Correlation Aware Sparsified Mean Estimation Using Random Projection
Abstract
We study the problem of communication-efficient distributed vector mean estimation, a commonly used subroutine in distributed optimization and Federated Learning (FL). Rand- sparsification is a commonly used technique to reduce communication cost, where each client sends of its coordinates to the server. However, Rand- is agnostic to any correlations, that might exist between clients in practical scenarios. The recently proposed Rand--Spatial estimator leverages the cross-client correlation information at the server to improve Rand-’s performance. Yet, the performance of Rand--Spatial is suboptimal. We propose the Rand-Proj-Spatial estimator with a more flexible encoding-decoding procedure, which generalizes the encoding of Rand- by projecting the client vectors to a random -dimensional subspace. We utilize Subsampled Randomized Hadamard Transform (SRHT) as the projection matrix and show that Rand-Proj-Spatial with SRHT outperforms Rand--Spatial, using the correlation information more efficiently. Furthermore, we propose an approach to incorporate varying degrees of correlation and suggest a practical variant of Rand-Proj-Spatial when the correlation information is not available to the server. Experiments on real-world distributed optimization tasks showcase the superior performance of Rand-Proj-Spatial compared to Rand--Spatial and other more sophisticated sparsification techniques.
1 Introduction
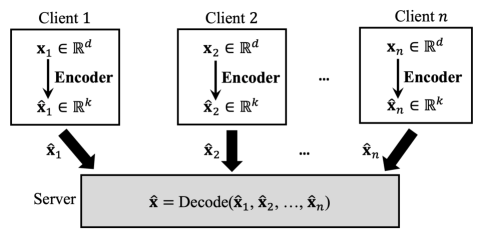
In modern machine learning applications, data is naturally distributed across a large number of edge devices or clients. The underlying learning task in such settings is modeled by distributed optimization or the recent paradigm of Federated Learning (FL) konevcny16federated ; fedavg17aistats ; kairouz2021advances ; wang2021field . A crucial subtask in distributed learning is for the server to compute the mean of the vectors sent by the clients. In FL, for example, clients run training steps on their local data and once-in-a-while send their local models (or local gradients) to the server, which averages them to compute the new global model. However, with the ever-increasing size of machine learning models simonyan2014very ; brown2020language , and the limited battery life of the edge clients, communication cost is often the major constraint for the clients. This motivates the problem of (empirical) distributed mean estimation (DME) under communication constraints, as illustrated in Figure 1. Each of the clients holds a vector , on which there are no distributional assumptions. Given a communication budget, each client sends a compressed version of its vector to the server, which utilizes these to compute an estimate of the mean vector .
Quantization and sparsification are two major techniques for reducing the communication costs of DME. Quantization gubner1993distributed ; davies2021new_bounds_dme_var_reduction ; vargaftik2022eden ; suresh2017dme_icml involves compressing each coordinate of the client vector to a given precision and aims to reduce the number of bits to represent each coordinate, achieving a constant reduction in the communication cost. However, the communication cost still remains . Sparsification, on the other hand, aims to reduce the number of coordinates each clinet sends and compresses each client vector to only of its coordinates (e.g. Rand- konevcny2018rand_dme ). As a result, sparsification reduces communication costs more aggressively compared to quantization, achieving better communication efficiency at a cost of only . While in practice, one can use a combination of quantization and sparsification techniques for communication cost reduction, in this work, we focus on the more aggressive sparsification techniques. We call , the dimension of the vector each client sends to the server, the per-client communication budget.
Most existing works on sparsification ignore the potential correlation (or similarity) among the client vectors, which often exists in practice. For example, the data of a specific client in federated learning can be similar to that of multiple clients. Hence, it is reasonable to expect their models (or gradients) to be similar as well. To the best of our knowledge, jhunjhunwala2021dme_spatial_temporal is the first work to account for spatial correlation across individual client vectors. They propose the Rand--Spatial family of unbiased estimators, which generalizes Rand- and achieves a better estimation error in the presence of cross-client correlation. However, their approach is focused only on the server-side decoding procedure, while the clients do simple Rand- encoding.
In this work, we consider a more general encoding scheme that directly compresses a vector from to using a (random) linear map. The encoded vector consists of linear combinations of the original coordinates. Intuitively, this has a higher chance of capturing the large-magnitude coordinates (“heavy hitters”) of the vector than randomly sampling out of the coordinates (Rand-), which is crucial for the estimator to recover the true mean vector. For example, consider a vector where only a few coordinates are heavy hitters. For small , Rand- has a decent chance of missing all the heavy hitters. But with a linear-maps-based general encoding procedure, the large coordinates are more likely to be encoded in the linear measurements, resulting in a more accurate estimator of the mean vector. Guided by this intuition, we ask:
Can we design an improved joint encoding-decoding scheme that utilizes the correlation information and achieves an improved estimation error?
One naïve solution is to apply the same random rotation matrix to each client vector, before applying Rand- or Rand--Spatial encoding. Indeed, such preprocessing is applied to improve the estimator using quantization techniques on heterogeneous vectors suresh2022correlated_dme_icml ; suresh2017dme_icml . However, as we see in Appendix A.1, for sparsification, we can show that this leads to no improvement. But what happens if every client uses a different random matrix, or applies a random -dimensional linear map? How to design the corresponding decoding procedure to leverage cross-client correlation? As there is no way for one to directly apply the decoding procedure of Rand--Spatial in such cases. To answer these questions, we propose the Rand-Proj-Spatial family estimator. We propose a flexible encoding procedure in which each client applies its own random linear map to encode the vector. Further, our novel decoding procedure can better leverage cross-client correlation. The resulting mean estimator generalizes and improves over the Rand--Spatial family estimator.
Next, we discuss some reasonable restrictions we expect our mean estimator to obey. 1) Unbiased. An unbiased mean estimator is theoretically more convenient compared to a biased one horvath2021induced . 2) Non-adaptive. We focus on an encoding procedure that does not depend on the actual client data, as opposed to the adaptive ones, e.g. Rand- with vector-based sampling probability konevcny2018rand_dme ; wangni2018grad_sparse . Designing a data-adaptive encoding procedure is computationally expensive as this might require using an iterative procedure to find out the sampling probabilities konevcny2018rand_dme . In practice, however, clients often have limited computational power compared to the server. Further, as discussed earlier, mean estimation is often a subroutine in more complicated tasks. For applications with streaming data nokleby2018stochastic , the additional computational overhead of adaptive schemes is challenging to maintain. Note that both Rand- and Rand--Spatial family estimator jhunjhunwala2021dme_spatial_temporal are unbiased and non-adaptive.
In this paper, we focus on the severely communication-constrained case , when the server receives very limited information about any single client vector. If , we see in Appendix A.2 that the cross-client information has no additional advantage in terms of improving the mean estimate under both Rand--Spatial or Rand-Proj-Spatial, with different choices of random linear maps. Furthermore, when , the performance of both the estimators converges to that of Rand-. Intuitively, this means when the server receives sufficient information regarding the client vectors, it does not need to leverage cross-client correlation to improve the mean estimator.
Our contributions can be summarized as follows:
-
1.
We propose the Rand-Proj-Spatial family estimator with a more flexible encoding-decoding procedure, which can better leverage the cross-client correlation information to achieve a more general and improved mean estimator compared to existing ones.
-
2.
We show the benefit of using Subsampled Randomized Hadamard Transform (SRHT) as the random linear maps in Rand-Proj-Spatial in terms of better mean estimation error (MSE). We theoretically analyze the case when the correlation information is known at the server (see Theorems 4.3, 4.4 and Section 4.3). Further, we propose a practical configuration called Rand-Proj-Spatial(Avg) when the correlation is unknown.
-
3.
We conduct experiments on common distributed optimization tasks, and demonstrate the superior performance of Rand-Proj-Spatial compared to existing sparsification techniques.
2 Related Work
Quantization and Sparsification. Commonly used techniques to achieve communication efficiency are quantization, sparsification, or more generic compression schemes, which generalize the former two basu2019qsparse . Quantization involves either representing each coordinate of the vector by a small number of bits davies2021new_bounds_dme_var_reduction ; vargaftik2022eden ; suresh2017dme_icml ; alistarh2017qsgd_neurips ; bernstein2018signsgd ; reisizadeh2020fedpaq_aistats , or more involved vector quantization techniques shlezinger2020uveqfed_tsp ; gandikota2021vqsgd_aistats . Sparsification wangni2018grad_sparse ; alistarh2018convergence ; stich2018sparsified ; karimireddy2019error ; sattler2019robust , on the other hand, involves communicating a small number of coordinates, to the server. Common protocols include Rand- konevcny2018rand_dme , sending uniformly randomly selected coordinates; Top- shi2019topk , sending the largest magnitude coordinates; and a combination of the two barnes2020rtop_jsait . Some recent works, with a focus on distributed learning, further refine these communication-saving mechanisms ozfatura2021time by incorporating temporal correlation or error feedback horvath2021induced ; karimireddy2019error .
Distributed Mean Estimation (DME). DME has wide applications in distributed optimization and FL. Most of the existing literature on DME either considers statistical mean estimation zhang2013lower_bd ; garg2014comm_neurips , assuming that the data across clients is generated i.i.d. according to the same distribution, or empirical mean estimation suresh2017dme_icml ; chen2020breaking ; mayekar2021wyner ; jhunjhunwala2021dme_spatial_temporal ; konevcny2018rand_dme ; vargaftik2021drive_neurips ; vargaftik2022eden_icml , without making any distributional assumptions on the data. A recent line of work on empirical DME considers applying additional information available to the server, to further improve the mean estimate. This side information includes cross-client correlation jhunjhunwala2021dme_spatial_temporal ; suresh2022correlated_dme_icml , or the memory of the past updates sent by the clients liang2021improved_isit .
Subsampled Randomized Hadamard Transformation (SRHT). SRHT was introduced for random dimensionality reduction using sketching Ailon2006srht_initial ; tropp2011improved ; lacotte2020optimal_iter_sketching_srht . Common applications of SRHT include faster computation of matrix problems, such as low-rank approximation Balabanov2022block_srht_dist_low_rank ; boutsidis2013improved_srht , and machine learning tasks, such as ridge regression lu2013ridge_reg_srht , and least square problems Chehreghani2020graph_reg_srht ; dan2022least_sq_srht ; lacotte2020optimal_first_order_srht . SRHT has also been applied to improve communication efficiency in distributed optimization ivkin2019distSGD_sketch_neurips and FL haddadpour2020fedsketch ; rothchild2020fetchsgd_icml .
3 Preliminaries
Notation. We use bold lowercase (uppercase) letters, e.g. () to denote vectors (matrices). , for , denotes the -th canonical basis vector. denotes the Euclidean norm. For a vector , denotes its -th coordinate. Given integer , we denote by the set .
Problem Setup. Consider geographically separated clients coordinated by a central server. Each client holds a vector , while the server wants to estimate the mean vector . Given a per-client communication budget of , each client computes and sends it to the central server. is an approximation of that belongs to a random -dimensional subspace. Each client also sends a random seed to the server, which conveys the subspace information, and can usually be communicated using a negligible amount of bits. Having received the encoded vectors , the server then computes , an estimator of . We consider the severely communication-constrained setting where , when only a limited amount of information about the client vectors is seen by the server.
Error Metric. We measure the quality of the decoded vector using the Mean Squared Error (MSE) , where the expectation is with respect to all the randomness in the encoding-decoding scheme. Our goal is to design an encoding-decoding algorithm to achieve an unbiased estimate (i.e. ) that minimizes the MSE, given the per-client communication budget . To consider an example, in rand- sparsification, each client sends randomly selected out of its coordinates to the server. The server then computes the mean estimate as . By (jhunjhunwala2021dme_spatial_temporal, , Lemma 1), the MSE of Rand- sparsification is given by
| (1) |
The Rand--Spatial Family Estimator. For large values of , the Rand- MSE in Eq. 1 can be prohibitive. jhunjhunwala2021dme_spatial_temporal proposed the Rand--Spatial family estimator, which achieves an improved MSE, by leveraging the knowledge of the correlation between client vectors at the server. The encoded vectors are the same as in Rand-. However, the -th coordinate of the decoded vector is given as
| (2) |
Here, is a pre-defined transformation function of , the number of clients which sent their -th coordinate, and is a normalization constant to ensure is an unbiased estimator of . The resulting MSE is given by
| (3) |
where are constants dependent on and , but independent of client vectors . When the client vectors are orthogonal, i.e., , for all , jhunjhunwala2021dme_spatial_temporal show that with appropriately chosen , the MSE in Eq. 3 reduces to Eq. 1. However, if there exists a positive correlation between the vectors, the MSE in Eq. 3 is strictly smaller than that for Rand- Eq. 1.
4 The Rand-Proj-Spatial Family Estimator
While the Rand--Spatial family estimator proposed in jhunjhunwala2021dme_spatial_temporal focuses only on improving the decoding at the server, we consider a more general encoding-decoding scheme. Rather than simply communicating out of the coordinates of its vector to the server, client applies a (random) linear map to and sends to the server. The decoding process on the server first projects the encoded vectors back to the -dimensional space and then forms an estimate . We motivate our new decoding procedure with the following regression problem:
| (4) |
To understand the motivation behind Eq. 4, first consider the special case where for all , that is, the clients communicate their vectors without compressing. The server can then exactly compute the mean . Equivalently, is the solution of . In the more general setting, we require that the mean estimate when encoded using the map , should be “close” to the encoded vector originally sent by client , for all clients .
We note the above intuition can also be translated into different regression problems to motivate the design of the new decoding procedure. We discuss in Appendix B.2 intuitive alternatives which, unfortunately, either do not enable the usage of cross-client correlation information, or do not use such information effectively. We choose the formulation in Eq. 4 due to its analytical tractability and its direct relevance to our target error metric MSE. We note that it is possible to consider the problem in Eq. 4 in the other norms, such as the sum of norms (without the squares) or the norm. We leave this as a future direction to explore.
The solution to Eq. 4 is given by , where denotes the Moore-Penrose pseudo inverse golub2013matrix_book . However, while minimizes the error of the regression problem, our goal is to design an unbiased estimator that also improves the MSE. Therefore, we make the following two modifications to : First, to ensure that the mean estimate is unbiased, we scale the solution by a normalization factor 111We show that it suffices for to be a scalar in Appendix B.1. . Second, to incorporate varying degrees of correlation among the clients, we propose to apply a scalar transformation function to each of the eigenvalues of . The resulting Rand-Proj-Spatial family estimator is given by
| (5) |
Though applying the transformation function in Rand-Proj-Spatial requires computing the eigendecomposition of . However, this happens only at the server, which has more computational power than the clients. Next, we observe that for appropriate choice of , the Rand-Proj-Spatial family estimator reduces to the Rand--Spatial family estimator jhunjhunwala2021dme_spatial_temporal .
Lemma 4.1 (Recovering Rand--Spatial).
Suppose client generates a subsampling matrix , where are the canonical basis vectors, and are sampled from without replacement. The encoded vectors are given as . Given a function , computed as in Eq. 5 recovers the Rand--Spatial estimator.
The proof details are in Appendix C.5. We discuss the choice of and how it compares to Rand--Spatial in detail in Section 4.3.
Remark 4.2.
In the simple case when ’s are subsampling matrices (as in Rand--Spatial jhunjhunwala2021dme_spatial_temporal ), the -th diagonal entry of , conveys the number of clients which sent the -th coordinate. Rand--Spatial incorporates correlation among client vectors by applying a function to . Intuitively, it means scaling different coordinates differently. This is in contrast to Rand-, which scales all the coordinates by . In our more general case, we apply a function to the eigenvalues of to similarly incorporate correlation in Rand-Proj-Spatial.
To showcase the utility of the Rand-Proj-Spatial family estimator, we propose to set the random linear maps to be scaled Subsampled Randomized Hadamard Transform (SRHT, e.g. tropp2011improved ). Assuming to be a power of , the linear map is given as
| (6) |
where is the subsampling matrix, is the (deterministic) Hadamard matrix and is a diagonal matrix with independent Rademacher random variables as its diagonal entries. We choose SRHT due to its superior performance compared to other random matrices. Other possible choices of random matrices for Rand-Proj-Spatial estimator include sketching matrices commonly used for dimensionality reduction, such as Gaussian weinberger2004learning ; tripathy2016gaussian , row-normalized Gaussian, and Count Sketch minton2013improved_bounds_countsketch , as well as error-correction coding matrices, such as Low-Density Parity Check (LDPC) gallager1962LDPC and Fountain Codes Shokrollahi2005fountain_codes . However, in the absence of correlation between client vectors, all these matrices suffer a higher MSE.
In the following, we first compare the MSE of Rand-Proj-Spatial with SRHT against Rand- and Rand--Spatial in two extreme cases: when all the client vectors are identical, and when all the client vectors are orthogonal to each other. In both cases, we highlight the transformation function used in Rand-Proj-Spatial (Eq. 5) to incorporate the knowledge of cross-client correlation. We define
| (7) |
to measure the correlation between the client vectors. Note that . implies all client vectors are orthogonal, while implies identical client vectors.
4.1 Case I: Identical Client Vectors ()
When all the client vectors are identical (), jhunjhunwala2021dme_spatial_temporal showed that setting the transformation to identity, i.e., , for all , leads to the minimum MSE in the Rand--Spatial family of estimators. The resulting estimator is called Rand--Spatial (Max). Under the same setting, using the same transformation in Rand-Proj-Spatial with SRHT, the decoded vector in Eq. 5 simplifies to
| (8) |
where . By construction, , and we focus on the case .
Limitation of Subsampling matrices. As mentioned above, with , we recover the Rand--Spatial family of estimators. In this case, is a diagonal matrix, where each diagonal entry , . is the number of clients which sent their -th coordinate to the server. To ensure , we need , i.e., each of the coordinates is sent by at most one client. If all the clients sample their matrices independently, this happens with probability . As an example, for , (because ). Therefore, to guarantee that is full-rank, each client would need the subsampling information of all the other clients. This not only requires additional communication but also has serious privacy implications. Essentially, the limitation with subsampling matrices is that the eigenvectors of are restricted to be canonical basis vectors . Generalizing ’s to general rank matrices relaxes this constraint and hence we can ensure that is full-rank with high probability. In the next result, we show the benefit of choosing as SRHT matrices. We call the resulting estimator Rand-Proj-Spatial(Max).
Theorem 4.3 (MSE under Full Correlation).
Consider clients, each holding the same vector . Suppose we set , in Eq. 5, and the random linear map at each client to be an SRHT matrix. Let be the probability that does not have full rank. Then, for ,
| (9) |
The proof details are in Appendix C.1. To compare the performance of Rand-Proj-Spatial(Max) against Rand-, we show in Appendix C.2 that for , as long as , the MSE of Rand-Proj-Spatial(Max) is less than that of Rand-. Furthermore, in Appendix C.3 we empirically demonstrate that with and different values of , the rank of is full with high probability, i.e., . This implies .
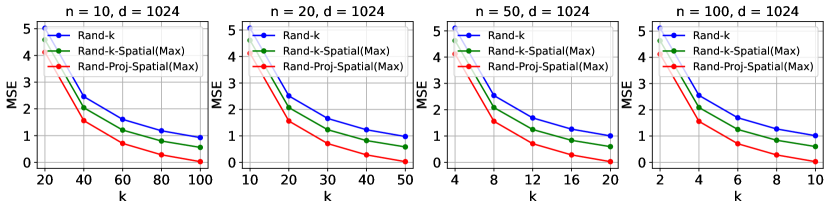
Futhermore, since setting as SRHT significantly increases the probability of recovering coordinates of , the MSE of Rand-Proj-Spatial with SRHT (Eq. 4.3) is strictly less than that of Rand--Spatial (Eq. 3). We also compare the MSEs of the three estimators in Figure 2 in the following setting: , and small values such that .
4.2 Case II: Orthogonal Client Vectors ()
When all the client vectors are orthogonal to each other, jhunjhunwala2021dme_spatial_temporal showed that Rand- has the lowest MSE among the Rand--Spatial family of decoders. We show in the next result that if we set the random linear maps at client to be SRHT, and choose the fixed transformation as in jhunjhunwala2021dme_spatial_temporal , Rand-Proj-Spatial achieves the same MSE as that of Rand-.
Theorem 4.4 (MSE under No Correlation).
Consider clients, each holding a vector , . Suppose we set , in Eq. 5, and the random linear map at each client to be an SRHT matrix. Then, for ,
| (10) |
4.3 Incorporating Varying Degrees of Correlation
In practice, it unlikely that all the client vectors are either identical or orthogonal to each other. In general, there is some “imperfect” correlation among the client vectors, i.e., . Given correlation level , jhunjhunwala2021dme_spatial_temporal shows that the estimator from the Rand--Spatial family that minimizes the MSE is given by the following transformation.
| (11) |
Recall from Section 4.1 (Section 4.2) that setting () leads to the estimator among the Rand--Spatial family that minimizes MSE when there is zero (maximum) correlation among the client vectors. We observe the function defined in Eq. 11 essentially interpolates between the two extreme cases, using the normalized degree of correlation as the weight. This motivates us to apply the same function defined in Eq. 11 on the eigenvalues of in Rand-Proj-Spatial. As we shall see in our results, the resulting Rand-Proj-Spatial family estimator improves over the MSE of both Rand- and Rand--Spatial family estimator.
We note that deriving a closed-form expression of MSE for Rand-Proj-Spatial with SRHT in the general case with the transformation function (Eq. 11) is hard (we elaborate on this in Appendix B.3), as this requires a closed form expression for the non-asymptotic distributions of eigenvalues and eigenvectors of the random matrix . To the best of our knowledge, previous analyses of SRHT, for example in Ailon2006srht_initial ; tropp2011improved ; lacotte2020optimal_iter_sketching_srht ; lacotte2020optimal_first_order_srht ; lei20srht_topk_aaai , rely on the asymptotic properties of SRHT, such as the limiting eigen spectrum, or concentration bounds on the singular values, to derive asymptotic or approximate guarantees. However, to analyze the MSE of Rand-Proj-Spatial, we need an exact, non-asymptotic analysis of the eigenvalues and eigenvectors distribution of SRHT. Given the apparent intractability of the theoretical analysis, we compare the MSE of Rand-Proj-Spatial, Rand--Spatial, and Rand- via simulations.
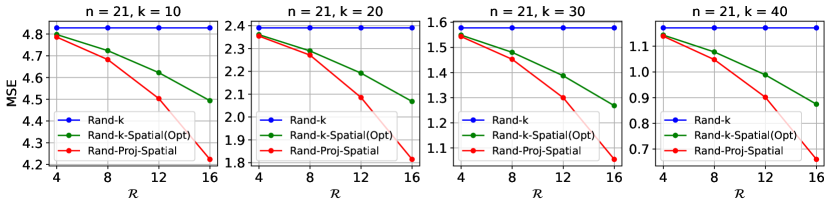
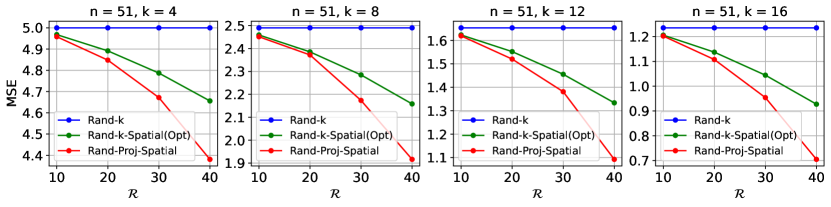
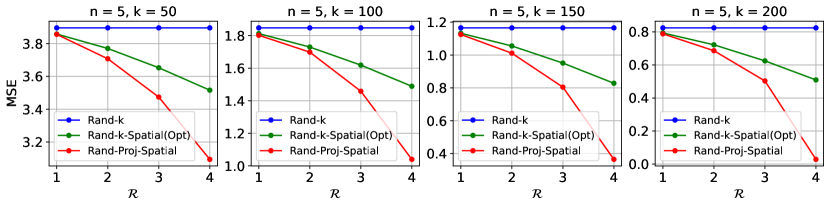
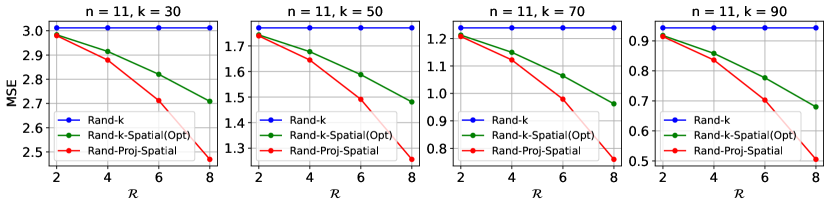
Simulations. In each experiment, we first simulate in Eq. 5, which ensures our estimator is unbiased, based on random runs. Given the degree of correlation , we then compute the squared error, i.e. , where Rand-Proj-Spatial has as SRHT matrix (Eq. 6) and as in Eq. 11. We plot the average over random runs as an approximation to MSE. Each client holds a -dimensional base vector for some , and so two clients either hold the same or orthogonal vectors. We control the degree of correlation by changing the number of clients which hold the same vector. We consider , . We consider positive correlation values, where is chosen to be linearly spaced within . Hence, for , we use and for , we use . All results are presented in Figure 3. As expected, given , Rand-Proj-Spatial consistently achieves a lower MSE than the lowest possible MSE from the Rand--Spatial family decoder. Additional results with different values of , including the setting , can be found in Appendix B.4.
A Practical Configuration. In reality, it is hard to know the correlation information among the client vectors. jhunjhunwala2021dme_spatial_temporal uses the transformation function which interpolates to the middle point between the full correlation and no correlation cases, such that . Rand--Spatial with such is called Rand--Spatial(Avg). Following this approach, we evaluate Rand-Proj-Spatial with SRHT using this , and call it Rand-Proj-Spatial(Avg) in practical settings (see Figure 4).
5 Experiments
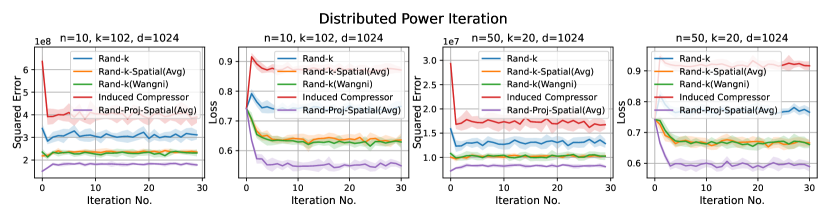
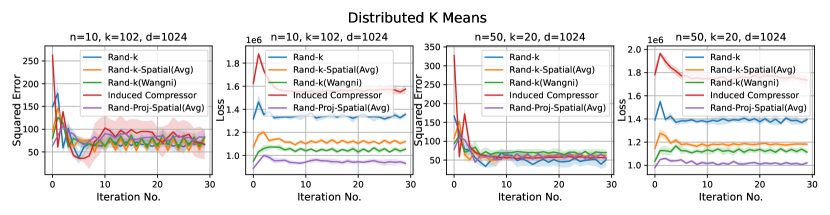
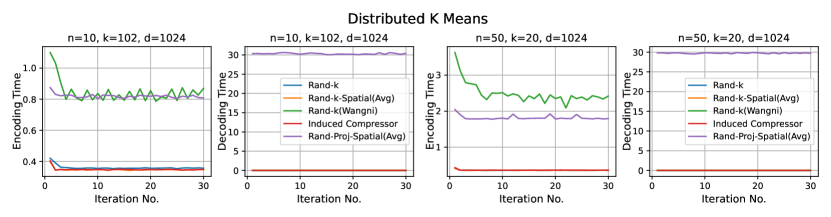
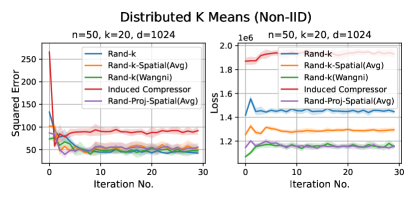
We consider three practical distributed optimization tasks for evaluation: distributed power iteration, distributed -means and distributed linear regression. We compare Rand-Proj-Spatial(Avg) against Rand-, Rand--Spatial(Avg), and two more sophisticated but widely used sparsification schemes: non-uniform coordinate-wise gradient sparsification wangni2018grad_sparse (we call it Rand-(Wangni)) and the Induced compressor with Rand- + Top- horvath2021induced . The results are presented in Figure 4.
Dataset. For both distributed power iteration and distributed -means, we use the test set of the Fashion-MNIST dataset xiao2017fashion consisting of samples. The original images from Fashion-MNIST are in size. We preprocess and resize each image to be . Resizing images to have their dimension as a power of 2 is a common technique used in computer vision to accelerate the convolution operation. We use the UJIndoor dataset 222https://archive.ics.uci.edu/ml/datasets/ujiindoorloc for distributed linear regression. We subsample data points, and use the first out of the total features on signals of phone calls. The task is to predict the longitude of the location of a phone call. In all the experiments in Figure 4, the datasets are split IID across the clients via random shuffling. In Appendix D.1, we have additional results for non-IID data split across the clients.
Setup and Metric. Recall that denotes the number of clients, the per-client communication budget, and the vector dimension. For Rand-Proj-Spatial, we use the first iterations to estimate (see Eq. 5). Note that only depends on , and (the transformation function in Eq. 5), but is independent of the dataset. We repeat the experiments across 10 independent runs, and report the mean MSE (solid lines) and one standard deviation (shaded regions) for each estimator. For each task, we plot the squared error of the mean estimator , i.e., , and the values of the task-specific loss function, detailed below.
Tasks and Settings:
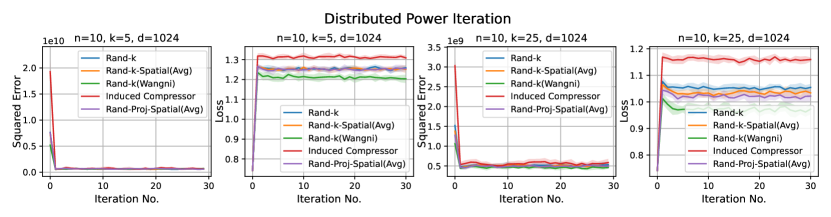
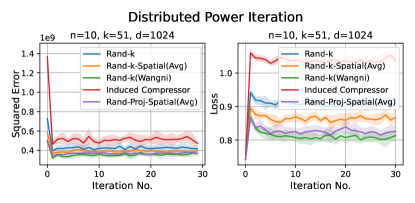
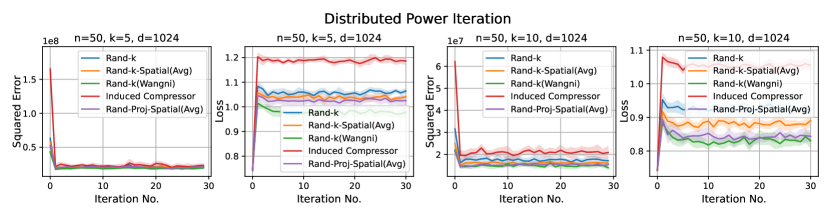
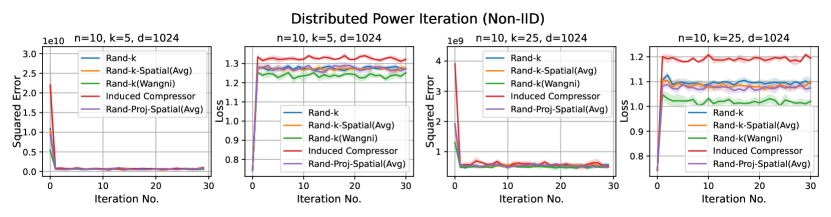
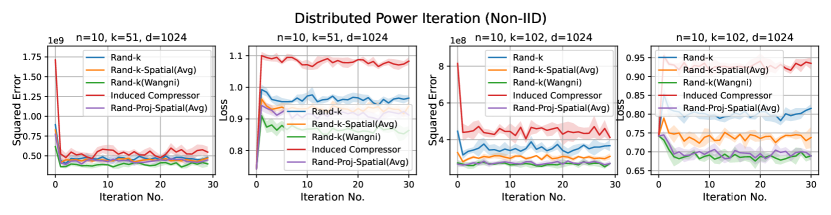
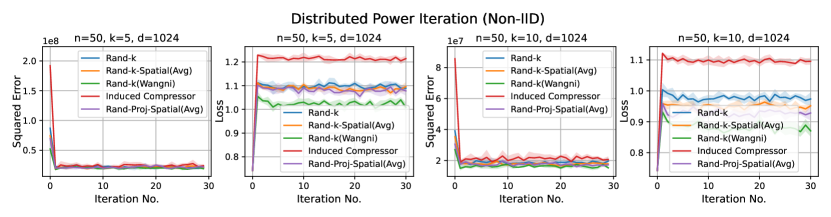
1. Distributed power iteration. We estimate the principle eigenvector of the covariance matrix, with the dataset (Fashion-MNIST) distributed across the clients. In each iteration, each client computes a local principle eigenvector estimate based on a single power iteration and sends an encoded version to the server. The server then computes a global estimate and sends it back to the clients. The task-specific loss here is , where is the global estimate of the principal eigenvector at iteration , and is the true principle eigenvector.
2. Distributed -means. We perform -means clustering balcan2013distributed with the data distributed across clients (Fashion-MNIST, 10 classes) using Lloyd’s algorithm. At each iteration, each client performs a single iteration of -means to find its local centroids and sends the encoded version to the server. The server then computes an estimate of the global centroids and sends them back to the clients. We report the average squared mean estimation error across 10 clusters, and the -means loss, i.e., the sum of the squared distances of the data points to the centroids.
For both distributed power iterations and distributed -means, we run the experiments for iterations and consider two different settings: and .
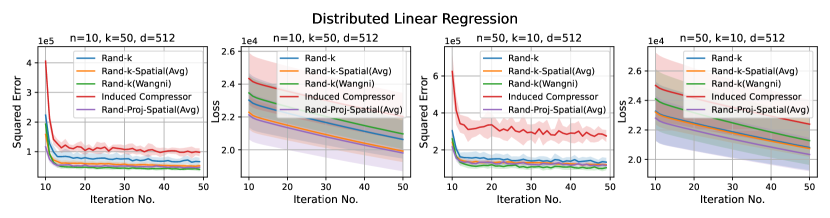
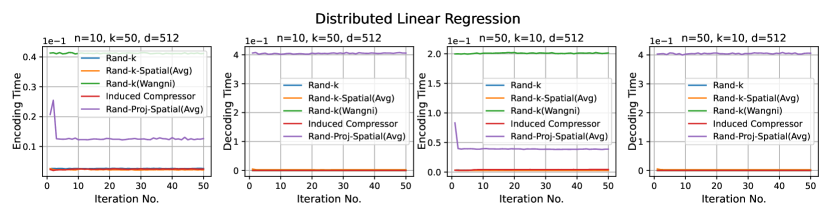
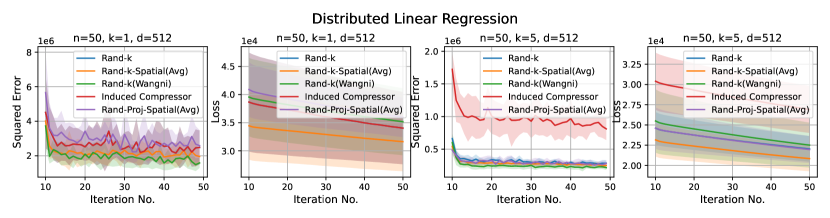
3. Distributed linear regression. We perform linear regression on the UJIndoor dataset distributed across clients using SGD. At each iteration, each client computes a local gradient and sends an encoded version to the server. The server computes a global estimate of the gradient, performs an SGD step, and sends the updated parameter to the clients. We run the experiments for iterations with learning rate . The task-specific loss is the linear regression loss, i.e. empirical mean squared error. To have a proper scale that better showcases the difference in performance of different estimators, we plot the results starting from the 10th iteration.
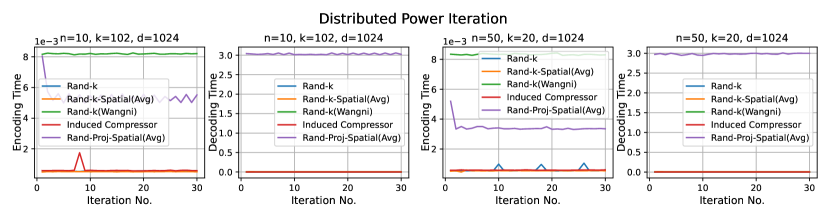
Results. It is evident from Figure 4 that Rand-Proj-Spatial(Avg), our estimator with the practical configuration (see Section 4.3) that does not require the knowledge of the actual degree of correlation among clients, consistently outperforms the other estimators in all three tasks. Additional experiments for the three tasks are included in Appendix D.1. Furthermore, we present the wall-clock time to encode and decode client vectors using different sparsification schemes in Figure 5. Though Rand-Proj-Spatial(Avg) has the longest decoding time, the encoding time of Rand-Proj-Spatial(Avg) is less than that of the adaptive Rand-(Wangni) sparsifier. In practice, the server has more computational power than the clients and hence can afford a longer decoding time. Therefore, it is more important to have efficient encoding procedures.
6 Limitations
We note two practical limitations of the proposed Rand-Proj-Spatial.
1) Computation Time of Rand-Proj-Spatial.
The encoding time of Rand-Proj-Spatial is , while the decoding time is . The computation bottleneck in decoding is computing the eigendecomposition of the matrix of rank at most .
Improving the computation time for both the encoding and decoding schemes is an important direction for future work.
2) Perfect Shared Randomness.
It is common to assume perfect shared randomness between the server and the clients in distributed settings zhou2022ldp_sparse_vec_agg . However,
to perfectly simulate randomness using Pseudo Random Number Generator (PRNG), at least bits of the seed need to be exchanged in practice.
We acknowledge this gap between theory and practice.
7 Conclusion
In this paper, we propose the Rand-Proj-Spatial estimator, a novel encoding-decoding scheme, for communication-efficient distributed mean estimation. The proposed client-side encoding generalizes and improves the commonly used Rand- sparsification, by utilizing projections onto general -dimensional subspaces. On the server side, cross-client correlation is leveraged to improve the approximation error. Compared to existing methods, the proposed scheme consistently achieves better mean estimation error across a variety of tasks. Potential future directions include improving the computation time of Rand-Proj-Spatial and exploring whether the proposed Rand-Proj-Spatial achieves the optimal estimation error among the class of non-adaptive estimators, given correlation information. Furthermore, combining sparsification and quantization techniques and deriving such algorithms with the optimal communication cost-estimation error trade-offs would be interesting.
Acknowledgments
We would like to thank the anonymous reviewer for providing valuable feedback on the title of this work, interesting open problems, alternative motivating regression problems and practical limitations of shared randomness. This work was supported in part by NSF grants CCF 2045694, CCF 2107085, CNS-2112471, and ONR N00014-23-1- 2149.
References
- (1) Jakub Konečnỳ, H Brendan McMahan, Daniel Ramage, and Peter Richtárik. Federated optimization: Distributed machine learning for on-device intelligence. arXiv preprint arXiv:1610.02527, 2016.
- (2) Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics, pages 1273–1282. PMLR, 2017.
- (3) Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and open problems in federated learning. Foundations and Trends® in Machine Learning, 14(1–2):1–210, 2021.
- (4) Jianyu Wang, Zachary Charles, Zheng Xu, Gauri Joshi, H Brendan McMahan, Maruan Al-Shedivat, Galen Andrew, Salman Avestimehr, Katharine Daly, Deepesh Data, et al. A field guide to federated optimization. arXiv preprint arXiv:2107.06917, 2021.
- (5) Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- (6) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- (7) John A Gubner. Distributed estimation and quantization. IEEE Transactions on Information Theory, 39(4):1456–1459, 1993.
- (8) Peter Davies, Vijaykrishna Gurunathan, Niusha Moshrefi, Saleh Ashkboos, and Dan Alistarh. New bounds for distributed mean estimation and variance reduction, 2021.
- (9) Shay Vargaftik, Ran Ben Basat, Amit Portnoy, Gal Mendelson, Yaniv Ben-Itzhak, and Michael Mitzenmacher. Eden: Communication-efficient and robust distributed mean estimation for federated learning, 2022.
- (10) Ananda Theertha Suresh, X Yu Felix, Sanjiv Kumar, and H Brendan McMahan. Distributed mean estimation with limited communication. In International conference on machine learning, pages 3329–3337. PMLR, 2017.
- (11) Jakub Konečnỳ and Peter Richtárik. Randomized distributed mean estimation: Accuracy vs. communication. Frontiers in Applied Mathematics and Statistics, 4:62, 2018.
- (12) Divyansh Jhunjhunwala, Ankur Mallick, Advait Harshal Gadhikar, Swanand Kadhe, and Gauri Joshi. Leveraging spatial and temporal correlations in sparsified mean estimation. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021.
- (13) Ananda Theertha Suresh, Ziteng Sun, Jae Ro, and Felix Yu. Correlated quantization for distributed mean estimation and optimization. In International Conference on Machine Learning, pages 20856–20876. PMLR, 2022.
- (14) Samuel Horváth and Peter Richtarik. A better alternative to error feedback for communication-efficient distributed learning. In International Conference on Learning Representations, 2021.
- (15) Jianqiao Wangni, Jialei Wang, Ji Liu, and Tong Zhang. Gradient sparsification for communication-efficient distributed optimization. Advances in Neural Information Processing Systems, 31, 2018.
- (16) Matthew Nokleby and Waheed U Bajwa. Stochastic optimization from distributed streaming data in rate-limited networks. IEEE transactions on signal and information processing over networks, 5(1):152–167, 2018.
- (17) Debraj Basu, Deepesh Data, Can Karakus, and Suhas Diggavi. Qsparse-local-sgd: Distributed sgd with quantization, sparsification and local computations. Advances in Neural Information Processing Systems, 32, 2019.
- (18) Dan Alistarh, Demjan Grubic, Jerry Li, Ryota Tomioka, and Milan Vojnovic. Qsgd: Communication-efficient sgd via gradient quantization and encoding. Advances in neural information processing systems, 30, 2017.
- (19) Jeremy Bernstein, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Animashree Anandkumar. signsgd: Compressed optimisation for non-convex problems. In International Conference on Machine Learning, pages 560–569. PMLR, 2018.
- (20) Amirhossein Reisizadeh, Aryan Mokhtari, Hamed Hassani, Ali Jadbabaie, and Ramtin Pedarsani. Fedpaq: A communication-efficient federated learning method with periodic averaging and quantization. In International Conference on Artificial Intelligence and Statistics, pages 2021–2031. PMLR, 2020.
- (21) Nir Shlezinger, Mingzhe Chen, Yonina C Eldar, H Vincent Poor, and Shuguang Cui. Uveqfed: Universal vector quantization for federated learning. IEEE Transactions on Signal Processing, 69:500–514, 2020.
- (22) Venkata Gandikota, Daniel Kane, Raj Kumar Maity, and Arya Mazumdar. vqsgd: Vector quantized stochastic gradient descent. In International Conference on Artificial Intelligence and Statistics, pages 2197–2205. PMLR, 2021.
- (23) Dan Alistarh, Torsten Hoefler, Mikael Johansson, Nikola Konstantinov, Sarit Khirirat, and Cédric Renggli. The convergence of sparsified gradient methods. Advances in Neural Information Processing Systems, 31, 2018.
- (24) Sebastian U Stich, Jean-Baptiste Cordonnier, and Martin Jaggi. Sparsified sgd with memory. Advances in Neural Information Processing Systems, 31, 2018.
- (25) Sai Praneeth Karimireddy, Quentin Rebjock, Sebastian Stich, and Martin Jaggi. Error feedback fixes signsgd and other gradient compression schemes. In International Conference on Machine Learning, pages 3252–3261. PMLR, 2019.
- (26) Felix Sattler, Simon Wiedemann, Klaus-Robert Müller, and Wojciech Samek. Robust and communication-efficient federated learning from non-iid data. IEEE transactions on neural networks and learning systems, 31(9):3400–3413, 2019.
- (27) Shaohuai Shi, Xiaowen Chu, Ka Chun Cheung, and Simon See. Understanding top-k sparsification in distributed deep learning. arXiv preprint arXiv:1911.08772, 2019.
- (28) Leighton Pate Barnes, Huseyin A Inan, Berivan Isik, and Ayfer Özgür. rtop-k: A statistical estimation approach to distributed sgd. IEEE Journal on Selected Areas in Information Theory, 1(3):897–907, 2020.
- (29) Emre Ozfatura, Kerem Ozfatura, and Deniz Gündüz. Time-correlated sparsification for communication-efficient federated learning. In 2021 IEEE International Symposium on Information Theory (ISIT), pages 461–466. IEEE, 2021.
- (30) Yuchen Zhang, John Duchi, Michael I Jordan, and Martin J Wainwright. Information-theoretic lower bounds for distributed statistical estimation with communication constraints. Advances in Neural Information Processing Systems, 26, 2013.
- (31) Ankit Garg, Tengyu Ma, and Huy Nguyen. On communication cost of distributed statistical estimation and dimensionality. Advances in Neural Information Processing Systems, 27, 2014.
- (32) Wei-Ning Chen, Peter Kairouz, and Ayfer Ozgur. Breaking the communication-privacy-accuracy trilemma. Advances in Neural Information Processing Systems, 33:3312–3324, 2020.
- (33) Prathamesh Mayekar, Ananda Theertha Suresh, and Himanshu Tyagi. Wyner-ziv estimators: Efficient distributed mean estimation with side-information. In International Conference on Artificial Intelligence and Statistics, pages 3502–3510. PMLR, 2021.
- (34) Shay Vargaftik, Ran Ben-Basat, Amit Portnoy, Gal Mendelson, Yaniv Ben-Itzhak, and Michael Mitzenmacher. Drive: One-bit distributed mean estimation. Advances in Neural Information Processing Systems, 34:362–377, 2021.
- (35) Shay Vargaftik, Ran Ben Basat, Amit Portnoy, Gal Mendelson, Yaniv Ben Itzhak, and Michael Mitzenmacher. Eden: Communication-efficient and robust distributed mean estimation for federated learning. In International Conference on Machine Learning, pages 21984–22014. PMLR, 2022.
- (36) Kai Liang and Youlong Wu. Improved communication efficiency for distributed mean estimation with side information. In 2021 IEEE International Symposium on Information Theory (ISIT), pages 3185–3190. IEEE, 2021.
- (37) Nir Ailon and Bernard Chazelle. Approximate nearest neighbors and the fast johnson-lindenstrauss transform. In Proceedings of the Thirty-Eighth Annual ACM Symposium on Theory of Computing, STOC ’06, page 557–563, New York, NY, USA, 2006. Association for Computing Machinery.
- (38) Joel A. Tropp. Improved analysis of the subsampled randomized hadamard transform, 2011.
- (39) Jonathan Lacotte, Sifan Liu, Edgar Dobriban, and Mert Pilanci. Optimal iterative sketching with the subsampled randomized hadamard transform, 2020.
- (40) Oleg Balabanov, Matthias Beaupère, Laura Grigori, and Victor Lederer. Block subsampled randomized Hadamard transform for low-rank approximation on distributed architectures. working paper or preprint, October 2022.
- (41) Christos Boutsidis and Alex Gittens. Improved matrix algorithms via the subsampled randomized hadamard transform, 2013.
- (42) Yichao Lu, Paramveer Dhillon, Dean P Foster, and Lyle Ungar. Faster ridge regression via the subsampled randomized hadamard transform. In C.J. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc., 2013.
- (43) Mostafa Haghir Chehreghani. Subsampled randomized hadamard transform for regression of dynamic graphs. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, CIKM ’20, page 2045–2048, New York, NY, USA, 2020. Association for Computing Machinery.
- (44) Dan Teng, Xiaowei Zhang, Li Cheng, and Delin Chu. Least squares approximation via sparse subsampled randomized hadamard transform. IEEE Transactions on Big Data, 8(2):446–457, 2022.
- (45) Jonathan Lacotte and Mert Pilanci. Optimal randomized first-order methods for least-squares problems, 2020.
- (46) Nikita Ivkin, Daniel Rothchild, Enayat Ullah, Ion Stoica, Raman Arora, et al. Communication-efficient distributed sgd with sketching. Advances in Neural Information Processing Systems, 32, 2019.
- (47) Farzin Haddadpour, Belhal Karimi, Ping Li, and Xiaoyun Li. Fedsketch: Communication-efficient and private federated learning via sketching. arXiv preprint arXiv:2008.04975, 2020.
- (48) Daniel Rothchild, Ashwinee Panda, Enayat Ullah, Nikita Ivkin, Ion Stoica, Vladimir Braverman, Joseph Gonzalez, and Raman Arora. Fetchsgd: Communication-efficient federated learning with sketching. In International Conference on Machine Learning, pages 8253–8265. PMLR, 2020.
- (49) Gene H Golub and Charles F Van Loan. Matrix computations. JHU press, 2013.
- (50) Kilian Q Weinberger, Fei Sha, and Lawrence K Saul. Learning a kernel matrix for nonlinear dimensionality reduction. In Proceedings of the twenty-first international conference on Machine learning, page 106, 2004.
- (51) Rohit Tripathy, Ilias Bilionis, and Marcial Gonzalez. Gaussian processes with built-in dimensionality reduction: Applications to high-dimensional uncertainty propagation. Journal of Computational Physics, 321:191–223, 2016.
- (52) Gregory T. Minton and Eric Price. Improved concentration bounds for count-sketch, 2013.
- (53) R. Gallager. Low-density parity-check codes. IRE Transactions on Information Theory, 8(1):21–28, 1962.
- (54) Amin Shokrollahi. Fountain codes. Iee Proceedings-communications - IEE PROC-COMMUN, 152, 01 2005.
- (55) Zijian Lei and Liang Lan. Improved subsampled randomized hadamard transform for linear svm. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 4519–4526, 2020.
- (56) Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
- (57) Maria-Florina F Balcan, Steven Ehrlich, and Yingyu Liang. Distributed -means and -median clustering on general topologies. Advances in neural information processing systems, 26, 2013.
- (58) Mingxun Zhou, Tianhao Wang, T-H. Hubert Chan, Giulia Fanti, and Elaine Shi. Locally differentially private sparse vector aggregation. In 2022 IEEE Symposium on Security and Privacy (SP), pages 422–439, 2022.
- (59) Gene H. Golub. Some modified matrix eigenvalue problems. SIAM Review, 15(2):318–334, 1973.
- (60) Ming Gu and Stanley C. Eisenstat. A stable and efficient algorithm for the rank-one modification of the symmetric eigenproblem. SIAM Journal on Matrix Analysis and Applications, 15(4):1266–1276, 1994.
- (61) Peter Arbenz, Walter Gander, and Gene H. Golub. Restricted rank modification of the symmetric eigenvalue problem: Theoretical considerations. Linear Algebra and its Applications, 104:75–95, 1988.
- (62) H. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. Communication-efficient learning of deep networks from decentralized data, 2023.
Appendix A Additional Details on Motivation in Introduction
A.1 Preprocssing all client vectors by the same random matrix does not improve performance
Consider clients. Suppose client holds a vector . We want to apply Rand- or Rand--Spatial, while also making the encoding process more flexible than just randomly choosing out of coordinates. One naïve way of doing this is for each client to pre-process its vector by applying an orthogonal matrix that is the same across all clients. Such a technique might be helpful in improving the performance of quantization because the MSE due to quantization often depends on how uniform the coordinates of ’s are, i.e. whether the coordinates of have values close to each other. is designed to be the random matrix (e.g. SRHT) that rotates and makes its coordinates uniform.
Each client sends the server , where is the subsamaping matrix. If we use Rand-, the server can decode each client vector by first applying the decoding procedure of Rand- and then rotating it back to the original space, i.e., . Note that
Hence, is unbiased. The MSE of is given as
| (12) |
Next, we bound the first term in Eq. 12.
| () | |||
| (13) |
The second term in Eq. 12 can also be simplified as follows.
| (14) |
Plugging Eq. 13 and Eq. 14 into Eq. 12, we get the MSE is
which has exactly the same MSE as that of Rand-. The problem is that if each client applies the same rotational matrix , simply rotating the vectors will not change the norm of the decoded vector, and hence the MSE. Similarly, if one applies Rand--Spatial, one ends up having exactly the same MSE as that of Rand--Spatial as well. Hence, we need to design a new decoding procedure when the encoding procedure at the clients are more flexible.
A.2 is not interesting
One can rewrite in the Rand-Proj-Spatial estimator (Eq. 5) as , where and are the rows of . Since when , due to Law of Large Numbers, one way to see the limiting MSE of Rand-Proj-Spatial when is large is to approximate by its expectation.
By Lemma 4.1, when , Rand-Proj-Spatial recovers Rand--Spatial. We now discuss the limiting behavior of Rand--Spatial when by leveraging our proposed Rand-Proj-Spatial. In this case, each can be viewed as a random based vector for randomly chosen in . . And so the scalar in Eq. 5 to ensure an unbiased estimator is computed as
And the MSE is now
which is exactly the same MSE as Rand-. This implies when is large, the MSE of Rand--Spatial does not get improved compared to Rand- with correlation information. Intuitively, this implies when , the server gets enough amount of information from the client, and does not need correlation to improve its estimator. Hence, we focus on the more interesting case when — that is, when the server does not have enough information from the clients, and thus wants to use additional information, i.e. cross-client correlation, to improve its estimator.
Appendix B Additional Details on the Rand-Proj-Spatial Family Estimator
B.1 is a scalar
From Eq. 20 in the proof of Theorem 4.3 and Eq. 25 in the proof of Theorem 4.4, it is evident that the unbiasedness of the mean estimator is ensured collectively by
-
•
The random sampling matrices .
-
•
The orthogonality of scaled Hadamard matrices .
-
•
The rademacher diagonal matrices, with the property .
B.2 Alternative motivating regression problems
Alternative motivating regression problem 1.
Let and be the encoding and decoding matrix for client . One possible alternative estimator that translates the intuition that the decoded vector should be close to the client’s original vector, for all clients, is by solving the following regression problem,
| (15) |
where and the constraint enforces unbiasedness of the estimator. The estimator is then the solution of the above problem. However, we note that optimizing a decoding matrix for each client leads to performing individual decoding of each client’s compressed vector instead of a joint decoding process that considers all clients’ compressed vectors. Only a joint decoding process can achieve the goal of leveraging cross-client information to reduce the estimation error. Indeed, we show as follows that solving the above optimization problem in Eq. B.2 recovers the MSE of our baseline Rand-. Note
| (16) |
By the constraint of unbiasedness, i.e., , there is
We now show that a sufficient and necessary condition to satisfy the above unbiasedness constraint is that for all , .
Sufficiency. It is obvious that if for all , , then we have .
Necessity. Consider the special case that for some and , , where is the -th canonical basis vector, and , and for all . Then,
where denotes the -th column of matrix .
Since our approach is agnostic to the choice of vectors, we need this choice of decoder matrices, by varying over , we see that we need . And by varying over , we see that we need for all .
Therefore, .
This implies the second term of in Eq. 16 is 0, that is,
Hence, we only need to solve
| (17) |
Since each appears in separately, each can be optimized separately, via solving
One natural solution is to take , . For , let be its SVD, where and are orthogonal matrices. Then,
where is a diagonal matrix with 0s and 1s on the diagonal.
For simplicity, we assume the random matrix follows a continuous distribution. being discrete follows a similar analysis. Let be the measure of .
which means the estimator satisfies unbiasedness. The MSE is now
Again, let be its SVD and consider , where is a diagonal matrix with 0s and 1s. Then,
Since has rank , is a diagonal matrix with out of entries being 1 and the rest being 0. Let be the measure of . Hence, for ,
Therefore, the MSE of the estimator, which is the solution of the optimization problem in Eq. B.2, is
which is the same MSE as that of Rand-.
Alternative motivating regression problem 2.
Another motivating regression problem based on which we can design our estimator is
| (18) |
Note that , and so the solution to the above problem is
and to ensure unbiasedness of the estimator, we can set and have the estimator as
It is not hard to see this estimator does not lead to an MSE as low as Rand-Proj-Spatial does. Consider the full correlation case, i.e., , for example, the estimator is now
Note that is at most , since , . This limits the amount of information of the server can recover.
While recall that in this case, the Rand-Proj-Spatial estimator is
where can have rank at most .
B.3 Why deriving the MSE of Rand-Proj-Spatial with SRHT is hard
To analyze Eq. 11, one needs to compute the distribution of eigendecomposition of , i.e. the sum of the covariance of SRHT. To the best of our knowledge, there is no non-trivial closed form expression of the distribution of eigen-decomposition of even a single , when is SRHT, or other commonly used random matrices, e.g. Gaussian. When is SRHT, since and the eigenvalues of are just diagonal entries, one might attempt to analyze . While the hardmard matrix ’s eigenvalues and eigenvectors are known333See this note https://core.ac.uk/download/pdf/81967428.pdf, the result can hardly be applied to analyze the distribution of singular values or singular vectors of .
Even if one knows the eigen-decomposition of a single , it is still hard to get the eigen-decomposition of . The eigenvalues of a matrix can be viewed as a non-linear function in the , and hence it is in general hard to derive closed form expressions for the eigenvalues of , given the eigenvalues of and that of . One exception is when and have the same eigenvector and the eigenvalues of becomes a sum of the eigenvalues of and . Recall when , Rand-Proj-Spatial recovers Rand--Spatial. Since ’s all have the same eigenvectors (i.e. same as ), the eigenvalues of are just the sum of diagonal entries of ’s. Hence, deriving the MSE for Rand--Spatial is not hard compared to the more general case when ’s can have different eigenvectors.
Since one can also view , i.e. the sum of rank-one matrices, one might attempt to recursively analyze the eigen-decomposition of for . One related problem is eigen-decomposition of a low-rank updated matrix in perturbation analysis: Given the eigen-decomposition of a matrix , what is the eigen-decomposition of , where is low-rank matrix (or more commonly rank-one)? To compute the eigenvalues of directly from that of , the most effective and widely applied solution is to solve the so-called secular equation, e.g. [59, 60, 61]. While this can be done computationally efficiently, it is hard to get a closed form expression for the eigenvalues of from the secular equation.
The previous analysis of SRHT in e.g. [37, 38, 39, 45, 55] is based on asymptotic properties of SRHT, such as the limiting eigen-spectrum, or concentration bounds that bounds the singular values. To analyze the MSE of Rand-Proj-Spatial, however, we need an exact, non-asymptotic analysis of the distribution of SRHT. Concentration bounds does not apply, since computing the pseudo-inverse in Eq. 5 naturally bounds the eigenvalues, and applying concentration bounds will only lead to a loose upper bound on MSE.
B.4 More simulation results on incorporating various degrees of correlation
Appendix C All Proof Details
C.1 Proof of Theorem 4.3
Theorem 4.3 (MSE under Full Correlation).
Consider clients, each holding the same vector . Suppose we set , in Eq. 5, and the random linear map at each client to be an SRHT matrix. Let be the probability that does not have full rank. Then, for ,
| (19) |
Proof.
All clients have the same vector . Hence, , and the decoding scheme is
where . Let be its eigendecomposition. Since is a real symmetric matrix, is orthogonal, i.e., . Also, , where is a diagonal matrix, such that
Let be the probability that has rank , for . Note that . For vector , we use to denote the matrix whose diagonal entries correspond to the coordinates of and the rest of the entries are zeros.
Computing . First, we compute . To ensure that our estimator is unbiased, we need . Consequently,
| (20) |
where in , such that
Also, by construction of , . Further, follows by symmetry across the dimensions.
Since , there is
| (21) |
Computing the MSE. Next, we use the value of in Eq. 20 to compute MSE.
| (Using unbiasedness of ) | |||
| (22) |
Using ,
| (23) |
C.2 Comparing against Rand-
Next, we compare the MSE of Rand-Proj-Spatial(Max) with the MSE of the baseline Rand- analytically in the full-correlation case. Recall that in this case,
We have
Since , for , the above implies when
the MSE of Rand-Proj-Spatial(Max) is always less than that of Rand-.
C.3 has full rank with high probability
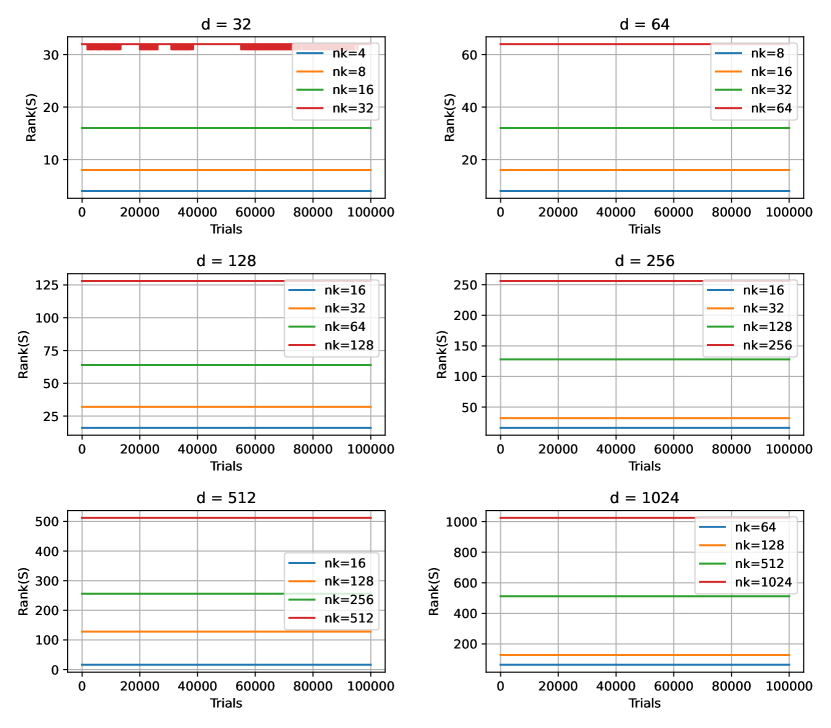
We empirically verify that . With and 4 different value such that for each , we compute for trials for each pair of values, and plot the results for all trials. All results are presented in Figure 7. As one can observe from the plots, with high probability, suggesting .
This implies the MSE of Rand-Proj-Spatial(Max) is
in the full correlation case.
C.4 Proof of Theorem 4.4
Theorem 4.4 (MSE under No Correlation).
Consider clients, each holding a vector , . Suppose we set , in Eq. 5, and the random linear map at each client to be an SRHT matrix. Then, for ,
Proof.
When the client vectors are all orthogonal to each other, we define the transformation function on the eigenvalue to be . We show that by considering the above constant , SRHT becomes the same as rand . Recall and let be its eigendecompostion. Then,
Hence, . And the decoded vector for client becomes
| (24) | ||||
is a diagonal matrix. Also, is a diagonal matrix, where the -th entry is 0 or 1.
Computing . To ensure that is an unbiased estimator, from Eq. 24
| ( is independent of ) | ||||
| ( ) | ||||
| ( is now deterministic.) | ||||
| (25) |
C.5 Rand-Proj-Spatial recovers Rand--Spatial (Proof of Lemma 4.1)
Lemma 4.1 (Recovering Rand--Spatial).
Suppose client generates a subsampling matrix , where are the canonical basis vectors, and are sampled from without replacement. The encoded vectors are given as . Given a function , computed as in Eq. 5 recovers the Rand--Spatial estimator.
Proof.
If client applies as the random matrix to encode in Rand-Proj-Spatial, by Eq. 5, client ’s encoded vector is now
| (29) |
Notice is a diagonal matrix, where the -th diagonal entry is if coordinate of is chosen. Hence, can be viewed as choosing coordinates of without replacement, which is exactly the same as Rand--Spatial’s (and Rand-’s) encoding procedure.
Notice is also a diagonal matrix, where the -th diagonal entry is exactly , i.e. the number of clients who selects the -th coordinate as in Rand--Spatial [12]. Furthermore, notice is also a diagonal matrix, where the -th diagonal entry is , which recovers the scaling factor used in Rand--Spatial’s decoding procedure.
Rand-Proj-Spatial computes as . Since and recover the scaling factor and the encoding procedure of Rand--Spatial, and is computed in exactly the same way as Rand--Spatial does, will be exactly the same as in Rand--Spatial.
Therefore, in Eq. 29 with as the random matrix at client recovers . This implies Rand-Proj-Spatial recovers Rand--Spatial in this case. ∎
Appendix D Additional Experiment Details and Results
Implementation. All experiments are conducted in a cluster of machines, each of which has 40 cores. The implementation is in Python, mainly based on numpy and scipy. All code used for the experiments can be found at https://github.com/11hifish/Rand-Proj-Spatial.
Data Split. For the non-IID dataset split across the clients, we follow [62] to split Fashion-MNIST, which is used in distributed power iteration and distributed -means. Specifically, the data is first sorted by labels and then divided into 2 shards with each shard corresponding to the data of a particular label. Each client is then assigned 2 shards (i.e., data from classes). However, this approach only works for datasets with discrete labels (i.e. datasets used in classification tasks). For the other dataset UJIndoor, which is used in distributed linear regression, we first sort the dataset by the ground truth prediction and then divides the sorted dataset across the clients.
D.1 Additional experimental results
For each one of the three tasks, distributed power iteration, distributed -means, and distributed linear regression, we provide additional results when the data split is IID across the clients for smaller values in Section D.1.1, and when the data split is Non-IID across the clients in Section D.1.2. For the Non-IID case, we use the same settings (i.e. values) as in the IID case.
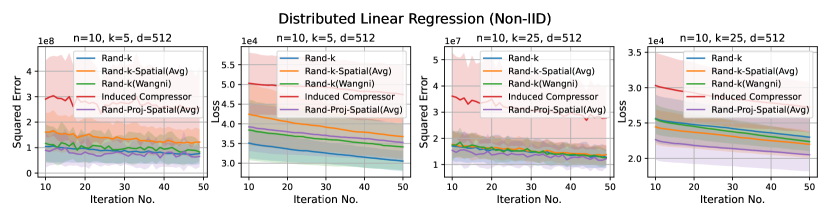
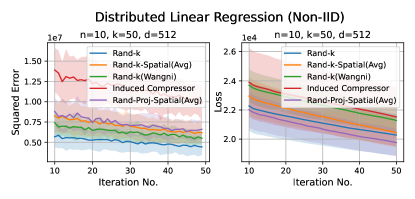
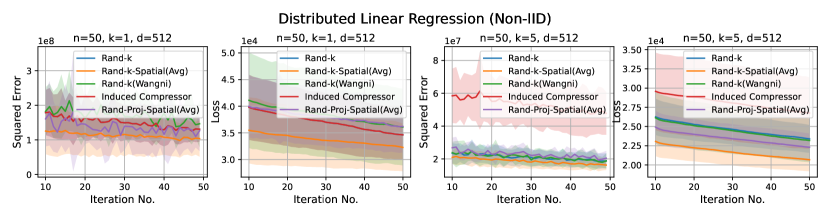
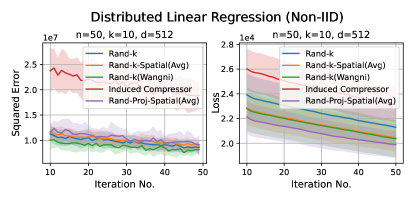
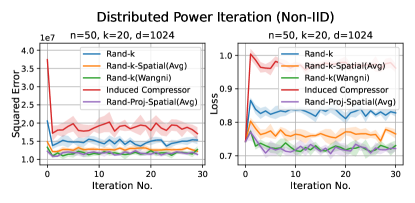
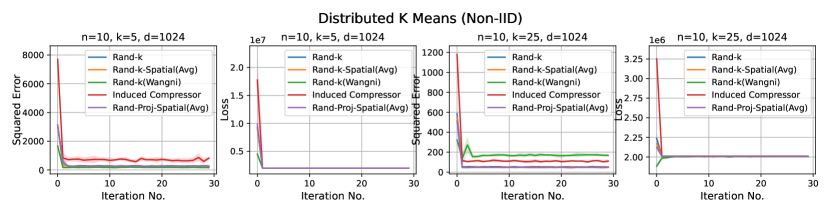
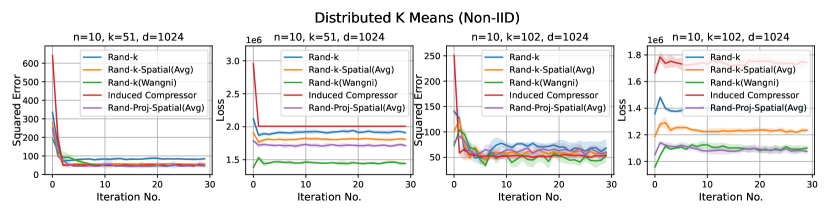
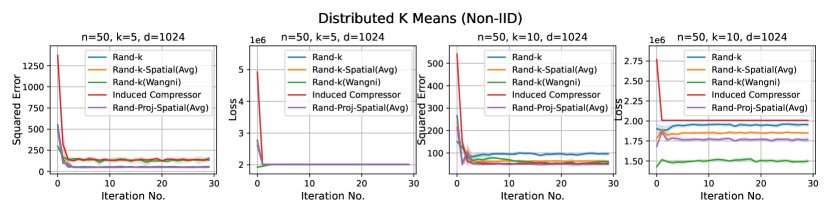
Discussion. For smaller values compared to the data dimension , there is less information or less correlation from the client vectors. Hence, both Rand--Spatial and Rand-Proj-Spatial perform better as increases. When is small, one might notice Rand-Proj-Spatial performs worse than Rand--Wangni in some settings. However, Rand--Wangni is an adaptive estimator, which optimizes the sampling weights for choosing the client vector coordinates through an iterative process. That means Rand--Wangni requires more computation from the clients, while in practice, the clients often have limited computational power. In contrast, our Rand-Proj-Spatial estimator is non-adaptive and the server does more computation instead of the clients. This is more practical since the central server usually has more computational power than the clients in applications like FL. See the introduction for more discussion.
In most settings, we observe the proposed Rand-Proj-Spatial has a better performance compared to Rand--Spatial. Furthermore, as one would expect, both Rand--Spatial and Rand-Proj-Spatial perform better when the data split is IID across the clients since there is more correlation among the client vectors in the IID case than in the Non-IID case.
D.1.1 More results in the IID case
Distributed Power Iteration and Distribued -Means. We use the Fashion-MNIST dataset for both distributed power iteration and distributed -means, which has a dimension of . We consider more settings for distributed power iteration and distributed -means here: , and .
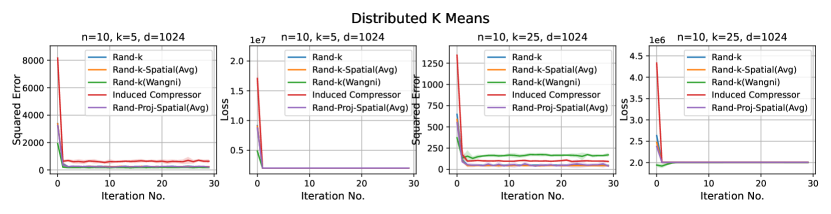
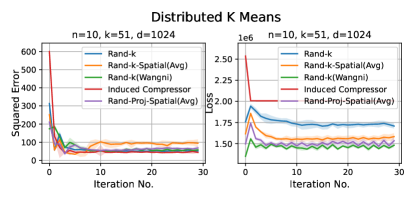
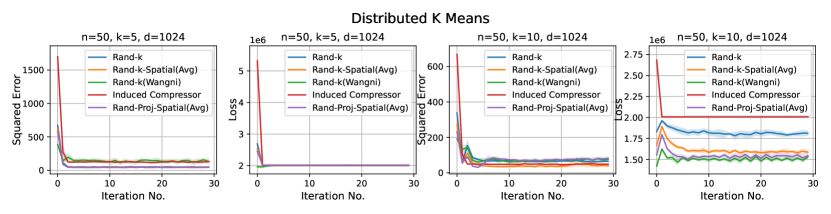
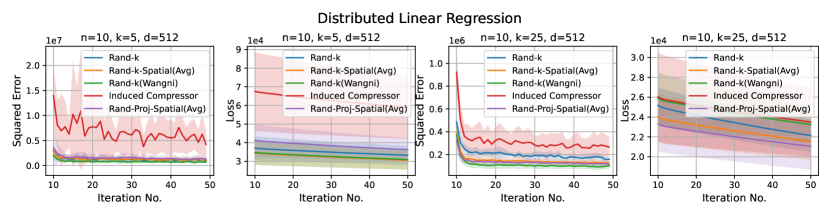
Distributed Linear Regression. We use the UJIndoor dataset distributed linear regression, which has a dimension of . We consider more settings here: and .
D.1.2 Additional results in the Non-IID case
In this section, we report results when the dataset split across the clients are Non-IID, using the same datasets as in the IID case. We choose exactly the same set of values as in the IID case.
Distributed Power Iteration and Distributed -Means. Again, both distributed power iteration and distributed -means use the Fashion-MNIST dataset, with a dimension . We consider the following settings for both tasks: and .
Distributed Linear Regression. Again, we use the UJIndoor dataset for distributed linear regression, which has a dimension . We consider the following settings: and .