Computing finite index congruences of finitely presented semigroups and monoids
Abstract
In this paper, we describe an algorithm for computing the left, right, or 2-sided congruences of a finitely presented semigroup or monoid with finitely many classes, and an alternative algorithm when the finitely presented semigroup or monoid is finite. We compare the two algorithms presented with existing algorithms and implementations. The first algorithm is a generalization of Sims’ low-index subgroup algorithm for finding the congruences of a monoid. The second algorithm involves determining the distinct principal congruences, and then finding all of their possible joins. Variations of this algorithm have been suggested in numerous contexts by numerous authors. We show how to utilize the theory of relative Green’s relations, and a version of Schreier’s Lemma for monoids, to reduce the number of principal congruences that must be generated as the first step of this approach. Both of the algorithms described in this paper are implemented in the GAP [29] package Semigroups [54], and the first algorithm is available in the C++ library libsemigroups [53] and in its Python bindings libsemigroups_pybind11 [52].
1 Introduction
In this paper, we are concerned with the problem of computing finite index congruences of a finitely presented semigroup or monoid. One case of particular interest is computing the entire lattice of congruences of a finite semigroup or monoid. We will present two algorithms that can perform these computations and compare them with each other and to existing algorithms and their implementations. The first algorithm is the only one of its kind, permitting the computation of finite index 1-sided and 2-sided congruences, and a host of other things (see Section 5) of infinite finitely presented semigroups and monoids. Although this first algorithm is not specifically designed to find finite index subgroups of finitely presented groups, it can be used for such computations and is sometimes faster than the existing implementations in 3Manifolds [15] and GAP [29]; see Table A.5. The second algorithm we present is, for many examples, several orders of magnitude faster than any existing method, and in many cases permits computations that were previously unfeasible. Examples where an implementation of an existing algorithm, such as that in [58], is faster are limited to those with total runtime below 1 second; see Table A.6. Some further highlights include: computing the numbers of right/left congruences of many classical examples of finite transformation and diagram monoids, see Appendix B; reproducing and extending the computations from [6] to find the number of congruences in free semigroups and monoids (see Table B.13); computational experiments with the algorithms implemented were crucial in determining the minimum transformation representation of the so-called diagram monoids in [11]; and in classifying the maximal and minimal 1-sided congruences of the full transformation monoids in [12]. In Appendix A, we present significant quantitative data exhibiting the performance of our algorithms. Appendix B provides a wealth of data generated using the implementation of the algorithms described here. For example, the sequences of numbers of minimal 1-sided congruences of a number of well-studied transformation monoids are apparent in several of the tables in Appendix B, such as Table B.12.
The question of determining the lattice of 2-sided congruences of a semigroup or monoid is classical and has been widely studied in the literature; see, for example, [47]. Somewhat more recently, this interest was rekindled by Araújo, Bentz, and Gomes in [2], Young (né Torpey) in [70], and the third author of the present article, which resulted in [23] and its numerous offshoots [7, 16, 18, 19, 20, 21, 22]. The theory of 2-sided congruences of a monoid is analogous to the theory of normal subgroups of a group, and 2-sided congruences play the same role for monoids with respect to quotients and homomorphisms. As such, it is perhaps not surprising that the theory of 2-sided congruences of semigroups and monoids is rather rich. The 2-sided congruences of certain types of semigroup are completely classified, for a small sample among many, via linked triples for regular Rees 0-matrix semigroups [35, Theorem 3.5.8], or via the kernel and trace for inverse semigroups [35, Section 5.3].
The literature relating to 1-sided congruences is less well-developed; see, for example, [7, 51]. Subgroups are to groups what 1-sided congruences are to semigroups. This accounts, at least in part, for the relative scarcity of results in the literature on 1-sided congruences. The number of such congruences can be enormous, and the structure of the corresponding lattices can be wild. For example, the full transformation monoid of degree has size and possesses right congruences111This number was computed for the first time using the algorithm described in Section 4 as implemented in the C++ library libsemigroups [53] whose authors include the authors of the present paper. It was not previously known.. Another example is that of the stylic monoids from [1], which are finite quotients of the well-known plactic monoids [44, 45]. The stylic monoid with generators has size , while the number of left congruences is \@footnotemark.
The purpose of this paper is to provide general computational tools for computing the 1- and 2-sided congruences of a finite, or finitely presented, monoid. There are a number of examples in the literature of such general algorithms; notable examples include [25], [70], and [4], which describes an implementation of the algorithms from [25].
The first of the two algorithms we present is a generalization of Sims’ low-index subgroup algorithm for congruences of a finitely presented monoid; see Section 5.6 in [65] for details of Sims’ algorithm; some related algorithms and applications of the low-index subgroups algorithm can be found in [32], [37], [55, Section 6], and [60]. A somewhat similar algorithm for computing low-index ideals of a finitely presented monoid with decidable word problem was given by Jura in [39] and [40] (see also [61]). We will refer to the algorithm presented here as the low-index congruence algorithm. We present a unified framework for computing various special types of congruences, including: 2-sided congruences; congruences including or excluding given pairs of elements (leading to the ability to compute specific parts of a congruence lattice); solving the word problem in residually finite semigroups or monoids; congruences such that the corresponding quotient is a group; congruences arising from 1- or 2-sided ideals; and 1-sided congruences representing a faithful action of the original monoid; see Section 5 for details. This allows us to, for example, implement a method for computing the finite index ideals of a finitely presented semigroup akin to [39, 40] by implementing a single function (Algorithm 4) which determines if a finite index right congruence is a Rees congruence.
The low-index congruence algorithm takes as input a finite monoid presentation defining a monoid , and a positive integer . It permits the congruences with up to classes to be iterated through without repetition, while only holding a representation of a single such congruence in memory. Each congruence is represented as a certain type of directed graph, which we refer to as word graphs; see Section 2 for the definition. The space complexity of this approach is where is the number of generators of the input monoid, and is the input positive integer. Roughly speaking, the low-index algorithm performs a backtracking search in a tree whose nodes are word graphs. If the monoid is finite, then setting allows us to determine all of the left, right, or 2-sided congruences of . Finding all of the subgroups of a finite group was perhaps not the original motivation behind Sims’ low-index subgroup algorithm from [65, Section 5.6]. In particular, there are likely better ways of finding all subgroups of a finite group; see, for example, [33], [36] and the references therein. On the other hand, in some sense, the structure of semigroups and monoids in general is less constrained than that of groups, and in some cases the low-index congruence algorithm is the best or only available means of computing congruences.
To compute the actual lattice of congruences obtained from the low-index congruences algorithm, we require a mechanism for computing the join or meet of two congruences given by word graphs. We show that two well-known algorithms for finite state automata can be used to do this. More specifically, a superficial modification of the Hopcroft-Karp Algorithm [34], for checking if two finite state automata recognise the same language, can be used to compute the join of two congruences. Similarly, a minor modification of the standard construction of an automaton recognising the intersection of two regular languages can be utilised to compute meets; see for example [68, Theorem 1.25]. For more background on automata theory, see [59].
As described in Section 5.6 of [65], one motivation of Sims’ low-index subgroup algorithm was to provide an algorithm for proving non-triviality of the group defined by a finite group presentation by showing that has a subgroup of index greater than . The low-index congruences algorithm presented here can similarly be used to prove the non-triviality of the monoid defined by a finite monoid presentation by showing that has a congruence with more than one class. There are a number of other possible applications: to determine small degree transformation representations of monoids (every monoid has a faithful action on the classes of a right congruence); to prove that certain relations in a presentation are irredundant; or more generally to show that the monoids defined by two presentations are not isomorphic (if the monoids defined by and have different numbers of congruences with classes, then they are not isomorphic). Further applications are discussed in Section 5.
The low-index congruence algorithm is implemented in the open-source C++ library libsemigroups [53], and available for use in the GAP [29] package Semigroups [54], and the Python package libsemigroups_pybind11 [52]. The low-index algorithm is almost embarrassingly parallel, and the implementation in libsemigroups [53] is parallelised using a version of the work stealing queue described in [74, Section 9.1.5]; see Section 4 and Appendix A for more details.
The second algorithm we present is more straightforward than the low-index congruence algorithm, and is a variation on a theme that has been suggested in numerous contexts, for example, in [4, 25, 70]. There are two main steps to this procedure. First, the distinct principal congruences are determined, and, second, all possible joins of the principal congruences are found. Unlike the low-index congruence algorithm, this algorithm cannot be used to compute anything about infinite finitely presented semigroups or monoids. This second algorithm is implemented in the GAP [29] package Semigroups [54].
The first step of the second algorithm, as described in, for example, [4, 25, 70], involves computing the principal congruence, of the input monoid , generated by every pair . Of course, in practice, if , then the principal congruences generated by and are the same, and so only principal congruences are actually generated. In either case, this requires the computation of such principal congruences. We will show that certain of the results from [22] can be generalized to provide a sometimes smaller set of pairs required to generate all of the principal congruences of . In particular, we show how to compute relative Green’s -class and -class representatives of elements in the direct product modulo its submonoid . Relative Green’s relations were introduced in [73]; see also [9, 30]. It is straightforward to verify that if are -related modulo , then the principal right congruences generated by and coincide; see 7.1i for a proof. We will show that it is possible to reduce the problem of computing relative -class representatives to the problems of computing the right action of on a set, and membership testing in an associated (permutation) group. The relative -class representatives correspond to strongly connected components of the action of on the relative -classes by left multiplication, and can be found whenever the relative -classes can be. In many examples, the time taken to find such relative -class and -class representatives is negligible when compared to the overall time required to compute the lattice of congruences, and in some examples there is a dramatic reduction in the number of principal congruences that must be generated. For example, if is the general linear monoid of matrices over the finite field of order , then and so . On the other hand, the numbers of relative - and -classes of elements of modulo are and , has and principal 2-sided and right congruences, respectively, and the total number of 2-sided congruences is . Another example: if is the monoid consisting of all matrices over the finite field with elements with determinant or , then and so , but the numbers of relative - and -classes are and , there are and principal 2-sided and right congruences, respectively, and the total number of 2-sided congruences is . Of course, there are other examples where there is no reduction in the number of principal congruences that must be generated, and as such the time taken to compute the relative Green’s classes is wasted; see Appendix A for a more thorough analysis.
One question we have not yet addressed is how to compute a (principal) congruence from its generating pairs. For the purpose of computing the lattice of congruences, it suffices to be able to compare congruences by containment. There are a number of different approaches to this: such as the algorithm suggested in [25, Algorithm 2] and implemented in [4], and that suggested in [70, Chapter 2] and implemented in the GAP [29] package Semigroups [54] and the C++ library libsemigroups [53]. The former is essentially a brute force enumeration of the pairs belonging to the congruence, and congruences are represented by the well-known disjoint sets data structure. The latter involves running two instances of the Todd–Coxeter Algorithm in parallel; see [70, Chapter 2] and [13] for more details.
We conclude this introduction with some comments about the relative merits and de-merits of the different approaches outlined above, and we refer the reader to Appendix A for some justification for the claims we are about to make.
As might be expected, the runtime of the low-index congruence algorithm is highly dependent on the input presentation, and it seems difficult (or impossible) to predict what properties of a presentation reduce the runtime. We define the length of a presentation to be the sum of the lengths of the words appearing in relations plus the number of generators. On the one hand, for a fixed monoid , long presentations appear to have an adverse impact on the performance, but so too do very short presentations. Perhaps one explanation for this is that a long presentation increases the cost of processing each node in the search tree, while a short presentation does not make it evident that certain branches of the tree contain no solutions until many nodes in the tree have been explored. If is finite, then it is possible to find a presentation for using, for example, the Froidure-Pin Algorithm [26]. In some examples, the presentations produced mechanically (i.e. non-human presentations) qualify as long in the preceding discussion. In some examples presentations from the literature (i.e. human presentations) work better than their non-human counterparts, but in other examples they qualify as short in the preceding discussion, and are worse. It seems that in many cases some experimentation is required to find a presentation for which the low-index congruence algorithm works best. On the other hand, in examples where the number of congruences is large, say in the millions, running any implementation of the second algorithm is infeasible because it requires too much space. Having said that, there are still some relatively small examples where the low-index congruences algorithm is faster than the implementations of the second algorithm in Semigroups [54] and in CREAM [58], and others where the opposite holds; see Table A.6.
One key difference between the implementation of the low-index subgroup algorithm in, say, GAP [29], and the low-index congruence algorithm in libsemigroups [53] is that the former finds conjugacy class representatives of subgroups with index at most . As far as the authors are aware, there is no meaningful notion of conjugacy that can be applied to the low-index congruences algorithm for semigroups and monoids in general. Despite the lack of any optimizations for groups in the implementation of the low-index congruence algorithm in libsemigroups [53], its performance is often better than or comparable to that of the implementations of Sims’ low-index subgroup algorithm in [15] and GAP [29]; see Table A.5 for more details.
The present paper is organised as follows: in Section 2 we present some preliminaries required in the rest of the paper; in Section 3 we state and prove some results related to actions, word graphs, and congruences; in Section 4 we state the low-index congruence algorithm and prove that it is correct; in Section 5 we give numerous applications of the low-index congruences algorithm; in Section 6 we show how to compute the joins and meets of congruences represented by word graphs; in Section 7 we describe the algorithm based on [22] for computing relative Green’s relations. In Appendix A, we provide some benchmarks that compare the performance of the implementations in libsemigroups [53], Semigroups [54], and CREAM [58]. Finally in Appendix B we present some tables containing statistics about the lattices of congruences of some well-known families of monoids.
2 Preliminaries
In this section we introduce some notions that are required for the latter sections of the paper.
Throughout the paper we use the symbol to denote an “undefined” value, and note that is not an element of any set except where it is explicitly included.
Let be a semigroup. An equivalence relation is a right congruence if for all and all . Left congruences are defined analogously, and a 2-sided congruence is both a left and a right congruence. We refer to the number of classes of a congruence as its index.
If is any set, and is a function, then is a right action of on if for all and for all . If in addition has an identity element (i.e. if is a monoid), we require for all also. Left actions are defined dually. In this paper we will primarily be concerned with right actions of monoids.
If is a monoid, and and are right actions of on sets and , then we say that is a homomorphism of the right actions and if
for all and all . An isomorphism of right actions is a bijective homomorphism.
Let be any alphabet and let denote the free monoid generated by (consisting of all words over with operation juxtaposition and identity the empty word ). We define a word graph over the alphabet to be a digraph with set of nodes and edges . Word graphs are essentially finite state automata without initial or accept states. More specifically, if is a word graph over , then for any and any , we can define a finite state automaton where: the state set is ; the alphabet is ; the start state is ; the transition function is defined by whenever ; and denotes the accept states.
If is an edge in a word graph , then is the source, is the label, and is the target of . A word graph is complete if for every node and every letter there is at least one edge with source labelled by . A word graph is finite if the sets of nodes and edges are finite. A word graph is deterministic if for every node and every there is at most one edge with source and label .
If , then an -path is a sequence of edges where and and ; is the source of the path; the word labels the path; is the target of the path; and the length of the path is . We say that there exists an -path of length labelled by for all . For , and we will write to mean that labels a -path in , and if does not label a path with source in . When there are no opportunities for ambiguity we will omit the subscript from . If and there is an -path in , then we say that is reachable from . If is a node in a word graph , then the strongly connected component of is the set of all nodes such that is reachable from and is reachable from . If is a word graph and denotes the power set of , then the path relation of is the function defined by . If is a complete word graph and is a node in , then is a right congruence on . If , is a word graph, and is the path relation of , then we say that is compatible with if whenever and for all and for all . Equivalently, if is complete, then is compatible with if and only if for every node in . It is routine to verify that if a word graph is compatible with , then it is also compatible with the least (2-sided) congruence on containing ; we denote this congruence by .
3 Word graphs and right congruences
In this section we establish some fundamental results related to word graphs and right congruences. It seems likely to the authors that the results presented in this section are well-known; similar ideas occur in [38], [42], [65], and probably elsewhere. However, we did not find any suitable references that suit our purpose here, particularly in Section 3.3, and have included some of the proofs of these results for completeness.
This section has three subsections: in Section 3.1 we describe the relationship between right congruences and word graphs; in Section 3.2 we present some results about homomorphisms between word graphs; and finally in Section 3.3 we give some technical results about standard word graphs.
3.1 Right congruences
Suppose that is the monoid defined by the monoid presentation and is a right action of on a set . Recall that is isomorphic to the quotient of the free monoid by . If is the surjective homomorphism with , then we can define a complete deterministic word graph over the alphabet such that whenever . Conversely, if is a complete word graph that is compatible with , then we define by
| (3.1) |
whenever labels an -path in . It is routine to verify that the functions just described mapping a right action to a word graph, and vice versa, are mutual inverses. For future reference, we record these observations in the next proposition.
Proposition 3.1.
Let be the monoid defined by the monoid presentation . Then there is a one-to-one correspondence between right actions of and complete deterministic word graphs over compatible with .
If and are word graphs over the same alphabet , then is a word graph homomorphism if implies ; and we write . An isomorphism of word graphs and is a bijection such that both and are homomorphisms. If is a word graph homomorphism and labels an -path in , then it is routine to verify that labels a -path in .
The correspondence between right actions and word graphs given in 3.1 also preserves isomorphisms, which we record in the next proposition.
Proposition 3.2.
Let be a monoid generated by a set , let and be right actions of , and let and be the word graphs over corresponding to these actions. Then and are isomorphic actions if and only if and are isomorphic word graphs.
Proof.
Assume that and are isomorphic word graphs. Then there exists a bijection . Since and are isomorphic word graphs, labels an -path in if and only if labels a -path in . Hence for all and so is an isomorphism of the actions and .
Conversely, assume that and are isomorphic right actions of on sets and , respectively. Then there exists a bijective homomorphism of right actions such that for all . We will prove that is a word graph isomorphism. It suffices to show that if and only if . If , then and hence . Since is an isomorphism of right actions and so . Similarly, it can be shown that if , then and hence defines a word graph isomorphism. ∎
In Section 4 we are concerned with enumerating the right congruences of a monoid subject to certain restrictions, such as those containing a given set or those with a given number of equivalence classes. If is the monoid defined by the presentation and is a right congruence on , then the function defined by is a right action of on where is the equivalence class of in and . It follows by 3.1 that corresponds to a complete deterministic word graph over compatible with . In particular, the nodes of are the classes , and the edges are .
On the other hand, not every right action of a monoid is an action on the classes of a right congruence. For example, if is a rectangular band with an adjoined identity, then two faithful right actions of are depicted in Fig. 3.1 with respect to the generating set . It can be shown that the action of on shown in Fig. 3.1 corresponds to a right congruence of but that the action of on does not.
In a word graph corresponding to the action of a monoid on a right congruence , if , then there exist such that , and so labels the path from to in . In particular, every node in is reachable from the node . The converse statement, that every complete deterministic word graph compatible with where every node is reachable from corresponds to a right congruence on is established in the next proposition.
If and are semigroups, is a binary relation and is a homomorphism. Then abusing our notation somewhat we write
Proposition 3.3.
Let be the monoid defined by the monoid presentation , let be the unique homomorphism with , and let be a word graph over that is complete, deterministic, compatible with and where every node is reachable from some . Then is a right congruence on , where is the path relation on .
Proof.
Suppose that for some and that is arbitrary. Then and . Hence . Since is complete, , and so . Therefore , and is a right congruence. ∎
It follows from 3.3 that in order to enumerate the right congruences of it suffices to enumerate the word graphs over that are complete, deterministic, compatible with and where every node is reachable from a node . Of course, we only want to obtain every right congruence of once, for which we require the next proposition. Henceforth we will suppose that if is a word graph over , then for some and so, in particular, is always a node in . Moreover, we will assume that the node corresponds to the equivalence class of the identity of .
Proposition 3.4.
Let and be word graphs over corresponding to right congruences of a monoid generated by . Then and represent the same right congruence of if and only if there exists a word graph isomorphism such that .
Proof.
We denote the right congruences associated to and by and , respectively.
Suppose that there exists a word graph isomorphism such that and that the words label -paths in . Then and label -paths and so . Since is a word graph isomorphism satisfying , it follows that , and so , as required.
Conversely, assume that and represent the same right congruence of . We define a word graph homomorphism as follows. For every , fix a word that labels a -path in . We define to be the target of the path with source labelled by in . If , then both and label -paths in , and so . Hence is an edge of . In addition, and it is clear that if , then and hence is a bijection. ∎
It follows from 3.4 that to enumerate the right congruences of a monoid defined by the presentation it suffices to enumerate the complete deterministic word graphs over compatible with where every node is reachable from 0 up to isomorphism. On the face of it, this is not much of an improvement because, in general, graph isomorphism is a difficult problem. However, word graph isomorphism, in the context of 3.4, is trivial by comparison.
If the alphabet and , then we define if or and is less than or equal to in the usual lexicographic order on arising from the linear order on . The order is called the short-lex ordering on . If and , then we write . If is a node in a word graph and is reachable from , then there is a -minimum word labelling a -path; we denote this path by .
The following definition is central to the algorithm presented in Section 4.
Definition 3.5.
A complete word graph over is standard if the following hold:
-
(i)
is deterministic;
-
(ii)
every node is reachable from ;
-
(iii)
for all , if and only if .
Proposition 3.6.
[cf. Proposition 8.1 in [65]] Let and be standard complete word graphs over the same alphabet. Then there exists a word graph isomorphism such that if and only if .
By 3.6, every complete deterministic word graph in which every node is reachable from 0 is isomorphic to a unique standard complete word graph. It is straightforward to compute this standard word graph from the original graph by relabelling the nodes, for example, using the procedure SWITCH from [65, Section 4.7]. We refer to this process as standardizing .
Another consequence of 3.4 and 3.6 is that enumerating the right congruences of a monoid defined by a presentation is equivalent to enumerating the standard complete word graphs over that are compatible with . As mentioned above, the right action of on the classes of a right congruence is isomorphic to the right action represented by the corresponding word graph . We record this in the following theorem.
Theorem 3.7.
Let be a monoid defined by a monoid presentation . Then there is a one-to-one correspondence between the right congruences of and the standard complete word graphs over compatible with .
If is a right congruence on and is the corresponding word graph, then the right actions of on and on are isomorphic; and where is the unique homomorphism with and is the path relation on .
It is possible to determine a one-to-one correspondence between the right congruences of a semigroup and certain word graphs arising from , as a consequence of 3.7.
Corollary 3.8.
Let be a semigroup defined by a semigroup presentation . Then there is a one-to-one correspondence between the right congruences of and the complete word graphs for over compatible with such that for all and all .
If is a right congruence of and is the corresponding word graph for , then the right actions of on and on are isomorphic.
Proof.
By 3.7 it follows that there is a one-to-one correspondence between the right congruences of and the complete word graphs for over compatible with . In addition, there is a one-to-one correspondence between the right congruences of and the right congruences of such that if and only if . Since and coincide it follows that there is a one-to-one correspondence between the right congruences of such that if and only if and the complete word graphs for over compatible with such that for all and all . The argument to prove that the right actions of on and on are isomorphic is identical to the argument in the proof of 3.7. ∎
Given 3.7, we will refer to the standard complete word graph over compatible with corresponding to a given right congruence as the word graph of .
We require the following lemma.
Lemma 3.9.
Let and be semigroup, let , and let be a homomorphism. Then the following hold:
-
(i)
if , is transitive and are such that and for some , then ;
-
(ii)
if is surjective and is contained in the least (left, right, or 2-sided) congruence on containing , then the least (left, right, or 2-sided) congruence on containing is .
Lemma 3.9(i) can be reformulated as follows.
Corollary 3.10.
If and is transitive, then if and only if for all .
A convenient consequence of the correspondence between right congruences and their word graphs allows us to determine a set of generating pairs for from . This method is similar to Stalling’s method for finding a generating set of a subgroup of a free group from its associated coset graph, see, for example, [41, Proposition 6.7].
Lemma 3.11.
Let be a monoid defined by a monoid presentation , let be a right congruence of , and let be the word graph of . Then generates the path relation as a right congruence.
In particular, if is the natural homomorphism with , then
generates as a right congruence.
Proof.
We set where is the short-lex minimum word labelling any -path in for every .
We denote by the right congruence on generated by . If , then since , it follows that both and label -paths in . In particular, and so, since is the least right congruence containing and is a right congruence, also.
For the converse inclusion, we will show that for every that labels a -path in . It will follow from this that .
Suppose that labels a -path in . We write where is the longest prefix of belonging to . We proceed by induction on . If , then , and so . Hence and so by reflexivity. This establishes the base case.
Suppose that for some , for all such that labels a -path and where . Let for some with . Then we may write for some and with . Since is complete, there is an edge for some . Hence by definition.
If we set , then also labels a -path in . Again we write where is the maximal prefix of in and . Since is a prefix of and is maximal, is a (not necessarily proper) prefix of . In particular, and so . Hence by induction . In addition , since and is a right congruence. Therefore by transitivity , as required.
From this point in the paper onwards, for the purposes of describing the time or space complexity of some claims, we assume that we are using the RAM model of computation. The following corollary is probably well-known.
Corollary 3.12.
Let be a monoid defined by a monoid presentation , and let be a right congruence on . If has finite index , then is finitely generated as a right congruence and a set of generating pairs for can be determined in time from the word graph associated to .
Proof.
This follows immediately since the generating set for given in Lemma 3.11 has size , and it can be found by a breadth first traversal of the word graph. The breadth first traversal of the word graph has time complexity . To store the generating pairs for requires at most space and time, yielding the stated time complexity. ∎
3.2 Homomorphisms of word graphs
In this section we state some results relating homomorphisms of word graphs and containment of the associated congruences.
Lemma 3.13.
If and are deterministic word graphs on the same alphabet such that every node in and is reachable from and , respectively, then there exists at most one word graph homomorphism such that .
Proof.
Suppose that are word graph homomorphisms such that and . Then there exists a node such that . If is any word labelling a -path, then, since word graph homomorphisms preserve paths, labels - and -paths in , which contradicts the assumption that is deterministic. ∎
Suppose that and are word graphs. At various points in the paper it will be useful to consider the disjoint union of and , which has set of nodes, after appropriate relabelling, and edges . If , then we will write if it is necessary to distinguish which graph the node belongs to. We will also abuse notation by assuming that and .
Corollary 3.14.
If , , and are word graphs over the same alphabet, and every node in each word graph is reachable from for , then there is at most one word graph homomorphism such that .
Proof.
Suppose that are word graph homomorphisms such that . Then is a word graph homomorphism for and . Hence, by Lemma 3.13, and , and so . ∎
The final lemma in this subsection relates word graph homomorphisms and containment of the associated congruences.
Lemma 3.15.
Let and be word graphs over an alphabet representing congruences and on a monoid . Then there exists a word graph homomorphism such that if and only if .
Proof.
() If is a word graph homomorphism such that , and labels a -path in , then labels a -path in . If , then and label -paths in and so and label -paths in . Hence and so .
() Conversely, assume that . We define as follows. For every , we fix a word labelling a -path. Such a path exists for every because every node is reachable from . We define for all . If , then and both label -paths, and so . Since , it follows that and so and both label -paths in . In particular, is an edge of , and is a homomorphism. ∎
3.3 Standard word graphs
In this section we prove some essential results about standard word graphs.
Suppose that is a word graph where for some and where . The ordering on and induces the lexicographic ordering on and , and the latter orders the edges of any word graph . We write for any and all of these orders.
We defined standard complete word graphs in 3.5, we now extend this definition to incomplete word graphs by adding the following requirement:
-
(iv)
if is a missing edge in , for some , and there exists such that , then .
An edge is a short-lex defining edge in if .
Lemma 3.16.
Let be a deterministic word graph over an alphabet , let , and let
be an -path labelled by . If is the short-lex least word labelling any -path in , then the following hold:
-
(i)
if and only if , hence the -path labelled by does not contain duplicate edges;
-
(ii)
is the short-lex least word labelling any -path for all such that .
Lemma 3.17.
Let be a standard word graph over the alphabet , let , and let
be a -path labelled by . If is the short-lex least word labelling any -path in , then:
-
(i)
every edge is a short-lex defining edge;
-
(ii)
.
Proof.
For (i), let be the short-lex least word labelling a -path for each . By Lemma 3.16(ii), . Hence and so is a short-lex defining edge as required.
For (ii), since , it follows that and so by 3.5(iii), for every . ∎
If is an incomplete word graph over , then we refer to as a missing edge if for all . Recall that the missing edges are ordered lexicographically according to the orders on and as defined at the start of Section 3.3.
Lemma 3.18.
Let be an incomplete standard word graph over the alphabet , and let be a missing edge. Then for all .
Proof.
If , then as required. Assume that . Then and, in particular, there is at least one edge on the -path labelled by . Let be the last such edge. By Lemma 3.16(ii), , and, by 3.5(iv), . If , then is not a missing edge. Hence , and so, either ; or and . If , then, by 3.5(iii), and so , as required. If and , then . ∎
Lemma 3.19.
Let be an incomplete standard word graph over the alphabet , let be a missing edge, let , and let . If , then the following hold:
-
(i)
for all where is the short-lex least word labelling any -path in ;
-
(ii)
is standard.
Proof.
(i). Since every path in is also a path in , for all . Let be arbitrary. If the -path labelled by in does not contain the newly added edge , then also labels a -path in and so .
Seeking a contradiction suppose that -path labelled by in contains the newly added edge . Then we can write where labels a -path and labels a -path in . By Lemma 3.16(ii), labels the short-lex least -path in and so . Since was a missing edge, is deterministic, so by Lemma 3.16(i) in , the -path labelled by does not contain the edge . Hence also labels a -path in and so . By Lemma 3.16(ii) again, . But now by Lemma 3.18 in , , which is a contradiction.
Hence the -path labelled by in does not contain for any , and so .
(ii). Clearly, parts (i) and (ii) of 3.5 hold in . Part (iii) of 3.5 holds by part (i) of this lemma.
To show that 3.5(iv) holds, suppose that is a missing edge of and for some and such that . Note that every missing edge of is a missing edge of also. In particular, is a missing edge of .
If , then, by 3.5(iv) applied to , . But part (i) implies that and , and so also. In particular, satisfies 3.5(iv) in this case.
Applying Lemma 3.18 to and yields . So, if , then . Applying part (i) as in the previous case implies that . ∎
The final lemma in this section shows that the analogue of Lemma 3.19(ii) holds when the target of the missing edge is defined to be a new node.
Lemma 3.20.
Let be an incomplete standard word graph over the alphabet , let be the shortlex least missing edge in , and let . Then is standard.
Proof.
The word graph is deterministic since is a missing edge in . Hence satisfies 3.5(i). Since is standard, every node in is reachable from in and . In particular, is reachable from in and hence so too is . Thus 3.5(ii) holds for .
We set and , so that . As in Lemma 3.19(i), for every , we denote by the short-lex least word labelling any -path in . There are no edges in with source and , and so if , then no -path in contains the newly added edge . Therefore for each . Since is the only edge with target , and from Lemma 3.16(ii), . But then Lemma 3.18 implies that for all . So, if and , then either or . In both cases, and so 3.5(iii) holds for .
To establish that 3.5(iv) holds for , suppose that is a missing edge of and for some and with . There are three cases to consider:
-
(a)
is a missing edge in and ;
-
(b)
is a missing edge in and ;
-
(c)
is not a missing edge in .
If (a) holds, then by 3.5(iv) applied to . But Lemma 3.19 implies that and and so in this case.
We conclude the proof by showing that neither (b) nor (c) holds.
If (b) holds, then . But is the least missing edge of , so , which contradicts the assumption that . Hence (b) does not hold.
If (c) holds, then . Since there are no edges with source in , it follows that and so . But then , which again contradicts the assumption that . ∎
Combining Lemma 3.19(ii) and Lemma 3.20 we obtain the following corollary.
Corollary 3.21.
Let be an incomplete standard word graph over the alphabet , let be the short-lex least missing edge in , and let . Then is also standard.
4 Algorithm 1: the low-index right congruences algorithm
Throughout this section we suppose that: is a fixed finite monoid presentation defining a monoid ; and that is fixed. The purpose of this section is to describe a procedure for iterating through the right congruences of with at most congruence classes. This procedure is based on the Todd–Coxeter Algorithm (see for example [13], [38] or [69]) and is related to Sims’ “low-index” algorithm for computing subgroups of finitely presented groups described in Chapter 5.6 of [65].
As shown in 3.7, there is a bijective correspondence between complete standard word graphs with at most nodes that are compatible with , and the right congruences of with index at most . As we hope to demonstrate, the key advantage of this correspondence is that word graphs are inherently combinatorial objects which lend themselves nicely to various enumeration methods. The algorithm we describe in this section is a more or less classical backtracking algorithm, or depth-first search.
This section is organised as follows. We begin with a brief general description of backtracking algorithms and refining functions in Section 4.1. For a more detailed overview of backtracking search methods see [43, Section 7.2.2]. In Section 4.2 we construct a specific search tree for the problem at hand, whose nodes are standard word graphs; in Section 4.3 we introduce various refining functions that improve the performance of finding right congruences.
4.1 Backtracking search and refining functions
We start with the definition of the search space where we are performing the backtracking search. To do so we require the notion of a digraph where is the set of nodes, and is the set of edges. We denote such digraphs using blackboard fonts to distinguish them from the word graphs defined above.
A multitree is a digraph such that for all there exists at most one directed path from to in . For a node we write to denote the set of all nodes reachable from in .
Given a multitree and a (possibly infinite) set , we say that is a search multitree for if there exists such that . We refer to any such node as a root node of . Recall that the symbol is used to mean “undefined” and does not belong to .
Definition 4.1.
A function is a refining function for if the following hold for all :
-
(i)
,
-
(ii)
if , then ,
-
(iii)
if , then .
For example, the identity function is a refining function for subset of .
If , then we refer to the set
as the children of in . Given algorithms for computing the refining function , testing membership in , and determining the children of any , the backtracking algorithm outputs the set for any . As a consequence if is any root node of . Pseudocode for the algorithm is given in Algorithm 1.
Input: A refining function for and a node .
Output: .
Of course, if is infinite, then will not terminate. In practice, if is finite but is infinite, some care is required when choosing a refining function to ensure that terminates. On the other hand if for only finitely many , then clearly, will terminate.
can be modified to simply count the number of elements in , to apply any function to each element of as it is discovered, or to search for an element of with a particular property by modifying line 5 and 8.
The following properties of search multitrees and refining functions will be useful later:
Proposition 4.2.
Let be a search multitree for . Then
-
(i)
If , then is also a search multitree for ;
-
(ii)
If and and are refining functions for and respectively, then is a refining function for .
4.2 The search multitree of standard word graphs
In this section, we describe the specific search multitree required for the low-index congruences algorithm.
We define to be the set of all standard word graphs over a fixed finite alphabet and we define to consist of the edges if and only if , , is the short-lex least missing edge in , and . Since every word graph over is finite by definition, the set is countably infinite.
We write if and .
Lemma 4.3.
The digraph is a multitree.
Proof.
Suppose that and are paths in such that and . From the definition of it follows that and . Seeking a contradiction suppose that is the least value such that . If is the least missing edge in , then and for some with . It follows that , and so is not deterministic, and hence not standard, which is a contradiction. ∎
We denote the set of all complete standard word graphs over by . Note that, by 3.7, the word graphs in are in bijective correspondence with the right congruences of the free monoid ; see Appendix B. We do not use this correspondence explicitly.
We will now show that every is reachable from the trivial word graph in , so that is a search multitree for .
Lemma 4.4.
Let be any complete standard word graph over . Then there exists a sequence of standard word graphs
such that is an edge in for every . In particular, , and so is a search multitree for .
Proof.
Suppose that we have defined for some such that and is an edge in for every . Let be the least missing edge in . Since is deterministic, there exists such that . We define . Clearly, by definition and .
Since is finite, and the form a strictly increasing sequence of subsets of , it follows that the sequence of is finite. ∎
If is an incomplete standard word graph with least missing edge , then the children of in are:
Clearly, since is finite, it can be computed in linear time in . Also it is possible to check if is complete in constant time by checking whether . Hence we can check whether belongs to in constant time.
We conclude this subsection with some comments about the implementational issues related to for some refining function of and word graph . It might appear that to iterate over in line 7 of Algorithm 1, it is necessary to copy with the appropriate edge added, so that the recursive call to in line 8 does not modify . However, this approach is extremely memory inefficient, requiring memory proportional to the size of the search tree. This is especially bad when is used to count the word graphs satisfying certain criteria or used to find a word graph satisfying a particular property. We briefly outline how to iterate over by modifying inplace, which requires no extra memory (other than that needed to store the additional edge). If the maximum number of nodes in any word graph that will be encountered during the search is known beforehand, then counting and random sampling of within the search multitree can be performed with constant space.
To do this, the underlying datastructure used to store must support the following operations: retrieving the total number of edges, adding an edge (with a potentially new node as its target), removing the most recently added edge (and any incident nodes that become isolated). It is possible to implement a datastructure where each of these operations takes constant time and space, this is the approach used in libsemigroups [53]. Of course, the refining functions may also modify inplace.
Given such a datastructure and refining functions, we can then perform the loop in lines 7-9 of Algorithm 1 as follows:
-
(1)
Let be the total number of edges of , let be the least missing edge of and let .
-
(2)
Add the edge to .
-
(3)
Set , noting that the recursive call takes the modified as input.
-
(4)
If , then repeatedly remove the most recently added edge from until .
-
(5)
Increment . If , then terminate. Otherwise go to Step 2.
The word graph is equal to one of its children after the edge is added in Step 2. After Step 4, is restored to its original state before the recursive call was made. Note that we cannot just remove the last added edge, as the refining function may have added extra edges to in the recursive call, and these extra edges are not removed in the recursive call.
4.3 Refining functions for standard word graphs
We denote the set of complete standard word graphs over
-
•
with at most nodes by ;
-
•
compatible with by .
By 3.7, the word graphs in are precisely the word graphs of the right congruences of the monoid defined by with index at most .
In this section we define the refining functions and for and , respectively. It follows from 4.2(ii) that is a refining function for . We also define two further refining functions for that try to reduce the number of word graphs (or equivalently nodes in the search multitree) visited by ; we will say more about this later.
The first refining function is for any defined by
for every (the set of standard word graphs over and ). It is routine to verify that is a refining function for .
If is a standard word graph, then checking whether (i.e. is complete) can be done in constant time, and checking that (i.e. that ) also has constant time complexity. Moreover, for only finitely many standard word graphs over , and thus terminates and outputs .
It is possible to check if a, not necessarily standard, word graph belongs to in linear time in the length of the presentation . Again since , is a multisearch tree for . This gives us an immediate, if rather inefficient, method for computing all the right congruences with index at most of a given finitely presented monoid: simply run to obtain , and then check each word graph in for compatibility with .
This method would explore just as many nodes of the search tree for the free monoid as it would for the trivial monoid . On the other hand, when considering the trivial monoid, as soon as we define an edge leading to a node other than , both of the relations and are violated and hence there is no need to consider any of the descendants of the current node in the multitree. So that we can take advantage of this observation, we define the function by
Recall from the definition, if , then is compatible with if for every such that and . The non-existence of a path with source labelled by or , however, does not make incompatible with . So it may be possible to extend so that and do label paths with source and common target . Hence does not return just because some relation word does not label a path from some node in . It is straightforward to verify that is a refining function for .
By 4.2(ii), is a refining function for . Therefore the output of is . For comparison, the number of standard word graphs visited by where , for the -generated plactic monoid (with the standard presentation, see [44, 45]) is . On the other hand, the number for is . This example illustrates that it can be significantly faster to check for compatibility with at every node in the search multitree rather than first finding and then checking for compatibility. The extra time spent per word graph (or node in the search multitree) checking compatibility with is negligible in comparison to the saving achieved in this example.
The refiner can be improved. Consider the situation where with for some word and letter . If there is a node such that and , but , then is a missing edge in . There is only one choice for the target of this missing edge which will not break compatibility with . This situation is shown diagrammatically in Fig. 4.1.
So, if , then must be an edge in . Of course, it is not guaranteed that is such that is the least missing edge of any descendent of in the search multitree . However by Lemma 3.19ii, if , then and so is standard.
We now improve the refining function by adding the ability to define edges along paths that are one letter away from fully labelling a relation word in the manner described above. We denote this new refining function for by and define it in Algorithm 2.
Input: A standard word graph or
.
Output: A standard word graph or .
Lemma 4.5.
is a refining function for .
Proof.
We verify the conditions in 4.1.
Clearly, and so 4.1(i) holds. Let . If , then the execution of the algorithm constructs a sequence of word graphs such that is obtained from by adding an edge in line 7 or line 9 of Algorithm 2, where is the final word graph constructed before returning in either line 11 or 14. In the final iteration of the for loop in line 5, is the output word graph, and so the conditions in lines 6 and 8 do not hold because no more edges are added to . The condition in line 10 will only hold if is not compatible with . Therefore if and only if and otherwise. If , then 4.1(ii) and (iii) both hold since is a refining function for .
It suffices to establish that when . The claim can then be established for by straightforward induction. We may also assume without loss of generality is obtained from in line 9 of Algorithm 2. The other case when an edge is added in line 7 of Algorithm 2 is dual.
If we add an edge to in line 9, then the condition in line 8 of Algorithm 2 holds. Therefore, there exist , , , and such that the following hold: ; for some ; for some ; and .
We must show that . Since contains , it is clear that .
Let . It suffices to show that . Since is complete, there exists such that . Since labels an -path in , also labels such a path in . Likewise, labels an -path in . Hence labels an -path in . Since and is compatible with , it follows that and so .
By the definition of there exists a sequence of word graphs
and of edges such that is the least missing edge of and for every .
If is such that , then we consider the sequence of word graphs
Suppose the least missing edge in is . Every missing edge of is also a missing edge of , and so , since is the least missing edge in . Since and differ by the single edge , it follows that either and ; or and . Similarly, if , then by the same argument, the least missing edge in is for every . Therefore
is a path in and so , as required. ∎
It is possible that . To ensure that we add as many edges to as possible we could keep track of whether adds any edges to its input, and run Algorithm 2 again until no more edges are added. We denote this algorithm by ; see Algorithm 3 for pseudocode.
Input: A word graph or .
Output: A word graph or .
That is a refining function for follows by repeatedly applying 4.2(ii). Therefore both and are refining functions for .
While is more computationally expensive than , every edge added to by reduces the number of nodes in that must be traversed in where is by a factor of at least . This tradeoff seems quite useful in practice as can be seen in Appendix A.
Although in line 5 of we loop over all nodes and all relations in , in practice this is not necessary. Clearly, if the word graph is compatible with , then we only need to follow those paths labelled by relations that include any new edges. A technique for doing just this is given in [13, Section 7.2], and it is this that is implemented in libsemigroups [53]. A comparison of the refining functions for presented in this section is given in Table 4.1
| 1 | 2 | 3 | 4 | |
|---|---|---|---|---|
| 6 | 165 | 15,989 | 3,556,169 | |
| 6 | 120 | 1,680 | 29,800 | |
| 6 | 75 | 723 | 6,403 | |
| 6 | 75 | 695 | 6,145 |
5 Applications of Algorithm 1
In this section we describe a number of applications of the low-index right congruences algorithm. Recall that is a monoid defined by the presentation . Each application essentially consists of defining a refining function so that returns a particular subset of right congruences. In brief these subsets are:
-
(a)
left congruences;
-
(b)
2-sided congruences;
-
(c)
right congruences including, or excluding, a given subset of ;
-
(d)
2-sided congruences such that the quotient is a finite group;
-
(e)
non-trivial right Rees congruences when has decidable word problem; and
-
(f)
right congruences where the right action of on the nodes of the word graph of is faithful.
with index up to . A further application of (c) provides a practical algorithm for solving the word problem in finitely presented residually finite monoids; this is described in Section 5.4. Each application enumerated above is described in a separate subsection below.
A further application of the implementations of the algorithms described in this section is to reproduce, and extend, some of the results from [6].
5.1 Left congruences
In Sections 3 and 4, we only considered right congruences, and, in some sense, word graphs are inherently “right handed”. It is possible to state an analogue of 3.7 for left congruences, for which we require the following notation. If , then we write to denote the reverse of . If is arbitrary, then we denote by the set of relations containing for all .
An analogue of 3.1 holds for left actions. More specifically, if is a left action of a monoid on a set , and is as above, then the corresponding word graph is where whenever . Conversely, if is a word graph, then we define a left action by
whenever labels an -path in .
Theorem 5.1.
Let be a monoid defined by a monoid presentation . Then there is a one-to-one correspondence between the left congruences of and the standard complete word graphs over compatible with .
If is a left congruence on and is the corresponding word graph, then the left actions of on (by left multiplication) and on are isomorphic; and where is the unique homomorphism with and is the path relation on .
It follows from 5.1 that the left congruences of a monoid can be enumerated using the same method for enumerating right congruences applied to . Some care is required here, in particular, since the corresponding word graphs are associated to right congruences on the dual of the original monoid (defined by the presentation ), rather than to left congruences on .
5.2 2-sided congruences
The word graph corresponding to a 2-sided congruence of is just the right Cayley graph of with respect to . Therefore characterizing -sided congruences is equivalent to characterizing Cayley graphs. The corresponding question for groups — given a word graph , determine whether is the Cayley graph of a group — was investigated in [41, Theorem 8.14]. An important necessary condition, in our notation, is that for all . In some sense, this condition states that the automorphism group of is transitive. We will next show that the corresponding condition for monoids is that for all . This condition for monoids is, in the same sense as for groups, equivalent to the statement that for every node of the Cayley word graph there is an endomorphism mapping the identity to that node.
Lemma 5.2.
Let be the monoid defined by the monoid presentation , and let be a right congruence on with word graph . Then is a 2-sided congruence if and only if for all .
Proof.
For every , we denote by the short-lex minimum word labelling any -path in . We also denote by the unique surjective homomorphism with . Recall that, since is compatible with , and so, by 3.10, if and only if . Also, by 3.7, .
For the forward implication, suppose that is a 2-sided congruence and that . Then . Since is a 2-sided congruence,
for all . In particular, again by 3.10, . Thus . Since , it follows that and so as required.
We can further refine Lemma 5.2 by using the generating pairs of Lemma 3.11 to yield a computationally testable condition as follows.
Theorem 5.3.
Let be the monoid defined by the monoid presentation , and let be a right congruence on with word graph . Then is a 2-sided congruence if and only if is compatible with where is the short-lex minimum word labelling any -path in .
Proof.
Let be the unique surjective homomorphism with and let denote the set
() If is a 2-sided congruence, then by Lemma 5.2, for all . The relation is contained in by definition. Therefore for all . Hence is compatible with as required.
() Assume that is compatible with . Then and so . Since and is the least right congruence containing , it follows that . Hence by Lemma 3.9ii. Therefore . But is generated as a right congruence by by Lemma 3.11 and so giving equality throughout. In particular, is a 2-sided congruence, as required. ∎
In 5.3 we showed there is a bijection between the 2-sided congruences of the monoid defined by and the complete standard word graphs compatible with both and the set . We denote by the set of complete standard word graphs corresponding to 2-sided congruences of . Recall from 3.12 that we can compute from in time. We can also verify that a given word graph is compatible with in where is the sum of the lengths of the words occurring in , using, for example, .
We define the function by
for all .
Lemma 5.4.
TwoSidedMakeCompatibleRepeatedly is a refining function for .
Proof.
On superficial inspection, it might seem that TwoSidedMakeCompatibleRepeatedly is a refining function because is a refining function. However, this does not follow immediately because the set is dependent on the input word graph .
Clearly, so 4.1(i) holds.
It follows that where is the refining function returns the set of word graphs of the 2-sided congruences of the monoid defined by with index at most . As a practical comparison, the number of word graphs visited by where and for the -generated plactic monoid is . On the other hand, the number of word graphs visited when using the refining function is only .
As an example, in Table B.13 we compute the number of 2-sided congruences with index at most of the free monoid when and are not too large. For example, we compute the number of 2-sided congruences of up to index , , and , when , and , respectively.
5.3 Congruences including or excluding a relation
Given two elements and of the monoid defined by the finite presentation , we might be interested in finding finite index right congruences containing or not containing . Suppose that and are such that where is the unique homomorphism with . By 3.7, if is a right congruence of , then if and only if in the word graph of .
For , we denote by the set of complete standard word graphs such that . Similarly, we denote by the set of complete standard word graphs such that .
We also define refining functions and by
It is routine to verify that and are refining functions for and , respectively.
Composing these refining functions with and any of the refining functions for one or 2-sided congruences from Section 4 and Section 5.2 allows us to find one or 2-sided congruences of with index at most that include or exclude a given relation.
5.4 McKinsey’s algorithm
A monoid is residually finite if for all with there exists a finite monoid and homomorphism such that . In [50], McKinsey gave an algorithm for deciding the word problem in finitely presented residually finite monoids. McKinsey’s Algorithm in [50] is, in fact, more general, and can be applied to residually finite universal algebras.
McKinsey’s algorithm relies on two semidecision procedures — one for testing equality in a finitely presented monoid and the other for testing inequality in a finitely generated residually finite monoid. It is well-known (and easy to show) that testing equality is semidecidable for every finitely presented monoid.
Suppose that is finitely presented by and that is residually finite. There are only finitely many finite monoids of every size, and only finitely many possible functions from to . If is any such function, then it is possible to verify that extends to a homomorphism by checking that satisfies the (finite set of) relation . Clearly, if and for some , then, since is a function, . It follows that it is theoretically possible to verify that by looping over the finite monoids , the functions , and for every that extends to a homomorphism , testing whether . Thus testing inequality in a finitely presented residually finite monoid is also semidecidable.
McKinsey’s algorithm proceeds by running semidecision algorithms for testing equality and inequality in parallel; this is guaranteed to terminate, and so the word problem for finitely presented residually finite monoids is decidable in theory. In practice, checking for equality in a finitely presented monoid with presentation can be done somewhat efficiently by performing a backtracking search in the space of all elementary sequences over . On the other hand, the semidecision procedure given above for checking inequality is extremely inefficient. For example, the number of monoids of size at most up to isomorphism and anti-isomorphism is ; see [17].
The low-index congruences algorithm provides a more efficient algorithm for deciding inequality in a finitely presented residually finite monoid by utilizing the refining function for some . The set consists of exactly the 2-sided congruences on with index at most such that (where is the natural homomorphism). Hence in if and only if for some . Therefore can be used to implement McKinsey’s algorithm with a higher degree of practicality.
5.5 Congruences defining groups
We say that a 2-sided congruence on is a group congruence if the quotient monoid is a group. A 2-sided congruence is a group congruence if and only if for every there exists such that and where is the identity element. If is generated by , then is a group congruence if and only if for every there exists such that and . We say that a word graph is injective if for all and there is at most one edge in with target and label . This is the dual of the definition of determinism. We can decide if a finite word graph corresponds to a group congruence as follows.
Theorem 5.5.
Let be the monoid defined by the monoid presentation , and let be a finite index 2-sided congruence on with word graph . Then is a group congruence if and only if is injective.
Proof.
Let be the unique surjective homomorphism with .
Let for some and . Since defines a group there exists such that . Since is a 2-sided congruence, and so and similarly . But and both label -paths in , and so . Hence by transitivity . Then, by 3.10 and 3.7, and so . We have shown that is injective.
Suppose that . Since the set is infinite but has only finitely many nodes, it follows from the pigeonhole principle that there exists and with such that and both label -paths in . Assume that is the least such value. If , then there exist such that and label - and -paths respectively. It follows that and so by injectivity . In particular, and both label -paths, and this contradicts the minimality of .
Therefore and so . Hence, by 3.7, . In particular, if , then . Since is surjective, and was arbitrary, it follows that is a group congruence. ∎
It is possible to verify if a given word graph over is injective, or not. In particular, in the representation used in libsemigroups [53], this can be verified in time linear in . Furthermore, if is not injective, then neither is any descendent of in the search multitree . Hence the following function is a refining function for the set of all word graphs corresponding to group congruences:
Composing IsInjective, , and any of the refining functions for of word graphs corresponding to 2-sided congruences of , this gives us a method for computing all group congruences with index at most of the monoid presented by .
5.6 Rees congruences
In this section we describe how to use the low-index right congruences algorithm to compute Rees congruences, i.e. those arising from ideals. A related algorithm for finding low-index Rees congruences is given in [39] and [40]. Like the low-index congruences algorithm, Jura’s Algorithm in [39] and [40] also uses some aspects of the Todd–Coxeter Algorithm. The algorithm presented in this section is distinct from Jura’s Algorithm. In general, the problem of computing the finite index ideals of a finitely presented monoid is undecidable; see [40] and [61, Theorem 5.5]. However, if the word problem happens to be decidable for a finitely presented monoid, then so too is the problem of computing the finite index ideals of that monoid.
Given a right ideal of a monoid , the right Rees congruence of is . The trivial congruence is a right Rees congruence if and only if has a right zero; and the trivial congruence has finite index if and only if is finite. As such, we will restrict ourselves, in this section, to considering only non-trivial finite index right Rees congruence.
Let be a standard word graph of a right congruence of and let be the unique homomorphism with . We call a node a sink if for all . We say that a sink is non-trivial if there exists an edge such that , where as usual is the short-lex least word labelling a -path in .
If is compatible with the relations defining , is the right congruence of any complete standard word graph compatible with that contains , and is a non-trivial sink, then the equivalence class of on corresponding to contains at least 2 elements: and . In particular, is non-trivial, which explains why we called a non-trivial sink.
We give a criterion for deciding if a complete standard word graph corresponds to a non-trivial right Rees congruence in the next theorem.
Theorem 5.6.
Let be the monoid defined by the monoid presentation , let be a right congruence on with word graph , and let be the unique homomorphism with . Then is a non-trivial right Rees congruence if and only if the following conditions hold:
-
(i)
there exists a unique non-trivial sink ;
-
(ii)
if and , then .
Proof.
() Let be a right ideal of such that and , and let be the corresponding non-trivial right Rees congruence with complete standard word graph . If is such that , then since is complete, for some .
If for some , then since is a right Rees congruence. By 3.10, it follows that , and so also. Conversely, if , then and hence . Hence labels a -path in if and only if .
In particular and if is arbitrary, then , and so also labels a -path in . It follows that for all and is a sink. To show that (i) holds, it remains to show that is non-trivial and unique.
To show that is non-trivial, consider the set
Since and is surjective, this set is non-empty. We set to be the short-lex least word in . Since , and is the short-lex least such word, and , it follows that . Hence for some and some . If labels a -path in for some , then and so it suffices to show that . If , then . Since , it would follow that and is non-trivial. Hence it suffices to show that .
If , then , and so . But implies that and so since is a Rees congruence, as required. If , then and so . Since and is the least element of , it follows that and so , as required. We have shown that is non-trivial.
To establish the uniqueness of , let be a non-trivial sink. By the definition of non-trivial sinks, there exists such that . Since , it follows that . If or , then, since is a Rees congruence, , which is a contradiction. Hence and so .
To show that (ii) holds, let and . It follows that neither , and so . On the other hand implies and so again since is a right Rees congruence.
() Let be the unique node satisfying condition (i) and let
If , then , and is a non-trivial Rees congruence. Hence we may suppose that .
By assumption for all and so for all . Hence if labels a -path in , then so does for all and so for all and . Since is surjective, this implies that is a right ideal of . It suffices by 3.7 to show that .
Suppose that . If , then there exist such that and . Hence by the definition of , both and label -paths in . This implies and so . Otherwise, if , then by reflexivity since is a right congruence. Hence .
For the converse, suppose that for some such that . We proceed by induction on . If , then and so by reflexivity.
Suppose that for some and for all with , implies . Let be such that and . Without loss of generality there are two cases to consider: when ; and when and .
If , then by assumption. Hence we can write for some and . If , then and so . In particular, and so by induction . Thus . Since and , it follows by (ii) that . Hence by transitivity.
If and , then we can write and for some and . If and , then . Since , it follows that . Similarly . Hence, by induction, and so . If , then by (ii) applied to , it follows that . Thus, by transitivity, , and the proof is complete. ∎
Unlike in the previous subsections, the conditions of 5.6 can only be tested if a method for solving the word problem in the monoid is known. Given an algorithm for solving the word problem, the non-triviality of a sink in 5.6(i) and the condition in 5.6(ii) can both be verified computationally.
Let be the set of all standard complete word graphs corresponding to non-trivial right Rees congruences on the monoid presented by . The function is defined in Algorithm 4. We will show that the function , is a refining function for in Lemma 5.7.
Input: A word graph or .
Output: A word graph or .
Lemma 5.7.
is a refining function for .
Proof.
Suppose that and . Then returns in line 10 or line 20 of Algorithm 4. If returns in line 10, then there exist such that and . If any descendent of has a unique non-trivial sink , then or . In particular, 5.6(ii) does not hold, and so , and so 4.1(ii) holds.
If returns in line 20, then there exists a unique and such that . The node is the unique node with this property for every descendent of also. But, by the condition of line 19, is not a sink in , and hence no descendent of contains a unique non-trivial sink. In other words, , and so 4.1(ii) holds.
Finally assume that returns in line 24 of Algorithm 4. We must show that . Since , certainly . Suppose that . The if statement in line 15 implies that has been assigned a value in and therefore it is the unique non-trivial sink of every descendent of in including . Since edges are only added to in line 18, it follows that and so 4.1(iii) holds. ∎
It follows from Lemma 5.7 that where is .
If is a right ideal of , then the Rees congruence is a 2-sided congruence if and only if is a 2-sided ideal of . Hence is the set of all standard complete word graphs corresponding to Rees congruences by 2-sided ideals. Combining the criteria of 5.6 and 5.3 we can computationally check if a word graph belongs to . Therefore where is .
5.7 Congruences representing faithful actions
If is a (right) monoid action, then every induces a transformation defined by . We say that is faithful if implies that for all . Of course, if is a faithful right action of , then and are isomorphic monoids. Several recent papers have studied transformation representations of various classes of semigroups and monoids; see [3], [10], [11], and [49] and the references therein. The implementations of the algorithms in this paper were crucial in [11] and can be used to verify, in finitely many cases, some of the results in [49].
Recall that to every complete deterministic word graph compatible with we associate the right action given by for all , where is the unique homomorphism with .
We require the following theorem.
Theorem 5.8 (cf. Proposition 1.2 in [71] or Chapter I, Proposition 5.24 in [42]).
Let be a monoid and let be a right congruence on . Then the action of on by right multiplication is faithful if and only if the only 2-sided congruence contained in is trivial.
A 2-sided congruence on a monoid is principal if there exists such that and is the least 2-sided congruence containing , i.e. . We also refer to the pair in the preceding sentence as the generating pair of the principal congruence . Note that if is a principal 2-sided congruence, then by definition.
Clearly, every non-trivial 2-sided congruence contains a principal 2-sided congruence. If is a right congruence not containing any principal 2-sided congruences, then contains no non-trivial 2-sided congruences. Hence, by 5.8, acts faithfully on by right multiplication. This argument establishes one implication of the next theorem.
Theorem 5.9.
Let be the monoid defined by the monoid presentation , let be the natural surjective homomorphism, let be a right congruence on , let be the word graph of , and let be the associated right action. If is such that contains a generating pair for every principal 2-sided congruence of , then is faithful if and only if for all there exists some with .
Proof.
() If is arbitrary, then by assumption there exists some such that . If , then and by 3.10 we have that . But then , a contradiction. Hence contains no principal 2-sided congruences, and this implication follows by the argument before the theorem.
() We prove the contrapositive. Assume that there exists such that for all . Then by definition for all . In other words, , and since , is not faithful. ∎
The condition of 5.9 can only be tested if it is possible to compute . On the other hand, only finite monoids can have a faithful action on a finite set. Therefore it is only meaningful to look for faithful finite index congruences of finite monoids, in which case if the set can be computed, then the condition of 5.9 can be tested. In practice there are two ways of computing a set of generating pairs for the principal congruences of . The first is computational (such as the approach described in Section 7); the second is mathematical: if a description of the lattice of congruences of a particular monoid is known (such as those given in [22]), then we can obtain a set from this description directly.
Let be given by
where is a set of generating pairs for the principal congruences of . That is a refining function for the set of standard word graphs corresponding to faithful right congruences can be easily verified.
The primary application of faithful right congruences is in finding small transformation representations of finite monoids. Of course, every such monoid has a transformation representation of degree ; we refer to this as the right regular representation of . However, computing this representation requires computing the action of on itself by right multiplication, which requires all of the elements of to be stored in memory. This is only feasible when is relatively small; see [22, Section 1] for a more detailed discussion. If a presentation for is known, then iterating through the faithful right congruences of index at most using BacktrackingSearch we can find the smallest transformation representation arising from a right congruence. This is often quite slow in practice especially when is large. This method can be improved by modifying BacktrackingSearch to return the first faithful right congruence with index at most . If a faithful right congruence of index is known, then we call BacktrackingSearch to find the first faithful right congruence with index at most . If no such faithful right congruence exists, then is the minimum index of any faithful right congruence on . Otherwise, if a faithful right congruence with index is found, then we repeat this process. This is implemented in libsemigroups [53], and has been successfully employed to find transformation representations of relatively small degree for several classes of monoids where the best previous known bounds were ; see [11] for more details.
We provide two examples where the algorithm presented in this section returns minimal transformation representations.
Example 5.10.
Let be the Rees matrix semigroup over the symmetric group of degree with matrix:
where id is the identity permutation, and . Then the minimum degree transformation representation of , , and found by the algorithm described in this section are , , and . This agrees with the minimum degree transformation representation from [49, Theorem 2.19].
Example 5.11.
The opposite of a semigroup has multiplication defined by
where the multiplication on the right hand side of the equality is the multiplication in . It is shown in [49, Theorem 2.2] that the minimum degree transformation of the opposite of the full transformation monoids of degree is ; and this agrees with the output of the algorithm in this section.
As expected, the algorithm in this section does not always return the minimum degree transformation representation, since such a representation does not always correspond to an action on the classes of a right congruence; see, for example, Fig. 3.1 and [10, Table 3.1 and Theorem 3.9].
In [63], the minimal degree partial permutation representation of an arbitrary inverse semigroup is given in terms of the minimal degrees of certain subgroups of . This is implemented in the Semigroups [54] package for GAP [29]. In the example of the dual symmetric inverse monoid , the output of the algorithm described in this section as an application of the low-index congruences algorithm when agrees with the theoretical minimum found in [48] of , and with the output of Schein’s algorithm from [63].
Of course, as a consequence of 3.1 and 3.7, not every faithful action arises from a faithful right congruence. However, since 3.1 does give a bijection between word graphs and right actions, it may be possible to extend the backtracking search over standard word graphs given in this paper to cover a wider class of word graphs, and adapt the criterion given in 5.6 to word graphs representing faithful actions in general. This would give an algorithm for finding minimal transformation representations of finite monoids.
6 Meets and joins for congruences represented by word graphs
Although AllRightCongruences can be used to find all of the 1-sided congruences of a monoid, to compute the lattice of such congruences we require a mechanism for computing joins or meets of congruences represented by word graphs. In this section we will show that the Hopcroft-Karp Algorithm [34], for checking whether two finite state automata recognise the same language, can be used to determine the join of two congruences represented by word graphs. We will also show that the standard construction of an automaton recognising the union of two regular languages can be used to compute the meet of two congruences represented by word graphs.
6.1 The Hopcroft-Karp Algorithm for joins
In this section we present Algorithm 5 which can be used to compute the join of two congruences represented by word graphs. This is a slightly modified version of the Hopcroft-Karp Algorithm for checking whether two finite state automata recognise the same language. The key difference between Algorithm 5 and the Hopcroft-Karp Algorithm is that the inputs are word graphs rather than automata. As mentioned in the introduction a word graph is essentially an automaton without initial or accept states. The initial states of the automata that form the input to the Hopcroft-Karp Algorithm are only used at the beginning of the algorithm (when the pair consisting of the start states of the two automata are pushed into the stack). In our context, the node will play the role of the start state. Similarly the accept states are only used at the last step of the algorithm. As such the only difference between the Hopcroft-Karp Algorithm described in [34] (and [56]) and the version here are: the inputs, the values used to initialise the stack, and the return value. The time complexity of JoinWordGraphs is where .
Algorithm 5 makes use of the well-known disjoint sets data structure (originating in [27], see also [14, Chapter 21]) which provides an efficient representation of a partition of . We identify the disjoint sets data structure for a partition of and the partition itself. If denotes a disjoint sets data structure, then we require the following related functions:
- Union:
-
unites the parts of the partition containing ;
- Find:
-
returns a canonical representative of the part of the partition containing .
Note that belong to the same part of the partition represented by our disjoint sets data structure if and only if . If is an equivalence relation on the nodes of a word graph , then we define the quotient of by to be the word graph (after an appropriate relabelling) with nodes and edges . Note that is not necessarily deterministic.
Input: Word graph and
representing right congruences and of the monoid .
Output: The word graph of the join of
and .
In order to prove the correctness of JoinWordGraphs we need the following definition. An equivalence relation over is called right invariant if for all , implies , where and are such that and . The following result is Lemma 1 in [34].
Lemma 6.1.
Let be the equivalence relation on in line 15 of JoinWordGraphs. Then is the least right invariant equivalence relation on containing .
The next result relates right invariant equivalences on a word graph to its deterministic quotients.
Lemma 6.2.
If is a complete word graph and is an equivalence relation on , then is deterministic if and only if is right invariant.
Proof.
() Suppose that is an equivalence relation on such that is deterministic. Suppose that and that are arbitrary. We will prove that implies that where are the unique edges labelled by with sources and .
Assume that are such that . By the definition, and are edges in . Since is deterministic and , it follows that and so , as required.
() Conversely, let be a right invariant equivalence relation on . The word graph is complete by definition. If and are edges in such that , then, since is right invariant . It follows that is deterministic. ∎
We can now show that the quotient word graph returned by JoinWordGraphs represents the join of the congruences represented by the input word graphs.
Proposition 6.3.
The word graph returned by JoinWordGraphs in Algorithm 5 is the graph of the join of congruences and represented by and respectively.
Proof.
Let and . We start by showing that if is a right invariant equivalence relation on containing , then the quotient graph represents a right congruence of containing both and . To show that represents a right congruence of the monoid defined by the presentation it suffices by 3.7 to show that is complete, deterministic, compatible with , and every node is reachable from .
Since and are complete graphs, any quotient of is also complete. By Lemma 6.2, is deterministic. Since both and are compatible with , it follows that is also compatible with . Suppose that is the natural word graph homomorphism with . Then, since word graph homomorphisms preserve paths, it follows that is compatible with too. By assumption, every node in is reachable from and every node in is reachable from in , and . Thus every node in is reachable from . It follows that represents a right congruence on . Again, since the homomorphism preserves paths, and by 3.7, the path relations and on and , respectively, are contained in the path relation .
Suppose that is the word graph of . Then, since and , by Lemma 3.15, there exist unique word graph homomorphisms , and such that . Clearly, defined by for is a word graph homomorphism where , and this homomorphism is unique by 3.14. Since and , and is a right congruence, it follows that . Hence, again by Lemma 3.15, there exist a unique word graph homomorphism such that ; see Fig. 6.1. We will show that .
Since the composition of word graph homomorphisms is a word graph homomorphism, it follows that is a word graph homomorphism and
But is also a word graph homomorphism with , and so by 3.14. In particular, . Since is a word graph representing a right congruence, it is deterministic. Hence, by Lemma 6.2, it follows that is right invariant. Also implies that . But is the least right invariant equivalence relation on containing , by Lemma 6.1, and so . It follows that and coincide, and so represents , as required. ∎
6.2 Automata intersection for meets
In this section we present a slightly modified version of a standard algorithm from automata theory for finding an automaton recognising the intersection of two regular languages. As in the previous section the key difference is that we use word graphs rather than automata.
If and are word graphs over the same alphabet , then we define a word graph where is the largest subset of such that every node in is reachable from in and if and only if and ; we will refer to as the meet word graph of and . This is directly analogous to the corresponding construction for automata; for more details see the comments following the proof of Theorem 1.25 in [68].
Proposition 6.4.
If and are word graphs representing congruences of the monoid defined by the presentation , then the meet word graph of and is a complete deterministic word graph which is compatible with and each node of is reachable from .
Proof.
The word graph is complete and deterministic since and are, and was constructed so that every node is reachable from .
It remains to prove that is compatible with the set of relations . If , then, since and are complete, then for and each node in , there is a unique path in labeled by with source . If labels a -path in and an -path in , then labels a -path in . Since is compatible with , for every and for every there exists a such that both and label -paths in . Similarly, for every there is such that and both label -paths in . Hence for every and every there exists such that both and label -paths in , and so is compatible with also. ∎
Corollary 6.5.
If and are word graphs representing congruences and , respectively, of the monoid defined by the presentation , then the meet word graph of and represents the meet of and .
Proof.
The algorithm MeetWordGraphs in Algorithm 6 can be used to construct the meet word graph from the input word graphs and . Algorithm 6 starts by constructing a graph with nodes that have the form for . These nodes get relabeled at the last step of the procedure and a standard word graph is returned by MeetWordGraphs. The triples belonging to in MeetWordGraphs, then the first component corresponds to a node in , the second component to a node in , and the third component labels the corresponding node in the meet word graph returned by Algorithm 6.
Input: Word graphs and
corresponding to the right congruences and
of the monoid .
Output: The word graph of the meet of
and
In comparison to the procedure for the construction of the intersection automaton in [68, Theorem 1.25], MeetWordGraphs includes a few extra steps so that the output word graph is standard.
Proposition 6.6.
The output of MeetWordGraphs in Algorithm 6 is a complete deterministic standard word graph which is compatible with and each node of this word graph is reachable from 0.
Proof.
Let denote the word graph obtained in Algorithm 6 before the relabelling of the nodes in line 14. It is clear that this word graph is isomorphic to the meet word graph of and and hence it follows by 6.4 that it is complete, deterministic, compatible with and each node in is reachable from 0. For every node the edge leaving labelled by is defined before the edge labelled by whenever . In addition, all edges with source have been defined before any edge with source is defined. It follows that the output word graph after the relabelling in line 14 is standard. ∎
7 Algorithm 2: principal congruences and joins
In the preceding sections we described algorithms that permit the computation of the lattice of right or left congruences of a finitely presented semigroup or monoid. In this section we consider an alternative method for computing the lattice of 1-sided or 2-sided congruences of a finite monoid.
If is a finite monoid, then the basic outline of the method considered in this section is: to compute the set of all principal congruences of ; and then compute all possible joins of the principal congruences. This approach has been considered by several authors; particularly relevant here are [4, 25, 70]. To compute the set of all principal congruences of a monoid , it suffices to compute the principal congruence generated by for every , and to find those pairs generating distinct congruences. This requires the computation of principal congruences. In this part of the paper, we describe a technique based on [22] for reducing the number of pairs that must be considered. More specifically, we perform a preprocessing step where some pairs that generate the same congruence are eliminated. The time taken by this preprocessing step is often insignificant when compared to the total time required to compute the lattice, as mentioned above, in many cases results in a significant reduction in the number of principal congruences that must be computed, and in the overall time to compute the lattice; see Appendix A for more details. Of course, there are also examples where the preprocessing step produces little or no reduction in the number of principal congruences that must be computed, and so increases the total time required to compute the lattice (the Gossip monoids [8] are class of such examples).
Recall that a submonoid of a monoid is a subset of , which is a monoid under the same operation as with the same identity element; we denote this by . If , then the least submonoid of containing is called the submonoid generated by and is denoted by .
For the remainder of the paper, we suppose that is a monoid, is a submonoid of , and is a submonoid of . We also denote the identity element of any of these 3 monoids by . Recall that is regular if for every there exists some such that .
In the case that is regular, in [22], it was shown, roughly speaking, how to utilise the Green’s structure of to determine the Green’s structure of . The idea being that the structure of is “known”, in some sense. The prototypical example is when is the full transformation monoid (see [46]), consisting of all transformations on the set for some . In this case, the Green’s structure of is known and can be used to compute the Green’s structure of any submonoid of . In this part of the paper, we will show that certain results from [22] hold in greater generality, for the so-called, relative Green’s relations.
We say that are -related if the sets and coincide; and we refer to as the relative Green’s -relation on . The relative Green’s -relation on is defined dually. We say that are -related if the sets and coincide; and we refer to as the relative Green’s -relation on . When , we recover the classical definition of Green’s relations, which are ubiquitous in the study of semigroups and monoids. For further information about Green’s relations see [35]. Relative Green’s relations were first introduced in [72, 73] and further studied in [9, 30]. It is routine to show that each of , , and is an equivalence relation on ; and that is a right congruence, and a left congruence. We denote the -, -, or -class of an element by , and , respectively.
It may be reasonable to ask, at this point, what any of this has to do with determining the principal congruences of a monoid? This is addressed in the next proposition.
Proposition 7.1.
Let be a monoid and let . Then the following hold:
-
(i)
If , then the right congruences generated by and coincide;
-
(ii)
If , then the left congruences generated by and coincide;
-
(iii)
If , then the 2-sided congruences generated by and coincide.
Proof.
We only prove part i, the proofs in the other cases are similar. If , then there exists such that . In particular, belongs to the right congruence generated by . By symmetry also belongs to the right congruence generated by and so these two congruences coincide. ∎
A corollary of 7.1 is: if is a set of -class representatives in , then every principal right congruence on is generated by a pair in . So, knowing -class representatives in , will allow us to compute the set of all principal right congruences of . By doing this we hope for two things: that we can compute the representatives efficiently and that the number of such representatives is relatively small compared to . Analogous statements hold for principal left congruences and ; and for 2-sided congruences and .
The rest of this section is dedicated to showing how to can compute -, and -class representatives in . We will not discuss -classes beyond the following comments. Suppose that we can compute relative -class representatives in for any arbitrary monoid . Relative -classes can be computed in one of two ways: by performing the dual of what is described in this section for computing relative -classes; or by computing an anti-isomorphism from from to its dual , and computing relative -class representatives in . For the sake of simplicity, we opt for the second approach. An anti-isomorphism into a transformation monoid can be found from the left Cayley graph of . The lattice of congruences of a monoid is generally several orders of magnitude harder to determine than the left Cayley graph, and as such computing an anti-isomorphism from to a transformation monoid is an insignificant step in this process. The degree of the transformation representation of obtained from the left Cayley graph of is . If is large, this can have an adverse impact on the computation of relative -class representatives. However, it is possible to reduce the degree of this representation by finding a right congruence of on which acts faithfully using the algorithms given in Section 4.
If is a fixed regular monoid, is an arbitrary submonoid of , and an arbitrary submonoid of , then we show how to compute -class representatives for using the structure of . Algorithm 11 in [22] describes how to obtain the -class representatives for . We will show that, with minimal changes, Algorithm 11 from [22] can be used to compute -class representatives for . We will then show how, as a by-product of the algorithm used to compute -class representatives, to compute -class representatives.
The essential idea is to represent an -class by a group and a strongly connected component of the action of on the -class containing elements of . We will show (in 7.8) that this representation reduces the problem of checking membership in an -class to checking membership in the corresponding group. Starting with the -class of the identity, new -class representatives are computed by left multiplying the existing representatives by the generators of , and testing whether these multiples are -related to an existing representative.
Before we can describe the algorithm and prove the results showing that it is valid, we require the following. If is a right action of on a finite set , is any subset of , and , then we define
and we define by
for all and all . When is clear from the context, we may write and instead of and , respectively. We define the stabiliser of to be
Clearly, if , then is a permutation of . The quotient of the stabiliser by the kernel of its action on , i.e. the congruence
is isomorphic to which is a subgroup of the symmetric group on . When using the notation for actions we write to denote the kernel of the action . We denote the equivalence class of an element with respect to by . Clearly, since is a submonoid of , is a subgroup of .
We denote the right action of the monoid on by right multiplication by . If is a -class of , then the group , and its subgroup , act faithfully by permutations on . The algorithms described in this part of the paper involve computing with these permutation groups using standard algorithms from computational group theory, such as the Schreier-Sims Algorithm [64, 66, 67]. The -classes are often too large themselves for it to be practical to compute with permutations of -classes directly. For many well-studied classes of monoids , such as the full transformation monoid, the symmetric inverse monoid, or the partition monoid, there are natural faithful representations of the action of on the -class in a symmetric group of relatively low degree. To avoid duplication we refer the reader to [22, Section 4] for details. Throughout the rest of this paper, we will abuse notation by writing , to mean a faithful low-degree representation of when one is readily computable.
It might be worth noting that we are interested in computing -class representatives, but the results in [22] apply to submonoids of when is the full transformation monoid , the partition monoid , or the symmetric inverse monoid , for example, rather than to submonoids of . If a monoid is regular, then so too is , and hence we may apply the techniques from [22] to compute submonoids of . The missing ingredients, however, are the analogues for of the results in [22, Section 4], that provide efficient faithful representations of the right action of on the -classes containing elements of . It is possible to prove such analogues for . However, in the case that is one of , , and , at least, this is not necessary, since embeds into . As such we may directly reuse the methods described in [22, Section 4].
In order to make practical use of , it is necessary that we can efficiently obtain a generating set. The following analogue of Schreier’s Lemma for monoids provides a method for doing so. If is any set and , then we denote the identity function from to by .
Proposition 7.2 (cf. Proposition 2.3 in [22]).
Let be a monoid, let be a right action of , and let be the elements of a strongly connected component of the right action of on induced by . Then the following hold:
-
(i)
if for some , then there exists such that , , and ;
-
(ii)
and are conjugate subgroups of for all ;
-
(iii)
if and are as in part i for , then is generated by
We require the following two right actions of . One is the action on induced by right multiplication, i.e. for and :
| (7.1) |
The second right action of is that on -classes:
| (7.2) |
where and . The latter is an action because is a right congruence on . The actions given in (7.1) and (7.2) coincide in the case described by the following lemma.
Lemma 7.3 (cf. Lemma 3.3 in [22]).
Lemma 7.3 allows us use the actions defined in (7.1) and (7.2) interchangeably within a strongly connected component of either action. We will denote both of the right actions in (7.1) and (7.2) by . Although the actions in (7.1) and (7.2) are interchangeable the corresponding stabilisers are not. Indeed, the stabiliser of any -class with respect to the action given in (7.2) is always trivial, but the stabiliser with respect to (7.1) is not. When we write or for some subset of , we will always mean the stabiliser with respect to (7.1).
We require the following result from [22] which relate to non-relative Green’s relations and classes.
Lemma 7.4 (cf. Lemma 3.6 in [22]).
Let and be arbitrary. Then for all if and only if there exists such that .
We also require the following results, which are modifications of the corresponding results in [22] for relative Green’s relations and classes.
If , then we write to denote that the -classes and belong to the same strongly connected component of either of the right actions of defined in (7.1) or (7.2). Similarly, we write for the analogous statement for -classes.
Recall that we do not propose acting on the -classes directly but rather we use a more convenient isomorphic action when available. For example, if is the full transformation monoid, then the action of any submonoid of on -classes of elements in is isomorphic to the natural right action of on the set ; for more examples and details see [22, Section 4]. In [22, Algorithm 1] a (simple brute force) algorithm is stated that can be used to compute the word graph corresponding to the right action of on . In the present paper we must compute the word graph for the right action of on . [22, Algorithm 1] relies on the fact that . Clearly, is not equal to in general. As such we cannot use [22, Algorithm 1] directly to compute . However, we can apply [22, Algorithm 1] to compute the set and subsequently compute the word graph of the action of on this set. The latter can be accomplished by repeating [22, Algorithm 1] with the generating set for , setting in line 1. Since is a submonoid of , the condition in line 3 never holds, and the condition in line 6 always holds.
The next result states some properties of relative Green’s relations that are required to prove the main propositions in this section.
Lemma 7.5 (cf. Lemma 3.4, Corollaries 3.8 and 3.13 in [22]).
Let and let . Then the following hold:
-
(i)
if and only if ;
-
(ii)
if and , then ;
-
(iii)
if and , then defined by is a bijection.
Proof.
(i). () By assumption, and belong to the same strongly connected component of the action of on by right multiplication. Hence, by 7.2i, there exists such that and acts on as the identity. Hence, in particular, and so .
() Suppose . Then there exists such that . It follows that and . Hence .
(ii). Since there exists such that . Hence and . In particular, and so, by part i, , as required.
The next proposition allows us to decompose the -class of into the sets where the form a -strongly connected component with respect to .
Proposition 7.6 (cf. Proposition 3.7(a) in [22]).
Suppose that are arbitrary. If , then . Conversely, if , then there exists such that and .
Proof.
The next result, when combined with 7.6, completes the decomposition of the -class of into -strongly connected component with respect to and a group, by showing that is a group with the operation defined in part i of the next proposition.
Proposition 7.7 (cf. Proposition 3.9 in [22]).
Suppose that and there exists where (i.e. is regular in ). Then the following hold:
-
(i)
is a group under the multiplication defined by for all and its identity is ;
-
(ii)
defined by , for all , is an isomorphism;
-
(iii)
is defined by for all .
Proof.
We begin by showing that is an identity under the multiplication of . Since and are idempotents, it follows that is a right identity for and is a left identity for . So, if is arbitrary, then
as required.
We will prove that part (b) holds, which implies part (a).
is well-defined. If and , then . Hence, by Lemma 7.5ii, and so . If is such that , then, by Lemma 7.4, .
is surjective. Let be arbitrary. Then since is the identity of . It follows that
and so . Since , there exists such that . It follows that and, by Lemma 7.4, . Thus and is surjective.
is a homomorphism. Let . Then, since and is a right identity for ,
as required.
is injective. Let be defined by for all . We will show that is the identity mapping on , which implies that is injective, that for all (since is surjective), and also proves part (c) of the proposition. If , then . But and so by Lemma 7.4. Therefore, , as required. ∎
Finally, we combine the preceding results to test membership in an -class.
Proposition 7.8.
Suppose that and there is with . If is arbitrary, then if and only if , , and where is any element such that .
Proof.
We have shown that analogues of all the results required to prove the correctness of [22, Algorithm 11] hold for relative Green’s relations in addition to their non-relative counterparts. For the sake of completeness, we state a version of Algorithm 11 from [22] that computes the set of -class representatives and the word graph of the left action (by left multiplication) of on ; see Algorithm 7. We require the word graph to compute -class representatives in the next section, it is not required for finding the -class representatives. The algorithm presented in Algorithm 7 is simplified somewhat from Algorithm 11 from [22] because we only require the representatives and the word graph, and not the associated data structures.
The next proposition shows that relative -classes correspond to strongly connected components of the word graph output by Algorithm 7.
Proposition 7.9.
Let . Then if and only if and belong to the same strongly connected component of the action of on the -classes of by left multiplication.
Proof.
This follows almost immediately since , because and are finite. ∎
It follows from 7.9 that we can compute -class representatives by using Algorithm 7 to find the word graph , and then using one of the standard algorithms from graph theory to compute the strongly connected components of .
References
- [1] A. Abram and C. Reutenauer “The stylic monoid” In Semigroup Forum 105.1 Springer ScienceBusiness Media LLC, 2022, pp. 1–45 DOI: 10.1007/s00233-022-10285-3
- [2] João Araújo, Wolfram Bentz and Gracinda M.. Gomes “Congruences on direct products of transformation and matrix monoids” In Semigroup Forum Springer Nature, 2018 DOI: 10.1007/s00233-018-9931-8
- [3] João Araújo and Friedrich Wehrung “Embedding properties of endomorphism semigroups” In Fundamenta Mathematicae 202.2, 2009, pp. 125–146 URL: http://eudml.org/doc/286492
- [4] João Araújo et al. “CREAM: a Package to Compute [Auto, Endo, Iso, Mono, Epi]-morphisms, Congruences, Divisors and More for Algebras of Type ”, 2022 eprint: arXiv:2202.00613
- [5] Robert E. Arthur and N. Ruškuc “Presentations for Two Extensions of the Monoid of Order-Preserving Mappings on a Finite Chain” In Southeast Asian Bulletin of Mathematics 24.1 Springer ScienceBusiness Media LLC, 2000, pp. 1–7 DOI: 10.1007/s10012-000-0001-1
- [6] Alex Bailey, Martin Finn-Sell and Robert Snocken “Subsemigroup, ideal and congruence growth of free semigroups” In Israel Journal of Mathematics 215.1, 2016, pp. 459–501 DOI: 10.1007/s11856-016-1384-8
- [7] Matthew David George Kenworthy Brookes “Lattices of congruence relations for inverse semigroups”, 2020 URL: https://etheses.whiterose.ac.uk/29077/
- [8] Andries E. Brouwer, Jan Draisma and Bart J. Frenk “Lossy Gossip and Composition of Metrics” In Discrete & Computational Geometry 53.4 Springer ScienceBusiness Media LLC, 2015, pp. 890–913 DOI: 10.1007/s00454-015-9666-1
- [9] Alan J. Cain, Robert Gray and Nik Ruškuc “Green index in semigroups: generators, presentations, and automatic structures” In Semigroup Forum 85.3 Springer ScienceBusiness Media LLC, 2012, pp. 448–476 DOI: 10.1007/s00233-012-9406-2
- [10] Peter J. Cameron et al. “Minimum degrees of finite rectangular bands, null semigroups, and variants of full transformation semigroups” In Combinatorial Theory 3.3 California Digital Library (CDL), 2023 DOI: 10.5070/c63362799
- [11] Reinis Cirpons, James East and James D. Mitchell “Transformation representations of diagram monoids”, 2024 eprint: arXiv:2411.14693
- [12] Reinis Cirpons, James D. Mitchell and Yann Péresse “Maximal and minimal one sided congruences of the full transformation monoid”, 2025
- [13] T… Coleman, J.. Mitchell, F.. Smith and M. Tsalakou “The Todd–Coxeter algorithm for semigroups and monoids” In Semigroup Forum 108.3 Springer ScienceBusiness Media LLC, 2024, pp. 536–593 DOI: 10.1007/s00233-024-10431-z
- [14] Thomas H Cormen, Charles E Leiserson, Ronald L Rivest and Clifford Stein “Introduction to Algorithms”, The MIT Press London, England: MIT Press, 2009
- [15] Marc Culler, Matthias Goerner and Nathan Dunfield “3manifolds/low_index”, 2025 URL: https://github.com/3-manifolds/low_index
- [16] Yang Dandan, Victoria Gould, Thomas Quinn-Gregson and Rida-E Zenab “Semigroups with finitely generated universal left congruence” In Monatshefte für Mathematik 190.4 Springer ScienceBusiness Media LLC, 2019, pp. 689–724 DOI: 10.1007/s00605-019-01274-w
- [17] Andreas Distler and Tom Kelsey “The monoids of orders eight, nine & ten” In Annals of Mathematics and Artificial Intelligence 56.1 Springer ScienceBusiness Media LLC, 2009, pp. 3–21 DOI: 10.1007/s10472-009-9140-y
- [18] James East and Nik Ruškuc “Classification of congruences of twisted partition monoids” In Advances in Mathematics 395 Elsevier BV, 2022, pp. 108097 DOI: 10.1016/j.aim.2021.108097
- [19] James East and Nik Ruškuc “Congruence Lattices of Ideals in Categories and (Partial) Semigroups” In Memoirs of the American Mathematical Society 284.1408 American Mathematical Society (AMS), 2023 DOI: 10.1090/memo/1408
- [20] James East and Nik Ruškuc “Congruences on Infinite Partition and Partial Brauer Monoids” In Moscow Mathematical Journal 22.2 National Research University, Higher School of Economics (HSE), 2022, pp. 295–372 DOI: 10.17323/1609-4514-2022-22-2-295-372
- [21] James East and Nik Ruškuc “Properties of congruences of twisted partition monoids and their lattices” In Journal of the London Mathematical Society 106.1 Wiley, 2022, pp. 311–357 DOI: 10.1112/jlms.12574
- [22] James East, Attila Egri-Nagy, James D. Mitchell and Yann Péresse “Computing finite semigroups” In Journal of Symbolic Computation 92 Elsevier BV, 2019, pp. 110–155 DOI: 10.1016/j.jsc.2018.01.002
- [23] James East, James D. Mitchell, Nik Ruškuc and Michael Torpey “Congruence lattices of finite diagram monoids” In Advances in Mathematics 333 Elsevier BV, 2018, pp. 931–1003 DOI: 10.1016/j.aim.2018.05.016
- [24] Vitor H Fernandes “On the cyclic inverse monoid on a finite set” In Asian-Eur. J. Math. World Scientific Pub Co Pte Ltd, 2024
- [25] Ralph Freese “Computing congruences efficiently” In Algebra universalis 59.3-4 Springer ScienceBusiness Media LLC, 2008, pp. 337–343 DOI: 10.1007/s00012-008-2073-1
- [26] Véronique Froidure and Jean-Éric Pin “Algorithms for computing finite semigroups” In Foundations of computational mathematics (Rio de Janeiro, 1997) Berlin: Springer, 1997, pp. 112–126
- [27] Bernard A. Galler and Michael J. Fisher “An improved equivalence algorithm” In Communications of the ACM 7.5 Association for Computing Machinery (ACM), 1964, pp. 301–303 DOI: 10.1145/364099.364331
- [28] Olexandr Ganyushkin and Volodymyr Mazorchuk “Classical Finite Transformation Semigroups” Springer London, 2009 DOI: 10.1007/978-1-84800-281-4
- [29] “GAP – Groups, Algorithms, and Programming, Version 4.14.0”, 2024 The GAP Group URL: https://www.gap-system.org
- [30] R. Gray and N. Ruškuc “Green index and finiteness conditions for semigroups” In Journal of Algebra 320.8 Elsevier BV, 2008, pp. 3145–3164 DOI: 10.1016/j.jalgebra.2008.07.008
- [31] Peter M. Higgins “Combinatorial results for semigroups of order-preserving mappings” In Mathematical Proceedings of the Cambridge Philosophical Society 113.2 Cambridge University Press (CUP), 1993, pp. 281–296 DOI: 10.1017/s0305004100075964
- [32] D.F. Holt and Sarah Rees “Testing for isomorphism between finitely presented groups” In Groups, Combinatorics and Geometry, London Mathematical Society Lecture Note Series Cambridge University Press, 1992, pp. 459–475
- [33] Derek F Holt, Bettina Eick and Eamonn A O’Brien “Handbook of computational group theory”, Discrete Mathematics and Its Applications Philadelphia, PA: Chapman & Hall/CRC, 2005
- [34] J. Hopcroft and R. Karp “A Linear Algorithm for Testing Equivalence of Finite Automata”, 1971
- [35] John M. Howie “Fundamentals of semigroup theory” Oxford Science Publications 12, London Mathematical Society Monographs. New Series New York: The Clarendon Press Oxford University Press, 1995, pp. x+351
- [36] Alexander Hulpke “Calculating Subgroups with GAP” In Group Theory and Computation Springer Singapore, 2018, pp. 91–106 DOI: 10.1007/978-981-13-2047-7˙5
- [37] Alexander Hulpke “Representing Subgroups of Finitely Presented Groups by Quotient Subgroups” In Experimental Mathematics 10.3 A K Peters, Ltd., 2001, pp. 369–382
- [38] Andrzej Jura “Coset enumeration in a finitely presented semigroup” In Canad. Math. Bull. 21.1, 1978, pp. 37–46
- [39] Andrzej Jura “Determining ideals of a given finite index in a finitely presented semigroup” In Demonstratio Mathematica 11.3 De Gruyter Open, 1978, pp. 813–828
- [40] Andrzej Jura “Some remarks on non-existence of an algorithm for finding all ideals of a given finite index in a finitely presented semigroup” In Demonstratio Mathematica 13 De Gruyter Open, 1980, pp. 573–578
- [41] Ilya Kapovich and Alexei Myasnikov “Stallings Foldings and Subgroups of Free Groups” In Journal of Algebra 248.2, 2002, pp. 608–668 DOI: 10.1006/jabr.2001.9033
- [42] Mati Kilp, Ulrich Knauer and Alexander V. Mikhalev “Monoids, Acts and Categories: With Applications to Wreath Products and Graphs. A Handbook for Students and Researchers” DE GRUYTER, 2000 DOI: 10.1515/9783110812909
- [43] Donald Knuth “The Art of Computer Programming: Combinatorial Algorithms, Volume 4B” Addison-Wesley Professional, 2022
- [44] Donald E. Knuth “Permutations, matrices, and generalized Young tableaux” In Pacific J. Math. 34, 1970, pp. 709–727 URL: http://projecteuclid.org.ezproxy.st-andrews.ac.uk/euclid.pjm/1102971948
- [45] Alain Lascoux and Marcel-P. Schützenberger “Le monoïde plaxique” In Noncommutative structures in algebra and geometric combinatorics (Naples, 1978) 109, Quad. “Ricerca Sci.” CNR, Rome, 1981, pp. 129–156
- [46] S.A. Linton, G. Pfeiffer, E.F. Robertson and N. Ruškuc “Groups and actions in transformation semigroups” In Mathematische Zeitschrift 228.3 Springer ScienceBusiness Media LLC, 1998, pp. 435–450 DOI: 10.1007/pl00004628
- [47] Anatolii Ivanovich Mal’tsev “Symmetric groupoids” In Matematicheskii Sbornik 73.1 Russian Academy of Sciences, Steklov Mathematical Institute of Russian …, 1952, pp. 136–151
- [48] Victor Maltcev “On a new approach to the dual symmetric inverse monoid ” In Internat. J. Algebra Comput. 17.3, 2007, pp. 567–591 DOI: 10.1142/S0218196707003792
- [49] Stuart Margolis and Benjamin Steinberg “On the minimal faithful degree of Rhodes semisimple semigroups” In Journal of Algebra 633 Elsevier BV, 2023, pp. 788–813 DOI: 10.1016/j.jalgebra.2023.06.032
- [50] J… McKinsey “The Decision Problem for Some Classes of Sentences Without Quantifiers” In The Journal of Symbolic Logic 8.2 Association for Symbolic Logic, 1943, pp. 61–76 URL: http://www.jstor.org/stable/2268172
- [51] John Meakin “One-sided congruences on inverse semigroups” In Transactions of the American Mathematical Society 206 American Mathematical Society (AMS), 1975, pp. 67–67 DOI: 10.1090/s0002-9947-1975-0369580-9
- [52] James Mitchell and Chinmaya Nagpal and Maria Tsalakou “libsemigroups_pybind11 v0.10.1” Zenodo, 2023 DOI: 10.5281/ZENODO.7307278
- [53] James Mitchell et al. “libsemigroups C++ library for semigroups and monoids” Zenodo, 2025 DOI: 10.5281/zenodo.1437752
- [54] James Mitchell et al. “Semigroups package for GAP” Zenodo, 2023 DOI: 10.5281/zenodo.592893
- [55] J. Neubüser “An elementary introduction to coset table methods in computational group theory” In Groups - St Andrews 1981, London Mathematical Society Lecture Notes Series Cambridge University Press, 1982, pp. 1–45 DOI: 10.1017/CBO9780511661884.004
- [56] Daphne Norton “Algorithms for testing equivalence of finite automata, with a grading tool for JFLAP”, 2009
- [57] OEIS Foundation Inc. “The On-Line Encyclopedia of Integer Sequences” Published electronically at http://oeis.org, 2024
- [58] Rui Barradas Pereira “The CREAM GAP Package - Algebra CongRuences, Endomorphisms and AutomorphisMs”, 2022 URL: https://gitlab.com/rmbper/cream
- [59] Jean-Éric Pin “Mathematical Foundations of Automata Theory” Université Paris Laboratoire d’Informatique Algorithmique: Fondements et Applications, 2022 URL: https://www.irif.fr/~jep/PDF/MPRI/MPRI.pdf
- [60] Emmanuel Rauzy “Computability of finite quotients of finitely generated groups” In Journal of Group Theory 25.2 Walter de Gruyter GmbH, 2021, pp. 217–246 DOI: 10.1515/jgth-2020-0029
- [61] N. Ruškuc and R.M. Thomas “Syntactic and Rees Indices of Subsemigroups” In Journal of Algebra 205.2, 1998, pp. 435–450 DOI: https://doi.org/10.1006/jabr.1997.7392
- [62] Nikola Ruškuc “Semigroup presentations”, 1995 URL: https://hdl.handle.net/10023/2821
- [63] Boris M. Schein “The Minimal Degree of a Finite Inverse Semigroup” In Transactions of the American Mathematical Society 333.2 American Mathematical Society, 1992, pp. 877–888 URL: http://www.jstor.org/stable/2154068
- [64] Ákos Seress “Permutation group algorithms” 152, Cambridge Tracts in Mathematics Cambridge: Cambridge University Press, 2003, pp. x+264 DOI: 10.1017/CBO9780511546549
- [65] Charles C. Sims “Computation with Finitely Presented Groups”, Encyclopedia of Mathematics and its Applications Cambridge University Press, 1994 DOI: 10.1017/CBO9780511574702
- [66] Charles C. Sims “Computation with permutation groups” In Proceedings of the second ACM symposium on Symbolic and algebraic manipulation - SYMSAC ’71 ACM Press, 1971 DOI: 10.1145/800204.806264
- [67] Charles C. Sims “Computational methods in the study of permutation groups” In Computational Problems in Abstract Algebra Elsevier, 1970, pp. 169–183 DOI: 10.1016/b978-0-08-012975-4.50020-5
- [68] Michael Sipser “Introduction to the Theory of Computation” Boston, MA: Course Technology, 2013
- [69] J.. Todd and H… Coxeter “A practical method for enumerating cosets of a finite abstract group” In Proceedings of the Edinburgh Mathematical Society 5.01 Cambridge University Press (CUP), 1936, pp. 26–34 DOI: 10.1017/s0013091500008221
- [70] Michael Torpey “Semigroup congruences : computational techniques and theoretical applications” University of St Andrews, 2019 DOI: 10.17630/10023-17350
- [71] E.. Tully “Representation of a semigroup by transformations acting transitively on a set” In Amer. J. Math. 83, 1961, pp. 533–541
- [72] A. Wallace “Relative ideals in semigroups, I (Faucett’s Theorem)” In Colloquium Mathematicum 9.1 Institute of Mathematics, Polish Academy of Sciences, 1962, pp. 55–61 DOI: 10.4064/cm-9-1-55-61
- [73] A.. Wallace “Relative Ideals in Semigroups. II” In Acta Mathematica Academiae Scientiarum Hungaricae 14.1-2 Springer ScienceBusiness Media LLC, 1963, pp. 137–148 DOI: 10.1007/bf01901936
- [74] Anthony Williams “C++ Concurrency in Action, 2E” New York, NY: Manning Publications, 2019
Appendix A Performance comparison
In this section we present some data related to the performance of the low-index congruences algorithm as implemented in libsemigroups [53] and Algorithm 7 as implemented in version 5.3.0 of Semigroups [54] for GAP [29] by the authors. We compare the performance of our implementations in libsemigroups [53] and Semigroups [54] with the algorithm from [25] implemented in CREAM [58] and with earlier versions of Semigroups [54] which do not contain the optimizations described in Section 7. It may be worth bearing in mind that the input to the algorithms implemented in CREAM [58] is the multiplication table of a semigroup or monoid, and that these multiplication tables were computed using the methods in the Semigroups [54] package. The input to the low-index algorithm is the presentation of a semigroup or monoid and the input for Algorithm 7 is a black-box multiplication monoid and a set of generators of a submonoid.
A.1 A parallel implementation of the low-index congruences algorithm
In Fig. A.1 we present some data related to the performance of the parallel implementation of the low-index congruences algorithm in libsemigroups [53]. It can be seen in Fig. A.1 that, in these examples, doubling the number of threads, more or less, halves the execution time up to 4 threads (out of 8) on the left, and 16 threads (out of 64) on the right. Although the performance continues to improve after these numbers of threads, it does not continue to halve the runtime. The degradation in performance might be a consequence of using too many resources on the host computer, or due to there being insufficient work for the threads in the chosen examples.
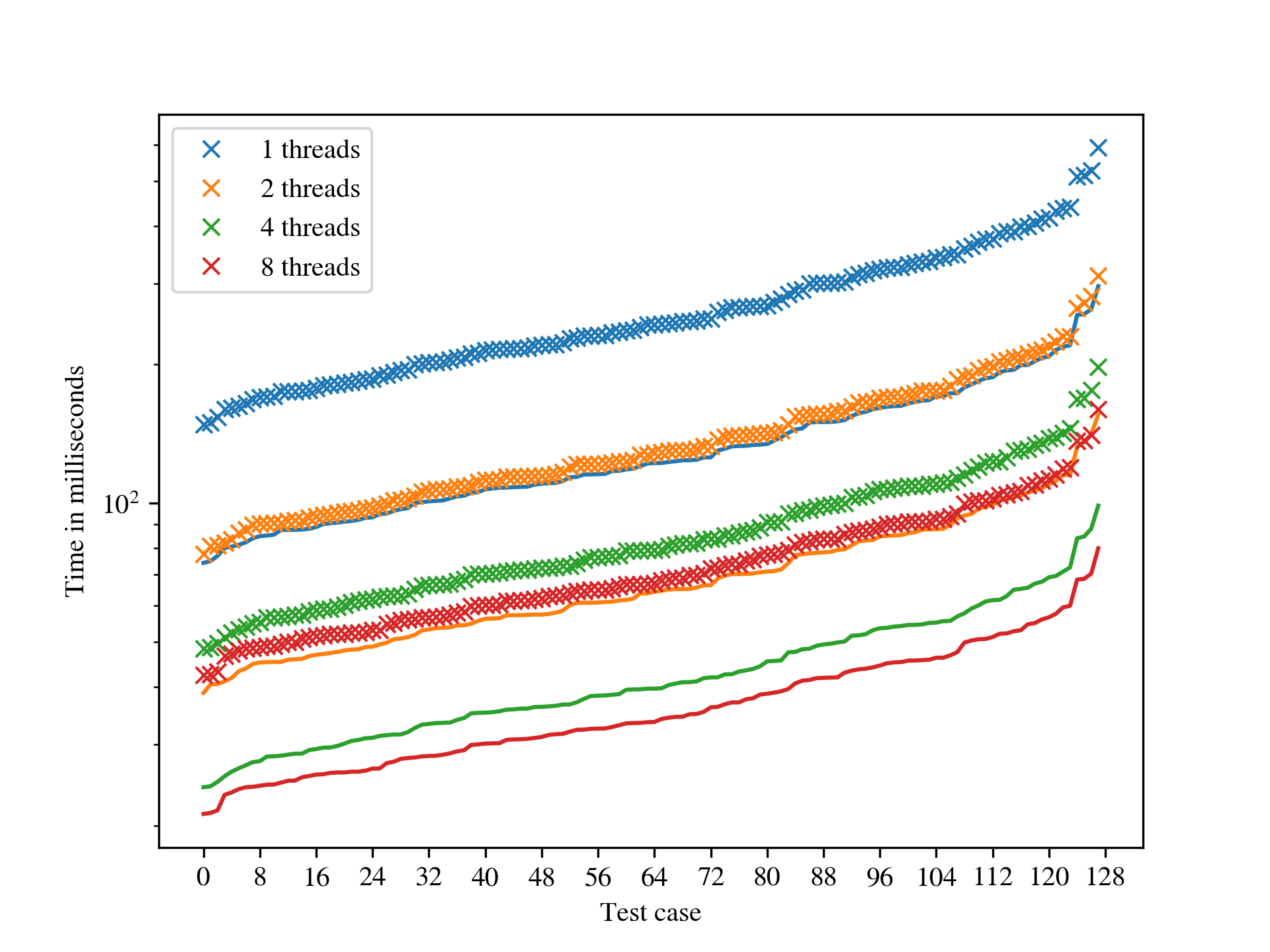
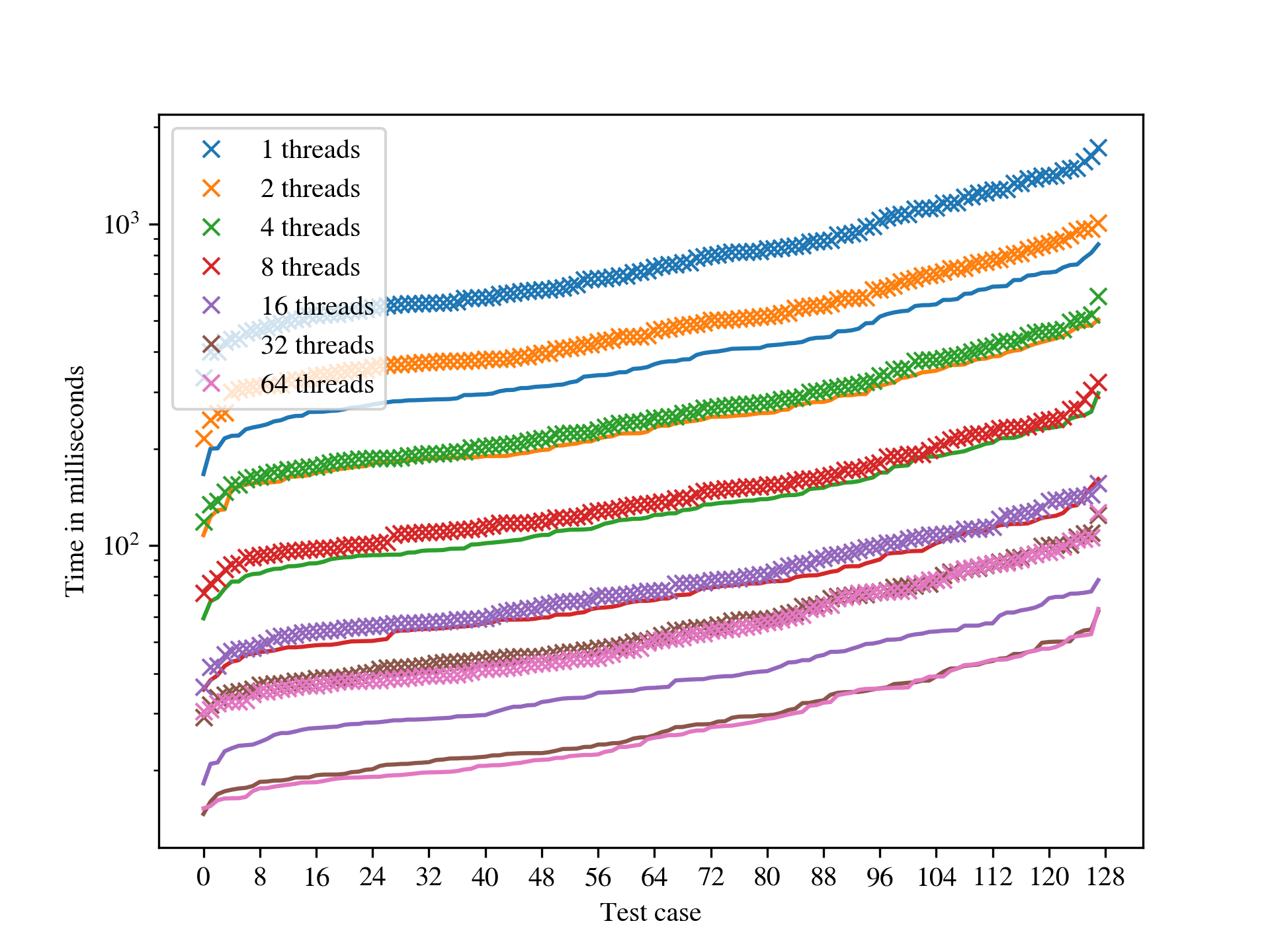
A.2 The impact of presentation length on the low-index congruences algorithm
In this section we present some experimental evidence about how the length of a presentation impacts the performance of the low-index congruences algorithm. If is a monoid presentation, then we refer to the sum of the lengths of the relation words in as the length of . In Fig. A.2, a comparison of the length of a presentation for the full transformation monoid versus the runtime of the implementation of the low-index congruences algorithm in libsemigroups [53] is given. In Fig. 2(a), the initial input presentations were Iwahori’s presentation from [28, Theorem 9.3.1] for the full transformation monoid , and a complete rewriting system for output from the Froidure-Pin Algorithm [26]. Both initial presentations contain many redundant relations, these were removed at a time, and the time to compute the number of left congruences of with at most classes is plotted for each resulting presentation. We also attempted to perform the same computation with input Aizenstat’s presentation from [62, Ch. 3, Prop 1.7] (which has length ), but the computation was extremely slow.
In Fig. 2(b) and Fig. 2(c), a similar approach is taken. The initial input presentations in Fig. 2(b) and Fig. 2(c) were Fernandes’ presentations from [24, Theorems 2.6 and 2.7], respectively, and the outputs of the Froidure-Pin Algorithm [26] with the corresponding generating sets.
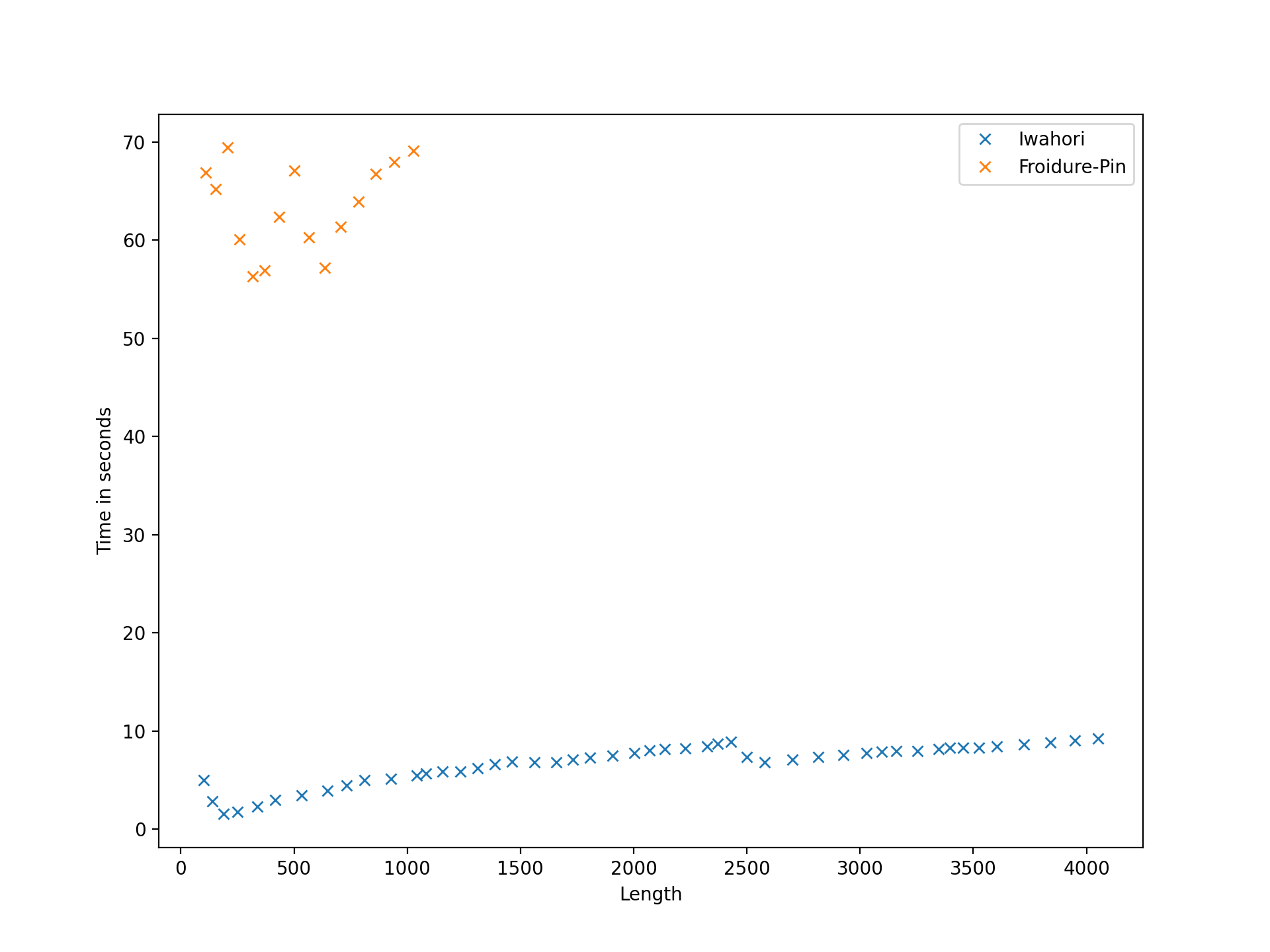
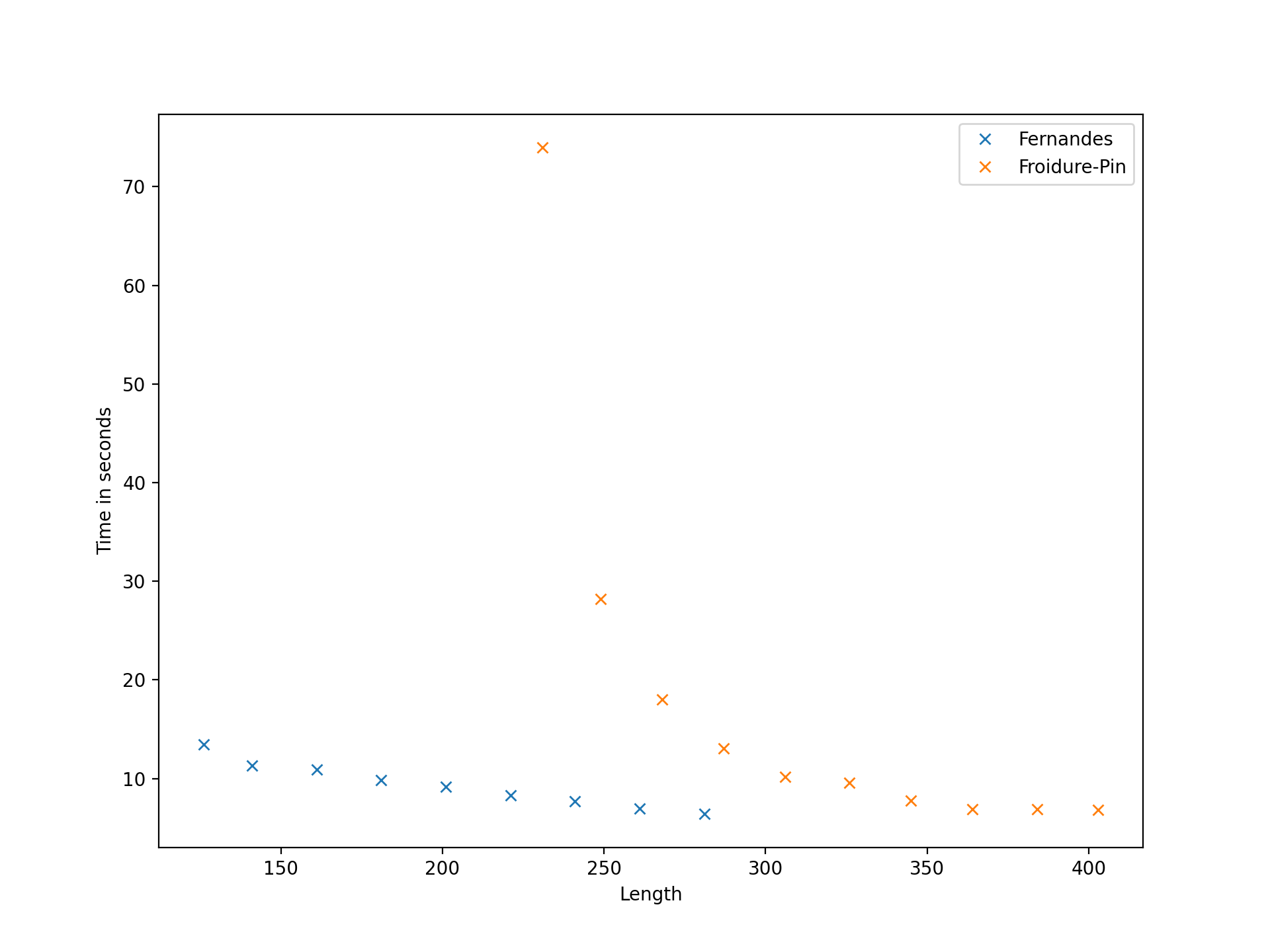
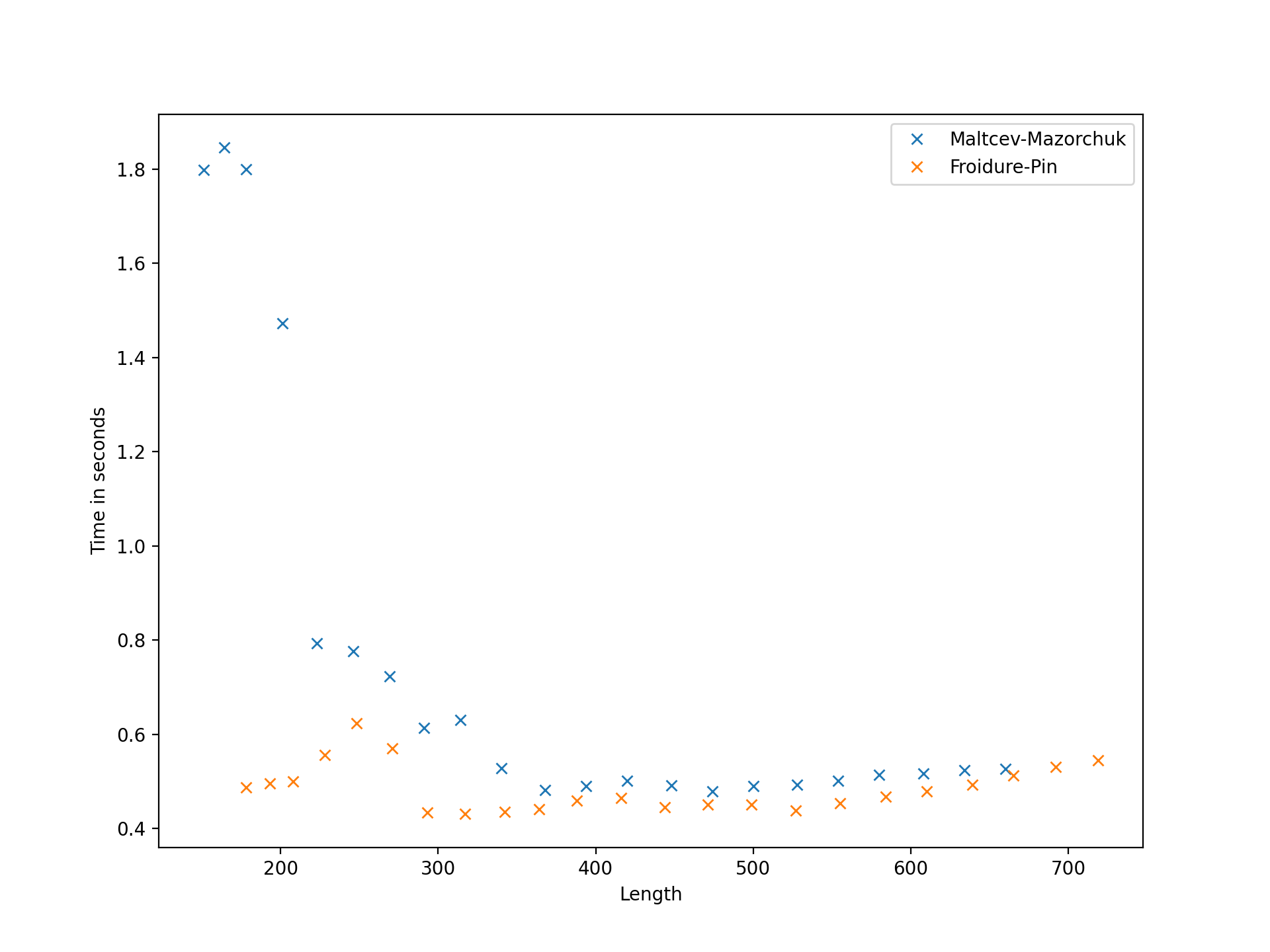
The outcome is mixed: in all of these examples the “human” presentations provide better performance than their “non-human” counterparts; for shorter means faster up to a point; for the first presentation for shorter means slower; for the second presentation for shorter means faster. There is only a single value for the computer generated presentation for with the second generating set because it was not straightforward to find redundant relations in this presentation. It might be worth noting that although the length of this presentation is , the time taken is still considerably less than the fastest time using the first presentation.
A.3 1-sided congruences on finite monoids
In this section we present some data about the relative performance of the implementation of low-index congruences algorithm, Algorithm 7, and [25] in libsemigroups [53], Semigroups [54], and CREAM [58], respectively; see Tables B.1, A.1, A.2, A.3, and A.4.
Again, the outcome is somewhat mixed. Generally in the examples presented in this section, the low-index congruence algorithm as implemented in libsemigroups [53] is fastest for finding all right congruences, followed by CREAM [58] for the small examples, and Algorithm 7 from Semigroups [54] for larger values. For finding only principal congruences, again CREAM [58] is faster for smaller examples, and Semigroups [54] is faster for larger examples.
Given that CREAM [58] is tool for arbitrary finite algebras of type (i.e. with a finite number of binary and unary operations), it might be expected that specialised algorithms (such as those in this article) for semigroups and monoids would always perform better. There are two possible reasons for this. Firstly, as mentioned above, for some examples, the number of pairs output by Algorithm 7 is more or less the same as the maximum possible number; see Fig. A.3(a), Fig. A.4(a) and Fig. A.5(a). As such running Algorithm 7 prior to finding principal congruences, and then computing the joins, can increase the overall runtime. Secondly, the implementation in CREAM [58] is written almost entirely in C, and the main loop of the corresponding implementation in Semigroups [54] is written in the interpreted GAP [29] language. Specifically, the main loops in the implementation of Algorithm 7 in Semigroups [54], and the code for determining the set of principal congruences are written in GAP [29]. The code for forming all joins in Semigroups [54] is written in C++. Interpreted languages typically incur a performance penalty when compared to compiled languages.
| low-index | Algorithm 7 | Algorithm 7 + joins | ||||
| mean | s.d. | mean | s.d. | mean | s.d. | |
| 1 | ||||||
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| 5 | Exceeded available memory | |||||
| 6 | Exceeded available time | Exceeded available memory | ||||
| 7 | Exceeded available time | Exceeded available memory | ||||
| principal | all | |||
| mean | s.d. | mean | s.d. | |
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | Exceeded available memory | |||
| 6 | Seg. fault | Seg. fault | ||
| 7 | Seg. fault | Seg. fault | ||
| low-index | Algorithm 7 | Algorithm 7 + joins | ||||
| mean | s.d. | mean | s.d. | mean | s.d. | |
| 1 | ||||||
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | Exceeded available time | Exceeded available memory | ||||
| 7 | Exceeded available time | - | Exceeded available memory | |||
| principal | all | |||
| mean | s.d. | mean | s.d. | |
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 | Exceeded available memory | |||
| 7 | Seg. fault | Seg. fault | ||
A.4 Low index subgroups
In this section, we compare the performance of: the implementation of the low-index congruences algorithm in libsemigroups [53]; the function LowIndexSubgroups in GAP [29]; the function permutation_reps from the C++ library 3Manifolds [15]; see Table A.5. The authors thank Derek Holt for suggesting the examples in this section. It is important to note that the implementation in libsemigroups [53] has no optimizations for groups, and that the inputs to libsemigroups [53] are monoid presentations; while the input to [15] and GAP [29] are group presentations. For details of the particular presentations used please see https://github.com/libsemigroups/libsemigroups/tree/main/benchmarks/sims.
| group | index | subgroups | 3manifolds [15] | GAP [29] | libsemigroups [53] |
| -triangle | |||||
| 4-generated braid group | |||||
| modular group | |||||
| fundamental group of K11n34 | |||||
| Heineken | |||||
| fundamental group of K15n12345 | |||||
| fundamental group of o9 |
A.5 2-sided congruences of finite monoids
In this section we present a comparison of the performance of computing the distinct 2-sided principal congruences of a selection of finite monoids. We compare several different versions of Semigroups [54] for GAP [29] that contain different optimisations. Semigroups [54] v3.4.1 contains none of the optimisations from the present paper, v4.0.2 uses Algorithm 7 where possible, and v5.3.0 uses Algorithm 7 and some further improvements to the code for finding distinct principal congruences. All computations in this section are single-threaded. We would have liked to include a comparison with CREAM [58] also, but unfortunately CREAM [58] suffers a segmentation fault (i.e. abnormal termination of the entire GAP [29] programme) on almost every input with more than approximately elements. This could have been circumvented, but due to time limitations, it was not. See Fig. A.3, Fig. A.4, Fig. A.5, and Table A.6.
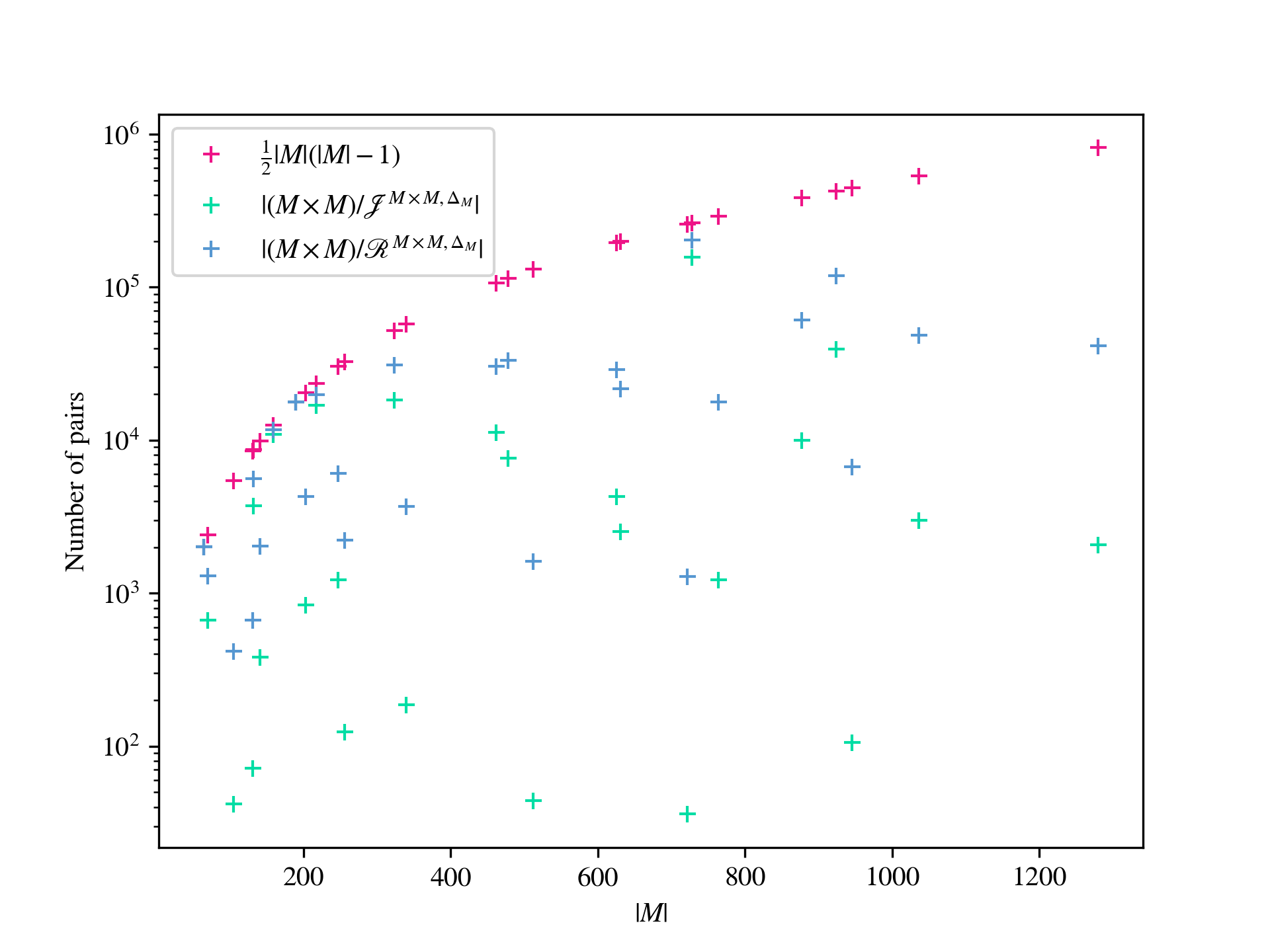
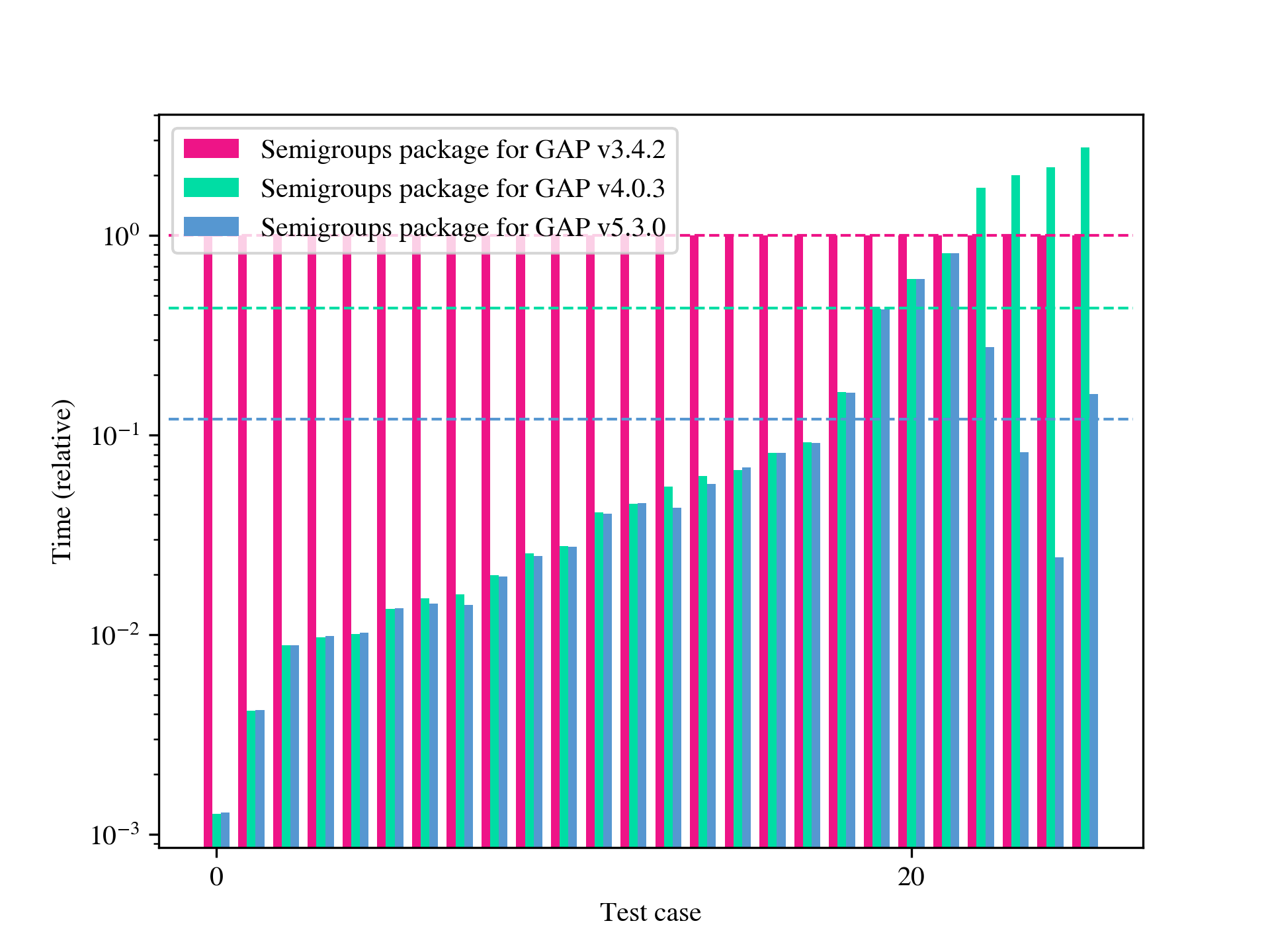
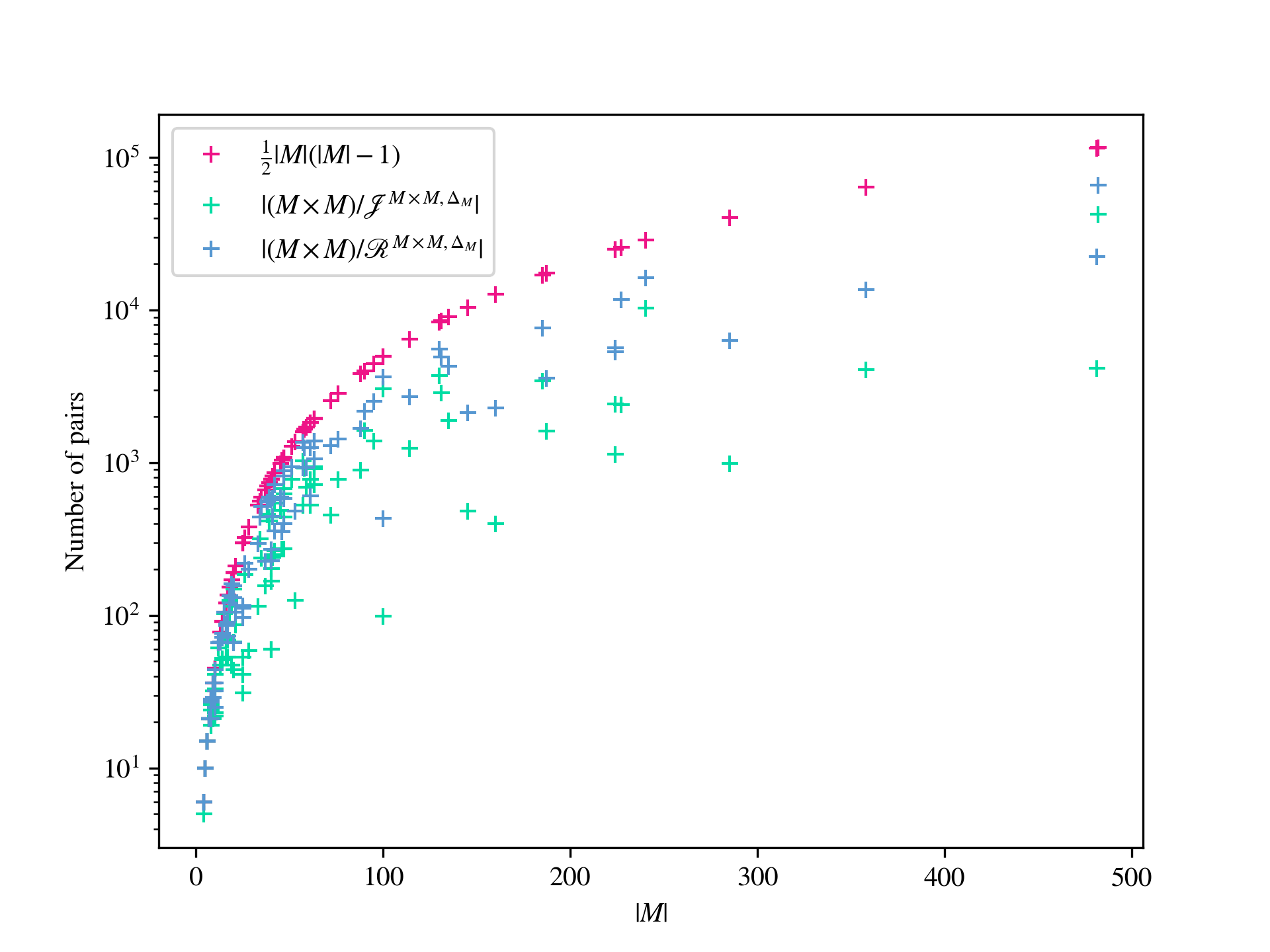
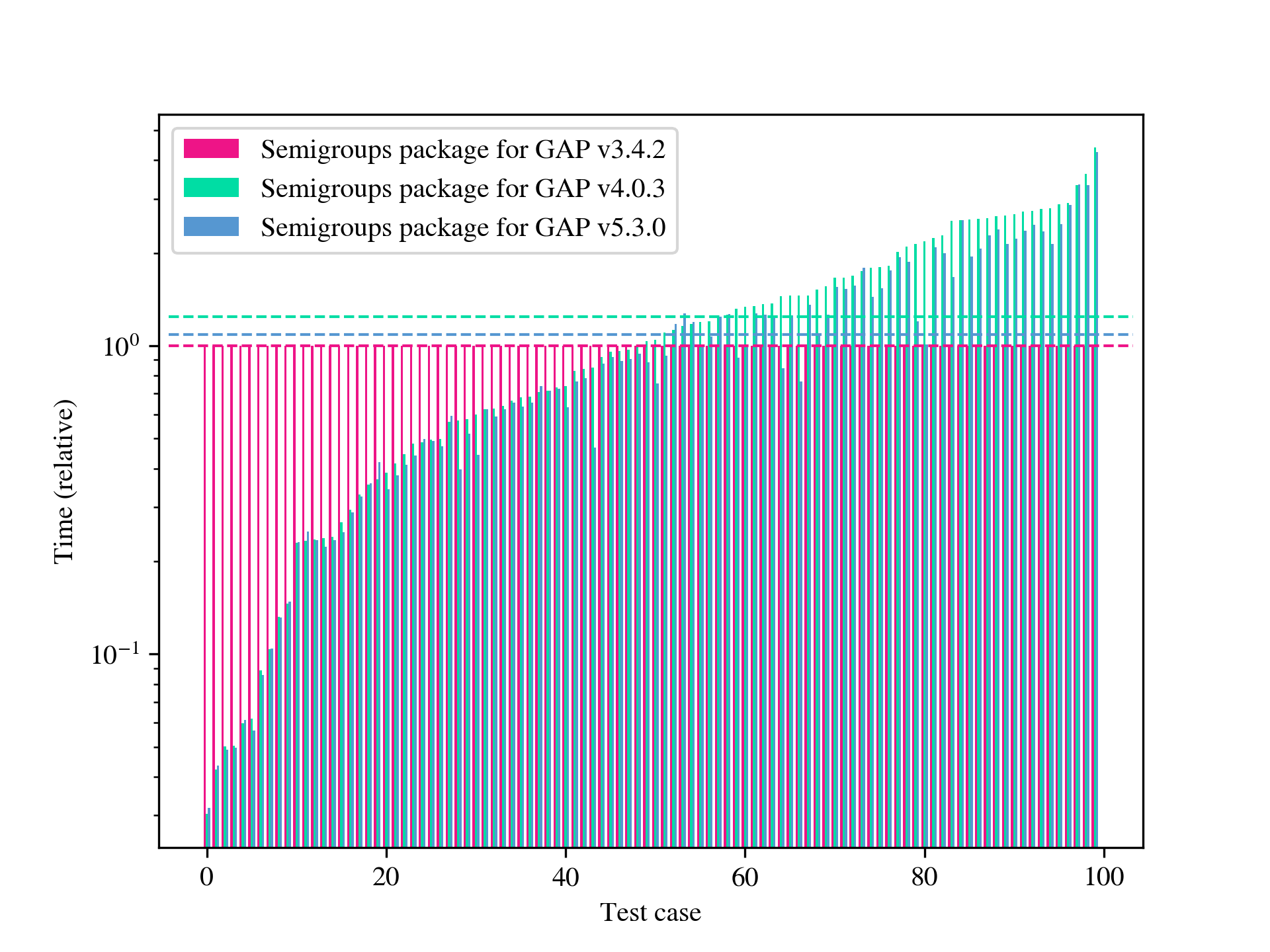
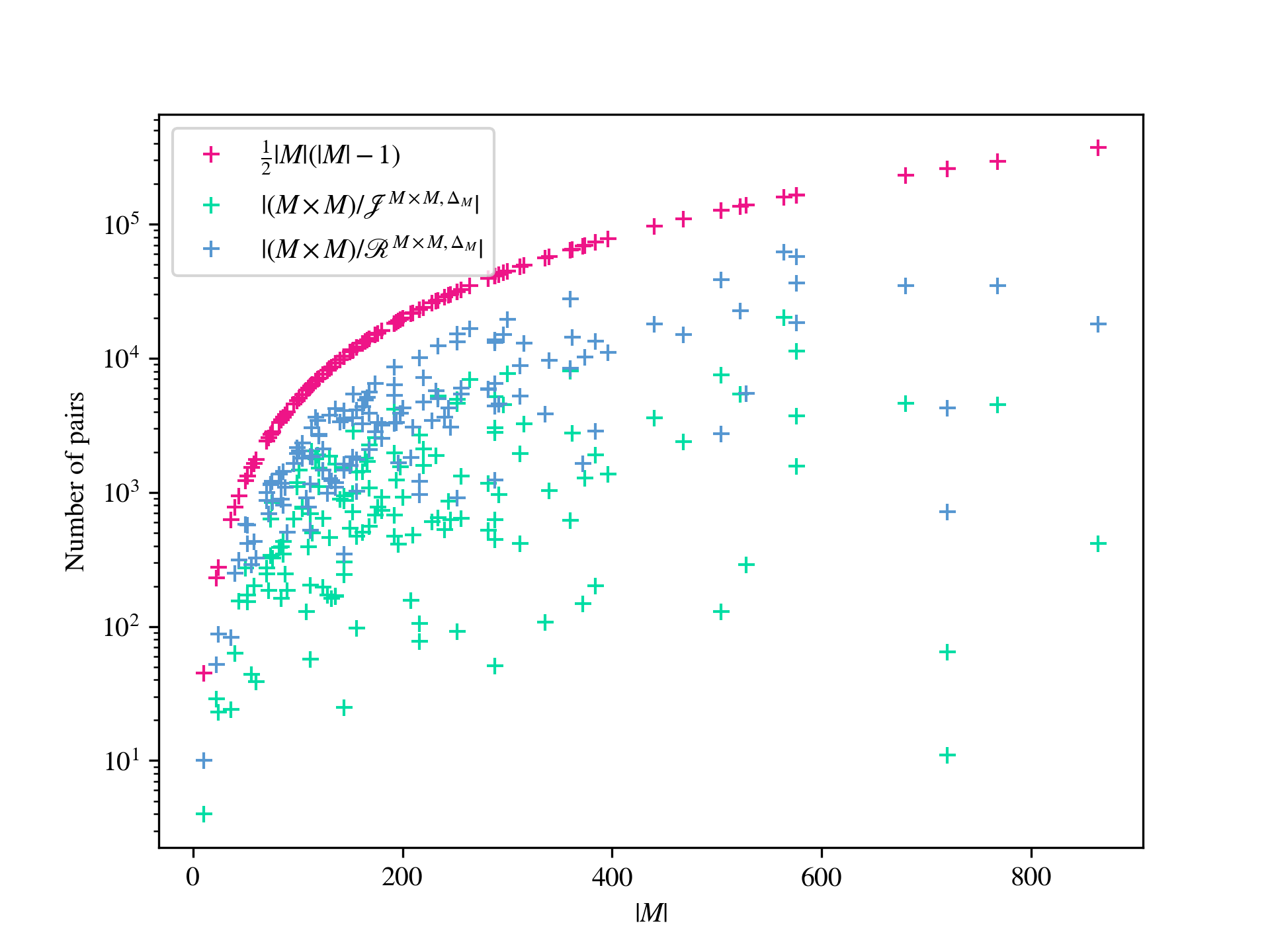
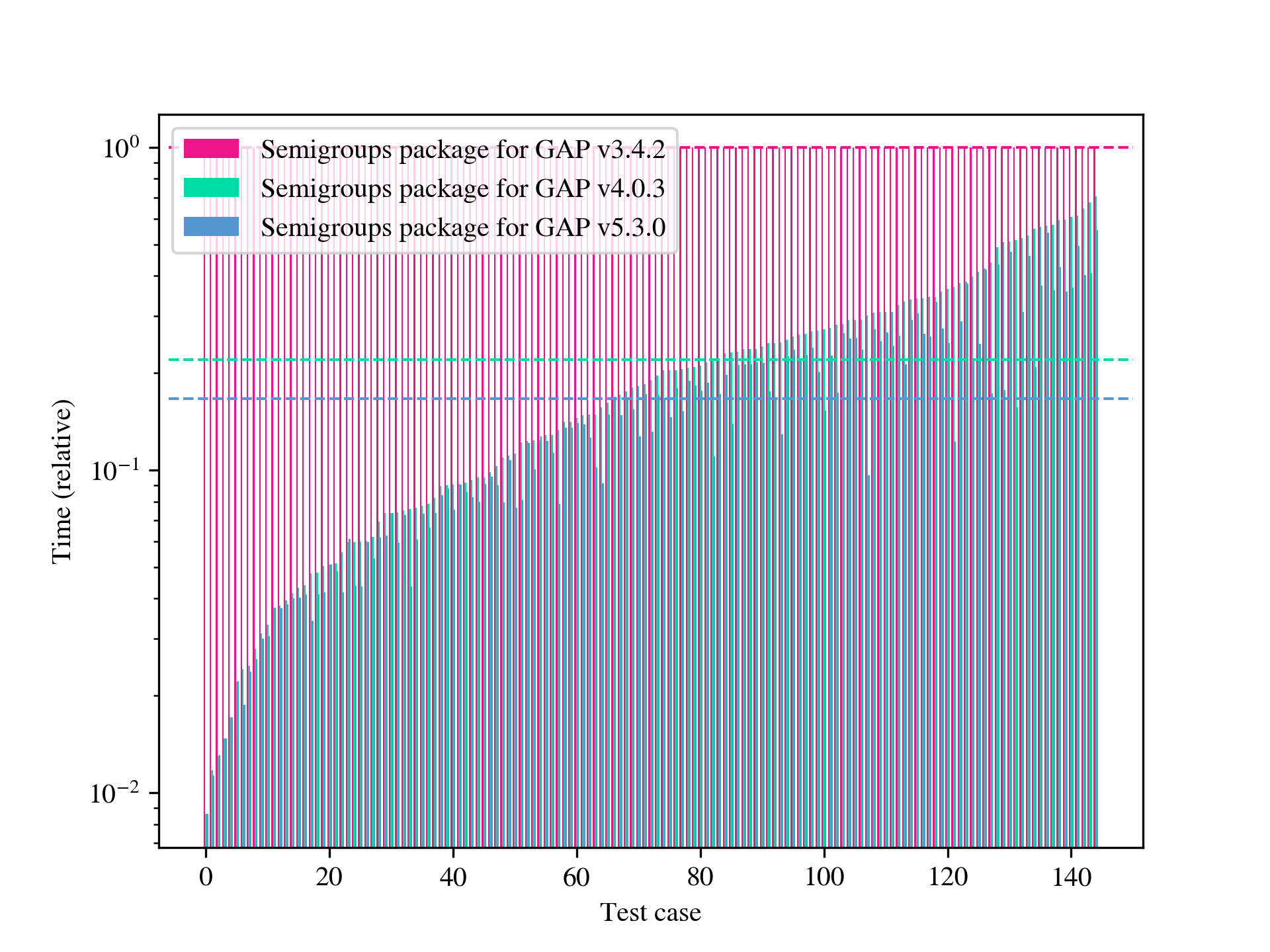
| Monoid = | CREAM [58] | Semigroups [54] | libsemigroups [53] | ||||||
|---|---|---|---|---|---|---|---|---|---|
| mean | s.d. | mean | s.d. | mean | s.d. | ||||
| Gossip | |||||||||
| Jones | |||||||||
| Brauer | |||||||||
| Partition | |||||||||
| Full PBR | |||||||||
| Symmetric group | |||||||||
| Full transformation | |||||||||
| Symmetric inverse | |||||||||
| Jones | |||||||||
| Motzkin | |||||||||
| Partial transformation | |||||||||
| Partial brauer | |||||||||
| Brauer | |||||||||
| Symmetric group | |||||||||
| Jones | |||||||||
| Partition | |||||||||
| Symmetric inverse | |||||||||
| Full transformation | |||||||||
| Motzkin | |||||||||
| Jones | |||||||||
Appendix B Congruence statistics
In this appendix we provide the numbers of finite index congruences of some well-known finite and infinite finitely presented monoids in a number of tables. By searching for these numbers in the [57] and in the literature, it appears that many of them were not previously known.
| principal | minimal | all | ||
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 1 |
| 2 | 2 | 1 | 0 | 2 |
| 3 | 5 | 8 | 3 | 11 |
| 4 | 14 | 67 | 6 | 575 |
| 5 | 42 | 641 | 10 | 5,295,135 |
| 6 | 132 | 6,790 | 15 | ? |
| 7 | 429 | 76,568 | 21 | ? |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| ? | ? | ? | ||
| A000108 | OEIS | OEIS | OEIS |
| principal | minimal | all | ||
|---|---|---|---|---|
| 1 | 2 | 1 | 1 | 2 |
| 2 | 7 | 8 | 3 | 10 |
| 3 | 34 | 59 | 6 | 274 |
| 4 | 209 | 516 | 10 | 195,709 |
| 5 | 1,546 | 5,667 | 15 | ? |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| ? | ? | ? | ||
| A002720 | OEIS | OEIS | OEIS |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 7 | 15 | 31 | 63 | 127 | 255 | 511 | 1023 | 2047 | 4095 | 8191 |
| 3 | 27 | 102 | 351 | 1146 | 3627 | 11262 | 34511 | 105186 | 318627 | 962022 | 2898351 |
| 4 | 94 | 616 | 3346 | 16360 | 75034 | 330256 | 1414066 | 5940760 | 24627274 | 101123296 | 412378786 |
| 5 | 275 | 3126 | 26483 | 189420 | 1220045 | 7335126 | 42061343 | 233221440 | 1261948865 | 6705793626 | 35151482003 |
| 6 | 833 | 16914 | 222425 | 2289148 | 20263055 | 162391586 | 1214730797 | 8646767880 | 59332761467 | 396002654398 | |
| 7 | 2307 | 91072 | 1927625 | 28829987 | 349842816 | 3703956326 | 35686022019 | 321211486801 | |||
| 8 | 6488 | 491767 | 36892600 | 995133667 | 17898782992 | 257691084789 | 3222193441904 | ||||
| 9 | 18207 | 2583262 | 955309568 | 457189474269 | |||||||
| 10 | 52960 | 14222001 | 12834025602 | ||||||||
| 11 | 156100 | 87797807 | |||||||||
| 12 | 462271 | 676179934 | |||||||||
| 13 | 1387117 | 7373636081 | |||||||||
| 14 | 4330708 | 120976491573 | |||||||||
| 15 | 14361633 | ||||||||||
| 16 | 51895901 | ||||||||||
| 17 | 209067418 | ||||||||||
| 18 | 955165194 | ||||||||||
| 19 | 4777286691 | ||||||||||
| 20 | 24434867465 | ||||||||||
| 21 | 114830826032 | ||||||||||
| 22 | 499062448513 |
| index | index | index | index | index | index | index | |
|---|---|---|---|---|---|---|---|
| 3 | 29 | 484 | 6,896 | 103,204 | 1,773,360 | 35,874,182 | 849,953,461 |
| 4 | 67 | 2,794 | 106,264 | 4,795,980 | 278,253,841 | 20,855,970,290 | - |
| 5 | 145 | 14,851 | 1,496,113 | 198,996,912 | 37,585,675,984 | - | - |
| 6 | 303 | 77,409 | 20,526,128 | 7,778,840,717 | - | - | - |
| 7 | 621 | 408,024 | 281,600,130 | - | - | - | - |
| 8 | 1,259 | 2,201,564 | - | - | - | - | - |
| ? | ? | ? | ? | ? | ? |