Controlled and Conditional Text to Image Generation with Diffusion Prior
Abstract
Denoising Diffusion models have shown remarkable performance in generating diverse, high quality images from text. Numerous techniques have been proposed on top of or in alignment with models like Stable Diffusion and Imagen that generate images directly from text. A lesser explored approach is DALLE-2’s two step process comprising a Diffusion Prior that generates a CLIP image embedding from text and a Diffusion Decoder that generates an image from a CLIP image embedding. We explore the capabilities of the Diffusion Prior and the advantages of an intermediate CLIP representation. We observe that Diffusion Prior can be used in a memory and compute efficient way to constrain the generation to a specific domain without altering the larger Diffusion Decoder. Moreover, we show that the Diffusion Prior can be trained with additional conditional information such as color histogram to further control the generation. We show quantitatively and qualitatively that the proposed approaches perform better than prompt engineering for domain specific generation and existing baselines for color conditioned generation. We believe that our observations and results will instigate further research into the diffusion prior and uncover more of its capabilities.

1 Introduction
Diffusion Models [24] have shown remarkable performance in generating high quality and diverse images from text [25, 48]. There have been numerous efforts to improve quality of generation [54, 61], improve training and sampling speed [57, 62, 68, 39] and apply such models for editing [42, 23, 33, 8] or finetuning for conditional or domains specific generations [75, 6]. However, most of these works focus on architectures similar to [57, 61] that condition the diffusion decoder directly on text embedding and encodings. In [54], authors propose a text–to–image generation model comprising of two steps. Firstly, a Diffusion Prior model generates CLIP [52] image embedding conditioned on CLIP text embedding of the input text. Following that, a Diffusion Decoder model generates the final image conditioned on the generated CLIP image embedding. There is limited research based on this approach largely because of the lack of publicly available models, unlike the text conditioned Latent Diffusion Models (LDM) [57].
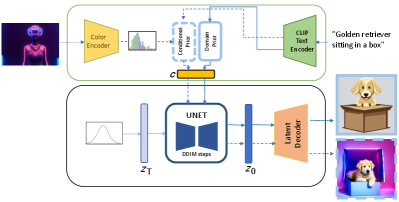
In [54], the authors showed that having a common intermediate CLIP representation allows for improved diversity, native support for image variations, interpolations and latent manipulation. In this paper, we look further into the capabilities and advantages of having a common intermediate representation as well as the Diffusion Prior model. Since there aren’t publicly available weights or code for the DALLE-2 model, we leverage the Diffusion Prior model111https://github.com/LAION-AI/conditioned-prior trained by LAION222https://laion.ai as the baseline for our experiments. For the Diffusion Decoder as described in Appendix Sec. C.2, we train a LDM using the publicly available code from [57] but modify the cross–attention layers to condition on CLIP-L/14 image embedding instead of text embedding and encodings. We call our setup (similar to [54]) for text-to-image generation with Diffusion Prior and Diffusion Decoder together as a Hybrid Diffusion Model (HDM) different from DALLE-2 Hierarchical Diffusion Model that comprises of a sequence of diffusion models that generate and then upsample the generated images.
We explore the possibilities with Diffusion Prior model to answer the following question. ”Can we control the image generations from HDM to be within a specific constrained desirable sub-space in CLIP without finetuning the larger Diffusion Decoder model?” To answer this question, we explore the following applications: (i) Text to Texture (ii) Text to Rasterized Vectors (iii) Text to Isolated Objects (iv) Color Conditioned Text to Image. We term the first three applications as domain specific generation to emphasize that the generations are pixel images corresponding to specific domains that can further be used to synthesize texture [79] or vectors in Scalable Vector Graphics (SVG) [30] format. The last problem is the well known conditional generation where the conditional input is text and desired color histogram. Though we evaluate on these specific domains, we believe the approach is simple and robustly applicable across other domains and conditional inputs.
An example of what is possible with the proposed setup is shown in Fig.Controlled and Conditional Text to Image Generation with Diffusion Prior. These domain specific or conditional generations are difficult to generate with naive prompt engineering in existing models such as Stable Diffusion as shown in Sec.5. Generation of these domain specific images usually require finetuning the large model on domain specific data [30] which is computationally expensive. We train a new Diffusion Prior model for each of these applications while keeping the larger Diffusion Decoder model intact from the original pretrained HDM. We show that, by training smaller Diffusion Prior models on domain specific dataset or conditioned on additional input, we can effectively control the generated images to a desired domain or correspond to a specific desirable color palette. We further show that the proposed setup is more efficient in terms of memory and compute since Diffusion Prior model is significantly smaller (order of 5 [54]) compared to larger models [30, 56] and performs quantitatively and qualitatively better than existing baselines.
The summary of our contributions are:
– We explore the versatile capabilities of Diffusion Prior and having a common intermediate CLIP embedding space by training small domain specific and color conditional prior models for controllable and conditional text-to-image generation.
– To convert the outputs from our prior models to images, we train an LDM conditioned on normalized CLIP L/14 image embeddings to support our experiments.
– We perform a comprehensive quantitative and qualitative performance evaluation on our proposed setup on three domains texture, vector and isolated objects for domain specific generations and on color for conditional generation.
To the best of our knowledge, there is no existing work that shows effective semantic aware color conditional generation and domain specific generations using the HDM architecture by modifying only the Diffusion Prior. We hope that our observation and results lead to further research into the HDM architecture and the Diffusion Prior for various applications.
2 Related Work
Diffusion models [24] (DMs) are likelihood-based models and have become more popular in image synthesis than Generative Adversarial Networks (GANs)[12, 20]. More details about preliminary relevant works in DMs are provided in Appendix Sec.B.
2.1 Diffusion Prior
The Diffusion Prior was introduced in OpenAI’s DALLE-2 [54] which is a hierarchical text-conditional DM. The Diffusion Prior is capable of mapping an input text embedding vector to an image embedding vector in a CLIP latent space. A decoder (unCLIP) then translates the CLIP image embedding into synthetic images. The Diffusion Prior is a classifier-free guidance DM that uses a Transformer backbone instead of U-Net. In DALLE-2, the Diffusion Prior is shown to outperform the autoregression prior in model size and training time. Recent works that use Diffusion Prior models include Make-A-Video [66], Dream3D [72] and Shifted Diffusion [78]. While Shifted Diffusion [78] proposes a more optimal prior model, Make-A-Video and Dream3D utilize existing prior formulation to support text-to-image generation in their pipeline. Compared to text conditioned diffusion model like [57, 61], there is limited work that builds on top of the Diffusion Prior proposed in DALLE-2[54]. We explore its capabilities and its applications to domain specific and conditional generation.
2.2 Color Conditioned Generation
Color is an important attribute of an image that provides contextual information as well as sets the mood of viewer’s perception. Although there has been lot of research around generating images with specific styles as condition [77, 37, 5, 28], using only color palette for generating images has not been explored much by the research community. This could be a useful tool for artists and content creators to generate images with varied color palette portfolios without changing their authentic styles. There are some works on image colorization [60, 10, 71, 21] of grayscale images and image color transfer between colored images [55, 3, 73, 26, 35], but these methods work well when an image is available as input. In [2], the authors propose color conditional generation by controlling the color palette when generating images by injecting color histograms in log-chroma space into the StyleGan [32] architecture but do not show text and color conditioned generation.
Limitations: Leveraging the aforementioned techniques for text and color conditioned image generation would be a two step process where we first generate an image given a text prompt and then perform color transfer on it. Though this is a possible solution, the lack of semantic awareness in the color transfer step and its independence to the generation step might lead to unsatisfactory results with color saturation artifacts. In our method, since the final generated image is from a valid CLIP embedding, the images look natural and are semantic aware compared to generic color transfer.
2.3 Domain Specific Generation
In recent years, domain adaptation has become popular in image synthesis where large pretrained models are fine-tuned on a smaller dataset from a specific domain like [49, 59, 19]. In contrast to domain adaptation, domain specific generation aims to constrain generations from a pretrained model to a specific sub space or domain within the seen larger distribution.
Texture Domain: Texture synthesis has been studied for a long time in Computer Vision (CV) literature [11, 13, 22]. Recently, deep learning techniques have been used to generate textures [79, 18, 64]. These approaches are a primer to 3D texture synthesis and transfer [7]. Pretrained text-to-image diffusion models have also been explored for 3D texture and shape generation [51, 56].
Vectors and Isolated Objects Domain:
Scalable Vector Graphics (SVG) is a suitable format for expressing visual concepts as primitives and for exporting designs at arbitrarily high quality [30]. These are most commonly applicable when generating posters, templates, card and other graphics. Previous work such as [29, 17] optimize CLIP image similarity to generate vectors from text prompts. [63] extends [17] with style loss to generate vectors from images whereas [16] uses a hierarchical neural Lindenmeyer system to optimize SVG paths and [44] uses evolutionary approach to generate collages. Recently, [30] proposed a multi-step optimization approach on top of Stable Diffusion [57] to use the large conceptual pretrained knowledge of diffusion models for text to vector generation.
Limitations: Most of these techniques have as a first step to generate images that can easily be converted to vectors either by optimization or by using existing algorithms such as [41]. Since SVGs comprise of simple abstract shapes and curves to compose concepts, photorealistic images generated by existing text-to-image diffusion models are not suitable for conversion to SVGs. However, these diffusion models have seen images that show abstract concepts [30] that can be generated using some prompt engineering. Though this works to a certain extent, this is not robust to all prompts
[30]. We overcome these limitations by proposing to train the Diffusion Prior in HDM on images within a specific domain (textures, vectors or isolated objects). The generated images can then be used with existing vectorization [41] and material generation [7] techniques or as it is for further applications.
Concurrent Works: More recently, concurrent works like ControlNet [75], Composer [27] and T2I-Adapter [46] that support multiple conditional inputs and composable generations including color have been proposed. We emphasize that our paper is focused on revealing the capabilities of CLIP latent space based diffusion prior model which is lightweight and support conditional and domain specific generation without additional objectives or modifications in the base HDM architecture. This method is robust to domains and conditioning inputs and retains the advantages of the CLIP space such as latent interpolation and directional attribute manipulation while being efficient in terms of compute and memory.
3 Proposed Method
Our base text-to-image generation model, HDM follows DALLE-2 architecture and has a Diffusion Prior and Diffusion Decoder model. Let be the text prompt provided as input to the HDM and the final generated image. An example of inference with our setup is shown in Fig.2. We follow the same two step hybrid architecture for text-to-image generation as [54]. For the prior, we use the pre-trained and publicly available LAION model as baseline for comparison and the corresponding architecture and code for training the domain and color priors. For the decoder, we train a custom LDM conditioned on normalized CLIP L/14 image embeddings using [57] as the base model architecture. Some example generations using the publicly available LAION prior and our trained LDM is shown in the first column of Fig.Controlled and Conditional Text to Image Generation with Diffusion Prior and Appendix Sec.G. Further details about the HDM architecture are provided in Appendix Sec.C. We describe the modifications for domain specific and color conditional prior in this section.
3.1 Domain Specific Prior
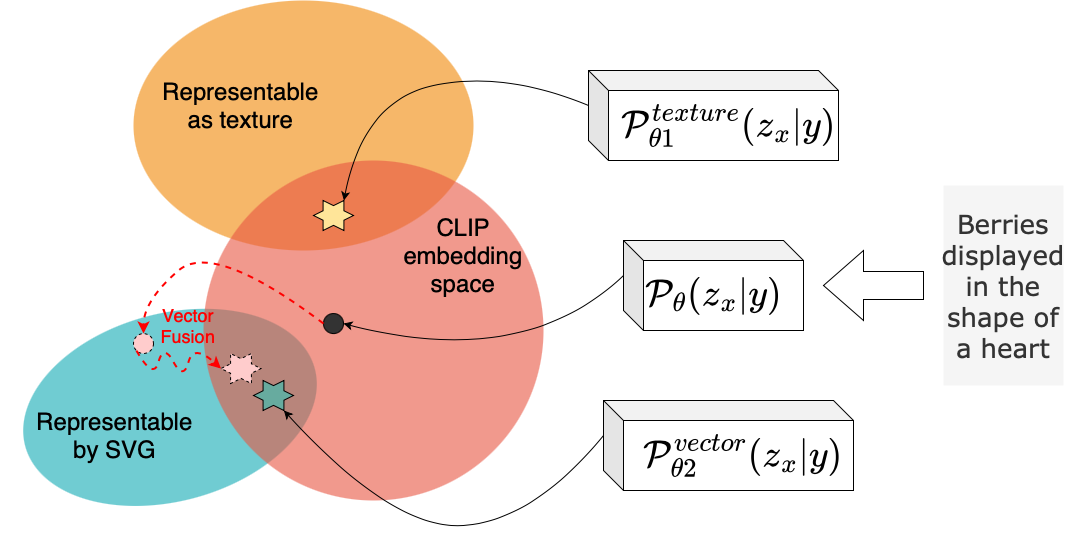
For each of the domain specific priors, we retain the HDM pipeline as is but train a separate Diffusion Prior model for each domain. We first obtain a curated internal dataset of images with texture, suitable for vectors and are of isolated objects or concepts as described in Sec.4.1. Then, we train a domain specific Diffusion Prior model as described in Appendix Sec.C on the curated dataset following the same setup as LAION prior. In contrast to the base prior model , the domain specific models , and generate image embeddings within a specific sub-space in the CLIP embedding space that corresponds to their respective domain. Embeddings from each of the priors can be visualized by the LDM to generate domain specific images. Note that the domain specific priors only differ by the data they were trained on. There is no additional domain specific information, conditional input or finetuning.
To better understand the advantages of the domain specific prior, we provide a conceptual illustration in Fig.2 (Right). In VectorFusion [30], a sample generated by a diffusion model or a random SVG is further optimized to be within the desirable domain specific space (red dotted arrows). Our domain specific priors directly generate desirable domain specific images by generating CLIP embeddings within the desirable subspace highlighted by the intersecting areas (generation path shown by black arrows from the domain priors). This is because, the domain specific prior models are trained only on CLIP embeddings of images from the specific domain. This also ensures the priors do not generate embeddings outside this area even for complex prompts.
3.2 Conditional Prior
There are many studies on style, shape and semantic map conditioned generations (ref. Sec.2.2) but little to no work that focuses on color conditioned text-to-image generation. Being able to condition image generations with a color palette directly or obtained from another exemplar image is helpful for many creative workflows. We modify the Diffusion Prior described in Appendix Sec.C.1 to take as input another token that represents the desired color information. Formally, our conditional Diffusion Prior is where corresponds to the color information. If corresponds to the color representation, we simply add it as an additional token to as utilized by the prior by cross attention.
Color Histogram:
Studies of color distribution for images are generally seen in the form 3D histograms [15, 55], color triads [65] or 2D Histograms such as log-chroma space [4, 1, 2]. In our experiments, we use 3D color histograms proposed in [45] as obtained from the ground truth image . The reason to use the LAB space over log-chroma or RGB space is because it is perceptually closer with respect to human color vision as its perceptual distances corresponds to Euclidean distances [45]. We choose a 1089 histogram and zero-pad to get the total dimension to 768 corresponding to CLIP L/14 text embedding and encodings. We take the square root of the histogram before passing it in the prior to make it more uniform. We also follow classifier free guidance approach [25] during training by dropping color histogram with 0.5 to better capture textual content and relevance and both color and text with 0.1 for unconditional training. Color histogram is never provided without text to prevent content dependency on color information for generation.
4 Experimental Setup
4.1 Dataset
We use an internal dataset to train the prior and decoder models.
Data for Decoder: To train the Diffusion Decoder LDM as described in Appendix Sec.C.2, we remove images that contain humans or texts as detected using classifiers to reduce the size and complexity of the dataset to 77M images. The classifiers are a single linear layer on top of frozen CLIP L/14 embeddings. Only the linear layer is trained. We tested other complicated architecture but this worked reasonably well for all cases. The details about the classifiers are provided in Appendix Sec.D.2.
Data for Priors: For the domain specific priors, we train separate classifiers to detect the domains from images and use them to gather data. For color prior, we use a subset of text image pairs from the 77M filtered data. More information in Appendix Sec.D.1.
4.2 Training and Inference Details
Our Diffusion Decoder LDM has the same number of parameters as Stable Diffusion but trained on a relatively smaller dataset for fewer GPU hours as shown in Table.1. We can also see that the prior models have significantly lower number of parameters and training time, measured in A100-40GB hours similar to [57]. All the prior models are trained from scratch in 8-GPU A100-40GB instances. We train a smaller prior for vectors as we observed reasonable performance with a smaller model. The priors are trained with cosine schedule and all parameters are similar to those used in LAION prior1 while the LDM uses linear schedule with 1000 DDPM timesteps for training and uses the same architecture as [57].
The dataset size and training time for all the models are provided in Table.1. We emphasize that training the prior model from scratch takes lesser time and compute compared to finetuning the larger decoder or stable diffusion for the same application. For reference, [75] trains only a small part of stable diffusion model and uses an average of 600 A100-80GB GPU-hours for canny-edge conditioned finetuning of Stable Diffusion model on 3M images. In comparison, our isolated object prior model takes 1344 A100-40GB hours to train on a dataset of 20M image-text pairs. If we use a conservative 1.5 factor speed up from A100-40GB to A100-80GB, this translates to 896 A100-80GB GPU hours for 20M samples. If we also scale the training data with another conservative 6 factor to get closer to 3M samples, we get 150 A1000-80GB GPU hours which is significantly less despite the differences in conditioning input. Similarly, the color prior with same calculations get to around 112 GPU hours on A100-80GB compared to 150-600 GPU hours for various conditioning inputs based finetuning in [75].
For all our experiments we use 100 DDIM steps for sampling the CLIP embedding from Diffusion Prior and 50 DDIM steps to generate an image using the Diffusion Decoder. We use linear sampling schedule. To improve relevance in the prior, we generate 10 embeddings per prompt and choose the embedding with highest CLIP score to input text prompt as done in [54]. For all qualitative examples, we use the same random seed per prompt across all baselines.
| Models | Compute | Nparams | Data Size |
|---|---|---|---|
| (A100 hours) | (Million) | (Million) | |
| Isolated Prior | 1344 | 249.22 | 20 |
| Vector Prior | 1680 | 101.76 | 26 |
| Texture Prior | 576 | 249.22 | 10 |
| Color Prior | 3072 | 249.28 | 61 |
| Our LDM | 117600 | 859.52 | 77 |
| Stable Diffusion | 150000 | 859.52 | 2000 |
4.3 Baselines
We represent our method in the results as ‘ours’. This corresponds to the HDM pipeline consisting of the prior and LDM. Unless otherwise specified, both prior and LDM are the models we trained as described in Sec.4.2.
4.3.1 Domain Specific Generation
For qualitative examples we randomly sample prompts from our test set and use the following methods to generate images for visual comparison. For quantitative experiments, we compare our method with Stable Diffusion baselines.
| Ours | SD | SD-prompt | LAION | LAION-prompt | Ours | SD | SD-prompt | LAION | LAION-prompt |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Text prompt: ”heap of ripe raspberries with leaves” | Text prompt: ”scarf on coat-hanger cartoon icon” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Text prompt: ”bees on honeycomb” | Text prompt: ”deer with spruce branches in a red cup in a blue circle” | ||||||||
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Text prompt: ”Island in the middle of the ocean with palm trees” | Text prompt: ”a winter landscape in a christmas ball” | ||||||||
| Ours | SD | SD-prompt | LAION | LAION-prompt |
 |
 |
 |
 |
 |
| Text prompt: ”brown suede detail” | ||||
 |
 |
 |
 |
 |
| Text prompt: ”green glossy plaster wall paint” | ||||
 |
 |
 |
 |
 |
| Text prompt: ”a texture of snail climbing a tree bark” | ||||
Stable Diffusion (SD):
We use Stable Diffusion v1.4 [57] for comparison as a baseline.
Stable Diffusion with Suffix (SD-prompt):
Existing methods like [30] use prompt engineering with stable diffusion to get images closer to the desirable space. Similarly, we add ‘texture background’, ‘vector illustration’ and ‘isolated background’ as suffix to prompts to compare with texture, vector and isolated priors.
Baseline Prior (LAION):
As a baseline for the domain Diffusion Prior models, we use pretrained and publicly available LAION prior 333https://github.com/LAION-AI/conditioned-prior with our trained LDM Diffusion Decoder.
Baseline Prior with Suffix (LAION-prompt):
We also use the suffixes mentioned above with the LAION prior to support the baseline further.
4.3.2 Color Conditional Generation
To the best of our knoweldge, there aren’t existing techniques that perform color conditioned text to image generation (excluding concurrent works). We hence use popular color transfer techniques on images generated by Stable Diffusion for comparison.
WCT-RGB [36]: We combine [36] that does style transfer using covariance matrix matching on an intermediate deep space with a traditional mean/std matching way [55] of performing color transfer on RGB color space. This leads to covariance matrix matching on RGB color space.
CTHA [35]: This method encodes color histograms of reference color image and generated image using an encoder and repeatedly fuses into features of a U-Net [58] decoder network. This method also uses semantic segmentations of the images to perform color transfer and therefore, is semantic aware. We use [69] to generate the semantic segmentations.
ReHistoGAN [2]: This is primarily a noise to image generator model which works by injecting color histogram of reference color image into StyleGAN[32]. The model is trained to transfer color while keeping the image realistic and preserving the input image’s structure. We use the Universal ReHistoGAN model for our comparisons.
4.4 Metrics
For all quantitative results, for each domain, we use 5000 random prompts from their respective test set to generate images for comparison.
Quality: To measure quality of the generated image and its alignment with the training distribution, we use the Frechet
inception distance (FID) [50] metric. For all priors, we use ground truth images corresponding to 5000 prompts from test set as the real distribution. The test set is different for different domains (ref. Appendix Sec.D.1).
Prompt Relevance: To measure relevance of the generated image to input text prompt irrespective of the domain or conditional input used, we use the CLIP [52] score.
Domain Relevance: To further measure relevance to the specific domain of generation, we use our domain classifiers mentioned in D.1 to get average confidence over all generated images from the test set.
Color Relevance: To measure the relevance of color palette in the generated image to the exemplar image, we use Hellinger distance and KL divergence on the color histograms[45] from both the images.

5 Results and Analysis
5.1 Domain Specific Generation
We can see from Table.2 that our method outperforms existing large pretrained Stable Diffusion across all metrics including quality and relevance. Moreover, adding domain specific modifiers to the prompts though helps a little for vector and textures in improving domain relevance measured by the classifiers, it is significantly lower compared to using the domain specific prior. The FID scores also show that the generated images from the proposed technique are of higher quality and are more relevant to the specific domain’s real distribution.
We also show some qualitative examples in Fig.3 and 4 for all the domain specific priors and generation. We can observe that irrespective of the complexity of the prompt, the generated image using our method does not generate out of domain images. The LDM and the common CLIP space ensure relevance to prompt and generalization across concepts whereas the domain specific priors ensures the images are within the desired domain. For example, ‘bees on honeycomb’ generates the background as a honeycomb in Stable Diffusion and LAION prior baseline whereas our model generated relevant image while maintaining the white background. Similarly, prompts such as ‘snail climbing on a tree’ or ‘ a winter landscape in a christmas ball’ bias the baseline models towards content based generation even with additional prompt engineering. However, the domain prior results in relevant images within the desired domain.
| Method | Clf.Score | CLIP | FID |
| Isolated Background Domain | |||
| SD | 0.268 | 0.267 | 35.257 |
| SD-prompt | 0.250 | 0.264 | 38.569 |
| Ours | 0.496 | 0.265 | 25.795 |
| Vector Domain | |||
| SD | 0.550 | 0.247 | 58.200 |
| SD-prompt | 0.761 | 0.245 | 69.344 |
| Ours | 0.950 | 0.248 | 21.600 |
| Texture Domain | |||
| SD | 0.663 | 0.258 | 40.559 |
| SD-prompt | 0.788 | 0.255 | 40.284 |
| Ours | 0.860 | 0.261 | 35.524 |
5.2 Color Conditional Generation
Quantitative results for the color prior model comparing with baselines is provided in Table 3. We observe a clear trade off between color transfer and quality of the images generated in existing baselines. For example, SD+WCTRGB shows the best performance in color transfer as measured by Hellinger distance and KL divergence metrics but has the least quality in generation. Since WCTRGB is a statistical histogram matching based algorithm, it ensures the color palette of the transferred image matches with the exemplar while sacrificing quality. Similarly, SD+ReHistoGAN shows least performance in color transfer with better FID score relative to the proposed model showing conservative color transfers. Our methods strikes the right balance and ensures the generated images are of high quality while also having color relevant to the exemplar image. Interestingly, all color transfer methods degrade the quality of the baseline Stable Diffusion generated image showing absence of semantic awareness.
| Method | H dist. | KL div. | FID |
|---|---|---|---|
| SD | - | - | 20.613 |
| SD+WCTRGB | 0.468 | 1.779 | 23.616 |
| SD+ReHistoGAN | 0.566 | 4.704 | 21.299 |
| SD+CTHA | 0.496 | 2.330 | 21.950 |
| Ours with zero cond | - | - | 22.144 |
| Ours | 0.480 | 3.164 | 21.670 |
We can make similar observations from the qualitative examples provided in Fig.5. The proposed technique relates the input text prompt and color histogram generating a realistic possible image visualizing the inputs. Our model generates images with objects and concepts that realistically fit the color distribution of the exemplar image. Berries in the first row become blueberries because of the input exemplar color image (compare with raspberries seen in the generation without color palette). Though SD+WCTRGB performed better with color transfer metrics, the images generated for all examples shown in Fig.5 are unrealistic and have a global hue that corresponds to the color palette applied over an existing image. Though this is mainly due to the color transfer being applied on an existing image of strawberries from Stable Diffusion, it shows the inability of these models as a plug-in for color conditioned text to image generation.
6 Conclusion
In this paper, we show the advantages of having a common CLIP embedding space in the text to image generation pipeline and the effectiveness of the Diffusion Prior model trained on the CLIP embedding space. We show that the prior model is smaller in memory and requires significantly less time to be trained on a specific desired domain of text-image pairs. Once trained, this prior model can be combined with an existing large decoder model to generate domain specific images. Since the prior model has not seen embeddings outside the domain specific subspace in the CLIP embedding space, it avoids generating out of domain images and is robust to complex prompts. Prompt Engineering on existing diffusion models show lower performance and finetuning such large models even with just few layers or optimization is expensive in compute and memory.
We also show that the Diffusion Prior model can be trained to accept additional conditioning input (color histogram in our paper) to generate images that align with the input text prompt as well as the color palette without losing on semantics or quality. We compare our domain specific and color conditioned priors qualitatively and quantitatively with existing baselines and show on par or better performance across all metrics and domains.
We hope that this paper opens up new research and possibilities into the HDM architecture and the capabilities of a small latent space diffusion model like the Diffusion Prior.
References
- [1] Mahmoud Afifi and Michael S. Brown. Sensor-independent illumination estimation for dnn models. 2019.
- [2] Mahmoud Afifi, Marcus A. Brubaker, and Michael S. Brown. Histogan: Controlling colors of gan-generated and real images via color histograms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2021.
- [3] Mahmoud Afifi, Brian Price, Scott Cohen, and Michael Brown. Image recoloring based on object color distributions. 05 2019.
- [4] Mahmoud Afifi, Brian Price, Scott Cohen, and Michael S. Brown. When color constancy goes wrong: Correcting improperly white-balanced images. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1535–1544, 2019.
- [5] Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, Bryan Catanzaro, Tero Karras, and Ming-Yu Liu. ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv:2211.01324, 2022.
- [6] Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. Multidiffusion: Fusing diffusion paths for controlled image generation, 2023.
- [7] Toby P Breckon and Robert B Fisher. A hierarchical extension to 3d non-parametric surface relief completion. Pattern Recognition, 45(1):172–185, 2012.
- [8] Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow image editing instructions, 2022.
- [9] Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T. Freeman, Michael Rubinstein, Yuanzhen Li, and Dilip Krishnan. Muse: Text-to-image generation via masked generative transformers. 2023.
- [10] Wonwoong Cho, Hyojin Bahng, David Keetae Park, Seungjoo Yoo, Ziming Wu, Xiaojuan Ma, and Jaegul Choo. Text2colors: Guiding image colorization through text-driven palette generation. CoRR, abs/1804.04128, 2018.
- [11] Jeremy S De Bonet. Multiresolution sampling procedure for analysis and synthesis of texture images. In Proceedings of the 24th annual conference on Computer graphics and interactive techniques, pages 361–368, 1997.
- [12] Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis. arXiv:2105.05233, 2021.
- [13] Alexei A Efros and Thomas K Leung. Texture synthesis by non-parametric sampling. In Proceedings of the seventh IEEE international conference on computer vision, volume 2, pages 1033–1038. IEEE, 1999.
- [14] Patrick Esser, Robin Rombach, and Björn Ommer. Taming transformers for high-resolution image synthesis. arXiv:2012.09841, 2020.
- [15] H. Sheikh Faridul, T. Pouli, C. Chamaret, J. Stauder, E. Reinhard, D. Kuzovkin, and A. Tremeau. Colour Mapping: A Review of Recent Methods, Extensions and Applications. Computer Graphics Forum, 2016.
- [16] Chrisantha Fernando, SM Eslami, Jean-Baptiste Alayrac, Piotr Mirowski, Dylan Banarse, and Simon Osindero. Generative art using neural visual grammars and dual encoders. arXiv preprint arXiv:2105.00162, 2021.
- [17] Kevin Frans, Lisa B Soros, and Olaf Witkowski. Clipdraw: Exploring text-to-drawing synthesis through language-image encoders. arXiv preprint arXiv:2106.14843, 2021.
- [18] Anna Frühstück, Ibraheem Alhashim, and Peter Wonka. Tilegan: Synthesis of large-scale non-homogeneous textures. ACM Transactions on Graphics, 38(4):1–11, jul 2019.
- [19] Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. 2022.
- [20] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. arXiv:1406.2661, 2014.
- [21] Mingming He, Dongdong Chen, Jing Liao, Pedro V. Sander, and Lu Yuan. Deep exemplar-based colorization, 2018.
- [22] David J Heeger and James R Bergen. Pyramid-based texture analysis/synthesis. In Proceedings of the 22nd annual conference on Computer graphics and interactive techniques, pages 229–238, 1995.
- [23] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
- [24] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. arXiv:2006.11239, 2020.
- [25] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv:2207.12598, 2022.
- [26] Kibeom Hong, Seogkyu Jeon, Huan Yang, Jianlong Fu, and Hyeran Byun. Domain-aware universal style transfer, 2021.
- [27] Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, and Jingren Zhou. Composer: Creative and controllable image synthesis with composable conditions, 2023.
- [28] Nisha Huang, Yuxin Zhang, Fan Tang, Chongyang Ma, Haibin Huang, Yong Zhang, Weiming Dong, and Changsheng Xu. Diffstyler: Controllable dual diffusion for text-driven image stylization, 2022.
- [29] Ajay Jain. Vectorascent: Generate vector graphics from a textual description, 2021.
- [30] Ajay Jain, Amber Xie, and Pieter Abbeel. Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models, 2022.
- [31] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models, 2022.
- [32] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan, 2019.
- [33] Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models, 2022.
- [34] Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. 2022.
- [35] Junyong Lee, Hyeongseok Son, Gunhee Lee, Jonghyeop Lee, Sunghyun Cho, and Seungyong Lee. Deep color transfer using histogram analogy. The Visual Computer, 36(10):2129–2143, 2020.
- [36] Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, and Ming-Hsuan Yang. Universal style transfer via feature transforms, 2017.
- [37] Jun Hao Liew, Hanshu Yan, Daquan Zhou, and Jiashi Feng. Magicmix: Semantic mixing with diffusion models, 2022.
- [38] Luping Liu, Yi Ren, Zhijie Lin, and Zhou Zhao. Pseudo numerical methods for diffusion models on manifolds. arXiv:2202.09778, 2022.
- [39] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. arXiv:2211.01095, 2022.
- [40] Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. 2022.
- [41] Xu Ma, Yuqian Zhou, Xingqian Xu, Bin Sun, Valerii Filev, Nikita Orlov, Yun Fu, and Humphrey Shi. Towards layer-wise image vectorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16314–16323, 2022.
- [42] Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. 2021.
- [43] Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik P. Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. arXiv:2210.03142, 2022.
- [44] Piotr Mirowski, Dylan Banarse, Mateusz Malinowski, Simon Osindero, and Chrisantha Fernando. Clip-clop: Clip-guided collage and photomontage. arXiv preprint arXiv:2205.03146, 2022.
- [45] Saeid Motiian, Zhe Lin, Samarth Gulati, Pramod Srinivasan, Jose Ignacio Echevarria Vallespi, and Baldo Antonio Faieta. Multi-resolution color-based image search, Jan. 4 2022. US Patent 11,216,505.
- [46] Chong Mou, Xintao Wang, Liangbin Xie, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models, 2023.
- [47] Alex Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. arXiv:2102.09672, 2021.
- [48] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv:2112.10741, 2021.
- [49] Yotam Nitzan, Kfir Aberman, Qiurui He, Orly Liba, Michal Yarom, Yossi Gandelsman, Inbar Mosseri, Yael Pritch, and Daniel Cohen-or. Mystyle: A personalized generative prior. 2022.
- [50] Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. In CVPR, 2022.
- [51] Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022.
- [52] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. 2021.
- [53] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. 2019.
- [54] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv:2204.06125, 2022.
- [55] Erik Reinhard, Michael Ashikhmin, Bruce Gooch, and Peter Shirley. Color transfer between images. IEEE Computer Graphics and Applications, 21:34–41, 10 2001.
- [56] Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, and Daniel Cohen-Or. Texture: Text-guided texturing of 3d shapes, 2023.
- [57] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. arXiv:2112.10752, 2021.
- [58] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation, 2015.
- [59] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. 2022.
- [60] Chitwan Saharia, William Chan, Huiwen Chang, Chris A. Lee, Jonathan Ho, Tim Salimans, David J. Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. CoRR, abs/2111.05826, 2021.
- [61] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. 2022.
- [62] Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv:2202.00512, 2022.
- [63] Peter Schaldenbrand, Zhixuan Liu, and Jean Oh. Styleclipdraw: Coupling content and style in text-to-drawing translation. arXiv preprint arXiv:2202.12362, 2022.
- [64] Omry Sendik and Daniel Cohen-Or. Deep correlations for texture synthesis. ACM Trans. Graph., jul 2017.
- [65] Maria Shugrina, Amlan Kar, Karan Singh, and Sanja Fidler. Nonlinear color triads for approximation, learning and direct manipulation of color distributions. 2020.
- [66] Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data. 2022.
- [67] Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics, 2015.
- [68] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv:2010.02502, 2020.
- [69] Ke Sun, Yang Zhao, Borui Jiang, Tianheng Cheng, Bin Xiao, Dong Liu, Yadong Mu, Xinggang Wang, Wenyu Liu, and Jingdong Wang. High-resolution representations for labeling pixels and regions, 2019.
- [70] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2017.
- [71] Yi Wang, Menghan Xia, Lu Qi, Jing Shao, and Yu Qiao. Palgan: Image colorization with palette generative adversarial networks, 2022.
- [72] Jiale Xu, Xintao Wang, Weihao Cheng, Yan-Pei Cao, Ying Shan, Xiaohu Qie, and Shenghua Gao. Dream3d: Zero-shot text-to-3d synthesis using 3d shape prior and text-to-image diffusion models. 2022.
- [73] Jaejun Yoo, Youngjung Uh, Sanghyuk Chun, Byeongkyu Kang, and Jung-Woo Ha. Photorealistic style transfer via wavelet transforms, 2019.
- [74] Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Yonghui Wu. Scaling autoregressive models for content-rich text-to-image generation. 2022.
- [75] Lvmin Zhang and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. arXiv preprint arXiv:2302.05543, 2023.
- [76] Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator. arXiv:2204.13902, 2022.
- [77] Yuxin Zhang, Nisha Huang, Fan Tang, Haibin Huang, Chongyang Ma, Weiming Dong, and Changsheng Xu. Inversion-based creativity transfer with diffusion models, 2022.
- [78] Yufan Zhou, Bingchen Liu, Yizhe Zhu, Xiao Yang, Changyou Chen, and Jinhui Xu. Shifted diffusion for text-to-image generation. 2022.
- [79] Yang Zhou, Zhen Zhu, Xiang Bai, Dani Lischinski, Daniel Cohen-Or, and Hui Huang. Non-stationary texture synthesis by adversarial expansion. (4), 2018.
Appendix
Appendix A Introduction
In this paper, we leverage the Diffusion Prior model trained to generate CLIP image embeddings conditioned on CLIP text embeddings for controlled and conditional text to image generation. We show that training the Diffusion Prior is memory and compute efficient since it works on a low dimensional latent space and is architecturally less complex compared to the larger decoder models. Moreover, training the prior on a dataset of just textures, vectors or isolated objects is less expensive than finetuning larger models and results in more robust domain specific generations. The Diffusion Prior can also take additional conditional input like color histogram to generate images from text, conditioned on a specific color palette. Since the prior generates valid CLIP embeddings, the generations are semantic aware and do not lose realism as shown qualitatively and quantitatively in the main paper.
In the Appendix, we start by discussing additional related works in Sec.B. We then give detailed information on the Diffusion Prior and Diffusion Decoder models that we trained in Sec.C. We describe the classifiers that were used to get domain specific data in Sec.D.1 and those used to simplify the data to train the Diffusion Decoder in Sec.D.2. Note that we use the same classifiers to also quantitatively measure if the generations are within a specific domain in Sec.5. We discuss limitations in Sec.F followed by additional examples of text to image generation and image variations using the trained HDM in Sec.G. We also provide additional results for domain specific generations for all the domains and color conditioned generation in Sec.G.
Appendix B Related Works
Diffusion Models (DMs) are based on Gaussian denoising process [67] which assumes that the noises added to the original images are drawn from Gaussian distributions. The denoising process involves predicting the added noises using a convolutional neural network called U-Net [58]. Compared to GANs, DMs are easier to train and scale. DMs have been shown to achieve state-of-the-art of image quality [12, 24].
B.1 Diffusion Models
Interesting approaches to strengthen controllability as well as improve efficiency have been proposed in recent times. The classifier guidance method allows DMs to condition on the predictions of a classifier [12, 48] during sampling, whereas [25] proposes classifier-free guidance that does not require pretrained classifiers. DMs can be conditioned on texts, images, or both [5, 9, 12, 25, 47, 48, 54, 57, 61, 74]. These conditions are usually in the forms of embedding vectors from CLIP [52] or T5 [53] which are based on the Transformer architecture [70]. DMs can also be applied to other computer vision tasks such as super-resolution [48, 61], and inpainting [40, 42, 54, 60].
There have been many techniques introduced recently to improve DM’s training and sampling speed. Instead of operating in the pixel space, Latent DMs [57] are trained and sampled from a latent space [14] which is much smaller. Fast sampling methods [31, 38, 39, 68, 76], on the other hand, reduce significantly the number of sampling steps. Recent distillation techniques [43, 62] reduce the model’s size and sampling speed even further. These works though improve diffusion models in general, do not directly analyze the Diffusion Prior model or its applications for domain specific and conditional generation.
In domain adaptation techniques like MyStyle [49], a pretrained StyleGAN face generator is fine-tuned on a small set of 100 images of a specific entity. However, MyStyle works only in the face domain. In Dreambooth [59], a pretrained DM is fine-tuned on a much smaller set of 3-5 images of different types of subjects such as animals, objects, etc. By utilizing a new class-specific prior preservation loss, Dreambooth can synthesize the subject in different scenes and poses that are not available in the reference photos. Instead of fine-tuning all parameters in a pretrained DM model, Textual Inversion [19] trains a new word embedding vector for the new subject. In Custom Diffusion [34], a subset of cross-attention layers is fine-tuned on new concepts.
Appendix C Training HDM
The HDM can be used to generate images from text the same way as [54] up to 512512 resolution.
C.1 Diffusion Prior Model
The Prior model is a denoising diffusion model as proposed in [54] that generates a normalized CLIP L/14 image embedding conditioned on an input prompt . The Diffusion Prior parameterized by is a Causal Transformer [70, 54] that takes as input a random noise sampled from and a CLIP text embedding = where is the l2 normalized text embedding while is the per token encoding, both from a pretrained CLIP L/14 text encoder [52]. The maximum sequence length for CLIP is and hence has dimensions x . Additionally, an embedding for the diffusion timestep, the noised CLIP image embedding and a final embedding whose output from the Transformer is used to predict the unnoised CLIP image embedding are added with a causal attention mask and a Mean Squared Error (MSE) objective as done in the LAION prior1.
C.2 Diffusion Decoder Model
For the Diffusion Decoder, instead of the multi-stage pixel diffusion model proposed in [54], we train a custom latent space model inspired by [57] for memory and compute efficiency. Our LDM is a denoising diffusion model parameterized by that takes as input random sample from and the CLIP image embedding to generate the VAE [57] latent . It is to be noted that the bold notation for VAE latent is different from the notation for CLIP embeddings . The generated latent is passed through a frozen decoder VAEdec [57] of a pretrained VAE to generate the final image . The LDM’s architecture is unchanged from [57] except the conditioning input to the U-Net [58] is modified to be normalized CLIP L/14 embedding instead of as in Stable Diffusion. The pretrained VAEs from [57] are used as is. During inference, we can provide from an image to generate variations of it [54] or provide the generated embedding from the Diffusion Prior to generate image from text for text-to-image generation. The Diffusion Prior, pre-trained VAE and CLIP L/14 models are frozen while the Diffusion Decoder is trained.
Appendix D Data Collection using Classifiers
We show few examples of text image pairs from the training data obtained for each domain specific prior as well as the large decoder. Example training samples for the isolated objects domain is shown in Fig.7, vectors in Fig.8, for texture in Fig.9 and for the larger decoder in Fig.10.
D.1 Prior
Texture: We manually annotated 30K images from stock to use as positive samples for training. We get an F1-score of 69% for the positive class of texture images and 89% for the negative class. We then use this to get 10M images that were used to train the texture prior .
Vectors: We use stock metadata to gather 1M positive and negative samples for vectors to train a classifier. We then use this to get 26M images that were used to train the vector prior
Isolated Objects: We manually annotated 28K images from stock to use as positive samples. We get an F1-score of 85% for the positive class of images isolated on plain backgrounds and 74% for the negative class. We then use this to get 20M images that were used to train the isolated object prior
Color: For color prior , we train on a 61M only English subset of image-text pairs from the original 77M filtered stock data used to train the LDM as described in Sec.3.2
D.2 Decoder
Human presence: To detect images that contain humans, we manually annotated 180K images from stock and then train a classifier to classify human presence/absence. We get an F1-score of 95% for presence of humans and 98% for the absence.
Text Presence: Similarly, we manually annotate 40K images for text presence and train a classifier. We get an F1-score of 94% in detecting images without text and 78% for images with text as tested on a random 5K images test set.
Once we have human and text presence classifiers, we run those on whole of stock data to get 77M images that have no humans or text. This simplifies the distribution but has no consequence over the priors, its capabilities and the results. With the LDM trained on a large dataset of diverse images, we now describe the process of dataset curation for the specific domains. To ensure that the model doesn’t generate NSFW images, we also remove NSFW images from the training corpus using a pretrained NSFW classifier.
Appendix E Composable Diffusion
In Fig. 6 we show that the different priors are compositional and can be combined to generate domain specific images in a specific color. For this experiment, we sample from both prior models and at each timestep, the output from the prior models are composed before being passed on to the models for next step. We can see from Fig.6 that when composed, we can get domain specific images based on the domain prior used, while also adhering to the color palette passed through the color prior. This enables the possibility of training multiple smaller specialized priors and ensembling for better controllability.
| Color Image | Color Only | Texture Only | Color + Texture | |
 |
 |
 |
 |
|
| Text prompt: ”old stone moss wall at the hillside” | ||||
| Color Image | Color Only | Isolated Only | Color + Isolated | |
 |
 |
 |
 |
|
| Text prompt: ”gift boxes wrapped with ribbons” | ||||
Appendix F Limitations
We see that with the color prior, when a vector/illustration is used as an exemplar, we get a vector image as output. We believe that feeding the color histogram of the ground truth image to the Diffusion Prior model during training makes the model associate the color distribution to the image to be generated. We tried to discritize the color histograms for all images to match that of vectors to overcome this issue, but this caused loss in color relevance possibly because the discretization is a lossy process. We also experimented with prompts which already have color words in them and observed that the model generally gives more priority to the color histogram to get the color cues over the color words present in the text prompt unless there is an overlap between colors in the text and color histogram. For the domain priors, we believe that the Diffusion Prior could be reduced in capacity even further without tradinf off quality or domain relevance. Though we show results for texture, isolated objects and vectors as the domains and color as the additional conditional input, we believe that the general approach would work for most other domains as well as other conditional inputs.
Appendix G Additional Examples
We provide more qualitative examples for the proposed method. We show example image variations from the largest LDM decoder model trained on an internal dataset for quality check in Fig.12.
To ensure the overall HDM pipeline works, we show examples of images generated by using the existing publicly available LAION prior model with our trained LDM for text to image generation in Fig.11.
Further examples for domain specific generation using the isolated objects prior with our LDM is shown in Fig.13. Examples for text-to-vector domain image generation using the vector prior and the LDM is shown in Fig.14 while that of text-to-texture domain images is shown in Fig.15.
| Watercolor illustration of Christmas tree toys on a white background | Japanese teapot with flower. Isolated on white background | bengal tiger isolated | Pink Bows set of realistic, isolated on white background | Pattern, glasses with homemade macaroons on a colored background |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| Collection of trees. tree set isolated on white background. vector illustration | Abstract horizontal background with colorful waves. Trendy vector illustration in style retro 60s, 70s. Pastel colors | Octopus eating Ramen inside a bowl vector illustration. Food, restaurant, comics, funny design concept | Eggs on plate pattern , illustration, vector on white background | Lion head vector hand drawn |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| Plaid and check modern repeat pattern | blank old vintage gold wood table, wall or floor for work and place object on top view horizontal, or wooden board for food preparation in the kitchen and use for background | Marble ink abstract art from exquisite original painting for abstract background. Painting was painted on high quality paper texture to create smooth marble background pattern of ombre alcohol ink | green leaf texture - in detail | Real skin texture of Leopard |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| closeup of water waves isolated on white | Two siberian husky play among themselves | Seahorse and starfish seamless pattern. Sea life summer background. Cute sea life background. Design for fabric and decor | Abstract Golden Christmas - christmas background illustration | Vase with still life a bouquet of flowers. Oil painting |
|---|---|---|---|---|
 |
 |
 |
 |
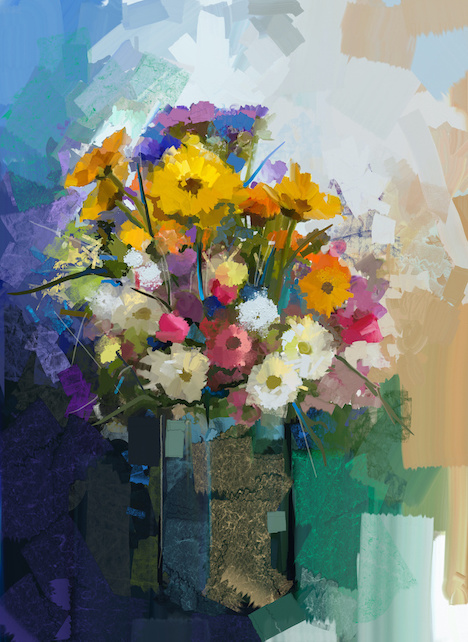 |
| Acrylic colors and ink in water. Ink blot | bulb breaking with splash of color, creative idea | Cute cat. Portrait of a black tabby cat sleeping |
 |
 |
 |
| geometric polygonal of earth globe | Fantasy hero in armor. sketch art for artist creativity and inspiration | The interior design of a lavish side outside garden, with a teak hardwood deck and pergola |
 |
 |
 |
| dramatic sea dark sky thunderstorm ghost ship | backpack covered with leaves | new york city on a foggy afternoon, watercolor |
 |
 |
 |
| Input | Variations | ||
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
 |
 |
 |
|
| dark chocolate bonbons with milk souffle fillings | ball of colorful strings | geometric polygonal raging bull charging |
 |
 |
 |
| green brown grasshopper on a leaf, watercolor | set of fresh vegetables icons | ink droplet splash in water |
 |
 |
 |
| coffee cup with latte art with coffee beans | chicken tikka masala with rice and fresh coriander | beautiful sunflower on a bright sunny day |
 |
 |
 |
| grater icon design | Metal glossy shiny geometric shapes with 3d effect composition. Techno futuristic abstract background For Wallpaper, Banner, Background, Card, Book Illustration, landing page | Silver line Bottle of olive oil icon isolated on dark red background. Jug with olive oil icon |
 |
 |
 |
| Hummingbird | retro cartoon caterpillar | wardrobe icon image |
 |
 |
 |
| Side view of cute turtle with small shell | Isolated videogame portable console control line style icon | Advertising billboards |
 |
 |
 |
| crochet pattern | office carpet black white red pattern | felt fabric |
 |
 |
 |
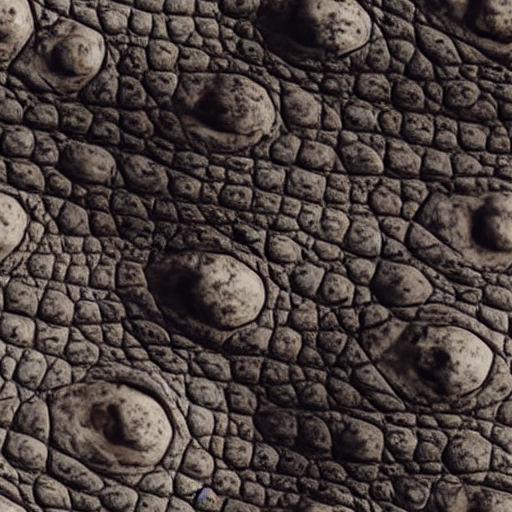
| majestic crocodile with mouth open | old worn out hardwood floor | polished concrete |
 |
 |
 |
| strawberry milkshake with foam | peeling painted interior wall, rusted | fresh erupted lava from volcano |
 |
 |
 |
| Acrylic colors and ink in water. Ink blot | bulb breaking with splash of color, creative idea | Cute cat. Portrait of a black tabby cat sleeping |
 |
 |
 |
| geometric polygonal of earth globe | Fantasy hero in armor. sketch art for artist creativity and inspiration | The interior design of a lavish side outside garden, with a teak hardwood deck and pergola |
 |
 |
 |
| dramatic sea dark sky thunderstorm ghost ship | backpack covered with leaves | new york city on a foggy afternoon, watercolor |
 |
 |
 |
| Acrylic colors and ink in water. Ink blot | bulb breaking with splash of color, creative idea | Cute cat. Portrait of a black tabby cat sleeping |
 |
 |
 |
| geometric polygonal of earth globe | Fantasy hero in armor. sketch art for artist creativity and inspiration | The interior design of a lavish side outside garden, with a teak hardwood deck and pergola |
 |
 |
 |
| dramatic sea dark sky thunderstorm ghost ship | backpack covered with leaves | new york city on a foggy afternoon, watercolor |
 |
 |
 |