Computing one-bit compressive sensing via zero-norm regularized DC loss model and its surrogate
Abstract
One-bit compressed sensing is very popular in signal processing and communications due to its low storage costs and low hardware complexity, but it is a challenging task to recover the signal by using the one-bit information. In this paper, we propose a zero-norm regularized smooth difference of convexity (DC) loss model and derive a family of equivalent nonconvex surrogates covering the MCP and SCAD surrogates as special cases. Compared to the existing models, the new model and its SCAD surrogate have better robustness. To compute their -stationary points, we develop a proximal gradient algorithm with extrapolation and establish the convergence of the whole iterate sequence. Also, the convergence is proved to have a linear rate under a mild condition by studying the KL property of exponent of the models. Numerical comparisons with several state-of-art methods show that in terms of the quality of solution, the proposed model and its SCAD surrogate are remarkably superior to the -norm regularized models, and are comparable even superior to those sparsity constrained models with the true sparsity and the sign flip ratio as inputs.
Keywords: One-bit compressive sensing, zero-norm, DC loss, equivalent surrogates, global convergence, KL property
1 Introduction
Compressive sensing (CS) has gained significant progress in theory and algorithms over the past few decades since the seminal works [10, 13]. It aims to recover a sparse signal from a small number of linear measurements. One-bit compressive sensing, as a variant of the CS, was proposed in [6] and had attracted considerable interests in the past few years (see, e.g., [12, 23, 30, 46, 51, 21]). Unlike the conventional CS which relies on real-valued measurements, one-bit CS aims to reconstruct the sparse signal from the sign of measurement. Such a new setup is appealing because (i) the hardware implementation of one-bit quantizer is low-cost and efficient; (ii) one-bit measurement is robust to nonlinear distortions [8]; and (iii) in certain situations, for example, when the signal-to-noise ratio is low, one-bit CS performs even better than the conventional one [25]. For the applications of one-bit CS, we refer to the recent survey paper [26].
1.1 Review on the related works
In the noiseless setup, the one-bit CS acquires the measurements via the linear model , where is the measurement matrix and the function is applied to in a component-wise way. Here, for any , if and otherwise, which has a little difference from the common . By following the theory of conventional CS, the ideal optimization model for one-bit CS is as follows:
| (1) |
where denotes the zero-norm (i.e., the number of nonzero entries) of , and means the Euclidean norm of . The unit sphere constraint is introduced into (1) to address the issue that the scale information of a signal is lost during the one-bit quantization. Due to the combinatorial properties of the functions and , the problem (1) is NP-hard. Some earlier works (see, e.g., [6, 30, 43]) mainly focus on its convex relaxation model, obtained by replacing the zero-norm by the -norm and relaxing the consistency constraint into the linear constraint , where the notation “” means the Hadamard operation of vectors.
In practice the measurement is often contaminated by noise before the quantization and some signs will be flipped after quantization due to quantization distoration, i.e.,
| (2) |
where is a random binary vector and denotes the noise vector. Let be a loss function to ensure data fidelity as well as to tolerate the existence of sign flips. Then, it is natural to consider the zero-norm regularized loss model:
| (3) |
and achieve a desirable estimation for the true signal by tuning the parameter . Consider that the projection mapping onto the intersection of the sparsity constraint set and the unit sphere has a closed norm. Some researchers prefer the following model or a similar variant to achieve a desirable estimation for (see, e.g., [7, 46, 12, 52]):
| (4) |
where the positive integer is an estimation for the sparsity of . For this model, if there is a big difference between the estimation from the true sparsity , the mean-squared-error (MSE) of the associated solutions will become worse. Take the model in [52] for example. If the difference between the estimation from the true sparsity is , the MSE of the associated solutions will have a difference at least (see Figure 1). Moreover, now it is unclear how to achieve such a tight estimation for . We find that the numerical experiments for the zero-norm constrained model all use the true sparsity as an input (see [46, 52]). In this work, we are interested in the regularization models.

The existing loss functions for the one-bit CS are mostly convex, including the one-sided loss [23, 46], the linear loss [31, 51], the one-sided loss [23, 46, 33], the pinball loss [21] and the logistic loss [16]. Among others, the one-sided loss is closely related to the hinge loss function in machine learning [11, 50], which was reported to have a superior performance to the one-sided loss (see [23]), and the pinball loss provides a bridge between the hinge loss and the linear loss. One can observe that these convex loss functions all impose a large penalty on the flipped samples, which inevitably imposes a negative effect on the solution quality of the model (3). In fact, for the pinball loss in [21], when the involved parameter is closer to , the penalty degree on the flipped samples becomes smaller. This partly accounts for instead of used for numerical experiments there. Recently, Dai et al. [12] derived a one-sided zero-norm loss by maximizing a posteriori estimation of the true signal. This loss function and its lower semicontinuous (lsc) majorization proposed there impose a constant penalty for those flipped samples, but their combinatorial property brings much difficulty to the solution of the associated optimization models. Inspired by the superiority of the ramp loss in SVM [9, 22], in this work we are interested in a more general DC loss:
| (5) |
where is a constant representing the penalty degree imposed on the flip outlier. Clearly, the DC function imposes a small fixed penalty for those flip outliers.
Due to the nonconvexity of the zero-norm and the sphere constraint, some researchers are interested in the convex relaxation of (3) obtained by replacing the zero-norm by the -norm and the unit sphere constraint by the unit ball constraint; see [51, 21, 24, 31]. However, as in the conventional CS, the -norm convex relaxation not only has a weak sparsity-promoting ability but also leads to a biased solution; see the discussion in [14]. Motivated by this, many researchers resort to the nonconvex surrogate functions of the zero-norm, such as the minimax concave penalty (MCP) [53, 20], the sorted penalty [20], the logarithmic smoothing functions [40], the -norm [15], and the Schur-concave functions [32], and then develop algorithms for solving the associated nonconvex surrogate problems to achieve a better sparse solution. To the best of our knowledge, most of these algorithms are lack of convergence certificate. Although many nonconvex surrogates of the zero-norm are used for the one-bit CS, there is no work to investigate the equivalence between the surrogate problems and the model (3) in a global sense.
1.2 Main contributions
The nonsmooth DC loss is desirable to ensure data fidelity and tolerate the existence of sign flips, but its nonsmoothness is inconvenient for the solution of the associated regularization model (3). With we construct a smooth approximation to it:
| (6) |
Clearly, as the parameter approaches to , is closer to . As illustrated in Figure 2, the smooth function approximates very well even with . Therefore, in this paper we are interested in the zero-norm regularized smooth DC loss model
| (7) |
where denotes a unit sphere whose dimension is known from the context, and means the indicator function of , i.e., if and otherwise .

Let denote the family of proper lsc convex functions satisfying
| (8) |
With an arbitrary , the model (7) is reformulated as a mathematical program with an equilibrium constraint (MPEC) in Section 3, and by studying its global exact penalty induced by the equilibrium constraint, we derive a family of equivalent surrogates
| (9) |
in the sense that the problem (9) associated to every has the same global optimal solution set as the problem (7) does. Here with being the penalty parameter and being the conjugate function of :
This family of equivalent surrogates is illustrated to include the one associated to the MCP function (see [49, 53, 20]) and the SCAD function [14]. The SCAD function corresponds to for , whose conjugate has the form
| (10) |
Figure 3 below shows that with in (10) approximates every well for , though the model (9) has the same global optimal solution set as the model (7) does only when is over the theoretical threshold . Unless otherwise stated, the function appearing in the rest of this paper always represents the one associated to in (10).

For the nonconvex nonsmooth optimization problems (7) and (9), we develop a proximal gradient (PG) method with extrapolation to solve them, establish the convergence of the whole iterate sequence generated, and analyze its local linear convergence rate under a mild condition. The main contributions of this paper can be summarized as follows:
-
(i)
We introduce a smooth DC loss function well suited for the data with a high sign flip ratio, and propose the zero-norm regularized smooth DC loss model (7) which, unlike those models in [7, 12, 46, 52], does not require any priori information on the sparsity of the true signal and the number of sign flips. In particular, a family of equivalent nonconvex surrogates is derived for the model (7). We also introduce a class of -stationary points for the model (7) and its equivalent surrogate (9) associated to in (10), which is stronger than the limiting critical points of the corresponding objective functions.
-
(ii)
By characterizing the closed form of the proximal operators of and , we develop a proximal gradient (PG) algorithm with extrapolation for solving the problem (7) (PGe-znorm) and its surrogate (9) associated to in (10) (PGe-scad) and establish the convergence of the whole iterate sequences. Also, by analyzing the KL property of exponent of and , the convergence is shown to have a linear rate under a mild condition. It is worth pointing out that to verify if a nonconvex and nonsmooth function has the KL property of exponent not more than is not an easy task because there is lack of a criterion for it.
-
(iii)
Numerical experiments indicate that the proposed models armed with the PGe-znorm and PGe-scad are robust to a large range of , and numerical comparisons with several state-of-art methods demonstrate that the proposed models are well suited for high noise and/or high sign flip ratio. The obtained solutions are remarkably superior to those yielded by other regularization models, and for the data with a high flip ratio they are also superior to those yielded by the models with the true sparsity as an input, in terms of MSE and Hamming error.
2 Notation and preliminaries
Throughout this paper, denotes the extended real number set , and denote an identity matrix and a vector of all ones, whose dimensions are known from the context; and denotes the orthonormal basis of . For a integer , write . For a vector , denotes the smallest nonzero entry of the vector , means the vector of the entries of arranged in a nonincreasing order, and means the vector . For given index sets and , denotes the submatrix of consisting of those rows with , and denotes the submatrix of consisting of those columns with . For a proper , denotes its effective domain, and for any given , represents the set . For any and any , write and define
| (11) | |||
| (12) |
For a proper lsc , the proximal mapping of associated to is defined as
When is convex, is a Lipschitz continuous mapping with modulus . When is an indicator function of a closed set , is the projection mapping onto .
2.1 Proximal mappings of and
To characterize the proximal mapping of the nonconvex nonsmooth function , we need the following lemma, whose proof is not included due to the simplicity.
Lemma 2.1
Fix any and an integer . Consider the following problem
| (13) |
Then, , where is an signed permutation matrix such that .
Proposition 2.1
Fix any and . For any , by letting be an signed permutation matrix such that , it holds that with
| (14) |
For any with , by letting with , if ; if ; otherwise .
Proof: By the definition of , for any , . Since for any signed permutation matrix and any , and , it is easy to verify that . The first part of the conclusions then follows. For the second part, we first argue that the following inequality relations hold:
| (15) |
Indeed, for each , from the definition of , it is immediate to have
Along with , we get and the relations in (15) hold. Let denote the optimal value of (14). Then with
| (16) |
From Lemma 2.1, it follows that . Then,
When , we have for all . From the last equation, for , which means that Hence, , and follows by Lemma 2.1. Using the similar arguments, we can obtain the rest of the conclusions.
To characterize the proximal mapping of the nonconvex nonsmooth function , we need the following lemma, whose proof is omitted due to the simplicity.
Lemma 2.2
Let . For any , by letting be an permutation matrix such that , it holds that . Also, for any with , if ; if , otherwise .
Proposition 2.2
Fix any and . For any , by letting be an signed permutation matrix with , .
Proof: Fix any with . Consider the following problem
| (17) |
where is a regularization parameter. By the definition of , , so it suffices to argue that . Indeed, if is a global optimal solution of (17), then necessarily holds. If not, we will have . Let . Take for each and for each . Clearly, and . However, it holds that , which contradicts the fact that is a global optimal solution of (17). This implies that Consequently, . The desired equality then follows.
2.2 Generalized subdifferentials
Definition 2.1
(see [36, Definition 8.3]) Consider a function and a point . The regular subdifferential of at , denoted by , is defined as
and the (limiting) subdifferential of at , denoted by , is defined as
Remark 2.1
(i) At each , , is always closed and convex, and is closed but generally nonconvex. When is convex, , which is precisely the subdifferential of at in the sense of convex analysis.
(ii) Let be a sequence in the graph of that converges to as . By invoking Definition 2.1, if as , then .
(iii) A point at which () is called a limiting (regular) critical point of . In the sequel, we denote by the limiting critical point set of .
When is an indicator function of a closed set , the subdifferential of at is the normal cone to at , denoted by . The following lemma characterizes the (regular) subdifferentials of and at any point of their domains.
Lemma 2.3
Fix any and . Consider any . Then,
-
(i)
is a smooth function whose gradient is Lipschitz continuous with the modulus .
-
(ii)
.
-
(iii)
.
-
(iv)
When , it holds that .
Proof: (i) The result is immediate by the definition of and the expression of .
(ii) From [42, Lemma 3.1-3.2 & 3.4], . Together with part (i) and [36, Exercise 8.8], we obtain the desired result.
(iii) By the convexity and Lipschitz continuity of -norm and [36, Exercise 10.10], it follows that . Let for . Clearly, . By the expression of in (10), it is easy to verify that is smooth and is Lipschitz continuous with modulus . Hence, is a smooth function whose gradient is Lipschitz continuous. Together with [36, Exercise 8.8] and , we obtain the desired equalities.
(iv) Let be the function defined as above. After an elementary calculation, we have
Along with and the expression of in (10), we have and . By part (iii), . Comparing in part (iii) with in part (ii) yields that .
2.3 Stationary points
Lemma 2.3 shows that for the functions and the set of their regular critical points coincides with that of their limiting critical points, so we call the critical point of a stationary point of (7), and the critical point of a stationary point of (9). Motivated by the work [4], we introduce a class of -stationary points for them.
Definition 2.2
In the sequel, we denote by and the -stationary point set of (7) and (9), respectively. By Proposition 2.1 and 2.2, we have the following result for them.
Lemma 2.4
Fix any and . Then, and .
Proof: Pick any . Then . By Proposition 2.1, for each , for some (depending on ). Then, for each , it holds that . Recall that
| (18) |
We have , and hence by Lemma 2.3 (ii).
Pick any . Write . Then, we have . Let and . For each , . Since the subdifferential of the function at is , it holds that
By Proposition 2.2, we have Together with ,
By the expression of in (18), from the last two equations it follows that
By Lemma 2.3 (iii), this shows that . The proof is completed.
Note that if is a stationary point of (7), then for , does not necessarily equal . A similar case also occurs for the stationary point of (9). This means that the two inclusions in Lemma 2.4 are generally strict. By combining Lemma 2.4 with [36, Theorem 10.1], it is immediate to obtain the following conclusion.
2.4 Kurdyka-Łöjasiewicz property
Definition 2.3
(see [2]) A proper lsc function is said to have the KL property at if there exist , a neighborhood of , and a continuous concave function that is continuously differentiable on with for all and , such that for all ,
If can be chosen as with for some , then is said to have the KL property of exponent at . If has the KL property (of exponent ) at each point of , then it is called a KL function (of exponent ).
Remark 2.2
(a) As discussed thoroughly in [2, Section 4], there are a large number of nonconvex nonsmooth functions are the KL functions, which include real semi-algebraic functions and those functions definable in an o-minimal structure.
(b) From [2, Lemma 2.1], a proper lsc function has the KL property of exponent at any noncritical point. Thus, to prove that a proper lsc is a KL function (of exponent ), it suffices to achieve its KL property (of exponent ) at critical points. On the calculation of KL exponent, please refer to the recent works [34, 48].
3 Equivalent surrogates of the model (7)
Pick any . By invoking equation (8), it is immediate to verify that for any ,
This means that the zero-norm regularized problem (7) can be reformulated as
| (19) |
in the following sense: if is globally optimal to the problem (7), then is a global optimal solution of the problem (19), and conversely, if is a global optimal solution of (19), then is globally optimal to (7). The problem (19) is a mathematical program with an equilibrium constraint . In this section, we shall show that the penalty problem induced by this equilibrium constraint, i.e.,
| (20) |
is a global exact penalty of (19) and from this global exact penalty achieve the equivalent surrogate in (9), where is the penalty parameter. For each , write
To get the conclusion of this section, we need the following global error bound result.
Lemma 3.1
For each , there exists such that for all ,
where denotes the sum of the first largest entries of the vector .
Proof: Fix any . We first argue that the following multifunction
is calm at for every . Pick any . By [39, Theorem 3.1], the calmness of at for is equivalent to the existence of and such that
| (21) |
Since , there exists such that for all , . Fix any . Clearly, . This means that . Pick any . Clearly, and . Then, with ,
This shows that the inequality (21) holds for and . Consequently, the mapping is calm at for every . Now by invoking [39, Theorem 3.3] and the compactness of , we obtain the desired result. The proof is completed.
Proposition 3.1
Let where is such that , is the left derivative of at , is the Lipschitz constant of on , and with given by Lemma 3.1. Then, for any ,
| (22) |
where is an arbitrary global optimal solution of (19), and consequently the problem (20) associated to each has the same global optimal solution set as (19) does.
Proof: By Lemma 3.1 and , for each and any ,
| (23) |
Fix any . Let and . By invoking (23) for with , there exists such that
| (24) |
Let and . Note that
By invoking [35, Lemma 1] with for each , it immediately follows that
Notice that . From the last inequality, we have
| (25) |
where the last inequality is due to (24) and the definition of . Since and , we have . Together with the last inequality,
| (26) |
Now take for and for . Clearly, is a feasible point of the MPEC (19) with . Then, it holds that
Together with (26), we obtain the inequality (22). Notice that . The inequality (22) implies that every global optimal solution of (19) is globally optimal to the problem (20) associated to every . Conversely, by fixing any and letting be a global optimal solution of the problem (20) associated to , it holds that
which implies that . Since and , we obtain . Together with the last inequality, it follows that is a global optimal solution of (19). The second part then follows.
By the definition of , the penalty problem (20) can be rewritten in a compact form
which, by the definition of the conjugate function , can be simplified to be (9). Then, Proposition 3.1 implies that the problem (9) associated to every and is an equivalent surrogate of the problem (7). For a specific , since and are known, the threshold is also known by Lemma 3.1 though is a rough estimate.
When is the one in Section 1.2, it is easy to verify that with and is exactly the SCAD function proposed in [14]. Since and for this , the SCAD function with is an equivalent surrogate of (7). When for ,
It is not hard to verify that the function with and is exactly the one with used in [20, Section 3.3]. Since and for this , the MCP function used in [20] with and is also an equivalent surrogate of the problem (7).
4 PG method with extrapolation
4.1 PG with extrapolation for solving (7)
Recall that is a smooth function whose gradient is Lipschitz continuous with modulus . While by Proposition 2.1 the proximal mapping of has a closed form. This inspires us to apply the PG method with extrapolation to solving (7).
Initialization: Choose and an initial point . Set and .
while the termination condition is not satisfied do
-
1.
Let . Compute .
-
3.
Choose . Let and go to Step 1.
end (while)
Remark 4.1
The main computation work of Algorithm 1 in each iteration is to seek
| (27) |
By Proposition 2.1, to achieve a global optimal solution of the nonconvex problem (27) requires about flops. Owing to the good performance of the Nesterov’s acceleration strategy [37, 38], one can use this strategy to choose the extrapolation parameter , i.e.,
| (28) |
In Algorithm 1, an upper bound is imposed on just for the convergence analysis. It is easy to check that as approaches to , say , can take .
The PG method with extrapolation, first proposed in [37] and extended to a general composite setting in [3], is a popular first-order one for solving nonconvex nonsmooth composite optimization problems such as (7) and (9). In the past several years, the PGe and its variants have received extensive attentions (see, e.g., [17, 27, 41, 29, 28, 45, 47]). Due to the nonconvexity of the sphere constraint and the zero-norm, the results obtained in [17, 41, 29] are not applicable to (7). Although Algorithm 1 is a special case of those studied in [27, 45, 47], the convergence results of [27, 47] are obtained for the objective value sequence and the convergence result of [45] on the iterate sequence requires a strong restriction on , i.e., it is such that the objective value sequence is nonincreasing.
Next we provide the proof for the convergence and local convergence rate of the iterate sequence yielded by Algorithm 1. For any and , we define the function
| (29) |
The following lemma summarizes the properties of on the sequence .
Lemma 4.1
Let be the sequence generated by Algorithm 1. Then,
-
(i)
for each ,
-
(ii)
The sequence is convergent and .
-
(iii)
For each , there exists with , where and are the constants independent of .
Proof: (i) Since is globally Lipschitz continuous, from the descent lemma we have
| (30) |
From the definition of or the equation (27), for each it holds that
Together with the inequality (30) for and , it follows that
Using and the Lipschitz continuity of yields that
where the second is due to with , and , and the last is due to . Combining the last inequality with the definition of , we obtain the result.
(ii) Note that is lower bounded by the lower boundedness of the function . The nonincreasing of the sequence in part (i) implies its convergence, and consequently, follows by using part (i) again.
(iii) From the definition of and [36, Exercise 8.8], for any ,
| (31) |
Fix any . By the optimality of to the nonconvex problem (27), it follows that
which is equivalent to Write
By comparing with (31), we have . From the Lipschitz continuity of and Step 1, . Since , the result holds with and .
Lemma 4.2
Let be the sequence generated by Algorithm 1 and denote by the set of accumulation points of . Then, the following assertions hold:
-
(i)
is a nonempty compact set and ;
-
(ii)
with ;
-
(iii)
the function is finite and keeps the constant on the set .
Proof: (i) Since , we have . Since can be viewed as an intersection of compact sets, i.e., , it is also compact. Now pick any . There exists a subsequence with as . Note that implied by Lemma 4.1 (ii). Then, and as . Recall that and . When , we have and then . In addition, since is proximally bounded with threshold , i.e., for any and , , from [36, Example 5.23] it follows that is outer semicontinuous. Thus, from for each , we have , and then . By the arbitrariness of , the first inclusion follows. The second inclusion is given by Lemma 2.4.
(ii)-(iii) The result of part (ii) is immediate, so it suffices to prove part (iii). By Lemma 4.1 (i), the sequence is convergent and denote its limit by . Pick any . There exists a subsequence with as . If , then the convergence of implies that , which by the arbitrariness of shows that the function is finite and keeps the constant on . Hence, it suffices to argue that . Recall that by Lemma 4.1 (ii). We only need argue that . From (27), it holds that
Together with the inequality (30) with and , we obtain that
which by implies that . In addition, by the lower semicontinuity of , . The two sides show that . The proof is then completed.
Since is a piecewise linear-quadratic function, it is semi-algebraic. Recall that the zero-norm is semi-algebraic. Hence, and are also semi-algebraic, and then the KL functions. By using Lemma 4.1-4.2 and following the arguments as those for [5, Theorem 1] and [1, Theorem 2] we can establish the following convergence results.
Theorem 4.1
Let be the sequence generated by Algorithm 1. Then,
-
(i)
and consequently converges to some .
-
(ii)
If is a KL function of exponent , then there exist and such that for all sufficiently large , .
Proof: (i) For each , write . Since is bounded, there exists a subsequence with as . By the proof of Lemma 4.2 (iii), with . If there exists such that , by Lemma 4.1 (i) we have for all and the result follows. Thus, it suffices to consider that for all . Since , for any there exists such that for all , . In addition, from Lemma 4.2 (ii), for any there exists such that for all , . Then, for all ,
By combining Lemma 4.2 (iii) and [5, Lemma 6], there exist , and a continuous concave function satisfying the conditions in Definition 2.3 such that for all and all ,
Consequently, for all , . By Lemma 4.1 (iii), there exists with . Then,
Together with the concavity of and Lemma 4.1 (i), it follows that for all ,
For each , let . For all ,
where the second inequality is due to for any . For any , summing the last inequality from to yields that
| (32) |
By passing the limit to the last inequality, we obtain the desired result.
(ii) Since is a KL function of exponent , by [34, Theorem 3.6] and the expression of , it follows that is also a KL function of exponent . From the arguments for part (i) with for and Lemma 4.1 (iii), for all it holds that
Consequently, . Together with the inequality (32), by letting , for any we have
For each , let . Passing the limit to this inequality, we obtain which means that for . The result follows by this recursion.
It is worthwhile to point out that by Lemma 4.1-4.2 and the proof of Lemma 4.2 (iii), applying [28, Theorem 10] directly can yield . Here, we include its proof just for the convergence rate analysis in Theorem 4.1 (ii). Notice that Theorem 4.1 (ii) requires the KL property of exponent of the function . The following lemma shows that indeed has such an important property under a mild condition.
Lemma 4.3
If any has , then is a KL function of exponent .
Proof: Write for . For any , by [36, Exercise 8.8],
| (33) |
Fix any with . Let , and . Since , we have . Moreover, from the continuity, there exists such that for all , and the following inequalities hold:
| (34) |
By the continuity of , there exists such that for all , . Set and pick any . Next we argue that
which by Definition 2.3 implies that is a KL function of exponent . Suppose on the contradiction that there exists . From , we have . Together with , we deduce that (if not, , which along with implies , a contradiction to ). Now from , equation (34), the expression of and , it follows that
| (35) |
Recall that and with and . Hence,
| (36) | |||
| (37) |
By comparing (33) with Lemma 2.3 (ii), we have . Since , we also have . Then, it holds that
| (38) |
Since , from the expression of we have
Together with the equations (36)-(4.1), it immediately follows that
Since , the last inequality implies that , which is a contradiction to the inequality (35). The proof is then completed.
Remark 4.2
By the definition of , when is small enough, it is highly possible for and then for to be a KL function of exponent .
4.2 PG with extrapolation for solving (9)
By the proof of Lemma 2.3, is a smooth function and is globally Lipschitz continuous with Lipschitz constant . While by Proposition 2.2, the proximal mapping of has a closed form. This motivates us to apply the PG method with extrapolation to solving the problem (9).
Initialization: Choose and an initial point . Set and .
while the termination condition is not satisfied do
-
1.
Let and compute .
-
3.
Choose . Let and go to Step 1.
end (while)
Similar to Algorithm 1, the extrapolation parameter in Algorithm 2 can be chosen in terms of the rule in (28). For any and , we define the potential function
| (39) |
Then, by following the same arguments as those for Lemma 4.1 and 4.2, we can establish the following properties of on the sequence generated by Algorithm 2.
Lemma 4.4
Let be the sequence generated by Algorithm 2 and denote by the set of accumulation points of . Then, the following assertions hold.
-
(i)
For each , Consequently, is convergent and .
-
(ii)
For each , there exists with , where and are the constants independent of .
-
(iii)
is a nonempty compact set and .
-
(iv)
, and is finite and keeps the constant on the set .
By using Lemma 4.4 and following the same arguments as those for Theorem 4.1, it is not difficult to achieve the following convergence results for Algorithm 2.
Theorem 4.2
Let be the sequence generated by Algorithm 2. Then,
-
(i)
and consequently converges to some .
-
(ii)
If is a KL function of exponent , then there exist and such that for all sufficiently large , .
Theorem 4.2 (ii) requires that is a KL function of exponent . We next show that it indeed holds under a little stronger condition than the one used in Lemma 4.3.
Lemma 4.5
If and are chosen with and all satisfy and , then is a KL function of exponent .
Proof: Fix any with and . Let and . Let be the function in the proof of Lemma 2.3. Since , the given assumption means that . By the continuity, there exists such that for all , Let and be same as in the proof of Lemma 4.3. Then, there exists such that for all , and the relations in (35) hold. By the continuity, there exist such that for all , with and
| (40) |
Set . Pick any . Next we argue that , which by Definition 2.3 implies that is a KL function of exponent . Suppose on the contradiction that there exists . From , we have , which along with implies that (if not, we will have , which along with (40) and for implies that , a contradiction to ). Now from and for , it is not hard to verify that . Together with and the expression of , we have
| (41) |
Moreover, the equalities in (36)-(37) still hold for . Let be same as in the proof of Lemma 4.3. Clearly, . Then, it holds that
Notice that and . From the last equation, it follows that
| (42) |
Since and , by the proof of Lemma 2.3 (iii) and , there exists such that with . Together with (36)-(37) and (4.2),
Since , the last inequality implies that , which is a contradiction to the inequality (41). The proof is then completed.
5 Numerical experiments
In this section we demonstrate the performance of the zero-norm regularized DC loss model (7) and its surrogate (9), which are respectively solved with PGe-znorm and PGe-scad. All numerical experiments are performed in MATLAB on a laptop running on 64-bit Windows System with an Intel(R) Core(TM) i7-7700HQ CPU 2.80GHz and 16 GB RAM. The MATLAB package for reproducing all the numerical results can be found at https://github.com/SCUT-OptGroup/onebit.
5.1 Experiment setup
The setup of our experiments is similar to the one in [46, 19]. Specifically, we generate the original -sparse signal with the support chosen uniformly from and taking the form of , where the entries of are drawn from the standard normal distribution. Then, we obtain the observation vector via (2), where the sampling matrix is generated in the two ways: (I) the rows of are i.i.d. samples of with for (II) the entries of are i.i.d. and follow the standard normal distribution; the noise is generated from ; and the entries of is set by . In the sequel, we denote the corresponding data with the two triples and , where means the correlation factor, denotes the noise level and means the sign flip ratio.
We evaluate the quality of an output of a solver in terms of the mean squared error (MSE), the Hamming error (Herr), the ratio of missing support (FNR) and the ratio of misidentified support (FPR), which are defined as follows
where, in our numerical experiments, a component of a vector being nonzero means that its absolute value is larger than . Clearly, a solver has a better performance if its output has the smaller MSE, , FNR and FPR.
5.2 Implementation of PGe-znorm and PGe-scad
From the definition of in PGe-znorm and PGe-scad, we have and . Together with the expression of and , when is small enough, can be viewed as an approximate -stationary point. Hence, we terminate PGe-znorm and PGe-scad at the iterate once or . In addition, we also terminate the two algorithms at when for and . The extrapolation parameters in the two algorithms are chosen by (28) with . The starting point of PGe-znorm and PGe-scad is always chosen to be .
5.3 Choice of the model parameters
The model (7) and its surrogate (9) involve the parameters and . By Figure 2 and 3, we choose for the subsequent tests. To choose an appropriate , we generate the original signal , the sampling matrix of type I and the observation with , and then solve the model (7) associated to for each with PGe-znorm and the model (9) associated to for each with PGe-scad. Figure 4 plots the average MSE of trials for each . We see that is a desirable choice, so choose for the two models in the subsequent experiments.

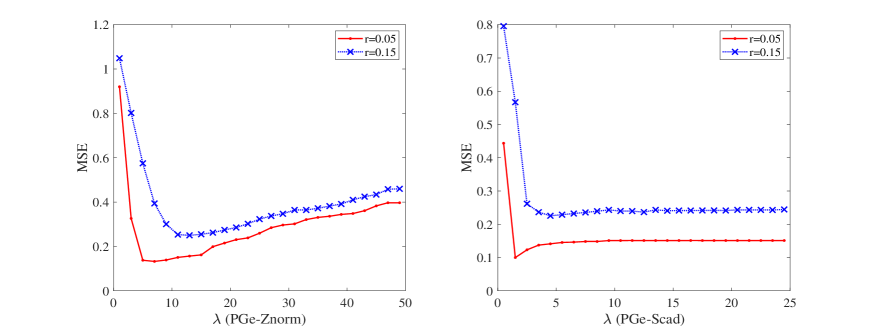
Next we take a closer look at the influence of on the models (7) and (9). To this end, we generate the signal , the sampling matrix of type I, and the observation with and , and then solve the model (7) associated to for each with PGe-znorm and solve the model (9) associated to for each with PGe-scad. Figure 5 plots the average MSE of trials for each . When , the MSE from the model (7) has a small variation for , while the MSE from the model (9) has a small variation for . When , the MSE from the model (7) has a small variation for and is relatively low for , while the MSE from the model (9) has a tiny change for . In view of this, we always choose for the model (7), and choose and for the model (9) with and , respectively, in the subsequent experiments.
5.4 Numerical comparisons
We compare PGe-znorm and PGe-scad with six state-of-the-art solvers, which are BIHT-AOP [46], PIHT [20], PIHT-AOP [21], GPSP [52] (https://github.com/ShenglongZhou/GPSP), PDASC [19] and WPDASC [15]. Among others, the codes for BIHT-AOP, PIHT and PIHT-AOP can be found at http://www.esat.kuleuven.be/stadius/ADB/huang/downloads/1bitCSLab.zip and the codes for PDASC and WPDASC can be found at https://github.com/cjia80/numericalSimulation. It is worth pointing out that BIHT-AOP, GPSP and PIHT-AOP all require an estimation on and as an input, PIHT require an estimation on as an input, while PDASC, WPDASC, PGe-znorm and PGe-scad do not need these prior information. For the solvers to require an estimation on and , we directly input the true sparsity and as those papers do. During the testing, PGe-znorm and PGe-scad use the parameters described before, and other solvers use their default setting except the PIHT is terminated once its iteration is over .
We first apply the eight solvers to solving the test problems with the sampling matrix of type I and low noise. Table 1 reports their average MSE, Herr, FNR, FPR and CPU time for trials. We see that among the four solvers without requiring any information on , PGe-scad and PGe-znorm yield the lower MSE, Herr and FNR than PDASC and WPDASC do, and PGe-scad is the best one in terms of MSE, Herr and FNR; while among the four solvers requiring some information on , BIHT-AOP and PIHT-AOP yield the smaller MSE and Herr than PIHT and GPSP do, and the former also yields the lower FNR and FPR under the scenario of . When comparing PGe-scad with BIHT-AOP and PIHT-AOP, the former yields the smaller MSE, Herr, FNR and FPR under the scenario of , and under the scenario of , it also yields the comparable MSE, Herr and FNR as BIHT-AOP and PIHT-AOP do.
| solvers | MSE | Herr | FNR | FPR | time(s) | MSE | Herr | FNR | FPR | time(s) | MSE | Herr | FNR | FPR | time(s) |
| PIHT | 2.57e-1 | 6.80e-2 | 3.26e-1 | 1.64e-3 | 1.55e-1 | 2.75e-1 | 7.27e-2 | 3.52e-1 | 1.77e-3 | 1.57e-1 | 3.52e-1 | 9.22e-2 | 4.24e-1 | 2.13e-3 | 1.58e-1 |
| BIHT-AOP | 1.46e-1 | 4.36e-2 | 1.94e-1 | 9.75e-4 | 5.30e-1 | 1.32e-1 | 3.85e-2 | 1.80e-1 | 9.05e-4 | 5.47e-1 | 1.46e-1 | 4.18e-2 | 2.06e-1 | 1.04e-3 | 5.45e-1 |
| PIHT-AOP | 1.61e-1 | 4.67e-2 | 2.06e-1 | 1.04e-3 | 1.81e-1 | 1.55e-1 | 4.60e-2 | 1.90e-1 | 9.55e-4 | 1.92e-1 | 1.40e-1 | 4.17e-2 | 2.02e-1 | 1.02e-3 | 1.86e-1 |
| GPSP | 1.91e-1 | 5.02e-2 | 2.56e-1 | 1.29e-3 | 1.60e-2 | 1.87e-1 | 4.83e-2 | 2.40e-1 | 1.21e-3 | 1.83e-2 | 1.89e-1 | 4.78e-2 | 2.52e-1 | 1.27e-3 | 2.31e-2 |
| PGe-scad | 2.15e-1 | 6.70e-2 | 3.34e-1 | 0 | 2.29e-1 | 2.04e-1 | 6.36e-2 | 3.32e-1 | 0 | 2.79e-1 | 2.10e-1 | 6.42e-2 | 3.44e-1 | 1.01e-5 | 2.82e-1 |
| PGe-znorm | 2.10e-1 | 6.52e-2 | 3.58e-1 | 2.01e-5 | 1.19e-1 | 2.10e-1 | 6.41e-2 | 3.62e-1 | 4.02e-5 | 1.24e-1 | 2.22e-1 | 6.82e-2 | 3.72e-1 | 3.02e-5 | 1.26e-1 |
| PDASC | 4.29e-1 | 1.34e-1 | 5.94e-1 | 0 | 6.04e-2 | 4.27e-1 | 1.33e-1 | 5.92e-1 | 0 | 5.98e-2 | 4.53e-1 | 1.37e-1 | 6.08e-1 | 1.01e-5 | 5.93e-2 |
| WPDASC | 4.38e-1 | 1.37e-1 | 6.02e-1 | 0 | 9.31e-2 | 4.20e-1 | 1.30e-1 | 5.78e-1 | 0 | 9.32e-2 | 3.97e-1 | 1.20e-1 | 5.56e-1 | 1.01e-5 | 9.69e-2 |
| MSE | Herr | FNR | FPR | time(s) | MSE | Herr | FNR | FPR | time(s) | MSE | Herr | FNR | FPR | time(s) | |
| PIHT | 4.10e-1 | 1.13e-1 | 4.04e-1 | 2.03e-3 | 1.61e-1 | 4.01e-1 | 1.08e-1 | 2.90e-1 | 1.96e-3 | 1.57e-1 | 4.18e-1 | 1.12e-1 | 4.02e-1 | 2.02e-1 | 1.60e-1 |
| BIHT-AOP | 3.77e-1 | 1.04e-1 | 4.10e-1 | 2.06e-3 | 5.41e-1 | 3.74e-1 | 9.88e-2 | 4.16e-1 | 2.09e-3 | 5.51e-1 | 3.56e-1 | 9.49e-2 | 3.94e-1 | 1.98e-3 | 5.38e-1 |
| PIHT-AOP | 3.48e-1 | 9.80e-2 | 3.82e-1 | 1.92e-3 | 1.85e-1 | 3.70e-1 | 1.01e-1 | 4.10e-1 | 2.06e-3 | 1.91e-1 | 3.65e-1 | 9.68e-2 | 4.08e-1 | 2.05e-3 | 1.87e-1 |
| GPSP | 3.90e-1 | 1.05e-1 | 3.86e-1 | 1.94e-3 | 1.86e-2 | 3.73e-1 | 1.01e-1 | 3.76e-1 | 1.89e-3 | 2.04e-2 | 3.63e-1 | 9.31e-2 | 3.74e-1 | 1.88e-3 | 2.48e-2 |
| PGe-scad | 2.72e-1 | 8.54e-2 | 3.98e-1 | 1.51e-4 | 2.31e-1 | 2.78e-1 | 8.67e-2 | 3.90e-1 | 1.81e-4 | 2.83e-1 | 2.83e-1 | 8.39e-2 | 4.02e-1 | 1.91e-4 | 2.63e-1 |
| PGe-znorm | 3.33e-1 | 9.82e-2 | 4.20e-1 | 8.24e-4 | 1.34e-1 | 3.31e-1 | 9.64e-2 | 4.16e-1 | 9.45e-3 | 1.34e-1 | 3.42e-1 | 9.56e-2 | 4.14e-1 | 9.55e-4 | 1.50e-1 |
| PDASC | 5.63e-1 | 1.80e-1 | 6.88e-1 | 0 | 5.08e-2 | 5.89e-1 | 1.85e-1 | 7.12e-1 | 0 | 5.18e-2 | 5.58e-1 | 1.73e-1 | 6.90e-1 | 4.02e-5 | 5.18e-2 |
| WPDASC | 5.40e-1 | 1.71e-1 | 6.72e-1 | 0 | 7.93e-2 | 5.87e-1 | 1.83e-1 | 7.10e-1 | 1.01e-5 | 8.32e-2 | 5.63e-1 | 1.75e-1 | 6.98e-1 | 0 | 8.08e-2 |
Next we use the eight solvers to solve the test problems with the sampling matrix of type I and high noise. Table 2 reports the average MSE, Herr, FNR, FPR and CPU time for trials. Now among the four solvers requiring partial information on , GPSP yields the smallest MSE, Herr, FNR and FPR, and among the four solvers without requiring any information on , PGe-scad is still the best one. Also, for those problems with , PGe-scad yields the smaller MSE, Herr and FNR than GPSP does.
| solvers | MSE | Herr | FNR | FPR | time(s) | MSE | Herr | FNR | FPR | time(s) | MSE | Herr | FNR | FPR | time(s) |
| PIHT | 3.48e-1 | 9.53e-2 | 4.15e-1 | 1.25e-3 | 5.42e-1 | 3.40e-1 | 9.54e-2 | 4.19e-1 | 1.26e-3 | 5.46e-1 | 3.62e-1 | 9.67e-2 | 4.47e-1 | 1.34e-3 | 5.56e-1 |
| BIHT-AOP | 3.57e-1 | 1.11e-1 | 3.80e-1 | 1.14e-3 | 1.59e-0 | 3.47e-1 | 1.09e-1 | 3.67e-1 | 1.10e-3 | 1.60e-0 | 3.25e-1 | 1.05e-1 | 3.61e-1 | 1.09e-3 | 1.61e-0 |
| PIHT-AOP | 3.71e-1 | 1.17e-1 | 3.83e-1 | 1.15e-3 | 5.66e-1 | 3.47e-1 | 1.10e-1 | 3.71e-1 | 1.11e-3 | 5.79e-1 | 3.30e-1 | 1.10e-1 | 3.59e-1 | 1.08e-3 | 5.83e-1 |
| GPSP | 2.64e-1 | 7.33e-2 | 3.31e-1 | 9.95e-4 | 5.77e-2 | 2.68e-1 | 7.52e-2 | 3.32e-1 | 9.99e-4 | 5.19e-2 | 2.95e-1 | 8.08e-2 | 3.63e-1 | 1.09e-3 | 4.89e-2 |
| PGe-scad | 2.65e-1 | 8.36e-2 | 3.87e-1 | 2.21e-4 | 1.05e-0 | 2.67e-1 | 8.35e-2 | 3.85e-1 | 2.45e-4 | 1.01e-0 | 2.65e-1 | 8.13e-2 | 3.93e-1 | 2.29e-4 | 1.10e-0 |
| PGe-znorm | 2.89e-1 | 8.85e-2 | 4.67e-1 | 8.83e-5 | 4.05e-1 | 2.92e-1 | 8.89e-2 | 4.69e-1 | 7.22e-5 | 4.17e-1 | 3.00e-1 | 8.95e-2 | 4.77e-1 | 9.63e-5 | 4.20e-1 |
| PDASC | 5.55e-1 | 1.77e-1 | 7.24e-1 | 0 | 1.63e-1 | 5.80e-1 | 1.84e-1 | 7.44e-1 | 0 | 1.64e-1 | 5.96e-1 | 1.89e-1 | 7.48e-1 | 4.01e-6 | 1.65e-1 |
| WPDASC | 5.73e-1 | 1.84e-1 | 7.36e-1 | 0 | 2.66e-1 | 5.54e-1 | 1.76e-1 | 7.19e-1 | 0 | 2.68e-1 | 5.96e-1 | 1.88e-1 | 7.49e-1 | 0 | 2.70e-1 |
| MSE | Herr | FNR | FPR | time(s) | MSE | Herr | FNR | FPR | time(s) | MSE | Herr | FNR | FPR | time(s) | |
| PIHT | 5.28e-1 | 1.48e-1 | 4.97e-1 | 1.50e-3 | 5.52e-1 | 5.42e-1 | 1.51e-1 | 5.09e-1 | 1.53e-3 | 5.50e-1 | 5.30e-1 | 1.47e-1 | 4.81e-1 | 1.45e-3 | 5.46e-1 |
| BIHT-AOP | 5.23e-1 | 1.51e-1 | 5.13e-1 | 1.54e-3 | 1.61e-0 | 4.97e-1 | 1.45e-1 | 5.00e-1 | 1.50e-3 | 1.60e-0 | 5.19e-1 | 1.46e-1 | 5.35e-1 | 1.61e-3 | 1.61e-0 |
| PIHT-AOP | 5.13e-1 | 1.46e-1 | 5.09e-1 | 1.53e-3 | 5.78e-1 | 5.04e-1 | 1.47e-1 | 5.13e-1 | 1.54e-3 | 5.79e-1 | 5.30e-1 | 1.52e-1 | 5.45e-1 | 1.64e-3 | 5.70e-1 |
| GPSP | 4.60e-1 | 1.29e-1 | 4.59e-1 | 1.38e-3 | 8.21e-2 | 4.60e-1 | 1.29e-1 | 4.65e-1 | 1.40e-3 | 8.13e-2 | 4.90e-1 | 1.33e-1 | 4.77e-1 | 1.44e-3 | 6.03e-2 |
| PGe-scad | 3.55e-1 | 1.09e-1 | 4.76e-1 | 1.34e-3 | 1.05e-0 | 3.63e-1 | 1.12e-1 | 4.81e-1 | 1.50e-3 | 1.11e-0 | 3.63e-1 | 1.12e-1 | 4.80e-1 | 1.38e-3 | 1.27e-0 |
| PGe-znorm | 4.22e-1 | 1.24e-2 | 5.17e-1 | 6.38e-4 | 4.19e-1 | 4.51e-1 | 1.30e-1 | 5.19e-1 | 7.94e-4 | 4.06e-1 | 4.41e-1 | 1.27e-1 | 5.21e-1 | 6.62e-4 | 4.49e-1 |
| PDASC | 6.90e-1 | 2.24e-1 | 8.12e-1 | 4.01e-6 | 1.35e-1 | 7.07e-1 | 2.26e-1 | 8.24e-1 | 4.01e-6 | 1.34e-1 | 7.11e-1 | 2.27e-1 | 8.27e-1 | 0 | 1.33e-1 |
| WPDASC | 6.62e-1 | 2.14e-1 | 7.92e-1 | 0 | 2.35e-1 | 6.82e-1 | 2.18e-1 | 8.03e-1 | 4.01e-6 | 2.34e-1 | 7.04e-1 | 2.25e-1 | 8.20e-1 | 4.01e-6 | 2.30e-1 |
Finally, we use the eight solvers to solve the test problems with the sampling matrix of type II. Table 3 reports the average MSE, Herr, FNR, FPR and CPU time for trials. From Table 3, among the four solvers requiring partial information on , PIHT yields the better MSE, Herr,FNR and FPR than others for those examples with high noise, and among the four solvers without needing any information on , PGe-scad is still the best one. Moreover, PGe-scad yields the smaller MSE, Herr and FNR than PIHT does for and . We also observe that among the eight solvers, GPSP always requires the least CPU time, and PGe-scad and PGe-znorm requires the comparable CPU time as PIHT, BIHT-AOP and PIHT-AOP do for all test examples.
| MSE | Herr | FNR | FPR | time(s) | MSE | Herr | FNR | FPR | time(s) | MSE | Herr | FNR | FPR | time(s) | |
| PIHT | 2.57e-1 | 7.23e-1 | 3.44e-1 | 6.89e-4 | 2.55 | 2.74e-1 | 8.15e-2 | 3.49e-1 | 6.99e-4 | 2.54 | 3.14e-1 | 9.58e-2 | 3.69e-1 | 7.39e-4 | 2.54 |
| BIHT-AOP | 1.54e-1 | 4.61e-2 | 2.40e-1 | 4.81e-4 | 7.70 | 3.06e-1 | 9.84e-2 | 3.36e-1 | 6.73e-3 | 7.68 | 4.23e-1 | 1.29e-1 | 3.95e-1 | 7.92e-4 | 7.64 |
| PIHT-AOP | 1.68e-1 | 5.08e-2 | 2.44e-1 | 4.89e-4 | 2.66 | 3.16e-1 | 1.03e-1 | 3.38e-1 | 6.77e-4 | 2.66 | 4.62e-1 | 1.52e-1 | 4.14e-1 | 8.30e-4 | 2.66 |
| GPSP | 2.45e-1 | 6.88e-2 | 3.36e-1 | 6.73e-4 | 0.19 | 2.77e-1 | 8.22e-2 | 3.51e-1 | 7.03e-4 | 0.19 | 3.23e-1 | 9.68e-2 | 3.73e-1 | 7.47e-4 | 0.19 |
| PGe-scad | 2.10e-1 | 6.65e-2 | 3.08e-1 | 2.61e-5 | 2.79 | 2.44e-1 | 7.82e-2 | 3.61e-1 | 2.10e-4 | 2.71 | 2.92e-1 | 9.34e-2 | 4.14e-1 | 6.89e-4 | 2.75 |
| PGe-znorm | 2.34e-1 | 7.36e-2 | 4.25e-1 | 2.00e-6 | 1.78 | 2.44e-1 | 7.71e-2 | 4.27e-1 | 8.02e-6 | 1.78 | 2.74e-1 | 8.70e-2 | 4.45e-1 | 3.21e-5 | 1.77 |
| PDASC | 5.41e-1 | 1.73e-1 | 6.84e-1 | 0 | 8.28e-1 | 6.26e-1 | 2.01e-1 | 7.50e-1 | 0 | 8.07e-1 | 6.28e-1 | 2.03e-1 | 7.56e-1 | 4.02e-5 | 7.66e-1 |
| WPDASC | 5.41e-1 | 1.73e-1 | 6.83e-1 | 0 | 1.01 | 5.62e-1 | 1.81e-1 | 7.03e-1 | 0 | 9.98e-1 | 6.17e-1 | 1.99e-1 | 7.37e-1 | 0 | 9.71e-1 |
6 Conclusion
We proposed a zero-norm regularized smooth DC loss model and derived a family of equivalent nonconvex surrogates that cover the MCP and SCAD surrogates as special cases. For the proposed model and its SCAD surrogate, we developed the PG method with extrapolation to compute their -stationary points and provided its convergence certificate by establishing the convergence of the whole iterate sequence and its local linear convergence rate. Numerical comparisons with several state-of-art methods demonstrate that the two new models are well suited for high noise and/or high sign flip ratio. An interesting future topic is to analyze the statistical error bound for them.
References
- [1] H. Attouch and J. Bolte, On the convergence of the proximal algorithm for nonsmooth functions involving analytic features, Mathematical Programming, 116(2009): 5-16.
- [2] H. Attouch, J. Bolte, P. Redont and A. Soubeyran, Proximal alternating minimization and projection methods for nonconvex problems: an approach based on the Kurdyka-Łojasiewicz inequality, Mathematics of Operations Research, 35(2010): 438-457.
- [3] A. Beck and M. Teboulle, Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems, IEEE Transactions on Image Processing, 18(2009): 2419-2434.
- [4] A. Beck and N. Hallak, Optimization problems involving group sparsity terms, Mathematical Programming, 178(2019): 39-67.
- [5] J. Bolte, S. Sabach and M. Teboulle, Proximal alternating linearized minimization for nonconvex and nonsmooth problems, Mathematical Programming, 146(2014): 459-494.
- [6] P. T. Boufounos and R. G. Baraniuk, 1-bit compressive sensing, Proceedings of the Forty Second Annual Conference on Information Sciences and Systems, 2008, pp. 16-21.
- [7] P. T. Boufounos, Greedy sparse signal reconstruction from sign measurements, Proceedings of the Asilomar Conference on Signals, Systems, and Computers, 2009: 1305-1309.
- [8] P. T. Boufounos, Reconstruction of sparse signals from distorted randomized measurements, In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing, 2010, pp. 3998-4001.
- [9] J. P. Brooks, Support vector machines with the ramp Loss and the hard margin loss, Operations Research, 59(2011): 467-479.
- [10] E. J. Candès and T. Tao, Decoding by linear programming, IEEE Transactions on Information Theory, 51(2005): 4203-4215.
- [11] F. Cucker and D. X. Zhou, Learning Theory: An Approximation Theory Viewpoint, Cambridge, U.K.: Cambridge Univ. Press, 2007.
- [12] D. Q. Dai, L. X. Shen, Y. S. Xu and N. Zhang, Noisy 1-bit compressive sensing: models and algorithms, Applied and Computational Harmonic Analysis, 40(2016): 1-32.
- [13] D. L. Donoho, Compressed sensing, IEEE Transactions on Information Theory, 52(2006): 1289-1306.
- [14] J. Q. Fan and R. Z. Li, Variable selection via nonconcave penalized likelihood and its oracle properties, Journal of American Statistics Association, 96(2001): 1348-1360.
- [15] Q. B. Fan, C. Jia, J. Liu and Y. Luo, Robust recovery in 1-bit compressive sensing via -constrained least squares, Signal Processing, 179(2021): 107822.
- [16] J. Fang, Y. N. Shen, H. B. Li and Z. Ren, Sparse signal recovery from one-bit quantized data: an iterative reweighted algorithm, Signal Processing, 102(2014): 201-206.
- [17] S. Ghadimi and G. Lan, Accelerated gradient methods for nonconvex nonlinear and stochastic programming, Mathematical Programming, 156(2016):59-99.
- [18] S. Gopi, P. Netrapalli, P. Jain and A. Nori, One-bit compressed sensing: Provable support and vector recovery, in Int. Conf. Mach. Learn. PMLR, 2013, pp. 154-162.
- [19] J. Huang, Y. L. Jiao, X. L. Lu and L. P. Zhu, Robust decoding from 1-bit compressive sampling with ordinary and regularized least squares, SIAM Journal on Scientific Computing, 40(2018): A2062-A2086.
- [20] X. L. Huang and M. Yan, Nonconvex penalties with analytical solutions for one-bit compressive sensing, Signal Processing, 144(2018): 341-351.
- [21] X. L. Huang, L. Shi, M. Yan and J. A. K. Suykens, Pinball loss minimization for one-bit compressive sensing: convex models and algorithms, Neurocomputing, 314(2018): 275-283.
- [22] X. L. Huang, L. Shi and J. A. K. Suykens, Ramp loss linear programming support vector machine, Journal of Machine Learning Research, 15(2014): 2185-2211.
- [23] L. Jacques, J. N. Laska, P. T. Boufounos and R. G. Baraniuk, Robust 1-bit compressive sensing via binary stable embeddings of sparse vectors, IEEE Transactions on Information Theory, 59(2013): 2082-2102.
- [24] J. N. Laska, Z. W. Wen, W. T. Yin and R. G. Baraniuk, Trust, but verify: fast and accurate signal recovery from 1-bit compressive measurements, IEEE Transactions on Signal Processing, 59(2011): 5289-5301.
- [25] J. N. Laska and R. G. Baraniuk, Regime change: Bitdepth versus measurement-rate in compressive sensing, IEEE Transactions on Signal Processing, 60(2012): 3496-3505.
- [26] Z. L. Li, W. B. Xu, X. B. Zhang and J. R. Lin, A survey on one-bit compressed sensing: theory and applications, Frontiers of Computer Science, 12(2018): 217-230.
- [27] H. Li and Z. Lin, Accelerated proximal gradient methods for nonconvex programming, In Advances in Neural Information Processing Systems, 2015: 379-387.
- [28] P. Ochs, Unifying abstract inexact convergence theorems and block coordiate variable metric IPIANO, SIAM Journal on Optimization, 29(2019): 511-570.
- [29] P. Ochs, Y. Chen, T. Brox and T. Pock, iPiano: Inertial proximal algorithm for nonconvex optimization, SIAM Journal on Optimization, 7(2014): 1388-1419.
- [30] Y. Plan and R. Vershynin, One-bit compressed sensing by linear programming, Communications on Pure and Applied Mathematics, 66(2013): 1275-1297.
- [31] Y. Plan and R. Vershynin, Robust 1-bit compressed sensing and sparse logistic regression: a convex programming approach, IEEE Transactions on Information Theory, 59(2013): 482-494.
- [32] X. Peng, B. Liao and J. Li, One-bit compressive sensing via Schur-concave function minimization, IEEE Transactions on Signal Processing, 67(2019): 4139-4151.
- [33] X. Peng, B. Liao, X. D. Huang and Z. Quan, 1-bit compressive sensing with an improved algorithm based on fixed-point continuation, Signal Processing, 154(2019): 168-173.
- [34] G. Y. Li and T. K. Pong, Calculus of the exponent of Kurdyka-Łöjasiewicz inequality and its applications to linear convergence of first-order methods, Foundations of Computational Mathematics, 18(2018): 1199-1232.
- [35] Y. L. Liu, S. J. Bi and S. H. Pan, Equivalent Lipschitz surrogates for zero-norm and rank optimization problems, Journal of Global Optimization, 72(2018): 679-704.
- [36] R. T. Rockafellar and R. J-B. Wets, Variational Analysis, Springer, 1998.
- [37] Y. Nesterov, A method of solving a convex programming problem with convergence rate , Soviet Mathematics Doklady, 27: 372-376, 1983.
- [38] Y. Nesterov, Introductory Lectures on Convex Optimization: A Basic Course, Kluwer Academic Publishers, Boston, 2004.
- [39] Y. T. Qian and S. H. Pan, Calmness of partial perturbation to composite rank constraint systems and its applications, arXiv:2102.10373v2, October 8, 2021.
- [40] L. X. Shen and B. W. Suter, One-bit compressive sampling via minimization, EURASIP Journal on Advances in Signal Processing, 71(2016).
- [41] B. Wen, X. Chen, and T. K. Pong, Linear convergence of proximal gradient algorithm with extrapolation for a class of nonconvex nonsmooth minimization problems, SIAM Journal on Optimization, 27(2017): 124-145.
- [42] Y. Q. Wu, S. H. Pan and S. J. Bi, Kurdyka-Łojasiewicz property of zero-norm composite functions, Journal of Optimization Theory and Applications, 188(2021): 94-112.
- [43] H. Wang, X. Huang, Y. Liu, H. Sabine Van and W. Qun, Binary reweighted l1-norm minimization for one-bit compressed sensing, In 8th International Conference on Bio-inspired Systems & Signal Processing, 2015.
- [44] P. Xiao, B. Liao and J. Li, One-bit compressive sensing via Schur-concave function minimization, IEEE Transactions on Signal Processing, 16(2019): 4139-4151.
- [45] Y. Y. Xu and W. Yin, A globally convergent algorithm for nonconvex optimization based on block coordinate update, Journal of Scientific Computing, 72(2017): 700-734.
- [46] M. Yan, Y. Yang and S. Osher, Robust 1-bit compressive sensing using adaptive outlier pursuit, IEEE Transactions on Signal Processing, 60(2012): 3868-3875.
- [47] L. Yang, Proximal gradient method with extrapolation and line-search for a class of nonconvex and nonsmooth problems, arXiv:1711.06831v4, 2021.
- [48] P. R. Yu, G. Y. Li and T. K. Pong, Kurdyka-Łöjasiewicz exponent via inf-projection, Foundations of Computational Mathematics, DOI: https://doi.org/10.1007/s10208-021-09528-6.
- [49] C. H. Zhang, Nearly unbiased variable selection under minimax concave penalty, Annals of Statistics, 38(2010): 894-942.
- [50] T. Zhang, Statistical analysis of some multi-category large margin classification methods, Journal of Machine Learning Research, 5(2004): 1225-1251.
- [51] L. Zhang, J. Yi and R. Jin, Efficient algorithms for robust one-bit compressive sensing, Proceedings of the thirty First International Conference on Machine Learning, 2014, pp. 820-828.
- [52] S. L. Zhou, Z. Y. Luo, N. H. Xiu and G. Y. Li, Computing One-bit compressive sensing via double-sparsity constrained optimization, Journal of Machine Learning Research, 5(2004): 1225-1251.
- [53] R. D. Zhu and Q. Q. Gu, Towards a lower sample complexity for robust one-bit compressed sensing, Proceedings of the 32nd International Conference on Machine Learning, PMLR, 37(2015): 739-747.