Cross-Network Social User Embedding with Hybrid Differential Privacy Guarantees
Abstract.
Integrating multiple online social networks (OSNs) has important implications for many downstream social mining tasks, such as user preference modelling, recommendation, and link prediction. However, it is unfortunately accompanied by growing privacy concerns about leaking sensitive user information. How to fully utilize the data from different online social networks while preserving user privacy remains largely unsolved. To this end, we propose a Cross-network Social User Embedding framework, namely DP-CroSUE, to learn the comprehensive representations of users in a privacy-preserving way. We jointly consider information from partially aligned social networks with differential privacy guarantees. In particular, for each heterogeneous social network, we first introduce a hybrid differential privacy notion to capture the variation of privacy expectations for heterogeneous data types. Next, to find user linkages across social networks, we make unsupervised user embedding-based alignment in which the user embeddings are achieved by the heterogeneous network embedding technology. To further enhance user embeddings, a novel cross-network GCN embedding model is designed to transfer knowledge across networks through those aligned users. Extensive experiments on three real-world datasets demonstrate that our approach makes a significant improvement on user interest prediction tasks as well as defending user attribute inference attacks from embedding.
1. Introduction
Social media-based user embedding plays an important role in user representation, user analysis and many downstream applications. Nowadays, to incorporate more information and get enhanced user embeddings, new technologies (Zhang et al., 2013; Yan et al., 2013, 2016; Zhang et al., 2017; Lin et al., 2019; Cui et al., 2021) which fuse and mine multiple social networks together show promising trends. However, this trend is now challenged by serious privacy concerns. Authors in (Kats, 2018) report that more than 80% US Internet users were worried about the usage of their personal data. Meanwhile, more rigorous regulations like EU’s GDPR111https://gdpr-info.eu are enacted to regulate the usage of personal information. For example, companies cannot share a user’s data without his/her consent. Henceforth, raw social networks which encode individual’s sensitive information (e.g., friendship, gender, occupation) should not be disclosed to others directly. This paper initiates the study on privacy-preserving social user embeddings across multiple online social networks (OSNs).
Nevertheless, the real-world scenarios are complex because OSNs contain different types of information, which are formulated as heterogeneous social networks (HSNs). To protect privacy, existing works use 1) various anonymization techniques and 2) differential privacy (DP) mechanisms. Since anonymization techniques, including -anonymity (Sweeney, 2002), -diversity (Machanavajjhala et al., 2007), -closeness (Li et al., 2007), etc, may be vulnerable to deanonymization attacks (Narayanan and Shmatikov, 2009) and lacking a rigorous theoretical guarantee, we adopt DP in our work. As a mathematically rigorous privacy-preserving framework, DP has been widely used to release social graphs (Sala et al., 2011; Wang and Wu, 2013; Lu and Miklau, 2014; Xiao et al., 2014; Nguyen et al., 2016; Liu et al., 2020b; Yang et al., 2021b; Jorgensen et al., 2016; Ji et al., 2019; Wang et al., 2021; Peng et al., 2021). Among them, the standard techniques (Sala et al., 2011; Wang and Wu, 2013; Lu and Miklau, 2014; Xiao et al., 2014; Nguyen et al., 2016; Liu et al., 2020b; Yang et al., 2021b) only consider to sanitize graph structure and ignore vertex attributes. The follow-up works (Ji et al., 2019; Jorgensen et al., 2016; Wang et al., 2021) make up for this deficiency and study releasing attributed graphs. However, they are limited to homogeneous graphs. Considering real-world social networks contain multiple types of information, and different types of information have different privacy protection expectations, how to publish HSNs with proper differential privacy guarantees remains an open challenge. In this work, we propose a hybrid DP mechanism to handle each kind of data independently.
Suppose we have multiple protected heterogeneous social networks under differential privacy protection, another challenging problem is how to integrate them together to generate more comprehensive user representations. Obviously, two key issues in network fusion are user linkage and cross-network information transferring. Prior user linkage methods can be divided into 1) user attribute-based ones and 2) embedding-based ones. Attribute-based methods such as (Andreou et al., 2017; Buraya et al., 2017; Chen et al., 2012; Yao et al., 2021) aim to link the same user across different OSNs through the comparison of real user information. However, those perturbed social networks no longer contain accurate information. Thus, attribute-based methods will fail. Embedding-based alignment methods (Liu et al., 2016; Man et al., 2016; Lample et al., 2018; Chu et al., 2019; Liang et al., 2021) have gained lots of attention in recent years. It is worth noting that those perturbed networks still preserve important characteristics of the original ones. Therefore, if embedding-based methods are trained to capture essential characteristics (Ma et al., 2022), they are still able to learn important semantics and achieve alignment. As such, we adopt embedding-based methods in our framework to find user linkages. To further leverage multi-source data for improving cross-network analysis, a series of works (Zhang et al., 2013; Yan et al., 2013, 2016; Zhang et al., 2017; Lin et al., 2019; Liu et al., 2021; Xu et al., 2021; Che et al., 2022; Chen et al., 2020; Yang et al., 2021a) have made great success in applications such as user profile modelling, social recommendation and so on. However, as mentioned before, most of them have ignored the privacy leakage problem. To sum up, how to support social network integration with proper user privacy protection is an important yet under-explored problem.
To achieve privacy-preserving social network integration for improving social user embeddings, we propose a novel framework, called DP-CroSUE. Particularly, we perturb those heterogeneous social networks before data exchange to protect users’ privacy. There are various sensitive data types in the social network, including graph topological data (user friendship), multi-dimensional numerical and categorical data (user attributes like age and gender), and text data (the posts), where each data has different privacy expectations. We introduce a hybrid differential privacy mechanism to generate proper perturbations. Our mechanism ensures data utility while preserving necessary privacy. To find user linkages across networks for further integration, we apply generative adversarial networks (GANs) to conduct unsupervised user alignment. Finally, a novel cross-network GCN embedding model including inter-graph propagation and hierarchy intra-graph propagation is proposed to transfer information both inside and across networks. We evaluate DP-CroSUE on three real-world social network platforms considering the embedding usefulness for user interest prediction tasks and its ability to resist two user attribute inference attacks: gender inference and occupation inference. Noted that the DP-CroSUE framework can also be generalized to other tasks like recommendation. We mainly focus on user interest prediction tasks for illustration purpose in this paper. Experimental results indicate that DP-CroSUE makes a good balance in both user feature utility and user privacy protection. The source code and data are available at GitHub222https://github.com/RingBDStack/DP-CroSUE.
Our contributions are three-fold: 1) We propose DP-CroSUE, the first attempt to integrate multiple HSNs for comprehensive social user embeddings with a hybrid differential privacy guarantee. Our approach demonstrates a competitive trade-off between user feature utility and user privacy protection. 2) We introduce a hybrid differential privacy mechanism capturing the variation of privacy expectations for heterogeneous social graphs. 3) We propose a novel cross-network GCN embedding model including inter-graph propagation and hierarchy intra-graph propagation to transfer information both inside and across social networks to make complete information integration.
2. Related Work
Differential Privacy. DP (Dwork et al., 2006) has been widely used for privacy-preserving statistical analysis. The intuition behind it is to randomise the output to ensure that the presence of any individual in the input has a negligible impact on the probability of any particular output. Earlier DP mechanisms such as Laplace mechanism and Exponential mechanism are proposed to protect single numerical (Dwork et al., 2006; Ding et al., 2017) and categorical (Erlingsson et al., 2014; Wang et al., 2017) data. Whereas recently, mechanisms have been developed for different data types and domains (Zhou et al., 2020; Truex et al., 2020; Feyisetan et al., 2019, 2020; Lyu et al., 2020a, b). For example, authors in (Truex et al., 2020) extend original methods to handle multi-dimensional data. In the NLP domain, a few works directly inject high-dimensional DP noise into text representations (Feyisetan et al., 2019, 2020; Lyu et al., 2020a, b). However, due to “the curse of dimensionality”, they fail to strike a nice privacy-utility balance. Authors in (Yue et al., 2021) solve this problem by sampling a close word substitute to ensure utility. In the social network domain, a series of works (Sala et al., 2011; Wang and Wu, 2013; Lu and Miklau, 2014; Xiao et al., 2014; Yang et al., 2021b) have been proposed to protect graph structure. They focus on edge-DP and protect graph topologies only. The follow-up works (Jorgensen et al., 2016; Ji et al., 2019) cover this shortage by taking users’ attributes into account. However, they only consider the homogeneous networks. How to perturb heterogeneous social networks is not covered in the literature.
User Linkage and Social Network Integration. User linkage (Narayanan and Shmatikov, 2010), also known as social network alignment, has been an important issue to make further utilization of social network data. Existing works (Andreou et al., 2017; Buraya et al., 2017; Chen et al., 2012) make alignments by carefully comparing the user attributes. These solutions are now challenged by privacy concerns about the disclosure of sensitive user attributes. Recently, authors in (Yao et al., 2021) make the first attempt to study privacy-preserving user linkage across multiple OSNs. However, it still needs some user ”volunteers” whose linkages are known in advance. In recent years, embedding-based alignment methods (Liu et al., 2016; Man et al., 2016; Lample et al., 2018; Chu et al., 2019; Liang et al., 2021) have achieved great success in finding anchor users across two or more social networks, which gives opportunities to make social network integration. Meanwhile, the cross-network results have been proved to enhance various social network applications. For example, some works (Cao and Yu, 2017; Lim et al., 2015; Jiang et al., 2016; Ren et al., 2020) fuse different social networks to provide a better understanding of users’ interests and behaviours.
3. Terminology definition and problem formulation
3.1. Definitions
Differential Privacy (Dwork et al., 2006) has emerged as a strong privacy definition for statistical data release with the intuition that a randomized algorithm behaves similarly on neighbouring datasets.
Definition 3.1.
(-DP (Duchi et al., 2013)) For any , a randomized mechanism satisfies -DP if for any two inputs in the domain of , and for any output of , we have:
| (1) |
where represents probability, corresponds to privacy budget. Smaller asserts a better privacy protection but lower data utility.
Noted that early DP is oriented toward structured data. For the protection of graph data, the notion of -edge-DP is proposed.
Definition 3.2.
(-Edge-DP (Blocki et al., 2012)) For any , a randomized mechanism satisfies -Edge-DP if for any two neighbouring graphs , which differ by at most one edge, and for any output of range(), we have:
| (2) |
Being a very strong privacy notion, -DP, however, is unsuitable to protect text privacy with utility (Yue et al., 2021). Because under -DP protection, a word will be transformed to any other words with equal probabilities, no matter how unrelated they are. Thus a sanitized token may not capture the semantics. The relaxed notion of Metric DP (MDP) can address this problem.
Definition 3.3.
(MDP (Alvim et al., 2018)) Given and a distance metric , a randomized mechanism satisfies MDP if for two inputs in the domain of , and for any output of , we have:
| (3) |
For MDP, the indistinguishability of output distributions is further controlled by the corresponding distance between the inputs, and the metric needs to be defined according to the specific application. Considering different characteristics and privacy expectations of heterogeneous social networks, we introduce a novel hybrid-DP notion which preserves various graph properties through carefully designing the injected noise.
Definition 3.4.
(Hybrid-DP) Given for attribute feature, for graph edge, for textual data, and a distance metric , suppose there are two neighbouring heterogeneous social graphs and which differ in one user node’s attribute vector, the presence of a single edge and one post, a randomized mechanism satisfies hybrid-DP if for any output of , we have:
| (4) |
where and represent the textual data (posts) in the graphs.
3.2. Problem Formulation
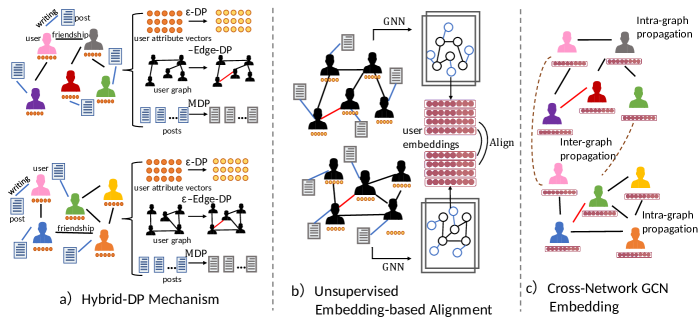
Generally, each online social network can be represented as a heterogeneous graph. In particular, as shown in Figure 1, we map every single network to a heterogeneous network containing two types of nodes: (i) users ; (ii) textual posts written by users, and two types of edge relationships: (i) friendship (user-user) and (ii) writing (user-post). The user-type nodes have their respective multi-dimensional user attribute features .
The problem of DP-CroSUE is to obtain more comprehensive representations of social users by combining multiple HSNs together without raw data leakage. Formally, this problem can be divided as follows: 1) Heterogeneous social graph protection with hybrid differential privacy guarantees: Given a social network company’s data which can be represented as a heterogeneous network , we need to design a hybrid randomized mechanism : by fully considering the different characteristics and privacy expectations of different data types. That is to say, for each data type, we should adopt the proper DP notion and set a proper privacy budget. 2) Cross-network information transferring: Given two protected social networks and , to transfer knowledge across these two networks, a set of anchor users need to be found. Next, with those anchor pairs working as a ”bridge”, we need to design a transferring architecture which propagates information across and within these two networks effectively.
4. Model
In this section, we describe DP-CroSUE in detail. The whole framework is shown in Figure 1.
4.1. Hybrid-DP Mechanism
As mentioned in Section 3.2, we consider privacy protection of three types of sensitive information in heterogeneous social networks - user attribute features, user friendship relationships and posts written by users. They correspond to three data formats respectively: multidimensional numerical and categorical data, graph edge data and textual data. Given the different characteristics of different data formats and users’ heterogeneous privacy expectations, treating all the data types as equally sensitive will add too much unneeded noise and sacrifice utility. For example, the strict notion applied in text data will totally change the original semantics and result in low utility. Besides, the contributions of a user’s attribute information, the numerous posts he/she has posted and the friendship relations to the final prediction tasks and information leakage differ a lot. Thus, a hybrid differential privacy mechanism which carefully designs the injected noise is highly needed. Specifically, we adopt -DP, -Edge-DP and MDP for attribute data, graph edge data and textual data respectively. Meanwhile, we also give insights into allocating proper privacy budgets.
We first introduce the three strategies for different data formats. To protect user attributes, we directly inject noise to the user attribute vector containing both numerical and categorical features. The extended PM algorithm proposed in (Zhang et al., 2021) is adopted. According to the proof in (Zhang et al., 2021), it satisfies -DP. For the protection of user friendship relations, we extract the homogeneous user graph and enforce edge-DP to it. Specifically, we adopt TmF (Nguyen et al., 2015) algorithm, which first computes a new, noisy number of graph edges, then utilizes a filter to decide whether the original edge should be preserved or not. As proved in (Nguyen et al., 2015), TmF satisfies -Edge-DP.
To protect text with utility, we develop a sanitation mechanism with a MDP guarantee. First, we inject each word in the corpus to an embedding. We denote the injection function , which can be any of the well-known word embedding algorithms (e.g., Word2Vec (Mikolov et al., 2013), GloVe (Pennington et al., 2014), or FastText (Bojanowski et al., 2017)). Here we select Word2Vec(Mikolov et al., 2013). For any two words and , we define their distance , where represents the Euclidean distance. To achieve MDP, for each word , we run the randomized mechanism to sample a sanitized with probability:
| (5) |
Theorem 4.1.
Given and a distance metric , the randomized mechanism depicted in Eq. 5 satisfies MDP.
Proof of Theorem 4.1. Consider a sentence only having one word ¡¿, another sentence which is ¡¿ (), and a possible output . We set .
| (6) |
We now analyze the overall differential privacy guarantee by combining all the above three information perturbations. We have the following theorem:
Theorem 4.2.
Assume that we independently adopt the three perturbation algorithms described above and the attribute feature, graph edge, and textual data satisfy -DP, -Edge-DP, and -MDP, respectively. This hybrid perturbation mechanism satisfies our hybrid-DP notion defined in Definition 3.4.
Proof of Theorem 4.2. We assume the three kinds of data in the heterogeneous graph are independent and denote the three perturbation mechanisms for user attributes, graph structure and user posts as , , , respectively. Meanwhile, we utilize , and to represent the attribute features, graph structure and posts alone. , and are the corresponding neighbouring datasets for each data type. Noted that the hybrid-DP mechanism is the combination of the three randomized mechanisms mentioned above and denotes the whole perturbed heterogeneous social network. Since the attribute part, graph edge part and textual part satisfies -DP, -Edge-DP and MDP, respectively, we have:
| (7) |
Note that these three perturbation strategies are designed according to the characteristics of different data formats. Additionally, how to set privacy budgets (, and ) to achieve proper privacy levels as well as utility for heterogeneous graph properties is also challenging. We solve this by referring to the Task-relevance to Message-inference Ratio (TMR). The intuition behind is that less noise being injected into the extracted data type which is more relevant to the target task will bring out more utility. Meanwhile, more noise should be injected into those data types causing accurate personal message inference to satisfy privacy. In this work, we leverage the precision score obtained through a single piece of information in the interest prediction task to measure task relevance and use the sum of precision scores in inference attacks as the message-inference value. Since larger privacy budget means less injected noise, we set larger for data with high TMR values. More details can be seen in Section 5.2.
| Dataset | Network | Nodes | Relationships | |||
| #(Users) | #(Anchor Users) | #(Posts) | #(friendship) | #(write) | ||
| Foursquare-Twitter | Foursquare | 5392 | 3388 | 48756 | 76972 | 48756 |
| 5223 | 615,515 | 164,920 | 615,515 | |||
| Sub-weibo1 | 8117 | 2969 | 158,823 | 12000 | 158,823 | |
| Sub-weibo2 | 8539 | 153,741 | 12000 | 153,741 | ||
4.2. Embedding-based Social User Alignment
We leverage embedding-based alignment methods to find anchor user linkages, which is divided into two procedures: 1) heterogeneous social network embedding learning and 2) unsupervised user linkage prediction.
To fully encode all kinds of information in the perturbed heterogeneous social network , we adopt relation-specific transformations and the propagation function is:
| (8) |
where is the updated representation in the -th layer. represents the set of one-hop neighbor indices of node under relation and . Suppose the final user embedding is (), the loss function can be expressed as:
| (9) |
where is the one-hop neighbours of . defines negative sampling distribution of user nodes. is the number of negative samples.
Next, we leverage the obtained social user embeddings and to make the alignment. As the spaces of and are learnt independently, we need to learn the matrix such that to reconcile them. Here the source network is and the target one is . We get by Generative Adversarial Networks (GANs), where the generator learns the transformation matrix , ensuring that the transformed approximates as closely as possible. The discriminator tries to classify whether the embeddings are real or those transformed ones. When is trained well, we utilize the similarity measure CSLS proposed in (Lample et al., 2018) to find equivalent users.
| data | Foursquare | Sub-Weibo1 | Sub-Weibo2 | |
| attribute | 0.287 | 0.274 | 0.118 | 0.144 |
| friendship | 0.743 | 0.665 | 0.225 | 0.249 |
| posts | 0.645 | 0.537 | 0.207 | 0.222 |
4.3. Cross-network GCN Embedding Model
After finding anchor users, we further integrate the partially aligned homogeneous user networks and . To integrate them together, we propose a novel cross-network GCN embedding model, which is composed by an inter-graph propagation layer and a hierarchy intra-graph propagation layer.
inter-graph propagation layer: We first update those aligned user nodes in both networks by fusing their information together. Considering the existing network disparity of and , we leverage transformation matrices and to project embeddings into the other network space. For example, is used to project users of into the space of . Suppose two social users and are aligned, the representations of them after inter-graph propagation are:
| (10) |
where denotes the activation function.
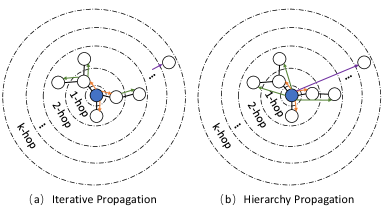
hierarchy intra-graph propagation layer: We set the two user embeddings and with those aligned users getting updated through inter-graph propagation, while others are still the initial representations learned by GNN model. Now those anchor users’ representations contain knowledge from both networks. Considering the number of anchor users is limited, propagating the cross-graph information from those aligned users to the entire graph needs more hops. Considering the over-fitting and over-smoothing problems of GCN (Liu et al., 2020a), we leverage a hierarchy intra-graph propagation layer which emphasizes the role of anchor users and directly transfers information to nodes within -hop range. Suppose and are the normalized adjacency matrices of the two user networks, and and are the diagonal matrices with the positions of anchors being set to one while others are zeroes, the propagation function is:
| (11) |
To show the difference between the original iterative propagation layer in GCN and our hierarchy one clearly, we depict their propagation processes in Figure 2. As shown in Figure 2(a), for the iterative architecture, it needs transformations to transfer the carrying knowledge in the anchor user to its -hop neighbours. For example, the forward propagation process of iterative architecture in is formulated as . Obviously, when becomes large, there will be too many transformation parameters which will make the network difficult to train. Meanwhile, according to (Liu et al., 2020a), if we apply iterative architecture to a connected graph, when goes to infinity, nodes become indistinguishable. However, as for the hierarchy architecture, each anchor user can be transferred to other users inside -hops directly. It only needs one transformation thus the knowledge of anchor users will not be changed too much when they are transferred to distant users. Meanwhile, the emphasis of anchor users can further help transfer cross-network knowledge. By considering the information of multiple hops together, the hierarchy architecture has more capacities in capturing its local information compared to the iterative architecture, which helps make users distinguishable.
Objective Function: We jointly train these two networks together to integrate them. The loss includes three parts: the graph-based losses and computed as per Eq. 9, and the hard alignment regularization which measures the anchor nodes’ representation distance in the two networks to regularize the output representation spaces. Overall, the total loss is:
| (12) |
5. Experiments
In this section, we evaluate DP-CroSUE on both user interest prediction capacities and privacy protection strength. Specifically, we aim to answer the following questions: Q1: Compared with undisturbed single network knowledge, can the cross-network results of DP-CroSUE get improved in user interest prediction tasks? Q2: Can DP-CroSUE effectively protect sensitive user attribute information? Q3: How does each part of the perturbation paradigm of different information affect the accuracy of user interest prediction and the privacy-preserving property of DP-CroSUE? Q4: How does the novel cross-network GCN embedding model perform?
5.1. Datasets
We select three online social platforms: Foursquare, Twitter and Weibo, and make two partially-aligned dataset pairs. One is the Foursquare-Twitter pair from (Zhang et al., 2017). For the other, we crawled the Weibo platform and divided it into two sub-networks containing a part of sharing users. We manually labelled users from 10 possible interest categories according to their biographies and posts, including: (1) travel; (2) art; (3) health; (4) food; (5) technology; (6) sports; (7) business; (8) politics; (9) game; (10) fashion. Each user may be classified into multiple interests (multi-label classification). Table 1 shows the detailed statistical information about these datasets. The corresponding user attribute information extracted form the datasets are: (1) user screen name (We decompose the name into sub-string sets and convert them into numerical values using SimHash (Sadowski and Levin, 2007).), (2) number of followers, (3) number of followees, (4) number of posts, (5) gender, (6) occupation.
| Methods | Foursquare | Sub-Weibo1 | Sub-Weibo2 | |||||
| Precision | Micro-f1 | Precision | Micro-f1 | Precision | Micro-f1 | Precision | Micro-f1 | |
| Word2Vec (Mikolov et al., 2013) | 0.463±0.013 | 0.455±0.009 | 0.463±0.002 | 0.450±0.003 | 0.226±0.001 | 0.238±0.002 | 0.231±0.011 | 0.236±0.009 |
| SANTEXT (Yue et al., 2021) | 0.457±0.022 | 0.446±0.018 | 0.446±0.020 | 0.442±0.015 | 0.207±0.012 | 0.193±0.020 | 0.229±0.019 | 0.233±0.016 |
| DeepWalk (Perozzi et al., 2014) | 0.453±0.012 | 0.447±0.008 | 0.413±0.010 | 0.409±0.007 | 0.215±0.003 | 0.176±0.004 | 0.247±0.004 | 0.243±0.004 |
| SNE (Liao et al., 2018) | 0.509±0.006 | 0.511±0.005 | 0.554±0.007 | 0.547±0.007 | 0.249±0.012 | 0.238±0.011 | 0.275±0.003 | 0.274±0.002 |
| UDMF (Zhang et al., 2018) | 0.515±0.003 | 0.514±0.003 | 0.523±0.007 | 0.515±0.006 | 0.254±0.004 | 0.252±0.005 | 0.308±0.003 | 0.306±0.002 |
| R-GCN (Schlichtkrull et al., 2018) | 0.530±0.002 | 0.522±0.001 | 0.546±0.001 | 0.542±0.001 | 0.283±0.002 | 0.279±0.002 | 0.317±0.007 | 0.312±0.005 |
| DP-R-GCN | 0.514±0.001 | 0.510±0.002 | 0.534±0.004 | 0.532±0.003 | 0.235±0.001 | 0.230±0.002 | 0.271±0.006 | 0.270±0.005 |
| DP-CroSUE | 0.549±0.006 | 0.541±0.005 | 0.561±0.001 | 0.558±0.001 | 0.303±0.003 | 0.296±0.002 | 0.332±0.003 | 0.334±0.002 |
| CroSUE | 0.556±0.004 | 0.551±0.003 | 0.571±0.002 | 0.569±0.001 | 0.332±0.001 | 0.330±0.001 | 0.360±0.004 | 0.361±0.003 |
5.2. Baseline and Hyperparameter Setting
We compare DP-CroSUE with the following methods.
Single-view methods: In general, single-view methods can be divided into text-based ones and structure-based ones. We select Word2Vec (Mikolov et al., 2013), SANTEXT (Yue et al., 2021), and DeepWalk (Perozzi et al., 2014) as single-view baselines. Among them, Word2Vec maps a sequence of social media posts into a vector representation. SANTEXT gets text representations under differential privacy. DeepWalk learns the latent representations of users in the homogeneous user network.
Multi-view methods: For multi-view methods, we choose SNE (Liao et al., 2018), UDMF (Zhang et al., 2018) and R-GCN (Schlichtkrull et al., 2018) as multi-view baselines. SNE learns user representations by preserving both structural proximity and attribute proximity. UDMF is a novel hybrid DNN-based framework that fuses information across different modalities. R-GCN aggregates information on HSNs based on different relations.
Variants of DP-CroSUE: We utilize R-GCN and DP-R-GCN to observe the performances of single-network user embeddings obtained on the raw heterogeneous social networks and the perturbed ones, respectively. We also create a non-private model called CroSUE, which is a variant of DP-CroSUE deleting the Hybrid DP perturbation mechanism, to show the performance of the cross-network user embeddings without privacy protection.
In DP-CroSUE, to get the perturbed heterogeneous social graph, we set the privacy budget for user attribute feature perturbation, for user graph edge perturbation and for textual data perturbation. Our guidance is the TMR values as shown in Table 2. The TMR values of attribute information and textual information are obtained through the corresponding attribute features and sentence embeddings (i.e., averaging word embeddings (Mikolov et al., 2013)), respectively, while the TMR of friendship information is obtained through the features learnt by DeepWalk (Perozzi et al., 2014). To get initial user embeddings, we use a two-layer R-GCN. The first layer embedding dimension is 256 and the second embedding dimension is 128. For the cross-network GCN model, we set and in the hierarchy intra-graph propagation layer. The final embedding dimension is 128.
5.3. Evaluation Metrics
The evaluation metrics for user interest prediction and attribute inference attack are as follows:
User Interest Prediction. After getting the social user embeddings, we utilize the decision tree classifier to conduct multi-label user interest classification. We randomly pick 80% of data for training, while the rest 20% is for evaluation. To be more convincing, we report the mean and standard deviation of the results after repeating experiments for 5 times. The specific metrics we leverage to judge the quality are precision and micro- score.
Attribute Inference Attack. To evaluate all models’ robustness and capabilities in preserving sensitive user attribute information, we quantify the privacy leakage in social user embeddings through two inference attacks: gender inference and occupation inference. For gender inference, it is a binary classification problem. We use Logistic Regression as the attacker to make classification. For the occupation inference attack, we use the decision tree classifier to make classification. Similarly, we repeat the experiments for 5 times.
| Attribute | Methods | Foursquare | Sub-Weibo1 | Sub-Weibo2 | |||||
| Precision | Micro-f1 | Precision | Micro-f1 | Precision | Micro-f1 | Precision | Micro-f1 | ||
| Gender | Word2Vec (Mikolov et al., 2013) | 0.569±0.001 | 0.587±0.001 | 0.705±0.001 | 0.700±0.001 | 0.570±0.001 | 0.567±0.001 | 0.533±0.001 | 0.621±0.001 |
| SANTEXT (Yue et al., 2021) | 0.559±0.001 | 0.578±0.001 | 0.644±0.001 | 0.639±0.001 | 0.560±0.001 | 0.555±0.001 | 0.517±0.001 | 0.614±0.001 | |
| DeepWalk (Perozzi et al., 2014) | 0.508±0.001 | 0.510±0.001 | 0.501±0.001 | 0.509±0.002 | 0.506±0.001 | 0.517±0.001 | 0.498±0.001 | 0.583±0.001 | |
| SNE (Liao et al., 2018) | 0.615±0.001 | 0.624±0.001 | 0.682±0.001 | 0.684±0.001 | 0.590±0.001 | 0.591±0.001 | 0.549±0.001 | 0.647±0.001 | |
| UDMF (Zhang et al., 2018) | 0.995±0.001 | 0.995±0.001 | 0.999±0.001 | 0.999±0.001 | 0.999±0.001 | 0.999±0.001 | 0.998±0.001 | 0.998±0.001 | |
| R-GCN (Schlichtkrull et al., 2018) | 0.791±0.001 | 0.794±0.001 | 0.738±0.001 | 0.739±0.001 | 0.727±0.001 | 0.727±0.001 | 0.684±0.001 | 0.727±0.001 | |
| DP-R-GCN | 0.568±0.002 | 0.579±0.001 | 0.624±0.001 | 0.627±0.001 | 0.538±0.001 | 0.537±0.001 | 0.518±0.001 | 0.617±0.001 | |
| DP-CroSUE | 0.554±0.001 | 0.575±0.001 | 0.640±0.001 | 0.644±0.001 | 0.536±0.001 | 0.535±0.001 | 0.506±0.001 | 0.601±0.001 | |
| CroSUE | 0.655±0.001 | 0.644±0.001 | 0.703±0.001 | 0.704±0.001 | 0.649±0.001 | 0.649±0.001 | 0.611±0.001 | 0.674±0.001 | |
| Attribute | Methods | Precision | Micro-f1 | Precision | Micro-f1 | Precision | Micro-f1 | Precision | Micro-f1 |
| Occupation | Word2Vec (Mikolov et al., 2013) | 0.149±0.023 | 0.147±0.022 | 0.158±0.007 | 0.154±0.008 | 0.524±0.018 | 0.528±0.017 | 0.508±0.007 | 0.519±0.007 |
| SANTEXT (Yue et al., 2021) | 0.139±0.012 | 0.140±0.018 | 0.143±0.010 | 0.139±0.007 | 0.510±0.013 | 0.513±0.012 | 0.497±0.004 | 0.490±0.014 | |
| DeepWalk (Perozzi et al., 2014) | 0.102±0.016 | 0.098±0.015 | 0.120±0.003 | 0.118±0.005 | 0.450±0.001 | 0.462±0.001 | 0.495±0.023 | 0.484±0.028 | |
| SNE (Liao et al., 2018) | 0.187±0.019 | 0.176±0.018 | 0.165±0.012 | 0.156±0.011 | 0.527±0.006 | 0.529±0.007 | 0.520±0.008 | 0.520±0.006 | |
| UDMF (Zhang et al., 2018) | 0.702±0.016 | 0.707±0.017 | 0.938±0.001 | 0.954±0.001 | 0.963±0.002 | 0.974±0.002 | 0.912±0.008 | 0.934±0.011 | |
| R-GCN (Schlichtkrull et al., 2018) | 0.160±0.015 | 0.158±0.014 | 0.184±0.005 | 0.185±0.004 | 0.525±0.002 | 0.536±0.003 | 0.553±0.004 | 0.540±0.007 | |
| DP-R-GCN | 0.134±0.005 | 0.135±0.006 | 0.160±0.005 | 0.157±0.007 | 0.474±0.006 | 0.497±0.012 | 0.411±0.012 | 0.417±0.009 | |
| DP-CroSUE | 0.132±0.015 | 0.136±0.017 | 0.134±0.005 | 0.128±0.005 | 0.466±0.016 | 0.474±0.017 | 0.405±0.015 | 0.397±0.013 | |
| CroSUE | 0.150±0.014 | 0.155±0.012 | 0.198±0.005 | 0.194±0.003 | 0.539±0.003 | 0.543±0.002 | 0.488±0.015 | 0.482±0.014 | |
5.4. User Interest Prediction (Q1)
All models’ performances on predicting user interests are summarized in Table 3. DP-CroSUE outperforms all baselines and is only next to CroSUE, which is the same method using the unsanitized network data. Generally, single-view based embedding methods - DeepWalk, SANTEXT and Word2vec get the worst performances. Compared to single-view methods, SNE which incorporates structure and attributes together works better. It achieves maximum relative improvements of 14.1% in precision on Twitter compared to DeepWalk. Moreover, UDMF and R-GCN which incorporate more kinds of information perform even better than SNE on most datasets. For example, compared to SNE, R-GCN gets an improvement of 13.4% in precision on Sub-Weibo1. These observations demonstrate that incorporating more user information can help predict user interests. Compared with R-GCN, DP-R-GCN gets worse precision and Micro- score. This is reasonable because DP-R-GCN extracts user information from the perturbed heterogeneous social network. These methods mentioned above are all single-network methods. Obviously, the best single-network method is R-GCN applied in real social networks. As observed, DP-CroSUE consistently outperforms R-GCN on all the datasets. For example, the precision of DP-CroSUE is 2.0% higher than R-GCN on Sub-Weibo1 dataset. This indicates that DP-CroSUE, though operating on perturbed networks for the purpose of information protection, can achieve satisfactory results. In addition, CroSUE achieves the best performance. This further confirms the effectiveness of fusing networks together. However, since CroSUE works directly on real social networks, it faces user information leakage problems.
5.5. Attribute Inference Attacks (Q2)
Table 4 shows the results of the attribute inference attack models depicted in Section 5.3 on all the datasets. Note that lower scores show higher resistance to inference attacks. As shown in Table 4, all baselines operating on real social networks except for DeepWalk achieve high precision and Micro- score in attribute inference attacks. For example, the precision scores of DeepWalk on all datasets are nearly 50.0%. That means DeepWalk has no ability to infer user’s gender. This is predictable as DeepWalk only extracts network structure information but does not involve user personal attribute features at all. It is also worth noting that DP-CroSUE can achieve the second or third best results on almost all datasets. Given that DeepWalk does not have a chance to learn user attribute features during training, the result that DP-CroSUE is only worse than DeepWalk highly validates the capability of DP-CroSUE in private attribute protection. Meanwhile, the better performance of DP-R-GCN compared to R-GCN also indicates the effectiveness of our hybrid DP mechanism. For example, compared to R-GCN, the precision of DP-R-GCN drops significantly on Foursquare dataset in both gender inference and occupation inference (22.3% and 2.6% reduction). In addition, we noticed that DP-CroSUE, which incorporates information from two perturbed networks, performs even better in resisting attribute inference attacks than DP-R-GCN on most datasets. The reason is that if a user’s attribute is disturbed into fake in one network, but remains true in another, linking these two nodes may result in both being inferred to false. This further shows the superiority of DP-CroSUE in privacy protection.
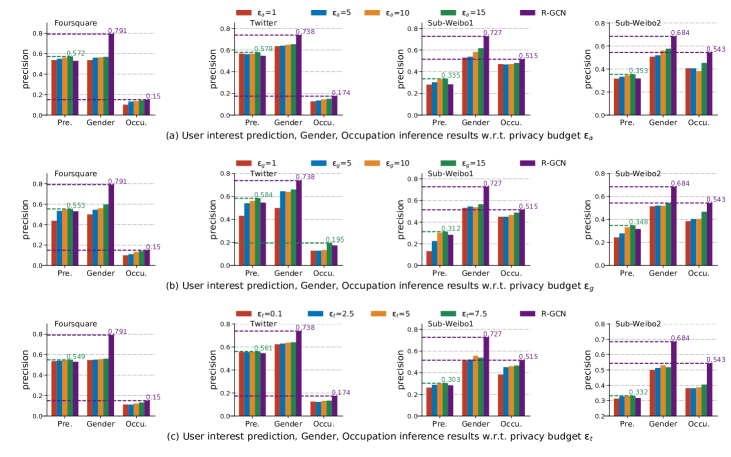
5.6. Accuracy and Privacy (Q3)
To investigate how does each part of the perturbation paradigm of DP-CroSUE affect its performance on user interest prediction and privacy protection, we independently vary the privacy budget , and , and report the new results in Figure 3.
Impact of user attribute perturbation privacy budget . We vary the privacy budget . The results are shown in Figure 3(a). In general, for all the datasets, the results of user interest prediction get improvement with the increase of . Because larger means less privacy thus more accurate user attributes, which helps predict user interests. For example, if we know a user is a woman, she may be more interested in fashion compared to a man. Meanwhile, for all the we selected, DP-CroSUE consistently outperforms R-GCN in terms of user interest prediction. This further confirms the effectiveness of our model. As for the privacy protection capabilities, larger , negatively influences the privacy protection results. Because more accurate user attributes are encoded into the final user representations. However, the gender and occupation information still can be effectively protected even when is set to a large value. From Figure 3(a), even when is set to 15, the precision scores of attribute inference attacks are lower than R-GCN. Our analysis is that by aligning and aggregating two perturbed datasets together, user’s gender and occupation information may be further masked. Since if a user’s gender or occupation is perturbed into fake in one network with the user attribute perturbation algorithm, his/her attribute in the other network may also be influenced. All the above results validate the superiority of DP-CroSUE in privacy protection.
Impact of user edge perturbation privacy budget . We choose the value of from and plot the results in Figure 3(b). Similarly, larger results in better user interest prediction performance. However, the prediction precision degrades significantly when the privacy budget is small. For example, when , the precision is even lower than R-GCN. As we know, the nature of GCN is smoothing - making connected nodes similar. Real social networks have the homophily property. People tend to follow those who have similar interests with them. If we inject a large amount of noise into the network structure, the homophily level of the graph will be impacted. Thus user prediction results will decrease while the user information can be better protected. In this way, we should choose a proper to achieve a good trade-off between privacy protection and recommendation accuracy.
Impact of user text perturbation privacy budget . We study the impact of privacy budget in text perturbation with . As we can see from Figure 3(c), in general, larger brings higher user interest prediction precision. Meanwhile, we find that the improvement is relatively slow with the increase of . The reason behind is the high utility property of the relaxed MDP notion applied in the textual data perturbation algorithm. Even when privacy budget is comparably small, with the computed substitution words, the original semantics may still be kept. Thus the user interest prediction performance can be guaranteed. What’s more, it is worth noting that the perturbation of user text effectively preserves user attribute information compared to R-GCN. Since users may declare their gender and occupation in the original posts, substituting the original words can prevent information leakage effectively. For example, the word ”girl” may be substituted by the word ”boy”.
To sum up, to make a good trade-off of interest prediction tasks and privacy protection, we recommend a comparably small attribute privacy budget, and comparably large edge and text privacy budgets. A good budget setting can be: and . The total privacy budget is .
5.7. Ablation Study (Q4)
To study the performance of the novel cross-network GCN embedding model in network integration and user interests prediction, we evaluate different degraded model versions and record the precision scores in Table 5. For convenience, we denote the original cross-network GCN model introduced in Section 4.3 as CroGCN. We create CroGCN-NH by replacing the hierarchy intra-graph propagation layer with iterative propagation layers like standard GCN model. Besides, we also remove the hard alignment regularization and denote the new version as CroGCN-NA. As shown in Table 5, on all the datasets, CroGCN gets highest user interest prediction scores. The better performance of CroGCN compared with CroGCN-NH demonstrates the superiority of the hierarchy intra-graph propagation layer in transferring knowledge to the whole network. Meanwhile, the worse performance of CroGCN-NA also proves the importance of the hard alignment regularization.
| Methods | Foursquare | Sub-Weibo1 | Sub-Weibo2 | |
| CroGCN-NH | 0.539±0.006 | 0.543±0.002 | 0.298±0.006 | 0.325±0.009 |
| CroGCN-NA | 0.538±0.009 | 0.545±0.004 | 0.291±0.005 | 0.322±0.008 |
| CroGCN | 0.549±0.006 | 0.561±0.001 | 0.303±0.003 | 0.332±0.003 |
6. Conclusion
In this work, we propose DP-CroSUE, which obtains privacy-preserving cross-network social user embeddings. DP-CroSUE perturbs users’ different information including attribute features, friendship relations and user posts through a hybrid-DP mechanism to allow further data sharing. Next, through embedding-based alignment, anchor nodes can be found and different social networks can be learnt jointly in a pairwise manner without knowing the real user information. Extensive experiments demonstrate that DP-CroSUE simultaneously guards users against personal attribute inference attacks and maintain great utility in interest prediction tasks. Noted that DP-CroSUE can be easily generalized to other tasks like recommendation, exploitation on other tasks is left to future works.
Acknowledgements.
The authors of this paper were supported by the National Key R&D Program of China through grant 2021YFB1714800, NSFC through grant U20B2053, S&T Program of Hebei through grant 21340301D, Beijing Natural Science Foundation through grant 4222030, and the Fundamental Research Funds for the Central Universities. Philip S. Yu was supported by NSF under grants III-1763325, III-1909323, III-2106758, and SaTC-1930941. Thanks for computing infrastructure provided by Huawei MindSpore platform. For any correspondence, please refer to Lei Jiang and Hao Peng.References
- (1)
- Alvim et al. (2018) Mário Alvim, Konstantinos Chatzikokolakis, Catuscia Palamidessi, and Anna Pazii. 2018. Local differential privacy on metric spaces: optimizing the trade-off with utility. In CSF. IEEE, 262–267.
- Andreou et al. (2017) Athanasios Andreou, Oana Goga, and Patrick Loiseau. 2017. Identity vs. attribute disclosure risks for users with multiple social profiles. In ASONAM. 163–170.
- Blocki et al. (2012) Jeremiah Blocki, Avrim Blum, Anupam Datta, and Or Sheffet. 2012. The johnson-lindenstrauss transform itself preserves differential privacy. In SFCS. IEEE, 410–419.
- Bojanowski et al. (2017) Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. Enriching word vectors with subword information. TACL 5 (2017), 135–146.
- Buraya et al. (2017) Kseniya Buraya, Aleksandr Farseev, Andrey Filchenkov, and Tat-Seng Chua. 2017. Towards user personality profiling from multiple social networks. In AAAI. 4909–4910.
- Cao and Yu (2017) Xuezhi Cao and Yong Yu. 2017. Joint User Modeling Across Aligned Heterogeneous Sites Using Neural Networks. In ECML-PKDD. Springer, 799–815.
- Che et al. (2022) Sicong Che, Zhaoming Kong, Hao Peng, Lichao Sun, Alex Leow, Yong Chen, and Lifang He. 2022. Federated multi-view learning for private medical data integration and analysis. ACM TIST 13, 4 (2022), 1–23.
- Chen et al. (2020) Chaochao Chen, Jamie Cui, Guanfeng Liu, Jia Wu, and Li Wang. 2020. Survey and open problems in privacy preserving knowledge graph: Merging, query, representation, completion and applications. arXiv preprint arXiv:2011.10180 (2020).
- Chen et al. (2012) Terence Chen, Mohamed Ali Kaafar, Arik Friedman, and Roksana Boreli. 2012. Is more always merrier? A deep dive into online social footprints. In WOSN. 67–72.
- Chu et al. (2019) Xiaokai Chu, Xinxin Fan, Di Yao, Zhihua Zhu, Jianhui Huang, and Jingping Bi. 2019. Cross-network embedding for multi-network alignment. In WWW. 273–284.
- Cui et al. (2021) Jinming Cui, Chaochao Chen, Lingjuan Lyu, Carl Yang, and Wang Li. 2021. Exploiting Data Sparsity in Secure Cross-Platform Social Recommendation. NIPS 34 (2021).
- Ding et al. (2017) Bolin Ding, Janardhan Kulkarni, and Sergey Yekhanin. 2017. Collecting telemetry data privately. NIPS 30 (2017).
- Duchi et al. (2013) John C Duchi, Michael I Jordan, and Martin J Wainwright. 2013. Local privacy and statistical minimax rates. In FOCS. IEEE, 429–438.
- Dwork et al. (2006) Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. Calibrating noise to sensitivity in private data analysis. In TCC. Springer, 265–284.
- Erlingsson et al. (2014) Úlfar Erlingsson, Vasyl Pihur, and Aleksandra Korolova. 2014. Rappor: Randomized aggregatable privacy-preserving ordinal response. In SIGSAC. 1054–1067.
- Feyisetan et al. (2020) Oluwaseyi Feyisetan, Borja Balle, Thomas Drake, and Tom Diethe. 2020. Privacy-and utility-preserving textual analysis via calibrated multivariate perturbations. In WSDM. 178–186.
- Feyisetan et al. (2019) Oluwaseyi Feyisetan, Tom Diethe, and Thomas Drake. 2019. Leveraging hierarchical representations for preserving privacy and utility in text. In ICDM. IEEE, 210–219.
- Ji et al. (2019) Tianxi Ji, Changqing Luo, Yifan Guo, Jinlong Ji, Weixian Liao, and Pan Li. 2019. Differentially private community detection in attributed social networks. In ACML. PMLR, 16–31.
- Jiang et al. (2016) Meng Jiang, Peng Cui, Nicholas Jing Yuan, Xing Xie, and Shiqiang Yang. 2016. Little Is Much: Bridging Cross-Platform Behaviors through Overlapped Crowds. In AAAI, Vol. 30.
- Jorgensen et al. (2016) Zach Jorgensen, Ting Yu, and Graham Cormode. 2016. Publishing attributed social graphs with formal privacy guarantees. In SIGMOD. 107–122.
- Kats (2018) Rimma Kats. 2018. Many Facebook Users Are Sharing Less Content. Recuperado de https://www. emarketer. com/content/many-facebook-users-are-sharing-less-content-because-of-privacy-concerns (2018).
- Lample et al. (2018) Guillaume Lample, Alexis Conneau, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2018. Word translation without parallel data. In ICLR.
- Li et al. (2007) Ninghui Li, Tiancheng Li, and Suresh Venkatasubramanian. 2007. t-closeness: Privacy beyond k-anonymity and l-diversity. In ICDE. IEEE, 106–115.
- Liang et al. (2021) Zhehan Liang, Yu Rong, Chenxin Li, Yunlong Zhang, Yue Huang, Tingyang Xu, Xinghao Ding, and Junzhou Huang. 2021. Unsupervised Large-Scale Social Network Alignment via Cross Network Embedding. In CIKM. 1008–1017.
- Liao et al. (2018) Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua. 2018. Attributed social network embedding. TKDE 30, 12 (2018), 2257–2270.
- Lim et al. (2015) Bang Hui Lim, Dongyuan Lu, Tao Chen, and Min-Yen Kan. 2015. # mytweet via instagram: Exploring user behaviour across multiple social networks. In ASONAM. IEEE, 113–120.
- Lin et al. (2019) Tzu-Heng Lin, Chen Gao, and Yong Li. 2019. Cross: Cross-platform recommendation for social e-commerce. In SIGIR. 515–524.
- Liu et al. (2016) Li Liu, William K Cheung, Xin Li, and Lejian Liao. 2016. Aligning Users across Social Networks Using Network Embedding.. In IJCAI. 1774–1780.
- Liu et al. (2020a) Meng Liu, Hongyang Gao, and Shuiwang Ji. 2020a. Towards deeper graph neural networks. In SIGKDD. 338–348.
- Liu et al. (2020b) Peng Liu, YuanXin Xu, Quan Jiang, Yuwei Tang, Yameng Guo, Li-e Wang, and Xianxian Li. 2020b. Local differential privacy for social network publishing. Neurocomputing 391 (2020), 273–279.
- Liu et al. (2021) Zhiwei Liu, Liangwei Yang, Ziwei Fan, Hao Peng, and Philip S. Yu. 2021. Federated social recommendation with graph neural network. ACM TIST (2021).
- Lu and Miklau (2014) Wentian Lu and Gerome Miklau. 2014. Exponential random graph estimation under differential privacy. In SIGKDD. 921–930.
- Lyu et al. (2020a) Lingjuan Lyu, Xuanli He, and Yitong Li. 2020a. Differentially Private Representation for NLP: Formal Guarantee and An Empirical Study on Privacy and Fairness. In Findings of the Association for Computational Linguistics: EMNLP 2020. 2355–2365.
- Lyu et al. (2020b) Lingjuan Lyu, Yitong Li, Xuanli He, and Tong Xiao. 2020b. Towards differentially private text representations. In SIGIR. 1813–1816.
- Ma et al. (2022) Xiaoxiao Ma, Shan Xue, Jia Wu, Jian Yang, Cecile Paris, Surya Nepal, and Quan Z Sheng. 2022. Deep Multi-Attributed-View Graph Representation Learning. IEEE Trans. Netw. Sci. Eng. (2022).
- Machanavajjhala et al. (2007) Ashwin Machanavajjhala, Daniel Kifer, Johannes Gehrke, and Muthuramakrishnan Venkitasubramaniam. 2007. l-diversity: Privacy beyond k-anonymity. TKDD 1, 1 (2007), 3–es.
- Man et al. (2016) Tong Man, Huawei Shen, Shenghua Liu, Xiaolong Jin, and Xueqi Cheng. 2016. Predict anchor links across social networks via an embedding approach.. In IJCAI, Vol. 16. 1823–1829.
- Mikolov et al. (2013) Tomas Mikolov, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space. In ICLR.
- Narayanan and Shmatikov (2009) Arvind Narayanan and Vitaly Shmatikov. 2009. De-anonymizing social networks. In SSP. IEEE, 173–187.
- Narayanan and Shmatikov (2010) Arvind Narayanan and Vitaly Shmatikov. 2010. Myths and fallacies of” personally identifiable information”. CACM 53, 6 (2010), 24–26.
- Nguyen et al. (2016) Hiep Nguyen, Abdessamad Imine, and Michaël Rusinowitch. 2016. Network structure release under differential privacy. Transactions on Data Privacy 9, 3 (2016), 26.
- Nguyen et al. (2015) Hiep H Nguyen, Abdessamad Imine, and Michaël Rusinowitch. 2015. Differentially private publication of social graphs at linear cost. In ASONAM. IEEE, 596–599.
- Peng et al. (2021) Hao Peng, Haoran Li, Yangqiu Song, Vincent Zheng, and Jianxin Li. 2021. Differentially private federated knowledge graphs embedding. In CIKM. 1416–1425.
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. Glove: Global vectors for word representation. In EMNLP. 1532–1543.
- Perozzi et al. (2014) Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. Deepwalk: Online learning of social representations. In SIGKDD. 701–710.
- Ren et al. (2020) Fuxin Ren, Zhongbao Zhang, Jiawei Zhang, Sen Su, Li Sun, Guozhen Zhu, and Congying Guo. 2020. BANANA: when Behavior ANAlysis meets social Network Alignment. In IJCAI. 1438–1444.
- Sadowski and Levin (2007) Caitlin Sadowski and Greg Levin. 2007. Simhash: Hash-based similarity detection. Technical report, Google (2007).
- Sala et al. (2011) Alessandra Sala, Xiaohan Zhao, Christo Wilson, Haitao Zheng, and Ben Y Zhao. 2011. Sharing graphs using differentially private graph models. In SIGCOMM. 81–98.
- Schlichtkrull et al. (2018) Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne Van Den Berg, Ivan Titov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. In ESWC. Springer, 593–607.
- Sweeney (2002) Latanya Sweeney. 2002. k-anonymity: A model for protecting privacy. IJUFKS 10, 05 (2002), 557–570.
- Truex et al. (2020) Stacey Truex, Ling Liu, Ka-Ho Chow, Mehmet Emre Gursoy, and Wenqi Wei. 2020. LDP-Fed: Federated learning with local differential privacy. In EdgeSys. 61–66.
- Wang et al. (2017) Tianhao Wang, Jeremiah Blocki, Ninghui Li, and Somesh Jha. 2017. Locally differentially private protocols for frequency estimation. In USENIX Security 17. 729–745.
- Wang and Wu (2013) Yue Wang and Xintao Wu. 2013. Preserving differential privacy in degree-correlation based graph generation. Transactions on data privacy 6, 2 (2013), 127.
- Wang et al. (2021) Yuye Wang, Jing Yang, and Jianpei Zhan. 2021. Differentially Private Attributed Network Releasing Based on Early Fusion. Security and Communication Networks 2021 (2021).
- Xiao et al. (2014) Qian Xiao, Rui Chen, and Kian-Lee Tan. 2014. Differentially private network data release via structural inference. In SIGKDD. 911–920.
- Xu et al. (2021) Xiaohang Xu, Hao Peng, Md Zakirul Alam Bhuiyan, Zhifeng Hao, Lianzhong Liu, Lichao Sun, and Lifang He. 2021. Privacy-Preserving Federated Depression Detection From Multisource Mobile Health Data. IEEE ISSN 18, 7 (2021), 4788–4797.
- Yan et al. (2013) Ming Yan, Jitao Sang, Tao Mei, and Changsheng Xu. 2013. Friend transfer: Cold-start friend recommendation with cross-platform transfer learning of social knowledge. In ICME. IEEE, 1–6.
- Yan et al. (2016) Ming Yan, Jitao Sang, Changsheng Xu, and M Shamim Hossain. 2016. A unified video recommendation by cross-network user modeling. TOMM 12, 4 (2016), 1–24.
- Yang et al. (2021b) Carl Yang, Haonan Wang, Ke Zhang, Liang Chen, and Lichao Sun. 2021b. Secure Deep Graph Generation with Link Differential Privacy. In IJCAI. 3271–3278.
- Yang et al. (2021a) Liangwei Yang, Zhiwei Liu, Yingtong Dou, Jing Ma, and Philip S Yu. 2021a. Consisrec: Enhancing gnn for social recommendation via consistent neighbor aggregation. In Proceedings of the 44th international ACM SIGIR conference on Research and development in information retrieval. 2141–2145.
- Yao et al. (2021) Xin Yao, Rui Zhang, and Yanchao Zhang. 2021. Differential Privacy-Preserving User Linkage across Online Social Networks. In IWQOS. IEEE, 1–10.
- Yue et al. (2021) Xiang Yue, Minxin Du, Tianhao Wang, Yaliang Li, Huan Sun, and Sherman S. M. Chow. 2021. Differential Privacy for Text Analytics via Natural Text Sanitization. In ACL-IJCNLP.
- Zhang et al. (2013) Jiawei Zhang, Xiangnan Kong, and Philip S. Yu. 2013. Predicting social links for new users across aligned heterogeneous social networks. In ICDM. IEEE, 1289–1294.
- Zhang et al. (2017) Jiawei Zhang, Congying Xia, Chenwei Zhang, Limeng Cui, Yanjie Fu, and Philip S. Yu. 2017. BL-MNE: emerging heterogeneous social network embedding through broad learning with aligned autoencoder. In ICDM. IEEE, 605–614.
- Zhang et al. (2021) Shijie Zhang, Hongzhi Yin, Tong Chen, Zi Huang, Lizhen Cui, and Xiangliang Zhang. 2021. Graph Embedding for Recommendation against Attribute Inference Attacks. In WWW. 3002–3014.
- Zhang et al. (2018) Wei Zhang, Wen Wang, Jun Wang, and Hongyuan Zha. 2018. User-guided hierarchical attention network for multi-modal social image popularity prediction. In WWW. 1277–1286.
- Zhou et al. (2020) Jun Zhou, Chaochao Chen, Longfei Zheng, Huiwen Wu, Jia Wu, Xiaolin Zheng, Bingzhe Wu, Ziqi Liu, and Li Wang. 2020. Vertically federated graph neural network for privacy-preserving node classification. arXiv preprint arXiv:2005.11903 (2020).