Conic-Optimization Based Algorithms for
Nonnegative Matrix Factorization
Abstract
Nonnegative matrix factorization is the following problem: given a nonnegative input matrix and a factorization rank , compute two nonnegative matrices, with columns and with rows, such that approximates as well as possible. In this paper, we propose two new approaches for computing high-quality NMF solutions using conic optimization. These approaches rely on the same two steps. First, we reformulate NMF as minimizing a concave function over a product of convex cones–one approach is based on the exponential cone, and the other on the second-order cone. Then, we solve these reformulations iteratively: at each step, we minimize exactly, over the feasible set, a majorization of the objective functions obtained via linearization at the current iterate. Hence these subproblems are convex conic programs and can be solved efficiently using dedicated algorithms. We prove that our approaches reach a stationary point with an accuracy decreasing as , where denotes the iteration number. To the best of our knowledge, our analysis is the first to provide a convergence rate to stationary points for NMF. Furthermore, in the particular cases of rank-one factorizations (that is, ), we show that one of our formulations can be expressed as a convex optimization problem implying that optimal rank-one approximations can be computed efficiently. Finally, we show on several numerical examples that our approaches are able to frequently compute exact NMFs (that is, with ), and compete favorably with the state of the art.
keywords:
nonnegative matrix factorization, nonnegative rank, exponential cone, second-order cone, concave minimization, conic optimization, Frank-Wolfe gap, convergence to stationary points1 Introduction
Nonnegative matrix factorization (NMF) is the problem of approximating a given nonnegative matrix, , as the product of two smaller nonnegative matrices, and , where is a given parameter known as the factorization rank. One aims at finding the best approximation, that is, the one that minimizes the discrepancy between and the product , often measured by the Frobenius norm of their difference, . Despite the fact that NMF is NP-hard in general [30] (see also [27]), it has been used successfully in many domains such as probability, geoscience, medical imaging, computational geometry, combinatorial optimization, analytical chemistry, and machine learning; see [11, 13] and the references therein. Many local optimization schemes have been developed to compute NMFs. They aim to identify local minima or stationary points of optimization problems that minimize the discrepancy between and the approximation . Most of these iterative algorithms rely on a two-block coordinate descent scheme that consists in (approximatively) optimizing alternatively over with fixed, and vice-versa; see [5, 13] and the references therein. In this paper, we are interested in computing high-quality local minima for the NMF optimization problems without relying on the block coordinate descent (BCD) framework. We will perform the optimization over and jointly. Moreover, our focus is on finding exact NMFs, that is, computing nonnegative factors and such that , although our approaches can be used to find approximate NMFs as well.
The minimum factorization rank for which an exact NMF exists is called the nonnegative rank of and is denoted , we have
The computation of the nonnegative rank is NP-hard [30], and is a research topic on its own; see [13, Chapter 3][9, 8] and the references therein for recent progress on this question.
1.1 Computational complexity
Solving exact NMF can be used to compute the nonnegative rank, by finding the smallest such that an exact NMF exists. Cohen and Rothblum [7] give a super-exponential time algorithm for this problem. Vavasis [30] proved that checking whether , where is part of the input, is NP-hard. Since determining the nonnnegative rank is a generalization of exact NMF, the results in [30] imply that computing an exact NMF is also NP-hard. Similarly, the standard NMF problem using any norm is a generalization of exact NMF, and therefore any hardness result that applies to exact NMF also applies to most approximated NMF models [30]. Hence, unless P=NP, no algorithm can solve exact NMF using a number of arithmetic operations bounded by a polynomial in and in the size of ; see also [27] that gives a different proof using algebraic arguments.
More recently, Arora et al. [2] showed that no algorithm to solve this problem can run in time unless1113-SAT, or 3-satisfiability, is an instrumental problem in computational complexity to prove NP-completeness results. 3-SAT is the problem of deciding whether a set of disjunctions containing 3 Boolean variables or their negation can be satisfied. 3-SAT can be solved in time on instances with variables. However, in practice, is small and it makes senses to wonder what is the complexity if is assumed to be a fixed constant. In that case, they showed that exact NMF can be solved in polynomial time in and , namely in time for some constant , which Moitra [24] later improved to .
The argument is based on quantifier elimination theory, using the seminal result by Basu, Pollack and Roy [3]. Unfortunately, this approach cannot be used in practice, even for small size matrices, because of its high computational cost: although the term is a polynomial in and for fixed, it grows extremely fast (and the hidden constants are usually very large). Let us illustrate with a 4-by-4 matrix with , we have a complexity of order and for a 5-by-5 matrix with , the complexity raises up to . Therefore developing an effective computational technique for exact NMF of small matrices is an important direction of research. Some heuristics have been recently developed that allow solving exact NMF for matrices up to a few dozen rows and columns [29].
1.2 Contribution and outline of the paper
In this paper, we introduce two formulations for computing an NMF using conic optimization. They rely on the same two steps. First, in Section 2, we reformulate NMF as minimizing a concave function over a product of convex cones; one approach is based on the exponential cone and leads to under-approximations, and the other on the second-order cone and leads to over-approximations. For the latter formulation, in the case of a rank-one factorization, we show that it can be cast as a convex optimization problem, leading to an efficient computation of the optimal rank-one over-approximation. Then, in Section 3, we solve these reformulations iteratively: at each step, we minimize exactly over the feasible set a majorization of the objective functions obtained via linearization at the current iterate. Hence these subproblems are convex conic programs and can be solved efficiently using dedicated algorithms. In Section 4, we show that our optimization scheme relying on successive linearizations is a special case of the Frank-Wolfe (FW) algorithm. By using an appropriate measure of stationarity, namely the FW gap, we show in Theorem 4.1 that the minimal FW gap generated by our algorithm converges as , where is the iteration index. Finally, in Section 5, we use our approaches to compute exact NMFs, and show that they compete favorably with the state of the art when applied to several classes of nonnegative matrices; namely, randomly generated, infinitesimally rigid and slack matrices.
Remark 1 (Focus on exact NMF).
Our two NMF formulations can be used to compute approximate factorizations (namely, under- and over-approximations). However, in this paper, we focus on exact NMF for the numerical experiments. The reason is twofold:
-
1.
Exact NMF problems allow us to guarantee whether a globally optimal solution is reached, and hence compare algorithms in terms of global optimality.
-
2.
Our current algorithms rely on interior-point methods that do not scale well. Therefore, they are significantly slower, at this point, than state-of-the-art algorithms to compute approximate NMFs on large data sets (such as images or documents). Making our approach scalable is a topic of further research. Moreover, because of the under/over-approximations, the error obtained with the proposed algorithms would be larger, and the comparison would not be fair. Here is a simple example, let
The best rank-one NMF of is (with two digits of accuracy) with Frobenius error , while a best rank-one under-approximation (resp. over-approximation) of is (resp. ) with Frobenius error 1. (Note however that under-/over-approximations can have some useful properties in practice [16, 28].)
2 NMF formulations based on conic optimization
In this section we propose two new formulations for NMF, where the feasible set is represented using the exponential cone (Section 2.1) and the second-order cone (Section 2.2).
2.1 NMF formulation via exponential cones
Given a non-negative matrix and a positive integer , we want to compute an NMF. Our first proposed formulation is the following:
| (1) | ||||||
| subject to | ||||||
where , and . Any feasible solution of (1) provides an under-approximation of , because of the elementwise constraint . The objective function of (1) maximizes the sum of the entries of . Therefore, if admits an exact NMF of size , that is, , any optimal solution of (1) must satisfy , and hence will provide an exact NMF of . Note that this problem is nonconvex because of the bilinear terms appearing in the objective and the constraint .
Let us now reformulate (1) using exponential cones. In order to deal with nonnegativity constraints on the entries of and , we use the following change of variables: and , where and , with , and and . By applying a logarithm on top of this change of variables to the objective function, and on both sides of the inequality constraints , (1) can be nearly equivalently rewritten as follows, the difference being that zero elements in and are now excluded:
| (2) | ||||||
| subject to |
which corresponds to the maximization of a convex function (logarithm of the sums of exponentials) over a convex set, each constraint being convex for the same reason.
We rewrite the convex feasible set of (2) with explicit conic constraints as follows:
| (3) | ||||
where denotes the (primal) exponential cone defined as:
| (4) |
Note that the exponential cone is closed and includes the subset , therefore the scenarios for which the entries are equal to zero can be handled by exponential conic constraints, which was not possible with formulation (2) since the function is not defined at zero. Hence the optimization problem (1) can be written completely equivalently as
| (5) | ||||||
| subject to | ||||||
This leads to inequality constraints and the introduction of exponential cones. In Section 3, we propose an algorithm to tackle (5) using successive linearizations of the objective function.
2.2 NMF formulation via rotated second-order cones
Our second proposed NMF formulation is the following:
| (6) | ||||||
| subject to | ||||||
Any feasible solution of (6) provides an over-approximation of , because of the constraint . The objective function of (1) minimizes the sum of the entries of . Therefore, if , any optimal solution of (1) must satisfy , and hence will provide an exact NMF of . Again the problem is nonconvex due to the bilinear terms.
Let us use the following change of variables: we let and where and , with , and , this time with . Thus the optimization problem (6) can be equivalently rewritten as:
| (7) | ||||||
| subject to |
which minimizes a concave function over a convex set. Indeed, the function is concave.
This set can be written with conic constraints as follows:
| (8) | ||||
where denotes the -dimensional rotated second-order cone defined as:
Thus, the optimization problem (7) becomes
| (9) | ||||||
| subject to | ||||||
which leads to inequality constraints and the introduction of of rotated quadratic cones. In section 3, we present an algorithm to tackle (5) and (9).
2.2.1 Rank-one Nonnegative Matrix Over-approximation
In this section, we show that our over-approximation formulation (6) can be expressed as a convex optimization problem in the case of a rank-one factorization (that is, ). Hence we will be able to compute an optimal rank-one nonnegative matrix over-approximation (NMO). For , (6) becomes:
| (10) | ||||||
| subject to | ||||||
Any feasible solution of (10) provides a rank-one NMO of , because of the constraints. The objective function of (10) minimizes the sum of the entries of , which is equal to , where denotes the all-one factor of appropriate dimension. Since any solution can be rescaled as for any , we can assume without loss of generality (w.l.o.g.) that , and hence (10) can be equivalently written as follows:
| (11) | ||||||
| subject to | ||||||
Then, by letting each take the minimal value allowed by the constraints, that is, for each , and replacing by its inverse, for each , (11) becomes:
| (12) | ||||||
| subject to |
The feasible set of (12) can be formulated by using various conic constraints:
-
•
a semi-definite programming formulation: introduce variables such that to obtain
where denotes the set of positive semi-definite matrices of dimension 2.
-
•
a power-cone formulation: for the function is convex for and the inequality is equivalent to where is a power cone. In our case, by introducing , we obtain
-
•
a (rotated) quadratic formulation: introducing variables such that for , this can be formulated as follows: where denotes the set of rotated quadratic cones of dimension 3. We then have :
In this paper, we consider the (rotated) quadratic formulation which is the easiest to implement in the MOSEK software [25].
Further, the objective function of (12) is a sum of convex piece-wise linear functions. Hence by posing , (12) can equivalently be formulated as follows:
| (13) | ||||||
| subject to | ||||||
which involves variables and constraints.
This problem can be solved to optimality and efficiently with an interior-point method (IPM), as available for example in MOSEK [25].
3 A successive linearization algorithm
In this section, we present an iterative algorithm to tackle problems (5) and (9). Both problems can be written as the minimization of a concave function over a convex set denoted by . Note that designates either the feasible set of (5) or the feasible set of (9). We perform this minimization by solving a sequence of simpler problems in which the objective function is replaced by its linearization constructed at the current solution . Let us denote the th iterate of our algorithm. At each iteration , we update as follows:
| (14) | ||||
where is the objective function of (5) or (9). Since the objective of (14) is linear in , the subproblems become convex. Moreover they are particular structured conic optimization problems. In this paper, we use the MOSEK software [25] to solve each successive problem (14) with an IPM. Algorithm 1 summarizes our proposed method to tackle (5) and (9).
To initialize and , we chose to randomly initialize and (using the uniform distribution in the interval for each entry of and ) and apply the two changes of variables, , to compute the initializations for and .
In this paper, we use a tolerance for the relative error equal to , that is, we assume that an exact NMF is found for an input matrix as soon as , as done in [29].
The main algorithm integrates a procedure that automatically updates the optimization problems in the case subsets of entries of the solution tend to zero. Indeed, due to numerical limitations of the solver, the required level of accuracy cannot be reached in some numerical tests even if the solution is close to convergence. This procedure is referred to as Sparsity Patterns Integration (SPI) and is detailed in Appendix B. Note that the update of the optimization problem is computationally costly, in particular the update of the matrix of coefficients defining the constraints. Hence, SPI is triggered twice; at 80% and 95% of the maximum number of iterations. This practical choice has been motivated by numerical experiments that showed that two activations in the final iterations are sufficient to reach the tolerance error when the current solution is close enough to a high-accuracy local optimum. However, for exponential cones, in some numerical tests, the relative error can be stuck in the interval . In this context only, a final refinement step further improves the output of the main algorithm using the state-of-the-art accelerated HALS algorithm, an exact BCD method for NMF, from [14] to go below the tolerance.
4 Convergence results
Let us focus on the following optimization problem
| (15) |
where is a concave continuously differentiable function over the domain which is assumed to be convex and compact. Let us first describe the convergence of the sequence of objective function values obtained with Algorithm 1. Since is concave, its linearization around the current iterate provides an upper approximation, that is,
| (16) |
This upper bound is tight at the current iterate and is exactly minimized over the feasible set at each iteration. Hence Algorithm 1 is a majorization-minimization algorithm. This implies that is nonincreasing under the updates of Algorithm 1 and since is bounded below on , by construction, the sequence of objective function values converges.
We now focus on the convergence analysis of the sequence of iterates generated by Algorithm 1, in particular convergence to a stationary point. To achieve this goal, we first recall some basics about the Frank-Wolfe (FW) algorithm. The FW algorithm [10] is a popular first-order method to solve (15) that relies on the ability to compute efficiently the so-called Linear Minimization Oracle (LMO), that is, where denotes some search direction. The FW algorithm with adaptive step size is given in Algorithm 2. A step of this algorithm can be briefly summarized as follows: at a current iterate , the algorithm considers the first-order model of the objective function (its linearization), and moves towards a minimizer of this linear function, computed on the same domain .
Algorithm 1 is a particular case of Algorithm 2 for which for all . In the last decade, FW-based methods have regained interest in many fields, mainly driven by their good scalability and the crucial property that Algorithm 2 maintains its iterates as a convex combination of a few extreme points. This results in the generation of sparse and low-rank solutions since at most one additional extreme point of the set is added to the convex combination at each iteration. More details and insights about the later observations can be found in [6, 17]. FW algorithms have been recently studied in terms of convergence guarantees for the minimization of various classes of functions over convex sets, such as convex functions with Lipschitz continous gradient [18], and non-convex differentiable functions [22]. However, we are not aware of any convergence rates proven for Algorithm 2 when solving (15) assuming only concavity of the objective. To derive rates in the concave setting, we need to define a measure of stationarity for our iterates. In this paper, we consider the so-called FW gap of at defined as follows:
| (17) |
This quantity is standard in the analysis of FW algorithms, see [18, 22] and the references therein. A point is a stationary point for the constrained optimization problem (15) if and only if . Moreover, the FW gap
-
•
provides a lower bound on the accuracy: for all , where ,
- •
-
•
is not tied to any specific choice of norms, unlike criteria such as .
Let us provide a convergence rate for the FW algorithm (Algorithm 2).
Theorem 4.1.
Consider the problem (15) where is a continuously differentiable concave function over the compact convex domain . Let us denote the sequence of iterates generated by the FW algorithm (Algorithm 2) applied on (15). Assume there exists a constant such that for all . Then the minimal FW gap, defined as , satisfies, for all ,
| (18) |
where is the (global) accuracy of the initial iterate.
Proof.
Using (16), any points and generated by Algorithm 2 satisfy
| (19) |
Let us substitute by its construction in Algorithm 2 (line 5) in (19) to obtain
| (20) | ||||
Let us show that is equal to defined in Equation (17):
| (21) | ||||
where the fourth equality holds be definition of from Algorithm 2 (line 3). Equation (20) becomes:
| (22) |
By recursively applying (22) for the iterates generated by Algorithm 2, we obtain
| (23) |
Let define the quantities , the minimal FW gap encountered along iterates, and such that for all , so that inequality (23) implies
| (24) |
Finally, using the fact that where , inequality (24) becomes
| (25) |
which concludes the proof. ∎
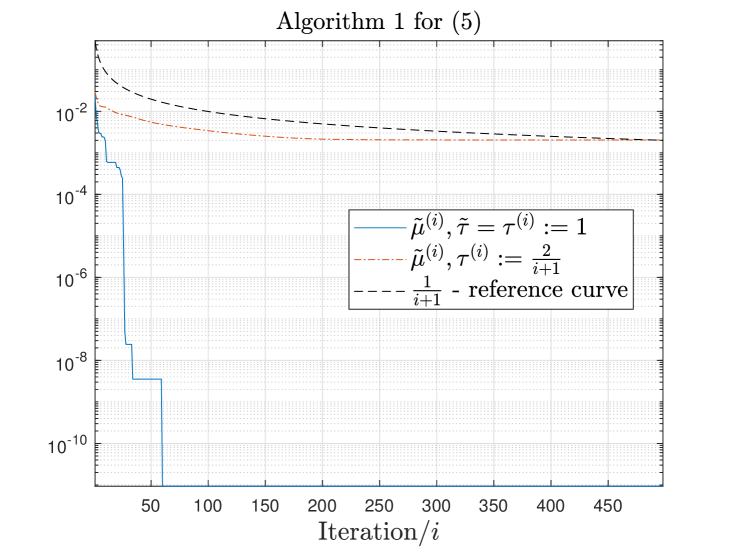
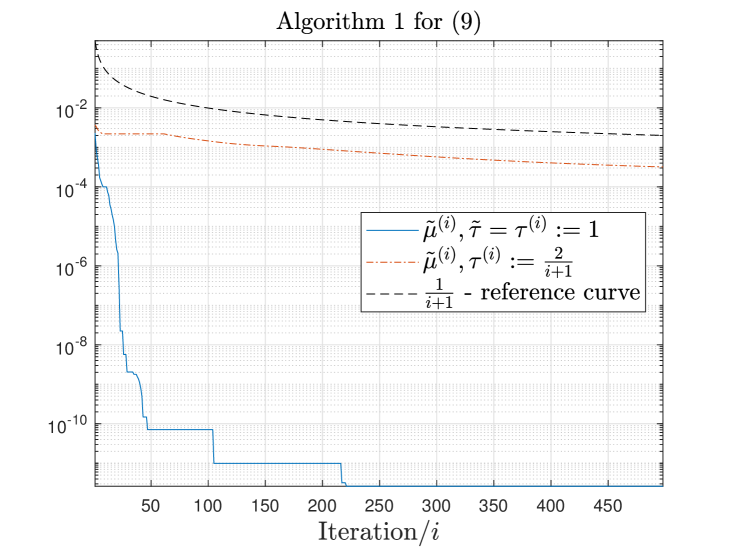
Theorem 4.1 shows that it takes at most iterations to find an approximate stationary point with gap smaller than . Note that Theorem 4.1 requires and, for example, the standard choice does not satisfy this assumption.
4.1 Compactness assumption and convergence of Algorithm 1
By looking at the convergence rate given by (18), it is tempting to take as large as possible. However, since the set is convex, the maximum allowed value for is 1 to ensure that the iterates remain feasible. This setting leads to a convergence rate of , given the assumptions of Theorem 4.1 are satisfied, and corresponds to Algorithm 1. In Theorem 4.1, we need the set to be compact. Let us discuss this assumption in the context of Algorithm 1 that relies on our two formulations:
-
1.
For the formulation using exponential cones (5), a variable (resp. ) equal to zero will correspond to (resp. ) going to , which is not bounded. As recommended by Mosek, we use additional artificial component-wise lower and upper bounds for and , namely, -35 and 10. Therefore, our implementation actually solves a component-wise bounded version of (5). However, since and , numerically, these constraints do not exclude good approximations of in practice, as long as the entries in belong to a reasonable range which can be assumed w.l.o.g. by a proper preprocessing of , e.g., so that for all ; see, e.g., the discussion in [15, page 66].
-
2.
For the formulation using second-order cones (9), we can assume compactness w.l.o.g. In fact, for simplicity, let us consider the formulation (6) in variables , since the change of variables is the component-wise square root, and keeps the feasible set compact. We can w.l.o.g. add a set of normalization constraints on the rows of , such as for all which leads to a compact set for , since we can use the degree of freedom in scaling between the columns of and rows of . It remains to show that can be assumed to be in a compact set. Let us show that the level sets of the objective function are compact, which will give the result. The objective function of (6) is the component-wise norm, . Then, let be an arbitrary feasible solution of (6) (such a solution can be easily constructed), and add the constraint to formulation (6), which does not modify its optimal solution set. We have for all
which shows that in that modified formulation also belongs to a compact set. The second equality and first inequality follow from nonnegativity of and .
under these modifications that make the feasible set compact, we have the following corollary.
Corollary 4.2.
Remark 2 (Difference-of-convex-functions optimization).
Algorithm 1 can also be interpreted as a special case of a difference-of-convex algorithm that minimizes the difference between two convex functions, namely [23]. In our case, we would have . For such problems, a convergence rate to stationary points of order has also been derived when optimizing over a convex compact feasible set, but using a different measure of stationary [1].
Remark 3.
Using a proper normalization (see Section 4.1), the original NMF problem can be tackled directly by the FW algorithm (Algorithm 2), as the linear minimization oracle can be computed in closed form. Hence one could use existing results on FW to derive a convergence rate. However, the FW algorithm applied to smooth nonconvex problems leads to a worse rate of [22].
5 Numerical experiments
In this section, Algorithm 1, using both formulations (5) and (9), is tested for the computation of exact NMF for particular classes of matrices usually considered in the literature: (1) -by- matrices randomly generated with nonnegative rank (each matrix is generated by multiplying two random rank-5 nonnegative matrices), (2) four -by- infinitesimally rigid factorizations with nonnegative rank [20], denoted for , and (3) four -by- slack matrices corresponding to nested hexagons, denoted , with nonnegative ranks depending on a parameter , respectively. These matrices are described in more details in the Appendix A.
In order to make Algorithm 1 practically more effective, we incorporate two improvements in the context of Exact NMF:
-
1.
Sparsity patterns integration: in NMF, entries of and are expected to be equal to zero at optimality. Hence, when some entries of or are sufficiently close to zero, fixing them to zero for all remaining iterations reduces the number of variables and hence accelerates the subsequent iterations of Algorithm 1; see Appendix B for the details.
- 2.
For each of the matrices, we run our Algorithm 1 for 750 iterations for nested hexagons and random matrices and 3000 iterations for infinitesimally rigid matrices, and compare with the state-of-the-art algorithms from [29] with Multi-Start 1 heuristic ”ms1” and the Rank-by-rank heuristic ”rbr”. For each method, we run 100 initializations with SPARSE10, as recommended in [29], with target precision . Note that a different random matrix is generated each time for the experiments on random matrices, following the procedure described in the Appendix A. All tests are preformed using Matlab R2021b on a laptop Intel CORE i7-11800H CPU @2.3GHz 16GB RAM. The code is available from https://bit.ly/3FqMqhD.
Table 1 reports the number of successes over 100 attempts to compute the exact NMF of the input matrices, where the success is defined as obtaining a solution where is below the target precision, namely .
We observe the following:
- •
- •
-
•
For some matrices (namely, and ), “rbr” from [29] is able to compute exact NMF for all initializations, which is not the case of the other algorithms. However, “rbr” is not able to compute exact NMFs for and .
In summary, Algorithm 1 competes favorably with the algorithms proposed in [29], and appears to be more robust in the sense that it computes exact NMFs in all the tested cases. In addition, the second-order cone formulation, Algorithm 1 with (9), performs slightly better than with the exponential cone formulation, Algorithm 1 with (5).
Computational time
In terms of computational time, Algorithm 1 performs similarly to algorithm from [29] for the considered matrices, but it does not scale as well. The main reason is that it relies on interior-point methods, while [29] relies on first-order methods (more precisely, exact BCD). For example, for the infinitesimally rigid matrices, Algorithm 1 and [29] take between 2 and 16 seconds. We would report slower performance for Algorithm 1 compared to [29] for larger matrices. Hence a possible direction of research would be to use faster methods to tackle the conic optimization problems.
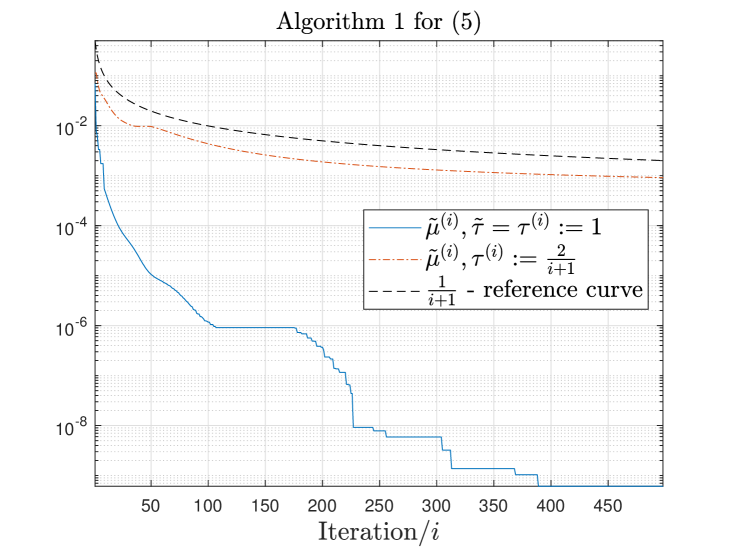
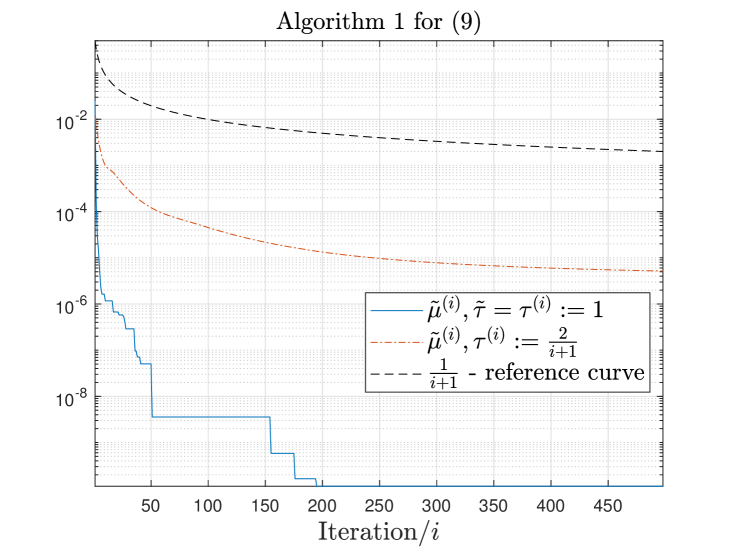
Numerical validation of the rate of convergence
As a simple empirical validation of the rate of convergence proposed in Section 4, we report in Figure 1 the evolution of the minimum FW gap computed along iterations by Algorithm 1 (for (5) and (9)) for one tested matrix, namely . Similar behaviours were observed for all the tested input matrices: additional figures are given in Appendix C. Note that we also integrated a variant of Algorithm 1 for which (a standard choice in the literature for FW algorithms). In Figure 1, we observe that the behaviour of the minimal FW gap is in line with the theoretical results from Section 4. Furthermore, the choice leads to faster decrease of the minimal FW gap encountered along iterations, as expected.
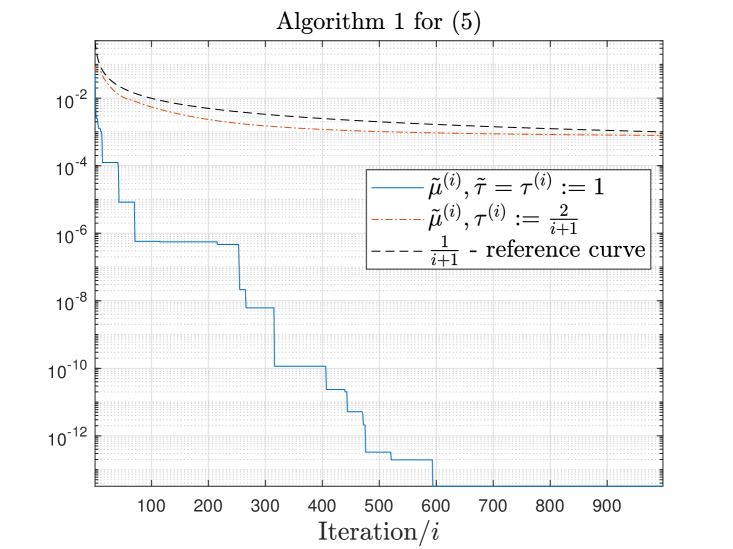
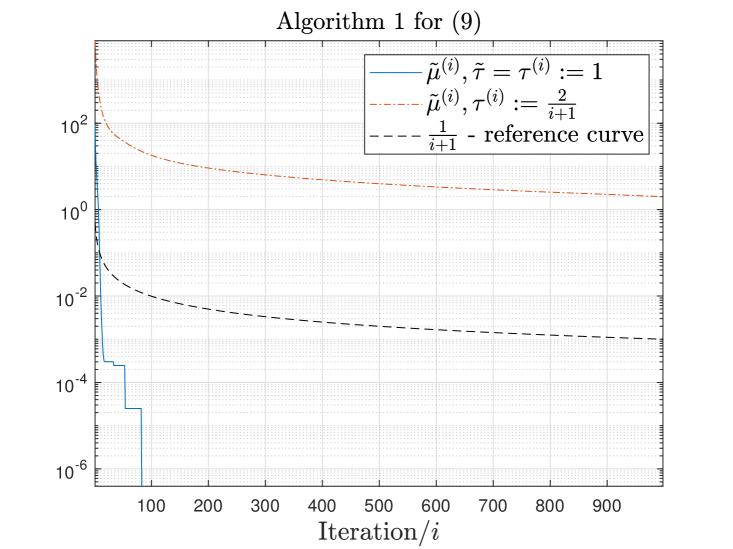
Impact of the initialization
We also investigated the impact of using an improved initialization for our Algorithm 1 with (9), based on a rank-one NMO slightly perturbed with nonnegative random uniform values. More precisely, we set where is the rank-one NMO computed with the methodology detailed in Section 2.2.1, is a matrix of appropriate size of uniformly distributed random numbers in the interval , and is a parameter to be defined by the user. In our numerical experiments, we chose values for within the interval . We find that Algorithm 1 with (9) using that dedicated initialization found respectively 74, 65 and 52 successes for matrices , and , respectively, a marked improvement over the default random initialization (where it had 42, 38, 20 successes, respectively). For the other tested matrices, it did not change the result significantly (only a few additional successes). Therefore a possible direction of research would be the design of more advanced strategies for the initialization of .
6 Conclusion
In this paper, we introduced two formulations for computing exact NMFs, namely (1) and (6) that are under- and upper-approximation formulations for NMF, respectively. For each formulation, we used a particular change of variables that enabled the use of two convex cones, namely the exponential and second-order cones, to reformulate these problems as the minimization of a concave function over a convex feasible set. In order to solve the two optimization problems, we proposed Algorithm 1 that relies on the resolution of successive linear approximations of the objective functions and the use of interior-point methods. We also showed that our optimization scheme relying on successive linearizations is a special case of the Frank-Wolfe (FW) algorithm. Using an appropriate measure of stationarity, namely the FW gap, we showed in Theorem 4.1 that the minimal FW gap generated by our algorithm converges as , where is the iteration index. We believe this type of global convergence rate to a stationary point is new for NMF. We showed that Algorithm 1 is able to compute exact NMFs for several classes of nonnegative matrices (namely, randomly generated matrices, infinitesimally rigid matrices, and slack matrices of nested hexagons) and as such demonstrate its competitiveness compared to recent methods from the literature. However, we have only tested Algorithm 1 on a limited number of nonnegative matrices for exact NMF. In the future we plan to test it on a larger library of nonnegative matrices and also to compute approximate NMFs in data analysis applications, in order to better understand the behavior of Algorithm 1 along with the two formulations, (5) and (9).
Further works also include:
-
•
The design of more advanced strategies for the initialization of .
-
•
The elaboration of alternative formulations for (5) and (9) to deal with the non-uniqueness of the NMF models. In particular, we plan to develop new formulations that discard solutions of the form for a given solution and for invertible matrices such that and . For example, one could remove the permutation and scaling ambiguity for the columns of and rows of , to remove some degrees of freedom in the formulations. We refer the interested reader to [11] and [13, Chapter 4], and the references therein, for more information on the non-uniqueness of NMF.
- •
-
•
The use of upper-approximations that are more accurate than linearizations for concave functions such as second-order models, and study the convergence for such models.
Acknowledgements
We thank the two reviewers for their careful reading and insightful feedback that helped us improve the paper significantly.
References
- [1] H. Abbaszadehpeivasti, E. de Klerk, and M. Zamani, On the rate of convergence of the difference-of-convex algorithm (DCA), arXiv preprint arXiv:2109.13566 (2021).
- [2] S. Arora, R. Ge, R. Kannan, and A. Moitra, Computing a nonnegative matrix factorization—provably, SIAM Journal on Computing 45 (2016), pp. 1582–1611.
- [3] S. Basu, R. Pollack, and M.F. Roy, On the combinatorial and algebraic complexity of quantifier elimination, Journal of the ACM (JACM) 43 (1996), pp. 1002–1045.
- [4] A. Berman and N. Shaked-Monderer, Completely positive matrices, World Scientific, 2003.
- [5] A. Cichocki, R. Zdunek, A.H. Phan, and S.i. Amari, Nonnegative matrix and tensor factorizations: applications to exploratory multi-way data analysis and blind source separation, John Wiley & Sons, 2009.
- [6] K.L. Clarkson, Coresets, sparse greedy approximation, and the Frank-Wolfe algorithm, ACM Trans. Algorithms 6 (2010).
- [7] J.E. Cohen and U.G. Rothblum, Nonnegative ranks, decompositions, and factorizations of nonnegative matrices, Linear Algebra and its Applications 190 (1993), pp. 149–168.
- [8] J. Dewez, Computational approaches for lower bounds on the nonnegative rank, Ph.D. diss., UCLouvain, 2022.
- [9] J. Dewez, N. Gillis, and F. Glineur, A geometric lower bound on the extension complexity of polytopes based on the -vector, Discrete Applied Mathematics 303 (2021), pp. 22–388.
- [10] M. Frank and P. Wolfe, An algorithm for quadratic programming, Naval Research Logistics Quarterly 3 (1956), pp. 95–110.
- [11] X. Fu, K. Huang, N.D. Sidiropoulos, and W.K. Ma, Nonnegative matrix factorization for signal and data analytics: Identifiability, algorithms, and applications., IEEE Signal Process. Mag. 36 (2019), pp. 59–80.
- [12] N. Gillis, Approximation et sous-approximation de matrices par factorisation positive : algorithmes, complexite et applications, Master’s thesis, Universite Catholique de Louvain, 2007.
- [13] N. Gillis, Nonnegative Matrix Factorization, SIAM, Philadelphia, 2020.
- [14] N. Gillis and F. Glineur, Accelerated multiplicative updates and hierarchical ALS algorithms for nonnegative matrix factorization, Neural Computation 24 (2012), pp. 1085–1105.
- [15] N. Gillis, et al., Nonnegative matrix factorization: Complexity, algorithms and applications, Unpublished doctoral dissertation, Université catholique de Louvain. Louvain-La-Neuve: CORE (2011).
- [16] N. Gillis and F. Glineur, Using underapproximations for sparse nonnegative matrix factorization, Pattern recognition 43 (2010), pp. 1676–1687.
- [17] M. Jaggi, Sparse convex optimization methods for machine learning, Ph.D. diss., ETH Zurich, 2011.
- [18] M. Jaggi, Revisiting Frank-Wolfe: Projection-Free Sparse Convex Optimization, in Proceedings of the 30th International Conference on Machine Learning, Proceedings of Machine Learning Research Vol. 28, 17–19 Jun, Atlanta, Georgia, USA. PMLR, 2013, pp. 427–435.
- [19] J. Kim and H. Park, Fast nonnegative matrix factorization: An active-set-like method and comparisons, SIAM Journal on Scientific Computing 33 (2011), pp. 3261–3281.
- [20] R. Krone and K. Kubjas, Uniqueness of nonnegative matrix factorizations by rigidity theory, SIAM Journal on Matrix Analysis and Applications 42 (2021), p. 134–164.
- [21] D. Kuang, C. Ding, and H. Park, Symmetric Nonnegative Matrix Factorization for Graph Clustering, in Proceedings of the 2012 SIAM International Conference on Data Mining. pp. 106–117.
- [22] S. Lacoste-Julien, Convergence rate of Frank-Wolfe for non-convex objectives, arXiv preprint arXiv:1607.00345 (2016).
- [23] H.A. Le Thi and T. Pham Dinh, DC programming and DCA: thirty years of developments, Mathematical Programming 169 (2018), pp. 5–68.
- [24] A. Moitra, An Almost Optimal Algorithm for Computing Nonnegative Rank, in Proc. of the 24th Annual ACM-SIAM Symp. on Discrete Algorithms (SODA ’13). 2013, pp. 1454–1464.
- [25] Mosek APS, Optimization software. Available at https://www.mosek.com/.
- [26] R. Sharma and K. Sharma, A new dual based procedure for the transportation problem, European Journal of Operational Research 122 (2000), pp. 611–624.
- [27] Y. Shitov, The nonnegative rank of a matrix: Hard problems, easy solutions, SIAM Review 59 (2017), pp. 794–800.
- [28] M. Tepper and G. Sapiro, Nonnegative matrix underapproximation for robust multiple model fitting, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, pp. 2059–2067.
- [29] A. Vandaele, N. Gillis, F. Glineur, and D. Tuyttens, Heuristics for exact nonnegative matrix factorization, J. of Global Optim 65 (2016), p. 369–400.
- [30] S.A. Vavasis, On the complexity of nonnegative matrix factorization, SIAM Journal on Optimization 20 (2010), pp. 1364–1377.
Appendix A Factorized matrices
In this appendix, we describe the matrices considered for the numerical experiments in Section 5:
-
•
Randomly generated matrices: It is standard in the NMF literature to use randomly generated matrices to compare algorithms (see, e.g., [19]). In this paper, we used the standard approach: where each entry of and is generated using the uniform distribution in the interval , and . With this approach, with probability one. In the numerical experiments reported in Section 5, we used and .
-
•
Infinitesimally rigid factorizations: in this paper, we consider four infinitesimally rigid factorizations for matrices with positive entries and with nonnegative rank equal to four from [20]:
These matrices have been shown to be challenging to factorize. We refer the reader to [20] for more details.
-
•
Nested hexagons problem: computing an exact NMF is equivalent to tackle a well-known problem in computational geometry which is referred to as nested polytope problem. Here we consider a family of input matrices whose exact NMF corresponds to finding a polytope nested between two hexagons; see [13, Chapter 2] and the references therein. Given , is defined as
which satisfies for any . The inner hexagon is smaller than the outer one with a ratio of . We consider three values for :
-
–
: the inner hexagon is twiced smaller than the outer one and we can fit a triangle between the two, thus .
-
–
: the inner hexagon is smaller than the outer one and we can fit a rectangle between the two, thus .
-
–
: .
-
–
, which gives:
with .
-
–
Appendix B Sparsity Patterns Integration
This appendix details the SPI procedure for quadratic cones, similar rationale has been followed for exponential cones. Due to nonnegative constraints on the entries of and , one can expect sparsity patterns for the solutions , as for the solution of (9) since and . Obviously, the sparsity for the solutions is reinforced by the sparsity of the input matrix . One can observe that the objective function from (9) is not L-smooth on the interior of the domain, that is the non-negative orthant. In the case the -entry of the current iterate tends to zero, the corresponding entry of the gradient of w.r.t. tends to which therefore ends the optimization process. In order to tackle this issue and enables the solution to reach the desired tolerance of , we integrated an additional stage within the second building block of Algorithm 1. This additional stage is referred to as ”Sparsity Pattern Integration”. Let us illustrate its principle on the following case: the entry tends to zero. Let us now fix to zero, drop this variable from the optimization process and observe the impact on the constraints of (7) in which variable is involved; the inequality constraints identified by index are:
First, since , there is no more constraints on for inequalities identified by index . Second, for the problem (9) and its successive linearizations, it is then clear that conic variables (and hence the associated conic constraints) can be dropped from the optimization process.
Finally, the linear term is removed from the current linearizations of . The same rationale is followed for the case entries of the current iterate for tend to zero.
On a practical point of view, at each activation of SPI, Algorithm 1 checks if entries of the current iterates are below a threshold defined by the user. Hence the corresponding entries of and are set to zero so that a sparsity pattern is determined, that are the indices of these entries. The successive linearizations of (9) are automatically updated based on the current sparsity pattern with the approach explained above.
Let us illustrate the impact of triggering the SPI procedure on the solutions obtained for the factorization of the following matrix :
| (26) |
The nonnegative rank of (26) is known and is equal to . Algorithm 1 is used to compute an exact NMF of with the following input parameters:
-
•
,
-
•
,
-
•
the maximum number of iterations defined by parameter maxiter is set to 500 and the SPI procedure is triggered at iteration .
Figure 2 displays the evolution of along iterations for (26) with a factorization rank . One can observe that, once the SPI is activated, the relative Frobenius error drops from 5 to 8 , hence below the tolerance of such that we assume an exact NMF is found. For this experiment, we obtain:
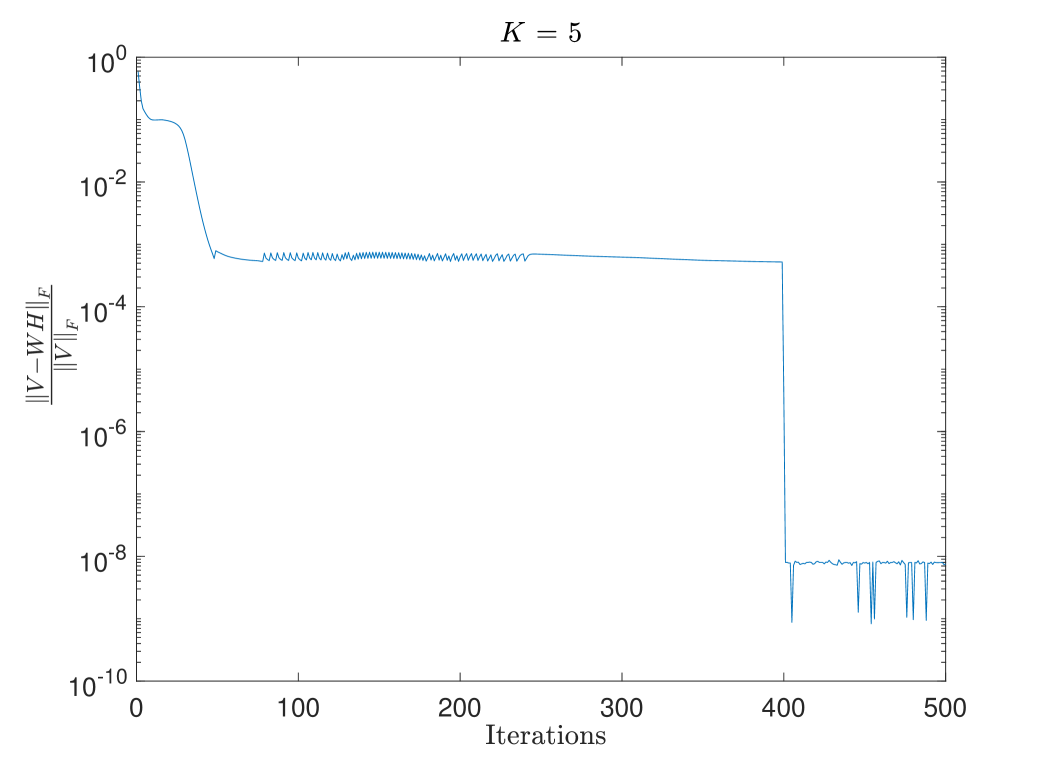
Appendix C Additional empirical validations of the convergence rates
In this appendix, we report in Figures 3 and 4 additional empirical validations of the convergence rate introduced in 4 for the two others classes on tested matrices, namely the random matrices and the matrices related to nested hexagons problem. For the later, we considered the particular case .