11email: {sunghwan,seokjucho,18wltnzzang,seungryongkim}@korea.ac.kr22institutetext: Microsoft Research Asia, Beijing, China
22email: stevelin@microsoft.com
Cost Aggregation with 4D Convolutional Swin Transformer for Few-Shot Segmentation
Abstract
This paper presents a novel cost aggregation network, called Volumetric Aggregation with Transformers (VAT), for few-shot segmentation. The use of transformers can benefit correlation map aggregation through self-attention over a global receptive field. However, the tokenization of a correlation map for transformer processing can be detrimental, because the discontinuity at token boundaries reduces the local context available near the token edges and decreases inductive bias. To address this problem, we propose a 4D Convolutional Swin Transformer, where a high-dimensional Swin Transformer is preceded by a series of small-kernel convolutions that impart local context to all pixels and introduce convolutional inductive bias. We additionally boost aggregation performance by applying transformers within a pyramidal structure, where aggregation at a coarser level guides aggregation at a finer level. Noise in the transformer output is then filtered in the subsequent decoder with the help of the query’s appearance embedding. With this model, a new state-of-the-art is set for all the standard benchmarks in few-shot segmentation. It is shown that VAT attains state-of-the-art performance for semantic correspondence as well, where cost aggregation also plays a central role. Code and trained models are available at https://seokju-cho.github.io/VAT/.
1 Introduction
Semantic segmentation is a fundamental computer vision task that aims to label each pixel in an image with its corresponding class. Substantial progress has been made in this direction with the help of deep neural networks and large-scale datasets containing ground-truth segmentation annotations [37, 46, 3, 4, 61]. Manual labeling of pixel-wise segmentation maps, however, requires considerable labor, making it difficult to add new classes. Towards reducing reliance on labeled data, attention has increasingly focused on few-shot segmentation [49, 55], where only a handful of support images and their associated masks are used in predicting the segmentation of a query image.

The key to few-shot segmentation is in making effective use of the few support samples. Many works attempt this by extracting a prototype model from the samples and using it for feature comparison with the query [58, 10, 35, 78]. However, such approaches disregard pixel-level pairwise relationships between support and query features or the spatial structure of features, which may lead to sub-optimal results.
To account for such relationships, we observe that few-shot segmentation can be reformulated as semantic correspondence, which aims to find pixel-level correspondences across semantically similar images which may contain large intra-class appearance and geometric variations [13, 14, 43]. Recent semantic correspondence models [50, 25, 51, 53, 42, 44, 34, 65, 41] follow the classical matching pipeline [54, 47] of feature extraction, cost aggregation and flow estimation. The cost aggregation stage, where matching scores are refined to produce more reliable correspondence estimates, is of particular importance and has been the focus of much research [53, 42, 52, 22, 34, 29, 41, 6]. Recently, CATs [6] proposed to use vision transformers [11] for cost aggregation, but its quadratic complexity to the number of input tokens limits its applicability. It also disregards the spatial structure of matching costs, which may hurt its performance.
In the area of few-shot segmentation, there also exist methods that attempt to leverage pairwise information by refining features through cross-attention [83] or graph attention [81, 68, 75]. However, they solely rely on raw correlation maps without aggregating the matching scores. As a result, their correspondence may suffer from ambiguities caused by repetitive patterns or background clutters [50, 25, 27, 65, 17]. To address this, HSNet [40] aggregates the matching scores with 4D convolutions, but its limited receptive fields prevent long-range context aggregation and it lacks an ability to adapt to the input content due to the use of fixed kernels.
In this paper, we introduce a novel cost aggregation network, called Volumetric Aggregation with Transformers (VAT), that tackles the few-shot segmentation task through a proposed 4D Convolutional Swin Transformer. Specifically, we first extend Swin Transformer [36] and its patch embedding module to handle a high-dimensional correlation map. The patch embedding module is further extended by incorporating 4D convolutions that alleviate issues caused by patch embedding, i.e., limited local context near patch boundaries and low inductive bias. The high-dimensional patch embedding module is designed as a series of overlapping small-kernel convolutions, bringing local contextual information to each pixel and imparting convolutional inductive bias. To further boost performance, we compose our architecture with a pyramidal structure that takes the aggregated correlation maps at a coarser level as additional input at a finer level, providing hierarchical guidance. Our affinity-aware decoder then refines the aggregated matching scores in a manner that exploits the higher-resolution spatial structure given by the query’s appearance embedding and finally outputs the segmentation mask prediction.
We demonstrate the effectiveness of our method on several benchmarks [55, 31, 30]. Our work attains state-of-the-art performance on all the benchmarks for few-shot segmentation and even for semantic correspondence, highlighting the importance of cost aggregation for both tasks and showing its potential for general matching. We also include ablation studies to justify our design choices.
2 Related Work
2.0.1 Few-shot Segmentation.
Inspired by the few-shot learning paradigm [49, 58], which learns to learn a model for a novel task with only a limited number of samples, few-shot segmentation has received considerable attention. Following the success of [55], prototypical networks [58] and numerous other works [10, 45, 56, 69, 35, 78, 33, 76, 79, 60, 84, 28] proposed to extract a prototype from support samples, which is used to identify foreground features in the query. In addition, inspired by [82] which observed that simply adding high-level features in feature processing leads to a performance drop, [63] proposed to instead utilize high-level features to compute a prior map that helps to identify targets in the query image. Many variants [60, 80] extended this idea of utilizing prior maps to act as additional information for aggregating feature maps.
However, as methods based on prototypes or prior maps have apparent limitations, e.g., disregarding pairwise relationships between support and query features or spatial structure of feature maps, numerous recent works [81, 68, 40, 75, 32] utilize a correlation map to leverage the pairwise relationships between source and query features. Specifically, [81, 68, 75] use graph attention, HSNet [40] proposes 4D convolutions to exploit multi-level features, and [32] formulates the task as an optimal transport problem. However, these approaches do not provide a means to aggregate the matching scores, solely utilize convolutions for cost aggregation, or use a handcrafted method that is neither learnable nor robust to severe deformations.
Recently, [83] utilized transformers and proposed to use a cycle-consistent attention mechanism to refine the feature maps to become more discriminative, without considering aggregation of matching scores. [60] propose a global and local enhancement module to refine the features using transformers and convolutions, respectively. [39] focuses solely on the transformer-based classifier by freezing the encoder and decoder. Unlike these works, we propose a 4D Convolutional Swin Transformer for an enhanced and efficient cost aggregation.
2.0.2 Semantic Correspondence.
The objective of semantic correspondence is to find correspondences between semantically similar images with additional challenges posed by large intra-class appearance and geometric variations [34, 6, 41]. This is highly similar to the few-shot segmentation setting in that few-shot segmentation also aims to label objects of the same class with large intra-class variation, and thus recent works on both tasks have taken similar approaches. The latest methods [53, 42, 52, 22, 34, 29, 41, 6] in semantic correspondence focus on the cost aggregation stage to find reliable correspondences and demonstrated its importance. Among them, [41] proposed to use 4D convolutions for cost aggregation, though exhibiting apparent limitations due to the limited receptive fields of convolutions and lack of adaptability. CATs [6] resolves this issue and sets a new state-of-the-art by leveraging transformers [66] to aggregate the cost volume. However, it disregards the spatial structure of correlation maps and imparts less inductive bias, i.e., translation equivariance, which limits its generalization power [36, 7, 8]. Moreover, its quadratic complexity may limit applicability when it is used to aggregate correlation maps on its own. In this paper, we propose to resolve the aforementioned issues.
2.0.3 Vision Transformer.
Recently, transformer [66], the standard architecture in Natural Language Processing (NLP), has been widely adopted in Computer Vision. Since the pioneering work on ViT [11], numerous works [39, 83, 60, 23, 73, 6, 36] have adopted transformers to replace CNNs or to be used together with CNNs in a hybrid manner. However, due to quadratic complexity to sequence length, transformers often suffer from large a computational burden. Efficient transformers [70, 24, 77, 72] aim to reduce the computational load via an approximated or simplified self-attention. Swin Transformer [36], a network we extend from, reduces computation by performing self-attention within pre-defined local windows. However, these works inherit the issues caused by patch embedding, which we alleviate by incorporating 4D convolutions.
3 Methodology
3.1 Problem Formulation
The goal of few-shot segmentation is to segment objects from unseen classes in a query image given only a few annotated examples [67]. To mitigate the overfitting caused by insufficient training data, we follow the common protocol of episodic training [67]. Let us denote the training and test sets as and , respectively, where the object classes of both sets do not overlap. Under the -shot setting, multiple episodes are formed from both sets, each consisting of a support set , where is -th support image and its corresponding mask pair, and a query sample , where is a query image and is its paired mask. During training, our model takes a sampled episode from and learns a mapping from and to a prediction . At inference, our model predicts given randomly sampled and from .
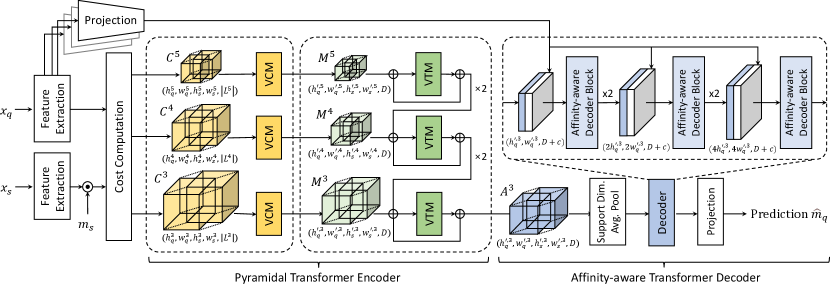
3.2 Motivation and Overview
The key to few-shot segmentation is how to effectively utilize the support samples provided for a query image. While conventional methods [63, 60, 83, 79, 28] utilize global- or part-level prototypes extracted from support features, recent methods [81, 68, 40, 75, 32, 83] instead leverage pairwise matching relationships between query and support. However, exploring such relationships is notoriously challenging due to intra-class variations, background clutters, and repetitive patterns. One of the state-of-the-art methods, HSNet [40], aggregates the matching scores with 4D convolutions. However, solely utilizing convolutions may limit performance due to limited receptive fields or lack of adaptability for convolutional kernels. While there has been no approach to aggregate the matching scores with transformers in few-shot segmentation, CATs [6] proposes cost aggregation with transformers in semantic correspondence, demonstrating the effectiveness of transformers as a cost aggregator. On the other hand, the quadratic complexity of transformers with respect to the number of tokens may limit its utility for segmentation. The absence of operations that impart inductive bias, i.e., translation equivariance, may limit its performance as well. Also, CATs [6] defines the tokens of a correlation map in a way that disregards spatial structure, which is likely to be harmful.
The proposed Volumetric Aggregation with Transformers (VAT) is designed to overcome these problems. In the following, we first describe its feature extraction and cost computation. We then present a general extension of Swin Transformer [36] for cost aggregation. Subsequently, we present 4D Convolutional Swin Transformer for resolving the aforementioned issues. Lastly, we introduce several additional techniques including Guided Pyramidal Processing (GPP) and Affinity-aware Transformer Decoder (ATD) to further boost performance, and combine them to complete the design.
3.3 Feature Extraction and Cost Computation
We extract features from query and support images and compute an initial cost between them following the conventional process [50, 59, 53, 52, 65, 17, 6]. Given query and support images, and , we use a CNN [16, 57] to produce a sequence of feature maps, , where and denote query and support feature maps at the -th level. A support mask, , is used to encode segmentation information and filter out the background information as done in [28, 40, 80]. We obtain a masked support feature as , where denotes the Hadamard product and denotes a function that resizes the given tensor followed by expansion along the channel dimension of the -th layer.
Given a pair of feature maps, and , we compute a correlation map using the inner product between -2 normalized features such that
| (1) |
where and denote 2D spatial positions of feature maps. As done in [40], we collect correlation maps computed from all the intermediate features of the same spatial size and stack them to obtain a stacked correlation map , where and are the height and width of the query and support feature maps, respectively, and is a subset of CNN layer indices at pyramid layer , containing correlation maps of identical spatial size.
3.4 Pyramidal Transformer Encoder
In this section, we present 4D Convolutional Swin Transformer for aggregating the correlation maps and then incorporate it into a pyramidal architecture.
3.4.1 Cost Aggregation with Transformers.
For a transformer to process a correlation map, a means for token reduction is essential, since it would be infeasible for even an efficient transformer [70, 24, 77, 72, 36] to handle a correlation map otherwise. However, when one employs a transformer for cost aggregation, the problem of how to define the tokens for correlation maps, which differ in shape from images, text or features [66, 11], is non-trivial. The first attempt to process correlation maps is CATs [6], which reshapes the 4D correlation maps into 2D maps and performs self-attention in 2D. This disregards the spatial structure of correlation maps, i.e., over both support and query, which could limit its performance. To address this, one may treat all the spatial entries, e.g., , as tokens and treat as the feature dimension for tokens. However, this results in a substantial computational burden that increases with larger correlation maps. This prevents the use of standard transformers [66, 11] and encourages use of efficient versions as in [70, 24, 77, 72, 36]. However, the use of simplified (or approximated) self-attention may be sub-optimal for performance, as will be discussed in Section 4.4. Furthermore, as proven in the optical flow and semantic correspondence literature [59, 52], neighboring pixels tend to have similar correspondences. To preserve the spatial structure of correlation maps, we choose to use Swin Transformer [36] as it not only provides efficient self-attention computation, but also maintains the smoothness property of correlation maps while still providing sufficient long-range self-attention.
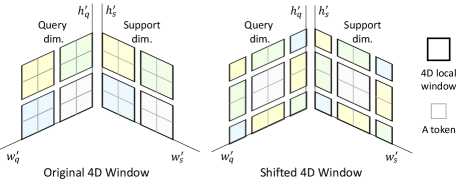
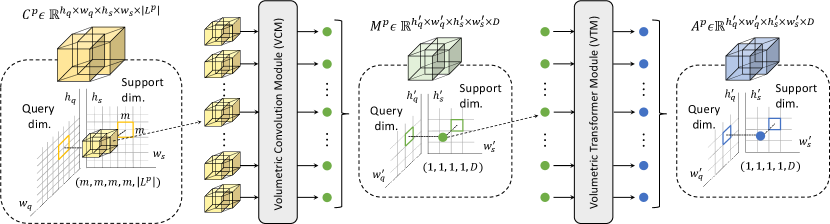
To employ Swin Transformer [36] for cost aggregation, we need to extend it to process higher dimensional input, specifically a 4D correlation map. We first follow the conventional patch embedding procedure [11] to embed correlation maps, as they cannot be processed by transformers due to the large number of tokens. However, we extend the patch embedding module to a Volumetric Embedding Module (VEM) which handles higher dimensional inputs, such that . Following a procedure similar to patch embedding, we reshape the correlation map to a sequence of flattened 4D windows using a large convolutional kernel, e.g., 16161616. Then, we extend the self-attention computations, as shown in Fig. 3, by evenly partitioning the query and support spatial dimensions of into non-overlapping sub-correlation maps . We compute self-attention within each partitioned sub-correlation map. Subsequently, we shift the windows by a displacement of pixels from the previously partitioned windows, then perform self-attention within the newly created windows. Then as done in the original Swin Transformer [36], we simply roll the correlation map back to its original form. In computing self-attention, we use relative position bias and take the values from an expanded parameterized bias matrix, following [19, 20, 36]. We leave the other components of Swin Transformer blocks unchanged, e.g., Layer Normalization (LN) [1] and MLP layers. We call this extension the Volumetric Transformer Module (VTM). To summarize, the overall process is defined as:
| (2) |
3.4.2 4D Convolutional Swin Transformer.
Although the proposed cost aggregation with transformers can solve the aforementioned issues of using CNNs and the high computational burden of using standard transformers, it may not avoid the issue that other transformers share [11, 70, 24, 77, 72]: lack of translation equivariance. This is primarily caused by utilizing non-overlapping operations prior to self-attention computation. Although Swin Transformer alleviates the issue to some extent by using relative positioning bias [36], it provides an insufficient approximation. We argue that the Volumetric Embedding Module is what needs to be addressed as it leads to several issues. First, the use of large non-overlapping convolution kernels only provides limited inductive bias. Relatively lower translation equivariance is achieved from non-overlapping operations compared to that which are overlapping. This limited inductive bias results in relatively lower generalization power and performance [74, 8, 7, 36]. Furthermore, we argue that for dense prediction tasks, disregarding window boundaries due to non-overlapping kernels hurts overall performance due to discontinuity.
To address the above issues, we replace the Volumetric Embedding Module (VEM) with a module consisting of a series of overlapping convolutions, which we call the Volumetric Convolution Module (VCM). Concretely, we sequentially reduce spatial dimensions of the support and query by applying 4D spatial max-pooling, overlapping 4D convolutions, ReLU, and Group Normalization (GN), where we project the multi-level similarity vector at each 4D position, i.e., projecting a vector size of , to an arbitrary fixed dimension denoted as . Considering receptive fields as a 4D window, i.e., , we obtain a tensor from , where , , and are the processed sizes. Note that a different size of can be chosen for the support and query spatial dimensions. An overview of VCM is illustrated in Fig. 4. Overall, we define such a process as the following:
| (3) |
In this way, our model benefits from additional inductive bias as well as better handling at window boundaries.
Moreover, to stabilize the learning, we propose an additional technique to enforce the networks to estimate residual matching scores as complementary details. We add residual connections in order to expedite the learning process [16, 6, 85], accounting for the fact that at the initial phase when the input is fed, erroneous matching scores are inferred due to randomly-initialized parameters of transformers, which could complicate the learning process as the networks need to learn the complete matching details from random matching scores.
3.4.3 Guided Pyramidal Processing.
Following [40, 60], we also employ a coarse-to-fine approach through pyramidal processing as illustrated in Fig. 2. Motivated by numerous recent works [83, 41, 6, 40] in both semantic matching and few-shot segmentation which have demonstrated that leveraging multi-level features can boost performance by a large margin, we also use a pyramidal architecture.
In our coarse-to-fine approach, which we refer to as Guided Pyramidal Processing (GPP), the aggregation of a finer-level correlation map is guided by the aggregated correlation map of the previous (coarser) level . Concretely, an aggregated correlation map is up-sampled into a map which is added to the next level’s correlation map to serve as guidance. This process is repeated until the finest-level aggregated map is computed and passed to the decoder. As shown in Table 5, GPP leads to appreciable performance gains.
With GPP, the pyramidal transformer encoder is finally defined as:
| (4) |
where denotes bilinear upsampling.
3.5 Affinity-Aware Transformer Decoder
Given the aggregated correlation map produced by the pyramidal transformer encoder, a transformer-based decoder generates the final segmentation mask. To improve performance, we propose to conduct further aggregation within the decoder with the aid of the appearance embedding obtained from query feature maps. The query’s appearance embedding can help in two ways. First, appearance affinity information is an effective guide for filtering noise in matching scores, as proven in the stereo matching literature, e.g., Cost Volume Filtering (CVF) [18, 59]. In addition, the higher-resolution spatial structure provided by an appearance embedding can be exploited to improve up-sampling quality, resulting in a highly accurate prediction mask where fine details are preserved.
For the design of our Affinity-aware Transformer Decoder (ATD), we take the average over the support image dimensions of , concatenate it with the appearance embedding from query feature maps, and then aggregate by transformers [66, 70, 72, 36] with subsequent bilinear interpolation. The process is defined as the following:
| (5) |
where is extracted by average pooling on over the spatial dimensions of the support image, is a linear projection, , and denotes concatenation. We sequentially refine the output immediately after bilinear upsampling to recapture fine details and integrate appearance information.
3.6 Extension to -Shot Setting
Given pairs of support image and mask and a query image , our model forward-passes times to obtain different query masks . We sum up all the predictions at each spatial location, and if the sum divided by exceeds a threshold , the location is predicted as foreground, and otherwise it is background.
| Backbone network | Methods | 1-shot | 5-shot | # learnable | ||||||||||||
| mIoU | FB-IoU | mBA | mIoU | FB-IoU | mBA | params | ||||||||||
| ResNet50 [16] | PANet [69] | 44.0 | 57.5 | 50.8 | 44.0 | 49.1 | - | - | 55.3 | 67.2 | 61.3 | 53.2 | 59.3 | - | - | 23.5M |
| PFENet [63] | 61.7 | 69.5 | 55.4 | 56.3 | 60.8 | 73.3 | - | 63.1 | 70.7 | 55.8 | 57.9 | 61.9 | 73.9 | - | 10.8M | |
| ASGNet [28] | 58.8 | 67.9 | 56.8 | 53.7 | 59.3 | 69.2 | - | 63.4 | 70.6 | 64.2 | 57.4 | 63.9 | 74.2 | - | 10.4M | |
| CWT [39] | 56.3 | 62.0 | 59.9 | 47.2 | 56.4 | - | - | 61.3 | 68.5 | 68.5 | 56.6 | 63.7 | - | - | - | |
| RePRI [2] | 59.8 | 68.3 | 62.1 | 48.5 | 59.7 | - | 49.0 | 64.6 | 71.4 | 71.1 | 59.3 | 66.6 | - | 43.8 | - | |
| HSNet [40] | 64.3 | 70.7 | 60.3 | 60.5 | 64.0 | 76.7 | 53.9 | 70.3 | 73.2 | 67.4 | 67.1 | 69.5 | 80.6 | 54.5 | 2.6M | |
| CyCTR [83] | 65.7 | 71.0 | 59.5 | 59.7 | 64.0 | - | - | 69.3 | 73.5 | 63.8 | 63.5 | 67.5 | - | - | - | |
| VAT (ours) | 67.6 | 72.0 | 62.3 | 60.1 | 65.5 | 77.8 | 54.4 | 72.4 | 73.6 | 68.6 | 65.7 | 70.1 | 80.9 | 54.8 | 3.2M | |
| ResNet101 [16] | FWB [45] | 51.3 | 64.5 | 56.7 | 52.2 | 56.2 | - | - | 54.8 | 67.4 | 62.2 | 55.3 | 59.9 | - | - | 43.0M |
| DAN [68] | 54.7 | 68.6 | 57.8 | 51.6 | 58.2 | 71.9 | - | 57.9 | 69.0 | 60.1 | 54.9 | 60.5 | 72.3 | - | - | |
| PFENet [63] | 60.5 | 69.4 | 54.4 | 55.9 | 60.1 | 72.9 | - | 62.8 | 70.4 | 54.9 | 57.6 | 61.4 | 73.5 | - | 10.8M | |
| ASGNet [28] | 59.8 | 67.4 | 55.6 | 54.4 | 59.3 | 71.7 | - | 64.6 | 71.3 | 64.2 | 57.3 | 64.4 | 75.2 | - | 10.4M | |
| CWT [39] | 56.9 | 65.2 | 61.2 | 48.8 | 58.0 | - | - | 62.6 | 70.2 | 68.8 | 57.2 | 64.7 | - | - | - | |
| RePRI [2] | 59.6 | 68.6 | 62.2 | 47.2 | 59.4 | - | 45.1 | 66.2 | 71.4 | 67.0 | 57.7 | 65.6 | - | 42.0 | - | |
| HSNet [40] | 67.3 | 72.3 | 62.0 | 63.1 | 66.2 | 77.6 | 53.9 | 71.8 | 74.4 | 67.0 | 68.3 | 70.4 | 80.6 | 54.4 | 2.6M | |
| CyCTR [83] | 67.2 | 71.1 | 57.6 | 59.0 | 63.7 | 73.0 | - | 71.0 | 75.0 | 58.5 | 65.0 | 67.4 | 75.4 | - | - | |
| VAT (ours) | 70.0 | 72.5 | 64.8 | 64.2 | 67.9 | 79.6 | 54.7 | 75.0 | 75.2 | 68.4 | 69.5 | 72.0 | 83.2 | 54.8 | 3.3M | |
| Backbone feature | Methods | 1-shot | 5-shot | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | FB-IoU | mBA | mean | FB-IoU | mBA | ||||||||||
| ResNet50 [16] | PMM [78] | 29.3 | 34.8 | 27.1 | 27.3 | 29.6 | - | - | 33.0 | 40.6 | 30.3 | 33.3 | 34.3 | - | - |
| RPMM [78] | 29.5 | 36.8 | 28.9 | 27.0 | 30.6 | - | - | 33.8 | 42.0 | 33.0 | 33.3 | 35.5 | - | - | |
| PFENet [63] | 36.5 | 38.6 | 34.5 | 33.8 | 35.8 | - | - | 36.5 | 43.3 | 37.8 | 38.4 | 39.0 | - | - | |
| ASGNet [28] | - | - | - | - | 34.6 | 60.4 | - | - | - | - | - | 42.5 | 67.0 | - | |
| RePRI [2] | 32.0 | 38.7 | 32.7 | 33.1 | 34.1 | - | 6.31 | 39.3 | 45.4 | 39.7 | 41.8 | 41.6 | - | 4.21 | |
| HSNet [40] | 36.3 | 43.1 | 38.7 | 38.7 | 39.2 | 68.2 | 53.0 | 43.3 | 51.3 | 48.2 | 45.0 | 46.9 | 70.7 | 53.8 | |
| CyCTR [83] | 38.9 | 43.0 | 39.6 | 39.8 | 40.3 | - | - | 41.1 | 48.9 | 45.2 | 47.0 | 45.6 | - | - | |
| VAT (ours) | 39.0 | 43.8 | 42.6 | 39.7 | 41.3 | 68.8 | 54.2 | 44.1 | 51.1 | 50.2 | 46.1 | 47.9 | 72.4 | 54.9 | |
| Backbone feature | Methods | mIoU | FB-IoU | mBA | |||
|---|---|---|---|---|---|---|---|
| 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | ||
| ResNet50 [16] | FSOT [32] | 82.5 | 83.8 | - | - | - | - |
| HSNet [40] | 85.5 | 87.8 | 91.0 | 92.5 | 62.1 | 63.3 | |
| VAT | 90.1 | 90.7 | 93.8 | 94.2 | 68.3 | 68.4 | |
| ResNet101 [16] | DAN [68] | 85.2 | 88.1 | - | - | - | - |
| HSNet [40] | 86.5 | 88.5 | 91.6 | 92.9 | 62.4 | 63.6 | |
| VAT | 90.3 | 90.8 | 94.0 | 94.4 | 68.0 | 68.6 | |
4 Experiments
4.1 Implementation Details
We use ResNet50 and ResNet101 [16] pre-trained on ImageNet [9] and freeze the weights during training, following [40, 82]. No data augmentation is used for training, as explained in the supplementary material. We set the input image sizes to 417 or 473, following [28, 2]. The window size for Swin Transformer is set to 4. We use AdamW [38] with a learning rate of . Feature maps from conv3x (), conv4x () and conv5x () are taken for cost computation. The -shot threshold is set to and the embedding dimension to . For appearance affinity, we take the last layers from conv2x, conv3x and conv4x when training on FSS-1000 [30], and conv4x is excluded when training on PASCAL-5i [55] and COCO-20i [31]. We set to 16, 32, and 64 for conv2x, conv3x, and conv4x.
4.2 Experimental Settings
4.2.1 Datasets.
We evaluate our approach on three standard few-shot segmentation datasets, PASCAL-5i [55], COCO-20i [31], and FSS-1000 [30]. PASCAL-5i contains images from PASCAL VOC 2012 [12] with added mask annotations [15]. It consists of 20 object classes, and as done in OSLSM [55], they are evenly divided into 4 folds for cross-validation, where each fold contains 5 classes. COCO-20i contains 80 object classes, and as done for PASCAL-5i, the dataset is evenly divided into 4 folds of 20 classes each. FSS-1000 is a more diverse dataset consisting of 1000 object classes. Following [30], we divide the 1000 categories into 3 splits for training, validation and testing, which consist of 520, 240 and 240 classes, respectively. For PASCAL-5i and COCO-20i, we follow the common evaluation practice [40, 63, 35] and standard cross-validation protocol, where each fold is used for evaluation with the other folds used for training.
4.2.2 Evaluation Metric.
Following common practice [82, 63, 40, 83], we adopt mean intersection over union (mIoU) and foreground-background IoU (FB-IoU) as our evaluation metrics. The mIoU averages over all IoU values for all object classes such that , where is the number of classes in each fold, e.g., for COCO-20i. FB-IoU disregards the object classes and instead averages over foreground and background IoU ( and ) such that . We additionally adopt Mean Boundary Accuracy (mBA) introduced in [5] to evaluate the model’s ability to capture fine details. To measure mBA, we first sample 5 radii in at a uniform interval, where and are width and height of input image, and average the segmentation accuracy within each radius from the ground-truth boundary.
4.3 Few-shot Segmentation Results
Table 1 summarizes quantitative results on PASCAL-5i [55]. The tests were conducted on two backbone networks, ResNet50 and ResNet101 [16]. The proposed method outperforms the others on almost all the folds in terms of both mIoU and FB-IoU. It surpasses the others, including HSNet [40], in mBA as well, since our ATD helps to improve up-sampling quality by providing higher-level spatial structure for reference. Consistent with this, VAT also attains state-of-the-art performance on COCO-20i [31], as shown in Table 2. Interestingly, for the most recent dataset specifically created for few-shot segmentation, FSS-1000 [30], VAT outperforms HSNet [40] and FSOT [32] by a large margin, almost a 4.6 increase in mIoU compared to HSNet with ResNet50 as shown in Table 3. VAT sets a new state-of-the-art for all of these benchmarks. We note that our method outperforms HSNet [40] despite having more learnable parameters, which is known to have an inverse relation to generalization power [62], a trend seen in Table 1. With the proposed method, i.e., 4D convolutional Swin Transformer, that is designed to address the issues like lack of inductive bias, VAT can have a larger number of learnable parameters than that of HSNet [40], yet VAT has greater generalization power as well.
4.4 Ablation Study
We conducted ablations on FSS-1000 [30], a large-scale dataset specifically constructed for few-shot segmentation.
4.4.1 Effectiveness of each component in VAT.
As the baseline model, we take the architecture composed of VEM and the 2D convolution decoder used in HSNet [40]. We then progressively add our components one-by-one as shown in Table 5. Note that we included (IV) and (V) to show the effectiveness of VCM alone and the performance of a model highly similar to HSNet [40], respectively.
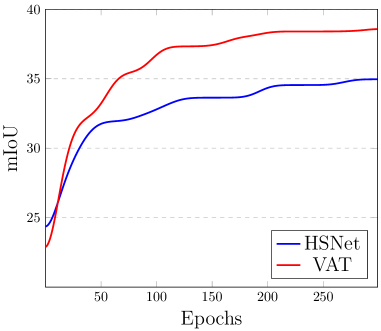
As summarized in Table 5, each component helps to boost performance. Starting from the baseline (I), adding Swin Transformer (II) brings a large gain, which indicates that Swin Transformer effectively performs cost aggregation thanks to its approximated inductive bias and ability to consider spatial structure. When the VEM is replaced by VCM (III), we also observe a significant improvement, which confirms that the issues due to non-overlap are alleviated. We note that (IV) also highlights the importance of inductive bias. As (V) is approximately equivalent to HSNet [40], we first compare it with (III), which shows the superiority of the proposed 4D Convolutional Swin Transformer. By including the additional components in (VI) and (VII), the performance is further boosted. Moreover, we observe a large gain in mBA by adding ATD. This shows that the higher-resolution spatial structure provided by appearance embeddings help to refine the fine details. We additionally provide a visualization of convergence in comparison to HSNet [40] in Fig. 5. Thanks to the early convolutions [74], VAT quickly converges and exceeds HSNet [40] even though it starts at a lower mIOU.
4.4.2 Base architecture of VTM.
As summarized in Table 5, we provide an ablation study to evaluate the effectiveness of different aggregators for VTM. For cost aggregation, there exists a few learnable aggregators, including MLP-, convolution- and transformer-based aggregators, any of which could be used as a base architecture for VTM. It should be noted that the use of standard transformer [66] and MLP-mixer [64] is not feasible due to memory requirements. Specifically, we calculated the memory consumption of each and found that using standard transformer requires approximately 84 GB per batch, while the memory for MLP-Mixer could not be measured as it is much greater than standard transformer. Also, we note that the architecture with center-pivot convolutions is equivalent to a deeper version of the architecture with VCM.
| Components | FSS-1000 [30] | ||||
|---|---|---|---|---|---|
| mIoU () | mBA () | ||||
| 1-shot | 5-shot | 1-shot | 5-shot | ||
| (I) | Baseline | 80.0 | 81.8 | 56.7 | 56.9 |
| (II) | + Swin Trans. | 85.4 | 87.4 | 58.8 | 59.5 |
| (III) | + VCM | 87.0 | 88.6 | 60.1 | 61.3 |
| (IV) | only VCM | 86.4 | 88.0 | 59.6 | 60.1 |
| (V) | (IV) + 4D mix | 86.4 | 87.8 | 59.9 | 59.6 |
| (VI) | (III) + GPP | 87.3 | 88.8 | 60.7 | 61.4 |
| (VII) | + ATD | 90.3 | 90.8 | 68.0 | 68.6 |
| Different aggregators | FSS-1000 [30] | Memory | Run-time | |
|---|---|---|---|---|
| mIoU (%) | mBA (%) | (GB) | (ms) | |
| Standard transformer [66] | OOM | OOM | 84 | N/A |
| MLP-Mixer [64] | OOM | OOM | OOM | N/A |
| Center-pivot 4D convolutions [40] | 88.1 | 66.5 | 3.5 | 52.7 |
| Linear transformer [24] | 87.7 | 66.5 | 3.5 | 56.8 |
| Fastformer [72] | 87.8 | 66.4 | 3.5 | 122.9 |
| 4D Conv. Swin transformer (Ours) | 90.3 | 68.0 | 3.8 | 57.3 |
For a fair comparison, we only replace VTM with another aggregator and leave all the other components in our architecture unchanged. We observe that our method outperforms the other aggregators by a large margin. Interestingly, although center-pivot 4D convolution [40] also focuses on locality as in Swin Transformer [36], the performance gap indicates that the ability to adaptively consider pixel-wise interactions is critical. Also, we conjecture that the SW-MSA operation helps to compensate for the lack of global aggregation, which center-pivot convolutions lack. Another interesting point is that Linear Transformer [24] and Fastformer [72], which benefit from the global receptive fields of transformers and approximate the self-attention computation, achieve similar performance.
We additionally provide memory and run-time comparison to other aggregators in Table 5. The results are obtained using a single NVIDIA GeForce RTX 3090 GPU and Intel Core i7-10700 CPU. We observe that VAT is relatively slower and consumes more memory. However, 0.3 GB more memory consumption and 5 ms slower run time is a minor sacrifice for better performance.
4.4.3 Can VAT also perform well on semantic correspondence?
To tackle the few-shot segmentation task, we reformulated it as finding semantic correspondences under large intra-class variations and geometric deformations. This suggests that the proposed method could be effective for semantic correspondence as well. Here, we compare VAT to other state-of-the-art methods in semantic correspondence.
| Methods | F.T. Feat. | Data Aug. | Cost Aggregation | SPair-71k [43] | PF-PASCAL [14] | PF-WILLOW [13] | ||||||||
| PCK @ | PCK @ | PCK @ | ||||||||||||
| 0.03 | 0.05 | 0.1 | 0.15 | 0.03 | 0.05 | 0.1 | 0.15 | 0.05 | 0.1 | 0.15 | ||||
| NC-Net [53] | ✓ | ✗ | 4D Conv. | - | - | 20.1 | - | 30.9 | 54.3 | 78.9 | 86.0 | 33.8 | 67.0 | 83.7 |
| SCOT [34] | - | ✗ | OT-RHM | - | - | 35.6 | - | - | 63.1 | 85.4 | 92.7 | 47.8 | 76.0 | 87.1 |
| CHM [41]* | ✓ | ✗ | 4D Conv. | 14.9 | 27.2 | 46.3 | 57.5 | 67.5 | 80.1 | 91.6 | 94.9 | 52.7 | 79.4 | 87.5 |
| MMNet [85] | ✓ | ✗ | - | - | - | 40.9 | - | - | 77.6 | 89.1 | 94.3 | - | - | - |
| PMNC [26] | ✓ | ✗ | 4D Conv. | - | - | 50.4 | - | 71.6 | 82.4 | 90.6 | - | - | - | - |
| DHPF [44]* | ✓ | ✗ | RHM | 11.0 | 20.9 | 37.3 | 47.5 | 52.0 | 75.7 | 90.7 | 95.0 | 49.5 | 77.6 | 89.1 |
| ✓ | ✓ | RHM | - | - | 39.4 | - | - | - | - | - | - | - | - | |
| CATs [6]* | ✓ | ✗ | Transformer | 10.2 | 21.6 | 43.5 | 55.0 | 41.6 | 67.5 | 89.1 | 94.9 | 46.6 | 75.6 | 87.5 |
| ✓ | ✓ | Transformer | 13.8 | 27.7 | 49.9 | 61.7 | 49.9 | 75.4 | 92.6 | 96.4 | 50.3 | 79.2 | 90.3 | |
| VAT | ✓ | ✗ | Transformer | 14.9 | 28.3 | 48.4 | 59.1 | 54.6 | 72.9 | 91.1 | 95.6 | 46.0 | 78.8 | 91.3 |
| ✓ | ✓ | Transformer | 19.6 | 35.0 | 55.5 | 65.1 | 62.7 | 78.2 | 92.3 | 96.2 | 52.8 | 81.6 | 91.4 | |
In order to ensure a fair comparison, we note whether each method leverages multi-level features and fine-tunes the backbone networks. We additionally denote the types of cost aggregation. Note that the only difference we made for this experiment is the objective function for loss computation. Following the common protocol [42, 44, 85, 21, 41, 6], we use standard benchmarks for this task and our model was trained on the training split of PF-PASCAL [14] when evaluated on the test split of PF-PASCAL [14] and PF-WILLOW [13], and trained on SPair-71k [43] when evaluated on SPair-71k [43]. Experimental setting and implementation details can be found in supplementary material.
As shown in Table 6, VAT either sets a new state-of-the-art [43, 13] or attains the second highest PCK [14], indicating the importance of cost aggregation in both few-shot segmentation and semantic correspondence. It also has the potential to benefit general-purpose matching networks as well. Furthermore, when data augmentation is used, we observe a relatively large performance gain compared to DHPF [44], showing that augmentation helps to address the heavy need for data and lack of inductive bias in transformers [11, 6]. Although VAT is on par with state-of-the-art on PF-PASCAL [14], we argue that PF-PASCAL [14] is almost saturated, which makes a comparison difficult. Also, it should be noted that for performance on PF-WILLOW [13], VAT outperforms other methods by large margin, which clearly shows superior generalization power of the proposed 4D Convolutional Swin Transformer.
5 Conclusion
In this paper, we presented a novel cost aggregation network for few-shot segmentation. To address issues that arise from tokenization of a correlation map for transformer processing, we proposed a 4D Convolutional Swin Transformer, where a high-dimensional Swin Transformer is preceded by a series of small-kernel convolutions. To boost aggregation performance, we applied transformers within a pyramidal structure, and the output is then filtered and in the subsequent decoder with the help of image’s appearance embedding. We have shown that the proposed method attains state-of-the-art performance for all the standard benchmarks for both few-shot segmentation and semantic correspondence, where cost aggregation plays a central role.
5.0.1 Acknowledgements.
This research was supported by the MSIT, Korea (IITP-2022-2020-0-01819, ICT Creative Consilience program), and National Research Foundation of Korea (NRF-2021R1C1C1006897).
Appendix
Appendix A. Experimental Setting for Semantic Correspondence
5.0.2 Datasets.
For the datasets we used, we follow the common protocol [42, 44, 53, 85, 21, 41, 6] and use standard benchmarks [13, 14, 43]. Specifically, we consider SPair-71k [43], which provides a total of 70,958 image pairs with extreme and diverse viewpoints, scale variations, and rich annotations for each image pair. We also consider relatively small-scale datasets, which include PF-PASCAL [14] containing 1,351 image pairs from 20 categories and PF-WILLOW [13] containing 900 image pairs from 4 categories, where each dataset provides corresponding ground-truth annotations.
5.0.3 Evaluation metric.
For evaluation on SPair-71k [43], PF-PASCAL [14], and PF-WILLOW [13], we employ the percentage of correct keypoints (PCK). It is computed as the ratio of estimated keypoints within the threshold from ground-truths to the total number of keypoints. Concretely, given predicted keypoint and ground-truth keypoint , we count the number of predicted keypoints that satisfy the following condition: , where denotes Euclidean distance; denotes a threshold value; and denote height and width of the object bounding box or the entire image, respectively. We evaluate on PF-PASCAL with , and SPair-71k, and PF-WILLOW with following the common protocol.
5.0.4 Implementation Details.
We use ResNet-101 [16] pre-trained on ImageNet [9] for the backbone feature extraction networks. We leave all the components in VAT unchanged. However, we build a different objective function. As in [42, 44, 41], we assume ground-truth keypoints are provided. We utilize Average End-Point Error (AEPE) [65] and compute it by averaging the Euclidean distance between the ground-truth and estimated flow. Specifically, we compute the loss as , where is the ground-truth flow field and is the predicted flow field. Note that we achieve this without making any modification to the network architecture. To report the results for different thresholds, we employ the pre-trained weights released by authors, and simply evaluate without making any changes to their architectures. We use the same data augmentation used in CATs [6]. For the learning rate, we use the AdamW [38] optimizer with for VAT and for the backbone feature networks. Finally, we use appearance embedding from conv, conv and conv as done for FSS-1000 [30].
Appendix B. Additional Ablation Study
5.0.5 Ablation study for feature backbone.
| Backbones feature | FSS-1000 [30] | |
|---|---|---|
| mIoU () | ||
| 1-shot | 5-shot | |
| ResNet50 [16] | 90.1 | 90.7 |
| ResNet101 [16] | 90.3 | 90.8 |
| PVT [71] | 90.0 | 90.6 |
| Swin transformer [36] | 89.8 | 90.2 |
Conventional few-shot segmentation methods only utilized CNN-based feature backbones [16] for extracting features. [82] observed that high-level features contain semantics of objects which could lead to overfitting and is not suitable to use for the task of few-shot segmentation. Then the question naturally arises, what about other networks? As addressed in many works [48, 11], CNN and transformers see images differently, which means that the kinds of backbone networks may affect the performance significantly, but this has never been explored for this task. We thus exploit several well-known vision transformer architectures to explore the potential differences that may exist.
The results are summarized in Table 1. We find that both convolution- and transformer-based backbone networks attain similar performance. We conjecture that although it has been widely studied that convolutions and transformers see differently [48], as they are pre-trained on the same dataset [9], the representations learned by models are almost alike. Note that we only utilized backbones with a pyramidal structure, and the results may differ if other backbone networks are used, which we leave for future exploration.
5.0.6 Effectiveness of Data Augmentation.
We explore the effectiveness of data augmentation for few-shot segmentation. In this experiment, we employ two types of data augmentation, which are introduced either in PFE-Net [63] or CATs [6]. We summarize the augmentation types in Table 4 and Table 4. For this ablation study, we use two datasets, PASCAL-5i [55] and FSS-1000 [30]. The results are summarized in Table 2. Note that we use the same augmentation types and probability as theirs. For a fair comparison, we keep all the other experimental settings the same, e.g., number of iterations and learning rate.
| PFE-Net Aug. [63] | CATs Aug. [6] | PASCAL-5i [55] | FSS-1000 [30] | ||||
|---|---|---|---|---|---|---|---|
| mIoU () | mIoU () | ||||||
| mean | |||||||
| ✗ | ✗ | 70.0 | 72.5 | 64.8 | 64.2 | 67.9 | 90.3 |
| ✓ | ✗ | 68.4 | 72.3 | 64.4 | 63.9 | 67.3 | 90.0 |
| ✗ | ✓ | 65.7 | 72.2 | 62.3 | 64.3 | 66.1 | 90.1 |
| ✓ | ✓ | 65.2 | 71.1 | 63.2 | 63.4 | 65.7 | 90.2 |
As PFE-Net [63] does not address the effectiveness of data augmentation and CATs [6] is designed for the semantic correspondence task, we are the first to analyze the effectiveness of data augmentation in the few-shot segmentation setting. Overall, we observe that using the data augmentation techniques severely affects the overall performance. Interestingly, although the augmentation technique introduced by CATs [6] showed a significant performance boost in the semantic correspondence task, it attains the lowest mIoU when evaluated on PASCAL-5i [55] and the second lowest for FSS-1000 [30]. The severe performance drop in PASCAL-5i [55] indicates a detrimental influence of using CATs [6] data augmentation. However, given the small difference to the best performance (0.3) for FSS-1000 [30], the results may differ in a retrial. For PFE-Net [63] data augmentation, we observe results to be on par with the best reported results. However, at fold 0, there is a large gap between them, which indicates the detrimental effects of data augmentation on performance. Using both augmentations results in a large performance drop for PASCAL-5i [55], arguably due to the detrimental effects of both augmentations, but for FSS-1000 [30], we observe only a small difference.
| Augmentation type | Probability | |
|---|---|---|
| (I) | ToGray | 0.2 |
| (II) | Posterize | 0.2 |
| (III) | Equalize | 0.2 |
| (IV) | Sharpen | 0.2 |
| (V) | RandomBrightnessContrast | 0.2 |
| (VI) | Solarize | 0.2 |
| (VII) | ColorJitter | 0.2 |
| Strong Aug. type | Probability | |
|---|---|---|
| (I) | RandScale | 1 |
| (II) | Crop | 1 |
| (III) | Gaussian Blur | 0.5 |
| (IV) | Horizontal Flip | 0.5 |
| (V) | Rotate | 0.5 |
Consequently, we conjecture that the detrimental effects on PASCAL-5i [55] and seemingly trivial effects on FSS-1000 [30] could be attributed to a few reasons: First, as shown in Table 2, since the difference between the results of the non-data augmentation approach and the PFE-Net [63] augmentation approach is only 0.6 for PASCAL-5i, this may be due to the implementation details. For the training, we followed HSNet [40] to force randomness for diverse episode combinations, which may have made such a gap. Second, although the data augmentation may help transformers by providing inductive bias and addressing the heavy need for data, for few-shot setting, where the objective is to predict labels of unseen classes, the results may be different to that of semantic correspondence. It was demonstrated [6] that for semantic correspondence, data augmentation indeed helps to boost the performance, but a different problem formulation for few-shot segmentation may result in detrimental effects. Third, since we act on correlation maps, applying data augmentation may significantly affect the matching distribution at each pixel. Unlike those works directly working on feature refinement [63, 83], where adopting data augmentation has a direct influence on feature maps, VAT aggregates the correlation maps computed between the features extracted from augmented images, which may result in different effects (performance drop) when the objective is to predict unseen classes. Lastly, combining both augmentations may increase the difficulty of learning, which in turn impacts accuracy.
5.0.7 Ablation study for ATD.
In this ablation study, we show a quantitative comparison between the proposed ATD and a decoder without transformers [66, 70, 72, 36] to find out whether the model benefits from the use of transformers for further cost aggregation and filtering with the aid of the appearance embedding. For convenience, we call this Appearance-aware Decoder (AD). To implement this, we only exclude the transformers within ATD and leave all the other components and training settings unchanged, e.g., network architecture, hyperparameters, learning rate and number of iterations.
| Components | FSS-1000 [30] | |||||
|---|---|---|---|---|---|---|
| mIoU () | FB-IoU () | mBA () | ||||
| 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | |
| Convolutions | 87.3 | 88.8 | 92.2 | 93.2 | 66.8 | 67.2 |
| Transformers | 90.3 | 90.8 | 94.0 | 94.4 | 68.0 | 68.6 |
As shown in Table 5, we observe a large performance gap between AD and ATD, which demonstrates that using transformer allows for more effective aggregation, filtering and integration of correlation maps and appearance embedding. More specifically, we observe a 3 mIoU difference and find similar differences for FB-IoU and mBA. Without using transformers, where only convolutions are used, we observe that the results are equal to that of (VI) in the ablation study for VAT. This indicates that meaningful aggregation may not have occurred. It should be noted that we observe highly competitive results for mBA for both approaches, confirming a positive effect from the high-resolution spatial structure of the appearance embedding.
5.0.8 Ablation study for VCM.
For this ablation study, we aim to further support our claims that the VCM (overlapping convolutions) compensates for the lack of inductive bias and alleviates the detrimental effects caused at window boundaries. To this end, we use Linear transformer [24], Fastformer [72] and Swin Transformer [36] to validate the effectiveness. Note that we already reported the results for the ones with VCM, but we additionally provide FB-IoU and mBA results. For the implementation of VEM, we refer the readers to Algorithm 1.
| Components | FSS-1000 [30] | |||||
|---|---|---|---|---|---|---|
| mIoU () | FB-IoU () | mBA () | ||||
| 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | |
| VEM + Linear Transformer [24] | 87.0 | 87.4 | 90.7 | 91.0 | 65.0 | 64.9 |
| VEM + Fastformer [72] | 87.1 | 87.6 | 90.9 | 91.2 | 65.3 | 65.2 |
| VEM + Swin Transformer [36] | 89.9 | 90.5 | 92.9 | 94.0 | 67.8 | 68.2 |
| VCM + Linear Transformer [24] | 87.7 | 88.3 | 92.3 | 92.2 | 66.5 | 66.7 |
| VCM + Fastformer [72] | 87.8 | 88.2 | 91.8 | 91.9 | 66.4 | 66.4 |
| VCM + Swin Transformer [36] | 90.3 | 90.8 | 94.0 | 94.4 | 68.0 | 68.6 |
As shown in Table 6, we find a similar pattern to the results for VCM. Swin Transformer attained the best results, while Linear Transformer [24] and Fastformer [72] show similar results. Interestingly, when VCM is replaced with VEM, the performance difference for Swin Transformer and the other two differ substantially. Specifically, for Swin Transformer, the mIoU is 89.9 when equipped with VEM, which is a 0.4 performance drop and is a relatively lower drop compared to those of Linear Transformer and Fastformer. This could be due to the relative position bias that Swin Transformer provides, which the other two transformers lack. Furthermore, we suspect that the lower mIoU results could be explained by one of the following factors: simplified self-attention computation, local smoothness property of a correlation map, and consideration of spatial structure.
Appendix C. Limitations
An apparent limitation is that since our approach acts on correlation maps, we need to explicitly compute the global correlation maps and store them. This is indeed memory expensive, and increases with the spatial resolution of the correlation maps. Although we utilize a coarse-to-fine architecture, this does not make the training feasible when resolutions are high. Specifically, given a spatial resolution of feature maps at size 128128, the resultant size of correlation maps is at least 1284, and counting the level dimensions as well as other pyramidal levels , it is difficult to train with a sufficient batch size even with NVIDIA GeForce RTX-3090 GPUs. This might limit the accessibility of this approach. We also visualize failure cases in Fig. 1.

Appendix D. More Results
5.0.9 Quantitative Results for Semantic Correspondence.
As shown in Table 7, we provide per-class quantitative results on SPair-71k [43] in comparison to other semantic correspondence methods, including CNNGeo [50], WeakAlign [51], NC-Net [53], HPF [42], SFNet [27], DCC-Net [21], GSF [22], SCOT [34], DHPF [44], CHM [41], MMNet [85], PMNC [26] and CATs [6].
| Methods | aero. | bike | bird | boat | bott. | bus | car | cat | chai. | cow | dog | hors. | mbik. | pers. | plan. | shee. | trai. | tv | all |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CNNGeo [50] | 23.4 | 16.7 | 40.2 | 14.3 | 36.4 | 27.7 | 26.0 | 32.7 | 12.7 | 27.4 | 22.8 | 13.7 | 20.9 | 21.0 | 17.5 | 10.2 | 30.8 | 34.1 | 20.6 |
| WeakAlign [51] | 22.2 | 17.6 | 41.9 | 15.1 | 38.1 | 27.4 | 27.2 | 31.8 | 12.8 | 26.8 | 22.6 | 14.2 | 20.0 | 22.2 | 17.9 | 10.4 | 32.2 | 35.1 | 20.9 |
| NC-Net [53] | 17.9 | 12.2 | 32.1 | 11.7 | 29.0 | 19.9 | 16.1 | 39.2 | 9.9 | 23.9 | 18.8 | 15.7 | 17.4 | 15.9 | 14.8 | 9.6 | 24.2 | 31.1 | 20.1 |
| HPF [42] | 25.2 | 18.9 | 52.1 | 15.7 | 38.0 | 22.8 | 19.1 | 52.9 | 17.9 | 33.0 | 32.8 | 20.6 | 24.4 | 27.9 | 21.1 | 15.9 | 31.5 | 35.6 | 28.2 |
| SCOT [34] | 34.9 | 20.7 | 63.8 | 21.1 | 43.5 | 27.3 | 21.3 | 63.1 | 20.0 | 42.9 | 42.5 | 31.1 | 29.8 | 35.0 | 27.7 | 24.4 | 48.4 | 40.8 | 35.6 |
| DHPF [44] | 38.4 | 23.8 | 68.3 | 18.9 | 42.6 | 27.9 | 20.1 | 61.6 | 22.0 | 46.9 | 46.1 | 33.5 | 27.6 | 40.1 | 27.6 | 28.1 | 49.5 | 46.5 | 37.3 |
| CHM [41] | 49.1 | 33.6 | 64.5 | 32.7 | 44.6 | 47.5 | 43.5 | 57.8 | 21.0 | 61.3 | 54.6 | 43.8 | 35.1 | 43.7 | 38.1 | 33.5 | 70.6 | 55.9 | 46.3 |
| MMNet [85] | 43.5 | 27.0 | 62.4 | 27.3 | 40.1 | 50.1 | 37.5 | 60.0 | 21.0 | 56.3 | 50.3 | 41.3 | 30.9 | 19.2 | 30.1 | 33.2 | 642 | 43.6 | 40.9 |
| PMNC [26] | 54.1 | 35.9 | 74.9 | 36.5 | 42.1 | 48.8 | 40.0 | 72.6 | 21.1 | 67.6 | 58.1 | 50.5 | 40.1 | 54.1 | 43.3 | 35.7 | 74.5 | 59.9 | 50.4 |
| CATs [6] | 52.0 | 34.7 | 72.2 | 34.3 | 49.9 | 57.5 | 43.6 | 66.5 | 24.4 | 63.2 | 56.5 | 52.0 | 42.6 | 41.7 | 43.0 | 33.6 | 72.6 | 58.0 | 49.9 |
| VAT (ours) | 49.8 | 36.8 | 70.1 | 33.5 | 46.1 | 46.0 | 31.1 | 69.9 | 15.7 | 69.9 | 57.2 | 47.2 | 38.5 | 41.8 | 43.0 | 35.5 | 75.0 | 61.8 | 48.4 |
| VAT (ours) | 58.8 | 40.0 | 75.3 | 40.1 | 52.1 | 59.7 | 44.2 | 69.1 | 23.3 | 75.1 | 61.9 | 57.1 | 46.4 | 49.1 | 51.8 | 41.8 | 80.9 | 70.1 | 55.5 |
| Backbone network | Methods | 1-shot | 5-shot | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | mean | ||||||||||
| ResNet50 [16] | RePRI [2] | 45.8 | 53.7 | 46.6 | 50.0 | 49.0 | 45.4 | 46.9 | 41.8 | 41.0 | 43.8 |
| HSNet [40] | 53.9 | 54.7 | 53.3 | 53.6 | 53.9 | 54.6 | 55.1 | 54.0 | 54.2 | 54.5 | |
| VAT (ours) | 55.1 | 55.1 | 53.8 | 53.6 | 54.4 | 55.4 | 55.3 | 54.5 | 53.9 | 54.8 | |
| ResNet101 [16] | RePRI [2] | 47.6 | 47.6 | 41.9 | 43.3 | 45.1 | 46.4 | 44.4 | 38.4 | 38.7 | 42.0 |
| HSNet [40] | 53.9 | 54.4 | 53.5 | 53.9 | 53.9 | 54.3 | 54.7 | 54.2 | 54.2 | 54.4 | |
| VAT (ours) | 54.7 | 54.6 | 53.9 | 55.5 | 54.7 | 55.0 | 55.0 | 54.5 | 54.8 | 54.8 | |
5.0.10 More results for mBA comparison.
In Table 8 and Table 9, we provide per fold quantitative results for mBA. Note that we obtained the mBA results for HSNet [40] and RePRI [2] using the pre-trained weights and code released by the authors. We omit the results for CyCTR [83] as the official code and weights by the authors are not publicly available.
5.0.11 Qualitative Results.
As shown in Figure 2, Figure 3, Figure 4, Figure 5 and Figure 6, we provide qualitative results on all the benchmarks, which includes PASCAL-5i [55], COCO-20i [31], FSS-1000 [30], PF-PASCAL [14], PF-WILLOW [13] and SPair-71k [43].





References
- [1] Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
- [2] Boudiaf, M., Kervadec, H., Masud, Z.I., Piantanida, P., Ben Ayed, I., Dolz, J.: Few-shot segmentation without meta-learning: A good transductive inference is all you need? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
- [3] Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence (2017)
- [4] Chen, L.C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the European conference on computer vision (ECCV) (2018)
- [5] Cheng, H.K., Chung, J., Tai, Y.W., Tang, C.K.: CascadePSP: Toward class-agnostic and very high-resolution segmentation via global and local refinement. In: CVPR (2020)
- [6] Cho, S., Hong, S., Jeon, S., Lee, Y., Sohn, K., Kim, S.: Cats: Cost aggregation transformers for visual correspondence. In: Thirty-Fifth Conference on Neural Information Processing Systems (2021)
- [7] Dai, Z., Liu, H., Le, Q., Tan, M.: Coatnet: Marrying convolution and attention for all data sizes. Advances in Neural Information Processing Systems 34 (2021)
- [8] d’Ascoli, S., Touvron, H., Leavitt, M., Morcos, A., Biroli, G., Sagun, L.: Convit: Improving vision transformers with soft convolutional inductive biases. arXiv preprint arXiv:2103.10697 (2021)
- [9] Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. Ieee (2009)
- [10] Dong, N., Xing, E.P.: Few-shot semantic segmentation with prototype learning. In: BMVC (2018)
- [11] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
- [12] Everingham, M., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual object classes (voc) challenge. International journal of computer vision (2010)
- [13] Ham, B., Cho, M., Schmid, C., Ponce, J.: Proposal flow. In: CVPR (2016)
- [14] Ham, B., Cho, M., Schmid, C., Ponce, J.: Proposal flow: Semantic correspondences from object proposals. IEEE transactions on pattern analysis and machine intelligence (2017)
- [15] Hariharan, B., Arbeláez, P., Girshick, R., Malik, J.: Simultaneous detection and segmentation. In: European conference on computer vision. Springer (2014)
- [16] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition (2016)
- [17] Hong, S., Kim, S.: Deep matching prior: Test-time optimization for dense correspondence. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021)
- [18] Hosni, A., Rhemann, C., Bleyer, M., Rother, C., Gelautz, M.: Fast cost-volume filtering for visual correspondence and beyond. PAMI (2012)
- [19] Hu, H., Gu, J., Zhang, Z., Dai, J., Wei, Y.: Relation networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3588–3597 (2018)
- [20] Hu, H., Zhang, Z., Xie, Z., Lin, S.: Local relation networks for image recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3464–3473 (2019)
- [21] Huang, S., Wang, Q., Zhang, S., Yan, S., He, X.: Dynamic context correspondence network for semantic alignment. In: ICCV (2019)
- [22] Jeon, S., Min, D., Kim, S., Choe, J., Sohn, K.: Guided semantic flow. In: ECCV. Springer (2020)
- [23] Jiang, W., Trulls, E., Hosang, J., Tagliasacchi, A., Yi, K.M.: Cotr: Correspondence transformer for matching across images. arXiv preprint arXiv:2103.14167 (2021)
- [24] Katharopoulos, A., Vyas, A., Pappas, N., Fleuret, F.: Transformers are rnns: Fast autoregressive transformers with linear attention. In: International Conference on Machine Learning. pp. 5156–5165. PMLR (2020)
- [25] Kim, S., Min, D., Ham, B., Jeon, S., Lin, S., Sohn, K.: Fcss: Fully convolutional self-similarity for dense semantic correspondence. In: CVPR (2017)
- [26] Lee, J.Y., DeGol, J., Fragoso, V., Sinha, S.N.: Patchmatch-based neighborhood consensus for semantic correspondence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
- [27] Lee, J., Kim, D., Ponce, J., Ham, B.: Sfnet: Learning object-aware semantic correspondence. In: CVPR (2019)
- [28] Li, G., Jampani, V., Sevilla-Lara, L., Sun, D., Kim, J., Kim, J.: Adaptive prototype learning and allocation for few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8334–8343 (2021)
- [29] Li, S., Han, K., Costain, T.W., Howard-Jenkins, H., Prisacariu, V.: Correspondence networks with adaptive neighbourhood consensus. In: CVPR (2020)
- [30] Li, X., Wei, T., Chen, Y.P., Tai, Y.W., Tang, C.K.: Fss-1000: A 1000-class dataset for few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020)
- [31] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision (2014)
- [32] Liu, W., Zhang, C., Ding, H., Hung, T.Y., Lin, G.: Few-shot segmentation with optimal transport matching and message flow. arXiv preprint arXiv:2108.08518 (2021)
- [33] Liu, W., Zhang, C., Lin, G., Liu, F.: Crnet: Cross-reference networks for few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020)
- [34] Liu, Y., Zhu, L., Yamada, M., Yang, Y.: Semantic correspondence as an optimal transport problem. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020)
- [35] Liu, Y., Zhang, X., Zhang, S., He, X.: Part-aware prototype network for few-shot semantic segmentation. In: European Conference on Computer Vision. pp. 142–158. Springer (2020)
- [36] Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030 (2021)
- [37] Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (2015)
- [38] Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
- [39] Lu, Z., He, S., Zhu, X., Zhang, L., Song, Y.Z., Xiang, T.: Simpler is better: Few-shot semantic segmentation with classifier weight transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2021)
- [40] Min, J., Kang, D., Cho, M.: Hypercorrelation squeeze for few-shot segmentation. arXiv preprint arXiv:2104.01538 (2021)
- [41] Min, J., Kim, S., Cho, M.: Convolutional hough matching networks for robust and efficient visual correspondence. arXiv preprint arXiv:2109.05221 (2021)
- [42] Min, J., Lee, J., Ponce, J., Cho, M.: Hyperpixel flow: Semantic correspondence with multi-layer neural features. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2019)
- [43] Min, J., Lee, J., Ponce, J., Cho, M.: Spair-71k: A large-scale benchmark for semantic correspondence. arXiv preprint arXiv:1908.10543 (2019)
- [44] Min, J., Lee, J., Ponce, J., Cho, M.: Learning to compose hypercolumns for visual correspondence. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XV 16. Springer (2020)
- [45] Nguyen, K., Todorovic, S.: Feature weighting and boosting for few-shot segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 622–631 (2019)
- [46] Noh, H., Hong, S., Han, B.: Learning deconvolution network for semantic segmentation. In: Proceedings of the IEEE international conference on computer vision (2015)
- [47] Philbin, J., Chum, O., Isard, M., Sivic, J., Zisserman, A.: Object retrieval with large vocabularies and fast spatial matching. In: CVPR. IEEE (2007)
- [48] Raghu, M., Unterthiner, T., Kornblith, S., Zhang, C., Dosovitskiy, A.: Do vision transformers see like convolutional neural networks? arXiv preprint arXiv:2108.08810 (2021)
- [49] Ravi, S., Larochelle, H.: Optimization as a model for few-shot learning (2016)
- [50] Rocco, I., Arandjelovic, R., Sivic, J.: Convolutional neural network architecture for geometric matching. In: CVPR (2017)
- [51] Rocco, I., Arandjelović, R., Sivic, J.: End-to-end weakly-supervised semantic alignment. In: CVPR (2018)
- [52] Rocco, I., Arandjelović, R., Sivic, J.: Efficient neighbourhood consensus networks via submanifold sparse convolutions. In: ECCV (2020)
- [53] Rocco, I., Cimpoi, M., Arandjelović, R., Torii, A., Pajdla, T., Sivic, J.: Neighbourhood consensus networks. arXiv preprint arXiv:1810.10510 (2018)
- [54] Scharstein, D., Szeliski, R.: A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. International journal of computer vision (2002)
- [55] Shaban, A., Bansal, S., Liu, Z., Essa, I., Boots, B.: One-shot learning for semantic segmentation. arXiv preprint arXiv:1709.03410 (2017)
- [56] Siam, M., Oreshkin, B., Jagersand, M.: Adaptive masked proxies for few-shot segmentation. arXiv preprint arXiv:1902.11123 (2019)
- [57] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
- [58] Snell, J., Swersky, K., Zemel, R.S.: Prototypical networks for few-shot learning. arXiv preprint arXiv:1703.05175 (2017)
- [59] Sun, D., Yang, X., Liu, M.Y., Kautz, J.: Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In: CVPR (2018)
- [60] Sun, G., Liu, Y., Liang, J., Van Gool, L.: Boosting few-shot semantic segmentation with transformers. arXiv preprint arXiv:2108.02266 (2021)
- [61] Tao, A., Sapra, K., Catanzaro, B.: Hierarchical multi-scale attention for semantic segmentation. arXiv preprint arXiv:2005.10821 (2020)
- [62] Tetko, I.V., Livingstone, D.J., Luik, A.I.: Neural network studies, 1. comparison of overfitting and overtraining. J. Chem. Inf. Comput. Sci. 35, 826–833 (1995)
- [63] Tian, Z., Zhao, H., Shu, M., Yang, Z., Li, R., Jia, J.: Prior guided feature enrichment network for few-shot segmentation. IEEE Transactions on Pattern Analysis & Machine Intelligence (2020)
- [64] Tolstikhin, I.O., Houlsby, N., Kolesnikov, A., Beyer, L., Zhai, X., Unterthiner, T., Yung, J., Steiner, A., Keysers, D., Uszkoreit, J., et al.: Mlp-mixer: An all-mlp architecture for vision. Advances in Neural Information Processing Systems 34 (2021)
- [65] Truong, P., Danelljan, M., Timofte, R.: Glu-net: Global-local universal network for dense flow and correspondences. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6258–6268 (2020)
- [66] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems (2017)
- [67] Vinyals, O., Blundell, C., Lillicrap, T., Wierstra, D., et al.: Matching networks for one shot learning. Advances in neural information processing systems (2016)
- [68] Wang, H., Zhang, X., Hu, Y., Yang, Y., Cao, X., Zhen, X.: Few-shot semantic segmentation with democratic attention networks. In: European Conference on Computer Vision (2020)
- [69] Wang, K., Liew, J.H., Zou, Y., Zhou, D., Feng, J.: Panet: Few-shot image semantic segmentation with prototype alignment. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2019)
- [70] Wang, S., Li, B.Z., Khabsa, M., Fang, H., Ma, H.: Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768 (2020)
- [71] Wang, W., Xie, E., Li, X., Fan, D.P., Song, K., Liang, D., Lu, T., Luo, P., Shao, L.: Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv preprint arXiv:2102.12122 (2021)
- [72] Wu, C., Wu, F., Qi, T., Huang, Y., Xie, X.: Fastformer: Additive attention can be all you need. arXiv preprint arXiv:2108.09084 (2021)
- [73] Wu, S., Wu, T., Lin, F., Tian, S., Guo, G.: Fully transformer networks for semantic image segmentation. arXiv preprint arXiv:2106.04108 (2021)
- [74] Xiao, T., Singh, M., Mintun, E., Darrell, T., Dollár, P., Girshick, R.: Early convolutions help transformers see better. arXiv preprint arXiv:2106.14881 (2021)
- [75] Xie, G.S., Liu, J., Xiong, H., Shao, L.: Scale-aware graph neural network for few-shot semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5475–5484 (2021)
- [76] Xie, G.S., Xiong, H., Liu, J., Yao, Y., Shao, L.: Few-shot semantic segmentation with cyclic memory network. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2021)
- [77] Xiong, Y., Zeng, Z., Chakraborty, R., Tan, M., Fung, G., Li, Y., Singh, V.: Nyströmformer: A nyström-based algorithm for approximating self-attention (2021)
- [78] Yang, B., Liu, C., Li, B., Jiao, J., Ye, Q.: Prototype mixture models for few-shot semantic segmentation. In: European Conference on Computer Vision. Springer (2020)
- [79] Yang, L., Zhuo, W., Qi, L., Shi, Y., Gao, Y.: Mining latent classes for few-shot segmentation. arXiv preprint arXiv:2103.15402 (2021)
- [80] Zhang, B., Xiao, J., Qin, T.: Self-guided and cross-guided learning for few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
- [81] Zhang, C., Lin, G., Liu, F., Guo, J., Wu, Q., Yao, R.: Pyramid graph networks with connection attentions for region-based one-shot semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9587–9595 (2019)
- [82] Zhang, C., Lin, G., Liu, F., Yao, R., Shen, C.: Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5217–5226 (2019)
- [83] Zhang, G., Kang, G., Wei, Y., Yang, Y.: Few-shot segmentation via cycle-consistent transformer. arXiv preprint arXiv:2106.02320 (2021)
- [84] Zhang, H., Ding, H.: Prototypical matching and open set rejection for zero-shot semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2021)
- [85] Zhao, D., Song, Z., Ji, Z., Zhao, G., Ge, W., Yu, Y.: Multi-scale matching networks for semantic correspondence. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3354–3364 (2021)