ine \useunder\ul
CVLNet: Cross-View Semantic Correspondence Learning for Video-based Camera Localization
Abstract
This paper tackles the problem of Cross-view Video-based camera Localization (CVL). The task is to localize a query camera by leveraging information from its past observations, i.e., a continuous sequence of images observed at previous time stamps, and matching them to a large overhead-view satellite image. The critical challenge of this task is to learn a powerful global feature descriptor for the sequential ground-view images while considering its domain alignment with reference satellite images. For this purpose, we introduce CVLNet, which first projects the sequential ground-view images into an overhead view by exploring the ground-and-overhead geometric correspondences and then leverages the photo consistency among the projected images to form a global representation. In this way, the cross-view domain differences are bridged. Since the reference satellite images are usually pre-cropped and regularly sampled, there is always a misalignment between the query camera location and its matching satellite image center. Motivated by this, we propose estimating the query camera’s relative displacement to a satellite image before similarity matching. In this displacement estimation process, we also consider the uncertainty of the camera location. For example, a camera is unlikely to be on top of trees. To evaluate the performance of the proposed method, we collect satellite images from Google Map for the KITTI dataset and construct a new cross-view video-based localization benchmark dataset, KITTI-CVL. Extensive experiments have demonstrated the effectiveness of video-based localization over single image-based localization and the superiority of each proposed module over other alternatives.
1 Introduction
Cross-view image-based localization using ground-to-satellite image matching has attracted significant attention these days [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]. It has found many practical applications such as autonomous driving and robot navigation. Prior works have been focused on localizing omnidirectional ground-view images with a Field-of-View (FoV), which helps to provide rich and discriminative features for localization. However, when a regular forward-looking camera with a limited FoV is used, those omnidirectional camera-based algorithms suffer severe performance degradation.
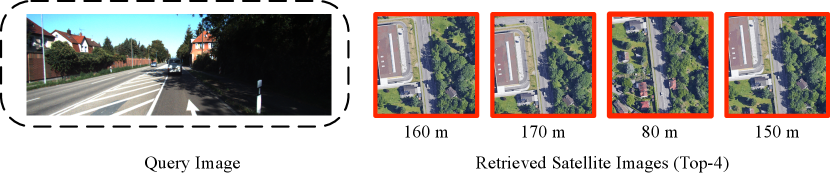
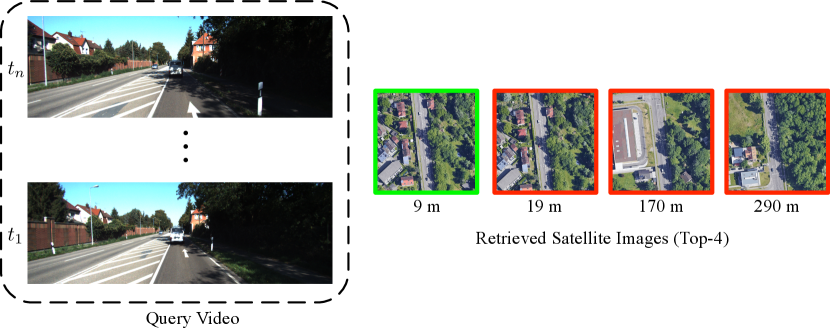
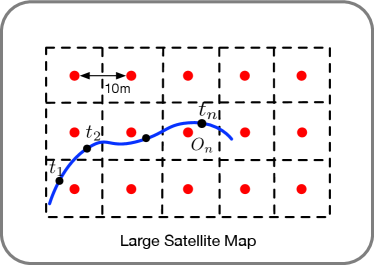
To tackle this challenge, this paper proposes to use a continuous short video, i.e., a sequence of ground-view images, as input for the task of visual localization. Specifically, we localize a camera at the current time stamp by augmenting it with previous observations at time i.e., , as shown in Fig. 1. Compared to using a single query image, a short video provides richer visual and dynamic information about the current location.
We present a Cross-view Video-based Localization Network, named CVLNet, to address the camera localization problem. To the best of our knowledge, our CVLNet is the first vision- and deep-based cross-view geo-localization framework that exploits a continuous video rather than a single image to pinpoint the camera location.
Our CVLNet is composed of two branches that extract deep features from ground and satellite images, respectively. Considering the drastic viewpoint changes between the two-view images, we first introduce a Geometry-driven View Projection (GVP) module to transform ground-view features to the overhead view by explicitly exploring their geometric correspondences. Then, we design a Photo-consistency Constrained Sequence Fusion (PCSF) module to fuse the sequential features. Our PCSF first estimates the reliability of the sequential ground-view features in overhead view by leveraging photo-consistency across them and then aggregates them as a global query descriptor. In this manner, we achieve more discriminative and reliable ground-view feature representation.
Since satellite images in a database are usually pre-cropped and sampled at discretized locations, there would be a misalignment between a query camera location and its matching satellite image center. Furthermore, a query camera is usually impossible in some regions (e.g., on top of a tree), while likely on the other areas (e.g., road). Hence, we propose a Scene-prior driven Similarity Matching (SSM) strategy to estimate the relative displacement between a query camera location and a satellite image center while restricting the search space by scene priors. The scene priors are learned statistically from training rather than pre-defined. With the help of SSM, our CVLNet can eliminate unreasonable localization results.
In order to train and evaluate our method, we curate a new cross-view dataset by collecting satellite images for the KITTI dataset [12] from Google Map [13]. The new dataset combines sequential ground-view images from the original KITTI dataset and the newly collected satellite images. To the best of our knowledge, it is not only the first cross-view video-based localization dataset, but also the first cross-view localization dataset where ground-view images are captured by a perspective pin-hole camera with a restricted FoV (rather than being cropped from Google street-view panoramas [1, 8]). Extensive experiments on the newly collected dataset demonstrate that our method effectively localizes camera positions and outperforms the state-of-the-art remarkably.
2 Related Work
Image-based localization. The image-based localization problem is initially tackled as a ground-to-ground image matching [14, 15, 16, 17, 18, 19], where both the query and database images are captured at the ground level. However, those methods cannot localize query images when there is no corresponding reference image in the database. Thanks to the wide-spread coverage and easy accessibility of satellite imagery, recent works [20, 21, 22, 1, 23, 2, 3, 4, 5, 6, 24, 7, 8, 9, 10, 11, 25, 26, 27, 28, 29] resort to satellite images for city-scale localization.
While recent works on city-scale ground-to-satellite localization have achieved promising results, they mostly focus on localizing isolated omnidirectional ground images. When the query camera has a limited FoV, we propose using a continuous video instead of a single image for camera localization, improving the discriminativeness of the query location representation.
Video-based localization. The concept of video-based localization can be divided into three main categories; Visual Odometry (VO) [30, 31, 32], Visual-SLAM (vSLAM) [33, 34, 35, 36, 37, 38] and Visual Localization [39, 40, 41, 42, 43, 44, 45]. VO techniques can be classified according to their camera setup — either monocular or stereoscopic or their processing techniques — either feature-based or appearance-based. VO methods usually use a combination of feature tracking and feature matching [46, 47]. vSLAM pertains to simultaneously creating a map of features and localizing the robot in that map, all using visual information [48, 49]. Many a time, the map is pre-built, and the robot needs to localize itself using camera-based map-matching, which is referred to as Visual Localization [50]. Even though these methods use a series of image frames to determine the robot’s location, they match information from the same viewpoint. In our work, we have developed a cross-view video-based localization approach by leveraging a sequence of images with varied viewpoints and limited FoVs, aiming to improve the representativeness of a query location significantly.
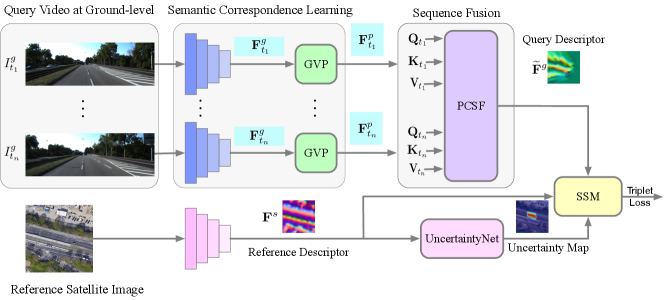
3 CVLNet: Cross-view Video-based Localization
This paper tackles the ground-to-satellite localization task. Instead of using a single query image captured at the ground level, we augment the query image with a short video containing previous observations. To solve this task, our motivation is first projecting the images in the ground video to an overhead111For clarity, we use “overhead” throughout the paper to denote the projected features from ground-views, and “satellite” to indicate the real satellite image/features. perspective and then extracting a global description from the projected image sequence for localization. An overview of our pipeline is illustrated in Fig. 2.
3.1 Geometry-driven view projection (GVP)
Prior methods often resort to a satellite to ground projection to bridge the cross-view domain gap. This is achieved either by a polar transform [6, 8, 10] or a projective transform [51, 25, 52]. However, both transforms need to know the query camera location with respect to the satellite image center. In the CVUSA and CVACT dataset where polar transform performs excellent, the query images accidentally align with their matching satellite image center, which however does not occur in practice. When there is a large offset between the real camera location and its assumed location with respect to its matching satellite image (e.g., satellite image center in polar transform), the performance will be impeded significntly. Hence, instead of projecting satellite images to ground views, we introduce a Geometry-driven View Projection (GVP) module to transform ground-view images to overhead view.
Starting from a blank canvas in the overhead view with its center corresponds to the geospatial location of the query camera, we aim to fill it with features collected from ground-view images. We set the origin of the world coordinate system to the geo-spatial query camera location as well, with its -axis pointing to the south direction, axis pointing to the east direction, and the -axis vertically upward. Different ground-view images in a video sequence are projected to the same overhead-view coordinate system so that they are geographically aligned after projection. Fig. 3 provides a visual illustration of the coordinate systems.
Parallel projection of a satellite camera. The projection between the satellite image coordinate system and the world coordinate system can be approximated as a parallel projection [51], , where indicates the satellite map center, indicates the real-world distance between two neighboring pixels in the satellite map.
Perspective projection of ground-view images. Denote and as the rotation and translation for the camera at time step in the world coordinate, as the camera intrinsic, and as the sequence number. The relative and can be easily obtained by Structure from Motion [53]. The projection between the world coordinate system and the ground-view camera coordinate system is expressed as , where is a scale factor in the perspective projection.
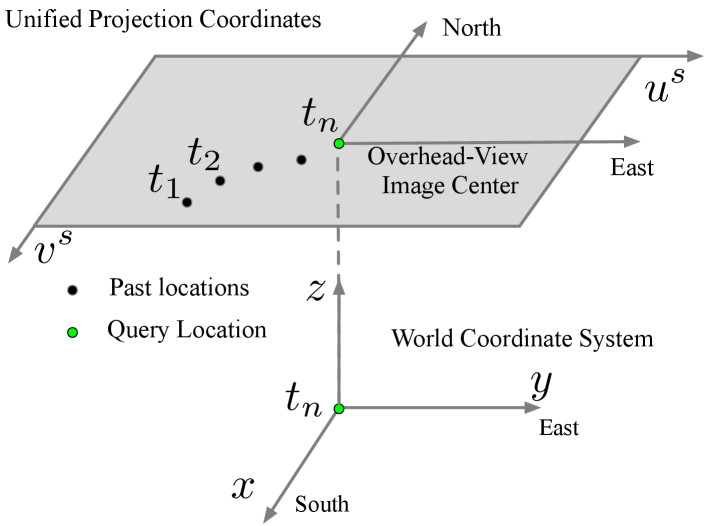
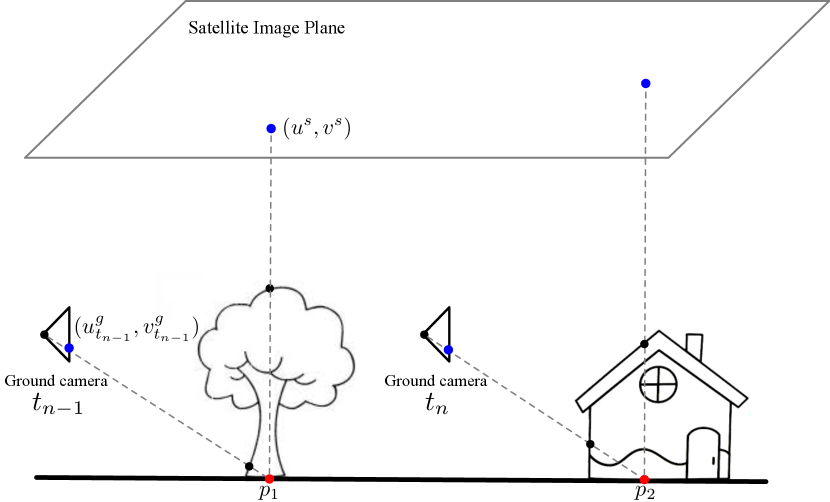
Ground-to-satellite projection. There is a height ambiguity of satellite pixels in the ground-to-satellite projection. Instead of explicitly estimating the heights, we present a simple yet effective solution. Specifically, we project ground-view observations to the overhead view assuming satellite pixels lie on the ground plane. Rather than projecting original image RGB pixels, we project high-level deep features. The geometric projection from the ground-view to the overhead-view is derived as,
| (1) |
where is the height of the query camera with respect to the ground plane, and can be computed from the above equation.
Denote as ground-view image features by a CNN backbone, where , and are the height, width and channels of the features, respectively, and as the geometry-driven view projection operation illustrated in Eq. (1). The projected features in overhead view are then obtained by , where indicates the overhead-view feature map resolution.
This projection establishes the exact geometric correspondences between the ground and overhead views for scene contents on the ground plane. For scene objects with higher heights, projecting features rather than image pixels can alleviate the strict constraint while providing a cue that corresponding objects exist between the views. As shown in Fig. 4, for pixel , the projected feature from the ground-view at represents the tree trunk, but the feature in the satellite image corresponds to the tree canopy. Both tree canopy and tree trunk indicate there is a tree at location . Then, by applying a matching loss between the two features (tree trunk and tree canopy), the network will be trained to learn viewpoint invariant features, i.e., both tree trunk and tree canopy are mapped to the semantic features of “tree”.
The coverage of the canvas for ground-to-satellite projection is set to the reference satellite image coverage, i.e., around , with its center corresponding to the query camera location. When the sequence is too long with some previous image contents exceeding the canvas’s pre-set coverage, the exceeded contents will not be collected. This is because scene contents that are too far from the query camera location are less important for localization, and it is better to cover most of the synthetic overhead-view feature map by referencing satellite images.
3.2 Photo-consistency constrained sequence fusion
We leverage photo consistency among different ground-views for the video sequence fusion. For a satellite pixel, when its corresponding features in several (more than two) ground views are similar, the existence of a scene object at this geographical location is highly reliable for these ground-views. We should highlight these corresponding features when generating descriptors for scene contents. Driven by this, we design a Photo-consistency Constrained Sequence Fusion (PCSF) module. Our PCSF module employs an attention mechanism [54] to emphasize reliable features in fusing a video sequence and obtaining a global descriptor for the video.
Our GVP block has aligned the original ground-view features at different time steps in a unified overhead-view coordinate. When the features of a geographical location observed by different ground views are similar, those features should be more reliable for localization. We leverage the self-attention mechanism [54] to measure the photo-consistency/similarity across different views and find reliable features. Specifically, for each projected feature map at time step , we compute its query, key and value by two stacked convolutional layers, denoted by , respectively. The stacked convolutional layers increase the receptive field and the representative ability of the key, query, and value features at each spatial location. Next, we compute the similarities between each projected feature map at and other projected feature maps at , , and normalize them across all possible by a softmax operation, expressed as,
| (2) |
The final fused feature is obtained by,
| (3) |
In this way, we highlight the common features across the views and make the global descriptor reliable.
3.3 Scene-prior driven similarity matching
We want to address the location misalignment between a query camera location and its matching satellite image center by ground-to-satellite projection and spatial correlation between the projected features and the real satellite features. Hence, the satellite feature descriptors should be translational equivariant, which is an inherent property of conventional CNNs. Following most previous works [2, 6, 7, 8, 11], we use VGG16 [55] as our backbone for satellite (and ground) feature extraction. The extracted satellite features, denoted as , share the same spatial scale as the global representation of the query video. Next, we adopt a Normalized spatial Cross-Correlation (NCC) to estimate latent alignment between the query location and a satellite image center.
Denote as a shifted version of a satellite feature map with its center at in the original satellite feature map, and correspond to the center of the original satellite feature map. The similarity between and aligned at computed by NCC is,
| (4) |
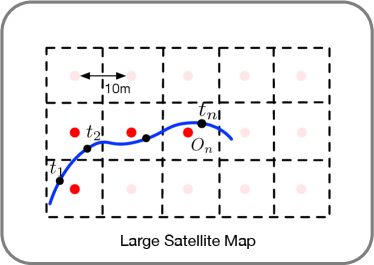
where denotes the similarity matrix between and at all possible spatial-aligned locations, , and . A potential spatial-aligned location of the satellite map lies in a region of in our KITTI-CVL dataset, as the database satellite image is collected very ten meters.
To exclude impossible query camera locations, e.g., top of trees, we estimate an uncertainty map from the satellite semantic features, , , where is the uncertainty net, composed of a set of convolutional layers. The value of each element in is within the range of , forced by a Sigmoid layer. By encoding the uncertainty, The similarity between and aligned at is then written as,
| (5) |
When the uncertainty at is large, the similarity between and aligned at this location will be decreased. We do not have explicit supervisions for the uncertainty map. Rather, it is learned statistically from training. The relative displacement between and is obtained by,
| (6) |
During inference, we have no idea which one is the matching reference image for a query image. Thus the uncertainty-guided similarity matching is applied to all reference features (including non-matching ones). Furthermore, it is more challenging when a similarity score between non-matching ground and satellite features is high. Hence, we apply the similarity matching scheme to the pairs of query and non-matching reference images as well during training and minimize their maximum similarity, making the learned features more discriminative.
3.4 Training objective
We employ the soft-weighted triplet loss [2] to train our network. The loss includes a positive term to maximize the similarity between the matching query and reference pairs and a negative term to minimize the similarity between non-matching pairs. The non-matching term also prevents our view projection module from trivial solutions. Therefore, it is formulated as,
| (7) |
where is the matching satellite image feature to the ground feature , is the non-matching satellite image feature, is the distance between its two inputs after alignment, and is set to 10.
4 The KITTI-CVL Dataset
KITTI is one of the widely used benchmark datasets for testing computer vision algorithms for autonomous driving [12]. In this paper, we intend to investigate a method for using a short video sequence for satellite image-based camera localization. For this purpose, we supplement the KITTI drive sequences with corresponding satellite images. This is done by cropping high-definition Google earth satellite images using the KITTI-provided GPS tags for vehicle trajectories. Based on these GPS tags of the ground-view images, we select a large region that covers the vehicle trajectory. We then uniformly partition the region into overlapping satellite image patches. Each satellite image patch has a resolution of pixels, amounting to about 20 cm per pixel.
Training, Validation and Test sets. The KITTI data contains different trajectories captured at different time. In our Training, Validation and Test set split, the images of Training and Validation set are from the same region. The Validation set is constructed in this way to select the best model during training. In contrast, the images in the test set are captured at different regions from the Training and Validation sets. The test set aims to evaluate the generalization ability of the compared algorithms.
Only the nearest satellite image for each ground image in the sampled grids is retained for the Training and Validation set. We use the same method to construct our first test set, Test-1. Furthermore, we construct the second test set, Test-2, where all satellite images in the sampled grids are reserved. In other words, Test-2 contains many distracting satellite images, and it considers the real deployment scenario compared to Test-1. Visual illustrations of the differences between Test-1 and Test-2 are provided in the supplementary material. Tab. 1 presents the query ground image numbers of the Training, Validation, Test-1, and Test-2 sets.
| Training | Validation | Test-1 | Test-2 | |
|---|---|---|---|---|
| Distractor | ✗ | ✗ | ✗ | ✓ |
| Query Num | 23,905 | 2,362 | 2,473 | 2,473 |
5 Experiments
Evaluation metrics. Following the previous cross-view localization work [3], we use the distance and recall at top () for the performance evaluation. Specifically, when one of the retrieved top reference images is within meters to the query ground location, it is regarded as a successful localization. The percentage of successfully localized query images is recorded as recall at top . we set to , , and , respectively.
Implementation details. The input satellite image size is , center cropped from the collected images. The coverage of them is approximately . The ground image resolution is . The sizes of our global descriptor for query videos and satellite images are both , which is a typical descriptor dimension in image retrieval. We follow prior arts [2, 3, 4, 5, 6, 7, 8, 9, 10, 11] to adopt an exhaustive mini-batch strategy [1] with a batch size of to prepare the training triplets. The Adam optimizer [56] with a learning rate of is employed, and our network is trained end-to-end with five epochs. Our source code with every detail will be released, and the satellite images will be available for research purposes only and upon request.
| Model Size | Test-1 | Test-2 | |||||||||
| r@1 | r@5 | r@10 | r@100 | r@1 | r@5 | r@10 | r@100 | ||||
| View Projection | Ours w/o GVP (Unet) | 66.4M | 0.08 | 0.61 | 1.70 | 26.24 | 0.00 | 0.00 | 0.00 | 1.09 | |
| Ours w/o GVP | 66.2M | 1.66 | 4.33 | 7.97 | 36.35 | 0.04 | 0.16 | 0.20 | 5.22 | ||
| Direct Fusion | Conv2D | 66.0M | 1.25 | 5.90 | 10.80 | 65.91 | 8.90 | 18.44 | 26.61 | 76.51 | |
| Conv3D | 66.0M | 15.08 | 41.57 | 53.17 | 93.09 | 7.00 | 20.38 | 30.33 | 75.90 | ||
| LSTM | 66.2M | 12.53 | 32.11 | 50.42 | 96.93 | 5.78 | 15.89 | 23.01 | 70.60 | ||
| Attention based Fusion | Conv2D | 66.0M | 18.80 | 47.03 | 61.75 | 96.64 | 11.69 | 25.03 | 36.55 | 81.52 | |
| Conv3D | 66.0M | 19.65 | 43.27 | 58.39 | 97.41 | 11.36 | 24.02 | 34.45 | 83.58 | ||
| LSTM | 66.1M | 15.93 | 47.88 | 66.03 | 97.61 | 9.70 | 24.30 | 35.26 | 85.08 | ||
| Ours | 66.2M | 21.80 | 47.92 | 64.94 | 99.07 | 12.90 | 27.34 | 38.62 | 85.00 | ||
5.1 Cross-view video-based localization
Since there are no existing video-based cross-view localization algorithms, we conduct extensive experiments to dissect the effectiveness and necessity of each component in our framework.
5.1.1 Geometry-driven view projection.
Although our GVP module is the basis for the following sequence fusion and similarity matching steps, we investigate whether it can be replaced or removed. We first replace it with an Unet and expect the domain correspondences can be learned implicitly during training, denoted as “Ours w/o GVP (Unet)”. Next, we remove it from our pipeline and directly feed the original ground-view features to our sequence fusion module, denoted as “Ours w/o GVP”. As indicated by the results in Tab. 2, the performance of the two baselines is significantly inferior to our whole pipeline, demonstrating the necessity of our geometry-driven view projection module.
Learned viewpoint-invariant semantic features. To fully understand the capability of our view projection module, we visualize the learned viewpoint-invariant semantic features of our network by using the techniques of Grad-Cam [57]. As seen in Fig. 5, salient features on roads and roads edges are successfully recognized in ground-view images (Fig. 5(a)). The detected salient features in satellite images also concentrate on roads and scene objects along roads edges (Fig. 5(b)). By using our view projection module and the photo-consistency constrained sequence fusion mechanism, the learned global representations of the ground video (Fig. 5(c)) capture similar scene patterns to those of their matching satellite counterparts (Fig. 5(d)).

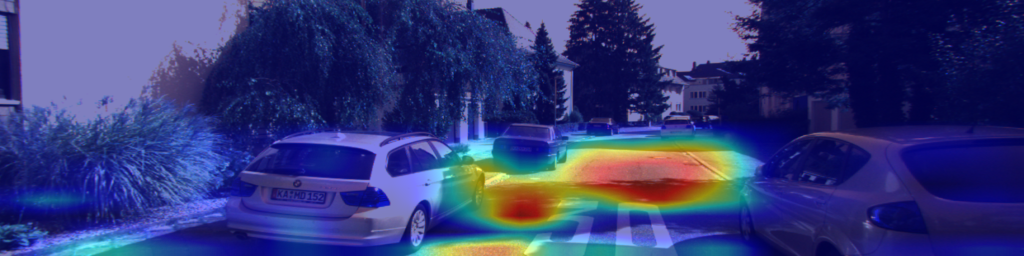


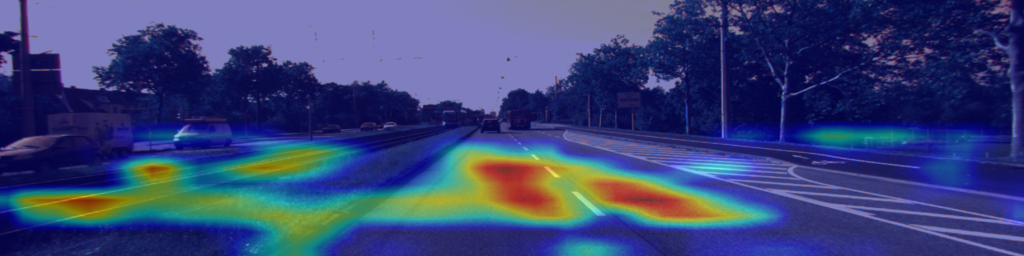















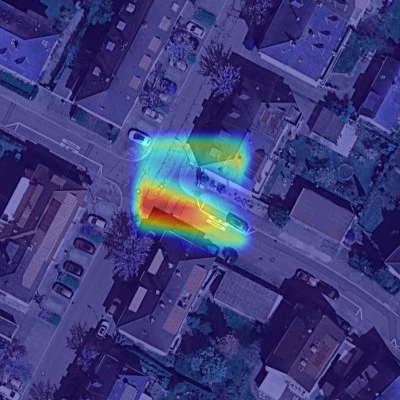


5.1.2 Photo-consistency constrained sequence fusion.
Our goal is to synthesize an overhead-view feature map from a query ground video. To this end, our PCSF module measures the photo consistency for each overhead view pixel across different ground-view images and fuses them with an attention-based (transformer) architecture. Apart from this design, LSTM (RNNs) and 3D CNNs are also known for their power to handle sequential signals. Hence, we compare with these architectures. For completeness, we also experiment with 2D CNNs.
Direct fusion. We first replace our PCSF module with Conv2D, Conv3D, and LSTM based networks, respectively. The Conv2D-based fusion network takes the projected sequential ground-view features separately and computes the average of the outputs of different time steps. The Conv3D-based fusion network uses its third dimension to operate on the temporal dimension. The LSTM-based network includes two bidirectional LSTM layers to enhance the sequential relationship encoding. The outputs of the Conv3D-based and the LSTM-based networks are both directly fused features for the query video. The results are presented in the middle part of Tab. 2. It can be seen that the performance is significantly inferior to ours.
Attention-based fusion. Based on the above observations, we infer that it may be difficult for a network to fuse a sequence of features implicitly. Hence, we employ the Conv2D, Conv3D, and LSTM based network to regress the attention weights for the projected features at different time steps, denoted as . Then, the global query descriptor is obtained by a dot product between the attention weight and the features . The results are presented in the bottom part of Tab. 2. It can be seen that the attention-based fusion methods all outperform the direct fusion methods, indicating that the attention-based decomposition helps to achieve better performance. Among the attention-based fusion ablations, our method achieves the best overall performance. This should be attributed to the explicit photo consistency computation across different ground-views by our PCSF module.
5.1.3 Different choices for network backbone.
In this section, we conduct ablation study on different network backbones, including Vision transformer (ViT) [58], Swin transformer [59], Renet50 [60] and VGG16 [55](ours). Transformers are known of their superior feature extraction ability than CNNs. However, they do not preserve the translational equivariance ability, which however is an essential element in estimating the relative displacement between query camera locations and their matching satellite image centers. Thus, transformers achieve slightly worse performance than CNNs, as indicated by Tab. 3. Compared to VGG16, Resnet50 does not make significant improvement. Hence, following most previous works [2, 6, 7, 8, 11], we use VGG16 as our network backbone.
| Test-1 | Test-2 | |||||||
|---|---|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@100 | r@1 | r@5 | r@10 | r@100 | |
| ViT [58] | 20.05 | 45.13 | 60.17 | 97.53 | 12.86 | 27.94 | 38.86 | 81.64 |
| Swin [59] | 18.40 | 47.80 | 63.73 | 99.11 | 12.29 | 22.31 | 35.29 | 80.70 |
| Resnet [60] | 22.68 | 55.16 | 67.69 | 97.90 | 9.75 | 28.31 | 38.45 | 73.72 |
| VGG16 [55] (Ours) | 21.80 | 47.92 | 64.94 | 99.07 | 12.90 | 27.34 | 38.62 | 85.00 |
| Test-1 | Test-2 | |||||||
|---|---|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@100 | r@1 | r@5 | r@10 | r@100 | |
| Ours w/o SSM | 6.35 | 25.76 | 41.97 | 97.61 | 3.48 | 9.42 | 14.03 | 63.04 |
| Ours w/o U | 13.26 | 36.76 | 55.72 | 97.05 | 10.47 | 27.42 | 39.51 | 88.92 |
| Ours | 21.80 | 47.92 | 64.94 | 99.07 | 12.90 | 27.34 | 38.62 | 85.00 |
5.1.4 Scene-prior driven similarity matching.
Next, we study whether the NCC-based similarity matching can be removed. In this experiment, the distance between the satellite features and the fused ground-view features is directly computed without estimating their potential alignments. Instead, they are assumed to be aligned at the satellite image center. The results are presented in the first row of Tab. 4. The performance drops significantly compared to our whole baseline, demonstrating that the network does not have the ability to tolerate the spatial shifts between query camera locations, and our explicit alignment strategy (NCC-based similarity matching) is effective.
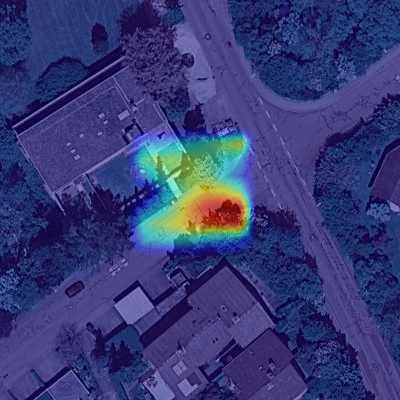
Furthermore, we investigate the effectiveness of the learned scene prior by the uncertainty map (Eq. 5). To do so, we remove the term of uncertainty map in Eq. (5), denoted as “Ours w/o U”. The results in the second row of Tab. 4 indicates the learned uncertainty map boosts the localization performance. Fig. 5(e) visualizes the generated confidence maps (inverse of uncertainty) by our method. It can be seen that the higher confidence regions mainly concentrate on roads, indicating that the confidence maps successfully encode the semantic information of satellite images and recognize the correct possible regions for a vehicle location.




559 m

10811 m

9479 m

3 m

1 m

10802 m

9363 m

7 m

5990 m

10808 m

10901 m

5990 m

5995 m

9 m

7 m

5939 m

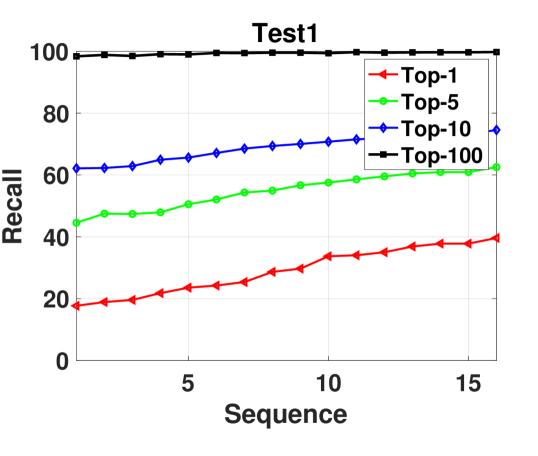
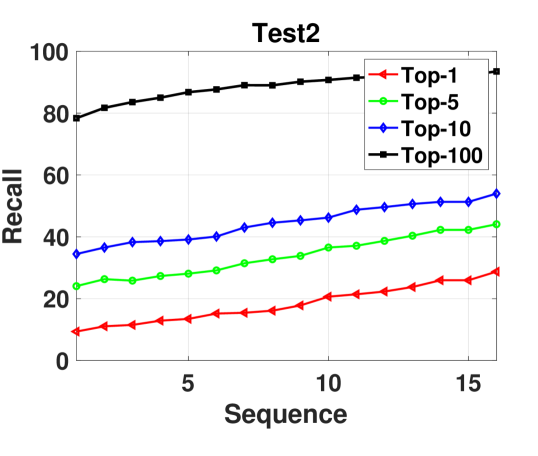
5.1.5 Varying sequence lengths.
One desired property for a video-based localization method is to be robust to various input video lengths after a model is trained. Hence, we investigate the performance of our method on different query video sequences (1-16) using a model trained on sequence 4. Fig. 6 shows that the performance increases elegantly with the increase in number of video sequences. This confirms our general intuition that more input images will increase the discriminativeness of the query place and help boost the localization performance. Note that when keep increasing the sequence length until the cameras at previous time steps exceed the pre-set coverage of the projected features, the performance will not increase but stay same because we did not fuse exceeded information. Scene contents too far from the query camera location are also less useful for localization.
When only using one image for localization, the feature extraction time for a query descriptor is s. With the increasing of sequence numbers, the query descriptor extraction time increases linearly. We expect this can be accelerated by parallel computation. The retrieval time for each ground image on Test-2 is around 3ms, and the coverage of satellite images in Test-2 is about . It takes 8GB GPU memory when the sequence=4 and 24GB when the sequence=16. We show some qualitative examples of retrieved results in Fig. 7 using sequence number 4.
5.2 Single image-based localization
Single image-based localization is a special case of video-based localization, i.e., when the image frame count in the video is one. In this section, we compare the performance of our method with the recent state-of-the-art (SOTA) that are invented for cross-view single image-based localization, including CVM-NET [2], CVFT [7], SAFA [6], Polar-SAFA [6], DSM [8], Zhu et al. [11], and Toker et al. [10]. The results are presented in Tab. 5. It can be seen that our method significantly outperforms the recent SOTA algorithms.
Among the compared algorithms, DSM [8] achieves the best performance, because it explicitly addresses the challenge of limited FoV problem of query images while the others assume that query images are full FoV panoramas. By comparing SAFA and Polar-SAFA, we can observe that the polar transform boosts the performance on Test-1 (one-to-one matching) while impairs the performance on Test-2 (one-to-many matching). This is consistent with the conclusion in Shi et al. [6] and Zhu et al. [11].
Based on SAFA, Zhu et al. [11] proposes two training losses: (1) an IoU loss and (2) a GPS loss. However, we do not found the two items work well on the KITTI-CVL dataset. We guess that the IoU loss is only suitable for the panorama case. The limited FoV images in the KITTI-CVL dataset have a smaller overlap with satellite images than panoramas, and thus the original IoU loss may not provide correct guidance for training. The GPS loss does not help mainly because of the inaccuracy of the GPS data in our dataset. We provide the GPS accuracy analysis of the KITTI dataset in the supplementary material. In contrast, our method does not rely on the accurate GPS tags of ground or satellite images.
| Method | Test-1 | Test-2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@100 | r@1 | r@5 | r@10 | r@100 | ||
| CVM-NET [2] | 6.43 | 20.74 | 32.47 | 84.07 | 1.01 | 4.33 | 7.52 | 32.88 | |
| CVFT [7] | 1.78 | 7.20 | 14.40 | 73.55 | 0.20 | 1.29 | 3.03 | 16.86 | |
| SAFA [6] | 4.89 | 15.77 | 23.29 | 87.75 | 1.62 | 4.73 | 7.40 | 30.13 | |
| Polar-SAFA [6] | 6.67 | 17.06 | 27.62 | 86.53 | 1.13 | 3.76 | 6.23 | 28.22 | |
| DSM [8] | 13.18 | 41.16 | 58.67 | 97.17 | 5.38 | 18.12 | 28.63 | 75.70 | |
| Zhu et al. [11] | 5.26 | 17.79 | 28.22 | 88.44 | 0.73 | 3.28 | 5.66 | 27.86 | |
| Toker et al. [10] | 2.79 | 7.72 | 11.69 | 58.92 | 2.39 | 5.50 | 8.90 | 27.05 | |
| Ours | 17.71 | 44.56 | 62.15 | 98.38 | 9.38 | 24.06 | 34.45 | 85.00 | |
| CVUSA | CVACT | ||||||||
| SAFA[6] | Polar-SAFA[6] | DSM[8] | Zhu et al.[11] | Ours | SAFA[6] | Polar-SAFA[6] | DSM[8] | Zhu et al.[11] | Ours |
| 68.03 | 72.15 | 63.17 | 53.77 | 72.75 | 56.69 | 62.71 | 55.07 | 49.45 | 66.30 |
CVUSA & CVACT. Our method applies to panoramas as long as camera parameters are given. However, they are not available in the existing panorama datasets, e.g., CVUSA and CVACT. Furthermore, the matching satellite image centers align precisely with query locations in the two datasets, which is not in practice. To make the experiments meaningful, we (i) approximate the camera parameters of the two datasets by visual and geometry verifications; and (ii) randomly translate satellite images (0-36 pixels) to make their centers not aligned with query locations. Results are shown in Tab. 6. It can be seen our method outperforms SOTA methods. The SOTA results are inferior to that in their original paper because of the practical setting (as in (ii)).
5.3 Limitations
Our method assumes that the north direction is provided by a compass, following previous works [3, 6, 8, 10, 11], and the absolute scale of camera translations can be estimated roughly from the vehicle velocity. We have not investigated how significant tilt and roll angle changes will affect the performance, because the tilt and roll angles in the KITTI dataset are very small and we set them to zero. In autonomous driving scenarios, the vehicle-mounted cameras are usually perpendicular to the ground plane. Thus there are only slight changes in tilt and toll during driving.
6 Conclusions
This paper introduced a novel geometry-driven semantic correspondence learning approach for cross-view video-based localization. Our method includes a Geometry-driven View Projection block to bridge the cross-view domain gap, a Photo-consistency Constrained Sequence Fusion module to aggregate the sequential ground-view observations and a Scene-prior driven similarity matching mechanism to determine the location of a ground camera with respect to a satellite image center. Benefiting from the proposed components, we demonstrate that using a video rather than a single image for localization significantly facilitates the localization performance considerably.
References
- [1] Vo, N.N., Hays, J.: Localizing and orienting street views using overhead imagery. In: European Conference on Computer Vision, Springer (2016) 494–509
- [2] Hu, S., Feng, M., Nguyen, R.M.H., Hee Lee, G.: Cvm-net: Cross-view matching network for image-based ground-to-aerial geo-localization. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (2018)
- [3] Liu, L., Li, H.: Lending orientation to neural networks for cross-view geo-localization. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (2019)
- [4] Regmi, K., Shah, M.: Bridging the domain gap for ground-to-aerial image matching. In: The IEEE International Conference on Computer Vision (ICCV). (2019)
- [5] Cai, S., Guo, Y., Khan, S., Hu, J., Wen, G.: Ground-to-aerial image geo-localization with a hard exemplar reweighting triplet loss. In: The IEEE International Conference on Computer Vision (ICCV). (2019)
- [6] Shi, Y., Liu, L., Yu, X., Li, H.: Spatial-aware feature aggregation for image based cross-view geo-localization. In: Advances in Neural Information Processing Systems. (2019) 10090–10100
- [7] Shi, Y., Yu, X., Liu, L., Zhang, T., Li, H.: Optimal feature transport for cross-view image geo-localization. In: AAAI. (2020) 11990–11997
- [8] Shi, Y., Yu, X., Campbell, D., Li, H.: Where am I looking at? joint location and orientation estimation by cross-view matching. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (2020) 4064–4072
- [9] Zhu, S., Yang, T., Chen, C.: Revisiting street-to-aerial view image geo-localization and orientation estimation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. (2021) 756–765
- [10] Toker, A., Zhou, Q., Maximov, M., Leal-Taixé, L.: Coming down to earth: Satellite-to-street view synthesis for geo-localization. CVPR (2021)
- [11] Zhu, S., Yang, T., Chen, C.: Vigor: Cross-view image geo-localization beyond one-to-one retrieval. CVPR (2021)
- [12] Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. The International Journal of Robotics Research 32 (2013) 1231–1237
- [13] (https://developers.google.com/maps/documentation/maps-static/overview)
- [14] Arandjelovic, R., Gronat, P., Torii, A., Pajdla, T., Sivic, J.: Netvlad: Cnn architecture for weakly supervised place recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2016) 5297–5307
- [15] Kim, H.J., Dunn, E., Frahm, J.M.: Learned contextual feature reweighting for image geo-localization. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE (2017) 3251–3260
- [16] Liu, L., Li, H., Dai, Y.: Stochastic attraction-repulsion embedding for large scale image localization. In: Proceedings of the IEEE International Conference on Computer Vision. (2019) 2570–2579
- [17] Noh, H., Araujo, A., Sim, J., Weyand, T., Han, B.: Large-scale image retrieval with attentive deep local features. In: Proceedings of the IEEE international conference on computer vision. (2017) 3456–3465
- [18] Ge, Y., Wang, H., Zhu, F., Zhao, R., Li, H.: Self-supervising fine-grained region similarities for large-scale image localization. In: European Conference on Computer Vision, Springer (2020) 369–386
- [19] Zhou, Y., Wan, G., Hou, S., Yu, L., Wang, G., Rui, X., Song, S.: Da4ad: End-to-end deep attention-based visual localization for autonomous driving. In: European Conference on Computer Vision, Springer (2020) 271–289
- [20] Castaldo, F., Zamir, A., Angst, R., Palmieri, F., Savarese, S.: Semantic cross-view matching. In: Proceedings of the IEEE International Conference on Computer Vision Workshops. (2015) 9–17
- [21] Lin, T.Y., Belongie, S., Hays, J.: Cross-view image geolocalization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2013) 891–898
- [22] Mousavian, A., Kosecka, J.: Semantic image based geolocation given a map. arXiv preprint arXiv:1609.00278 (2016)
- [23] Tian, Y., Chen, C., Shah, M.: Cross-view image matching for geo-localization in urban environments. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2017) 3608–3616
- [24] Hu, S., Lee, G.H.: Image-based geo-localization using satellite imagery. International Journal of Computer Vision 128 (2020) 1205–1219
- [25] Shi, Y., Yu, X., Liu, L., Campbell, D., Koniusz, P., Li, H.: Accurate 3-dof camera geo-localization via ground-to-satellite image matching. arXiv preprint arXiv:2203.14148 (2022)
- [26] Zhu, S., Shah, M., Chen, C.: Transgeo: Transformer is all you need for cross-view image geo-localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). (2022) 1162–1171
- [27] Elhashash, M., Qin, R.: Cross-view slam solver: Global pose estimation of monocular ground-level video frames for 3d reconstruction using a reference 3d model from satellite images. ISPRS Journal of Photogrammetry and Remote Sensing 188 (2022) 62–74
- [28] Guo, Y., Choi, M., Li, K., Boussaid, F., Bennamoun, M.: Soft exemplar highlighting for cross-view image-based geo-localization. IEEE Transactions on Image Processing 31 (2022) 2094–2105
- [29] Zhao, J., Zhai, Q., Huang, R., Cheng, H.: Mutual generative transformer learning for cross-view geo-localization. arXiv preprint arXiv:2203.09135 (2022)
- [30] Bloesch, M., Omari, S., Hutter, M., Siegwart, R.: Robust visual inertial odometry using a direct ekf-based approach. In: 2015 IEEE/RSJ international conference on intelligent robots and systems (IROS), IEEE (2015) 298–304
- [31] Leutenegger, S., Lynen, S., Bosse, M., Siegwart, R., Furgale, P.: Keyframe-based visual–inertial odometry using nonlinear optimization. The International Journal of Robotics Research 34 (2015) 314–334
- [32] Chien, H.J., Chuang, C.C., Chen, C.Y., Klette, R.: When to use what feature? sift, surf, orb, or a-kaze features for monocular visual odometry. 2016 International Conference on Image and Vision Computing New Zealand (IVCNZ) (2016) 1–6
- [33] Cadena, C., Carlone, L., Carrillo, H., Latif, Y., Scaramuzza, D., Neira, J., Reid, I., Leonard, J.J.: Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Transactions on robotics 32 (2016) 1309–1332
- [34] Engel, J., Schöps, T., Cremers, D.: Lsd-slam: Large-scale direct monocular slam. In: European conference on computer vision, Springer (2014) 834–849
- [35] Klein, G., Murray, D.: Parallel tracking and mapping for small ar workspaces. In: 2007 6th IEEE and ACM international symposium on mixed and augmented reality, IEEE (2007) 225–234
- [36] Mur-Artal, R., Montiel, J.M.M., Tardos, J.D.: Orb-slam: a versatile and accurate monocular slam system. IEEE transactions on robotics 31 (2015) 1147–1163
- [37] Mur-Artal, R., Tardós, J.D.: Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE transactions on robotics 33 (2017) 1255–1262
- [38] Campos, C., Elvira, R., Rodríguez, J.J.G., Montiel, J.M., Tardós, J.D.: Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Transactions on Robotics (2021)
- [39] Mur-Artal, R., Tardós, J.D.: Visual-inertial monocular slam with map reuse. IEEE Robotics and Automation Letters 2 (2017) 796–803
- [40] Wolcott, R.W., Eustice, R.M.: Visual localization within lidar maps for automated urban driving. 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems (2014) 176–183
- [41] Voodarla, M., Shrivastava, S., Manglani, S., Vora, A., Agarwal, S., Chakravarty, P.: S-bev: Semantic birds-eye view representation for weather and lighting invariant 3-dof localization (2021)
- [42] Stenborg, E., Toft, C., Hammarstrand, L.: Long-term visual localization using semantically segmented images. In: 2018 IEEE international conference on robotics and automation (ICRA), IEEE (2018) 6484–6490
- [43] Stenborg, E., Sattler, T., Hammarstrand, L.: Using image sequences for long-term visual localization. In: 2020 International Conference on 3D Vision (3DV), IEEE (2020) 938–948
- [44] Vaca-Castano, G., Zamir, A.R., Shah, M.: City scale geo-spatial trajectory estimation of a moving camera. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition, IEEE (2012) 1186–1193
- [45] Regmi, K., Shah, M.: Video geo-localization employing geo-temporal feature learning and gps trajectory smoothing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. (2021) 12126–12135
- [46] Yousif, K., Bab-Hadiashar, A., Hoseinnezhad, R.: An overview to visual odometry and visual slam: Applications to mobile robotics. Intelligent Industrial Systems 1 (2015) 289–311
- [47] Scaramuzza, D., Fraundorfer, F.: Visual odometry [tutorial]. IEEE Robotics & Automation Magazine 18 (2011) 80–92
- [48] Gao, X., Wang, R., Demmel, N., Cremers, D.: Ldso: Direct sparse odometry with loop closure. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE (2018) 2198–2204
- [49] Kasyanov, A., Engelmann, F., Stückler, J., Leibe, B.: Keyframe-based visual-inertial online slam with relocalization. In: 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), IEEE (2017) 6662–6669
- [50] Liu, D., Cui, Y., Guo, X., Ding, W., Yang, B., Chen, Y.: Visual localization for autonomous driving: Mapping the accurate location in the city maze (2020)
- [51] Shi, Y., Campbell, D.J., Yu, X., Li, H.: Geometry-guided street-view panorama synthesis from satellite imagery. IEEE Transactions on Pattern Analysis and Machine Intelligence (2022)
- [52] Shi, Y., Li, H.: Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (2022) 17010–17020
- [53] Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2016) 4104–4113
- [54] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems. (2017) 5998–6008
- [55] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. CoRR abs/1409.1556 (2014)
- [56] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
- [57] Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad-cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). (2017)
- [58] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
- [59] Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. (2021) 10012–10022
- [60] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. (2016) 770–778
Appendix 0.A Dataset Statistics
In this section, we provide more illustrations of the introduced KITTI-CVL dataset. Fig. 8 presents an overview of the sampling distributions of the training and testing sets, where training images are captured from the red area, and testing images are sampled in the blue region. The training and testing sets do not overlap. The Validation set is sampled from the same area of the training set.

lat = 49.025527549337
lon = 8.4485623653485

lat = 49.025527483717
lon = 8.4485623463895

lat = 49.025527419798
lon = 8.4485623793197

Ground Image

Satellite Image


Ground Image


Projected Image
Satellite Image
Differences between Test-1 and Test-2. Our two test sets, i.e., Test-1 and Test-2, share the same query ground images. Their differences lie in satellite images in the database. As shown in the left of Fig. 9, in Test-1, only the nearest satellite image of each query image is retained in the database. While in Test-2, all the satellite images within the large area are reserved. Test-2 has more distracting images in the database and thus is a more challenging test set than Test-1.
GPS noise. We found there is slight noise in the GPS raw data provided by KITTI. For example, as shown in Fig. 11, the ground camera is not moving, while the provided GPS data varies for these images. Fig. 11 presents another example where the camera is expected to be on the road while the camera location provided by the GPS data is on top of the vegetation area. We guess those minor errors make the GPS loss proposed in Zhu et al. [51] not work well in the KITTI-CVL dataset.
| Method | Test-1 | Test-2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@100 | r@1 | r@5 | r@10 | r@100 | ||
| Ours (GVP on Img) | 1.33 | 5.82 | 10.23 | 54.14 | 0.16 | 0.36 | 0.93 | 13.18 | |
| Ours w/o High Objects | 2.35 | 6.67 | 10.76 | 52.45 | 0.65 | 2.71 | 3.80 | 23.49 | |
| Ours | 21.80 | 47.92 | 64.94 | 99.07 | 12.90 | 27.34 | 38.62 | 85.00 | |
Appendix 0.B Additional Illustrations and Experiments
To better illustrate that GVP is able to project ground-view images following the geometric constraints, we apply the GVP to the original ground-view images, as shown in Fig. 12. It can be seen that pixels on the ground plane have been successfully restored in the overhead view. While for pixels above the ground plane, they undergo obvious distortions. Hence, we apply the GVP to feature level rather than image level in our framework. The high-level features are expected to establish semantic correspondences between the two views and circumvent the side effects of distortions in projection. We provide the performance of applying GVP to image level in the first row of Tab. 7, denoted as “Ours (GVP on Img)”. Not surprisingly, it is significantly inferior to Ours, where the GVP is applied to the feature level.
Next, we use semantic maps to filter out the scene objects above the ground plane, e.g., buildings, trees, sky, etc. from the input ground-view images, and feed the processed images to our network, denoted as “Ours w/o High Objects”. Fig. 13 shows the comparison between the original ground-view images and the processed images. The performance of “Ours w/o High Objects” is presented in the second row of Tab. 7. It can be seen that the performance is also worse than ours, indicating that our GVP module on feature level successfully encodes information of scene objects that have higher heights.




| Seq | Test-1 | Test-2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Direct Fusion | Conv2D | 1 | 1.98 | 5.30 | 9.50 | 60.01 | 7.60 | 18.48 | 26.49 | 72.71 |
| 4 | 1.25 | 5.90 | 10.80 | 65.91 | 8.90 | 18.44 | 26.61 | 76.51 | ||
| LSTM | 1 | 7.44 | 22.16 | 35.06 | 93.97 | 3.36 | 9.87 | 16.17 | 64.46 | |
| 4 | 12.53 | 32.11 | 50.42 | 96.93 | 5.78 | 15.89 | 23.01 | 70.60 | ||
| Attention-based Fusion | Conv2D | 1 | 15.37 | 41.16 | 56.98 | 95.79 | 9.18 | 20.58 | 30.53 | 76.83 |
| 4 | 18.80 | 47.03 | 61.75 | 96.64 | 11.69 | 25.03 | 36.55 | 81.52 | ||
| LSTM | 1 | 11.69 | 37.28 | 56.65 | 96.44 | 7.04 | 18.16 | 26.57 | 79.09 | |
| 4 | 15.93 | 47.88 | 66.03 | 97.61 | 9.70 | 24.30 | 35.26 | 85.08 | ||
| Ours | 1 | 17.71 | 44.56 | 62.15 | 98.38 | 9.38 | 24.06 | 34.45 | 78.37 | |
| 4 | 21.80 | 47.92 | 64.94 | 99.07 | 12.90 | 27.34 | 38.62 | 85.00 | ||
| Test-1 | Test-2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Ours w/ height estimation | 21.57 | 47.41 | 65.16 | 98.30 | 12.15 | 26.70 | 38.72 | 84.95 | |
| Ours w/o height estimation | 21.80 | 47.92 | 64.94 | 99.07 | 12.90 | 27.34 | 38.62 | 85.00 | |
We also add the baseline results with a sequence number as one for all the sequence fusion alternatives illustrated in Sec. 5.1.2 in the main paper, as shown in Tab. 8. Note that “Conv3D” is the same as “Conv2D” when sequence=1. The results indicate that using a longer sequence generally helps achieve better performance. Furthermore, we tried to borrow ideas from MVS to estimate overhead-view satellite image height maps from sequential ground view images. The comparison results between with and without height estimation are shown in Tab. 9. There are no significant differences in the final results, but height estimation introduces more computation and memory. Hence, we do not include height estimation in our final method but use the ground-plane assumption in the projection.