataset with 192 images into 120 training and 72 test image set. Further, different features were extracted at all the scales, and only a few scales were chosen to represent the age-adapted changes in scene viewing behavior. The use of center map feature was altered by including a weight factor for tuning the age-related differences in center bias tendency as reported in our analysis. Top 10 strong positive and negative samples from top 5% of the human saliency map and similarly 10% strong negative pixels from bottom 20
Further, as suggested by the agreement score analysis, strong positive and negative samples from the age-specific human saliency maps were used for training as it was seen that saliency maps of adults were poor predictors for the fixation landings of children and old observers and it is advisable to use the saliency maps of the child observers and old observers to predict fixation landings of observers of these individual groups respectively.
For a given set of feature and levels (positive and negative samples) selected over the age-based human saliency map, SVM is used to learn the optimal weights for depth features i.e. model parameters for each age group in order to predict salient locations for different age groups. Further, for a given image of test dataset, a final saliency map is generated by combining different feature extracted at different scales over an age-specific optimal weights learned for newly included depth map during training the model. Although the prediction accuracy is mentioned for different image categories as shown in Table 2 but the model parameters are learned over all the images independent of the class of the image.
| (3) |
Where and are optimal weights for age group , i.e., children, adults, and old separately, is feature vector for the test image, this vector is of different size for different age group due to the proposed optimal feature scale mechanism. Based on the saliency values we classified the local pixel as salient or not.

Performance of our proposed age-adapted model was evaluated using AUC metrics (Judd et al., 2009). The evaluation score is listed in Table 2 and the resulted saliency map for sample images are shown in Figure 13. We compared our model with several state-of-the art methods reported in (Itti et al., 1998; Harel et al., 2007; Jansen et al., 2009). The result shows that the proposed age-adapted model outperform the existing saliency models for all age groups independent of the image categories. It is also interesting to note that children observers show better prediction accuracy independent of the saliency model, however the age-adapted model optimized the prediction accuracy each age groups, which suggest that our modifications especially including depth map in leaning based model works well for adult observes as well.
8. Conclusion
In this work we analyzed the age-related differences in scene viewing behavior for three different age groups: children, adult and elderly observers while they viewed the scenes belonging to ”natural”, ”man-made” and ”fractals” image categories. The analysis was mainly focused to measure the age-related changes in depth bias, center bias, explorativeness, and inter-individual similarity. The result showed significant impact of age on fixation landings independent of the class of the scene viewed. Further, the analysis results helped in feature scale selection, depth map insertions, and age-specific learning in our proposed age-adapted learning based saliency model.
The prediction accuracy of our proposed model outperforms the existing saliency models for all the age groups. The possible application of this work can be in understanding the differences in visual strategies and competencies in adults and old drivers, which can further help in optimizing the drivers training and preventing the accidents in old drivers. Prior knowledge about scene viewing behavior of different age groups can help in designing the advertisement targeted to specific age group.
Acknowledgements.
We are thankful to Dr. Alpher Acik for providing the gaze data used in this study. This work is partially supported by JST CREST, JPMJCR1686, and NTT Communication Science Laboratories, NTT Corporation, Japan.References
- (1)
- Açık et al. (2010) Alper Açık, Adjmal Sarwary, Rafael Schultze-Kraft, Selim Onat, and Peter König. 2010. Developmental changes in natural viewing behavior: bottom-up and top-down differences between children, young adults and older adults. Frontiers in psychology 1 (2010).
- Aring et al. (2007) Eva Aring, Marita Andersson Grönlund, Ann Hellström, and Jan Ygge. 2007. Visual fixation development in children. Graefe’s Archive for Clinical and Experimental Ophthalmology 245, 11 (2007), 1659–1665.
- Balkenius (2000) Christian Balkenius. 2000. Attention, habituation and conditioning: Toward a computational model. Cognitive Science Quarterly 1, 2 (2000), 171–214.
- Cave and Wolfe (1990) Kyle R Cave and Jeremy M Wolfe. 1990. Modeling the role of parallel processing in visual search. Cognitive psychology 22, 2 (1990), 225–271.
- Erdem and Erdem (2013) Erkut Erdem and Aykut Erdem. 2013. Visual saliency estimation by nonlinearly integrating features using region covariances. Journal of vision 13, 4 (2013), 11–11.
- Fioravanti et al. (1995) F Fioravanti, P Inchingolo, S Pensiero, and M Spanio. 1995. Saccadic eye movement conjugation in children. Vision research 35, 23 (1995), 3217–3228.
- Fischer et al. (1997) Burkhart Fischer, Monica Biscaldi, and Stefan Gezeck. 1997. On the development of voluntary and reflexive components in human saccade generation. Brain research 754, 1 (1997), 285–297.
- Fukushima et al. (2006) Junko Fukushima, Teppei Akao, Sergei Kurkin, Chris RS Kaneko, and Kikuro Fukushima. 2006. The vestibular-related frontal cortex and its role in smooth-pursuit eye movements and vestibular-pursuit interactions. Journal of Vestibular Research 16, 1, 2 (2006), 1–22.
- Fukushima et al. (2000) Junko Fukushima, Tatsuo Hatta, and Kikuro Fukushima. 2000. Development of voluntary control of saccadic eye movements: I. Age-related changes in normal children. Brain and Development 22, 3 (2000), 173–180.
- Gautier and Le Meur (2012) Josselin Gautier and Olivier Le Meur. 2012. A time-dependent saliency model combining center and depth biases for 2D and 3D viewing conditions. Cognitive Computation 4, 2 (2012), 141–156.
- Harel et al. (2007) Jonathan Harel, Christof Koch, and Pietro Perona. 2007. Graph-based visual saliency. In Advances in neural information processing systems. 545–552.
- Hayhoe and Ballard (2005) Mary Hayhoe and Dana Ballard. 2005. Eye movements in natural behavior. Trends in cognitive sciences 9, 4 (2005), 188–194.
- Helo et al. (2014) Andrea Helo, Sebastian Pannasch, Louah Sirri, and Pia Rämä. 2014. The maturation of eye movement behavior: Scene viewing characteristics in children and adults. Vision research 103 (2014), 83–91.
- Irving et al. (2006) Elizabeth L Irving, Martin J Steinbach, Linda Lillakas, Raiju J Babu, and Natalie Hutchings. 2006. Horizontal saccade dynamics across the human life span. Investigative ophthalmology & visual science 47, 6 (2006), 2478–2484.
- Itti and Koch (2001) Laurent Itti and Christof Koch. 2001. Computational modelling of visual attention. Nature reviews. Neuroscience 2, 3 (2001), 194.
- Itti et al. (1998) Laurent Itti, Christof Koch, and Ernst Niebur. 1998. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on pattern analysis and machine intelligence 20, 11 (1998), 1254–1259.
- Jansen et al. (2009) Lina Jansen, Selim Onat, and Peter König. 2009. Influence of disparity on fixation and saccades in free viewing of natural scenes. Journal of Vision 9, 1 (2009), 29–29.
- Judd et al. (2011) Tilke Judd, Fredo Durand, and Antonio Torralba. 2011. Fixations on low-resolution images. Journal of Vision 11, 4 (2011), 14–14.
- Judd et al. (2009) Tilke Judd, Krista Ehinger, Frédo Durand, and Antonio Torralba. 2009. Learning to predict where humans look. In Computer Vision, 2009 IEEE 12th international conference on. IEEE, 2106–2113.
- Klein (2001) Christoph Klein. 2001. Developmental functions for saccadic eye movement parameters derived from pro-and antisaccade tasks. Experimental Brain Research 139, 1 (2001), 1–17.
- Klein and Feige (2005) Christoph Klein and Bernd Feige. 2005. An independent components analysis (ICA) approach to the study of developmental differences in the saccadic contingent negative variation. Biological Psychology 70, 2 (2005), 105–114.
- Koffka (2013) Kurt Koffka. 2013. Principles of Gestalt psychology. Vol. 44. Routledge.
- Krishna et al. (2017) Onkar Krishna, Kiyoharu Aizawa, Andrea Helo, and Rama Pia. 2017. Gaze Distribution Analysis and Saliency Prediction Across Age Groups. arXiv preprint arXiv:1705.07284 (2017).
- Le Meur and Baccino (2013) Olivier Le Meur and Thierry Baccino. 2013. Methods for comparing scanpaths and saliency maps: strengths and weaknesses. Behavior research methods 45, 1 (2013), 251–266.
- Liu et al. (2015) Fayao Liu, Chunhua Shen, and Guosheng Lin. 2015. Deep convolutional neural fields for depth estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5162–5170.
- Luna et al. (2004) Beatriz Luna, Krista E Garver, Trinity A Urban, Nicole A Lazar, and John A Sweeney. 2004. Maturation of cognitive processes from late childhood to adulthood. Child development 75, 5 (2004), 1357–1372.
- Luna et al. (2008) Beatriz Luna, Katerina Velanova, and Charles F Geier. 2008. Development of eye-movement control. Brain and cognition 68, 3 (2008), 293–308.
- Navalpakkam and Itti (2006) Vidhya Navalpakkam and Laurent Itti. 2006. Top–down attention selection is fine grained. Journal of Vision 6, 11 (2006), 4–4.
- Nelson et al. (2000) Charles A Nelson, Christopher S Monk, Joseph Lin, Leslie J Carver, Kathleen M Thomas, and Charles L Truwit. 2000. Functional neuroanatomy of spatial working memory in children. Developmental psychology 36, 1 (2000), 109.
- Simoncelli and Freeman (1995) Eero P Simoncelli and William T Freeman. 1995. The steerable pyramid: A flexible architecture for multi-scale derivative computation. In Image Processing, 1995. Proceedings., International Conference on, Vol. 3. IEEE, 444–447.
- Stankiewicz et al. (2011) J Stankiewicz, Nathan J Anderson, and Richard J Moore. 2011. Using performance efficiency for testing and optimization of visual attention models. In Proceedings of SPIE, Vol. 7867. 78670Y.
- Tatler (2007) Benjamin W Tatler. 2007. The central fixation bias in scene viewing: Selecting an optimal viewing position independently of motor biases and image feature distributions. Journal of vision 7, 14 (2007), 4–4.
- Tatler et al. (2010) Benjamin W Tatler, Nicholas J Wade, Hoi Kwan, John M Findlay, and Boris M Velichkovsky. 2010. Yarbus, eye movements, and vision. i-Perception 1, 1 (2010), 7–27.
- Taylor and Fragopanagos (2005) JG Taylor and N Fragopanagos. 2005. Modelling the interaction of attention and emotion. In Neural Networks, 2005. IJCNN’05. Proceedings. 2005 IEEE International Joint Conference on, Vol. 3. IEEE, 1663–1668.
- Torralba (2003) Antonio Torralba. 2003. Modeling global scene factors in attention. JOSA A 20, 7 (2003), 1407–1418.
- Torralba et al. (2006) Antonio Torralba, Aude Oliva, Monica S Castelhano, and John M Henderson. 2006. Contextual guidance of eye movements and attention in real-world scenes: the role of global features in object search. Psychological review 113, 4 (2006), 766.
- Treisman (1993) A Treisman. 1993. The perception of features and objects in Attention: Selection, Awareness and Control. (1993).
- Unema et al. (2005) Pieter JA Unema, Sebastian Pannasch, Markus Joos, and Boris M Velichkovsky. 2005. Time course of information processing during scene perception: The relationship between saccade amplitude and fixation duration. Visual cognition 12, 3 (2005), 473–494.
- Velichkovsky et al. (1996) Boris Velichkovsky, Marc Pomplun, and Johannes Rieser. 1996. Attention and communication: Eye-movement-based research paradigms. Advances in Psychology 116 (1996), 125–154.
- Wilming et al. (2017) Niklas Wilming, Selim Onat, José P Ossandón, Alper Açık, Tim C Kietzmann, Kai Kaspar, Ricardo R Gameiro, Alexandra Vormberg, and Peter König. 2017. An extensive dataset of eye movements during viewing of complex images. Scientific data 4 (2017), 160126.
- Wolfe et al. (1989) Jeremy M Wolfe, Kyle R Cave, and Susan L Franzel. 1989. Guided search: an alternative to the feature integration model for visual search. Journal of Experimental Psychology: Human perception and performance 15, 3 (1989), 419.
- Wu et al. (2014) Chia-Chien Wu, Farahnaz Ahmed Wick, and Marc Pomplun. 2014. Guidance of visual attention by semantic information in real-world scenes. Frontiers in psychology 5 (2014).
- Ygge et al. (2005) JN Ygge, Eva Aring, Ying Han, Roberto Bolzani, and Ann HellstrÖm. 2005. Fixation stability in normal children. Annals of the New York Academy of Sciences 1039, 1 (2005), 480–483.
- Zhang et al. (2008) Lingyun Zhang, Matthew H Tong, Tim K Marks, Honghao Shan, and Garrison W Cottrell. 2008. SUN: A Bayesian framework for saliency using natural statistics. Journal of vision 8, 7 (2008), 32–32.
- Zhang et al. (2016) Libo Zhang, Lin Yang, and Tiejian Luo. 2016. Unified saliency detection model using color and texture features. PloS one 11, 2 (2016), e0149328.