ConvBLS: An Effective and Efficient Incremental Convolutional Broad Learning System
for Image Classification
Abstract
Deep learning generally suffers from enormous computational resources and time-consuming training processes. Broad Learning System (BLS) and its convolutional variants have been proposed to mitigate these issues and have achieved superb performance in image classification. However, the existing convolutional-based broad learning system (C-BLS) either lacks an efficient training method and incremental learning capability or suffers from poor performance. To this end, we propose a convolutional broad learning system (ConvBLS) based on the spherical K-means (SKM) algorithm and two-stage multi-scale (TSMS) feature fusion, which consists of the convolutional feature (CF) layer, convolutional enhancement (CE) layer, TSMS feature fusion layer, and output layer. First, unlike the current C-BLS, the simple yet efficient SKM algorithm is utilized to learn the weights of CF layers. Compared with random filters, the SKM algorithm makes the CF layer learn more comprehensive spatial features. Second, similar to the vanilla BLS, CE layers are established to expand the feature space. Third, the TSMS feature fusion layer is proposed to extract more effective multi-scale features through the integration of CF layers and CE layers. Thanks to the above design and the pseudo-inverse calculation of the output layer weights, our proposed ConvBLS method is unprecedentedly efficient and effective. Finally, the corresponding incremental learning algorithms are presented for rapid remodeling if the model deems to expand. Experiments and comparisons demonstrate the superiority of our method.
Index Terms:
Broad learning system, convolutional neural network (CNN), spherical k-means, spatial pyramid pooling (SPP), incremental learning.I Introduction
With the rapid development of deep learning, extensive breakthrough achievements have been acquired in various tasks, including image classification[1, 2, 3, 4, 5, 6], semantic segmentation[7, 8, 9], object detection[10, 11, 12], etc. Unfortunately, deep neural networks (DNNs) with enormous parameters generally suffer from the time-consuming training processes due to over-complicated architectures. Additionally, once the network structure needs to be modified to obtain better accuracy, a complete retraining process is inevitable.
To overcome the aforementioned weaknesses, BLS has been proposed as an alternative model to deep learning algorithms[13, 14]. Owing to its effectiveness and efficiency, BLS has attracted increasing attention and has been frequently used in many different fields[15]. Nevertheless, as a specific flattened fully-connected neural network, the vanilla BLS handles image data in an unrolled one-dimensional vector manner, which makes it challenging to extract hierarchical spatial features[14]. Importantly, superior spatial image features are essential for performance improvement in image classification tasks[1, 16, 17].
For the purpose of improving the spatial feature representation ability of BLS, a mass of C-BLS variants[14, 18, 19, 20, 21, 22, 23] have been proposed by introducing local inductive bias of convolution operation. Some works[21, 22] immediately feed the final features of the last layer of CNNs into the original BLS. Other works[14, 18, 19, 20] cascade feature layers and enhancement layers to improve the final classification performance. Despite these progresses, they still lack flexible and rich multi-scale features for obtaining excellent performance [24, 25].
Furthermore, the existing optimization methods of convolutional filters for C-BLS are divided into two categories, including random convolutional filters (RCF)[14, 18, 19, 21, 22, 23] and trained convolutional filters (TCF) via a gradient descent algorithm [20]. For RCF-based methods, the weights of convolutional filters are randomly sampled under a given distribution. They can boost the performance to some extent but still suffer from the following problems: 1) the model stability is poor, and 2) there remains a tremendous performance gap between them and typical DNNs. For TCF-based methods, the weights of convolutional filters are optimized by a stochastic gradient descent algorithm using back-propagation (BP). As a result, the shortcomings of deep learning, such as incredible training time, massive computing resource consumption, and poor generalization, also exist in these methods.
Last but not least, the incremental learning capability makes BLS dynamically adjust the network structure without a tedious retraining process. However, a majority of existing C-BLS variants [14, 18, 20, 22, 23] fail to equipped with incremental learning ability except BCNN[19] and CNNBL[21]. Even so, both BCNN[19] and CNNBL[21] are optimized by RCF-based methods and thus can not achieve the required performance. Therefore, it is significant to design incremental learning algorithms for models whose convolutional filters require training.
Considering the above issues, we propose an effective and efficient convolutional broad learning system (ConvBLS) based on the SKM algorithm and TSMS feature fusion. It adopts a naive unsupervised learning algorithm, SKM, for the efficient filter learning of CF layers, which only requires low computing resources and training time. Additionally, the orthogonal CE layer is designed to expand the feature space. To further mine the features of CF layers and CE layers, a TSMS feature fusion layer is proposed to obtain abundant multi-scale features used for decision. Importantly, because of more discriminative features extracted by CF and CE layers, ConvBLS is naturally suitable for semi-supervised learning scenarios with few labeled data. Lastly, it is equipped with two proposed incremental learning algorithms to achieve fast remodeling without the tedious retraining process. The main contributions of this article are summarized as follows.
-
1.
A novel and effective ConvBLS architecture is developed, which is composed of the CF layer, CE layer, TSMS feature fusion layer, and output layer. Among them, the TSMS feature fusion layer is designed for the first time to extract richer multi-scale features by combining CF layers, CE layers, and SPP techniques.
-
2.
We present a rapid and efficient training method for ConvBLS. Due to the powerful unsupervised feature extraction capability, our method can be adapted to semi-supervised learning tasks without modification.
-
3.
We design two incremental learning algorithms to adjust the model dynamically. To our best knowledge, it is the first time to propose incremental learning algorithms for C-BLS methods whose convolutional filters need to be trained.
The rest of this paper is organized as follows. In Section II, the related works of this article are given. Section III illustrates the technical details of the proposed ConvBLS. Extensive experiments are carried out to demonstrate the effectiveness and efficiency of our method in Section IV. Finally, Section V concludes this article and discusses several future research directions.
II Related Works
The main topic of this article is to design a valid ConvBLS architecture and develop a rapid training algorithm and corresponding incremental learning algorithms. Consequently, in this Section, BLS and its convolutional variants are first reviewed. Then, to understand the TSMS feature fusion, the typical SPP technique is recalled. Finally, the existing convolutional filter training methods without supervised signals are introduced to improve the training method of the C-BLS.
II-A Broad Learning System and Its Convolutional Variants
BLS[13, 14] is an alternative model to DNNs, that consists of three parts, feature nodes, enhancement nodes, and output nodes. First, the input data is randomly mapped into feature nodes. Then all feature nodes are randomly mapped into enhancement nodes. After that, all feature nodes and enhancement nodes are connected with the output nodes. Because the weights of the output nodes can be obtained by pseudo-inverse calculation, the training of BLS is extremely fast. More details about BLS and corresponding incremental learning algorithms can be found in [13].
Different from the flat single hidden layer architecture of BLS, several variants[14] such as CFBLS, CEBLS, and CFEBLS have been developed to elevate the performance by deepening the network. However, the performance of these variants is poor on image classification tasks due to a lack of inductive bias and poor feature extraction ability. To tackle these problems, Chen et al. [14] presented CCFBLS, a pioneer of C-BLS, to extract image features using the random convolutional layer. Unlike CCFBLS, Yang et al. [18] leveraged principal component analysis to reduce the dimension of features extracted from random convolutional layers, which reduces the model complexity. Yu et al. [19] proposed BCNN and related incremental learning algorithms, which have excellent results in fault diagnosis. Similarly, CNNBL[21], RCNNBL[22], and MRC-BLS[23], characterized by random convolutional filters, have been successfully applied to facial expression recognition, music classification, and hyperspectral image classification tasks, respectively. In addition, instead of random convolutional filters, Li et al.[20] improved the performance in image classification by utilizing the Adam algorithm[26] to fine-tune the weights of convolutional layers.
Despite these advances, they still have their own problems. For example, the RCF-based methods[14, 18, 19, 21, 22, 23] lack strong feature extraction ability. Conversely, the TCF-based methods[20] require tedious training time inherited from BP algorithms. Thus, in this study, we try to synthesize the merits of both methods to design an efficient and effective ConvBLS.
II-B Spatial Pyramid Pooling
Being one of the most successful techniques in the traditional computer vision community, spatial pyramid matching[24, 25] (a.k.a. spatial pyramid pooling, SPP) has been suggested to extract more robust multi-scale feature representations. Inspired by [24, 25], SPP-net[27] has been proposed by He et al., which first couples SPP into CNNs for image classification and object detection tasks. Specifically, SPP pools the input feature maps through multiple branches and combines the output features of all these branches to form the final spatial pyramid features. To obtain semantic features at different scales, pooling operators in different branches, with various pooling window sizes and strides, are performed separately. Among them, the number of layers of a pyramid (i.e., the number of branches) and the number of features (i.e., the number of spatial bins) in each layer of a pyramid usually need to be manually specified. Despite its conceptual simplicity, SPP is more efficient than the approaches that use more complex spatial paradigms. After that, SPP has been widely applied to various recognition tasks such as hyperspectral image classification[28], hand gesture recognition[29, 30], and traffic sign recognition[31, 32]. Unlike existing work that explores SPP in CNNs for specific tasks, we propose to combine the concept of SPP and BLS to extract more effective and comprehensive TSMS features.
II-C Training Convolutional Filters without Supervised Signals
As the successful application of CNNs in computer vision[1, 2, 3], the optimization techniques of convolutional filters fall into two categories. The first category refers to the methods that optimize convolutional filters through the pseudo-label and BP algorithm. For example, the generative adversarial networks and their variants[33, 34, 35] train a generator and a discriminator by the learning strategy as the rule of the minimax game. Among them, labels used for model training can be obtained easily by the program itself. DeepCluster[36] iteratively clusters the sample features with K-means and uses the generated assignments as supervision to update convolutional filters. Similarly, Exemplar-CNN[37] and SimCLR[38] generate pseudo-labels by image transformations and use them for filter training. Despite their superb performance, they require comparable or even larger training costs than typical supervised DNNs.
The second utilizes simple unsupervised learning algorithms to optimize convolutional filters without the BP algorithm. Coates et al.[39, 40, 41] used the K-means algorithm to train filters for extracting features on input image maps in a convolutional manner. With an elaborate feature coding scheme, these methods exceeded many complex unsupervised learning methods in image classification. However, compared to typical CNNs[2, 4, 5, 6], these models have enormous convolutional filters (e.g., 4096) and few convolutional layers, which require huge running memory and lack hierarchical spatial features. Most related to ours is the method proposed by Culurciello et al.[42], which utilizes a few filters trained by K-means followed by fully-connected layers for classification in real-time scenarios. The main difference between [42] and our work is that we use the CE layer and the TSMS feature fusion layer to leverage features extracted by K-means instead of naive downsampling of inputs as a supplement to final features. Similarly, Dundar et al.[43] used convolution k-means to learn filters and supervised methods to learn the connection weights between layers, which not only increases the computation cost but also makes the training pipeline exceedingly complicated. Hence, it is ongoing work to design an elegant algorithm to balance its generalization performance and computational complexity.
III Methodology
The key to developing an effective and efficient model is closely related to the model architecture and training algorithm. Hence, in this Section, the proposed effective ConvBLS architecture is detailed first. Additionally, the simple yet efficient training algorithm for ConvBLS is given. At last, incremental learning algorithms are introduced to avoid tedious retraining processes if the model deems to expand.
III-A Convolutional Broad Learning System
For intuitional understanding, the overview architecture of ConvBLS is depicted in Fig. 1.
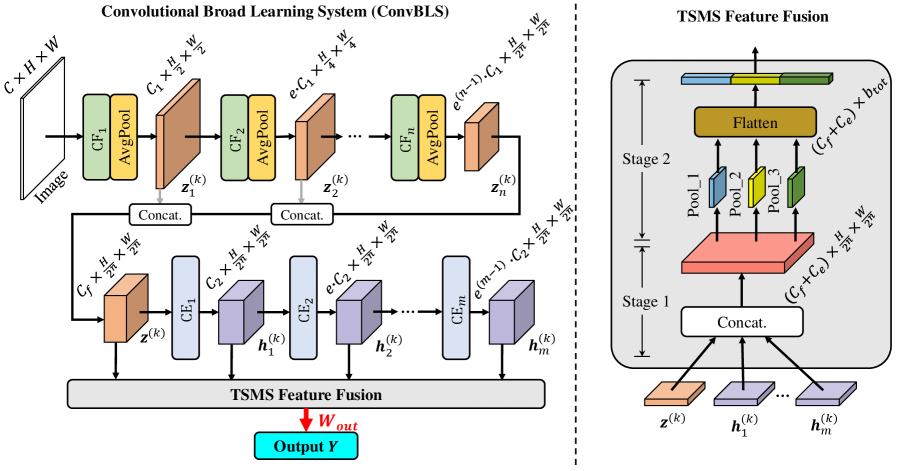
The proposed ConvBLS is composed of CF layers denoted as CFi (), CE layers denoted as CEj (), one TSMS feature fusion layer and one output layer . To avoid overfitting, each CF layer follows by an average pooling layer. Moreover, , , , and are the number of output channels in the CF1 layer, the total number of feature maps in all CF layers, the number of output channels in the CE1 layer, and the total number of feature maps in all CE layers, respectively. Note that a feature map is regarded as a feature node or enhancement node for ConvBLS. Therefore, and also denote the total number of feature and enhancement nodes, respectively. Again, represents the expansion ratio of the number of output channels throughout the CF and CE layers. Among, is determined by , , and . At last, denotes the feature dimension after the TSMS feature fusion for each feature map. With CF layers and CE layers, and defined by the user denote the width of the ConvBLS. In the following, we will introduce them in detail.
III-A1 Convolutional Feature Layer
Suppose that the input data set , where , , , and denote the number of samples, the number of channels, height, and width, respectively. Taking the th image as the input, the output of CFi (i.e., the th feature node group) can be defined as follows:
| (1) |
where and are the weight matrix and bias matrix, respectively. Among them, is obtained by the SKM algorithm. Similar to [44], we set to be a zero matrix to simplify the learning of CF layers. Because it is difficult for the SKM algorithm to learn features in a very high-dimensional feature space, we split the high-dimensional feature space into several sub-spaces and utilize the SKM algorithm to learn filters separately in each subspace. Thus, to divide the subspace and ensure that the filters are only used to extract features in the subspace where they are trained, we use group convolution here represented as . In other words, the features from different feature sub-spaces (i.e., different feature groups) do not interact. And is the number of feature maps for each feature group in the CFi layer. Particularly, we set to be the number of channels of the input image for the CF1 layer. As for the subsequent CF layers, and can be different for . Without loss of generality, we have , where . At last, represents the ReLU activation function. In other words, each CF layer utilizes the output of its precursor CF layer to obtain more abstract features. Furthermore, in the CF1 layer, the input is defined as . Unlike the group convolution typically used in DNNs, we pre-process all patches extracted from previous feature maps by normalization and whitening before convolution.
III-A2 Convolutional Enhancement Layer
Denote , which is the concatenation of all feature node groups. To keep the spatial size of the feature nodes consistent, pooling operations are used in appropriate locations. Since each feature node is a feature map obtained by convolution, there are still significant spatial relationships amongst the feature values within each map. Consequently, we use convolution for two-dimensional feature enhancement instead of the one-dimensional feature enhancement used in BLS to preserve the spatial relationships of feature values. The output of CEj (i.e., the th enhancement node group) can be formulated as follows:
| (2) |
where and are randomly generated weight matrix and bias matrix, respectively. stands for convolutional operation and denotes a selected activation function. Similarly, is equivalent to in the CE1 layer.
III-A3 Two-stage Multi-scale Feature Fusion
To obtain promising performance, all feature node groups and enhancement node groups (with various feature scales) are concatenated directly to yield the first stage multi-scale features, which can be expressed as follows:
| (3) |
where is a concatenation function and represents the first stage multi-scale features. Subsequently, more reasonable and comprehensive two-stage multi-scale features are attained by the typical SPP technique. The second stage multi-scale features are defined as follows:
| (4) |
where is the number of feature pyramid layers and denotes the size of the feature maps for the th layer feature pyramid. represents a function combination of SPP and flattening. Suppose that the shape of is , in which and are usually equal, thus we set . Take the th layer pyramid as an example, to obtain the features with the specified scale, we have a pooling layer with the window size and stride , where and represent ceiling and floor operations. Besides, denotes the second stage multi-scale features. Combining Eq. (3) and Eq. (4), the TSMS features of the th sample can be obtained. For simplicity, the subscript is omitted in the rest of this paper.
III-A4 Output Layer
The final representation of each sample is a comprehensive feature vector, which is, to some extent, translation invariant and scales invariant inherited from convolutions and has rich multi-scale semantic information. Similar to the vanilla BLS, the output layer of ConvBLS is still a plain linear classification layer that can be represented as the equation of the form:
| (5) |
where is the weight matrix and denotes the final output of ConvBLS for input image . Furthermore, the outstanding classification performance of ConvBLS can also be ensured by the efficient training algorithm, which will be illustrated later.
III-B Efficient Training Algorithm for ConvBLS
The training process of ConvBLS is roughly divided into two phases: the first phase is to train the parameters of CF layers using an unsupervised learning algorithm. Conversely, the second phase is to train the parameters of the output layer (i.e., the classifier) using a supervised learning algorithm.
III-B1 Unsupervised Learning for the CF Layer
The weights of convolutional filters for CF layers are trained using the SKM algorithm in a greedy manner. When training the CFi layer, the extracted features for all training samples at the CFi-1 layer are available. We collect the features of all training samples in the CFi-1 layer as . The equation for is denoted as , where represents the features of all samples and denotes the features of one sample. Moreover, when the CF1 layer is trained, is defined as . Given the number of feature maps within each feature group for the CFi layer, the features extracted from the CFi-1 layer can be divided into groups. Additionally, for , where represents the th feature group, the training procedure begins by extracting random patches from the feature group . Each patch has dimension -by--by-, with referred to as the receptive field size. After that, pre-processing operations are necessary. First, every patch is normalized by subtracting the mean and dividing by the standard deviation of its elements to normalize the brightness and contrast. Subsequently, to overcome the correlations between adjacent pixels, the ZCA whitening transform[45] should be used. We then gather all of the patches and construct a new dataset for the training of this set of convolutional filters. The dataset is represented as , where , and represents the number of patches.
After pre-processing, the core issue becomes how to learn the weights of convolution filters from patches. As we know, the principle of deep neural networks essentially involves a template-matching problem. For CNNs, each convolution filter is a template (i.e., pattern) used to extract the corresponding feature from the response of the precursor layer. Thus, a set of excellent templates must produce similar responses on the same class of samples and vice versa, which is crucial for the classification task. However, the RCF-based methods[14, 18, 19, 21, 22, 23] whose convolutional filters are generated randomly can not meet the above requirements. Inspired by the earlier works that use the K-means algorithm for unsupervised feature learning[39, 40, 41, 42, 43], we utilize the SKM to learn better convolutional filters (i.e., templates) for CF layers. In this context, the data points to be clustered are randomly extracted patches, and the centroids are the convolutional filters used to extract features from the corresponding output of the predecessor CF layer. The algorithm finds the convolutional filters as follows:
| (6) | ||||
where is the code vector associated with the input , and is the -th convolutional filter in CFi for the th feature group . Note that the convolution filters learned in the th feature group can only be utilized to extract more abstract features in the th feature group eventually. Recalling the feature grouping method mentioned earlier, we can attain the weights of convolutional filters associated with other feature groups in a similar manner. Finally, the convolutional filters for all CF layers can be fine-tuned in this way.
III-B2 Supervised Learning for the Ouput Layer
The weights of the output layer are trained using the ridge regression algorithm. To this end, the TSMS features of all training samples that are robust to object deformation are first calculated using Eq. (4). Denoting the final TSMS feature matrix as and the real label vector as , the optimization problem of the output layer is expressed as follows:
| (7) |
where represents the regularization coefficient to balance the mean squared error term and L2 normalization term. Also, the problem is convex, and the solution can be obtained by the ridge regression theory, which produces an approximation to the Moore-Penrose generalized inverse by adding a positive number to the diagonal of or . Therefore, the weights of output layer can be calculated as follows:
| (8) |
where is an identity matrix with the same shape as .
By combining the above two phases, all the weights to be trained in our ConvBLS can be optimized. It should be noted that since the weights of CF layers are optimized without tedious fine-tuned processes using the BP algorithm, the training procedure of the entire model is extremely efficient. Thanks to the powerful feature extraction capability of the CF layer and CE layer, the training of the output layer can achieve excellent classification performance without requiring a lot of labeled data. Thus, our method also has remarkable performance in semi-supervised classification.
III-C Incremental Learning Algorithms
Incremental learning capability is significant for practical application. However, the existing TCF-based approaches that usually mean higher performance failed to be equipped with incremental learning algorithms. Therefore, two incremental learning algorithms for ConvBLS are developed, i.e., the increment of additional feature nodes and the increment of additional enhancement nodes. Note that due to the unique design of ConvBLS, the input data increment algorithm is similar to that of BLS. Hence, it has been omitted.
As described in Section III.A, the feature nodes and enhancement nodes for ConvBLS are feature maps instead of feature values in BLS. And the number of feature nodes or enhancement nodes for each layer depends on the number of output nodes for the predecessor layer and the corresponding expansion ratio. Therefore, in the following elaboration, we only need to add a certain number of nodes to the CF1 layer or the CE1 layer, and the number of nodes in the rest of the layers will vary according to the predefined expansion ratio.
III-C1 Incremental of Additional Enhancement Nodes
Recall that the weights and biases of CE layers do not require training. Therefore, we add additional enhancement nodes for CE layers to improve the performance quickly. For convenience to introduce the incremental learning algorithm of the enhancement nodes, we rewrite the CE layer with four-dimensional tensors. In other words, the entire training set rather than a single image are fed into the ConvBLS at once to calculate the enhancement features . Next, we detail the broad expansion method for adding additional enhancement nodes in the CE1 layer. The output of the CEj layer for additional enhancement nodes can be formulated as follows:
| (9) |
where
| (10) |
and are randomly generated. Specifically, similarly to Eq. (2), is defined as . And then, the new TSMS features can be formulated as follows:
| (11) |
where is a function combination of and in Eq. (3) and Eq. (4). Then, we deduce the pseudoinverse of the new matrix as
| (12) |
where ,
| (13) |
and
Again, the new weight matrix is
| (14) |
The incremental learning algorithm of additional enhancement nodes is listed in Algorithm 1.
III-C2 Incremental of Additional Feature Nodes
In some cases, due to the insufficient feature nodes, adding enhancement nodes solely does not meet the performance requirements. Here, we describe the incremental learning for newly incremental feature nodes. Similarly, we rewrite the CF layer in four-dimensional tensors. Assume that there are and output channels in the CF1 and CE1 layers of the initial architecture, respectively. Consider adding feature nodes to the CF1 layer, the additional output of the th feature layer can be expressed as follows:
| (15) |
where is defined as . Denote , the corresponding enhancement nodes are randomly generated as follows:
| (16) |
where is defined as . Then, the TSMS features can be expressed as follows:
| (17) |
Similarly, we deduce the pseudoinverse of the new matrix as
| (18) |
where ,
| (19) |
and ,
Again, the new weight matrix is
| (20) |
The incremental learning algorithm of additional feature nodes is listed in Algorithm 2.
Inspired by the great success of deep transfer learning, we also use the pre-trained deep convolutional neural network as the CF layer. Compared with the CF layer trained by the SKM algorithm, using the pre-training model as the CF layer also maintains the training efficiency of BLS and has better performance on more complex tasks.
IV Experimental results
In this Section, experimental results are given to verify the proposed ConvBLS. The experiments are conducted on the Ubuntu 20.04 operating system, and the CPU is Intel Xeon Gold 6226R.
IV-A Dataset
The experiments are conducted on the following datasets: 1) MNIST, 2) Fashion-MNIST, and 3) NORB.
IV-A1 MNIST
The dataset[46] contains 60 000 training samples and 10 000 test samples, which are evenly distributed over 10 classes of handwritten digital images. Among them, every sample is a gray-scale image with 2828 pixels.
IV-A2 Fashion-MNIST
The dataset[47] is consistent with the MNIST dataset, except that it has more complex image features. Besides, all samples fall into 10 categories, including 1) T-shirt/top, 2) trouser, 3) pullover, 4) dress, 5) coat, 6) sandal, 7) shirt, 8) sneaker, 9) bag, and 10) ankle boot.
IV-A3 NORB
The dataset[48] is a more complicated dataset compared with MNIST and Fashion-MNIST datasets, which is composed of 48 600 images with the size of 2 32 32 pixels. The NORB contains images of 50 different 3-D toy objects labeled by five distinct categories: 1) animals, 2) humans, 3) airplanes, 4) trucks, and 5) cars. Here, 24 300 images of 25 objects are used for training, and the other 24 300 images are used for testing.
IV-B Performance of ConvBLS
To investigate the superiority of the proposed model, We perform extensive comparison experiments with four types of methods, including 1) traditional methods, 2) broad topology-based methods, 3) deep topology-based methods, and 4) deep and broad topology-based methods. Unless the relevant papers do not provide valid structural hyperparameters and training details (we marked the training time of these methods with a unique superscript ), for the sake of reliability and fairness, all the remaining approaches are reproduced on our experimental platform with the same hyperparameters as the original papers, and the corresponding training time is listed. It should be noted that in all experiments, the data augmentation technique is avoided, and we mainly focus on the verification of the effectiveness of the proposed ConvBLS.
The structure parameters of ConvBLS are listed as follows: the number of CF layers is set to 3, and the number of CE layers is set to 1. In addition, the number of pyramid layers in the second phase of the TSMS feature fusion layer is set to 3, and the corresponding number of spatial bins is set to {33,
22, 11}. After that, the remaining structural parameters depend on the complexity of the specific task. As for the training-related parameters, the number of patches extracted from the output of the previous CF layer is set to 400 000. The regularization coefficient for the output layer is chosen from the set .
IV-B1 Experimental Results on MNIST Dataset
Our results are shown in Table I. The experimental results of the comparison methods, including SAE, DBN, and MLELM, are cited from [49], while that of Stacked BLS are cited from [50]. For our ConvBLS, we set the initial number of output channels in the CF1 layer as and the corresponding expansion ratio as .
We can observe that ConvBLS has the highest test accuracy of , even with the extremely short training time. Specifically, our method have a speedup of more than times compared to the most time-consuming method, which is attributed to the TSMS feature extracted by the effective model architecture and the efficient training algorithm.
| Method | Test Accuracy (%) | Training Times (s) | Speedup Times | Topology |
| SAE [49] | 98.60 | 36448.40† | 1.46014 | - |
| DBN [49] | 98.87 | 53219.77† | 1 | - |
| MLELM [49] | 99.04 | 475.83† | 111.8462 | - |
| BLS [13] | 98.740 | 47.3725 | 1123.432 | broad |
| CFEBLS [14] | 98.83 | 24.1333 | 2205.242 | broad |
| R-BLS [51] | 98.95 | - | - | broad |
| CFBLS-pyramid [52] | 98.65 ± 0.14 | 64.4368 | 825.922 | broad |
| Stacked BLS [50] | 99.120 | 30.1916† | 1762.734 | broad |
| MLP [53] | 97.39 | 633.8427 | 83.96369 | deep |
| LeNet-5 [1] | 95.63 | 732.8154 | 72.62371 | deep |
| ResNet34 [5] | 98.960 | 20469.234 | 2.599988 | deep |
| CNNBLS [18] | 96.940 | 377.4365 | 141.0032 | deep + broad |
| CNN + BLS [20] | 99.230 | 790.492 | 67.32487 | deep + broad |
| Ours | 99.280 | 228.8355 | 232.5678 | deep + broad |
| Method | Test Accuracy (%) | Training Times (s) | Speedup Times | Topology |
| KNN [52] | 84.70 ± 0.00 | 4927† | 6.759972 | - |
| RF [50] | 87.3 | - | - | - |
| Xgboost [50] | 89.82 | - | - | - |
| Dyra-Net [50] | 90.6 | - | - | - |
| BLS [13] | 91.39 | 46.6083 | 714.6019 | broad |
| CFEBLS [14] | 87.130 | 24.5927 | 1354.32 | broad |
| R-BLS [51] | 87.48 | - | - | broad |
| CFBLS-pyramid [52] | 89.88 ± 0.15 | 66.4128 | 501.5054 | broad |
| Stacked BLS [50] | 91.53 | - | - | broad |
| AlexNet [2] | 87.1 | 1016.595 | 32.76268 | deep |
| VGG16 [3] | 90.28 | 6400.780 | 5.203488 | deep |
| GoogLeNet [4] | 91.75 | 7792.025 | 4.274419 | deep |
| DenseNet [6] | 90.75 | 33306.380 | 1 | deep |
| CNNBLS [18] | 84.210 | 576.8780 | 57.73557 | deep + broad |
| CNN + BLS [20] | 91.170 | 826.8948 | 40.27886 | deep + broad |
| Ours | 92.430 | 332.7186 | 100.1038 | deep + broad |
| Method | Test Accuracy (%) | Training Times (s) | Speedup Times | Topology |
| K-means (Triangle) + SVM [39] | 97.0 | 433.7307 | 97.83569 | - |
| BLS [13] | 89.27 | 11.9946 | 3537.787 | broad |
| CFEBLS [14] | 90.02 | 20.8354 | 2036.646 | broad |
| CEBLS-dense [52] | 88.40 ± 0.29 | 37.1291 | 1142.886 | broad |
| K-means-BLS [16] | 95.971 | 309.9045 | 136.9272 | broad |
| Stacked BLS [50] | 91.90 | 5.1718† | 8204.946 | broad |
| MLP [53] | 85.325 | 299.4026 | 141.73 | deep |
| LeNet-5 (ReLU) [1] | 87.453 | 212.2769 | 199.9009 | deep |
| AlexNet-small [2] | 91.218 | 594.974 | 71.32134 | deep |
| AlexNet-base [2] | 91.930 | 1107.2195 | 38.32514 | deep |
| AlexNet-large [2] | 93.049 | 3497.686 | 12.13212 | deep |
| VGG13 [3] | 96.486 | 4380.396 | 9.68733 | deep |
| ResNet18 [5] | 94.646 | 12658.889 | 3.352138 | deep |
| ResNet34 [5] | 93.988 | 18975.880 | 2.236225 | deep |
| ResNet50 [5] | 95.045 | 42434.341 | 1 | deep |
| CNNBLS [18] | 90.066 | 218.7023 | 194.0279 | deep + broad |
| CNN+BLS [20] | 91.016 | 279.224 | 151.9724 | deep + broad |
| Ours | 97.193 | 194.4663 | 218.2092 | deep + broad |
IV-B2 Experimental Results on Fashion-MNIST Dataset
Table II presents the results. To make the experimental conclusions more reliable, the test accuracy of several comparison methods, including AlexNet, VGG16, GoogLeNet, and DenseNet, are cited from [54] and [55]. Conversely, the training time of these models are obtained by re-running them on our experimental platform with the same training details as the original papers for a fair comparison. For CNNBLS and CNN+BLS, the model structures and training details we adopted are the same as that on the MNIST dataset. At last, given the more challenging data set, the number of initial output channels and expansion ratio was set to and , respectively.
As shown in Table II, similar to the MNIST dataset case, our method achieve the state-of-the-art performance among the existing approaches with a superfast speed in computation. Thus, the proposed ConvBLS model is very appealing. In particular, our approach surpasses many classical DNNs in both time and accuracy.
| Datasets | Incremental Algorithm | Number of Initial Channels in the CF1 Layer | Number of Initial Channels in the CE1 Layer | Test Accuracy (%) | Additional Training Time (s) | Accumulative Training Time (s) |
| MNIST | Feature Nodes | 16 | 224 | 98.850 | 150.1506 | 150.1506 |
| 16 20 | 224 280 | 98.930 | 68.9228 | 219.0734 | ||
| 20 24 | 280 336 | 98.950 | 69.5863 | 288.6597 | ||
| 24 28 | 336 392 | 98.990 | 70.2971 | 358.9568 | ||
| 28 32 | 392 448 | 99.050 | 70.7071 | 429.6578 | ||
| Enhancement Nodes | 16 | 112 | 98.670 | 114.5602 | 114.5602 | |
| 16 | 112 140 | 98.720 | 1.7916 | 116.3518 | ||
| 16 | 140 168 | 98.760 | 1.9123 | 118.2641 | ||
| 16 | 168 196 | 98.770 | 1.9750 | 120.2391 | ||
| 16 | 196 224 | 98.790 | 2.1035 | 122.3426 | ||
| Fashion-MNIST | Feature Nodes | 32 | 228 | 91.680 | 216.3523 | 216.3523 |
| 32 40 | 228 285 | 91.900 | 88.5769 | 304.9292 | ||
| 40 48 | 285 342 | 92.410 | 92.5383 | 397.4675 | ||
| 48 56 | 342 399 | 92.670 | 95.6273 | 493.0948 | ||
| 56 64 | 399 456 | 92.750 | 92.1845 | 585.2793 | ||
| Enhancement Nodes | 32 | 114 | 91.390 | 166.2956 | 166.2956 | |
| 32 | 114 142 | 91.570 | 2.0621 | 168.3577 | ||
| 32 | 142 170 | 91.760 | 2.2059 | 170.5636 | ||
| 32 | 170 198 | 91.810 | 2.2369 | 172.8005 | ||
| 32 | 198 226 | 91.940 | 2.6206 | 175.4211 | ||
| NORB | Feature Nodes | 32 | 228 | 95.564 | 149.4078 | 149.4078 |
| 32 40 | 228 285 | 95.704 | 68.5435 | 217.9513 | ||
| 40 48 | 285 342 | 95.852 | 71.7318 | 289.6831 | ||
| 48 56 | 342 399 | 96.296 | 70.7071 | 360.3902 | ||
| 56 64 | 399 456 | 96.811 | 70.2468 | 430.6370 | ||
| Enhancement Nodes | 32 | 114 | 95.547 | 120.3834 | 120.3834 | |
| 32 | 114 142 | 95.560 | 1.0154 | 121.3988 | ||
| 32 | 142 170 | 95.593 | 1.0771 | 122.4759 | ||
| 32 | 170 198 | 95.675 | 1.0751 | 123.5510 | ||
| 32 | 198 226 | 95.712 | 1.1784 | 124.7294 |
IV-B3 Experimental Results on NORB Dataset
The experimental results are reported in Table III. In the first methods, the k-means and triangle activation are used for single-layer feature extraction, and a support vector machine is used for classification, which generally requires a large number of features. For reference, K-means-BLS, one of the most similar works to ours, that use k-means to extract features and use a complete BLS to classify features, are reproduced on the NORB dataset, and the relevant hyper-parameters are as follows: the number of features in K-means feature extraction is set to , and BLS is constructed by total feature nodes and enhancement nodes. Moreover, to our knowledge, no work attempts to perform classification tasks on NORB datasets using typical CNNs. Therefore, we instantiate some common CNNs as deep topology-based comparison methods. In the first convolutional layer, AlexNet-small, AlexNet-base, and AlexNet-large have , , and output channels, respectively, and the number of output channels of the remaining layers vary accordingly. For the comparison methods trained by the BP algorithm, similar to [49] and [13], the training procedure is set as epochs, and the remaining training hyperparameters are finetuned to make the models converge. Lastly, the ConvBLS structure keeps same as that on Fashion-MNIST dataset.
The results also indicate that ConvBLS outperforms all of the comparison methods. In particular, our method significantly outperforms the broad topology-based and deep topology-based comparison methods in terms of test accuracy with a very short training time, which also validates our conjecture that convolution is very effective in processing image data, yet the arduous BP-based training for convolution filters is not necessary on relatively small-scale image datasets.
IV-C Incremental Learning Experiments
To illustrate the incremental learning ability of ConvBLS, incremental learning experiments are conducted, and the results are reported in Table IV. In this part, we perform two types of incremental experiments: 1) feature node increments and 2) enhancement node increments. All the above experiments are performed on the MNIST, Fashion-MNIST, and NORB datasets.
Since the experimental setup is similar on the three datasets, next, we present the incremental experiments on the MNIST dataset as an example. For the experiments of increments of feature nodes, the initial number of feature nodes and enhancement nodes in the CF1 layer and the CE1 layer is and , respectively. In the incremental process, feature nodes and enhancement nodes are added each time. For the experiments of increments of enhancement nodes, it initially has feature nodes and enhancement nodes in the CF1 layer and CE1 layer, and each incremental step inserts enhancement nodes.
In Table IV, the first conclusion is that the two incremental learning algorithms are effective. As the number of feature nodes or enhancement nodes increases, the test accuracy gradually improves at the cost of acceptable additional training
time. Subsequently, comparing the two incremental learning algorithms, we can see that incremental learning for enhancement nodes is more efficient because the weights of CE layers do not need to be trained. Therefore, we can first increment the CE layer when we consider expanding our model.
IV-D Semi-supervised Learning Experiments
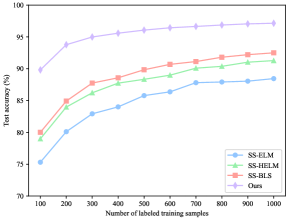
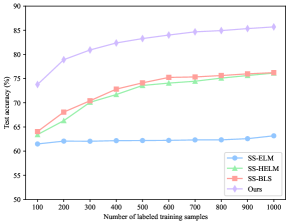
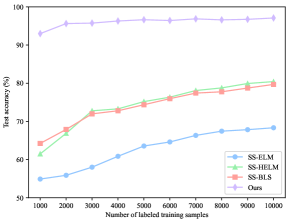
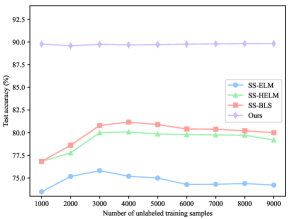
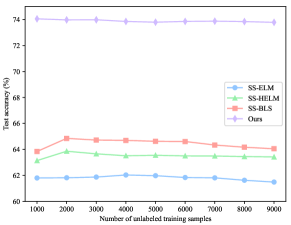
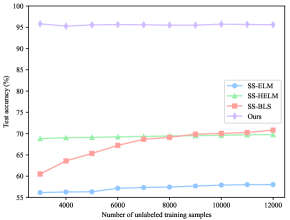
To verify the superiority of our ConvBLS in semi-supervised classification, we perform extensive experiments following the experimental design of SS-BLS[56], which is the most typical method to modify BLS for semi-supervised scenarios. First, on the MNIST dataset, to analyze the performance of ConvBLS as the number of labeled training samples increases, the initialized number of labeled training samples is 100, the number of unlabeled training samples is 9000, and the number of labeled test samples is 60 000. Then, the number of labeled training samples is increased by 100 each time until 1000. To analyze the performance as the number of unlabeled training samples increases, the number of labeled training samples is 100, the number of initial unlabeled training samples is 1000, and the number of labeled test samples is 60 000. And then, the number of unlabeled training samples is increased by 1000 each time until 9000. Second, on the Fashion-MNIST dataset, the experimental design is the same as that on the MNIST dataset. Lastly, two sets of experiments are conducted on the NORB dataset. For the first one, the number of initial labeled training samples is 1000, the number of unlabeled training samples is 14 300, and the number of labeled test samples is 24 300. Subsequently, the number of labeled training samples is increased by 1000 each time until 10 000. For the second one, the number of labeled training samples is 2500, the number of initial unlabeled training samples is 3000, and the number of labeled test samples is 24 300. After that, the number of unlabeled training samples is increased by 1000 each time until 12 000.
The results of all comparison methods on MNIST and NORB datasets are cited from [56], and that on the Fashion-MNIST dataset is obtained by reproducing them under the above setting. Similarly, the structural and regularization parameters are obtained by grid search. For our ConvBLS, all parameters are identical to that in Section IV.B. To eliminate the random factor, we run each experiment 10 times independently, and their means are selected as the final performance.
As depicted in Fig. 2, the testing accuracy of ConvBLS is significantly higher than that of comparison methods in all settings. Moreover, the test accuracy can gradually improve with the increase of the number of labeled training samples, which does not hold in Fig. 2(d)-(f) yet. Thus, it may indicate that despite the ingenious semi-supervised framework developed by the comparison methods, almost all of them still fail to take full advantage of the information from the unlabeled data. Consequently, we argue that richer and more comprehensive semantic features are as important as elaborate semi-supervised framework designs, which typically use complex graph theory and manifold regularization, rather than sample unsupervised feature learning.
IV-E Ablation Study
To investigate the necessities and effectiveness of each component of ConvBLS, ablation experiments fall into three parts. The first one verifies the effectiveness of the unsupervised training algorithm for CF layers. Second, experiments are designed to demonstrate the effectiveness of TSMS feature fusion. At last, we progressively construct our model to achieve increasing performance.
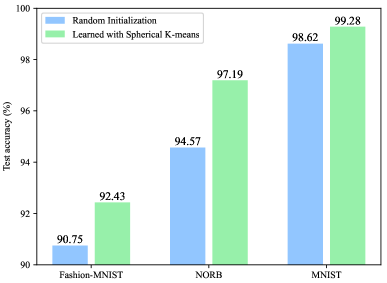
In the first part, the comparison method is de facto identical to our ConvBLS except that the filter parameters of CF layers are randomly generated. Additionally, hyperparameters of both the comparison method and our ConvBLS are consistent with that in Section IV.B. As shown in Fig. 3, our ConvBLS outperforms the comparison method on all of the three datasets, which indicate that the unsupervised learning algorithm we designed for CF layers is effective.
To investigate the reason why the filters trained using the SKM significantly outperform the random filters, we visualize the filters of the CF1 layer for both our method and comparison method on the FashionMNIST dataset as an example. As illustrated in Fig. 4, compared to the randomly initialized filters, the filters obtained using the SKM are more like, to some extent, edge detectors and corner detectors.


This distinct selectivity for local features is crucial, especially in the image feature extraction procedure. With these merits, our methods can achieve better accuracies than comparison methods.
Secondly, we conduct a set of ablation experiments on the TSMS feature fusion. For each dataset, four models with 1*1 bins, 2*2 bins, 3*3 bins, and all three pyramid features are trained and evaluated. Fig. 5 shows that pyramid layers with more spatial bins have higher accuracy, and the spatial pyramids with all the above pyramid layers have the highest accuracy.
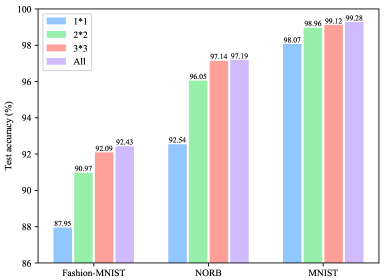
Note that the method with a three-level pyramid has TSMS features, while the comparison methods do not. Thus, we can safely conclude that the TSMS features are more robust and effective for image classification tasks.
Lastly, we add modules proposed in this research one by one and construct progressively three individual ConvBLS models. The results are presented in Table V. The hyperparameters are identical to that in Section III.B, except specifically mentioned in this table. We can see that the most complete model has the best accuracy, and each module is beneficial for performance improvement.
| 1 CF Layer | 2 CF Layers | 3 CF Layers | 3 CF Layers with CE Layers | 3 CF Layers with CE Layers and TSMS | MNIST | Fashion-MNIST | NORB |
| ✓ | 97.81% | 88.50% | 93.580% | ||||
| ✓ | ✓ | 98.45% | 89.62% | 93.963% | |||
| ✓ | ✓ | ✓ | 98.56% | 89.65% | 95.132% | ||
| ✓ | ✓ | ✓ | ✓ | 98.96% | 90.97% | 95.132% | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 99.28% | 92.43% | 97.193% |
IV-F The Hyper-parameter Sensitivity Analysis of the ConvBLS
We analyze the sensitivity of the hyper-parameters, including kernel size, stride, activation function, and the number of output channels in ConvBLS by testing how the hyper-parameters influence performance. In the following sections, except for the hyper-parameters we are analyzing, the others are identical to that in the Section IV.B. As an example, all the experiments below are conducted on the NORB dataset.
IV-F1 The effect of output channels
Our experiments consider several activation functions (which we will discuss in the next section) and the number of output channels for the CF1 layer. As shown in Fig. 6, our methods with different activation functions generally achieve higher performance by learning more feature maps as expected.
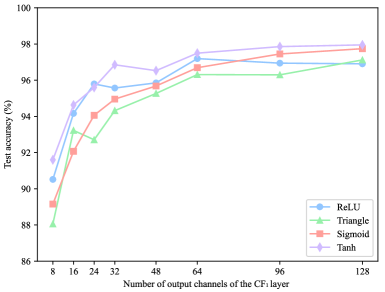
However, as the number of output channels increases, the accuracy of all methods rapidly saturates. In other words, we can attempt to increase the width (number of output channels) of the ConvBLS to improve accuracy, which is the basis of the incremental learning algorithm for ConvBLS.
IV-F2 The effect of activation functions
The selection of the activation function is also an important issue. In this part, four activation functions, including Tanh, ReLU, Sigmoid, and Triangle, are validated. As shown in Fig. 6, the Tanh function works best, while the Triangle has the worst accuracy. Besides, the ReLU and Sigmoid activation functions have similar accuracy. Given that Triangle is computationally expensive and its accuracy is the worst, we further investigate the remaining three activation functions in the following experiments. Lastly, considering the simplicity of ReLU, we use the ReLU activation function to construct our ConvBLS model.
IV-F3 The effect of kernel sizes
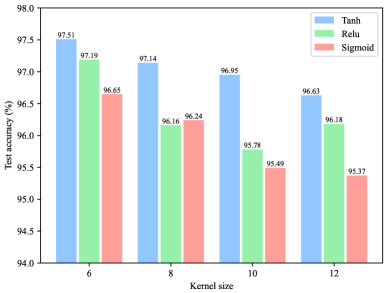
Different kernel sizes can capture features of different scales. Hence, we test kernel sizes of , , , and . As shown in Fig. 7, the methods with a smaller kernel size in CF layers work better. The reason for the above phenomenon is as follows. In particular, as the kernel size increases, the dimension of the feature space where the unsupervised learning algorithm works also becomes larger. This makes it difficult for the algorithm to discover the selective filters.
IV-F4 The effect of strides
We vary the stride over , , and . Fig. 8 depicts the results.
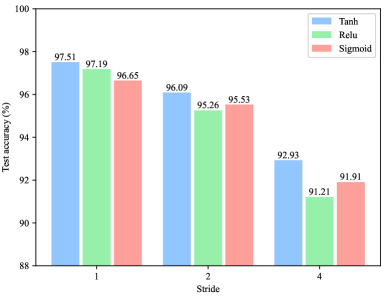
Overall, the 1-pixel stride works best and the larger the stride the worse the accuracy. Because the larger the stride, the less the number of features we can extract. Thus, if we have computational resource to spare, our results suggest that it is better to spend it on reducing the stride and selecting a small kernel size.
V Conclusions and Future Work
In this article, a convolutional broad learning system is proposed for image classification. To design an efficient and effective ConvBLS, we provide a solution from the perspective of the model architecture and training algorithm simultaneously. On one hand, a ConvBLS architecture is developed, which consists of the CF layer, CE layer, TSMS feature fusion layer, and output layer. Thanks to the architectural design and TSMS feature fusion mechanism, the architecture of ConvBLS is effective. On the other hand, a training algorithm for ConvBLS is proposed. Benefiting from the SKM for the CF layers and supervised learning for the output layer, the training of our ConvBLS is very efficient. Finally, we develop two corresponding incremental learning algorithms to adjust the structure of the model dynamically. Experiments on MNIST, Fashion-MNIST, and NORB datasets clearly demonstrate the effectiveness and efficiency of our ConvBLS.
There are still some works worthy of in-depth study. First, the proposed training algorithm for our ConvBLS is a framework about using unsupervised learning algorithm to optimize the weights of CF layers and using supervised learning algorithm to calculate the weights of the output layer. The SKM is just used as an example. Therefore, whether other unsupervised learning algorithms are more suitable for such a training framework is a question worth investigating. Second, it is necessary to further investigate how to tune the hyper-parameters and other complex architectural parameters. All hyperparameters in ConvBLS are tuned manually based on expert experience, which is inefficient. In the next step, we will try to use the neural architecture search approach for automatic tuning of hyper-parameters. At last, our ConvBLS is solely a theoretical framework, which is validated on generic datasets. In the following, we can apply the ConvBLS to specific scenario, such as human action recognition, face recognition, and facial expression recognition.
References
- [1] Y. LeCun, B. Boser, J. Denker, D. Henderson, R. Howard, W. Hubbard, and L. Jackel, “Handwritten digit recognition with a back-propagation network,” Advances in neural information processing systems, vol. 2, 1989.
- [2] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in neural information processing systems, vol. 25, 2012.
- [3] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [4] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1–9.
- [5] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [6] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708.
- [7] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440.
- [8] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 4, pp. 834–848, 2017.
- [9] G. Lin, A. Milan, C. Shen, and I. Reid, “Refinenet: Multi-path refinement networks for high-resolution semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1925–1934.
- [10] R. Girshick, “Fast r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1440–1448.
- [11] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” Advances in neural information processing systems, vol. 28, 2015.
- [12] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 779–788.
- [13] C. P. Chen and Z. Liu, “Broad learning system: An effective and efficient incremental learning system without the need for deep architecture,” IEEE transactions on neural networks and learning systems, vol. 29, no. 1, pp. 10–24, 2017.
- [14] C. P. Chen, Z. Liu, and S. Feng, “Universal approximation capability of broad learning system and its structural variations,” IEEE transactions on neural networks and learning systems, vol. 30, no. 4, pp. 1191–1204, 2018.
- [15] X. Gong, T. Zhang, C. P. Chen, and Z. Liu, “Research review for broad learning system: Algorithms, theory, and applications,” IEEE Transactions on Cybernetics, 2021.
- [16] Z. Liu, J. Zhou, and C. P. Chen, “Broad learning system: Feature extraction based on k-means clustering algorithm,” in 2017 4th International Conference on Information, Cybernetics and Computational Social Systems (ICCSS). IEEE, 2017, pp. 683–687.
- [17] R. Liu, Y. Liu, Y. Zhao, X. Chen, S. Cui, F. Wang, and L. Yi, “Multi-feature broad learning system for image classification,” International Journal of Pattern Recognition and Artificial Intelligence, vol. 35, no. 15, p. 2150033, 2021.
- [18] F. Yang, “A cnn-based broad learning system,” in 2018 IEEE 4th International Conference on Computer and Communications (ICCC). IEEE, 2018, pp. 2105–2109.
- [19] W. Yu and C. Zhao, “Broad convolutional neural network based industrial process fault diagnosis with incremental learning capability,” IEEE Transactions on Industrial Electronics, vol. 67, no. 6, pp. 5081–5091, 2019.
- [20] T. Li, B. Fang, J. Qian, and X. Wu, “Cnn-based broad learning system,” in 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP). IEEE, 2019, pp. 132–136.
- [21] L. Chen, M. Li, X. Lai, K. Hirota, and W. Pedrycz, “Cnn-based broad learning with efficient incremental reconstruction model for facial emotion recognition,” IFAC-PapersOnLine, vol. 53, no. 2, pp. 10 236–10 241, 2020.
- [22] H. Tang and N. Chen, “Combining cnn and broad learning for music classification,” IEICE Transactions on Information and Systems, vol. 103, no. 3, pp. 695–701, 2020.
- [23] Y. Ma, Z. Liu, and C. P. Chen, “Multiscale random convolution broad learning system for hyperspectral image classification,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2021.
- [24] K. Grauman and T. Darrell, “The pyramid match kernel: Discriminative classification with sets of image features,” in Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, vol. 2. IEEE, 2005, pp. 1458–1465.
- [25] S. Lazebnik, C. Schmid, and J. Ponce, “Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories,” in 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), vol. 2. IEEE, 2006, pp. 2169–2178.
- [26] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015.
- [27] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 9, pp. 1904–1916, 2015.
- [28] J. Yue, S. Mao, and M. Li, “A deep learning framework for hyperspectral image classification using spatial pyramid pooling,” Remote Sensing Letters, vol. 7, no. 9, pp. 875–884, 2016.
- [29] Y. S. Tan, K. M. Lim, C. Tee, C. P. Lee, and C. Y. Low, “Convolutional neural network with spatial pyramid pooling for hand gesture recognition,” Neural Computing and Applications, vol. 33, no. 10, pp. 5339–5351, 2021.
- [30] A. Ashiquzzaman, H. Lee, K. Kim, H.-Y. Kim, J. Park, and J. Kim, “Compact spatial pyramid pooling deep convolutional neural network based hand gestures decoder,” Applied Sciences, vol. 10, no. 21, p. 7898, 2020.
- [31] C. Dewi, R.-C. Chen, and S.-K. Tai, “Evaluation of robust spatial pyramid pooling based on convolutional neural network for traffic sign recognition system,” Electronics, vol. 9, no. 6, p. 889, 2020.
- [32] S.-K. Tai, C. Dewi, R.-C. Chen, Y.-T. Liu, X. Jiang, and H. Yu, “Deep learning for traffic sign recognition based on spatial pyramid pooling with scale analysis,” Applied Sciences, vol. 10, no. 19, p. 6997, 2020.
- [33] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020.
- [34] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” arXiv preprint arXiv:1511.06434, 2015.
- [35] X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel, “Infogan: Interpretable representation learning by information maximizing generative adversarial nets,” Advances in neural information processing systems, vol. 29, 2016.
- [36] M. Caron, P. Bojanowski, A. Joulin, and M. Douze, “Deep clustering for unsupervised learning of visual features,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 132–149.
- [37] A. Dosovitskiy, J. T. Springenberg, M. Riedmiller, and T. Brox, “Discriminative unsupervised feature learning with convolutional neural networks,” Advances in neural information processing systems, vol. 27, 2014.
- [38] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in International conference on machine learning. PMLR, 2020, pp. 1597–1607.
- [39] A. Coates, A. Ng, and H. Lee, “An analysis of single-layer networks in unsupervised feature learning,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 215–223.
- [40] A. Coates and A. Y. Ng, “Learning feature representations with k-means,” in Neural networks: Tricks of the trade. Springer, 2012, pp. 561–580.
- [41] A. Coates and A. Ng, “Selecting receptive fields in deep networks,” Advances in neural information processing systems, vol. 24, 2011.
- [42] E. Culurciello, J. Jin, A. Dundar, and J. Bates, “An analysis of the connections between layers of deep neural networks,” arXiv preprint arXiv:1306.0152, 2013.
- [43] A. Dundar, J. Jin, and E. Culurciello, “Convolutional clustering for unsupervised learning,” arXiv preprint arXiv:1511.06241, 2015.
- [44] G.-B. Huang, Z. Bai, L. L. C. Kasun, and C. M. Vong, “Local receptive fields based extreme learning machine,” IEEE Computational intelligence magazine, vol. 10, no. 2, pp. 18–29, 2015.
- [45] M. Ranzato, A. Krizhevsky, and G. Hinton, “Factored 3-way restricted boltzmann machines for modeling natural images,” in Proceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2010, pp. 621–628.
- [46] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [47] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” arXiv preprint arXiv:1708.07747, 2017.
- [48] Y. LeCun, F. J. Huang, and L. Bottou, “Learning methods for generic object recognition with invariance to pose and lighting,” in Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004., vol. 2. IEEE, 2004, pp. II–104.
- [49] J. Tang, C. Deng, and G.-B. Huang, “Extreme learning machine for multilayer perceptron,” IEEE transactions on neural networks and learning systems, vol. 27, no. 4, pp. 809–821, 2015.
- [50] Z. Liu, C. P. Chen, S. Feng, Q. Feng, and T. Zhang, “Stacked broad learning system: From incremental flatted structure to deep model,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 51, no. 1, pp. 209–222, 2020.
- [51] T.-L. Zhang, R. Chen, X. Yang, and S. Guo, “Rich feature combination for cost-based broad learning system,” IEEE access, vol. 7, pp. 160–172, 2018.
- [52] L. Zhang, J. Li, G. Lu, P. Shen, M. Bennamoun, S. A. A. Shah, Q. Miao, G. Zhu, P. Li, and X. Lu, “Analysis and variants of broad learning system,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020.
- [53] C. M. Bishop and N. M. Nasrabadi, Pattern recognition and machine learning. Springer, 2006, vol. 4, no. 4.
- [54] K. Meshkini, J. Platos, and H. Ghassemain, “An analysis of convolutional neural network for fashion images classification (fashion-mnist),” in International Conference on Intelligent Information Technologies for Industry. Springer, 2019, pp. 85–95.
- [55] C. Duan, P. Yin, Y. Zhi, and X. Li, “Image classification of fashion-mnist data set based on vgg network,” in Proceedings of 2019 2nd International Conference on Information Science and Electronic Technology (ISET 2019). International Informatization and Engineering Associations: Computer Science and Electronic Technology International Society, vol. 19, 2019.
- [56] H. Zhao, J. Zheng, W. Deng, and Y. Song, “Semi-supervised broad learning system based on manifold regularization and broad network,” IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 67, no. 3, pp. 983–994, 2020.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/db9657eb-3910-41ce-aa77-7a33eb8ef6f1/lcy-white.jpg) |
Chunyu Lei received the B.S. degree in computer science and technology from Zhengzhou University, Zhengzhou, China, in 2020. He is currently pursuing the Ph.D. degree in computer science and technology from South China University of Technology, Guangzhou, China. His research interests include broad learning system, neural architecture search, and computational intelligence. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/db9657eb-3910-41ce-aa77-7a33eb8ef6f1/philip.jpg) |
C. L. Philip Chen (S’88–M’88–SM’94–F’07) received the M.S. degree from the University of Michigan at Ann Arbor, Ann Arbor, MI, USA, in 1985 and the Ph.D. degree from the Purdue University in 1988, all in electrical and computer science. He is the Chair Professor and Dean of the College of Computer Science and Engineering, South China University of Technology. He is the former Dean of the Faculty of Science and Technology. He is a Fellow of IEEE, AAAS, IAPR, CAA, and HKIE; a member of Academia Europaea (AE) and European Academy of Sciences and Arts (EASA). He received IEEE Norbert Wiener Award in 2018 for his contribution in systems and cybernetics, and machine learnings. He is also a highly cited researcher by Clarivate Analytics in 2018, 2019, 2020, 2021, and 2022. He was the Editor-in-Chief of the IEEE Transactions on Cybernetics (2020-2021) after he completed his term as the Editor-in-Chief of the IEEE Transactions on Systems, Man, and Cybernetics: Systems (2014-2019), followed by serving as the IEEE Systems, Man, and Cybernetics Society President from 2012 to 2013. Currently, he serves as a deputy director of CAAI Transactions on Artificial Intelligence, an Associate Editor of the IEEE Transactions on Artificial Intelligence, IEEE Trans on SMC: Systems, and IEEE Transactions on Fuzzy Systems, an Associate Editor of China Sciences: Information Sciences. He received Macau FDCT Natural Science Award three times and a First-rank Guangdong Province Scientific and Technology Advancement Award in 2019. His current research interests include cybernetics, computational intelligence, and systems. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/db9657eb-3910-41ce-aa77-7a33eb8ef6f1/x15.png) |
Jifeng Guo received the B.S. and M.S. degrees in computer science and technology from the University of Jinan, Jinan, China, in 2016 and 2019, respectively. She is currently pursuing the Ph.D. degree in computer science and technology with the South China University of Technology, Guangzhou, China. Her current research interests include computational intelligence, semi-supervised learning, broad learning systems, deep learning, emotion recognition, computer simulation, cement modeling, and data mining. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/db9657eb-3910-41ce-aa77-7a33eb8ef6f1/tony.jpg) |
Tong Zhang (S’12-M’16) received the B.S. degree in software engineering from Sun Yat-sen University, at Guangzhou, China, in 2009, and the M.S. degree in applied mathematics from University of Macau, at Macau, China, in 2011, and the Ph.D. degree in software engineering from the University of Macau, at Macau, China in 2016. Dr. Zhang currently is a professor with the School of Computer Science and Engineering, South China University of Technology, China. His research interests include affective computing, evolutionary computation, neural network, and other machine learning techniques and their applications. Dr. Zhang is an Associate Editor of the IEEE Transactions on Computational Social Systems. He has been working in publication matters for many IEEE conferences. |