Conditional Generative Modeling via Learning the Latent Space
Abstract
Although deep learning has achieved appealing results on several machine learning tasks, most of the models are deterministic at inference, limiting their application to single-modal settings. We propose a novel general-purpose framework for conditional generation in multimodal spaces, that uses latent variables to model generalizable learning patterns while minimizing a family of regression cost functions. At inference, the latent variables are optimized to find optimal solutions corresponding to multiple output modes. Compared to existing generative solutions, our approach demonstrates faster and stable convergence, and can learn better representations for downstream tasks. Importantly, it provides a simple generic model that can beat highly engineered pipelines tailored using domain expertise on a variety of tasks, while generating diverse outputs. Our codes will be released.
1 Introduction
Conditional generative models provide a natural mechanism to jointly learn a data distribution and optimize predictions. In contrast, discriminative models improve predictions by modeling the label distribution. Learning to model the data distribution allows generating novel samples and is considered a preferred way to understand the real world. Existing conditional generative models have generally been explored in single-modal settings, where a one-to-one mapping between input and output domains exists (Nalisnick et al., 2019; Fetaya et al., 2020). Here, we investigate continuous multimodal (CMM) spaces for generative modeling, where one-to-many mappings exist between input and output domains. This is critical since many real world situations are inherently multi-modal, e.g., humans can imagine several outcomes for a given occluded image. In a discrete setting, this problem becomes relatively easy to tackle using techniques such as maximum-likelihood-estimation, since the output can be predicted as a vector (Zhang et al., 2016), which is not possible in continuous domains. Consequently, generative modeling in CMM spaces remains a challenging task.
To model CMM spaces, a prominent approach in the literature is to use a combination of reconstruction and adversarial losses (Isola et al., 2017; Zhang et al., 2016; Pathak et al., 2016). However, this entails key shortcomings. 1) The goals of adversarial and reconstruction losses are contradictory (Sec. 4), hence model engineering and numerous regularizers are required to support convergence (Lee et al., 2019; Mao et al., 2019), thereby resulting in less-generic models tailored for specific applications (Zeng et al., 2019; Vitoria et al., 2020). 2) The adversarial loss based models are notorious for difficult convergence due to the challenge of finding Nash equilibrium of a non-convex min-max game in high-dimensions (Barnett, 2018; Chu et al., 2020; Kodali et al., 2017). 3) The convergence is heavily dependent on the architecture, hence such models show lack of scalability (Thanh-Tung et al., 2019; Arora & Zhang, 2017). 4) The promise of assisting downstream tasks remains challenging, with a large gap in performance between the generative modelling approaches and their discriminative counterparts (Grathwohl et al., 2020; Jing & Tian, 2020).
In this work, we propose a general-purpose framework for modeling CMM spaces using a set of domain-agnostic regression cost functions instead of the adversarial loss. This improves both the stability and eliminates the incompatibility between the adversarial and reconstruction losses, allowing more precise outputs while maintaining diversity. The underlying notion is to learn the ‘behaviour of the latent variables’ in minimizing these cost functions while converging to an optimum mode during the training phase, and mimicking the same at inference. Despite being a novel direction, the proposed framework showcases promising attributes by: (a) achieving state-of-the-art results on a diverse set of tasks using a generic model, implying generalizability, (b) rapid convergence to optimal modes despite architectural changes, (c) learning useful features for downstream tasks, and (d) producing diverse outputs via traversal through multiple output modes at inference.
2 Proposed Methodology
We define a family of cost functions , where is the input, is the ground-truth mode for , is a generator function with weights , and is a distance function. Note that the number of cost functions for a given can vary over . Our aim here is to come up with a generator function , that can minimize each as . However, since is a deterministic function ( and are both fixed at inference), it can only produce a single output. Therefore, we introduce a latent vector to the generator function, that can be used to converge towards a at inference, and possibly, to multiple solutions. Formally, the family of cost functions now becomes: Then, our training objective can be defined as finding a set of optimal and by minimizing , where is the number of possible solutions for . Note that is fixed for all and a different exists for each . Considering all the training samples , our training objective becomes,
| (1) |
Eq. 1 can be optimized via Algorithm 1 (proof in App. 2.2). Intuitively, the goal of Eq. 1 is to obtain a family of optimal latent codes {, each causing a global minima in the corresponding as . Consequently, at inference, we can optimize to converge to an optimal mode in the output space by varying . Therefore, we predict an estimated at inference,
| (2) |
for each , which in turn can be used to obtain the prediction . In other words, for a selected , let be the initial estimate for . At inference, can traverse gradually towards an optimum point in the space, forcing , in finite steps ().
However, still a critical problem exists: Eq. 2 depends on , which is not available at inference. As a remedy, we enforce Lipschitz constraints on over , which bounds the gradient norm as,
| (3) |
where is an arbitrary random initialization, is a constant, and is a straight path from to (proof in App. 2.1) . Intuitively, Eq. 3 implies that the gradients along the path do not tend to vanish or explode, hence, finding the path to optimal in the space becomes a fairly straight forward regression problem. Moreover, enforcing the Lipschitz constraint encourages meaningful structuring of the latent space: suppose and are two optimal codes corresponding to two ground truth modes for a particular input. Since is lower bounded by , where is the Lipschitz constant, the minimum distance between the two latent codes is proportional to the difference between the corresponding ground truth modes. In practice, we observed that this encourages the optimum latent codes to be placed sparsely (visual illustration in App. 2), which helps a network to learn distinctive paths towards different modes.
2.1 Convergence at inference
We formulate finding the convergence path of at inference as a regression problem, i.e., . We implement as a recurrent neural network (RNN). The series of predicted values can be modeled as a first-order Markov chain requiring no memory for the RNN. We observe that enforcing Lipschitz continuity on over leads to smooth trajectories even in high dimensional settings, hence, memorizing more than one step in to the history is redundant. However, is not a state variable, i.e., the existence of multiple modes for output prediction leads to multiple possible solutions for . On the contrary, is a state variable w.r.t. the state , which can be used as an approximation to reach the optimal at inference. Therefore, instead of directly learning , we learn a simplified version . Intuitively, the whole process can be understood as observing the behavior of on a smooth surface at the training stage, and predicting the movement at inference. A key aspect of is that the model is capable of converging to multiple possible optimum modes at inference based on the initial position of .
2.2 Momentum as a supplementary aid
Based on Sec. 2.1, can now traverse to an optimal position during inference. However, there can exist rare symmetrical positions in the where , although far away from , forcing . Simply, the above phenomenon can occur if some has traveled in many non-orthogonal directions, so the vector addition of . This can fool the system to falsely identify convergence points, forming phantom optimum point distributions amongst the true distribution (see Fig. 2). To avoid such behavior, we consider . Then, we learn the expected momentum at each during the training phase, where is an empirically chosen scalar. In practice, as . Thus, to avoid phantom distributions, we improve the update as,
| (4) |
Since both and are functions on , we jointly learn these two functions using a single network . Note that coefficient serves two practical purposes: 1) slows down the movement of near true distributions, 2) pushes out of the phantom distributions.
3 Overall Design
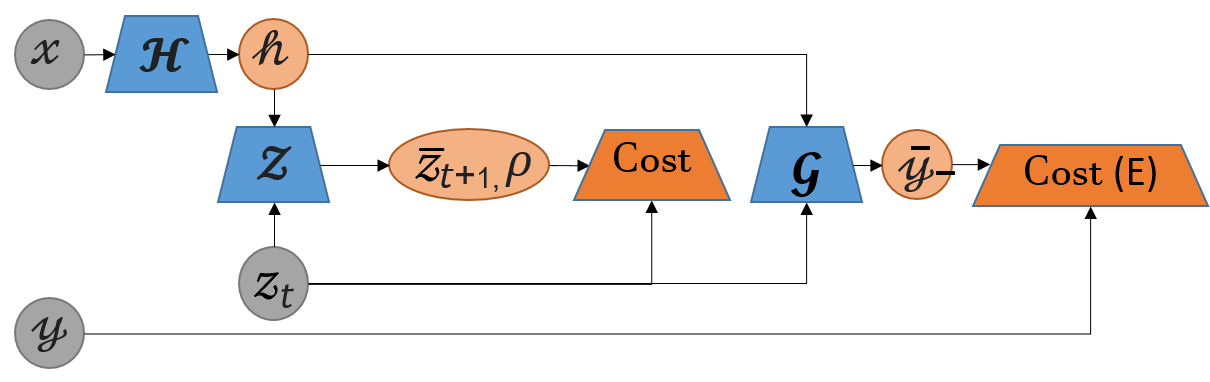
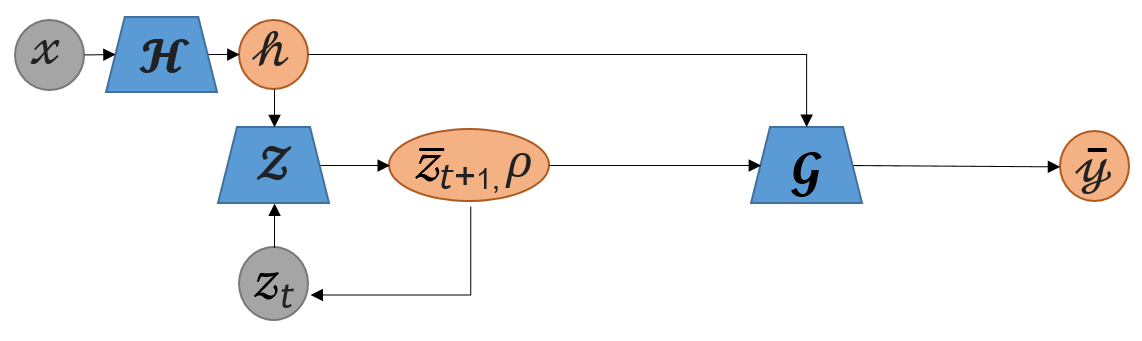
The proposed model consists of three major blocks as shown in Fig. 1: an encoder , a generator , and . Note that for derivations in Sec. 2, we used instead of , as is a high-level representation of . The training process is illustrated in Algorithm 1. At each optimization , is trained separately to approximate . At inference, is fed to , and then the optimizes the output by updating for a pre-defined number of iterations of Eq. 4. For , we use loss. Furthermore, it is important to limit the search space for , to improve the performance of . To this end, we sample from the surface of the -dimensional sphere (). Moreover, to ensure faster convergence of the model, we force the Lipschitz continuity on both and the (App. 2.4) . For hyper-parameters and training details, see App. 3.1.
4 Motivation
Here, we explain the drawbacks of conditional GAN methods and illustrate our idea via a toy example.
Incompatibility of adversarial and reconstruction losses: cGANs use a combination of adversarial and reconstruction losses. We note that this combination is suboptimal to model CMM spaces.
Remark: Consider a generator and a discriminator , where and are the input and the noise vector, respectively. Then, consider an arbitrary input and the corresponding set of ground-truths . Further, let us define the optimal generator , and . Then, where , . (Proof in App. 2.3).
Generalizability: The incompatibility of above mentioned loss functions demands domain specific design choices from models that target high realism in CMM settings. This hinders the generalizability across different tasks (Vitoria et al., 2020; Zeng et al., 2019). We further argue that due to this discrepancy, cGANs learn sub-optimal features which are less useful for downstream tasks (Sec. 5.3).
Convergence and the sensitivity to the architecture: The difficulty of converging GANs to the Nash equilibrium of a non-convex min-max game in high-dimensional spaces is well explored (Barnett, 2018; Chu et al., 2020; Kodali et al., 2017). Goodfellow et al. (2014b) underlines if the discriminator has enough capacity, and is optimal at every step of the GAN algorithm, then the generated distribution converges to the real distribution; that cannot be guaranteed in a practical scenario. In fact, Arora et al. (2018) confirmed that the adversarial objective can easily approach to an equilibrium even if the generated distribution has very low support, and further, the number of training samples required to avoid mode collapse can be in order of ( is the data dimension).
Multimodality: The ability to generate diverse outputs, i.e., convergence to multiple modes in the output space, is an important requirement. Despite the typical noise input, cGANs generally lack the ability to generate diverse outputs (Lee et al., 2019). Pathak et al. (2016) and Iizuka et al. (2016) even state that better results are obtained when the noise is completely removed. Further, variants of cGAN that target diversity often face a trafe-off between the realism and diversity (He et al., 2018), as they have to compromise between the reconstruction and adversarial losses.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/lpred_1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_wok1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/kenergy1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/lpred_2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_wok2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/kenergy2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred2.png)

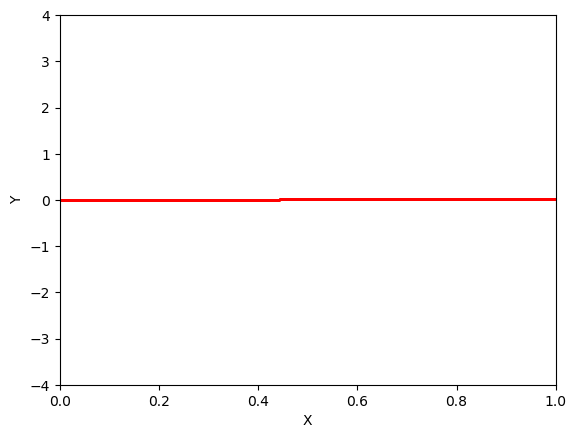
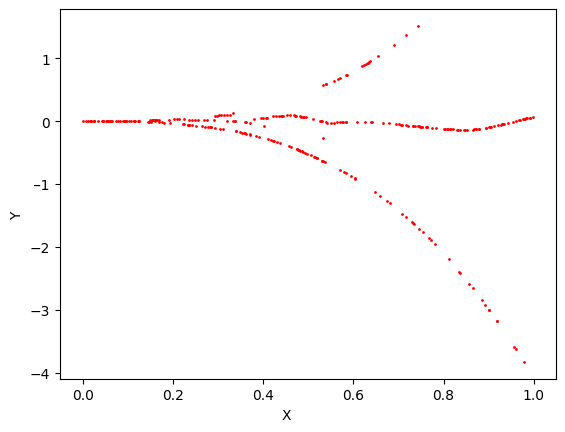
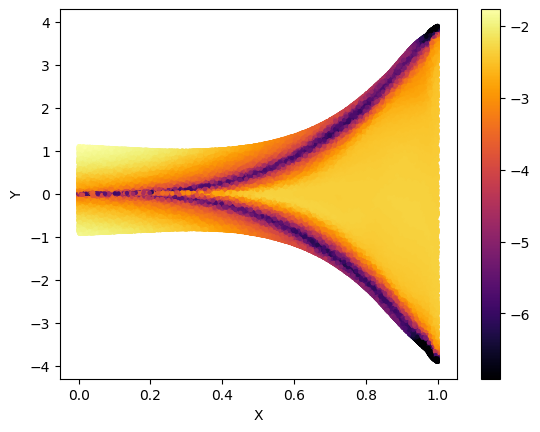
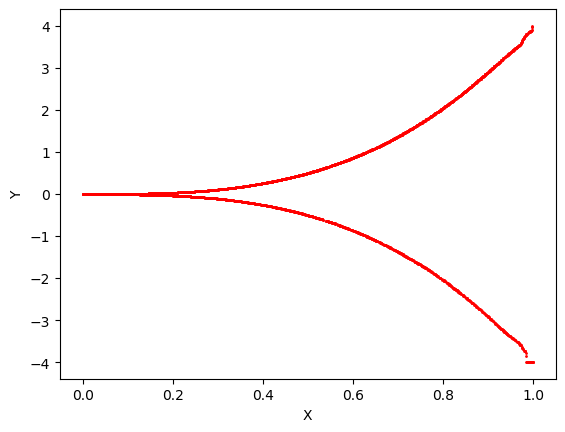
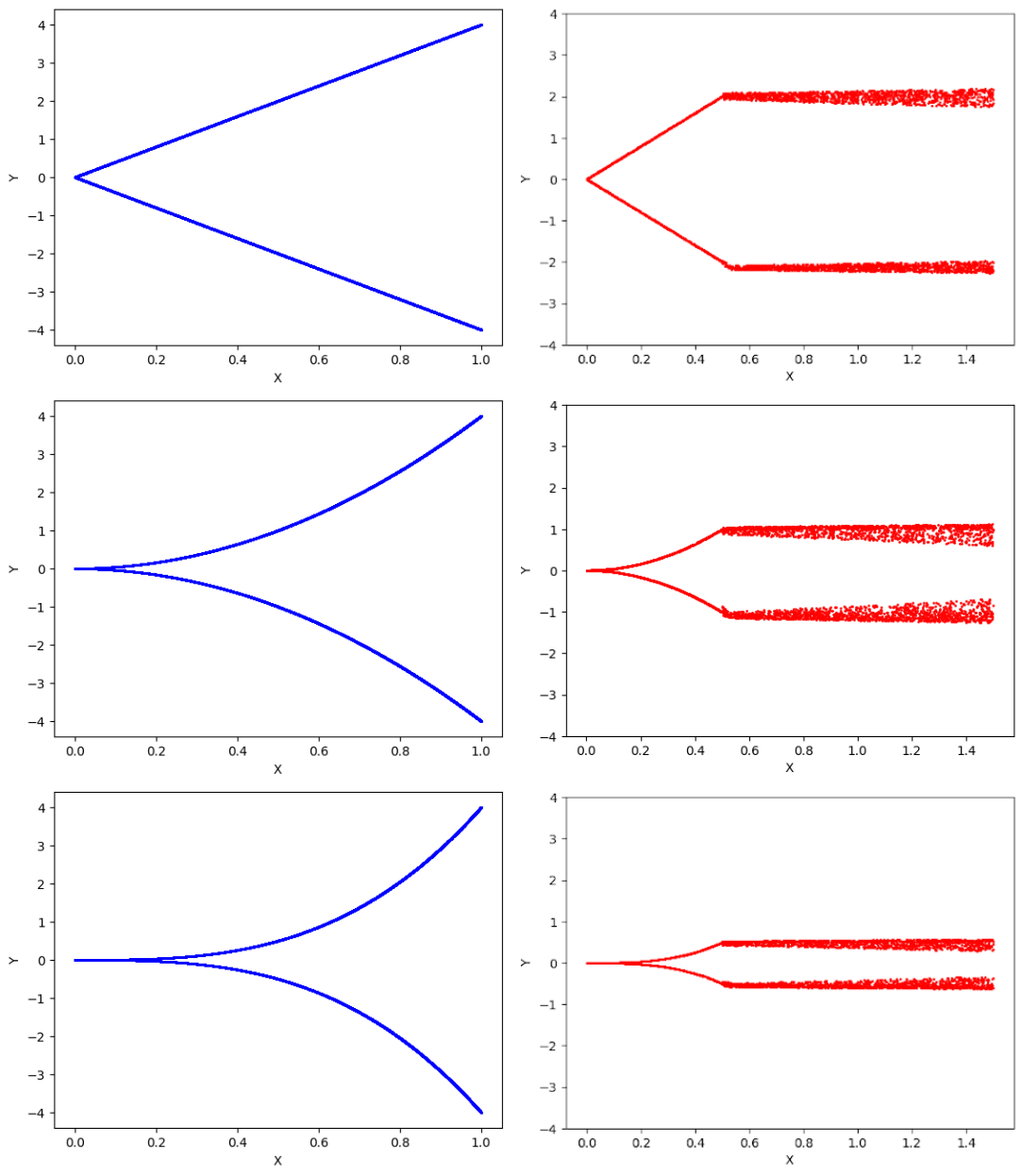
A toy example: Here, we experiment with the formulations in Sec. 2. Consider a 3D CMM space . Then, we construct three layer multi-layer perceptrons (MLP) to represent each of the functions, , , and , and compare the proposed method against the loss. Figure 2 illustrates the results. As expected, loss generates the line , and is inadequate to model the multimodal space. As explained in Sec. 2.2, without momentum correction, the network is fooled by a phantom distribution where at training time. However, the push of momentum removes the phantom distribution and refines the output to closely resemble the input distribution. As implied in Sec. 2.2, the momentum is maximized near the true distribution and minimized otherwise.
5 Experiments and discussions
The distribution of natural images lies on a high dimensional manifold, making the task of modelling it extremely challenging. Moreover, conditional image generation poses an additional challenge with their constrained multimodal output space (a single input may correspond to multiple outputs while not all of them are available for training). In this section, we experiment on several such tasks. For a fair comparison with a similar capacity GAN, we use the encoder and decoder architectures used in Pathak et al. (2016) for and respectively. We make two minor modifications: the channel-wise fully connected (FC) layers are removed and U-Net style skip connections are added (see App. 3.1). We train the existing models for a maximum of epochs where pretrained weights are not provided, and demonstrate the generalizability of our theoretical framework in diverse practical settings by using a generic network for all the experiments. Models used for comparisons are denoted as follows: PN (Zeng et al., 2019), CA (Yu et al., 2018b), DSGAN (Yang et al., 2019), CIC (Zhang et al., 2016), Chroma (Vitoria et al., 2020), P2P (Isola et al., 2017), Izuka (Iizuka et al., 2016), CE (Pathak et al., 2016), CRN (Chen & Koltun, 2017a), and B-GAN (Zhu et al., 2017b).
GT
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_5.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_6.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_7.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_8.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_9.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_10.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_11.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_12.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_13.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_14.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_15.png)
Input
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_5.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_6.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_7.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_8.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_9.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_10.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_11.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_12.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_13.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_14.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_15.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_5.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_6.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_7.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_8.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_9.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_10.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_11.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_12.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_13.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_14.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_15.png)
CE
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_5.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_6.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_7.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_8.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_9.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_10.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_11.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_12.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_13.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_14.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ce_15.png)
Ours
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_5.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_6.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_7.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_8.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_10.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_11.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_12.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_13.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_14.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pred_15.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_c1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_c1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_c2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_c2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_4.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_c4.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_4.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_c4.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_4.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_l.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_cl.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp_l.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_cl.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz_l.png)
GT 1 (70%)
GT 2 (30%)
Input
Output 1
Output 2
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/11.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/111.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/1111.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/11111.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/22.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/222.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/2222.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/22222.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/33.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/333.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/3333.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/33333.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/4.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/44.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/444.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/4444.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/44444.png)
itr 0
itr 5
itr 10
itr 15
itr 20
| Method | User study | Turing test | |
| STL | ImageNet | ImageNet | |
| Izuka | 21.89 | 32.28 | - |
| Chroma | 32.40 | 31.67 | - |
| Ours | 45.71 | 36.05 | 31.66 |
| Method | STL | ImageNet | ||||||
|---|---|---|---|---|---|---|---|---|
| LPIP | PieAPP | SSIM | PSNR | LPIP | PieAPP | SSIM | PSNR | |
| Izuka | 0.18 | 2.37 | 0.81 | 24.30 | 0.17 | 2.47 | 0.87 | 18.43 |
| P2P | 1.21 | 2.69 | 0.73 | 17.80 | 2.01 | 2.80 | 0.87 | 18.43 |
| CIC | 0.18 | 2.81 | 0.71 | 22.04 | 0.19 | 2.56 | 0.71 | 19.11 |
| Chroma | 0.16 | 2.06 | 0.91 | 25.57 | 0.16 | 2.13 | 0.90 | 23.33 |
| Ours | 0.12 | 1.47 | 0.95 | 27.03 | 0.16 | 2.04 | 0.92 | 24.51 |
| Ours (w/o ) | 0.16 | 1.90 | 0.89 | 25.02 | 0.20 | 2.11 | 0.88 | 23.21 |
5.1 Corrupted Image Recovery
We design this task as image completion, i.e., given a masked image as input, our goal is to recover the masked area. Interestingly, we observed that the MNIST dataset, in its original form, does not have a multimodal behaviour, i.e., a fraction of the input image only maps to a single output. Therefore, we modify the training data as follows: first, we overlap the top half of an input image with the top half of another randomly sampled image. We carry out this corruption for of the training data. Corrupted samples are not fixed across epochs. Then, we apply a random sized mask to the top half, and ask the network to predict the missing pixels. We choose two competitive baselines here: our network with the loss and CE. Fig. 3 illustrates the predictions. As shown, our model converges to the most probable non-corrupted mode without any ambiguity, while other baselines give sub-optimal results. In the next experiment, we add a small white box to the top part of the ground-truth images at different rates. At inference, our model was able to converge to both the modes (Fig. 4), depending on the initial position of , as the probability of the alternate mode reaches .
5.2 Automatic image colorization
Deep models have tackled this problem using semantic priors (Iizuka et al., 2016; Vitoria et al., 2020), adversarial and losses (Isola et al., 2017; Zhu et al., 2017a; Lee et al., 2019), or by conversion to a discrete form through binning of color values (Zhang et al., 2016). Although these methods provide compelling results, several inherent limitations exist: (a) use of semantic priors results in complex models, (b) adversarial loss suffers from drawbacks (see Sec. 4), and (c) discretization reduces the precision. In contrast, we achieve better results using a simpler model.
The input and the output of the network are and planes respectively (LAB color space). However, since the color distributions of and spaces are highly imbalanced over a natural dataset (Zhang et al., 2016), we add another constraint to the cost function to push the predicted and colors towards a uniform distribution: , where . Here, is the divergence and is a uniform distribution (see App. 3.3). Fig. 6 and Table 2 depict our qualitative and quantitative results, respectively. We demonstrate the superior performance of our method against four metrics: LPIP, PieAPP, SSIM and PSNR (App. 3.2). Fig. 5.2 depicts examples of multimodality captured by our model (more examples in App. 3.4). Fig. 5 shows colorization behaviour as the converges during inference.
User study: We also conduct two user studies to further validate the quality of generated samples (Table 1). a) In the Psychophysical study, we present volunteers with batches of 3 images, each generated with a different method. A batch is displayed for 5 secs and the user has to pick the most realistic image. After 5 secs, the next image batch is displayed. b) We conduct a Turing test to validate our output quality against the ground-truth, following the setting proposed by Zhang et al. (2016). The volunteers are presented with a series of paired images (ground-truth and our output). The images are visible for 1 sec, and then the user has an unlimited time to pick the realistic image.
GT










Izuka










P2P










Chroma










CIC









Ours










GT
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt5.png)
Input
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/inp5.png)
Ours
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/predz5.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/in1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/p1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ca1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pn1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/o1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/in2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/p2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ca2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pn2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/o2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/in3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/p3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/ca3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pn3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/o3.png)
GT
Input
P2P
CA
PN
Ours
| Method | 10% corruption | 15% corruption | 25% corruption | |||||||||
| LPIP | PieAPP | PSNR | SSIM | LPIP | PieAPP | PSNR | SSIM | LPIP | PieAPP | PSNR | SSIM | |
| DSGAN | 0.101 | 1.577 | 20.13 | 0.67 | 0.189 | 2.970 | 18.45 | 0.55 | 0.213 | 3.54 | 16.44 | 0.49 |
| PN | 0.045 | 0.639 | 27.11 | 0.88 | 0.084 | 0.680 | 20.50 | 0.71 | 0.147 | 0.764 | 19.41 | 0.63 |
| CE | 0.092 | 1.134 | 22.34 | 0.71 | 0.134 | 2.134 | 19.11 | 0.63 | 0.189 | 2.717 | 17.44 | 0.51 |
| P2P | 0.074 | 0.942 | 22.33 | 0.79 | 0.101 | 1.971 | 19.34 | 0.70 | 0.185 | 2.378 | 17.81 | 0.57 |
| CA | 0.048 | 0.731 | 26.45 | 0.83 | 0.091 | 0.933 | 20.12 | 0.72 | 0.166 | 0.822 | 21.43 | 0.72 |
| Ours (w/o ) | 0.053 | 0.799 | 27.77 | 0.83 | 0.085 | 0.844 | 23.22 | 0.76 | 0.141 | 0.812 | 22.31 | 0.74 |
| Ours | 0.051 | 0.727 | 27.83 | 0.89 | 0.080 | 0.740 | 26.43 | 0.80 | 0.129 | 0.760 | 24.16 | 0.77 |



















Mode 1
Mode 2
Mode 1
Mode 2
Mode 1
Mode 2
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/face_diversity.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/in_1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/13.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/14.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/in_2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/21.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/23.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/24.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/in_3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/31.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/32.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/34.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/in_4.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/41.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/42.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/43.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/51.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/52.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/53.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/54.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/out1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/out2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/out3.png)
5.3 Image completion
In this case, we show that our generic model outperforms a similar capacity GAN (CE) as well as task-specific GANs. In contrast to task-specific models, we do not use any domain-specific modifications to make our outputs perceptually pleasing. We observe that with random irregular and fixed-sized masks, all the models perform well, and we were not able to visually observe a considerable difference (Fig. 7, see App. 3.11 for more results). Therefore, we presented models with a more challenging task: train with random sized square-shaped masks and evaluate the performance against masks of varying sizes. Fig. 8 illustrates qualitative results of the models with 25% masked data. As evident, our model recovers details more accurately compared to the state-of-the-art. Notably, all models produce comparable results when trained with a fixed sized center mask, but find this setting more challenging. Table 3 includes a quantitative comparison. Observe that in the case of smaller sized masks, PN performs slightly better than ours, but worse otherwise. We also evaluate the learned features of the models against a downstream classification task (Table 5). First, we train all the models on Facades (Tyleček & Šára, 2013) against random masks, and then apply the trained models on CIFAR10 (Krizhevsky et al., 2009) to extract bottleneck features, and finally pass them through a FC layer for classification (App. 3.7). We compare PN and ours against an oracle (AlexNet features pre-trained on ImageNet) and show our model performs closer to the oracle.
.


![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gt_580.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/out580s.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/out580sm.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/out580l.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pc3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pc2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pc1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/pce.png)
Input
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gan1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/v1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/our1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gan2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/v2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/our2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/gan3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/v3.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/376e06a5-310c-43d5-94e7-66ce0becb1f3/our3.png)
GT
Input
CE
cVAE
Ours
5.3.1 Diversity and other compelling attributes
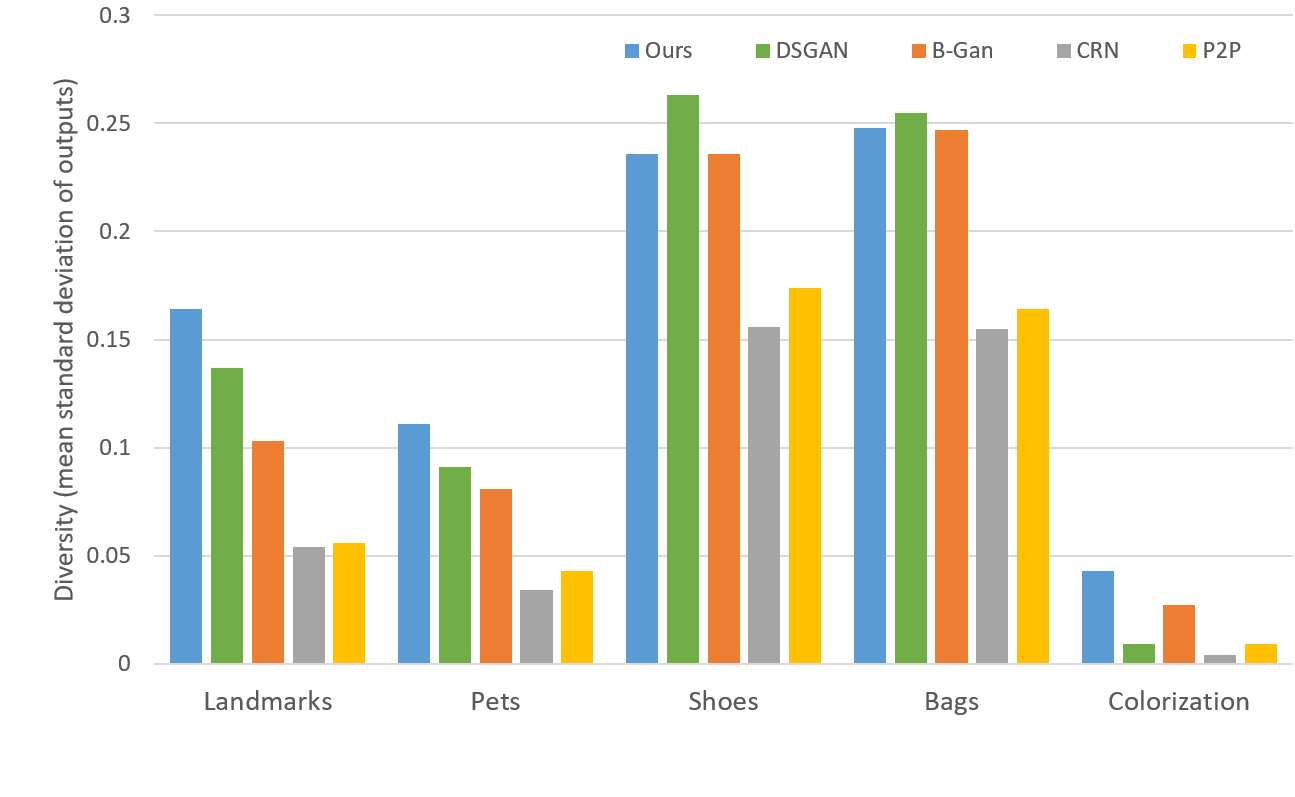
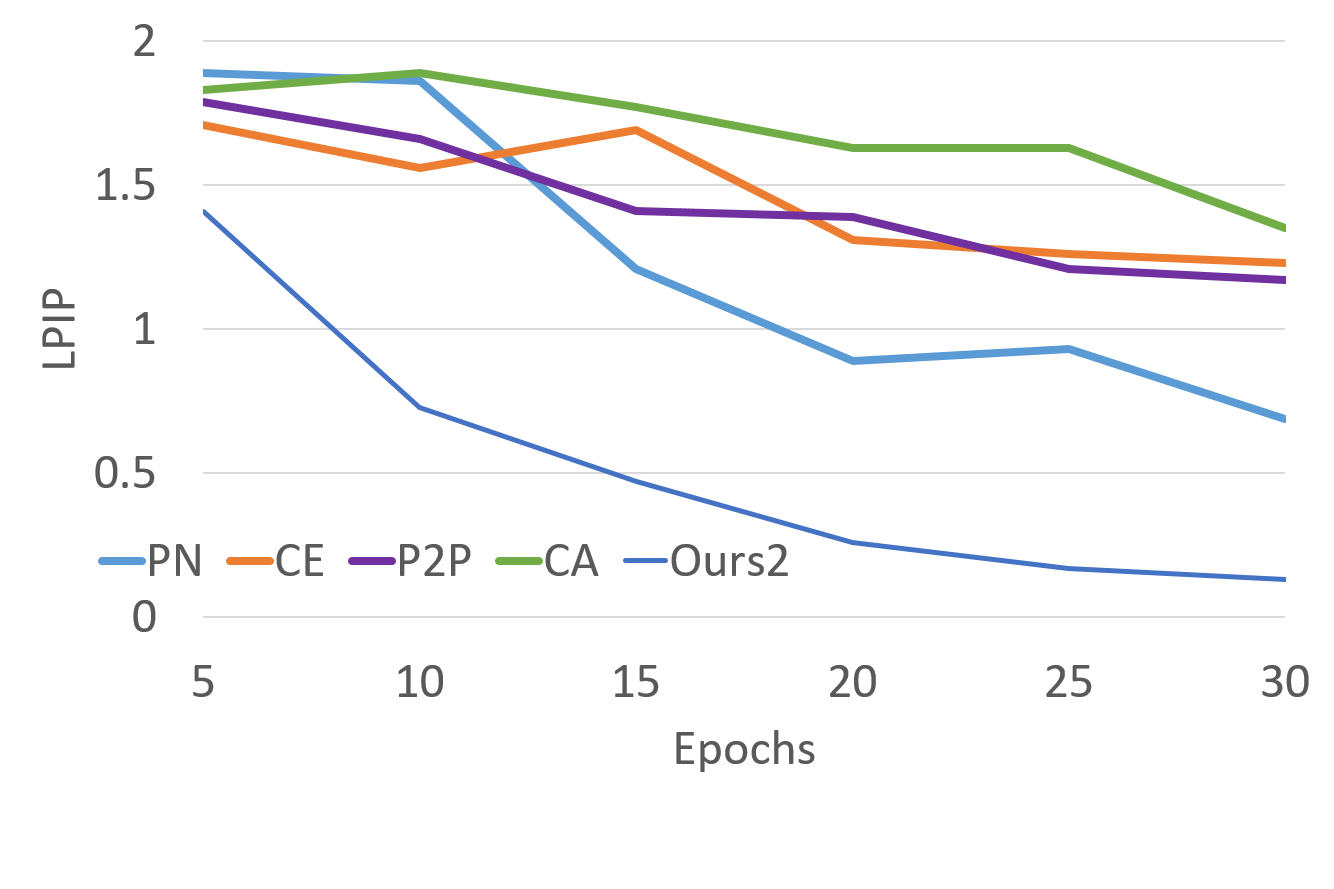
We also experiment on a diverse set of image translation tasks to demonstrate our generalizability. Fig. 11, 12, 13, 15 and 16 illustrate the qualitative results of sketch-to-handbag, sketch-to-shoes, map-to-arial, lanmarks-to-faces and surface-normals-to-pets tasks. Fig. 5.2, 10, 11, 12, 15 and 16 show the ability of our model to converge to multiple modes, depending on the initialization. Fig. 14 demonstrates the quantitative comparison against other models. See App. 3.4 for further details on experiments. Another appealing feature of our model is its strong convergence properties irrespective of the architecture, hence, scalability to different input sizes. Fig. 17 shows examples from image completion and colorization for varying input sizes. We add layers to the architecture to be trained on increasingly high-resolution inputs, where our model was able to converge to optimal modes at each scale (App. 3.8). Fig. 19 demonstrates our faster and stable convergence.
| Method | M10 | M40 |
|---|---|---|
| Sharma et al. (2016) | 80.5% | 75.5% |
| Han et al. (2019) | 92.2% | 90.2% |
| Achlioptas et al. (2017) | 95.3% | 85.7% |
| Yang et al. (2018) | 94.4% | 88.4% |
| Sauder & Sievers (2019) | 94.5% | 90.6% |
| Ramasinghe et al. (2019c) | 93.1% | - |
| Khan et al. (2019) | 92.2% | - |
| Ours | 92.4% | 90.9% |
| Method | Pretext | Acc. (%) |
|---|---|---|
| ResNet∗ | ImageNet Cls. | 74.2 |
| PN | Im. Completion | 40.3 |
| Ours | Im. Completion | 62.5 |
| Method | M10 | M40 |
|---|---|---|
| CE | 10.3 | 4.6 |
| cVAE | 8.7 | 4.2 |
| Ours | 84.2 | 79.4 |
5.4 Denoising of 3D objects in spectral space
Spectral moments of 3D objects provide a compact representation, and help building light-weight networks (Ramasinghe et al., 2020, 2019b; Cohen et al., 2018; Esteves et al., 2018). However, spectral information of 3D objects has not been used before for self-supervised learning, a key reason being the difficulty of learning representations in the spectral domain due to the complex structure and unbounded spectral coefficients. Here, we present an efficient pretext task that is conducted in the spectral domain: denoising 3D spectral maps. We use two types of spectral spaces: spherical harmonics and Zernike polynomials (App. 4). We first convert the 3D point clouds to spherical harmonic coefficients, arrange the values as a 2D map, and mask or add noise to a map portion (App. 3.12). The goal is to recover the original spectral map. Fig. 18 and Table 6 depicts our qualitative and quantitative results. We perform favorably well against other methods. To evaluate the learned features, we use Zernike polynomials, as they are more discriminative compared to spherical harmonics (Ramasinghe et al., 2019a). We first train the network on the 55k ShapeNet objects by denoising spectral maps, and then apply the trained network on the ModelNet10 & 40. The features are then extracted from the bottleneck (similar to Sec. 5.3), and fed to a FC classifier (Table 4). We achieve the state-of-the-art results in ModelNet40 with a simple pretext task.
6 Conclusion
Conditional generation in multimodal domains is a challenging task due to its ill-posed nature. In this paper, we propose a novel generative framework that minimize a family of cost functions during training. Further, it observes the convergence patterns of latent variables and applies this knowledge during inference to traverse to multiple output modes during inference. Despite using a simple and generic architecture, we show impressive results on a diverse set of tasks. The proposed approach demonstrates faster convergence, scalability, generalizability, diversity and superior representation learning capability for downstream tasks.
References
- Achlioptas et al. (2017) Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, and Leonidas Guibas. Representation learning and adversarial generation of 3d point clouds. arXiv preprint arXiv:1707.02392, 2017.
- Arora & Zhang (2017) Sanjeev Arora and Yi Zhang. Do gans actually learn the distribution? an empirical study. arXiv preprint arXiv:1706.08224, 2017.
- Arora et al. (2018) Sanjeev Arora, Andrej Risteski, and Yi Zhang. Do GANs learn the distribution? some theory and empirics. In International Conference on Learning Representations, 2018.
- Bansal et al. (2017a) Aayush Bansal, Xinlei Chen, Bryan Russell, Abhinav Gupta, and Deva Ramanan. Pixelnet: Representation of the pixels, by the pixels, and for the pixels. arXiv preprint arXiv:1702.06506, 2017a.
- Bansal et al. (2017b) Aayush Bansal, Yaser Sheikh, and Deva Ramanan. Pixelnn: Example-based image synthesis. arXiv preprint arXiv:1708.05349, 2017b.
- Bao et al. (2017) Jianmin Bao, Dong Chen, Fang Wen, Houqiang Li, and Gang Hua. Cvae-gan: Fine-grained image generation through asymmetric training. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- Barnett (2018) Samuel A Barnett. Convergence problems with generative adversarial networks (gans). arXiv preprint arXiv:1806.11382, 2018.
- Chen & Koltun (2017a) Qifeng Chen and Vladlen Koltun. Photographic image synthesis with cascaded refinement networks. In Proceedings of the IEEE international conference on computer vision, pp. 1511–1520, 2017a.
- Chen & Koltun (2017b) Qifeng Chen and Vladlen Koltun. Photographic image synthesis with cascaded refinement networks. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017b.
- Chu et al. (2020) Casey Chu, Kentaro Minami, and Kenji Fukumizu. Smoothness and stability in gans. arXiv preprint arXiv:2002.04185, 2020.
- Cohen et al. (2018) Taco S Cohen, Mario Geiger, Jonas Köhler, and Max Welling. Spherical cnns. arXiv preprint arXiv:1801.10130, 2018.
- Deshpande et al. (2017) Aditya Deshpande, Jiajun Lu, Mao-Chuang Yeh, Min Jin Chong, and David Forsyth. Learning diverse image colorization. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- Driscoll & Healy (1994) James R Driscoll and Dennis M Healy. Computing fourier transforms and convolutions on the 2-sphere. Advances in applied mathematics, 15(2):202–250, 1994.
- Du & Mordatch (2019) Yilun Du and Igor Mordatch. Implicit generation and modeling with energy based models. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d Alché-Buc, E. Fox, and R. Garnett (eds.), Advances in Neural Information Processing Systems 32, pp. 3608–3618. Curran Associates, Inc., 2019.
- Esteves et al. (2018) Carlos Esteves, Christine Allen-Blanchette, Ameesh Makadia, and Kostas Daniilidis. Learning so (3) equivariant representations with spherical cnns. In Proceedings of the European Conference on Computer Vision (ECCV), pp. 52–68, 2018.
- Fetaya et al. (2020) Ethan Fetaya, Jörn-Henrik Jacobsen, Will Grathwohl, and Richard Zemel. Understanding the limitations of conditional generative models. In International Conference on Learning Representations, 2020.
- Ghosh et al. (2018) Arnab Ghosh, Viveka Kulharia, Vinay P. Namboodiri, Philip H.S. Torr, and Puneet K. Dokania. Multi-agent diverse generative adversarial networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- Goodfellow et al. (2014a) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems 27, pp. 2672–2680. 2014a.
- Goodfellow et al. (2014b) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pp. 2672–2680, 2014b.
- Grathwohl et al. (2020) Will Grathwohl, Kuan-Chieh Wang, Joern-Henrik Jacobsen, David Duvenaud, Mohammad Norouzi, and Kevin Swersky. Your classifier is secretly an energy based model and you should treat it like one. In International Conference on Learning Representations, 2020.
- Han et al. (2019) Zhizhong Han, Mingyang Shang, Yu-Shen Liu, and Matthias Zwicker. View inter-prediction gan: Unsupervised representation learning for 3d shapes by learning global shape memories to support local view predictions. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pp. 8376–8384, 2019.
- He et al. (2018) Yang He, Bernt Schiele, and Mario Fritz. Diverse conditional image generation by stochastic regression with latent drop-out codes. In Proceedings of the European Conference on Computer Vision (ECCV), pp. 406–421, 2018.
- Huang et al. (2018) Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. Multimodal unsupervised image-to-image translation. In The European Conference on Computer Vision (ECCV), September 2018.
- Iizuka et al. (2016) Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. Let there be color! joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification. ACM Transactions on Graphics (ToG), 35(4):1–11, 2016.
- Isola et al. (2017) Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1125–1134, 2017.
- Jing & Tian (2020) Longlong Jing and Yingli Tian. Self-supervised visual feature learning with deep neural networks: A survey. IEEE transactions on pattern analysis and machine intelligence, 2020.
- Khan et al. (2019) Salman H Khan, Yulan Guo, Munawar Hayat, and Nick Barnes. Unsupervised primitive discovery for improved 3d generative modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 9739–9748, 2019.
- Kingma & Welling (2014) Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. CoRR, abs/1312.6114, 2014.
- Kodali et al. (2017) Naveen Kodali, Jacob Abernethy, James Hays, and Zsolt Kira. On convergence and stability of gans. arXiv preprint arXiv:1705.07215, 2017.
- Krizhevsky et al. (2009) Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. Cifar-10 (canadian institute for advanced research). 2009. URL http://www.cs.toronto.edu/~kriz/cifar.html.
- Lee et al. (2018) Hsin-Ying Lee, Hung-Yu Tseng, Jia-Bin Huang, Maneesh Singh, and Ming-Hsuan Yang. Diverse image-to-image translation via disentangled representations. In The European Conference on Computer Vision (ECCV), September 2018.
- Lee et al. (2019) Soochan Lee, Junsoo Ha, and Gunhee Kim. Harmonizing maximum likelihood with GANs for multimodal conditional generation. In International Conference on Learning Representations, 2019.
- Liu et al. (2018) Guilin Liu, Fitsum A Reda, Kevin J Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), pp. 85–100, 2018.
- Loquercio et al. (2019) Antonio Loquercio, Mattia Segù, and Davide Scaramuzza. A general framework for uncertainty estimation in deep learning. arXiv preprint arXiv:1907.06890, 2019.
- Maaløe et al. (2019) Lars Maaløe, Marco Fraccaro, Valentin Liévin, and Ole Winther. Biva: A very deep hierarchy of latent variables for generative modeling. In Advances in neural information processing systems, pp. 6548–6558, 2019.
- Mao et al. (2019) Qi Mao, Hsin-Ying Lee, Hung-Yu Tseng, Siwei Ma, and Ming-Hsuan Yang. Mode seeking generative adversarial networks for diverse image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1429–1437, 2019.
- Mathieu et al. (2015) Michaël Mathieu, Camille Couprie, and Yann LeCun. Deep multi-scale video prediction beyond mean square error. CoRR, abs/1511.05440, 2015.
- Mirza & Osindero (2014) Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. ArXiv, abs/1411.1784, 2014.
- Nalisnick et al. (2019) Eric Nalisnick, Akihiro Matsukawa, Yee Whye Teh, Dilan Gorur, and Balaji Lakshminarayanan. Do deep generative models know what they don’t know? International Conference on Learning Representations, 2019.
- Parkhi et al. (2012) Omkar M. Parkhi, Andrea Vedaldi, Andrew Zisserman, and C. V. Jawahar. Cats and dogs. In IEEE Conference on Computer Vision and Pattern Recognition, 2012.
- Pathak et al. (2016) Deepak Pathak, Philipp Krähenbühl, Jeff Donahue, Trevor Darrell, and Alexei Efros. Context encoders: Feature learning by inpainting. 2016.
- Perraudin et al. (2019) Nathanaël Perraudin, Michaël Defferrard, Tomasz Kacprzak, and Raphael Sgier. Deepsphere: Efficient spherical convolutional neural network with healpix sampling for cosmological applications. Astronomy and Computing, 27:130–146, 2019.
- Prashnani et al. (2018) Ekta Prashnani, Hong Cai, Yasamin Mostofi, and Pradeep Sen. Pieapp: Perceptual image-error assessment through pairwise preference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1808–1817, 2018.
- Ramasinghe et al. (2019a) Sameera Ramasinghe, Salman Khan, and Nick Barnes. Volumetric convolution: Automatic representation learning in unit ball. arXiv preprint arXiv:1901.00616, 2019a.
- Ramasinghe et al. (2019b) Sameera Ramasinghe, Salman Khan, Nick Barnes, and Stephen Gould. Representation learning on unit ball with 3d roto-translational equivariance. International Journal of Computer Vision, pp. 1–23, 2019b.
- Ramasinghe et al. (2019c) Sameera Ramasinghe, Salman Khan, Nick Barnes, and Stephen Gould. Spectral-gans for high-resolution 3d point-cloud generation. arXiv preprint arXiv:1912.01800, 2019c.
- Ramasinghe et al. (2020) Sameera Ramasinghe, Salman Khan, Nick Barnes, and Stephen Gould. Blended convolution and synthesis for efficient discrimination of 3d shapes. In The IEEE Winter Conference on Applications of Computer Vision, pp. 21–31, 2020.
- Robbins (2007) Herbert E. Robbins. A stochastic approximation method. Annals of Mathematical Statistics, 22:400–407, 2007.
- Sagong et al. (2019) Min-cheol Sagong, Yong-goo Shin, Seung-wook Kim, Seung Park, and Sung-jea Ko. Pepsi : Fast image inpainting with parallel decoding network. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Salimans et al. (2016) Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In Advances in neural information processing systems, pp. 2234–2242, 2016.
- Sauder & Sievers (2019) Jonathan Sauder and Bjarne Sievers. Self-supervised deep learning on point clouds by reconstructing space. In Advances in Neural Information Processing Systems, pp. 12942–12952, 2019.
- Sharma et al. (2016) Abhishek Sharma, Oliver Grau, and Mario Fritz. Vconv-dae: Deep volumetric shape learning without object labels. In European Conference on Computer Vision, pp. 236–250. Springer, 2016.
- Sohn et al. (2015) Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models. In Advances in Neural Information Processing Systems 28. 2015.
- Thanh-Tung et al. (2019) Hoang Thanh-Tung, Truyen Tran, and Svetha Venkatesh. Improving generalization and stability of generative adversarial networks. arXiv preprint arXiv:1902.03984, 2019.
- Tyleček & Šára (2013) Radim Tyleček and Radim Šára. Spatial pattern templates for recognition of objects with regular structure. In Proc. GCPR, Saarbrucken, Germany, 2013.
- Vitoria et al. (2020) Patricia Vitoria, Lara Raad, and Coloma Ballester. Chromagan: Adversarial picture colorization with semantic class distribution. In The IEEE Winter Conference on Applications of Computer Vision, pp. 2445–2454, 2020.
- Wang et al. (2018) Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia. Image inpainting via generative multi-column convolutional neural networks. In Advances in Neural Information Processing Systems 31. 2018.
- Wang et al. (2003) Zhou Wang, Eero P Simoncelli, and Alan C Bovik. Multiscale structural similarity for image quality assessment. In The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, volume 2, pp. 1398–1402. Ieee, 2003.
- Wang et al. (2004) Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004.
- Xie et al. (2018) You Xie, Erik Franz, Mengyu Chu, and Nils Thuerey. tempoGAN: A Temporally Coherent, Volumetric GAN for Super-resolution Fluid Flow. ACM Transactions on Graphics (TOG), 37(4):95, 2018.
- Yang et al. (2019) Dingdong Yang, Seunghoon Hong, Yunseok Jang, Tianchen Zhao, and Honglak Lee. Diversity-sensitive conditional generative adversarial networks. arXiv preprint arXiv:1901.09024, 2019.
- Yang et al. (2018) Yaoqing Yang, Chen Feng, Yiru Shen, and Dong Tian. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 206–215, 2018.
- Yu et al. (2018a) Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang. Generative image inpainting with contextual attention. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018a.
- Yu et al. (2018b) Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang. Generative image inpainting with contextual attention. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5505–5514, 2018b.
- Zeng et al. (2019) Yanhong Zeng, Jianlong Fu, Hongyang Chao, and Baining Guo. Learning pyramid-context encoder network for high-quality image inpainting. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1486–1494, 2019.
- Zhang et al. (2011) Lin Zhang, Lei Zhang, Xuanqin Mou, and David Zhang. Fsim: A feature similarity index for image quality assessment. IEEE transactions on Image Processing, 20(8):2378–2386, 2011.
- Zhang et al. (2016) Richard Zhang, Phillip Isola, and Alexei A Efros. Colorful image colorization. In European conference on computer vision, pp. 649–666. Springer, 2016.
- Zhang et al. (2018) Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018.
- Zhang & Qi (2017) Song-Yang Zhang, Zhifei and Hairong Qi. Age progression/regression by conditional adversarial autoencoder. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017.
- Zhang et al. (2020) Xian Zhang, Xin Wang, Bin Kong, Youbing Yin, Qi Song, Siwei Lyu, Jiancheng Lv, Canghong Shi, and Xiaojie Li. Domain embedded multi-model generative adversarial networks for image-based face inpainting. ArXiv, abs/2002.02909, 2020.
- Zhu et al. (2016) Jun-Yan Zhu, Philipp Krähenbühl, Eli Shechtman, and Alexei A. Efros. Generative visual manipulation on the natural image manifold. In Proceedings of European Conference on Computer Vision (ECCV), 2016.
- Zhu et al. (2017a) Jun-Yan Zhu, Richard Zhang, Deepak Pathak, Trevor Darrell, Alexei A Efros, Oliver Wang, and Eli Shechtman. Toward multimodal image-to-image translation. In Advances in Neural Information Processing Systems 30. 2017a.
- Zhu et al. (2017b) Jun-Yan Zhu, Richard Zhang, Deepak Pathak, Trevor Darrell, Alexei A Efros, Oliver Wang, and Eli Shechtman. Toward multimodal image-to-image translation. In Advances in neural information processing systems, pp. 465–476, 2017b.
Appendix
1 Related work
Conditional Generative Modeling. Conditional generation involves modeling the data distribution given a set of conditioning variables that control of modes of the generated samples. With the success of VAEs (Kingma & Welling, 2014) and GANs (Goodfellow et al., 2014a) in standard generative modeling tasks, their conditioned counterparts (Sohn et al., 2015; Mirza & Osindero, 2014) have dominated conditional generative tasks recently (Vitoria et al., 2020; Zhang et al., 2016; Isola et al., 2017; Pathak et al., 2016; Lee et al., 2019; Zhu et al., 2017a; Bao et al., 2017; Lee et al., 2018; Zeng et al., 2019). While probabilistic latent variable models such as VAEs generate relatively low quality samples and poor likelihood estimates at inference (Maaløe et al., 2019), GAN based models perform significantly better at high dimensional distributions like natural images but demonstrate unstable training behaviour. A distinct feature of GANs is its mapping of points from a random noise distribution to the various modes of the output distribution. However, in the conditional case where an additional loss is incorporated to enforce the conditioning on the input, the significantly better performance of GANs is achieved at the expense of multimodality; the conditioning loss pushes the GAN to learn to mostly ignore its noise distribution. In fact, some works intentionally ignore the noise input in order to achieve more stable training (Isola et al., 2017; Pathak et al., 2016; Mathieu et al., 2015; Xie et al., 2018).
Multimodality. Conditional VAE-GANs are one popular approach for generating multimodal outputs (Bao et al., 2017; Zhu et al., 2017a) using the VAE’s ability to enforce diversity through its latent variable representation and the GAN’s ability to enforce output fidelity through its learnt discrimanator model. Mixture models (Chen & Koltun, 2017b; Ghosh et al., 2018; Deshpande et al., 2017) that discretize the output space are another approach. Domain specific disentangled representations (Lee et al., 2018; Huang et al., 2018) and explicit encoding of multiple modes as inputs Zhu et al. (2016); Isola et al. (2017) have also been successful in generating diverse outputs. Sampling-based loss functions enforcing similarity at a distribution level (Lee et al., 2019) have also been successful in multimoal generative tasks. Further, the use of additional specialized reconstruction losses (often using higher-level features extracted from the data distribution) and attention mechanisms also achieves multimodality through intricate model architectures in domain specific cases (Zeng et al., 2019; Chen & Koltun, 2017b; Vitoria et al., 2020; Zhang et al., 2016; Iizuka et al., 2016; Zhang et al., 2020; Yu et al., 2018a; Sagong et al., 2019; Wang et al., 2018; Iizuka et al., 2016).
We propose a simpler direction through our domain-independent energy function based approach that is also capable of learning generic representations that better support downstream tasks. Notably, our work contrasts from energy based models previously investigated for likelihood modeling due to their simplicity, however, such models are notoriously difficult to train especially on high-dimensional spaces (Du & Mordatch, 2019).
2 Theoretical results
2.1 Proof for Eq. 3
| (5) |
Let be a straight path from to , where and . Then,
| (6) |
| (7) |
| (8) |
| (9) |
On the other hand the Lipschitz constraint ensures,
| (10) |
| (11) |
2.2 Convergence of the training algorithm.
Proof: Let us consider a particular input and an associated ground truth . Then, for this particular case, we denote our cost function to be . Further, a family of cost functions can be defined as,
| (12) |
for each . Further, let us consider an arbitrary initial setting (). Then, with enough iterations, gradient descent by converges to,
| (13) |
Next, with enough iterations, gradient descent by converges to,
| (14) |
Observe that , where the equality occurs when . If has a unique global minima, repeating Equation 13 and 14 converges to that global minima, giving . It is straight forward to see that using a small number of iterations (usually one in our case) for each sample set for Equation 14, i.e., stochastic gradient descent, gives us,
| (15) |
where is fixed for all samples and modes (Robbins, 2007). Note that the proof is valid only for the convex case, and we rely on stochastic gradient descent to converge to at least a good local minima, as commonly done in many deep learning settings.
2.3 Proof for Remark
Remark:
Consider a generator and a discriminator with a finite capacity, where and are input and the noise vector, respectively. Then, consider an arbitrary input and the corresponding set of ground truths . Further, let us define the optimal generator , and . Then, where , . Proof.
It is straightforward to derive the equilibrium point of from the original GAN formulation. However, for clarity, we show some steps here.
Let,
| (16) |
Let denote the probability distribution. Then,
| (17) |
| (18) |
Consider the inner loop. It is straightforward to see that is maximized w.r.t. when . Then,
| (19) |
Then, following the Theorem 1 from Goodfellow et al. (2014b), it can be shown that the global minimum of the virtual training criterion is achieved if and only if .
Next, consider the loss for ,
| (20) |
| (21) |
For to approach to a minima, . Since is not a singleton, when , .
Now, let us consider the loss,
| (22) |
| (23) |
For , However, omitting the very specific case where , which is highly unlikely in a complex distribution, as , . Therefore, the goals of and are contradictory and . Note that we do not extend our proof to high order losses as it is intuitive.
2.4 Lipschitz continuity and structuring of the latent space
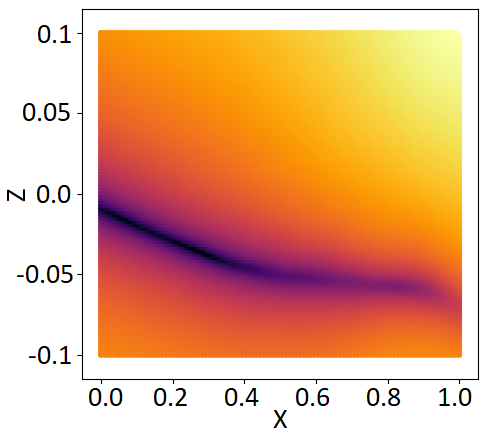
Enforcing the Lipschitz constraint encourages meaningful structuring of the latent space: suppose and are two optimal codes corresponding to two ground truth modes for a particular input. Since is lower bounded by , where is the Lipschitz constant, the minimum distance between the two latent codes is proportional to the difference between the corresponding ground truth modes. Also, in practice, we observed that this encourages the optimum latent codes to be placed sparsely. Fig. 20 illustrates a visualization from the toy example. As the training progresses, the optimal corresponding to minimas of are identified and placed sparsely. Note that as expected, at the epoch the distance between the two optimum increases as goes from to , in other words, as the increases.
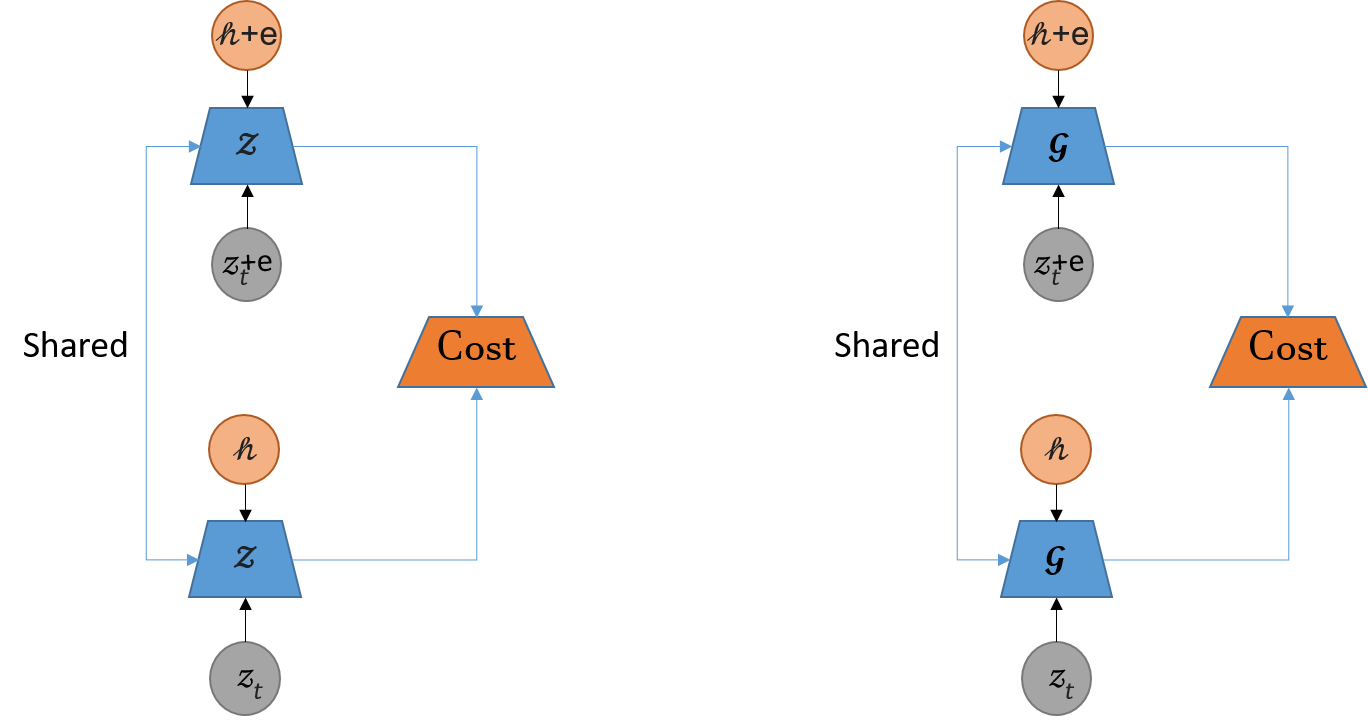
Practical implementation is done as follows: during the training phase, a small noise is injected to the inputs of and , and the networks are penalized for any difference in output. More formally, and now become, and , respectively. Fig. 24 illustrates the procedure.
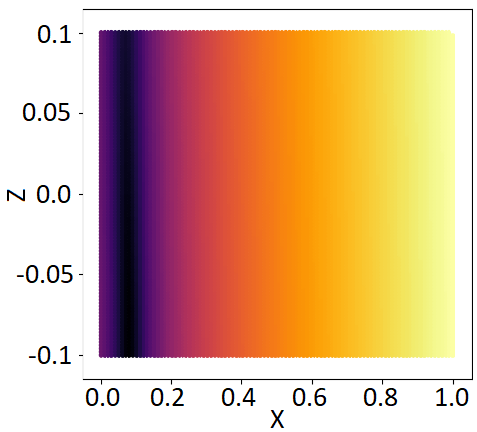
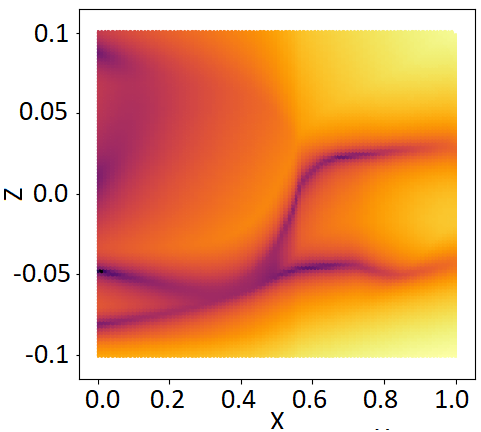
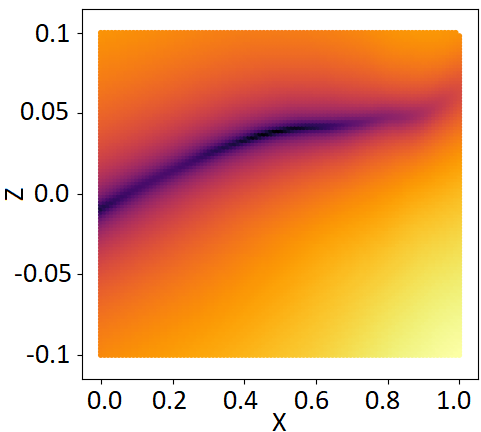
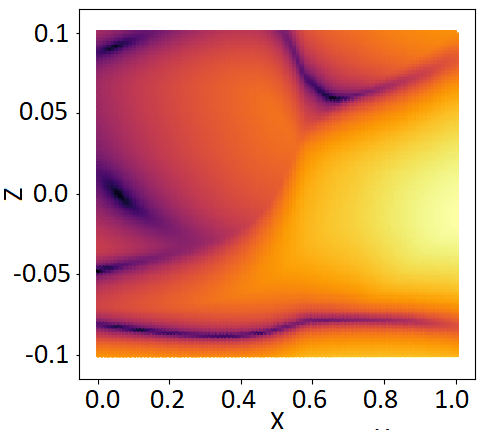
2.5 Towards a measurement of uncertainty
In Bayesian approaches, the uncertainty is represented using the distribution of the network parameters . Since a network output is unique for fixed , sampling from the output is equivalent to sampling from . Often, is modeled as a parametric distribution or obtained through sampling, and at inference, the model uncertainty can be estimated as . One intuition behind this is that for more confident inputs, will showcase less variance over the distribution of —hence lower —as the network parameters have learned redundant information (Loquercio et al., 2019).
As opposed to sampling from the distribution of network parameters, we model the optimal for a particular input as a probability distribution , and measure where . Our intuition is that in the vicinity of well observed data is lower, since for training data 1) we enforce the Lipschitz constraint on over and 2) resides in a relatively stable local minima against for observed data, as in practice, for a given , where is some random noise which is susceptible to change over each epoch. Further, Let and be the inputs to a network and the corresponding ground truth label, respectively.
Formally, let and , where is some variable describing the noise in the input and is a small positive scalar. Then,
| (24) |
where is the sample covariance.
proof: .
=
=
=
=
Let , and . Then, by Monte-Carlo approximation,
Next, consider,
.
Note that in similar to Bayesian uncertainty estimations, where an approximate distribution is used to estimate , where is data, our model sample from the an empirical distribution . In practice, we treat as a constant over all the samples–hence omit from the calculation—and use stochastic forward passes to obtain Eq. 24. Then, the diagonal entries are used to calculate the uncertainty in the each dimension of the output. We test this hypothesis on the toy example and the colorization task, as shown in Fig. 21 and Fig. 22, respectively.

3 Experiments
3.1 Experimental architectures
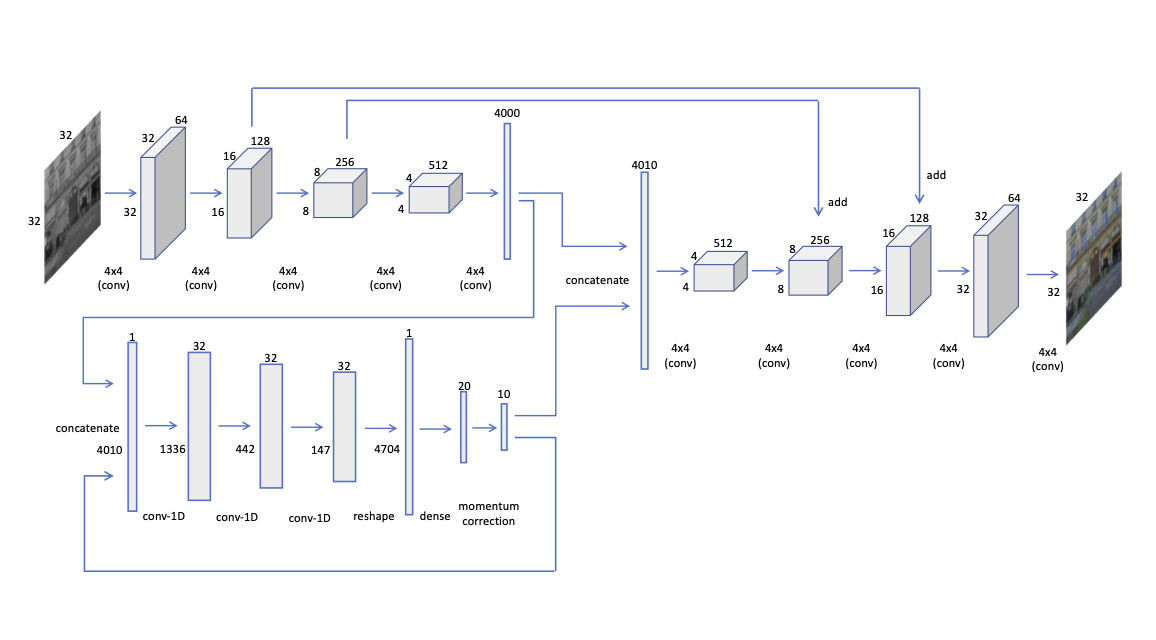
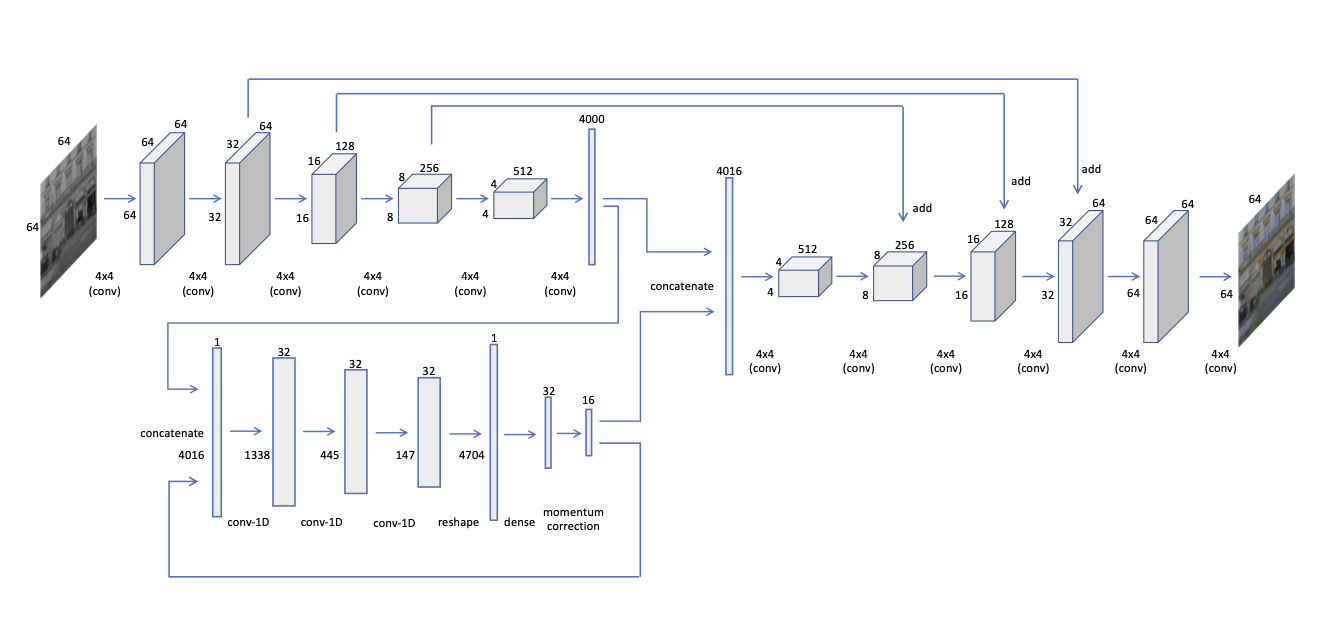
For the experiments on images, we mainly use size inputs. However, to demonstrate the scalability, we use several different architectures and show that the proposed framework is capable of converging irrespective of the architecture. Fig. 23 shows the architectures for different input sizes.
For training, we use the Adam optimizer with hyper-parameters , and a learning rate . We use batch normalization after each convolution layer, and leaky ReLu as the activation, except the last layer where we use . All the weights are initialized using a random normal distribution with mean and standard deviation. Furthermore, we use a batch size of 20 for training, though we did not observe much change in performance for different batch sizes. We choose the dimensions of to be for , , , input sizes, respectively. An important aspect to note here is that the dimension of should not be increased too much, as it would increase the search space for unnecessarily. While training, is updated times for a single update. Similarly, at inference, we use update steps for , in order to converge to the optimal solution. All the values are chosen empirically.
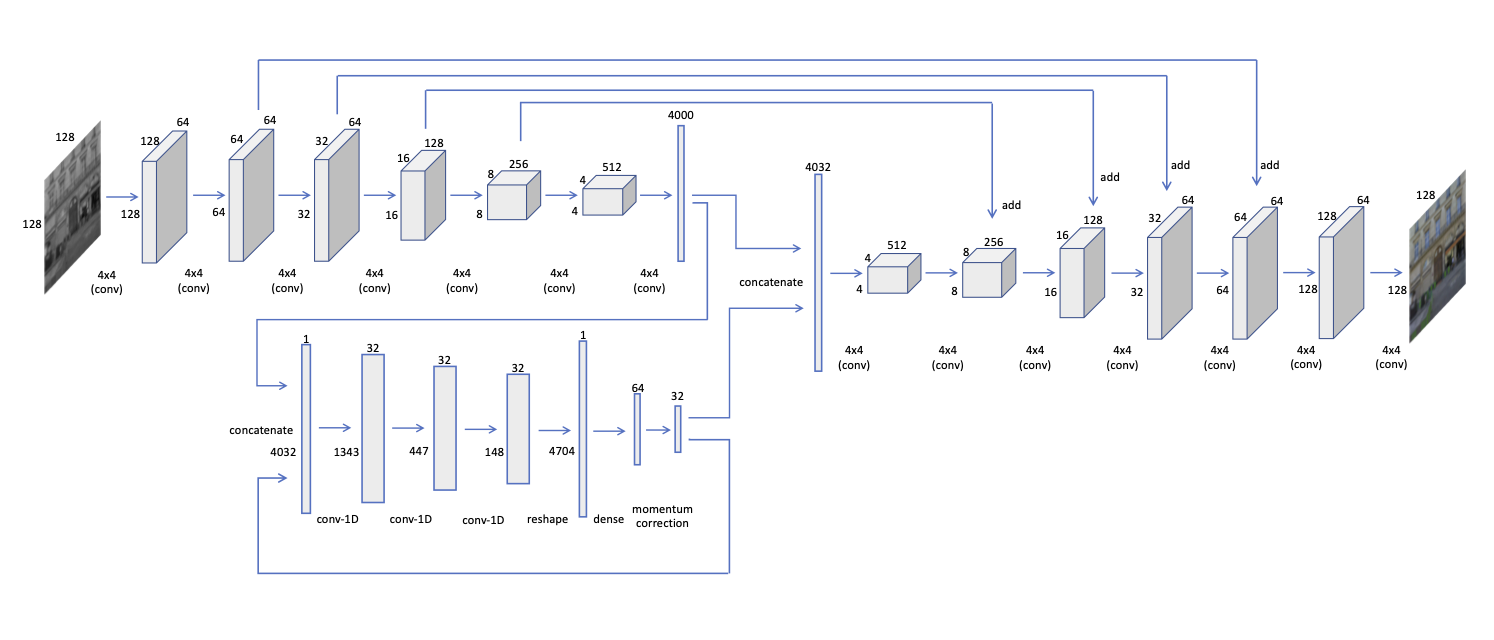
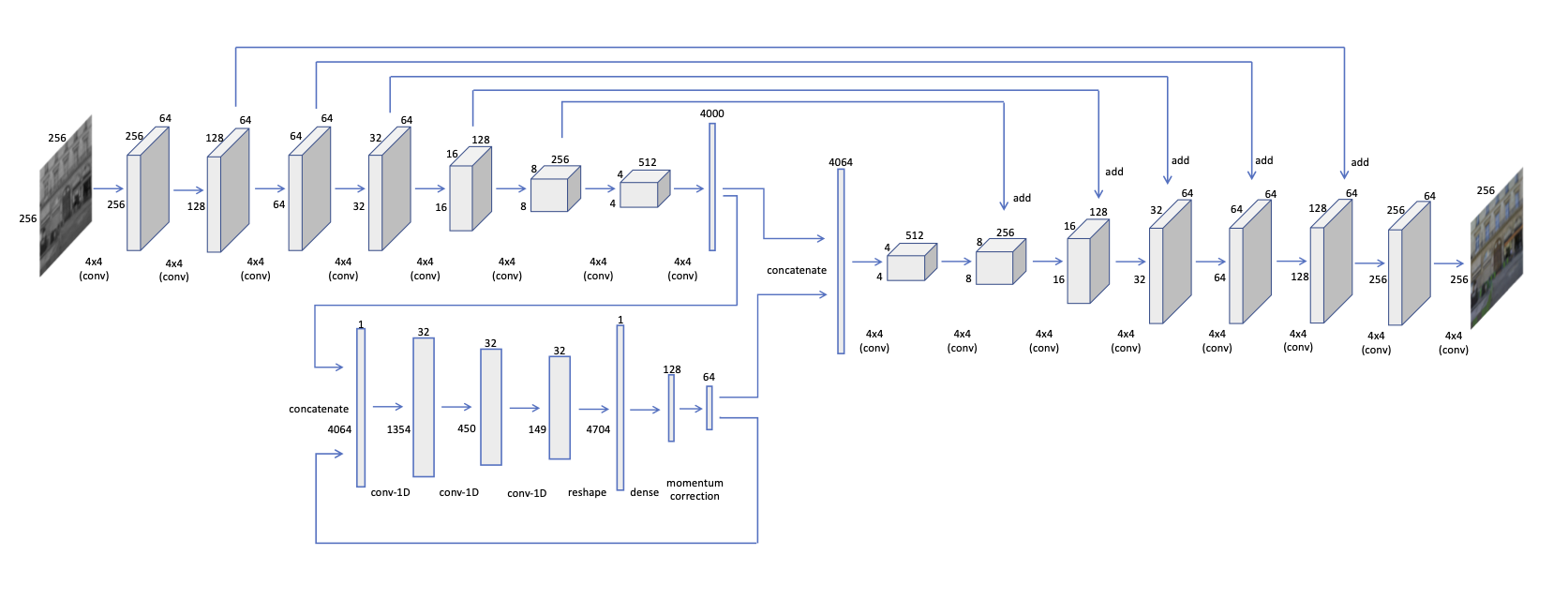
.
3.2 Evaluation metrics
Although heavily used in the literature, per pixel metrics such as PSNR does not effectively capture the perceptual quality of an image. To overcome this shortcoming, more perceptually motivated metrics have been proposed such as SSIM Wang et al. (2004), MSSIM Wang et al. (2003), and FSIM Zhang et al. (2011). However the similarity of two images is largely context dependant, and may not be captured by the aforementioned metrics. As a solution, recently, two deep feature based perceptual metrics–LPIP Zhang et al. (2018) and PieAPP Prashnani et al. (2018)–were proposed, which coincide well with the human judgement. To cover all these aspects, we evaluate our experiments against four metrics: LPIP, PieAPP, PSNR and SSIM.
3.3 Unbalanced color distributions
The color distribution of a natural dataset in and planes (LAB space) are strongly biased towards low values. If not taken into account, the loss function can be dominated by these desaturated values. Richard et al. Zhang et al. (2016) addressed this problem by rebalancing class weights according to the probability of color occurrence. However, this is only possible in a case where the output domain is discretized. To tackle this problem in the continuous domain, we push the output color distribution towards a uniform distribution as explained in Sec. 5.2 in the main paper.
3.4 Multimodality
An appealing attribute of our network is its ability to converge to multiple optimal modes at inference. A few such examples are shown in Fig. 26, Fig. 25, Fig. 30 Fig. 31, Fig. 28, Fig. 29 and Fig. 27. For the facial-land-marks-to-faces experiment, we used the UTKFace dataset (Zhang & Qi, 2017). For the surface-normals-to-pets experiment, we used the Oxford Pet dataset (Parkhi et al., 2012). In order to get the surface normal images, we follow Bansal Bansal et al. (2017b). First, we crop the bounding boxes of pet faces and then apply PixelNet (Bansal et al., 2017a) to extract surface normals. For maps-to-ariel and edges-to-photos experiments, we used the datasets provided by Isola et al. (2017).
For measuring the diversity, we adapt the following procedure: 1) we generate 20 random samples from the model. 2) calculate the mean pixel value of each sample. 3) pick the closest sample to the average of all the mean pixels . 4) pick the samples which have maximum mean pixel distance from . 5) calculate the mean standard deviation of the samples picked in step 4. 6) repeat the experiment times for each model and get the expected standard deviation.







3.5 Colorization on STL dataset
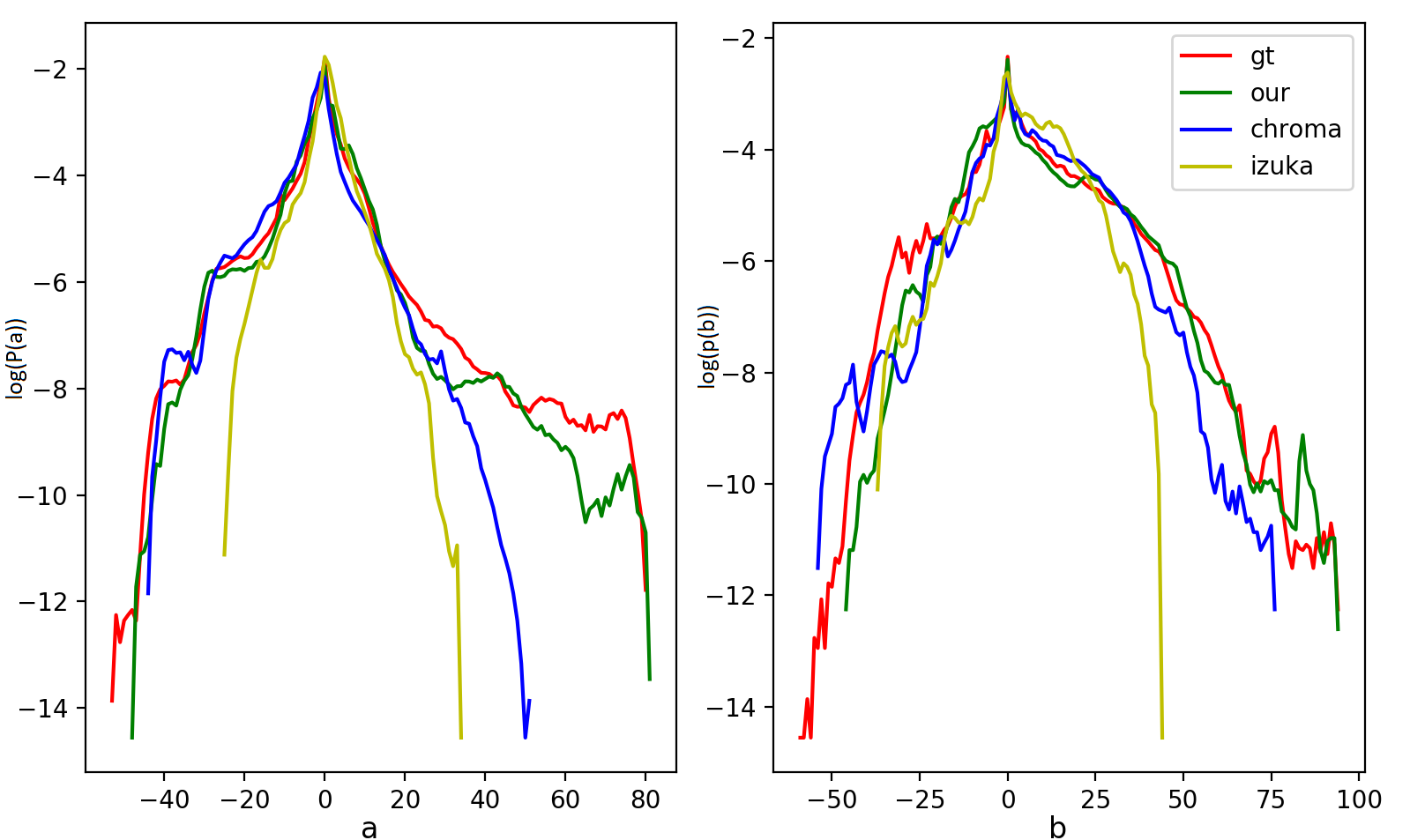
Additional colorization examples on the STL dataset are shown in Fig. 33. We also compare the color distributions of the predicted planes with state-of-the-art. The results are shown in Fig. 32 and Table 7. As evident, our method predicts the closest color distribution to the ground truth.
| Method | a | b |
|---|---|---|
| Chroma | 0.71 | 0.78 |
| Izuka | 0.68 | 0.63 |
| Ours | 0.82% | 0.80% |

3.6 Colorization on ImageNet dataset
Additional colorization examples on the ImageNet dataset are shown in Fig. 34.

3.7 Self-supervised learning setup
Here we evaluate the performance of our model on down-stream tasks, using three distinct setups involving bottleneck features of trained models. The bottleneck layer features (of models trained on some dataset) are fed to a fully-connected layer and trained on a different dataset.
The baseline experiment uses the output of the penultimate layer in a Resnet-50 trained on ImageNet for classification as the bottleneck features. The comparison to state-of-the-art experiment involves Zeng et al. (2019) where the five outputs of its multi-scale decoder are max-pooled and concatenated to use as the bottleneck features. The outputs of layers before this were also experimented with, and the highest performance was obtained for these selected features. In our network, the output of the encoder network was used as the bottleneck features.
3.8 Scalability
One promising attribute of the proposed method compared to the state-of-the-art is its scalability. In other words, we propose a generic framework which is not bound to the architecture, hence, the model can be scaled to different input sizes without affecting the convergence behaviour. To demonstrate this, we use 4 different architectures and train them on 4 different input sizes (, , , ) on the same tasks: image completion and colorization. The different architectures we use are shown in Fig. 23.
3.9 Ablation study on the dimension
To demonstrate the effect of dimension of on the model accuracy, we conduct an ablation study for the colorization task for the input size . Table 8 shows the results. The quality of the outputs increases to a maximum when , and then decreases. This is intuitive because when the search space of gets unnecessarily high, it becomes difficult for to learn the paths to optimum modes, due to limited capacity.
| Dimensionality | LPIP | PieAPP | Diversity |
|---|---|---|---|
| 5 | 1.05 | 3.40 | 0.01 |
| 10 | 0.58 | 2.91 | 0.018 |
| 16 | 0.14 | 1.89 | 0.021 |
| 32 | 0.12 | 1.47 | 0.043 |
| 64 | 0.27 | 1.71 | 0.048 |
| 128 | 0.69 | 2.12 | 0.043 |
3.10 User studies
Evaluation of synthesized images is an open problem (Salimans et al., 2016). Although recent metrics such as LPIP (Zhang et al., 2018) and PieAPP (Prashnani et al., 2018) have been proposed, which coincide closely with human judgement, perceptual user studies remain the preferred method. Therefore, to evaluate the quality of our synthesized images in the colorization task, we conduct two types of user studies: a Turing test and a psychophysical study. In the Turing test, we show the users a series of paired images, ground truth and our predictions, and ask the users to pick the most realistic image. Here, following Zhang et al. (2016), we display each image for 1 second, and then give the users an unlimited amount of time to make the choice. For the psychophysical study, we choose the two best performing methods according to the LPIP metric: Vitoria et al. (2020) and Iizuka et al. (2016). We create a series of batches of three images, Vitoria et al. (2020), Iizuka et al. (2016) and ours, and ask the users to pick the best quality image. In this case, each batch is shown to the users for 5 seconds, and the users have to make this decision during that time. We conduct the Turing test on ImageNet, and the psychophysical study on both ImageNet and STL datasets. For each test, we use randomly sampled batches and users.
We also conduct Turing tests to evaluate the image completion tasks on Facades and Celeb-HQ datasets. The results are shown in Table 9.
| Dataset | Celeb-HQ | Facades |
|---|---|---|
| GT | 59.11% | 55.75% |
| Ours | 40.89% | 44.25% |
3.11 Image completion
The additional image completion examples are provided in Figs. 35 and 36. Our turing test results on Celeb-HQ and Facades are shown in Table 9.


3.12 3D spectral map denoising
In this experiment, we use two types of spectral moments: spherical harmonics and Zernike polynomials (see App. 4). The minimum number of sample points required to accurately represent a finite energy function in a particular function space depends on the used sampling theorem. According to Driscoll and Healy’s theorem Driscoll & Healy (1994), equiangular sampled points are needed to represent a function on using spherical moments at a maximum degree . Therefore, we compute the first spherical moments of 3D objects where by sampling equiangular points in and directions, where and . Afterwards, we arrange the spherical moments as a feature map, and convolve with a kernel with stride size to downsample the feature map to size. The output is then fed to -size architecture. We add Gaussian noise and mask portions of the spectral map to corrupt it. Afterwards, the model is trained to de-noise the input.
For Zernike polynomials, we compute the first moments for each 3D object where , and arrange the moments as a feature map. Then, the feature map is upsampled using transposed convolution by using a kernel and with a stride size . The upsamapled feature map is fed to a -size network and trained end-to-end to denoise. We first train the network on 55k objects in ShapeNet, and then apply the trained network on the Modelnet10 and Modelnet40 to extract the bottleneck features. These features are then fed to a single fully connected layer for classification.
4 Spectral domain representation of 3D objects
Spherical harmonics and Zernike polynomials are orthogonal and complete functions in and , respectively, hence, 3D point clouds can be represented by a set of coefficients corresponding to a linear combination of these functions Perraudin et al. (2019); Ramasinghe et al. (2019a, c).
4.1 Spherical harmonics
Spherical harmonics are complete and orthogonal functions defined on the unit sphere () as,
| (25) |
where is the azimuth angle, is the polar angle, , , and . Here, is the associated Legendre function defined as,
| (26) |
Spherical harmonics demonstrate the following orthogonal property,
| (27) |
where † denotes the complex conjugate and,
| (28) |
Since spherical harmonics are complete in , any function with finite energy can be rewritten as
| (29) |
where,
| (30) |
4.2 3D Zernike polynomials
3D Zernike polynomials are complete and orthogonal on and defined as,
| (31) |
where,
| (32) |
and is a scaler defined as
| (33) |
Here is the spherical harmonics function, , , and is even. 3D Zernike polynomials also show orthogonal properties as,
| (34) |
Since Zernike polynomials are complete in , any function with finite energy can be rewritten as,
| (35) |
where can be obtained using
| (36) |
5 Image-to-Image translation
5.1 Sketch-to-shoes qualitative results
Additional qualitative results of the sketch-to-shoe translation task are shown in Fig. 37.
5.2 Map-to-photo qualitative results
Additional qualitative results of the map-to-photo translation task are shown in Fig. 38.


6 Convergence at inference
A key aspect of our method is the optimization of the predictions at inference. Fig. 39 and Fig. 40 demonstrate this behaviour on the MNIST image completion and STL colorization tasks, respectively.

