Conformal inference for regression on Riemannian Manifolds
Abstract
Regression on manifolds, and, more broadly, statistics on manifolds, has garnered significant importance in recent years due to the vast number of applications for non Euclidean data. Circular data is a classic example, but so is data in the space of covariance matrices, data on the Grassmannian manifold obtained as a result of principal component analysis, among many others. In this work we investigate prediction sets for regression scenarios when the response variable, denoted by , resides in a manifold, and the covariable, denoted by , lies in an Euclidean space. This extends the concepts delineated in [61] to this novel context. Aligning with traditional principles in conformal inference, these prediction sets are distribution-free, indicating that no specific assumptions are imposed on the joint distribution of , and they maintain a non-parametric character. We prove the asymptotic almost sure convergence of the empirical version of these regions on the manifold to their population counterparts. The efficiency of this method is shown through a comprehensive simulation study and an analysis involving real-world data.
1 Introduction
Conformal prediction is a powerful set of statistical tools that operates under minimal assumptions about the underlying model. It is primarily used to construct confidence sets that are applicable to a diverse range of problems in fields such as machine learning and statistics. Is unique in its ability to construct prediction regions that guarantee a specified level of coverage for finite samples, irrespective of the distribution of the data. This is particularly crucial in high-stakes decision-making scenarios where maintaining a certain level of coverage is critical.
Unlike other methods, conformal prediction does not require strong assumptions about the sample distribution, such as normality. The aim is to construct prediction regions as small as possible to yield informative and precise predictions, enhancing the tool’s utility in various applications.
The approach was first proposed by Vovk, Gammerman, and Shafer in the late 1990s, as referenced in [57]. Since its inception, it has been the subject of intense research activity. Originally formulated for binary classification problems, the method has since been expanded to accommodate regression, multi-class classification, functional data, functional time series, and anomaly detection, among others. Several applications of this method can be found in the book [5].
In the context of regression, conformal prediction has proven to be efficient in constructing prediction sets, as evidenced by works such as [61], [62], and [34]. To enhance the performance of these prediction sets, particularly to decrease the length of prediction intervals (when the output is one-dimensional), a combination of conformal inference and quantile regression was proposed in [53]. In [20], computationally efficient conformal inference methods for Bayesian models were proposed.
The method has also been extended to functional regression, where the predictors and responses are functions, rather than vectors, see for instance [41], [21] and [18]. In this case, the prediction regions take the form of functional envelopes that have a high probability of containing the true function.
In the field of classification, conformal prediction has been employed to tackle a broad spectrum of problems. These include image classification, as in [40], and text classification, as in [58]. For multi-class classification, a prevalent approach is to create prediction sets that have a high likelihood of encompassing the correct class. This can be realized via the use of ‘Venn prediction sets’, as outlined in [43]. These sets partition the label space into overlapping regions, each one corresponding to a distinct class.
In summary, conformal prediction provides powerful statistical tools and has been successfully applied to a wide range of problems in machine learning, statistics, and related fields. Its main advantage is its ability to provide distribution-free prediction regions that can be used in the presence of any underlying distribution of the data. As this field of research continues to evolve, it is expected to find even more applications in the future.
2 Conformal inference on manifolds
Although, as mentioned, it has been extended to various scenarios, there are no proposals or extensions to the case where the output is in a Riemannian manifold. This case is of cumbersome importance because there are certain types of data that, due to their inherent characteristics, must be treated as data on manifolds. A prominent example of this are covariance matrices (for instance, the volatility of a portfolio, see [8] and [28]), which are data in the manifold of positive definite matrices (see [14]). Another example is given by Vectorcardiograms that are condensed into data on the Stiefel manifold (see [13]). The outcome of performing a principal component analysis results in data on the Grassmannian manifold (see [27]), and the wind measurements can be represented as data on the cylinder (see [12]).
Other applications in image analysis are developed in [49] and more generally in machine learning in [24].
The extension to this context is not trivial since when the output belongs to a Riemannian manifold , several arguments used in Euclidean conformal inference are not straightforwardly extendable. For instance, the Frechet mean on the manifold can be defined, but it does not always exist nor is it necessarily unique. Moreover, formulating a regression model on the manifold is not easy because of the absence of any additive structure, although there have been recent advances in this area (see for instance [50]).
We extend the methodologies outlined by [61] to the broader context of pairs where and the response has support included on a, smooth enough, -dimensional manifold . [61] is focused on the scenario where is a real-valued variable, constructing confidence sets—referred to as confidence bands—via density estimators. One of the key tools to get the consistency of the empirical conformal region to its population counterpart, as in [61], is Theorem 1. It states that the kernel-density estimator is uniformly consistent on manifolds. Once this is established, to adapt the ideas in [61], it must also be proved that the conditional density is uniformly bounded from above, this is done in Lemma 4. Finally, a further distinction from [61] is that—because the manifold may possess a nonempty boundary—points located well inside the manifold are handled differently from those situated near its edge. Here, we obtain an upper bound for the discrepancy between the empirical confidence set and its theoretical counterpart , in terms of , the volume measure on . More precisely, as detailed in Theorem 2 (see also Remark 1) the probability that this discrepancy being larger than is bounded from above by , for any , being a constant that depends only on , where denotes the dimensionality of and . Our main and stronger theorem is for compact manifolds, however, we considered in section 5 the case of non-compact manifolds.
The kernel-based density estimator proposed in [12] uses the Euclidean distance instead of the geodesic distance on the manifold, which may be unknown in some cases, see Equation (4). Due to the curse of dimensionality, kernel-based density estimators are generally unsuitable for high-dimensional problems. In Section 6, we discuss an approach to overcome this limitation that builds on the ideas introduced in [30]. In essence, instead of estimating the conditional density locally (i.e., using only sample points close to ), the proposed method uses all sample points whose estimated conditional densities are similar (in a sense to be defined).
Conformal inference is tackled in metric spaces in [44]; however, given the generality, convergence rates are not provided, as in the present work, but only consistency in probability, for the case where the confidence bands are constructed through regression.
2.1 Conformal inference in a nutshell
In this section, we briefly provide the basic foundations of conformal inference to facilitate the reading of the following sections. For a more detailed reading see [22]. A key hypothesis in conformal inference is the exchangeability assumption, which means that for any permutation of the distribution of the sample where is a random element in some measurable space is the same as the distribution of . Quoting [22] “A nonconformity measure is a way of scoring how different an example is from a bag . Let us define, where and ” For “we define the prediction set .” The following Proposition is given in [58].
Proposition 1 (Proposition 2.1).
Under the exchangeability assumption,
In the regression setting, that is, when has distribution , previous construction build a level set on the joint distribution (see Equation 4 in [61]). Nevertheless, controlling is much more convenient in regression (see [61]). In this case we speak of “conditional coverage”. When there exists a conditional density (see hypothesis H1 in subsection 3), the “conditional oracle set”, , (in [61] it is called conditional oracle band), is defined as
| (1) |
where satisfies
| (2) |
The empirical version of obtained from constituted by an i.i.d. sample of with distribution , is called a conditionally valid set (see [61]).
Definition 1.
Given , and in the support of , a set is said to be conditionally valid if
This definition captures the notion of a set of possible values of that provides a specified level of coverage for a given imput .
As is shown in Lemma 1 of [61], non-trivial finite sample conditional validity for all in the support of is impossible for a continuous distribution. To overcome this limitation, the following notion of local validity is introduced.
Definition 2.
Let be a partition of . A prediction set is locally valid with respect to if
| (3) |
Whenever , we will write for the conditional density, w.r.t. , of given . We aim to prove (see Theorem 2) that locally valid sets converges to when is supported on a manifold.
3 Assumptions
In the following, denotes an i.i.d. sample of with distribution , where and . Here is a compact -dimensional submanifold of . The case of non compact manifolds is discussed in Section 5. We further denote by the marginal distribution of and by its support. We denote the volume measure on by and use to denote the Euclidean norm on . We denote by the -dimensional Lebesgue measure in .
We will now give the set of assumptions that we will require. H1 to H4 are also imposed in [61]. Hypotheses H0 and H5 are imposed to guarantee the uniform convergence of the kernel-based density estimator of the conditional density.
-
H0
is a submanifold, and if , then is also a submanifold.
-
H1
The joint distribution has a density w.r.t. , and the marginal distribution has a density (w.r.t. ). We denote by the conditional density, where if .
-
H2
is such that that there exist such that for all in the support of .
-
H3
is Lipschitz continuous as a function of , i.e., there exists a constant such that .
-
H4
There are positive constants , , , and such that for all in the support of ,
for all , where is given by (2). Moreover .
-
H5
has continuous partial second derivatives, for short .
The hypothesis H0 is satisfied by a very wide range of manifolds, among them, the Stieffel and Grassmannian Manifold. The cone of positive definite matrices, among many others. It is not a restrictive hypothesis in applications.
Assumptions H1 to H5 impose regularity on the joint and conditional densities of the data. In particular, the assumption of Lipschitz continuity H3 ensures that small changes in the input lead to small changes in the output . Assumption H2 implies that es compactly supported. Regarding Assumption H4, quoting [61], “is related to the notion of the ‘-exponent’ condition that was introduced by [51], and widely used in the density level set literature ([56, 52]). It ensures that the conditional density is neither too flat nor too steep near the contour at level , so the cut-off value and the conditional density level set can be approximated from a finite sample […]. Assumption H4 also requires that the optimal cut-off values be bounded away from zero.”. Assumption H5 is required to get the uniform convergence of the Kernel based estimator of on manifolds, see [7]. These assumptions play a crucial role in the development and analysis of conformal prediction methods.
Let us introduce some important sequences of positive real numbers that will play a key rol all along the manuscript.
-
1.
,
-
2.
, being the positive constant introduced in H2. Observe that .
-
3.
Given as , we will consider the subsquences , and being as before.
4 Locally valid sets from a kernel density estimator
In this section we introduce a slightly modified version of the estimated local marginal density and of the local conformity rank originally introduced in [61]. We make the assumption that , and that is a finite partition of consisting of equilateral cubes with sides of length . This is a quite common and technical assumption in conformal inference, but we can assume that, for instance, is such that , for some . It only changes the constants appearing in Theorem 2, which remains true.
Let . Given a sequence , a kernel function , and , we define
| (4) |
We aim to prove that provides a uniform estimate of across and . To achieve this, we need to ensure that there are sufficiently many sample points in each . This is guaranteed by lemma 9 of [61], which states that if we choose , then, with probability one, for all large enough,
| (5) |
Recall that and were defined in Assumption H2. In what follows, we assume that is sufficiently large to ensure (5).
The corresponding augmented estimate, based on is, for any ,
For any , consider the following local conformity rank
| (6) |
As proved in Proposition 2 of [61], the set
| (7) |
has finite sample local validity, i.e., it satisfies (3). The finite sample local validity, as established by (7), does not require any assumptions and it holds under very general conditions.
The following result is the key theorem. Its proof is deferred to the Appendix. The proof follows the ideas used to prove Theorem 1 of [12]. It states that can be estimated uniformly by (4) for all that are far enough from the boundary of . Additionally, this estimation can be made uniformly across all . We assume, as in [12], that is a Gaussian kernel. This restriction is, as in [12], purely technical. More recent references on kernel-density estimation on manifolds are [9, 10], [15, 16, 6, 63].
This result is of fundamental importance in conformal prediction, as it provides a way to estimate the conditional density of given for any in a non-parametric way. It implies that the estimation error is uniform across all partitions , which is a key requirement for conformal prediction methods. In particular, it allows us to construct conformal prediction regions that are valid with a given level of confidence.
Theorem 1.
Let be a compact -dimensional manifold satisfying H0. Let be a sequence of closed sets, and let be a sequence of setwidths such that . We assume that is such that monotonically. Additionally, we assume that satisfies H5. Then, we have
| (8) |
where .
The following theorem is the main result of our paper. It states that consistently estimates uniformly for all . The proof, which is deferred to the Appendix, see Subsection 9.1, is based on some ideas from the proof of Theorem 1 of [61]. Specifically, Lemma 1 and Lemma 3 are adapted from [61], while Lemma 2 is new and is required to adapt the proof of Lemma 3. Lemma 4 is the same as Lemma 8 of [61]. Finally, the proof of Theorem 2 uses the adapted lemmas and considers separately the sample points that are close to and those that are far away from this boundary. The first set of points is shown to be negligible with respect to using techniques from geometric measure theory.
Theorem 2.
Remark 1.
It can be easily seen that, up to logarithmic factors, the rate of is .
5 Non-compact manifolds
In this section, we discuss how to remove the compactness assumption imposed in Theorem 2, while retaining all the other hypotheses. We will prove that the set satisfies asymptotic conditional validity (see [30]). In other words, there exist random sets such that
and
According to Theorem 6 in [30], to obtain asymptotic conditional validity it suffices to prove that
| (10) |
Theorem 3.
It worth to be mentioned that asymptotic conditional validity is considerably weaker than (9) when is bounded from above.
6 Computational aspects
A different method for estimating the conformal region is introduced in [30]. Instead of using a partition of on cubes to get a partition of , to build kernel-based estimators, this approach employs a new partition constructed as follows. Consider, as in [30], the functions
where is any estimator of , not necessarily kernel-based. Define the conditional -quantile of by Similarly, let , be the estimate of the conditional -quantile of .
Let be a partition of . Then we create a partition of by assigning and to the same set if and only if and lie in the same element of . We then build the kernel-based estimator (4) according to this new partition. This approach is particularly suitable for high-dimensional feature spaces.
We propose either the set (as defined in (7)) or one of the algorithms presented in [30]. According to Theorem 25 in [30], to establish the asymptotic conditional validity of this proposal (in the sense of (10)), it is necessary to assume some smoothness of (see Assumption 23 in [30]), as well as the compactness of and the existence of sequences and satisfying
This condition indeed holds in our case; however, proving it in detail would require rewriting the proof of Theorem 1 in [12]. We leave this verification to the reader. As in the non-compact case, the consistency result obtained is considerably weaker than (9).
Since the computational burden of approximating is high, [61] proposes replacing that set with , see (11), which, by including , has coverage of at least . Let the element that contains .
-
1.
Let be the joint density estimator based on the subsample (of cardinality ) of points for which
-
2.
Let for , and let denote the sample ordered increasingly by .
-
3.
Let and define
(11)
7 Simulation examples
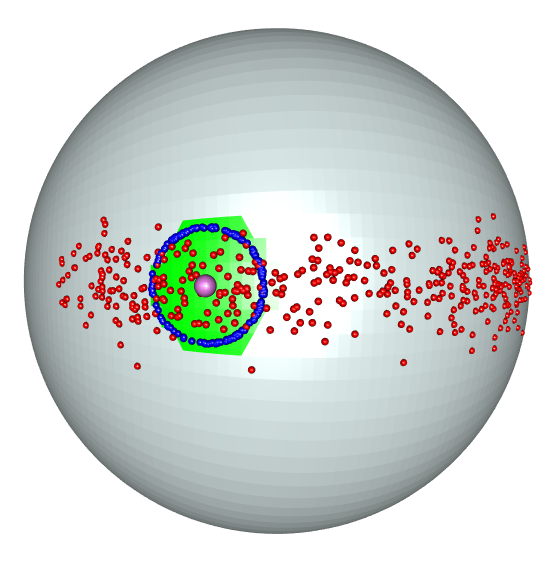
7.1 Toy model: Output on the sphere
We consider a regression model with output variable denoted by defined on the unit sphere . The input variable takes values in the interval . The model is given by the following probability distribution:
Here, denotes the Von Mises–Fisher distribution (see [45]), and is an i.i.d. sample. For the simulation study, we set , , and .
To estimate the kernel density, we use the estimator given by Equation (4) with a setwidth parameter . Additionally, we partition the data into intervals , where .
Using the proposed method, we obtain a confidence set , shown in green in Figure 1. In this particular case, the unobserved output was , which is illustrated in purple in Figure 1. Points belonging to the boundary of the theoretical confidence set 1 for are displayed in blue.
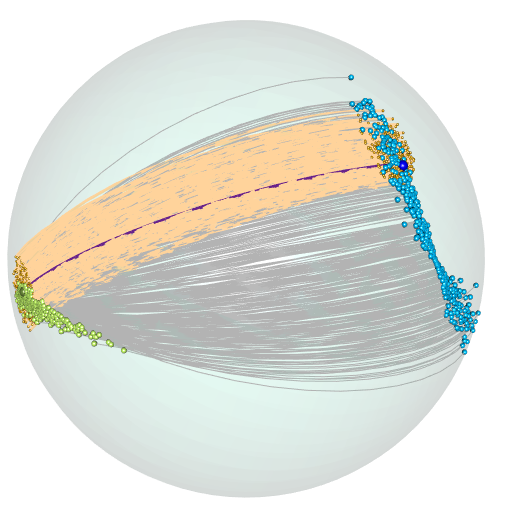
7.2 Output in a Stiefel manifold.
It is common to summarize information from a set of variables using Principal Component Analysis (PCA) or Factor Analysis. This approach is frequently employed in constructing indices within the social sciences, as demonstrated by Vyas (2006). Subsequently, researchers often attempt to explain these indices using other covariates. To illustrate this scenario, we provide a ‘toy example’ using simulations.
We will define a regression model whose output lies on the Stiefel Riemannian manifold , represented by two-dimensional orthonormal vectors in . The construction of the regression is as follows.
The input variable, denoted by , is uniformly distributed on the interval . For each value of , we sample points from a 3-dimensional Gaussian distribution centered at the origin . The covariance matrix of this Gaussian distribution has eigenvalues , , and , along with the corresponding eigenvectors , , and , respectively.
After generating these points for each value of , the output is obtained by applying a PCA to these points and retaining only the first two principal directions. To conduct the simulations analysis, we sample points, denoted by .
In Figure 2, we display a sample of output values, represented as gray arcs. The specific output value , corresponding to the input , is depicted as a purple dotted arc.
To estimate the density, we use the estimator given by Equation (4), with a setwidth parameter . Additionally, we divide the data into intervals , where . It is important to note that the data are embedded in (), and we consider the Euclidean distance in this space. The dimension of the submanifold in this case is .
To visualize the confidence set, we draw points within . The points falling within the confidence set are highlighted in orange in Figure 2.
8 Real-data examples
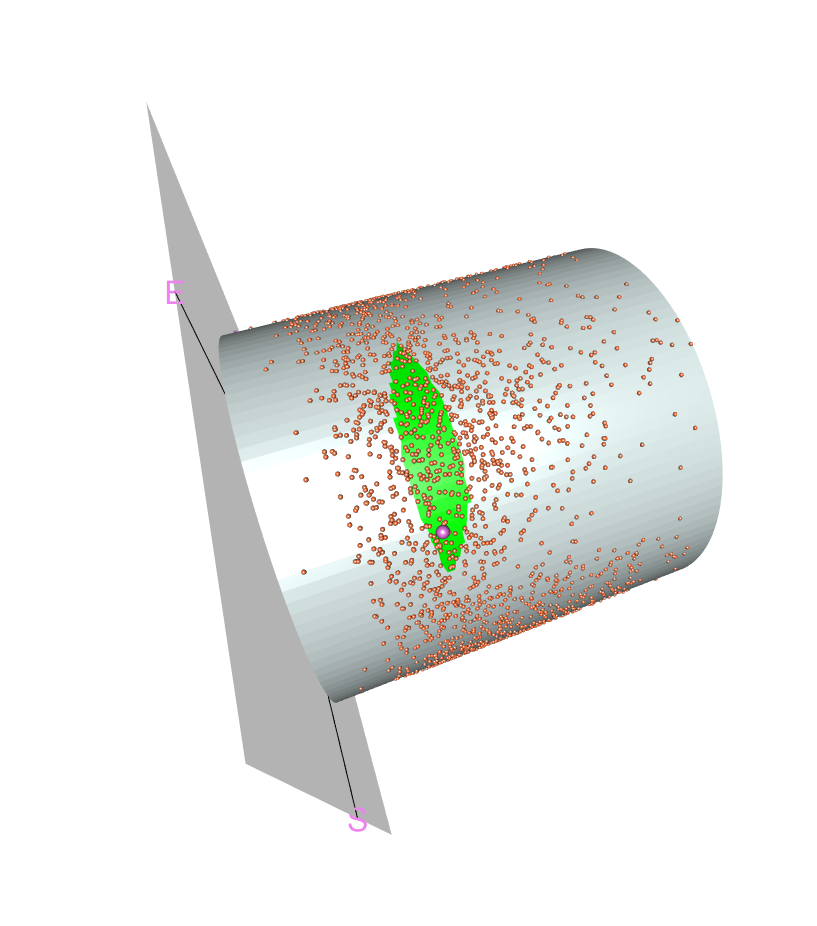
8.1 Example 1: Regression between cylindrical manifolds with application to wind modeling
In this study we address a problem of substantial practical relevance for the development of wind energy infrastructure in Uruguay. Specifically, the goal is construct prediction sets for wind intensity and direction , at a meteorological station located in Montevideo, based on simultaneous observations from a nearby station in Maldonado. These variables together form a point on a cylinder , where represents the directional component (wind angle) and the non-negative intensity. Thus, the regression problem consists of learning a mapping from one cylindrical manifold to another.
This task is not only of theoretical interest due to the non-Euclidean structure of the input and output spaces, but also of strategic importance for national energy planning. Accurate prediction of wind behavior at candidate sites is a critical step in the optimal placement of wind turbines, which are a major source of renewable energy in Uruguay’s energy matrix.
We focus on moderate and extreme wind regimes (within the range 0 to 20 m/s), using hourly meteorological data recorded during the month of July between 2008 and 2016. The data were collected at two locations: the Laguna del Sauce Weather Station in Maldonado (Station 1) and the Carrasco International Airport Weather Station in Montevideo (Station 2), which are approximately 84 kilometers apart. To ensure reliability, only time points for which both stations reported valid measurements were retained, resulting in a total of 5,362 matched observations.
Our objective is to construct conformal prediction sets, for wind conditions at Station 2 given observations from Station 1. These sets aim to quantify predictive uncertainty while respecting the cylindrical geometry of the variables involved, offering robust tools for risk assessment and decision-making in wind farm siting.
Figures 3 and 4 show that there is a correlation in both wind direction and intensity between the two stations. The -correlation, see [11], between the intensities is . In the case of the directions, the angular correlation is . The angular correlation is the linear correlation between the variables and , see [31].
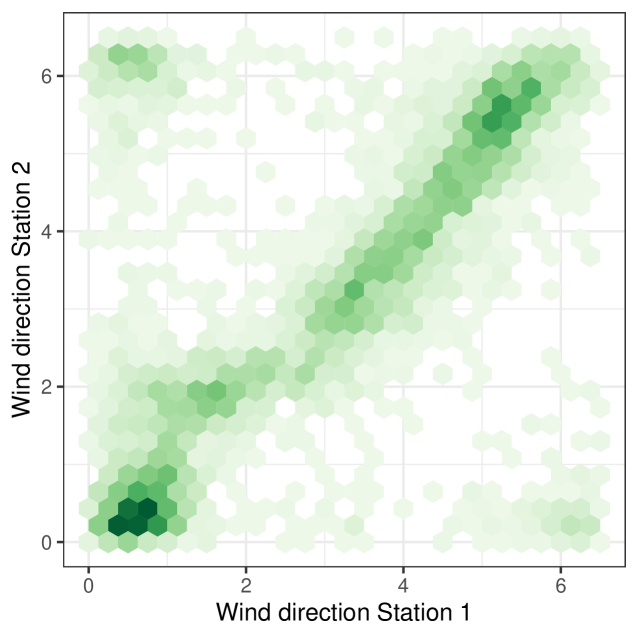
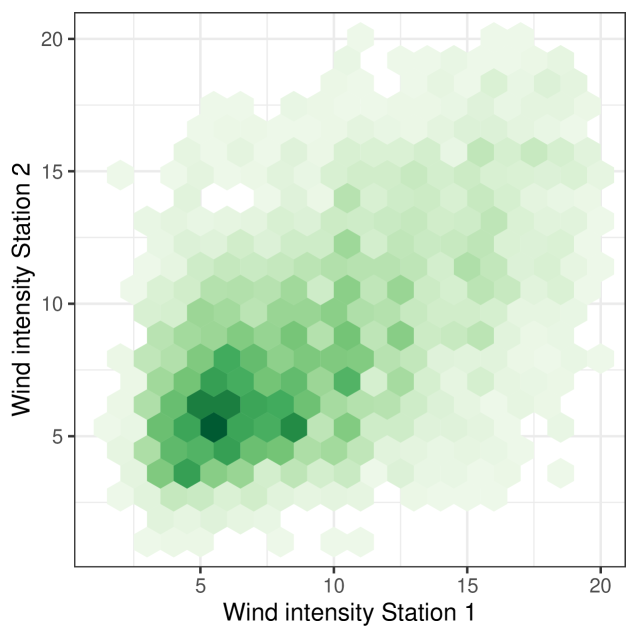
In this example, the partition is
with and . For the kernel density estimator we choose .
Figure 5 shows the confidence set (at 80%) obtained by our method for . This was recorded at Station 1 on 2008-07-01 at 7 pm. On the same date and time the data recorded at Station 2 were (point depicted in purple in Figure 5).
8.2 Example 2: Regression on the simplex with application to multiclass classification
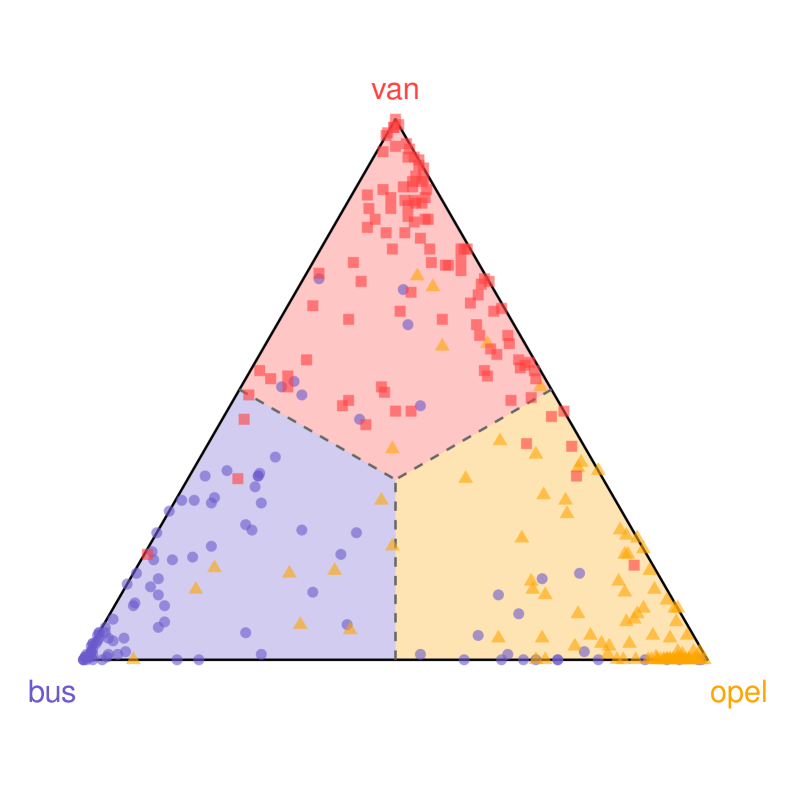
Regression models whose outputs lie in the -dimensional unit simplex play an essential role in many applied contexts (see, for example, [3, 48]). In supervised classification, a variety of machine-learning algorithms produce vectors of class-membership probabilities—i.e., elements of —which we denote by . Here, each is obtained by using Random Forest (RF). Because these vectors reside in , their components naturally estimate the probability of membership in each class. The final class prediction is then chosen as the one with the highest estimated probability, equivalent to identifying the Voronoi cell of the simplex in which falls (see Figure 6).
Our goal is to construct a confidence region for observations on the simplex by adapting Algorithm 1 from [30] (CD-split) to this setting. In particular, we follow [29] to estimate the conditional density, employing an appropriate Fourier‐type basis on the simplex—such as the Bernstein polynomial basis [19, 23].
The intersection of this confidence region with the Voronoi tessellation of yields the conformal class set, i.e., the subset of classes that are statistically consistent with the observation at level . Moreover, this approach provides insight into how the predictive uncertainty is distributed among the classes, by analyzing the proportion of the confidence region that falls within each Voronoi cell.
An application of the proposed methodology is carried out on a real-world dataset, where the covariate space is 5-dimensional and the response variable lies on , representing class probabilities, obtained, we it was said, by means of RF. To this end, we consider the publicly available Vehicle dataset from the mlbench package in R [42].
The Vehicle dataset originates from a benchmark study conducted at the Turing Institute in the early 1990s. It was designed to evaluate the performance of classification algorithms in distinguishing between different types of road vehicles based on geometric features extracted from digitized images of their silhouettes. Each observation in the dataset corresponds to a vehicle image and is characterized by numerical covariates, such as aspect ratio, edge count, and moment-based shape descriptors.
The categorical response variable indicates the type of vehicle. For the purposes of this study, we restrict attention to a subset of the data containing three of the four classes (bus, opel, and van), so that the associated output probabilities lie on . This structure is ideal for illustrating our simplex-based predictive modelling approach. The dataset contains a total of observations, and its moderate size, combined with its multi-class nature, makes it well-suited for benchmarking methods involving compositional or probabilistic responses.
The dataset is randomly split into two equal parts: 50% of the observations are used for training the model, and the remaining 50% are reserved as a test set for evaluating predictive performance.
Figure 7 displays the test data projected onto . Each point corresponds to a predicted probability vector, and its color indicates the true class label. The predicted class for a point is the Voronoi cell that contains the point.
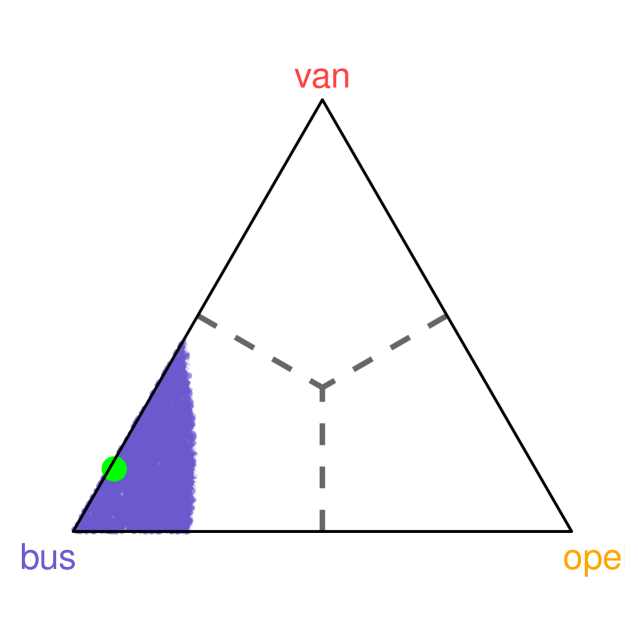
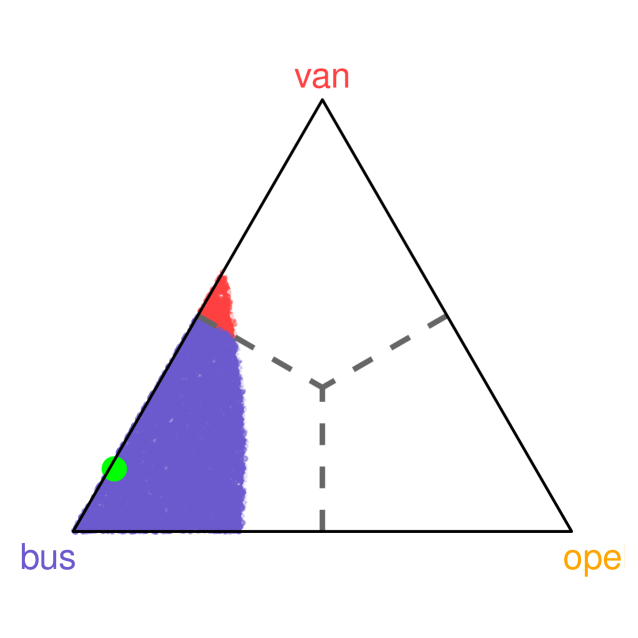
We assess confidence levels of and for the covariate vector . The corresponding class probabilities predicted by the Random Forest are , highlighted in purple in Figure 7. The resulting class band, restricted to the “bus” and “van” categories, offers a detailed decomposition of predictive uncertainty by indicating the fraction of the confidence region attributable to each class. At the confidence level, approximately of the band resides within the “bus” region, while the remaining falls within the “van” region.
9 Conclusions and future work
We work within the conformal‐inference framework, where the response variable takes values on a Riemannian manifold while the covariates lie in . Under assumptions analogous to those in [61], we extend their results to show that the conditional oracle set can be estimated consistently. A central tool in our analysis is the almost‐sure, uniform consistency of the classical kernel density estimator on manifolds, as proved in [12]. We also cover the cases of manifolds with boundary and non‐compact manifolds, and we discuss computational strategies for handling high‐dimensional input data.
Our theoretical contributions are demonstrated through two simulation studies and two real-world data examples.
Finally, one could explore alternative nonconformity scores beyond the KDE-based criterion we employ—for example, quantile-based or regression-based scores—each of which demands a nontrivial adaptation of the Euclidean theory to the manifold setting.
Appendix
Proof of Theorem 1.
Since , then, from theorem 1 of [12], for all , with probability one, for all large enough,
| (12) |
Note that the index for which (12) holds depends on the choice of . However, from (5), we know that with probability one, for all when is sufficiently large. Since monotonically, it follows that for all , . Hence, we can conclude that (8) holds for all . ∎
9.1 Proof of Theorem 2
The proof of Theorem 2 is based on some technical lemmas. To state them, let us define as the set of such that , and as the set of such that . We also define and as the corresponding sets for , given by (4).
Lemma 1.
Under the hypotheses of Theorem 1, assume also H0 to H3. Let . Then, with probability one, for sufficiently large, we have
| (13) |
where and .
Proof.
Lemma 2.
Assume H0 to H4. Let , and assume that and are as in Lemma 1. Then, there exists such that with probability one, for large enough
Proof.
Recall that we are assuming to be a Gaussian kernel. We assume that is large enough so that (5) holds. Following the proof of theorem 1 of [12], we define
, and . Let and consider a covering of . Then,
| (15) |
Since is Lipschitz, we have for some constant . Applying Bernstein’s inequality to for fixed and , we get
where and are positive constants.
Then, if ,
By the Borel–Cantelli lemma, it follows that almost surely.
Next, we will bound . First, we bound ,
Since and are bounded for all and , it is enough to bound from above
which is bounded because we assumed that is a Gaussian kernel. ∎
Lemma 6 of [61] proves a slightly modified version of the following lemma.
Lemma 3.
Assume H0 to H5. Let , , and be a sequence of closed sets such that . Then, for any , there exists such that, for large enough,
| (16) |
where . Here, is the empirical distribution of , is given in H4, and .
Proof.
We will provide a sketch of the proof of this lemma since it follows essentially the same idea used to prove lemma 6 of [61].
Let be fixed. Note that is a nested class of sets with Vapnik–Chervonenkis dimension 2. Then, for all and ,
where we used that . On the other hand,
Let . Then
where . From (30) in [61],
Here, is a positive constant and is as in H4. From (29) in [61], for some positive constant . Lastly, is bounded, for large enough, using Lemma 2. ∎
We recall lemma 8 of [61].
Lemma 4.
Fix , and . Suppose that is a density function that satisfies H4, and an estimator such that . Let be a probability measure satisfying . Define
Assume that and are sufficiently small so that and where and are the constants given in H4. Then
Moreover, for any such that , if , then there are constants and such that .
Proof of Theorem 2
In what follows we assume that is sufficiently large to satisfy (5). We will consider a sequence of compact sets such that and , where is chosen such that .
Throughout the proof we denote by a generic positive constant. Write
where is as in Lemma 3 and is a sequence of closed sets such that satisfies .
We will first prove that there exists a such that
| (17) |
Since is , it has positive reach, denoted by , as shown in proposition 14 of [55]. Let . From
it follows that .
We write , and from proposition A.1 in [1], we know that covers . Since has finite Minkowski content due to its positive reach (see corollary 3 of [4]), and when , there exists a such that for all sufficiently large , where is the -dimensional Lebesgue measure of .
Thus, can be covered by at most balls of radius centered at , and the -measure of each of these balls is bounded from above by by corollary 1 of [2]. From this, 17 follows.
Now, to bound , we follow the approach used in the proof of theorem 1 in [61]. We apply Lemma 4 to the density function and the empirical measure , as well as the estimated density function . Here, we provide a sketch of the main changes made to the proof. We denote by the upper level set of .
Let . From lemma 3 in [61], conditioning on ,
where with is the element of
such that ranks . Let . It is easy to check that
Consider the event
From , it follows that . Then from Lemmas 1 and 3, . Let . Since , then the event
is such that for all large enough, . From Lemma (4) with and , we obtain that, for large enough,
| (18) |
Let and . From , it follows that . Applying Lemma 4, we get that
Since for large enough, we get that
| (19) |
Lastly, we write
Proof of Theorem 3
To prove (10), fix any and choose a sufficiently large compact smooth submanifold fulfilling H0, such that The existence of such a submanifold follows from the existence of smooth exhaustion functions (see Proposition 2.28 in [35]). Then, by a simple union bound,
Now, fixing , we take—as in the proof of Theorem 2—a sequence of closed sets such that
Then we decompose equals
Acknowledgment
Authors are grateful with Tyrus Berry, for his insightful comments on the results obtained in his work with Timothy Sauer. . The research of the first and third authors has been partially supported by grant FCE-3-2022-1-172289 from ANII (Uruguay), 22MATH-07 form MATH – AmSud (France-Uruguay) and 22520220100031UD from CSIC (Uruguay).
References
- [1] Aamari, E., C. Aaron, and C. Levrard (2023). Minimax boundary estimation and estimation with boundary. Bernoulli, 29(4), 3334–3368.
- [2] Aaron, C. and A. Cholaquidis (2020). On boundary detection. Ann. Inst. H. Poincaré Probab. Statist., 56(3), 2028–2050.
- [3] Aitchison, J. (1986). The Statistical Analysis of Compositional Data. Chapman & Hall.
- [4] Ambrosio, L., A. Colesanti, and E. Villa (2008). Outer Minkowski content for some classes of closed sets. Mathematische Annalen, 342(4), 727–748.
- [5] Balasubramanian, V., S.-S. Ho, and V. Vovk (2014). Conformal prediction for reliable machine learning: theory, adaptations and applications. Newnes.
- [6] Berenfeld, C. and M. Hoffmann (2021). Density estimation on an unknown submanifold. Electronic Journal of Statistics, 15(1), 2179–2223.
- [7] Berry, T. and T. Sauer (2017). Density estimation on manifolds with boundary. Computational Statistics & Data Analysis, 107, 1–17.
- [8] Best, M. J. (2010). Portfolio optimization. CRC Press.
- [9] Bouzebda, S. and N. Taachouche (2024a). Oracle inequalities and upper bounds for kernel conditional U-statistics estimators on manifolds and more general metric spaces associated with operators. Stochastics: An International Journal of Probability and Stochastic Processes, 96(8), 2135–2198.
- [10] Bouzebda, S. and N. Taachouche (2024b). Rates of the Strong Uniform Consistency with Rates for Conditional U-Statistics Estimators with General Kernels on Manifolds. Mathematical Methods of Statistics, 33(2), 95–153.
- [11] Chatterjee, S. (2021). A new coefficient of correlation. Journal of the American Statistical Association, 116(536), 2009–2022.
- [12] Cholaquidis, A., R. Fraiman, and L. Moreno (2022). Level set and density estimation on manifolds. Journal of Multivariate Analysis, 189, 104925.
- [13] Cholaquidis, A., R. Fraiman, and L. Moreno (2023). Level sets of depth measures in abstract spaces. TEST, 1–16.
- [14] Cholaquidis, A., R. Fraiman, F. Gamboa, and L. Moreno (2023). Weighted lens depth: Some applications to supervised classification. Canadian Journal of Statistics, 51(2), 652–673.
- [15] Cleanthous, G., A. G. Georgiadis, G. Kerkyacharian, P. Petrushev, and D. Picard (2020). Kernel and wavelet density estimators on manifolds and more general metric spaces. Bernoulli, 26(3), 1832–1862.
- [16] Cleanthous, G., A. G. Georgiadis, and E. Porcu (2022). Oracle inequalities and upper bounds for kernel density estimators on manifolds and more general metric spaces. Journal of Nonparametric Statistics, 34(4), 734–757.
- [17] Diquigiovanni, J., M. Fontana, and S. Vantini (2021). Distribution-free prediction bands for multivariate functional time series: an application to the Italian gas market. arXiv preprint arXiv:2107.00527.
- [18] Diquigiovanni, J., M. Fontana, and S. Vantini (2022). Conformal prediction bands for multivariate functional data. Journal of Multivariate Analysis, 189, 104879.
- [19] Farouki, R. T., T. N. Goodman, and T. Sauer (2003). Construction of orthogonal bases for polynomials in Bernstein form on triangular and simplex domains. Computer Aided Geometric Design, 20(4), 209–230.
- [20] Fong, E. and C. C. Holmes (2021). Conformal Bayesian computation. Advances in Neural Information Processing Systems, 34, 18268–18279.
- [21] Fontana, M., S. Vantini, M. Tavoni, and A. Gammerman (2020). A Conformal Approach for Distribution-free Prediction of Functional Data. In Functional and High-Dimensional Statistics and Related Fields 5, pp. 83–90. Springer.
- [22] Fontana, M., G. Zeni, and S. Vantini (2023). Conformal prediction: A unified review of theory and new challenges. Bernoulli, 29(1), 1–23.
- [23] Ghosal, S. (2001). Convergence rates for density estimation with Bernstein polynomials. The Annals of Statistics, 29(5), 1264–1280.
- [24] Guigui, N., N. Miolane, X. Pennec, et al. (2023). Introduction to Riemannian Geometry and Geometric Statistics: from basic theory to implementation with Geomstats. Foundations and Trends® in Machine Learning, 16(3), 329–493.
- [25] Guo, C., G. Pleiss, Y. Sun, and K. Q. Weinberger (2017). On Calibration of Modern Neural Networks. International Conference on Machine Learning.
- [26] Hall, P., J. Racine, and Q. Li (2004). Cross-validation and the estimation of conditional probability densities. Journal of the American Statistical Association, 99(468), 1015–1026.
- [27] Hong, Y., R. Kwitt, N. Singh, N. Vasconcelos, and M. Niethammer (2016). Parametric regression on the Grassmannian. IEEE transactions on pattern analysis and machine intelligence, 38(11), 2284–2297.
- [28] Huang, Y. and G. Kou (2014). A kernel entropy manifold learning approach for financial data analysis. Decision Support Systems, 64, 31–42.
- [29] Izbicki, R. and A. B. Lee (2017). Converting high-dimensional regression to high-dimensional conditional density estimation. Electronic Journal of Statistics, 11(2), 2800–2831.
- [30] Izbicki, R., G. Shimizu, and R. B. Stern (2022). Cd-split and hpd-split: Efficient conformal regions in high dimensions. Journal of Machine Learning Research, 23(87), 1–32.
- [31] Jammalamadaka, S. R. and Y. R. Sarma (1988). A correlation coefficient for angular variables. Statistical theory and data analysis II, 349–364.
- [32] Koh, P. W., P. Liang, and J. Zhu (2019). Understanding Black-Box Predictions via Influence Functions. International Conference on Machine Learning.
- [33] Koh, P. W., P. Liang, A. Bekasov, J. Fu, R. Kondor, and J. Zhu (2020). Probabilistic Uncertainty Quantification for Deep Learning. Advances in Neural Information Processing Systems, 33.
- [34] Kuleshov, A., A. Bernstein, and E. Burnaev (2018). Conformal prediction in manifold learning. In Conformal and Probabilistic Prediction and Applications, pp. 234–253. PMLR.
- [35] Lee, J. M. (2013). Introduction to Smooth Manifolds (2nd ed.), Volume 218 of Graduate Texts in Mathematics. Springer.
- [36] Lei, J. (2014). Classification with confidence. Biometrika, 101(4), 755–769.
- [37] Lei, J. and L. Wasserman (2016). The Adaptive and the Honest: A Dichotomy in Conformal Prediction and Its Implications. The Annals of Statistics, 44(6), 2293–2323.
- [38] Lei, L. and E. J. Candès (2021). Conformal inference of counterfactuals and individual treatment effects. Journal of the Royal Statistical Society Series B: Statistical Methodology, 83(5), 911–938.
- [39] Lei, J., J. Robins, and L. Wasserman (2013). Distribution-free prediction sets. Journal of the American Statistical Association, 108(501), 278–287.
- [40] Lei, J. (2014). Classification with confidence. Biometrika, 101(4), 755–769.
- [41] Lei, J., A. Rinaldo, and L. Wasserman (2015). A conformal prediction approach to explore functional data. Annals of Mathematics and Artificial Intelligence, 74, 29–43.
- [42] Leisch, F., E. Dimitriadou, K. Hornik, D. Meyer, and A. Weingessel (2007). mlbench: Machine Learning Benchmark Problems. https://CRAN.R-project.org/package=mlbench. R package version 2.1-3.
- [43] Liu, H. and L. Wasserman (2016). Conformal Prediction for Multi-Class Classification. Journal of Machine Learning Research, 17, 1–28.
- [44] Lugosi, G. and M. Matabuena (2024). Uncertainty quantification in metric spaces. arXiv preprint arXiv:2405.05110.
- [45] Mardia, K. V., P. E. Jupp, and K. V. Mardia (2000). Directional statistics, Volume 2. Wiley Online Library.
- [46] Papadopoulos, H., T. Poggio, and S. Vempala (2002). Combining Classifiers via Confidence. In Advances in Neural Information Processing Systems, pp. 705–712.
- [47] Papadopoulos, H., K. Proedrou, V. Vovk, and A. Gammerman (2002). Inductive confidence machines for regression. In Machine Learning: ECML 2002, pp. 345–356. Springer.
- [48] Pawlowsky-Glahn, V., J. J. Egozcue, and R. Tolosana-Delgado (2015). Modeling and analysis of compositional data. John Wiley & Sons.
- [49] Pennec, X., S. Sommer, and T. Fletcher (2019). Riemannian geometric statistics in medical image analysis. Academic Press.
- [50] Petersen, A. and H.-G. Müller (2019). Fréchet regression for random objects with Euclidean predictors. arXiv preprint arXiv:1608.03012.
- [51] Polonik, W. (1995). Measuring mass concentrations and estimating density contour clusters-an excess mass approach. The annals of Statistics, 855–881.
- [52] Rigollet, P. and R. Vert (2009). Optimal rates for plug-in estimators of density level sets. Bernoulli, 14, 1154–1178.
- [53] Romano, Y., E. Patterson, and E. Candes (2019). Conformalized quantile regression. Advances in neural information processing systems, 32.
- [54] Shafer, G. (2008). A Mathematical Theory of Evidence. Princeton University Press.
- [55] Thäle, C. (2008). 50 years sets with positive reach–a survey. Surveys in Mathematics and its Applications, 3, 123–165.
- [56] Tsybakov, A. B. (1997). On nonparametric estimation of density level sets. The Annals of Statistics, 25(3), 948–969.
- [57] Vovk, V., A. Gammerman, and G. Shafer (1998). Algorithmic Learning in a Random World. Machine Learning, 30(2-3), 119–138.
- [58] Vovk, V., A. Gammerman, and G. Shafer (2005). Algorithmic Learning in a Random World. Springer-Verlag.
- [59] Vovk, V. (2009). Conditional Validity, Exchangeability, and Calibration of Probability Forecasts. Journal of Machine Learning Research, 10, 987–1016.
- [60] Vyas, S. and L. Kumaranayake (2006). Constructing socio-economic status indices: how to use principal components analysis. Health policy and planning, 21(6), 459–468.
- [61] Lei, J. and L. Wasserman (2014). Distribution-free prediction bands for non-parametric regression. Journal of the Royal Statistical Society: Series B: Statistical Methodology, 71–96.
- [62] Wäschle, K., M. Bobak, S. Pölsterl, S. Gehrmann, D. Dettmering, J. Hornegger, and A. Maier (2014). Conformal Prediction for Regression. IEEE Transactions on Medical Imaging, 33(2), 407–418.
- [63] Wu, H.-T. and N. Wu (2022). Strong Uniform Consistency with Rates for Kernel Density Estimators with General Kernels on Manifolds. Information and Inference: A Journal of the IMA, 11(2), 781–799.
- [64] Xu, Z., Z. Zhao, and W. B. Wu (2020). Conformal Prediction for Time Series. Journal of the American Statistical Association, 115(530), 1585–1594.