Context-Aware Multi-Task Learning for
Traffic Scene Recognition in Autonomous Vehicles
Abstract
Traffic scene recognition, which requires various visual classification tasks, is a critical ingredient in autonomous vehicles. However, most existing approaches treat each relevant task independently from one another, never considering the entire system as a whole. Because of this, they are limited to utilizing a task-specific set of features for all possible tasks of inference-time, which ignores the capability to leverage common task-invariant contextual knowledge for the task at hand. To address this problem, we propose an algorithm to jointly learn the task-specific and shared representations by adopting a multi-task learning network. Specifically, we present a lower bound for the mutual information constraint between shared feature embedding and input that is considered to be able to extract common contextual information across tasks while preserving essential information of each task jointly. The learned representations capture richer contextual information without additional task-specific network. Extensive experiments on the large-scale dataset HSD demonstrate the effectiveness and superiority of our network over state-of-the-art methods.
I INTRODUCTION
Traffic scene recognition from input images is one of the fundamental technologies for Automated Driving Systems (ADS) and Advanced Driver Assistance Systems (ADAS) applications, including object modeling [1], semantic segmentation [2], object recognition [3, 4, 5], localization and mapping [6, 7, 8], etc. It is perceived as an essential key-step towards understanding traffic scenes and serves to eliminate the gap between resulting performance and visual reasoning capability of human beings. Unlike the previous works which typically optimize a single objective function, it is not merely a general classification problem since what we are dealing with here is multi-objective optimization. For example, traffic scenes contain diverse scene attributes, such as road place, weather, road surface, and road environment. Also, the bottom-level of the road place consists of how they are annotated to temporal action labels inside its place. Thus, a prominent challenge in traffic scene recognition is to make a model that can operate with online frame-wise inference despite multiple tasks.
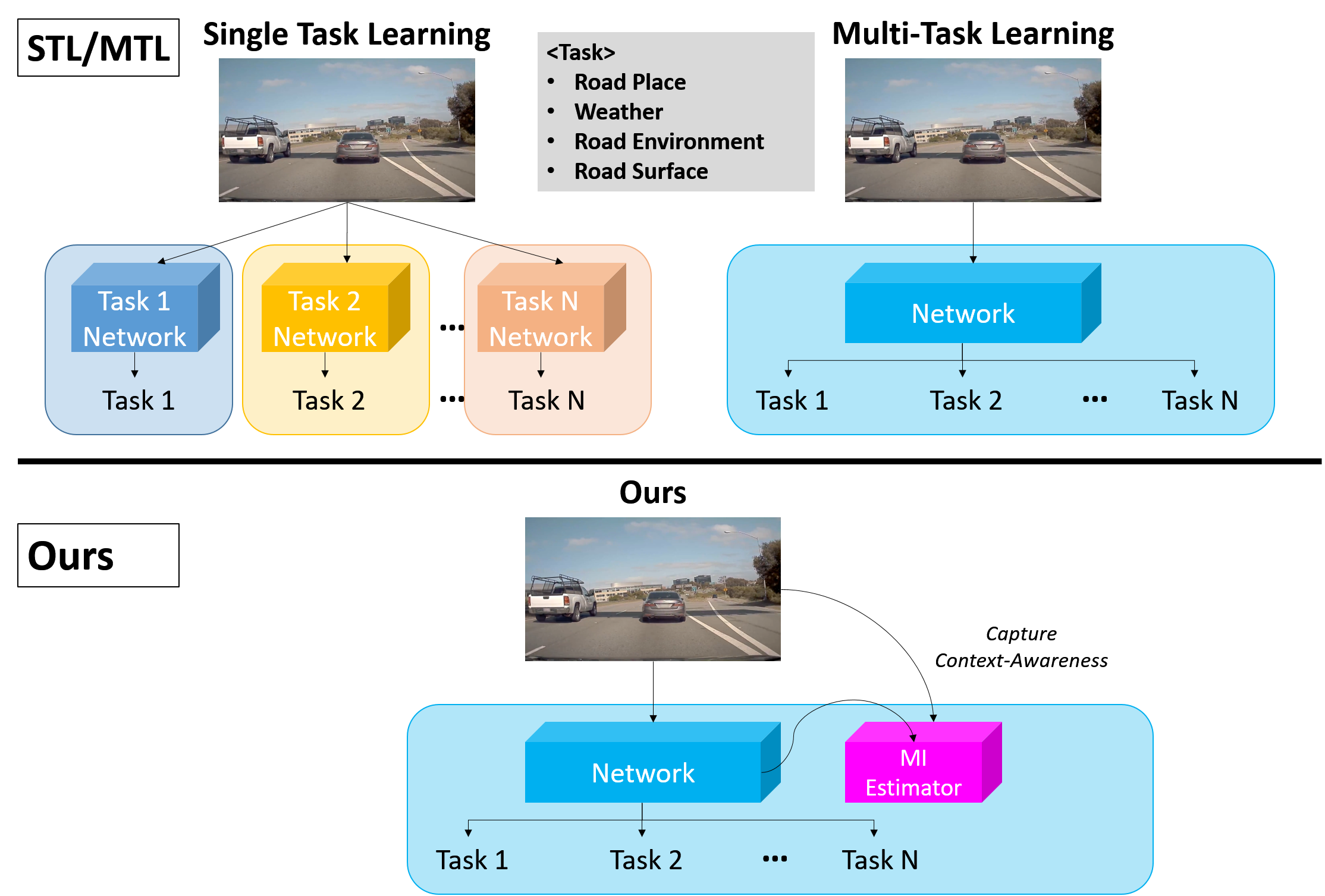
A naïve algorithm capable of performing multiple tasks simultaneously is to employ a suite of independent networks, one for each task. However, simply training a single network for a particular task, no matter how adequately optimized on each task, is far from satisfactory in terms of performance on every task. The reason is that such approach does not share any essential information that must be considered among tasks.
A solution to this difficulty is to design a multi-task learning (MTL) network, where multiple tasks are solved simultaneously, assuming the same input. Recently, the emerged MTL studies [9, 10, 11, 12] show benefits on visual scene recognition. These methods rely on the sharing of the encoder’s representation using auto-encoder-based Convolutional Neural Networks (CNNs) so that decoders corresponding to each task can be applied to independent targets. Although previous works on the MTL have made great efforts on enhancing the performance of multiple recognition tasks within limited parameters, there still remain gaps when in dynamic driving scenarios. The reason is that the sufficient contextual information from changing spatial and temporal relationships is not adequately exploited due to no more either a deeper and larger network or well-chosen hyper-parameters.
To gain a fundamental understanding of efficient structure inside these visual multiple tasks, we believe that scene context illustrates the human’s ability to understand the scene, even though the visual signal representing the scene is disturbed or insufficient. This assumption comes from the fact [13] that visual context is vital in the human visual system. Thus, without complementary measures, if the shared encoder learns to operate multiple tasks, its features important for task-specific factors might be wrongly aligned, leading to incomplete convergence with low saturation. Every task-specific decoders try to assign appropriate features directly through the shared encoder, but weights of the previous task might be shifted, whenever focusing on the current task. Unfortunately, repeating the above convergence, they are likely that an entire framework would show deterioration in performance termed as ”catastrophic forgetting” [14, 15, 16].
In this paper, we propose a context-aware MTL network, based on mutual information estimation, for traffic scene recognition in autonomous vehicles. As shown in Fig. 1, we start from a general MTL-based scene recognition setting, where an image classifier based on CNN framework (e.g. ResNet [17] and DenseNet [18]) is given and scene annotations are available from the traffic scene dataset [19]. The core idea of our method is to estimate mutual information constraint that calculates the lower-bound between input and task-specific latent space, leveraging shared encoder. Therefore, we refer to it as a new regularization loss term that enforces the MTL framework to be better context-aware features for easier recognition. This capture common contextual information across the entire feature representation including shared encoder and decoders while considering its unique properties of input image. Moreover, in spite of learning the way of decoders targeted on only own task, our approach would acquire good task-specific features in each decoder, maintaining high-quality context-aware features. We empirically show that the proposed approach is substantially effective for accurate scene recognition.
We highlight our key contributions as follows: First, we propose a novel multi-task learning (MTL) framework for traffic scene recognition, where a shared encoder and decoders for each task are introduced to perform multi-objective optimization. Second, we introduce a novel mutual information-based regularization loss to promote the MTL network within no additional network parameters while preserving task-specific features and generating common context-aware features simultaneously. Finally, we demonstrate the effectiveness of our approach, which acquires the useful context-aware feature space and shows that the multi-task recognition performance outperforms other state-of-the-art methods, especially on the online inference.
II RELATED WORKS

II-A Scene Recognition
Scene recognition has been a topic of considerable research in the fields of the vehicle surrounding environment perception due to its important role in a wide variety of ADAS and ADS applications. Early works employed hand-crafted feature-based methods [20, 21, 22, 23, 24, 25] to extract spatiotemporal information of the scene. However, most of the scene recognition systems based on hand-crafted features rely heavily on heuristic priors and low-level features, thus resulting in not robust to complex environments. Moreover, relatively insufficient traffic-scene datasets compared to general-scene datasets (e.g. Maryland [23], YUPENN [24] and SUN [26]) restricted the performance of the methods, especially in unconstrained settings.
Recently, with increasing research interests in traffic scene understanding, some large-scale datasets [27, 28, 29, 30, 19] have been published in the past few years. Besides, several methods [19, 30, 31, 32, 33] focus on the deep neural architectures, inspired by the great success of image classification. [33] developed a multi-label classification framework that is suitable for many mobile agents through short image descriptors. [19, 32] proposed large-scale datasets for the dynamic driving scene and designs multi-label architecture including event proposal network and resolution-adaptive mechanism so that showed better performance than the previous methods. Nevertheless, most of such methods have not been concentrated on explicitly extracting contextual information. This can lead to problems of catastrophic forgetting, where learned feature representations can gradually end up worse recognition performance.
In this work, our proposed model adopts a context-aware learning approach. Although numerous methods are using the deeper and wider CNN module for better performance, our approach differs in the view of explicitly defining the degree of contextual information, which has not fully addressed in existing methods.
II-B Multi-Task Learning.
Multi-task learning (MTL) addresses the problem of conducting parameter sharing across the tasks. For surveys of this field, we recommend reviews by [34, 35] on the basis of the proposed network structure that is most closely our work. As we add the tasks of numerous traffic situations for the human-like visual understanding of autonomous vehicles, the number of task-specific networks to optimize is proportional. Therefore, the importance of MTL multiple tasks at the same time is obviously growing because MTL reduces the computation needed for inference as well as convergence time for training. Existing deep learning-based MTL methods in computer vision [36, 37, 38, 39, 10, 40, 41] demonstrated the efficiency, highlighting the extensibility for future developments and applications. A few works [42, 43, 11] considered the multi-modal inputs where multi-task network commonly handles multiple types of input. None of these methods attempts to explicitly define contextual information from the relationship between latent space and input. Our work focused on calculating neural mutual information for calculating contextual information. It is worth noting that, to our best knowledge, our work may be the first work to apply contextual information estimation for MTL.
III PROPOSED METHOD
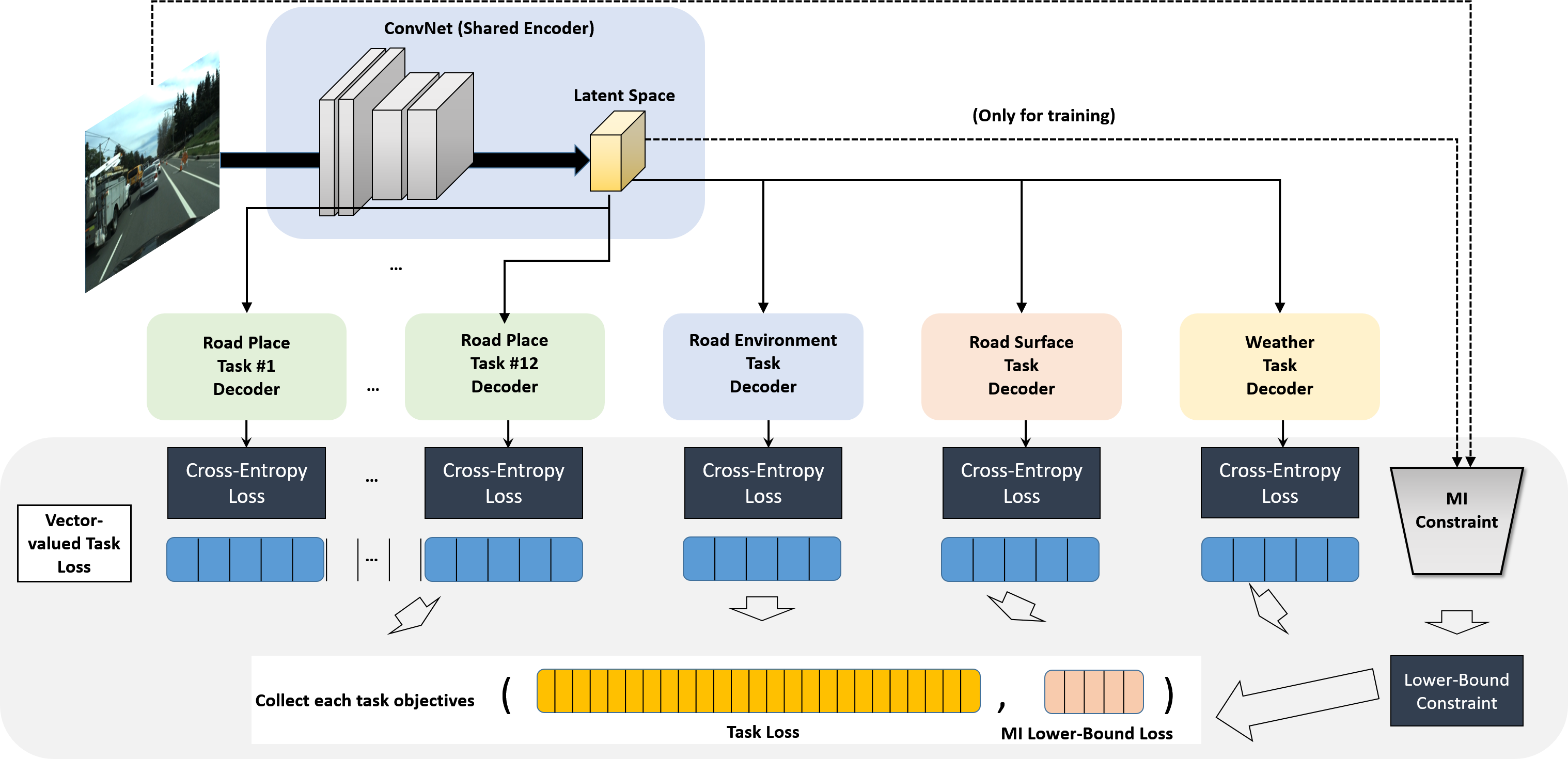
In this section, we describe our approach to traffic scene recognition. First, we illustrate problem settings and the overall idea for the problem. Next, we present the proposed mutual information constraint. Lastly, we introduce a lower bound of each mutual information estimation across tasks and represent the final loss function for training the MTL network. Our MTL framework is shown in Fig 2.
III-A Formulation
We focus on the problem of context-aware MTL using deep learning in traffic scene recognition. Then we have the multi-task training set of frames where the task spaces with the number of tasks . We denote as the random variables of input image on the frame. We consider each image sample to project into a latent representation that is dynamically learned for a variety of tasks. To resolve this goal, we utilize a deep feature extraction function : , with encoder network parameters . Our encoders are learned and run with weight sharing for all tasks, while decoders are defined separately for each task. We acquire the representation from input image by sampling through conditional probability with set of parameters .
Regarding multi-task decoders, let denotes the task-specific network for neural hypothesis class per task that takes latent space as input. In this paper, we create decoders for a total of 23 tasks, including 12 in Road Place, 4 in Weather, 2 in Road Surface, and 5 in Road Environment. The decoder is parameterized as follows: . For , the th image has MTL training labels: . Specifically, we employ multi-objective optimization based on Pareto optimality for eliminating the task-wise weights, which is a computationally inexpensive way. The multi-objective optimization for MTL using a vector-valued cross-entropy loss is
| (1) |
Although this objective is intuitively appealing, it often reveals the performance of MTL is not better than single-task learning on the multi-task dataset. To handle the issue, we propose to regularization for capturing contextual information in the region of latent representations, thus assisting MTL optimization.
III-B Mutual Information Constraint
To create the context-aware latent representation, we adopt an information-theoretically constraint using mutual information. As previously discussed, the maintenance of contextual information for each task is essential. We encourage our encoder to extract context-aware features from the input image. Hence, the resulting latent representations of encoder would contain abundant information of input while preserving task-specific information. We now propose a useful term that retains task-specific information and captures contextual information of input image. Generally defines as the random variables of representations from -th task. Let rewrite the MTL objective formulation (1) limiting of mutual information value for all of the task:
| (2) |
where the hyper-parameter controls the amount of mutual information. The equation (2) can be equivalently expressed with Lagrangian multipliers as follows:
| (3) |
However, objective (3) is not tractable in practice. Hence, we give a tractable approximation by using the lower bound of mutual information.
III-C Lower Bound of Constraint
Although task-specific patterns are ignored by equation (1), forcing the similarity in the marginal distribution does not directly affect the capture of valid information in each task. In particular, traffic scenes require task-specific information to be maintained, as the geometric and semantic context-aware representation of the image. Therefore, maintaining contextual information that is mapped by input images can contribute to the abundant preservation of the essential characteristics of the image. To solve this issue, we limit the minimum value of MI for all tasks and this maintains the representation specified by all tasks.
Mutual information is lower bounded by Noise Contrastive Estimation [44]:
| (4) |
where is sampled from the distribution = . By providing stable approximation results [45], mutual information can be maximized by replacing maximization in Jensen-Shannon divergence (JSD):
| (5) |
where is a softplus function. As discussed in [45], the decoder can share backbone encoder so that maximizing equation. (5) will maximize the MI . Finally equation. (3) can be rewritten as follows:
| (6) |
IV EXPERIMENTAL RESULTS
IV-A Setup
All the reported implementations are based on the PyTorch frameworks, and our method has done on one NVIDIA TITAN X GPU and one Intel Core i7-6700K CPU. In all the experiments, we use a gradient clipping trick and the Adam optimizer [46] with = 0.9, = 0.98, and weight decay to 0.0005. The proposed share encoder is implemented as a standard ResNet-50 architecture following the setting [19]. For the task decoders, we use a 2-layer CNN with global average pooling. In this paper, we deal with 23 tasks from HSD and optimize with only one objective function equation (6). The last convolutional layer is pooled to a size of class categories, respectively. All models adopt HSD dataset as the training set and are trained for the first 10 epochs with a learning rate of , and then for the remaining epochs at the learning rate of . Leaky-ReLU [47] and Batch normalization [48] are used in all layers of our networks with the mini-batch size set to 16 samples.
IV-B Dataset
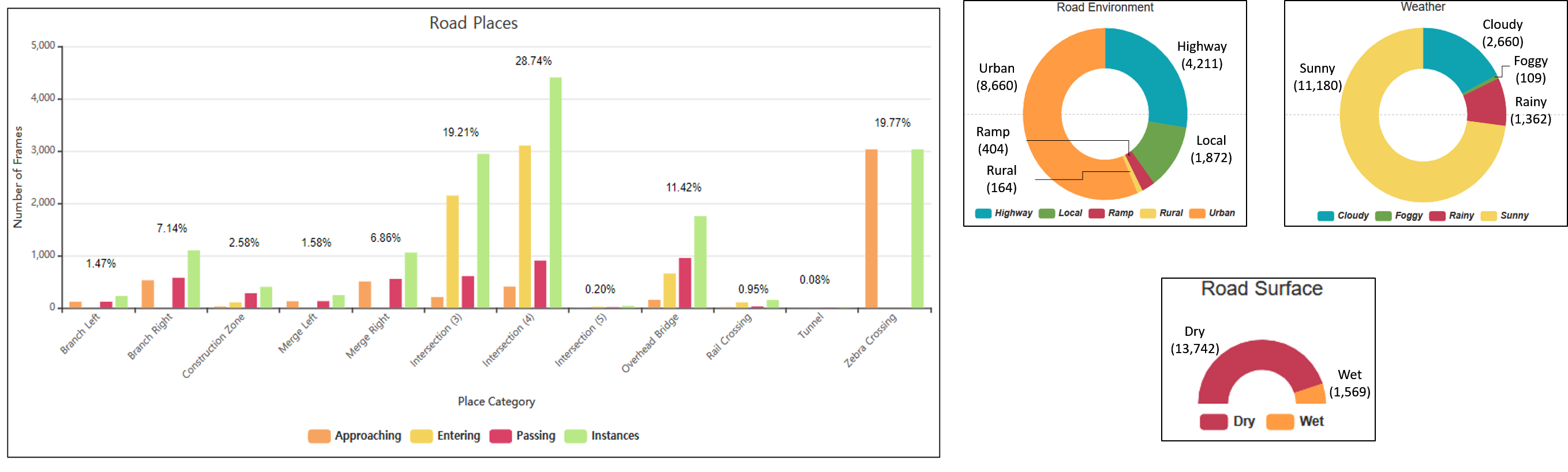
The Honda Scenes dataset (HSD) [19] is a large scale annotated dataset and created to enable practical scene classification. The dataset contains 80 hours of diverse high quality driving video samples collected in the San Francisco Bay, USA. The dataset contains temporal annotations for road places, weather, road environments, and road surface conditions.
Road Places The dataset contains 12 classes of road places - branch with gore on left, branch with gore on right, construction zone, merge with gore on left, merge with gore on right, 3-way intersection, 4-way intersection, 5-way intersection, overhead bridge, railway crossing, tunnel, and zebra crossing. Most classes have 3 temporal sub-classes, including approaching, entering, and passing. The merge and branch classes have approaching and passing sub-classes, while the zebra-crossing class has just approaching.
Road Environments and Weather The dataset spans 4 classes of road environments - rural, urban, highway and ramp and 4 weather conditions - rainy, sunny, cloudy, and foggy.
Road Surfaces The dataset contains 2 classes of road surfaces - dry and wet.
The dataset contains a total of about 20,000 instances spanned over these 12 classes. Moreover, the collected video images with camera are converted to a 1280 X 720 at 25 fps. The figure 3 outlines key statistics in the dataset.
| Type | Road Place | Weather | Road Surface | Road Environment |
|---|---|---|---|---|
| A | 0.285 | 0.910 | 0.950 | 0.560 |
| B | 0.277 | 0.908 | 0.936 | 0.580 |
| C (ours) | 0.303 | 0.916 | 0.950 | 0.601 |
IV-C Ablation Studies
As our method can properly be extended to deal with multi-task, we compare our proposed method with the baseline traffic scene recognition researches to prove the effectiveness. Results on HSD are reported for the following three types of models where each approach is gradually added: a) Single-Task Network; b) Multi-Task Network (Baseline); c) adding MI constraint to (b) (Ours).
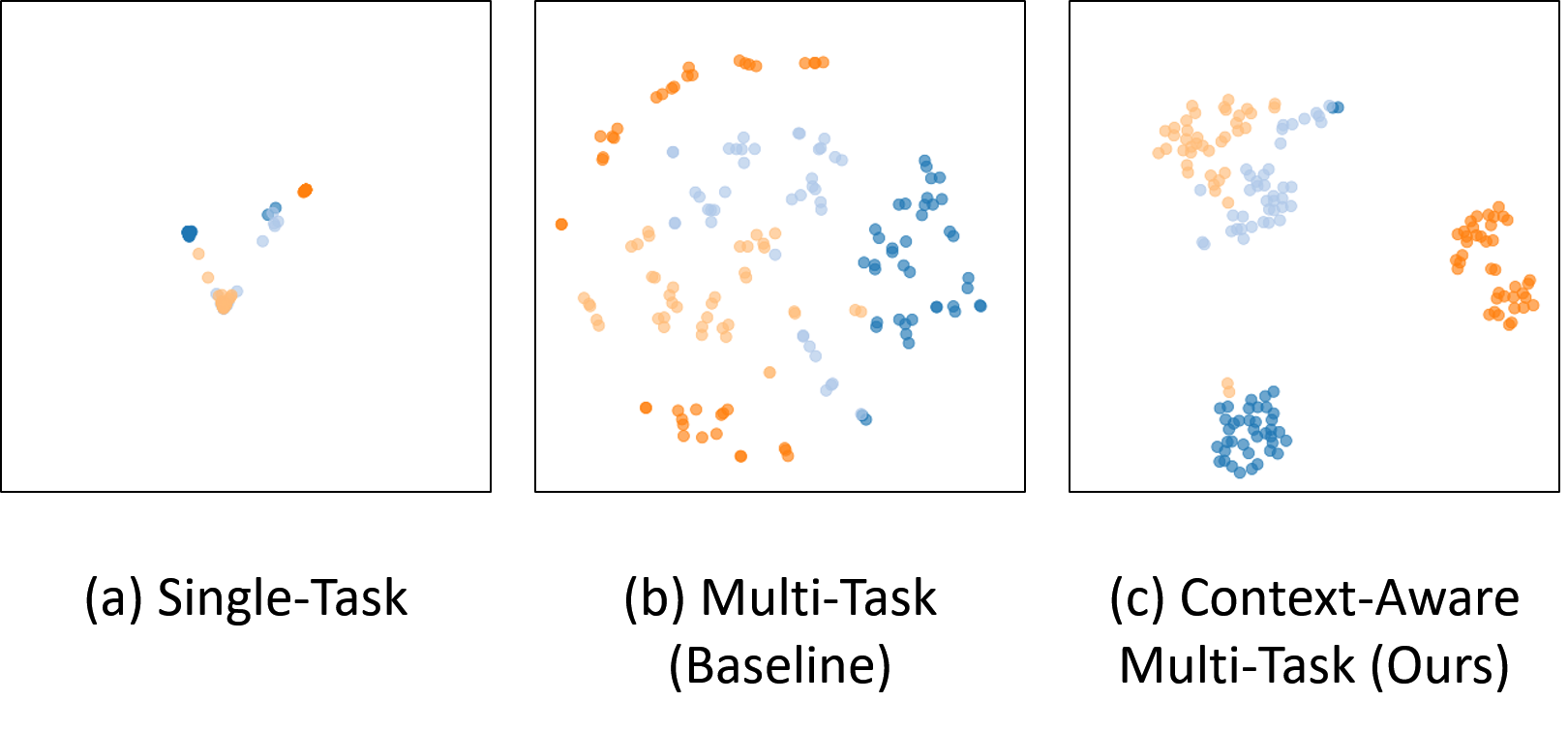
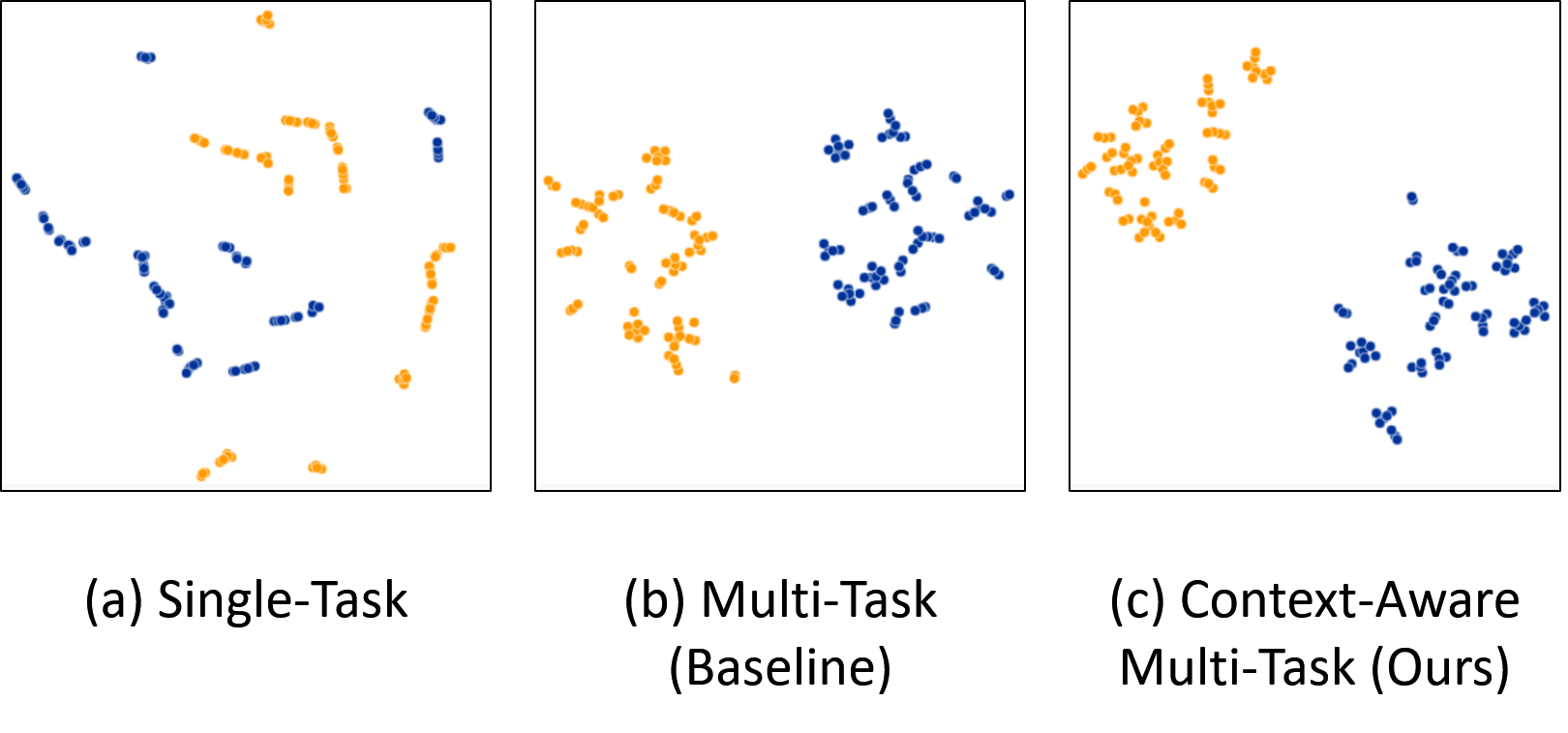
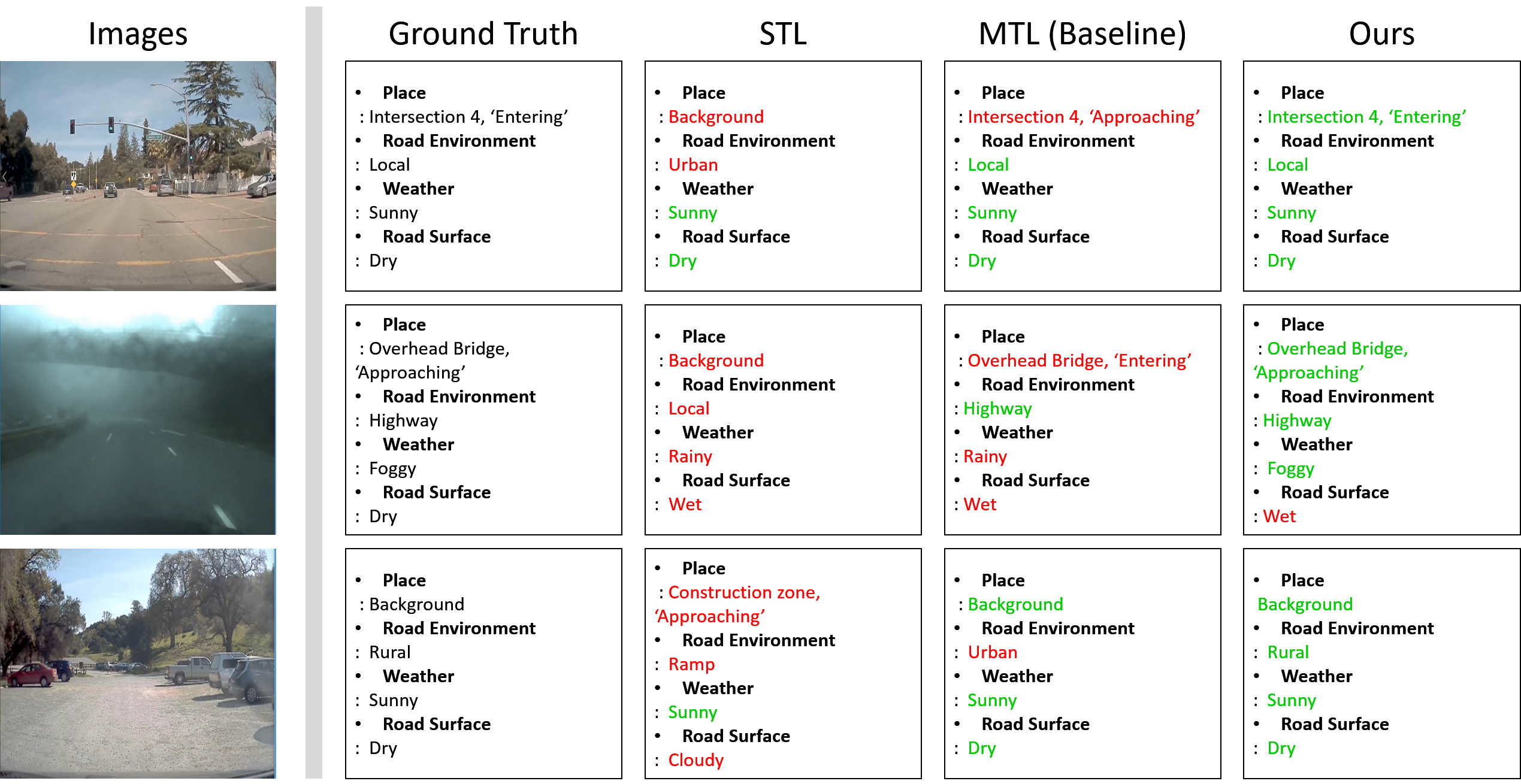
We present the multi-task traffic scene recognition accuracy for each type on HSD in Table 1, and the evaluation results are shown in Figure 8. From Table 1, we can identify that expanding simply MTL network does not improve recognition performance. As shown in Figure 8., ’Place’ category is difficult to recognize due to unbalanced dataset distribution. Therefore, when mutual information constraint is added to the proposed MTL, recognition results can be better (Figure 8. (last column)) and we observe some enhancements on traffic scene recognition performance (Table 1. e)). This confirms that applying MI constraint at the same time is more helpful to capture contextual information. Accordingly, the results in Figure 8 are the most accurate of all results.
| Road Place | ||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BL | BR | CZ | ML | MR | I3 | I4 | I5 | OB | RC | T | ZC | |||||||||||||||||||
| A | P | A | P | A | E | P | A | P | A | P | A | E | P | A | E | P | A | E | P | A | E | P | A | E | P | A | E | P | A | |
| Bi-LSTM [49] | 0.36 | 0.22 | 0.28 | 0.28 | 0.02 | 0.05 | 0.29 | 0.09 | 0.28 | 0.16 | 0.23 | 0.03 | 0.28 | 0.27 | 0.14 | 0.68 | 0.66 | 0.00 | 0.00 | 0.09 | 0.23 | 0.55 | 0.53 | 0.24 | 0.14 | 0.46 | - | - | - | - |
| Narayanan et al. [19] | 0.30 | 0.19 | 0.24 | 0.24 | 0.02 | 0.06 | 0.38 | 0.056 | 0.08 | 0.13 | 0.16 | 0.08 | 0.16 | 0.23 | 0.31 | 0.70 | 0.67 | 0.00 | 0.00 | 0.00 | 0.42 | 0.58 | 0.59 | 0.23 | 0.47 | 0.46 | - | - | - | - |
| Single-Task | 0.25 | 0.17 | 0.21 | 0.18 | 0.00 | 0.04 | 0.37 | 0.04 | 0.06 | 0.06 | 0.16 | 0.02 | 0.24 | 0.24 | 0.23 | 0.71 | 0.62 | 0.00 | 0.00 | 0.00 | 0.17 | 0.40 | 0.48 | 0.00 | 0.22 | 0.00 | 0.00 | 0.5 | 0.57 | 0.89 |
| Multi-Task | 0.28 | 0.17 | 0.23 | 0.21 | 0.00 | 0.02 | 0.36 | 0.03 | 0.03 | 0.07 | 0.15 | 0.00 | 0.23 | 0.20 | 0.20 | 0.61 | 0.68 | 0.00 | 0.00 | 0.00 | 0.28 | 0.48 | 0.54 | 0.00 | 0.11 | 0.00 | 0.00 | 0.00 | 0.00 | 0.83 |
| Ours | 0.33 | 0.19 | 0.34 | 0.27 | 0.00 | 0.04 | 0.38 | 0.04 | 0.06 | 0.26 | 0.18 | 0.11 | 0.38 | 0.28 | 0.14 | 0.78 | 0.79 | 0.00 | 0.06 | 0.00 | 0.47 | 0.59 | 0.60 | 0.10 | 0.35 | 0.52 | 0.00 | 0.5 | 0.57 | 0.90 |
| Weather | Surface | Environment | ||||||||||||||||||||||||||||
| Sunny | Foggy | Cloudy | Rainy | Dry | Wet | Local | Highway | Ramp | Rural | Urban | ||||||||||||||||||||
| Bi-LSTM [49] | - | - | - | - | - | - | - | - | - | - | - | |||||||||||||||||||
| Narayanan et al. [19] | 0.86 | 0.83 | - | 0.83 | 0.93 | 0.92 | 0.33 | 0.91 | 0.20 | - | 0.83 | |||||||||||||||||||
| Single-Task | 0.86 | 0.83 | 0.81 | 0.83 | 0.93 | 0.92 | 0.33 | 0.91 | 0.20 | 0.08 | 0.83 | |||||||||||||||||||
| Multi-Task | 0.88 | 0.25 | 0.79 | 0.86 | 0.93 | 0.85 | 0.32 | 0.92 | 0.21 | 0.07 | 0.80 | |||||||||||||||||||
| Ours | 0.9320 | 0.4495 | 0.8398 | 0.9699 | 0.9603 | 0.8617 | 0.36 | 0.92 | 0.21 | 0.16 | 0.81 | |||||||||||||||||||
| Road Place | Weather | Surface | Enviroment | |
|---|---|---|---|---|
| Bi-LSTM [49] | 0.275 | - | - | - |
| Narayanan et al. [19] | 0.285 | 0.91 | 0.95 | 0.56 |
| ResNet (STL) | 0.263 | 0.93 | 0.96 | 0.73 |
| DenseNet (STL) | 0.229 | 0.88 | 0.86 | 0.68 |
| Baseline (MTL) | 0.252 | 0.91 | 0.93 | 0.64 |
| Ours | 0.303 | 0.92 | 0.95 | 0.76 |
IV-D Comparison with Other Methods
We demonstrate the effectiveness of our MI-based MTL approach for the application of traffic scene recognition [19]. Table 2 shows the task-wise F-Scores and the recognition performance generally outperforms the existing methods across most of tasks. This mainly due to the fact that traffic scene samples are processed with context-aware feature representations. Note that what we want to highlight in HSD benchmark (especially notice the difference between Single-Task [19] and ours) is that the proposed method can benefit from MI based MTL framework which captures the context-aware properties of images despite only one optimization formula and less memory volume.
V Discussion
V-A Visualizing Analysis
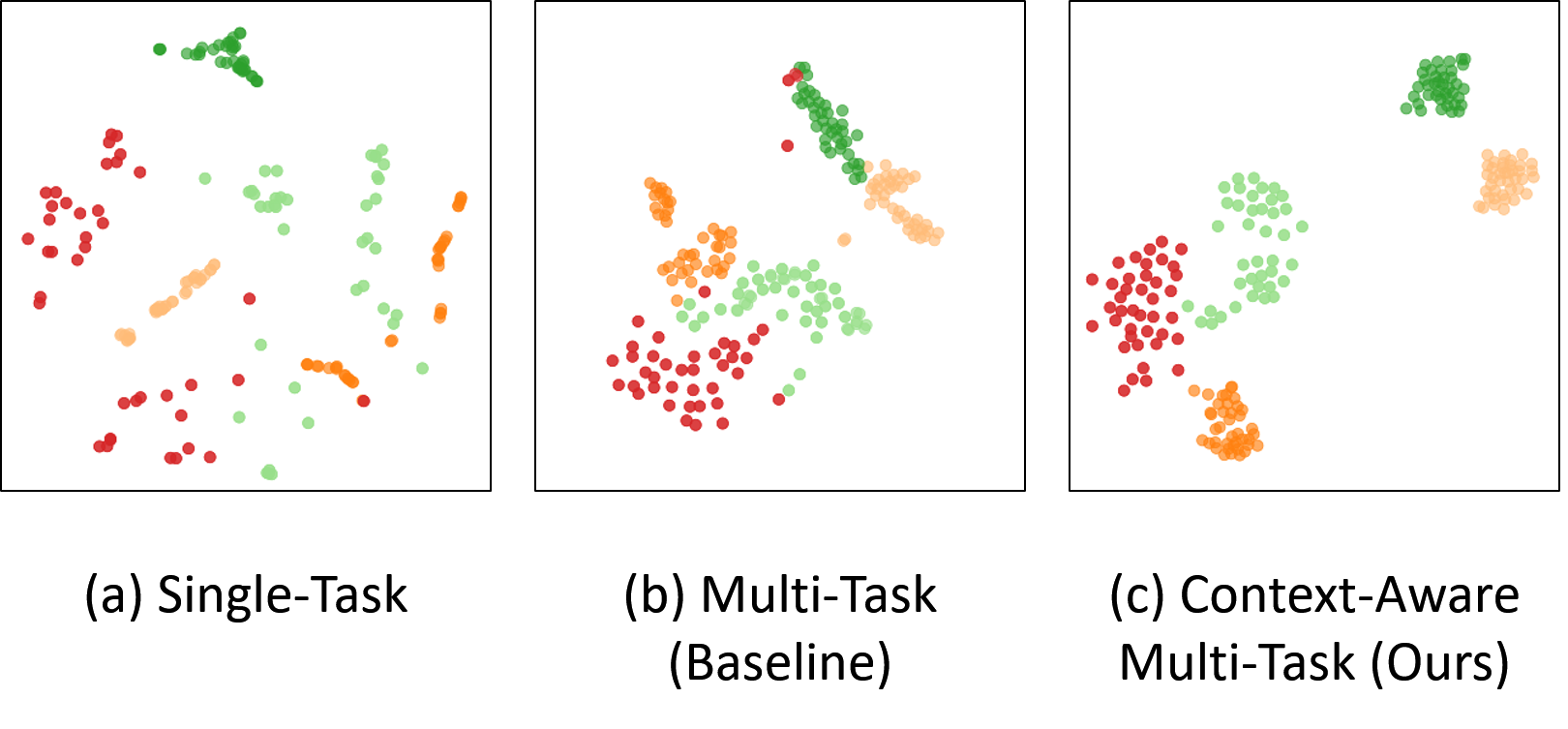
Figure 5,6, and 7 indicate out method is significantly better than existing MTL method. Our visualization results based on t-SNE [50] indicate that our approach proves the ability of discriminative representation and the shared encoder can have a better context-awareness ability.
V-B Limitations
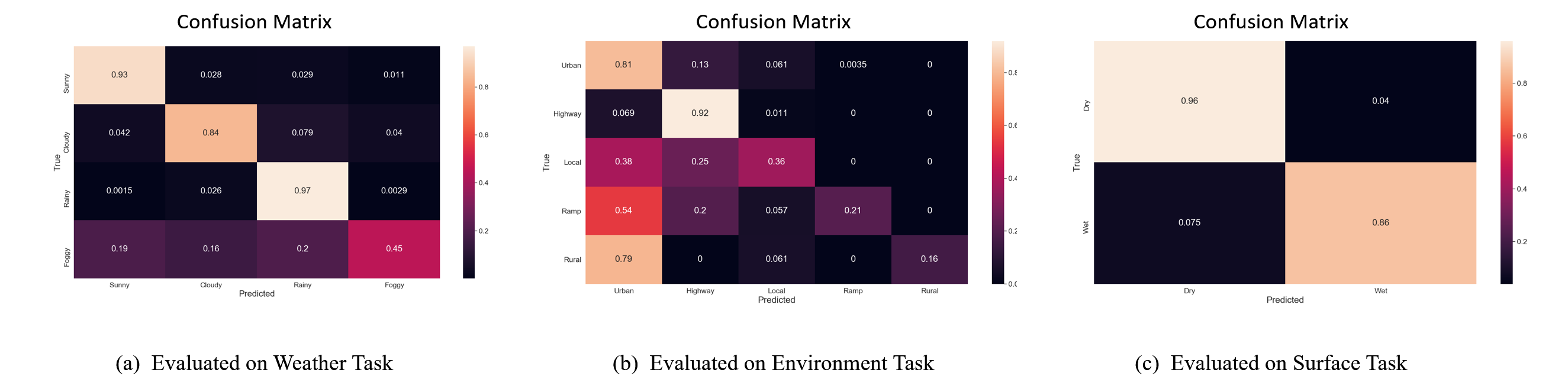
Here, we discuss two challenging problems, for which our method fails to recognize prediction. First, our method may fail to worst performance about classes with an extremely small number of data samples, e.g., Intersection-5 and Merge Left in the road place and ramp and rural in the road environment. In fact, the performance imbalance caused by this data imbalance can be found not only in our method but also in all existing methods. Second, our approach may wrongly recognize temporal classes in road place category. To address this issue, we believe that an online action proposal technique is needed for the MTL network to learn temporal-aware representations. Besides, we may carefully examine other possible mechanisms to avoid manual annotations for collecting more data.
VI CONCLUSIONS
In this paper, we have introduced a novel context-aware multi-task network for traffic scene recognition in autonomous vehicles. By calculating an information-theoretically motivated mutual information constraint, it is able to make use of task-invariant commonality and task-specific uniqueness properties, both of which are fundamental to visual recognition. Moreover, we introduce a multi-objective loss to the multi-task network, which can optimize an end-to-end trainable multi-task network without additional task-specific network. Extensive experiments on a large-scale dataset HSD demonstrate our method can convincingly improve the performance over baseline methods. Furthermore, our proposed framework significantly performs favorably against the state-of-the-art methods in both single-task and multi-task settings. For future directions, we potentially expect this approach to be integrated into ADAS applications on farther ranges and various categories.
ACKNOWLEDGMENT
This work was partly supported by Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No.2014-3-00077, AI National Strategy Project) and the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. 2019R1A2C2087489).
References
- [1] S. Azam, F. Munir, A. Rafique, Y. Ko, A. M. Sheri, and M. Jeon, “Object modeling from 3d point cloud data for self-driving vehicles,” in 2018 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2018, pp. 409–414.
- [2] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3213–3223.
- [3] Z. Cheng, Z. Wang, H. Huang, and Y. Liu, “Dense-acssd for end-to-end traffic scenes recognition,” in 2019 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2019, pp. 460–465.
- [4] V. Q. Dinh, Y. Lee, H. Choi, and M. Jeon, “Real-time traffic sign recognition,” in 2018 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia). IEEE, 2018, pp. 206–212.
- [5] Y. Lee, J. Lee, Y. Hong, Y. Ko, and M. Jeon, “Unconstrained road marking recognition with generative adversarial networks,” in 2019 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2019, pp. 1414–1419.
- [6] J. Ziegler, H. Lategahn, M. Schreiber, C. G. Keller, C. Knöppel, J. Hipp, M. Haueis, and C. Stiller, “Video based localization for bertha,” in 2014 IEEE Intelligent Vehicles Symposium Proceedings. IEEE, 2014, pp. 1231–1238.
- [7] G. Bresson, Z. Alsayed, L. Yu, and S. Glaser, “Simultaneous localization and mapping: A survey of current trends in autonomous driving,” IEEE Transactions on Intelligent Vehicles, vol. 2, no. 3, pp. 194–220, 2017.
- [8] F. Munir, S. Azam, M. I. Hussain, A. M. Sheri, and M. Jeon, “Autonomous vehicle: The architecture aspect of self driving car,” in Proceedings of the 2018 International Conference on Sensors, Signal and Image Processing, 2018, pp. 1–5.
- [9] N. Dvornik, K. Shmelkov, J. Mairal, and C. Schmid, “Blitznet: A real-time deep network for scene understanding,” in The IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- [10] M. Teichmann, M. Weber, M. Zoellner, R. Cipolla, and R. Urtasun, “Multinet: Real-time joint semantic reasoning for autonomous driving,” in 2018 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2018, pp. 1013–1020.
- [11] S. Chowdhuri, T. Pankaj, and K. Zipser, “Multinet: Multi-modal multi-task learning for autonomous driving,” in 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2019, pp. 1496–1504.
- [12] S. Chennupati, G. Sistu, S. Yogamani, and S. A Rawashdeh, “Multinet++: Multi-stream feature aggregation and geometric loss strategy for multi-task learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2019, pp. 0–0.
- [13] A. Oliva and A. Torralba, “The role of context in object recognition,” Trends in cognitive sciences, vol. 11, no. 12, pp. 520–527, 2007.
- [14] M. McCloskey and N. J. Cohen, “Catastrophic interference in connectionist networks: The sequential learning problem,” in Psychology of learning and motivation. Elsevier, 1989, vol. 24, pp. 109–165.
- [15] R. Ratcliff, “Connectionist models of recognition memory: constraints imposed by learning and forgetting functions.” Psychological review, vol. 97, no. 2, p. 285, 1990.
- [16] I. J. Goodfellow, M. Mirza, D. Xiao, A. Courville, and Y. Bengio, “An empirical investigation of catastrophic forgeting in gradientbased neural networks,” in In Proceedings of International Conference on Learning Representations (ICLR), 2014.
- [17] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [18] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708.
- [19] A. Narayanan, I. Dwivedi, and B. Dariush, “Dynamic traffic scene classification with space-time coherence,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 5629–5635.
- [20] P. Parodi and G. Piccioli, “A feature-based recognition scheme for traffic scenes,” in Proceedings of the Intelligent Vehicles’ 95. Symposium. IEEE, 1995, pp. 229–234.
- [21] C. Siagian and L. Itti, “Rapid biologically-inspired scene classification using features shared with visual attention,” IEEE transactions on pattern analysis and machine intelligence, vol. 29, no. 2, pp. 300–312, 2007.
- [22] D. Song and D. Tao, “Biologically inspired feature manifold for scene classification,” IEEE Transactions on Image Processing, vol. 19, no. 1, pp. 174–184, 2009.
- [23] N. Shroff, P. Turaga, and R. Chellappa, “Moving vistas: Exploiting motion for describing scenes,” in 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE, 2010, pp. 1911–1918.
- [24] K. G. Derpanis, M. Lecce, K. Daniilidis, and R. P. Wildes, “Dynamic scene understanding: The role of orientation features in space and time in scene classification,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2012, pp. 1306–1313.
- [25] C. Feichtenhofer, A. Pinz, and R. P. Wildes, “Dynamic scene recognition with complementary spatiotemporal features,” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 12, pp. 2389–2401, 2016.
- [26] J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba, “Sun database: Large-scale scene recognition from abbey to zoo,” in 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE, 2010, pp. 3485–3492.
- [27] I. Sikirić, K. Brkić, J. Krapac, and S. Šegvić, “Image representations on a budget: Traffic scene classification in a restricted bandwidth scenario,” in 2014 IEEE Intelligent Vehicles Symposium Proceedings. IEEE, 2014, pp. 845–852.
- [28] A. Jain, H. S. Koppula, B. Raghavan, S. Soh, and A. Saxena, “Car that knows before you do: Anticipating maneuvers via learning temporal driving models,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 3182–3190.
- [29] H. Xu, Y. Gao, F. Yu, and T. Darrell, “End-to-end learning of driving models from large-scale video datasets,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2174–2182.
- [30] V. Ramanishka, Y.-T. Chen, T. Misu, and K. Saenko, “Toward driving scene understanding: A dataset for learning driver behavior and causal reasoning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7699–7707.
- [31] F. Wu, S. Yan, J. S. Smith, and B. Zhang, “Deep multiple classifier fusion for traffic scene recognition,” Granular Computing, pp. 1–12, 2019.
- [32] L. Chen, W. Zhan, W. Tian, Y. He, and Q. Zou, “Deep integration: A multi-label architecture for road scene recognition,” IEEE Transactions on Image Processing, vol. 28, no. 10, pp. 4883–4898, 2019.
- [33] I. Sikirić, K. Brkić, P. Bevandić, I. Krešo, J. Krapac, and S. Šegvić, “Traffic scene classification on a representation budget,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 1, pp. 336–345, 2019.
- [34] S. Ruder, “An overview of multi-task learning in deep neural networks,” arXiv preprint arXiv:1706.05098, 2017.
- [35] Y. Zhang and Q. Yang, “An overview of multi-task learning,” National Science Review, vol. 5, no. 1, pp. 30–43, 2018.
- [36] I. Misra, A. Shrivastava, A. Gupta, and M. Hebert, “Cross-stitch networks for multi-task learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 3994–4003.
- [37] E. M. Rudd, M. Günther, and T. E. Boult, “Moon: A mixed objective optimization network for the recognition of facial attributes,” in European Conference on Computer Vision. Springer, 2016, pp. 19–35.
- [38] I. Kokkinos, “Ubernet: Training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6129–6138.
- [39] A. Atapour-Abarghouei and T. P. Breckon, “Veritatem dies aperit-temporally consistent depth prediction enabled by a multi-task geometric and semantic scene understanding approach,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 3373–3384.
- [40] Y. Lee, J. Lee, H. Ahn, and M. Jeon, “Snider: Single noisy image denoising and rectification for improving license plate recognition,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, 2019, pp. 0–0.
- [41] S. Yogamani, C. Hughes, J. Horgan, G. Sistu, P. Varley, D. O’Dea, M. Uricar, S. Milz, M. Simon, K. Amende, C. Witt, H. Rashed, S. Chennupati, S. Nayak, S. Mansoor, X. Perrotton, and P. Perez, “Woodscape: A multi-task, multi-camera fisheye dataset for autonomous driving,” in The IEEE International Conference on Computer Vision (ICCV), October 2019.
- [42] C. Hong, J. Yu, J. Zhang, X. Jin, and K.-H. Lee, “Multimodal face-pose estimation with multitask manifold deep learning,” IEEE Transactions on Industrial Informatics, vol. 15, no. 7, pp. 3952–3961, 2018.
- [43] Z. Yang, Y. Zhang, J. Yu, J. Cai, and J. Luo, “End-to-end multi-modal multi-task vehicle control for self-driving cars with visual perceptions,” in 2018 24th International Conference on Pattern Recognition (ICPR). IEEE, 2018, pp. 2289–2294.
- [44] A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018.
- [45] R. D. Hjelm, A. Fedorov, S. Lavoie-Marchildon, K. Grewal, P. Bachman, A. Trischler, and Y. Bengio, “Learning deep representations by mutual information estimation and maximization,” arXiv preprint arXiv:1808.06670, 2018.
- [46] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [47] A. L. Maas, A. Y. Hannun, and A. Y. Ng, “Rectifier nonlinearities improve neural network acoustic models,” in Proc. icml, vol. 30, no. 1, 2013, p. 3.
- [48] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” arXiv preprint arXiv:1502.03167, 2015.
- [49] J. Yue-Hei Ng, M. Hausknecht, S. Vijayanarasimhan, O. Vinyals, R. Monga, and G. Toderici, “Beyond short snippets: Deep networks for video classification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 4694–4702.
- [50] L. v. d. Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of machine learning research, vol. 9, no. Nov, pp. 2579–2605, 2008.