Convergence Results of Two-Step Inertial Proximal Point Algorithm
Abstract
This paper proposes a two-point inertial proximal point algorithm to find zero of maximal monotone
operators in Hilbert spaces. We obtain weak convergence results and non-asymptotic convergence rate of our proposed algorithm in non-ergodic sense. Applications of our results to various well-known convex optimization methods, such as the proximal method of multipliers and the alternating direction method of multipliers are given. Numerical results are given to demonstrate the accelerating behaviors of our method over other related methods in the literature.
Keywords:Proximal point algorithm; Two-point inertia; Maximal monotone operators; Weak and non-asymptotic convergence; Hilbert spaces.
2010 MSC classification: 90C25, 90C30, 90C60, 68Q25, 49M25, 90C22
1 Introduction
Suppose is a real Hilbert space with inner product and induced norm Given a maximal monotone set-valued operator, we consider the following inclusion problem:
| (1) |
Throughout this paper, we shall denote by , the set of solutions to (1). It is well known that the inclusion problem (1) serves as a unifying model for many problems of fundamental importance, including
fixed point problem, variational inequality problem, minimization of closed proper convex functions, and
their variants and extensions. Therefore, its efficient solution is of practical interest in many situations.
Related works. The proximal point algorithm (PPA), which was first studied by Martinet and further developed by Rockafellar and others (see, for example, [23, 41, 43, 44, 50]) has been used for many years for studying the inclusion problem (1). Starting from an arbitrary point the PPA iteratively generates its sequence by
| (2) |
(where the operator is the so-called resolvent operator, that has been introduced by Moreau in [43]) which is equivalent to
| (3) |
where called proximal parameter. The PPA (2) is a very powerful algorithmic tool and contains many well known algorithms as special cases, including the classical augmented Lagrangian method [33, 49], the Douglas-Rachford splitting method [27, 37] and the alternating direction method of multipliers [30, 31]. Interesting results on weak convergence and rate of convergence of PPA have been obtained in [28, 32, 42]. The equivalent representation of the PPA (3), can be written as
| (4) |
This can be viewed as an implicit discretization of the evolution differential inclusion problem
| (5) |
It has been shown that the solution trajectory of (5) converges to a solution of (1) provided that satisfies certain conditions (see, for example, [13]).
To speed up convergence of PPA (2), the following second order evolution differential inclusion problem was introduced in the literature:
| (6) |
where is a friction parameter. If where is a differentiable convex function with attainable minimum, the system (6) characterizes roughly the motion of a heavy ball which rolls under its own inertia over the graph of until friction stops it at a stationary point of In this case, the three terms in (6) denote, respectively, inertial force, friction force and gravity force. Consequently, the system (6) is usually referred to as the heavy-ball with friction (HBF) system (see [45]). In theory, the convergence of the solution trajectories of the HBF system to a solution of (1) can be faster than those of the first-order system (5), while in practice the second order inertial term can be exploited to design faster algorithms (see, e.g., [1, 5]). As a result of the properties of (6), an implicit discretization method was proposed in [2, 3] as follows, given and , the next point is determined via
| (7) |
which result to an iterative algorithm of the form
| (8) |
where and
In fact, if we replace in (7) with
, we obtain a general algorithm of (8) with
and
Note also that (8) is the proximal point step applied to the
extrapolated point rather than as in the classical PPA (2). We call the iterative method in (8) one-step inertial PPA. Convergence properties of (8) have been studied in [2, 4, 3, 38, 40, 44] under some assumptions on the parameters and The inertial PPA (8) has been adapted to studying inertial Douglas-Rachford splitting method [7, 17, 14, 26, 27, 37], inertial alternating method of multipliers (ADMM) [15, 24, 26, 31, 32] and demonstrated their performance numerically on some imaging and data analysis problems. In all the references mentioned above, the inertial PPA (8) (which is the PPA (2) with the one-step inertial extrapolation) has been studied. This is a different approach we that we take in this paper, where we consider the PPA (2) with the two-step inertial extrapolation. Our result is motivated by the results given in [35], where an accelerated proximal point algorithm (which involves both the one-step inertial term and correction term) for maximal monotone operator is studied. In contrast to the method of Kim [35], we replace iterate in the correction term of [35] with to obtain two-step inertial extrapolation and investigate the convergence properties.
From another point of view, our proposed two-step inertial PPA can be regarded as a general parametrized proximal point algorithm. Recent and interesting results on parametrized proximal point algorithm can be found in [9, 39], where parametrized proximal point algorithm is developed for solving a class of separable convex programming problems subject to linear and convex constraints.
In these papers [9, 39], it was shown numerically that parametrized proximal point algorithm could perform significantly better for solving sparse optimization problems than ADMM and relaxed proximal point algorithm.
Advantages of two-step proximal point algorithms. In [47, 48], Poon and Liang discussed some limitations of inertial Douglas-Rachford splitting method and inertial ADMM. For example, consider the following feasibility problem in .
Example 1.1.
Let be two subspaces such that . Find such that .
It was shown in [48, Section 4] that two-step inertial Douglas-Rachford splitting method, where
converges faster than one-step inertial Douglas-Rachford splitting method
for Example 1.1. In fact, it was shown using this Example 1.1 that one-step inertial Douglas-Rachford splitting method
converges slower than the Douglas-Rachford splitting method
where
is the Douglas-Rachford splitting operator. This example therefore shows that one-step inertial Douglas-Rachford splitting method may fail to provide acceleration. Therefore, for certain cases, the use of inertia of more than two points could be beneficial. It was remark in [36, Chapter 4] that the use of more than two points could provide acceleration. For example, the following two-step inertial extrapolation
| (9) |
with and can provide acceleration. The failure of one-step inertial acceleration of ADMM was also discussed in [47, Section 3] and adaptive acceleration for ADMM was proposed instead. Polyak [46] also discussed that the multi-step inertial methods can boost the speed of optimization methods even though neither the convergence nor the rate result of such multi-step inertial methods is established in [46]. Some results on multi-step inertial methods have recently been studied in [22, 25].
Our contribution. In this paper, we propose an inertial proximal point algorithm with two-step inertial extrapolation step. We obtain weak convergence results and give non-asymptotic convergence rate of our proposed algorithm in non-ergodic sense. The summability conditions of the inertial parameters and the sequence of iterates imposed in [22, Algorithm 1.2], [25, Theorem 4.2 (35)], and [36, Chapter 4, (4.2.5)] are dispensed with in our results. We apply our results to the proximal method of multipliers and the alternating direction method of multipliers. We support our theoretical analysis with some preliminary computational experiments, which confirm the superiority of our method over other related ones in the literature.
Outline. In Section 2, we give some basic definitions and results needed in subsequent sections. In Section 3, we derive our method from the dynamical systems and later introduce our proposed method. We also give both weak convergence and non-asymptotic convergence rate of our method in Section 3. We give applications of our results to convex-concave saddle-point problems, the proximal method of multipliers, ADMM, primal–dual hybrid gradient method and Douglas–Rachford splitting method in Section 4. We give some numerical illustrations in Section 5 and concluding remarks are given in Section 6.
2 Preliminaries
In this section, we give some definitions and basic results that will be used in our subsequent analysis. The weak and the strong convergence of to is denoted by and as respectively.
Definition 2.1.
A mapping is called
-
(i)
nonexpansive if for all
-
(ii)
firmly nonexpansive if for all Equivalently, is firmly nonexpansive if for all
-
(iii)
averaged if can be expressed as the averaged of the identity mapping and a nonexpansive mapping , i.e., with Alternatively, is -averaged if
Definition 2.2.
A multivalued mapping is said to be monotone if for any
where and The Graph of is defined by
If is not properly contained in the graph of any other monotone mapping, then we say that is maximal. It is well-known that for each , and , there is a unique such that . The single-valued operator is called the resolvent of (see [28]).
Lemma 2.3.
The following identities hold for all :
Lemma 2.4.
Let and . Then
3 Main Results
3.1 Motivations from Dynamical Systems
Consider the following second order dynamical system
| (10) |
where are Lebesgue measurable functions and . Let be two weighting parameters such that , is the time step-size, and . Consider an explicit Euler forward discretization with respect to , explicit discretization of , and a weighted sum of explicit and implicit discretization of , we have
| (11) |
where performs ”extrapolation” onto the points and , which will be chosen later. We observe that since is Lipschitz continuous, there is some flexibility in this choice. Therefore, (3.1) becomes
| (12) |
This implies that
| (13) | |||||
Set
Then we have from (13) that
| (14) | |||||
Choosing , then (14) becomes
| (17) |
This is two-step inertial proximal point algorithm we intend to study in the next section of this paper.
3.2 Proposed Method
In this subsection, we consider two-step inertial proximal point algorithm given in (17) with and for the sake of simplicity.
In our convergence analysis, we assume that parameters and lie in the following region:
| (18) |
One can see clearly from (18) that .
We now present our proposed method as follows:
| (21) |
Remark 3.1.
When in our proposed Algorithm 1, our method reduces to the inertial proximal point algorithm studied in [3, 4, 6, 7, 8, 14, 20, 38, 40] to mention but a few. Our method is an extension of the inertial proximal point algorithm in [3, 4, 6, 7, 8, 14, 20, 38, 40]. We will show the advantage gained with the introduction of in the numerical experiments in Section 5.
3.3 Convergence Analysis
We present the weak convergence analysis of sequence of iterates generated by our proposed Algorithm 1 in this subsection.
Theorem 3.2.
Let be a maximal monotone. Suppose and let be generated by Algorithm 1. Then converges weakly to a point in
Proof.
Let . Then
Therefore, by Lemma 2.4, we obtain
| (22) | |||||
By Cauchy-Schwartz inequality, we obtain
| (23) |
| (24) |
and
| (25) | |||||
By (23), (24) and (25), we obtain
| (26) | |||||
Using (22) and (26) in (21), we have (noting that is firmly nonexpansive and )
| (27) | |||||
Therefore,
| (28) | |||||
Now, define
We show that Observe that
| (29) |
So,
| (30) | |||||
since and . Furthermore, we obtain from (28) that
| (31) | |||||
where and Noting that since , we then have that
Furthermore,
Observe that if , then
This implies by (18) that both and if
| (32) |
By (31), we obtain
| (33) | |||||
Letting , we obtain from (33) that
| (34) |
This implies from (34) that the sequence is decreasing and thus exists. Consequently, we have from (33) that
| (35) |
Hence,
| (36) |
Using (36) and existence of limit of , we have that exists. Furthermore,
| (37) | |||||
as Therefore,
| (38) |
Also,
| (39) |
Since exists and , we obtain from (30) that the sequence is bounded. Hence has at least one accumulation point . Assume that such that . Since , we have that , . Also, by (38), we have that . Since we obtain
By the monotonicity of , we have ,
| (40) |
Using (38) in (40) we get
satisfying . Since is maximal monotone, we conclude that (see, for example, [51]).
Since exists and , we have that
| (41) |
exists.
We now show that . Let us assume that there exist and such that and . We show that .
Observe that
| (42) |
| (43) |
and
| (44) |
Therefore,
| (45) | |||||
and
| (46) | |||||
Addition of (42), (45) and (46) gives
According to (41), we have
exists and
exists. This implies that
exists. Now,
and this yields
Since , we obtain that . Hence, converges weakly to a point in . This completes the proof.
∎
Remark 3.3.
(a) The conditions imposed on the parameters in our proposed Algorithm 1 are weaker than the ones imposed in
[25, 4.1 Algorithms] and [36, Chapter 4, (4.2.5)]. For example, we do not impose the summability conditions in [25, Theorem 4.1 (32)], [25, Theorem 4.2 (35)] and [36, Chapter 4 (4.2.5)] in our Algorithm 1. Therefore, our results are improvements over the results obtained in [25].
(b) The assumptions on the parameters in Algorithm 1 are also different from the conditions imposed on the iterative parameters in [22, Algorithm 1.2]. For example, conditions (b) and (c) of [22, Algorithm 1.2] are not needed in our convergence analysis. More importantly, we do not assume that (as imposed in [22, Algorithm 1.2]) in our convergence analysis
In the next result, we give a non-asymptotic convergence rate of our proposed Algorithm 1.
Theorem 3.4.
Let be a maximal monotone. Assume that and . Let be generated by Algorithm 1. Then, for any and , it holds that
| (47) |
where .
Proof.
4 Applications
We give some applications of our proposed two-step inertial proximal point Algorithm 1 to solving convex-concave saddle-point problem using two-step inertial versions of augmented Lagrangian, the proximal method of multipliers, and ADMM. We also consider two-step inertial versions primal–dual hybrid gradient method and Douglas–Rachford splitting method.
4.1 Convex–Concave Saddle-Point Problem
Let us consider the following convex-concave saddle-point problem:
| (56) |
where and are real Hilbert spaces equipped with inner product and , where the associated saddle subdifferential operator
| (57) |
is monotone. Using the ideas in [51], we apply our proposed Algorithm 1 to solve problem (56) below.
| (60) |
Furthermore, let us consider the following convex–concave Lagrangian problem:
| (61) |
which is associated with the following linearly constrained problem
| (64) |
where and . Applying our proposed Algorithm 1 to solving problem (61) gives
| (68) |
4.2 Version of Primal–Dual Hybrid Gradient Method
In this section, let us consider the following coupled convex-concave saddle-point problem
| (69) |
where and . The primal-dual hybrid gradient (PDHG) method (see, for example, [18, 29]) is one of the popular methods for solving problem (69) and it is a preconditioned proximal point algorithm with for the saddle subdifferential operator of given in (57) (see, [19, 34]). Given the associated preconditioner as
| (70) |
which is positive definite when , ; we adapt our proposed Algorithm 1 to solve problem (69) as given below:
| (75) |
4.3 Version of Douglas–Rachford Splitting Method
This section presents an application of Algorithm 1 to the
Douglas-Rachford splitting method for finding zeros of an operator
such that is the sum of two maximal monotone operators,
i.e. with being maximal monotone
multi-functions on a Hilbert space . The method was originally
introduced in [27] in a finite-dimensional setting,
its extension to maximal monotone mappings in Hilbert spaces can be
found in [37].
The Douglas–Rachford splitting method [27, 37] iteratively applies the operator
| (76) |
and has found to be effective in many applications including ADMM. In [28, Theorem 4], the Douglas–Rachford operator (76) was found to be a resolvent of a maximal monotone operator
| (77) |
Therefore, the Douglas–Rachford splitting method is a special case of the proximal point method (with ), written as
| (78) |
Hence, we can apply our Algorithm 1 to the Douglas-Rachford splitting method as given below:
| (81) |
4.4 Version of Alternating Direction Method of Multipliers (ADMM)
Suppose and are real Hilbert spaces and let us consider the following linearly constrained convex problem
| (84) |
where and . The dual of problem (84) is given by
| (85) |
where the conjugate of is given by and the conjugate of is given by . Solving the dual problem (85) is equivalent to solving the inclusion problem: find subject to
| (86) |
Using similar ideas in [35, Section 6.4], we adapt the 2-Step Inertial Douglas-Rachford Splitting Method in Algorithm 5 to the following 2-Step Inertial ADMM (where we apply Algorithm 5 is adapted to monotone inclusion problem (86)):
| (93) |
5 Numerical Illustrations
The focus of this section is to provide some computational experiments to demonstrate the effectiveness, accuracy and easy-to-implement nature of our proposed algorithms. We further compare our proposed schemes with some existing methods in the literature. All codes were written in MATLAB R2020b and performed on a PC Desktop Intel(R) Core(TM) i7-6600U CPU @ 3.00GHz 3.00 GHz, RAM 32.00 GB.
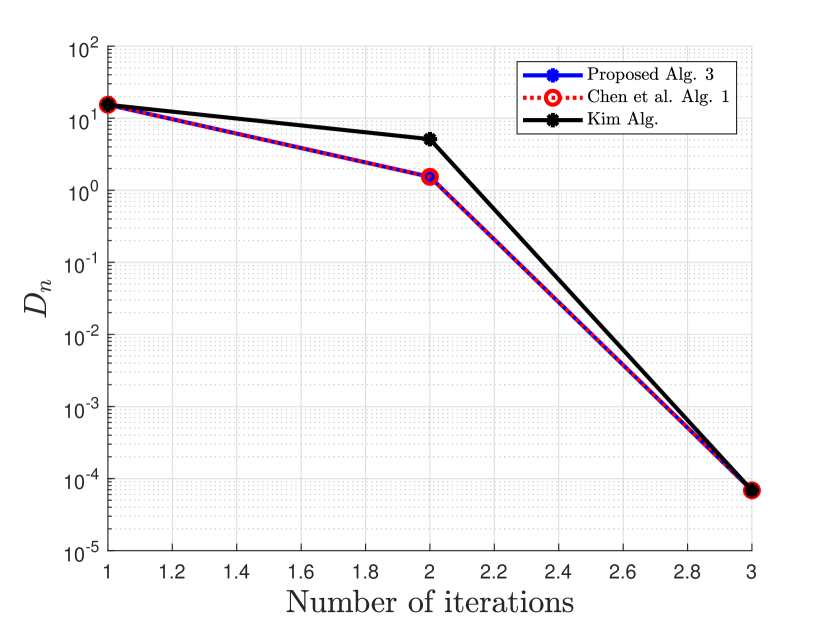
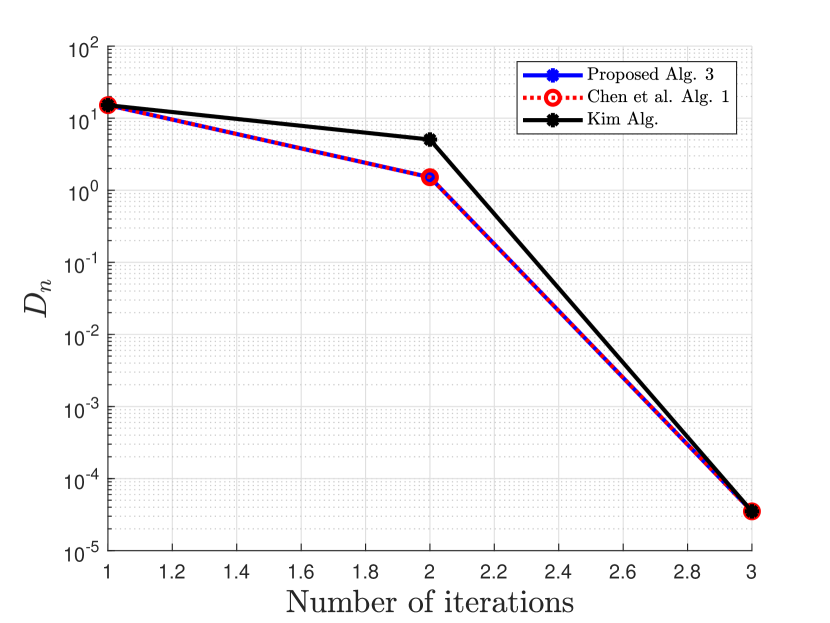
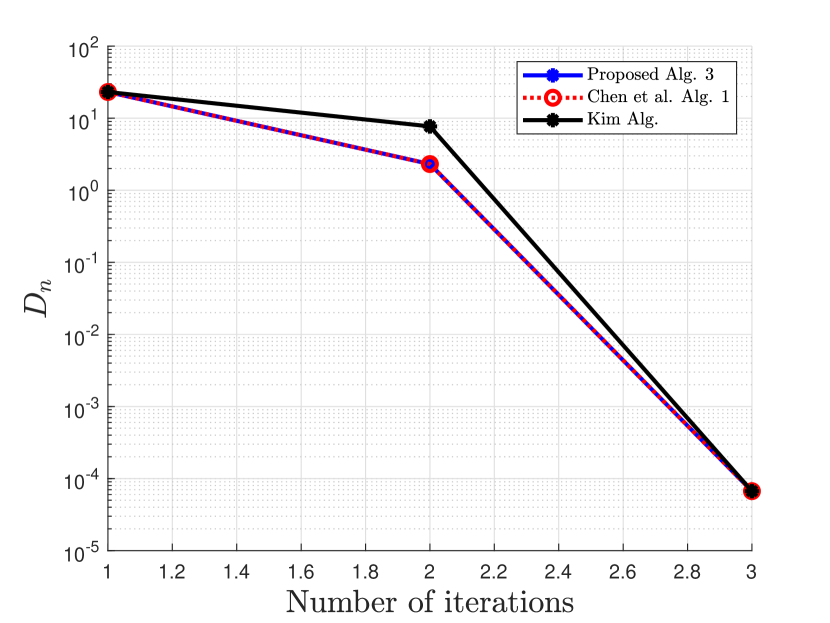
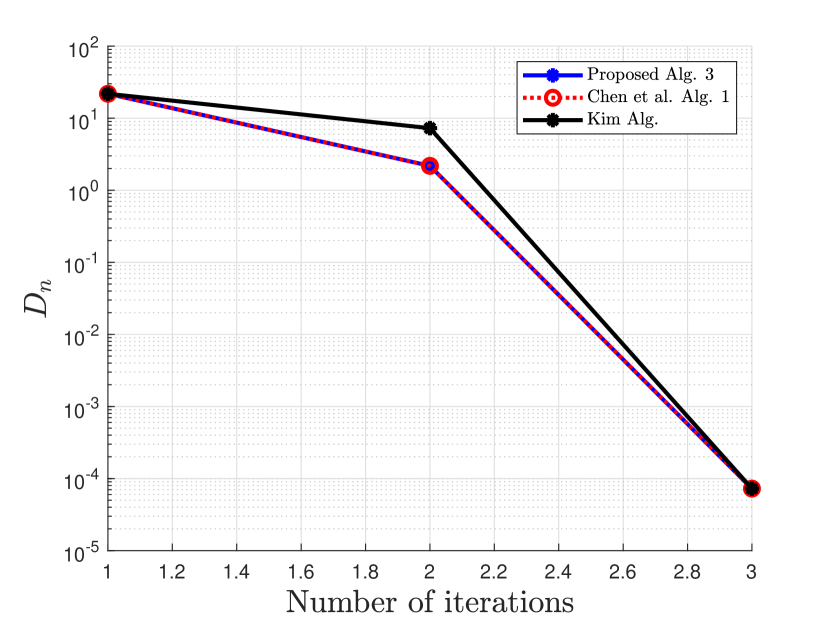
Numerical comparisons are made with the algorithm proposed in [20], denoted as Chen et al. Alg. 1, algorithm proposed in [35], denoted as Kim Alg, and algorithm proposed in [9], denoted as P-PPA Alg.
Example 5.1.
First, we compare our proposed 2-Step Inertial Proximal Method of Multipliers in Algorithm 3 with the methods in [20, 35] using the following basis pursuit problem:
| (96) |
where and . In our experiment, we consider and and is randomly generated. A true sparse is randomly generated followed by a thresholding to sparsify nonzero elements, and is then given by . We run 100 iterations of the proximal method of multipliers and its variants with initial . Since the -update does not have a closed form, we used a sufficient number of iterations to solve the -update using the strongly convex version of FISTA [12] in [16, Theorem 4.10]. The stopping criterion for this example is , where . The parameter used are provided in Table 1
| No. of Iter. | CPU Time | No. of Iter. | CPU Time | |
| Proposed Alg. 3 | 3 | 3 | ||
| Chen et al. Alg. 1 | 3 | 3 | ||
| Kim Alg. | 3 | 3 | ||
| No. of Iter. | CPU Time | No. of Iter. | CPU Time | |
| Proposed Alg. 3 | 3 | 3 | ||
| Chen et al. Alg. 1 | 3 | 3 | ||
| Kim Alg. | 3 | 3 | ||
Example 5.2.
In this example, we apply our proposed 2-Step Inertial ADMM (Algorithm 6) to the problem
| (99) |
where and compare with the methods in [9, 20, 35]. The problem (99) is associated with the total-variation-regularized least squares problem
| (100) |
where , and a matrix is given as
| (110) |
where is the soft-thresholding operator,
with the element-wise absolute value, maximum and multiplication operators, and , respectively.
In this numerical test, we consider different cases for the choices of , , and . A true vector
is constructed such that a vector has few nonzero elements. A matrix is randomly generated and a noisy vector is generated by adding randomly generated (noise) vector to .
Case 1: , , and
Case 2: , , and
Case 3: , , and
Case 4: , , and
The stopping criterion for this example is , where . The parameter used are provided in Table 3.
| Case 1 | Case 2 | |||
| No. of Iter. | CPU Time | No. of Iter. | CPU Time | |
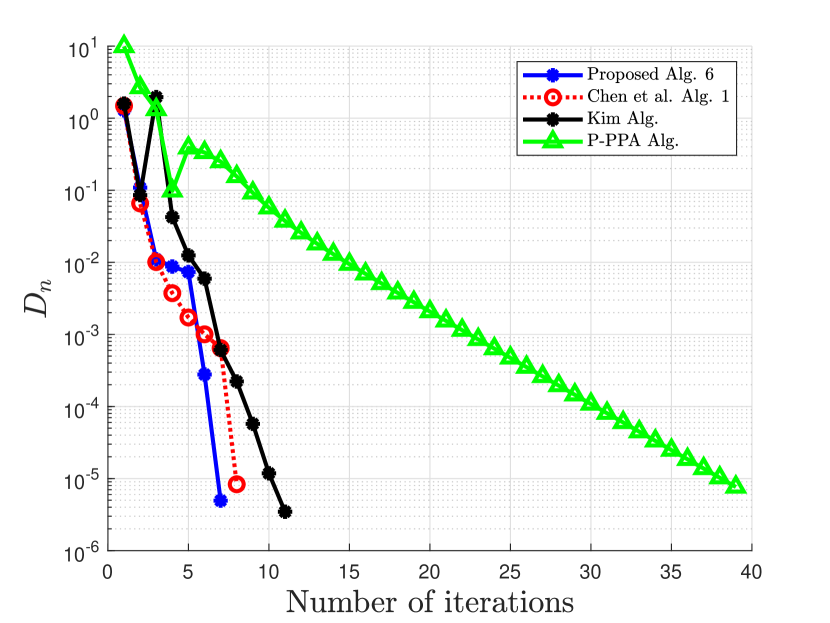
| Proposed Alg. 6 | 7 | 21 | ||
| Chen et al. Alg. 1 | 8 | 43 | ||
| Kim Alg. | 11 | 41 | ||
| P-PPA Alg. | 39 | 40 | ||
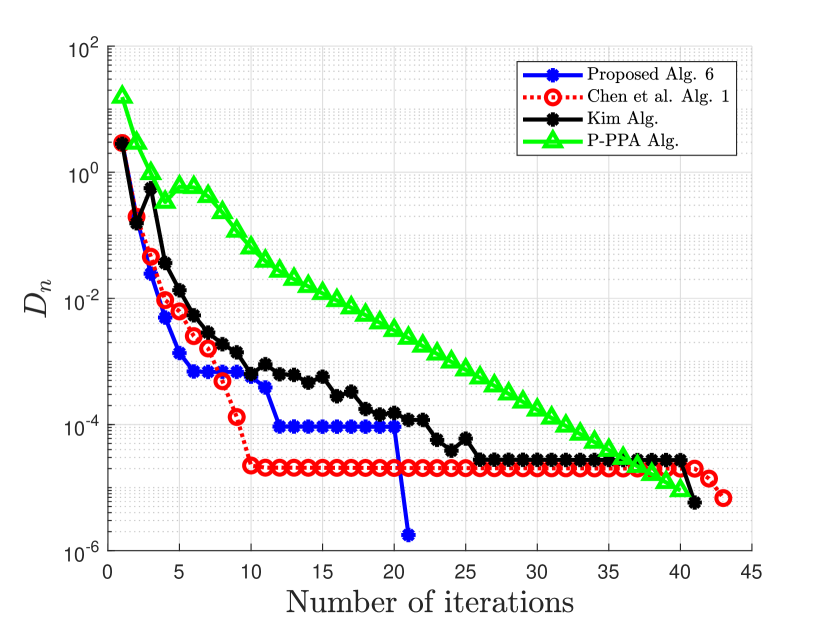
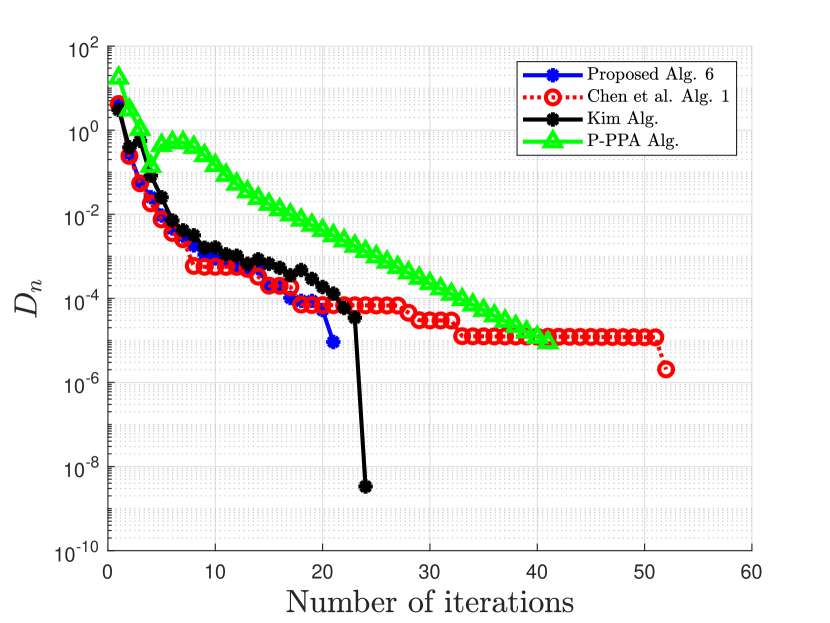
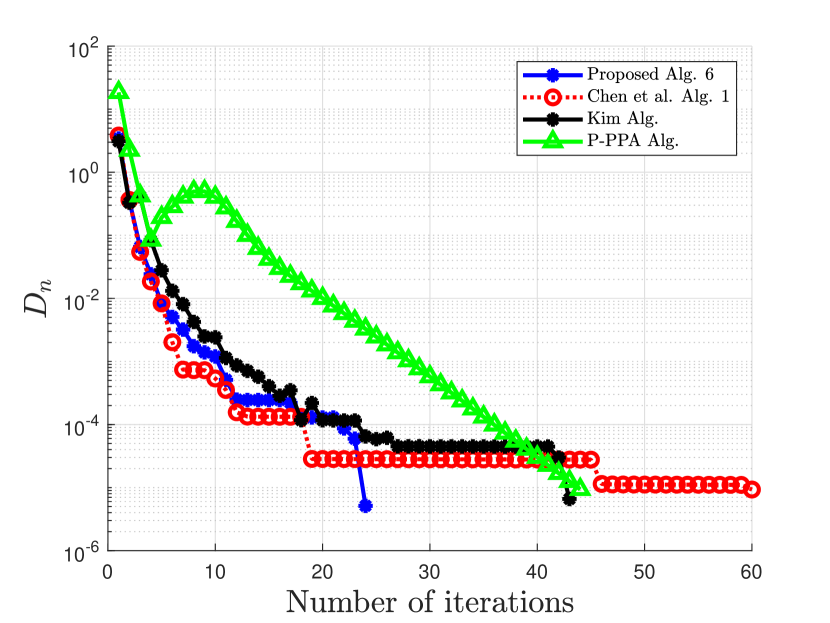
| Case 3 | Case 4 | |||
| No. of Iter. | CPU Time | No. of Iter. | CPU Time | |
| Proposed Alg. 3 | 21 | 24 | ||
| Chen et al. Alg. 1 | 52 | 60 | ||
| Kim Alg. | 24 | 43 | ||
| P-PPA Alg. | 41 | 44 | ||
Remark 5.3.
From the above numerical Examples 5.1 and 5.2, we give the following remarks.
- (1).
-
(2).
Clearly from the numerical Example 5.2, our proposed Algorithm 6 outperforms the algorithm proposed by Chen et al. in [20], the algorithm proposed by Kim in [35], and the algorithm proposed by Bai et al. in [9] with respect to the number of iterations and the CPU time. The proposed algorithm 3 also competes favorably with Chen et al. Alg. 1 in [20] and that of Kim in [35] for the case of Example 5.1.
6 Conclusion
We have introduced in this paper, a two-step inertial proximal point algorithm for monotone inclusion problem in Hilbert spaces. Weak convergence of the sequence of iterates are obtained under standard conditions and non-asymptotic rate of convergence in the ergodic sense given. We support the theoretical analysis of our method with numerical illustrations derived from basis pursuit problem and numerical implementation of two-step inertial ADMM. Preliminary numerical results show that our proposed method is competitive and outperforms some related and recent proximal point algorithms in the literature. Part of our future projects is to study two-step inertial proximal point algorithm with corrected term for the monotone inclusion considered in this paper.
Acknowledgements
The authors are grateful to the associate editor and the two anonymous referees for their insightful comments and suggestions which have improved greatly on the earlier version of the paper.
References
- [1] Aluffi-Pentini F, Parisi V., Zirilli F. Algorithm 617. DAFNE: a differential-equations algorithm for nonlinear equations. ACM Trans. Math. Software 10 (1984), 317-324.
- [2] Alvarez F. On the minimizing property of a second order dissipative system in Hilbert spaces. SIAM J. Control Optim. 38 (2000), 1102–1119.
- [3] Alvarez F., Attouch H. An inertial proximal method for maximal monotone operators via discretization of a nonlinear oscillator with damping. Set-Valued Anal. 9 (2001), 3–11.
- [4] Alvarez F. Weak convergence of a relaxed and inertial hybrid projection-proximal point algorithm for maximal monotone operators in Hilbert space. SIAM J. Optim. 14 (2004), 773–782.
- [5] Antipin A. S. Minimization of convex functions on convex sets by means of differential equations. Differentsial’nye Uravneniya 30 (1994), 1475-1486, 1652; translation in Differential Equations 30 (1994), 1365–1375.
- [6] Attouch H., Cabot, A. Convergence rate of a relaxed inertial proximal algorithm for convex minimization. Optimization 69 (2020), 1281-1312.
- [7] Attouch H., Peypouquet J., Redont P. A dynamical approach to an inertial forward-backward algorithm for convex minimization. SIAM J. Optim. 24 (2014), 232-256.
- [8] Aujol J.-F. , Dossal C., Rondepierre A. Optimal Convergence Rates for Nesterov Acceleration. SIAM J. Optim. 29 (2019), 3131-3153.
- [9] Bai, J., Zhang, H., Li, J. A parameterized proximal point algorithm for separable convex optimization. Optim. Lett. 12 (2018), 1589-1608.
- [10] Bai, J., Hager, W., Zhang, H. An inexact accelerated stochastic ADMM for separable composite convex optimization. Comput. Optim. Appl. 81 (2022), 479-518.
- [11] Bai, J., Han, D., Sun, H., Zhang, H. Convergence analysis of an inexact accelerated stochastic ADMM with larger stepsizes. CSIAM Trans. Appl. Math. To appear, arXiv:2103.16154v2, (2022).
- [12] A. Beck and M. Teboulle; A fast iterative shrinkage-thresholding algorithm for linear inverse problems, SIAM J. Imaging Sci. 2 (1) (2009), 183-202.
- [13] Bruck R. E., Jr. Asymptotic convergence of nonlinear contraction semigroups in Hilbert space. J. Functional Analysis 18 (1975), 15–26.
- [14] Bot R. I., Csetnek E. R., Hendrich C. Inertial Douglas-Rachford splitting for monotone inclusion problems. Appl. Math. Comput. 256 (2015), 472–487.
- [15] Bot R. I., Csetnek E. R. An inertial alternating direction method of multipliers. Minimax Theory Appl. 1 (2016), 29-49.
- [16] Chambolle, A., Pock, T. An introduction to continuous optimization for imaging. Acta Numer. 25, 161–319 (2016).
- [17] Chambolle, A., Pock, T. On the ergodic convergence rates of a first-order primal-dual algorithm. Math. Program. 159 (2016), Ser. A, 253–287.
- [18] A. Chambolle, T. Pock; A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging and Vision 40(1) (2011), 120-145.
- [19] A. Chambolle and T. Pock; On the ergodic convergence rates of a first-order primal–dual algorithm, Math. Program. 159 (2016), 253-287.
- [20] C. Chen, S. Ma, and J. Yang; A general inertial proximal point algorithm for mixed variational inequality problem, SIAM J. Optim. 25 (2015), 2120–2142.
- [21] Cholamjiak P., Thong D.V., Cho Y.J. A novel inertial projection and contraction method for solving pseudomonotone variational inequality problems. Acta Appl. Math. 169 (2020), 217-245.
- [22] Combettes, P. L., Glaudin, L. E. Quasi-nonexpansive iterations on the affine hull of orbits: from Mann’s mean value algorithm to inertial methods. SIAM J. Optim. 27 (2017), 2356-2380.
- [23] Corman, E., Yuan, X. M. A generalized proximal point algorithm and its convergence rate. SIAM J. Optim. 24 (2014), 1614-1638.
- [24] Davis, D., Yin W. Faster convergence rates of relaxed Peaceman-Rachford and ADMM under regularity assumptions. Math. Oper. Res. 42 (2017), 783-805.
- [25] Dong, Q.L., Huang, J.Z., Li, X.H., Cho, Y. J., Rassias, Th. M. MiKM: multi-step inertial Krasnosel’skii–Mann algorithm and its applications. J. Global Optim. 73, 801–824 (2019).
- [26] Dong Q. L., Jiang D., Cholamjiak P., Shehu Y. A strong convergence result involving an inertial forward-backward algorithm for monotone inclusions. J. Fixed Point Theory Appl. 19 (2017), 3097-3118.
- [27] J. Douglas and H.H. Rachford; On the numerical solution of heat conduction problems in two or three space variables, Trans. Amer. Math. Soc. 82 (1956), 421-439.
- [28] Eckstein, J., Bertsekas, D.P. On the Douglas-Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math. Program. 55 (1992), Ser. A, 293-318.
- [29] Esser, E., Zhang, X., Chan, T. A general framework for a class of first order primal-dual algorithms for convex optimization in imaging science. SIAM J. Imaging Sci. 3(4), 1015–46 (2010).
- [30] Gabay, D., Mercier, B. A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput. Math. Appl. 2 (1976), 17-40.
- [31] Glowinski, R., Marrocco, A. Sur l’approximation, par élḿents finis d’ordre un, et la résolution, par pénalisation-dualité, d’une classe de problèmes de Dirichlet non linéaires. (French) Rev. Française Automat. Informat. Recherche Opérationnelle Sér. Rouge Anal. Numér. 9 (1975), no. R-2, 41-76.
- [32] Gler, O. New proximal point algorithms for convex minimization. SIAM J. Optim. 2 (1992), 649-664.
- [33] Hestenes, M. R. Multiplier and gradient methods. J. Optim. Theory Appl. 4 (1969), 303-320.
- [34] He, B., Yuan, X. Convergence analysis of primal-dual algorithms for a saddle-point problem: from contraction perspective. SIAM J. Imaging Sci. 5(1), 119–49 (2012).
- [35] Kim, D., Accelerated proximal point method for maximally monotone operators. Math. Program. 190 (2021), 57–87.
- [36] J. Liang, Convergence rates of first-order operator splitting methods. PhD thesis, Normandie Université; GREYC CNRS UMR 6072, 2016.
- [37] P.L. Lions and B. Mercier; Splitting algorithms for the sum of two nonlinear operators, SIAM J. Numer. Anal. 16 (1979), 964-979.
- [38] Lorenz, D. A., Pock, T. An inertial forward-backward algorithm for monotone inclusions. J. Math. Imaging Vision 51 (2015), 311-325.
- [39] Ma, F., Ni, M. A class of customized proximal point algorithms for linearly constrained convex optimization. Comp. Appl. Math. 37 (2018), 896-911.
- [40] Maingé, P. E., Merabet, N. A new inertial-type hybrid projection-proximal algorithm for monotone inclusions. Appl. Math. Comput. 215 (2010), 3149-3162.
- [41] Martinet, B. Régularisation d’inéquations variationnelles par approximations successives. (French) Rev. Française Informat. Recherche Opérationnelle 4 (1970), Sér. R-3, 154–158.
- [42] Tao, M., Yuan, X. On the optimal linear convergence rate of a generalized proximal point algorithm. J. Sci. Comput. 74 (2018), 826-850.
- [43] Moreau, J. J. Proximité et dualité dans un espace Hilbertien. (French) Bull. Soc. Math. France 93 (1965), 273-299.
- [44] Moudafi, A., Elisabeth, E. An approximate inertial proximal method using the enlargement of a maximal monotone operator. Int. J. Pure Appl. Math. 5 (2003), 283-299.
- [45] B.T. Polyak, Some methods of speeding up the convergence of iterates methods, U.S.S.R Comput. Math. Phys., 4 (5) (1964), 1-17.
- [46] B. T. Polyak, Introduction to optimization. New York, Optimization Software, Publications Division, 1987.
- [47] C. Poon, J. Liang, Trajectory of Alternating Direction Method of Multipliers and Adaptive Acceleration, In Advances In Neural Information Processing Systems (2019).
- [48] C. Poon, J. Liang, Geometry of First-Order Methods and Adaptive Acceleration, arXiv:2003.03910.
- [49] Powell, M. J. D. A method for nonlinear constraints in minimization problems. 1969 Optimization (Sympos., Univ. Keele, Keele, 1968) pp. 283–298 Academic Press, London.
- [50] Rockafellar, R. T. Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 14 (1976), 877–898.
- [51] R. T. Rockafellar; Monotone operators and the proximal point algorithm, SIAM J. Control. Optim. 14 (1976) 877-898.