Confidence bands for a log-concave density
Abstract
We present a new approach for inference about a univariate log-concave distribution: Instead of using the method of maximum likelihood, we propose to incorporate the log-concavity constraint in an appropriate nonparametric confidence set for the cdf . This approach has the advantage that it automatically provides a measure of statistical uncertainty and it thus overcomes a marked limitation of the maximum likelihood estimate. In particular, we show how to construct confidence bands for the density that have a finite sample guaranteed confidence level. The nonparametric confidence set for which we introduce here has attractive computational and statistical properties: It allows to bring modern tools from optimization to bear on this problem via difference of convex programming, and it results in optimal statistical inference. We show that the width of the resulting confidence bands converges at nearly the parametric rate when the log density is -affine.
1 Introduction
Statistical inference under shape constraints has been the subject of continued considerable research activity. Imposing shape constraints on the inference about a function , that is, assuming that the function satisfies certain qualitative properties, such as monotonicity or convexity on certain subsets of its domain, has two main motivations: First, such shape constraints may directly arise from the problem under investigation and it is then desirable that the result of the inference reflects this fact. The second reason is that alternative nonparametric estimators typically involve the choice of a tuning parameter, such as the bandwidth in the case of a kernel estimator. A good choice for such a tuning parameter is usually far from trivial. More importantly, selecting a tuning parameter injects a certain amount of subjectivity into the estimator, and the resulting choice may prove quite consequential for relevant aspects of the inference. In contrast, imposing shape constraints often allows to derive an estimator that does not depend on a tuning parameter while at the same time exhibiting a good statistical performance, such as achieving optimal minimax rates of convergence to the underlying function .
This paper is concerned with inference about a univariate log-concave density, i.e. a density of the form
where is a concave function. It was argued in Walther (2002) that log-concave densities represent an attractive and useful nonparametric surrogate for the class of Gaussian distributions for a range of problems in inference and modeling. The appealing properties of this class are that it contains most commonly encountered parametric families of unimodal densities with exponentially decaying tails and that the class is closed under convolution, affine transformations, convergence in distribution and marginalization. In a similar vein as a normal distribution can be seen as a prototypical model for a homogenous population, one can use the class of log-concave densities as a more flexible nonparametric model for this task, from which heterogenous models can then be built e.g. via location mixtures. Historically such homogenous distributions have been modeled with unimodal densities, but it is known that the maximum likelihood estimate (MLE) of a unimodal density does not exist, see e.g. Birgé (1997). In contrast, it was shown in Walther (2002) that the MLE of a log-concave density exists and can be computed with readily available algorithms. Therefore, the class of log-concave densities is a sufficiently rich nonparametric model while at the same time it is small enough to allow nonparametric inference without a tuning parameter.
Due to these attractive properties there has been a considerable research activity in the last 15 years about the statistical properties of the MLE, computational aspects, applications in modeling and inference, and the multivariate setting. Many of the key properties of the MLE are now well understood: Existence of the MLE was shown in Walther (2002), consistency was proved by Pal, Woodroofe and Meyer (2007), and rates of convergence in certain uniform metrics was established by Dümbgen and Rufibach (2009). Balabdaoui, Rufibach and Wellner (2009) provided pointwise limit distributribution theory, while Doss and Wellner (2016) and Kim and Samworth (2016) gave rates of convergence in the Hellinger metric, and Kim, Guntuboyina and Samworth (2018) proved adaptation properties. Accompanying results for the multivariate case are given in e.g. Cule, Samworth and Stewart (2010), Schuhmacher and Dümbgen (2010), Seregin and Wellner (2010), Kim and Samworth (2016), and Feng, Guntuboyina, Kim and Samworth (2020).
Computation of the univariate MLE was initially approached with the Iterative Convex Minorant Algorithm, see Walther (2002), Pal, Woodroofe and Meyer (2007) and Rufibach (2007), but it appears that the fastest algorithms currently available are the active set algorithm given in Dümbgen, Hüsler and Rufibach (2007) and the constrained Newton method proposed by Liu and Wang (2018).
Overviews of some of these results and other work involving modeling and inference with log-concave distributions are given in the review papers of Walther (2009), Saumard and Wellner (2014) and Samworth (2018).
Notably, the existing methodology for estimating a log-concave density appears to be exclusively focused on the method of maximum likelihood. Here we will employ a different methodology: We will derive a confidence band by intersecting the log-concavity constraint with a goodness-of-fit test. One important advantage of this approach is that such a confidence band satisfies a key principle of statistical inference: an estimate needs to be accompanied by some measure of standard error in order to be useful for inference. There appears to be no known method for obtaining such a confidence band via the maximum likelihood approach. Balabdaoui et al. (2009) construct pointwise confidence intervals for a log-concave density based on asymptotic limit theory, which requires to estimate the second derivative of . Azadbakhsh et al. (2014) compare several methods for estimating this nuisance parameter and they report that this task is quite difficult. An alternative approach is given by Deng et al. (2020). In Section 5 we compare the confidence bands introduced here with pointwise confidence intervals obtained via the asymptotic limit theory as well as with the bootstrap. Of course, pointwise confidence intervals have a different goal than confidence bands. The pointwise intervals will be be shorter but the the confidence level will not hold simultaneously across multiple locations. In contrast, the method we introduce here comes with strong guarantees in terms of finite sample valid coverage levels across locations.
2 Constructing a confidence band for a log-concave density
Given data from a log-concave density we want to find functions and such that
for a given confidence level . It is well known that in the case of a general density no non-trivial confidence interval exists, see e.g. Donoho (1988). However, assuming a shape-constraint for such as log-concavity allows to construct pointwise and uniform confidence statements as follows:
Let be a confidence set for the distribution function of , i.e.
| (1) |
Such a nonparametric confidence set always exists, e.g. the Kolmogorov-Smirnov bands give a confidence set for (albeit a non-optimal one). Define
| (2) |
and define analogously with sup in place of inf. If is log-concave then (1) and (2) imply
so we obtain a confidence interval for by solving the optimization problem (2). Moreover, if we solve (2) at multiple locations , then we obtain
| (3) |
So the coverage probability is automatically simultaneous across multiple locations and comes with a finite sample guarantee, since it is inherited from the confidence set in (1). Likewise, the quality of the confidence band, as measured e.g. by the width , will also derive from , which therefore plays a central role in this approach. Finally, the log-concavity constraint allows to extend the confidence set (3) to a confidence band on the real line, as we will show in Section 2.4.
Hengartner and Stark (1995), Dümbgen (1998), Dümbgen (2003) and Davies and Kovac (2004) employ the above approach for inference about a unimodal or a -modal density. Here we introduce a new confidence set for . This confidence set is adapted from methodology developed in the abstract Gaussian White Noise model by Walther and Perry (2019) for optimal inference in settings related to the one considered here. Therefore this confidence set should also prove useful for the works about inference in the unimodal and -modal setting cited above.
The key conceptual problem for solving the optimization problem (2) is that is infinite dimensional. We will overcome this by using the log-concavity of to relax to a finite dimensional superset, which makes it possible to compute (2) with fast optimization algorithms. We will address these tasks in turn in the following subsections.
2.1 A confidence set for
Given i.i.d. from the continuous cdf we set and
| (4) |
where denotes the th order statistic. Our analysis will use only the subset of the data, i.e. the set containing every th order statistic; see Remark 3 for why this is sufficient.
Translating the methodology of the ‘Bonferroni scan’ developed in Walther and Perry (2019) from the Gaussian White Noise model to the density setting suggests employing a confidence set of the form
with given below. The idea is to choose an index set that is rich enough to detect relevant deviations from the empirical distribution, but which is also sparse enough so that the constraints can be combined with a simple weighted Bonferroni adjustment and still result in optimal inference. The second key ingredient of this construction is to let the weights of the Bonferroni adjustment depend on in a certain way. See Walther and Perry (2019) for a comparison of the finite sample and asymptotic performance of this approach with other relevant calibrations, such as the ones used in the works cited above.
Note that the confidence set checks the probability content of random intervals , which automatically adapt to the empirical distribution. This makes it possible to detect relevant deviations from the empirical distribution with a relatively small number of such intervals, which is key for making the Bonferroni adjustment powerful as well as for efficient computation. Moreover, using such random intervals makes the bounds distribution-free since , see Ch. 3.1 in Shorack and Wellner (1986).
The precise specifications of are as follows:
where and denotes the -quantile of the beta distribution with parameters and . The term is a weighting factor in the Bonferroni adjustment which results in an advantageous statistical performance, see Walther and Perry (2019). It follows from the union bound that whenever is continuous.
Remarks: 1. An alternative way to control the distribution of is via a log-likelihood ratio type transformation and Hoeffding’s inequality, see Rivera and Walther (2013) and Li, Munk, Sieling and Walther (2020). This results in a loss of power due to the slack in Hoeffding’s inequality and the slack from inverting the log-likelihood ratio transformation with an inequality. Simulations show that the above approach using an exact beta distribution is less conservative despite the use of Bonferroni’s inequality to combine the statistics across .
2. The inference is based on the statistic , i.e. the unknown evaluated on the random interval , rather than on the more commonly used statistic , which evaluates the empirical measure on deterministic intervals . The latter statistic follows a binomial distribution whose discreteness makes it difficult to combine these statistics across using Bonferroni’s inequality without incurring substantial conservatism and hence loss of power. This is another important reason for using random intervals besides the adaptivity property mentioned above. Moreover, a deterministic system of intervals would have to be anchored around the range of the data and this dependence on the data is difficult to account for and is therefore typically glossed over in the inference.
3. The definition of in (4) means that we do not consider intervals with . Thus, as opposed to the regression setting in Walther and Perry (2019) we omit the first block111We also shift the index to let it start at 0 rather than at 2. This results in a simpler notation but does not change the methodology. of intervals. This derives from the folklore knowledge in density estimation that at least observations are required in order to obtain consistent inference simultaneously across such intervals. Indeed, this choice is sufficient to yield the asymptotic optimality result in Theorem 1.
We further simplify the construction in Walther and Perry (2019) by restricting ourselves to a dyadic spacing of the indices since we already obtain quite satisfactory results with this set of intervals.
2.2 Bounds for when is log-concave
The confidence set describes a set of plausible distributions in terms of for infinite dimensional . In the special case when is log-concave it is possible to construct a finite dimensional superset of by deriving bounds for this integral in terms of functions of a finite number of variables:
Lemma 1
Let be a univariate log-concave function. For given write , . Then there exist real numbers such that
and
where
is a strictly convex and infinitely often differentiable function.
Importantly, the bounds given in the lemma are convex and smooth functions of the and , despite the fact that these variables appear in the denominator in the formula for . This makes it possible to bring fast optimization routines to bear on the problem (2).
2.3 Computing pointwise confidence intervals
We are now in position to define a superset of by relaxing the inequalities in the definition of . To this end define for the functions
where , , and is defined in Lemma 1.
Given the subset of the order statistics defined in (4), we define to be the set of densities for which there exist real such that , , satisfy (5)-(8):
| (5) | ||||
| (6) | ||||
| (7) | ||||
| (8) |
Now we can implement a computable version of the confidence bound (2) by optimizing over rather than over . Note that if is log-concave then it follows from Lemma 1 that implies . This proves the following key result:
Proposition 1
If is log-concave then . Consequently, if we define pointwise lower and upper confidence bounds at the , , via the optimization problems
| (9) | ||||
then the following simultaneous confidence statement holds whenever is log-concave:
It is an important feature of these confidence bounds that they come with a finite sample guaranteed confidence level . On the other hand, it is desirable that the construction is not overly conservative (i.e. has coverage not much larger than ) as otherwise it would result in unnecessarily wide confidence bands. This is the motivation for deriving a statistically optimal confidence set in Section 2.1 and for deriving bounds in Lemma 1 that are sufficiently tight. Indeed, it will be shown in Section 4 that the above construction results in statistically optimal confidence bands.
2.4 Constructing confidence bands
The simultaneous pointwise confidence bounds , from the optimization problem (9) imply a confidence band on the real line due to the concavity of . In more detail, we can extend the definition of to the real line simply by interpolating between the :
| (10) |
Then for implies for since is concave and is piecewise linear. (In fact, it follows from (9) that is also concave.)
In order to construct an upper confidence bound note that concavity of together with for all implies for with :
and likewise for with :
Hence is bounded above by
with
where .
Thus we proved:
Proposition 2
If is log-concave then
The upper bound need not be concave but it is minimal in the sense that it can be shown that for every real there exist a concave function with for all and .
As an alternative to we tried a simple interpolation between the points . This interpolation will result in a smoother bound than , but the coverage guarantee of Proposition 2 does not apply any longer. However, the difference between and the interpolation will vanish as the sample size increases (or by increasing the number of design points in (4) for a given sample size ), and the simulations in Section 5 show that the empirical coverage exceeds the nominal level in all cases considered. Therefore we also recommend this interpolation as a simple and smoother alternative to .
Finally, we point out that the computational effort can be lightened simply by solving the optimization problem (9) for a subset of and then constructing and as described above based on that smaller subset of . Such a confidence band will still satisfy Proposition 2, but it will be somewhat wider at locations between those design points as it is based on fewer pointwise confidence bounds. Hence there is a trade-off between the width of the band and the computational effort required. While a larger subset of the will result in a somewhat reduced width of the band between the , there are diminishing returns as the width at the will not change. It follows from Theorem 1 below that solving the optimization problem (9) for with given in (4) is sufficient to produce statistically optimal confidence bands in a representative setting.
3 Solving the optimization problem
Next we describe a method for computing the pointwise confidence intervals , from observations , by efficiently solving the optimization problems (9). Constructing the confidence band is then straightforward with the post-processing steps given in Section 2.4.
Inspecting the optimization problems (9), we see that these problems possess some interesting structure: The criterion functions are linear, and the constraints (5) and (8) are convex. However, the constraints (6) and (7) are non-convex. Finding the global minimizer of a non-convex optimization problem (even a well-structured one) can be challenging; instead, we focus on a method for finding critical points of the problems (9). Taking a closer look at the non-convex constraints (6) and (7), we make the simple observation that they may be expressed as the difference of two convex functions (namely, a constant function minus a convex function). This property puts the problems (9) into the special class of non-convex problems commonly referred to as difference of convex programs (Hartman, 1959; Tao, 1986; Horst and Thoai, 1999; Horst et al., 2000), for which a critical point can be efficiently found. The class of difference of convex programs is quite broad, encompassing many problems encountered in practice, with a good amount of research into this area continuing on today. Important references include Hartman (1959), Tao (1986), Horst and Thoai (1999), Horst et al. (2000), Yuille and Rangarajan (2003), Smola et al. (2005), and Lipp and Boyd (2016).
| (11) | ||||
| (12) | ||||
A natural approach to finding a critical point of a difference of convex program is to linearize the non-convex constraints, then solve the convexified problem using any suitable off-the-shelf solver, and repeating these steps as necessary. This strategy underlies the well-known convex-concave procedure in Yuille and Rangarajan (2003), a popular heuristic for difference of convex programs. In more detail, the convex-concave iteration as applied to the problems (9) works as follows: Given feasible initial points, we first replace the (non-convex) constraints (6) and (7) by their first-order Taylor approximations centered around the inital points. Formally, letting and denote the log-densities and subgradients on iteration , respectively, we form
| (13) | ||||
| (14) |
for . We then solve the convexified problems (using the constraints (13), (14) instead of (6), (7)) with any off-the-shelf solver. Then we re-compute the approximations using the obtained solutions to the convexified problems and repeat these steps until an appropriate stopping criterion has been satisfied (e.g., some pre-determined maximum number of iterations has been reached, the change in criterion values are smaller than some specified tolerance, the sum of the slack variables is less than some tolerance, and/or we have that ). From this description, it may be apparent to the reader that the convex-concave procedure is actually a generalization of the majorization-minimization class of algorithms (which includes the well-known expectation-maximization algorithm as a special case).
We give a complete description of the convex-concave procedure as applied to the optimization problems (9) in Algorithm 1 appearing above, along with one important modification that we explain now. In practice it is not easy to obtain feasible initial points for the problems (9). Therefore, the penalty convex-concave procedure, a modification to the basic convex-concave procedure that was introduced by Le Thi and Dinh (2014), Dinh and Le Thi (2014), and Lipp and Boyd (2016), works around this issue by allowing for an (arbitrary) infeasible initial point and then gradually driving the iterates into feasibility by adding a penalty for constraint violations into the criterion that grows with the number of iterations (explaining the word “penalty” in the name of the procedure), through the use of slack variables.
Standard convergence theory for the (penalty) convex-concave procedure (see, e.g., Section 3.1 in Lipp and Boyd (2016) as well as Theorem 10 in Sriperumbudur and Lanckriet (2009) and Proposition 1 in Khamaru and Wainwright (2018) tells us that the criterion values (11) and (12) generated by Algorithm 1 converge. Moreover, under regularity conditions (see Section 3.1 in Lipp and Boyd (2016)), the iterates generated by Algorithm 1 converge to critical points of the problems (9). At convergence, the pointwise confidence intervals generated by Algorithm 1 can be turned in confidence bands as described in Section 2.4.
Finally, we mention that although not necessary, additionally linearizing the (convex) constraints (8) around the previous iterate, i.e., forming
on iteration , can help circumvent numerical issues. Furthermore, as all the constraints in the problems (11) and (12) are now evidently affine functions, this relaxation has the added benefit of turning the problems (11) and (12) into linear programs, for which there (of course) exist heavily optimized solvers.
4 Large sample statistical performance
The large sample performance of the log-concave MLE has been studied intensively, see e.g. Dümbgen and Rufibach (2009), Kim and Samworth (2016) and Doss and Wellner (2016). The main message is that the MLE attains the optimal minimax rate of convergence of with respect to various global loss functions. Recently, Kim, Guntuboyina and Samworth (2018) have shown that the MLE can achieve a faster rate of convergence when the log density is -affine, i.e. when consists of linear pieces . They show that the MLE is able to adapt to this simpler model, where it will converge with nearly the parametric rate, namely with . Here we show that the construction of our confidence band via the particular confidence set will also result in a nearly parametric rate of convergence for the width of the confidence band in that case. To this end, we first consider the case where some part of is log-linear:
Theorem 1
Let be a log-concave density and suppose is linear on some interval . (So may be a proper subset of the support of ). Then on every closed interal :
for some constant , and the same statement holds for in place of . In particular, the width of the confidence band satisfies with probability converging to 1.
If there are such intervals, then the theorem holds for the maximum width over the intervals. This includes -affine log densities as a special case.
We conjecture that the width of the confidence band will likewise achieve the optimal minimax rate if is smooth rather than linear.
5 Some examples
Finally, we present some numerical examples of our methodology, highlighting the empirical coverage and widths of our confidence bands as well as the computational cost of computing the bands, for a number of different distributions.
To calculate coverage, we first simulated observations from a (i) standard normal distribution, (ii) uniform distribution on , (iii) chi-squared distribution with three degrees of freedom, and (iv) exponential distribution with parameter 1. Then, we computed our confidence bands from the data by running the penalty convex-concave procedure described in Algorithm 1 and then computing and as discussed in Section 2.4, where was computed by linearly interpolating between the . We repeated these two steps (simulating data and computing bands) 1000 times. We calculated the empirical coverage for each density by evaluating the band at 10000 points , evenly spaced across the range of the data, to check whether for all , and then computed the empirical frequency of this event across the 1000 repetitions. In order to calculate the widths of the bands, we averaged the widths at the sample quartiles over all of the repetitions. We calculated the computational effort by averaging the runtimes, obtained by running Algorithm 1 on a workstation with four Intel E5-4620 2.20GHz processors and 15 GB of RAM, over all the repetitions. To speed up the computation for , we ran Algorithm 1 on a subset of 30% of the points , as discussed at the end of Section 2.4; the coverages and widths were virtually indistinguishable from those obtained using the full set of points .
Algorithm 1 requires a few tuning parameters, which are important for assuring quick convergence. In general, we found that the initial penalty strength , the maximum penalty strength , and the penalty growth factor had the greatest impact on convergence. In our experience, setting to a small value and to a large value worked well; we used and , with the most suitable values depending on the characteristics of the problem. We experimented with various penalty growth factors , finding that the best value of again varied with the problem setup. We always set the maximum number of iterations as our method usually converged after around 20-30 iterations across all problem settings. We initialized the points randomly. Finally, we set the miscoverage level but we also report results for .
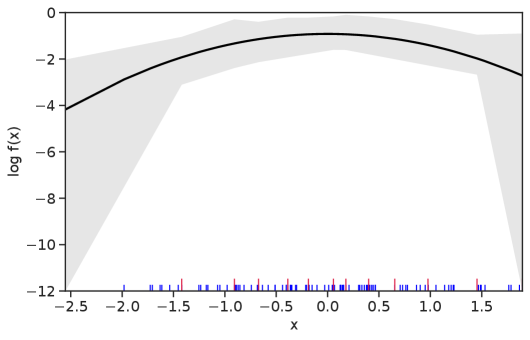
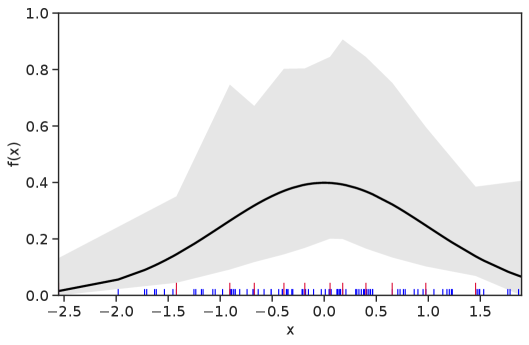
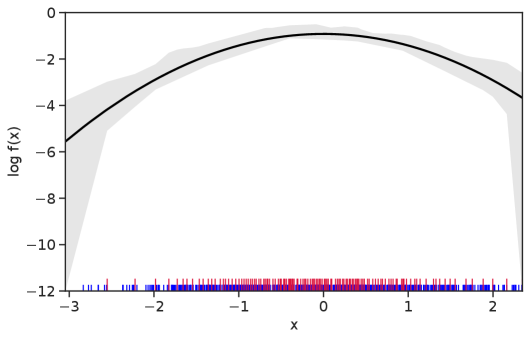
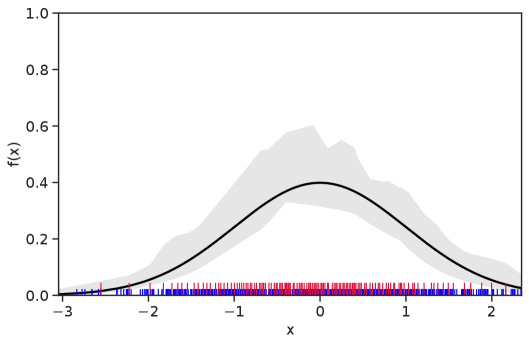
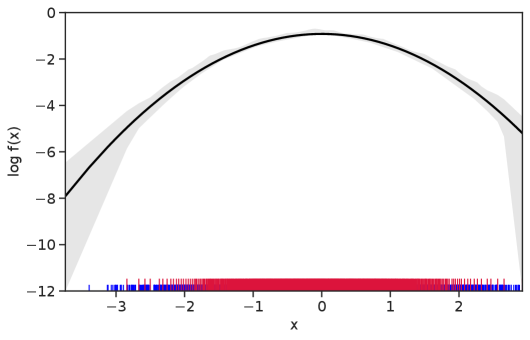
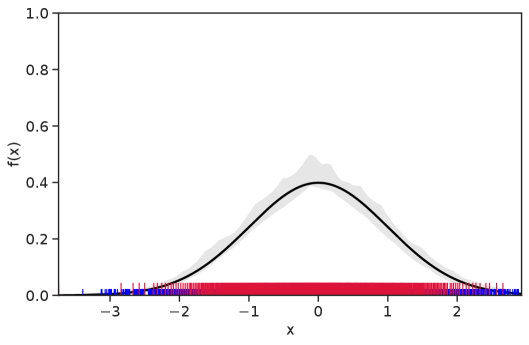
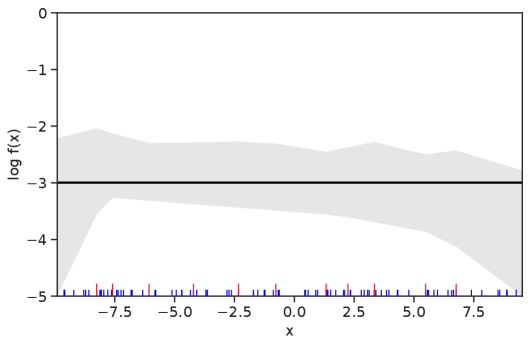
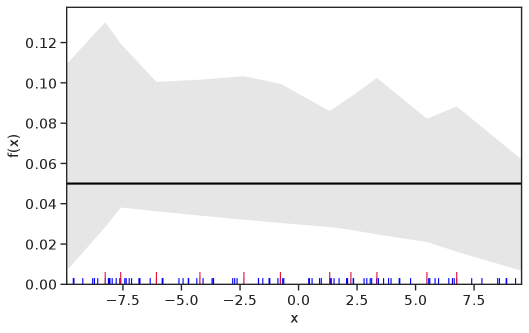
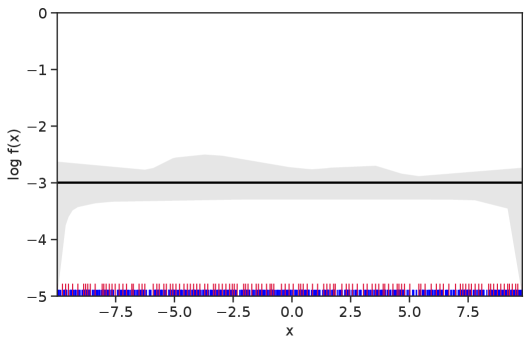
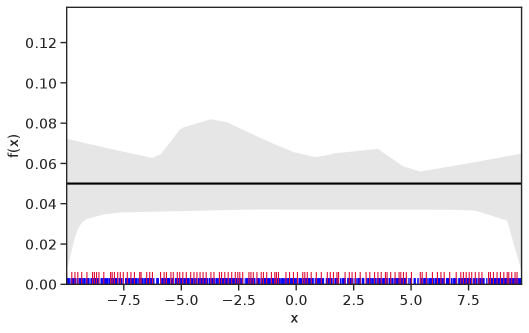
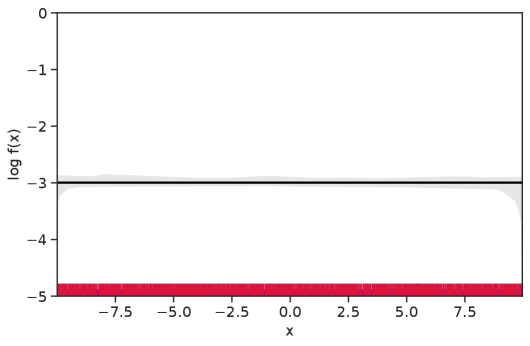
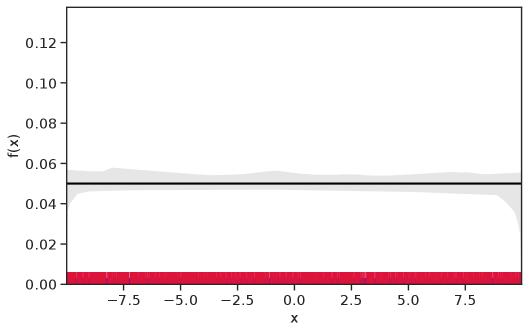
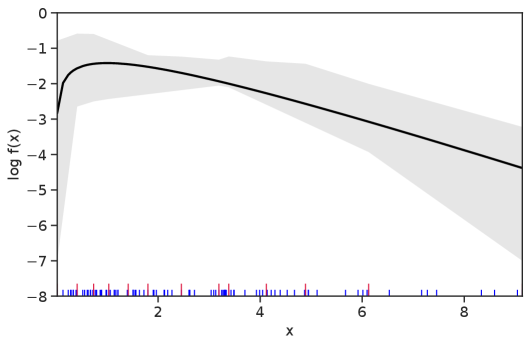
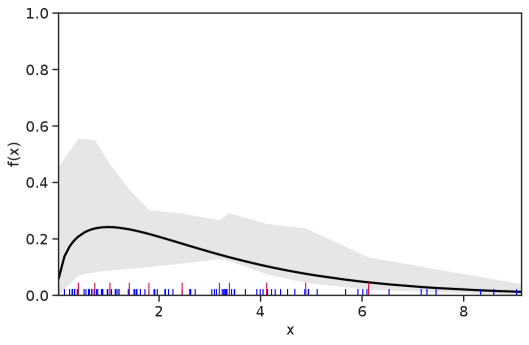
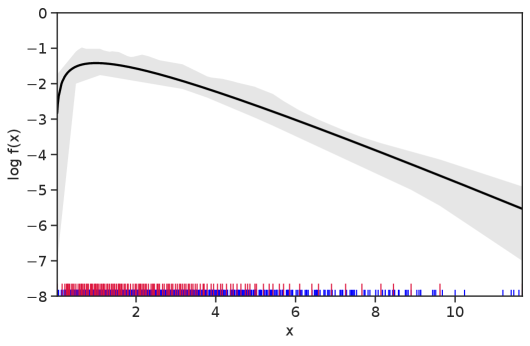
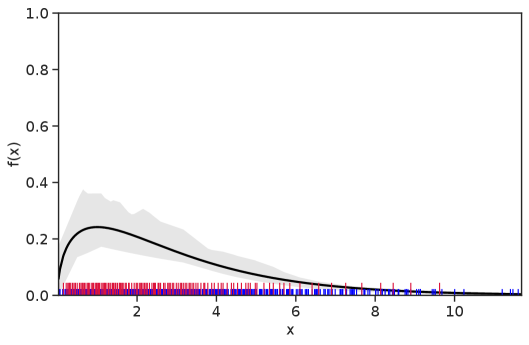
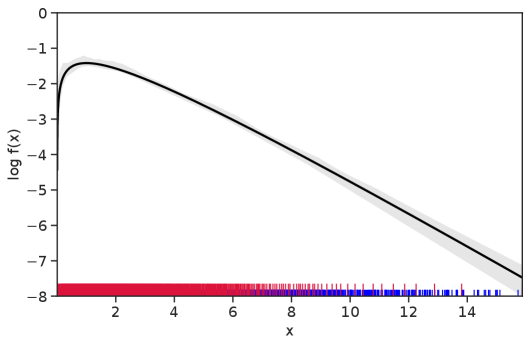
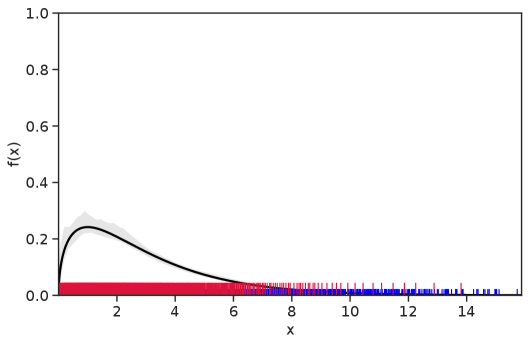
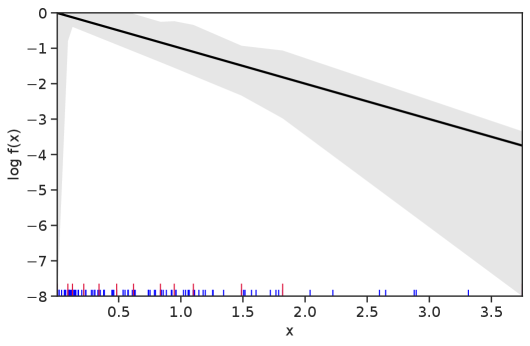
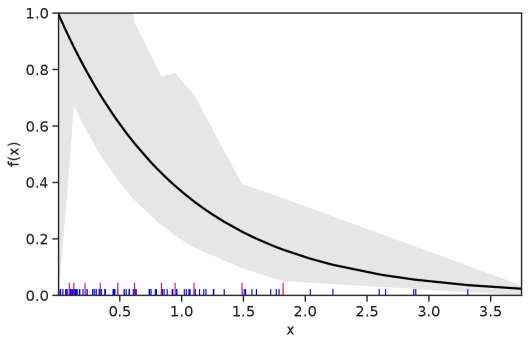
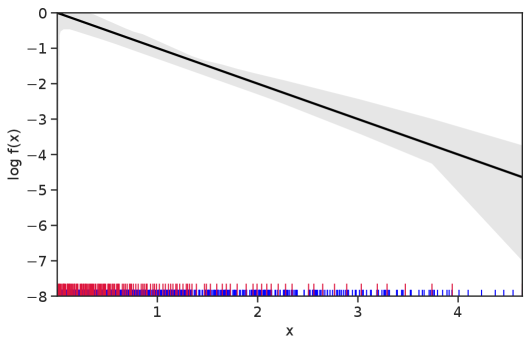
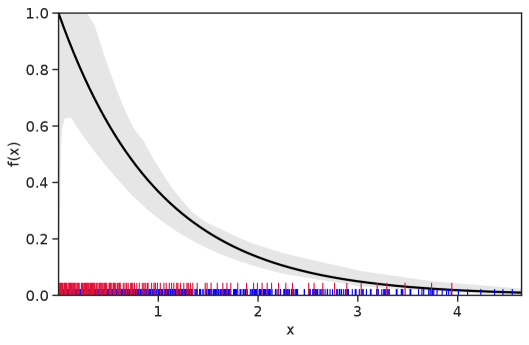
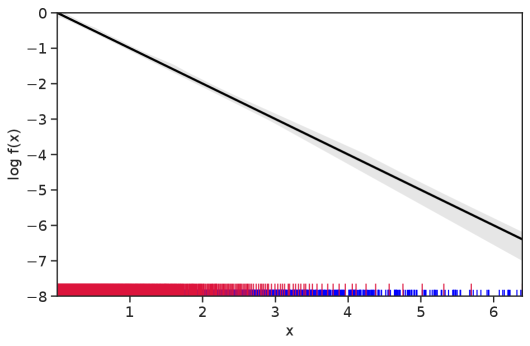
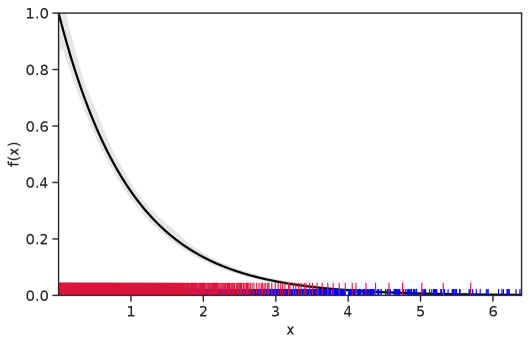
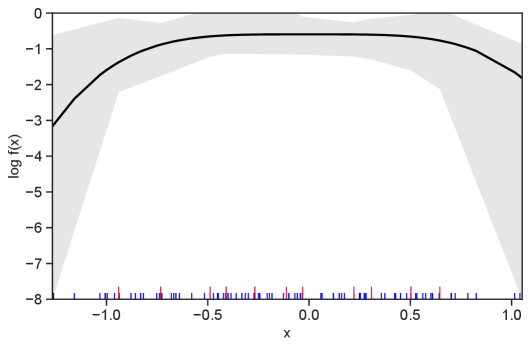
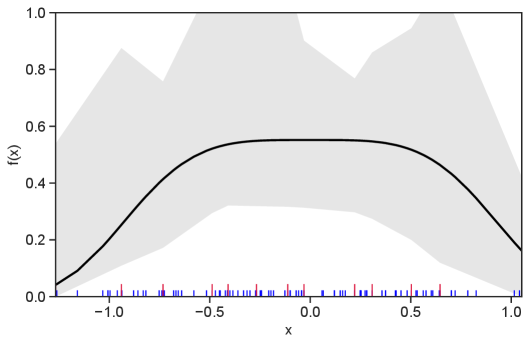
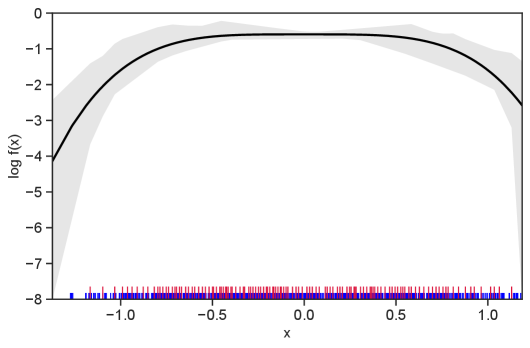
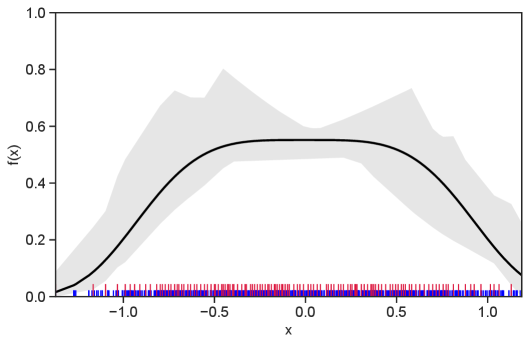
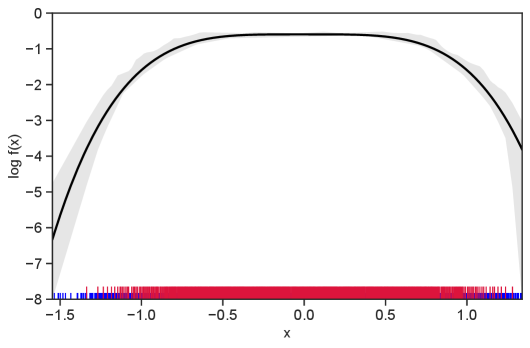
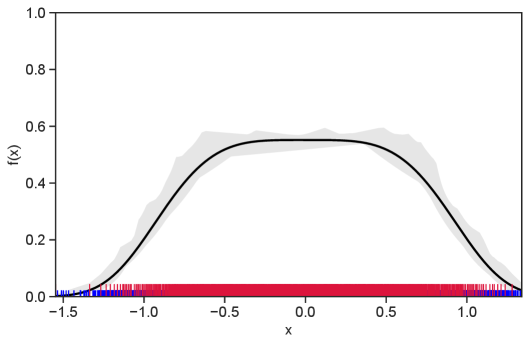
Table 1 summarizes the results. The table (reassuringly) shows us that the bands achieve coverage at or above the nominal level. In Figures 1–5 we present a visualization of the bands, from a single repetition chosen at random, for each of the four underlying densities as well as for a density that is proportional to . In addition, we depict the bands for the case of a larger sample with . The figures and Table 1 show that while the bands are naturally wider when the sample size is small (), they quickly tighten as the sample size grows ().
As for the computational cost, we found that around 20-30 iterations of Algorithm 1 were enough to reach convergence, for each point . Table 1 shows that this translates into just a few seconds to compute the entire band when , and a couple of minutes when . We found that Algorithm 1 converged to the exact same solutions even when started from a number of different initial points, suggesting that it is in fact finding the global minimizers of the problems (9). Therefore, these runtimes appear to be reasonable, as it is worth bearing in mind that Algorithm 1 is effectively solving a potentially large number of non-convex optimization problems (precisely: 13, 39, and 188 such problems, corresponding to , respectively). Moreover, we point out that the computation in Algorithm 1 can easily be parallelized, e.g. across the points .
In order to compare the confidence band with pointwise confidence intervals, we performed these experiments also with two methods that compute pointwise confidence intervals for log-concave densities. Azadbakhsh et al. (2014) compare several such methods and report that no one approach appears to uniformly dominate the others and that each method works well only in a certain range of the data. The first group of methods examined by Azadbakhsh et al. (2014) is based on the pointwise asymptotic theory developed in Balabdaoui et al. (2009) and requires estimating a nuisance parameter, for which Azadbakhsh et al. (2014) investigate several options. We picked the option that they report works best, namely their method (iv) in their Section 4. This method is called ‘Asymptotic theory with approximation’ in Table 2. The second group of methods analyzed by Azadbakhsh et al. (2014) concerns various bootstrapping schemes, and we chose the one that they report to have the best performance, namely the ECDF-bootstrap, listed as (v) in their Section 4, which we use with 250 bootstrap repetitions. This method computes the MLE for each bootstrap sample and then computes the bootstrap percentile interval at a point based on the 250 bootstrap replicates of the MLE at . We used the R function logConCI produced by Azadbakhsh et al. (2014) for implementing both methods. With each of the two methods we compute the pointwise 90% confidence interval for each point in the grid of points that we use to evaluate empirical coverage. Since these are pointwise 90% confidence intervals, we expect that the coverage for the band (i.e. the simultaneous coverage across all in the grid) is smaller than 90%, but that the intervals are narrower than those for a simultaneous confidence band. This is confirmed by the results in Table 2, which show that both methods seriously undercover. The bootstrap is also seen to be significantly more computationally intensive than the method based on asymptotic theory as well as Algorithm 1.
| Nominal coverage 90% | Nominal coverage 95% | |||||||||
| Distribution | Coverage | Width | Coverage | Width | Time | |||||
| (secs.) | ||||||||||
| Gaussian | 100 | 0.96 | 0.58 | 0.65 | 0.61 | 0.98 | 0.66 | 0.74 | 0.70 | 5.6 |
| 1000 | 0.95 | 0.24 | 0.28 | 0.24 | 0.97 | 0.27 | 0.31 | 0.27 | 151.2 | |
| Uniform | 100 | 0.93 | 0.08 | 0.07 | 0.08 | 0.96 | 0.09 | 0.08 | 0.09 | 5.1 |
| 1000 | 0.91 | 0.03 | 0.03 | 0.03 | 0.97 | 0.03 | 0.03 | 0.03 | 128.8 | |
| Chi-squared | 100 | 0.94 | 0.36 | 0.28 | 0.19 | 0.98 | 0.41 | 0.33 | 0.23 | 5.4 |
| 1000 | 0.94 | 0.16 | 0.12 | 0.07 | 0.97 | 0.18 | 0.13 | 0.08 | 132.5 | |
| Exponential | 100 | 0.93 | 0.94 | 0.69 | 0.44 | 0.96 | 1.06 | 0.77 | 0.51 | 5.7 |
| 1000 | 0.91 | 0.38 | 0.25 | 0.15 | 0.97 | 0.43 | 0.29 | 0.17 | 140.4 | |
| Asymptotic theory with approximation | Bootstrap | ||||||||||
| Distribution | Coverage | Width | Time | Coverage | Width | Time | |||||
| (secs.) | (secs.) | ||||||||||
| Gaussian | 100 | 0.22 | 0.13 | 0.20 | 0.13 | 1.4 | 0.37 | 0.16 | 0.16 | 0.12 | 98.2 |
| 1000 | 0.08 | 0.04 | 0.08 | 0.04 | 6.4 | 0.15 | 0.04 | 0.07 | 0.03 | 194.8 | |
| Uniform | 100 | 0.32 | 0.03 | 0.03 | 0.03 | 1.4 | 0.01 | 0.02 | 0.01 | 0.02 | 97.4 |
| 1000 | 0.15 | 0.01 | 0.01 | 0.01 | 6.5 | 0.11 | 0.01 | 0.01 | 0.01 | 184.5 | |
| Chi-squared | 100 | 0.06 | 0.08 | 0.04 | 0.02 | 1.4 | 0.52 | 0.04 | 0.03 | 0.02 | 97.2 |
| 1000 | 0.00 | 0.02 | 0.01 | 0.00 | 6.6 | 0.31 | 0.02 | 0.01 | 0.01 | 191.0 | |
| Exponential | 100 | 0.37 | 0.04 | 0.02 | 0.01 | 1.4 | 0.05 | 0.07 | 0.05 | 0.03 | 95.7 |
| 1000 | 0.15 | 0.01 | 0.01 | 0.01 | 6.5 | 0.04 | 0.02 | 0.01 | 0.01 | 180.0 | |
6 Discussion
The paper shows how to construct confidence bands for a log-concave density by intersecting the log-concavity constraint with an appropriate nonparametric confidence set. This approach has three strong points: First, it produces confidence bands with a finite sample guaranteed confidence level. Our simulations have shown that this guaranteed confidence level is not overly conservative. Second, the approach allows to bring modern tools from optimization to bear on this problem. This aspect is particularly important in a multivariate setting where it is known that computing the MLE is very time consuming. We expect that the key ideas of the univariate construction introduced here can be carried over to the multivariate setting and we are working on implementing this program in the multivariate setting. Third, it was shown that this approach results in attractive statistical properties, namely that the confidence bands converge at nearly the parametric rate when the log density is -affine. We conjecture that the width of these confidence bands will likewise achieve the optimal minimax rate if is smooth rather than piecewise linear, and we leave the proof of such a result as an open problem.
7 Proofs
7.1 Proof of Lemma 1
It is well known that if is a concave function then there exist real numbers such that
see e.g. Boyd and Vandenberghe (2004). We found it computationally advantageous to employ these inequalities only for . Those inequalities immediately yield
| (15) |
as well as for :
and for :
On the other hand, since is concave on it cannot be smaller than the chord from to . Hence for :
proving the lemma. For later use we note the following fact:
| If (15) holds, then (15) holds for all , and the are non-increasing in . | (16) |
This is because (15) implies both and , hence . This monotonicity property and (15) yield for :
and analogously for .
7.2 Proof of Theorem 1
Let be an integer that will be determined later as a function of , and set . So does not change with but does as increases with . Define the event
where . We will prove the theorem with a sequence of lemmata. The first lemma bounds the width of the confidence band on the discrete set , where with and :
Lemma 2
If is a feasible point for the optimization problem (9), then on
In order to extend the bound over the discrete set to a uniform bound over the interval we will use the following fact, which is readily proved using elementary calculations:
If the linear function and the concave function satisfy for , then .
Lemma 3
On the event
Therefore any concave function for which is feasible for (9) must satisfy
on , where and . Hence this bound applies to the lower and upper confidence limits and since is a concave function and , is feasible for (9), and for every real there exist a concave function such that and , is feasible for (9).
In order to conclude the proof of the theorem we will show
Lemma 4
and
Lemma 5
for a certain .
Then the claim of the theorem follows since the bound on the log densities carries over to the densities as implies
It remains to prove the Lemmata 2–5. We will use the following two facts:
Fact 1
If is a linear function, then , where is given in Lemma 1. One readily checks that the function is increasing in both and . Furthermore, since is increasing for we have for and :
and this inequality also holds for since is continuous.
Fact 2
Let and . Then for
where denotes the -quantile of the beta distribution with parameters and . This fact follows from Propostion 2.1 in Dümbgen (1998).
Proof of Lemma 2: Since is linear on we will assume that it is non-increasing on . The non-decreasing case is proved analogously. Let and set , so . The concavity constraint (5) implies that the function is concave on and hence not smaller than its secant . Hence
| (17) |
Suppose where . If then Fact 1 shows (note that as is non-increasing) that (17) is not smaller than
| (18) |
since is linear on . Now since , and hence . So on the event , (18) is not smaller than
by Fact 2, since implies , while , and therefore for large enough. Thus we arrive at a violation of the constraint (8).
On the other hand, suppose and . Set , and . Then by (21). By (5) and (16)
Hence for :
| (19) |
since is linear on . This yields
and likewise for :
Since the function is positive and increasing for we obtain with (19):
by Fact 2, yielding a violation of (7). Therefore we conclude as claimed. The lower bound for follows analogously.
Proof of Lemma 3: is monotone on since it is log-linear. Consider first the case where is non-increasing on . On we have for and , :
| (20) |
for large enough, since . Since is non-increasing on , (20) implies
| (21) |
and the claim of the Lemma follows. If is non-decreasing on then we obtain analogously for all and the claim of the Lemma follows also.
Proof of Lemma 4: Set . Then for
for large enough as . There are tuples in and
Hence, setting , and using Fact 2:
Proof of Lemma 5: Note that , where is the interval between the left endpoints of and , and is the interval between the right endpoints. Recall that is the smallest index such that . Hence and must both fall into if at least points fall into , i.e. if at least observations fall into . Therefore
where denotes the empirical distribution. Since is log-linear on :
Therefore
for , in which case Chebychev’s inequality gives
and the same result holds for .
References
-
Azadbakhsh, M., Jankowski, H. and Gao, X. (2014). Computing confidence intervals for log-concave densities. Comput. Statist. Data Anal. 75, 248–264.
-
Balabdaoui, F., Rufibach, K. and Wellner, J. A. (2009). Limit distribution theory for maximum likelihood estimation of a log-concave density. Ann. Statist. 37, 1299–1331.
-
Birgé, L. (1997). Estimation of unimodal densities without smoothness assumptions. Ann. Statist. 25, 970–981.
-
Boyd, S. and Vandenberghe, L. (2004). Convex Optimization. Cambridge University Press, New York.
-
Chan, H.P. and Walther, G. (2013). Detection with the scan and the average likelihood ratio. Statist. Sinica 23, 409–428.
-
Cule, M., Samworth, R. and Stewart, M. (2010). Maximum likelihood estimation of a multi-dimensional log-concave density. J. R. Stat. Soc. Ser. B Stat. Methodol. 72, 545–607.
-
Davies, P.L. and Kovac, A. (2004). Densities, spectral densities and modality. Ann. Statist. 32, 1093-1136.
-
Deng, H., Han, Q. and Sen, B. (2020). Inference for local parameters in convexity constrained models. arXiv preprint arXiv:2006.10264.
-
Dinh, T. P. and Le Thi, H. A. (2014). Recent advances in DC programming and DCA. In Transactions on computational intelligence XIII, 1-37. Springer, Berlin, Heidelberg.
-
Donoho, D.L. (1988). One-sided inference for functionals of a density. Ann. Statist. 16, 1390-1420.
-
Doss, C. R. and Wellner, J. A. (2016). Global rates of convergence of the MLEs of log-concave and s-concave densities. Ann. Statist. 44, 954–981.
-
Dümbgen, L. (1998). New goodness-of-fit tests and their application to nonparametric confidence sets. Ann. Statist. 26, 288–314.
-
Dümbgen, L. (2003). Optimal confidence bands for shape-restricted curves. Bernoulli 9, 423–449.
-
Dümbgen, L., Hüsler, A. and Rufibach, K. (2007). Active set and EM algorithms for log-concave densities based on complete and censored data. arXiv preprint arXiv:0707.4643v4.
-
Dümbgen, L. and Rufibach, K. (2009). Maximum likelihood estimation of a log-concave density and its distribution function: basic properties and uniform consistency. Bernoulli 15, 40–68.
-
Feng, O., Guntuboyina, A., Kim, A. K. H. and Samworth, R. J. (2020+). Adaptation in multivariate log-concave density estimation. Ann. Statist., to appear.
-
Hartman, P. (1959). On functions representable as a difference of convex functions. Pacific Journal of Mathematics 9(3), 707-713.
-
Hengartner, N.W. and Stark, P.B. (1995). Finite-sample confidence envelopes for shaperestricted densities. Ann. Statist. 23, 525–550.
-
Horst, R., Pardalos, P. M. and Van Thoai, N. (2000). Introduction to global optimization. Springer Science and Business Media.
-
Horst, R. and Thoai, N. V. (1999). DC programming: overview. Journal of Optimization Theory and Applications 103(1), 1-43.
-
Khamaru, K. and Wainwright, M. J. (2018). Convergence guarantees for a class of non-convex and non-smooth optimization problems. arXiv preprint arXiv:1804.09629.
-
Kim, A. K. H. and Samworth, R. J. (2016). Global rates of convergence in log-concave density estimation. Ann. Statist. 44, 2756–2779.
-
Kim, A. K. H., Guntuboyina, A. and Samworth, R. J. (2018). Adaptation in log-concave density estimation. Ann. Statist. 46, 2279–2306.
-
Le Thi, H. A. and Dinh, T. P. (2014). DC programming and DCA for general DC programs. In Advanced Computational Methods for Knowledge Engineering, 15-35. Springer, Cham.
-
Li, H., Munk, A., Sieling, H. and Walther, G. (2020). The essential histogram. Biometrika 107, 347–364.
-
Lipp, T. and Boyd, S. (2016). Variations and extension of the convex–concave procedure. Optimization and Engineering 17(2), 263-287.
-
Liu, Y. and Wang, Y. (2018). A fast algorithm for univariate log-concave densityi estimation. Aust. N. Z. J. Stat. 60(2), 258–275.
-
Pal, J. K., Woodroofe, M. and Meyer, M. (2007). Estimating a Polya frequency function. In Complex datasets and inverse problems. IMS Lecture Notes Monogr. Ser. 54, 239–249. Inst. Math. Statist., Beachwood, OH.
-
Rivera, C. and Walther, G. (2013). Optimal detection of a jump in the intensity of a Poisson process or in a density with likelihood ratio statistics. Scand. J. Stat. 40, 752–769.
-
Samworth, R.J. (2018). Recent progress in log-concave density estimation. Statist. Sci. 33, 493-509.
-
Saumard, A. and Wellner, J.A. (2014). Log-concavity and strong log-concavity: a review. Statistics Surveys 8, 45-114.
-
Schuhmacher, D. and Dümbgen, L. (2010). Consistency of multivariate log-concave density estimators. Statist. Probab. Lett. 80, 376–380.
-
Seregin, A. and Wellner, J. A. (2010). Nonparametric estimation of multivariate convex-transformed densities. Ann. Statist. 38, 3751–3781.
-
Shorack, G.R. and Wellner, J.A. (1986). Empirical Processes with Applications to Statistics. Wiley, New York.
-
Smola, A. J., Vishwanathan, S. V. N. and Hofmann, T. (2005). Kernel Methods for Missing Variables. In AISTATS.
-
Sriperumbudur, B. K. and Lanckriet, G. R. (2009, December). On the convergence of the concave-convex procedure. In Proceedings of the 22nd International Conference on Neural Information Processing Systems, 1759-1767. Curran Associates Inc.
-
Tao, P. D. (1986). Algorithms for solving a class of nonconvex optimization problems. Methods of subgradients. In North-Holland Mathematics Studies 129, 249-271. North-Holland.
-
Walther, G. (2002). Detecting the presence of mixing with multiscale maximum likelihood. J. Amer. Statist. Assoc. 97, 508–513.
-
Walther, G. (2009). Inference and modeling with log-concave distributions. Statist. Sci. 24, 319–327.
-
Walther, G. (2010). Optimal and fast detection of spatial clusters with scan statistics. Ann. Statist. 38, 1010–1033.
-
Walther, G. and Perry, A. (2019). Calibrating the scan statistic: finite sample performance vs. asymptotics. arXiv preprint arXiv:2008.06136.
-
Yuille, A. L. and Rangarajan, A. (2003). The concave-convex procedure. Neural computation 15(4), 915-936.