Continuous-Time and Event-Triggered Online Optimization for Linear Multi-Agent Systems
Abstract
This paper studies the decentralized online convex optimization problem for heterogeneous linear multi-agent systems. Agents have access to their time-varying local cost functions related to their own outputs, and there are also time-varying coupling inequality constraints among them. The goal of each agent is to minimize the global cost function by selecting appropriate local actions only through communication between neighbors. We design a distributed controller based on the saddle-point method which achieves constant regret bound and sublinear fit bound. In addition, to reduce the communication overhead, we propose an event-triggered communication scheme and show that the constant regret bound and sublinear fit bound are still achieved in the case of discrete communications with no Zeno behavior. A numerical example is provided to verify the proposed algorithms.
I INTRODUCTION
Convex optimization has been widely studied as a pretty effective method in research fields involving optimization and decision-making, such as automatic control systems [1], communication networks [2], and machine learning [3]. Early convex optimization works were based on fixed cost functions and static constraints. However, in practice, optimization costs and constraints of many problems are possible to be time-varying and a priori unknown [4]. This motivated online convex optimization (OCO) which requires the decision maker to choose an action at each instant based on previous information. A widely used performance criterion of OCO is regret, that is, the gap between the cumulative loss of the selected action and that of the best ideal action made when knowing the global information beforehand. If regret is sublinear, the time average loss of the selected action is progressively not greater than that of the ideal action. Another performance indicator is fit, which measures the degree of violation of static/time-varying inequality constraints. For more details, a recent survey can be referenced [5].
The OCO framework was introduced by [6], where the projection-based online gradient descent algorithm was analyzed. Based on static constraints, the algorithm was proved to achieve static regret bound for time-varying convex cost functions with bounded subgradients. With the increase of data scale and problem complexity in recent years, distributed online convex optimization has also been widely studied in recent years [7]. In the continuous-time setting, the saddle-point algorithm proposed in [8] under constant constraints is shown to achieve sublinear bounds on the network disagreement and the regret achieved by the strategy. The authors of [9] generalized this result to the problem of time-varying constraints. In the discrete-time setting, [10, 11] used distributed primal-dual algorithms to solve online convex optimization with static independent and coupled inequality constraints. In order to solve the time-varying coupling constraints, the authors of [12] proposed a novel distributed online primal dual dynamic mirror descent algorithm to realize sublinear dynamic regret and constraint violation. A gradient-free distributed bandit online algorithm was proposed in [13], which is applicable to scenarios where it is difficult to obtain the gradient information of the cost functions. In the presence of aggregate variables in local cost functions, an online distributed gradient tracking algorithm was developed in [14] based on true or stochastic gradients.
In actual physical systems, the implementation of optimization strategies must take into account the complicated dynamics of each agent. Along this line, only a few works have investigated online convex optimization with physical systems in recent years. For continuous-time multi-agent systems with high-order integrators, the authors of [15] used PI control idea and gradient descent to solve the distributed OCO problem. The authors of [16] considered the online convex optimization problem of linear systems, but did not consider any constraints. The online convex optimization problem of linear time-invariant (LTI) system was studied in [17] based on the behavioral system theory, where a proposed data-driven algorithm that does not rely on the model achieves sublinear convergence. However, the above two papers for linear systems only provide centralized algorithms. The distributed setup for online optimization algorithm with linear systems is yet to be studied.
The main contributions of this paper are as follows.
-
•
Compared with the centralized OCO algorithms for linear systems with no constrains [16, 17], this paper studies the distributed online optimization of heterogeneous multi-agent systems with time-varying coupled inequality constraints for the first time. Agents only rely on the information of themselves and their neighbors to make decisions and achieve constant regret bound and fit bound. In comparison, most existing algorithms [12, 18] about distributed online optimization with coupled inequality constraints only achieve inferior sublinear regret bounds.
- •
The rest of the paper is organized as follows. Preliminaries are given in Section II. In Section III, the heterogeneous multi-agent system under investigation is described mathematically, the online convex optimization problem is defined and some useful lemmas are given. Following that, the control laws with continuous and event-triggered communication are proposed, respectively, and the constant regret bound and sublinear fit bound are established in Section IV. Then, a simulation example is provided to verify the effectiveness of the algorithm in Section V. Finally, the conclusion is discussed in Section VI.
II PRELIMINARIES
II-A Notations
Let , , , be the sets of real numbers, real vectors of dimension , non-negative real vectors of dimension , and real matrices of dimension , respectively. The identity matrix is denoted by . The all-one and all-zero column vectors are denoted by and , respectively. For a matrix , is its transpose and denotes a block diagonal matrix with diagonal blocks of , , . For a vector , is its -norm, is its -norm, and is a column vector by stacking vectors . represents the Kronecker product of matrices and . Let be the Euclidean projection of a vector onto the set , i.e., . For simplicity, let denote . Define the set-valued sign function as follows:
II-B Graph Theory
For a system with agents, its communication network is modeled by an undirected graph , where is a node set and is an edge set. If information exchange can occur between and , then with denoting its weight. is the adjacency matrix. If there exists a path from any node to any other node in , then is called connected.
III PROBLEM FORMULATION
Consider a multi-agent system consisting of heterogeneous agents indexed by , and the th agent has following linear dynamics:
| (1) | ||||
where , and are the state, input and output variables, respectively. , and are the state, input and output matrices, respectively.
Each agent has an output set such that the output variable . and are the private cost and constraint functions for agent . Denote , , , and . The objective of this paper is to design a controller for each agent by using only local interaction and information such that all agents cooperatively minimize the sum of the cost functions over a period of time with time-varying coupled inequality constraints:
| (2) | ||||
Let denote the optimal solution for problem (2) when the time-varying cost and constraint functions are known in advance.
In order to evaluate the cost performance of such output trajectories, we define two performance indicators: network regret and network fit. According to the previous definition, is the optimal output when the agents know all the information of network in the period of . But in reality, agents can only make decisions based on their own and neighbors’ current and previous information. Regret is described as the gap between the cumulative action incurred by and the cost incurred by the optimal output , i.e.,
| (3) |
In order to evaluate the fitness of output trajectories to the constraints (or in other words, the degree of violation of the constraints), we define fit as the projection of the cumulative constraints onto the nonnegative orthant:
| (4) |
This definition implicitly allows strictly feasible decisions to compensate for violations of constraints at certain times. This is reasonable when the variables can be stored or preserved, such as the average power constraints [19]. By , one can define as the th component of , i.e., . Further, define as the th component of the constraint integral. It can be easily deduced that
Assumption 1
The communication network is undirected and connected.
Assumption 2
Each set is convex and compact. For , functions and are convex, integrable and bounded on , i.e., there exist constants and such that and .
Assumption 3
The set of feasible outputs is non-empty.
Definition 1 ([20])
Let be a closed convex set. Then, for any and , the projection of over set at the point can be defined as
Lemma 1 ([19])
Let be a convex set and let , then
| (5) |
Assumption 4
is controllable, and
Remark 1
Assumption 2 is reasonable since the output variables in practice, such as voltage, often have a certain range. The cost functions and constraint functions are not required to be differentiable, which can be dealt with by using subgradients. The controllability in Assumption 4 is quite standard in dealing with the problem for linear systems.
IV MAIN RESULTS
IV-A Continuous Communication
For agent , to solve the online optimization problem (2), we can construct the time-varying Lagrangian
| (7) |
where is the local Lagrange multiplier for agent , is the preset parameter and is a metric of ’s disagreement [22].
Notice that , are convex and , hence the Lagrangian is convex with respect to . Let us denote by a subgradient of with respect to , i.e.,
| (8) |
The Lagrangian is concave with respect to and its subgradient is given by
| (9) |
For simplicity, define
| (10) |
where , , , , and . It can be easily verified that .
A controller following modified Arrow-Hurwicz algorithm for the th agent is proposed as
| (11a) | ||||
| (11b) | ||||
where is the step size, are feedback matrices that are the solutions of (6), and the initial value .
Substituting the controller (11) into the system (1), the system dynamics of the th agent is
| (12a) | ||||
| (12b) | ||||
| (12c) | ||||
For the subsequent analysis, consider the following energy function with any and :
| (13) |
The following lemma establishes the relationship between above energy function and time-varying Larangian (7) along the dynamics (12).
Lemma 3
Proof:
We now state the main results about the regret and fit bounds of continuous communication controller (11).
Theorem 1
Proof:
Consider the second term of the right-hand side of (19). Let for simplicity. Then, by introducing an intermediate variable and the relationship , one has that
| (20) |
Further, one can obtain that
| (21) |
Since is connected, there always exists a path connecting nodes and for any , i.e.,
| (22) |
Then for , one has that , i.e.,
| (23) |
∎
Theorem 2
Proof:
By Lemma 3 with and , where is a parameter to be determined later, one has that
| (25) |
Invoking Assumption 2 yields
| (26) |
By choosing
it can be concluded that
It can be further obtained by transposition that
| (27) |
∎
Remark 2
Theorems 1 and 2 mean that and under continuous communication. In comparison, explicit bounds on both the regret and fit with a sublinear growth are obtained in [12, 18] for single-integrator multi-agent systems, i.e., , in [12] and , in [18] for . Theorem 1 achieves stricter regret bound than [12, 18] under more complex system dynamics.
IV-B Event-triggered Communication
The above continuous-time control law, which requires each agent to know the real-time Lagrange multipliers of neighbors, may cause excessive communication overhead. In this section, an event-triggered protocol is proposed to avoid continuous communication.
For agent , suppose that is its th communication instant and is its communication instant sequence. Define as the available information of its neighbors and as the measurement error. It can be known that at any instant .
An event-triggered control law is proposed as
| (28a) | ||||
| (28b) | ||||
where is the step size, are feedback matrices that are solutions of (6), is the weight corresponding to the edge , and the initial value . Note that is chosen for the sign function in (28b) when its argument is zero.
Substituting controller (28) into (1), the system dynamics of the th agent becomes
| (29a) | ||||
| (29b) | ||||
| (29c) | ||||
The communication instant is chosen as
| (30) |
where and are prespecified positive real numbers.
The following lemma is a modification of Lemma 3 under event-triggered communication.
Lemma 4
Proof:
Similar to (15), one can obtain that
| (32) |
Since the Lagrangian (7) is convex with respect to and concave with respect to , one has that
| (33) |
Since and graph is undirected, it follows that
| (34) |
where the last inequality holds since the relationship .
Similarly, one has that
| (35) |
| (36) |
where the last inequality holds due to the trigger condition (30).
Summarizing the above-discussed analysis, in (32) is calculated as
By integrating it from to on both sides and omitting negative terms, it can be obtained that
| (37) |
∎
We now state the main results about the regret and fit bounds of event-triggered communication controller (29).
Theorem 3
Theorem 4
The proofs of Theorems 3 and 4 are similar to that of Theorems 1 and 2, except that Lemma 4 is used instead of Lemma 3. They are thus omitted here.
Remark 3
Theorems 3 and 4 mean that and still hold even under event-triggered communication. The bounds of regret and fit are determined by the communication frequency. Generally speaking, decreasing and increasing will achieve smaller bounds on regret and fit, but meanwhile increase the communication frequency, which results in a tradeoff between them.
Theorem 5
Proof:
In the trigger interval for agent , combining the definition of with (28b), one can write the upper right-hand Dini derivative as
| (40) |
It is obvious that . Then, for , the solution of (40) is
| (41) |
From Assumption 2 and the inequality (cf. Remark 2.1 in [20]), it can be obtained that the norm of the integral term in (41) is bounded, and let the upper bound of its norm be . It then follows from (41) that
| (42) |
Hence, condition (30) will definitely not be triggered before the following condition holds:
| (43) |
It is easy to obtain that the right-hand side of (43) is positive for any finite time , which further implies that . Hence, the value is strictly positive for finite , which implies that no Zeno behavior is exhibited. ∎
V SIMULATION
Consider a heterogeneous multi-agent system composed of agents described by (1), where , , , , , , , , , , .
The local objective functions are time-varying quadratic functions as follows:
The feasible set of output variables . The constraints are defined by a time-varying function
The above constraint selection ensures that must be a strictly feasible solution for all .
The clairvoyant optimal output can be computed by solving the problem
| (44) | ||||
The communication network among these agents is depicted in Fig. 1. It can be verified that Assumptions 14 hold.
For the numerical example, the selection of feedback matrices is based on (6), where , , , , , . The initial values are randomly selected in and .
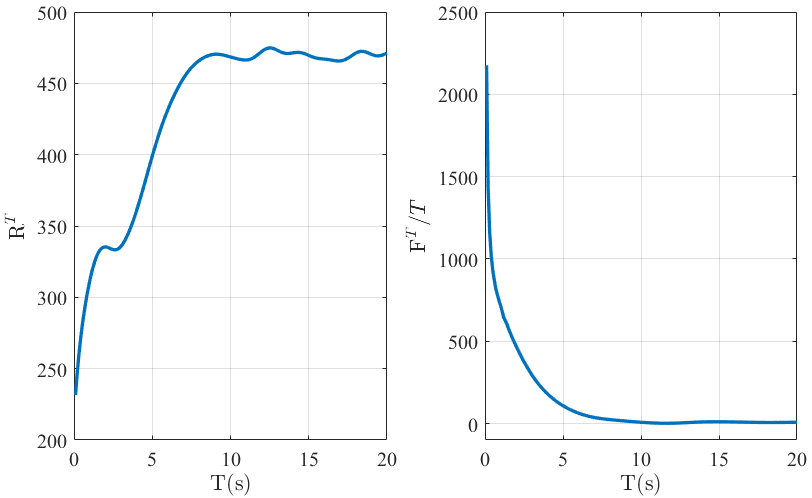
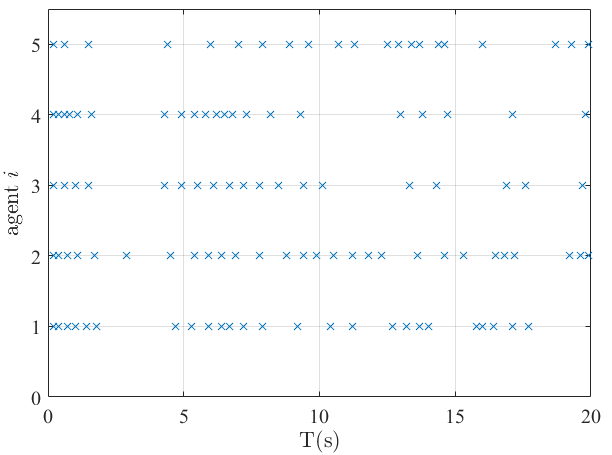
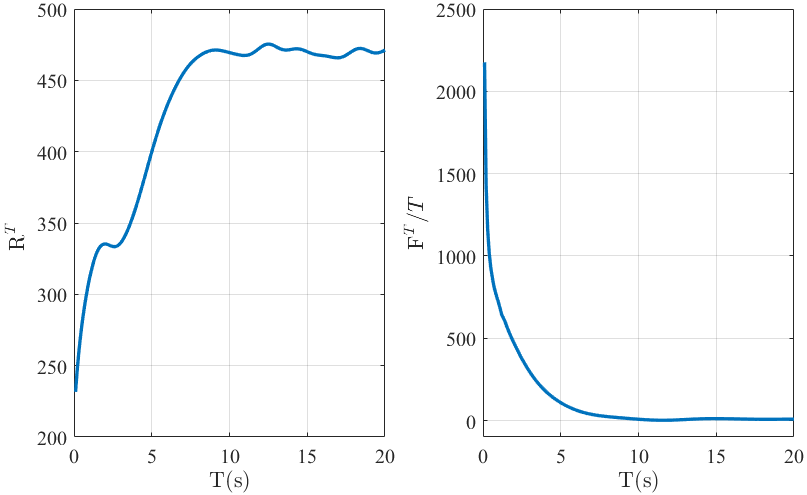
Fig. 2 illustrates that the continuous-time control law achieves constant regret bound and sublinear fit bound. The results are in accordance with those established in Theorems 1-2. Likewise, the similar results can be observed in Fig. 3 under event-triggered communication. Fig. 4 shows the communication moments of five agents with event-triggered control laws, from which one can observe that the communication among five agents is discrete and exhibits no Zeno behavior.
VI CONCLUSION
In this paper, we studied distributed online convex optimization for heterogeneous linear multi-agent systems with time-varying cost functions and time-varying coupling inequality constraints. A distributed controller was proposed based on the saddle-point method, showing the constant regret bound and sublinear fit bound. In order to avoid continuous communication and reduce the communication cost, an event-triggered communication scheme with no Zeno behavior was developed, which also achieves constant regret bound and sublinear fit bound.
References
- [1] M. A. Dahleh and I. J. Diaz-Bobillo, Control of Uncertain Systems: A Linear Programming Approach. Prentice-Hall, Englewood Cliffs, NJ, 1995.
- [2] Z. Luo, “Applications of convex optimization in signal processing and digital communication,” Math. Program., vol. 97, no. 1-2, pp. 177–207, 2003.
- [3] J. Qiu, Q. Wu, G. Ding, Y. Xu, and S. Feng, “A survey of machine learning for big data processing.,” EURASIP J. Adv. Signal Process., vol. 2016, p. 67, 2016.
- [4] S. Shalev-Shwartz, “Online learning and online convex optimization,” Foundations and Trends in Machine Learning, vol. 4, no. 2, pp. 107–194, 2011.
- [5] X. Li, L. Xie, and N. Li, “A survey of decentralized online learning,” arXiv preprint arXiv:2205.00473, 2022.
- [6] M. Zinkevich, “Online convex programming and generalized infinitesimal gradient ascent,” in Proceedings, Twentieth International Conference on Machine Learning, vol. 2, pp. 928–935, 2003.
- [7] X. Zhou, E. Dallanese, L. Chen, and A. Simonetto, “An incentive-based online optimization framework for distribution grids,” IEEE Transactions on Automatic Control, vol. 63, no. 7, pp. 2019–2031, 2018.
- [8] S. Lee, A. Ribeiro, and M. Zavlanos, “Distributed continuous-time online optimization using saddle-point methods,” in IEEE 55th Conference on Decision and Control, pp. 4314–4319, 2016.
- [9] S. Paternain, S. Lee, M. Zavlanos, and A. Ribeiro, “Distributed constrained online learning,” IEEE Transactions on Signal Processing, vol. 68, pp. 3486–3499, 2020.
- [10] D. Yuan, D. Ho, and G.-P. Jiang, “An adaptive primal-dual subgradient algorithm for online distributed constrained optimization,” IEEE Transactions on Cybernetics, vol. 48, no. 11, pp. 3045–3055, 2018.
- [11] X. Li, X. Yi, and L. Xie, “Distributed online optimization for multi-agent networks with coupled inequality constraints,” IEEE Transactions on Automatic Control, vol. 66, no. 8, pp. 3575–3591, 2021.
- [12] X. Yi, X. Li, L. Xie, and K. Johansson, “Distributed online convex optimization with time-varying coupled inequality constraints,” IEEE Transactions on Signal Processing, vol. 68, pp. 731–746, 2020.
- [13] X. Yi, X. Li, T. Yang, L. Xie, T. Chai, and K. H. Johansson, “Distributed bandit online convex optimization with time-varying coupled inequality constraints,” IEEE Transactions on Automatic Control, vol. 66, no. 10, pp. 4620–4635, 2021.
- [14] X. Li, X. Yi, and L. Xie, “Distributed online convex optimization with an aggregative variable,” IEEE Transactions on Control of Network Systems, pp. 1–8, 2021.
- [15] Z. Deng, Y. Zhang, and Y. Hong, “Distributed online optimization of high-order multi-agent systems,” in 2016 35th Chinese Control Conference (CCC), pp. 7672–7677, 2016.
- [16] M. Nonhoff and M. Müller, “Online gradient descent for linear dynamical systems,” in IFAC-PapersOnLine, vol. 53, pp. 945–952, 2020.
- [17] M. Nonhoff and M. A. Müller, “Data-driven online convex optimization for control of dynamical systems,” arXiv preprint arXiv:2103.09127, 2021.
- [18] J. Li, C. Gu, Z. Wu, and T. Huang, “Online learning algorithm for distributed convex optimization with time-varying coupled constraints and bandit feedback,” IEEE Transactions on Cybernetics, vol. 52, no. 2, pp. 1009–1020, 2022.
- [19] S. Paternain and A. Ribeiro, “Online learning of feasible strategies in unknown environments,” IEEE Transactions on Automatic Control, vol. 62, no. 6, pp. 2807–2822, 2017.
- [20] D. Zhang and A. Nagurney, “On the stability of projected dynamical systems,” Journal of Optimization Theory and Applications, vol. 85, no. 1, pp. 97–124, 1995.
- [21] L. Li, Y. Yu, X. Li, and L. Xie, “Exponential convergence of distributed optimization for heterogeneous linear multi-agent systems over unbalanced digraphs,” Automatica, vol. 141, p. 110259, 2022.
- [22] S. Liang, X. Zeng, and Y. Hong, “Distributed nonsmooth optimization with coupled inequality constraints via modified Lagrangian function,” IEEE Transactions on Automatic Control, vol. 63, no. 6, pp. 1753–1759, 2018.