Conditional Diffusion Model-Driven Generative Channels
for Double RIS-Aided Wireless Systems
Abstract
With the development of the upcoming sixth-generation networks (6G), reconfigurable intelligent surfaces (RISs) have gained significant attention due to its ability of reconfiguring wireless channels via smart reflections. However, traditional channel state information (CSI) acquisition techniques for double-RIS systems face challenges (e.g., high pilot overhead or multipath interference). This paper proposes a new channel generation method in double-RIS communication systems based on the tool of conditional diffusion model (CDM). The CDM is trained on synthetic channel data to capture channel characteristics. It addresses the limitations of traditional CSI generation methods, such as insufficient model understanding capability and poor environmental adaptability. We provide a detailed analysis of the diffusion process for channel generation, and it is validated through simulations. The simulation results demonstrate that the proposed CDM based method outperforms traditional channel acquisition methods in terms of normalized mean squared error (NMSE). This method offers a new paradigm for channel acquisition in double-RIS systems, which is expected to improve the quality of channel acquisition with low pilot overhead.
Index Terms:
Diffusion model, channel estimation, deep learning, double reconfigurable intelligent surface.I Introduction
WITH the rapid development of fifth-generation (5G) and the imminent arrival of sixth-generation (6G) wireless communication networks, the demand for innovative technologies that enhance performance, extend coverage, and improve energy efficiency has become increasingly critical [1][2]. Among these emerging solutions, reconfigurable intelligent surfaces (RISs) have gained prominence as a transformative technology that enables intelligent control of the radio propagation environment by dynamically adjusting the phase shifts of the incident signals. Composed of a large array of passive reflecting elements with ultra-low power consumption, RIS offers a new degree of freedom for wireless channel optimization and enhances network adaptability.
Although significant progress has been made in single-RIS systems, the performance is often constrained by the size, placement, and limited adaptability of the RIS in dynamic environments. To address these limitations, double-RIS has been proposed, wherein two RISs are deployed cooperatively to jointly optimize the transceiver design and passive beamforming of RISs. By strategically positioning and controlling both surfaces, double-RIS systems can significantly enhance system flexibility and performance, leading to the improved signal-to-noise ratio (SNR) and channel capacity [3]. This architecture has attracted growing attention for its potential to improve spatial diversity, exploit multipath propagation, and extend coverage in next-generation wireless networks.
However, unlocking the potential benefits of a high passive beamfomring gain provided by the double-RIS architecture relies on the accurate estimation of channel state information (CSI). Precise CSI is crucial for optimizing RIS configurations, enhancing transmission efficiency, and improving overall system throughput [4]. However, traditional CSI estimation techniques, including pilot-based and model-based methods, often rely on oversimplified assumptions regarding channel characteristics and system dynamics, which may fail in highly dynamic or complex propagation environments [5]. Moreover, compared with single-RIS architecture, presence of two RISs introduces a higher dimension of channel coefficients and more complex structures of channels. These interactions significantly increase modeling complexity, further limiting the practicality and effectiveness of conventional estimation techniques in real-world scenarios.
Recently, deep learning (DL) has emerged as a promising approach to address the limitations of conventional CSI estimation methods [6]. For example, a convolutional neural network (CNN) was employed in [7] to learn the mapping between received signals and channel responses. Similarly, a conditional generative adversarial network (CGAN)-based method was proposed in [8] to enhance CSI estimation accuracy in RIS-assisted mmWave MIMO systems. However, despite their effectiveness, these approaches suffer from two fundamental limitations: they fail to fully exploit the phase coherence properties of RIS elements.
To overcome the aforementioned issues, we propose a novel channel acquisition framework for double‐RIS communication systems based on a conditional diffusion model (CDM) that reconstructs complete CSI from partial observations. By leveraging spatial correlations between channel parameters and conditioning on received pilot signals from only a subset of reflecting elements, our generative model can produce high‐fidelity channel realizations that faithfully capture multipath fading, interference patterns, and spatial correlations under diverse RIS configurations. Unlike conventional schemes that require exhaustive, element‐wise estimation, this CDM‐based approach directly leverages partial channel information, thereby significantly reducing pilot overhead while maintaining estimation accuracy. Simulation results demonstrate that our method consistently outperforms traditional deep learning techniques in normalized mean squared error (NMSE), highlighting its promise for system design, performance optimization, and real‐time operation in complex double‐RIS deployments where efficient and accurate CSI acquisition is essential.
II Channel Model
We consider a double-RIS-assisted communication system, as illustrated in Fig. 1. In this system, a single-antenna user communicates with a base station (BS) equipped with antennas via two distributed RISs, denoted as RIS1 and RIS2, respectively. Due to the complexity of estimating the double-reflection link, we focus solely on this path, assuming that the direct user-BS link is blocked by environmental obstructions (e.g., walls or corners in indoor scenarios). To mitigate path loss and blockage effects, RIS1 is deployed near the user, and RIS2 is deployed close to the BS, enabling efficient communication via the double-reflection link. Let and denote the number of passive elements at RIS1 and RIS2, respectively. All channels are assumed to be quasi-static and follow a flat fading model within each coherence interval.
We define the channel from the user to RIS1 as where denotes the channel coefficient from the user to the -th RIS1 element. The channel between RIS1 and RIS2 is denoted by where each column represents the channel coefficients from the -th RIS1 element to all RIS2 elements. Here, is the channel coefficient between the -th RIS1 element and the -th RIS2 element. In addition, denotes the channel from RIS2 to the BS.The reflection coefficient vector of RISμ is denoted as where and denote the reflection amplitude and phase shift of the -th element of RIS1, respectively. We consider a challenging scenario, where both the direct link and single-reflection links are severely blocked due to dense obstacles. To this end, we concentrate our analysis on this specific propagation path. Accordingly, the equivalent end-to-end channel between the user and the BS can be expressed as
| (1) |
where denotes the diagonal reflection matrix of RISμ. Since we consider the fully passive RISs without signal reception or transmission capabilities, it is infeasible to acquire the CSI between the two RISs. To address this, we define the cascaded user RIS1 RIS2 channel as where represents the contribution of the -th RIS1 element weighted by its user-side channel coefficient. Then, the channel model in (1) can be equivalently expressed as
| h | ||||
| (2) |
where denotes the effective channel associated with the -th element of RIS, incorporating the complete path from the user to the BS via both RISs.
III Proposed Channel Generation Method
In large-scale double-RIS systems, the need to estimate CSI for numerous elements introduces substantial pilot overhead, which shortens the time available for data transmission and lowers system throughput. To mitigate this issue, we estimate the CSI of a selected subset of elements, significantly reducing pilot overhead. The full CSI is then inferred by exploiting spatial correlations among channels.
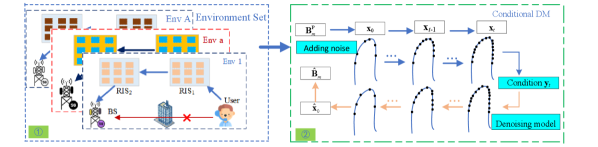
In this section, we propose a channel generation approach based on a CDM, which consists of two key stages including the forward and the reverse processes. The conditional diffusion model offers a robust framework for reconstructing complete CSI from partial channel state observations.
We formulate the double-RIS channel generation as a sampling process from a learned latent prior, where the double-RIS channel is reconstructed iteratively [9]. This process consists of main stages including a forward process and a reverse process [10]. In the forward process, double-RIS channel acquisition is modeled as a sampling procedurethat gradually transforms the initial data into a distribution resembling Gaussian noise. The reverse process then iteratively denoises this data to reconstruct the complete channel. A conditional diffusion model is employed to generate channel realizations that closely match the actual distribution. Let denote the partial estimated cascaded channel corresponding to a subset of elements. The mask ratio is defined as , indicating the fraction of elements with unestimated CSI. Tuning the mask ratio enables a flexible balance between pilot overhead and channel acquisition accuracy.
The partial cascaded channel is vectorized into a real-valued vector by stacking its real and imaginary components [11]. In the forward process, Gaussian noise is gradually added to , resulting in after T diffusion steps. This process is formally defined as
| (3) |
where denotes the diffusion step, and the variance schedule increases linearly from to , and represents standard Gaussian noise. Based on the Markov chain framework, the distribution of conditioned on the original input is given by
| (4) |
where , ,with represents the identity matrix. It is essential for the subsequent training process to obtain by sampling from the distribution in (4) .
During the conditional reverse process, the reverse transition also follows Gaussian distribution, and can be written as
| (5) |
where the mean and covariance are determined by the current state and the time step . If the reverse distribution can be obtained during the denoising process, the original data can be progressively reconstructed. To approximate this intractable distribution, we employ a neural network denoted as . The corresponding mean and variance are respectively expressed as
| (6) |
where denotes the predicted noise generated by the neural network, given the input at time step .
Input: , , , , and training epochs , weighting coefficient .
collected from environments 1 to environments A.
Initialization: Vectorize into a real-valued vector .
Initialize U-Net parameters randomly.
for do
for do
Generate noise-corrupted using and based on (3).
Extract for conditioning training data.
Train the U-Net to get based on (16).
Compute loss function based on (15).
Update using gradient descent on .
end for
end for
Output: Trained noise prediction network parameters .
Our objective is to train the model to accurately predict channel realizations based on the collected dataset. As shown in [10], the training loss can be simplified to the Kullback–Leibler (KL) divergence between the true reverse distribution and the approximation at each diffusion step
| (7) |
Conclusively,the training process is to minimize the discrepancy between the the noise predicted by the network and the true noise added during the forward process
| (8) |
To generate high-quality channel samples, relying solely on Gaussian noise to reconstruct may yield random and inaccurate results. Therefore, we incorporate the received signal , obtained from pilot transmissions, as an auxiliary input to the neural network.
In the double-RIS system, the user transmits a pilot symbol . For simplicity, which is typically set to 1 for simplicity. After propagation through the cascaded double-reflection links, the received signal at the BS is given by
| (9) |
where represents the additive noise. The conditional reverse distribution is then redefined as which can be expressed as follows by Bayesian theorem
| (10) |
Since both and are known during the denoising process, the term is treated as a constant and denoted by . Hence, (10) can be simplified as
| (11) |
Furthermore, the likelihood term can else be expressed as
| (12) |
Taking the logarithm of (12) and calculating the gradient, we can obtain
| (13) |
We approximate the conditional distribution using a parameterized neural network , and thus obtain
| (14) |
where is a weighting coefficient that quantifies the importance of the conditional inputs . Accordingly, we modify the loss function as
| (15) |
In (15), is the modified predicted noise.
| (16) |
where represents the noise predicted with the additional conditional inputs . The update process from to can be represent as
| (17) |
where is a Gaussian noise. We encode the diffusion step and the received signal through the step and conditional embedding modules, respectively. These embeddings are then integrated with the noisy input and fed into a U-net. A convolutional architecture is used to effectively fuse the three types of inputs. Finally, the network is trained by minimizing the loss function in (15) . The training and inference procedures are summarized in Algorithms 1 and 2, respectively.
IV Simulation Results
In this section, we provide the simulation settings and results to evaluate effectiveness of the proposed method in double-RIS-assisted. The BS is equipped with a uniform linear array with antennas. To enable full CSI reconstruction from partial observations, we incorporate spatial correlation into the channel model [12]. Consider RIS1 with reflecting elements, the spatial correlation matrix is defined as
| (20) |
where , , represents the distance between the adjacent reflecting elements, represents the wavelength at which the system operates. Similarly, the same correlation model is applied to RIS2.
We now detail the network configuration for the proposed CDM. The diffusion model is trained with T = 500 steps, and the noise is linearly increased from to 0.02. During the reverse process, a U-Net based convolutional neural network is employed to approximate the denoising distribution at each step. Furthermore, a conditional embedding module is utilized to incorporate the partial observed signals as auxiliary input.
NMSE is adopted as the metric of the estimation accuracy, which is defined as
| (21) |
where and represent the generative channel and the ground-truth, respectively.
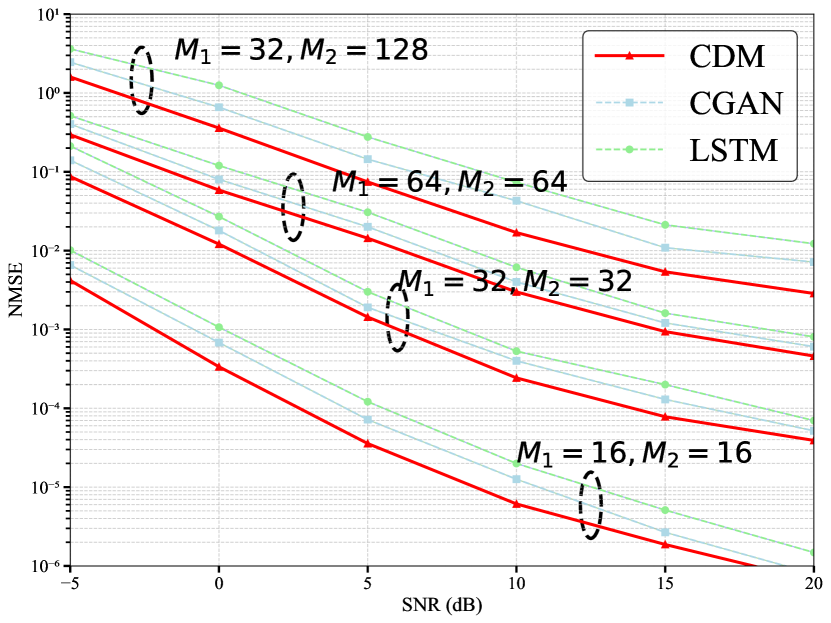
As shown in Figure 3, we present the NMSE performance of the proposed CDM in the double-RIS system. For comparison, we also incorporate the long short-term memory (LSTM) estimation algorithm and a representative deep learning method, the CGAN. We evaluate the NMSE performance of the double-RIS system under different numbers of array elements. All evaluations are conducted within a SNR range from -5 dB to 20 dB, and comparisons with other methods are also made under different numbers of array elements. We set the values of mask ratio to 0.2 uniformly. It can be observed that, in terms of NMSE, the proposed CDM significantly outperforms both the LSTM estimation algorithm and the method based on the CGAN. This performance improvement is attributed to the ability of this method to reconstruct the complete CSI from partial CSI by exploiting spatial correlation, leveraging both the forward and reverse diffusion processes, while ensuring strict consistency between the training phase and the inference phase. As a result, the model gradually mitigates the impact of noise during the reconstruction process. Regarding the influence of the array size, we observe that the NMSE performance deteriorates as the number of array elements increases. This degradation of performance is caused by the increased complexity of the cascaded channel matrix between the two RISs, which substantially increases the computational burden.
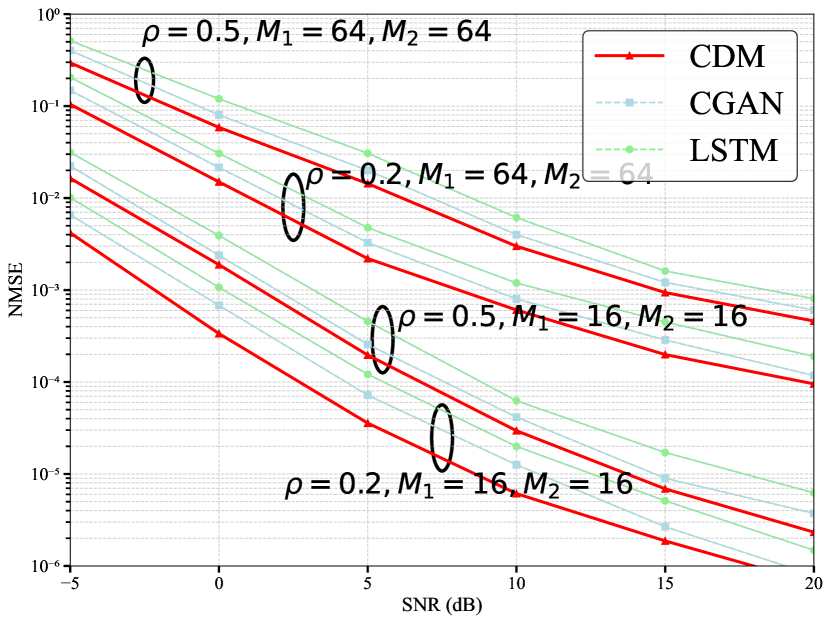
In Figure 4, we plot the comparison of the NMSE of the proposed CDM under different mask ratios and for different numbers of elements corresponding to these mask ratios. In this method, we use partial channel information for training to generate complete channel information. We compare the cases where the mask information ratios are 0.2 and 0.5 respectively, and also consider the cases where the number of array elements is 16 and 64 for these two ratios. It can be seen from the figure that as the SNR increases, the NMSE decreases, which is an expected result. In addition, at a fixed SNR level, the NMSE decreases as the partial information ratio increases. This phenomenon can be attributed to the fact that a higher ratio leads to an increase in the auxiliary information fed into the diffusion model network. Meanwhile, we also compare different methods under different mask ratios. It can be seen from the figure that under the same mask ratio, the proposed CDM outperforms the CGAN and the LSTM. This is because during the reverse denoising process of CDM, denoising is carried out step by step, enabling more complete utilization of the channel information, thus achieving better performance.
V Conclusion
In this paper, we proposed a novel double-RIS channel generation method leveraging a conditional diffusion model. The CDM method utilizes spatial correlation to generate the full channel state information from partial channel state information and incorporates pilot signals as conditional inputs, resulting in a significant performance improvement. The proposed method abandons the traditional channel estimation methods that rely on prior theoretical models, and thus is more efficient in channel acquisition.
References
- [1] Y. Ni, H. Zhao, Y. Liu, J. Wang, G. Gui and H. Zhang, “Analysis of RIS-aided communications over Nakagami- fading channels,” IEEE Trans. Veh. Technol., vol. 72, no. 7, pp. 8709-8721, Jul. 2023.
- [2] J. Zhang, J. Li, L. Shi, Z. Wang, S. Jin, W. Chen, and H. V. Poor, “Decision transformers for wireless communications: A new paradigm of resource management,” IEEE Wireless Commun., vol. 32, no. 2, pp. 180-186, Apr. 2025.
- [3] P. Zhang, S. Gong and S. Ma, “Double-RIS aided multi-user MIMO communications: Common reflection pattern and joint beamforming design,” IEEE Trans. Veh. Technol., vol. 73, no. 3, pp. 4418-4423, Mar. 2024.
- [4] Y. Chen, M. Jian and L. Dai, “Channel estimation for RIS assisted wireless communications: Stationary or non-stationary?,” IEEE Trans. Signal Process., vol. 72, pp. 3776-3791, 2024.
- [5] W. Chen, Y. Han, C. -K. Wen, X. Li and S. Jin, “Channel customization for low-complexity CSI acquisition in multi-RIS-assisted MIMO systems.” IEEE J. Sel. Areas Commun., vol. 43, no. 3, pp. 851-866, Mar. 2025.
- [6] J. Guo, W. Chen, C. -K. Wen and S. Jin, “Deep learning-based two-timescale CSI feedback for beamforming design in RIS-assisted communications.” IEEE Trans. Veh. Technol., vol. 72, no. 4, pp. 5452-5457, Apr. 2023.
- [7] Z. Mao, X. Liu and M. Peng, “Channel estimation for intelligent reflecting surface assisted massive MIMO systems—A deep learning approach.” IEEE Commun. Lett., vol. 26, no. 4, pp. 798-802, Apr. 2022.
- [8] M. Ye, C. Pan, Y. Xu and C. Li, “Generative adversarial networks-based channel estimation for intelligent reflecting surface assisted mmWave MIMO systems.” IEEE Trans. Cogn. Commun. Netw., vol. 26, no. 4, pp. 798-802, Apr. 2022.
- [9] W. Tong, W. Xu, F. Wang, W. Ni and J. Zhang, “Diffusion model-based channel estimation for RIS-aided communication systems.” IEEE Wireless Commun. Lett., vol. 13, no. 9, pp. 2586-2590, Sep. 2024.
- [10] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models.” Proc. Adv. Neural Inf. Process. Syst., vol. 33, 2020, pp. 6840–6851.
- [11] J. Zhang, J. Li, Z. Wang, Y. Han, L. Shi and B. Cao, “Decision transformer for IRS-assisted systems with diffusion-driven generative channels,” IEEE Int. Conf. Commun. China, ICCC, Hangzhou, China, 2024.
- [12] E. Björnson and L. Sanguinetti, “Rayleigh fading modeling and channel hardening for reconfigurable intelligent surfaces.” IEEE Wireless Commun. Lett., vol. 10, no. 4, pp. 830-834, Apr. 2021.