Counterfactual Fairness Is Not Demographic Parity,
and Other Observations
Abstract
Blanket statements of equivalence between causal concepts and purely probabilistic concepts should be approached with care. In this short note, I examine a recent claim that counterfactual fairness is equivalent to demographic parity. The claim fails to hold up upon closer examination. I will take the opportunity to address some broader misunderstandings about counterfactual fairness.
1 Introduction
This manuscript is motivated by [21], published at AAAI 2023. It is based on some misunderstandings about counterfactual fairness, leading to the incorrect conclusion that counterfactual fairness and demographic parity are equivalent. Emphatically, the goal of this manuscript is not to criticize any particular paper. Instead, it follows from the fact that none of the AAAI reviewers were able to help the authors of [21]. This suggests to me that will would be helpful to provide some notes on possible common missteps on understanding counterfactual fairness, using [21] just as a springboard for broader comments.
In a nutshell, counterfactual fairness is a notion of individual fairness that lies on Rung 3 of Pearl’s ladder of causality [19], while demographic parity is a non-causal notion of group fairness occurring at the purely probabilistic Rung 1. We illustrate that there are scenarios of strong causal assumptions where the two notions “coincide”, in an inconsequential equivalence that relies on narrow Rung 3 conditions. More generally, the equivalence breaks down. A simple way of seeing this is as follows: we already know that different causal models can induce different feasible regions of counterfactually fair predictors that do not coincide despite being observationally and interventionally equivalent [23]. Hence, for any given predictor respecting demographic parity, an adversary can pick a particular world that explains the data but in which is not counterfactually fair. In this manuscript, we give constructive examples on how trivial it is to break the counterfactual fairness of any predictor which respects demographic parity but disregards counterfactual assumptions, among other clarifications of common misunderstandings. We then proceed to look closer at other problematic claims about counterfactual fairness described by [6] and [20] that fall within the broader theme of how counterfactual fairness is sometimes misapplied.
In the interest of keeping this note short, I will not cover any background material and definitions that can be commonly found in the literature. See [3] for suitable background information.
2 On Counterfactual Fairness and Demographic Parity
Links between counterfactual fairness and demographic parity have been known from the beginning.
Relations between counterfactual fairness and demographic parity are known since the original paper [11], which has an appendix section with the relevant title “Relation to Demographic Parity” (Appendix S2, page 13). That section was primarily concerned about a less standard notion of demographic parity – the writing most definitely should have been clearer, as it muddles the presentation of the new variant with the more standard definition of demographic parity. The variant of demographic parity in that appendix was implicitly defined in terms of a predictor being functionally independent of protected attributes , rather than the more standard (and non-causal) definition . The latter can be checked using textbook methods from e.g. the graphical modeling literature.
Counterfactual fairness does not imply demographic parity.
The focus on Appendix S2 of [11] was on a functional variant of demographic parity, as I judged that interested readers can always deduce by themselves when standard demographic parity () holds. Here’s an illustration.
Figure 1(a) depicts a simple causal diagram where are protected attributes, are other measurements of an individual, is the error term for the structural equation of , and is a predictor. Adding to the diagram is fine regardless whether any intervention on is well-defined, as the graph also has the semantics of a probabilistic independence model. This is the type of diagram that an experienced reader would be able to mentally construct by eyeballing Figure 1 of [11], for instance. In it, is d-separated from , and hence for any model Markov with respect to that graph. In Figure 1(b), that’s not the case, and demographic parity is not entailed by the structural assumptions. The same with Figure 1(c), where are pre-treatment variables, and so on. Key extensions to the bare-bones counterfactual fairness idea, such as path-specific versions that were alluded in the original paper and developed in detail in contributions such as [4], also have no trivial connection to demographic parity.
What if we consider only inputs as in Figure 1(a), and only the basic total-effect counterfactual fairness criterion of the original paper? Let’s call this setup “special counterfactual fairness” (sCP) to clarify we are dealing with a specific case. A key question is: if a predictor satisfies demographic parity and we happen to know that is ignorable (that is, , where is the set of potential outcomes of ), does automatically satisfy counterfactual fairness? The answer is no.
Demographic parity does not imply counterfactual fairness.
Let’s provide a simple counterexample where given is Gaussian and is 0/1 binary. These distributions are unimportant but will make the presentation easier. We will use to denote the potential outcome of variable under an intervention that sets some variable to a fixed level . Any structural causal model (SCM) implies a joint distribution over potential outcomes [17].
Let and be the corresponding potential outcomes for under interventions on , and assume that they are jointly Gaussian with means , variances , and correlation . In SCM lingo, we could obtain that if the structural equation is e.g. , where are zero-mean Gaussian variables with the same covariance structure as .
Let’s define deterministically as the following function of and ,
We can do this if we know (learn) the density , since the marginals of the potential outcomes are identifiable here111Yes, in principle we should define as a function where minimizes some loss function with respect to some , but this is not relevant to the argument.. It is clear that , while and – that’s non-trivial demographic parity taking place. This also implies that and are equal in distribution, and that there is a one-to-one mapping between and when , and between and when .
What about counterfactual fairness? The only remaining unidentifiable parameter is . It would be terrific if we were able to ensure counterfactual fairness with only the relatively mild assumption of ignorability of . Alas, this is not meant to be:
where and are non-trivial functions of . The second line come from the consistency implication and the fact that by ignorability we have that .
This means that the above is in general different from
which, for starters, is a point-mass distribution. If for whatever reason we had chosen not to be a deterministic function of , the factual marginal is still not a function of . For instance, if and , then and , with the resulting integral for evidently different from the binary function , and in general a function of , even if is not a deterministic function of .
This means counterfactual fairness is in general not implied by demographic parity even in the most basic sCF scenario.
The assumptions of Gaussianity are not fundamental. For a scalar continuous , we know that we can parameterize any density as , where in uniformly distributed in and is the inverse of the conditional cdf (see [22] for a multivariate version of this idea). We can define (the distribution of) via for any (point-mass or not) conditional pmf/pdf of our choice, and thus we have that (the Markov blanket of still includes both and when we marginalize ). This all follows directly from a Markov structure equivalent to the one in Figure 1(a). However, one big point is that here is an arbitrary mathematical construct and by itself warrants no interpretation as the error term of a structural causal model..
Remarks.
Even an expert in SCMs may get confused about the meaning of a structural equation such as . The claim in this equation is that the error term is one-dimensional and shared by all potential outcomes. The set of potential outcomes forms a stochastic process, potentially infinite dimensional if is continuous, so something is being thrown away here222A one-dimensional error term can still represent a linear function of infinitely many variables – say, the shamelessly vague “sum of all other causes of ” – but it clearly won’t imply an infinite-dimensional model. As an analogy, think of the Gaussian distribution being parametric even when motivated as the average of infinitely many random variables..
Under all potential outcomes are deterministically related, as and therefore . Unlike the example in the previous paragraphs, this model has no free parameters for the correlation of the potential outcomes. What is the implication?
Say the world behaves according to a causal independence model given by the causal DAG (again, no confounding) with structural equation , where is Gaussian, and so is . Therefore, pdf is the pdf of a bivariate Gaussian. Say also that an analyst knows , which is in principle learnable from observational data.
The analyst sets themselves up to construct as a linear function of (and so also Gaussian) while enforcing , using no more than , causality seemingly playing no role. This is akin to creating an unfaithful distribution [25], with the total effect of on being canceled by combining the path against . Let’s assume and are marginally standard Gaussians for simplicity. From free parameters in and the covariance matrix of , we can pick (or any linear function of ) in order to guarantee . But that’s just (a linear function of) , and therefore it seems that from demographic parity only we were able to achieve counterfactual fairness.
Or were we? In fact, we were not. We are not showing anything like
Instead, we are showing (a special case of) the far less interesting result
This has a closer link to demographic parity, even if of dubious value added, than the initial set of assumptions about being ignorable and nothing else (which led to nowhere). However, even the link we just found would fail if the structural equation was instead , where means that, after fixing to , we pick out of a zero-mean infinite-dimensional Gaussian process indexed by the action space of (the real line). A discussion of finite-dimensional stochastic processes for counterfactuals with continuous-valued treatments is provided by [16].
The difference between and with a stationary Gaussian process is undetectable by experiment, even if the choice matters for counterfactual fairness. We are really stuck in what Pearl calls the “Rung 3” of causal inference [19]. Any claim to reduce it to “Rung 1”-level (purely probabilistic) should be taken apart to find out where the Rung 3 assumptions are hiding. It would be awesome and a relief to be able to stick to Rung 1, but I cannot even imagine a counterfactual world where that would be true. I do not doubt that there are other systematic families of counterfactual assumptions that could lead to e.g. demographic parity as an alternative construction rule for counterfactually fair predictors, although it is not clear in which practical sense this would make our life any easier than a method for extracting functions of error terms or potential outcomes. Such constructions could also end up being of no use in more general scenarios such as path-specific effects.
A closing comment in this section. The original paper [11], and some of the follow-ups, exploited one-dimensional error term models as an illustration of the ideal pipeline, without committing to it as a clearly universal counterfactual family. Before spurious statements such as “one-dimensional error terms are among the most common found in counterfactual fairness papers, therefore we will take it as part of the definition of counterfactual fairness etc.” start to show up as a follow-up to this note, let me quote directly from [11]:
Although this is well understood, it is worthwhile remembering that causal models always require strong assumptions, even more so when making counterfactual claims [8]. Counterfactuals assumptions such as structural equations are in general unfalsifiable even if interventional data for all variables is available. This is because there are infinitely many structural equations compatible with the same observable distribution …, be it observational or interventional. Having passed testable implications, the remaining components of a counterfactual model should be understood as conjectures formulated according to the best of our knowledge. Such models should be deemed provisional and prone to modifications if, for example, new data containing measurement of variables previously hidden contradict the current model.
Reference [8] in the quote above is a 20-year old paper by my colleague A.P. Dawid [5], a most merciless critique of the unnecessary use of counterfactuals/potential outcomes in causal models that in reality do not need them. Dawid calls counterfactual assumptions downright metaphysical, as there are no possible experiments to falsify some of their most general implications. I think it is important to have this critique in mind333Like Philip Dawid – who, post-retirement and pre-pandemic, still used to show up regularly at the visitor’s office in our department at UCL, a couple of doors down the corridor from mine – I do share a distaste for unnecessary usage of counterfactuals/potential outcomes. To be honest, I was never really bothered by their use when the point was merely to introduce convenient notation – for instance, I’m fond of using them in partial identification methods even for no-cross-world (“single-world”) questions. But once upon a time there was a genre, thankfully in decline, of ill-informed papers (primarily in statistics) dismissing the soundness of causal graphical models on the account they did not imply the existence of potential outcomes. My bafflement was due to the fact that in many of these papers there was indeed no need for potential outcomes at all. I would privately joke that those papers should get a Doubly-William Award, named after Occam and Shakespeare, for demanding counterfactuals in a context where they would boil down to no more than “entities multiplied without necessity, full of sound and fury, signifying nothing.”, but even Dawid agrees that there are genuine uses where counterfactual models play a central role despite untestable assumptions about the mere existence (!) of counterfactuals. With the rise of conformal prediction [27, 1] in particular, it is becoming more acceptable to complement point predictions with prediction intervals, and partially-identifiable counterfactual intervals (on top of aleatoric + estimation error intervals) are becoming more mainstream [13]. A direction worthwhile pursuing is on partial identifiability [16], where the companion paper [23] was an early but primitive example, followed by far more interesting work such as [28]. More of that would be welcome.
3 Comments on Rosenblatt and Witter (2023)
[21] attempts to show equivalence between counterfactual fairness and demographic parity. One direction is clearly correct, where sCP implies demographic parity, as in Figure 1(a) (although the paper imprecisely equates sCP with counterfactual fairness and there are no comments about path-specific variants). Their Theorem 4 states the converse, that demographic parity implies counterfactual fairness. As we have seen, this is not correct444It’s not always easy to understand what the exact claim is: sCP and demographic parity are meant to be “basically” equivalent in some unspecified sense of what “basically” means. In one passage it is stated that “Note that Proposition 9, combined with the fact that Listing 1 and 2 satisfy demographic parity and preserve group order, does not refute Theorem 4 since the method of estimating latent variables in the proof of the theorem uses a trivial causal model.” To the best of my understanding, this (an example of a predictor respecting demographic parity but not sCP) seems to directly refute Theorem 4. The argument in Theorem 4 literally states that , so that any predictor respecting demographic parity must be counterfactually fair under sCP, regardless or not whether the person designing carries out in their brain the construction of an imaginary latent variable model and predictor .. The bug in their proof is the conflation of mathematical constructs with latent variables that have causal semantics, a type of reification, along with tautological reasoning. Their argument relies on “estimating the latent variables” (presumably this can include the potentially infinite dimensional error term for the structural equation of ) using some preliminary , then using this “” to define another . This says nothing about conditional cross-world dependencies, and as a matter of fact it says nothing even about a correctly specified model for which could in any sense qualify as an “estimate” of . Even if we are not talking about error terms, this is entirely contrary to, for example, the advice in [11] when considering Level 2 modeling for counterfactual fairness (emphasis added),
Postulate background latent variables that act as non-deterministic causes of observable variables, based on explicit domain knowledge and learning algorithms.
This is not to pick on the authors: reification errors are a very common mistake in the literature that many have made at some point, present company included.
Interestingly, [21] cites [6] as showing links to demographic parity. But the main point of [6] are the challenges of constructing causal models that correctly capture ignorability conditions, and in fact demographic parity is only mentioned as a counterexample to Theorem 4, where demographic parity holds but counterfactual fairness does not (due to model misspecification). We will briefly discuss some aspects of [6] in the next section.
There are a few other issues I could comment on555An old favorite zombie is the following argument: i) race (for example) is a complex concept made of many constitutive aspects; ii) the existence of an overall intervention controlling all of those aspects is not self-evident; iii) we therefore conclude that we cannot possibly talk about any meaningful aspect of race as a cause. As there is so much in the literature about this, and this is not about the dependency structure of which is the topic of this manuscript, I’ll refrain from further comments. I’ll just leave here the acerbic comment of [24], footnote 2, Chapter 21: “It may be merely coincidence that … many of the statisticians who make such pronouncements [there is no meaning of race or sex as a cause] work or have worked for the Educational Testing Service, an organization with an interest in asserting that, strictly speaking, sex and race cannot have any causal role in the score anyone gets on the SAT.” We should do better than indulging Merchants of Doubt. See [29] for an example of how to properly lead a thoughtful discussion on the challenges of defining causal effects of composite variables., but in the interest of focus, I will keep to the topic of dependency structure of and basic ideas that follow from it that are sometimes overlooked.
Counterfactual fairness as a variable selection procedure.
One of the main motivations for counterfactual fairness is as follows. In a prediction problem, we do not want fairness through unawareness [3], that is, just to remove the protected attributes from being inputs to a predictive system. This is because other variables carry implications from protected attributes, where “implications” is a loaded word that carries multiple meanings. Value judgements are necessary: they are part of the input in a machine learning pipeline, to be communicated in a way it translates into removing sensitive information from a predictor that is indirectly implied by the protected attributes. The operational meaning of “removing” is also not straightforward. Section 6 of [8] does a good job of describing the challenges. In counterfactual fairness and its path-specific variants, this judgement is carried over by a notion of counterfactual effect, essentially operationalizing what needs to be removed and how. Regarding this goal, nothing could be more different than fairness through unawareness. It is puzzling that [21] uses fairness through unawareness as a substitute to the original Level 1 of [11], going as far as claiming that it “come(s) from the original counterfactual fairness paper”, as the approaches could not be more diametrically opposite to each other. I also do not understand what Level 3 in [21] is doing, but Level 3 in [11] is most definitely not meant to be a “compromise” between 1 and 2, as ambiguously stated. Statements such as “Level 3 is an example of an algorithm that ostensibly satisfies counterfactual fairness” (but fails to achieve demographic parity) are meaningless if the algorithm is based on misspecified causal models – in [11] we explicitly indicate that experiments on fairness measures were based on simulated data (generated from a model fitted to real data). The text in the experimental section of [21] seems not to distinguish a definition from the improper application of this definition to models that may be misspecified.
Counterfactual fairness defines constraints on a predictor, not the loss function, constraints which can be interpreted as filters or a variation on the idea of information bottleneck [26]. In fact, we can build optimal loss minimizers with respect to the information that counterfactual fairness allows to be used, which brings us to our next point.
Counterfactual fairness is agnostic to loss functions and other constraints.
If one wants to build a counterfactually fair predictor by flipping a coin, they can. The loss will be high, but this does not contradict counterfactual fairness666It also does not contradict our previous statement about needing causal assumptions: that is unconfounded with coin flip at a Rung 3 level is a causal assumption that e.g. the physical concept of superdeterminism does not need to assume.. The point is that counterfactual fairness allows for the use of information in that other (causal) concepts do not, and vice-versa (for instance, [15] does not allow for mediators to be used in any sense, while counterfactual fairness allows for mediators to be used, as long their role is in the inference of potential outcomes/error terms).
Once predictions are generated, decisions can incorporate other elements e.g. for college admissions we may want to avoid extremely uneven distribution of students according to (say) a notion of non-ignorable social economical status (as triggered by some moral judgment that no automated method should pretend to address), and so we may stratify our student ranking based not only on graduation success predictions but other desiderata such as the minimum intake of students of a particular background that the institution is targeting. Sometimes the term “decision” and the term “prediction” are informally used interchangeably (see for instance our own abstract of [11]). On a closer look, this creates confusion. In a broader sense, decisions and predictions are not the same thing. This is why, when speaking of actionable decisions, we go beyond the usual counterfactual fairness definitions see e.g. [12] and [7]. We can predict a first-year average for a prospective applicant, predictions which are reasonably independent across units. We can then decide how to allocate offers based partially on those predictions using a fixed rule that is not learned from data, where decisions entangle the units as resource allocation bottlenecks will take place – notice that the original counterfactual fairness, by design, is not meant to guide predictions that take into account information from multiple units. Yes, we could design a prediction task whether the label is a “decision” (offer/no offer) based on historical decisions – sometimes bizarrely justified as following the principles of empirical risk minimization (as if we knew which false negatives, i.e. “wrong” declines, took place!). But if you believe that historical decisions are biased, and that they are not independently distributed, then maybe, just maybe, you should consider that it is not a good idea to try to emulate them even if the goal is building a “fair projection” of a flawed decision stream (itself possibly generated by a spectrum of many mutually contradicting decision makers selected by no well-defined distribution).
Of course, just because counterfactual fairness is agnostic to the use of other constraints, it is still of interest to know when their intersection is empty.
In particular, [21] introduces a potentially interesting concept named group ordering preservation, described as “…relative ordering from a (possibly) unfair predictor should induce the same relative ordering as the fair predictor.” This deserves further consideration, but as currently written, it remains partially unclear to me what it means. Two algorithms777The difference between Listing 1 and Listing 2 is that the former assumes conditionally Gaussian cdfs. In what follows, we will focus on the latter., “Listing 1” and “Listing 2”, provide an implementation of this concept. In a nutshell, they take preliminary (“unfair”) labels for each data point in the sample and return “fair” labels defined by mapping the quantile of in the cdf to the same quantile in the marginal cdf . The idea is that, within any protected attributes stratum, “fair labels” should be ranked similarly to “unfair labels” once the unfair components are removed in some desirable sense (demographic parity, for the cases of Listing 1 and 2).
To summarize my understanding, this means that we want to satisfy some fairness constraint that does not necessarily follow, while enforcing that and have rank (Spearman) correlation of 1 within each stratum of . In particular, the template for Listing 2-like algorithms starts from a preliminary “unfair” predictor and produces
| (1) |
where is a increasingly monotonic function (say, the identity function). Notice that if respects both demographic parity and counterfactual fairness, then in the limit of infinite training data so will .
Proposition 9 of [21] attempts to claim that counterfactual fairness cannot in general obey the “group ordering preservation” criterion. It is not clear to me what this means, but the “counterexample” provided as the proof in Proposition 9 of [21] involves dependencies between units, and that is not even considered by counterfactual fairness. Presumably, there are the true labels (no other predictors are mentioned) and is a counterfactually fair predictor. It is of course impossible for any pair , regardless whether is counterfactually fair or not, to have a rank correlation of 1 if is not a deterministic function of (the only information we can use in a prediction ) so it is not clear what the goal is. This also does not clarify why we would want to align our with some other than , different alignments which can be vastly incompatible. More about that is discussed in the appendix to this manuscript, where I present what I believe are fundamental issues with the main experiment in [21].
4 Comments on Fawkes, Evans and Sejdinovic (2022)
[6] is an excellent paper about the challenges of causal modeling, particularly in the context of algorithmic fairness. Its emphasis is on selection bias, and I recommend it as a reading. I fully agree that selection bias is an extremely important aspect of modeling, and some of its challenges were mentioned already in our early review [14]. If anything, [6] does not go far enough, not mentioning general problems of selection bias in behavioral modeling by machine learning: distribution shift, a major problem for predictive modeling regardless of any causal or fairness issues, can in part be attributed to frequent changes in selection bias from training to test time.
However, one of the main barriers for addressing these problems in [10] appears to be an incorrect belief that counterfactual fairness requires ancestral closure of protected attributes: the notion that if some variable is a protected attribute, then any causal ancestor of must also be by default. This sometimes make sense, sometimes does not, but [6] go as far as claiming that “In the case of counterfactual fairness ancestral closure is mentioned as an explicit requirement on the set of sensitive attributes.” However, ancestral closure of protected attributes was never a fundamental property of counterfactual fairness.
Ancestral closure of protected attributes was never a fundamental property of counterfactual fairness.
Let us start with a verbatim quote from [11], page 5:
Suppose that a parent of a member of is not in . Counterfactual fairness allows for the use of it in the definition of .
As spelled out above, in no ambiguous terms, there isn’t at all any default requirement for ancestral closure. However, continuing from the same paragraph (emphasis added),
If this seems counterintuitive, then we argue that the fault should be at the postulated set of protected attributes rather than with the definition of counterfactual fairness, and that typically we should expect set to be closed under ancestral relationships given by the causal graph.
What if it does not seem counterintuitive to keep an ancestor of out of the set of protected attributes? Then we just keep it out. A modeler can augment their initial choice of after seeing the causal model (as the causal model can be built independently without judgments of which attributes are protected): it could be some ancestors of the initial , some non-ancestors, no ancestors etc. However, counterfactual fairness does not dictate what counts as a protected attribute: that’s a value judgement not be left to any automated procedure. is taken as a primitive, an input to the definition and algorithms.
The paragraph about ancestral closure of protected attributes came about after a discussion with reviewers from ICML 2017, to where the paper was originally submitted. This was one way of acknowledging their input, which helped to improve the clarity of the manuscript, but I take the responsibility for introducing this paragraph in a confusing way. The reason why the authors of [6] and others (such as [20]) got to conclude that ancestral closure is fundamental may be due to the formatting of Section 3.2 of [11], titled “Implications”: the title of the respective paragraph (“Ancestral closure of protected attributes”) should have been “Counterfactual fairness allows for the use of ancestors of in the definition of ”. The whole closure concept was meant only as an example of why one may want to revisit their choice of by thinking causally! Surely it makes no sense to claim that Definition 5 in [11] implies ancestral closure.
Finally, it is irrelevant whether [6] and [21] found that “(ignorability) is also assumed in most DAGs we can find in the literature”. The papers cited in [6] were introducing novel concepts where examples are kept simple to focus the attention of the reader. Selection bias, lack of ignorability and partial identifiability are all issues that are core to causal modeling. Counterfactual fairness added a link between causal modeling and algorithmic fairness, always fully acknowledging that it inherits all the demands that come with an appropriate account of causality.
What is counterfactual fairness for, after all?
[6] contains a very interesting example that is worth discussing (emphasis added):
We can imagine scenarios when treating counterfactuals like this could be intuitively very unfair. As an example, again we look at law school admissions, but now our sensitive attribute is the presence of a particular disability with severe adverse effects; for instance, it might mean that, on average, sufferers can only work or study for half the amount of time per day than someone who does not have this disability. If an individual were able to attend college to get a GPA, take the LSAT, and perform well enough in both of these to apply to law school despite having this disability, it is reasonable to assume that they are an exceptional candidate and would have performed exceptionally well relative to all candidates had they been born without any disability. However, their structural counterfactuals formed as above would look like an average applicant born without the disability. Therefore a predictor which is counterfactually fair relative to these structural counterfactuals would simply treat this candidate as an average applicant without the disability. This does not capture an intuitive notion of fairness in this scenario. Further it does not align with what we imagine counterfactual fairness as doing. The structural counterfactuals are failing to correcting for the difficulties of having this sensitive attribute, which is one of the main appeals and claims of counterfactual fairness.
I am puzzled by the above. Using a counterfactually fair predictor is one way of not to “simply treat this candidate as an average applicant without the disability.”
To see this, let be the (say) GPA score had the candidate have the disability and let be the corresponding score had the candidate not have the disability. One way of constructing a counterfactually fair predictor is to start from a postulated structural equation and build the predictor around . To make my argument more explicit, I will build using only and a.k.a. and – this has the advantage of avoiding the worry about the dimensionality of , for instance, which may as well be infinite-dimensional, as well as avoid speculating about the meaning of , like “grit index”888While we favored interpretations of latent variables in [11], and they can be useful in Level 2 modeling where an explicit measurement model is provided, they are in general for didactic motivation only.. For most reasonable outcomes , it is expected that is a non-decreasing monotone function of both and (say, for positive coefficients and , as an example).
So say we have two candidates, 1 and 2, who obtained exactly the same score , where one comes from the stratum () and the other from (. Under the assumption informally made by [6], for any individual indexed as , an assumption that can be hard-coded in the counterfactual model (monotonicity assumptions have a long history in cross-world causal analysis).
As , it follows that . The exceptionalism of candidate 1 has been recognized by counterfactual fairness as a straightforward consequence of the definition and the causal model, contrary to what could be interpreted from the quote above.
But let me use this example to discuss a more fundamental (and better motivated) criticism of counterfactual fairness that goes beyond technical questions of causal assumptions. A party with stakes at the college admission problem may, sensibly, wonder whether we are doing the candidate from group any favors, if the real outcome of interest e.g. successful graduation, still has lower odds of happening compared to incoming students from group . Our prediction may lump together and for all candidates when building , but it still does not change the fact that life continues to be hard once the candidate becomes a student, and challenges for outcome (again, not ) are of the same nature as challenges for pre-requisite . Perhaps such candidates of such characteristics may be better served by a less demanding (even if less prestigious) alternative program with higher chances of success.
As a another example, suppose that as part of a loan decision making pipeline we want the prediction of whether a business case will default the loan or not. One factor may be the ethnic background of the business owner, who may suffer from prejudice in the community where the business will take place. Suppose we can assume as a fact that odds are stacked against this individual. A counterfactual fair predictor will not single out just the observed characteristics of the applicant, but the whole set of counterfactual scenarios regardless of which one is the real one. It is still the case, though, that the world is unfair and odds are compromised. Are we doing this applicant any favor, given that the risk is real?
One idea is to hard-code a compromise, accept a candidate from a disadvantage background if their score is “just so” below the threshold of privileged groups. But setting such a fudge-factor threshold is not trivial and may raise contention, while at least in principle counterfactual fairness provides a constructive path to how predictions should take place. And regardless of the decision method, it is still a fact they are at a disadvantage, with all the consequences that are entailed.
Counterfactual fairness plays to the concept that we should not be fatalist about the outcome. Yes, the business owner has a higher chance of failing, but they are not predestined to fail. A reality check can still be done with the factual-only prediction about extreme cases that should be filtered out. Counterfactual fairness scores can still be used to rank candidates that pass this triage into the next stage of the pipeline.
But, more importantly, perhaps society and institutions should be better prepared to share the burden of failure. It is convenient, and understandable, for a bank to follow the fatalist route and refuse a loan to those cases which do not reach the threshold, with or without a fudge factor to account for less privileged cases, as the applicant may otherwise end up struggling with debt and miss out on alternatives to the possibly-doomed business plan. An admissions officer in a competitive university program may have learned from experience that candidates from some underprivileged group may struggle and fail in their studies, wasting time and money in their lives. The officer may conclude that the moral thing to do is to statistically protect this individual by denying acceptance unless they show exceptional evidence that they are especially prepared. However, the above is predicated on the burden of failure mostly falling on the shoulders of the applicant: it is their time to lose, their money at stake. An alternative is being better prepared to spread the risk: the provision of government or charity funds, or even tax incentives to banks, to mitigate the stakes put forward by a loan applicant from an underprivileged background who is partially set up to fail for issues out of their control; fast-tracking schemes for underprivileged candidates in a demanding university program to transfer to another one that better accommodates their personal situation when needed. None of this is an easy path to follow, but the first and humble step is to acknowledge that merely predicting a biased-by-construction outcome “as is” can end up being a perversion of how machine learning algorithms are meant to serve the public. The main fights are on the non-technical aspects of decision-making which are societal, not technological, considerations, but this does not mean getting a free pass to ignore the causal effects of someone’s membership in an underprivileged group against the criteria by which we constantly judge such an individual.
5 Comments on Plecko and Bareinboim (2022)
The survey by Plecko and Bareinboim [20] is a terrific resource for those interested in the uses of causal modeling in algorithmic fairness. I strongly recommend it! Among its broad scope, Section 4.4.1 in that paper covers counterfactual fairness. Unfortunately, that section doesn’t quite get right some its key aspects. In what follows, I will touch upon a sample of the main issues.
Pearl’s “notational confusion”.
Section 4.4.1 of [20] starts by challenging our notation in [11], but the arguments don’t add up. I do not believe there is a justifiable basis for the misunderstanding, as I will explain soon. I do believe, though, that the difficulties that led to the misunderstanding has origins on Pearl’s unorthodox way of denoting counterfactuals, so let’s start with it.
The classic paper by Holland [9] popularized the notation “” to denote the potential outcome of variable for unit under intervention . In Holland’s notation, units come from an population , not to be confused by the usual symbol used to denote background variables in the structural causal model (SCM) framework. In Holland’s notation, all that it means is an abstract way of indexing data points. For instance, using to denote the -th sample of some variable , we can denote a dataset of three data points as
If this dataset is our population, we can think of Holland’s as nothing more than a placeholder for 1, 2, 3, and as nothing more than . This is particularly suitable for the type of analysis that researchers like Rubin, Holland, Rosenbaum and several others have been interested on across the years, following Fisher’s original framework for randomized controlled trials (RCTs): there is (typically) a finite population (say, the people in the RCT), the potential outcomes are fixed, and all the randomness is in the treatment assignment. By construction, this is a framework with zero out-of-sample predictive abilities999Think of the analogue in survey sampling: instead of, say, forecasting who would win an election, consider the problem of estimating a snapshot of how many votes a candidate would get today assuming fixed vote intentions, where the role of randomization is to decide who gets to be asked about their choice on the day. In classic Fisherian RCT analysis, “who gets to be asked” corresponds to which potential outcome gets to be probed. “Snapshot analysis” is of course useful for some problems of algorithmic fairness such as auditing a fixed dataset/finite population, but clearly not the point of predictive algorithmic fairness for out-of-sample datapoints.
When Pearl introduced his framework [17], he overloaded the meaning of in his notation: both as background latent variables with a probability distribution, and as an abstract data point index! This can easily confuse any reader, even more so those used to Rubin/Holland’s notation. For an example, consider Chapter 4, p. 92, of Primer [18, Pearl’s website edition],
It is in this sense that every assignment corresponds to a single member or “unit” in a population, or to a “situation” in “nature”.
In that chapter, bounces back from being a random variable (Eq. 4.3 and 4.4), to being a Hollandesque data point index (“… corresponds to a single member…”), to being a realization of a random variable (what else “” is trying to convey if not the realization of a random variable, using the standard notation of all probability textbooks?). It is all very confusing101010Not confusing enough? Consider the fact there is no logical reason why two units cannot have the same value for , i.e., units and could very well have realizations . Sure, if we assume is continuous, this can only happen with probability zero. But measure-theoretical cop-outs should not stop us from pointing out the logical shortcomings of statements such as “…every assignment corresponds to a single member or “unit” in a population…”. – but notice that I wrote the title of this section in scare quotes (“notational confusion”) because I’m sure Pearl understands the differences, and all he tries to do is a type of notational overloading that is sometimes helpful111111That is not even Pearl’s most famous unusual twist of notation: a statement such that is itself a source of confusion for the more orthodox-minded statistician, as it suggests that “do(x)” is a realization of a random variable as opposed to the index of a regime. The orthodox notation would be something along the lines of or , but it is easy – at least for me – to appreciate Pearl’s choice of notation, as it leads to more syntactically elegant manipulations when deriving identification results using the do-calculus. in some of his derivations and definitions. For instance, as far as I know, he never writes , with capital , suggesting that is more of a Holland-style incarnation of as an “unit” index, as opposed to the realization of random variable/process .
Why did I spend time in this detour? Because I think many people in causal machine learning do not appreciate it, partially because it is a minutia that does not mean much in practice. Nevertheless, [20], probably by trying to orthodoxally follow Pearl’s unorthodox notation, gets our definition (5) from [11] very wrong. We use to denote, constructively, that can (and usually should) be a function of background variables – it is capital , not lower case – and in potential outcome notation it should very clearly be equivalent to
| (2) |
which I believe is what Eq. 198 of [20] is meant to capture. If the use of capital letters is not clear enough to indicate that is a random variable, then the explicit sampling of in the FairLearning algorithm should send the point home. Unlike my writing about “ancestral closure” (see previous section) which could induce confusion, I do not think this confusion in [20] is justifiable.
As a matter of fact, prior to the first draft of [11], I considered whether to go with formulation (2) instead of the one with explicit background variables . In the end, I suggested the one found in the final paper only because it more explicitly and constructively linked to algorithms in which the abduction step of Pearl’s SCM framework is implemented. But it is (conceptually) immaterial whether one chooses to use or the whole principal stratum as inputs to . We just did this in an example in the previous section.
Is counterfactual fairness an individual fairness notion? Yes.
Further confusion follows in [20], which challenges our claim of counterfactual fairness as an individual, as opposed to group, notion of fairness. Basically, the argument is that, because we don’t adopt as the definition, then our definition is not “individual-level enough” (for the lack of a better term).
As a matter of fact, we discuss all of these differences in Appendix S1 of [11], which is not mentioned by [20]. Given that our Appendix S2 on demographic parity was summarily ignored by [21], I can only conclude that reading appendices of NeurIPS papers is not a popular pastime. In the interest of being self-contained, I will paraphrase S1 here, noting that what follows below will be familiar those who read the original counterfactual fairness paper in its entirety.
Put simply, I thought that defining counterfactual fairness as was a bad way of introducing a novel approach for looking into predictive algorithmic fairness. The definition that was ultimately used in the paper came about because we wanted to make explicit that fairness through unawareness was a silly concept, as conditioning on directly is actually important; and we wanted to show that an alternative idea such as [15] was overly conservative, as it forbade conditioning on mediators. What was a way of explicitly acknowledging that conditioning on and was not only allowed, but fundamentally a core characteristic of counterfactual fairness? That’s right, Eq. (5) as originally introduced in [11], which can be interpreted as equality in distribution between any pair and under the measure induced by conditioning on .
Is this still fundamentally an individual-level quantity? Of course it is. As described by Holland, Rubin and others, interventional contrasts obtained by conditioning on mediators, such as
are “not even wrong”, in the sense that they do not define a “causal effect” as normally understood as comparing interventions at an individual level. To be clear, a predictive distribution conditioned on a mediator, such as is well-defined: for instance, in a control problem/reinforcement learning scenario, this may tell us whether we should do a “course correction” towards a desirable outcome given that we controlled at level in the past and we just observed a recent state . However, the contrast is non-sensical, since a same person in general will not have under both scenarios and . At best, the contrast compares two different groups of people who happen to coincide at . Completely unlike that, the cross-world counterfactual estimand , among any other functionals of the respective distributions, is not only a well-defined but fundamentally an unit-level contrast, unlike what [20] may imply.
Now, do we miss anything in the sense that we can have Eq. (2) while ? Yes – in essentially useless scenarios. Consider the case where and and, for whatever reasons unbeknownst to you and me, where and are different variables but equal in distribution – a construction not entirely dissimilar to the basic example in Section 2 used to debunk the equivalence between demographic parity and counterfactual fairness, except that here is outside the structural model for . Then and are equal in distribution, but (using now in the sense of “unit”, just to illustrate Pearl’s “notational confusion”) . My judgement is that sacrificing the explicit link to the observed values of and found naturally in the equality-in-distribution definition of counterfactual fairness, in order to tackle these cases, is an exercise in futility.
I would also point out that our Appendix S1 goes beyond the variations described by [20] and mentions the “almost sure” alternative definition of counterfactual fairness (that is, ), arguably a more interesting case than as again it makes the conditioning on and explicit). As in the “sure” case, we judged this variation to be pointless.
What is counterfactual fairness for, after all? (Round 2).
I applaud the thoroughness and breadth of examples in [20], which provides a great service to readers interested in the causal aspects of fairness. That been said, Example 14 in [20] does not quite make sense. Let’s revisit it.
The framing is that is the gender of a prospective employee, is a measure of performance and is the salary to be paid. The causal model (in our notation) is given by
-
•
-
•
-
•
where is uniformly distributed in and error terms are mutually independent. With some basic algebra we can show that and are equal in distribution given and . By interpreting this equality in distribution as counterfactual fairness, [20] are dissatisfied, because:
-
•
Gender 0 produces more than Gender 1 by equation . They “should” be paid more, but is independent of ;
-
•
Seemingly outrageously, further discriminates against genders, as shows up in the equation for .
There are quite a few conceptual problems in this analysis, at least to the extent they have anything to do with counterfactual fairness. To start with, framing it as counterfactual fairness is already ill-posed as there is no prediction problem being specified: there is no . A simulacrum of “counterfactual fairness” is used here to diagnose “the fairness” of an existing outcome variable that is set in place, a task which we did not aim at and in which we had little interest when we came up with the concept. This distinction matters, let’s see why.
Let’s ignore the variable of the original example as the target of a fairness analysis – the outcome can very well be biased, but we assume that there is nothing that we can do (at least immediately) about that. Instead, our starting point, if we were to choose to build a total-effect counterfactually fair predictor121212Just why we would like to predict salaries is entirely lost on me. As I mentioned in previous sections (“let’s predict college-level academic performance for school admissions, not placement offers”), the natural thing to do would be a prediction of performance, with salary offers following from a transparent deterministic rule of that prediction and other factors such as competitiveness. But let’s go with it for the sake of keeping the same example. of , is to define some that best fits given by, say, mean squared error. We get , implying that , given and , is equal to . It makes little sense to say that is automatically discriminatory by the virtue of being expressible as a function of : the Red Car example that opens up our paper makes clear that in general we should be using the protected attributes in the construction of the predictor in an indirect way, via a dependency on that can be re-expressed as a dependency on by conditioning.
If we are not happy to base our predictions on instead of , we have nobody to blame but ourselves, since we chose to hide the information about contained in . The discussion in [20] then goes on a tangent about the perils of total effect analysis, rigidly assuming that counterfactual fairness is bound to total effects by some Law of Nature, as opposed to our clear statement that [11, page 5]
…it is desirable to define path-specific variations of counterfactual fairness that allow for the inclusion of some descendants of , as discussed by [21, 27] and the Supplementary Material131313Who reads that, anyway? Jokes aside, the appendix on path-specific effects was indeed meant to be only a very light acknowledgement that a thorough coverage of the topic was yet to follow..
The problem here has just one path: (in counterfactual fairness as originally used, it doesn’t make much sense to consider the paths into – to be clear, one can use the same counterfactual fairness constraint with respect to any variable of interest, but whether to judge the presence of in the structural equation for as problematic or not will require further problem-specific justifications). It is not clear to me what exactly the path-specific problem we would like to get out of Example 14 is. I will assume (hopefully correctly) that the claim is that is protected, but path is not. All this means is that can be a function of , but not of , prior to conditioning on . This implies anyway. To the best of my educated guess, this recovers the intention of Example 14.
To illustrate the conceptual simplicity of path-specific variants, let’s also consider the following complementary problem: what if we had a graph and we wanted the path to be allowed to carry information from , but not ? The game is the same: is free-for-all, but edge is broken, its tail replaced by fixed indices corresponding to any subset of the sample space of that we want. For instance, if , are the structural equations, we can define as a function of (a.k.a. ) and (any fixed subset of) (a.k.a. , in the subscript indicating that is set to the value it would naturally occur anyway, so etc.). Any resemblance to the idea of overriding protected attributes in (say) job applications, while propagating changes only to a subset of the content of the application, is not a coincidence. For the record, please notice that while the path-specific conceptualization may follow naturally, I would never say that implementing it is easy. Partial identification is arguably the way to go here even if challenging, with [28] being an early example.
A shortcoming in the counterfactual fairness coverage of [20] was the apparent belief that tackling the problem of diagnosing unfairness was enough in order to comment on the problem of prediction. It is not. To repeat myself, the primary goal of counterfactual fairness, as originally defined, is to provide a way of selecting information within that is deemed to be fair, blocking “channels” of information from into only, not into . We can’t change in the problem setup of [11] (at least not in the short term, see [14]), but we can change . The very idea of using causal concepts in fairness problems is that is not enough to know which values the measurements took, but also how they came to be. By failing to acknowledging some of the “how” aspects of the target variable in counterfactual fairness, [20] ends up not being sufficiently causal in its analysis.
6 Conclusion
There are connections between counterfactual fairness and demographic parity. We know that since the original paper [11, Appendix S2]. Further connections claimed by [21], however, do not hold up. Counterfactual fairness does not imply demographic parity and demographic parity does not imply counterfactual fairness, not even approximately. It would be terrific if possible, but we cannot magically reduce definitions relying on Pearl’s Rung 3 assumptions to Rung 1 or even Rung 2 assumptions. With the knowledge in this note, I hope that the interested reader can critically read papers such as e.g. [2] and assess which gaps they may or may not have, and how to fill them up where needed with the necessary explicit assumptions.
I took the chance of highlighting other aspects of counterfactual fairness that are sometimes misunderstood. To summarize:
-
•
counterfactual fairness can be interpreted as a “variable selection” (information bottleneck/filtering) protocol for building predictors, agnostic to loss functions, other constraints and other decision steps. It arose to answer information selection questions that methods such as fairness through unawareness could not satisfactorily address. There is no reason not to build optimal predictors with respect to the information filtered by counterfactual fairness, subject to other constraints, if any. If one thinks counterfactual fairness by itself should suffice to magically solve arbitrary resource allocation requirements/Pareto optimalities/ranking constraints/other balances not already implied by the independence structure of the causal model, then they have seriously misunderstood it;
-
•
ancestral closure of protected attributes was never a fundamental property of counterfactual fairness. I have no problems accepting that ambiguous writing in the original manuscript could lead to this confusion, but it is a matter of fact that “counterfactual fairness allows for the use of (causal ancestors of protected attributes) in the definition of ” [11, page 5].
Acknowledgements
This work was partially funded by the EPSRC fellowship EP/W024330/1. I would like to thank Matt Kusner, Joshua Loftus and Chris Russell for helpful comments. Any mistakes are of my own making.
References
- [1] A. N. Angelopoulos and S. Bates. Conformal prediction: A gentle introduction. Foundations and Trends in Machine Learning, 16(4):494–591, 2023.
- [2] J. R. Anthis and V. Veitch. Causal context connects counterfactual fairness to robust prediction and group fairness. Neural Information Processing Systems (NeurIPS 2023), 2023.
- [3] S. Barocas, M. Hardt, and A. Narayanan. Fairness and Machine Learning: Limitations and Opportunities. The MIT Press, 2023.
- [4] S. Chiappa. Path-specific counterfactual fairness. Proceedings of the AAAI Conference on Artificial Intelligence, 33:7801–7808, 2019.
- [5] A. P. Dawid. Causal inference without counterfactuals. Journal of the American Statistical Association, pages 407–448, 2000.
- [6] J. Fawkes, R. Evans, and D. Sejdinovic. Selection, ignorability and challenges with causal fairness. Proceeding of the Conference on Causal Learning and Reasoning, PMLR 177:275–289, 2022.
- [7] L. Gultchin, S. Guo, A. Malek, S. Chiappa, and R. Silva. Pragmatic fairness: Developing policies with outcome disparity control. Proceeding of the 3rd Conference on Causal Learning and Reasoning, 2024.
- [8] M. Hardt, E. Price, and N. Srebro. Equality of opportunity in supervised learning. arXiv:1610.02413 (cs), 2016.
- [9] P. Holland. Statistics and causal inference. Journal of the American Statistical Association, 81:945–960, 1986.
- [10] Y. Kano and A. Harada. Stepwise variable selection in factor analysis. Psychometrika, 65:7–22, 2000.
- [11] M. J. Kusner, J. R. Loftus, C. Russell, and R. Silva. Counterfactual fairness. Advances in Neural Information Processing Systems, 30:424–431, 2017.
- [12] M. J. Kusner, C. Russell, J. R. Loftus, and R. Silva. Making decisions that reduce discriminatory impact. 36th International Conference on Machine Learning (ICML 2019), PMLR 97:424–431, 2019.
- [13] L. Lei and E. J. Candès. Conformal inference of counterfactuals and individual treatment effects. Journal of the Royal Statistical Society Series B: Statistical Methodology, 83(5):911–938, 2021.
- [14] J. R. Loftus, C. Russell, J. Kusner M, and R. Silva. Causal reasoning for algorithmic fairness. arXiv:1805.058598, 2018.
- [15] R. Nabi and I. Shpitser. Fair inference on outcomes. The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), pages 1931–1940, 2018.
- [16] K. Padh, J. Zeitler, D. Watson, M. Kusner, R. Silva, and N. Kilbertus. Stochastic causal programming for bounding treatment effects. Proceeding of the 2nd Conference on Causal Learning and Reasoning, PMLR 213:142–176, 2023.
- [17] J. Pearl. Causality: Models, Reasoning and Inference, 2nd edition. Cambridge University Press, 2009.
- [18] J. Pearl, M. Glymour, and N. Jewell. Causal Inference in Statistics: a Primer. Wiley, 2016.
- [19] J. Pearl and D. McKenzie. The Book of Why. Allen Lane, 2018.
- [20] D. Plecko and E. Bareinboim. Causal fairness analysis. arXiv:2207.11385, 2022.
- [21] L. Rosenblatt and R. T. Witter. Counterfactual fairness is basically demographic parity. The Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI-23), pages 14461–14469, 2023.
- [22] M. Rosenblatt. Remarks on a multivariate transformation. The Annals of Mathematical Statistics, 23(3):470–472, 1952.
- [23] C. Russell, J. Kusner M, J. Loftus, and R. Silva. When worlds collide: Integrating different counterfactual assumptions in fairness. Advances in Neural Information Processing Systems, 30:6417–6426, 2017.
- [24] C. Shalizi. Advanced Data Analysis from an Elementary Point of View. http://www.stat.cmu.edu/cshalizi/ADAfaEPoV/, 21st March edition, 2021.
- [25] P. Spirtes, C. Glymour, and R. Scheines. Causation, Prediction and Search. Cambridge University Press, 2000.
- [26] N. Tishby, F. Pereira, and W. Bialek. The information bottleneck method. The 37th annual Allerton Conference on Communication, Control, and Computing, pages 368–377, 1999.
- [27] V. Vovk, A. Gammerman, and G. Shafer. Algorithmic Learning in a Random World. Springer, 2005.
- [28] Y. Wu, L. Zhang, X. Wu, and H. Tong. PC-fairness: A unified framework for measuring causality-based fairness. Advances in Neural Information Processing Systems, 32, 2019.
- [29] R. S. Zoh, X. Yu, P. Dawid, G. D. Smith, S. J. French, and D. B. Allison. Causal models and causal modelling in obesity: foundations, methods and evidence. Philosophical Transactions of the Royal Society B, 378, 2023.
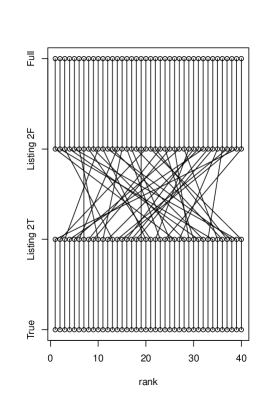
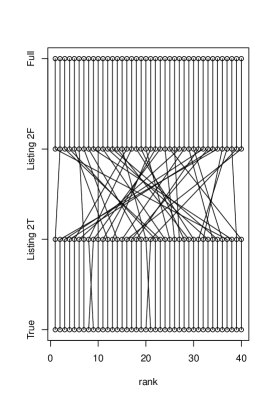
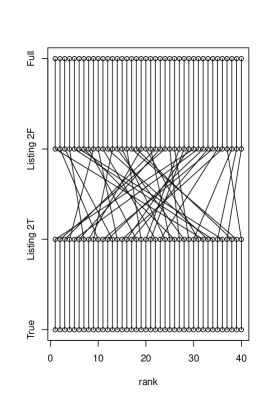
Appendix: A note on the rank plot experiment in [21].
The experimental section in [21] argues that if we take, for instance, 40 samples from the subpopulation where , then the rank statistics for and in the data are the same if we use Eq. (1). This is not surprising as this mapping between and , a composition of invertible mappings, is rank-preserving. The experimental section then goes on to point out that counterfactual fairness seems to return very different rankings in the particular study they present, which is seemingly a bad property – but actually, as we will see, it is entirely expected. The plot in Figure 4 of [21] displays six methods for predicting first year average from race, sex and two types of exams in the law school dataset also used in [11]. There are 40 columns of points representing a sample of 40 individuals recorded as Black in the race attribute of the dataset. The columns are sorted according to the rank statistics of for the baseline method, a linear regression that includes all variables (“Full”). For each data point, each of six predictors is represented by a point, with points of a same predictor aligned in the same horizontal line. This makes the plot a grid of points. For each pair of consecutive rows, a line segment connects points of two predictors that have the same marginal rank statistic.
Besides “Full”, we have Listing 1 and Listing 2 predictors built by transforming the “Full” predictions. By construction, all of these three vectors of predictions have rank correlation of near 1 (it is not exactly 1 as e.g. ties in the predictor means that , “Full”, is not fully continuous). When plotted as the three bottom rows of Figure 4, this results in vertical line segments cutting across the three rows, as expected.
The top three rows, which are inspired by counterfactual fairness, are poorly aligned with the bottom three and among themselves. This is exactly what we should expect. Each of the three “counterfactually fair”-inspired methods apply a different filter to the data: they use different subsets of information to build the predictor based on different assumptions141414And just as a reminder, real-world-assumptions-free rules to decide which information in carries unfair consequences of amount to snake oil, in the view of this writer. Domain-independent buttons to be pushed are convenient for machine learning companies, less so for the people at the receiving ending of their services., and in a relatively low signal-to-noise ratio problem as the law school one. Poor rank correlation is what one should anticipate. It would have been an anomaly if in Figure 4 of [21] we saw strong agreements among predictors which use different subsets of information in this dataset.
To drive the point home, let’s forget about counterfactual fairness and just redo the experiment with two choices of : the true label , which is of course not usable in a real predictor and here will play the role of an oracle; and the full linear regression predictor as in [21]. This emulates two predictors which rely on correlated but different sources of information. We will call the corresponding “fair” algorithms “Listing 2T” and “Listing 2F”. It is unclear why we would believe that alignment with an “unfair” predictor such as (say) full regression is of any relevance, if it shows such a poor relationship to the true “fair” alignment. Exemplar results are shown in Figure 2. R code to create plots of this type is shown below.
 |
 |
 |