Critical scaling in hidden state inference for linear Langevin dynamics
Abstract
We consider the problem of inferring the dynamics of unknown (i.e. hidden) nodes from a set of observed trajectories and study analytically the average prediction error and the typical relaxation time of correlations between errors. We focus on a stochastic linear dynamics of continuous degrees of freedom interacting via random Gaussian couplings in the infinite network size limit. The expected error on the hidden time courses can be found as the equal-time hidden-to-hidden covariance of the probability distribution conditioned on observations. In the stationary regime, we analyze the phase diagram in the space of relevant parameters, namely the ratio between the numbers of observed and hidden nodes, the degree of symmetry of the interactions and the amplitudes of the hidden-to-hidden and hidden-to-observed couplings relative to the decay constant of the internal hidden dynamics. In particular, we identify critical regions in parameter space where the relaxation time and the inference error diverge, and determine the corresponding scaling behaviour.
Keywords: Plefka Expansion, Inference, Mean Field, Critical Scaling, Biochemical Networks, Dynamical Functional
1 Introduction
The reconstruction of the time evolution of a system starting from macroscopic measurements of its dynamics is a challenge of primary interest in statistical physics; see e.g. [1, 2, 3, 4]. The problem can be cast as follows: given the set of interaction parameters and a temporal sequence of observed variables, the aim is to infer the states of the variables that are unobserved or, in the terminology of machine learning, “hidden”.
Recently, in [5], we have proposed a method to solve this problem for continuous degrees of freedom based on a dynamical mean-field theory, the Extended Plefka Expansion [6]. We specialized to the case of a linear stochastic dynamics for the purpose of a direct comparison with the exact computation implemented via the Kalman filter [7], a well-known inference technique in linear (Gaussian) state space models [8]. In these models, the posterior distribution over the hidden dynamics is Gaussian: while the posterior mean provides the best estimate of the hidden dynamics, the posterior equal-time variance measures the uncertainty of this prediction and thus the inference error. With mean-field couplings (weak and long-ranged) drawn at random from a Gaussian distribution, we investigated numerically the performance of the extended Plefka expansion, finding a clear improvement for large system size. In this paper, we calculate analytically the posterior statistics in the thermodynamic limit of an infinitely large hidden system at stationarity, with a focus on the inference error and the relaxation time, defined as the typical timescale over which correlations between inference errors decay. The thermodynamic limit expressions we find are expected to be exact as we show by comparison to other methods, appealing to Random Matrix Theory and dynamical functionals [9]. As the resulting scenario is analytically tractable, one can study the dependence of relaxation times and the average prediction error on key system parameters and thus shed light on the accuracy of the inference process. This, beyond the derivation of the general thermodynamic limit expressions, is the second major aim of this paper and can be seen as analogous to what has been done for learning from static data in a linear perceptron [10, 11], where solvable models allowed the authors to study how the prediction error scales with the number of training examples and spatial dimensions. The emphasis here is on understanding the prediction accuracy for hidden states from a theoretical point of view, including its dependence on macroscopic parameters that could be measurable, at least indirectly.
The paper is organized as follows. In section 2.1 we introduce the basic set up, a linear stochastic dynamics with hidden nodes, and we recall the main results of the Extended Plefka Expansion applied to this case [5], as the starting point for the analysis of this paper. In section 2.2 we consider the thermodynamic limit of infinite network size, shifting from local correlations to their macroscopic average across the network. The exactness of the extended Plefka predictions is shown in section 2.3 by comparison with expressions obtained elsewhere[9] by Kalman filter and Random Matrix Theory (RMT) methods. From section 3, we present a systematic analysis of these mean-field results in terms of the system properties and the number of observations. In section 3.1 we determine the relevant dimensionless parameters governing prediction accuracy, namely the ratio between the numbers of observed and hidden nodes, the degree of symmetry of the hidden interactions, and the amplitudes of the hidden-to-hidden and hidden-to-observed interactions relative to the decay constant of the internal hidden dynamics. We identify critical points in this parameter space by studying the behaviour of power spectra using a scaling approach (sections 3.2, 3.3 and A). In the main part of the analysis we then consider the temporal correlations in the posterior dynamics of the hidden nodes, revealing interesting long-time behaviour in the critical regions (sections 3.4-3.9 and B). More specifically, we first present the power laws governing relaxation times in sections 3.4 and 3.5, then discuss the corresponding correlation functions in sections 3.6 and 3.7, and finally extract predictions on the inference error in sections 3.8 and 3.9.
2 Extended Plefka Expansion with hidden nodes
2.1 Set up
Let us consider a generic network where only the dynamics of a subnetwork of nodes is observed while the others are hidden and form what we call the “bulk”. The indices and the superscript b are used for the hidden or bulk variables; similarly the indices and the superscript s for the observed or subnetwork nodes of the network. Assuming linear couplings , between hidden and observed variables , , their dynamical evolution is described by
| (2.1a) | ||||
| (2.1b) | ||||
(respectively ) gives the hidden-to-hidden (respectively observed-to-observed) interactions, while the coupling between observed and hidden variables is contained in and . is a self-interaction term acting as a decay constant and providing the basic timescale of the dynamics. The dynamical noises , are Gaussian white noises with zero mean and diagonal covariances ,
| (2.2) |
The application of the extended Plefka expansion to this problem with hidden and observed nodes [5] allows us to obtain a closed system of integral equations describing the second moments of the Gaussian posterior distribution over the hidden dynamics, i.e. conditioned on the observed trajectories. These second moments are denoted by , the hidden posterior variance, , the hidden posterior response, and , the posterior correlations of auxiliary variables introduced to represent the hidden and observed dynamics respectively à la Martin–Siggia–Rose–Janssen–De Dominicis [12, 13, 14]. They are diagonal in the site index but functions of two times by construction of the Extended Plefka Expansion [6], which gives an effectively non-interacting approximation of the dynamics where couplings among trajectories are replaced by a memory term (related to ) and a time-correlated noise (whose covariance is related to ).
Our main interest is in the posterior statistics: the equal-time variance of inference errors gives a mean-square prediction error, while the time correlations between the inference errors define a posterior relaxation time. To simplify the equations derived in [5], we consider long times, where a stationary regime is reached: all two-time functions become time translation invariant (TTI) and the Laplace-transformed equations yield a system of four coupled equations for , , , . Let us briefly recall it here, as it will be the starting point for the analysis
| (2.3a) | |||
| (2.3b) | |||
| (2.3c) | |||
| (2.3d) | |||
2.2 Thermodynamic Limit
We expect the extended Plefka approach to give exact values for posterior means and variances in the case of mean-field type couplings (i.e. weak and long-ranged), in the thermodynamic limit of an infinitely large system. More precisely we define the thermodynamic limit as the one of an infinitely large bulk and subnetwork, at constant ratio . For the mean-field couplings we assume, as in [6], that is a real matrix belonging to the Girko ensemble [15], i.e. its elements are independently and randomly distributed Gaussian variables with zero mean and variance satisfying
| (2.4) |
| (2.5) |
The parameter controls the degree to which the matrix is symmetric. In particular, the dynamics is non-equilibrium – it does not satisfy detailed balance – whenever . Similarly, is taken as a random matrix with uncorrelated zero mean Gaussian entries of variance
| (2.6) |
We have introduced amplitude parameters for (hidden-to-hidden) and for (hidden-to-observed) here. The scaling of both types of interaction parameters with ensures that, when the size of the hidden part of the system increases, the typical contribution it makes to the time evolution of each hidden and observed variable stays of the same order. The high connectivity, where all nodes interact with all other ones, implies that in the thermodynamic limit all nodes become equivalent. Local response and correlation functions therefore become identical to their averages over nodes, defined as
| (2.7) | |||
| (2.8) | |||
| (2.9) |
As a consequence, all site indices can be dropped and the correlation and response functions can be replaced by their mean values, , , . The superscripts bbs here emphasize that we are considering moments conditioned on subnetwork values though for brevity we drop them in the rest of the calculation. Similarly, for the correlations of auxiliary variables related to observations we can set . Of primary interest is then , the Laplace transformed posterior (co-)variance function of prediction errors, which as a site-average can be thought of as a macroscopic measure of prediction performance. This should become self-averaging in the thermodynamic limit. To see this, consider e.g. the sum . Replacing by , the prefactor is a sum of terms so converges to its average in the thermodynamic limit. So, as in [6], we can replace
Making this and similar substitutions in the system (2.3), and choosing scalar noise covariances and as in [9], one finds
| (2.10a) | ||||
| (2.10b) | ||||
| (2.10c) | ||||
Here has already been substituted into equations (2.10a) and (2.10c).
We comment briefly on the relation of the above results to the Fluctuation Dissipation Theorem (FDT), which in terms of Laplace transforms reads
| (2.11) |
This can be compared with the expression for that follows from (2.10b) (taken for and )
| (2.12) |
The r.h.s. of the FDT is then
| (2.13) |
Comparing with (2.11), the FDT is satisfied for symmetric couplings () as expected, while there are progressively stronger deviations from FDT as decreases towards .
2.3 Comparison with known results
As a consistency check and to support our claim of exactness in the thermodynamic limit, we briefly compare our results with expressions for and that can be worked out by alternative means.
In general, from (2.10b) we can get an expression for in terms of : this is (2.12). Substituting into (2.10a), can also be worked out as a function of . Using these expressions for and in equation (2.10c), one finds a closed algebraic equation for the posterior variance
| (2.14) |
This is the same expression as obtained by calculations in [9] using an explicit average over the quenched disorder variables and . Particular cases are also further validated by random matrix theory, as follows.
2.3.1 .
This case corresponds to the absence of observations. One has then , as these quantities simply play the role of Lagrange multipliers enforcing the conditioning on observations. To see this formally from the limit of (2.10) one sets and where the stay nonzero for . One verifies that under this assumption the system has as solution the responses and correlations known from [6] (where a thorough analysis of the thermodynamic limit of an analogous linear dynamics without observations was provided)
| (2.15) |
| (2.16) |
2.3.2 .
2.3.3 .
3 Critical regions
We can now proceed to the main contribution of this work, namely the study of the properties of our conditioned dynamical system. The focus will be first on the power spectrum of the posterior covariance, given by , the Laplace transform evaluated at , as this is the quantity that is immediately computable from the equations (2.10). We will then translate the insights from the frequency domain analysis into the time domain, to access key observables including the timescales of posterior correlations.
We use the formulae provided by the Plefka approach for our analysis but stress that the behaviour we find, including the presence of critical regions in parameter space, is not an artefact of the Plefka expansion. The Plefka expansion is known to have a finite radius of convergence [16] in terms of coupling strength, and so it might be thought that one should check whether our parameter ranges lie in the region of validity of the expansion. However, as highlighted in section 2.3, the Plefka results (2.10) fully agree with other methods that do not rely on perturbative expansions, namely random matrix theory and disorder-averaged dynamical functionals [9], which implies that there can be no issues with convergence of the Plefka expansion.
3.1 Dimensionless system for the power spectrum
We would like first to understand how depends on the parameters , , , , , and . The last two of these are already dimensionless. By extracting the appropriate dimensional scales, we can reduce the other five parameters to only two dimensionless combinations.
From (2.1) one sees that , , have dimensions , while the dimension of is . We can build from these the dimensionless parameters and . Here , which has dimension and contains the observation “intensity” as well as the ratio between the dynamical noises . The latter is a third dimensionless parameter but as it only enters one prefactor we will not need to keep it separately.
Extracting appropriate dimensional amplitudes for all four two-point functions, we write them as
| (3.1a) | ||||
| (3.1b) | ||||
| (3.1c) | ||||
| (3.1d) | ||||
Here is a dimensionless frequency; similarly , , and are dimensionless and depend on the dimensionless parameters , , and : for the sake of brevity, we do not write the subscripts indicating this dependence in the following. Let us briefly comment on (3.1a). One sees that is directly proportional to and inversely proportional to : the weaker the hidden-to-observed coupling and the stronger the dynamical noise acting on the observed variables, the less information one can extract from the subnetwork trajectories and the more uncertain the predictions for the behaviour of the bulk.
To summarize, we switch from eight original parameters to a set of five dimensionless parameters . For the dimensionless second moments (3.1), the system (2.10) becomes
| (3.2a) | |||
| (3.2b) | |||
| (3.2c) | |||
where we have dropped the frequency argument and introduced the shorthand . The solution for , already taken into account by substitution in (3.2), is given by .
3.2 Critical scaling
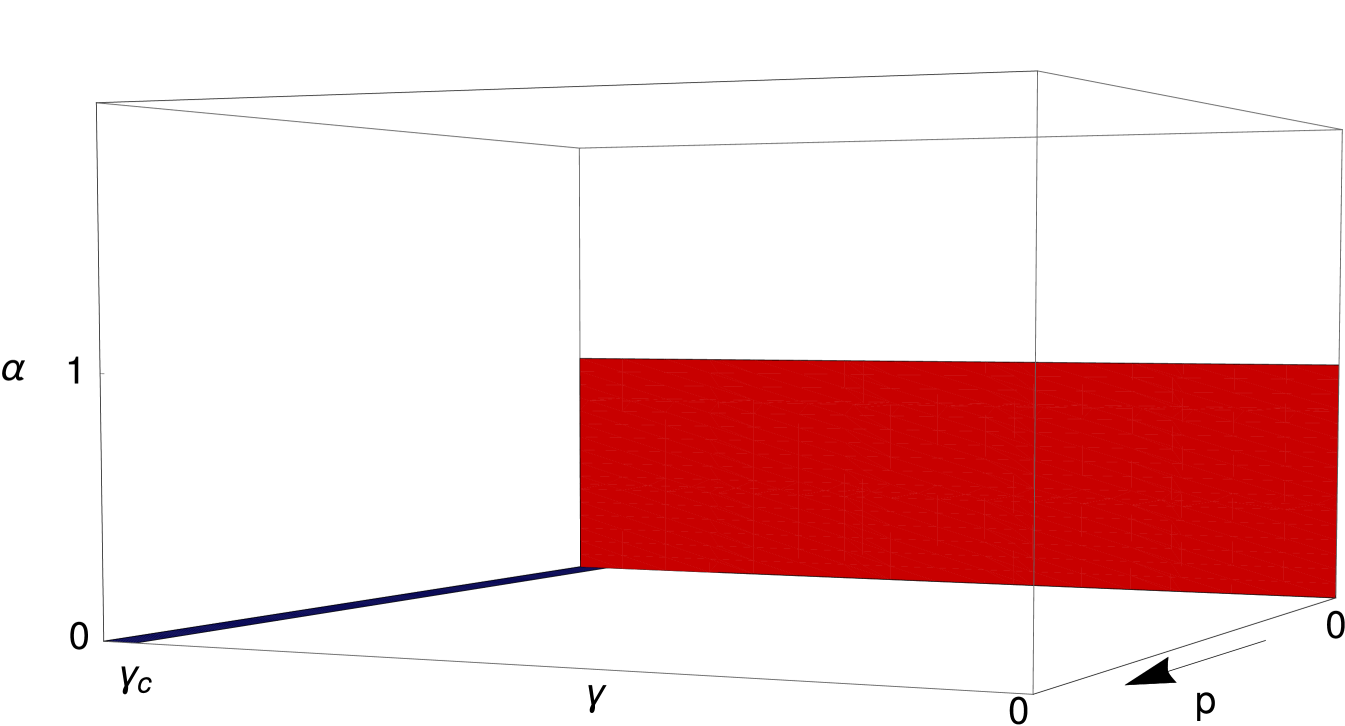
We next analyze in the parameter space (at fixed ) the singularities of , the (dimensionless) zero frequency posterior covariance. is a convenient quantity to look at in the first instance as it helps one detect where qualitative changes of behaviour occur. We will see that these then show up also in the relaxation time and the inference error itself, i.e. the equal time posterior variance . Their behaviour will be addressed respectively in sections 3.4, 3.5 and 3.8, 3.9, while in sections 3.6 and 3.7 we clarify further the interpretation of our results for the relaxation times by looking at the shape of the correlation functions.
Independently of , we find two critical regions that are shown graphically in figure 1:
-
1.
, and
-
2.
, and
The first case gives back the dynamics without observations (), for which is the condition of stability beyond which trajectories typically diverge in time (see [6]). Interestingly, as soon as , the constraints from observations make the solution stable irrespective of whether is smaller or bigger than the critical value. For the observed trajectories would then be divergent, and so would the predicted hidden trajectories, while the error (posterior variance) of the predictions would remain bounded. It is difficult to conceive of situations where divergent mean trajectories would make sense, however, so we only consider the range in our analysis. In what follows, we will plot all the curves that refer to this region of the parameter space in blue.
The second limit, , corresponds, for fixed ratio between noises , to : we call this scenario an “underconstrained” hidden system. In general for large the posterior variance decreases as , as used in the scaling (3.1a). But for there are directions in the space of hidden trajectories that are not constrained at all by subnetwork observations, and their variance will scale as instead. These directions give a large contributions to the dimensionless that diverges in the limit . In general one has a similar effect when , where the noise in the dynamics acts to effectively reduce the relevant interaction or decay constant. This behaviour is broadly analogous to what happens in learning of linear functions from static data [10, 11]: there the prediction error will also diverge when , which is then defined as the ratio of number of examples to number of spatial dimensions, is less than unity and no regularization is applied. For the curves belonging to this second region we choose the colour red.
Close to the two critical regions in the space of , and , is expected to exhibit a power-law dependence on the parameters specifying the distance away from the critical point. One can study this behaviour by using standard scaling techniques developed for the study of critical phase transitions [17]. The aim of this analysis, which we describe in A and summarize in the next section, is to find the master curves and associated exponents that describe the approach to the critical point(s). From the master curves for the power spectrum we can then derive (B) the corresponding scaling behaviour of the relaxation times and the inference error, which is discussed in sections 3.4–3.9 below.
3.3 Power Spectrum Master Curves
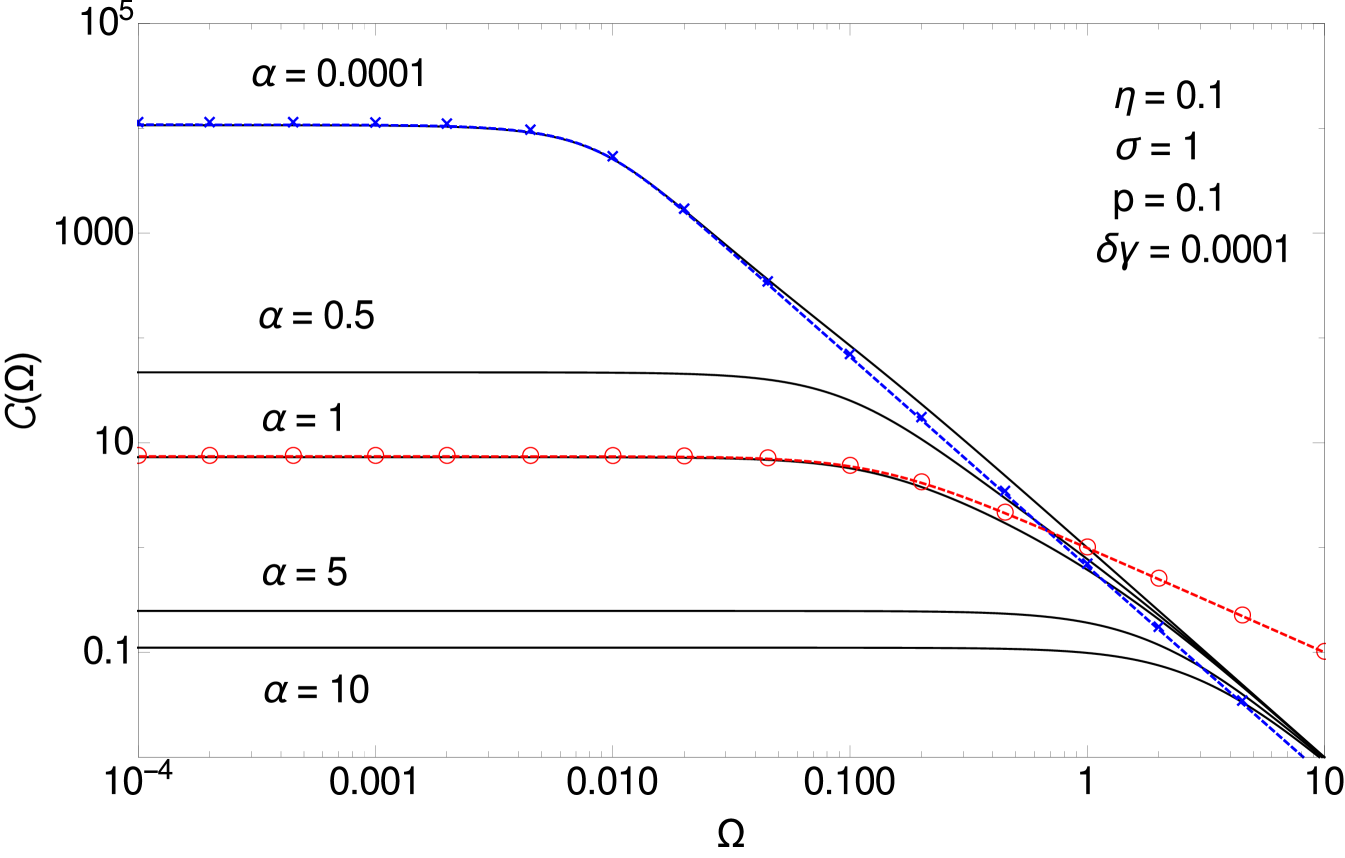
The master curves of the power spectrum describe its shape in the critical regions and for small frequencies of the order of a parameter-dependent characteristic frequency (see A). These master curves are useful because they highlight the two main trends (with and with ) that will manifest themselves in the relaxation time and in the inference error. In the first critical region where there are few observations, the conditional dynamics is dominated by hidden-hidden interactions. Their degree of symmetry therefore plays a key role and in fact determines a non-trivial crossover in the critical behaviour (see figure 9). As developed in A.1, this crossover from equilibrium to generic non-equilibrium dynamics can be studied by including as a small parameter in the scaling analysis. By contrast, in the second critical region the scaling functions do not depend on (see figure 8, right). The intuition here is that the critical behaviour is dominated by whether a direction in the hidden trajectory space is constrained by observations or not, i.e. by hidden-to-observed rather than hidden-to-hidden interactions.
Regarding the trend with , the main feature is the decrease in with increasing meaning that with many observations the predictions for the hidden dynamics will become arbitrarily precise, in line with intuition. This can be seen in figure 2, where one observes also that at all spectra collapse into a Lorentzian tail. This indicates an exponential decay of the correlations between prediction errors in the temporal domain. As the amplitude of the tail is largely -independent, the typical time of this exponential decay decreases with : with many observations, errors in the prediction of the hidden states become progressively less correlated with each other.
This already shows that from the power spectrum one can extract useful information on relaxation times and the same is true for the inference error, as we analyze more systematically in the next sections. Importantly, we find nontrivial power-law dependences on that arise from the dynamical nature of our problem and have no analogue in static learning [10, 11].
3.4 Relaxation time for and
We look at the relaxation time, which is a measure of time correlations in the errors of inferred hidden values. We study in particular how it depends on the number of observations and the interaction parameters.
The relaxation time can be defined in a mean-squared sense as
| (3.3) |
Given this relation, results for power spectra can be directly used to obtain the master curves for relaxation times, see B.1 and B.2. To construct these master curves, let us introduce the dimensionless version of the relaxation timescale,
| (3.4) |
We look separately at the two critical regions, starting in this subsection with the first one, i.e. in the vicinity of the “no observations” critical point. We summarize here the main findings, leaving details for B.1. The distance from the singularity is controlled by itself and . As mentioned in the overview in section 3.3, the behaviour in this region depends crucially on the symmetry parameter and so we break down the results accordingly.
3.4.1 .
3.4.2 .
3.4.3 Crossover at .
3.5 Relaxation time for and
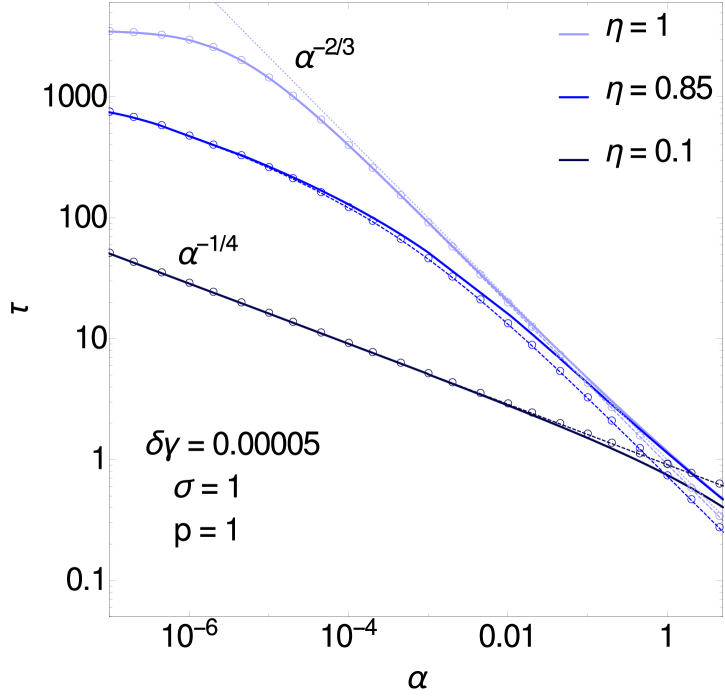
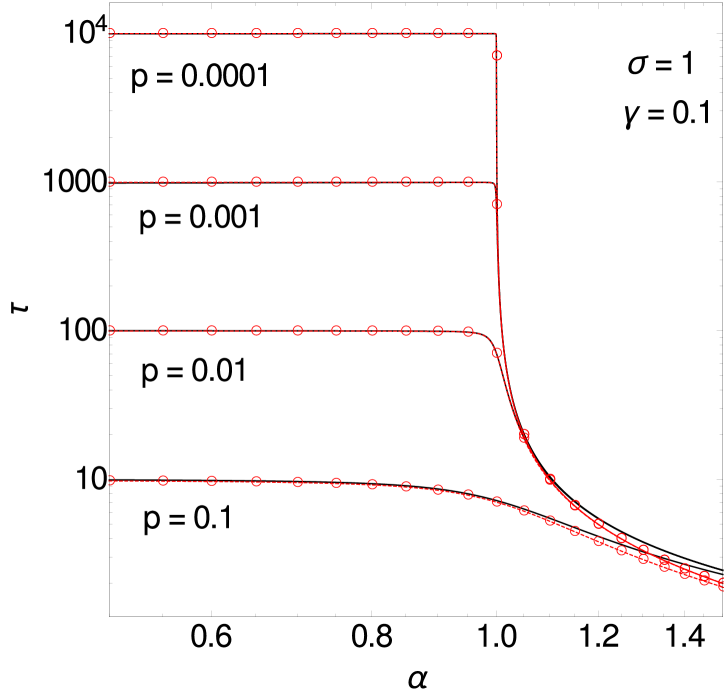
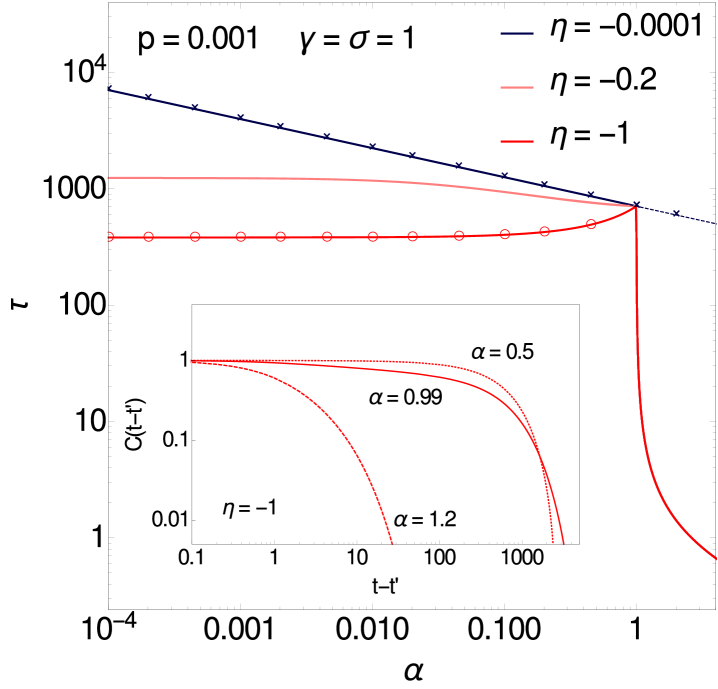
We next discuss the behaviour of the relaxation time in the second critical region, (i.e. ) and (i.e. at fixed ). The distance from the critical point is therefore represented by itself and by . As is shown in B.2, when both are small the results are independent of the degree of symmetry of the interactions among the hidden variables. For the dimensionless relaxation time we find for positive (see B.2)
| (3.7) |
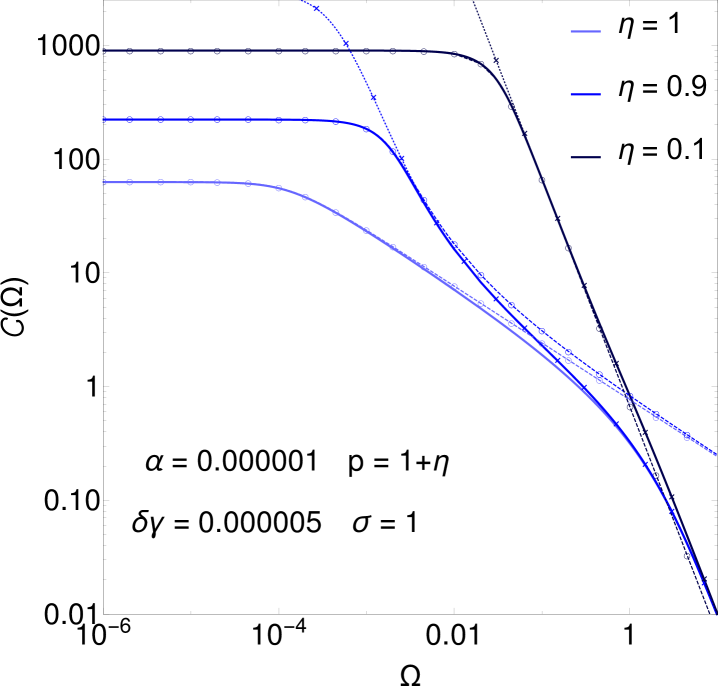
and this is consistent with numerical data for , see figure 3 (right). The figure also shows that as decreases below unity the relaxation time reaches a plateau, whose height can be worked out as . The plateau and the decay in eq. (3.7) are obtained as the two limiting behaviours of an -independent master curve that applies when is of order .
To understand the behaviour across the entire range one can work out a separate master curve for fixed and (see Eq. (B.12) in B), which is plotted in figure 4 (left) for along with numerical results. This curve does have a nontrivial dependence both on and on ; for it approaches a constant, whose value can be checked to be consistent with the result (Eq. (A.1)) as it must.
A comparison of figures 3 (right) and 4 (left) shows that the range around where relaxation times are independent of depends not just on but also on . For small as in figure 3 (right) we see good agreement with the -independent master curves down to at least . For , the value we take to plot curves for , figure 4 (left) shows that already at there is visible variation across different values of .
Figure 4 (left) contains a further insight: at fixed and moderate , varying can shift the system away from the second critical region () towards the first one (). Indeed, if , becomes small when is close to zero because . Accordingly for the curve in the figure, the relaxation time for small is captured better by the master curve for the first critical region (dark blue line with crosses) than the one for the second region. At fixed and for appropriate combinations of small and one can even see both critical regions as is increased. Figure 4 (right) shows a case in point.
As a general trend in the relaxation times one sees that they decrease significantly with increasing (see e.g. figure 4, right): as the values of the hidden variables become constrained increasingly strongly by those of the observed ones, the remaining uncertainty in the prediction becomes local in time. There are surprising counter-examples, however. Figure 4 (left) shows that for strongly anti-symmetric interactions, e.g. , the relaxation time increases with up until . This unusual trend is linked to a change of shape in the decay of the time-dependent correlation function, which is strongly non-exponential for but becomes close to exponential beyond (see the inset of figure 4, left).
3.6 Correlation functions for and
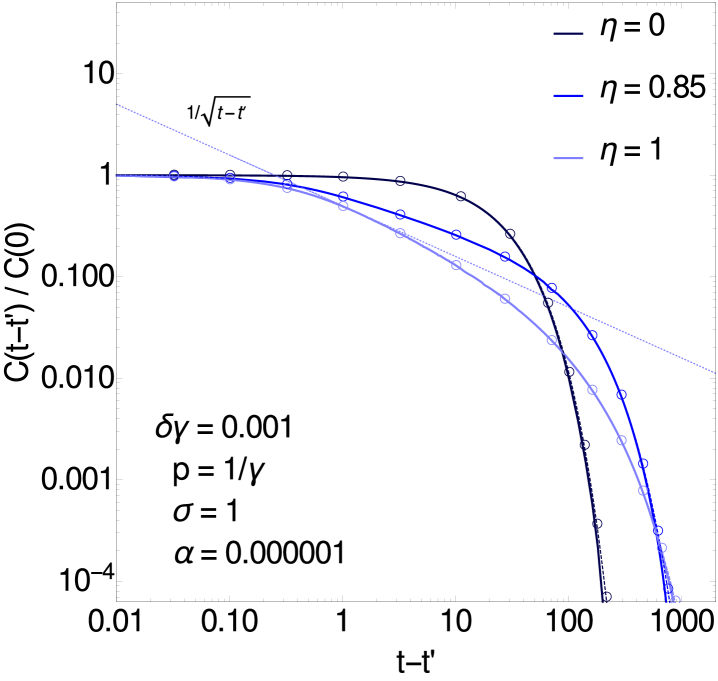
Having studied overall relaxation timescales, we next look more comprehensively at the time correlation functions , which can be obtained numerically by inverse Fourier transform of the power spectrum.
For the first critical region we refer to figure 5 (left). Here the master curves are the result at from [6]: for and these are given respectively by a pure exponential and by an exponentially weighted integral of a modified Bessel function . In the latter case the correlation function has a regime indicated in the figure, before crossing over to times an exponential cutoff (which kicks in around in the case shown in the figure). For intermediate symmetries (e.g. in figure 5 left) one has a crossover between this behaviour and the pure exponential for . This crossover occurs at a time (here as before), which is consistent with the frequency space crossover at frequency , see e.g. figure 9 (right).
For , in the case is a Bessel function of the first kind [6]. This has oscillations, and we find that this behaviour persists as is increased. This is shown in the inset of figure 5 (right) where the oscillations exhibit a longer decay time for consistently with the findings on relaxation times of figure 4 (left). Note that small oscillations are also present in the curve of figure 4 (left, inset) on longer times than shown in the graph.
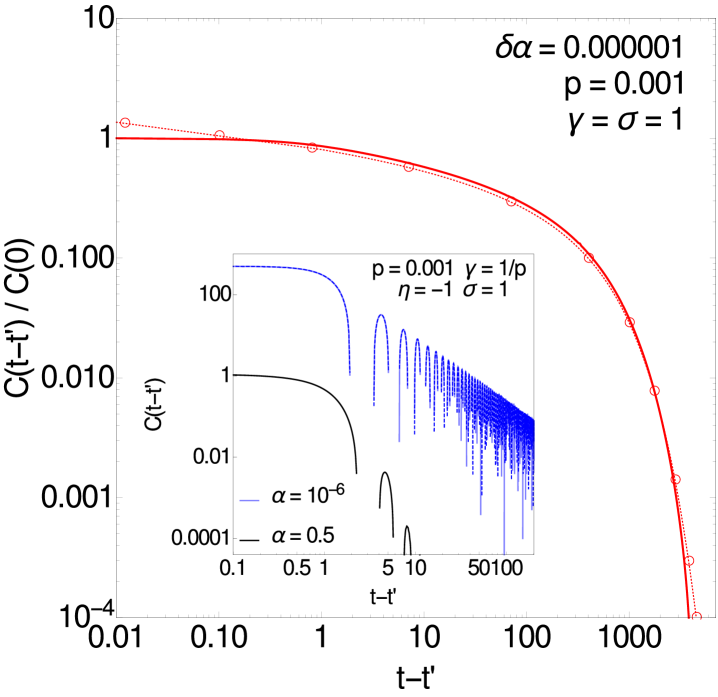
3.7 Correlation functions for and
We show an example of in this second critical region in figure 5 (right). The master curve for the power spectrum in this region (see A.2) for tends to , independently of . Its inverse Fourier transform gives a modified Bessel function in the time domain, which is plotted in the figure alongside the numerical results (dashed red line with circles).
3.8 Equal time posterior variance for and
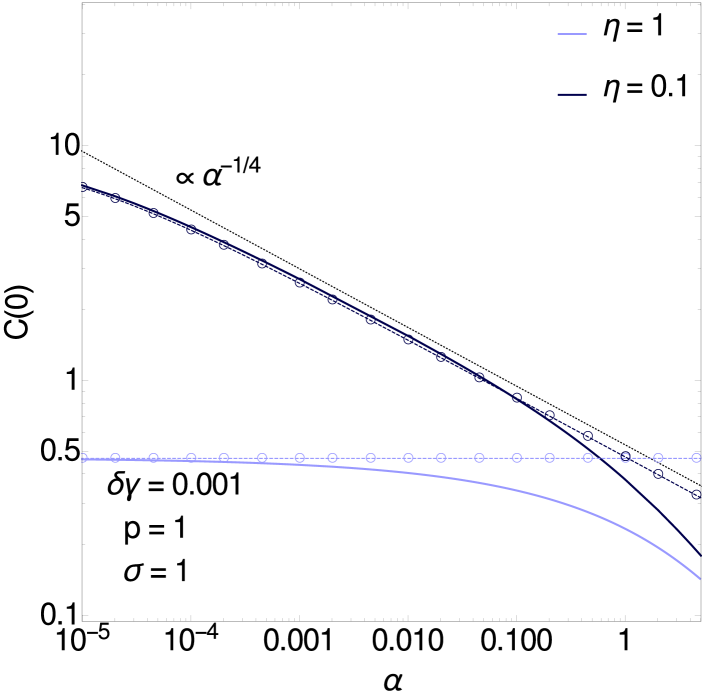
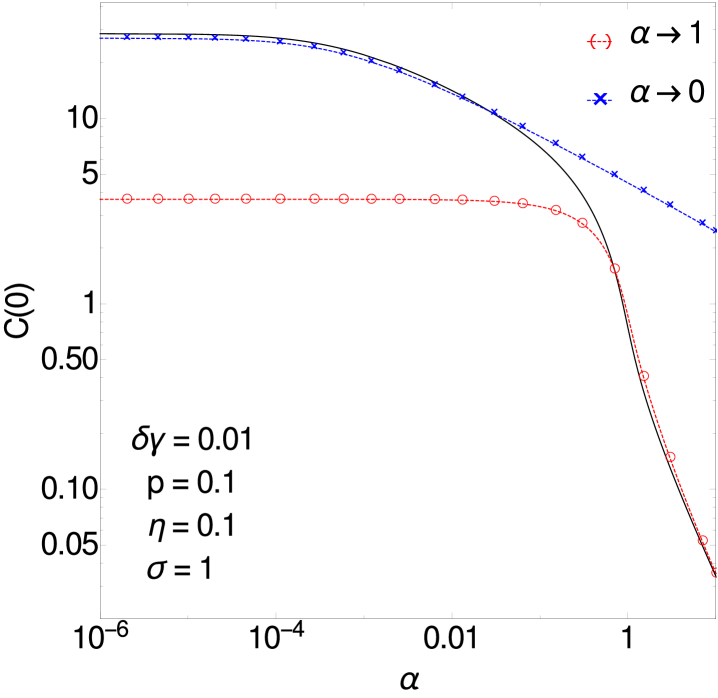
We turn finally to the behaviour of the inference error for the prediction of hidden unit trajectories. This is given by the equal time posterior correlator
| (3.8) |
where is a dimensionless equal time posterior variance. We see that the size of the error is generically proportional to the noise acting on the dynamics of hidden and observed variables, and inversely proportional to the hidden-to-observed interaction strength. We summarize in the following subsections our results for , with a focus on the -dependence, and leave details to B.3 and B.4. We begin with the first critical region.
3.8.1 .
For we find that the equal time correlator becomes essentially independent of for small , as one can see in figure 6 (left, curves for ). More generally the result is that the dependence on across the range is smooth, and to leading order unaffected by the vicinity of the critical region.
3.8.2 .
Here one obtains (see B.3)
| (3.9) |
We thus predict , and this is consistent with the numerics, see e.g. figure 6 (left, curves for ). It is notable that Eq. (3.9) is independent of ; this behaviour holds for , while for smaller the value of would become relevant. The power law behaviour is also consistent with the scaling that one would expect on general grounds: the zero frequency power spectrum is the integral of the correlation function, hence should scale as its amplitude times the decay time . That this relation holds here follows from our previous result, , and (see A.1).
3.9 Equal time posterior variance for and
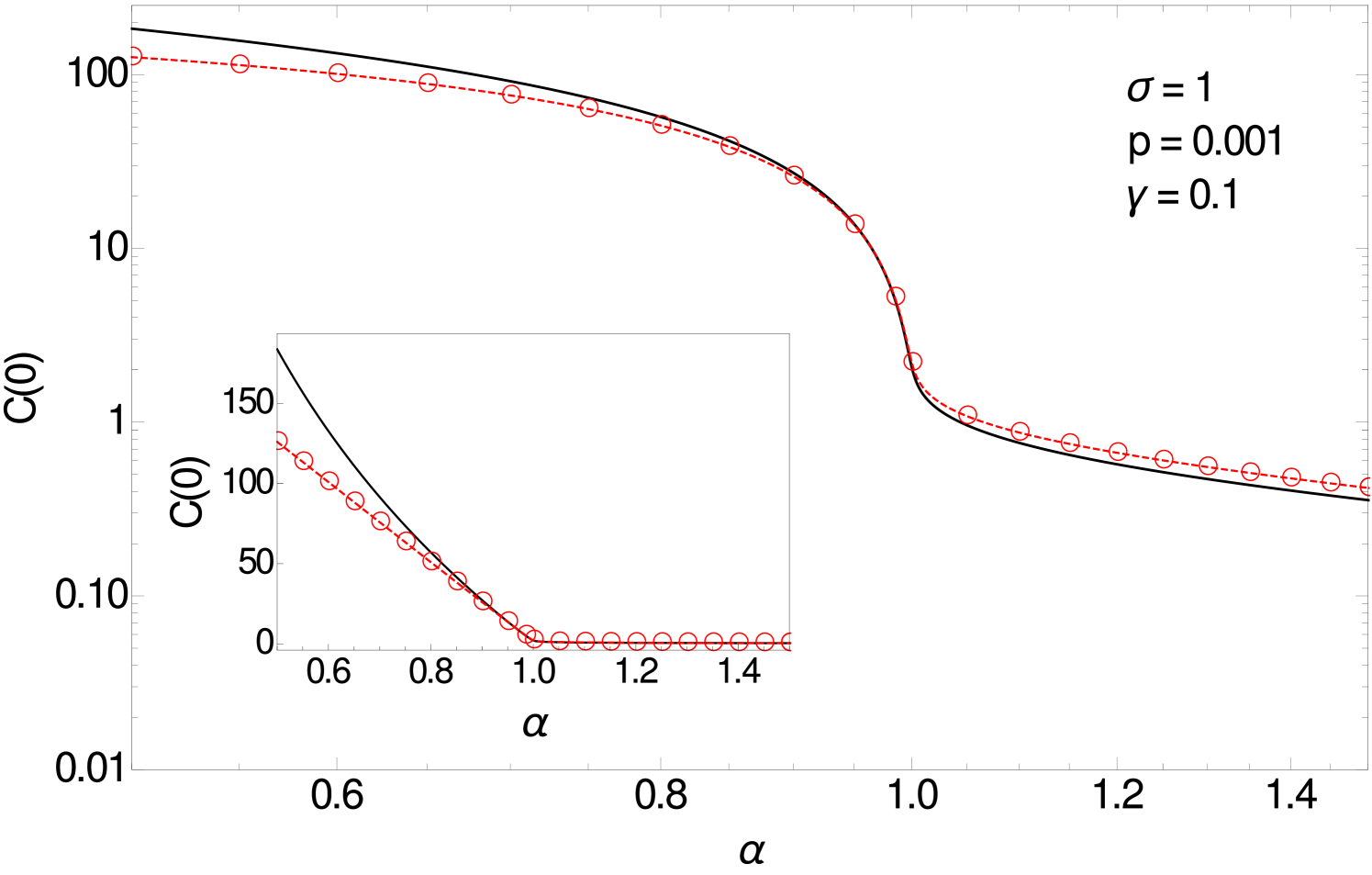
In the second critical region, the dominant terms of the integral (3.8) can be shown to scale near as for and for (see B.4). These terms are plotted (red line) in figure 7 where the linear scale inset clearly shows the linear dependence on . A separate master curve for fixed below 1 can also be derived (by integrating the solution of (A.36)) and matches smoothly to the behaviour around .
As a common trend across the two critical regions we have the intuitively reasonable result that the inference error decreases when the number of observed variables gets bigger. Figure 6 (right) summarizes this and shows that, as in the case of the relaxation times, the behaviour with increasing can cross over from the first critical region to the second provided that both and are small. It is worth re-emphasizing the non-trivial power law dependences of the inference error on that occur in our dynamical setting and are quite distinct from the simpler behaviour in static learning scenarios [10, 11].
4 Conclusion
In this paper we considered the problem of inferring hidden states over time in a network of continuous degrees of freedom given a set of observed trajectories. We started from the results for a linear dynamics with Langevin noise derived in [5] and in particular we looked at the hidden posterior variance as a measure of the inference error. To study the average performance case, we considered the stationary regime (where time translation invariance makes it convenient to work in Fourier space), mean-field couplings (all-to-all, weak and long-ranged) and the limit of an infinitely large bulk size. Under these conditions, the Extended Plefka expansion used in [5] becomes exact; also errors become site-independent self-consistently and equivalent to the average error, which measures the quality of the prediction from the macroscopic point of view.
Our main goal was to study the properties of this average inference error, and the associated correlation functions and timescales of the posterior dynamics, as a function of the relevant dimensionless parameters . Here is the ratio between observed and hidden nodes, is related to the bulk internal stability and gives the relative weight of self-interactions and hidden-to-observed couplings. These structural parameters are assumed to be known, either by direct measurement or by theoretical estimation, and our results for the posterior statistics then quantify their interplay in determining the prediction error.
As the parameter space is relatively large, we organized the analysis around the critical regions where the (suitably non-dimensionalized) prediction error diverges. We first studied the power spectrum of the posterior correlations, deploying critical scaling approaches to identify the relevant variables and find scaling functions. These results could then be straightforwardly translated into the corresponding ones for relaxation times and inference errors, providing master curves for appropriately scaled numerical data, with non-trivial power law dependences on e.g. resulting from the dynamical nature of our inference scenario.
The first critical region we analyzed corresponds to , where there are many fewer observed nodes than hidden ones. Here we found that the presence of interaction symmetry () leads to quite different scaling behaviour than for the generic case , indicating the importance of even small deviations from detailed balance for the dynamics. This is in qualitative agreement with earlier studies on systems without observations, e.g. [18, 19].
The second critical region is and , where some parts of the hidden dynamics are strongly constrained but because there are other parts that remain unconstrained as there are still not enough observed nodes. The resulting singularities are driven essentially by the hidden-to-observed couplings and are therefore independent of the hidden-to-hidden interaction symmetry. A qualitative analogy can be drawn here to studies on “underconstrained” learning in neural networks, e.g. [10, 11], where the inference error can diverge at the point where the number of patterns to be learned equals the number of degrees of freedom. This happens when no weight decay is imposed on the dynamics, which in our scenario corresponds to small and hence small . The analogy is only partial as our dynamical setting has a much richer range of behaviours overall.
Another interesting comparison can be made. The Extended Plefka Expansion has been applied also to spin systems for the inference of hidden states [1]. The analytically tractable scenario of an infinitely large network of spins with random asymmetric couplings was studied using a replica approach [2] and there the error in predicting the states of hidden nodes does not exhibit a singularity structure like the one we find. It would be interesting to consider scenarios between these two extremes as in e.g. [20], to understand the relative importance of the type of dynamics (linear vs nonlinear) and the type of degrees of freedom (continuous vs discrete) in this context.
We stress that here the only form of noise we have included is dynamical noise acting on the time evolution of the observed nodes, rather than measurement noise affecting the accuracy of the observed trajectory. We limited ourselves to this case to focus our analysis on the interplay of other parameters such as the interaction strength and the number of observations compared to the number hidden nodes. In future work it would be desirable to include measurement noise in the observation process as has been done in e.g. dynamical learning in neural networks [21]. A further extension would allow for observations that are both noisy and sparse (in time) [22].
In terms of other future work and potential applications, our results could be of interest in experimental design when only the spatio-temporal evolution of a few nodes can be controlled. Given our systematic analysis of the dependence of the average inference error on key parameters of the system, one could study how this might guide the experimental set-up in such a way as to maximize the inference accuracy. For example, the parameter measuring the relative number of nodes to monitor over time could enter the specification of a hypothetical experimental protocol. We recall that, for both critical regions, we found that the inference error decreases with this parameter and identified the relevant power laws. If we suppose that an estimate of other parameters (, , ) is available either from previous measurements or some a priori knowledge, then our explicit expressions for , the average inference error when many hidden trajectories are reconstructed, might serve to fix a minimal needed for achieving a below a set precision threshold.
A major, complementary problem when extracting information from data is the estimation of parameters, as well as identifiability [23] and ultimately model selection. Statistical physics-inspired techniques have already been successfully applied e.g. to signalling and regulatory networks [24, 25] for learning the couplings from steady state data. To see how our results could be relevant in this regard, note that tackling inverse problems relies on an interplay between state inference and parameter estimation. In this paper, we have analyzed the inference problem for the time courses of hidden nodes, assuming that the model parameters are randomly distributed with known average properties, such as the coupling strength and the degree of symmetry (i.e. the deviation from equilibrium). As a next step one could consider inferring the parameters by Expectation-Maximization [26], where the Expectation part relies precisely on computing the posterior statistics. Our simple expressions for the average posterior variance in terms of the average coupling strength and degree of symmetry would then simplify this procedure in some regimes and help investigate it in an analytically controlled, thus more insightful, way.
Acknowledgement
This work was supported by the Marie Curie Training Network NETADIS (FP7, grant 290038). The authors acknowledge the stimulating research environment provided by the EPSRC Centre for Doctoral Training in Cross-Disciplinary Approaches to Non-Equilibrium Systems (CANES, EP/L015854/1). BB acknowledges also the Simons Foundation Grant No. 454953.
Appendix A Scaling analysis: power spectra
A.1 Master curves for and
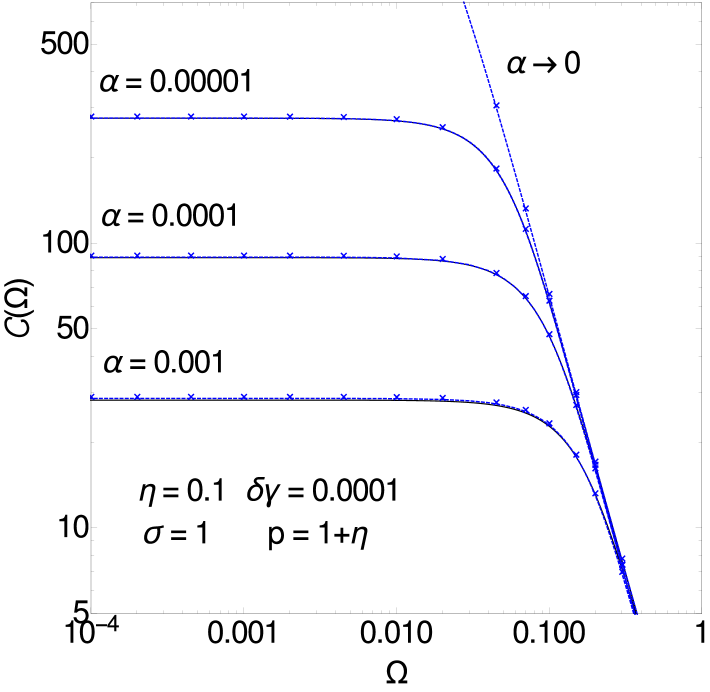
We begin with the behaviour of the posterior covariance power spectrum for and . We already know the limit curve for the power spectrum: it is given by the spectrum at the critical point. At this point we have an system, i.e. without observations [6]. As the interactions and noise level relating to observed nodes are then irrelevant, we can set , (i.e , and ). From the expression in [6], the dimensionless power spectrum then reads
| (A.1) |
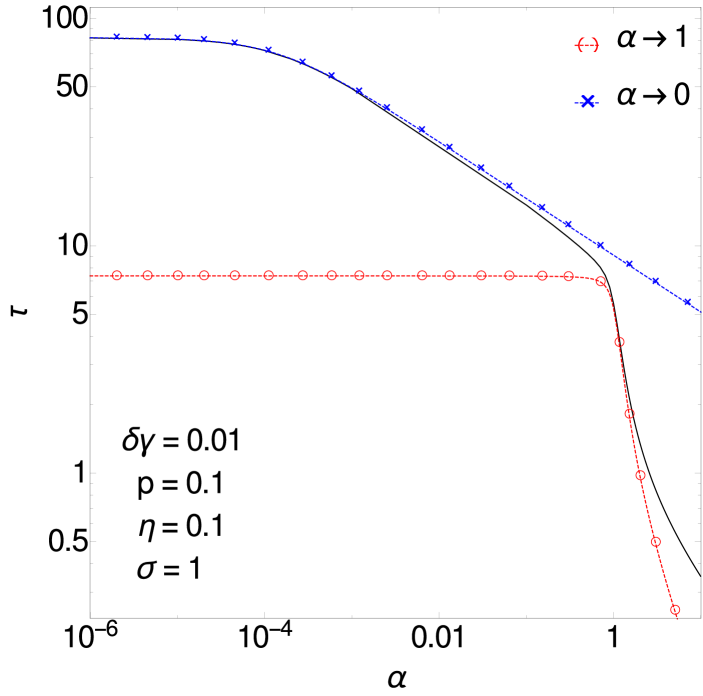
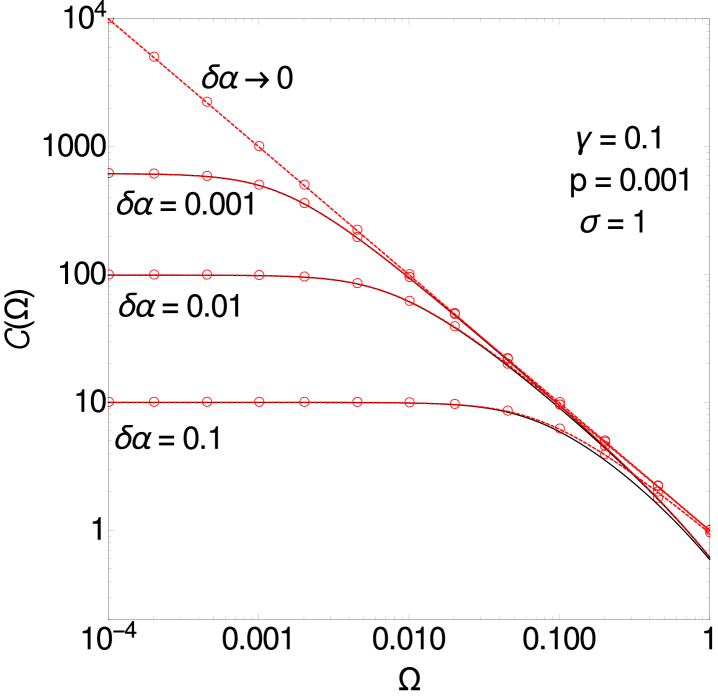
becomes singular when , as (A.1) then has a pole at . The approach to at decreasing is plotted in figure 8 (left).
A.1.1 .
To explain the rescaling procedure for understanding the approach to the singularity at when is nonzero, we first focus on the case . In section 2.3.3 we derived an algebraic equation for which, for the power spectrum , becomes
| (A.2) |
Approaching the singularity along either of the two directions or we get two distinct power law divergences of ; a third direction of approach is from nonzero at . Approaching along the -direction ( at ) we find from (A.2)
| (A.3) |
For at and , with as , the result is
| (A.4) |
Finally for at the low frequency tail of is known from [6] as
| (A.5) |
These three power laws can be combined into the scaling
| (A.6) | |||||
| (A.7) | |||||
| (A.8) |
where the exponents of in and are fixed by standard arguments (see [27] for details). Inserting this ansatz into (A.2) and taking the limit gives
| (A.9) |
This equation implicitly determines the master curve, i.e. the scaling function . It describes the power spectrum in the region where , and are all small but and are finite, which requires in particular that the dimensionless frequency must be of the order of . Numerical data in figure 9 (right) show good agreement with this master curve in the relevant regime.
A.1.2 .
Let us now consider , for which it is convenient to work with the entire system (3.2). For at one finds amplitudes and . At , we get . For the third direction we can read off from [6] that at , the low-frequency tail of the power spectrum is given by for . Comparing the first and third expression suggests a crossover frequency determined by , giving . Using this we define scaling functions for and as
| (A.10) | |||||
| (A.11) | |||||
| (A.12) | |||||
| (A.13) |
The somewhat complicated looking prefactors are chosen here to give scaling functions that will be independent of and . The response , which also features in the original equations (3.2), does not need to be rescaled as it turns out to be equal to unity to leading order.
We insert the above rescalings into the system (3.2) and again look at the limit . Some care is needed as there are competing orders of in the equations so that one has to expand the response not just to but to . One then finds simply and this makes sense: at we must retrieve the results of [6], where the normalization of the MSRJD path integral leads all moments of auxiliary variables to vanish. The master curve for the posterior covariance spectrum can also be obtained explicitly, as
| (A.14) |
It has the limits , and . The latter tells us how the prediction error decreases in the regime where is still small but larger than . The fit provided by the master curve (A.14) for different small values of is shown in figure 8 (left).
A.1.3 Crossover at .
Above we found different power law behaviours and scaling functions for and , thus a crossover must occur at . To see this, the two cases and can be analyzed as limit cases of a more general scaling ansatz that accounts explicitly for the effect of , i.e. the distance from the symmetric value . This becomes an additional critical parameter that enters the scaling functions in the combination
| (A.15) |
We define these scaling functions via
| (A.16) | |||||
| (A.17) | |||||
| (A.18) | |||||
| (A.19) |
We then find again while the master curve solves a fourth-order equation
| (A.20) |
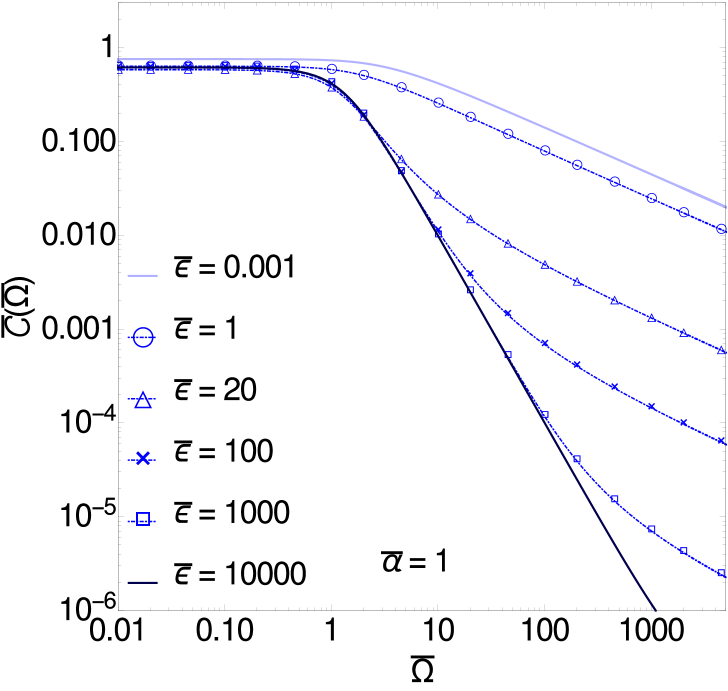
The solution of this for a range of different is plotted in figure 9 (left).
The two previous cases and (with ) are recovered as the limits respectively for and . In the first limit, and the rescaling relations (A.6), (A.7), (A.8) for are retrieved as they should be; accordingly, the equation (A.20) for the master curve becomes exactly (A.9). On the other hand, when , and we recover the rescalings - adopted for ; in this case (A.20) reduces to
| (A.21) |
whose positive solution is given by (A.14).
A.2 Master curves for and
In this section we look at the scaling around the second critical region, and . At , we find the following power law scaling with of the amplitudes
| (A.22) | |||
| (A.23) | |||
| (A.24) |
Approaching from the other direction, , gives . At and , finally, one finds for small nonzero frequency that . Equating the three divergences above identifies a crossover frequency and similarly a characteristic value for . We thus define rescaled quantities again
| (A.25) | |||||
| (A.26) | |||||
| (A.27) | |||||
| (A.28) | |||||
| (A.29) |
Inserting into the system (3.2), taking and keeping only the leading terms one finds as the master curve for
| (A.30) |
with limits , and . From the latter one sees again the decrease of the inference error for increasing number of observations (while remaining in the regime studied here where is small, ). The master curve predictions for generic are compared to direct numerical evaluation of in figure 8 (right).
So far we had focussed on the end of the second critical region. As this region covers the entire range , however, one can also study the critical behaviour as for fixed . The crossover into this region can be seen by taking , where from (A.30). Including the prefactor from (A.25) and using (A.28) gives
| (A.31) |
This suggests that in general, for finite , will be . Generalizing this suggests the following scaling for small and
| (A.32) | |||||
| (A.33) | |||||
| (A.34) | |||||
| (A.35) |
with . By substitution into the system (3.2) and taking the limit one can then obtain explicit solutions for , , . In particular we find , similarly to the previous cases, while satisfies
| (A.36) |
In the limit where one retrieves the result (A.31) as required for consistency between the two scaling limits.
The result above is of interest for negative symmetry parameters . As one approaches the extreme case , i.e. close to antisymmetry, the critical at tends to zero. As a consequence, for finite , one has that the approach to the stability limit of the hidden dynamics corresponds to and is therefore captured by the master curve (A.36).
Appendix B Scaling analysis: timescales and amplitudes
B.1 Relaxation time for and
The relaxation time is defined in a mean-squared sense by (3.3) and can be rewritten in terms of the rescaled power spectrum as
| (B.1) |
We consider the dimensionless version of this typical timescale (3.4), , and analyze separately the vicinity of the two critical points. As is determined directly from the power spectrum, its scaling behaviour follows from that of . Explicitly, in terms of the dimensionless frequency , which for critical scaling is rescaled further to , one has
| (B.2) |
with .
B.1.1 .
The relaxation time is rescaled using (B.2) as
| (B.3) |
where is the solution of a system of two equations
| (B.4) |
which can be obtained by deriving from (A.9) one equation for and one for and using relations (B.2) and (B.3). For simplicity we have denoted and as and . From these two equations we note and , which implies for the power law (3.5).
B.1.2 .
B.1.3 Crossover at .
The relaxation time scalings above can be seen as limit cases of a more general scaling linked to the parameter . From the general master curve (A.20) we can derive the following system of two equations
| (B.7) |
where is shorthand for and for . Consistent with the role of discussed above, one can check that the limit for is precisely the system (B.4), while for (LABEL:mcebar0) becomes
| (B.8) |
Here the first equation agrees with (A.14) as it should. Solving for , one finds (B.6).
For generic , the rescaled relaxation time must then exhibit a crossover in its large power law behaviour, i.e. from to . This crossover takes place around ; see figure 10.
B.2 Relaxation time for and
We next consider the behaviour of the relaxation time in the second critical region. From the rescaled expression of (A.30) one has
| (B.9) |
and
| (B.10) |
with the limit giving (3.7).
B.3 Equal time posterior variance for and
Finally we look at the equal time posterior correlator given by (3.8) in the main text. Its critical scaling properties depend on whether the integral over that defines is dominated by small frequencies , where is the relevant frequency scale in the appropriate critical region, or by . One has the first case when the critical master curve for has an integrable tail towards large (scaled) frequencies, otherwise the second. This illustrates how the analysis in the frequency domain is important in determining the power scaling of .
B.3.1 .
B.3.2 .
Here the dominant contribution to the prediction error comes from , thus one has to evaluate the integral of the master curve (A.14). To do so we note from (A.10) that can be written in scaled form as
| (B.13) |
with . This function encodes the entire -dependence in the critical region. It has a finite limit for while for large it decays as as one can show by noting that the relevant frequencies in (A.14) are then . Using this asymptotic behaviour in (B.13) and substituting also the expressions for and from (A.12) and (A.13), respectively, one obtains
| (B.14) |
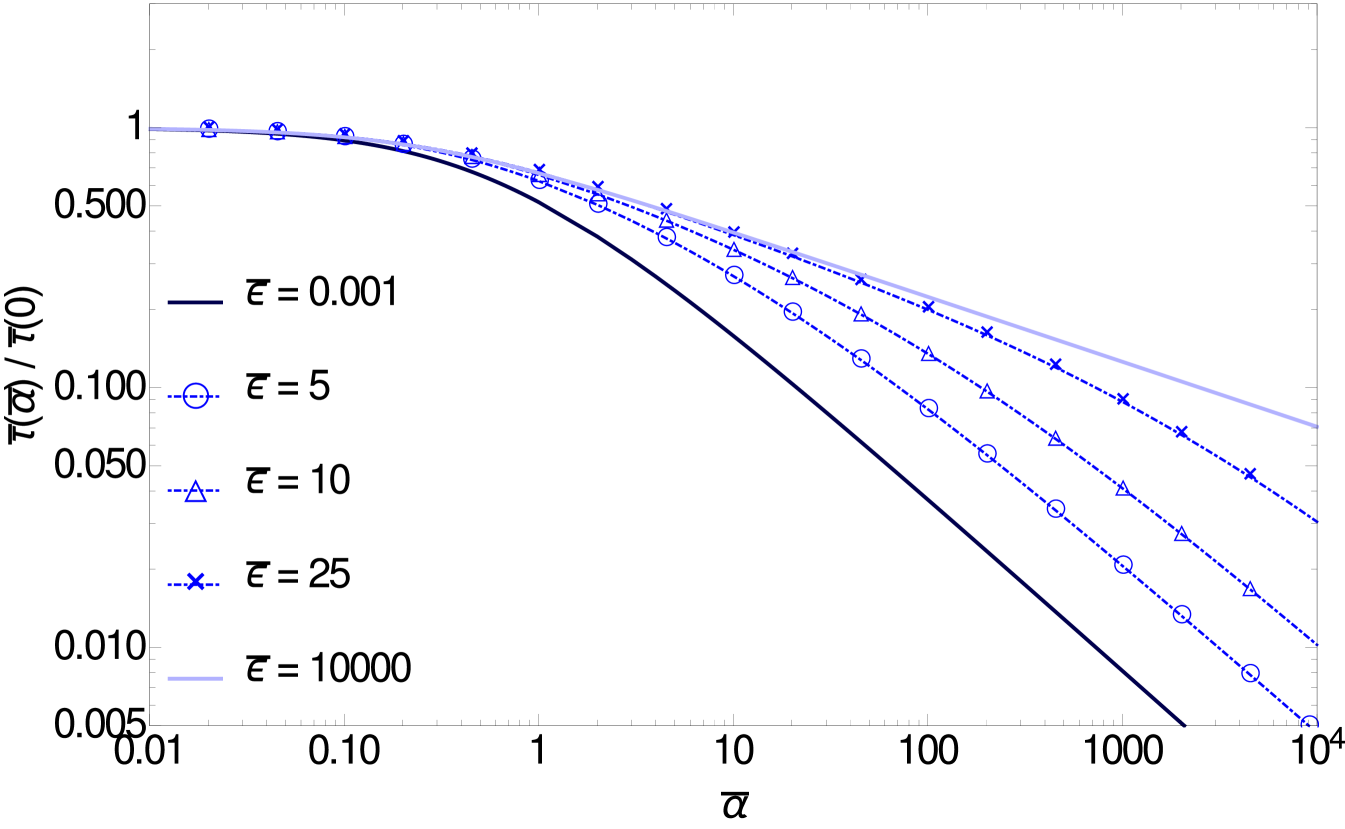
i.e. equation (3.9) in the main text. Thus one can derive , where corresponds to from (A.13).
B.4 Equal time posterior variance for and
In the second critical region and focussing on , we have an interesting marginal case where the equal-time variance (3.8) has contributions from all frequencies ranging from the critical frequency scale to . This is because the power spectrum (A.30) for critical frequencies has a tail for large , which gives a logarithmically divergent integral (3.8). This divergence is cut off only by the crossover to a Lorentzian tail when . Including the prefactor from (A.25), one thus estimates
| (B.15) |
The fraction in front of the integral equals unity as from (A.28) so from the tail one finds to leading order. All of the interesting dependence on is in the next subleading term, which is relevant in practice as it only competes with a logarithmic divergence. Writing as , this subleading term can be split off in the form
| (B.16) |
The remaining integral is convergent at the upper limit so we have taken the upper limit to infinity as is appropriate to get the leading contribution for . The integral is then a function of only, which one finds varies as for and as for .
Finally for the small end of this critical region, one should take the integral of the solution of (A.36). Here the only dependence on arises from (A.36) itself, and gives a smooth variation of with this parameter. Thus, independently of whether the integral determining the posterior variance is dominated by frequencies () or by frequencies in the vicinity of (), the result will also be a smooth function of .
References
References
- [1] Bachschmid-Romano L, Battistin C, Opper M and Roudi Y 2016 J. Phys. A: Math. Theor. 49 434003
- [2] Bachschmid-Romano L and Opper M 2014 J. Stat. Mech. P06013
- [3] Battistin C, Hertz J, Tyrcha J and Roudi Y 2015 J. Stat. Mech. P05021
- [4] Dunn B and Roudi Y 2013 Phys. Rev. E 87 022127
- [5] Bravi B and Sollich P 2016 Arxiv preprint 1603.05538
- [6] Bravi B, Sollich P and Opper M 2016 J. Phys. A: Math. Theor. 49 194003
- [7] Kalman R E 1960 J. Basic Eng. 82 35–45
- [8] Bishop C M 2006 Pattern Recognition and Machine Learning (Springer)
- [9] Bravi B, Opper M and Sollich P 2017 Phys. Rev. E 95 012122
- [10] Hertz J A, Krogh A and Thorbergsson G I 1989 J. Phys. A: Math. Gen. 22 2133–2150
- [11] Opper M 1989 Europhys. Lett. 8 389–392
- [12] Martin P, Siggia E and Rose H 1973 Phys. Rev. A 8 423–436
- [13] Janssen H K 1976 Z. Phys. B: Cond. Mat. 23 377–380
- [14] De Dominicis C 1978 Phys. Rev. B 18 4913–4919
- [15] Girko V L 1986 Theory Probab. Appl. 30 677–690
- [16] Plefka T 1982 J. Phys. A: Math. Gen. 15 1971–1978
- [17] Cardy J 1996 Scaling and Renormalization in Statistical Physics (Cambridge University Press)
- [18] Crisanti A and Sompolinsky H 1987 Phys. Rev. A 36 4922–4939
- [19] Cugliandolo L F, Kurchan J, Le Doussal P and Peliti L 1997 Phys. Rev. Lett. 78 350–353
- [20] Barra A, Genovese G, Sollich P and Tantari D 2017 Arxiv preprint 1702.05882
- [21] Krogh A 1992 J. Phys. A. Math. Gen. 25 1119–1133
- [22] Vrettas M, Opper M and Cornford D 2015 Phys. Rev. E 91 012148
- [23] Komorowski M, Costa M J, Rand D A and Stumpf M P H 2011 PNAS 108 8645–8650
- [24] Molinelli E J et al 2013 PLOS Computational Biology 9
- [25] Braunstein A, Pagnani A, Weigt M and Zecchina R 2008 J. Stat. Mech. P12001
- [26] McLachlan G J and Krishnan T 1997 The EM Algorithm and its Extensions (Wiley)
- [27] Bravi B 2016 Path integral approaches to subnetwork dynamics and inference Ph.D. thesis King’s College London