CPNet: Cross-Parallel Network for Efficient Anomaly Detection
Abstract
Anomaly detection in video streams is a challenging problem because of the scarcity of abnormal events and the difficulty of accurately annotating them. To alleviate these issues, unsupervised learning-based prediction methods have been previously applied. These approaches train the model with only normal events and predict a future frame from a sequence of preceding frames by use of encoder-decoder architectures so that they result in small prediction errors on normal events but large errors on abnormal events. The architecture, however, comes with the computational burden as some anomaly detection tasks require low computational cost without sacrificing performance. In this paper, Cross-Parallel Network (CPNet) for efficient anomaly detection is proposed here to minimize computations without performance drops. It consists of smaller parallel U-Net, each of which is designed to handle a single input frame, to make the calculations significantly more efficient. Additionally, an inter-network shift module is incorporated to capture temporal relationships among sequential frames to enable more accurate future predictions. The quantitative results show that our model requires less computational cost than the baseline U-Net while delivering equivalent performance in anomaly detection.
1 Introduction
Anomaly detection in videos is the identification of unexpected or unfamiliar events from video streams containing mostly normal or expected activities. With the great success of machine learning methodologies in other applications, automated detection of abnormalities in videos has attracted much interest in computer vision communities. It is a challenging task for supervised learning as manually annotating frame-wise labels for normality/abnormality and spatially localizing them are labor-intensive. Additionally, collecting abnormal events in the dataset is difficult, as by definition abnormal events are rare in real life. Thus, it leads to a class imbalance in the training set between normal and abnormal events.
For these reasons, unsupervised learning [7, 1] is the method of choice in anomaly detection. These approaches first train the models only with normal events. The expectation is that when an abnormal event is shown to the model, its output would be quite different from the model’s response to normal events. Most of these models employ a network composed of an encoder and a decoder such that the network trained with only normal events would reconstruct the input image with minimal error [9, 36, 19]. As the model is trained by normal events only, the video frames with small reconstruction errors are considered as normal events while those with large reconstruction errors are classified as abnormal events. Thus, the reconstruction error is used as an indicator of abnormal events. The key to this approach is to ensure that the model overfits to the normal events such that it would perform poorly in reconstructing inputs of abnormal events.
To weaken the model’s generalizability, a future prediction approach [14] has been proposed. Given a video clip, instead of reconstructing a current frame, this approach predicts a future frame based on its several preceding frames. As the input frames do not contain a target(future) frame to be predicted, the task is harder compared to the task of input image reconstruction. By making the task harder, the approach leads to much larger prediction errors on abnormal events compared to the error in the case of normal events used in the training.
U-Net [27] architecture, which exhibits good performance on image-to-image tasks such as segmentation and super-resolution, has been widely used in previous anomaly detection methods [14, 22, 24, 29]. When feeding multiple frames as an input in the prediction approach, these frames are concatenated through the channel dimension. As such, the network can capture both spatial and temporal correlations so that future frames can be predicted more accurately. The architecture, however, comes with the computational burden of having a large number of input channels as each input is composed of multiple frames stacked together over the channel dimension.
To alleviate this burden, we propose Cross-Parallel Network (CPNet) which is composed of parallel U-Net (U-PARL) with each U-Net designed to handle only a single temporal frame. The number of feature maps (channel dimensions) of both the input and the output of the convolution process is reduced by , resulting in a computational reduction of for a single path. Counting that the network is composed of parallel networks, the overall computational cost is reduced by compared to the conventional U-Net. As these encoder-decoder networks process each input frame independently, capturing temporal relationships among the frames is handled only at the final stage of image reconstruction. Therefore, the architecture by design makes it more difficult to predict the future frame compared to the network that takes the stacked input frames.
This suppression of the temporal relationships among the input frames resulted in large prediction errors even for normal events. In order to extract the temporal cross-frame correlations without much increase in computational cost, we introduce a cross-network shift frame strategy [13]. In this approach, a part of feature maps from one input frame is shifted to those of its sequentially neighboring frames at each network layer in parallel. Although this shift operation incurs some data movement costs, it will not increase the FLOP of the overall architecture.
The contributions of our method are summarized as follows:
1) A novel architecture CPNet for efficient and effective unsupervised anomaly detection framework is composed of a parallel U-Net architecture with inter-frame feature shifting modules.
2) We introduce a novel architecture composed of smaller parallel networks, each designed to process an individual image frame. The reduction of the channel dimensions of each path resulted in a significant reduction of computational cost.
3) We introduce a cross-network feature correlation strategy by shifting a part of the feature map from one input frame to its neighbors. The method allowed an effective abstraction of cross-network temporal correlations without much increase in computational cost.
4) The CPNet results in a significant reduction in computational cost while delivering equivalent performance on Ped2 [28] and Avenue [17] datasets.
2 Related work
Hand-crafted Unsupervised Anomaly Detection.
In the early years of anomaly detection, hand-crafted features were used as a discriminative basis for detecting abnormal events. Some efforts utilized low-level spatial-temporal features, such as histogram of oriented gradients (HOG) [4] or histogram of oriented flows (HOF) [5]. Other methods [32, 31] exploited low-level trajectory features to represent the patterns. Markov Random Field (MRF) [35, 11], Mixture of Dynamic Textures (MDT) [20], and Gaussian regression [3] were also utilized to characterize the statistical distribution in obtaining decision boundaries. However, these methods are susceptible to failure in crowded or complex scenes.
Reconstruction Approach for Anomaly Detection.
To combat the issue of data set class imbalance, some efforts explored unsupervised approaches using deep learning architecture. The idea is by first training a model with normal events only to the point of overfitting, the model will respond quite differently when it observes abnormal input. These models typically use autoencoder-type architectures to reconstruct input images, and the reconstruction error is used as the measure to determine if an event is abnormal. Many reconstructive approaches based on CNN have been proposed in recent years including convolutional auto-encoder [9, 36]. As Recurrent Neural Network (RNN) is capable of temporal modeling, some methods [19, 18] proposed convolutional LSTM to take advantages of CNN and RNN. Ravanbakhsh et al. [26] utilized Generative Adversarial Network (GAN) to boost anomaly detection performance. Some methods [8, 24] exploited memory networks to read and write normal patterns and made reconstructions biased to normal events. Zaheer et al. [34] employed an adversarial model for identifying real and fake data to distinguish good and bad quality reconstructions. Although these methods brought significant improvements in anomaly detection, their performance often plateaued when reconstruction errors become small on abnormal events. This is primarily due to generalizing capacity of deep neural networks.
Prediction Approach for Anomaly Detection.
The small error problem of deep neural networks can be addressed by making the task more challenging. Instead of the reconstruction task, a prediction task can be imposed here to force the network to predict future frames from preceding frames only. Since the input doesn’t include future frames, the task is harder than the reconstruction problem and also harder to generalize with small categorical data in the training set. In unsupervised video generation tasks, Mathieu et al. [21] employed adversarial learning to boost the performance to produce more natural frames in videos while Lotter et al. [16] predicted future frames in a video sequence with each layer in the network making local predictions and only forwarding deviations from those predictions to subsequent network layers. Chen et al. [2] predicted imaginary videos by transformation generation. Motivated by these methods, the unsupervised video generation techniques were employed in unsupervised anomaly detection. Liu et al. [14] and Nguyen et al. [22] utilized adversarial learning and added constraints in terms of appearance (intensity loss and gradient loss) and motion (optical flow loss). Tang et al. [29] employed both reconstruction and prediction approaches for improvement.
Although these methods achieved improved performance, most of them require heavy computations as they employ conventional U-Net for reconstruction or prediction [14, 22, 24, 29]. We propose a novel modified U-Net structure with temporal shifting to reduce computational cost while delivering equivalent performance on anomaly detection.
3 Method
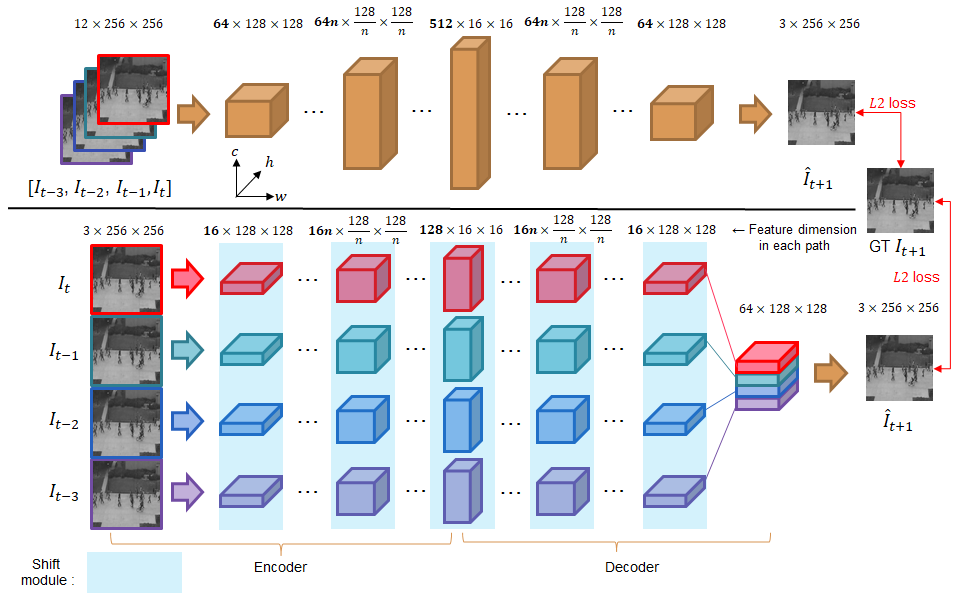
U-Net [27] is a convolutional neural network that is developed for bio-medical image segmentation. To alleviate the problem of information loss and gradient vanishing, U-Net is proposed to add shortcuts between lower-level layers and higher-level layers with the same resolution. Due to its effectiveness, U-Net is employed in many image-to-image tasks including image prediction. The proposed CPNet, in which modified U-Net is used as a future frame predictor for efficient anomaly detection, is illustrated in Figure 1. In the following subsections, we will describe our approach in detail.
3.1 Future Frame Predictor
Given a video with consecutive frames , the predictor predicts a future frame . For training the network, distance between the predicted frame and the ground truth is applied.
| (1) |
Many of the existing prediction based anomaly detection methods [14, 22, 29] employ four consecutive frames stacked together as the input to the prediction network. Convolutional operation on a stack of sequential frames strongly captures temporal relationships among them, thus it can predict future frame accurately. In order to make the prediction task harder, our network processes each input frame independently by four identical but independent network pathways and concatenates them at the final layer of image prediction as shown in Figure 1. The burden of extracting temporal relationships among the frames fall on the final convolution layer, thus its prediction capability is severely limited by design.
By dividing the U-Net into four smaller parallel networks and having each parallel network process a single input frame, the size of the output feature maps(channel dimension) is compared to the ones produced when all four frames are stacked as an input.
For a convolutional layer with an input feature map and an output feature map , its computational cost is
| (2) |
In our network, as each smaller U-Net has channel maps in comparison with the existing methods, e.g., and , its computational cost is reduced as
| (3) |
As there are four smaller U-Nets in our predictor, its net computational cost is of the existing prediction methods, which employed the conventional U-Net as a predictor, theoretically.
3.2 Inter-frame Feature Map Shift
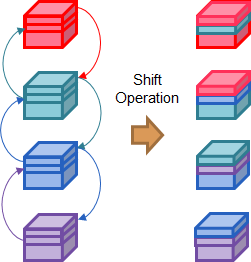
Relying on the last convolutional layer for extracting temporal relationships among the frames turned out to be too challenging even for normal events. To alleviate this issue, we employ an inter-network shift module [13], which shifts parts of the feature maps to neighboring frames to capture temporal relationships among consecutive frames. The operation of the shift module is illustrated in Figure 2. As in [13], feature maps from a frame-shift to those of its neighboring frames ( for each direction). This shift operation is adopted on each feature layer in parallel. Although the shift module incurs data movement, the shift operation is conceptually zero FLOP. Thus, adding this module increases computational cost only slightly.
3.3 Normality/Anomaly Decision during Testing
As only normal events are used to train the predictor without learning the decision process, a decision criterion for classifying video streams is necessary. The discriminating feature for the classifier is based on PSNR computed by comparing the predicted frame to the ground truth. Our model, by design, should produce high PSNR on normal events while it would result in low PSNR on abnormal events. Thus, normality or abnormality for video streams at test time is determined by PSNR based scores with a threshold. We compute the PSNR between the ground truth and prediction of a future frame as
| (4) |
After computing PSNR of each frame, we normalize PSNR of all the frames in each video to the range of [0, 1] by min-max normalization as a score defined by [21].
| (5) |
Thus, normality or abnormality for a frame is determined according to the score and a threshold as
| (6) |
where 0 and 1 from an abnormal events indicator indicate normal and abnormal events, respectively.
| Model | Encoder | Decoder | Shift | AUC (%) | GFLOPS | #MParam. |
|---|---|---|---|---|---|---|
| Baseline (U-Net) | 95.80 | 44.21 | 13.29 | |||
| CPNet-0.75 | ✓ | 96.55 | 33.34 (75.4%) | 8.65 (65.1%) | ||
| ✓ | ✓ | 96.24 | 33.34 (75.4%) | 8.65 (65.1%) | ||
| CPNet-0.37 | ✓ | ✓ | 94.91 | 16.70 (37.8%) | 3.42 (25.7%) | |
| ✓ | ✓ | ✓ | 96.13 | 16.70 (37.8%) | 3.42 (25.7%) |
4 Experiment
To evaluate the proposed method, experiments are conducted on Ped2 [28] and CUHK Avenue [17] datasets. We introduce datasets and implementation details first, then we proceed to describe series of experiments including qualitative and quantitative analyses.
4.1 Datasets
The UCSD Pedestrian 2 (Ped2) Dataset
contains 16 training videos and 12 testing videos with 12 abnormal events. All of these abnormal cases are about presence of vehicles, such as bicycles, automobiles or skateboards, with their riders in a pedestrian area. The resolution of each video is 360240.
CUHK Avenue Dataset
contains 16 training and 21 testing videos with 47 abnormal events in total, including running and throwing of objects. The resolution of each video is 640360.
4.2 Implementation Details
Our method is implemented on Pytorch [25]. Each video frame is resized to the size of 256256 and normalized to the range of [-1, 1]. We use the Adam optimizer [12] with and . The initial learning rate is set to 2-4 and we utilize a cosine annealing [15] as the learning rate scheduler. Our model is trained under one RTX TITAN with 4 mini-batch sizes for 60 epochs. All models are trained end-to-end and it takes about 1 and 9 hours for UCSD Ped2 and CUHK Avenue, respectively.
4.3 Evaluation Metric
4.4 Ablation Study
We conducted an ablation analysis to observe the efficiency and efficacy of our proposed CPNet. First, we evaluate different settings of CPNet by dividing the baseline U-Net into four parallel paths and applying the shift operation on the encoder part only or both of the encoder and decoder parts.
Table 1 shows the results of AUC, GFLOPs and the number of parameters on the baseline and CPNet with its variants. The model CPNet-0.75 111The suffix ‘-0.75’ means the percentage of GFLOPs to the baseline., which processes each frame independently on the encoder part only, results in the best AUC (96.55%) with 75.4% of GFLOPs and 65.1% of the parameter number compared to the baseline. The shift module does not improve the CPNet-0.75 as its decoder part is capable of capturing temporal relationships, where a stack of encoded feature maps is processed as the baseline U-Net.
When the division is applied on both the encoder and decoder parts, the model CPNet-0.37 results 37.8% and 25.7% in terms of GFLOPs and the parameter number compared to the baseline. It also requires half GFLOPs rather than CPNet-0.75. Without the shift module, CPNet-0.37 resulted in a significant performance drop as it struggles to capture temporal relationships and makes poor predictions. With the shift module, however, its performance improves to 96.13%, which is equivalent to that of the heavier networks CPNet-0.75 and better than the baseline.
Table 2 shows the PSNR and score on the baseline and CPNet-0.37. The baseline achieves the highest average PSNR regardless of normal and abnormal events. It highlights that the baseline prediction results in a small margin on score between normal and abnormal events. We further observe the prediction performance on our CPNet-0.37 with and without the shift module. According to PSNR, the shift module delivers large improvements on normal events but slight improvements on abnormal events. Thus, it yields larger margins on scores so that can be an effective discriminating feature for the task.
| Model | PSNR | |
|---|---|---|
| Baseline | 41.20 / 38.21 | 0.74 / 0.55 |
| (2.99) | (0.19) | |
| CPNet-0.37 | 39.29 / 36.91 | 0.66 / 0.50 |
| (2.38) | (0.16) | |
| CPNet-0.37 + Shift | 40.14 / 37.04 | 0.70 / 0.49 |
| (3.10) | (0.21) |
4.5 Comparison with the state-of-the-art methods
Quantitative Results.
Results of state-of-the-art methods are summarized in Table 3. Notice that MNAD-P performs best among the methods compared but requires 51.63GFLOPs (over 3 times of CPNet-0.37) and 15.65M Parameters (over 4.5 times of CPNet-0.37) due to the extra memory networks in the design. Our model notably outperforms or is comparable to the U-Net based methods [14, 6, 29]. As Tang et al. [29] delivers equivalent AUC on both Ped2 and Avenue datasets, it requires far more computational cost as it implements both reconstruction and prediction tasks with two U-Nets.
| Methods | Ped2 | Avenue |
|---|---|---|
| MPPCA [11] | 69.3 | - |
| MPPCA+SFA [11] | 61.3 | - |
| MDT [20] | 82.9 | - |
| AMDN [33] | 90.8 | - |
| Unmasking [30] | 82.2 | 80.6 |
| MT-FRCN [10] | 92.2 | - |
| AMC [23] | 96.2 | 86.9 |
| ConvAE [9] | 85.0 | 80.0 |
| TSC [19] | 91.0 | 80.6 |
| StackRNN [19] | 92.2 | 81.7 |
| AbnormalGAN [26] | 93.5 | - |
| Frame-Pred [14] | 95.4 | 85.1 |
| MemAE [8] | 94.1 | 83.3 |
| Dong et al. [6] | 95.6 | 84.9 |
| MNAD-R [24] | 90.2 | 82.8 |
| MNAD-P [24] | 97.0 | 88.5 |
| Tang et al. [29] | 96.2 | 85.1 |
| Baseline | 95.8 | 84.3 |
| CPNet-0.75 | 96.6 | 85.2 |
| CPNet-0.37 | 96.1 | 85.1 |

Qualitative Result.
Figure 3 shows anomaly detection results of CPNet-0.37 on Ped2 and Avenue datasets. They show the ground truth of future frames with abnormal regions denoted in red, prediction error maps and predicted future frames.
For the Ped2 dataset, our model well captures abnormal regions, i.e., riding a bicycle, riding a skateboard and driving a vehicle, as shown in Figure 3. Figure 4 in the left column shows some abnormal regions of ground truth (GT) and predicted frames (Pred.) on the Ped2 dataset. Those parts of the image associated with abnormal events are clearly distorted in the predicted images, such as distorted bicycle wheels or horizontal shifting of the skateboard and its rider.
For the Avenue dataset, the abnormal regions, i.e., throwing a bag and running, are successfully detected. Figure 4 in upper middle and upper right columns show abnormal regions of ground truth and the associated predicted frames are in the lower middle and the lower right columns respectively. In the predicted images, there are large distortions in the position of the bag and the appearance of people.
Frame Per Second.
Our method CPNet-0.37 achieves 85 fps for anomaly detection. It is far faster than other deep learning based state-of-the-art methods, e.g., 50fps for StackRNN [19], 45 fps for MemAE [8] and 25 fps for Frame-Pred [14] under the same setting.

5 Conclusions
In this paper, we proposed the Cross-Parallel Network (CPNet) in which the predictor handles each preceding frame independently with four smaller parallel U-Net and predicts a future frame. With feature maps in each smaller U-Net, it only required 37% GFLOPs and 25% of the number of parameters compared with the conventional U-Net. To mitigate the loss of cross-frame temporal relationships, the shift module was adopted. The CPNet resulted in a significant reduction in computational cost while delivering equivalent performance on Ped2 and Avenue datasets compared with the state-of-the-art methods. According to the qualitative results, our method accurately detected abnormal regions over a variety of abnormal situations.
References
- [1] S. Ahmad, A. Lavin, S. Purdy, and Z. Agha. Unsupervised real-time anomaly detection for streaming data. Neurocomputing, 262:134–147, 2017.
- [2] B. Chen, W. Wang, and J. Wang. Video imagination from a single image with transformation generation. In Proceedings of the on Thematic Workshops of ACM Multimedia 2017, pages 358–366, 2017.
- [3] K.-W. Cheng, Y.-T. Chen, and W.-H. Fang. Video anomaly detection and localization using hierarchical feature representation and gaussian process regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2909–2917, 2015.
- [4] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05), volume 1, pages 886–893. Ieee, 2005.
- [5] N. Dalal, B. Triggs, and C. Schmid. Human detection using oriented histograms of flow and appearance. In European conference on computer vision, pages 428–441. Springer, 2006.
- [6] F. Dong, Y. Zhang, and X. Nie. Dual discriminator generative adversarial network for video anomaly detection. IEEE Access, 8:88170–88176, 2020.
- [7] E. Eskin, A. Arnold, M. Prerau, L. Portnoy, and S. Stolfo. A geometric framework for unsupervised anomaly detection. In Applications of data mining in computer security, pages 77–101. Springer, 2002.
- [8] D. Gong, L. Liu, V. Le, B. Saha, M. R. Mansour, S. Venkatesh, and A. v. d. Hengel. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1705–1714, 2019.
- [9] M. Hasan, J. Choi, J. Neumann, A. K. Roy-Chowdhury, and L. S. Davis. Learning temporal regularity in video sequences. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 733–742, 2016.
- [10] R. Hinami, T. Mei, and S. Satoh. Joint detection and recounting of abnormal events by learning deep generic knowledge. In Proceedings of the IEEE International Conference on Computer Vision, pages 3619–3627, 2017.
- [11] J. Kim and K. Grauman. Observe locally, infer globally: a space-time mrf for detecting abnormal activities with incremental updates. In 2009 IEEE conference on computer vision and pattern recognition, pages 2921–2928. IEEE, 2009.
- [12] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [13] J. Lin, C. Gan, and S. Han. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7083–7093, 2019.
- [14] W. Liu, W. Luo, D. Lian, and S. Gao. Future frame prediction for anomaly detection–a new baseline. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6536–6545, 2018.
- [15] I. Loshchilov and F. Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- [16] W. Lotter, G. Kreiman, and D. Cox. Deep predictive coding networks for video prediction and unsupervised learning. arXiv preprint arXiv:1605.08104, 2016.
- [17] C. Lu, J. Shi, and J. Jia. Abnormal event detection at 150 fps in matlab. In Proceedings of the IEEE international conference on computer vision, pages 2720–2727, 2013.
- [18] W. Luo, W. Liu, and S. Gao. Remembering history with convolutional lstm for anomaly detection. In 2017 IEEE International Conference on Multimedia and Expo (ICME), pages 439–444. IEEE, 2017.
- [19] W. Luo, W. Liu, and S. Gao. A revisit of sparse coding based anomaly detection in stacked rnn framework. In Proceedings of the IEEE International Conference on Computer Vision, pages 341–349, 2017.
- [20] V. Mahadevan, W. Li, V. Bhalodia, and N. Vasconcelos. Anomaly detection in crowded scenes. In 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 1975–1981. IEEE, 2010.
- [21] M. Mathieu, C. Couprie, and Y. LeCun. Deep multi-scale video prediction beyond mean square error. arXiv preprint arXiv:1511.05440, 2015.
- [22] K.-T. Nguyen, D.-T. Dinh, M. N. Do, and M.-T. Tran. Anomaly detection in traffic surveillance videos with gan-based future frame prediction. In Proceedings of the 2020 International Conference on Multimedia Retrieval, pages 457–463, 2020.
- [23] T.-N. Nguyen and J. Meunier. Anomaly detection in video sequence with appearance-motion correspondence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1273–1283, 2019.
- [24] H. Park, J. Noh, and B. Ham. Learning memory-guided normality for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14372–14381, 2020.
- [25] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. Pytorch: An imperative style, high-performance deep learning library. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019.
- [26] M. Ravanbakhsh, M. Nabi, E. Sangineto, L. Marcenaro, C. Regazzoni, and N. Sebe. Abnormal event detection in videos using generative adversarial nets. In 2017 IEEE International Conference on Image Processing (ICIP), pages 1577–1581. IEEE, 2017.
- [27] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. CoRR, abs/1505.04597, 2015.
- [28] M. Sabokrou, M. Fayyaz, M. Fathy, and R. Klette. Deep-cascade: Cascading 3d deep neural networks for fast anomaly detection and localization in crowded scenes. IEEE Transactions on Image Processing, 26(4):1992–2004, 2017.
- [29] Y. Tang, L. Zhao, S. Zhang, C. Gong, G. Li, and J. Yang. Integrating prediction and reconstruction for anomaly detection. Pattern Recognition Letters, 129:123–130, 2020.
- [30] R. Tudor Ionescu, S. Smeureanu, B. Alexe, and M. Popescu. Unmasking the abnormal events in video. In Proceedings of the IEEE international conference on computer vision, pages 2895–2903, 2017.
- [31] F. Tung, J. S. Zelek, and D. A. Clausi. Goal-based trajectory analysis for unusual behaviour detection in intelligent surveillance. Image and Vision Computing, 29(4):230–240, 2011.
- [32] S. Wu, B. E. Moore, and M. Shah. Chaotic invariants of lagrangian particle trajectories for anomaly detection in crowded scenes. In 2010 IEEE computer society conference on computer vision and pattern recognition, pages 2054–2060. IEEE, 2010.
- [33] D. Xu, Y. Yan, E. Ricci, and N. Sebe. Detecting anomalous events in videos by learning deep representations of appearance and motion. Computer Vision and Image Understanding, 156:117–127, 2017.
- [34] M. Z. Zaheer, J.-h. Lee, M. Astrid, and S.-I. Lee. Old is gold: Redefining the adversarially learned one-class classifier training paradigm. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14183–14193, 2020.
- [35] D. Zhang, D. Gatica-Perez, S. Bengio, and I. McCowan. Semi-supervised adapted hmms for unusual event detection. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), volume 1, pages 611–618. IEEE, 2005.
- [36] Y. Zhao, B. Deng, C. Shen, Y. Liu, H. Lu, and X.-S. Hua. Spatio-temporal autoencoder for video anomaly detection. In Proceedings of the 25th ACM international conference on Multimedia, pages 1933–1941, 2017.