Consistent Feature Selection for Analytic Deep Neural Networks
Abstract
One of the most important steps toward interpretability and explainability of neural network models is feature selection, which aims to identify the subset of relevant features. Theoretical results in the field have mostly focused on the prediction aspect of the problem with virtually no work on feature selection consistency for deep neural networks due to the model’s severe nonlinearity and unidentifiability. This lack of theoretical foundation casts doubt on the applicability of deep learning to contexts where correct interpretations of the features play a central role.
In this work, we investigate the problem of feature selection for analytic deep networks. We prove that for a wide class of networks, including deep feed-forward neural networks, convolutional neural networks, and a major sub-class of residual neural networks, the Adaptive Group Lasso selection procedure with Group Lasso as the base estimator is selection-consistent. The work provides further evidence that Group Lasso might be inefficient for feature selection with neural networks and advocates the use of Adaptive Group Lasso over the popular Group Lasso.
1 Introduction
In recent years, neural networks have become one of the most popular models for learning systems for their strong approximation properties and superior predictive performance. Despite their successes, their “black box” nature provides little insight into how predictions are being made. This lack of interpretability and explainability stems from the fact that there has been little work that investigates statistical properties of neural networks due to its severe nonlinearity and unidentifiability.
One of the most important steps toward model interpretability is feature selection, which aims to identify the subset of relevant features with respect to an outcome. Numerous techniques have been developed in the statistics literature and adapted to neural networks over the years. For neural networks, standard Lasso is not ideal because a feature can only be dropped if all of its connections have been shrunk to zero together, an objective that Lasso does not actively pursue. Zhao et al. (2015), Scardapane et al. (2017) and Zhang et al. (2019) address this concern by utilizing Group Lasso and its variations for selecting features of deep neural networks (DNNs). Feng and Simon (2017) propose fitting a neural network with a Sparse Group Lasso penalty on the first-layer input weights while adding a sparsity penalty to later layers. Li et al. (2016) propose adding a sparse one-to-one linear layer between the input layer and the first hidden layer of a neural network and performing regularization on the weights of this extra layer. Similar ideas are also applied to various types of networks and learning contexts (Tank et al., 2018; Ainsworth et al., 2018; Lemhadri et al., 2019).
Beyond regularization-based methods, Horel and Giesecke (2019) develop a test to assess the statistical significance of the feature variables of a neural network. Alternatively, a ranking of feature importance based on local perturbations, which includes fitting a model in the local region around the input or locally perturbing the input to see how predictions change, can also be used as a proxy for feature selection (Simonyan et al., 2013; Ibrahim et al., 2014; Ribeiro et al., 2016; Nezhad et al., 2016; Lundberg and Lee, 2017; Shrikumar et al., 2017; Ching et al., 2018; Taherkhani et al., 2018; Lu et al., 2018). “Though these methods can yield insightful interpretations, they focus on specific architectures of DNNs and can be difficult to generalize" (Lu et al., 2018).
Despite the success of these approaches, little is known about their theoretical properties. Results in the field have been either about shallow networks with one hidden layer (Dinh and Ho, 2020; Liang et al., 2018; Ye and Sun, 2018), or focus on posterior concentration, prediction consistency, parameter-estimation consistency and convergence of feature importance (Feng and Simon, 2017; Farrell et al., 2018; Polson and Ročková, 2018; Fallahgoul et al., 2019; Shen et al., 2019; Liu, 2019), with virtually no work on feature selection consistency for deep networks. This lack of a theoretical foundation for feature selection casts doubt on the applicability of deep learning to applications where correct interpretations play a central role such as medical and engineering sciences. This is problematic since works in other contexts indicated that Lasso and Group Lasso could be inconsistent/inefficient for feature selection (Zou, 2006; Zhao and Yu, 2006; Wang and Leng, 2008), especially when the model is highly-nonlinear (Zhang et al., 2018).
In this work, we investigate the problem of feature selection for deep networks. We prove that for a wide class of deep analytic neural networks, the GroupLasso + AdaptiveGroupLasso procedure (i.e., the Adaptive Group Lasso selection with Group Lasso as the base estimator) is feature-selection-consistent. The results also provide further evidence that Group Lasso might be inconsistent for feature selection and advocate the use of the Adaptive Group Lasso over the popular Group Lasso.
2 Feature selection with analytic deep neural networks
Throughout the paper, we consider a general analytic neural network model described as follows. Given an input that belongs to be a bounded open set , the output map of an -layer neural network with parameters is defined by
-
•
input layer:
-
•
hidden layers:
-
•
output layer:
where denotes the number of nodes in the -th hidden layer, , , , , and are analytic functions parameterized by the hidden layers’ parameter . This framework allows interactions across layers of the network architecture and only requires that (i) the model interacts with inputs through a finite set of linear units, and (ii) the activation functions are analytic. This parameterization encompasses a wide class of models, including feed-forward networks, convolutional networks, and (a major subclass of) residual networks.
Hereafter, we assume that the set of all feasible vectors of the model is a hypercube and use the notation to denote the -th component of a vector and to denote the -entry of a matrix . We study the feature selection problem for regression in the model-based setting:
Assumption 2.1.
Training data are independent and identically distributed (i.i.d ) samples generated from such that the input density is positive and continuous on its domain and where and .
Remarks.
Although the analyses of the paper focus on Gaussian noise, the results also apply to all models for which is sub-Gaussian, including the cases of bounded noise. The assumption that the input density is positive and continuous on its bounded domain ensures that there is no perfect correlations among the inputs and plays an important role in our analysis. Throughout the paper, the network is assumed to be fixed, and we are interested in the asymptotic behaviors of estimators in the learning setting when the sample size increases.
We assume that the “true” model only depends on through a subset of significant features while being independent of the others. The goal of feature selection is to identify this set of significant features from the given data. For convenience, we separate the inputs into two groups and (with ) that denote the significant and non-significant variables of , respectively. Similarly, the parameters of the first layer ( and ) are grouped by their corresponding input, i.e.
where , , and . We note that this separation is simply for mathematical convenience and the training algorithm is not aware of such dichotomy.
We define significance and selection consistency as follows.
Definition 2.2 (Significance).
The -th input of a network is referred to as non-significant iff the output of the network does not depend on the value of that input variable. That is, let denote the vector obtained from by replacing the -th component of by , we have for all .
Definition 2.3 (Feature selection consistency).
An estimator with first layer’s parameters is feature selection consistent if for any , there exists such that for , we have
with probability at least .
One popular method for feature selection with neural networks is the Group Lasso (GL). Moreover, since the model of our framework only interacts with the inputs through the first layer, it is reasonable that the penalty should be imposed only on these parameters. A simple GL estimator for neural networks is thus defined by
is the square-loss, , is the standard Euclidean norm and is the vector of parameters associated with -th significant input.
While GL and its variation, the Sparse Group Lasso, have become the foundation for many feature selection algorithms in the field, there is no known result about selection consistency for this class of estimators. Furthermore, like the regular Lasso, GL penalizes groups of parameters with the same regularization strengths and it has been shown that excessive penalty applied to the significant variables can affect selection consistency (Zou, 2006; Wang and Leng, 2008). To address these issues, Dinh and Ho (2020) propose the “GroupLasso+AdaptiveGroupLasso” (GL+AGL) estimator for feature selection with neural networks, defined as
where
Here, we use the convention , , is the regularizing constant and , denotes the and components of the GL estimate . As typical with adaptive lasso estimators, GL+AGL uses its base estimator to provide a rough data-dependent estimate to shrink groups of parameters with different regularization strengths. As grows, the weights for non-significant features get inflated (to infinity) while the weights for significant ones remain bounded (Zou, 2006). Dinh and Ho (2020) prove that GL+AGL is selection-consistent for irreducible shallow networks with hyperbolic tangent activation. In this work, we argue that the results can be extended to general analytic deep networks.
3 Consistent feature selection via GroupLasso+AdaptiveGroupLasso
The analysis of GL+AGL is decomposed into two steps. First, we establish that the Group Lasso provides a good proxy to estimate regularization strengths. Specifically, we show that
-
•
The -components of are bounded away from zero
-
•
The -components of converge to zero with a polynomial rate.
Second, we prove that a selection procedure based on the weights obtained from the first step can correctly select the set of significant variables given informative data with high probability.
One technical difficulty of the proof concerns with the geometry of the risk function around the set of risk minimizers
where denotes the risk function . Since deep neural networks are highly unidentifiable, the set can be quite complex. For example:
-
(i)
A simple rearrangement of the nodes in the same hidden layer leads to a new configuration that produces the same mapping as the generating network
-
(ii)
If either all in-coming weights or all out-coming weights of a node is zero, changing the others also has no effect on the output
-
(iii)
For hyperbolic tangent activation, multiplying all the in-coming and out-coming parameters associated with a node by -1 also lead to an equivalent configuration
These unidentifiability create a barrier in studying deep neural networks. Existing results in the field either are about equivalent graph transformation (Chen et al., 1993) or only hold in some generic sense (Fefferman and Markel, 1994) and thus are not sufficient to establish consistency. Traditional convergence analyses also often rely on local expansions of the risk function around isolated optima, which is no longer the case for neural networks since may contain subsets of high dimension (e.g., case (ii) above) and the Hessian matrix (and high-order derivatives) at an optimum might be singular.
In this section, we illustrate that these issues can be avoided with two adjustments. First, we show that while the behavior of a generic estimator may be erratic, the regularization effect of Group Lasso constraints it to converge to a subset of “well-behaved” optima. Second, instead of using local expansions, we employ Lojasewicz’s inequality for analytic functions to upper bound the distance from to by the excess risk. This removes the necessity of the regularity of the Hessian matrix and enlarges the class of networks for which selection consistency can be analyzed.
3.1 Characterizing the set of risk minimizers
Lemma 3.1.
-
(i)
There exists such that for all and .
-
(ii)
For , the vector , obtained from be setting its -components to zero, also belongs to .
Proof.
We first prove that if and only if . Indeed, since , we have
with equality happens only if a.s. on the support of . Since is continuous and positive on its open domain and the maps are analytic, we deduce that everywhere.
(i) Assuming that no such exists, since is compact and is an analytic function in and , we deduce that there exists and such that . This means does not depend on significant input , which is a contradiction. (ii) Since , we have , which implies . ∎
Remarks.
Lemma 3.1 provides a way to study the behaviors of Group Lasso without a full characterization of the geometry of as in Dinh and Ho (2020). First, as long as , it is straight forward that its -components are bounded away from zero (part (i)). Second, it shows that for all , is a “better” hypothesis in terms of penalty while remaining an optimal hypothesis in terms of prediction. This enables us to prove that if we define
and converges to zero slowly enough, the regularization term will force . This helps establish that Group Lasso provides a good proxy to construct appropriate regularization strengths.
To provide a polynomial convergence rate of , we need the following Lemma.
Lemma 3.2.
There exist and such that for all .
Proof.
We first note that since is analytic in both and , the excess risk is also analytic in . Thus is the zero level-set of the analytic function . By Lojasewicz’s inequality for algebraic varieties (Ji et al., 1992), there exist positive constants and such that , which completes the proof. ∎
We note that for cases when is finite, Lemma 3.2 reduces to the standard Taylor’s inequality around a local optimum, with if the Hessian matrix at the optimum is non-singular (Dinh and Ho, 2020). When is a high-dimensional algebraic set, Lojasewicz’s inequality and Lemma 3.2 are more appropriate. For example, for , it is impossible to attain an inequality of the form
in any neighborhood of any minimum , while it is straightforward that
This approach provides a way to avoid dealing with model unidentfiability but requires some adaptation of the analysis to accommodate a new mode of convergence.
3.2 Convergence of Group Lasso
The two Lemmas in the previous section enables us to analyze the convergence of the Group Lasso estimate, in the sense that . First, we define the empirical risk function
and note that since the network of our framework is fixed, the learning problem is continuous and parametric, for which a standard generalization bound as follows can be obtained (proof in Appendix).
Lemma 3.3 (Generalization bound).
For any , there exist such that
with probability at least .
Theorem 3.4 (Convergence of Group Lasso).
For any , there exist and such that for all ,
with probability at least . Moreover, if , then with probability at least ,
Proof.
Let denote the weight vector obtained from by setting the -components to zero. If we define then and .
Since is a Lipschitz function, we have
which implies (through Young’s inequality, details in Appendix) that
Let denote the part of the regularization term without the -component. We note that is a Lipschitz function, for all , and . Thus,
This completes the proof. ∎
Together, the two parts of Theorem 3.4 shows that the Group Lasso estimator converges to the set of “well-behaved” optimal hypotheses (proof in Appendix)..
Corollary 3.5.
For any , there exist and such that for all ,
3.3 Feature selection consistency of GroupLasso + AdaptiveGroupLasso
We are now ready to prove the main theorem of our paper.
Theorem 3.6 (Feature selection consistency of GL+AGL).
Let , , , and , then the GroupLasso+AdaptiveGroupLasso is feature selection consistent.
Proof.
Since (Theorem 3.4), we have for all . By Lemma 3.1, we conclude that is bounded away from zero as . Thus,
which shows that . Thus is also bounded away from zero for large enough.
We now assume that for some and define a new weight configuration obtained from by setting the component to . By definition of the estimator , we have
By the (probabilistic) Lipschitzness of the empirical risk (proof in Appendix), there exists s.t.
with probability at least . Since , we deduce that . This contradicts Theorem 3.4, which proves that for large enough
with probability at least . This completes the proof. ∎
Remark.
One notable aspect of Theorem 3.6 is the absence of regularity conditions on the correlation of the inputs often used in lasso-type analyses, such as Irrepresentable Conditions (Meinshausen and Bühlmann, 2006) and (Zhao and Yu, 2006), restricted isometry property (Candes and Tao, 2005), restricted eigenvalue conditions (Bickel et al., 2009; Meinshausen and Yu, 2009) or sparse Riesz condition (Zhang and Huang, 2008). We recall that by using different regularization strengths for individual parameters, adaptive lasso estimators often require less strict conditions for selection consistency than standard lasso. For linear models, the classical adaptive lasso only assumes that the limiting design matrix is positive definite, i.e., there is no perfect correlation among the inputs) (Zou, 2006). In our framework, this corresponds to the assumption that the density of is positive on its open domain (Assumption 2.1), which plays an essential role in the proof of Lemma 3.1.
3.4 Simulations
To further illustrate the theoretical findings of the paper, we use both synthetic and real data to investigate algorithmic behaviors of GL and GL+AGL. 111The code is available at https://github.com/vucdinh/alg-net. The simulations, implemented in Pytorch, focus on single-output deep feed-forward networks with three hidden layers of constant width. In these experiments, regularizing constants are chosen from a course grid with using average test errors from random train-test splits of the corresponding dataset. The algorithms are trained over 20000 epochs using proximal gradient descent, which allows us to identify the exact support of estimators without having to use a cut-off value for selection.
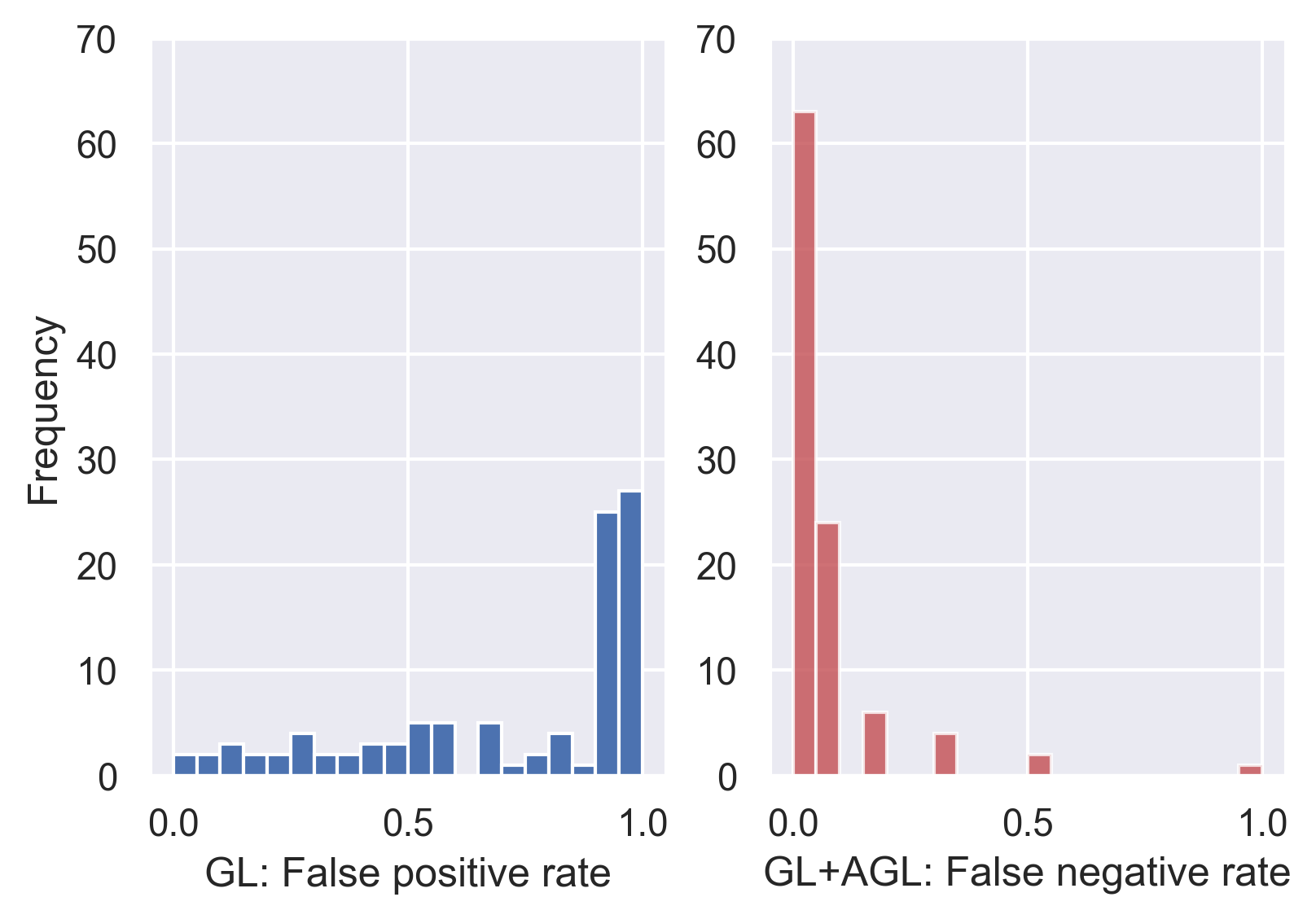
In the first experiment, we consider a network with three hidden layers of 20 nodes. The input consists of features, 10 of which are significant while the others are rendered insignificant by setting the corresponding weights to zero. We generate datasets of size from the generic model where and non-zero weights of are sampled independently from . We perform GL and GL+AGL on each simulated dataset with regularizing constants chosen using average test errors from three random three-fold train-test splits. We observe that overall, GL+AGL have a superior performance, selecting the correct support in out of runs, while GL cannot identify the support in any run. Except for one pathological case when both GL and GL+AGL choose a constant model, GL always selects the correct significant inputs but fail to de-select the insignificant ones (Figure 1, left panel) while GL+AGL always performs well with the insignificant inputs but sometimes over-shrinks the significant ones (Figure 1, right panel).
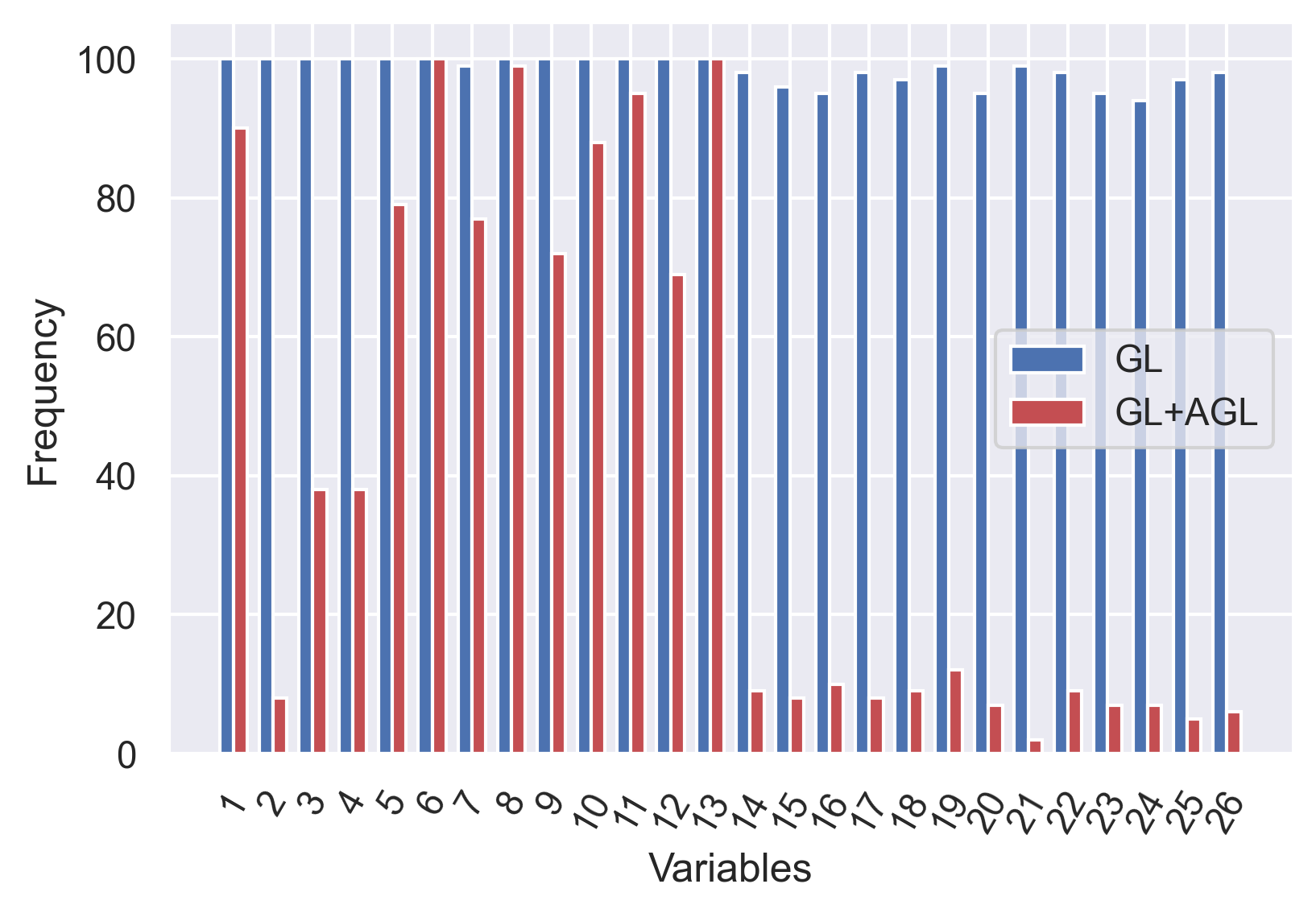
Next, we apply the methods to the Boston housing dataset 222http://lib.stat.cmu.edu/datasets/boston. This dataset consists of 506 observations of house prices and 13 predictors. To analyze the data, we consider a network with three hidden layers of 10 nodes. GL and GL+AGL are then performed on this dataset using average test errors from 20 random train-test splits (with the size of the test sets being of the original dataset). GL identifies all 13 predictors as important, while GL+AGL only selects 11 of them. To further investigate the robustness of the results, we follow the approach of Lemhadri et al. (2019) to add 13 random Gaussian noise predictors to the original dataset for analysis. such datasets are created to compare the performance of GL against GL+AGL using the same experimental setting as above. The results are presented in Figure 2, for which we observe that GL struggles to distinguish the random noises from the correct predictors. We note that Lemhadri et al. (2019) identifies 11 of the original predictors along with 2 random predictors as the optimal set of features for prediction, which is consistent with the performance of GL+AGL.
4 Conclusions and Discussions
In this work, we prove that GL+AGL is feature-selection-consistent for all analytic deep networks that interact with inputs through a finite set of linear units. Both theoretical and simulation results of the work advocate the use of GL+AGL over the popular Group Lasso for feature selection.
4.1 Comparison to related works
To the best of our knowledge, this is the first work that establishes selection consistency for deep networks. This is in contrast to Dinh and Ho (2020), Liang et al. (2018) and Ye and Sun (2018), which only provide results for shallow networks with one hidden layer, or Polson and Ročková (2018), Feng and Simon (2017), Liu (2019), which focus on posterior concentration, prediction consistency, parameter-estimation consistency and convergence of feature importance. We note that for classical linear model with lasso estimate, it is known that (see Section 2 of Zou (2006) and the discussion therein) the lasso estimator is parameter-estimation consistent as long as the regularizing parameter (Zou (2006), Lemmas 2 and 3), but is not feature-selection consistent for (Zou (2006), Proposition 1) or for all choices of if some necessary condition on the covariance matrix is not satisfied (Zou (2006), Theorem 1). For both linear model and neural network, parameter-estimation consistency directly implies prediction consistency and convergence of feature importance. In general, there’s no known trivial way to extending these approaches to obtain feature-selection-consistency.
Moreover, existing works usually assume that the network used for training has exactly the same size as the minimal network that generates the data. This is assumption is either made explicitly (as in Dinh and Ho (2020)) or implicitly implied by the regularity of the Hessian matrix at the optima (Assumption 5 in Ye and Sun (2018) and Condition 1 in Feng and Simon (2017)). We note that these latter two conditions cannot be satisfied if the size of the training network is not “correct” (for example, when data is generated by a one-hidden-layer network with 5 hidden nodes, but the training network is one with 10 nodes). The framework of our paper does not have this restriction. Finally, since our paper focus on model interpretability, the framework has been constructed in such a way that all assumptions are minimal/verifiable. This is in contrast to many previous results. For example, Ye and Sun (2018) takes Assumption 6 (which is difficult to check) as given while we can avoid this Assumption using Lemma 3.2.
4.2 Future works
There are many avenues for future directions. First, while simulations seem to hint that Group Lasso may not be optimal for feature selection with neural networks, a rigorous answer to this hypothesis requires a deeper understanding of the behavior of the estimator that is out of the scope of this paper. Second, the analyses in this work rely on the fact that the network model is analytic, which puts some restrictions on the type of activation function that can be used. While many tools to study non-analytic networks (as well as other learning settings, e.g., for classification, for regression with a different loss function, or networks that does not have a strict structure of layers) are already in existence, such extensions of the results require non-trivial efforts.
Throughout the paper, we assume that the network is fixed () when the sample size () increases. Although this assumption is reasonable in many application settings, in some contexts, for example for the task of identifying genes that increase the risk of a type of cancer, ones would be interested in the case of . There have been existing results of this type for neural networks from the prediction aspect of the problem Feng and Simon (2017); Farrell et al. (2018) and it would be of general interest how analyses of selection consistency apply in those cases. Finally, since the main interest of this work is theoretical, many aspects of the performance of the GL+AGL across different experimental settings and types of networks are left as subjects of future work.
Acknowlegments
LSTH was supported by startup funds from Dalhousie University, the Canada Research Chairs program, and the Natural Sciences and Engineering Research Council of Canada (NSERC) Discovery Grant RGPIN-2018-05447. VD was supported by a startup fund from University of Delaware and National Science Foundation grant DMS-1951474.
Broader Impact
Deep learning has transformed modern science in an unprecedented manner and created a new force for technological developments. However, its black-box nature and the lacking of theoretical justifications have hindered its applications in fields where correct interpretations play an essential role. In many applications, a linear model with a justified confidence interval and a rigorous feature selection procedure is much more favored than a deep learning system that cannot be interpreted. Usage of deep learning in a process that requires transparency such as judicial and public decisions is still completely out of the question.
To the best of our knowledge, this is the first work that establishes feature selection consistency, an important cornerstone of interpretable statistical inference, for deep learning. The results of this work will greatly extend the set of problems to which statistical inference with deep learning can be applied. Medical sciences, public health decisions, and various fields of engineering, which depend upon well-founded estimates of uncertainty, fall naturally on the domain the work tries to explore. Researchers from these fields and the public alike may benefit from such a development and no one is put at disadvantage from this research.
By trying to select a parsimonious and transparent model out of an over-parametrized deep learning system, the approach of this work further provides a systematic way to detect and reduce bias in machine learning analysis. The analytical tools and the theoretical framework derived in this work may also be of independent interest in statistics, machine learning, and other fields of applied sciences.
References
- Ainsworth et al. (2018) Samuel Ainsworth, Nicholas Foti, Adrian KC Lee, and Emily Fox. Interpretable VAEs for nonlinear group factor analysis. arXiv preprint arXiv:1802.06765, 2018.
- Bickel et al. (2009) Peter J Bickel, Yaácov Ritov, and Alexandre B Tsybakov. Simultaneous analysis of Lasso and Dantzig selector. The Annals of Statistics, 37(4):1705–1732, 2009.
- Candes and Tao (2005) Emmanuel J Candes and Terence Tao. Decoding by linear programming. IEEE Transactions on Information Theory, 51(12):4203–4215, 2005.
- Chen et al. (1993) An Mei Chen, Haw-minn Lu, and Robert Hecht-Nielsen. On the geometry of feedforward neural network error surfaces. Neural computation, 5(6):910–927, 1993.
- Ching et al. (2018) Travers Ching, Daniel S Himmelstein, Brett K Beaulieu-Jones, Alexandr A Kalinin, Brian T Do, Gregory P Way, Enrico Ferrero, Paul-Michael Agapow, Michael Zietz, and Michael M Hoffman. Opportunities and obstacles for deep learning in biology and medicine. Journal of The Royal Society Interface, 15(141):20170387, 2018.
- Dinh and Ho (2020) Vu Dinh and Lam Ho. Consistent feature selection for neural networks via Adaptive Group Lasso. arXiv preprint arXiv:2006.00334, 2020.
- Fallahgoul et al. (2019) Hasan Fallahgoul, Vincentius Franstianto, and Gregoire Loeper. Towards explaining the ReLU feed-forward network. Available at SSRN, 2019.
- Farrell et al. (2018) Max H Farrell, Tengyuan Liang, and Sanjog Misra. Deep neural networks for estimation and inference. arXiv preprint arXiv:1809.09953, 2018.
- Fefferman and Markel (1994) Charles Fefferman and Scott Markel. Recovering a feed-forward net from its output. In Advances in Neural Information Processing Systems, pages 335–342, 1994.
- Feng and Simon (2017) Jean Feng and Noah Simon. Sparse-input neural networks for high-dimensional nonparametric regression and classification. arXiv preprint arXiv:1711.07592, 2017.
- Horel and Giesecke (2019) Enguerrand Horel and Kay Giesecke. Towards Explainable AI: Significance tests for neural networks. arXiv preprint arXiv:1902.06021, 2019.
- Ibrahim et al. (2014) Rania Ibrahim, Noha A Yousri, Mohamed A Ismail, and Nagwa M El-Makky. Multi-level gene/MiRNA feature selection using deep belief nets and active learning. In 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, pages 3957–3960. IEEE, 2014.
- Ji et al. (1992) Shanyu Ji, János Kollár, and Bernard Shiffman. A global Lojasiewicz inequality for algebraic varieties. Transactions of the American Mathematical Society, 329(2):813–818, 1992.
- Lemhadri et al. (2019) Ismael Lemhadri, Feng Ruan, and Robert Tibshirani. A neural network with feature sparsity. arXiv preprint arXiv:1907.12207, 2019.
- Li et al. (2016) Yifeng Li, Chih-Yu Chen, and Wyeth W Wasserman. Deep feature selection: theory and application to identify enhancers and promoters. Journal of Computational Biology, 23(5):322–336, 2016.
- Liang et al. (2018) Faming Liang, Qizhai Li, and Lei Zhou. Bayesian neural networks for selection of drug sensitive genes. Journal of the American Statistical Association, 113(523):955–972, 2018.
- Liu (2019) Jeremiah Zhe Liu. Variable selection with rigorous uncertainty quantification using deep bayesian neural networks: Posterior concentration and bernstein-von mises phenomenon. arXiv preprint arXiv:1912.01189, 2019.
- Lu et al. (2018) Yang Lu, Yingying Fan, Jinchi Lv, and William Stafford Noble. DeepPINK: reproducible feature selection in deep neural networks. In Advances in Neural Information Processing Systems, pages 8676–8686, 2018.
- Lundberg and Lee (2017) Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, pages 4765–4774, 2017.
- Meinshausen and Bühlmann (2006) Nicolai Meinshausen and Peter Bühlmann. High-dimensional graphs and variable selection with the Lasso. The Annals of Statistics, 34(3):1436–1462, 2006.
- Meinshausen and Yu (2009) Nicolai Meinshausen and Bin Yu. Lasso-type recovery of sparse representations for high-dimensional data. The Annals of Statistics, 37(1):246–270, 2009.
- Nezhad et al. (2016) Milad Zafar Nezhad, Dongxiao Zhu, Xiangrui Li, Kai Yang, and Phillip Levy. SAFS: A deep feature selection approach for precision medicine. In 2016 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 501–506. IEEE, 2016.
- Polson and Ročková (2018) Nicholas G Polson and Veronika Ročková. Posterior concentration for sparse deep learning. In Advances in Neural Information Processing Systems, pages 930–941, 2018.
- Ribeiro et al. (2016) Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data mining, pages 1135–1144, 2016.
- Scardapane et al. (2017) Simone Scardapane, Danilo Comminiello, Amir Hussain, and Aurelio Uncini. Group sparse regularization for deep neural networks. Neurocomputing, 241:81–89, 2017.
- Shen et al. (2019) Xiaoxi Shen, Chang Jiang, Lyudmila Sakhanenko, and Qing Lu. Asymptotic properties of neural network sieve estimators. arXiv preprint arXiv:1906.00875, 2019.
- Shrikumar et al. (2017) Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 3145–3153, 2017.
- Simonyan et al. (2013) Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013.
- Taherkhani et al. (2018) Aboozar Taherkhani, Georgina Cosma, and T Martin McGinnity. Deep-FS: A feature selection algorithm for Deep Boltzmann Machines. Neurocomputing, 322:22–37, 2018.
- Tank et al. (2018) Alex Tank, Ian Covert, Nicholas Foti, Ali Shojaie, and Emily Fox. Neural Granger causality for nonlinear time series. arXiv preprint arXiv:1802.05842, 2018.
- Wang and Leng (2008) Hansheng Wang and Chenlei Leng. A note on Adaptive Group Lasso. Computational Statistics & Data Analysis, 52(12):5277–5286, 2008.
- Ye and Sun (2018) Mao Ye and Yan Sun. Variable selection via penalized neural network: a drop-out-one loss approach. In International Conference on Machine Learning, pages 5620–5629, 2018.
- Zhang et al. (2018) Cheng Zhang, Vu Dinh, and Frederick A Matsen IV. Non-bifurcating phylogenetic tree inference via the Adaptive Lasso. Journal of the American Statistical Association. arXiv preprint arXiv:1805.11073, 2018.
- Zhang and Huang (2008) Cun-Hui Zhang and Jian Huang. The sparsity and bias of the Lasso selection in high-dimensional linear regression. The Annals of Statistics, 36(4):1567–1594, 2008.
- Zhang et al. (2019) Huaqing Zhang, Jian Wang, Zhanquan Sun, Jacek M Zurada, and Nikhil R Pal. Feature selection for neural networks using Group Lasso regularization. IEEE Transactions on Knowledge and Data Engineering, 2019.
- Zhao et al. (2015) Lei Zhao, Qinghua Hu, and Wenwu Wang. Heterogeneous feature selection with multi-modal deep neural networks and Sparse Group Lasso. IEEE Transactions on Multimedia, 17(11):1936–1948, 2015.
- Zhao and Yu (2006) Peng Zhao and Bin Yu. On model selection consistency of Lasso. Journal of Machine learning Research, 7(Nov):2541–2563, 2006.
- Zou (2006) Hui Zou. The Adaptive Lasso and its oracle properties. Journal of the American Statistical Association, 101(476):1418–1429, 2006.
5 Appendix
5.1 Details of the proof of Theorem 3.4
In the first part of the proof of Theorem 3.4, we established that
Using Young’s inequality, we have
Combining the two estimates, we have
5.2 Proof of Corollary 3.5
5.3 Probabilistic Lipschitzness of the empirical risk
Since both and are bounded and is analytic, there exist such that
Therefore,
Similarly,
Thus, for all ,
5.4 Proof of Lemma 3.3
The proof of this Lemma is similar to that of Lemma 4.2 in Dinh and Ho [2020]. Since the network of our framework is fixed, a standard generalization bound (with constants depending on the dimension of the weight space ) can be obtained. For completeness, we include the proof of Lemma 4.2 in Dinh and Ho [2020] below.
Note that follows a non-central chi-squared distribution with degrees of freedom and is bounded. By applying Theorem 7 in Zhang and Zhou (2018) 333Zhang, Anru and Yuchen Zhou. ”On the non-asymptotic and sharp lower tail bounds of random variables.” arXiv preprint arXiv:1810.09006 (2018)., we have
for all
We define the events
and
Let , there exist and a finite set such that
where , denotes the open ball centered at with radius , and denotes the cardinality of . By a union bound, we have
Using the fact that , we deduce
Hence,
To complete the proof, we chose in such a way that . This can be done by choosing .