Conditional Distribution Function Estimation Using Neural Networks for Censored and Uncensored Data
Abstract
Most work in neural networks focuses on estimating the conditional mean of a continuous response variable given a set of covariates.
In this article, we consider estimating the conditional distribution function using neural networks for both censored and uncensored data. The algorithm is built upon the data structure particularly constructed for the Cox regression with time-dependent covariates. Without imposing any model assumption, we consider a loss function that is based on the full likelihood where the conditional hazard function is the only unknown nonparametric parameter, for which unconstraint optimization methods can be applied.
Through simulation studies, we show the proposed method possesses desirable performance, whereas the partial likelihood method and the traditional neural networks with loss yield biased estimates when model assumptions are violated. We further illustrate the proposed method with several real-world data sets. The implementation of the proposed methods is made available at https://github.com/bingqing0729/NNCDE.
Keywords: Conditional Distribution Estimation, Neural Networks, Predictive Interval, Survival Analysis, Time-Varying Covariates
1 Introduction
Neural networks are widely used in prediction. Depending on the nature of the outcome variable of interest, most of the current work falls into two categories: (i) estimating the conditional mean of a continuous response variable given a set of predictors, also called covariates, then predicting the outcome value given a new set of covariate values using the estimated conditional mean; (ii) estimating conditional probabilities of a categorical response variable given a set of covariates, then classifying a new data point only with known covariate values into one of the categories of the response variable. It is clearly seen that, from a statistical point of view, solving a classification problem is to estimate the conditional probability mass function, or equivalently, the conditional distribution function; whereas predicting a continuous outcome value often focuses on estimating a center of the conditional distribution function. In fact, estimating the conditional distribution function of a continuous response variable nonparametrically is of greater interest because it not only can determine the center of a distribution (mean or median), but also can set predictive intervals that are of great importance in prediction (Hall et al., 1999). It is a challenge, however, to estimate the conditional distribution function given multiple covariates uisng traditional statistical methods (Hall and Yao, 2005). In this article, we propose to estimate the conditional distribution function of a continuous random variable given multiple covariates using neural networks .
Our work is inspired by estimating the conditional survival function for censored failure time data, especially when covariates are time-dependent. In the survival analysis literature, a conditional survival function is usually estimated by fitting the semiparametric Cox proportional hazards model (Cox, 1972). Although it has been widely used, particularly in health studies, the Cox model still requires strong model assumptions that can be violated in practical settings. Researchers have been exploring the application of neural networks in survival analysis since 1990s. A line of research in the current literature uses neural networks to replace the linear component in a Cox model and the negative (logarithm of) partial likelihood as the loss function, see e.g. Faraggi and Simon (1995) and Xiang et al. (2000).
Recently, Katzman et al. (2018) revisited the Cox model and applied modern deep learning techniques (standardizing the input, using new activation function, new optimizer and learning rate scheduling) to optimizing the training of the network. Their neural networks model, called DeepSurv, outperforms Cox regressions evaluated by the C-index (Harrell et al., 1984) in several real data sets. In simulation studies, DeepSurv outperforms the Cox regression when the proportional hazards assumption is violated and performs similarly to the Cox regression when the proportional hazards assumption is satisfied.
Following a similar modeling strategy, Ching et al. (2018) developed the neural networks model Cox-nnet for high-dimensional genetics data. Building upon the methodology of nested case-control studies, Kvamme et al. (2019) proposed to use a loss function that modifies the partial likelihood by subsampling the risk sets. Their neural networks models Cox-MLP(CC) and Cox-Time are computationally efficient and scale well to large data sets. Both models are relative risk models with the same partial likelihood but Cox-Time further removes the proportionality constraint by including time as a covariate into the relative hazard. Cox-MLP(CC) and Cox-Time were compared to the classical Cox regression, DeepSurv and a few other models on 5 real-world data sets and found to be highly competitive. We will compare our method to Cox-MLP(CC) and Cox-Time on 4 of the data sets where numbers of tied survival times are negligible. In all aforementioned methods, the semi-parametric nature of the model is retained, hence the baseline hazard function needs to be estimated in order to estimate the conditional survival function, whereas our method estimates the conditional hazard function directly without specifying any baseline hazard function.
Another commonly used approach is to partition the time axis into a set of fixed intervals so that the survival probabilities are estimated on the set of discrete time points. Biganzoli et al. (1998) proposed a model called PLANN in which the neural networks contain a input vector of covariates and a discrete time point, and an output of the hazard rate
at this time point. They used the negative logarithm of a Bernoulli likelihood as the loss function. Street (1998) proposed a model that outputs a vector with each element representing the survival probability at a predefined time point, and used a modified relative entropy error (Solla et al., 1988) as the loss function.
Similar to Street (1998), Brown et al. (1997) proposed a model that estimates hazard components which is defined as a value in , the loss function is based on the sum of square errors. More recent work includes Nnet-survival (Gensheimer and Narasimhan, 2019) and RNN-SURV (Giunchiglia et al., 2018). Both models require fixed and evenly partitioned time intervals, where Nnet-survival includes a convolutional neural network structure (CNN) and RNN-SURV uses a recurrent neural network structure (RNN). They all use Bernoulli type loss functions with differently created binary variables, where RNN-SURV adds an upper bound of the negative C-index into the loss function.
There are several limitations in the current literature of survival analysis using neural networks. Cox-type neural network models are still relative risk models with baseline hazards, which retain certain model structure, and the networks only output the relative risks. Moreover, these methods only deal with time-independent covariates. Methods using time partition have potential to incorporate time-varying covariates, but usually require fixed time partition.
Furthermore, in these methods, loss functions are often constructed heuristically.
To overcome these limitations, we propose a new method to estimate the conditional hazard function directly using neural networks. In particular, inspired by the standard data-expansion approach for the Cox regression with time-varying covariates, we input time-varying covariates together with observed time points into a simple feed-forward network and output the logarithm of instantaneous hazard. We build the loss function from the logarithm of the full likelihood function, in which all functions, including the conditional hazard function, the conditional cumulative hazard function, and covariate processes, are evaluated only at the observed time points. Compared to existing methods, our new method has a number of advantages. First, we can handle time-varying covariates. Second, we make the least number of assumptions that only include conditional independent censoring and that the instantaneous hazard given entire covariate paths only depends on values of covariates observed at the current time. Third, estimating the (logarithm of) hazard function without imposing any constraint to the optimization automatically leads to a valid survival function estimator that is always monotone decreasing and bounded between 0 and 1.
Furthermore, since our loss function does not need to identify the risk set, scalable methods (e.g. training with batches in stochastic gradient descent) can be easily implemented to avoid blowing up the computer memory.
Estimating the conditional hazard function for censored survival data yields an estimation of the conditional survival function, hence equivalently the conditional distribution function, on the support of censored survival time given covariates. When there is no censoring, the problem naturally reduces to a general regression analysis, where the conditional distribution function is of interest. This clearly expands the scope of the current literature that primarily focuses on certain characteristic of the conditional distribution, for example, the conditional mean that corresponds to the mean regression.
Once we obtain an estimator of the conditional distribution function, we can easily calculate the conditional mean given covariates, which provides a robust alternative approach to the mean regression using the loss. Note that the mean regression requires a basic assumption that the error term is uncorrelated with any of the covariates, which can be easily violated if some important covariate is unknown or unmeasured and correlated with some measured covariate. Our likelihood estimating approach, however, does not need such an assumption.
2 The Estimating Method Using Neural Networks
In this section, we start with the likelihood-based loss function for estimating the conditional survival function given a set of time-varying covariates, then generalize the approach to estimating the conditional distribution function for an arbitrary continuous response variable, and finally provide an estimating procedure using neural networks.
2.1 Survival Analysis with Time-Varying Covariates
2.1.1 Data and Notation
For subject , we denote the time-varying covariate vector as , the underlying failure time as , and the underlying censoring time as , where possesses a Lebesgue density. Let the observed time be and the failure indicator be . We have independent and identically distributed (i.i.d.) observations , where denotes the covariate history up to time , that is, . We assume each of the processes has left continuous sample path with right limit. Let be the conditional Lebesgue density function of , be the conditional density function of , be the conditional survival function of , and be the conditional survival function of .
Noting that the conditional survival probability given time-varying covaraites is not well-defined if there is an internal covariate, we assume that all covariates are external (Kalbfleisch and Prentice, 2002). Specifically, the conditional hazard function of is independent of future covariate values and, furthermore, only depends on the current values of covariate processes:
Let . Then the conditional cumulative hazard function given covariate history has the following form:
and the conditional survival function is given by
| (1) |
Using instead of in the above expression removes the positivity constraint for , hence simplifies the optimization algorithm for estimating the conditional survival function (1). Furthermore, equation (1) is always a valid survival function for any function .
2.1.2 Likelihood
Assume censoring time is independent of failure time given covariates. Then given observed data , , the full likelihood function becomes
Thus, the log likelihood is given by
| (2) |
2.1.3 Data Structure and Discretized Loss
| start time | stop time | covariates | ||
| 1 | 0 | |||
| 1 | 0 | |||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 1 | ||||
| 2 | 0 | |||
| 2 | 0 | |||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 2 | ||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
When fitting the Cox model with time-varying covariates, the data set is usually expanded to the structure given in Table 1 so each row is treated as an individual observation, where are sorted values of observed times and . Specifically, the time axis is partitioned naturally by observed times. The same data structure can be applied to maximizing the log likelihood function (2) at the grid points , or equivalently, minimizing the following loss function:
| (3) |
where . It becomes clear that the expanded data set in Table 1 provides a natural way of implementing numerical integration in the negative log likelihood based on empirical data. Once an estimator of is obtained using neural networks (see Subsection 2.3 for details), the conditional survival function can be estimated by plugging the estimated into equation (1).
2.2 Estimation of Conditional Distribution for Uncensored Data
If there is no censoring, then for all in the log likelihood function (2). Now consider an arbitrary continuous response variable that is no longer “time.” Note that the time variable . We are interested in estimating , the conditional distribution function of given covariates , where is a random vector. Since there is no time component in general, covariates are no longer “time-varying.”
Assume , , are i.i.d. Denote the observed data as , .
We generalize the idea of using hazard function in survival analysis to estimate for an arbitrary continuous random variable . Again, let . Then the conditional cumulative hazard function becomes
which gives the conditional distribution function
| (4) |
Hence, the log likelihood function is given by
| (5) |
Note that the above log likelihood has the same form as (2) except that the covariates are not time-varying, for all , and integrals start from . As a way of evaluating integrals in the log likelihood, the expanded data structure in Table 1 can be useful in estimating with slight modifications given in Table 2.
| start | stop | covariates | ||
| 1 | 0 | |||
| 1 | 0 | |||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 1 | … | 1 | ||
| 2 | 0 | |||
| 2 | 0 | |||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 2 | … | 1 | ||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
To be numerically tractable, we assign to be the value of the distribution function at , in other words, we make , which is the empirical probability measure of at . Thus . Letting and evaluating the integrals in (5) on grid points that are sorted values of , we obtain the following loss function:
| (6) | |||||
Once an estimator of , denoted by , is obtained, the conditional distribution function (4) can be estimated by
| (7) |
Remark 1
If the support of the continuous response variable has a fixed finite lower bound, then the integration for the conditional cumulative hazard function is the same as that for survival data. In other words, there is no need to assign a point mass of at .
2.3 Neural Networks, Hyperparameters and Regularization
We propose to estimate the arbitrary function , or when covariates are not time-varying, by minimizing the respective loss function (3) or (6) using neural networks. We then obtain the estimated conditional survival curve or the conditional distribution function from Equation (1) or Equation (7), respectively. The input of neural networks is or in each row of Table 1 or Table 2, and the output is or , respectively. Note that the first row for each in Table 2 is excluded from the calculation.
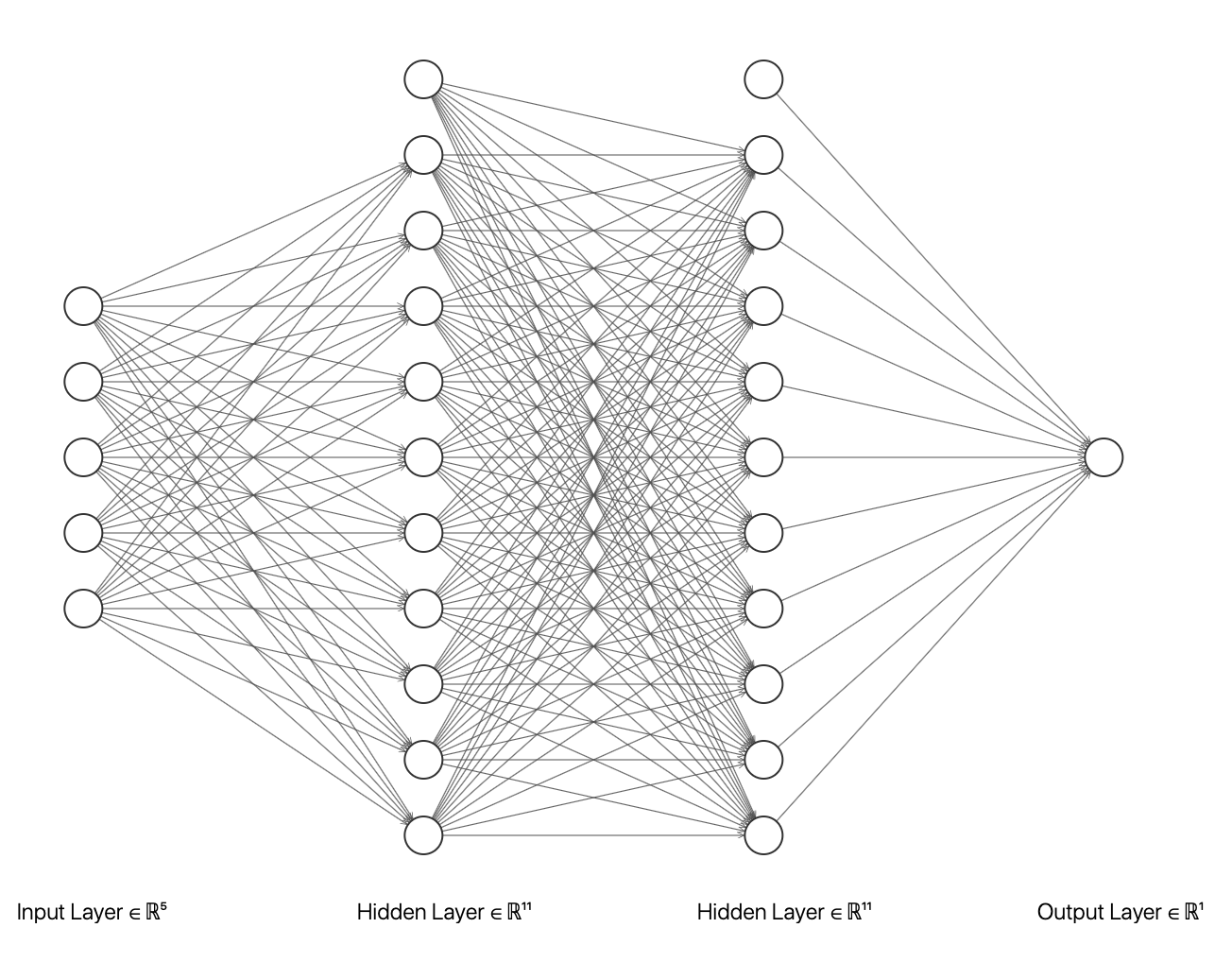
We use tensorflow.keras (Chollet et al., 2015) to build and train the neural networks. The network structure is a fully connected feed forward neural network with two hidden layers and a single output value. The input layer consists of , , and covariates. In addition, an intercept term is included in each layer (see Figure 1). The relu function is used as the activation function between input and hidden layers, and the linear function is used for the output so that the output value is not constrained. We use Adam (Kingma and Ba, 2014) as the optimizer. Other hyperparameters include the number of nodes in each layer, the batch size and the initial learning rate. In our simulations, the number of nodes in each hidden layer is 64, the batch size is 100, and the initial learning rate is 0.001. To have a fair comparison in real-world data examples, we tune the hyperparameters from the set of all combined values with the number of nodes in each hidden layer taken from , the initial learning rate from , and the batch size from .
We use early stopping to avoid over-fitting. According to Goodfellow et al. (2016), early stopping has the advantage over explicit regularization methods in that it automatically determines the correct amount of regularization.
Specifically, we randomly split the original data into training set and validation set with 1:1 proportion. When the validation loss is no longer decreasing in 10 consecutive steps, we stop the training. To fully use the data, we fit the neural networks again by swapping the training and the validation sets, then average both outputs as the final result.
3 Simulations
3.1 Censored Data with Time-Varying Covariates
For censored survival data with time-varying covariates, we aim to compare our method of using neural networks to the partial likelihood method for the Cox model under two different setups.
In the first setup, we generate data following the proportional hazards assumption so the Cox model is the gold standard. In the second setup, we generate data from the model with a quadratic term and an interaction term in the log relative hazard function so the Cox model with original covariates in the linear predictor becomes a misspecified model. Details are given below.
-
1.
In both setups, we use the hazard function of a scaled beta distribution as the baseline hazard:
where and are the density and the distribution functions of . We use so that .
-
2.
Generate time-varying covariates on a fine grid of . For with , , we generate random variables independently from a distribution, and independently from a distribution, and construct two time-varying covariates as follows:
The sample paths of both covariates are left-continuous step functions with right limit. We also generate three time-independent covariates:
-
3.
In Setup 1, the conditional hazard function is
(8) and in Setup 2,
(9) Clearly, fitting the Cox model with data generated from (9) in Setup 2 will not yield desirable results.
-
4.
Once covariates are generated, we numerically evaluate the conditional cumulative hazard function and the conditional survival function on the fine grid of survival time. Specifically, for ,
-
5.
For , we generate random variable from a distribution, then obtain the failure time by .
- 6.
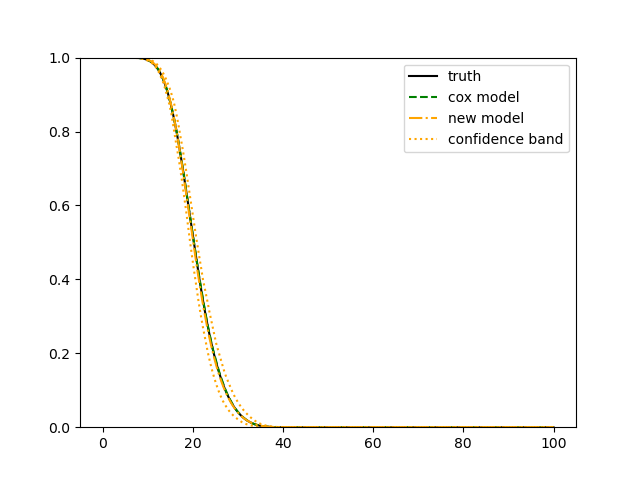
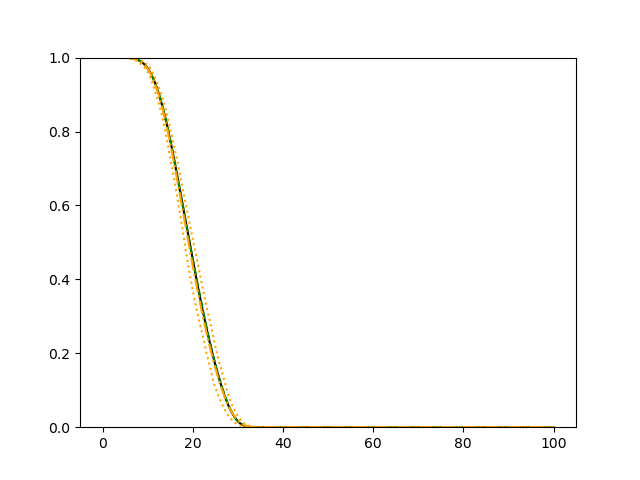
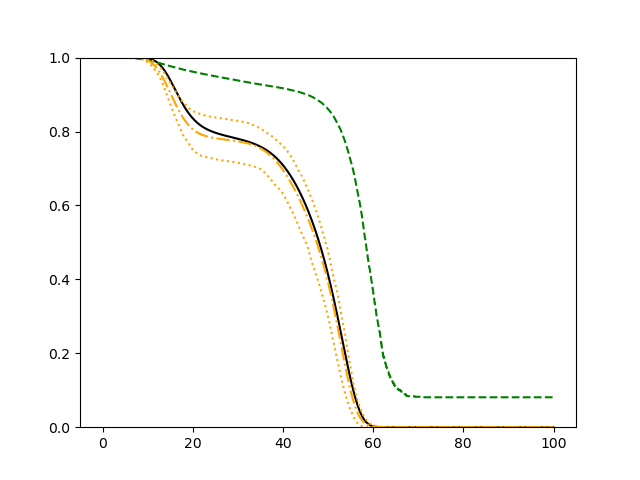
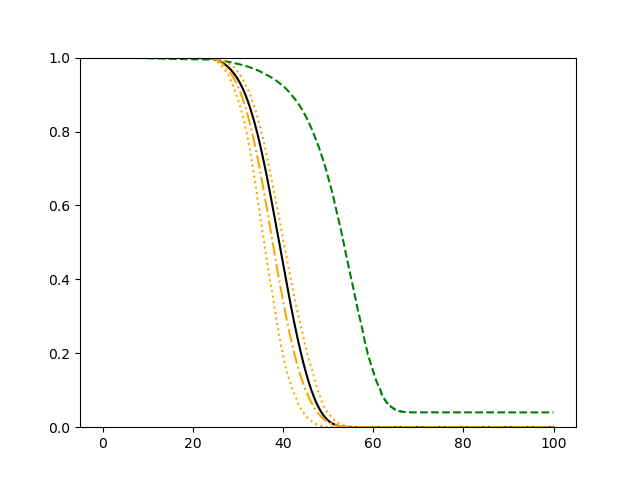
For each simulation setup, we independently generate a training set and a validation set with equal sample size, then fit our model using neural networks . We refit the model by swapping training and validation sets, and take the average as our estimator. For the Cox regression, we maximize the partial likelihood using all data. We repeat the process for independent data sets, and calculate the average and sample variance of these estimates at each time point on the fine grid for another set of randomly generated covariates. Finally, we plot the sample average of conditional survival curves estimated by neural networks together with the empirical confidence band, the average conditional survival curves estimated from the Cox regression, and the true conditional survival curve for a comparison.
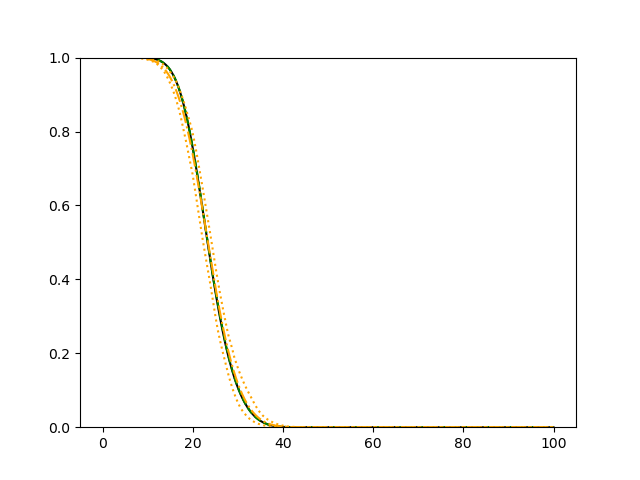
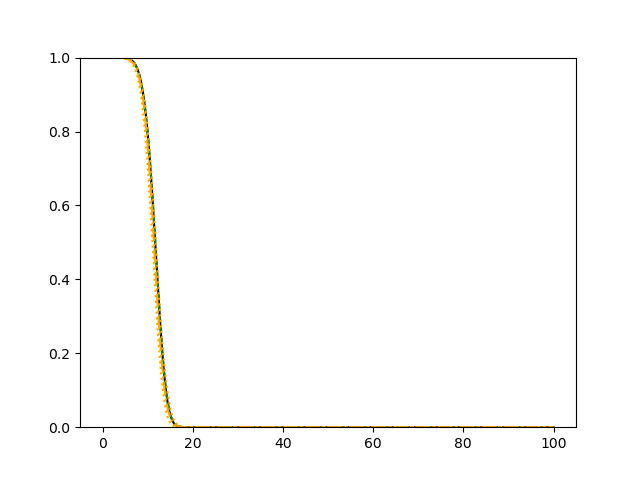
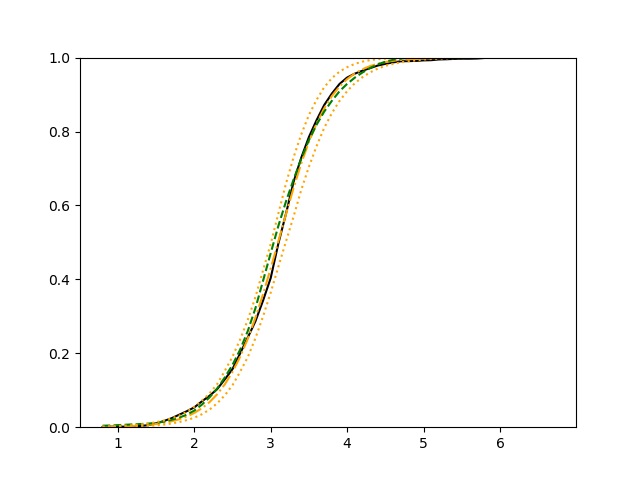
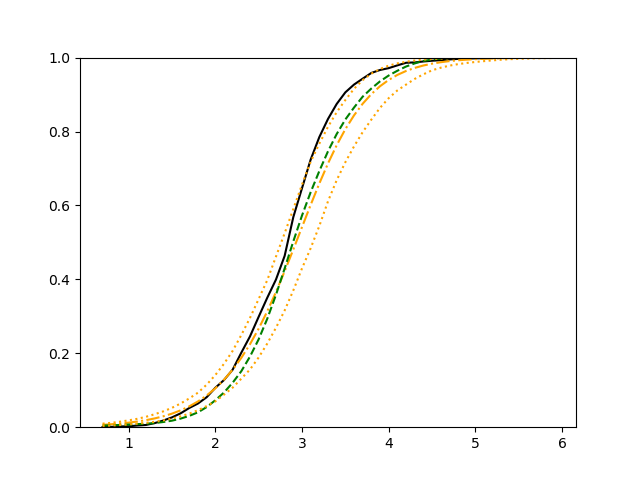
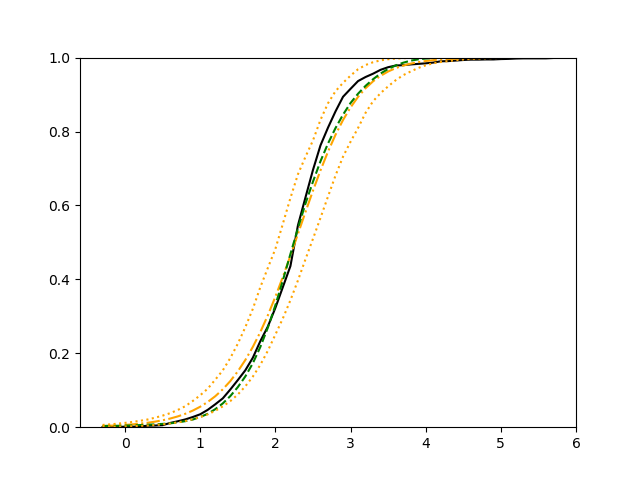
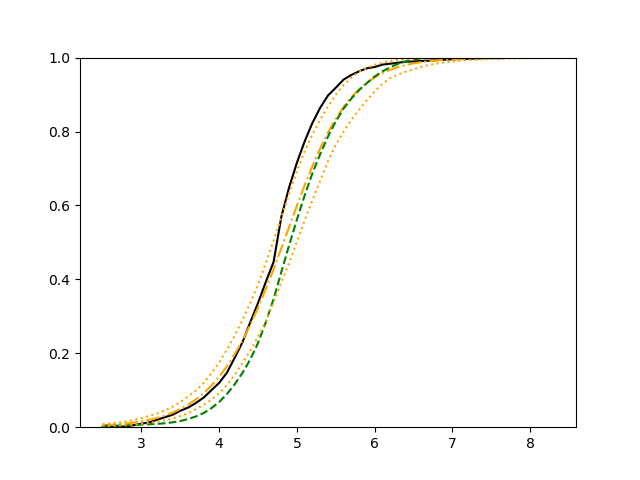
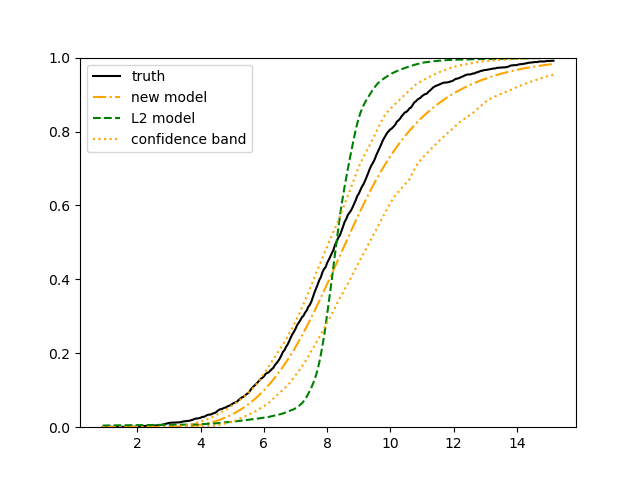
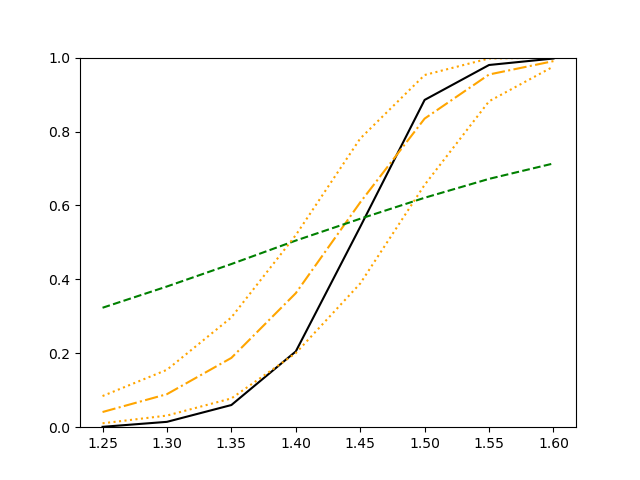
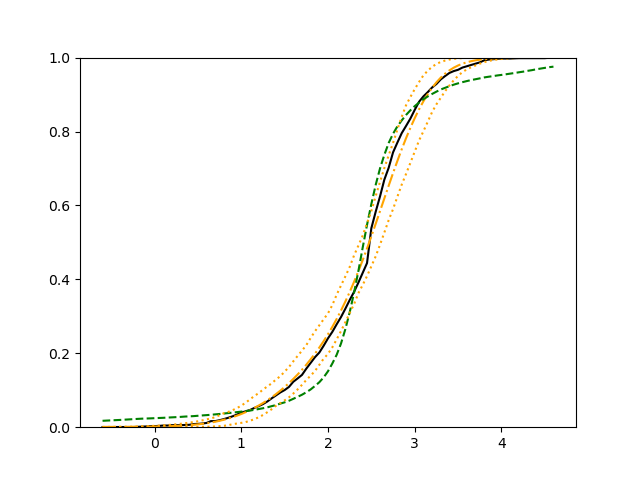
The simulation results illustrated in both Figure 2 and Figure 3 are based on a sample size of (1500 for training and 1500 for validation) with 100 repetitions, where the curves for 9 different sets of covariates are presented. The green dashed line is the average estimated curve by using the partial likelihood method, the orange dash-dot line is the average estimated curve by our proposed neural networks method, and the black solid line is the truth curve. The dotted orange curves are the 90% confidence band obtained from the 100 repeated simulation runs using the proposed method. From Figure 2 we see that when the Cox model is correctly specified, both the partial likelihood method and our proposed neural networks method perform well, with estimated survival curves nicely overlapping with the corresponding true curves. When the Cox model is misspecified, Figure 3 shows that the partial likelihood approach yields severe biases, whereas the proposed neural networks method still works well with a similar performance to that in Setup 1 shown in Figure 2 .
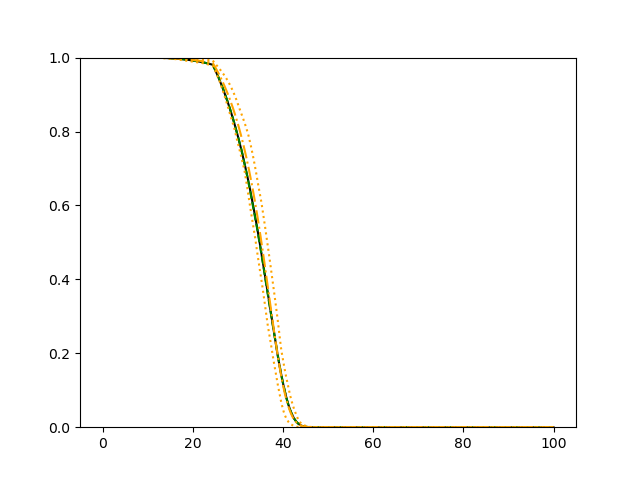
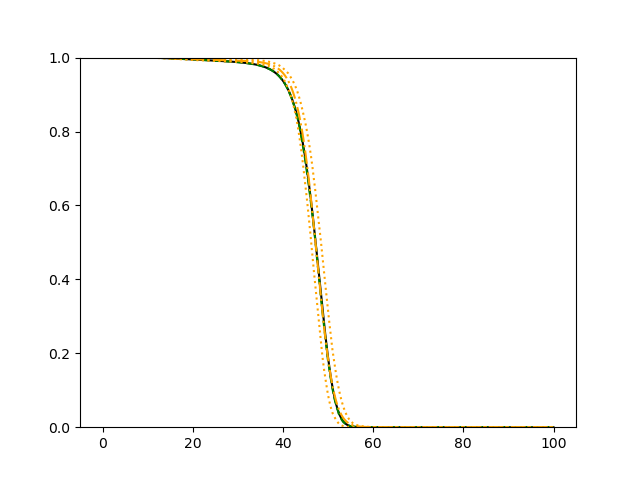
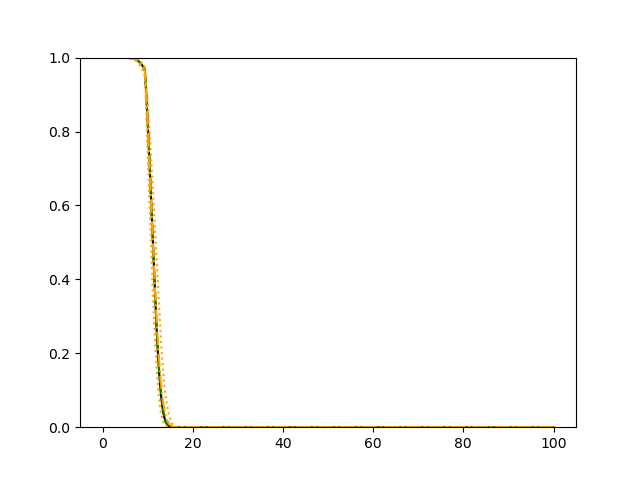
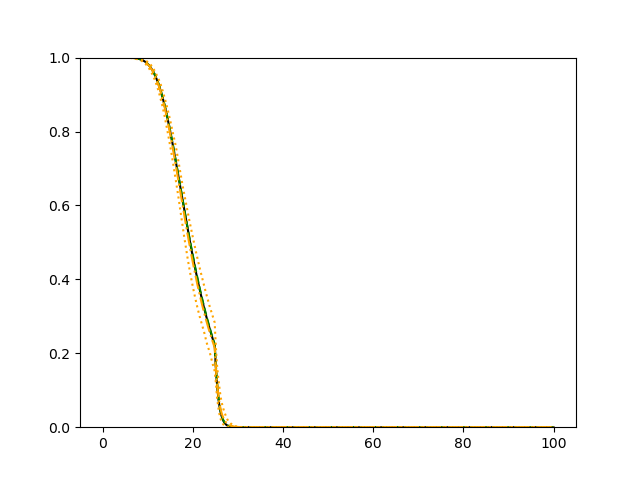
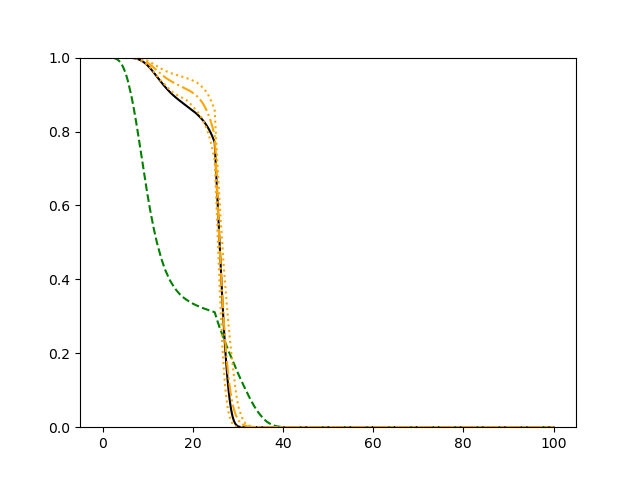
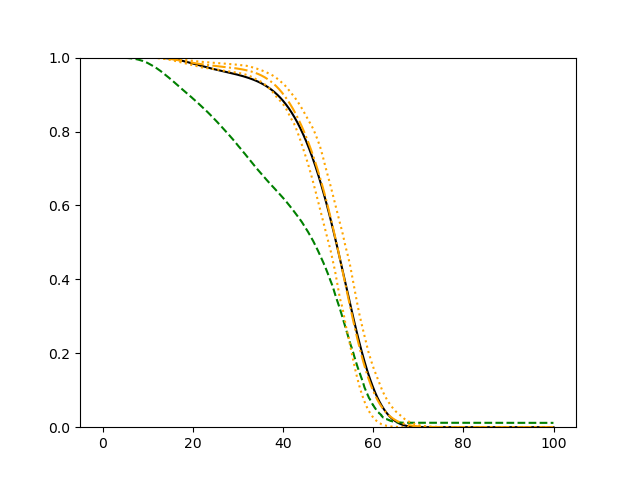
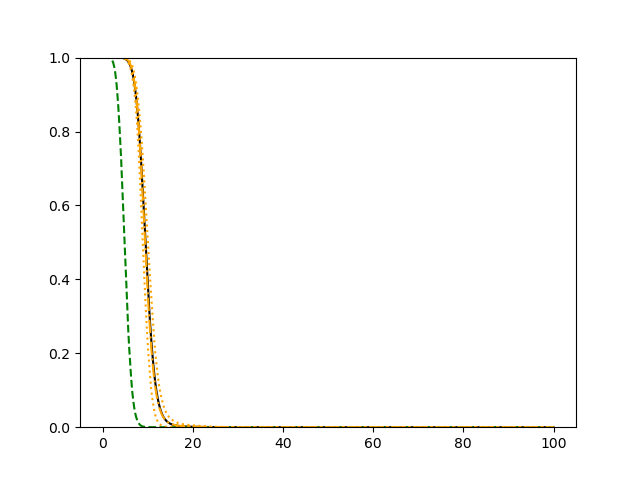
3.2 Uncensored Data
For uncensored continuous outcomes, the traditional neural networks method with the commonly used loss function gives the conditional mean estimator. Then the conditional distribution function given a set of covariate values can be estimated by shifting the center of the empirical distribution of training set residuals to the estimated conditional mean. This would yield a valid estimator under the assumption that the errors (outcomes subtract their conditional means) are i.i.d. and uncorrelated with conditional means. We will evaluate the impact of this widely imposed condition for the mean regression via simulations. On the other hand, an estimator of the conditional distribution function gives a conditional mean estimator as follows:
Thus, we will compare our method to the method with loss on the estimation of the conditional distribution function as well as the estimation of the conditional mean.
In the following simulation studies, we consider i.i.d. data generated from the following model:
, where denotes the -th vector of all covariates, is mean-zero given all covariates, and is a function of covariates, so is the -th error term with zero-mean. We consider two simulation setups. In the first setup, the error is uncorrelated with the mean and has constant variance. In the second setup, the error is correlated with the mean and has non-constant variance. We would expect our new method outperforms the method with loss since our loss function is based on the nonparametric likelihood function that is free of any model assumption. Specifically, covariate values are generated from the following distributions:
And the two setups are:
-
Setup 1 (uncorrelated error with constant variance): generate another covariate independently, then generate a mixture distribution of , , and with mixture probabilities , and let , where is a constant.
-
Setup 2 (correlated error with non-constant variance): generate another covariate , such that
then generate a mixture distribution of , , and with mixture probabilities , and let , where is a constant.
Note that different values of constant yield different signal to noise ratios in both setups.
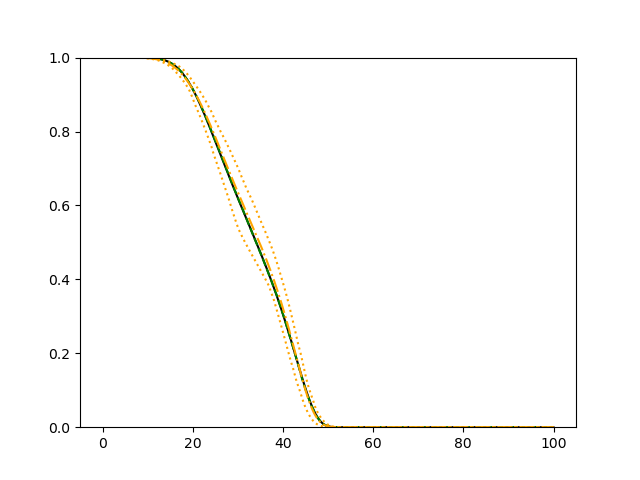
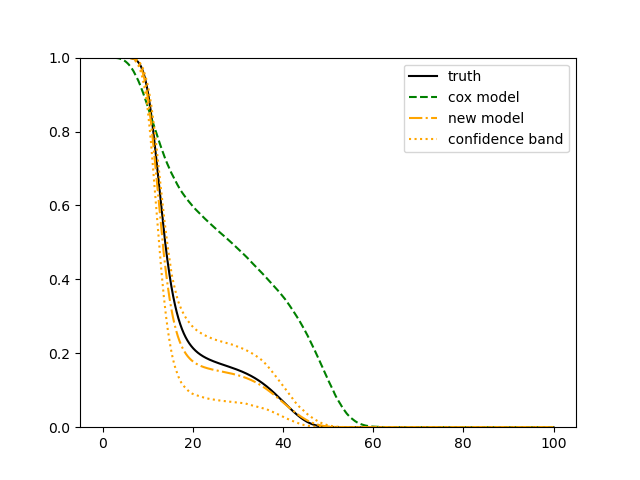
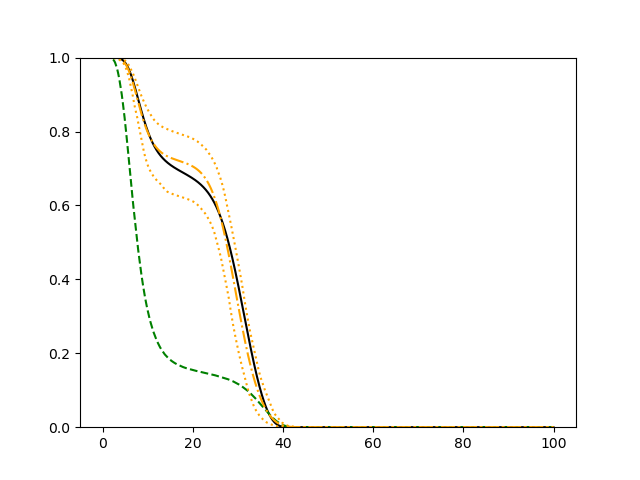
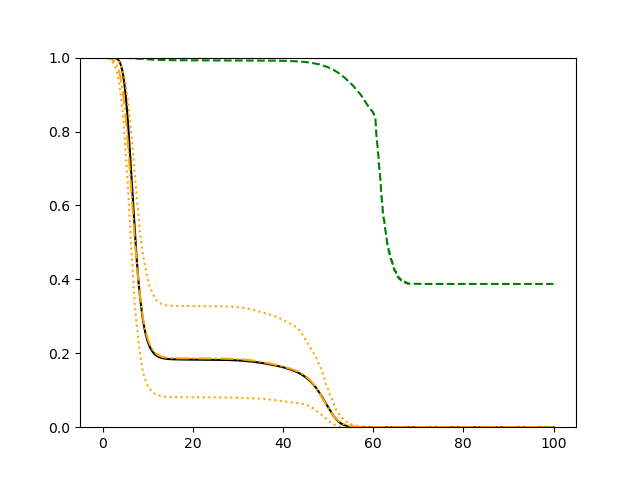
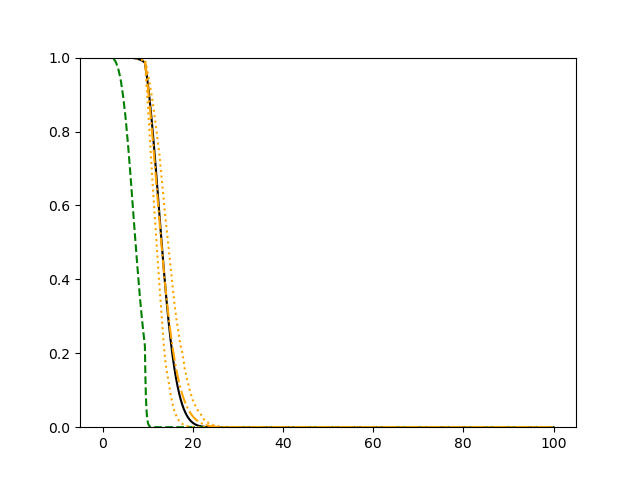
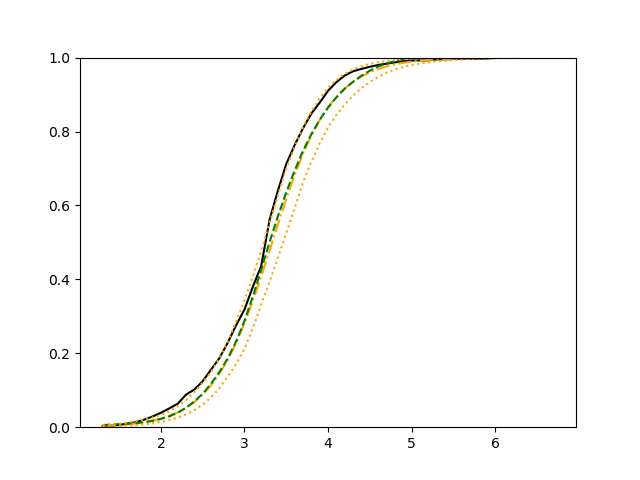
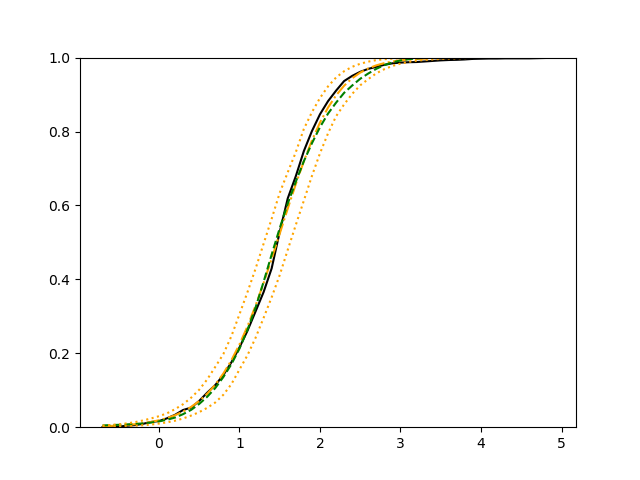
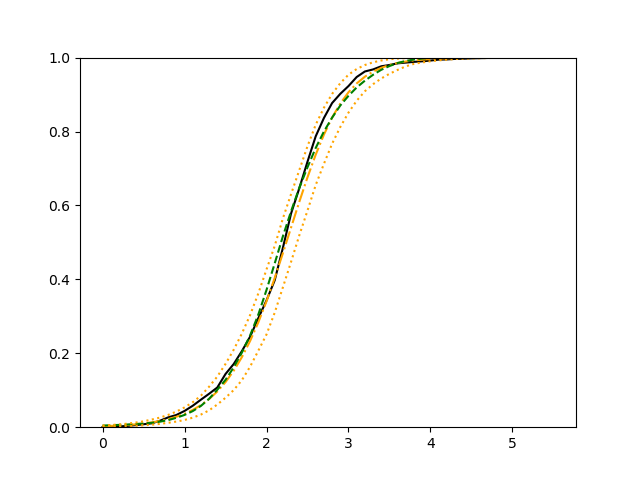
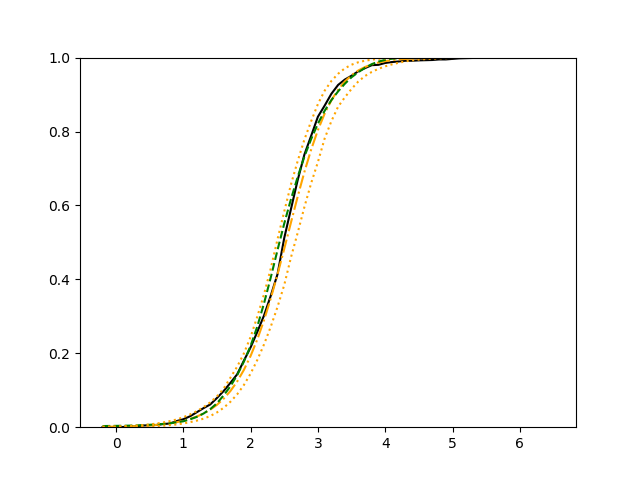
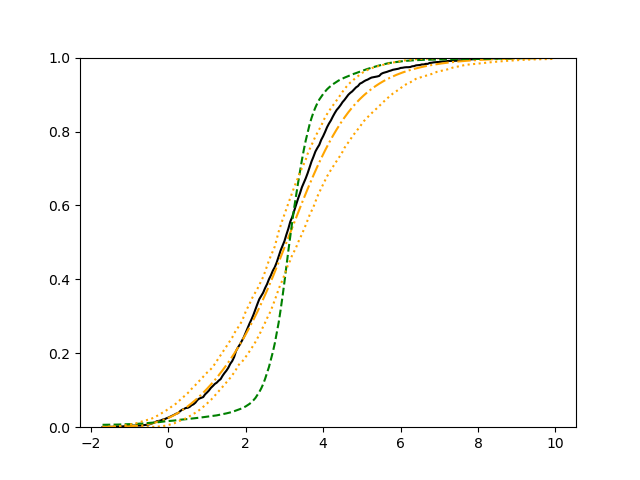
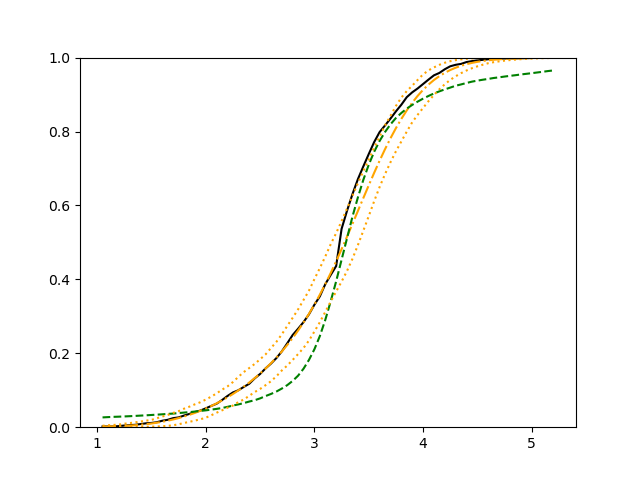
For each setup, we generate independent training and validation data sets with equal sample size, then fit both models with our general loss given in (6) and the loss using the same neural networks architecture. Figure 4 and Figure 5 illustrate the comparisons of estimated conditional distribution functions given 9 different sets of covariates between these two methods with a sample size of 5000 and 100 replications. In these figures, the black solid curve represents the true conditional distribution function, the green dashed curve represents the estimated conditional distribution function using loss, and the orange dash-dot curve represents the estimated conditional distribution using our method. The orange dotted curves are the 90% confidence band estimated using our method from the 100 repeated experiments. Figure 4 illustrates that when the error is uncorrelated with the covariates and has constant variance (Setup 1), both methods perform well in estimating the conditional distribution functions. When the error becomes correlated with the covariates and has non-constant variance (Setup 2), the traditional neural networks method using loss fails, which is illustrated in Figure 5.
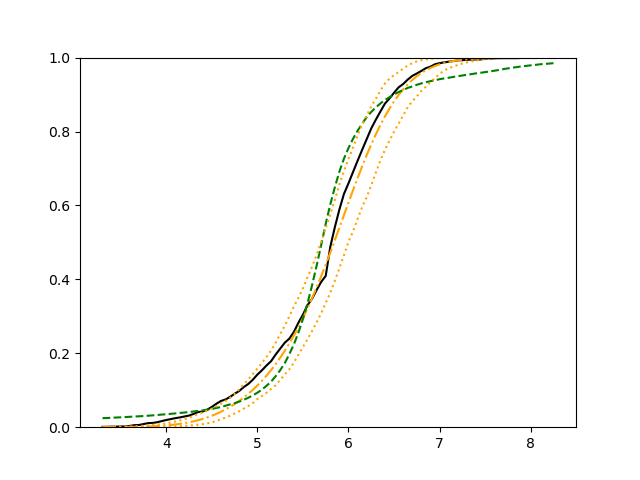
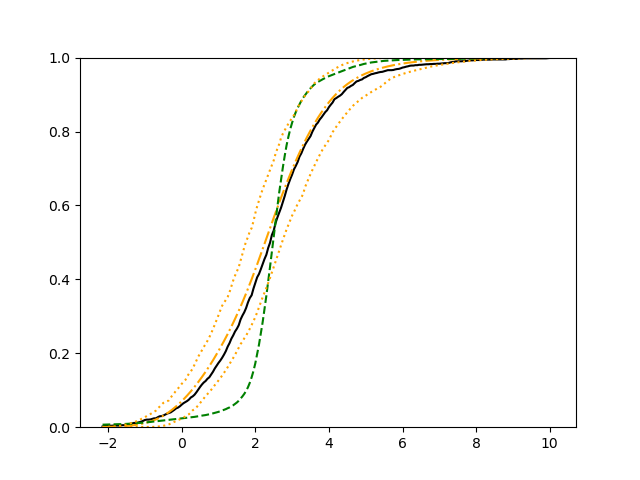
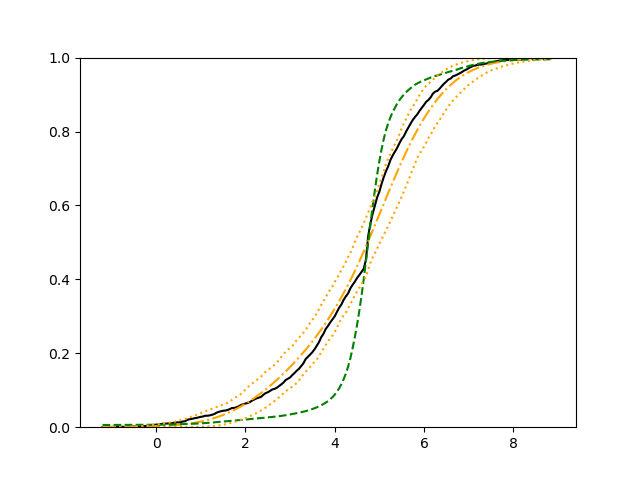
We also compare the conditional mean estimates of both methods under two different sample sizes ( and ) and two different magnitudes of noises ( and ). We evaluate the performance of both methods by averaging the mean and median squared prediction errors, respectively, of 500 independently generated test data points over 100 replications, and summarize the results in Table 3. Coverage rates of 90% and 95% predictive intervals obtained using our method are also presented in Table 3. In Setup 1, both methods have similar mean squared prediction error, and our method yields slightly smaller median squared prediction error. In Setup 2, our model yields slightly better mean squared error, and significantly better median squared error. Our model provides reasonable prediction coverage rates in both setups, with improved performance as the sample size increases.
| Sample size | 1000 | 5000 | ||
| Setup 1 | ||||
| 0.5 | 1 | 0.5 | 1 | |
| method mean squared error | 0.50 | 1.83 | 0.45 | 1.73 |
| new method mean squared error | 0.51 | 1.84 | 0.44 | 1.73 |
| method median squared error | 0.17 | 0.59 | 0.14 | 0.52 |
| new method median squared error | 0.16 | 0.56 | 0.13 | 0.51 |
| new method 90% coverage rate | 0.90 | 0.90 | 0.90 | 0.90 |
| new method 95% coverage rate | 0.95 | 0.95 | 0.95 | 0.96 |
| Setup 2 | ||||
| 0.5 | 1 | 0.5 | 1 | |
| method mean squared error | 1.79 | 6.90 | 1.65 | 6.47 |
| new method mean squared error | 1.74 | 6.84 | 1.58 | 6.34 |
| method median squared error | 0.09 | 0.27 | 0.04 | 0.13 |
| new method median squared error | 0.02 | 0.08 | 0.01 | 0.05 |
| new method 90% coverage rate | 0.87 | 0.87 | 0.91 | 0.91 |
| new method 95% coverage rate | 0.91 | 0.91 | 0.95 | 0.94 |
4 Real-World Data Sets
4.1 Censored Data Examples
There are five real-world data sets analyzed by Kvamme et al. (2019). We re-analyze all these data sets using our method and compare with Kvamme et al. (2019), except one data set that contains too many ties for which a discrete survival model would be more appropriate. Theses four data sets are: the Study to Understand Prognoses Preferences Outcomes and Risks of Treatment (SUPPORT), the Molecular Taxonomy of Breast Cancer International Consortium (METABRIC), the Rotterdam tumor bank and German Breast Cancer Study Group (Rot.& GBSG), and the Assay Of Serum Free Light Chain (FLCHAIN).
The first three data sets are introduced and preprocessed by Katzman et al. (2018). The fourth data set is from the survival package of R (Therneau (2021)) and preprocessed by Kvamme et al. (2019). These four data sets have sample sizes of a few thousand and the covariate numbers range from 7 to 14. The covariates in these data sets are all time-independent.
To compare with their method, we use the same 5-fold cross-validated evaluation criteria described in Kvamme et al. (2019), including concordance index (C-index), integrated Brier score (IBS) and integrated binomial log-likelihood (IBLL). The time-dependent C-index (Antolini et al., 2005) estimates the probability that the predicted survival times of two comparable individuals have the same ordering as their true survival times,
The generalized Brier score (Graf et al., 1999) can be interpreted as the mean squared error of the probability estimates. To account for censoring, the scores are weighted by inverse censoring survival probability. In particular, for a fixed time ,
where is the Kaplan-Meier estimate of the censoring time survival function. The binomial log-likelihood is similar to the Brier score,
The integrated Brier score IBS and the integrated binomial log-likelihood score IBLL are calculated by numerical integration over the time duration of the test set.
The results of our method are summarized in Table 4, together with the results of Kvamme et al. (2019) for a comparison. For SUPPORT and METABRIC data, our model yields the best integrated brier score and integrated binomial log-likelihood.
For Rot.&GBSG data, our model has the best C-index. The other results are comparable to that from the Kvamme et al. (2019). Note that in the 5-fold cross validation procedure, we use the set-aside data only as the test set for evaluation of the criteria and the rest of the data for training and validation of the neural networks, whereas Kvamme et al. (2019) use the set-aside data as both the test set and the validation set which would lead to more favorable evaluations.
| C-Index | IBS | IBLL | |||||||
|---|---|---|---|---|---|---|---|---|---|
| a | b | c | a | b | c | a | b | c | |
| SUPPORT | 0.613 | 0.629 | 0.609 | 0.213 | 0.212 | 0.195∗∗ | -0.615 | -0.613 | -0.574∗∗ |
| METABRIC | 0.643 | 0.662 | 0.174 | 0.172 | 0.166∗∗ | -0.515 | -0.511 | -0.496∗∗ | |
| Rot.&GBSG | 0.669 | 0.677 | 0.680∗∗ | 0.171 | 0.169 | 0.176 | -0.509 | -0.502 | -0.524 |
| FLCHAIN | 0.793 | 0.790 | 0.788 | 0.093 | 0.102 | 0.102∗ | -0.314 | -0.432 | -0.336∗ |
4.2 Uncensored Data
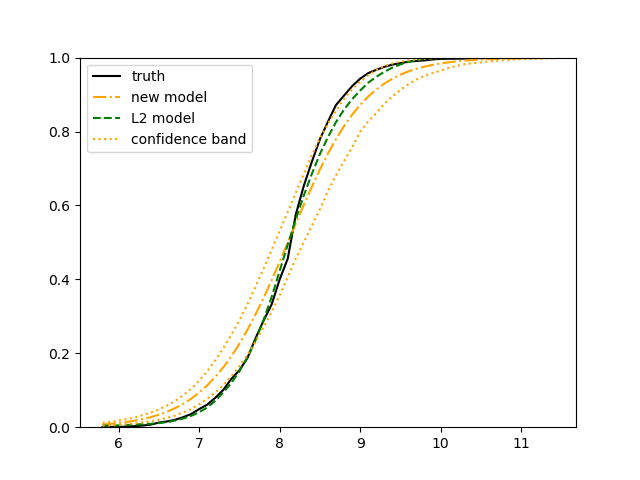
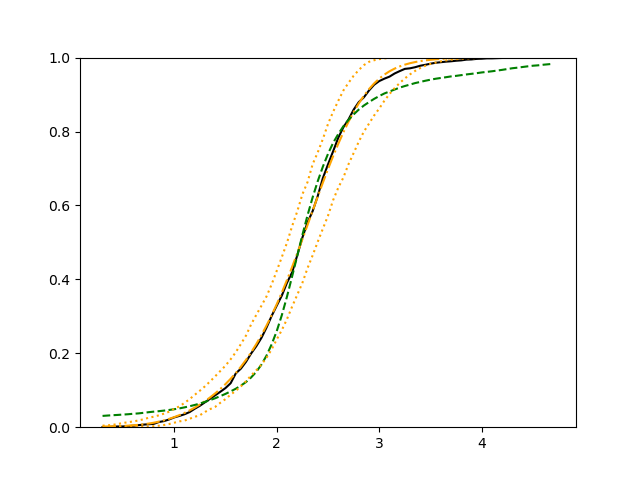
We use QSAR Fish Toxicity data set (Cassotti et al., 2015) for an illustration. This data set is collected for developing quantitative regression models to predict acute aquatic toxicity towards the fish Pimephales promelas (fathead minnow) on a set of 908 chemicals. Six molecular descriptors (representing the structure of chemical compounds) are used as the covariates and the concentration that causes death in 50% of test fish over a test duration of 96 hours, called 96 hours (ranges from 0.053 to 9.612 with a mean of 4.064) was used as model response. The 908 data points are curated and filtered from experimental data. The six molecular descriptors come from a variable selection procedure through genetic algorithms. In their original research article, the authors used a -nearest-neighbours (kNN) algorithm to estimate the mean. The data set can be obtained from the machine learning repository of the University of California, Irvine (https://archive.ics.uci.edu/ml/datasets/QSAR+fish+toxicity).
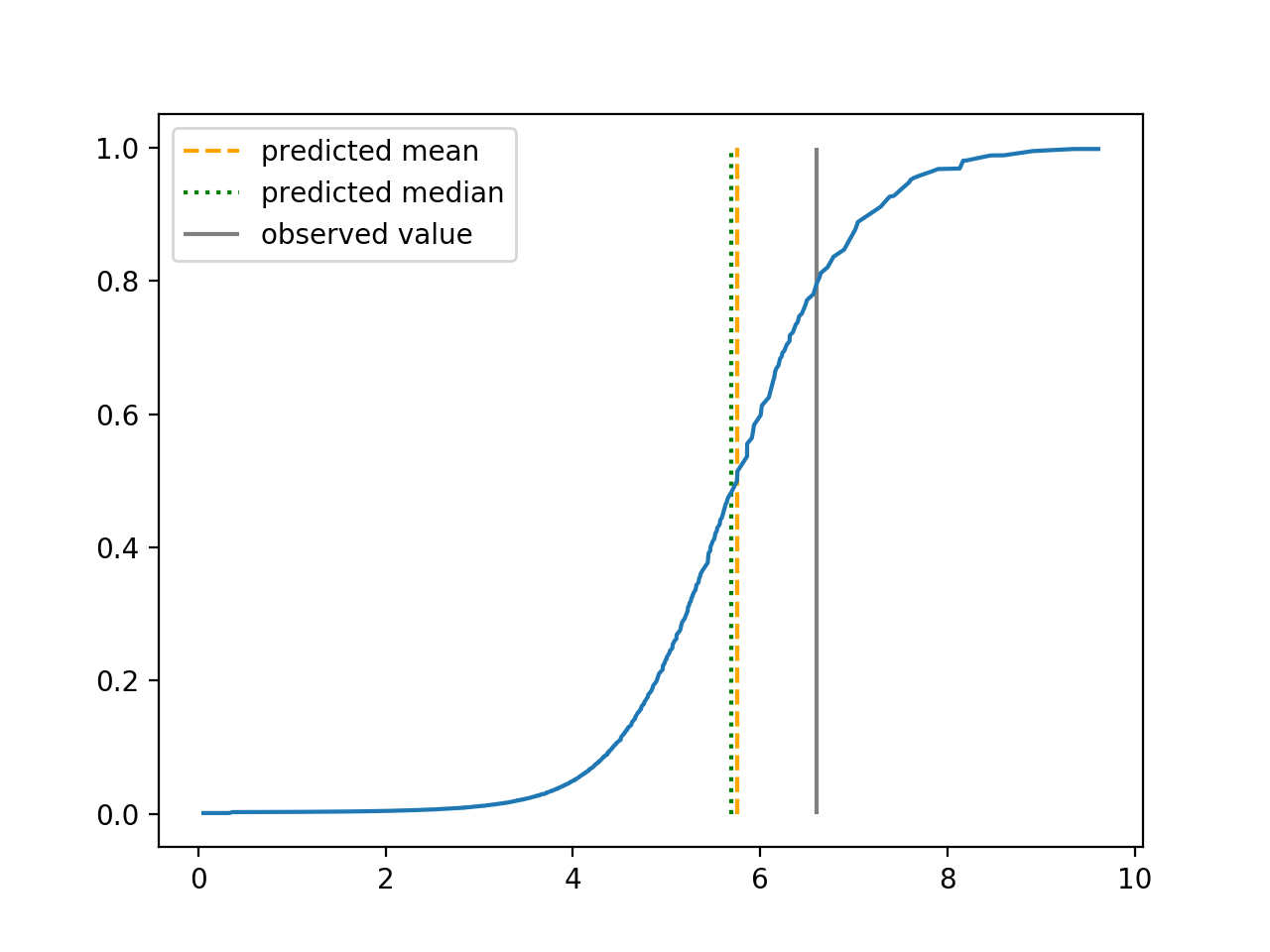
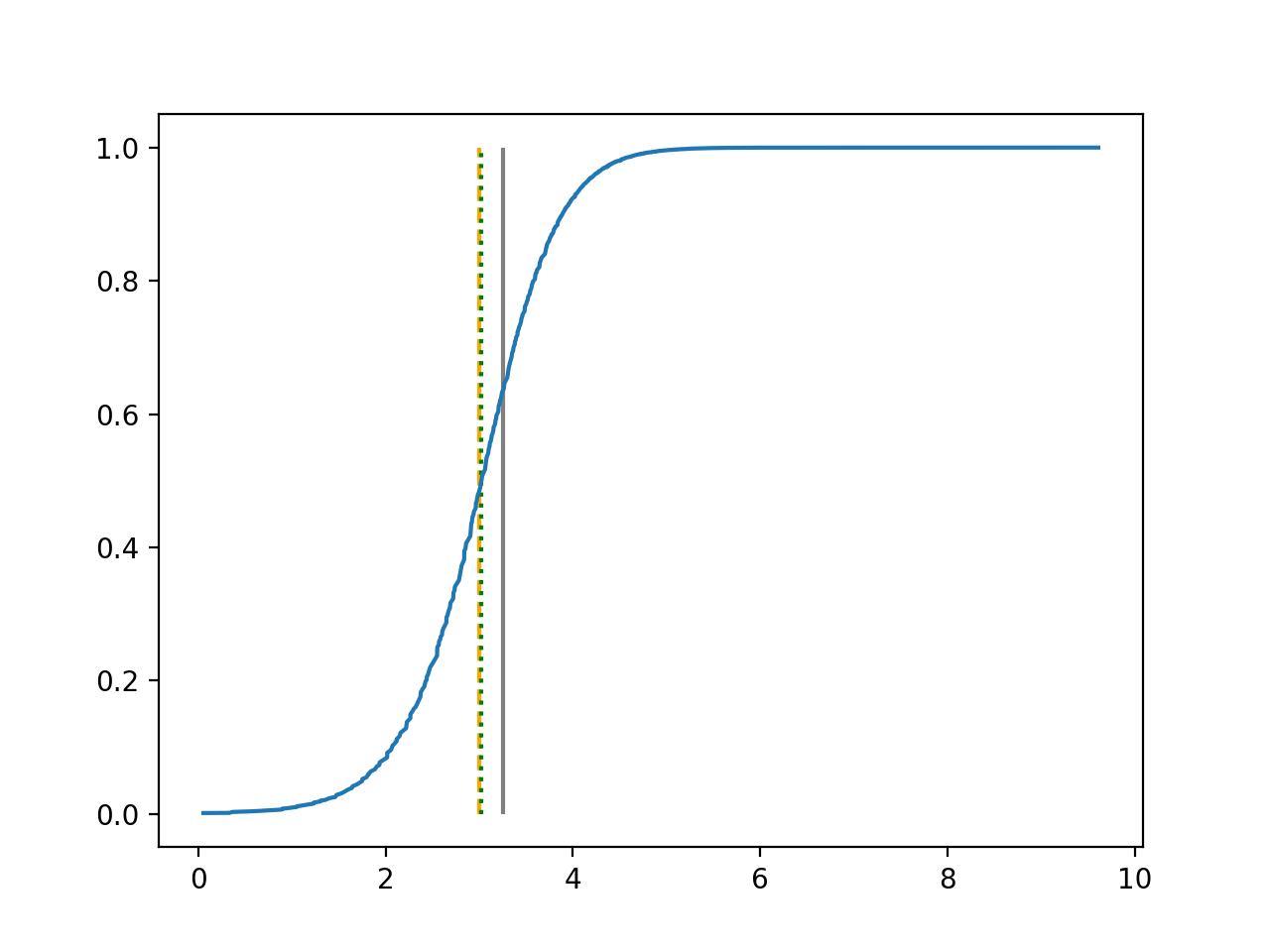
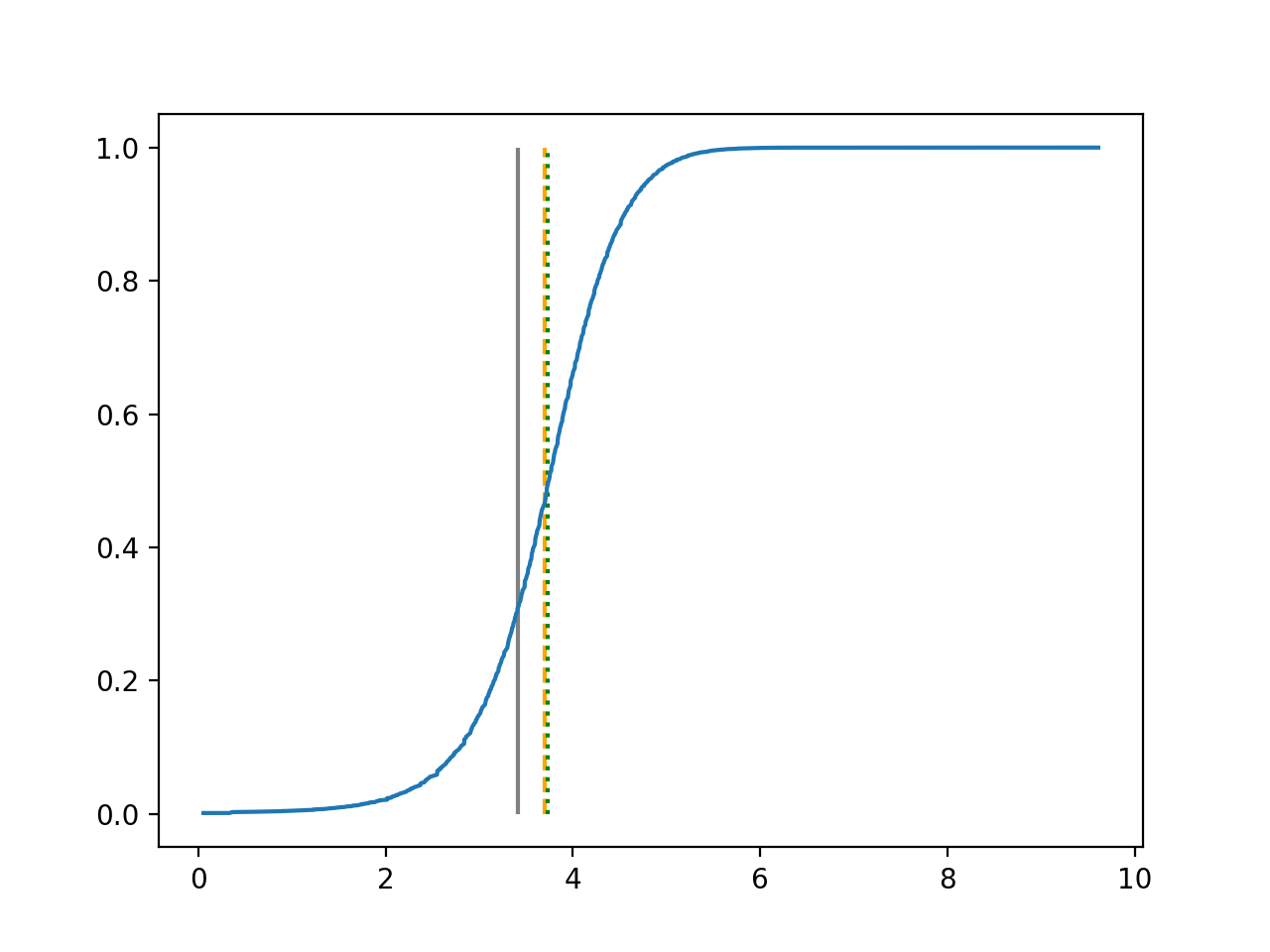
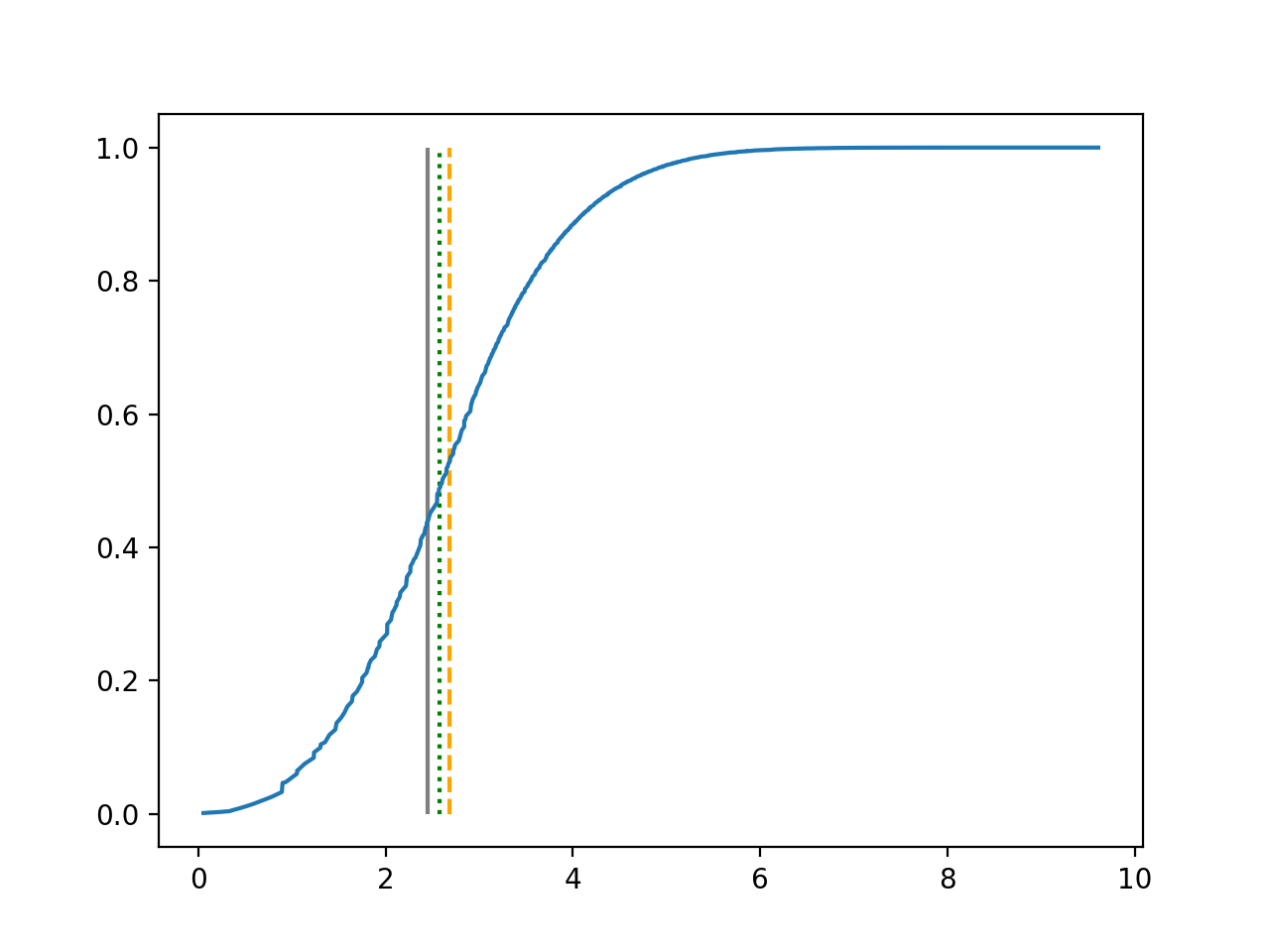
We use 5-fold cross-validated , mean squared error and median squared error to evaluate our method and the neural networks with loss on this real-world data set and summarize the results in Table 5. Our new method yields better prediction in all three criteria. Note that we obtain the same 5-fold cross-validated value of 0.61 as Cassotti et al. (2015) did by using kNN. Predicted conditional distribution functions given four different sets of covariate values provided by our method are presented in Figure 6 for an illustration.
| method | New method | |
|---|---|---|
| Mean squared error | 0.86 | 0.82 |
| Median squared error | 0.22 | 0.20 |
| 0.59 | 0.61 |
5 Discussion
Early stopping based on a hold-out validation set is used to prevent over-fitting in this work. It is well accepted in deep learning field that early stopping is an effective regularization method.
Goodfellow et al. (2016) pointed out that, in the case of a linear regression model with a quadratic error function and using simple gradient descent, early stopping is equivalent to regularization.
Thus, intuitively, the validation loss can be a good approximation of the population loss, which implies the estimator obtained using early stopping can be a good approximation of the minimizer of the population loss. A thorough investigation of the asymptotic behavior of our approach using early stopping would be of great interest.
The data expansion technique used in this article provides a simple and natural way of numerically evaluating the full likelihood based loss function. However, it seems that the data expansion would increase the effective sample size from to . This may not be a concern for the survival problem with time-varying covariates because each covariate process needs to be observed at least at all distinct time points, leading to an order of number of distinct data points. When covariates are random variables other than stochastic processes, the sample size is indeed , thus there should be a large room for developing more efficient numerical approaches. In particular, a recent work by Tang et al. (2022) comes to our attention, which combines neural networks with an ordinary differential equation (ODE) framework to estimate the conditional survival function given a set of baseline covariates, in other words, time-independent covariates. They use ODE solver to integrate the cumulative hazard function from an initial value and its derivative (the hazard function). Based on adjoint sensitivity analysis, they are able to avoid going into the ODE solver in back propagation, but use another ODE to calculate the gradient and update the parameters. They show such an algorithm is faster than conventional methods. It is of great interest to extend the ODE approach to the survival problem with time-varying covariates and the case of arbitrary uncensored data as well to potentially speed up the computation, which is under current investigation.
Acknowledgements
This work was supported in part by NIH R01 AG056764 and NSF DMS 1915711.
References
- Antolini et al. (2005) Laura Antolini, Patrizia Boracchi, and Elia M. Biganzoli. A time-dependent discrimination index for survival data. Statistics in medicine, 24 24:3927–44, 2005.
- Biganzoli et al. (1998) Elia Biganzoli, Patrizia Boracchi, Luigi Mariani, and Ettore Marubini. Feed forward neural networks for the analysis of censored survival data: a partial logistic regression approach. Statistics in Medicine, 17(10):1169–1186, 1998.
- Brown et al. (1997) Stephen F. Brown, Alan J. Branford, and William Moran. On the use of artificial neural networks for the analysis of survival data. IEEE Transactions on Neural Networks, 8(5):1071–1077, 1997.
- Cassotti et al. (2015) Matteo Cassotti, Davide Ballabio, Roberto Todeschini, and Viviana Consonni. A similarity-based qsar model for predicting acute toxicity towards the fathead minnow (pimephales promelas). SAR and QSAR in Environmental Research, 26(3):217–243, 2015.
- Ching et al. (2018) Travers Ching, Xun Zhu, and Lana X. Garmire. Cox-nnet: An artificial neural network method for prognosis prediction of high-throughput omics data. PLOS Computational Biology, 14(4):1–18, 04 2018.
- Chollet et al. (2015) Francois Chollet et al. Keras, 2015. URL https://github.com/fchollet/keras.
- Cox (1972) David R. Cox. Regression models and life-tables. Journal of the Royal Statistical Society: Series B (Methodological), 34(2):187–202, 1972.
- Faraggi and Simon (1995) David Faraggi and Richard Simon. A neural network model for survival data. Statistics in Medicine, 14(1):73–82, 1995.
- Gensheimer and Narasimhan (2019) Michael F. Gensheimer and Balasubramanian Narasimhan. A scalable discrete-time survival model for neural networks. PeerJ, 7:e6257–e6257, 01 2019.
- Giunchiglia et al. (2018) Eleonora Giunchiglia, Anton Nemchenko, and Mihaela van der Schaar. Rnn-surv: A deep recurrent model for survival analysis. pages 23–32, 2018.
- Goodfellow et al. (2016) Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
- Graf et al. (1999) Erika Graf, Claudia Schmoor, Willi Sauerbrei, and Martin Schumacher. Assessment and comparison of prognostic classification schemes for survival data. Statistics in medicine, 18 17-18:2529–45, 1999.
- Hall and Yao (2005) Peter Hall and Qiwei Yao. Approximating conditional distribution functions using dimension reduction. The Annals of Statistics, 33(3):1404–1421, 2005.
- Hall et al. (1999) Peter Hall, Rodney C. L. Wolff, and Qiwei Yao. Methods for estimating a conditional distribution function. Journal of the American Statistical Association, 94(445):154–163, 1999.
- Harrell et al. (1984) Frank E. Harrell, Kerry L. Lee, Robert M. Califf, David B. Pryor, and Robert A. Rosati. Regression modelling strategies for improved prognostic prediction. Statistics in medicine, 3(2):143—152, 1984.
- Kalbfleisch and Prentice (2002) John D. Kalbfleisch and Ross L. Prentice. The Statistical Analysis of Failure Time Data (2nd ed.). Hoboken, NJ:Wiley, 2002.
- Katzman et al. (2018) Jared L. Katzman, Uri Shaham, Alexander Cloninger, Jonathan Bates, Tingting Jiang, and Yuval Kluger. Deepsurv: personalized treatment recommender system using a cox proportional hazards deep neural network. BMC Medical Research Methodology, 18(1):24, 2018.
- Kingma and Ba (2014) Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint, 2014. URL https://arxiv.org/abs/1412.6980.
- Kvamme et al. (2019) Håvard Kvamme, Ørnulf Borgan, and Ida Scheel. Time-to-event prediction with neural networks and cox regression. Journal of Machine Learning Research, 20(129):1–30, 2019.
- Solla et al. (1988) Sara A. Solla, Esther Levin, and Michael Fleisher. Accelerated learning in layered neural networks. Complex Syst., 2, 1988.
- Street (1998) Nick W. Street. A neural network model for prognostic prediction. In ICML, pages 540–546. Citeseer, 1998.
- Tang et al. (2022) Weijing Tang, Jiaqi Ma, Qiaozhu Mei, and Ji Zhu. Soden: A scalable continuous-time survival model through ordinary differential equation networks. Journal of Machine Learning Research, 23(34):1–29, 2022.
- Therneau (2021) Terry M. Therneau. A Package for Survival Analysis in R, 2021. URL https://CRAN.R-project.org/package=survival. R package version 3.2-13.
- Xiang et al. (2000) Anny Xiang, Pablo Lapuerta, Alex Ryutov, Jonathan Buckley, and Stanley Azen. Comparison of the performance of neural network methods and cox regression for censored survival data. Computational Statistics & Data Analysis, 34(2):243 – 257, 2000.