Cooperative Reward Shaping for Multi-Agent Pathfinding
Abstract
The primary objective of Multi-Agent Pathfinding (MAPF) is to plan efficient and conflict-free paths for all agents. Traditional multi-agent path planning algorithms struggle to achieve efficient distributed path planning for multiple agents. In contrast, Multi-Agent Reinforcement Learning (MARL) has been demonstrated as an effective approach to achieve this objective. By modeling the MAPF problem as a MARL problem, agents can achieve efficient path planning and collision avoidance through distributed strategies under partial observation. However, MARL strategies often lack cooperation among agents due to the absence of global information, which subsequently leads to reduced MAPF efficiency. To address this challenge, this letter introduces a unique reward shaping technique based on Independent Q-Learning (IQL). The aim of this method is to evaluate the influence of one agent on its neighbors and integrate such an interaction into the reward function, leading to active cooperation among agents. This reward shaping method facilitates cooperation among agents while operating in a distributed manner. The proposed approach has been evaluated through experiments across various scenarios with different scales and agent counts. The results are compared with those from other state-of-the-art (SOTA) planners. The evidence suggests that the approach proposed in this letter parallels other planners in numerous aspects, and outperforms them in scenarios featuring a large number of agents.
Index Terms:
Multi-agent pathfinding, reinforcement learning, motion and pathfinding.I Introduction
MAPF is a fundamental research area in the field of multi-agent systems, aiming to find conflict-free routes for each agent. This has notable implications in various environments such as ports, airports [1, 2], and warehouses [3, 4, 5]. In these scenarios, there are typically a large number of mobile agents. These scenarios can generally be abstracted into grid maps, as illustrated in Fig. 1. The MAPF methodology is divided mainly into two classes: centralized and decentralized algorithms. Centralized algorithms [6, 7, 8] offer efficient paths by leveraging global information but fall short in scalability when handling a significant number of agents because of increased computational needs and extended planning time. In contrast, decentralized algorithms [9, 10] show better scalability in large-scale environments but struggle to ensure sufficient cooperation among agents, thereby affecting the success rate in pathfinding and overall efficiency.

MARL techniques, particularly those utilizing distributed execution, provide effective solutions to MAPF problems. By modeling MAPF as a partially observable Markov decision process (POMDP), MARL algorithms can develop policies that make decisions based on agents’ local observations and inter-agent communication. Given that MARL-trained policy networks do not rely on global observations, these methods exhibit excellent scalability and flexibility in dynamic environments. MARL enhances the success rate and robustness of path planning, making it particularly suitable for large-scale multi-agent scenarios. Algorithms such as [11, 12, 13] utilize a centralized training distributed execution (CTDE) framework and foster cooperation between agents using global information during training. However, they struggle to scale for larger numbers of agents due to increasing training costs. In contrast, algorithms based on distributed training distributed execution (DTDE) frameworks [14, 15] perform well in large-scale systems. However, due to the lack of global information, individual agents tend to solely focus on maximizing their own rewards, resulting in limited cooperation among the whole system. To address this issue, recent work [16, 17, 18] emerges that improves the performance of RL algorithms in distributed training frameworks through reward shaping. However, some of these reward shaping methods are too computationally complex, while others lack stability. This instability arises because an agent’s rewards are influenced by the actions of other agents, which are typically unknown to this agent.
In this letter, a reward shaping method named Cooperative Reward Shaping (CoRS) is devised to enhance MAPF efficiency within a DTDE framework. The approach is straightforward and tailored for a limited action space. The cooperative trend of action is represented by the maximum rewards that neighboring agents can achieve after agent performs . Specifically, when agent takes action , its neighbor traverses its action space, determining the maximum reward that can achieve given the condition of taking action . The shaped reward is then generated by weighting this index with the reward earned by itself.
The principal contributions of our work are as follows:
-
1.
This letter introduces a novel reward-shaping method CoRS, designed to promote cooperation among agents in MAPF tasks within the IQL framework. This reward-shaping method is unaffected by actions from other agents, ensures easy convergence during training, and is notable for its computational simplicity.
-
2.
It can be demonstrated that the CoRS method can alter the agent’s behavior, making it more inclined to cooperate with other agents, thereby improving the overall efficiency of the system.
-
3.
The CoRS method is challenged against present SOTA algorithms, showcasing equivalent or superior performance, eliminating the necessity for complex network structures.
II Related Works
II-A MAPF Based on Reinforcement Learning
RL-based planners such as [19, 20, 21, 22], typically cast MAPF as a MARL problem to learn distributed policies for agents from partial observations. This method is particularly effective in environments populated by a large number of agents. Techniques like Imitation Learning (IL) often enhance policy learning during this process. Notably, the PRIMAL algorithm [20] utilizes the Asynchronous Advantage Actor Critic (A3C) algorithm and applies behavior cloning for supervised RL training using experiences from the centralized planner ODrM* [23]. However, the use of a centralized planner limits its efficiency, as solving the MAPF problem can be time-intensive, particularly in complex environments with a large number of agents.
In contrast, Distributed Heuristic Coordination (DHC) [24] and Decision Causal Communication (DCC) [25] algorithms do not require a centralized planner. Although guided by an individual agent’s shortest path, DHC innovatively incorporates all potential shortest path choices into the model’s heuristic input rather than obligating an agent to a specific path. Additionally, DHC collects data from neighboring agents to inform its decisions and employs multi-head attention as a convolution kernel to calculate interactions among agents. DCC is an efficient algorithm that enhances the performance of agents by enabling selective communication with neighbors during both training and execution. Specifically, a neighboring agent is deemed significant only if its presence instigates a change in the decision of the central agent. The central agent only needs to communicate with its significant neighbors.
II-B Reward Shaping
The reward function significantly impacts the performance of RL algorithms. Researchers persistently focus on designing reward functions to optimize algorithm learning efficiency and agent performance. A previous study [26] analyzes the effect of modifying the reward function in Markov Decision Processes on optimal strategies, indicating that the addition of a transition reward function can boost the learning efficiency. In multi-agent systems, the aim is to encourage cooperation among agents through appropriate reward shaping methods, thereby improving overall system performance. [27] probes the enhancement of cooperative agent behavior within the context of a two-player Stag Hunt game, achieved through the design of reward functions. Introducing a prosocial coefficient, the study validates through experimentation that prosocial reward shaping methods elevate performance in multi-agent systems with static network structures. Moreover, [28] promotes cooperation among agents through the reward of an agent whose actions causally influence the behavior of other agents. The evaluation of causal impacts is achieved through counterfactual reasoning, with each agent simulating alternative actions at each time step and calculating their effect on other agents’ behaviors. Actions that lead to significant changes in the behavior of other agents are deemed influential and are rewarded accordingly.
Several studies, including [29, 17, 30], utilize the Shapley value decomposition method to calculate or redistribute each agent’s cooperative benefits. [30] confirms that if a transferable utility game is a convex game, the MARL reward redistribution, based on Shapley values, falls within the core, thereby securing stable and effective cooperation. Consequently, agents should maintain their partnerships or collaborative groups. This concept is the basis for a proposed cooperative strategy learning algorithm rooted in Shapley value reward redistribution. The effectiveness of this reward shaping method in promoting cooperation among agents, specifically within a basic autonomous driving scenario, is demonstrated in the paper. However, the process of calculating the Shapley value can be intricate and laborious. Ref. [29] aims to alleviate these computational challenges by introducing approximation of marginal contributions and employing Monte Carlo sampling to estimate Shapley values. Coordinated Policy Optimization (CoPO)[18] puts forth the concept of “cooperation coefficient”, which shapes the reward by taking a weighted average of an agent’s individual rewards and the average rewards of its neighboring agents, based on the cooperation coefficient. This approach proves that rewards shaped in this manner fulfill the Individual Global Max (IGM) condition. Findings from traffic simulation experiments further suggest that this method of reward shaping can significantly enhance the overall performance and safety of the system. However, this approach ties an agent’s rewards not merely to its personal actions but also to those of its neighbors. Such dependencies might compromise the stability during the training process and the efficiency of the converged strategy.
III Preliminary
III-A Cooperative Multi-Agent Reinforcement Learning
Consider a Markov process involving agents , represented by the tuple . represents agent . At each time step , chooses an action from its action space based on its state and observation according to its policy . All form a joint action , and all form a joint state . For convenience in further discussions, agent’s local observations are treated as a part of the agent’s state . Whenever a joint action is taken, the agents acquire a reward , which is determined by the local reward function with respect to the joint state and action. The state transition function characterizes the probability of transition from the current state to under action . The policy provides the probability of taking action in the state . represents the joint policy for all agents. The action-value function is given by , where the trajectory represents the path taken by the agent . The state-value function is given by and the discounted cumulative reward is , where represents the initial state distribution. For cooperative MARL tasks, the objective is to maximize the total cumulative reward for all agents.
III-B Multi-agent Pathfinding Environment Setup
This letter adopts the same definition of the multi-agent path-finding problem as presented in [24, 25]. Consider agents in an undirected grid graph with obstacles , where is the set of vertices in the graph, and all agents and obstacles located within . All vertices follow the 4-neighborhood rule, that is, for all . Each agent has its unique starting vertex and goal vertex , and its position at time is . The position of the obstacle is represented as . At each time step, each agent can execute an action chosen from its action space . During the execution process, two types of conflict can arise: vertex conflict ( or ) and edge conflict (). If two agents conflict with each other, their positions remain unchanged. The subscript for all the aforementioned variables can be omitted as long as it does not cause ambiguity. The goal of the MAPF problem is to find a set of non-conflicting paths for all agents, where the agent’s path is an ordered list of ’s position. Incorporating the setup of multi-agent reinforcement learning, we design a reward function for the MAPF task, as detailed in Table I. The design of the reward function basically follows [24, 25], with slight adjustments to increase the reward for the agent moving towards the target to better align with our reward shaping method.
| Action | Reward |
|---|---|
| Move (towards goal, away from goal) | -0.070, -0.075 |
| Stay (on goal, off goal) | 0, -0.075 |
| Collision (obstacle/agents) | -0.5 |
| Finish | 3 |
IV Cooperative Reward Shaping
Many algorithms employing MARL techniques to address the MAPF problem utilize IQL or other decentralized training and execution frameworks to ensure good scalability. For example, [24, 25] are developed based on IQL. Although IQL can be applied to scenarios with a large number of agents, it often performs poorly in tasks that require a high degree of cooperation among agents, such as the MAPF task. This poor performance arises because, within the IQL framework, each agent greedily maximizes its own cumulative reward, leading agents to behave in an egocentric and aggressive manner, thus reducing the overall efficiency of the system. To counteract this, this letter introduces a reward shaping method named Cooperative Reward Shaping (CoRS), and combines CoRS with the DHC algorithm. The framework combining CoRS with DHC is shown in Fig. 2. The aim of CoRS is to enhance performance within MAPF problem scenarios. The employment of reward shaping intends to stimulate collaboration among agents, effectively curtailing the performance decline in the multi-agent system caused by selfish behaviors within a distributed framework.
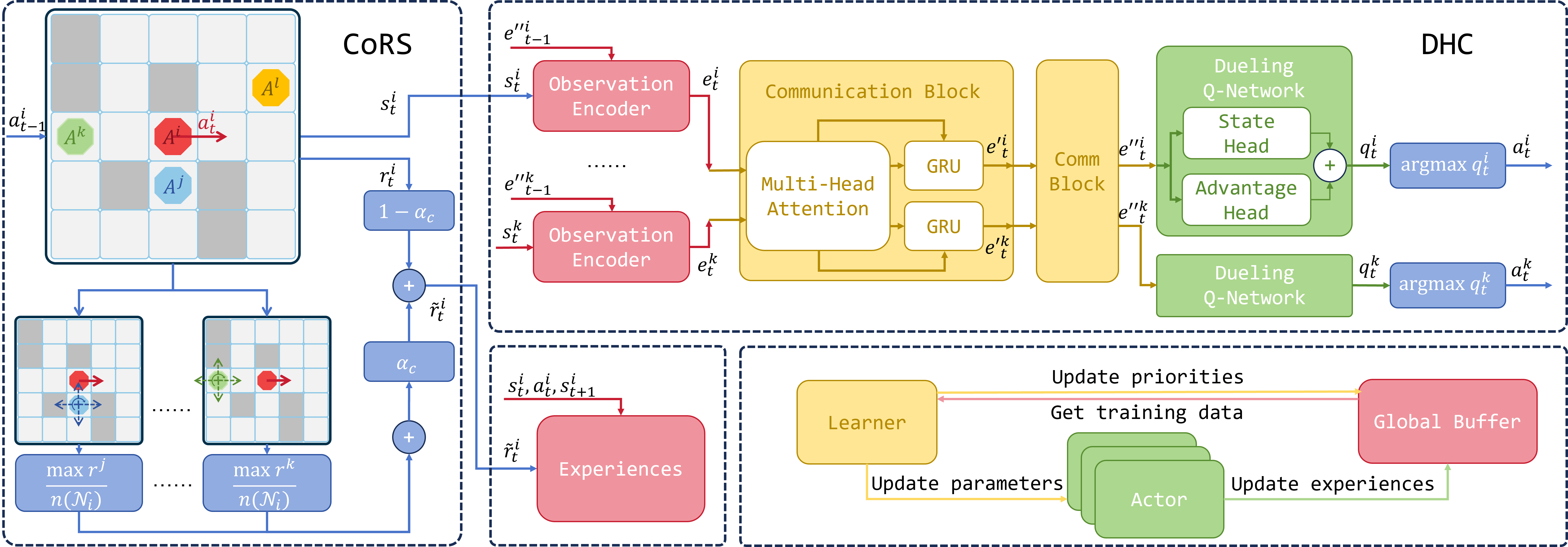
IV-A Design of the Reward Shaping Method
In the MAPF task, the policies trained using IQL often result in scenarios where one agent blocks the path of other agents or collides with them. To enhance cooperation among agents within the IQL framework, a feasible approach is reward shaping. Reward shaping involves meticulously designing the agents’ reward functions to influence their behavior. For example, when a certain type of behavior needs to be encouraged, a higher reward function is typically assigned to that behavior. Thus, to foster cooperation among agents in the MAPF problem, it is necessary to design a metric that accurately evaluates the collaboration of agents’ behavior and incorporate this metric into the agents’ rewards. Consequently, as each agent maximizes its own reward, it will consider the impact of its action on other agents, thereby promoting cooperation among agents and improving overall system efficiency.
Let be a metric that measures the cooperativeness of the action of agent . To better regulate the behavior of the agent, [27] introduces a cooperation coefficient and shapes the agent’s reward function in the following form:
| (1) |
where describes the cooperativeness of the agent. When , the agent completely disregards the impact of its actions on other agents, acting entirely selfishly and when , the agent behaves with complete altruism. For agent , an intuitive approach to measure the cooperativeness of ’s behavior is to use the average reward of all agents except :
| (2) |
where denotes the set of all agents except , and represents the number of agents in . This reward shaping method is equivalent to the neighborhood reward proposed in [18] when , the neighborhood radius of the agent, approaches infinity. The physical significance of Eq. (2) is as follows: If the average reward of the agents other than is relatively high, it indicates that ’s actions have not harmed the interests of other agents. Hence, ’s behavior can be considered as cooperative. Conversely, if the average reward of the other agents is low, it suggests that ’s behavior exhibits poor cooperation.
However, in Eq. (2) is unstable, which is not only related to but is also strongly correlated with the actions of other agents. Appendix B-A provides specific examples to illustrate this instability. Within the IQL framework, this instability in the reward function makes learning of Q-values challenging and can even prevent convergence. To address this issue, this letter proposes a new metric to assess the cooperativeness of agent behavior. The specific form of this metric is as follows:
| (3) |
Here . The use of the operator in Eq. (3) eliminates the influence of on while reflecting the impact of on other agents. The term represents the maximum reward that all the agents except can achieve under the condition of and , whereas the actual value of is determined by when is given. Accordingly, it holds true under any circumstances that . The complete reward shaping method is then as follows:
| (4) |
Fig. 3 gives an one step example to illustrate how this reward-shaping approach Eq. (4) is calculated and promotes inter-agent cooperation when . There are two agents, and , along with some obstacles. Without considering , has two optimal actions: “Up” and “Right”. Fig. 3 also illustrates the potential rewards that may receive when takes different actions. Table II presents the specific reward values for each agent in this example. According to the reward shaping method proposed in Eq. (4), choosing the “Right” action could yield a higher one-step reward, and in such case, should also take action“Right”. Appendix B-B provides another analysis of this example from the vantage point of the cumulative rewards of the agent, further elucidating how the reward shaping method Eq. (4) facilitates cooperation among agents.
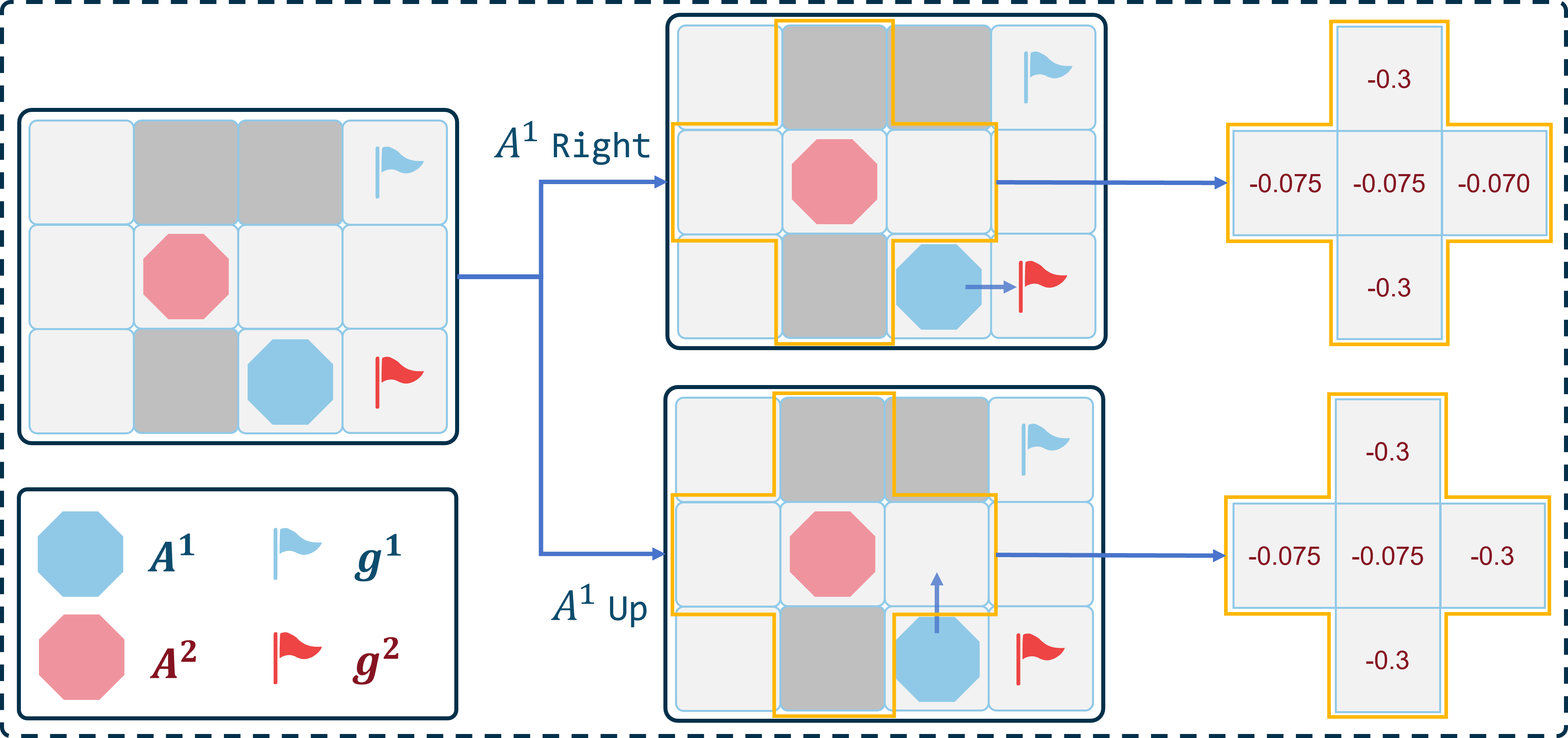
| wait | |||||||
|---|---|---|---|---|---|---|---|
| -0.3 | -0.3 | -0.075 | -0.070 | -0.075 | -0.07 | -0.140 | |
| -0.3 | -0.3 | -0.075 | -0.3 | -0.075 | -0.075 | -0.145 | |
IV-B Analysis of Reward Shaping
This section provides a detailed analysis of how reward shaping method Eq. (4) influences agent behavior. For ease of discussion, the subsequent analysis will be conducted from the perspective of .
In the MAPF problem, the actions of agents are tightly coupled. The action of may impact , and subsequently, the action of may also affect . Thus, the action of indirectly affect . This coupling makes it challenging to analyze the interactions among multiple agents. To mitigate this coupling, we consider all agents in as a single virtual agent . The action of is and its reward is their average reward . The use of average here ensures that and are placed on an equal footing. The virtual agent must satisfy the condition that no collisions occur between the agents constituting . It is important to note that the interaction between and is not entirely equivalent to the interaction between and agents in . This is because when considering the agents in as , all robots within fully cooperate. In contrast, treating these agents as independent individuals makes it difficult to ensure full cooperation. Nonetheless, can still represent the ideal behavior of agents in . Therefore, analyzing the interaction between and can still illustrate the impact of reward shaping on agent interactions. Consider the interaction between and in the time period . and are the cumulative reward of and . is the cumulative reward for both and . The optimal policies , , and . and will select their actions according to and . We hope that and will collectively maximize . Specifically,
That is, , , and satisfy the Individual-Global-Max (IGM) condition. The definition of the IGM condition can be found in [31]. We introduce the following two assumptions to facilitate the analysis.
Assumption 1.
The reward for the agents staying at the target point is , while the rewards for both movement and staying at non-target points are , and the collision reward .
Assumption 2.
During the interaction process between and , neither nor has ever reached its respective endpoint.
Here, not reaching destination means , has not reached its destination. Based on the assumptions, it can be proven that:
Proof.
The proof is provided in Appendix A. ∎
Theorem 1 demonstrates that the optimal policy, trained using the reward function given by Eq. (4), maximizes the overall rewards of and the virtual agents , rather than selfishly maximizing its own cumulative reward. This implies that will actively cooperate with other agents, thus improving the overall efficiency of the system. It should be noted that the impact of on the agent’s behavior is complex. The choice of here is a specific result derived from using the virtual agent . Although this illustrates how the reward shaping method in Eq. (4) induces cooperative behavior in agents, it does not imply that is the optimal value of in all scenarios.
IV-C Approximation
Theorem 1 illustrates that the reward shaping method Eq. (4) can promote cooperation among agents in MAPF tasks. However, calculating Eq. (3) requires traversing the joint action space of . For the MAPF problem where the action space size for each agent is 5, the joint action space for agents contains up to states, significantly reducing the computational efficiency of the reward shaping method.
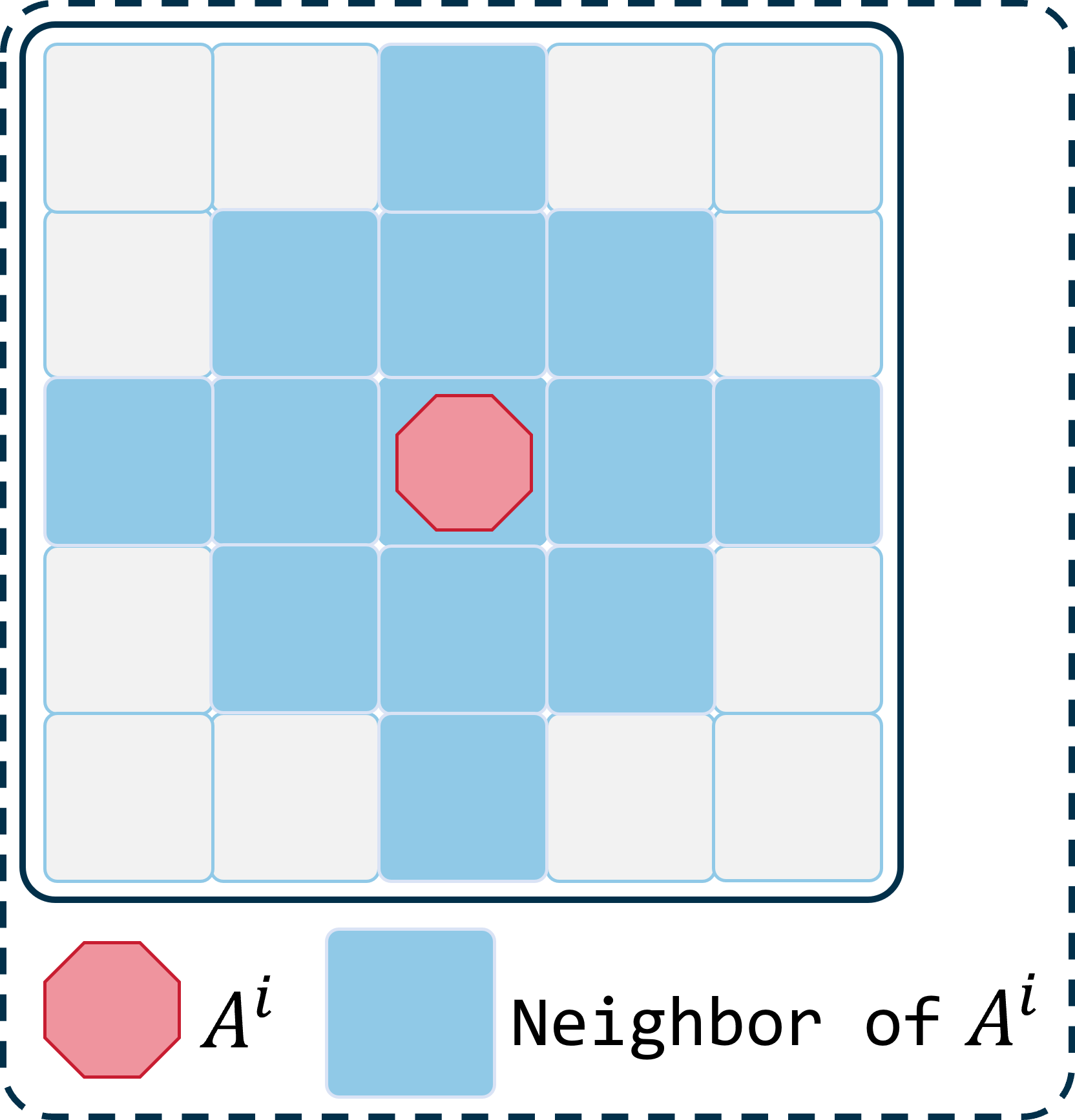
Therefore, we must simplify the calculation of Eq. (3). Before approximating Eq. (3), we first define the neighbors of an agent in the grid map as follows: is considered a neighbor of if the Manhattan distance between them is no more than , where is the neighborhood radius of the agent. If the Manhattan distance between two agents is no more than 2, a conflict may arise between them in a single step. Therefore, we choose , which maximally simplifies interactions between agents while adequately considering potential collisions. Let denote the set of neighboring agents of , and represent the number of neighbors of . Fig. 4 illustrates the neighbors of when .
Considering that in MAPF tasks, the direct interactions among agents are constrained by the distances between them, the interactions between any given agent and all other agents can be simplified to the interactions between the agent and its neighbors. That is:
where represents the joint actions of all neighbors of . Next, we approximate using . This approximation implies that we consider the interaction between agent and one of its neighbors at a time. The computational complexity of the approximate is much lower than the original complexity.
To approximate , we posit that when can observe its two-hop neighbors, its observation is considered sufficient, and its state can approximate to a certain extent, i.e., . When , the minimum observation range includes all grids within a Manhattan distance of no more than from the agent. For convenience, a square is chosen as the agent’s field of view (FOV), consistent with the settings in [24] and covering the agent’s minimum observation range. Consequently, the final reward shaping method is given by:
| (5) |
This reward shaping method possesses the following characteristics:
-
1.
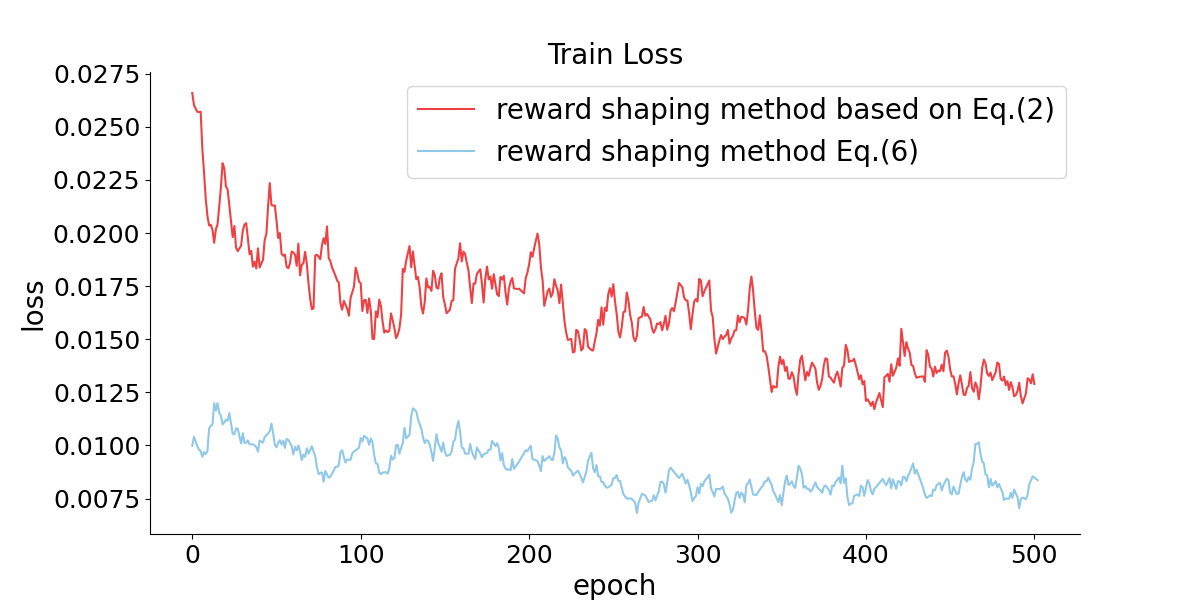
for is explicitly dependent on and is explicitly independent of for . This property improves the stability of the agent’s reward function and facilitates the convergence of the network, as shown in Fig. 5.
-
2.
This method of reward shaping is applicable to MAPF scenarios where the relationship among agents’ neighbors is time-varying.
-
3.
This method, which considers the interaction between just two agents at a time, dramatically reduces the computational difficulty of the reward.
IV-D Adjustment of the cooperation coefficient
For Eq. (5), it is necessary to adjust so that the agent can balance its own interests with the interests of other agents. To find an appropriate cooperation coefficient , it is advisable to examine how the policies trained under different perform in practice and then employ a gradient descent algorithm based on the performance of the policy to optimize . The cumulative reward of the agent often serves as a performance metric in RL. However, in environments with discrete action and state spaces, the cumulative reward is non-differentiable with respect to the , presenting a significant challenge for adjusting . Some work employs zero-order optimization of stochastic gradient estimation to handle non-differentiable optimization problems, that is, estimating the gradient by finite differences of function values. We also use differences in the cumulative reward of the agent to estimate the gradient of the cooperation coefficient :
where represents the maximum step size of the differential. If the update step length is too small, the updates are halted. To expedite the training process, a method of fine-tuning the network is employed. That is, after each adjustment of , the network is not trained from the initial state. Instead, fine-tuning training is performed based on the optimal policy network obtained previously. This training method improves the speed of the training process.
V Experiments
We conducted our experiments in the standard MAPF environment, where each agent has a FOV and can communicate with up to two nearest neighbors. Following the curriculum learning method [32] used by DHC, we gradually introduced more challenging tasks to the agents. Training began with a simple task that involved a single agent in a environment. Upon achieving a success rate above 0.9, we either added an agent or increased the environment size by 5 to establish two more complex tasks. The model was ultimately trained to handle 10 agents in a environment. The maximum number of steps per episode was set to 256. Training was carried out with a batch size of 192, a sequence length of 20, and a dynamic learning rate starting at , which was halved at 100,000 and 300,000 steps, with a maximum of 500,000 training steps. During fine-tuning, the learning rate was maintained at . Distributed training was used to improve efficiency, with 16 independent environments running in parallel to generate agent experiences, which were uploaded to a global buffer. The learner then retrieved these data from the buffer and trained the agent’s strategy on a GPU. CoRS-DHC adopted the same network structure as DHC. All training and testing were performed on an Intel® i5-13600KF and Nvidia® RTX2060 6G.
V-A Impact of Reward Shaping
Following several rounds of network fine-tuning and updates to the cooperation coefficient , a value of and strategy are obtained. Upon obtaining the final and , the CoRS-DHC-trained policy is compared with the original DHC algorithm-trained policy to assess the effect of the reward shaping method on performance improvement. For a fair comparison, the DHC and CoRS-DHC algorithms are tested on maps of different scales ( and ) with varying agent counts . Recognizing the larger environmental spatial capacity of the map, a scenario with 128 agents is also introduced for additional insights. Each experimental scenario includes 200 individual test cases, maintaining a consistent obstacle density of 0.3. The maximum time steps for the and maps are 256 and 386, respectively.
| Steps | Map Size 40 40 | Map Size 80 80 | ||
|---|---|---|---|---|
| Agents | DHC | CoRS-DHC | DHC | CoRS-DHC |
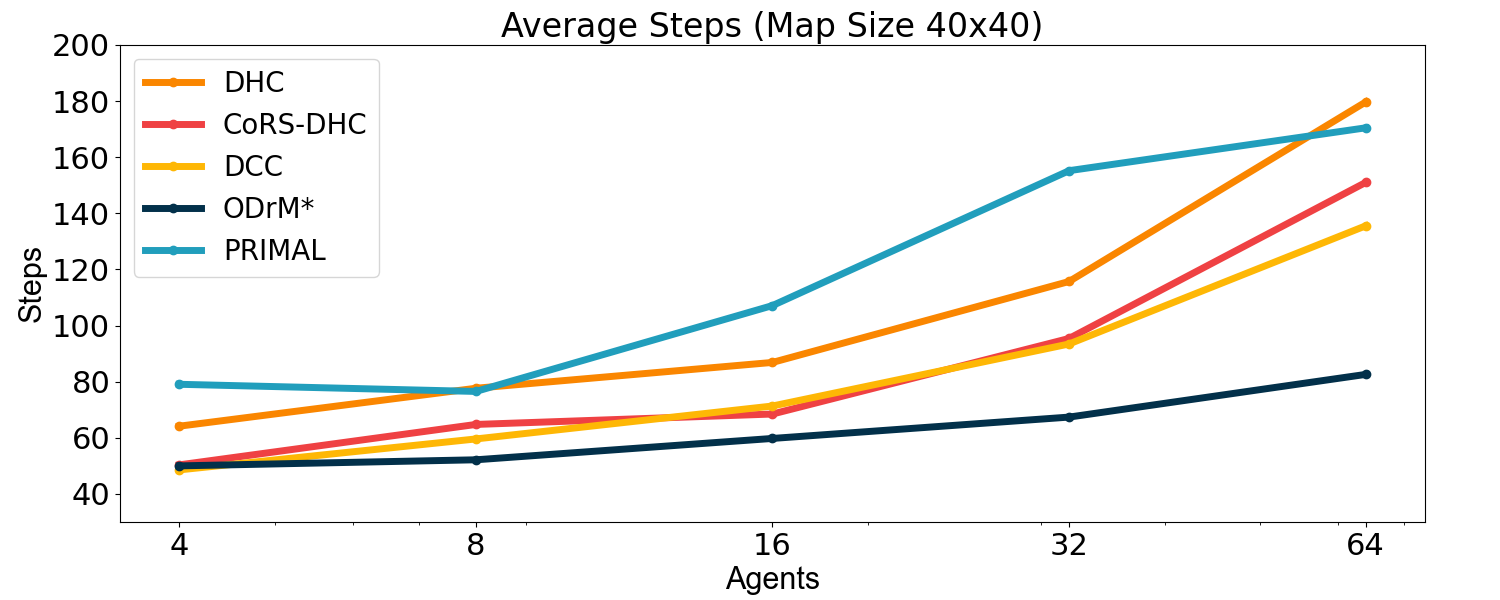
| 4 | 64.15 | 50.36 | 114.69 | 92.14 |
| 8 | 77.67 | 64.77 | 133.39 | 109.15 |
| 16 | 86.87 | 68.48 | 147.55 | 121.25 |
| 32 | 115.72 | 95.42 | 158.58 | 137.06 |
| 64 | 179.69 | 151.02 | 183.44 | 153.06 |
| 128 | 213.75 | 193.50 | ||
From the experimental results illustrated in Fig. 6, it is evident that our proposed CoRS-DHC significantly outperforms the existing DHC algorithm in all test sets. In high agent density scenarios, such as with 64 agents and with 128 agents, our CoRS-DHC improves the pathfinding success rate by more than 20% compared to DHC. Furthermore, as shown in Table III, CoRS effectively reduces the number of steps required for all agents to reach their target spot in various test scenarios. Although the DHC algorithm incorporates heuristic functions and inter-agent communication, it still struggles with cooperative issues among agents. In contrast, our CoRS-DHC promotes inter-agent collaboration through reward shaping, thereby substantially enhancing the performance of the DHC algorithm in high-density scenarios. Notably, this significant improvement was achieved without any changes to the algorithm’s structure or network scale, underscoring the effectiveness of our approach.
V-B Success Rate and Average Step
Additionally, the policy trained through CoRS-DHC is compared with other advanced MAPF algorithms. The current SOTA algorithm, DCC[25], which is also based on reinforcement learning, is selected as the main comparison object, with the centralized MAPF algorithm ODrM*[6] and PRIMAL[20] (based on RL and IL) serving as references. DCC is an efficient model designed to enhance agent performance by training agents to selectively communicate with their neighbors during both training and execution stages. It introduces a complex decision causal unit to each agent, which determines the appropriate neighbors for communication during these stages. Conversely, the PRIMAL algorithm achieves distributed MAPF by imitating ODrM* and incorporating reinforcement learning algorithms. ODrM* is a centralized algorithm designed to generate optimal paths for multiple agents. It is one of the best centralized MAPF algorithms currently available. We use it as a comparative baseline to show the differences between distributed and centralized algorithms. The experimental results are demonstrated in Fig. 7:
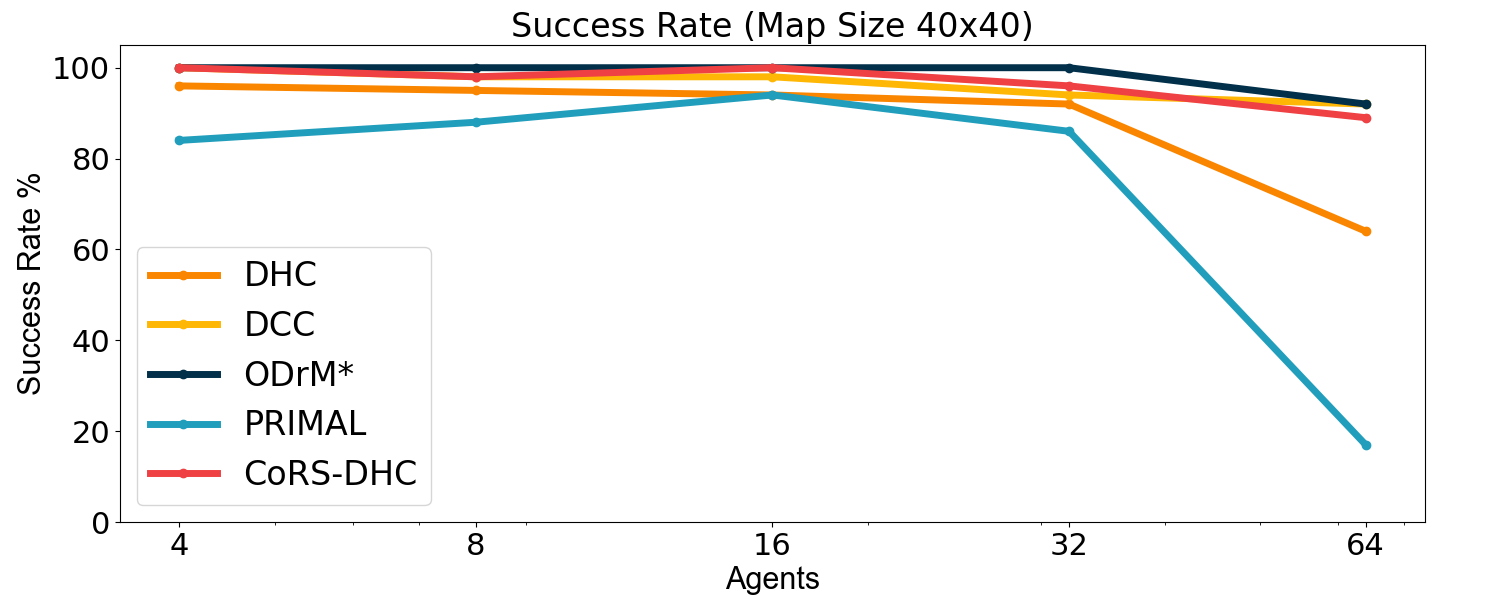
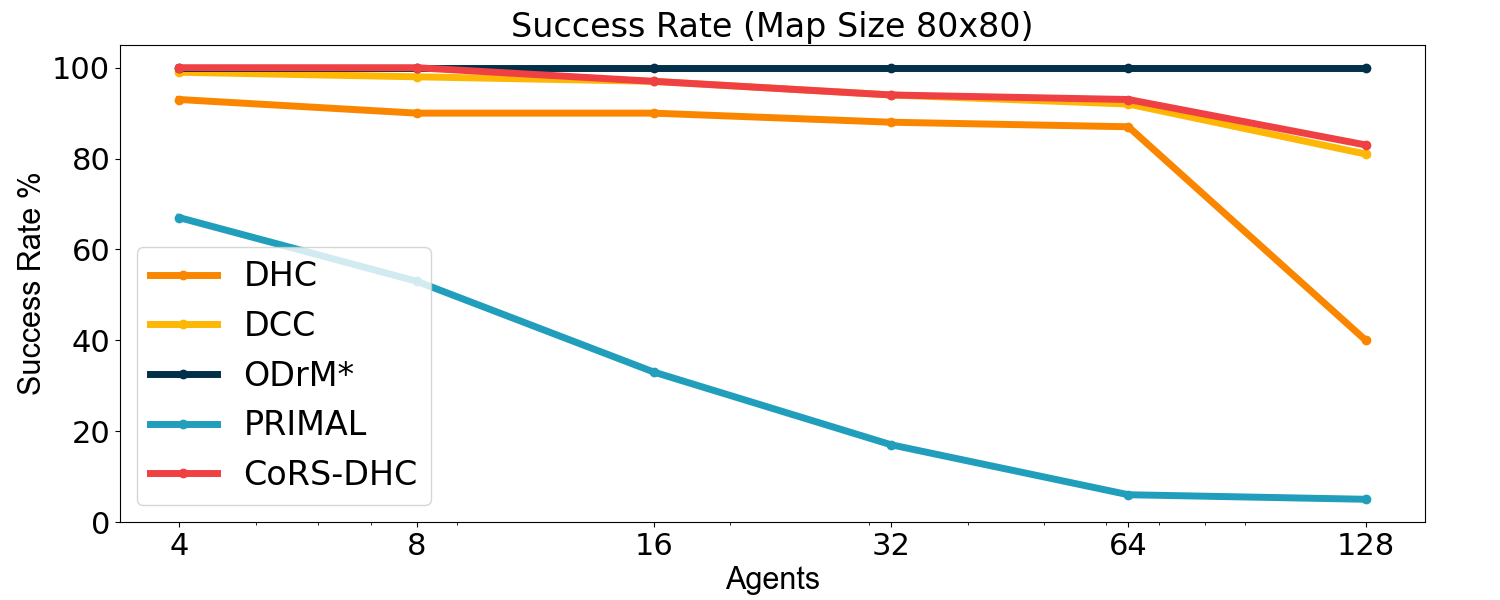
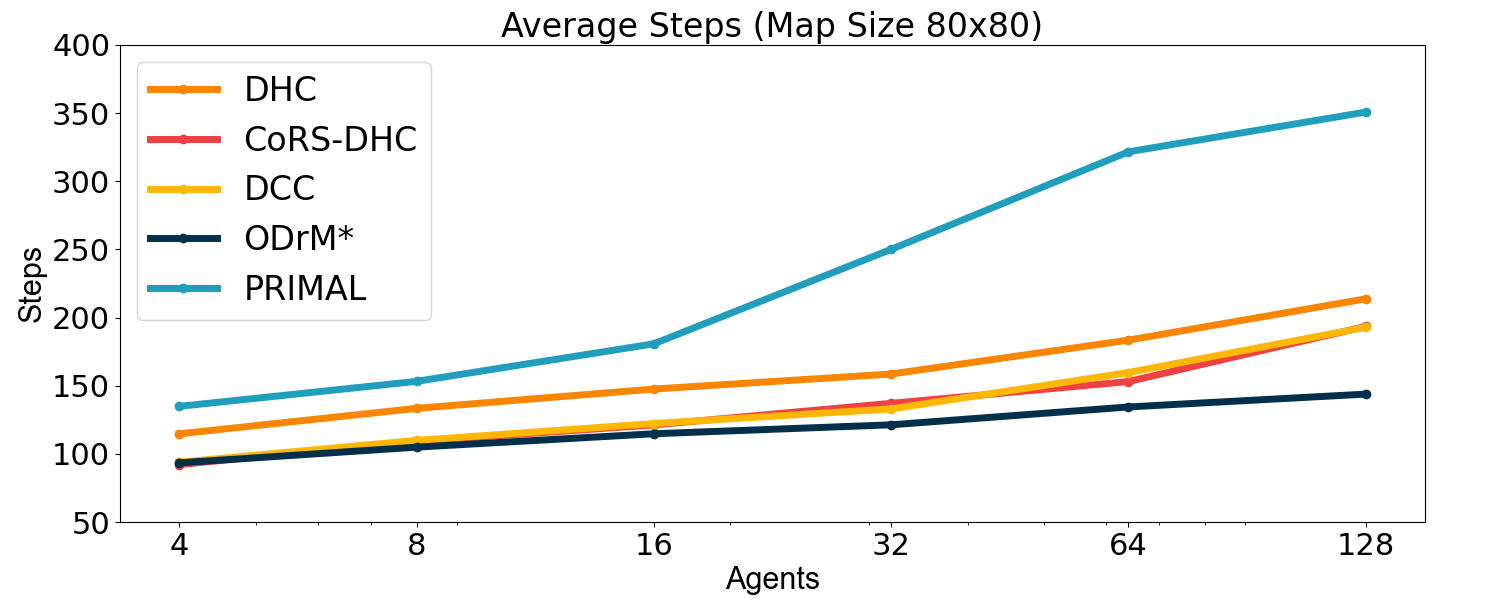
The experimental results indicate that our CoRS-DHC algorithm consistently exceeds the success rate of the DCC algorithm in the majority of scenarios. Additionally, aside from the grid with 64 agents, the makespan of the policies trained by the CoRS-DHC algorithm is comparable to or even shorter than that of the DCC algorithm across other scenarios. These results clearly demonstrate that our CoRS-DHC algorithm achieves a performance comparable to that of DCC. However, it should be noted that DCC employs a significantly more complex communication mechanism during both training and execution, while our CoRS algorithm only utilizes simple reward shaping during the training phase. Compared to PRIMAL and DHC, CoRS-DHC exhibits a remarkably superior performance.
VI Conclusion
This letter proposes a reward shaping method termed CoRS, applicable to the standard MAPF tasks. By promoting cooperative behavior among multiple agents, CoRS significantly improves the efficiency of MAPF. The experimental results indicate that CoRS significantly enhances the performance of the MARL algorithms in solving the MAPF problem. CoRS also has implications for other multi-agent reinforcement learning tasks. We plan to further extend the application of this reward-shaping strategy to a wider range of MARL environments in future exploration.
References
- [1] Fu Chen. Aircraft taxiing route planning based on multi-agent system. In 2016 IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), pages 1421–1425, 2016.
- [2] Jiankun Wang and Max Q-H Meng. Real-time decision making and path planning for robotic autonomous luggage trolley collection at airports. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 52(4):2174–2183, 2021.
- [3] Oren Salzman and Roni Stern. Research challenges and opportunities in multi-agent path finding and multi-agent pickup and delivery problems. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, pages 1711–1715, 2020.
- [4] Altan Yalcin. Multi-Agent Route Planning in Grid-Based Storage Systems. doctoralthesis, Europa-Universität Viadrina Frankfurt, 2018.
- [5] Kevin Nagorny, Armando Walter Colombo, and Uwe Schmidtmann. A service-and multi-agent-oriented manufacturing automation architecture: An iec 62264 level 2 compliant implementation. Computers in Industry, 63(8):813–823, 2012.
- [6] Cornelia Ferner, Glenn Wagner, and Howie Choset. Odrm* optimal multirobot path planning in low dimensional search spaces. In 2013 IEEE international conference on robotics and automation, pages 3854–3859. IEEE, 2013.
- [7] Teng Guo and Jingjin Yu. Sub-1.5 time-optimal multi-robot path planning on grids in polynomial time. arXiv preprint arXiv:2201.08976, 2022.
- [8] Han Zhang, Jiaoyang Li, Pavel Surynek, TK Satish Kumar, and Sven Koenig. Multi-agent path finding with mutex propagation. Artificial Intelligence, 311:103766, 2022.
- [9] Glenn Wagner and Howie Choset. Subdimensional expansion for multirobot path planning. Artificial intelligence, 219:1–24, 2015.
- [10] Na Fan, Nan Bao, Jiakuo Zuo, and Xixia Sun. Decentralized multi-robot collision avoidance algorithm based on rssi. In 2021 13th International Conference on Wireless Communications and Signal Processing (WCSP), pages 1–5. IEEE, 2021.
- [11] Chunyi Peng, Minkyong Kim, Zhe Zhang, and Hui Lei. Vdn: Virtual machine image distribution network for cloud data centers. In 2012 Proceedings IEEE INFOCOM, pages 181–189. IEEE, 2012.
- [12] Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning. Journal of Machine Learning Research, 21(178):1–51, 2020.
- [13] Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- [14] Wesley Suttle, Zhuoran Yang, Kaiqing Zhang, Zhaoran Wang, Tamer Başar, and Ji Liu. A multi-agent off-policy actor-critic algorithm for distributed reinforcement learning. IFAC-PapersOnLine, 53(2):1549–1554, 2020. 21st IFAC World Congress.
- [15] Ardi Tampuu, Tambet Matiisen, Dorian Kodelja, Ilya Kuzovkin, Kristjan Korjus, Juhan Aru, Jaan Aru, and Raul Vicente. Multiagent cooperation and competition with deep reinforcement learning. PloS one, 12(4):e0172395, 2017.
- [16] Sirui Chen, Zhaowei Zhang, Yaodong Yang, and Yali Du. Stas: Spatial-temporal return decomposition for multi-agent reinforcement learning. arXiv preprint arXiv:2304.07520, 2023.
- [17] Jiahui Li, Kun Kuang, Baoxiang Wang, Furui Liu, Long Chen, Fei Wu, and Jun Xiao. Shapley counterfactual credits for multi-agent reinforcement learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 934–942, 2021.
- [18] Zhenghao Peng, Quanyi Li, Ka Ming Hui, Chunxiao Liu, and Bolei Zhou. Learning to simulate self-driven particles system with coordinated policy optimization. Advances in Neural Information Processing Systems, 34:10784–10797, 2021.
- [19] Binyu Wang, Zhe Liu, Qingbiao Li, and Amanda Prorok. Mobile robot path planning in dynamic environments through globally guided reinforcement learning. IEEE Robotics and Automation Letters, 5(4):6932–6939, 2020.
- [20] Guillaume Sartoretti, Justin Kerr, Yunfei Shi, Glenn Wagner, TK Satish Kumar, Sven Koenig, and Howie Choset. Primal: Pathfinding via reinforcement and imitation multi-agent learning. IEEE Robotics and Automation Letters, 4(3):2378–2385, 2019.
- [21] Zuxin Liu, Baiming Chen, Hongyi Zhou, Guru Koushik, Martial Hebert, and Ding Zhao. Mapper: Multi-agent path planning with evolutionary reinforcement learning in mixed dynamic environments. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11748–11754. IEEE, 2020.
- [22] Qingbiao Li, Fernando Gama, Alejandro Ribeiro, and Amanda Prorok. Graph neural networks for decentralized multi-robot path planning. In 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 11785–11792. IEEE, 2020.
- [23] Cornelia Ferner, Glenn Wagner, and Howie Choset. Odrm* optimal multirobot path planning in low dimensional search spaces. In 2013 IEEE International Conference on Robotics and Automation, pages 3854–3859, 2013.
- [24] Ziyuan Ma, Yudong Luo, and Hang Ma. Distributed heuristic multi-agent path finding with communication. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 8699–8705. IEEE, 2021.
- [25] Ziyuan Ma, Yudong Luo, and Jia Pan. Learning selective communication for multi-agent path finding. IEEE Robotics and Automation Letters, 7(2):1455–1462, 2022.
- [26] Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transformations: Theory and application to reward shaping. In Icml, volume 99, pages 278–287, 1999.
- [27] Alexander Peysakhovich and Adam Lerer. Prosocial learning agents solve generalized stag hunts better than selfish ones. arXiv preprint arXiv:1709.02865, 2017.
- [28] Natasha Jaques, Angeliki Lazaridou, Edward Hughes, Caglar Gulcehre, Pedro Ortega, DJ Strouse, Joel Z Leibo, and Nando De Freitas. Social influence as intrinsic motivation for multi-agent deep reinforcement learning. In International conference on machine learning, pages 3040–3049. PMLR, 2019.
- [29] Sirui Chen, Zhaowei Zhang, Yaodong Yang, and Yali Du. Stas: Spatial-temporal return decomposition for solving sparse rewards problems in multi-agent reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17337–17345, 2024.
- [30] Songyang Han, He Wang, Sanbao Su, Yuanyuan Shi, and Fei Miao. Stable and efficient shapley value-based reward reallocation for multi-agent reinforcement learning of autonomous vehicles. In 2022 International Conference on Robotics and Automation (ICRA), pages 8765–8771. IEEE, 2022.
- [31] Kyunghwan Son, Daewoo Kim, Wan Ju Kang, David Earl Hostallero, and Yung Yi. Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In International conference on machine learning, pages 5887–5896. PMLR, 2019.
- [32] Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the 26th annual international conference on machine learning, pages 41–48, 2009.
Appendix A Proofs
In this section, proofs of Theorem 1 is provided. For clarity, we hereby reiterate the assumptions involved in the proof processes.
Assumption 1.
The reward for agents staying at the target point is , while the rewards for both movement and staying at non-target points are . The collision reward .
Assumption 2.
During the interaction process between and , neither nor has ever reached its respective endpoint.
Proof.
Theorem 1 is equivalent to the following statement: for , there exists , such that .
For the sake of simplicity in the discussion, we denote and as and , and as . When , and .
First, under Assumps. 1 and Assump. 2, if no collisions occur along the trajectory , then for all and , we have and . This holds because if and do not reach their goals, then and . Meanwhile, if no collisions occur along , then and . Thus, it follows that for all and , and .
Second, and , . This is because:
where (a) holds because the trajectory maximizes , when the trajectory is replaced by , .
Then consider and . There must be no collisions along , otherwise cannot be optimal. Therefore, . Furthermore, since , we find that , where . We select such that .
Based on the previous discussion, it can be deduced that and can maximize both and . Next, we demonstrate that can also maximize . Let . Given that there is no conflict in and represents the maximum accumulated reward of in state , we have . Assume there exists such that . Therefore:
which is clearly a contradiction. The validity of (b) follows from that . Therefore, .
∎
Appendix B Examples
In this section, some examples will be provided to facilitate the understanding of the CoRS algorithm.
B-A The instability of Eq. (2)
In this section, we illustrate the instability of Eq. (2) through an example. Fig. 8 presents two agents, and , with the blue and red flags representing their respective endpoints. The optimal trajectory in this scenario is already depicted in the figure. Based on the optimal trajectory, it is evident that the optimal action pair in the current state is Action Pair 1. We anticipate that when takes the action from Action Pair 1, will be higher than for other actions.
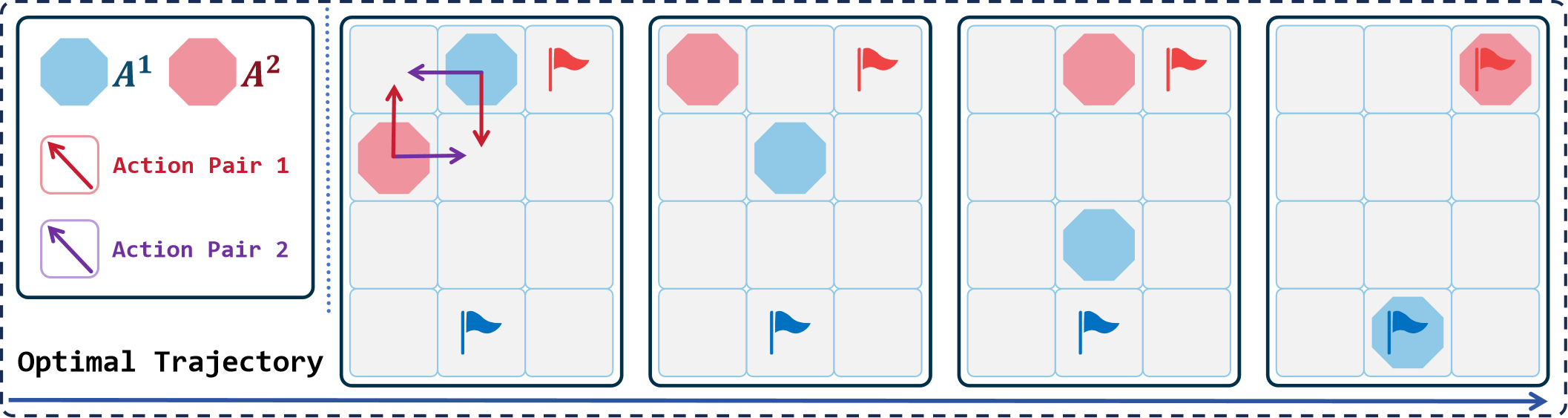
According to the calculation method provided in Eq. (2) and the reward function given in Table I, we compute the values of when takes the action from Action Pair 1 under different conditions. When takes the action in Action Pair 1, . When takes the action in Action Pair 2, a collision occurs between and , and . These calculations show that in the same state, even though takes the optimal action, the value of changes depending on . This indicates that the calculation method provided in Eq. (2) is unstable.
B-B How Reward Shaping Promotes Inter-Agent Cooperation
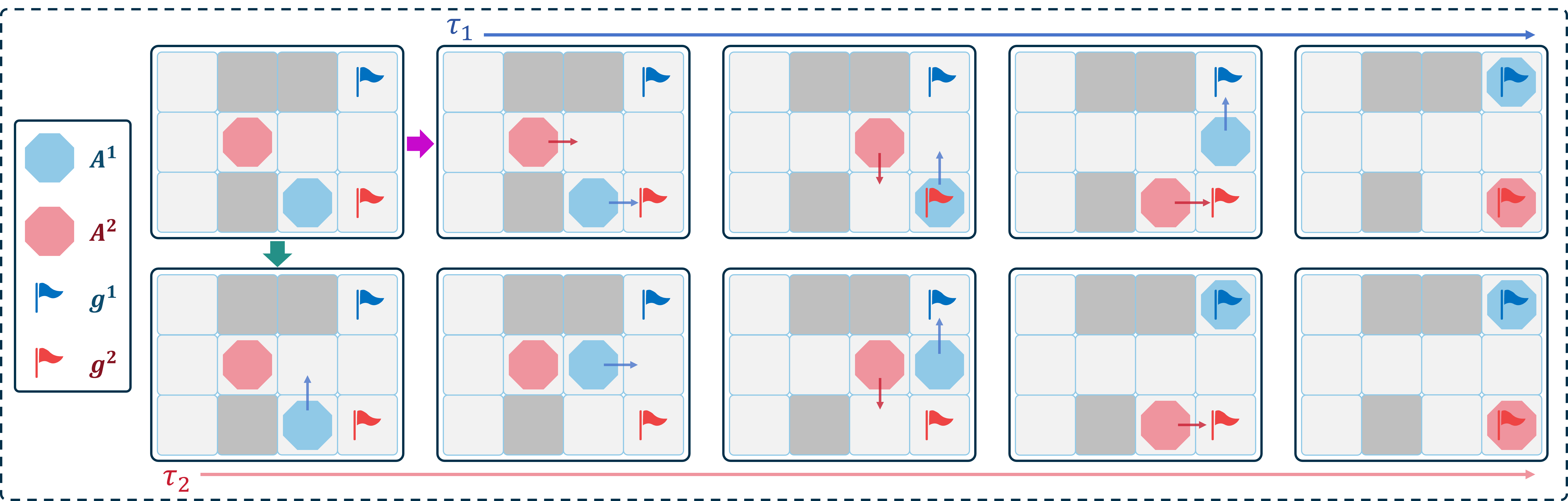
In this section, we illustrate with an example how the reward-shaping method Eq. (4) promotes inter-agent cooperation, thereby enhancing the overall system efficiency. Table I presents the reward function used in this example. As shown in Fig. 9, there are two agents, and , engaged in interaction. Throughout their interaction, and remain neighbors. Each agent aims to maximize its cumulative reward. For this two-agent scenario, we set . Two trajectories, and , are illustrated in Fig. 9. We will calculate the cumulative rewards that can obtain on the two trajectories using different reward functions. For the sake of simplicity, in this example, .
If uses as the reward function, the cumulative reward on the trajectory is , and on the trajectory it is . Consequently, may choose trajectory . In , will stop and wait due to being blocked by . This indicates that using the original reward function may not promote collaboration between agents, resulting in a decrease in overall system efficiency.
However, if adopts as its reward, the cumulative rewards for on trajectories is . In contrast, on trajectory , it is . Therefore, will choose the trajectory instead of , allowing to reach its goal as quickly as possible. This demonstrates that using the reward shaped by the reward-shaping method Eq. (4) enables to adequately consider the impact of its actions on other agents, thereby promoting cooperation among agents and enhancing the overall efficiency of the system.
Appendix C Details of Experiments
In this section, we provide detailed data in Section V. Table IV and Table V presents the success rates of different algorithms across various test scenarios, while Table VI and Table VII shows the makespan of different algorithms in these scenarios. The results for the ODrM* algorithm, which are considered optimal, are highlighted in bold. The best metrics among other algorithms that use reinforcement learning techniques are marked in red.
| Success Rate% | Map Size | ||||
|---|---|---|---|---|---|
| Agents | DHC | DCC | CoRS-DHC | PRIMAL | ODrM* |
| 4 | 96 | 100 | 100 | 84 | 100 |
| 8 | 95 | 98 | 98 | 88 | 100 |
| 16 | 94 | 98 | 100 | 94 | 100 |
| 32 | 92 | 94 | 96 | 86 | 100 |
| 64 | 64 | 91 | 89 | 17 | 92 |
| Success Rate% | Map Size | ||||
|---|---|---|---|---|---|
| Agents | DHC | DCC | CoRS-DHC | PRIMAL | ODrM* |
| 4 | 93 | 99 | 100 | 67 | 100 |
| 8 | 90 | 98 | 100 | 53 | 100 |
| 16 | 90 | 97 | 97 | 33 | 100 |
| 32 | 88 | 94 | 94 | 17 | 100 |
| 64 | 87 | 92 | 93 | 6 | 100 |
| 128 | 40 | 81 | 83 | 5 | 100 |
| Average Steps | Map Size | ||||
|---|---|---|---|---|---|
| Agents | DHC | DCC | CoRS-DHC | PRIMAL | ODrM* |
| 4 | 64.15 | 48.58 | 50.36 | 79.08 | 50 |
| 8 | 77.67 | 59.60 | 64.77 | 76.53 | 52.17 |
| 16 | 86.87 | 71.34 | 68.48 | 107.14 | 59.78 |
| 32 | 115.72 | 93.45 | 95.42 | 155.21 | 67.39 |
| 64 | 179.69 | 135.55 | 151.02 | 170.48 | 82.60 |
| Average Steps | Map Size | ||||
|---|---|---|---|---|---|
| Agents | DHC | DCC | CoRS-DHC | PRIMAL | ODrM* |
| 4 | 114.69 | 93.89 | 92.14 | 134.86 | 93.40 |
| 8 | 133.39 | 109.89 | 109.15 | 153.20 | 104.92 |
| 16 | 147.55 | 122.24 | 121.25 | 180.74 | 114.75 |
| 32 | 158.58 | 132.99 | 137.06 | 250.07 | 121.31 |
| 64 | 183.44 | 159.67 | 153.06 | 321.63 | 134.42 |
| 128 | 213.75 | 192.90 | 193.50 | 350.76 | 143.84 |