Contextual Bandits for Unbounded Context Distributions
Abstract
Nonparametric contextual bandit is an important model of sequential decision making problems. Under -Tsybakov margin condition, existing research has established a regret bound of for bounded supports. However, the optimal regret with unbounded contexts has not been analyzed. The challenge of solving contextual bandit problems with unbounded support is to achieve both exploration-exploitation tradeoff and bias-variance tradeoff simultaneously. In this paper, we solve the nonparametric contextual bandit problem with unbounded contexts. We propose two nearest neighbor methods combined with UCB exploration. The first method uses a fixed . Our analysis shows that this method achieves minimax optimal regret under a weak margin condition and relatively light-tailed context distributions. The second method uses adaptive . By a proper data-driven selection of , this method achieves an expected regret of , in which is a parameter describing the tail strength. This bound matches the minimax lower bound up to logarithm factors, indicating that the second method is approximately optimal.
1 Introduction
Multi-armed bandit (Robbins, 1952; Lai & Robbins, 1985) is an important sequential decision problem that has been extensively studied (Agrawal, 1995; Auer et al., 2002; Garivier & Cappé, 2011). In many practical applications such as recommender systems and information retrieval in healthcare and finance (Bouneffouf et al., 2020), decision problems are usually modeled as contextual bandits (Woodroofe, 1979), in which the reward depends on some side information, called contexts. At the -th iteration, the decision maker observes the context , and then pulls an arm based on and the previous trajectory . Many research assume linear rewards (Abbasi-Yadkori et al., 2011; Bastani & Bayati, 2020; Bastani et al., 2021; Qian et al., 2023; Langford & Zhang, 2007; Dudik et al., 2011; Chu et al., 2011; Li et al., 2010), which is restrictive and may not fit well into practical scenarios. Consequently, in recent years, nonparametric contextual bandits have received significant attention, which does not make any parametric assumption about the reward functions (Perchet & Rigollet, 2013; Guan & Jiang, 2018; Gur et al., 2022; Blanchard et al., 2023; Suk & Kpotufe, 2023; Suk, 2024; Cai et al., 2024).
Despite significant progress on nonparametric contextual bandits, existing studies focus only on the case with bounded contexts, and the probability density functions (pdf) of the contexts are required to be bounded away from zero. However, many practical applications often involve unbounded contexts, such as healthcare (Durand et al., 2018), dynamic pricing (Misra et al., 2019) and recommender systems (Zhou et al., 2017). In particular, the contexts may follow a heavy-tailed distribution (Zangerle & Bauer, 2022), which is significantly different from bounded contexts. Therefore, to bridge the gap between theoretical studies and practical applications of contextual bandits, an in-depth theoretical study of unbounded contexts is crucially needed. Compared with bounded contexts, heavy-tailed context distribution requires the learning method to be adaptive to the pdf of contexts, in order to balance the bias and variance of the estimation of reward functions. On the other hand, compared with existing works on nonparametric classification and regression with identically and independently distributed (i.i.d) data, bandit problems require us to achieve a good balance between exploration and exploitation, thus the learning method needs to be adaptive to the suboptimality gap of reward functions. Therefore, the main challenge of solving nonparametric contextual bandit problems with unbounded contexts is to achieve both bias-variance tradeoff and exploration-exploitation tradeoff using a single algorithm.
| Method | Bound of expected regret | ||
| Bounded context | Heavy-tailed context | ||
| (Rigollet & Zeevi, 2010) | UCBogram | None | |
| (Perchet & Rigollet, 2013) | ABSE | None | |
| (Gur et al., 2022) | SACB | None | |
| (Guan & Jiang, 2018) | kNN-UCB | None | |
| (Reeve et al., 2018) | kNN-UCB | None | |
| This work | kNN-UCB111Despite that the name kNN-UCB is the same as (Guan & Jiang, 2018) and (Reeve et al., 2018), the calculations of UCB are different between these methods. See details in the ”Nearest neighbor method with fixed ” section. | ||
| This work | Adaptive kNN-UCB | ||
| Minimax lower bound | |||
In this paper, we solve the nonparametric contextual bandit problem with heavy-tailed contexts. To begin with, we derive a minimax lower bound that characterizes the theoretical limits of contextual bandit learning. We then propose a relatively simple method that uses fixed combined with upper confidence bound (UCB) exploration and derive the bound of expected regret. Even for bounded contexts, our method improves over an existing nearest neighbor method (Guan & Jiang, 2018) for large margin parameter , since our method uses an improved UCB calculation which is more adaptive to the suboptimality gap of reward functions. Despite such progress, there is still some gap between the regret bound and the minimax lower bound, indicating room for further improvement. To close such a gap, we further propose a new adaptive nearest neighbor approach, which selects adaptively based on the density of samples and the suboptimality gap of reward functions. Our analysis shows that the regret bound of this new method nearly matches the minimax lower bound up to logarithmic factors, indicating that this method is approximately minimax optimal.
The general guidelines of our adaptive kNN method are summarized as follows. Firstly, with higher context pdf, we use larger , and vice versa. Secondly, given a specific context, if the value of an action is far away from optimal (i.e. large suboptimality gap), then we use smaller , and vice versa. Such a choice of achieves a good tradeoff between estimation bias and variance. With a lower pdf or larger suboptimality gap, the samples are relatively more sparse. As a result, a large bias may happen due to large kNN distances. Therefore, we use smaller to control the bias. On the contrary, with a higher pdf or smaller suboptimality gap, the samples are dense and thus we can use larger to reduce the variance. Note that the pdf and the suboptimality gap are unknown to the learner. Therefore, we design a method, such that the value of is selected by a data-driven manner, based on the density of existing samples.
1.1 Contribution
The contributions of this paper are summarized as follows.
-
•
We derive the minimax lower bound of nonparametric contextual bandits with heavy-tailed context distributions.
-
•
We propose a simple kNN method with UCB exploration. The regret bound matches the minimax lower bound with small and large .
-
•
We propose an adaptive kNN method, such that is selected based on previous steps. The regret bound matches the minimax lower bound under all parameter regimes.
Our results and the comparison with related works are summarized in Table 1. In general, to the best of our knowledge, our work is the first attempt to handle heavy-tailed context distribution in contextual bandit problems. In particular, our new proposed adaptive kNN method achieves the minimax lower bound for the first time. The proofs of all theoretical results in the paper are shown in the supplementary material.
2 Related Work
In this section, we briefly review the related works about contextual bandits and nearest neighbor methods.
Nonparametric contextual bandits with bounded contexts. (Yang & Zhu, 2002) first introduced the nonparametric contextual bandit problem, proposed an -greedy approach and proved the consistency. (Rigollet & Zeevi, 2010) derived a minimax lower bound on the regret, and showed that this bound is achievable by a UCB method. (Perchet & Rigollet, 2013) proposed Adaptively Binned Successive Elimination (ABSE), which adapts to the unknown margin parameter. (Qian & Yang, 2016) proposed a kernel estimation method. (Hu et al., 2020) analyzed nonparametric bandit problem under general Hölder smoothness assumption. (Gur et al., 2022) proposed Smoothness-Adaptive Contextual Bandits (SACB), which is adaptive to the smoothness parameter. (Slivkins, 2014; Suk & Kpotufe, 2023; Akhavan et al., 2024; Ghosh et al., 2024; Komiyama et al., 2024; Suk, 2024) analyzed the problem of dynamic regret. Furthermore, (Wanigasekara & Yu, 2019; Locatelli & Carpentier, 2018; Krishnamurthy et al., 2020; Zhu et al., 2022) discussed the case with continuous actions.
Nearest neighbor methods. Nearest neighbor classification has been analyzed in (Chaudhuri & Dasgupta, 2014; Döring et al., 2018) for bounded support of features. (Gadat et al., 2016; Kpotufe, 2011; Cannings et al., 2020; Zhao & Lai, 2021b, a) proposed adaptive nearest neighbor methods for heavy-tailed feature distributions. (Guan & Jiang, 2018) proposed kNN-UCB method for contextual bandits and proved a regret bound .
Compared with existing methods on nonparametric contextual bandits, for unbounded contexts, the methods need to adapt to different density levels of contexts and achieve a better bias and variance tradeoff in the estimation of reward functions. Moreover, existing works on nonparametric classification can not be easily extended here, since the samples are no longer i.i.d and we now need to bound the regret instead of the estimation error. These factors introduce new technical difficulties in theoretical analysis. In this work, to address these challenges, we design new algorithms that are adaptive to both the pdf and the suboptimality of reward functions and provide a corresponding theoretical analysis.
3 Preliminaries
Denote as the space of contexts, and as the space of actions. Throughout this paper, we discuss the case with infinite and finite . At the -th step, the context is a random variable drawn from a distribution with probability density function (pdf) . Then the agent takes action and receive reward :
| (1) |
in which for and is an unknown expected reward function, and denotes the noise, with .
Throughout this paper, define
| (2) |
as the maximum expected reward of context . For any suboptimal action , . Correspondingly, is called suboptimality gap.
The performance of an algorithm is evaluated by the expected regret
| (3) |
We then present the assumptions needed for the analysis. To begin with, we state some basic conditions in Assumption 1.
Assumption 1.
There exists some constants , , , such that
(a) (Tsybakov margin condition) For some , for all and , ;
(b) is subgaussian with parameter , i.e. ;
(c) For all , is Lipschitz with constant , i.e. for any and , .
Now we comment on these assumptions. (a) is the Tsybakov margin condition, which was first introduced in (Audibert & Tsybakov, 2007) for classification problems, and then used in contextual bandit problems (Perchet & Rigollet, 2013). Note that always hold, thus for any , (a) holds with and . Therefore, this assumption is nontrivial only if it holds with some . Moreover, we only consider the case with here. If , then an arm is either always or never optimal, thus it is easy to achieve logarithmic regret (see (Perchet & Rigollet, 2013), Proposition 3.1). An additional remark is that in (Perchet & Rigollet, 2013; Reeve et al., 2018), the margin assumption is , in which is the second largest one among . Our assumption (a) is slightly weaker than existing ones since we only impose margin conditions on the suboptimality gap for each separately, instead of on the minimum suboptimality gap. In (b), following existing works (Reeve et al., 2018), we assume that the noise has light tails. (c) is a common assumption for various literatures on nonparametric estimation (Mai & Johansson, 2021). It is possible to extend this work to a more general Hölder smoothness assumption by adaptive nearest neighbor weights (Cannings et al., 2020). In this paper, we focus only on Lipschitz continuity for convenience.
Assumption 2 is designed for the case that the contexts have bounded support.
Assumption 2.
for all , in which is the pdf of contexts.
In Assumption 2, the pdf is required to be bounded away from zero, which is also made in (Perchet & Rigollet, 2013; Guan & Jiang, 2018; Reeve et al., 2018). Note that even for estimation with i.i.d data, this assumption is common (Audibert & Tsybakov, 2007; Döring et al., 2018; Gao et al., 2018).
We then show some assumptions for heavy-tailed distributions.
Assumption 3.
(a) For any , for some constants and ;
(b) The difference of regret function among all actions are bounded, i.e. for some constant .
(a) is a common tail assumption for nonparametric statistics, which has been made in (Gadat et al., 2016; Zhao & Lai, 2021b). describes the tail strength. Smaller indicates that the context distribution has heavy tails, and vice versa. To further illustrate this assumption, we show several examples.
Example 1.
If has bounded support , then Assumption 3(a) holds with and , in which is the volume of the support set .
Example 2.
Proof.
The analysis of these examples and other related discussions are shown in the supplementary material. ∎
It worths mentioning that although the growth rate of the regret is affected by the value of , our proposed algorithms including both fixed and adaptive methods do not require knowing .
(b) restricts the suboptimality gap of each action. This is not necessary if the support is bounded. However, with unbounded support, without assumption (b), can increase appropriately with the decrease of , such that the regret of suboptimal action is large, and the identification of best action is hard.
Finally, we clarify notations as follows. Throughout this paper, denotes norm. denotes for some constant , which may depend on the constants in Assumption 2. The notation is defined conversely.
4 Minimax Analysis
In this section, we show the minimax lower bound, which characterizes the theoretical limit of regrets of contextual bandits. Throughout this section, denote as the policy, such that each action is selected according to policy . To be more precise,
| (4) |
which indicates that the action at time depends on the current context and the records of contexts and rewards in previous steps.
The minimax lower bound for the case with bounded support has been shown in Theorem 4.1 in (Rigollet & Zeevi, 2010). For completeness and notation consistency, we state the results below and provide a simplified proof.
Theorem 1.
We then show the minimax regret bounds for unbounded support, which is a new result that has not been obtained before.
Theorem 2.
Proof.
(Outline) For bounded support, we just derive the lower bound of regret by analyzing the minimax optimal number of suboptimal actions first. Define
| (7) |
can be lower bounded using standard tools in nonparametric statistics (Tsybakov, 2009), which constructs multiple hypotheses and bounds the minimum error probability. As shown in (Rigollet & Zeevi, 2010), the lower bound of can then be transformed to the lower bound of .
The minimax analysis becomes more complex with unbounded support. Firstly, the heavy-tailed context distribution requires different hypotheses construction. Secondly, the transformation from the lower bound of to does not yield tight lower bounds. We design new approaches to construct a set of candidate functions and derive lower bounds of directly. ∎
For bounded context support, regret comes mainly from the region with (which is the classical rate for nonparametric estimation (Tsybakov, 2009)), in which the identification of best action is not guaranteed to be correct. However, with heavy-tailed contexts, regret may also come from the tail, i.e. the region with small , where the number of samples around is not enough to yield a reliable best action identification. For heavy-tailed cases, i.e. is small, the regret caused by the tail region may dominate. This also explains why we need to use different techniques to derive the minimax lower bound for heavy-tailed contexts.
In the remainder of this paper, we claim that a method is nearly minimax optimal if the dependence of expected regret on matches (5) or (6). Following conventions in existing works (Rigollet & Zeevi, 2010; Perchet & Rigollet, 2013; Hu et al., 2020; Gur et al., 2022), currently, the minimax lower bounds are derived for contextual bandit problems with only two actions, thus we do not consider the minimax optimality of regrets with respect to the number of actions .
5 Nearest Neighbor Method with Fixed
To begin with, we propose and analyze a simple nearest neighbor method with fixed . We make the following definitions first.
Denote as the number of steps with action before time step . Let be the set of nearest neighbors among . Define
| (8) |
as the nearest neighbor distance, i.e. the distance from to its -th nearest neighbor among all previous steps with action .
With the above notations, we describe the fixed nearest neighbor method as follows. If , then
| (9) |
in which has a fixed value
| (10) |
If , then
| (11) |
Here we explain our design. If , then it is possible to give a UCB estimate of , shown in (9). bounds the estimation bias, while is an upper bound of the error caused by random noise that holds with high probability. In Lemma 5 in Appendix E, we show that is a valid UCB estimate of , i.e. holds with high probability. If , then it is impossible to give a UCB estimate. In this case, we just let to be infinite.
Finally, the algorithm selects the action with the maximum UCB value:
| (12) |
According to (11), as long as an action has not been taken for at least times, the UCB estimate of will be infinite. Note that the selection rule (12) ensures that the actions with infinite UCB values will be taken first. Therefore, the first steps are used for pure exploration. In this stage, the agent takes each action for times. After steps, the UCB values for all and become finite. Since then, at each step, the action is selected with the maximum UCB value specified in (9).
The procedures above are summarized in Algorithm 1. Compared with (Guan & Jiang, 2018), our method constructs the UCB differently. In (Guan & Jiang, 2018), the UCB is , in which is uniform among all with fixed action .
Therefore, the method (Guan & Jiang, 2018) is not adaptive to the suboptimality gap . On the contrary, our method has a term that varies for different , and thus adapts better to the suboptimality gap. The bound of regret is shown in Theorem 3.
Theorem 3.
Under Assumption 1 and 2, the regret of the simple nearest neighbor method with UCB exploration is bounded as follows:
(1) If , then with ,
| (13) |
(2) If , then with ,
| (14) |
We compare our result with (Guan & Jiang, 2018), which proposes a similar nearest neighbor method. The analysis in (Guan & Jiang, 2018) does not make Tsybakov margin assumption (Assumption 1(a)), and the regret bound is . Without any restriction on , Assumption 1(a) holds with and , under which (13) reduces to . Therefore, our result matches (Guan & Jiang, 2018) with . If , which indicates that a small optimality gap only happens with small probability, then the regret of the method in (Guan & Jiang, 2018) is still , while our result improves it to . As discussed earlier, compared with (Guan & Jiang, 2018), our method improves the UCB calculation in (17), and is thus more adaptive to the suboptimalilty gap . With , our method achieves smaller regret due to a better tradeoff between exploration and exploitation.
Compared with the minimax lower bound shown in Theorem 1, it can be found that the kNN method with fixed is not completely optimal. With , the upper bound matches the lower bound derived in Theorem 1. However, with , the regret is significantly higher than the minimax lower bound, indicating that there is room for further improvement.
We then analyze the performance for heavy-tailed context distribution. The result is shown in the following theorem.
Theorem 4.
From (15), there are two phase transitions. The first one is at , while the second one is at . Intuitively, the phase transition occurs because the regret is dominated by different regions depending on the settings and . Compared with the minimax lower bound shown in Theorem 2, it can be found that the kNN method with fixed achieves nearly minimax optimal regret up to logarithm factors if and , otherwise the regret bound is suboptimal. Here we provide an intuition of the reason why the kNN method with fixed achieves suboptimal regrets. In the region where the context pdf is low, or the suboptimality gap is large, the samples with action are relatively sparse. In this case, with fixed , the nearest neighbor distances are too large, resulting in a large estimation bias. On the contrary, if is high or is small, then samples with action are relatively dense, thus the bias is small, and we can increase to achieve a better bias and variance tradeoff. Therefore, if is fixed throughout the support set, then the algorithm estimates the reward function in an inefficient way, resulting in suboptimal regrets. Apart from suboptimal regret, another drawback is that with , the optimal selection of depends on the margin parameter , which is usually unknown in practice. In the next section, we propose an adaptive nearest neighbor method to address these issues mentioned above.
6 Nearest Neighbor Method with Adaptive
In the previous section, we have shown that the standard kNN method with fixed is suboptimal with or . The intuition is that the standard nearest neighbor method does not adjust based on the pdf and the suboptimality gap. In this section, we propose an adaptive nearest neighbor approach. To achieve a good exploration-exploitation tradeoff and bias-variance tradeoff, needs to be smaller for small pdf or large suboptimality gap , and vice versa. However, as both and are unknown to the learner, we need to decide based entirely on existing samples. The guideline of our design is that given a context at time , we use large if previous samples are relatively dense around , and vice versa. To be more precise, for all , let
| (16) |
in which is the distance from to its -th nearest neighbors among existing samples with action , i.e. . Such selection of makes the bias term matches the variance term , thus (16) achieves a good tradeoff between bias and variance. The exploration-exploitation tradeoff is also desirable as is large with large , which yields smaller . Note that (16) can be calculated only if , which means that the -nearest neighbor distance can not be too large. At some time step , for some action , if there is no existing samples, or is more than far away from any existing samples , then we can just let the UCB estimate to be infinite, i.e. . Otherwise, we calculate the upper confidence bound as follows:
| (17) |
in which is the set of neighbors of among , is the corresponding neighbor distance of , i.e. , and
| (18) |
Similar to the fixed nearest neighbor method, the last two terms in (17) cover the uncertainty of reward function estimation. The term gives a high probability bound of random error, and bounds the bias. With the UCB calculation in (17), the is an upper bound of that holds with high probability, so that the exploration and exploitation can be balanced well. The complete description of the newly proposed adaptive nearest neighbor method is shown in Algorithm 2.
We then analyze the regret of the adaptive method for both bounded and unbounded supports of contexts.
Theorem 5.
By comparing Theorem 5 with Theorem 3, it can be found that for the case with bounded support, the adaptive method improves over the fixed nearest neighbor method. From the minimax bound in Theorem 1, the fixed method is only optimal for , while the adaptive method is also optimal for , up to logarithm factors. An intuitive explanation is that with large , the suboptimality gap is small only in a small region, and the exploration-exploitation tradeoff becomes harder, thus the advantage of the adaptive method over the fixed one becomes more obvious.
We then analyze the performance of the adaptive nearest neighbor method for heavy-tailed distribution. The result is shown in the following theorem.
Theorem 6.
Compared with the minimax lower bound shown in Theorem 2, it can be found that our method achieves nearly minimax optimal regret up to a logarithm factor. Regarding this result, we have some additional remarks.
Remark 1.
Remark 2.
In (Zhao & Lai, 2021b), it is shown that the optimal rate of the excess risk of nonparametric classification is 222The analysis in (Zhao & Lai, 2021b) is under a general smoothness assumption with parameter . corresponds to the Lipschitz assumption (Assumption 1(c) in this paper). Therefore, here we replace the bounds in (Zhao & Lai, 2021b) with .. From (22), the average regret over all steps is , which has the same rate as the nonparametric classification problem.
7 Numerical Experiments
To begin with, to validate our theoretical analysis, we run experiments using some synthesized data. We then move on to experiments with the MNIST dataset (LeCun, 1998).
7.1 Synthesized Data
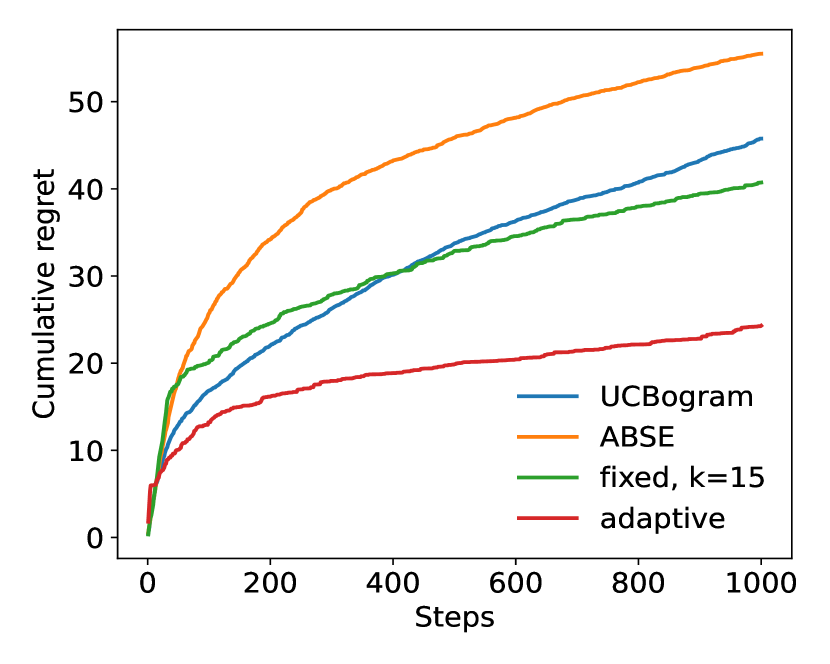
To begin with, we conduct experiments with . In each experiment, we run steps and compare the performance of the adaptive nearest neighbor method with the UCBogram (Rigollet & Zeevi, 2010), ABSE (Perchet & Rigollet, 2013) and fixed nearest neighbor method. For a fair comparison, for UCBogram and ABSE, we try different numbers of bins and only pick the one with the best performance. The results are shown in Figure 1. In (a), (b), (c), and (d), the contexts follow uniform distribution in , standard Gaussian distribution, distribution, and Cauchy distribution, respectively. The uniform distribution is an example of distributions with bounded support. The Gaussian, and Cauchy distribution satisfy the tail assumption (Assumption 3(a)) with , and , respectively. In each experiment, there are two actions. For uniform and Gaussian distribution, we have and . For and Cauchy distribution, since they are heavy-tailed, to ensure that Assumption 3(b) is satisfied, we do not use the linear reward function. Instead, we let and . To make the comparison more reliable, the values in each curve in Figure 1 are averaged over random and independent trials.
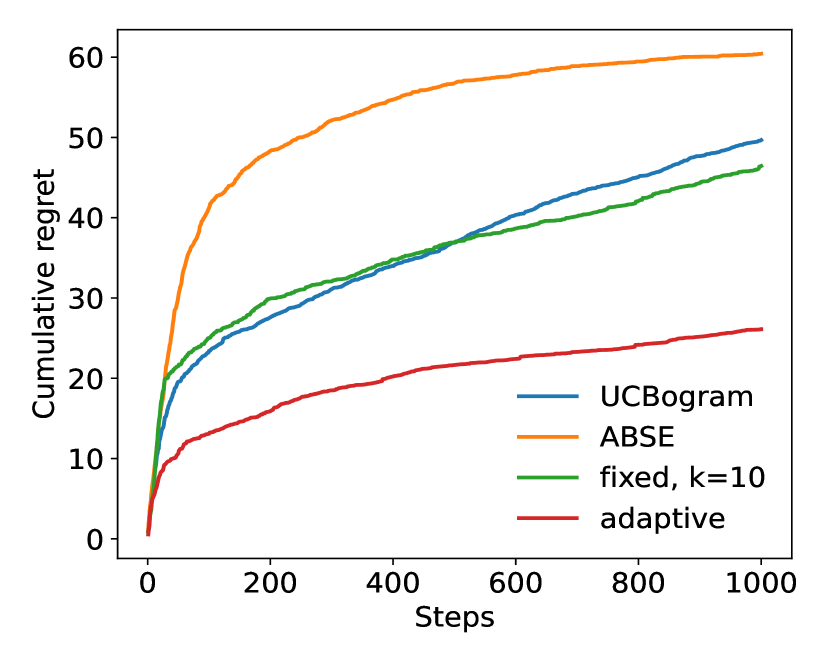
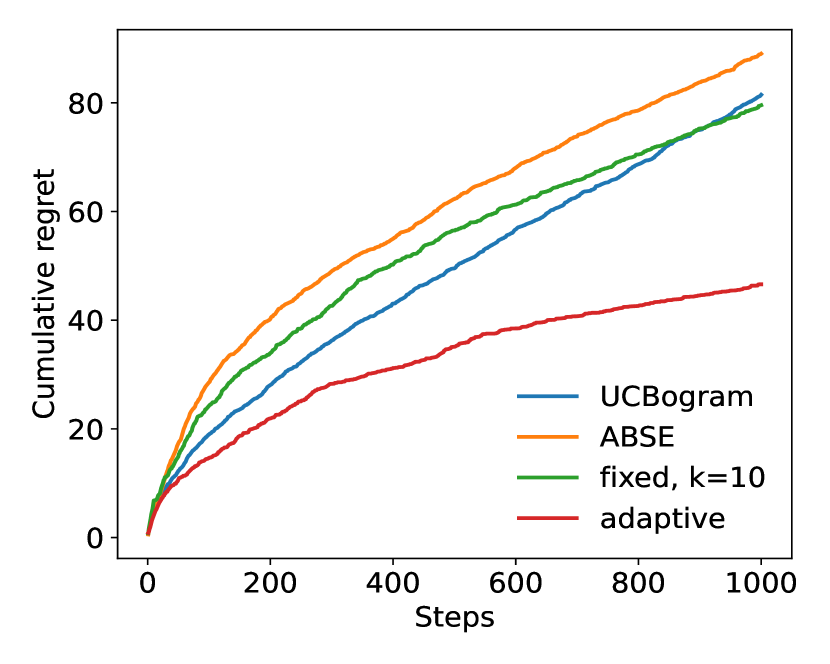
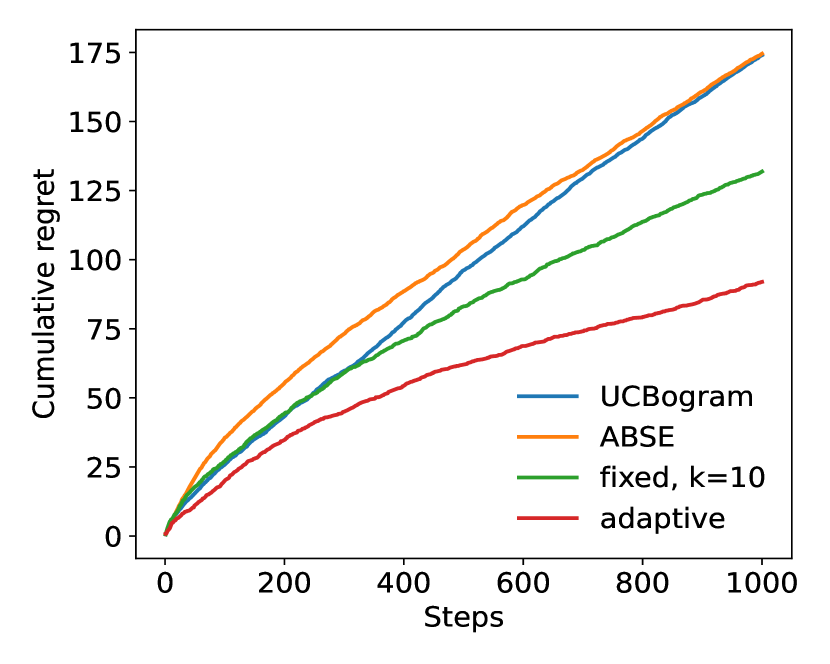
We then run experiments for two dimensional distributions. In these experiments, the context distributions are just Cartesian products of two one dimensional distributions. The two dimensional Gaussian distribution still satisfies Assumption 3(a) with , and the two dimensional and Cauchy distribution satisfy Assumption 3(a) with and , respectively, which are lower than the one dimensional case. The results are shown in Figure 2.
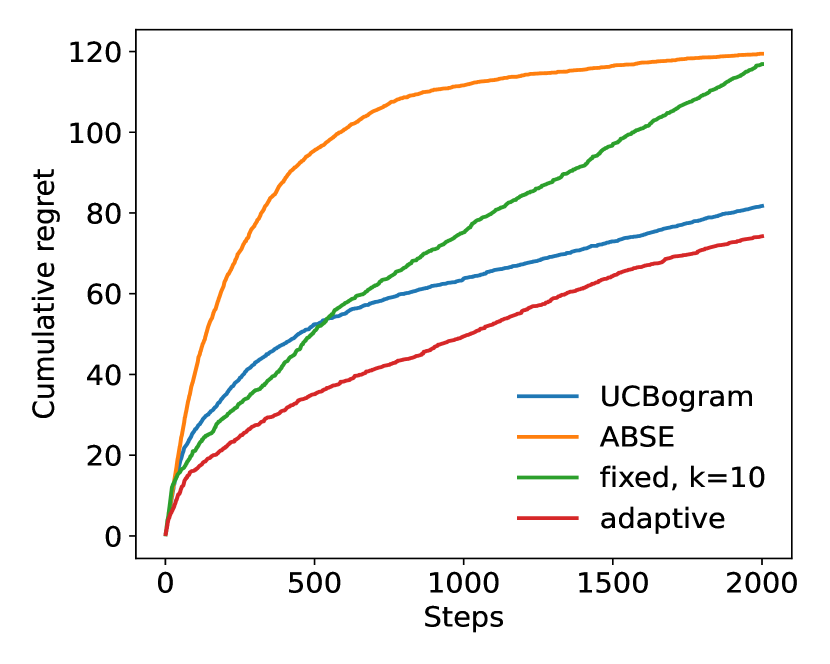
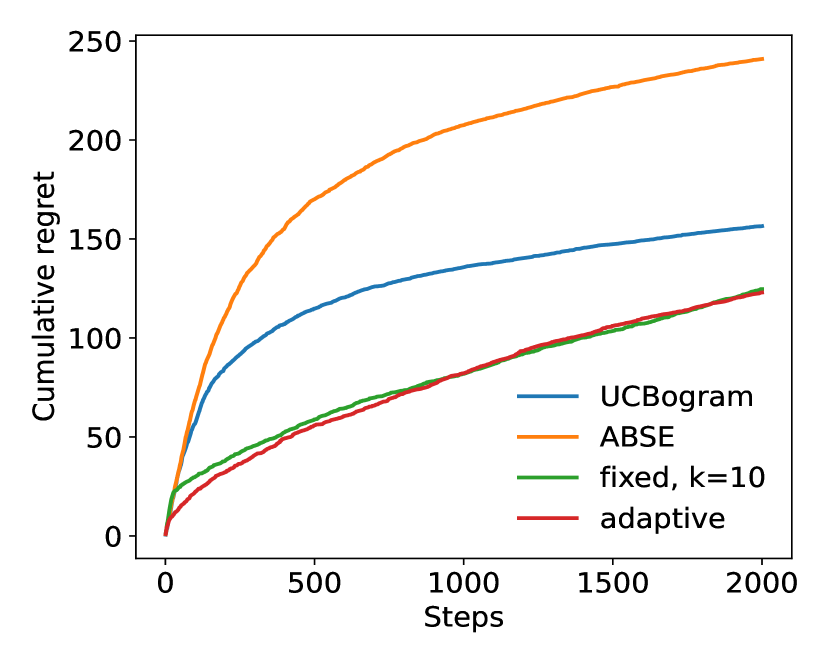
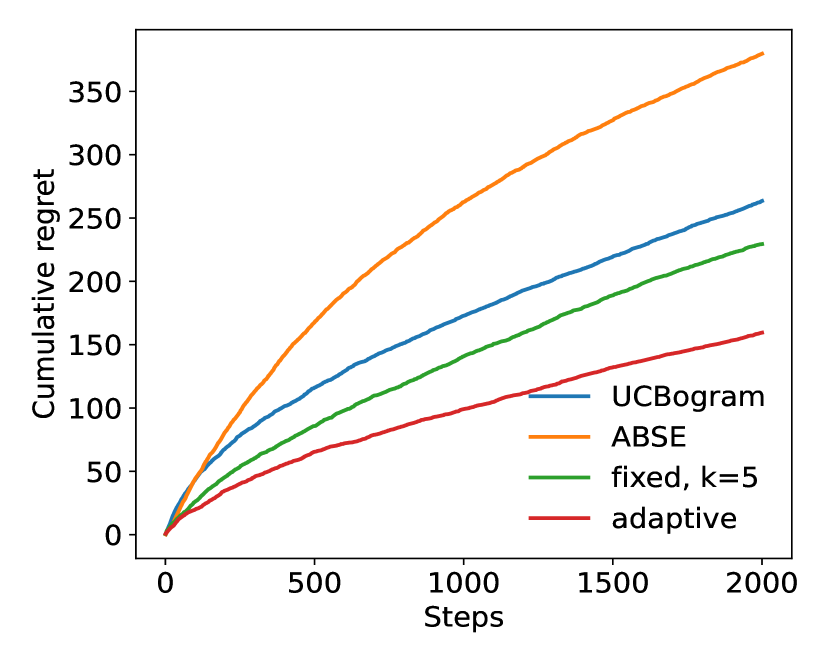
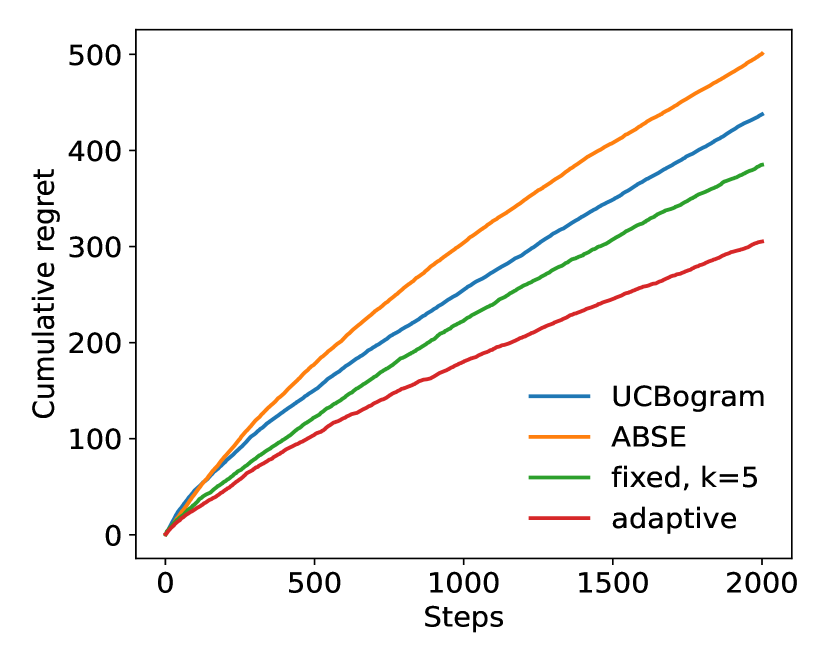
From these experiments, it can be observed that the adaptive nearest neighbor method significantly outperforms the other baselines.
7.2 Real Data
Now we run experiments using the MNIST dataset (LeCun, 1998), which contains images of handwritten digits with size . Following the settings in (Guan & Jiang, 2018), the images are regarded as contexts, and there are actions from to . The reward is if the selected action equals the true label, and otherwise. The results are shown in Figure 3. Image data have high dimensionality but low intrinsic dimensionality. Compared with bin splitting based methods (Rigollet & Zeevi, 2010; Perchet & Rigollet, 2013), nearest neighbor methods are more adaptive to local intrinsic dimension (Kpotufe, 2011). Therefore, in this experiment, we do not compare with the bin splitting based methods.
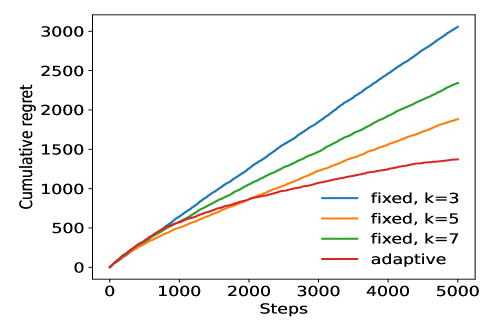
From Figure 3, the adaptive kNN method performs better than the standard kNN method with various values of .
8 Conclusion
This paper analyzes the contextual bandit problem that allows the context distribution to be heavy-tailed. To begin with, we have derived the minimax lower bound of the expected cumulative regret. We then show that the expected cumulative regret of the fixed nearest neighbor method is suboptimal compared with the minimax lower bound. To close the gap, we have proposed an adaptive nearest neighbor approach, which significantly improves the performance, and the bound of expected regret matches the minimax lower bound up to logarithm factors. Finally, we have conducted numerical experiments to validate our results.
In the future, this work can be extended in the following ways. Firstly, following existing analysis in (Gur et al., 2022), it may be meaningful to design a smoothness adaptive method that can handle any Hölder smoothness parameters. Secondly, it is worth extending current work to handle dynamic regret functions. Finally, the theories and methods developed in this paper can be extended to more complicated tasks, such as reinforcement learning (Zhao & Lai, 2024).
References
- Abbasi-Yadkori et al. (2011) Abbasi-Yadkori, Y., Pál, D., and Szepesvári, C. Improved algorithms for linear stochastic bandits. Advances in Neural Information Processing Systems, 24, 2011.
- Agrawal (1995) Agrawal, R. Sample mean based index policies by o (log n) regret for the multi-armed bandit problem. Advances in applied probability, 27(4):1054–1078, 1995.
- Akhavan et al. (2024) Akhavan, A., Lounici, K., Pontil, M., and Tsybakov, A. B. Contextual continuum bandits: Static versus dynamic regret. arXiv preprint arXiv:2406.05714, 2024.
- Audibert & Tsybakov (2007) Audibert, J.-Y. and Tsybakov, A. B. Fast learning rates for plug-in classifiers. The Annals of Statistics, pp. 608–633, 2007.
- Auer et al. (2002) Auer, P., Cesa-Bianchi, N., and Fischer, P. Finite-time analysis of the multiarmed bandit problem. Machine learning, 47:235–256, 2002.
- Bastani & Bayati (2020) Bastani, H. and Bayati, M. Online decision making with high-dimensional covariates. Operations Research, 68(1):276–294, 2020.
- Bastani et al. (2021) Bastani, H., Bayati, M., and Khosravi, K. Mostly exploration-free algorithms for contextual bandits. Management Science, 67(3):1329–1349, 2021.
- Blanchard et al. (2023) Blanchard, M., Hanneke, S., and Jaillet, P. Adversarial rewards in universal learning for contextual bandits. arXiv preprint arXiv:2302.07186, 2023.
- Bouneffouf et al. (2020) Bouneffouf, D., Rish, I., and Aggarwal, C. Survey on applications of multi-armed and contextual bandits. In 2020 IEEE Congress on Evolutionary Computation (CEC), pp. 1–8, 2020.
- Cai et al. (2024) Cai, C., Cai, T. T., and Li, H. Transfer learning for contextual multi-armed bandits. The Annals of Statistics, 52(1):207–232, 2024.
- Cannings et al. (2020) Cannings, T. I., Berrett, T. B., and Samworth, R. J. Local nearest neighbour classification with applications to semi-supervised learning. The Annals of Statistics, 48(3):1789–1814, 2020.
- Chaudhuri & Dasgupta (2014) Chaudhuri, K. and Dasgupta, S. Rates of convergence for nearest neighbor classification. In Advances in Neural Information Processing Systems, volume 27, 2014.
- Chu et al. (2011) Chu, W., Li, L., Reyzin, L., and Schapire, R. Contextual bandits with linear payoff functions. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, pp. 208–214, 2011.
- Döring et al. (2018) Döring, M., Györfi, L., and Walk, H. Rate of convergence of -nearest-neighbor classification rule. Journal of Machine Learning Research, 18(227):1–16, 2018.
- Dudik et al. (2011) Dudik, M., Hsu, D., Kale, S., Karampatziakis, N., Langford, J., Reyzin, L., and Zhang, T. Efficient optimal learning for contextual bandits. arXiv preprint arXiv:1106.2369, 2011.
- Durand et al. (2018) Durand, A., Achilleos, C., Iacovides, D., Strati, K., Mitsis, G. D., and Pineau, J. Contextual bandits for adapting treatment in a mouse model of de novo carcinogenesis. In Machine learning for healthcare conference, pp. 67–82, 2018.
- Fedotov et al. (2003) Fedotov, A. A., Harremoës, P., and Topsoe, F. Refinements of pinsker’s inequality. IEEE Transactions on Information Theory, 49(6):1491–1498, 2003.
- Gadat et al. (2016) Gadat, S., Klein, T., and Marteau, C. Classification in general finite dimensional spaces with the k nearest neighbor rule. The Annals of Statistics, pp. 982–1009, 2016.
- Gao et al. (2018) Gao, W., Oh, S., and Viswanath, P. Demystifying fixed -nearest neighbor information estimators. IEEE Transactions on Information Theory, 64(8):5629–5661, 2018.
- Garivier & Cappé (2011) Garivier, A. and Cappé, O. The kl-ucb algorithm for bounded stochastic bandits and beyond. In Proceedings of the 24th Annual Conference on Learning Theory, pp. 359–376, 2011.
- Ghosh et al. (2024) Ghosh, A., Sankararaman, A., Ramchandran, K., Javidi, T., and Mazumdar, A. Competing bandits in non-stationary matching markets. IEEE Transactions on Information Theory, 2024.
- Guan & Jiang (2018) Guan, M. and Jiang, H. Nonparametric stochastic contextual bandits. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- Gur et al. (2022) Gur, Y., Momeni, A., and Wager, S. Smoothness-adaptive contextual bandits. Operations Research, 70(6):3198–3216, 2022.
- Hu et al. (2020) Hu, Y., Kallus, N., and Mao, X. Smooth contextual bandits: Bridging the parametric and non-differentiable regret regimes. In Conference on Learning Theory, pp. 2007–2010, 2020.
- Jiang (2019) Jiang, H. Non-asymptotic uniform rates of consistency for k-nn regression. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pp. 3999–4006, 2019.
- Komiyama et al. (2024) Komiyama, J., Fouché, E., and Honda, J. Finite-time analysis of globally nonstationary multi-armed bandits. Journal of Machine Learning Research, 25(112):1–56, 2024.
- Kpotufe (2011) Kpotufe, S. k-nn regression adapts to local intrinsic dimension. In Advances in Neural Information Processing Systems, pp. 729–737, 2011.
- Krishnamurthy et al. (2020) Krishnamurthy, A., Langford, J., Slivkins, A., and Zhang, C. Contextual bandits with continuous actions: Smoothing, zooming, and adapting. Journal of Machine Learning Research, 21(137):1–45, 2020.
- Lai & Robbins (1985) Lai, T. L. and Robbins, H. Asymptotically efficient adaptive allocation rules. Advances in applied mathematics, 6(1):4–22, 1985.
- Langford & Zhang (2007) Langford, J. and Zhang, T. The epoch-greedy algorithm for multi-armed bandits with side information. Advances in Neural Information Processing Systems, 20, 2007.
- LeCun (1998) LeCun, Y. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/, 1998.
- Li et al. (2010) Li, L., Chu, W., Langford, J., and Schapire, R. E. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th international conference on World wide web, pp. 661–670, 2010.
- Locatelli & Carpentier (2018) Locatelli, A. and Carpentier, A. Adaptivity to smoothness in x-armed bandits. In Conference on Learning Theory, pp. 1463–1492, 2018.
- Mai & Johansson (2021) Mai, V. V. and Johansson, M. Stability and convergence of stochastic gradient clipping: Beyond lipschitz continuity and smoothness. In International Conference on Machine Learning, pp. 7325–7335, 2021.
- Misra et al. (2019) Misra, K., Schwartz, E. M., and Abernethy, J. Dynamic online pricing with incomplete information using multiarmed bandit experiments. Marketing Science, 38(2):226–252, 2019.
- Perchet & Rigollet (2013) Perchet, V. and Rigollet, P. The multi-armed bandit problem with covariates. The Annals of Statistics, 41(2):693–721, 2013.
- Qian & Yang (2016) Qian, W. and Yang, Y. Kernel estimation and model combination in a bandit problem with covariates. Journal of Machine Learning Research, 17(149):1–37, 2016.
- Qian et al. (2023) Qian, W., Ing, C.-K., and Liu, J. Adaptive algorithm for multi-armed bandit problem with high-dimensional covariates. Journal of the American Statistical Association, pp. 1–13, 2023.
- Reeve et al. (2018) Reeve, H., Mellor, J., and Brown, G. The k-nearest neighbour ucb algorithm for multi-armed bandits with covariates. In Algorithmic Learning Theory, pp. 725–752, 2018.
- Rigollet & Zeevi (2010) Rigollet, P. and Zeevi, A. Nonparametric bandits with covariates. 23th Annual Conference on Learning Theory, pp. 54, 2010.
- Robbins (1952) Robbins, H. Some aspects of the sequential design of experiments. Bulletin of the American Mathematical Society, 58(5):527–535, 1952.
- Slivkins (2014) Slivkins, A. Contextual bandits with similarity information. Journal of Machine Learning Research, 15:2533–2568, 2014.
- Suk (2024) Suk, J. Adaptive smooth non-stationary bandits. arXiv preprint arXiv:2407.08654, 2024.
- Suk & Kpotufe (2023) Suk, J. and Kpotufe, S. Tracking most significant shifts in nonparametric contextual bandits. Advances in Neural Information Processing Systems, 36:6202–6241, 2023.
- Tsybakov (2009) Tsybakov, A. B. Introduction to Nonparametric Estimation. 2009.
- Wanigasekara & Yu (2019) Wanigasekara, N. and Yu, C. L. Nonparametric contextual bandits in an unknown metric space. Advances in Neural Information Processing Systems, 32:14684–14694, 2019.
- Woodroofe (1979) Woodroofe, M. A one-armed bandit problem with a concomitant variable. Journal of the American Statistical Association, 74(368):799–806, 1979.
- Yang & Zhu (2002) Yang, Y. and Zhu, D. Randomized allocation with nonparametric estimation for a multi-armed bandit problem with covariates. The Annals of Statistics, 30(1):100–121, 2002.
- Zangerle & Bauer (2022) Zangerle, E. and Bauer, C. Evaluating recommender systems: survey and framework. ACM Computing Surveys, 55(8):1–38, 2022.
- Zhao & Lai (2021a) Zhao, P. and Lai, L. Efficient classification with adaptive knn. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 11007–11014, 2021a.
- Zhao & Lai (2021b) Zhao, P. and Lai, L. Minimax rate optimal adaptive nearest neighbor classification and regression. IEEE Transactions on Information Theory, 67(5):3155–3182, 2021b.
- Zhao & Lai (2022) Zhao, P. and Lai, L. Analysis of knn density estimation. IEEE Transactions on Information Theory, 68(12):7971–7995, 2022.
- Zhao & Lai (2024) Zhao, P. and Lai, L. Minimax optimal q learning with nearest neighbors. IEEE Transactions on Information Theory, 2024.
- Zhao & Wan (2024) Zhao, P. and Wan, Z. Robust nonparametric regression under poisoning attack. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 17007–17015, 2024.
- Zhou et al. (2017) Zhou, Q., Zhang, X., Xu, J., and Liang, B. Large-scale bandit approaches for recommender systems. In Neural Information Processing: 24th International Conference, ICONIP 2017, Guangzhou, China, November 14-18, 2017, Proceedings, Part I 24, pp. 811–821. Springer, 2017.
- Zhu et al. (2022) Zhu, Y., Foster, D. J., Langford, J., and Mineiro, P. Contextual bandits with large action spaces: Made practical. In International Conference on Machine Learning, pp. 27428–27453. PMLR, 2022.
Appendix A Examples of Heavy-tailed Distributions
This section explains Example 1 and 2 in the paper. For Example 1,
| (23) |
For Example 2, from Hölder’s inequality,
Let , then . If , then , thus . Hence , and
| (25) |
Therefore for all , Assumption 3(a) holds with some finite .
For subgaussian or subexponential random variables, holds for any , thus Assumption 3(a) holds for arbitrarily close to .
Appendix B Expected Sample Density
In this section, we define expected sample density, which is then used in the later analysis. Throughout this section, denote as the value of -th component of vector .
Definition 1.
(expected sample density) is defined as the function such that for all ,
| (26) |
Then we show the following basic lemmas.
Lemma 1.
Regardless of , satisfies
| (29) |
for almost all .
Proof.
Lemma 2.
, in which is defined as
| (31) |
Proof.
| (32) | |||||
The proof is complete. ∎
Appendix C Proof of Theorem 1
Recall that
| (33) |
Now we define
| (34) |
as the expected number of steps with suboptimal actions.
The following lemma characterizes the relationship between and .
Lemma 3.
There exists a constant , such that
| (35) |
Proof.
From now on, we only discuss the case with only two actions, such that . Construct disjoint balls with centers and radius . Let
| (36) |
in which is the -th ball. To ensure that the pdf defined above is normalized (i.e. ), and need to satisfy
| (37) |
in which is the volume of dimensional unit ball.
Let and , with
| (38) |
in which for . To satisfy the margin assumption (Assumption 1(a)), note that
| (41) |
Note that for any suboptimal action , . Assumption 1(a) requires that . Therefore, it suffices to ensure that
| (42) |
Then
| (43) | |||||
Define
| (44) |
Then
| (45) |
Since
| (46) |
we have
| (47) |
If , then
| (48) |
Therefore, from (43),
| (49) | |||||
Note that the error probability of hypothesis testing between distance and is at least , in which denotes the total variation distance. Let be a vector of random variables taking values from randomly. In other words, , and for different are i.i.d. Denote as the distribution of and conditional on . Moreover, means the distribution of and of the first samples conditional on . Then
| (50) | |||||
in which the second step uses Pinsker’s inequality (Fedotov et al., 2003), and denotes the Kullback-Leibler (KL) divergence between distributions and . Note that the KL divergence between the conditional distribution is bounded by
| (51) |
for . Therefore
| (52) | |||||
Hence, from (50),
| (53) | |||||
Recall (49),
| (54) | |||||
in which the last step comes from (42).
Appendix D Proof of Theorem 2
In this section, we derive the minimax lower bound of the expected regret with unbounded support. Recall that in the case with bounded support of contexts (Proof of Theorem 1 in Appendix C), we construct disjoint balls with pdf for all . Now for the case with unbounded support, the distribution of context has tails, on which the pdf is small. Therefore, we modify the construction of balls as follows. We now construct disjoint balls with center , such that
| (57) | |||||
| (58) |
Let
| (59) |
in which is unknown, and
| (60) |
in which will be determined later. Here we construct one ball that denotes the center region which has the most of probability mass, as well as balls that denotes the tail region. For simplicity, we let at the largest ball , and only
To satisfy the margin condition (i.e. Assumption 1(a)), note that now
| (63) |
The right hand side of (63) can not exceed , which requires
| (64) |
Moreover, to satisfy the tail assumption (Assumption 3(a)), note that
| (67) |
The right hand side of (67) can not exceed , which requires
| (68) |
Following (49), can be lower bounded by
| (69) | |||||
From (69), we pick and to ensure that
| (70) |
Then under three conditions (64), (68) and (70),
| (71) |
It remains to determine the value of , and based on these three conditions. Let
| (72) |
| (73) |
and
| (74) |
then
| (75) |
Based on Lemma 3,
| (76) |
It remains to show that . Let , and , the conditions (64), (68) and (70) are still satisfied. In this case,
| (77) |
Direct transformation using Lemma 3 yields suboptimal bound. Intuitively, for the case with heavy tails (i.e. is small), the regret mainly occur at the tail of the context distribution. Therefore, we bound the expected regret again.
| (78) | |||||
(a) comes from the construction of in (59). (b) holds since we set here.
Appendix E Proof of Theorem 3
To begin with, we show the following lemma.
Lemma 4.
For all ,
| (80) |
Proof.
The proof is shown in Appendix I.1. ∎
From Lemma 4, recall the definition of in (10),
| (81) |
Therefore, with probability , for all , and , . Denote as the event such that , , then
| (82) | |||||
Recall the calculation of UCB in (9). Based on Lemma 4, we then show some properties of the UCB in (9).
Lemma 5.
Under , if , then
| (83) |
Proof.
The proof is shown in Appendix I.2. ∎
We then bound the number of steps with suboptimal action . Define
| (84) |
Then the following lemma holds.
Lemma 6.
Under , for any , , if , define
| (85) |
then
| (86) |
Proof.
The proof is shown in Appendix I.3. ∎
From Lemma 6, the expectation of can be bounded as follows.
| (87) | |||||
in which the first step holds since even if does not hold, the number of steps in is no more than the total sample size . The second step uses (82). From (87) and the definition of expected sample density in (26),
| (88) |
It bounds the average value of over the neighborhood of . However, it does not bound directly. To bound , we introduce a new random variable , with pdf
| (89) |
in which , with defined in (10). is the constant for normalization. We then bound defined in (31). can be split into two terms:
| (90) | |||||
To begin with, we bound the first term in (90). We show the following lemma.
Lemma 7.
There exists a constant , such that
| (91) |
in which .
Now we bound the right hand side of (91). We show the following lemma.
Lemma 8.
| (95) |
in which is the lower bound of pdf of contexts, which comes from Assumption 2.
| (99) |
Now we bound the second term in (90). From Lemma 1, for almost all . Thus
| (100) | |||||
Therefore, from (90), (99) and (100),
| (104) |
Recall that
| (105) |
If , let , then
| (106) |
and
| (107) |
If , let , then
| (108) |
and
| (109) |
Appendix F Proof of Theorem 4
Recall the expression of regret shown in Lemma 2. We decompose as follows.
| (110) | |||||
in which is the same as the proof of Theorem 3 in Appendix 5, i.e. .
Bound of . From Lemma 1, for almost all . Hence
| (111) | |||||
Bound of . The regret of the high density region can be bounded similarly as the regret for pdf bounded away from zero. Follow the proof of Theorem 3 in Appendix 5, define
| (112) |
Similar to Lemma 5,
| (113) |
Similar to Lemma 6, now we replace with . Then
| (117) |
Therefore
| (121) |
Bound of . Here we introduce the following lemma.
Lemma 9.
(Restated from Lemma 6 in (Zhao & Lai, 2021b)) For any ,
| (125) |
Proof.
Based on Lemma 9, can be bounded by
| (128) | |||||
Bound of .
| (129) | |||||
Now we bound by selecting to minimize the sum of , , , . Recall that , in which is defined in (10), thus .
(1) If and , then with ,
| (130) | |||||
(2) If and , then with ,
| (131) | |||||
(3) If and , then with ,
| (132) | |||||
(4) If and , then with ,
| (133) | |||||
Combine all these cases, we conclude that
| (134) |
The proof of Theorem 4 is complete.
Appendix G Proof of Theorem 5
Lemma 10.
| (135) |
with being the set of neighbors among .
Lemma 11.
Define event , such that if
| (137) |
for all , then . Moreover, under ,
| (138) |
Proof.
With these preparations, we then bound the number of steps around each in the next lemma, which is crucially different with Lemma 6. Here we keep the definition to be the same as (84), but change the definition of and as follows.
Lemma 12.
Define
| (140) |
and
| (141) |
in which
| (142) |
Then under ,
| (143) |
Now we bound . Similar to (89), let random variable follows a distribution with pdf :
| (146) |
The difference with the case with fixed is that in (89), . However, now varies among , thus we do not determine based on . Instead, for the adaptive nearest neighbor method, will be determined after we get the final bound of .
We show the following lemma.
Lemma 13.
There exists a constant , such that
| (147) |
We then bound the right hand side of (147).
Lemma 14.
| (148) |
Appendix H Proof of Theorem 6
Define
| (155) |
in which
| (156) |
and is the normalization constant, which ensures that . Let be a random variable with pdf . We then bound for the case with unbounded support on the contexts, under Assumption 2 and 3.
| (157) | |||||
Now we bound three terms in (157) separately.
Bound of . Following Lemma 7 and 13, it can be shown that for some constant , such that
| (158) |
The right hand side of (158) can be bounded as follows.
| (159) | |||||
Hence
| (160) |
Let that will be determined later.
| (161) | |||||
To bound the integration of the other side, i.e. , we use Lemma 9.
Bound of . We still discuss and separately. For ,
| (172) | |||||
For ,
| (175) | |||||
Similar to , pick .
Appendix I Proof of Lemmas
I.1 Proof of Lemma 4
From Assumption 2(c), is subgaussian with parameter . Therefore for any fixed set with ,
| (180) |
and
| (181) | |||||
Now we need to give a union bound333The construction of hyperplanes follows the proof of Lemma 3 in (Jiang, 2019) and Appendix H.5 in (Zhao & Wan, 2024).. Let be dimensional hyperplane that bisects , . Then the number of planes is at most . Note that planes divide a dimensional space into at most regions. Therefore
| (182) |
The nearest neighbors for all within a region should be the same. Combining with the action space , there are at most regions. Hence
| (183) |
Therefore
| (184) |
The proof is complete.
I.2 Proof of Lemma 5
I.3 Proof of Lemma 6
We prove Lemma 6 by contradiction. If , then let
| (187) |
be the last step falling in with action a. Then , and thus there are at least points in . Therefore,
| (188) |
Denote
| (189) |
as the best action at context . is selected only if the UCB of action is not less than the UCB of action , i.e.
| (190) |
From Lemma 5,
| (191) |
and
| (192) |
| (193) |
which yields
| (194) | |||||
in which the last step comes from the definition of in (85). Note that (194) contradicts (188). Therefore . The proof of Lemma 6 is complete.
I.4 Proof of Lemma 7
| (195) | |||||
In (a), the order of integration is swapped. Note that if , then . From Assumption 2(d), . Then from (85),
| (197) | |||||
thus implies . Therefore (a) holds.
For (b) in (195), note that for , using Assumption 2(d) again,
| (198) |
Then
| (199) | |||||
in which the last step comes from the definition of in (85).
For (d), recall the statement of Lemma 7, . Therefore, if , then .
I.5 Proof of Lemma 8
(b) comes from (88).
I.6 Proof of Lemma 12
We prove Lemma 12 by contradiction. Suppose now that . Let be the last sample falling in , i.e.
| (211) |
We first show that . From (211) and the condition , before time step , there are already at least steps in . Note that , thus . Therefore, there are already at least samples with action in . Recall that . If , then . From (16),
| (212) |
then contradiction occurs. Therefore .
I.7 Proof of Lemma 13
| (220) | |||||
For (a), if , then from the definition of in (140),
| (221) |
For (b),
| (222) | |||||
I.8 Proof of Lemma 14
| (223) | |||||
For (a),
| (224) | |||||
I.9 Proof of Lemma 9
| (225) | |||||
If , i.e. , then
| (226) |
If , then
| (227) |
If , then
| (228) |
I.10 Proof of Lemma 3
Our proof follows the proof of Lemma 3.1 in (Rigollet & Zeevi, 2010).
| (229) |
and
| (230) |
Then and . For any ,
| (231) | |||||
Take expectations, we have
| (232) |
Now we minimize the right hand side of (232). By making the derivative to be zero, let
| (233) |
Then
| (234) | |||||
The proof is complete.