cosimmr: an R package for fast fitting of Stable Isotope Mixing Models with covariates
1 Abstract
-
1.
The study of animal diets and the proportional contribution that different foods make to their diets is an important task in ecology. Stable Isotope Mixing Models (SIMMs) are an important tool for studying an animal’s diet and understanding how the animal interacts with its environment.
-
2.
We present cosimmr, a new R package designed to include covariates when estimating diet proportions in SIMMs, with simple functions to produce plots and summary statistics. The inclusion of covariates allows for users to perform a more in-depth analysis of their system and to gain new insights into the diets of the organisms being studied.
-
3.
A common problem with the previous generation of SIMMs is that they are very slow to produce a posterior distribution of dietary estimates, especially for more complex model structures, such as when covariates are included. The widely-used Markov chain Monte Carlo (MCMC) algorithm used by many traditional SIMMs often requires a very large number of iterations to reach convergence. In contrast, cosimmr uses Fixed Form Variational Bayes (FFVB), which we demonstrate gives up to an order of magnitude speed improvement with no discernible loss of accuracy.
-
4.
We provide a full mathematical description of the model, which includes corrections for trophic discrimination and concentration dependence, and evaluate its performance against the state of the art MixSIAR model. Whilst MCMC is guaranteed to converge to the posterior distribution in the long term, FFVB converges to an approximation of the posterior distribution, which may lead to sub-optimal performance. However we show that the package produces equivalent results in a fraction of the time for all the examples on which we test. The package is designed to be user-friendly and is based on the existing simmr framework.
Keywords: bayesian statistics; mixing models; stable isotopes; trophic ecology; variational bayes;
2 Introduction
Stable Isotope Mixing Models (SIMMs) are commonly used in ecology to study the proportional contribution that different foods make to an animal’s diet (Phillips, 2012). This information can be important as it allows scientists to look at diet, which resources are important for different species (McDonald et al., 2020), and consequently niche overlap and competition (Teixeira et al., 2021; Aksu et al., 2023), as well as being useful in looking at trophic position and energy flow in an ecosystem (Manlick and Newsome, 2022). These models have been extensively used by ecologists over the past 20 years with recent papers revealing the foraging behaviour in Dugongs (Thibault et al., 2024), overlap in trophic niche between native and non-native species of carp (Aksu et al., 2023), and assessment of nursery areas used by the scalloped hammerhead shark (Paez-Rosas et al., 2024). SIMMs have been shown to produce results comparable to direct observation (Swan et al., 2020). The approach relies on the fact that the stable isotopes of several elements, but most usefully those of hydrogen(), carbon (), nitrogen () and sulphur (), are incorporated into animal tissues from the diet in a predicable manner (Inger and Bearhop, 2008). Thus, if the isotope ratios of potential dietary items are known then animal diets can be reconstructed from the stable isotope ratios from proteinaceous tissues using SIMMs. cosimmr is a new R package (R Core Team, 2021) developed to allow for the fast running of SIMMs, especially but not limited to those that include covariates. It has been designed to be easy to use for non-expert R users, with S3 classes used throughout. SIMMs are widely used and cited in other fields, such as geology (Munoz et al., 2019) and pollution studies (Zaryab et al., 2022), amongst many others. In other scientific areas, SIMMs and similar models can be referred to in the literature as ‘source apportionment models’ (Hopke, 1991), ‘end member analysis’ (Hooper et al., 1990), or ‘mass balance analysis’ (Miller et al., 1972). Further discussion of these models can be found in Govan et al. (2023).
The basic mathematical equation for a statistical SIMM is:
Here is the mixture (consumer tissues) value (for example, the or values for the species we wish to study), are the proportions contributed by each source (dietary item) (of total sources), is the source tracer value for source , and is a residual term. The parameters are usually the main focus of scientific interest. These models are commonly expanded in diet analyses to allow for processes that cause the mixture and source tracer values to differ besides the source proportions, such as Trophic Discrimination Factors (TDFs; Inger and Bearhop, 2008) and concentration dependence (Phillips and Koch, 2002). Other expansions include process error on the dietary proportions (Moore and Semmens, 2008) as well as hierarchical source fitting (Ward et al., 2010). The models are further made richer by incorporating random effects on the source values (Semmens et al., 2009). Here, whilst we include many of these extensions, our focus is on the inclusion of covariate dependence on the proportions . The restriction that these must sum to unity (i.e. a simplex) makes their estimation more complex, and specialist link functions are required to map their values on to covariates. We provide a more detailed explanation of the mathematical model behind cosimmr in Section 3.
Modern SIMMs are fitted using the standard tools of Bayesian inference. Most commonly this involves using Markov chain Monte Carlo (MCMC) to obtain samples from the posterior. For complex models with covariates this can be extremely slow, with models requiring millions of posterior samples and taking several days to converge, if they converge at all. By contrast in cosimmr we use Fixed Form Variational Bayes (FFVB), specifically Gaussian Variational Bayes with Cholesky Decomposed Variance (Titsias and Lázaro-Gredilla, 2014; Tan and Nott, 2018). FFVB is an optimisation-based algorithm which works by first defining the form of the posterior distribution (here a multivariate normal distribution), and then minimising the Kullback-Leibler divergence between this VB approximation and the true posterior distribution. More details on the assumed distributions used in cosimmr can be found in Section 4. The main advantage of using FFVB, and thus of cosimmr, is that it works by optimisation rather than sampling, and therefore can be much faster to produce a posterior distribution. However, convergence issues can still occur (Yao et al., 2018). Our approach gives cosimmr a key advantage over other packages, which tend to use JAGS (Plummer, 2003) to implement the MCMC algorithm. Additionally, cosimmr runs using C++ code via Rcpp (Eddelbuettel and François, 2011) which allows for an additional speed boost.
SIMMs have been a popular method for studying animal diets, with thousands of citations across different papers, and many packages have been developed in order to make this easier. Some of the most popular packages are listed below. A summary is also provided in Table 1. A more detailed comparison of cosimmr, simmr, and MixSIAR is provided in Table 2.
-
•
Isosource (Phillips and Gregg, 2003) was one of the earliest developed packages for running SIMMs. It worked by simulating possible values of each proportion to produce many potential combinations of proportions. Importantly, it lacked an explicit statistical basis.
-
•
MixSIR (Moore and Semmens, 2008) adopted a Bayesian framework and allowed for the inclusion of Trophic Discrimination Factors (TDFs). MixSIR utilised Importance Sampling, generating many samples of possible proportion combinations and calculating importance weights to produce the final posterior sample. MixSIR also allowed for the inclusion of prior information and allowed uncertainty to be incorporated into SIMMs.
-
•
SIAR (Parnell et al., 2010) was developed as an R package. It utilised Markov chain Monte Carlo (MCMC) sampling. SIAR also included a residual component in the model. SIAR is no longer updated and simmr was developed to replace it.
-
•
simmr (Govan et al., 2023) is an R package that follows a Bayesian framework, and provides the option of using either JAGS (Just Another Gibbs Sampler; Plummer, 2003) or Fixed Form Variational Bayes (FFVB; Tran et al., 2021) for running the models. simmr allows for the inclusion of concentration dependence and Trophic Discrimination Factors but does not allow for covariates on the dietary proportions.
-
•
FRUITS (Fernandes et al., 2014) allowed for the inclusion of concentration dependence and prior information in a Bayesian framework. FRUITS is encoded in Visual Basic and runs via the FRUITS computer programme. This package simplifies the incorporation of prior information.
-
•
IsotopeR (Hopkins III and Ferguson, 2012) adopted a Bayesian framework and allowed for inclusion of concentration dependence and TDFs, and also includes covariance. It uses MCMC for running the models.
-
•
MixSIAR (Stock et al., 2018) is an R package that fits models in JAGS. MixSIAR allows for the inclusion of covariates as fixed, random, or continuous effects. It fits the source means hierarchically, either using raw data or sample statistics (means, variances, and sample sizes).
| Software | Language | Algorithm | TDFs | Concentration Dependence | Covariates | Prior Info | Comments | Hierarchical/ Source Fitting | Reference |
| Isosource | Visual Basic | Trial and Error | N | N | N | N | Frequentist | N | Phillips and Gregg (2003) |
| simmr | R | MCMC and FFVB | Y | Y | N | Y | Ease-Of-Use Design | N | Govan et al. (2023) |
| FRUITS | Visual Basic | MCMC | Y | Y | N | Y | - | N | Fernandes et al. (2014) |
| IsotopeR | R | MCMC | Y | Y | N | Y | Hierarchical Model | Y | Hopkins III and Ferguson (2012) |
| MixSIAR | R | MCMC | Y | Y | Y | Y | Allows for Raw Data | Y | Stock et al. (2018) |
| cosimmr | R | FFVB | Y | Y | Y | Y | Aims for Speed | N | This Paper |
| simmr | MixSIAR | cosimmr | |
| TDFs | |||
| Concentration Dependence | |||
| Covariates | - | ||
| Prior Information | |||
| Hierarchical/Source Fitting | - | - | |
| Prior Visualisation | - | ||
| MCMC | - | ||
| FFVB | - |
TDFs (Trophic Discrimination Factors) account for the fact that consumers may differentially lose ‘light’ versions of isotopes with respect to ‘heavy’ versions during the process of assimilation (Inger and Bearhop, 2008). Thus, while TDFs are important in ecological applications, they have less relevance to geological or pollution-based applications as these same processes do not occur (although similar processes such as isotopic fractionation may need to be accounted for). TDFs can be calculated in the lab, or calculated mathematically, such as in Greer et al. (2015). Alternatively SIDER (Healy et al., 2018) is an R package that allows for estimates of TDFs based on phylogenetic relatedness of species. Estimates can also be obtained from the scientific literature.
Concentration dependence accounts for the fact that different food sources can contribute proportionally different amounts of each isotope (Phillips and Koch, 2002). The standard two-isotope model assumes all food sources contribute both isotopes equally. However, there are often occasions where a food source can be rich in one isotope and poor in another, thus not contributing equally to both. Instead, concentration dependence assumes a source’s contribution to each isotope is proportional to the mass of the food source times the elemental concentration of the isotope within the food source. Inclusion of concentration depedence facilitates conversion between consideration of either the total mass of food sources assimilated and the mass of specific elements within them.
The inclusion of covariates in the SIMM allows users to avoid pseudo-replication (Hurlbert, 1984), because if a covariate is important to the diet proportions, its exclusion violates the assumption that all mixtures are independently and identically distributed. Including covariates in SIMMs allows users to determine the potentially causal relationships between covariates and diet proportions. Although the model returns these coefficients, they are only available in a transformed space (via the link function) and not directly interpretable. We have designed cosimmr to produce interpretable output in ‘coefficient space’ where users can determine the direction of the relationship and evaluate uncertainty, and also in ‘proportion space’ (-space) which allows users to see the effect of the covariate directly on the dietary proportions. These tools are defined via a predict function that to allow the user to predict dietary proportions based on combinations of covariates that may not necessarily be present in the original dataset. We follow the ‘tidyverse’ (Wickham et al., 2019) style guide, with the Snake case naming convention and S3 classes used throughout. Being able to evaluate the model at new values of the covariates allows for a more detailed picture to be seen. Uncertainty intervals, in the form of Bayesian credible intervals, are provided for all estimated quantities. Advanced users have access to the full posterior distributions as created by the FFVB algorithm.
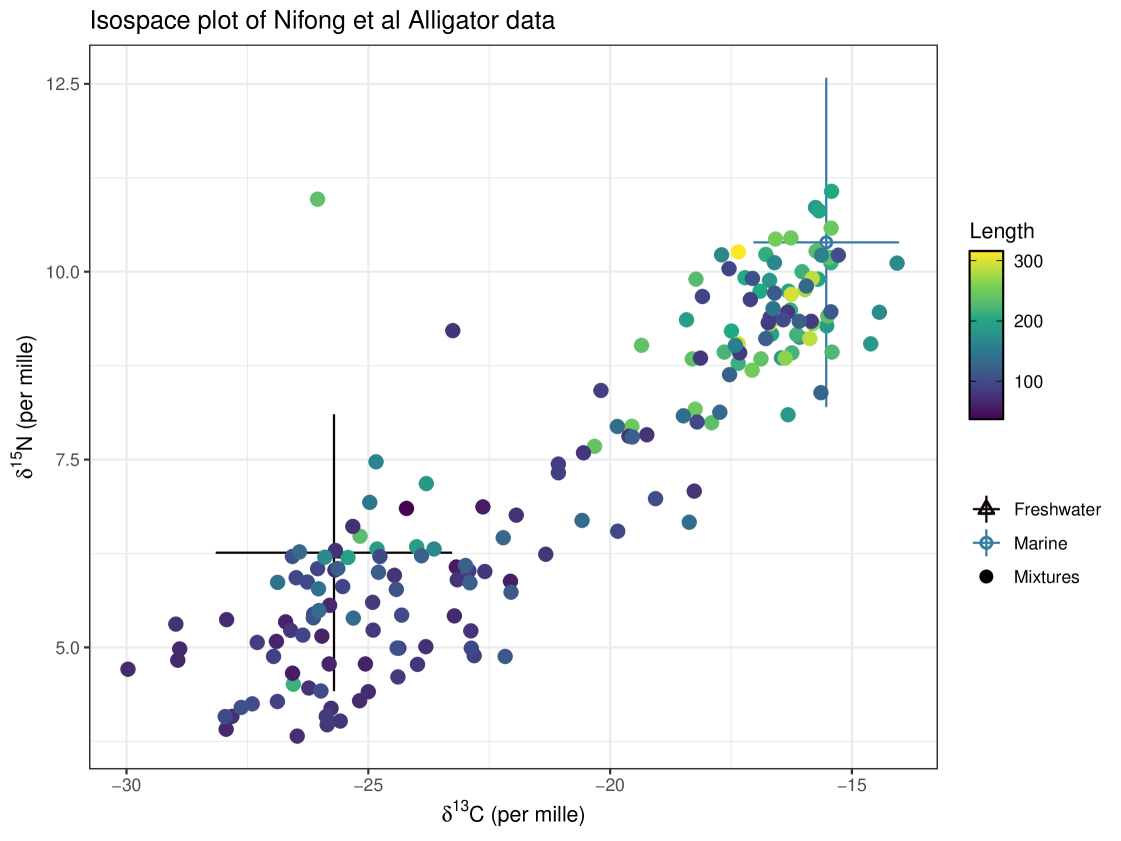
The data required by cosimmr can be illustrated by Figure 1. This example is discussed more fully in Section 7.3. This figure shows an ‘iso-space’ plot generated by cosimmr. It shows each individual plotted in iso-space, with the axes representing and . The diet sources (Marine and Freshwater in this case) are also plotted on the graph. It is important that all individuals lie within the mixing polygon created by the source means. If they do not, it indicates that the mixing system does not follow the model assumptions. Possible reasons for observations lying outside the mixing polygon include: issues with data collection; inaccurate TDFs; or missing food sources, amongst others. However, note that the mixing polygon vertices are sample means subject to sampling error, so there is some uncertainty in their exact position. Hierarchical Bayesian models allow for the source means to deviate from the source sample means by maximizing the likelihood of the source and mixture tracer data together (Ward et al., 2010; Hopkins III and Ferguson, 2012; Stock et al., 2018).
3 Statistical approaches to stable isotope mixing models
The fundamental SIMM we fit can be written as:
Where:
-
•
are the mixture/consumer tracer values of individual for tracer ,
-
•
are the proportions of each source contributing to the mixture value at each covariate value where is an -vector of covariate values for individual ,
-
•
represents the concentration dependence for tracer on source ,
-
•
is the consumed source value by individual of the food source on tracer ,
-
•
is the trophic discrimination factor of individual for source on tracer
-
•
is the residual error for individual on tracer
We index individuals as , tracers as , and sources as . We assume there are covariates so that . For notational brevity we write as . It is common to make the prior assumptions that , , and . Here may be assumed fixed as they are commonly available from other data sources, or learnt as part of a Bayesian hierarchical model. The residual standard deviation is usually given a Uniform or (inverse) Gamma weakly informative prior. Other approaches have used multivariate normal distributions for these terms (e.g. Hopkins III and Ferguson, 2012; Parnell et al., 2013; Stock et al., 2018) but these are not implemented in cosimmr as yet. The model of Stock et al. (2018) adds an additional multiplicative parameter to the first variance term to account for the assimilation of food items according to whether organisms are specialising in certain regions of the source probability distribution. Following their approach, we give the parameter a prior when this additional process error is required. A table of prior values set can be seen at 3.
| Term | Prior |
| U(0,20) | |
| N(0,1) | |
| Ga(1,1) |
The source and TDF random effects add an additional burden of parameters into the model which can cause a significant computational slowdown. Moore and Semmens (2008) proposed proposed marginalising across these parameters to produce a more complex, but more computationally tractable likelihood:
where and .
The remaining prior distribution is that of the terms which must retain the constraint that , but also allow for the terms to be dependent on the covariates . We use a Centralised Log-Ratio (CLR; Aitchison (1986)) link function so that:
This prior has the advantage that the resulting terms are unconstrained and made to depend directly on . We model this dependence linearly, but extensions that capture more nuanced dependence seem like a fruitful avenue for future research. We thus set: . In other words, we can write the proportion for individual consuming food as . where the parameters model the dependence of the covariates across source . We require a further prior distribution on to ensure identifiability. By default we thus set . In certain circumstances where prior information is available on the values we may use an informative prior of the form . The prior distribution for can be changed by the user in cosimmr via the cosimmr_ffvb function.
4 The Fixed Form Variational Bayes Algorithm
Fixed Form Variational Bayes (FFVB) is an optimisation-based algorithm that aims to approximate the posterior distribution of a Bayesian model in a pre-defined form (Salimans and Knowles, 2013). It aims to finds the parameters of the ‘closest’ probability distribution to that of the true posterior. Unlike traditional MCMC sampling methods, the greedy nature of the optimisation can usually find this approximate posterior far faster. In cosimmr we use a sub-type of FFVB known as Gaussian Variational Bayes with Cholesky decomposed covariance (Titsias and Lázaro-Gredilla, 2014; Tan and Nott, 2018). To avoid becoming diverted in mathematical detail, we defer a full description of our approach to Appendix A. However here we provide an intuitive guide to how the fitting process works.
Our model assumes that the joint posterior distribution of all the parameters is multivariate normal. The parameters for our model are , and , representing the regression parameters across sources and covariates, and the residual variances across tracers. Recall that is a deterministic function of so not included in the algorithm. Since the variances are all restricted to be positive, we model these on the log scale. We thus write as the set of parameters for which we want a posterior.
For FFVB we need to define the form of the posterior distribution. We use:
where and are the mean and covariance matrix of the approximated posterior distribution. To avoid the positive semi-definite constraints on we model the Cholesky decomposition of this matrix so that . Together these terms are vectorised and written as: . The goal of the algorithm is to provide a set of optimal values for which captures this posterior distribution. The main steps of the algorithm are as follows:
-
•
Get starting values and use these to get an estimate of the difference between the posterior and variational posterior.
-
•
Calculate the gradient of this difference and use this to update . The gradient of the posterior is calculated using automatic differentation and the gradient of the variational posterior is calculated manually.
-
•
Use new values of in place of starting values and repeat until stopping condition is met.
The algorithm requires several user-set hyper-parameters for fitting the model. The main hyper-parameters are: the patience , which determines when the algorithm stops; and which provides the number of parameter samples used at each stage of the algorithm. For other algorithm parameters, we have used the default values from Tran et al. (2021). These parameters include: the fixed (beta_1 and beta_2) and adaptive (eps_0) learning rates; the size of the window to use when calculating stopping conditions (t_W); and the threshold for exploring the learning space before a the learning rate is decreased (tau).The stopping conditions work by calculating a moving average of the lower bound (the difference between the log of the posterior and the log of the variational posterior). When the moving average does not improve after iterations then the algorithm stops. All hyper-parameters can be changed by the user if they wish when running the FFVB algorithm through cosimmr, though we have provided reasonable defaults which should work in most circumstances
The use of FFVB in covariate-dependent SIMMs is novel, and confers an advantage over MCMC due to the increase in speed. This method is flexible and can be extended in the future, to include hierarchical source fitting, raw data, as well as random effects, features which are currently available in other SIMM software. We see up to an order of magnitude speed increase when comparing FFVB to MCMC, with comparable results produced.
5 Running the cosimmr package
The cosimmr package is available via CRAN. The first step to use it is to install and load the package:
R> install.packages("cosimmr")
R> library(cosimmr)
The user must provide mixture data (), source means (), and source standard deviations () to run cosimmr. TDFs, Concentration Dependence, and any covariates are not necessary to run the model but they may need to be included in order for the model to be ecologically valid. The cosimmr_load function can be used to read the data into R. This ensures the data is loaded in the correct format. For illustration purposes we will use an artificially generated dataset, though see later sections for real case studies:
R> y = matrix(c(5, 5.1, 4.7, 3.6, 3.2, 0, -1, -2, -3, -7,
+ 3.1, 5.6, 3.6, 4.7, 1.3, 1, -4, -3, -7, -9),
+ ncol = 2)
R> colnames(y) = c("iso1", "iso2")
R> mu_s = matrix(c(-10, 0, 10, -10, 10, 0), ncol = 2, nrow = 3)
R> sigma_s = matrix(c(1, 1, 1, 1, 1, 1), ncol = 2, nrow = 3)
R> s_names = c("A", "B", "C")
R> x = c(1.6, 1.7, 2.1, 2.5, 1.1, 3.7, 4.5, 6.8, 7.1, 7.7)
This dataset contains measurements of two isotopic ratios, ‘iso1’ and ‘iso2’, as well as three food sources named ‘A’, ‘B’, and ‘C’. There is one continuous covariate, named ‘x’. These data can then be loaded into cosimmr using cosimmr_load to create an object of class cosimmr_in:
R> cosimmr_in_1 = cosimmr_load( + formula = y ~ x, + source_names = s_names, + source_means = mu_s, + source_sds = sigma_s )
As discussed in the introduction, it is recommended that these data are plotted on an ‘iso-space’ plot before modelling. The iso-space plot shows tracer values of the mixtures as well as sources, with each axis representing a tracer. These tracers are often isotope ratios. It is important that the mixture data lies within the polygon formed when the sources are joined with straight lines (this polygon is referred to as the mixing polygon). If the mixtures do not lie within this polygon it indicates that there is an issue - potential reasons are that TDFs are inappropriate or a food source has been omitted. The polygon vertices are subject to sampling error and this could be another potential source of error. The iso-space plot can be generated by cosimmr by running the following code:
R> plot(cosimmr_in_1, col_by_cov = TRUE, cov_name = "x")
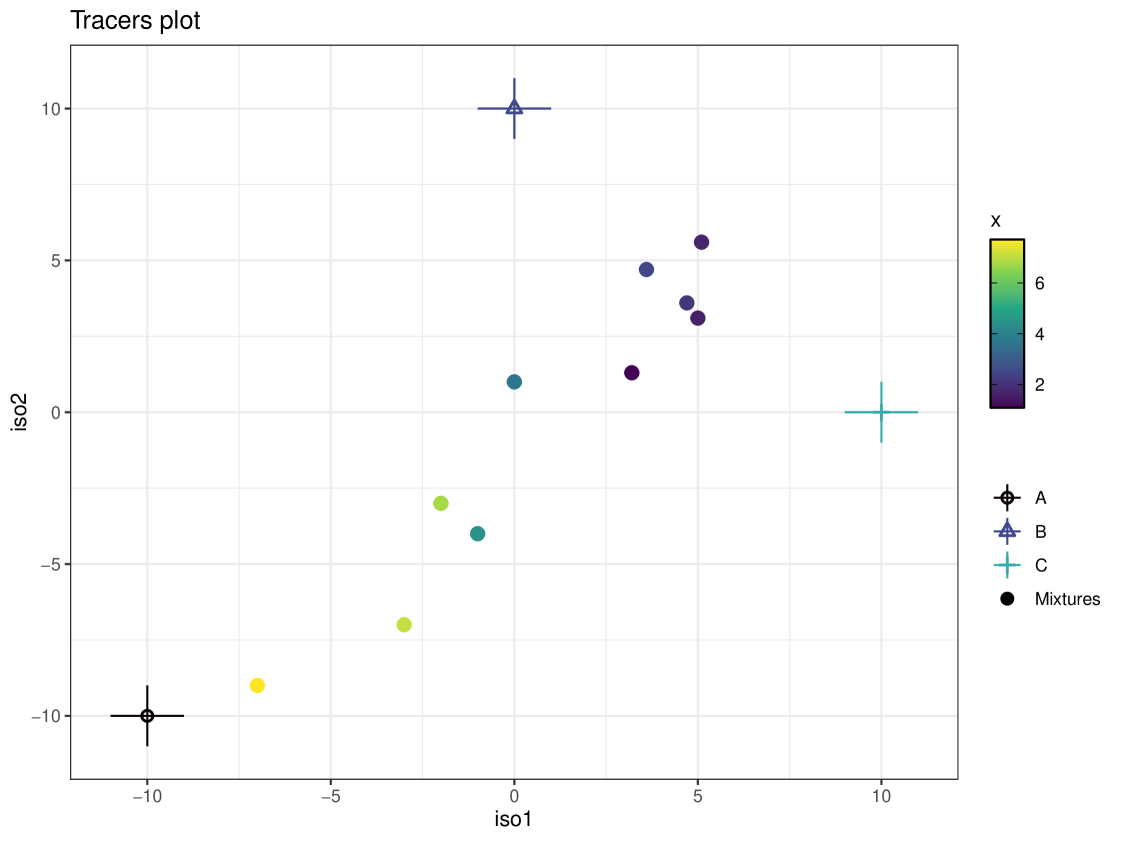
The resulting plot can be seen in Figure 2. It shows the mixtures lie within the mixing polygon. These data can then be run through the cosimmr_ffvb function to produce an output of class cosimmr_out:
R> cosimmr_out_1 = cosimmr_ffvb(cosimmr_in_1)
cosimmr has built-in functions to produce summaries of the model run. Both graphical and textual summaries can be produced, as shown below.
R> summary(cosimmr_out_1, type = "statistics")
Summary for Observation 1
mean sd
P(A) 0.093 0.026
P(B) 0.424 0.052
P(C) 0.482 0.045
sd_iso1 1.449 1.133
sd_iso2 1.790 1.437
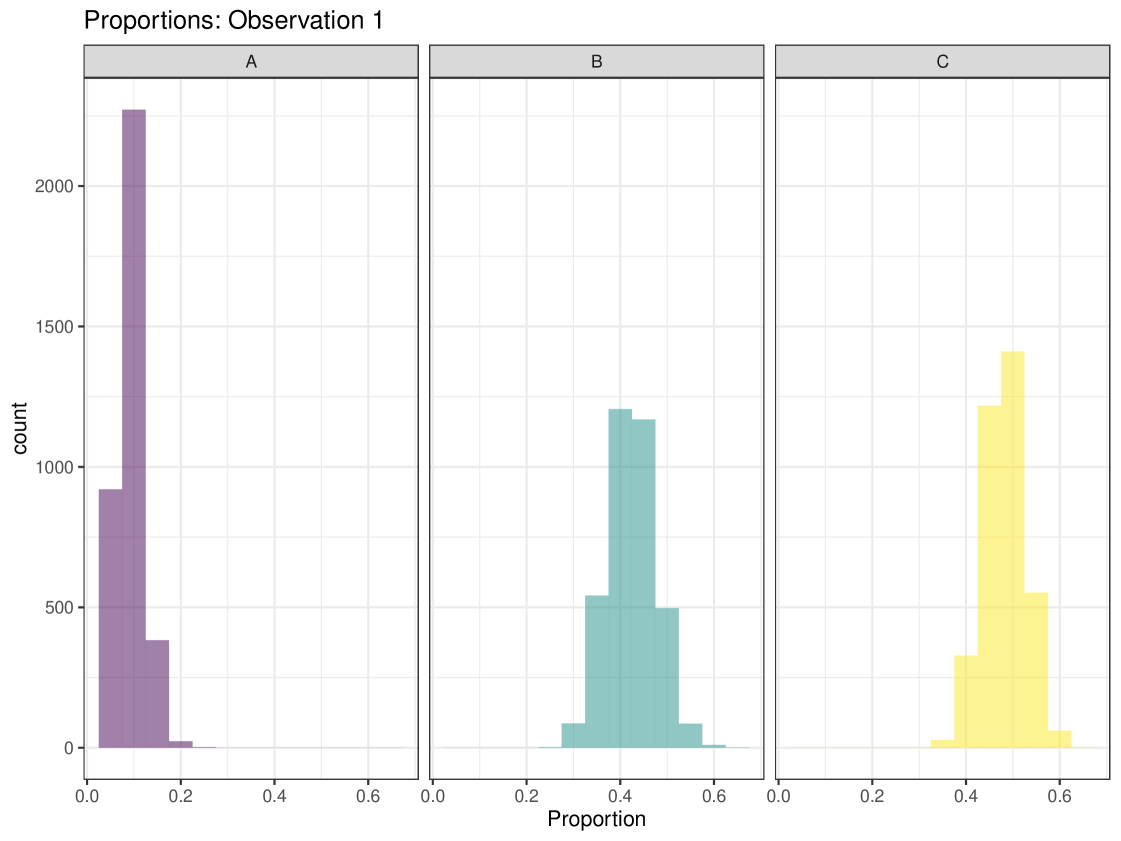
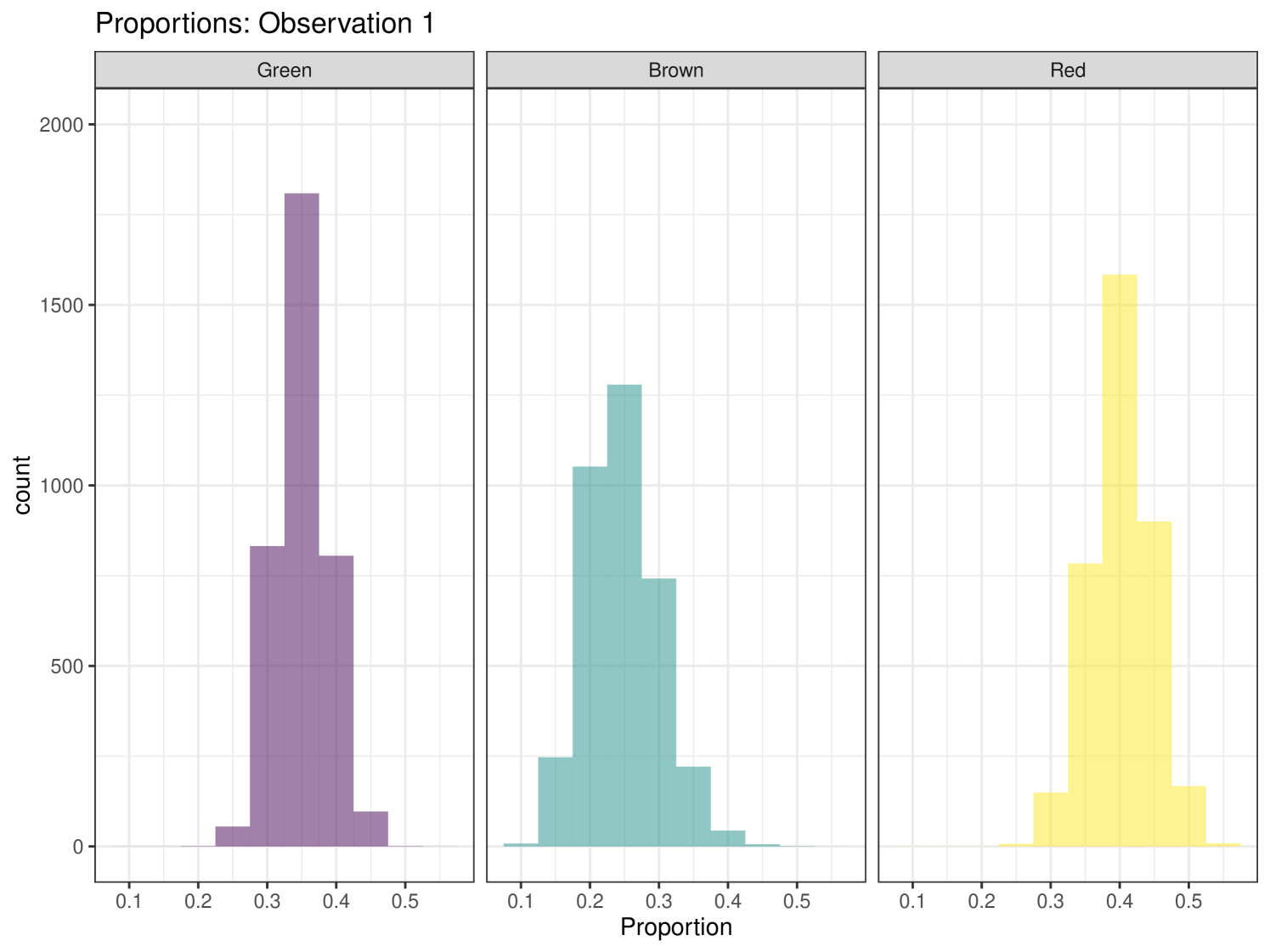
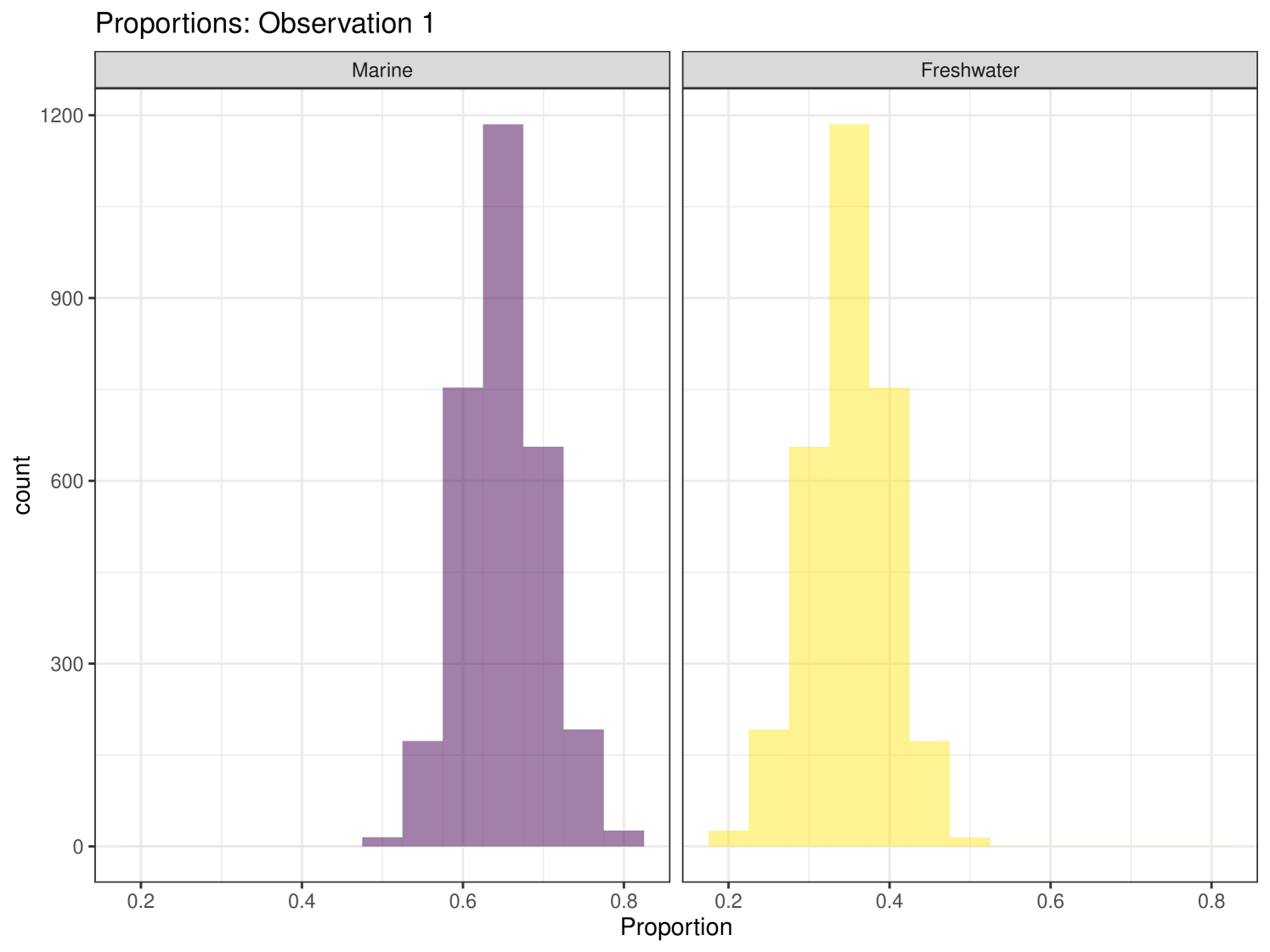
In this example, we have specified that we wish to produce ‘statistics’. As we have not specified an observation then the function defaults to returning statistics for observation 1. Any/multiple individuals can be selected and ‘statistics’, ‘quantiles’ or ‘correlations’ can be produced for each individual. The ‘statistics’ summary produces a table of the means and standard deviations for the estimates of the proportion of each food eaten by the individual. An estimate of the marginal residual error of the isotope ratios is produced. In this summary we can see that individual 1’s diet is mostly composed of foods B and C, with A contributing very little to their diet. This matches the observations we can make from the iso-space plot, where individual 1 lies at (5, 3.1), equidistant from food sources B and C and quite far away from food source A. The ‘quantiles’ summary produces the 2.5%, 25%, 50%, 75% and 97.5% quantiles for the same values as provided by the ‘statistics’ summary. The ‘correlations’ option produces the correlation values between each source and the residual error of the isotope ratios.
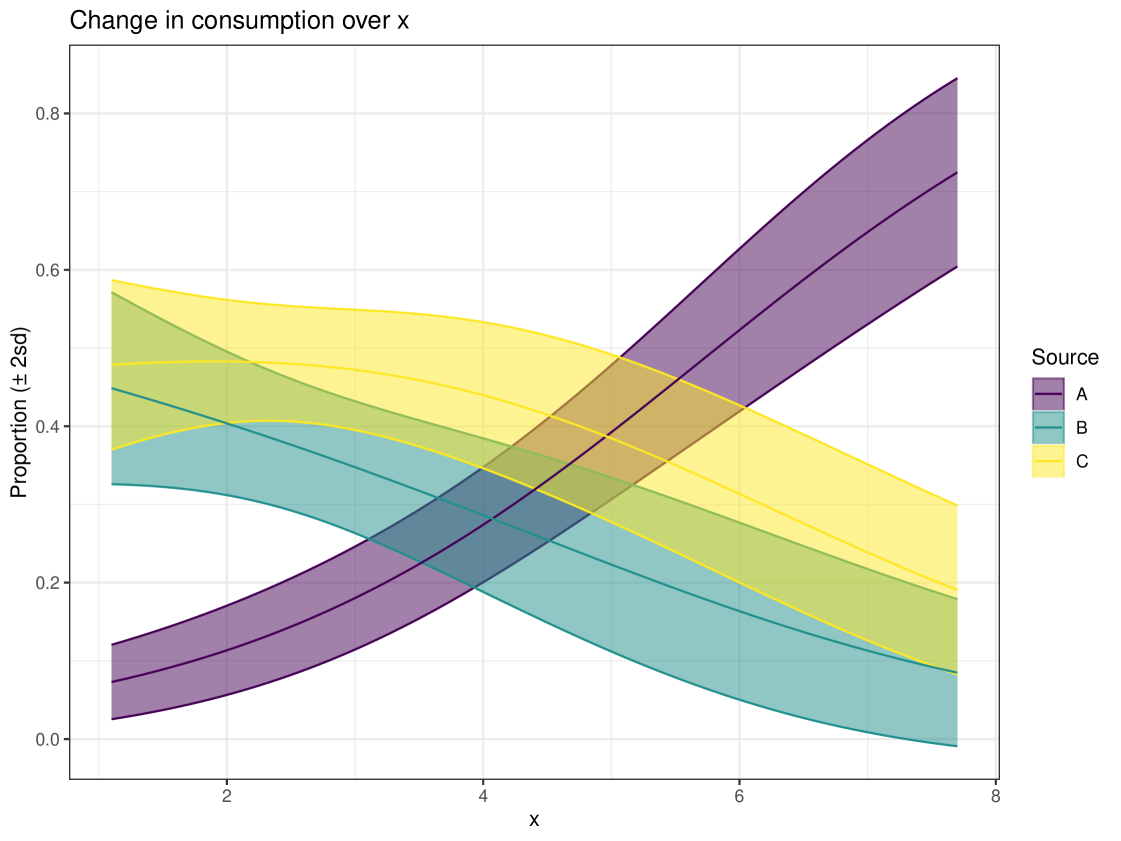
Graphical plots can be produced in cosimmr. For example, below we create a proportion plot for observation 1. We can see the plot in Figure 3. This shows the range of the proportion estimates for each food source for individual 1. We also create a ‘covariates plot’ which shows the change in the proportion of foods consumed as the covariate changes. This plot can be seen in Figure 4.
R> plot(cosimmr_out_1, type = c("prop_histogram", "covariates_plot"),
+ obs = 1, cov_name = "x")
Another important function within cosimmr is the ability to predict values based on covariate values, using the predict function, as illustrated below:
R> x_pred = data.frame(x = c(3, 5))
R> pred_out = predict(cosimmr_out_1, x_pred)
R> summary(pred_out, type = "statistics", obs = c(1,2))
Summary for Observation 1
mean sd
P(A) 0.181 0.033
P(B) 0.345 0.041
P(C) 0.474 0.039
Summary for Observation 2
mean sd
P(A) 0.393 0.043
P(B) 0.221 0.054
P(C) 0.386 0.054
Here we can select values of the covariate for which we have no observations with those values, add these to the predict function along with out cosimmr_out object, and return a new object which can then be used in the summary and plot functions as with a cosimmr_out object. In this example we return dietary predictions for observations with covariate values 3 and 5, and can see what their estimated diet would look like if there were individuals with these predicted values.
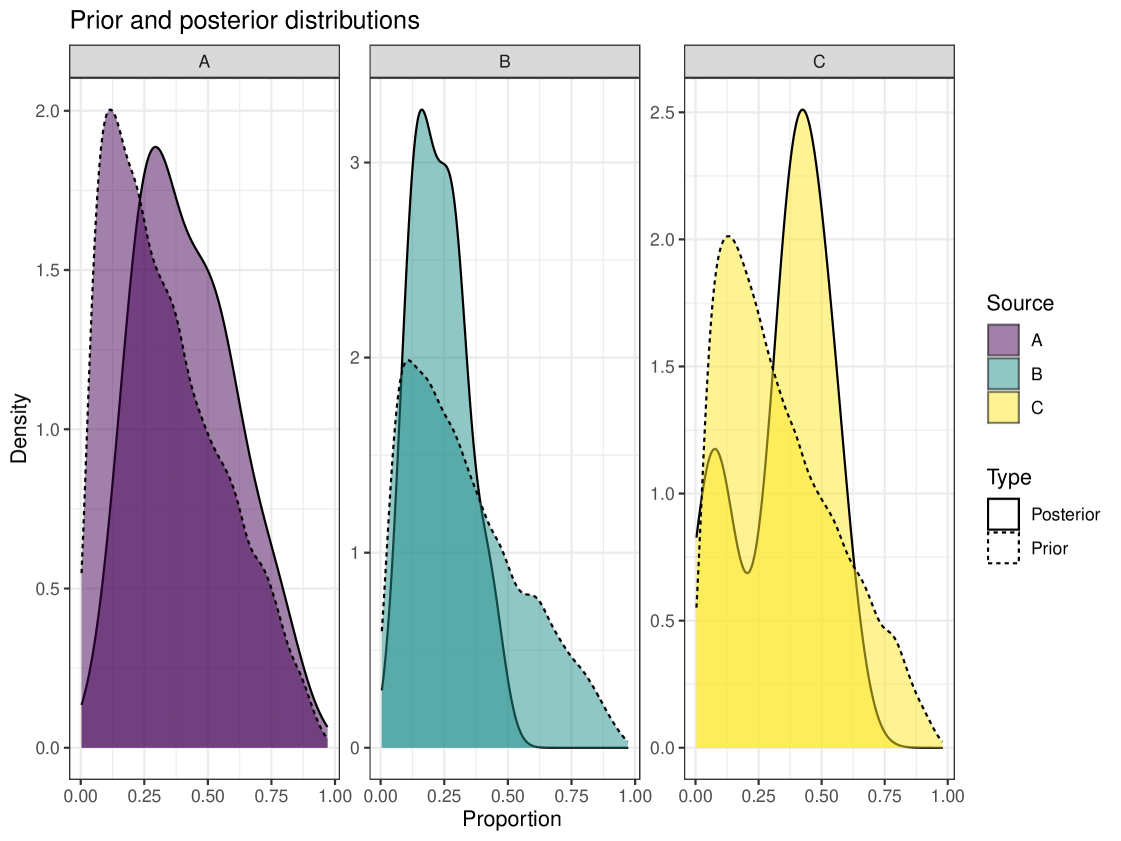
We can use the prior_viz function to visualise how the posterior has changed from the prior. This plot overlays the posterior distribution and the prior distribution to see how it has changed or if the posterior has not changed much from the prior. This plot can be seen in Figure 5. We can see that our posterior estimates have changed from the prior estimate. One figure is shown here but it is recommended that users create plots for multiple individuals when running a model.
For convenience a summary of the main cosimmr functions is presented in Table 4.
| cosimmr_load | Load in data in correct order/format |
| cosimmr_ffvb | Run SIMM using Fixed Form Variational Bayes algorithm |
| summary | Produce summary of proportion values. Options include |
| statistics, quantiles, and correlations | |
| plot | Create plots, options include histogram or boxplot of beta |
| values, iso-space plot, histogram or density plot of estimated | |
| proportions, plot of covariates vs proportions | |
| predict | Predict proportion values for covariates not present in |
| original dataset | |
| posterior_predictive | Create posterior predictive distribution of observations |
| and plots for each observation | |
| prior_viz | Create plots showing prior values set vs posterior obtained |
6 Simulation Checks
In this section we use simulated data to verify that cosimmr returns valid estimates when a run is performed. We simulate data from the model using a variety of different data set sizes, varying , , and , and changing the main parameters in the model. We evaluate the performance of the model by looking at how often the posterior distribution obtained by cosimmr matches the true values. The code for performing the runs in this section can be found at \urlhttps://github.com/emmagovan/cosimmr_paper/.
The values selected for several different simulations are presented in Table 5. We run low (, , , ), medium (, , , ) and high (, , , ) versions to capture a range of scenarios, where N = no. of individuals, J = no. of tracers, K = no. of food sources, and L = no. of covariates. For each of these we simulate data using the default prior distribution of and with . We set , and . TDFs and Concentration dependence are ignored for this example.
| Low | Medium | High | |
| N | 50 | 200 | 500 |
| J | 2 | 3 | 4 |
| K | 3 | 4 | 5 |
| L | 2 | 5 | 10 |
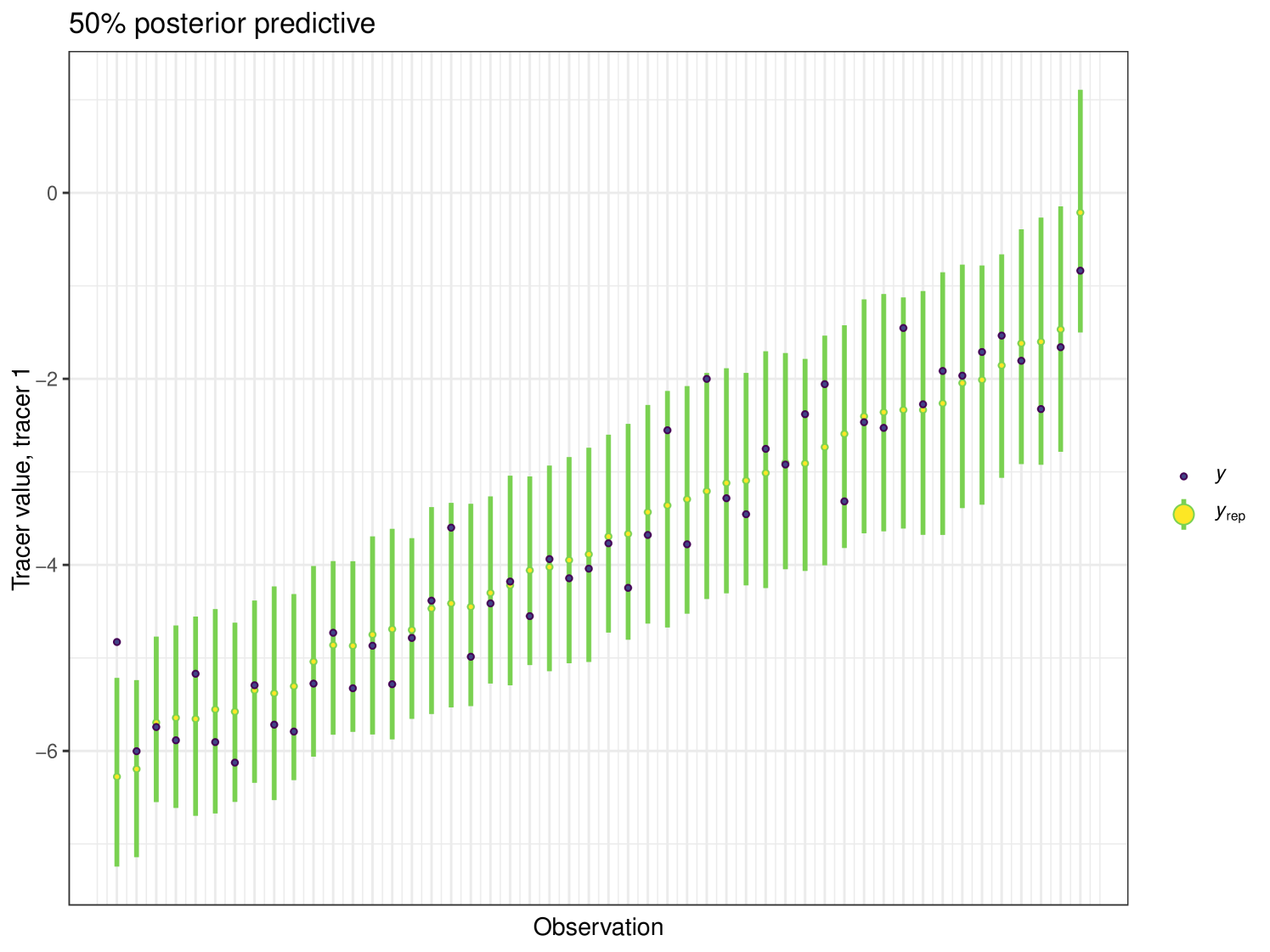
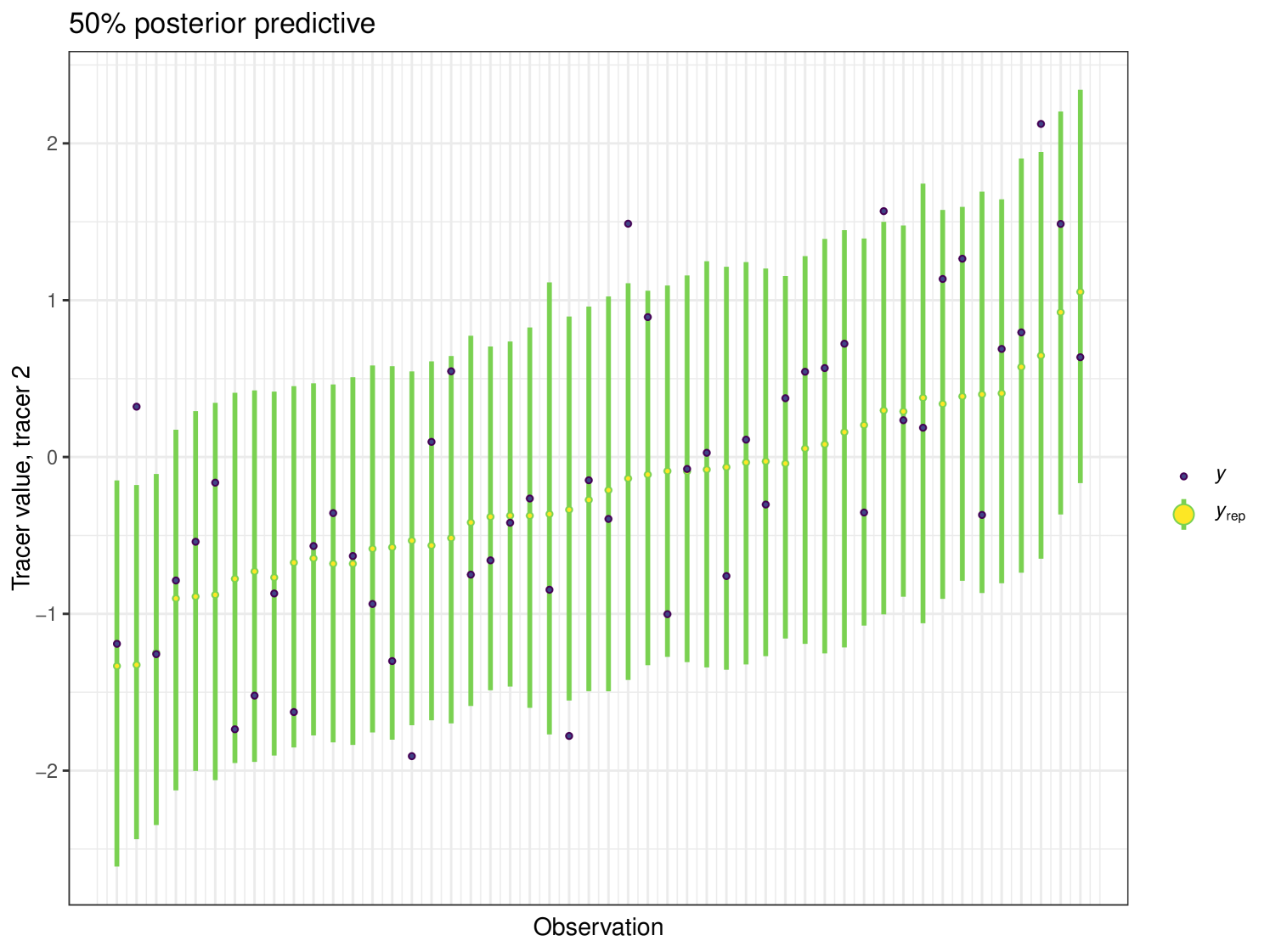
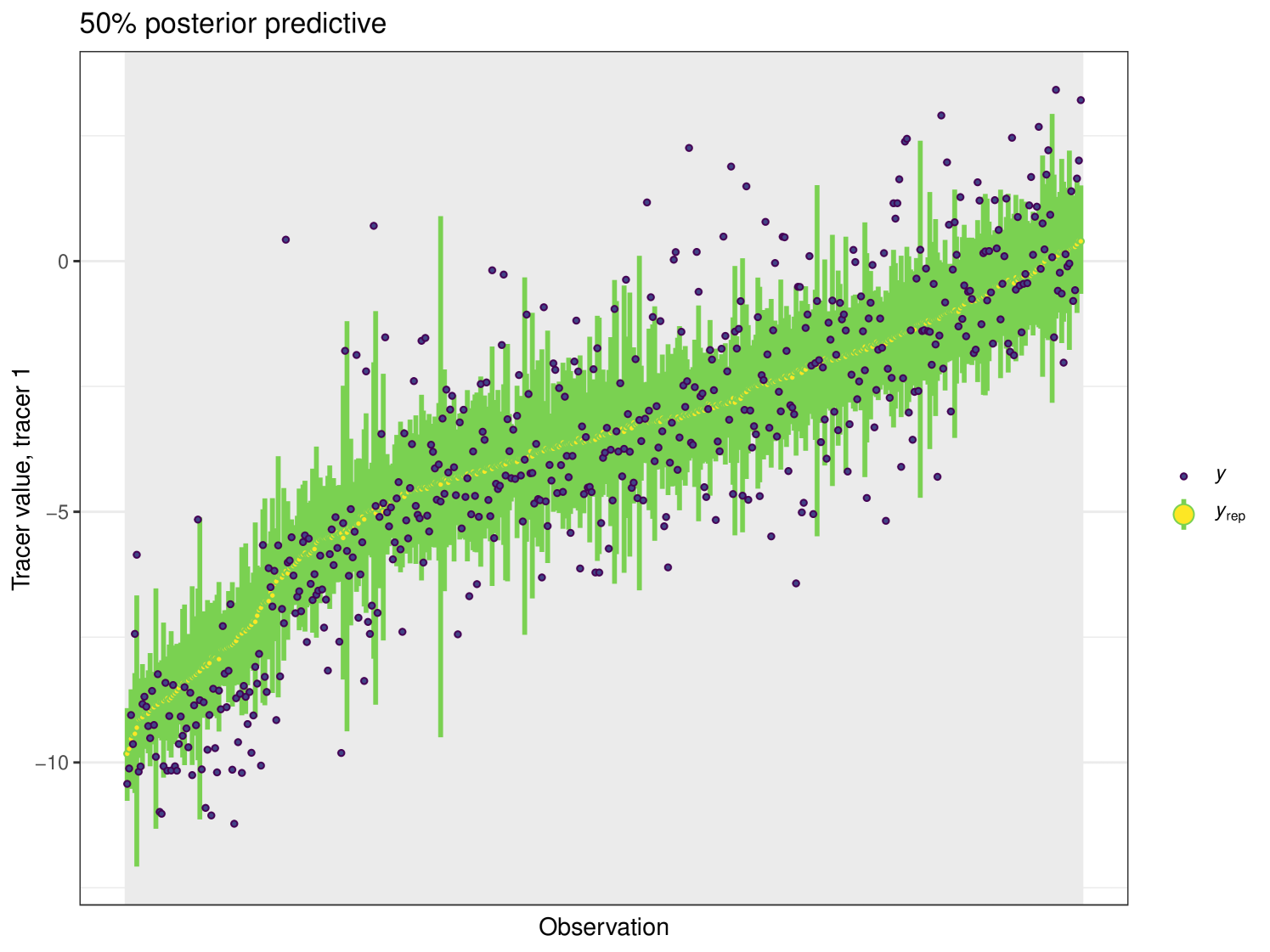
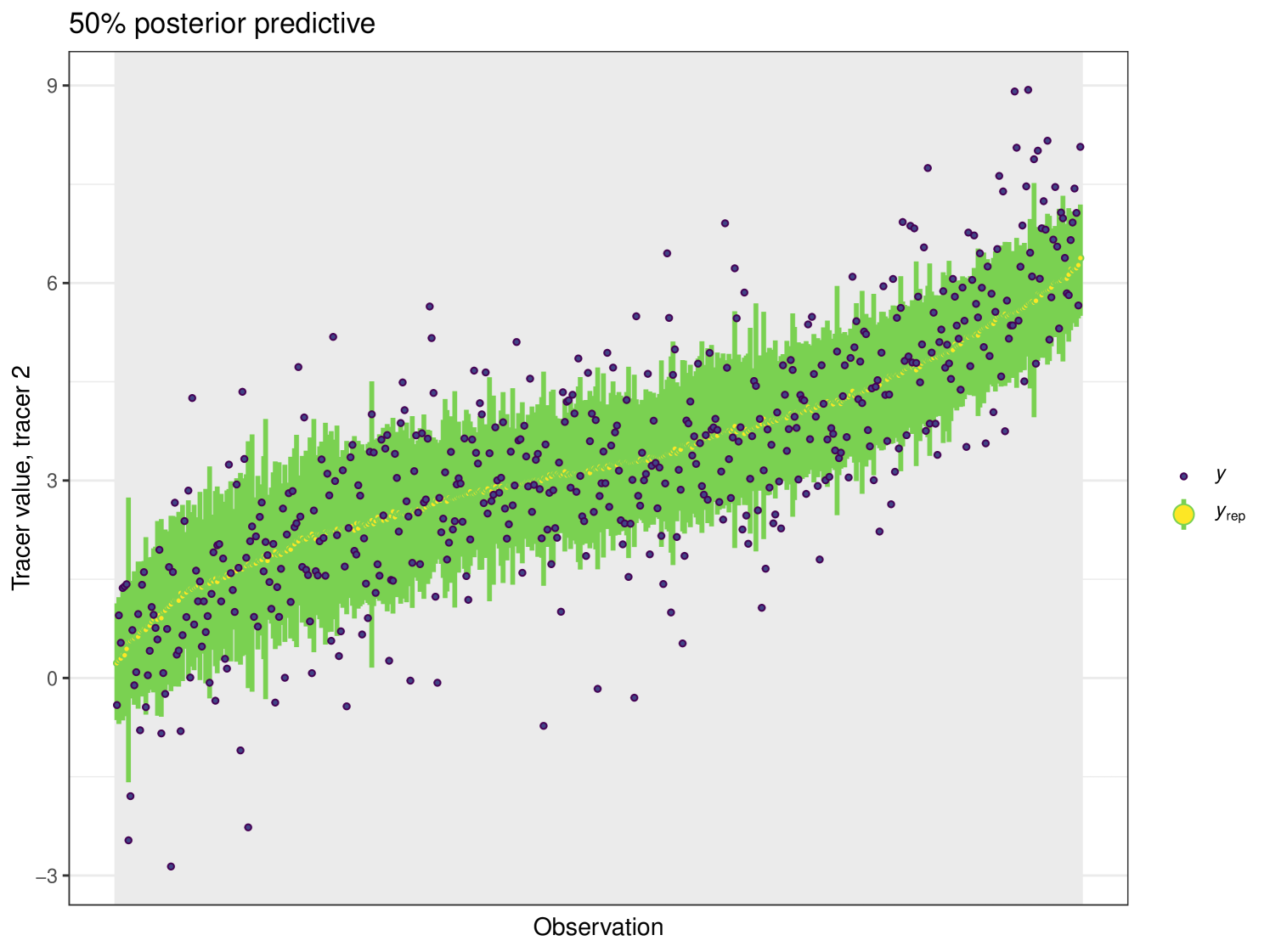
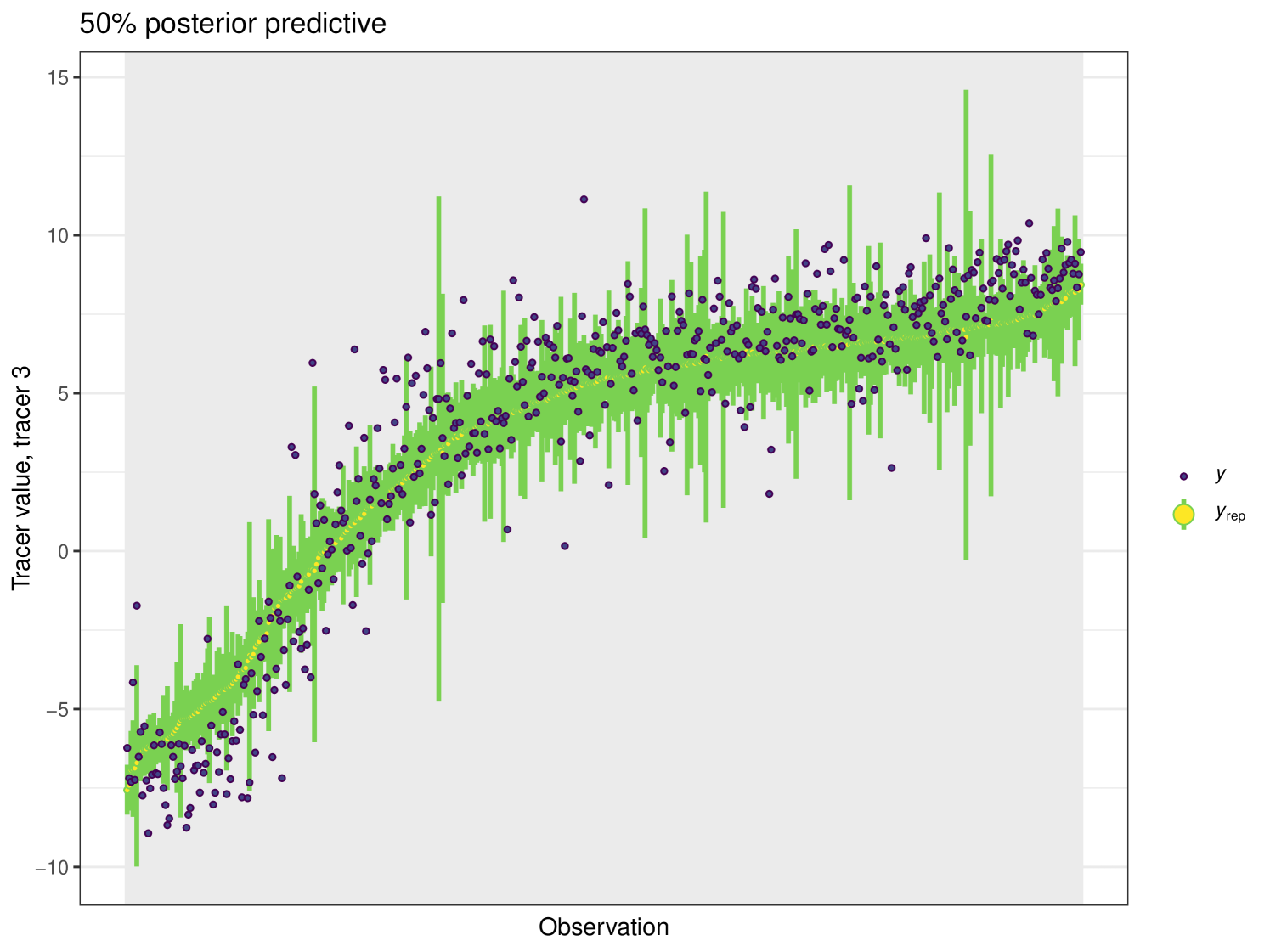
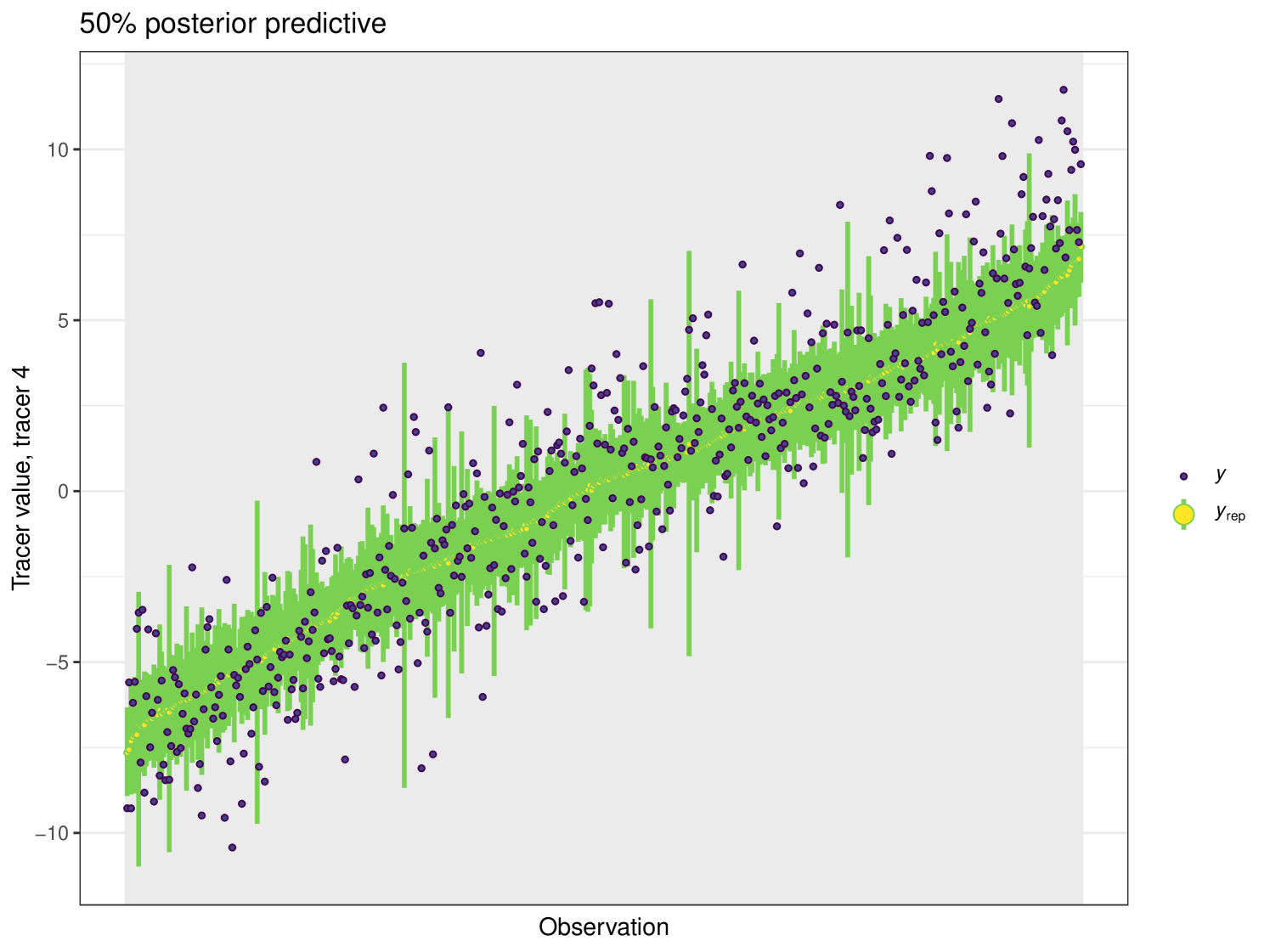
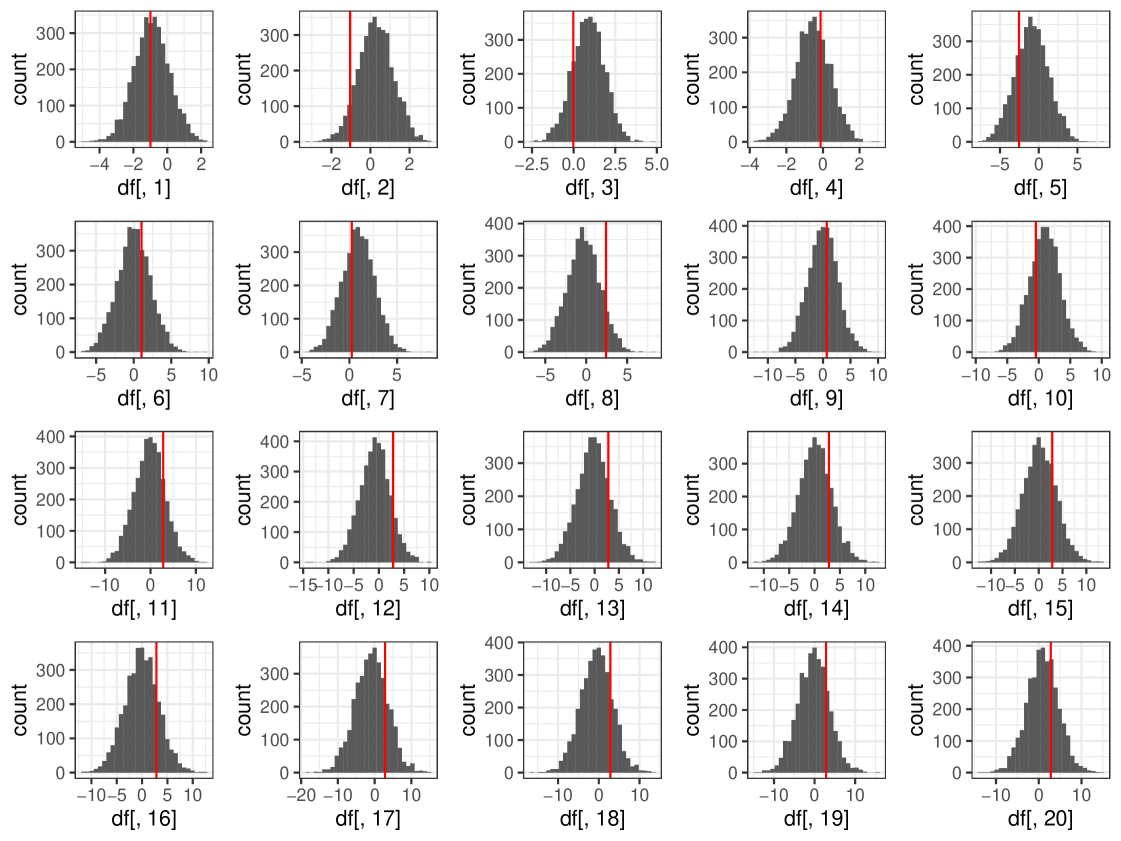
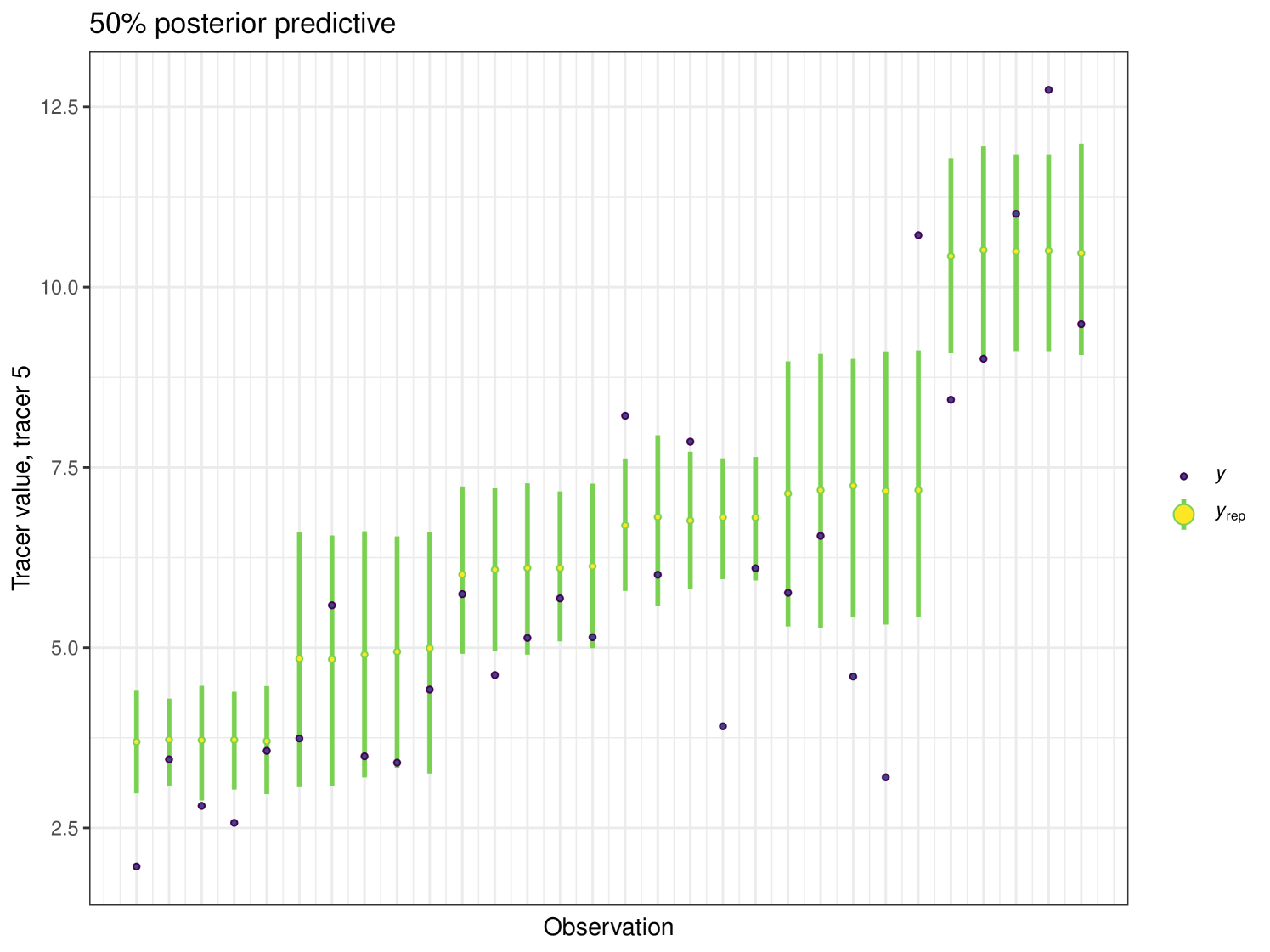
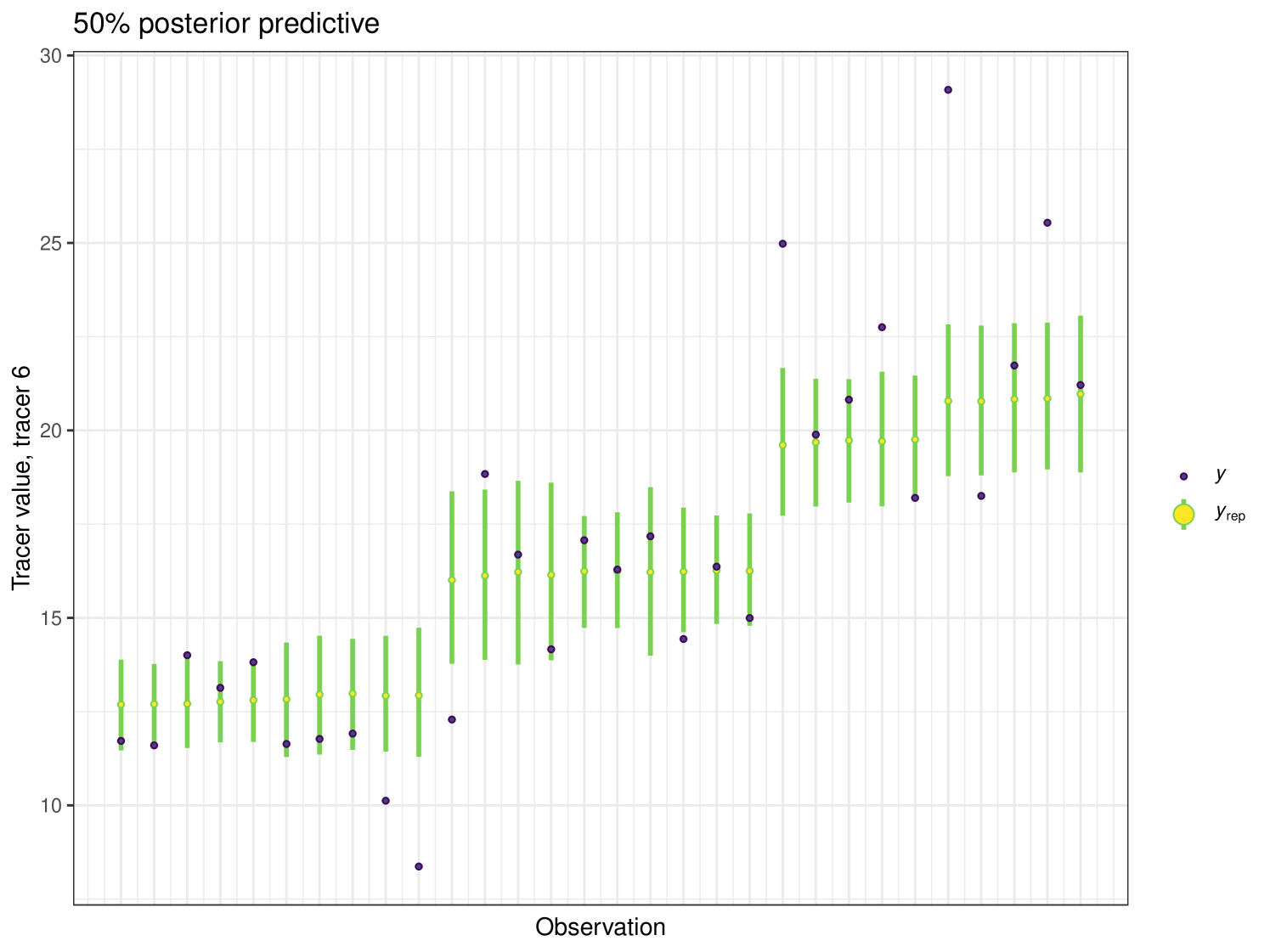
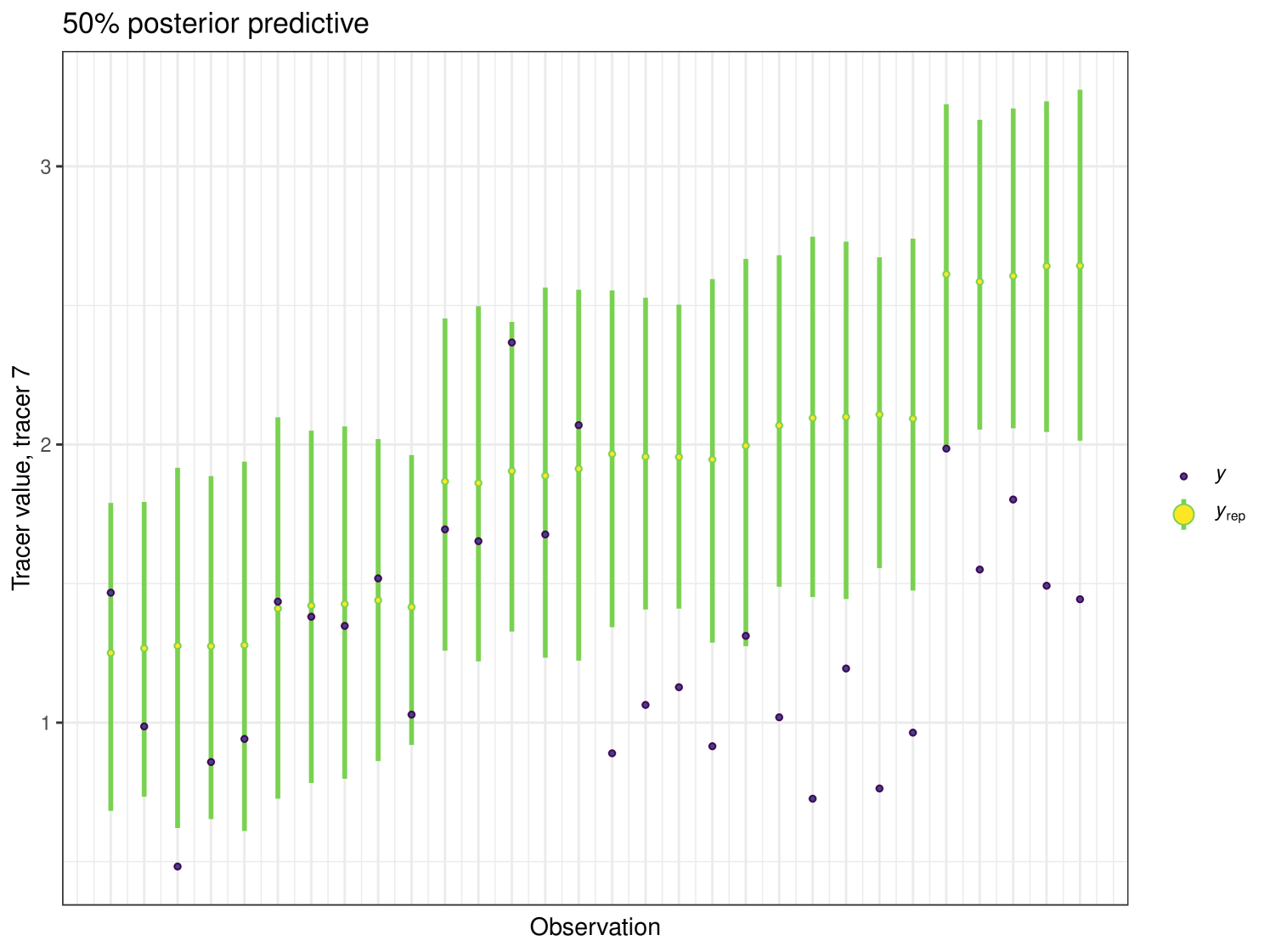
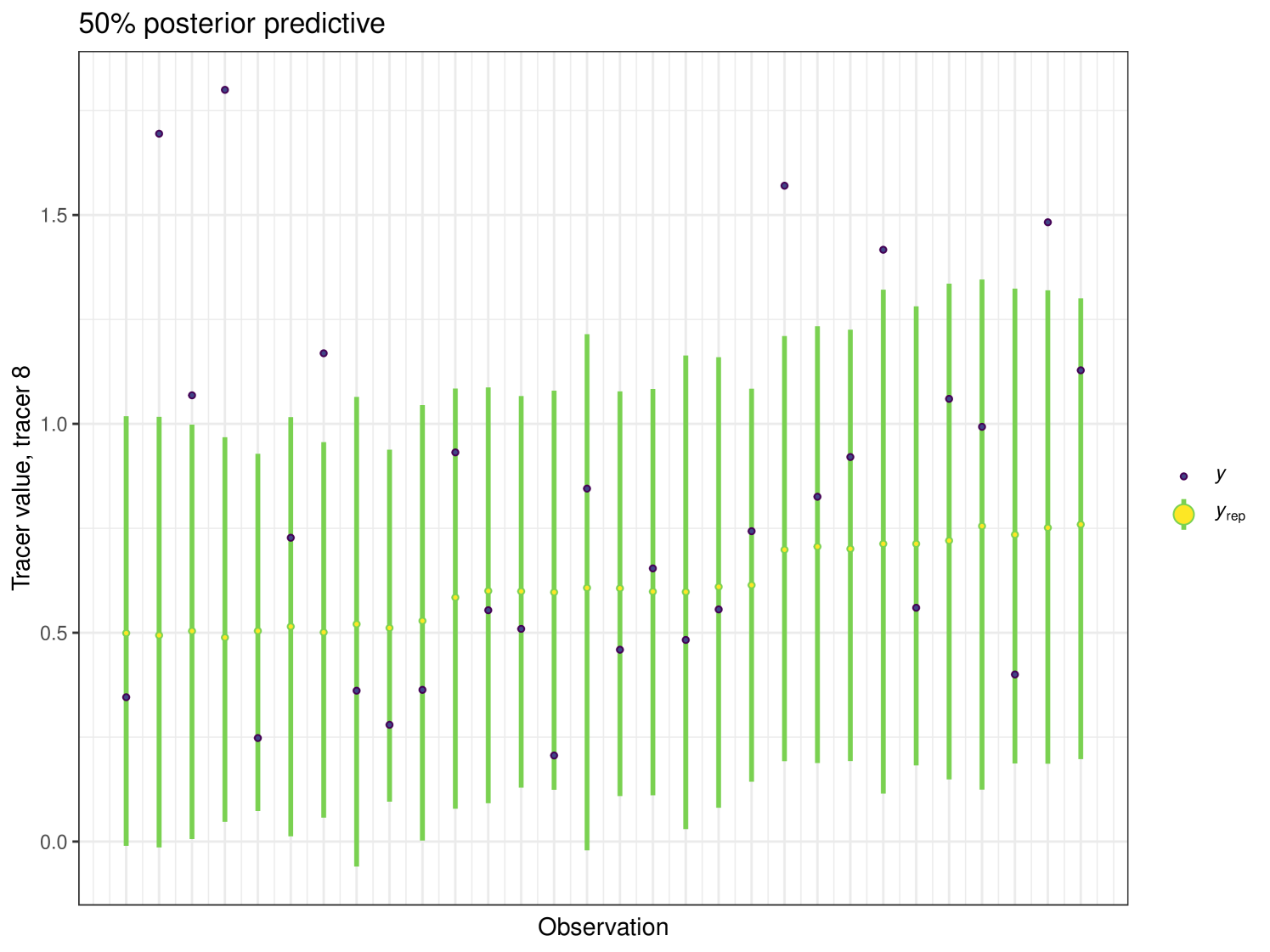
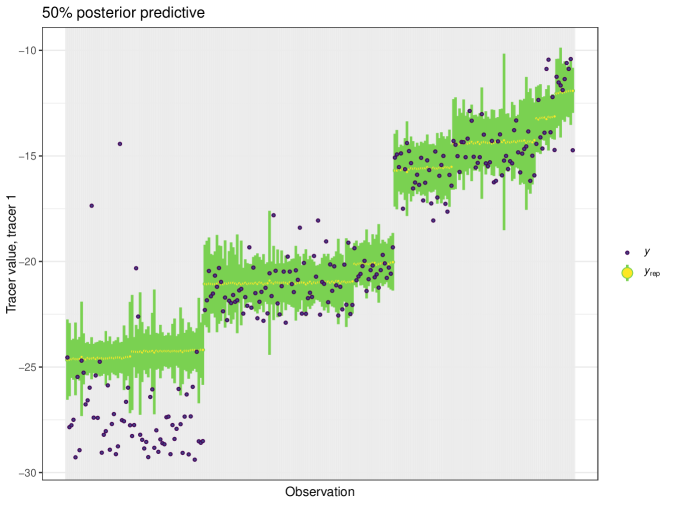
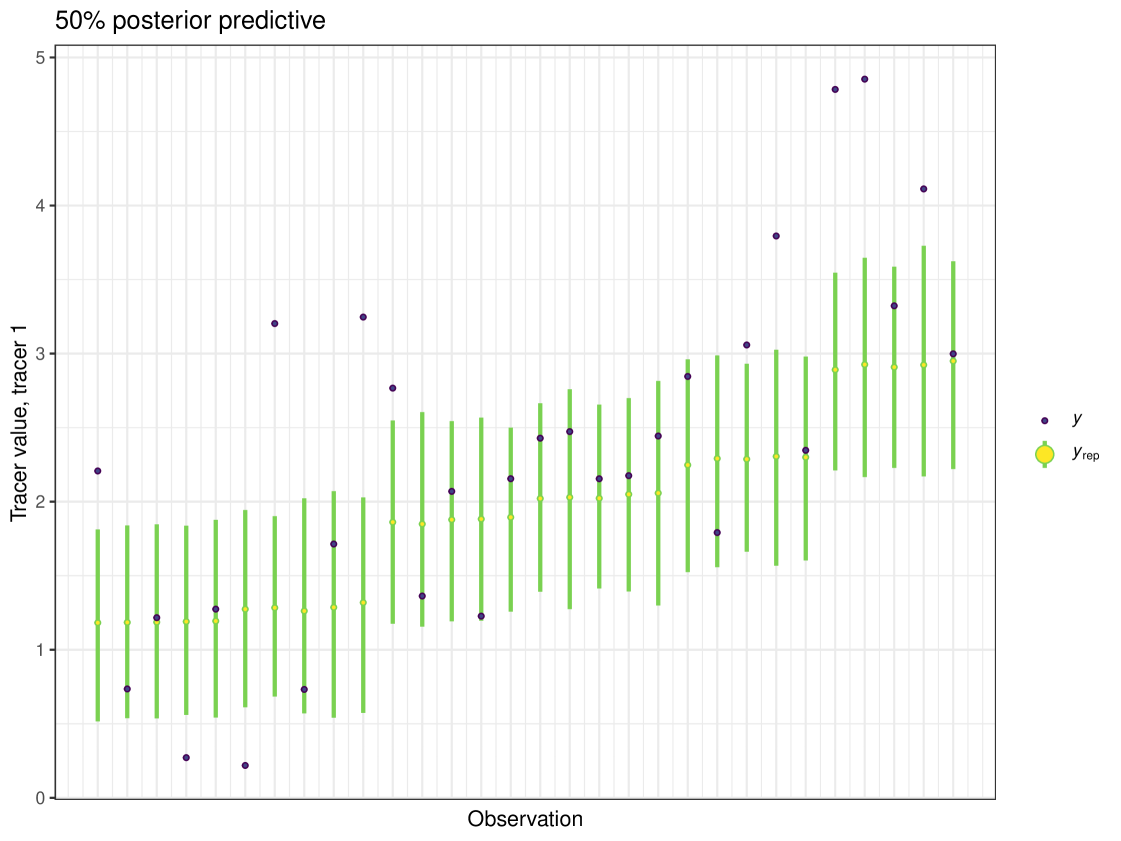
After running each model, we produce posterior uncertainty intervals at the 50% level and calculate the proportion of posterior samples inside these values. As an example, the posterior predictive plot for tracer 1 in the Medium run is shown in Figure 6. Posterior predictive plots for other simulations and tracers are found in the Appendix B (Figures 20, 21 and 22).
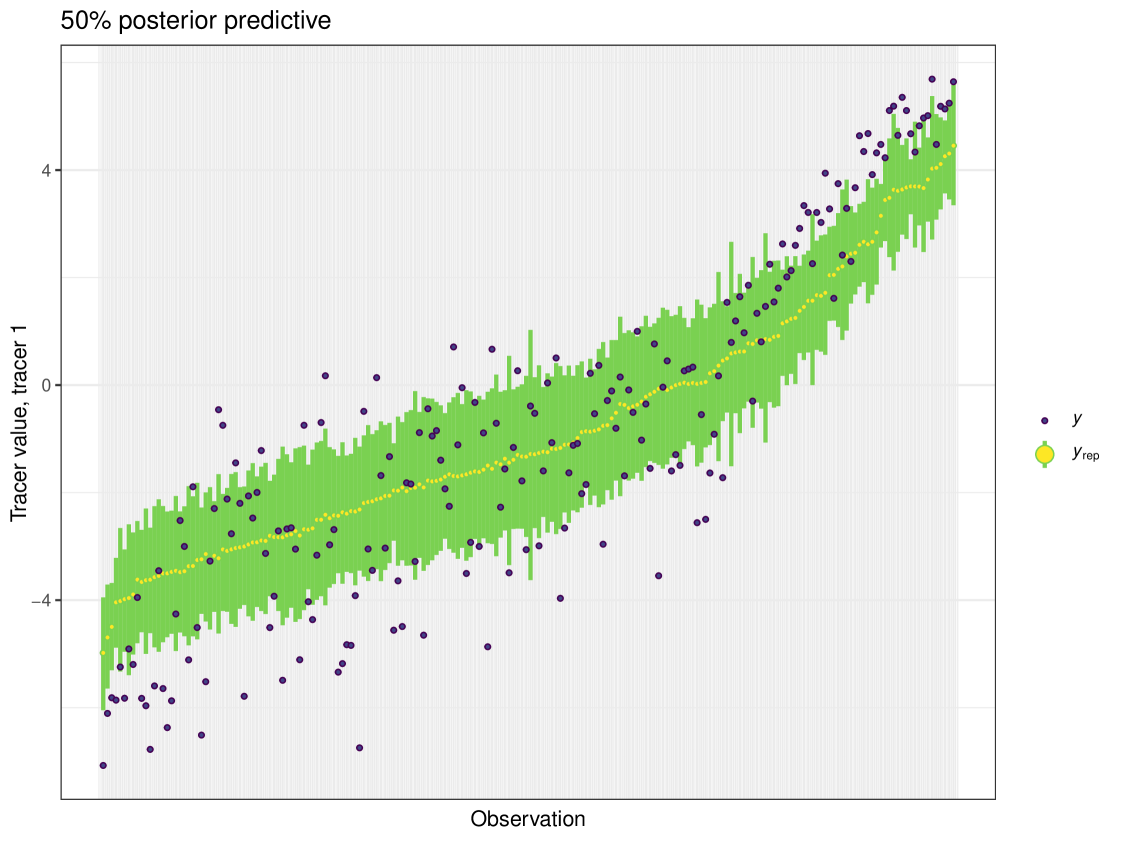
The results show that cosimmr produces accurate estimates for the posterior values, even with more complex data and increased numbers of tracers and covariates.
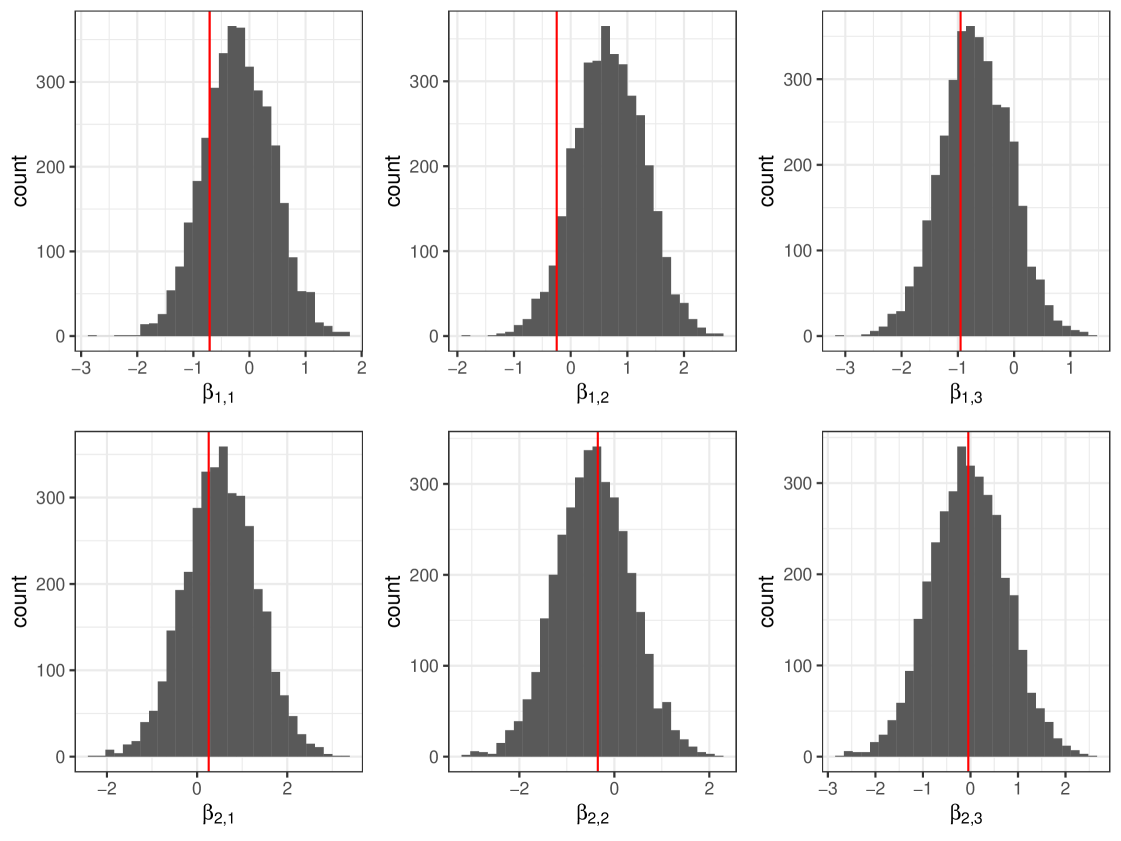
We show an example posterior distribution of in Figure 7 for the ‘Low’ run. From Figure 7 we can see that cosimmr is performing well and producing values similar to the original values used to generate data for this example, as illustrated by the red lines visible on the plots. This holds true for the Medium and High examples. Plots are omitted to avoid repetition.
7 Case Studies
We now perform a direct comparison of cosimmr and MixSIAR to evaluate both the accuracy of the FFVB posterior and check the computational gains. We provide three case studies: the first using the Geese data of Inger et al. (2006), for which we include a single categorical covariate (Group number). The second uses the Isopod data of Galloway et al. (2014) which contains 8 tracers and a single covariate (Site). The third uses the Alligator data of Nifong et al. (2015), for which we provide a detailed model comparison across 8 different potential covariate panels. In each case we compare the posterior distributions of the parameters, the posterior predictive performance, and the computational speed differences. All of the data for our model fits is available in the cosimmr package, available at \urlhttps://github.com/emmagovan/cosimmr and on CRAN, and the code for running the models is available at \urlhttps://github.com/emmagovan/cosimmr_paper.
7.1 Geese data (Inger et al., 2006)
Our first example looks at the Brent Geese (Branta bernicla hrota) dataset originally from Inger et al. (2006). The covariate in this example is ‘Group’ which is discrete. There are eight different groups which represent different time points at which individuals were sampled. and are the two isotopes used in this study. The iso-space plot for this data is seen in Figure 8. TDFs and concentration dependence are accounted for in this model.
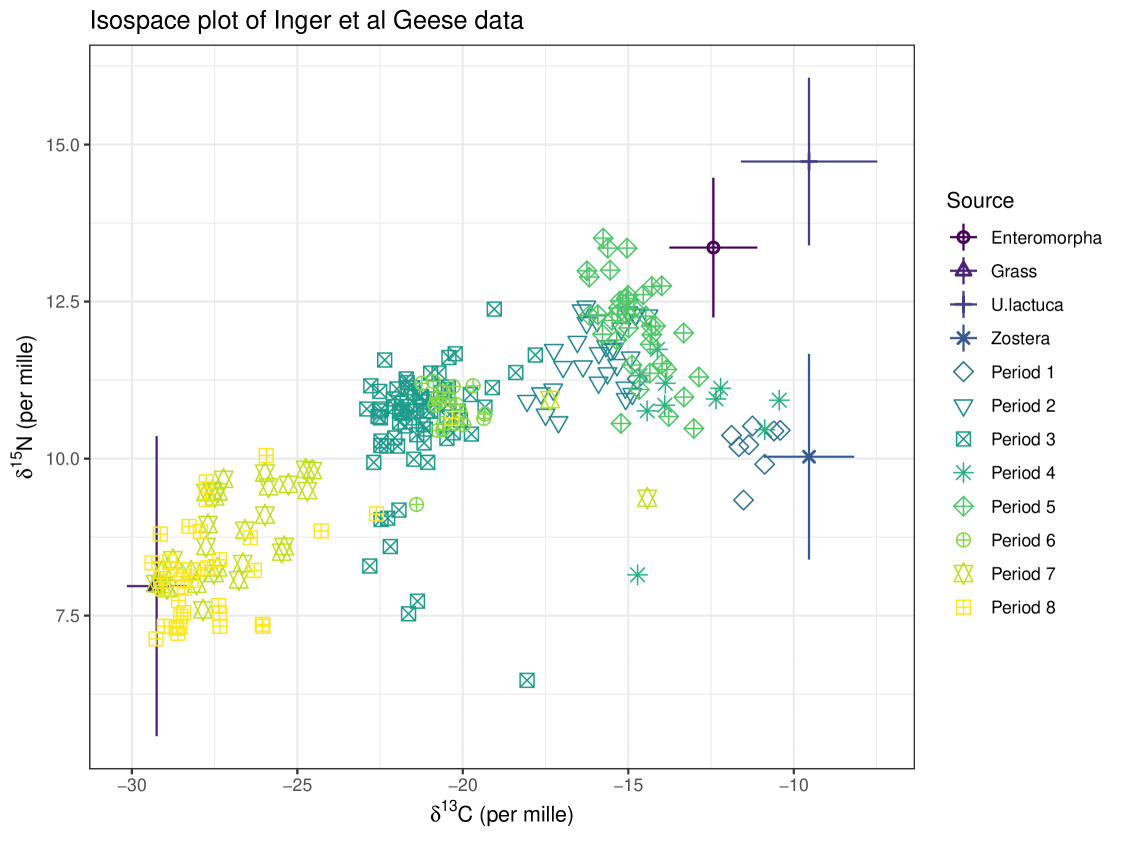
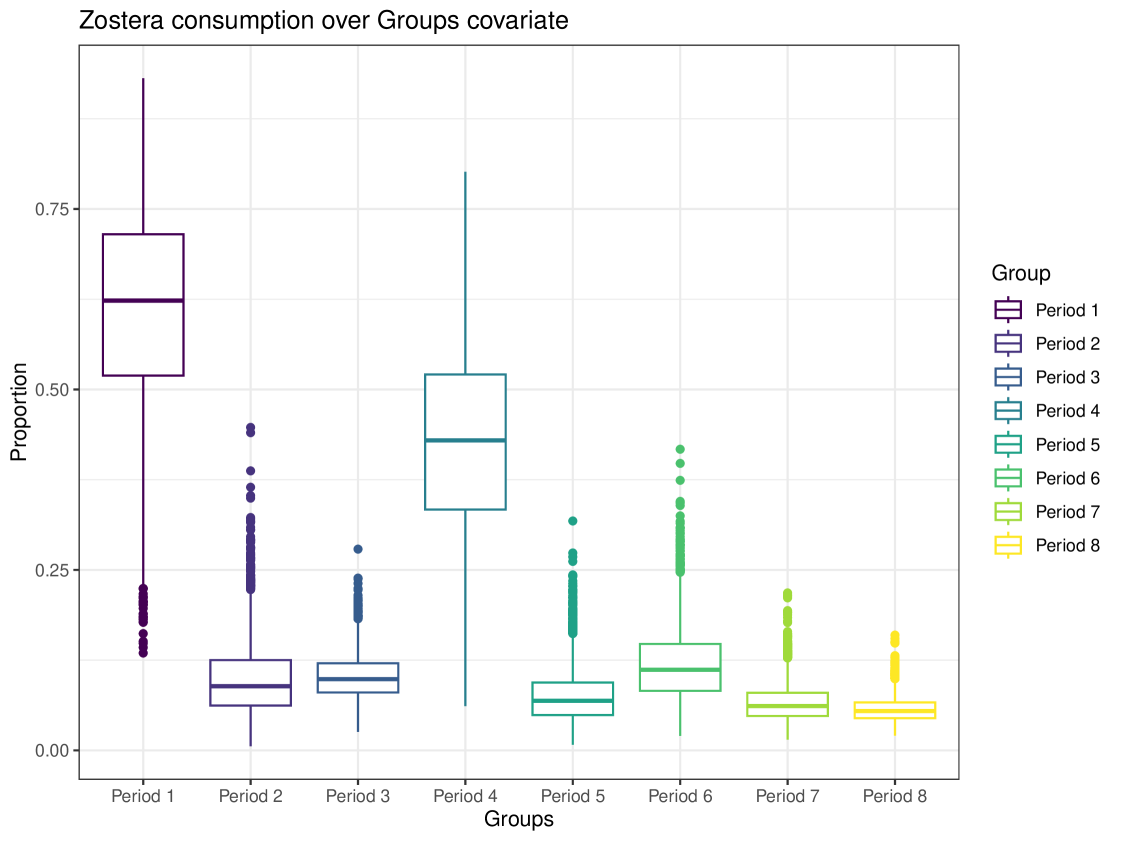
By looking at the Group covariate and how the proportion of each food in the diet of the geese differs between groups, we can see how their diet changes over time. This example highlights the usefulness and importance of covariates in SIMMs. The time of year influences the diet of these geese. They are known to consume Zostera spp. between October and December at Strangford Lough (where these data were collected), and as time passes the geese remaining on the lough consume more Enteromorpha spp. and Ulva lactuca (Mathers and Montgomery, 1997). To exclude time as a covariate in this example would violate the assumption that the data are IID, as their diets are influenced by the time of year, and consequently, by what food is easily available to the geese.
For this example, the Geese data was run through both cosimmr and MixSIAR. For MixSIAR a ‘long’ run was needed for convergence. The first thing to note from these model runs is that cosimmr produces these results in a much quicker timeframe than MixSIAR, as we can see in Table 6. cosimmr is over three times faster than MixSIAR for this example. The ‘Group’ covariate is discrete and therefore in cosimmr it is treated as eight covariates when transformed into numeric covariates. Therefore this example is slower in cosimmr than other examples with only one numeric covariate. The code for using a categorical covariate in cosimmr is demonstrated below:
R> data(geese_data)
R> cosimmr_geese_in = cosimmr_load(
formula = geese_data$mixtures ~ as.factor(geese_data$groups),
source_names = geese_data$source_names,
source_means = geese_data$source_means,
source_sds = geese_data$source_sds,
correction_means = geese_data$correction_means,
correction_sds = geese_data$correction_sds,
concentration_means = geese_data$concentration_means)
| min | lq | mean | median | uq | max | neval | |
| cosimmr | 29.5 | 30.4 | 38.0 | 33.7 | 45.0 | 61.2 | 10 |
| MixSIAR | 113.6 | 121.5 | 130.1 | 124.5 | 139.3 | 155.3 | 10 |
As well as comparing computational time, it is important that cosimmr produces results that are comparable to other SIMM software. From looking at Figure 9 we can see that cosimmr and MixSIAR produce comparable results in terms of proportional estimates. These figures show the estimated dietary proportions for group 1. We can see that both cosimmr and MixSIAR produce similar estimates for the percentage that each food makes up in the diet of the first group. This result holds for the other seven groups in this dataset. Differences in results may be due to a slight difference in error structure between cosimmr and MixSIAR.
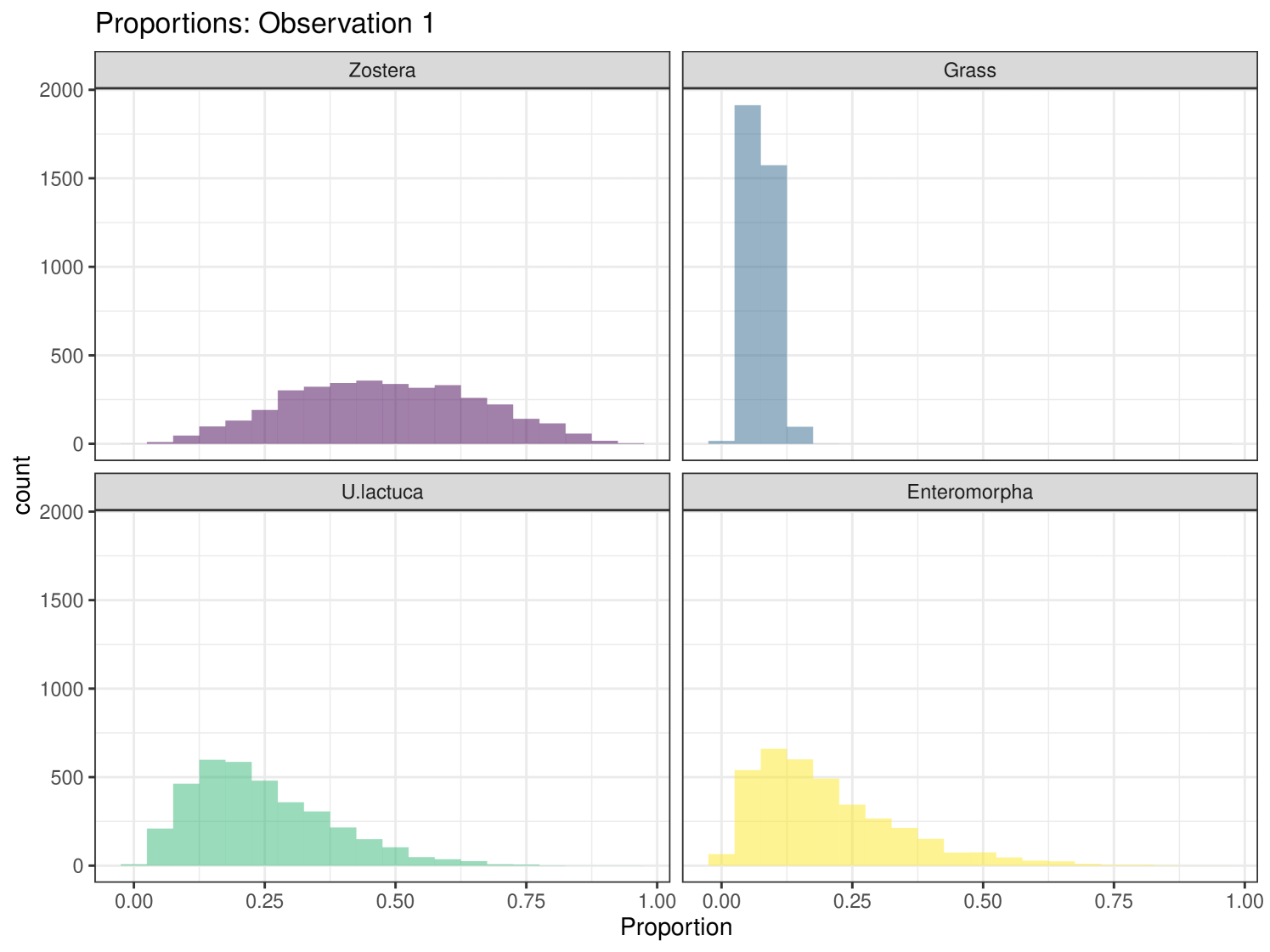
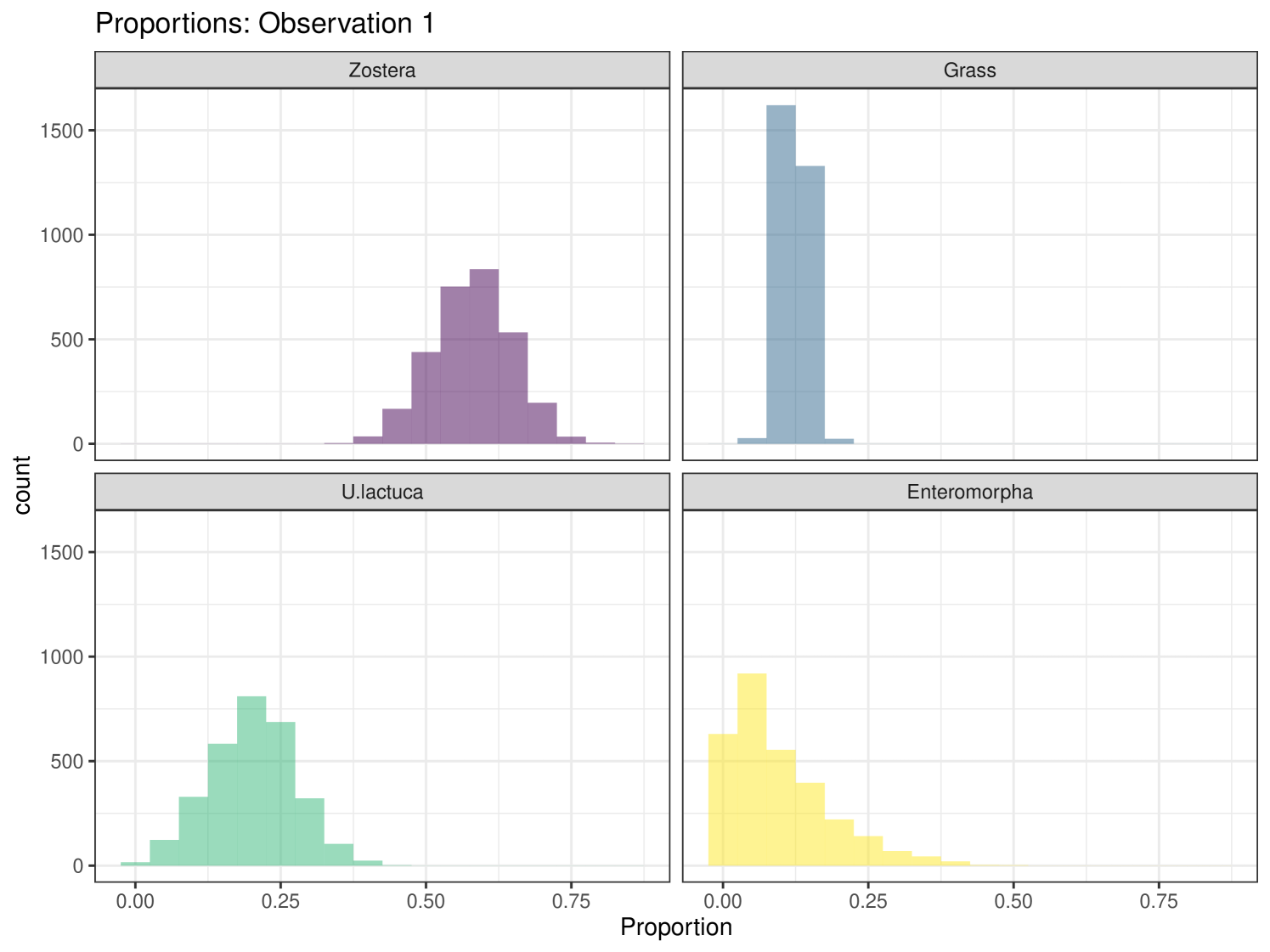
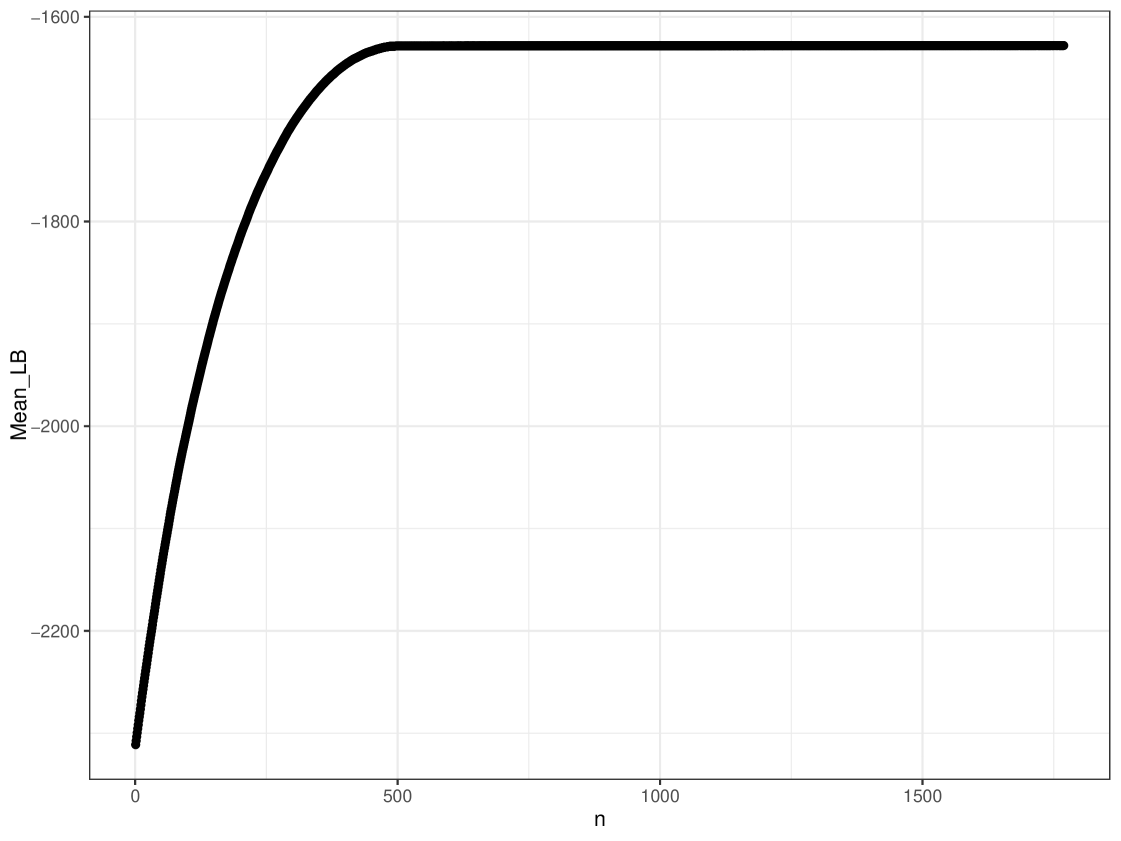
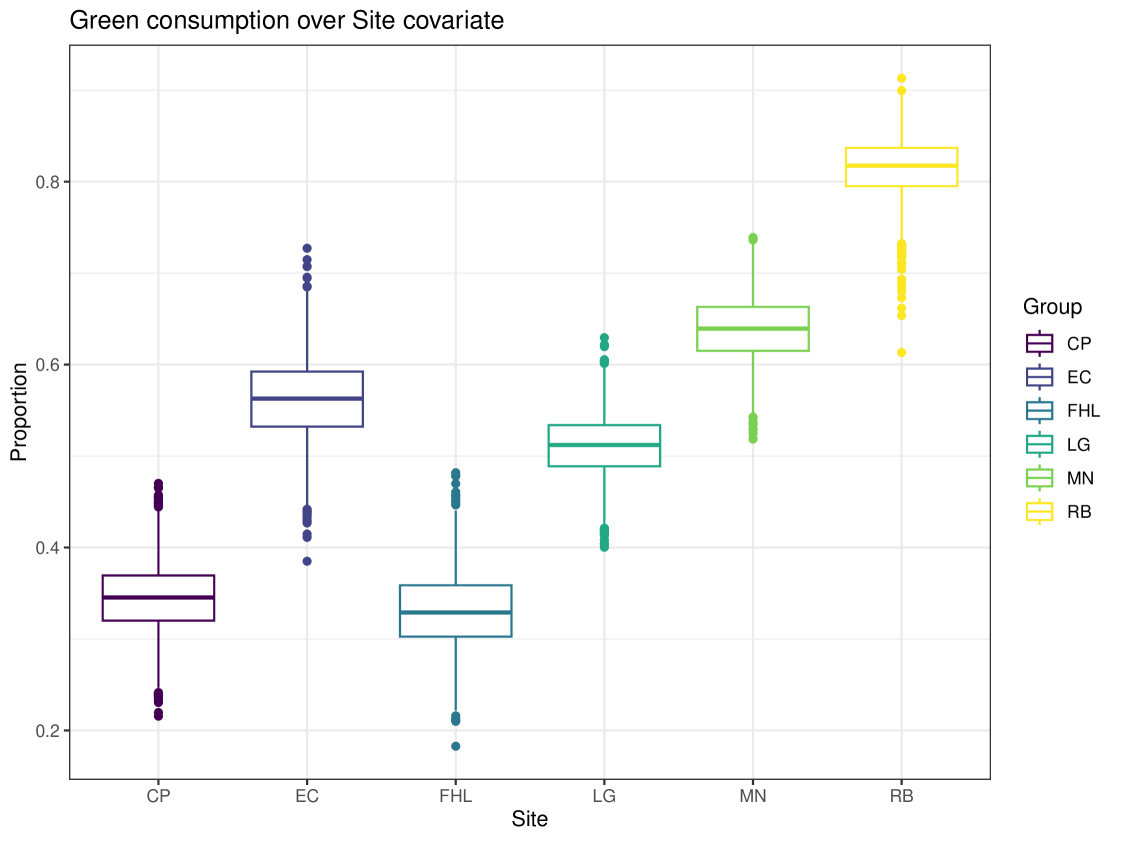
We can generate more complex plots using the plot function in cosimmr, to see how the consumption of a specific food changes between groups. In Figure 10 we see the difference in consumption of Zostera spp. across different groups. This highlights the usefulness of including covariates, as this detail would otherwise be lost. A convergence check can be performed using the function convergence_check. This function returns the mean lower bound values produced and shows that this value converges. The result of this can be seen in Figure 11.
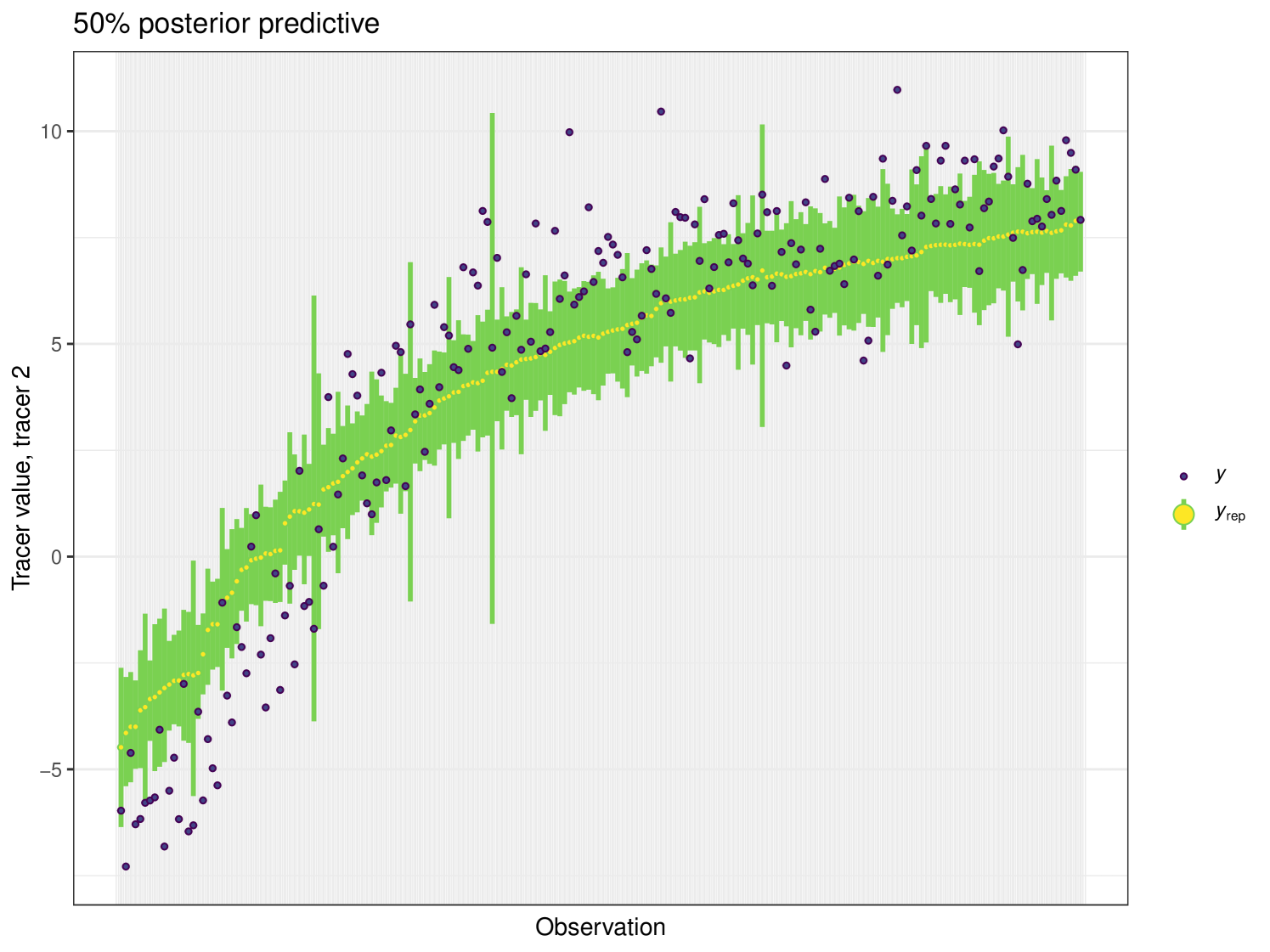
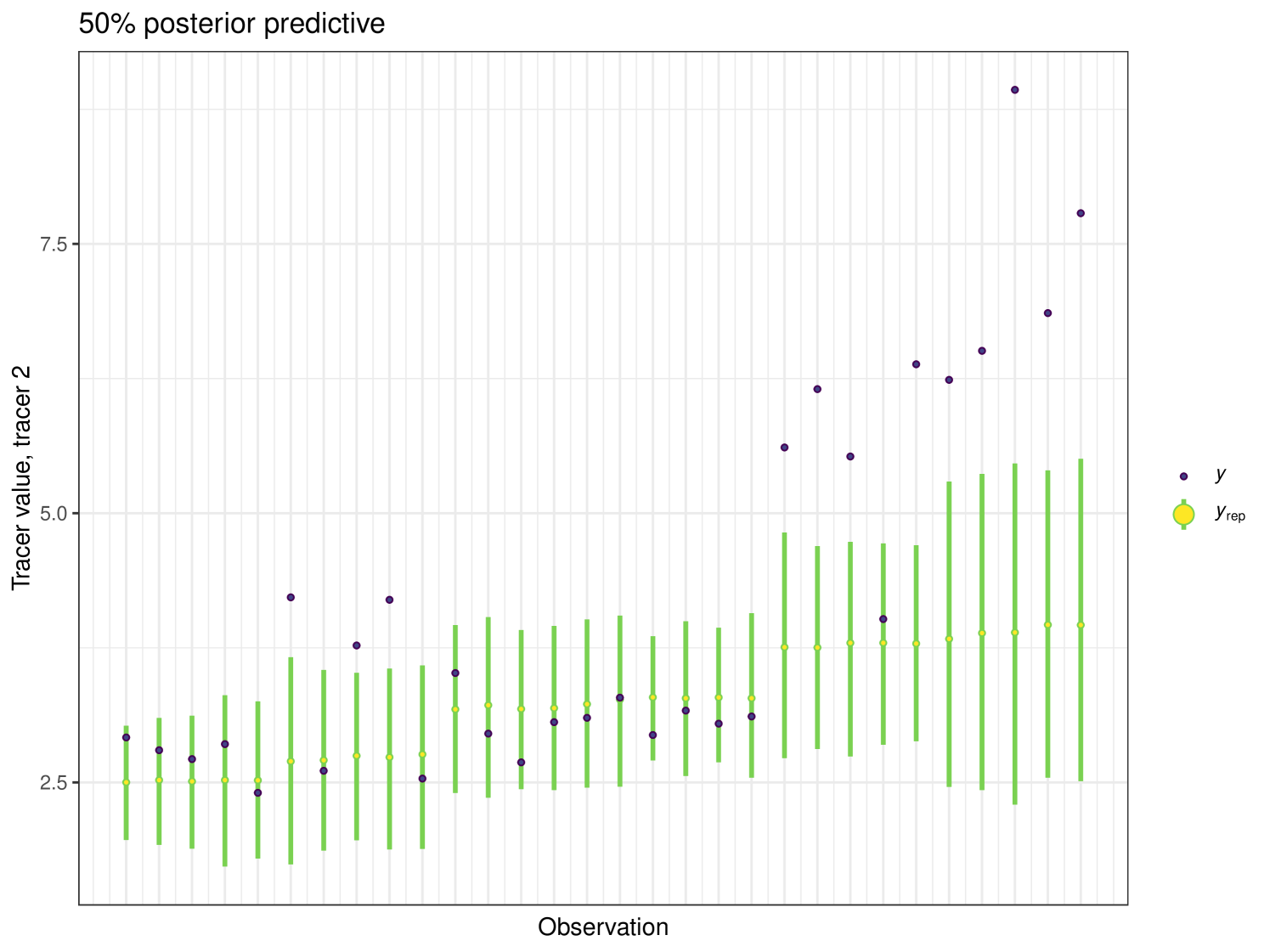
The posterior_predictive function can be used to produce a plot showing the posterior uncertainty intervals for this dataset. The produced plot is seen in Figure 12. We can see that 77% of the data lies within the 50% uncertainty intervals, showing that cosimmr is fitting the data adequately, although this value is above what we would expect. The posterior predictive values are a useful check of model fit and these are not available in other packages, so easy comparison is not available, but can be accessed using the posterior_predictive function in cosimmr. Groups 7 and 8 contain the outliers seen in Figure 12 and this may be a potential reason for these results. For 75% uncertainty intervals 87% of observations are inside these intervals and 93% are inside for 95% confidence intervals. From this example we can see the importance and usefulness of including covariates, as it allows for us to look at the diet of the geese over time to see how the proportions of different foods in their diets change as the season progresses. It also highlights observations that may require further scrutiny.
7.2 Isopod data (Galloway et al., 2014)
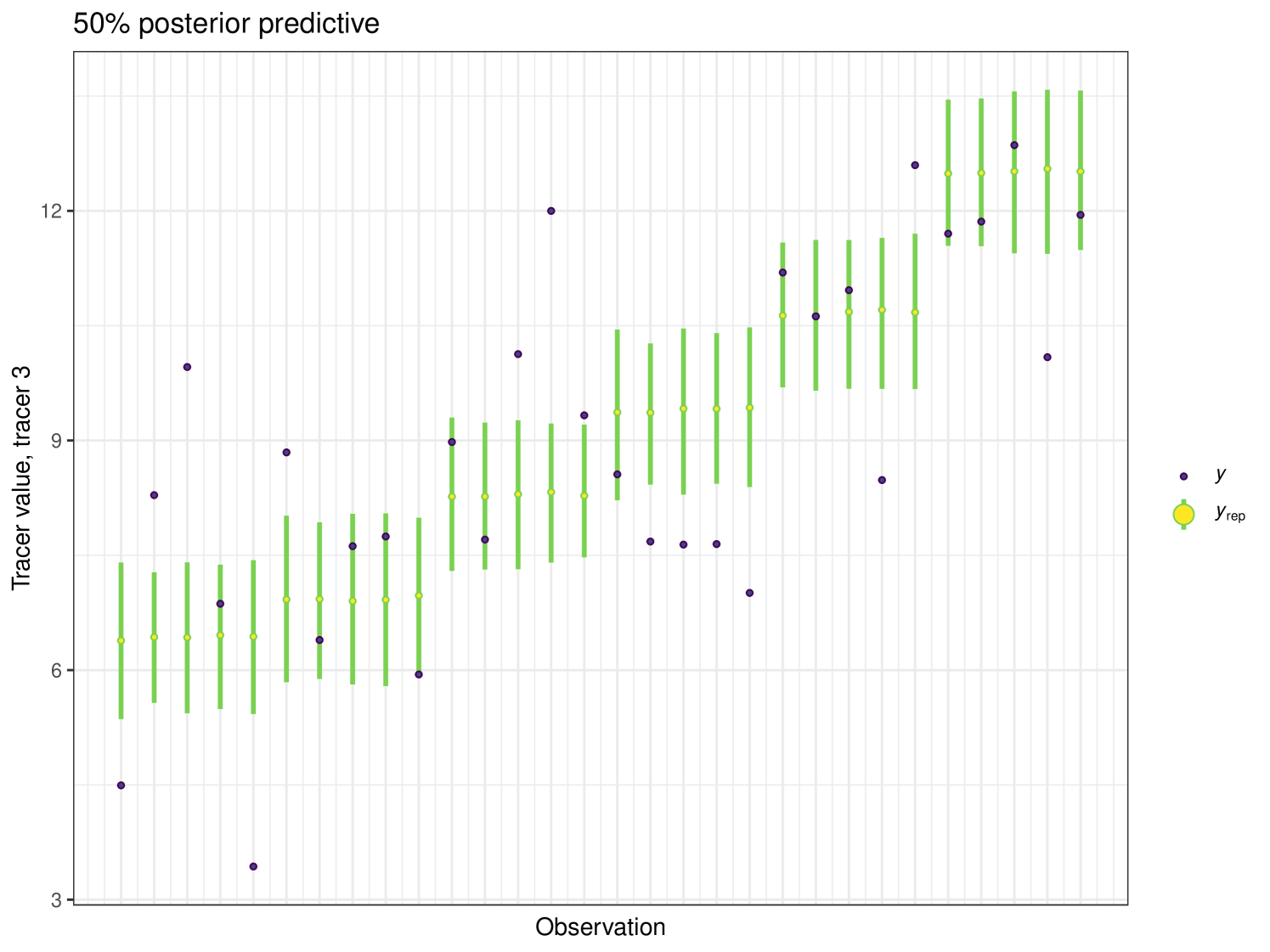
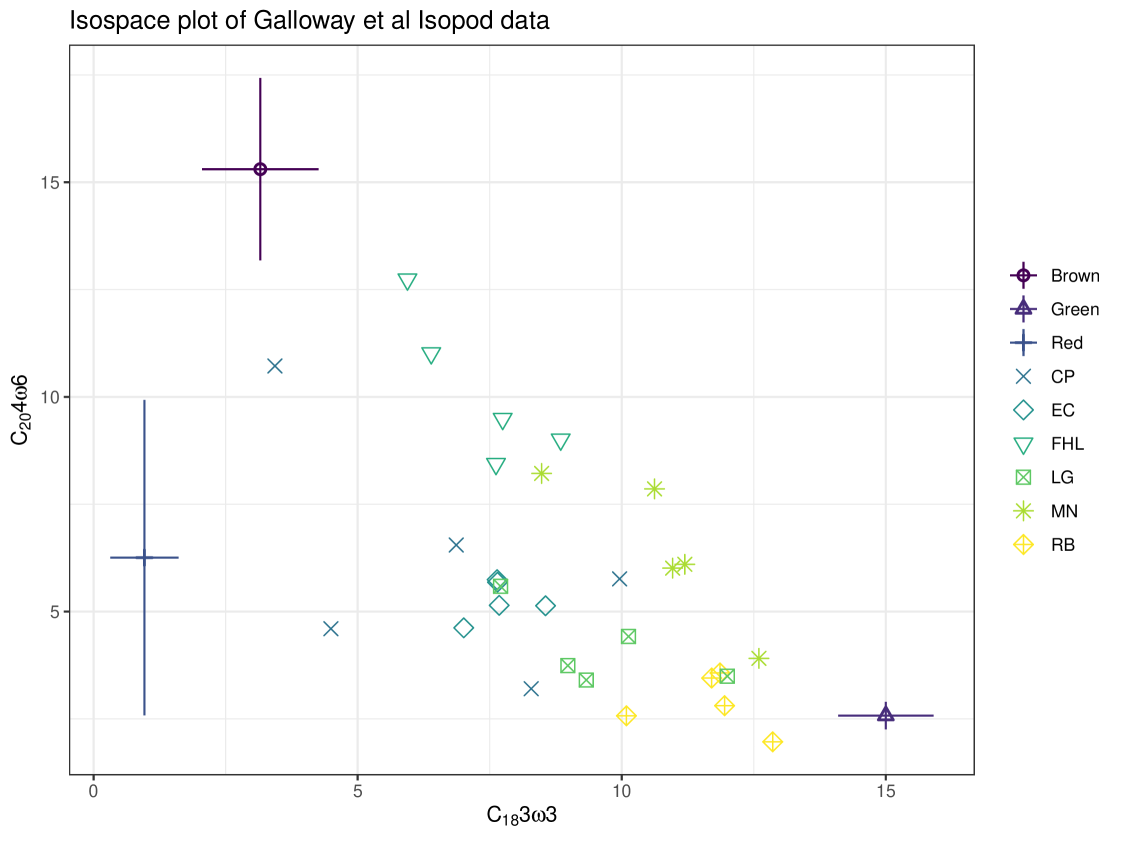
The second case study is the isopod dataset (Pentidotea wosnesenskii) from Galloway et al. (2014). Six sites were used, which varied in algal cover, and this is included as the sole covariate. Three food sources are included in this example: Green (phylum Chlorophyta), Brown (phylum Ochrophyta), and Red (phylum Rhodophyta) algae. There are eight tracers - fatty acids instead of stable isotopes, as fatty acid signatures are shown to differ significantly between algal phyla (Galloway et al., 2012). An iso-space plot for these data is seen in Figure 13, which is 2-dimensional and can therefore only show two of the eight tracers. cosimmr allows for users to specify which tracers they would like to plot in the iso-space plot. More than two tracers can make it difficult to check visually that all individuals lie within the multidimensional mixing polytope so caution is needed to ensure accurate TDFs are included and all relevant food sources are included. The posterior predictive plots can be particularly helpful when using 2 tracers to discover problem observations (or tracers themselves) because these are available per tracer as opposed to per pair of tracers in the iso-plot.
As in the previous example, comparing the proportion estimates for cosimmr and MixSIAR (Figure 14) across different covariates levels, we can see that both are returning similar estimates, with cosimmr returning those estimates in a much shorter time (Table 8). A ‘normal’ run in MixSIAR was enough to ensure convergence with this model. Numerical results are presented for both cosimmr and MixSIAR in Table 7. Slight differences in results may be due to the fact MixSIAR treats Site as a random effect vs cosimmr treating it as a fixed effect.
| Programme | Source | 25% | 50% | 75% |
| cosimmr | Green | 0.322 | 0.345 | 0.370 |
| MixSIAR | Green | 0.362 | 0.401 | 0.437 |
| cosimmr | Brown | 0.214 | 0.248 | 0.287 |
| MixSIAR | Brown | 0.095 | 0.144 | 0.196 |
| cosimmr | Red | 0.372 | 0.401 | 0.431 |
| MixSIAR | Red | 0.411 | 0.454 | 0.495 |
| min | lower quartile | mean | median | upper quartile | max | no. evaluations | |
| cosimmr | 418 | 455 | 587 | 582 | 748 | 791 | 10 |
| MixSIAR | 1182 | 1246 | 1268 | 1283 | 1292 | 1298 | 10 |
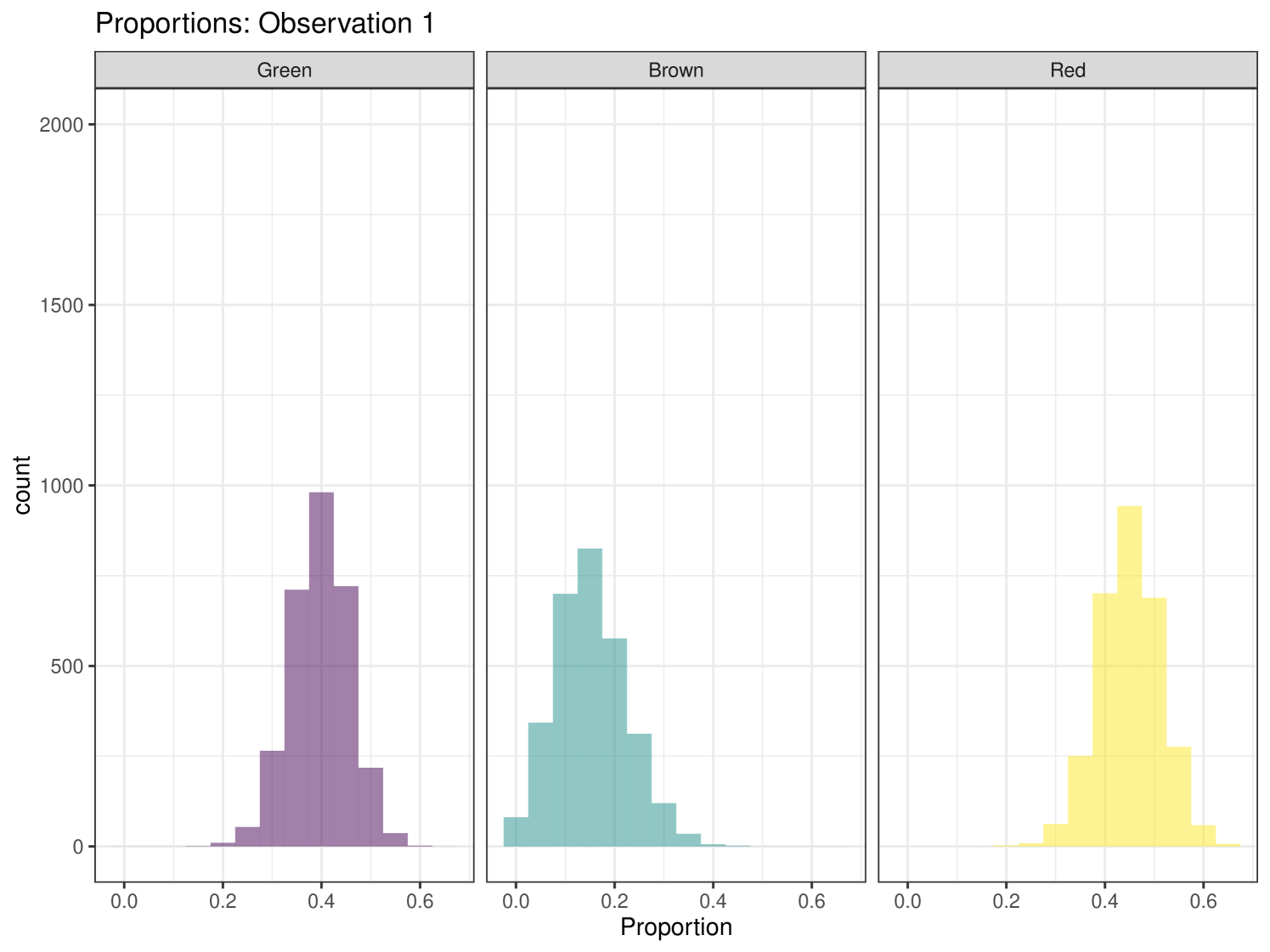
The importance of the covariate in this example is seen in Figure 15. This plot shows the difference in average consumption of Green algae across different sites. This allows us to see the importance of the included covariate and how it affects the dietary proportions of individuals at that site.
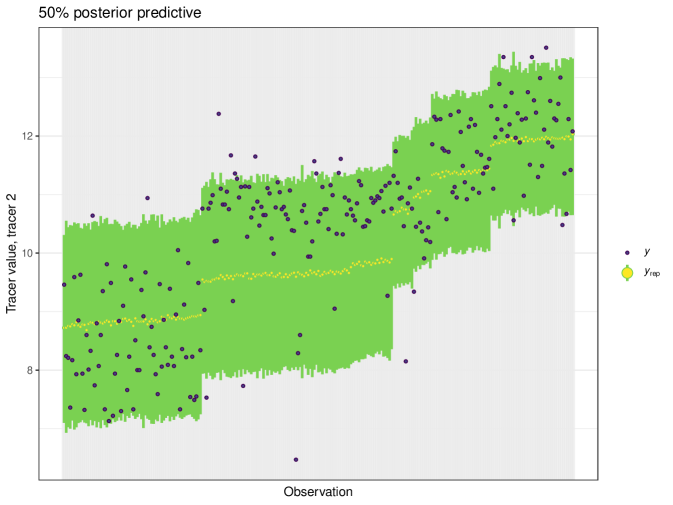
The posterior predictive plot can be produced using the posterior_predictive function. The resulting plot for tracer 1 can be seen in Figure 16. 59% of values are inside the 50% interval for this overall run. The posterior predictive for the other tracers can be viewed in the Appendix (Figure 24).
This example highlights the computational efficiency of cosimmr over MixSIAR and other SIMM software. cosimmr is producing similar results to other SIMMs for this example, but is much quicker thanks to the use of FFVB.
7.3 Alligator data (Nifong et al., 2015)
The final example utilises alligator (Alligator mississippiensis) data from Nifong et al. (2015). In this example we run 8 alternative models with both cosimmr and MixSIAR, where each model utilises a different combination of covariates, and determine the best model fit, with the aim being that both algorithms present the same model as the best fit. The eight models are described in Table 9.
| Model | Covariate(s) |
| 1 | NULL |
| 2 | Habitat (Fresh, Intermediate, Marine) |
| 3 | Sex (Male, Female) |
| 4 | Sclass (Small Juvenile, Large Juvenile, Sub-Adult, Adult) |
| 5 | Length (continuous effect) |
| 6 | Sex + Sclass |
| 7 | Sex + Length |
| 8 | Sex * Sclass |
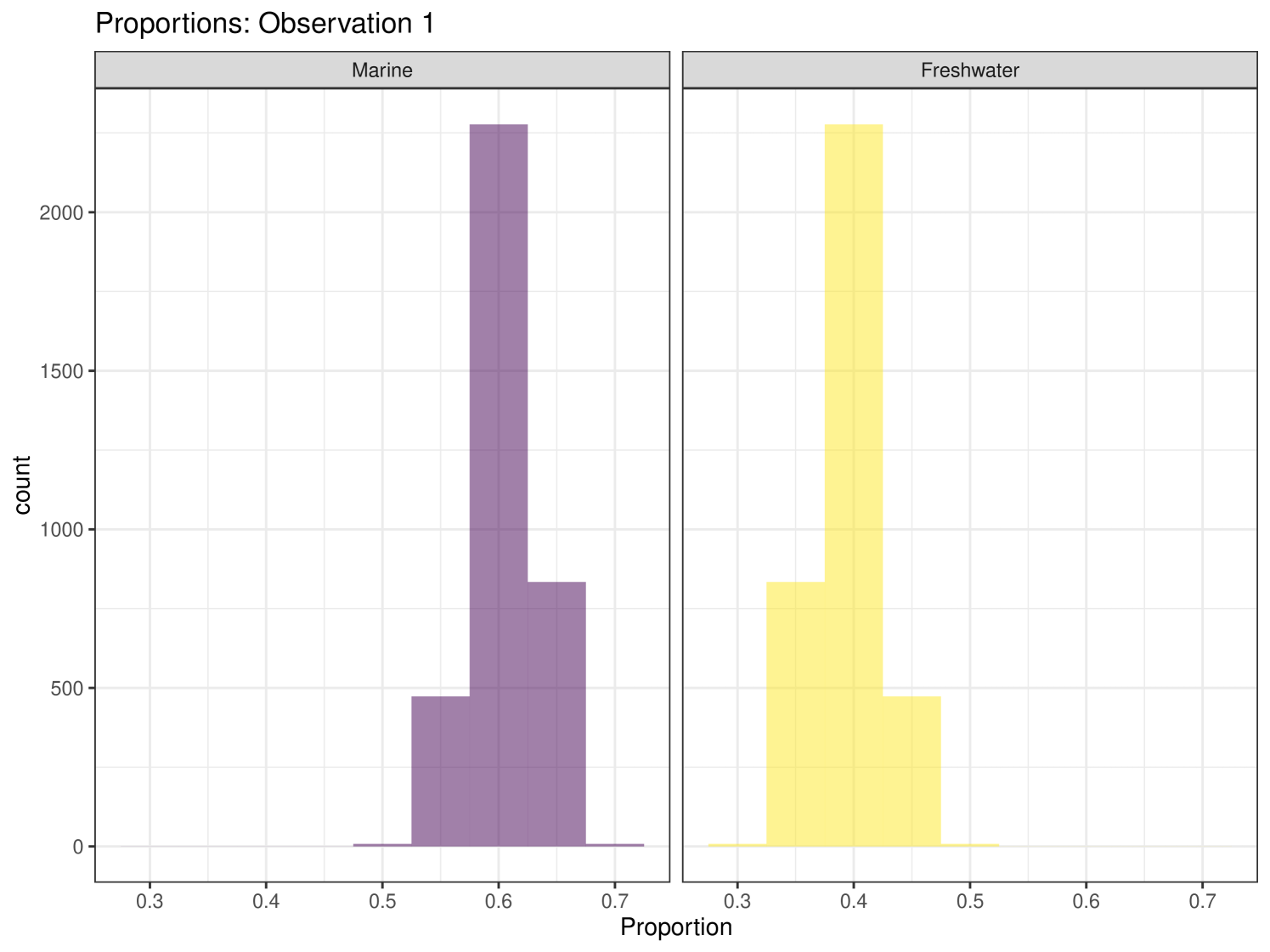
The iso-space data for this example can be seen in Figure 1. There are only two food sources in this set, Marine and Terrestrial. All food sources in this example were grouped into one of these two categories. The iso-space plot is coloured by covariate ‘Length’ (this covariate is used in Model 5 and Model 7).
All eight models were fitted in both cosimmr and MixSIAR. MixSIAR uses ‘LOO’ (leave-one-out cross validation) for choosing the best fitting model (Vehtari et al., 2024). We used the same package and method on results from cosimmr to choose the best fitting model. For both, model 5 (Length) is selected as the best model. The output of this model comparison can be seen in Table 10. The error structure of cosimmr and MixSIAR is slightly different. MixSIAR also utilises hierarchical source fitting which is not implemented in cosimmr. This may explain the slight differences in results obtained.
| cosimmr | MixSIAR | |||
| Model | looic | se_looic | looic | se_looic |
| Model 1 | 1990.9 | 31.2 | 1834.6 | 16.7 |
| Model 2 | 1943.1 | 61.0 | 1747.9 | 28.8 |
| Model 3 | 2072.8 | 45.6 | 1831.3 | 17.6 |
| Model 4 | 1833.3 | 60.0 | 1687.5 | 31.8 |
| Model 5 | 1754.1 | 41.8 | 1678.3 | 31.3 |
| Model 6 | 1844.7 | 57.5 | 1689.2 | 31.5 |
| Model 7 | 1822.5 | 54.6 | 1681.2 | 31.4 |
| Model 8 | 1770.8 | 37.8 | 1690.4 | 29.8 |
We can compare the output of both cosimmr and MixSIAR and see that they are returning comparable results. In Figure 17 we plot the estimates for Model 5 for observation 1, an individual alligator of length 186 cm. Comparing the time for both runs shows that cosimmr is approximately 10 times faster (See Table 11). The ‘short’ version of MixSIAR is a long enough run for convergence for this example.
| min | lower quartile | mean | median | upper quartile | max | ||
| cosimmr | 111 | 121 | 126 | 127 | 132 | 140 | 10 |
| MixSIAR | 1330 | 1349 | 1383 | 1379 | 1410 | 1449 | 10 |
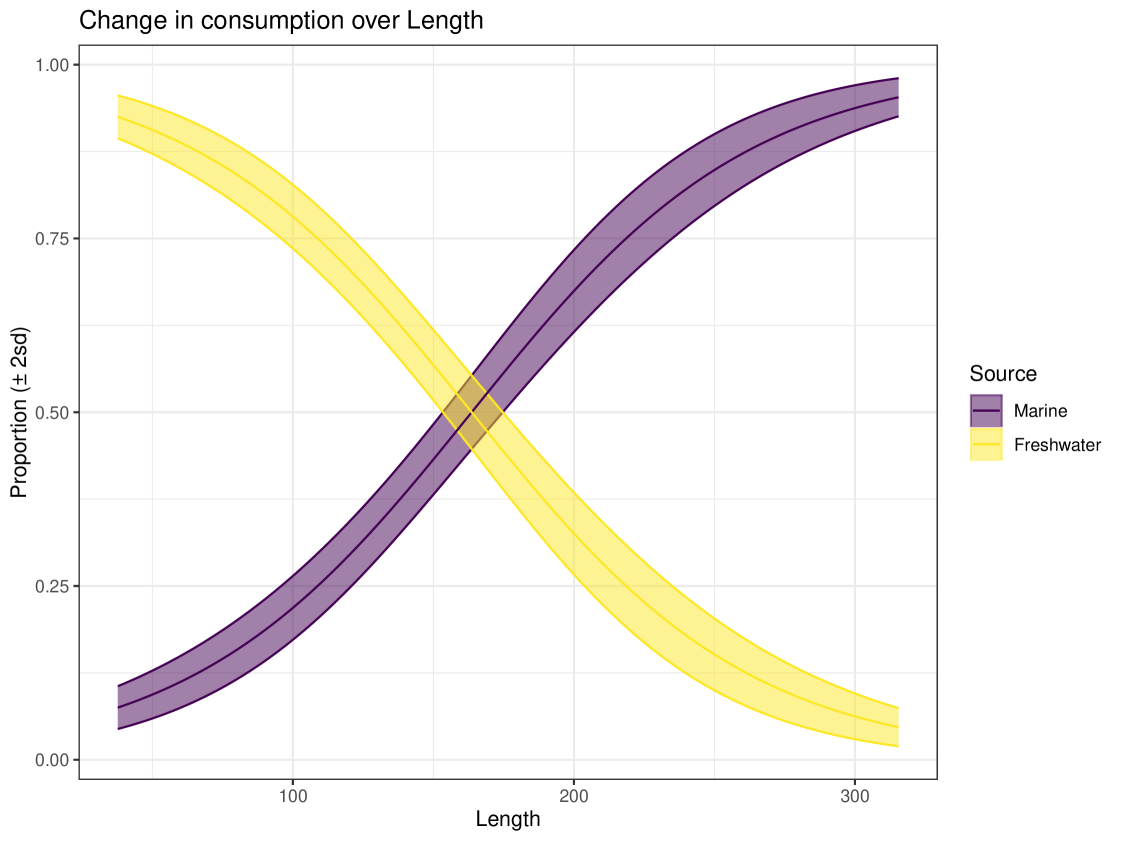
Figure 18 shows the predicted consumption of each food source varying with Length. The variable Length was provided to the predict function as a regular grid. This figure highlights why covariates can be a useful tool in SIMMs, as without covariates we get an average diet across all individuals. By including Length as a covariate, we get a much deeper insight into the animals diet. We can see that as an individual increases in length, it increases its consumption of Marine sources and consequently its consumption of Freshwater sources drops. Marine consumption increases from below 10% to above 90%. These findings agree with stomach content analysis performed by Nifong et al. (2015).
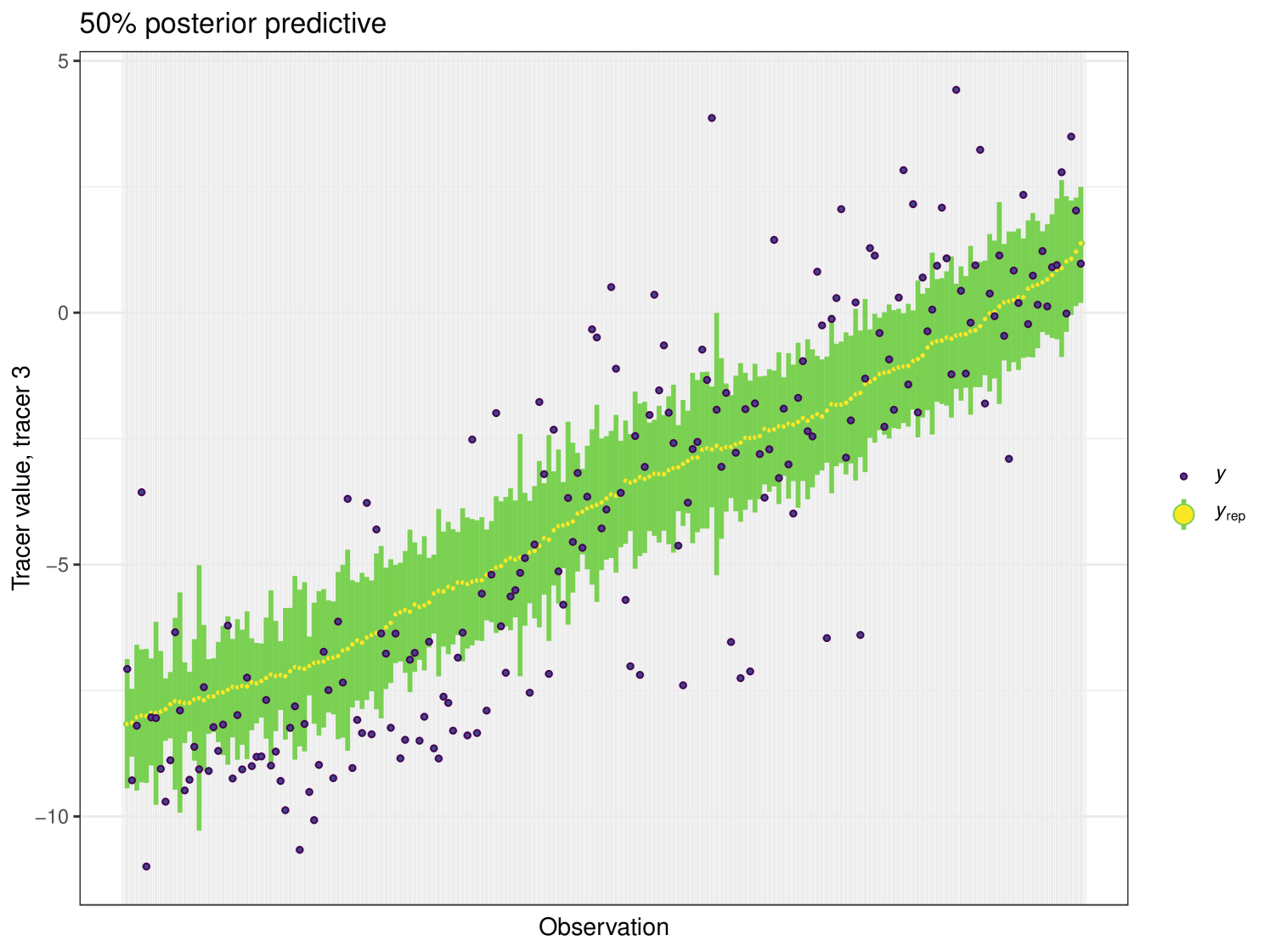
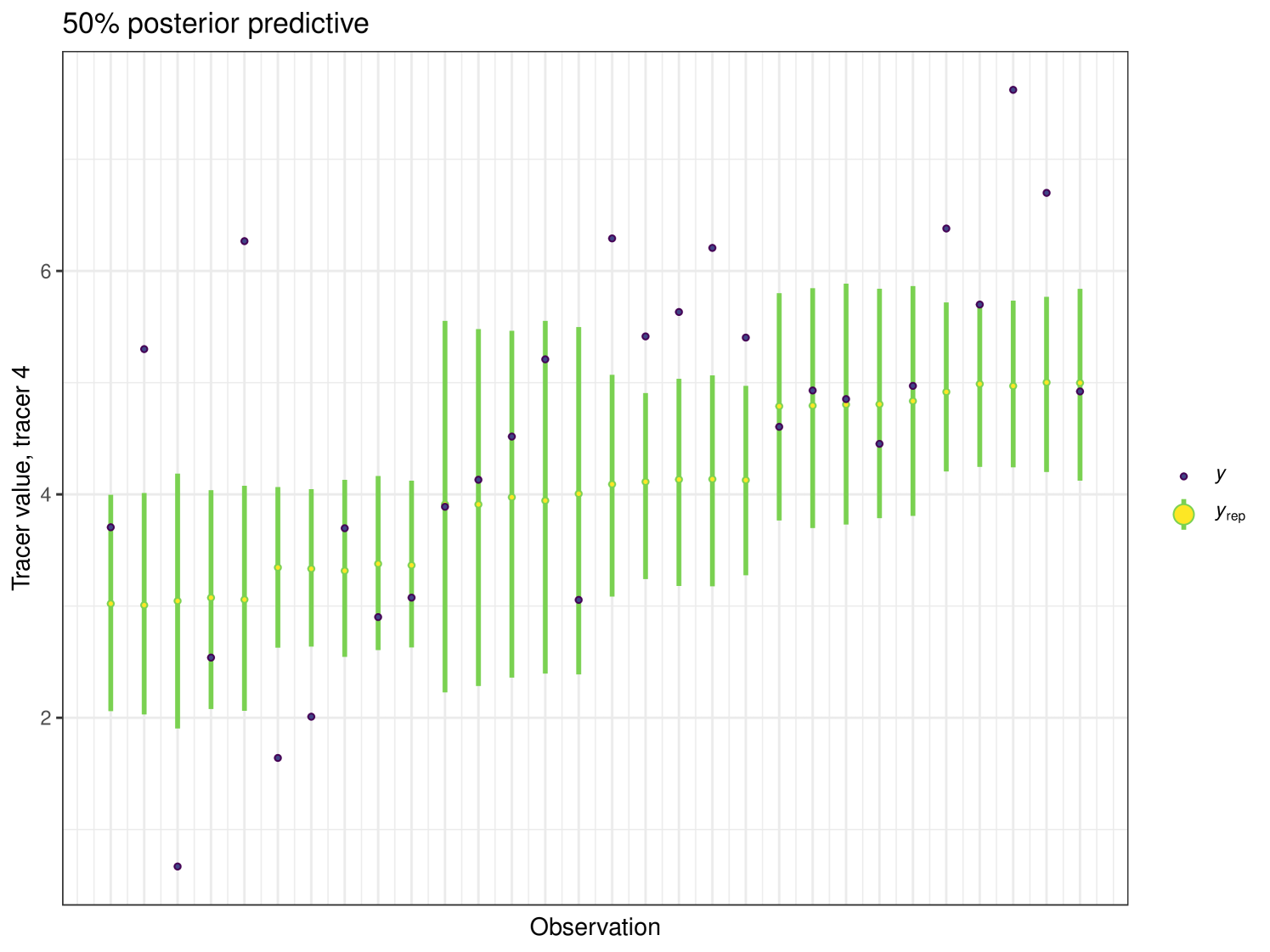
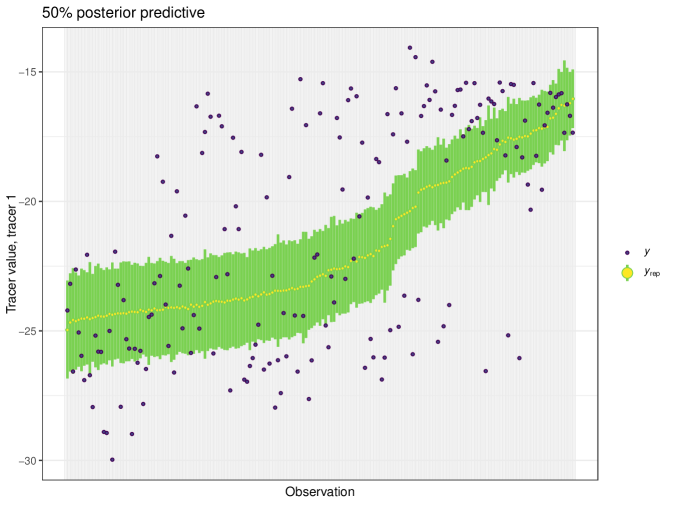
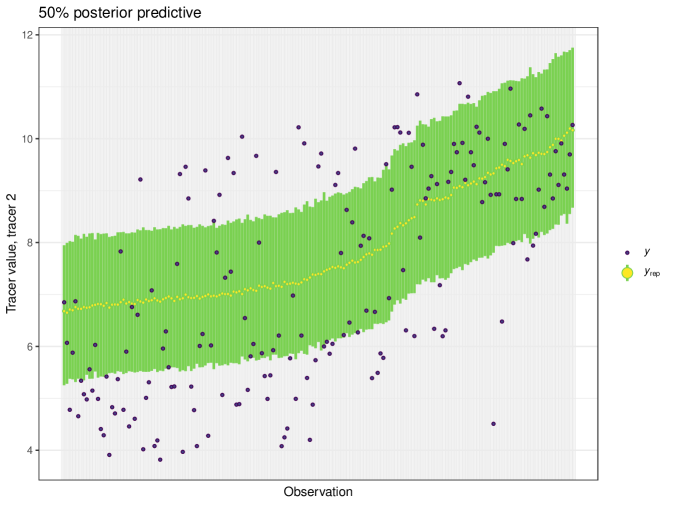
For this example we generate a posterior predictive plot, seen in Figure 19. Here for a 50% interval 42% of individuals lie inside. For a 75% interval 87% of individuals lie inside and this climbs to 93% for the 95% interval. This indicates a good level of fit for this model. Like previous examples, the posterior predictive plot highlights outliers and points that lie far outside the 50% interval. This is an indicator that these observations may require further scrutiny.
This example highlights the computational efficiency of cosimmr. The ten-fold increase in performance speed of cosimmr over MixSIAR highlights the high value of this package for those fitting multiple models. We see that the package produces comparable results to MixSIAR, both in terms of proportional output as well as when multiple models are compared against each other. The addition of the posterior_predictive function provides strong guidance (not available in other packages) as to how well the model is fitting, as well as highlighting observations for further inspection.
8 Conclusions
Fixed Form Variational Bayes is a novel technique within the field of Stable Isotope Mixing Models. It is an optimization-based algorithm which contrasts with the sampling-based approaches traditionally used in SIMMs, such as MCMC. FFVB works by estimating a variational posterior which approximates the true posterior. Through the examples presented in this paper we have demonstrated that it performs as well as MCMC in terms of results produced, while also offering a significant speed improvement of up to one order of magnitude.
The use of FFVB over MCMC allows users to run more complex models in a shorter time. Alternatively it may allow users to compare more models across differing covariates with a view to finding one that matches the data best. We believe that this speed advantage (without loss of accuracy) is an important development for SIMMs. It is important to remember that the FFVB method only ever produces an approximation of the posterior so model checking through, e.g. posterior predictive distributions, is especially important.
We have introduced the package cosimmr to implement these new methods. The inclusion of covariates allows users to avoid violating the assumption of IID data. The package contains functions that allow users to make predictions for combinations of covariates not found or recorded during data collection, allowing for a deeper understanding of the system being studied. We have shown that cosimmr is demonstrably faster than previous packages (due to FFVB), while returning comparable results. We have designed it to be user-friendly for non-expert users, with built-in summary, plotting and predict functions. It is important that users are aware plots are generally created for an individual observation, with the option to specify the individual(s) for which to create plots built into the package functions. Other functions help users to see which of their covariates are having an impact on the diet of the animal being studied, and how well the model fits the data.
Future work on cosimmr could include allowing for random effects, hierarchical modelling, or source fitting - these are all options that are currently available in MixSIAR but could also be implemented using FFVB in order to speed up model fitting. The challenge here is ensuring the optimization still converges satisfactorily despite the additional parameters. We plan to implement these options in a future evolution of the package.
Computational details
The results in this paper were obtained using R 4.4.1. R is available from the Comprehensive R Archive Network (CRAN) at \urlhttps://CRAN.R-project.org/. C++ compiler gcc version 13.1.0
Acknowledgments
This publication has emanated from research conducted with the financial support of Science Foundation Ireland under Grant number SFI/12/RC/2289_P2_Parnell to ACP. For the purpose of Open Access, the authors have applied a CC BY public copyright licence to any Author Accepted Manuscript version arising from this submission.
Author Contributions
Emma Govan and Andrew C. Parnell conceived the ideas, designed methodology and led the writing of the manuscript; All authors contributed critically to the drafts and gave final approval for publication.
References
- Aitchison (1986) J. Aitchison. The Statistical Analysis of Compositional Data. Chapman and Hall, 1986. ISBN 13:978-94-010-8324-9.
- Aksu et al. (2023) S. Aksu, Ö. Emiroğlu, P. Balzani, J. R. Britton, E. Köse, I. Kurtul, S. Başkurt, O. Mol, E. Çınar, P. J. Haubrock, et al. High trophic similarity between non-native common carp and gibel carp in Turkish freshwaters: Implications for management. Aquaculture and Fisheries, 2023. doi: 10.1016/j.aaf.2023.08.003.
- Eddelbuettel and François (2011) D. Eddelbuettel and R. François. Rcpp: Seamless R and C++ integration. Journal of Statistical Software, 40(8):1–18, 2011. doi: 10.18637/jss.v040.i08.
- Fernandes et al. (2014) R. Fernandes, A. R. Millard, M. Brabec, M.-J. Nadeau, and P. Grootes. Food reconstruction using isotopic transferred signals (FRUITS): A Bayesian model for diet reconstruction. PloS one, 9(2):e87436, 2014. doi: 10.1371/journal.pone.0087436.
- Galloway et al. (2014) A. Galloway, M. Eisenlord, M. Dethier, G. Holtgrieve, and M. Brett. Quantitative estimates of isopod resource utilization using a Bayesian fatty acid mixing model. Marine Ecology Progress Series, 507:219–232, 2014. doi: 10.3354/meps10860.
- Galloway et al. (2012) A. W. Galloway, K. H. Britton-Simmons, D. O. Duggins, P. W. Gabrielson, and M. T. Brett. Fatty acid signatures differentiate marine macrophytes at ordinal and family ranks. Journal of Phycology, 48(4):956–965, 2012. doi: 10.1111/j.1529-8817.2012.01173.x.
- Govan et al. (2023) E. Govan, A. L. Jackson, R. Inger, S. Bearhop, and A. C. Parnell. simmr: A package for fitting stable isotope mixing models in R. arXiv preprint arXiv:2306.07817, 2023.
- Greer et al. (2015) A. L. Greer, T. W. Horton, and X. J. Nelson. Simple ways to calculate stable isotope discrimination factors and convert between tissue types. Methods in Ecology and Evolution, 6(11):1341–1348, 2015. doi: 10.1111/2041-210X.12421.
- Healy et al. (2018) K. Healy, T. Guillerme, S. B. Kelly, R. Inger, S. Bearhop, and A. L. Jackson. SIDER: an R package for predicting trophic discrimination factors of consumers based on their ecology and phylogenetic relatedness. Ecography, 41(8):1393–1400, 2018. doi: 10.1111/ecog.03371.
- Hooper et al. (1990) R. P. Hooper, N. Christophersen, and N. E. Peters. Modelling streamwater chemistry as a mixture of soilwater end-members—an application to the Panola mountain catchment, Georgia, USA. Journal of Hydrology, 116(1-4):321–343, 1990. doi: 10.1016/0022-1694(90)90131-G.
- Hopke (1991) P. K. Hopke. Receptor modeling for air quality management. Elsevier, 1991.
- Hopkins III and Ferguson (2012) J. B. Hopkins III and J. M. Ferguson. Estimating the diets of animals using stable isotopes and a comprehensive Bayesian mixing model. PLoS one, 7(1):e28478, 2012. doi: 10.1371/journal.pone.0028478.
- Hurlbert (1984) S. H. Hurlbert. Pseudoreplication and the design of ecological field experiments. Ecological monographs, 54(2):187–211, 1984. doi: 10.2307/1942661.
- Inger and Bearhop (2008) R. Inger and S. Bearhop. Applications of stable isotope analyses to avian ecology. Ibis, 150(3):447–461, 2008. doi: 10.1111/j.1474-919X.2008.00839.x.
- Inger et al. (2006) R. Inger, G. D. Ruxton, J. Newton, K. Colhoun, J. A. Robinson, A. L. Jackson, and S. Bearhop. Temporal and intrapopulation variation in prey choice of wintering geese determined by stable isotope analysis. Journal of Animal Ecology, 75(5):1190–1200, 2006. doi: 10.111 1/j.1365-2656.2006.01142.x.
- Manlick and Newsome (2022) P. J. Manlick and S. D. Newsome. Stable isotope fingerprinting traces essential amino acid assimilation and multichannel feeding in a vertebrate consumer. Methods in Ecology and Evolution, 13(8):1819–1830, 2022. doi: 10.1111/2041-210X.13903.
- Mathers and Montgomery (1997) R. Mathers and W. Montgomery. Quality of food consumed by over wintering pale-bellied brent geese Branta bernicla hrota and wigeon Anas penelope. In Biology and Environment: Proceedings of the Royal Irish Academy, pages 81–89. JSTOR, 1997.
- McDonald et al. (2020) R. A. McDonald, J. K. Wilson-Aggarwal, G. J. Swan, C. E. Goodwin, T. Moundai, D. Sankara, G. Biswas, and J. A. Zingeser. Ecology of domestic dogs Canis familiaris as an emerging reservoir of guinea worm Dracunculus medinensis infection. PLoS neglected tropical diseases, 14(4):e0008170, 2020. doi: 10.1371/journal.pntd.0008170.
- Miller et al. (1972) M. Miller, S. Friedlander, and G. Hidy. A chemical element balance for the pasadena aerosol. Journal of Colloid and Interface Science, 39(1):165–176, 1972. doi: 10.1016/0021-9797(72)90152-X.
- Moore and Semmens (2008) J. W. Moore and B. X. Semmens. Incorporating uncertainty and prior information into stable isotope mixing models. Ecology letters, 11(5):470–480, 2008. doi: 10.1111/j.1461-0248.2008.01163.x.
- Munoz et al. (2019) S. E. Munoz, L. Giosan, J. Blusztajn, C. Rankin, and G. E. Stinchcomb. Radiogenic fingerprinting reveals anthropogenic and buffering controls on sediment dynamics of the Mississippi river system. Geology, 47(3):271–274, 2019. doi: 10.1130/G45194.1.
- Nifong et al. (2015) J. C. Nifong, C. A. Layman, and B. R. Silliman. Size, sex and individual-level behaviour drive intrapopulation variation in cross-ecosystem foraging of a top-predator. Journal of Animal Ecology, 84(1):35–48, 2015. doi: 10.1111/1365-2656.12306.
- Paez-Rosas et al. (2024) D. Paez-Rosas, J. Suarez-Moncada, C. Arnes-Urgelles, E. Espinoza, Y. Robles, and P. Salinas-De-Leon. Assessment of nursery areas for the scalloped hammerhead shark (sphyrna lewini) across the eastern tropical Pacific using a stable isotopes approach. Frontiers in Marine Science, 10, 2024. doi: 10.3389/fmars.2023.1288770.
- Parnell et al. (2010) A. C. Parnell, R. Inger, S. Bearhop, and A. L. Jackson. Source partitioning using stable isotopes: Coping with too much variation. PloS one, 5(3):e9672, 2010. doi: 10.1371/journal.pone.0009672.
- Parnell et al. (2013) A. C. Parnell, D. L. Phillips, S. Bearhop, B. X. Semmens, E. J. Ward, J. W. Moore, A. L. Jackson, J. Grey, D. J. Kelly, and R. Inger. Bayesian stable isotope mixing models. Environmetrics, 24(6):387–399, 2013. doi: 10.1002/env.2221.
- Phillips (2012) D. L. Phillips. Converting isotope values to diet composition: the use of mixing models. Journal of Mammalogy, 93(2):342–352, 2012. doi: 10.1644/11-MAMM-S-158.1.
- Phillips and Gregg (2003) D. L. Phillips and J. W. Gregg. Source partitioning using stable isotopes: Coping with too many sources. Oecologia, 136:261–269, 2003. doi: 10.1007/s00442-003-1218-3.
- Phillips and Koch (2002) D. L. Phillips and P. L. Koch. Incorporating concentration dependence in stable isotope mixing models. Oecologia, 130:114–125, 2002. doi: 10.1007/s004420100786.
- Plummer (2003) M. Plummer. JAGS: A program for analysis of Bayesian graphical models using Gibbs Sampling. In Proceedings of the 3rd international workshop on distributed statistical computing, volume 124, pages 1–10. Vienna, Austria., 2003.
- R Core Team (2021) R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2021. URL \urlhttps://www.R-project.org/.
- Salimans and Knowles (2013) T. Salimans and D. A. Knowles. Fixed-Form Variational Posterior Approximation through Stochastic Linear Regression. Bayesian Analysis, 8(4):837 – 882, 2013. doi: 10.1214/13-BA858. URL \urlhttps://doi.org/10.1214/13-BA858.
- Semmens et al. (2009) B. X. Semmens, E. J. Ward, J. W. Moore, and C. T. Darimont. Quantifying inter-and intra-population niche variability using hierarchical Bayesian stable isotope mixing models. PloS one, 4(7):e6187, 2009. doi: 10.1371/journal.pone.0006187.
- Stock et al. (2018) B. C. Stock, A. L. Jackson, E. J. Ward, A. C. Parnell, D. L. Phillips, and B. X. Semmens. Analyzing mixing systems using a new generation of Bayesian tracer mixing models. PeerJ, 6:e5096, 2018. doi: 10.7717/peerj.5096.
- Swan et al. (2020) G. J. Swan, S. Bearhop, S. M. Redpath, M. J. Silk, C. E. Goodwin, R. Inger, and R. A. McDonald. Evaluating bayesian stable isotope mixing models of wild animal diet and the effects of trophic discrimination factors and informative priors. Methods in Ecology and Evolution, 11(1):139–149, 2020. doi: 10.1111/2041-210X.13311.
- Tan and Nott (2018) L. S. Tan and D. J. Nott. Gaussian variational approximation with sparse precision matrices. Statistics and Computing, 28:259–275, 2018. doi: 10.1007/s11222-017-9729-7.
- Teixeira et al. (2021) C. R. Teixeira, S. Botta, F. G. Daura-Jorge, L. B. Pereira, S. D. Newsome, and P. C. Simões-Lopes. Niche overlap and diet composition of three sympatric coastal dolphin species in the southwest Atlantic ocean. Marine Mammal Science, 37(1):111–126, 2021. doi: 10.1111/mms.12726.
- Thibault et al. (2024) M. Thibault, Y. Letourneur, C. Cleguer, C. Bonneville, M. J. Briand, S. Derville, P. Bustamante, and C. Garrigue. C and N stable isotopes enlighten the trophic behaviour of the dugong (dugong dugon). Scientific Reports, 14(1):896, 2024. doi: 10.1038/s41598-023-50578-3.
- Titsias and Lázaro-Gredilla (2014) M. Titsias and M. Lázaro-Gredilla. Doubly stochastic variational bayes for non-conjugate inference. In International conference on machine learning, pages 1971–1979. PMLR, 2014.
- Tran et al. (2021) M.-N. Tran, T.-N. Nguyen, and V.-H. Dao. A practical tutorial on variational bayes. arXiv preprint arXiv:2103.01327, 2021. doi: 10.48550/arXiv.2103.01327.
- Vehtari et al. (2024) A. Vehtari, J. Gabry, M. Magnusson, Y. Yao, P.-C. Bürkner, T. Paananen, and A. Gelman. loo: Efficient leave-one-out cross-validation and waic for Bayesian models, 2024. URL \urlhttps://mc-stan.org/loo/. R package version 2.7.0.
- Ward et al. (2010) E. J. Ward, B. X. Semmens, and D. E. Schindler. Including source uncertainty and prior information in the analysis of stable isotope mixing models. Environmental science & technology, 44(12):4645–4650, 2010. doi: 10.1021/es100053v.
- Wickham et al. (2019) H. Wickham, M. Averick, J. Bryan, W. Chang, L. D. McGowan, R. François, G. Grolemund, A. Hayes, L. Henry, J. Hester, M. Kuhn, T. L. Pedersen, E. Miller, S. M. Bache, K. Müller, J. Ooms, D. Robinson, D. P. Seidel, V. Spinu, K. Takahashi, D. Vaughan, C. Wilke, K. Woo, and H. Yutani. Welcome to the tidyverse. Journal of Open Source Software, 4(43):1686, 2019. doi: 10.21105/joss.01686.
- Yao et al. (2018) Y. Yao, A. Vehtari, D. Simpson, and A. Gelman. Yes, but did it work?: Evaluating variational inference. In International Conference on Machine Learning, pages 5581–5590. PMLR, 2018.
- Zaryab et al. (2022) A. Zaryab, H. R. Nassery, K. Knoeller, F. Alijani, and E. Minet. Determining nitrate pollution sources in the Kabul plain aquifer (Afghanistan) using stable isotopes and Bayesian stable isotope mixing model. Science of the Total Environment, 823:153749, 2022. doi: 10.1016/j.scitotenv.2022.153749.
Appendix A Gaussian Variational Bayes with Cholesky Decomposed Covariance
We use the Gaussian Variational Bayes with Cholesky decomposed covariance algorithm of Tran et al. (2021). If we define the joint set of parameters as then we write our factorised variational posterior as:
where is the set of hyper-parameters associated with the variational posteriors:
To avoid the positive semi-definite constraints on we model the Cholesky decomposition of this matrix so that .
To start the algorithm, initial values are required for (we use parenthetical super-scripts to denote iterations), the sample size , the adaptive learning weights (), the fixed learning rate , the threshold , the rolling window size , the maximum patience .
Define to be the log of the joint distribution up to the constant of proportionality:
and to be the log of the ratio between the joint and the VB posterior:
The initialisation stage proceeds with:
-
1.
Generate samples from for
-
2.
Compute the unbiased estimate of the lower bound gradient:
Create estimates of
-
3.
Set
-
4.
Set , patience = 0, and ‘stop = FALSE’.
Now the algorithm runs with:
-
1.
Generate for . Recalculate and from
-
2.
Compute the unbiased estimate of the lower bound gradient:
where
with
-
3.
Compute:
-
4.
Update the learning rate:
and the variational hyper-parameters:
-
5.
Compute the lower bound estimate:
-
6.
If compute the moving average LB
If patience = 0, else patience = patience +1
-
7.
If patience P, ‘stop = TRUE‘
-
8.
Set
Appendix B Further plots