mystyle1TABLE \captiontext \captionstylemystyle1 \newcaptionstylemystyle2\captionlabel. \captiontext \captionstylemystyle2 \newcaptionstylemystyle3\captionlabel. \captiontext \captionstylemystyle3
Content Popularity Prediction in Fog-RANs: A Clustered Federated Learning Based Approach
Abstract
In this paper, the content popularity prediction problem in fog radio access networks (F-RANs) is investigated. Based on clustered federated learning, we propose a novel mobility-aware popularity prediction policy, which integrates content popularities in terms of local users and mobile users. For local users, the content popularity is predicted by learning the hidden representations of local users and contents. Initial features of local users and contents are generated by incorporating neighbor information with self information. Then, dual-channel neural network (DCNN) model is introduced to learn the hidden representations by producing deep latent features from initial features. For mobile users, the content popularity is predicted via user preference learning. In order to distinguish regional variations of content popularity, clustered federated learning (CFL) is employed, which enables fog access points (F-APs) with similar regional types to benefit from one another and provides a more specialized DCNN model for each F-AP. Simulation results show that our proposed policy achieves significant performance improvement over the traditional policies.
Index Terms:
F-RANs, popularity prediction, clustered federated learning, user preference, mobility-aware.I Introduction
With the unprecedented growth of smart devices and mobile application services, tremendous number of problems emerge in wireless networks, especially the congestion caused by the notable data traffic pressure on capacity-limited backhaul links. Fog radio access network (F-RAN) has been introduced as a promising architecture to alleviate the traffic burden on backhaul links via densely deployed fog access points (F-APs) at network edges [1]. F-APs can cache popular contents to satisfy user requests [2]. As a consequence of constrained caching capacity and computing resources, F-APs need to predict the future content popularity to decide which content to prefetch for the purpose of improving caching efficiency [3].
Continuous research efforts have been devoted to predicting content popularity. Except for the traditional methods such as least recently used (LRU) and least frequently used (LFU), machine learning has emerged as the most popular approach to predict content popularity. In [4], an online content popularity prediction was proposed to track the popularity in time by leveraging the content features and user preference. In [5], a content classifier was constructed and content popularity was predicted through training a simplified bidirectional long short-term memory (Bi-LSTM) network for every content class. In [6], the authors proposed a popularity prediction policy based on federated learning (FL) by leveraging user preference in adaptively partitioned context spaces. In [7], the authors utilized Bayesian learning to get the content request pattern modeled by a Gaussian process based Poisson regressor. In [8], a proactive content caching scheme based on FL was proposed to ensure the privacy of user data. In [9], user request behavior was modeled by probabilistic latent semantic analysis (pLSA) to predict content popularity. However, user mobility is neglected in these existing works except for [4] and [5]. In [5] and [6], the edge caching scenario is considered in a specific region, where all F-APs are thought to have the same content popularity. Confronted with the incongruent data distributions of F-APs with different regional types, a single popularity prediction model for all F-APs can hardly achieve satisfactory performance. Moreover, most works ignore the hidden representations of users and contents which contribute to predicting content popularity.
Motivated by the aforementioned discussions, we propose a mobility-aware popularity prediction policy based on clustered federated learning (CFL). On one hand, the content popularity in terms of local users is predicted by utilizing a dual-channel nerual network (DCNN) model. The DCNN model of each F-AP is learned automatically with historical request records and the initial features of local users and contents constructed by neighbor selection. Moreover, CFL is employed to provide a more specialized model for each F-AP. On the other hand, the content popularity in terms of mobile users is predicted via user preference learning. Finally, the content popularities in terms of both local users and mobile users are integrated.
The rest of this paper is organized as follows. In Section II, the system model is presented. The proposed popularity prediction policy is described in Section III. Simulation results are shown in Section IV. Final conclusions are drawn in Section V.
II System Model
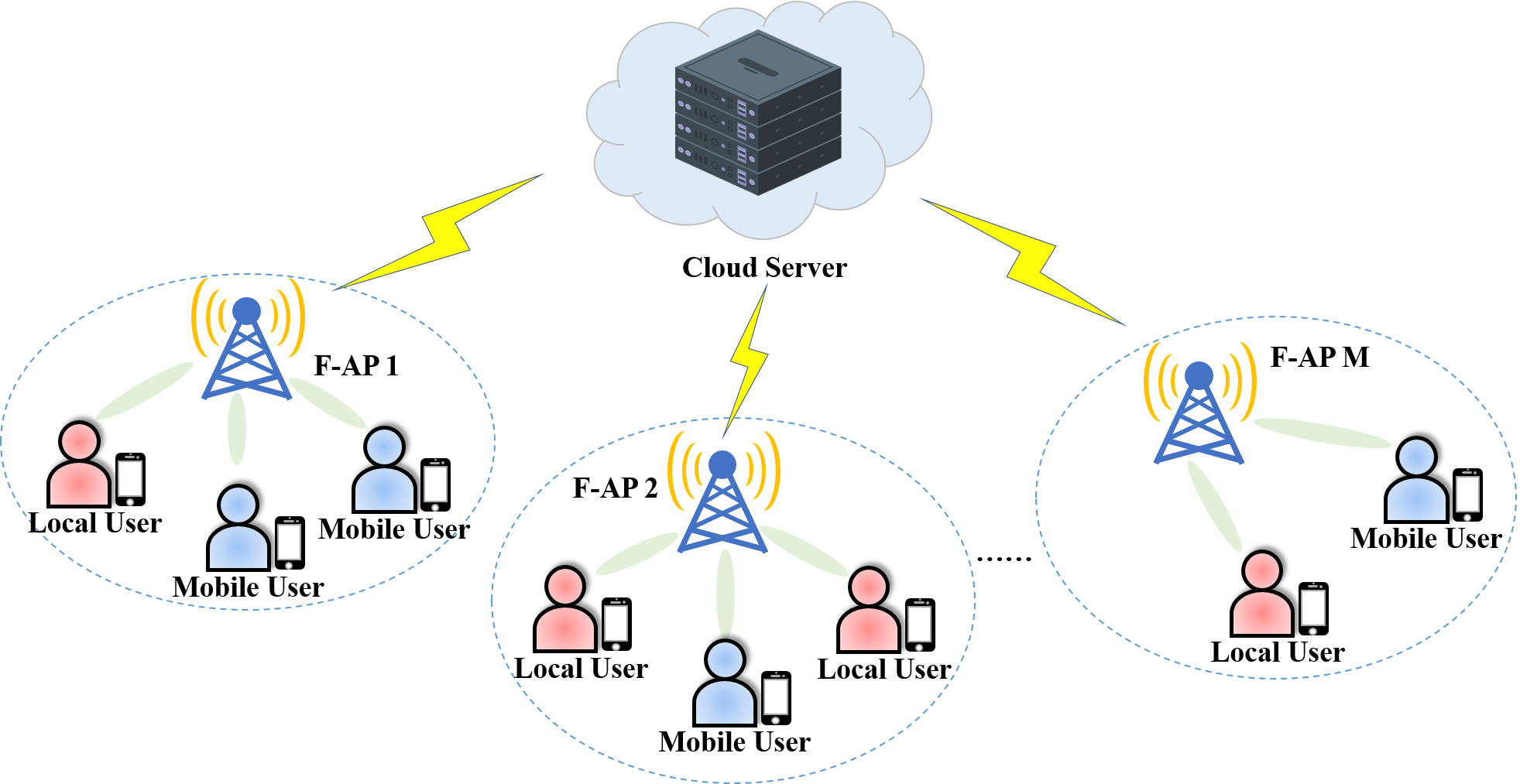
As illustrated in Fig. 1, the edge caching scenario is considered with F-APs and numerous users. Let denote the set of F-APs. It is assumed that each F-AP can serve users within its own coverage area by fetching contents from its storage-limited local cache [10]. We assume that according to user mobility, users can be categorized into two types: local users and mobile users [11]. Every local user is associated with a specific F-AP and will not move to any other F-AP within the considered time period in the future, whereas mobile users may randomly visit a certain F-AP at some moment and then keep associated with the F-AP until leaving its coverage area. Let denote the set of local users associated with F-AP , and the set of mobile users. Each F-AP continuously monitors mobile users in its coverage area. Without loss of generality, we assume that all the F-APs have the same storage space which can cache up to contents from the content library [12]. If a user requests content which has been stored in its associated F-AP, the user can fetch it from the local cache of the F-AP and a cache hit event occurs. Otherwise, the F-AP needs to fetch the content from the cloud server or its neighboring F-APs [13].
Content popularity prediction in a given F-AP should consider both local users and mobile users. On one hand, content popularity in terms of local users (referred to as local popularity) varies in F-APs with different regional types. Therefore, a more specialized model for each F-AP to predict local popularity is required. On the other hand, content popularity in terms of mobile users (referred to as mobile popularity) changes continuously due to user mobility [14]. In addition, F-APs cannot access user information and historical request records of mobile users due to privacy reasons. Therefore, user preference learning is required to be implemented independently by each mobile user to predict mobile popularity. Since the request probability of users reveals the level of acceptability of contents, we define the content popularity in a given F-AP as the average request probability of the users currently associated with the F-AP [15].
Let denote the real number of requests of content in F-AP , the total number of requests in F-AP , and the cache status of content in F-AP . if content is stored in F-AP , and otherwise. The cache hit rate of F-AP is defined as the ratio of the number of cache hits to the total requests, and is utilized to evaluate the caching performance, which can be expressed as follows:
| (1) |
With the content popularity in each F-AP determined, each F-AP can cache the most popular contents in its storage space.
This paper aims to find a content popularity prediction policy with a high accuracy to maximize the cache hit rate in every F-AP considering both user mobility and regional variations of content popularity.
III Proposed Clustered Federated Learning Based Popularity Prediction Policy
In this section, we propose a CFL based content popularity prediction policy, including local popularity prediction, mobile popularity prediction and popularity integration. The proposed policy utilizes user features and content features, and can accurately predict and dynamically update the content popularity with low communication overhead.
III-A Policy Description
1) Local popularity prediction: The content request pattern reflects the user-content interaction, and the hidden representations of users and contents are responsible for the interaction [16]. In order to learn the hidden representations of local users and contents which are helpful to capture user-content interaction, DCNN model is introduced to produce deep latent features of local users and contents from initial features constructed by neighbor selection. Then, the request probability can be predicted by merging the deep latent features of local users and contents. To distinguish regional variations of local popularity, CFL is employed to specialize the model parameters of DCNN of each F-AP by grouping F-APs with similar regional types into the same cluster. Bandwidth resource can also be saved because only model parameters need to be transmitted in CFL. The local popularity in each F-AP is the integration of the predicted request probability and the activity levels of local users.
2) Mobile popularity prediction: Due to the random mobility of mobile users as well as privacy reasons, in order to predict the mobile popularity in a given F-AP, user preference learning is implemented independently by each mobile user in an offline manner. With all the currently associated mobile users sending the request probability predicted via user preference and content information, mobile popularity of contents in a given F-AP can be obtained.
3) Popularity integration: The content popularity in a given F-AP can be obtained by integrating the content popularities in terms of local users and mobile users. By monitoring the request records of local users as well as the user mobility of mobile users, the content popularity can be dynamically updated to maximize the cache hit rate.
III-B Local Popularity Prediction
The procedure of local popularity prediction consists of the following three steps: neighbor selection based feature construction, DCNN model construction and CFL based model specialization.
1) Neighbor selection based feature construction: To construct initial features of local users or contents, it is meaningful to take the information of users with similar preference or the information of contents requested by similar users into account [17]. For example, if a user prefers to movies which are favored mostly by teenagers, then the user’s feature may be relevant to the information of teenagers. Therefore, we adopt a similarity computation method enhanced by inverse request frequency of users (IRFU) and inverse request frequency of contents (IRFC) to select neighbor set [18].
Based on Euclidean distance, the similarity between two local users enhanced by IRFU can be computed by the rating of contents they both have requested according to [18]. Defined as the logarithmic transformation of the ratio of the total users to the users who have requested a certain content, IRFU reflects the discrimination of contents when computing the similarity between two local users. By utilizing IRFC of users, the similarity between two contents in a given F-AP can be computed analogously. Given similarities within the scope of a given F-AP , the neighbor set of and of content are selected from the top most similar neighbors respectively.
In order to incorporate neighbor information with self information, we propose to generate initial features via information integration. Let and denote the information vectors of user and content respectively, where is the dimension of user information space and is the dimension of content information space. The initial feature vector of user is computed as the weighted sum of the self information vector and the average information vector of neighbor set:
| (2) |
where denotes the weight factor of self information in initial features. The initial feature vector of content in F-AP is computed in a similar way:
| (3) |
2) DCNN model construction: Given initial features of local users and contents, a DCNN model is leveraged to learn the hidden representations by producing deep latent features in a given F-AP. Motivated by [19], two feature transforming functions are constructed in DCNN to produce deep latent features of local users and contents respectively. Let and denote the feature transforming functions for local users and contents respectively. The deep latent features of local user and content in F-AP can be computed as and , where and denote the parameters of the feature transforming functions in F-AP . Let denote the request probability of local user for content . Then, it can be predicted by the inner product of the deep latent features as follows:
| (4) |
We introduce the multilayer perceptron (MLP) as the feature transforming function in DCNN model, which is effective to learn the hidden representaions between input and output. Compared with the latent features generated from the observed request data [9], deep latent features generated from initial features contain the hidden representations, which contributes to capturing the user-content interaction.
Let denote the set of training samples of F-AP , where is the binary request label. if local user has requested content , otherwise . The binary cross entropy (BCE) loss is utilized as the loss function for the optimization of parameters, which can be expressed as follows:
| (5) |
The DCNN model is trained by adjusting the parameters and through Adam optimizer with learning rate decaying.
As the predicted request probability above is essentially the probability conditional on a sended request, it is necessary to take user activity level into account [20]. The activity level of local user (i.e., the probability that local user sends a request) is defined as , where is the number of requests of local user . According to the theory of total probability, local popularity of content in F-AP can be expressed as:
| (6) |
3) CFL based model specialization: With training data stored in F-APs in a distributed manner, computational tasks for training a single global model can be distributed from the cloud server to F-APs via conventional FL [21]. Moreover, only model parameters need to be transmitted to the cloud server instead of all the training data, resulting in tremendous bandwidth resource savings. However, due to the diverse regional types of F-APs, local popularity in different F-APs varies. For example, users served by F-APs located near stadium are more likely to request contents related with sports, while users located at school tend to request educational contents. In this situation, only one single global model obtained from conventional FL can hardly predict local popularity accurately, as all the F-APs with incongruent data distributions are treated equally.
In order to solve the aforementioned problem with incongruent data distributions, CFL is adopted [22]. CFL not only retains the advantage of saving bandwidth resource, but also adaptively splits up F-APs with incongruent data distributions into separated clusters without the prior knowledge of cluster number. Thus, F-APs with similar regional types (i.e., similar data distributions) can benefit from one another’s training data in the same cluster, arriving at more specialized models with a higher accuracy.
Let denote the final clustering result generated by CFL, where is a cluster containing at least one F-AP. The clustering result can be obtained after valid bipartitions. Let denote the parameter of DCNN model. CFL will recursively split up F-APs and optimize model parameters in a top-down way. In the beginning, CFL is applied in the initial set of F-APs with initial model parameter . Then, CFL will perform FL according to Algorithm 1 with , where is the coefficient of FL stopping criteria.
After FL has converged, the FL solution of can be obtained. Then, the following clustering criteria is evaluated:
| (7) |
where is the coefficient of the clustering criteria. If the clustering criteria is satisfied in , all F-APs are thought to be sufficiently close to their optimal model parameters. CFL terminates and will serve as the solution for every F-AP in . If not satisfied, F-APs in are thought to be incongruent and the pairwise cosine similarity will be computed in by utilizing F-APs’ model weight updates:
| (8) |
Given the pairwise similarity, the cloud server will split up the F-APs in into two sub-clusters by minimizing the maximum similarity between F-APs from different sub-clusters:
| (9) |
Then, F-APs will aggregate their model parameters within the newly seperated clusters by averaging their model weight updates. Let denote the cluster containing F-AP . Then, the aggregation operation can be expressed as:
| (10) |
If any F-AP has not converged to its optimal model parameter, CFL will be recursively reapplied in each of the two sub-clusters based on their own updated model parameters and seperately. When none of the sub-clusters violates the clustering criteria in (7), all clusters of the congruent F-APs have been identified, and each F-AP will obtain a more specialized DCNN model with a higher accuracy. The detailed procedure of CFL based model specialization is presented in Algorithm 2.
III-C Mobile Popularity Prediction
Corresponding to the content information vector , let denote the user preference vector of mobile user , which represents the preference for different content information. The learning process of user preference will be carried out independently by mobile users.
For mobile user , the set of training samples is extracted from its local request records, where is the binary request label. if mobile user has requested content , otherwise . Let denote the probability that mobile user has requested content , which can be predicted based on content information and user preference as follows:
| (11) |
Given the predicted , the negative log-likelihood of is formulated as follows:
| (12) |
The “Follow The (Proximally) Regularized Leader”(FTRL-Proximal) algorithm is adopted to obtain the user preference of mobile users by minimizing in an offline manner [4], and the user preference will be periodically updated when exceeds a certain threshold.
Due to privacy reasons, F-APs cannot access historical request records of mobile users. Without loss of generality, we assume the activity levels of mobile users in an F-AP are the same. Let denote the set of mobile users currently associated with F-AP . All the currently associated mobile users only need to send the predicted request probability to the F-AP, which also contributes to the saving of bandwidth resource. Then, the predicted mobile popularity of content in F-AP can be computed as the average request probability of the currently associated mobile users:
| (13) |
III-D Popularity integration
In order to eliminate the differences between local popularity and mobile popularity, local popularity and mobile popularity of all the contents will be normalized respectively in each F-AP as follows: and . Then, the predicted popularity of content in F-AP can be calculated to be:
| (14) |
where is defined as the ratio of the currently associated mobile users to the total users in F-AP for the purpose of tackling the varying number of mobile users caused by user mobility. By the integration of local and mobile popularities, both user mobility and regional variations of content popularity are properly considered in our proposed content popularity prediction policy.
According to the above descriptions, the proposed popularity prediction policy not only dynamically updates the predicted content popularity by monitoring the request records of local users as well as the user mobility of mobile users, but also significantly reduces communication overhead.
IV Simulation Results
To evaluate the performance of the proposed popularity prediction policy, simulations are performed based on data extracted from the MovieLens 1M Dataset [23]. The dataset contains 1,000,209 ratings for approximately 3,900 movies created by 6,040 users. For each item, a user ID, a movie ID, a rating from 1 to 5 and a timestamp are included. Each record is regarded as a request of user for content. Demographic information of users is provided in the dataset, which includes gender, age, occupation and Zip-code. By utilizing one-hot encoding, the information of gender, age and occupation is transformed to a binary vector, which can serve as the user information. Furthermore, the provided genres of movies can be used as content information. In our simulations, we set the number of F-APs to 10, the size of neighbor set to 20 and the weight factor of self information to 0.5, respectively. Without considering mobile popularity, policies based on DCNN model obtained by CFL (DCNN-CFL), FL (DCNN-FL) and local learning (DCNN-LC), as well as the pLSA based policy [9], LFU and LRU are chosen as the benchmark policies.
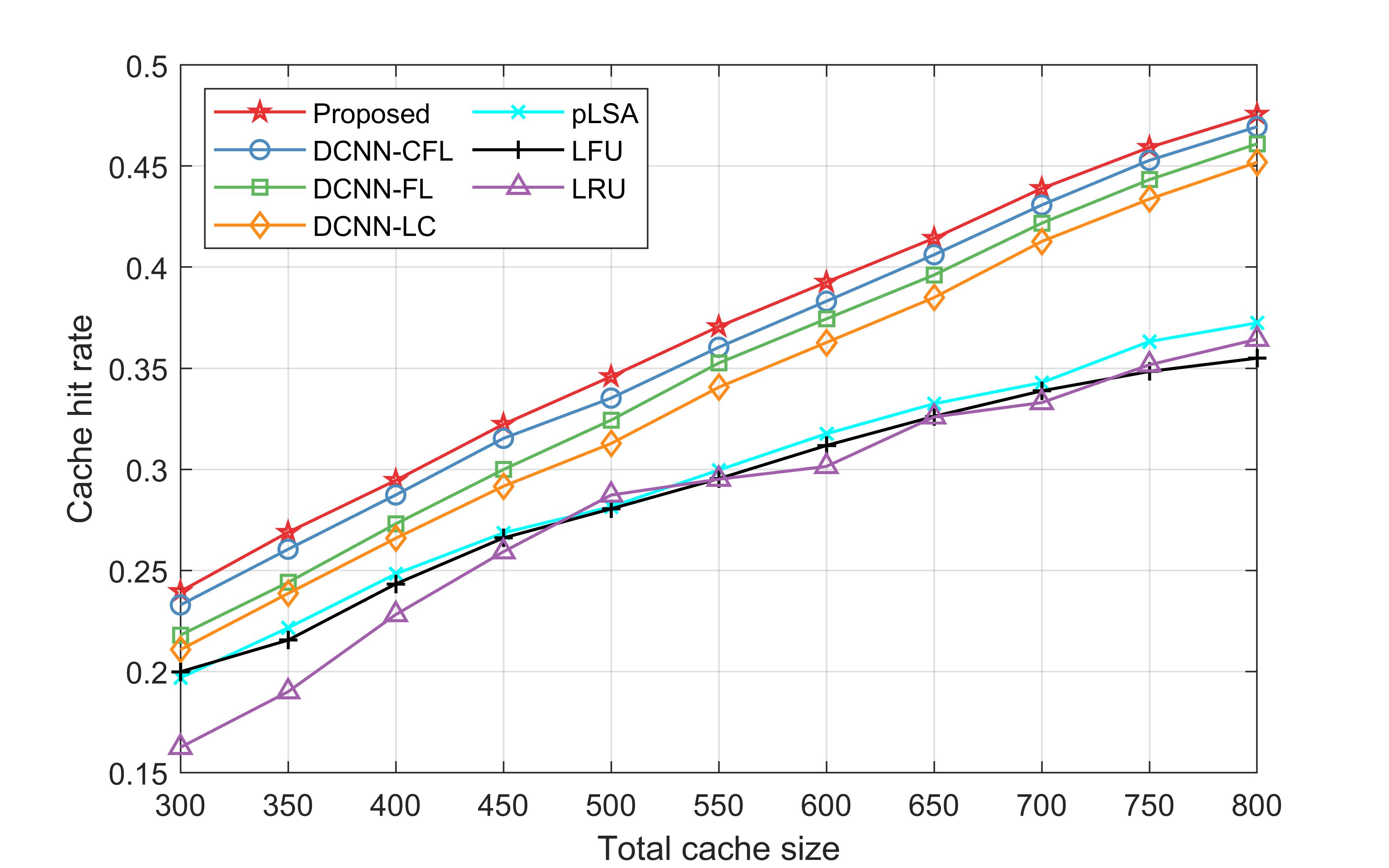
In Fig. 2, we show the cache hit rates of our proposed policy and the benchmark policies versus the total cache size with 25% mobile users in each F-AP. It can be observed that the cache hit rates of our proposed policy and the DCNN model based policies are larger than those of the other benchmark policies. The reason is that through DCNN model, the hidden representations are learned by producing deep latent features from initial features, which are helpful to capture user-content interaction. Furthermore, neighbor information is taken into consideration to generate initial features. Whereas the pLSA based policy extracts latent features merely through historical request records via a probabilistic method, and LFU and LRU can hardly achieve satisfactory performance due to the neglect of content popularity.
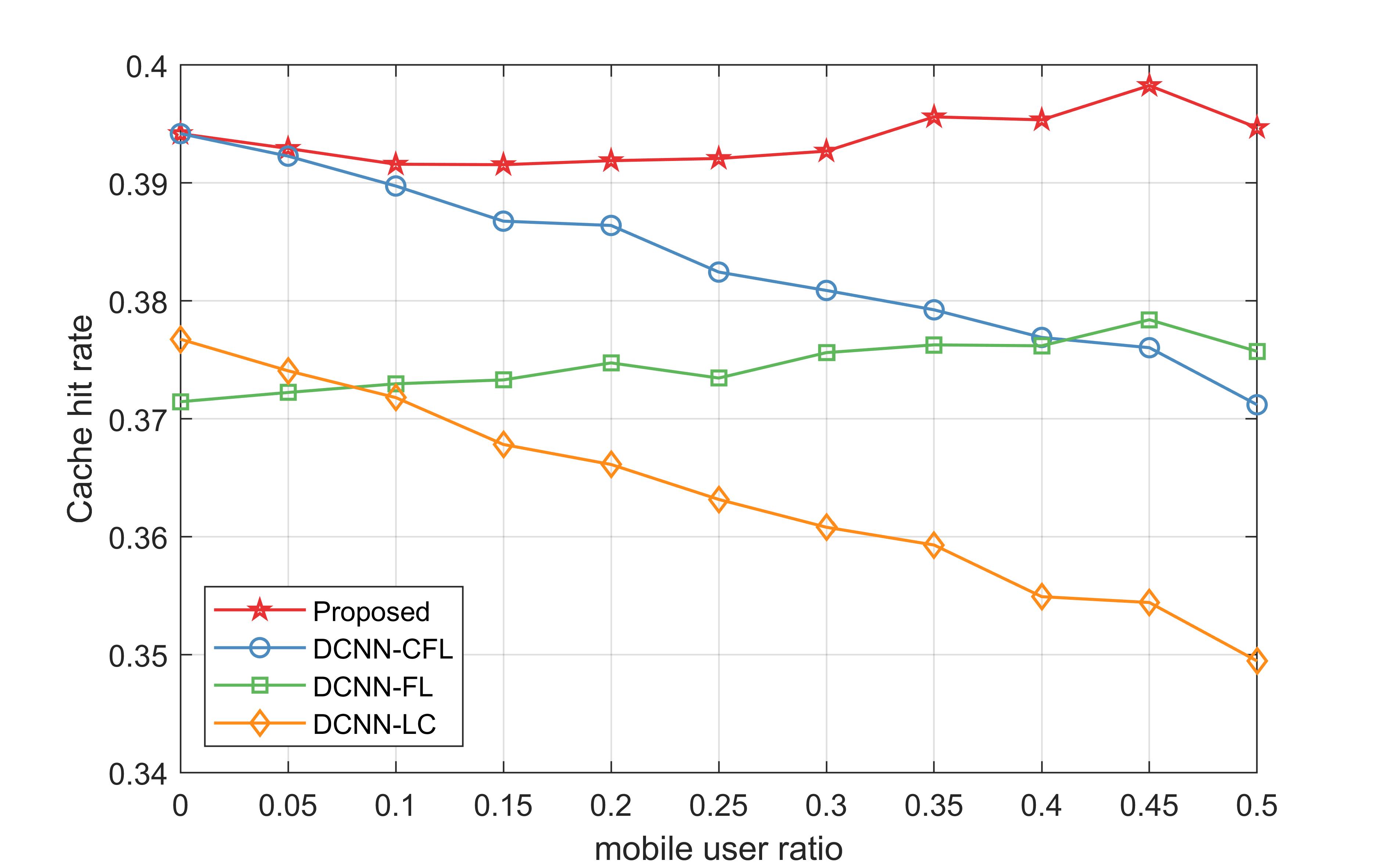
In Fig. 3, we show the cache hit rates of our proposed policy and the DCNN model based policies versus the mobile user ratio for a total cache size of 600. It can be observed that without any mobile users in F-APs, the proposed policy (i.e., DCNN-CFL) outperforms the other two policies. The reason is that our proposed policy enables F-APs with similar regional types (i.e., with similar data distributions) to benefit from one another while predicting local popularity. DCNN-FL has the worst performance when no mobile users in F-APs, as all the F-APs with incongruent data distributions are treated equally by training one single global model. It can also be observed that as the mobile user ratio increases, our proposed policy and DCNN-FL maintain their original preformance level with little fluctuation, whereas the other two policies suffer from a performance degradation. The reason is that our proposed policy predicts content popularity by integrating mobile popularity which is updated dynamically according to the mobility and the preference of mobile users. The content popularity predicted by DCNN-FL is more general and is adaptive to the request of mobile users, leveraging a global model obtained by FL. Moreover, the cache hit rate of our proposed policy is larger than that of DCNN-FL for all mobile user ratios. The reason is that our proposed policy predicts content popularity by integrating both local and mobile popularities.
V Conclusions
In this paper, we have proposed a novel mobility-aware popularity prediction policy based on CFL in F-RANs. Our proposed policy can accurately predict and dynamically update content popularity even when users move randomly among F-APs. The reason is that mobile popularity is considered by utilizing user preference learning. Specifically, we have proposed to utilize CFL to enable F-APs with similar regional types to benefit from one another, which provides a more specialized model with a higher accuracy for each F-AP and significantly reduces communication overhead. Simulation results have shown that our proposed policy outperforms benchmark policies in terms of cache hit rate.
Acknowledgments
This work was supported in part by the National Key Research and Development Program under Grant 2021YFB2900300, the National Natural Science Foundation of China under grant 61971129, and the Shenzhen Science and Technology Program under Grant KQTD20190929172545139.
References
- [1] E. Zeydan, E. Bastug, M. Bennis, M. A. Kader, I. A. Karatepe, A. S. Er, and M. Debbah, “Big data caching for networking: Moving from cloud to edge,” IEEE Communications Magazine, vol. 54, no. 9, pp. 36–42, Sept. 2016.
- [2] Y. Hu, Y. Jiang, M. Bennis, and F.-C. Zheng, “Distributed edge caching in ultra-dense fog radio access networks: A mean field approach,” in 2018 IEEE 88th Vehicular Technology Conference (VTC-Fall), Aug. 2018, pp. 1–6.
- [3] S. M. S. Tanzil, W. Hoiles, and V. Krishnamurthy, “Adaptive scheme for caching youtube content in a cellular network: Machine learning approach,” IEEE Access, vol. 5, pp. 5870–5881, Mar. 2017.
- [4] Y. Jiang, M. Ma, M. Bennis, F. Zheng, and X. You, “User preference learning-based edge caching for fog radio access network,” IEEE Transactions on Communications, vol. 67, no. 2, pp. 1268–1283, Feb. 2019.
- [5] H. Feng, Y. Jiang, D. Niyato, F.-C. Zheng, and X. You, “Content popularity prediction via deep learning in cache-enabled fog radio access networks,” in 2019 IEEE Global Communications Conference (GLOBECOM), Dec. 2019, pp. 1–6.
- [6] Y. Wu, Y. Jiang, M. Bennis, F. Zheng, X. Gao, and X. You, “Content popularity prediction in fog radio access networks: A federated learning based approach,” in 2020 IEEE International Conference on Communications (ICC), Jun. 2020, pp. 1–6.
- [7] Y. Tao, Y. Jiang, F. Zheng, M. Bennis, and X. You, “Content popularity prediction in fog-rans: A bayesian learning approach,” in 2021 IEEE Global Communications Conference (GLOBECOM), Dec. 2021, pp. 1–6.
- [8] Z. Yu, J. Hu, G. Min, H. Lu, Z. Zhao, H. Wang, and N. Georgalas, “Federated learning based proactive content caching in edge computing,” in 2018 IEEE Global Communications Conference (GLOBECOM), Dec. 2018, pp. 1–6.
- [9] B. Chen and C. Yang, “Caching policy for cache-enabled D2D communications by learning user preference,” IEEE Transactions on Communications, vol. 66, no. 12, pp. 6586–6601, Dec. 2018.
- [10] A. Peng, Y. Jiang, M. Bennis, F.-C. Zheng, and X. You, “Performance analysis and caching design in fog radio access networks,” in 2018 IEEE Globecom Workshops (GC Wkshps), Dec. 2018, pp. 1–6.
- [11] M. Balazinska and P. Castro, “Characterizing mobility and network usage in a corporate wireless local-area network,” in Proceedings of the 1st international conference on Mobile systems, applications and services, Jan. 2003, pp. 303–316.
- [12] Y. Jiang, X. Cui, M. Bennis, F.-C. Zheng, B. Fan, and X. You, “Cooperative caching in fog radio access networks: a graph-based approach,” IET Communications, vol. 13, no. 20, pp. 3519–3528, Nov. 2019.
- [13] Y. Jiang, A. Peng, C. Wan, Y. Cui, X. You, F.-C. Zheng, and S. Jin, “Analysis and optimization of cache-enabled fog radio access networks: Successful transmission probability, fractional offloaded traffic and delay,” IEEE Transactions on Vehicular Technology, vol. 69, no. 5, pp. 5219–5231, May 2020.
- [14] Y. Jiang, H. Feng, F.-C. Zheng, D. Niyato, and X. You, “Deep learning-based edge caching in fog radio access networks,” IEEE Transactions on Wireless Communications, vol. 19, no. 12, pp. 8442–8454, Dec. 2020.
- [15] L. Lu, Y. Jiang, M. Bennis, Z. Ding, F.-C. Zheng, and X. You, “Distributed edge caching via reinforcement learning in fog radio access networks,” in 2019 IEEE 89th Vehicular Technology Conference (VTC2019-Spring), Apr. 2019, pp. 1–6.
- [16] S. Rathore, J. H. Ryu, P. K. Sharma, and J. H. Park, “Deepcachnet: A proactive caching framework based on deep learning in cellular networks,” IEEE Network, vol. 33, no. 3, pp. 130–138, May/Jun. 2019.
- [17] Y. Yin, A. Song, G. Min, Y. Xu, and S. Wang, “QoS prediction for web service recommendation with network location-aware neighbor selection,” International Journal of Software Engineering and Knowledge Engineering, vol. 26, no. 4, pp. 611–632, May 2016.
- [18] Y. Yin, L. Chen, Y. Xu, J. Wan, and Z. Mai, “QoS prediction for service recommendation with deep feature learning in edge computing environment,” Mobile Networks and Applications, pp. 391–401, Apr. 2019.
- [19] B. Yi, X. Shen, H. Liu, Z. Zhang, W. Zhang, S. Liu, and N. Xiong, “Deep matrix factorization with implicit feedback embedding for recommendation system,” IEEE Transactions on Industrial Informatics, vol. 15, no. 8, pp. 4591–4601, Aug. 2019.
- [20] D. Liu and C. Yang, “Caching at base stations with heterogeneous user demands and spatial locality,” IEEE Transactions on Communications, vol. 67, no. 2, pp. 1554–1569, Feb. 2019.
- [21] M. Chen, Z. Yang, W. Saad, C. Yin, H. V. Poor, and S. Cui, “A joint learning and communications framework for federated learning over wireless networks,” IEEE Transactions on Wireless Communications, vol. 20, no. 1, pp. 269–283, Jan. 2021.
- [22] F. Sattler, K.-R. Müller, and W. Samek, “Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 8, pp. 3710–3722, Aug. 2021.
- [23] F. M. Harper and J. A. Konstan, “The movielens datasets: History and context,” ACM Transactions on Interactive Intelligent Systems, vol. 5, no. 4, pp. 1–19, Dec. 2015.