Cross-View Hierarchy Network for Stereo Image Super-Resolution
Abstract
Stereo image super-resolution aims to improve the quality of high-resolution stereo image pairs by exploiting complementary information across views. To attain superior performance, many methods have prioritized designing complex modules to fuse similar information across views, yet overlooking the importance of intra-view information for high-resolution reconstruction. It also leads to problems of wrong texture in recovered images. To address this issue, we explore the interdependencies between various hierarchies from intra-view and propose a novel method, named Cross-View Hierarchy Network for Stereo Image Super-Resolution (CVHSSR). Specifically, we design a cross-hierarchy information mining block (CHIMB) that leverages channel attention and large kernel convolution attention to extract both global and local features from the intra-view, enabling the efficient restoration of accurate texture details. Additionally, a cross-view interaction module (CVIM) is proposed to fuse similar features from different views by utilizing cross-view attention mechanisms, effectively adapting to the binocular scene. Extensive experiments demonstrate the effectiveness of our method. CVHSSR achieves the best stereo image super-resolution performance than other state-of-the-art methods while using fewer parameters. The source code and pre-trained models are available at https://github.com/AlexZou14/CVHSSR.
1 Introduction
Stereo image technology has made significant strides, leading to the successful application of stereo images in a variety of 3D scenarios, such as augmented reality (AR), virtual reality (VR), and autonomous driving. However, stereo imaging devices, such as the dual cameras on mobile phones, are subject to certain constraints that can result in the production of stereo image pairs with low resolution (LR). Stereo image super-resolution (SR), which has attracted much attention in recent years, aims to generate high-resolution stereo image pairs from their low-resolution counterparts to significantly enhance their visual perception. Therefore, this research has great potential to enhance the user experience in deploying immersive services.
In recent years, numerous deep learning-based algorithms for stereo image SR have been proposed, following the widespread use of convolution neural network (CNN) based methods in single image super-resolution (SISR) [18, 36, 39, 6, 17] tasks. Unlike SISR, which primarily focuses on finding similar textures within an image, stereo image SR must consider both intra-view and inter-view information, both of which play critical roles in stereo image reconstruction. Existing methods typically develop complex networks and loss functions to effectively fuse information from two viewpoints. For example, Jeon et al. [12] learned the parallax prior in stereo datasets through a two-stage network to recover high-resolution images. Wang et al. [28] introduced a parallax attention mechanism that incorporates global receptive fields to further improve network performance. Song et al. [25] proposed a self and parallax attention mechanism to reconstruct high-quality stereo image pairs. Recently, Chu et al. [4] used an efficient nonlinear activation-free block and cross-view attention module, achieving the best performance and winning first place in NTIRE2022 [27].
Although the existing stereo image SR methods have achieved impressive performance, they have not fully explored the rich hierarchy features of the intra-view, which could affect the information transfer between cross-views. Therefore, an interesting research question remains on how to effectively utilize both global and local features from stereo image pairs to further improve the quality of stereo image SR reconstruction.
In this paper, we propose a novel method to address the issue of unexplored intra-view hierarchical features in stereo image SR. The proposed method, named Cross-View Hierarchical Network for stereo image SR (CVHSSR), aims to extract rich feature representations from intra-views at different hierarchies and fuse them to enhance the performance of stereo image SR. To achieve this, we introduce two core modules: the cross-hierarchy information mining block (CHIMB) and the cross-view interaction module (CVIM), which explore and fuse similar features from different hierarchies across views. Specifically, the CHIMB module is designed to model and recover intra-view information at various hierarchies, utilizing the large kernel convolution attention and the channel attention mechanism. On the other hand, the CVIM module effectively integrates similar information from different views by utilizing the cross-view attention mechanism. By exploiting these modules, the CVHSSR can incorporate more diversified feature representations from different spatial levels of the two views, resulting in enhanced SR reconstruction quality.
The key contributions of this work are summarized as follows:
-
•
We propose the CHIMB to efficiently extract hierarchy information from intra-views. In contrast to the NAFBlock used in NAFNet [1], CHIMB models global and local information from intra-view by using channel attention and large kernel convolution attention, effectively helping the network to restore the correct texture features.
-
•
We have designed the CVIM to fuse similar information from different views in our method. Unlike the cross-view attention mechanism used in other methods, CVIM utilizes depth-wise convolution to capture similar information from intra-view, then facilitating cross-view information fusion.
-
•
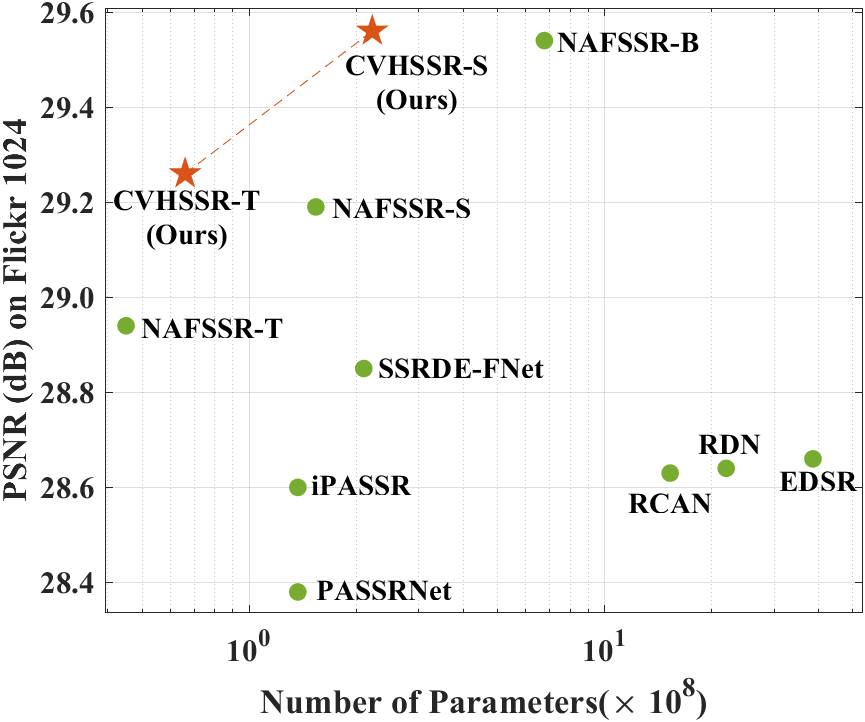
Based on CHIMB and CVIM, we propose a simple yet effective method for stereo image SR. Our approach achieves state-of-the-art performance with fewer parameters, as shown in Figure 1. Extensive experiments confirm the validity of our proposed CVHSSR.
2 Related Work
2.1 Single Image Super-Resolution
Image super-resolution is a regression problem that maps a low-resolution image to its corresponding high-resolution image. Since Dong et al. [8] introduce CNN into the SISR field with their pioneering work SRCNN, CNN-based methods have been proven to achieve impressive performance in SISR tasks. On this basis, Lim et al. [13] further improved network performance by deepening the network and increasing the dimension of intermediate features. With the development of deep learning technology, the researchers use residual and dense connections [40, 18, 14, 36] to control network information flow, thereby obtaining better image reconstruction performance. However, these methods did not consider the importance of different features, leading to redundant network design. Therefore, RCAN [39] introduced channel attention mechanisms to model the interdependence between feature channels and adaptively rescale the features of each channel. Subsequently, various attention mechanisms were proposed to enhance network expression ability, including spatial attention [7, 23], second-order attention[6], non-local attention[21, 20], and large kernel convolution attention [30].
Recently, the Transformer has achieved great success in the field of vision. Therefore, many researchers [16, 17, 38, 19, 33] introduce the Transformer into SISR tasks. With the powerful learning ability of Transformers, Transformer-based methods have achieved state-of-the-art performance in the field of single-image super-resolution. Despite the consistently improved performance, SISR cannot utilize complementary information from different views in stereo image pairs, which limits the performance of stereo image super-resolution.
2.2 Stereo Image Super-Resolution
Instead of SISR method, which only has access to context information from intro, stereo image SR can leverage the additional information provided by the cross-view information to enhance SR performance. However, the presence of binocular disparity between the left and right views in a stereo image pair can pose a significant challenge to the fusion of information across views. Thus, Jeon et al. [12] proposed the first deep learning-based model for stereo image SR (namely, StereoSR). This approach addresses the challenge of fusing complementary features of the left and right views by concatenating the left image and a stack of right images with predefined shifts. On this basis, Wang et al. [28, 29] introduced a parallax attention module (PAM) to model stereo correspondence by effectively capturing global contextual information along the epipolar line. These methods outperforms StereoSR and exhibits greater flexibility in accommodating disparity variation. In pursuit of more refined stereo correspondence, Song et al. [25] extended the parallax-attention mechanism to propose SPAM, which aggregates information from both the primary and cross views to generate stereo-consistent image pairs. Yan et al. [35] proposed a domain adaptive stereo SR network (DASSR) to achieve both stereo image SR and stereo image deblurring tasks. Xu et al. [34] introduced the concept of bilateral grid processing within a CNN framework, thereby proposing a bilateral stereo SR network. Then, Wang et al. [32] enhanced PASSRNet (ie. iPASSRNet) by leveraging the symmetry cues present in stereo image pairs. Ma et al. proposed a perception-oriented StereoSR framework, which aims to restore stereo images with improved subjective quality. More recently, Chu et al. [4] developed the NAFSSR network by utilizing nonlinear activation-free blocks [1] for intra-view feature extraction and PAM for cross-view feature interaction, which achieves the champion in the NTIRE 2022 Stereo Image SR Challenge [27].
Although existing methods have achieved superior performance in stereo image SR, they typically focus on modeling cross-view information while neglecting the hierarchical similarity relationships from intra-view. To address this limitation, we propose to leverage both local and global hierarchical feature representations to further improve the performance of state-of-the-art stereo image SR methods.
3 Cross-View Hierarchy Network
3.1 Overall Framwork
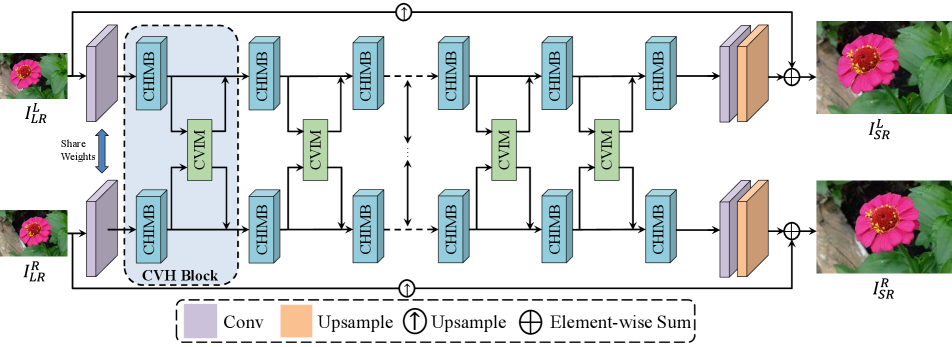
To avoid complex network designs that require a large number of parameters and computational effort, we adopt a simple weight-sharing two-branch network structure to recover the left and right view images, as illustrated in Figure 2. Our CVHSSR mainly consists of four components: the shallow feature extraction, the cross-hierarchy information mining block (CHIMB), the cross-view interaction modules (CVIM), and stereo image reconstruction. Specifically, the CHIMB is designed to extract similar features both locally and globally from the intra-view image, effectively restoring accurate texture details. The CVIM is mainly used to fuse features from two viewpoints. More details of CHIMB and CVIM are described in Sections 3.2 and 3.3.
Firstly, given an input stereo low-resolution images , CVHSSR first applies a convolution to obtain two-views shallow feature , where denotes the spatial dimension and is the number of channels. It can be formulated as:
| (1) |
where denotes convolution operation.
Next, we integrate CHIMB and CVIM into a cross-view hierarchy (CVH) block, which not only extracts deep intra-view features but also fuses information from different view images. Therefore, we stack CVH blocks to obtain output features that incorporate information from multiple perspectives. It can be expressed as:
| (2) | |||
where , and denote CVH block, CVIM, and CHIMB, respectively. denote the output of the -th CVH Block and -th CVHBlock, respectively.
Finally, we upsample the output features to the HR size using the pixel-shuffle operation. Additionally, we incorporate a global residual path to leverage the input stereo image information to further improve the super-resolution performance. It can be expressed as:
| (3) | |||
where denotes the upsampling operation. denotes the proposed CVHSSR network. denote the final restored left-view and right-view images, respectively.
3.2 Cross-Hierarchy Information Mining Block
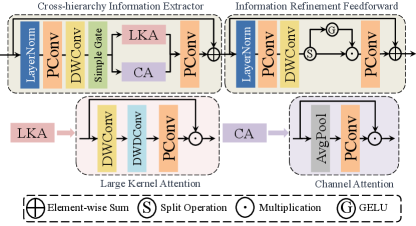
Many existing methods for stereo image SR focus mainly on modeling cross-view information and do not adequately exploit the hierarchy information from the intra-view image. This leads to difficulties in recovering clear texture details. To address this issue, we have proposed the CHIMB as depicted in Figure 3, which is capable of effectively extracting different hierarchy information features from images.
The CHIMB consists of two parts: (1) The cross-hierarchy information extractor (CHIE); (2) The information refinement feedforward network (IRFFN). The CHIMB incorporates both channel attention and large kernel convolution attention to capture both global and local similarity relationships. The channel attention calculates global statistics of the feature map to enhance the focus on important features. Meanwhile, the large kernel convolution attention utilizes larger kernel convolution to capture long-range dependencies in the intra-view image, thereby enhancing the attention to local information. These two attention mechanisms in combination enable the CHIE to effectively model the hierarchy information contained in the input images and accurately recover texture details.
Given an input tensor , the CHIE is formulated is:
| (4) |
where is the point-wise convolution and is the depth-wise convolution. denotes the output feature of CHIE. The denotes layer normalization. We use the notation and to represent the SimpleGate function and the hybrid attention operation, respectively. Specifically, the SimpleGate first split the input into two features along channel dimension. Then, it computes the output with the linear gate as , where denotes element-wise multiplication. The hybrid attention consists of two components: channel attention and large kernel convolution attention. It can be described as follows:
| (5) | ||||
where , and denote the large kernel convolution attention, the channel attention, and the average pooling operation, respectively. denotes element-wise multiplication. The and represent the depth-wise convolution and the depth-wise dilation convolution.
The IRFFN in our pipeline utilizes a non-linear gate mechanism to control the flow of information, allowing each channel to focus on fine details complementary to the other levels. The IRFFN process is formulated as:
| (6) |
where is the function of non-linear gate mechanism. Similar to SimpleGate, the non-linear gate mechanism divides the input along the channel dimension into two features . The output is then calculated by non-linear gating as , where denotes the activation function. The denote the output of CHIMB.
3.3 Cross-View Interaction Module
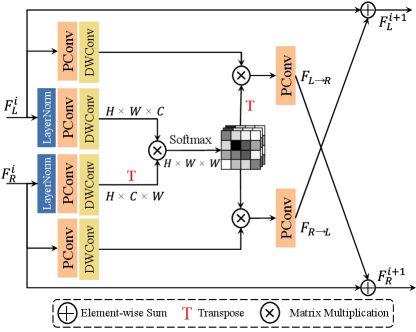
The details of the proposed CVIM as shown in Figure 4. This method employs Scaled DotProduct Attention [26], which involves calculating the dot product between the query and keys, followed by the application of a softmax function to generate weights assigned to the corresponding values:
| (7) |
where is query matrix projected by source intra-view feature (e.g. left-view), and are key, value matrices projected by target intra-view feature (e.g. right-view). Here, represents the height, width, and number of channels of the feature map.
The CVIM adopts a novel cross-view attention mechanism that integrates information from both left and right view images to generate cross-view attention maps. This approach allows for the exploitation of the distinctive information present in each view, leading to more effective feature fusion and better restoration results. In detail, given the input stereo intra-view features , we can get the cross-view fusion features as follows:
| (8) | ||||
| (9) | ||||
| (10) | ||||
| (11) |
where is the point-wise convolution. is the depth-wise convolution. It offers feature refinement from both channel and spatial perspectives.
With an analogous argument, we can obtain the cross-view fusion features as follows:
| (12) | ||||
| (13) | ||||
| (14) | ||||
| (15) |
Finally, the interacted cross-view information , and intra-view information , are fused by element-wise addition:
| (16) | |||
| (17) |
where and are trainable channel-wise scales and initialized with zeros for stabilizing training.
| Method | Scale | Params | |||||||
| KITTI2012 | KITTI2015 | Middlebury | KITTI2012 | KITTI2015 | Middlebury | Flickr1024 | |||
| VDSR [13] | 0.66M | 30.17/0.9062 | 28.99/0.9038 | 32.66/0.9101 | 30.30/0.9089 | 29.78/0.9150 | 32.77/0.9102 | 25.60/0.8534 | |
| EDSR [18] | 38.6M | 30.83/0.9199 | 29.94/0.9231 | 34.84/0.9489 | 30.96/0.9228 | 30.73/0.9335 | 34.95/0.9492 | 28.66/0.9087 | |
| RDN [40] | 22.0M | 30.81/0.9197 | 29.91/0.9224 | 34.85/0.9488 | 30.94/0.9227 | 30.70/0.9330 | 34.94/0.9491 | 28.64/0.9084 | |
| RCAN [39] | 15.3M | 30.88/0.9202 | 29.97/0.9231 | 34.80/0.9482 | 31.02/0.9232 | 30.77/0.9336 | 34.90/0.9486 | 28.63/0.9082 | |
| StereoSR [12] | 1.08M | 29.42/0.9040 | 28.53/0.9038 | 33.15/0.9343 | 29.51/0.9073 | 29.33/0.9168 | 33.23/0.9348 | 25.96/0.8599 | |
| PASSRnet [29] | 1.37M | 30.68/0.9159 | 29.81/0.9191 | 34.13/0.9421 | 30.81/0.9190 | 30.60/0.9300 | 34.23/0.9422 | 28.38/0.9038 | |
| IMSSRnet [15] | 6.84M | 30.90/- | 29.97/- | 34.66/- | 30.92/- | 30.66/- | 34.67/- | -/- | |
| iPASSR [32] | 1.37M | 30.97/0.9210 | 30.01/0.9234 | 34.41/0.9454 | 31.11/0.9240 | 30.81/0.9340 | 34.51/0.9454 | 28.60/0.9097 | |
| SSRDE-FNet [5] | 2.10M | 31.08/0.9224 | 30.10/0.9245 | 35.02/0.9508 | 31.23/0.9254 | 30.90/0.9352 | 35.09/0.9511 | 28.85/0.9132 | |
| PFT-SSR [10] | - | 31.15/0.9166 | 30.16/0.9187 | 35.08/0.9516 | 31.29/0.9195 | 30.96/0.9306 | 35.21/0.9520 | 29.05/0.9049 | |
| SwinFIR-T [38] | 0.89M | 31.09/0.9226 | 30.17/0.9258 | 35.00/0.9491 | 31.22/0.9254 | 30.96/0.9359 | 35.11/0.9497 | 29.03/0.9134 | |
| NAFSSR-T [4] | 0.45M | 31.12/0.9224 | 30.19/0.9253 | 34.93/0.9495 | 31.26/0.9254 | 30.99/0.9355 | 35.01/0.9495 | 28.94/0.9128 | |
| NAFSSR-S [4] | 1.54M | 31.23/0.9236 | 30.28/0.9266 | 35.23/0.9515 | 31.38/0.9266 | 31.08/0.9367 | 35.30/0.9514 | 29.19/0.9160 | |
| NAFSSR-B [4] | 6.77M | 31.40/0.9254 | 30.42/0.9282 | 35.62/0.9545 | 31.55/0.9283 | 31.22/0.9380 | 35.68/0.9544 | 29.54/0.9204 | |
| CVHSSR-T (Ours) | 0.66M | 31.31/0.9250 | 30.33/0.9277 | 35.41/0.9533 | 31.46/0.9280 | 31.13/0.9377 | 35.47/0.9532 | 29.26/0.9180 | |
| CVHSSR-S (Ours) | 2.22M | 31.42/0.9262 | 30.42/0.9287 | 35.73/0.9551 | 31.57/0.9291 | 31.22/0.9385 | 35.78/0.9550 | 29.56/0.9216 | |
| VDSR [13] | 0.66M | 25.54/0.7662 | 24.68/0.7456 | 27.60/0.7933 | 25.60/0.7722 | 25.32/0.7703 | 27.69/0.7941 | 22.46/0.6718 | |
| EDSR [18] | 38.9M | 26.26/0.7954 | 25.38/0.7811 | 29.15/0.8383 | 26.35/0.8015 | 26.04/0.8039 | 29.23/0.8397 | 23.46/0.7285 | |
| RDN [40] | 22.0M | 26.23/0.7952 | 25.37/0.7813 | 29.15/0.8387 | 26.32/0.8014 | 26.04/0.8043 | 29.27/0.8404 | 23.47/0.7295 | |
| RCAN [39] | 15.4M | 26.36/0.7968 | 25.53/0.7836 | 29.20/0.8381 | 26.44/0.8029 | 26.22/0.8068 | 29.30/0.8397 | 23.48/0.7286 | |
| StereoSR [12] | 1.42M | 24.49/0.7502 | 23.67/0.7273 | 27.70/0.8036 | 24.53/0.7555 | 24.21/0.7511 | 27.64/0.8022 | 21.70/0.6460 | |
| PASSRnet [29] | 1.42M | 26.26/0.7919 | 25.41/0.7772 | 28.61/0.8232 | 26.34/0.7981 | 26.08/0.8002 | 28.72/0.8236 | 23.31/0.7195 | |
| SRRes+SAM [37] | 1.73M | 26.35/0.7957 | 25.55/0.7825 | 28.76/0.8287 | 26.44/0.8018 | 26.22/0.8054 | 28.83/0.8290 | 23.27/0.7233 | |
| IMSSRnet [15] | 6.89M | 26.44/- | 25.59/- | 29.02/- | 26.43/- | 26.20/- | 29.02/- | -/- | |
| iPASSR [32] | 1.42M | 26.47/0.7993 | 25.61/0.7850 | 29.07/0.8363 | 26.56/0.8053 | 26.32/0.8084 | 29.16/0.8367 | 23.44/0.7287 | |
| SSRDE-FNet [5] | 2.24M | 26.61/0.8028 | 25.74/0.7884 | 29.29/0.8407 | 26.70/0.8082 | 26.43/0.8118 | 29.38/0.8411 | 23.59/0.7352 | |
| PFT-SSR [10] | - | 26.64/0.7913 | 25.76/0.7775 | 29.58/0.8418 | 26.77/0.7998 | 26.54/0.8083 | 29.74/0.8426 | 23.89/0.7277 | |
| SwinFIR-T [38] | 0.89M | 26.59/0.8017 | 25.78/0.7904 | 29.36/0.8409 | 26.68/0.8081 | 26.51/0.8135 | 29.48/0.8426 | 23.73/0.7400 | |
| NAFSSR-T [4] | 0.46M | 26.69/0.8045 | 25.90/0.7930 | 29.22/0.8403 | 26.79/0.8105 | 26.62/0.8159 | 29.32/0.8409 | 23.69/0.7384 | |
| NAFSSR-S [4] | 1.56M | 26.84/0.8086 | 26.03/0.7978 | 29.62/0.8482 | 26.93/0.8145 | 26.76/0.8203 | 29.72/0.8490 | 23.88/0.7468 | |
| NAFSSR-B [4] | 6.80M | 26.99/0.8121 | 26.17/0.8020 | 29.94/0.8561 | 27.08/0.8181 | 26.91/0.8245 | 30.04/0.8568 | 24.07/0.7551 | |
| CVHSSR-T (Ours) | 0.68M | 26.88/0.8105 | 26.03/0.7991 | 29.62/0.8496 | 26.98/0.8165 | 26.78/0.8218 | 29.74/0.8505 | 23.89/0.7484 | |
| CVHSSR-S (Ours) | 2.24M | 27.00/0.8139 | 26.15/0.8033 | 29.94/0.8577 | 27.10/0.8199 | 26.90/0.8258 | 30.05/0.8584 | 24.08/0.7570 | |


3.4 Loss Function
As image super-resolution tasks are primarily focused on restoring high-frequency details, we leverage both spatial and frequency domain losses to jointly guide our network in effectively recovering clear and sharp high-frequency textures. Specifically, given an input two view LR image , the proposed model predicts HR stereo image denote . We optimize our CVHSSR with the following loss function:
| (18) |
where represents the left-view and right-view HR image, and is the MSE loss:
| (19) |
In addition, is the frequency Charbonnier loss, defined as:
| (20) |
with constant emiprically set to for all the experiments. denotes a fast Fourier transform. The parameter in Eq. (18) is a hyper-parameter used to control the composition of the frequency Charbonnier loss function. The parameter is set to for all the experiments. More training details of our method are presented in Section 4.
4 Experiments
4.1 Implementation Details
In this section, we provide a detailed description of the experimental setting, including the datasets, the evaluation metrics, and the training configurations.
Dataset. Following the previous methods [32, 4, 38], we employ the training and validation datasets provided by the Flickr1024 [31]. To be specific, we employ 800 stereo images as the training data, and 112 stereo images as the validation data. We augment the training data with random horizontal, flips, rotations, and RGB channel shuffle. For testing, we use four benchmark datasets: KITTI 2012 [9], KITTI 2015 [22], Middlebury [24], and Flickr1024 [31].
Evaluation metrics. We adopted peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) as quantitative metrics for evaluation, which are calculated in the RGB color space between a pair of stereo images (i.e.,).
Model Setting. The numbers of the CHIMB blocks and feature channels are flexible and configurable. We construct two CVHSSR networks of varying sizes, which we named CVHSSR-T (Tiny) and CVHSSR-S (Small) by adjusting the number of channels and blocks. Specifically, the number of channels and blocks for CVHSSR-T are set to 48 and 16 respectively. The number of channels and blocks for CVHSSR-S are set to 64 and 32 respectively.
Training Settings. Our network was optimized using the Lion method [2] with =0.9, =0.999, and a batch size of 8. Our CVHSSR was implemented in PyTorch on a PC with four Nvidia RTX 3090 GPUs. The learning rate was initially set to and decayed the learning rate with the cosine strategy. We trained this model for 200,000 iterations. To alleviate the overfitting issue, we use stochastic depth [11] with 0.1 and 0.2 probability for CVHSSR-S and CVHSSR-B, respectively. Moreover, we also use Test-time Local Converter (TLC) [3] to further improve the model performance. The TLC method mainly aims to reduce the discrepancy between the distribution of global information during training and inference by converting global operations into local operations at inference.
4.2 Comparisons with State-of-the-art Methods
In this section, we conduct a comparative analysis between our CVHSSR (with 2 different variations) and existing super-resolution (SR) methods. The comparison involved SISR methods such as VDSR [13], EDSR [18], RDN [40], and RCAN [39], as well as stereo image SR methods like StereoSR [12], PASSRnet [29], SRRes+SAM [37], IMSSRnet [15], iPASSR [32], SSRDE-FNet [5], NAFSSR [4], SwinFIR [38], and PFT-SSR [10]. All these methods were trained on the same datasets as ours, and their PSNR and SSIM scores were evaluated and reported by [4].
Quantitative Evaluations. We present a comparative evaluation of our proposed CVHSSR against existing stereo SR methods at and upscaling factors, as summarized in Table 1. Notably, even our smallest CVHSSR-T model outperforms the NAFSSR-S method on all datasets while utilizing 60% fewer parameters. Moreover, our CVHSSR-S model achieves better results than the NAFSSR-B method while requiring 70% fewer parameters. Specifically, our CVHSSR-S method is 0.19 dB and 0.48 dB higher than NAFSSR-S and SRRDE-FNet, respectively, on the Flickr1024 dataset for the same amount of parameters. These results demonstrate the effectiveness of our proposed method and its superiority over existing methods in stereo image SR tasks.
Visual Comparison. In Figures 5 and 6, we present comparative results of stereo SR obtained by different stereo SR methods on the Flickr1024 [31], KITTI2012 [9], and KITTI2015 [22] datasets. The visual comparison of reconstructed images demonstrates that our proposed CVHSSR-S method achieves sharper and more accurate texture details compared to the NAFSSR-B method which still suffers from over-smoothing fine textures. This validates the superiority and effectiveness of our proposed CVHSSR method.
4.3 Ablation Study
In this section, we conduct a set of ablation experiments to evaluate the performance of each proposed module. The evaluation is performed on the Flickr1024 [31] validation dataset.
Effectiveness of Each Operation. To further substantiate the effectiveness of our proposed module, a series of ablation experiments were conducted and the results are presented in Table 2. Initially, the NAFSSR was used as the baseline, and subsequently, the corresponding module was modified continuously to verify the efficacy of the proposed module. As depicted in the table, LKA provided a performance improvement of 0.08 dB to the baseline due to its larger receptive field. However, merely enlarging the receptive field of the network does not fully exploit the hierarchical relationship of the intra-view. Hence, our proposed CHIE provided a superior performance improvement of 0.1 dB to the network. Compared to the simple FFN in NAFSSR [4], our proposed IRFFN more effectively regulated the information flow. Additionally, our proposed CVIM demonstrated a superior ability to fuse similar information from various perspectives and enhance network performance, compared to the traditional PAM [32]. These comparisons unequivocally underscore the effectiveness of our proposed methods.
| 1 | 2 | 3 | 4 | 5 | |
| Baseline | ✔ | ✔ | ✔ | ✔ | ✔ |
| LKA | ✘ | ✔ | ✘ | ✘ | ✘ |
| CHIE | ✘ | ✘ | ✔ | ✔ | ✔ |
| IRFFN | ✘ | ✘ | ✘ | ✔ | ✔ |
| CVIM | ✘ | ✘ | ✘ | ✘ | ✔ |
| PSNR | 23.59 | 23.67 | 23.69 | 23.70 | 23.72 |
| SSIM | 0.7345 | 0.739 | 0.7399 | 0.7402 | 0.7413 |
| PSNR | 0 | 0.08 | 0.10 | 0.11 | 0.13 |
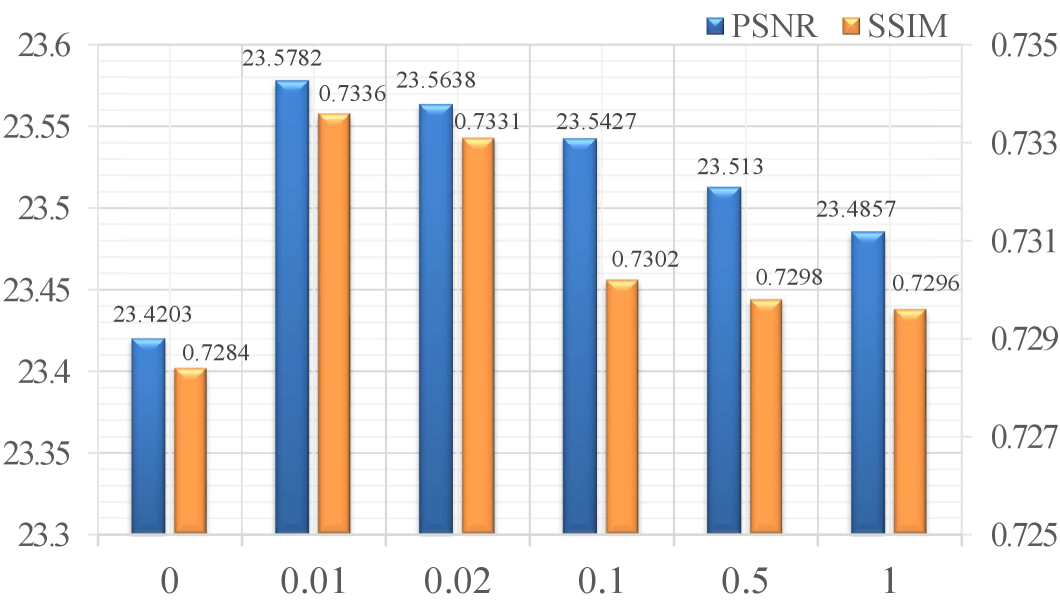
Effectiveness of in loss function. To evaluate the influence of different values of in the loss function, a series of experiments are conducted in this section. The hyperparameter is utilized to balance the trade-off between the MSE loss function and the frequency Charbonnier loss function. We conducted a range of empirical experiments with six different values within the range of [0,1], based on previous experience. The impact of different values on the model performance is illustrated in Figure 7. The results demonstrate that the network achieves optimal performance at .
4.4 NTIRE Stereo Image SR Challenge
We have submitted the results obtained from our proposed approach to the NTIRE 2023 Stereo Image Super-Resolution Challenge. To enhance the potential performance of our method, we have increased the depth and width of the CVHSSR-Based model. During test-time, we employed self-ensemble and model ensemble strategies. The final submission achieves 24.114 dB PSNR on the validation set and achieves 23.742 dB PSNR on the test set. We won 8th, 5th, and 4th on track 1 Fidelity & Bicubic, track 2 Perceptual & Bicubic, and tack 3 Fidelity & Realistic, respectively.
5 Conclusion
In this paper, we present an efficient stereo image SR method named Cross-View Hierarchy Network (CVHSSR). In particular, we design a cross-hierarchy information mining block that efficiently extracts similar features from intra-views by leveraging the hierarchical relationships of the features. Additionally, we introduce a cross-view interaction module to effectively convey mutual information between different views. The integration of these two modules enables our proposed network to achieve superior performance with fewer parameters. Comprehensive experimental evaluations demonstrate that our proposed CVHSSR method outperforms current state-of-the-art models in stereo image SR.
Acknowledgments
This work was funded by Science and Technology Project of Guangzhou (202103010003), Science and Technology Project in key areas of Foshan (2020001006285), Natural Science Foundation of Guangdong Province (2019A1515011041), Xijiang Innovation Team Project (XJCXTD3-2019-04B).
References
- [1] Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part VII, pages 17–33. Springer, 2022.
- [2] Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Yao Liu, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, et al. Symbolic discovery of optimization algorithms. arXiv preprint arXiv:2302.06675, 2023.
- [3] Xiaojie Chu, Liangyu Chen, , Chengpeng Chen, and Xin Lu. Improving image restoration by revisiting global information aggregation. arXiv preprint arXiv:2112.04491, 2021.
- [4] Xiaojie Chu, Liangyu Chen, and Wenqing Yu. Nafssr: stereo image super-resolution using nafnet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1239–1248, 2022.
- [5] Qinyan Dai, Juncheng Li, Qiaosi Yi, Faming Fang, and Guixu Zhang. Feedback network for mutually boosted stereo image super-resolution and disparity estimation. In Proceedings of the 29th ACM International Conference on Multimedia, pages 1985–1993, 2021.
- [6] T. Dai, J. Cai, Y. Zhang, S. Xia, and L. Zhang. Second-order attention network for single image super-resolution. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11057–11066, 2019.
- [7] Tao Dai, Hua Zha, Yong Jiang, and Shu-Tao Xia. Image super-resolution via residual block attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pages 0–0, 2019.
- [8] C. Dong, C. C. Loy, K. He, and X. Tang. Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(2):295–307, 2016.
- [9] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In 2012 IEEE conference on computer vision and pattern recognition, pages 3354–3361. IEEE, 2012.
- [10] Hansheng Guo, Juncheng Li, Guangwei Gao, Zhi Li, and Tieyong Zeng. Pft-ssr: Parallax fusion transformer for stereo image super-resolution. arXiv preprint arXiv:2303.13807, 2023.
- [11] Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, pages 646–661. Springer, 2016.
- [12] Daniel S Jeon, Seung-Hwan Baek, Inchang Choi, and Min H Kim. Enhancing the spatial resolution of stereo images using a parallax prior. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1721–1730, 2018.
- [13] J. Kim, J. K. Lee, and K. M. Lee. Accurate image super-resolution using very deep convolutional networks. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1646–1654, 2016.
- [14] J. Kim, J. K. Lee, and K. M. Lee. Deeply-recursive convolutional network for image super-resolution. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1637–1645, 2016.
- [15] Jianjun Lei, Zhe Zhang, Xiaoting Fan, Bolan Yang, Xinxin Li, Ying Chen, and Qingming Huang. Deep stereoscopic image super-resolution via interaction module. IEEE Transactions on Circuits and Systems for Video Technology, 31(8):3051–3061, 2020.
- [16] Wenbo Li, Xin Lu, Jiangbo Lu, Xiangyu Zhang, and Jiaya Jia. On efficient transformer and image pre-training for low-level vision. arXiv preprint arXiv:2112.10175, 2021.
- [17] Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1833–1844, 2021.
- [18] B. Lim, S. Son, H. Kim, S. Nah, and K. M. Lee. Enhanced deep residual networks for single image super-resolution. In 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1132–1140, 2017.
- [19] Zhisheng Lu, Juncheng Li, Hong Liu, Chaoyan Huang, Linlin Zhang, and Tieyong Zeng. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 457–466, 2022.
- [20] Yiqun Mei, Yuchen Fan, and Yuqian Zhou. Image super-resolution with non-local sparse attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3517–3526, 2021.
- [21] Yiqun Mei, Yuchen Fan, Yuqian Zhou, Lichao Huang, Thomas S Huang, and Honghui Shi. Image super-resolution with cross-scale non-local attention and exhaustive self-exemplars mining. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5690–5699, 2020.
- [22] Moritz Menze and Andreas Geiger. Object scene flow for autonomous vehicles. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3061–3070, 2015.
- [23] Ben Niu, Weilei Wen, Wenqi Ren, Xiangde Zhang, Lianping Yang, Shuzhen Wang, Kaihao Zhang, Xiaochun Cao, and Haifeng Shen. Single image super-resolution via a holistic attention network. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII 16, pages 191–207. Springer, 2020.
- [24] Daniel Scharstein, Heiko Hirschmüller, York Kitajima, Greg Krathwohl, Nera Nešić, Xi Wang, and Porter Westling. High-resolution stereo datasets with subpixel-accurate ground truth. In Pattern Recognition: 36th German Conference, GCPR 2014, Münster, Germany, September 2-5, 2014, Proceedings 36, pages 31–42. Springer, 2014.
- [25] Wonil Song, Sungil Choi, Somi Jeong, and Kwanghoon Sohn. Stereoscopic image super-resolution with stereo consistent feature. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 12031–12038, 2020.
- [26] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [27] Longguang Wang, Yulan Guo, Yingqian Wang, Juncheng Li, Shuhang Gu, Radu Timofte, Liangyu Chen, Xiaojie Chu, Wenqing Yu, Kai Jin, et al. Ntire 2022 challenge on stereo image super-resolution: Methods and results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 906–919, 2022.
- [28] Longguang Wang, Yulan Guo, Yingqian Wang, Zhengfa Liang, Zaiping Lin, Jungang Yang, and Wei An. Parallax attention for unsupervised stereo correspondence learning. IEEE transactions on pattern analysis and machine intelligence, 44(4):2108–2125, 2020.
- [29] Longguang Wang, Yingqian Wang, Zhengfa Liang, Zaiping Lin, Jungang Yang, Wei An, and Yulan Guo. Learning parallax attention for stereo image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12250–12259, 2019.
- [30] Yan Wang, Yusen Li, Gang Wang, and Xiaoguang Liu. Multi-scale attention network for single image super-resolution. arXiv preprint arXiv:2209.14145, 2022.
- [31] Yingqian Wang, Longguang Wang, Jungang Yang, Wei An, and Yulan Guo. Flickr1024: A large-scale dataset for stereo image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pages 0–0, 2019.
- [32] Yingqian Wang, Xinyi Ying, Longguang Wang, Jungang Yang, Wei An, and Yulan Guo. Symmetric parallax attention for stereo image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 766–775, June 2021.
- [33] Zhendong Wang, Xiaodong Cun, Jianmin Bao, Wengang Zhou, Jianzhuang Liu, and Houqiang Li. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17683–17693, 2022.
- [34] Qingyu Xu, Longguang Wang, Yingqian Wang, Weidong Sheng, and Xinpu Deng. Deep bilateral learning for stereo image super-resolution. IEEE Signal Processing Letters, 28:613–617, 2021.
- [35] Bo Yan, Chenxi Ma, Bahetiyaer Bare, Weimin Tan, and Steven CH Hoi. Disparity-aware domain adaptation in stereo image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13179–13187, 2020.
- [36] Xin Yang, Haiyang Mei, Jiqing Zhang, Ke Xu, Baocai Yin, Qiang Zhang, and Xiaopeng Wei. Drfn: Deep recurrent fusion network for single-image super-resolution with large factors. IEEE Transactions on Multimedia, 21(2):328–337, 2018.
- [37] Xinyi Ying, Yingqian Wang, Longguang Wang, Weidong Sheng, Wei An, and Yulan Guo. A stereo attention module for stereo image super-resolution. IEEE Signal Processing Letters, 27:496–500, 2020.
- [38] Dafeng Zhang, Feiyu Huang, Shizhuo Liu, Xiaobing Wang, and Zhezhu Jin. Swinfir: Revisiting the swinir with fast fourier convolution and improved training for image super-resolution. arXiv preprint arXiv:2208.11247, 2022.
- [39] Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European conference on computer vision (ECCV), pages 286–301, 2018.
- [40] Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2472–2481, 2018.