Cyber Mobility Mirror for Enabling Cooperative Driving Automation in Mixed Traffic:
A Co-Simulation Platform
Abstract
Endowed with automation and connectivity, Connected and Automated Vehicles are meant to be a revolutionary promoter for Cooperative Driving Automation. Nevertheless, CAVs need high-fidelity perception information on their surroundings, which is available but costly to collect from various onboard sensors as well as vehicle-to-everything (V2X) communications. Therefore, authentic perception information based on high-fidelity sensors via a cost-effective platform is crucial for enabling CDA-related research, e.g., cooperative decision-making or control. Most state-of-the-art traffic simulation studies for CAVs rely on the situation-awareness information by directly calling on intrinsic attributes of the objects, which impedes the reliability and fidelity of the assessment of CDA algorithms. In this study, a Cyber Mobility Mirror (CMM) Co-Simulation Platform is designed for enabling CDA by providing authentic perception information. The CMM Co-Simulation Platform can emulate the real world with a high-fidelity sensor perception system and a cyber world with a real-time rebuilding system acting as a “Mirror” of the real-world environment. Concretely, the real-world simulator is mainly in charge of simulating the traffic environment, sensors, as well as the authentic perception process. The mirror-world simulator is responsible for rebuilding objects and providing their information as intrinsic attributes of the simulator to support the development and evaluation of CDA algorithms. To illustrate the functionality of the proposed co-simulation platform, a roadside LiDAR-based vehicle perception system for enabling CDA is prototyped as a study case. Specific traffic environments and CDA tasks are designed for experiments whose results are demonstrated and analyzed to show the performance of the platform.
Index Terms:
Co-Simulation Platform; Connected and Automated Vehicles; Cooperative Driving Automation; 3D Object Detection.I Introduction
With rapid development of the economy and society, the field of transportation is facing several major challenges caused by drastically increased traffic demands, such as improving traffic safety, mitigating traffic congestion, and reducing mobile source emissions. Cooperative Driving Automation (CDA) enabled by Connected and Automated Vehicles (CAVs) is regarded as a promising solution to the aforementioned challenges [1]. In the past few decades, several projects have been conducted to explore the potential of CDA. The California PATH program [2] demonstrated the improvement of traffic throughput by an automated platoon utilizing connectivity. The European DRIVE C2X project [3] assessed the cooperative system by large-scale field operational tests of various connected vehicle applications. Fujitsu has launched a Digital Twin platform for supporting mobility by connectivity and artificial intelligence [4]. These projects have demonstrated CDA to be a transformative path toward the next-generation transportation system, which is enabled by ubiquitous perception, seamless communication, and advanced artificial intelligence technologies.
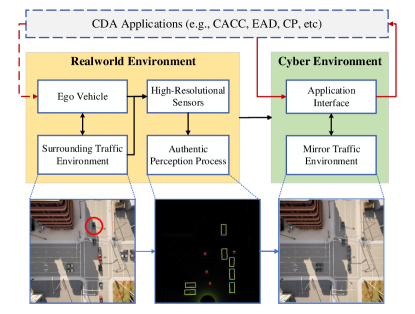
Given the fact that the cost of large-scale real-world deployment is prohibitive, it is imperative to design and assess CDA systems based on simulation. For instance, as one key component of a CDA system, connected and automated vehicle (CAV) technologies heavily rely on simulation to comprehensively assess their performance in terms of safety, efficiency, and environmental sustainability. Therefore, simulation platforms for CDA are of great significance and their development receives much attention.
Additionally, to enable CDA, accurate perception information can lay a solid foundation, which requires inputs from different types of high-fidelity sensors, such as radar, camera, and LiDAR. Direct implementation of these sensors to perceive the real-world environment may be costly or time-consuming, and in some cases, restricted by application scenarios. Thus, simulation platforms with high-fidelity sensor modeling and perception capability would provide a cost-effective alternative solution to CDA-related research.
Many existing traffic simulators have been developed to test various aspects of CDA. For instance, CARLA [5] and SVL [6] are designed for modeling autonomous vehicles (AVs), while SUMO [7] targets microscopic traffic flows. From the perspective of sensing fidelity, most existing studies directly use intrinsic attributes of target objects, without considering the potential imperfection of perception for CDA models. This considerably limits the transferability and reliability of the real-world deployment of these CDA models. To the best of our knowledge, this paper is the first attempt to integrate the entire deep learning-based perception pipeline into the simulator to create a cyber mobility mirror (CMM) system, in which simulated traffic objects are authentically perceived and reconstructed with 3D representation. The high-level CDA model can leverage such perceived information from the module output in a CMM system rather than intrinsic attributes of target objects, to improve model fidelity and validate the system with more confidence.
The systematic structure of CMM based on a co-simulation platform is shown in Figure 1, where one simulator is designed to model the real-world traffic environment and the authentic perception pipeline, while the other simulator is used to work as a mobility mirror, i.e., reconstructing the perceived objects and presenting them. The output interface provides readily retrieved post-perception data for CDA applications.
The main contributions of the paper can be summarized as follows: 1) This paper proposes a cyber mobility mirror (CMM) architecture for enabling CDA research and development; 2) A prototype CMM system is designed and developed using a CARLA-based co-simulation platform; 3) A CARLA-based 3D object detection training dataset is presented; and 4) Based on the CMM co-simulation platform, a case study is conducted for roadside-LiDAR based vehicle detection to demonstrate the functionality and necessity of the proposed co-simulation platform for enabling CDA algorithm development and validation.
The rest of this paper is organized as follows. A brief background about traffic simulation and object perception is given in Section II. In Section III, we first introduce the concept of CMM and then describe the design and development of the prototype system based on co-simulation. In Section IV, we present a case study for detecting and reconstructing vehicles based on roadside LiDAR sensing and deep learning methods, followed by the conclusion and discussion in Section V.
II Background
Simulation plays a crucial role in enabling cooperative driving automation, such as assessment of CAV cooperative perception algorithms and decision-making/control models [8, 9]. High-fidelity simulated sensor information lays a solid foundation for these high-level CDA algorithms and models. In this section, we briefly review the background information for simulators enabling CDA and object detection.
II-A Simulators Enabling Cooperative Driving Automation
II-A1 Microscopic Traffic Simulators
To model the evolution of traffic states based on traffic dynamics and interactions between traffic objects, microscopic traffic simulators have been developed for decades and greatly stimulated the development of intelligent transportation systems [10]. These simulators mainly consist of three components: 1) transportation network defining road topology; 2) traffic generator creating traffic flows with certain demand distributions; and 3) microscopic traffic flow control strategies, including traffic signal management, vehicle driving behaviors, and moving strategies for pedestrians.
Several simulation platforms are of great popularity in CDA research, such as VISSIM [11], Aimsun [12], and SUMO (Simulation of Urban MObility) [13]. Specifically, VISSIM and Aimsun are widely used in dealing with multi-modal traffic flow simulation due to their capabilities of providing fundamental 3D preview and statistical simulation results. SUMO is an open-source, highly portable, microscopic, and continuous traffic simulation package designed to handle large networks [7]. Additionally, high compatibility to connect and interact with different kinds of external simulators, e.g., OMNeT++ [14], CARLA, etc., is one of the key features of SUMO. These microscopic traffic simulators mainly focus on general assessment for traffic dynamic performance at the network level under different traffic scenarios. Nevertheless, the design and assessment of CDA-based cooperative perception, decision-making, or control models highly rely on the fidelity of sensor data, which is a major challenge for these conventional simulators. In recent years, simulators that are capable of modeling high-fidelity sensors gain more and more interests, which are introduced in the following section.
II-A2 Autonomous Driving Simulators
With the development of CDA, especially autonomous driving technologies (ADTs) [15], the requirement for high-fidelity sensors in simulators has gained more and more attention. In recent years, several autonomous driving simulators quipped with high-fidelity sensors have been developed based on game engines, such as Unity [16] and Unreal Engine [17]. For instance, AirSim [18], SVL, and CARLA have the capability to offer physically and visually realistic simulations for autonomous vehicle technologies (AVTs) as well as CDA systems. Specifically, AirSim includes a physics engine that can operate at a high frequency for real-time hardware-in-the-loop (HIL) simulations with support for popular protocols, such as MavLink [19]. SVL is a high-fidelity simulator for AVTs, which provides end-to-end and full-stack simulation that is ready to be hooked up with several open-source autonomous driving stacks, such as Autoware [20] and Apollo [21]. CARLA, an open-source simulator for autonomous driving, supports flexible specifications of sensor suites and environmental conditions. In addition to open-source codes and protocols, CARLA provides open digital assets (e.g., urban layouts, buildings, and vehicles) that can be used in a friendly manner for researchers.
These simulators have been developed from the ground up to support the development, training, and validation of AVTs, enabling the development of CDA. They have the capacity to assess the CDA system in a cost-effective manner as well as to provide high-fidelity sensing information.
Although having these existing simulators, researchers still get struggled with the imperative assumption that perception data (e.g., location, velocity, rotation, etc.) is collected directly from intrinsic attributes of simulation engines, when they develop and evaluate their high-level CAV functions, such as decision-making or control methods for CDA. Therefore, to develop a generic platform that can not only support physically and visually realistic simulation but also provide perception data based on high-fidelity sensor information is still a research gap for enabling CDA system research and development.
II-B Object Detection in Traffic Scenes
Object detection plays a crucial and fundamental role in enabling CDA, and it can be roughly divided into two major types: 1) traditional model-based algorithms, and 2) data-driven methods based on deep neural networks to extract hidden features from input signals and then generate detected results [22]. The following section will briefly introduce several state-of-the-art methods for each type and high-resolution sensors, e.g., camera and LiDAR, are mainly focused on.
II-B1 Model-based Methods
At the early stage of traffic detection, sensors with low-computational power are widely used, such as loop detectors, radar, ultrasonic, etc. Although most of them are still implemented in contemporary transportation systems, they suffer from different kinds of innate problems, such as detecting uncertainties, traffic disruption at installation, and high maintenance costs [23]. With the development of computer vision (CV) technology and the improvement of computational power, camera-based traffic object detection has been widely developed. Aslani and Mahdavi-Nasab [24] tried to gather useful information from stationary cameras for detecting moving objects in digital videos based on optical flow estimation. In situations where limited memory and computing resources are available, Lee et al. [25] presented a moving object detection method for real-time traffic surveillance applications based on a genetic algorithm.
Recently, LiDAR sensors is increasingly implemented for traffic object detection tasks due to their advantage of having higher tolerance of lighting conditions and accuracy of relative distance. Regarding traditional methods to deal with the 3D point cloud, one popular workflow is 1) background filtering; 2) traffic object clustering; and 3) object classification [26]. Additionally, the LiDAR point cloud can also be used to identify lane markings [27, 28]. Although some traditional methods have been applied to the 3D point cloud, the greater potential of LiDAR data should be tapped by data-driven methods (e.g., deep learning) which are introduced next.
II-B2 Data-driven Methods
The development of deep neural networks (DNNs) has significantly improved the possibility of dealing with large-scale data, such as high-fidelity images or 3D point clouds. With the great success of deep learning in the image recognition area [29, 30], many DNN-based models have been implemented in object detection for traffic scenarios using cameras or LiDAR sensors. Chabot et al. [31] presented an approach called Deep MANTA, for multi-task vehicle analysis based on the monocular image. In terms of different lighting conditions, Che-Tsung Lin developed a nighttime vehicle detection method based on image style transfer [32]. Chen et al. [33] proposed a shallow model named Concatenated Feature Pyramid Network (CFPN) to detect smaller objects in traffic flow from fish-eye camera images.
Additionally, 3D-LiDAR is also getting more popular in traffic object detection [34]. For instance, Asvadi et al. [35] presented an algorithm named DepthCN which used deep convolutional neural networks (CNNs) for vehicle detection. Considering the real-time requirement for autonomous driving applications, Zeng et al. [36] proposed a real-time 3D vehicle detection method by utilizing pre-RoI-pooling convolution and pose-sensitive feature maps. Simon et al. [37] proposed an Euler-Region-Proposal for real-time 3D object detection with point clouds, called ComplexYolo, which is capable of generating rotated bounding boxes for 3D objects. For CDA applications, traffic object detection needs meticulous consideration. Thus, in our CMM co-simulation framework, the ComplexYolo model is adapted with customized improvements for real-time vehicle and pedestrian detection.
III Platform Structure and Design
This section will describe the concept of cyber mobility mirror (CMM) in detail and the system architecture of the co-simulation platform based on CARLA. Specifically, the design and development of the real-world simulator, the mirror simulator, the data communication module, and the authentic perception module will be introduced.
III-A CMM Based Co-Simulation Architecture
As aforementioned, the cyber mobility mirror can further tap the potential of the traffic object surveillance systems to enable cooperative driving automation (CDA), especially for routing planning, cooperative decision-making, and motion control. From this perspective, this paper presents a co-simulation platform based on the CMM concept. Figure 2 demonstrates the concept of CMM with an intersection scenario and the system architecture of the CMM-based co-simulation.
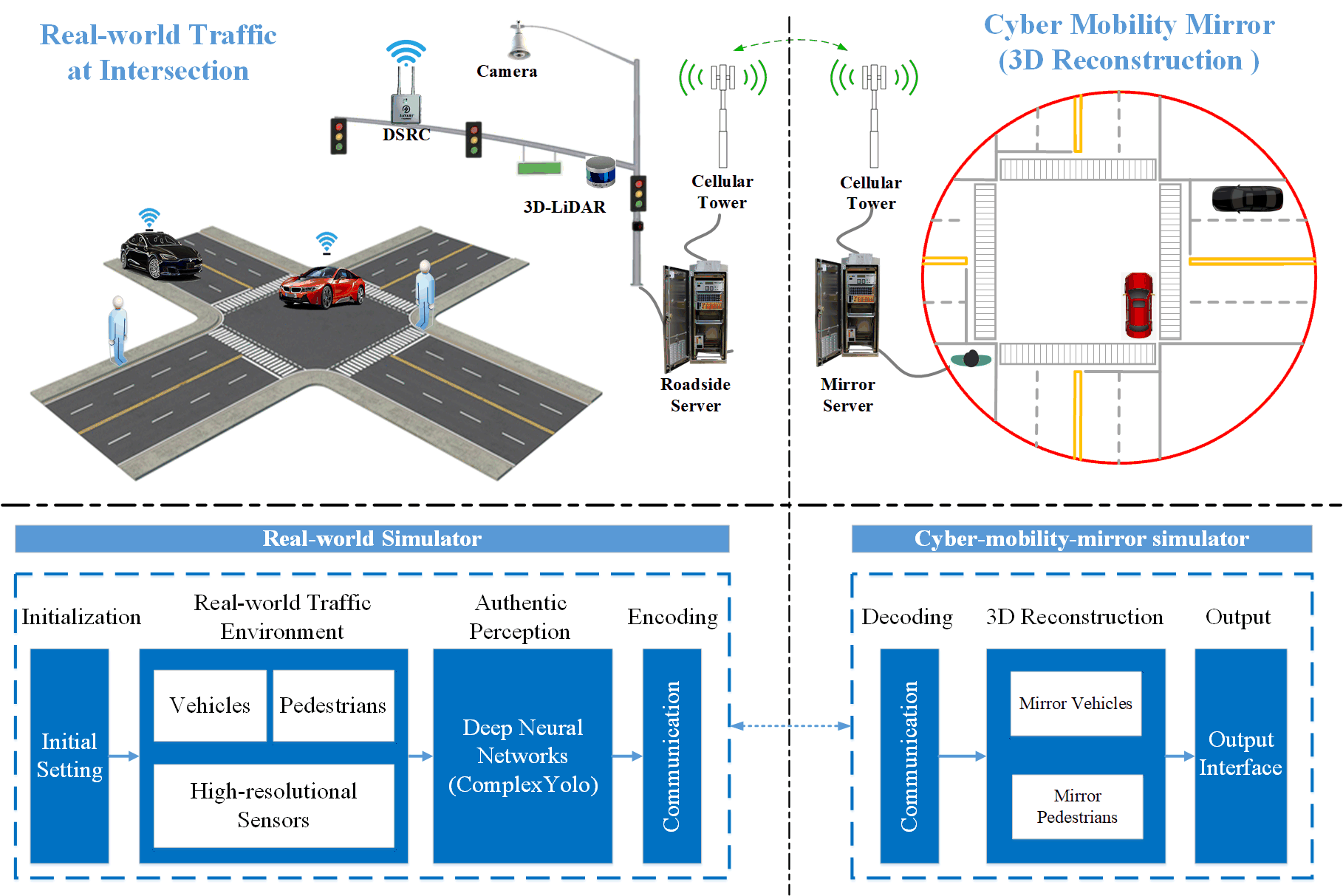
In Figure 2, the upper left part represents the real-world traffic scenario at an intersection, equipped with several roadside high-fidelity sensors, e.g., camera and 3D-LiDAR, roadside computing server, and communication system. High-fidelity sensor data is retrieved by the roadside server, in which perception tasks are executed, e.g., traffic object detection, classification, tracking, and motion prediction. Then perception results are encoded and transmitted to the CMM server via communication networks, e.g., cellular, DSRC or WLAN. The upper right part of Figure 2 represents the mirror environment, which reconstructs 3D objects based on perception information and outputs to CDA applications, e.g., collision avoidance, smart lane selection [38], and eco-driving [39], etc.
As aforementioned, building a comprehensive traffic object perception system in the real world requires plenty of hardware and labor resources. In this paper, we propose a cost-effective means to emulate the real-world traffic environment via a game-engine-based simulator, CARLA, which has the capability of generating traffic environment and high-fidelity sensor information. The structure of the real-world simulator, demonstrated in the lower left part of Figure 2, consists of four modules: 1) initialization of system settings; 2) configuration of CARLA-based traffic environment with traffic objects and equipped sensors; 3) authentic perception using DNNs, such as ComplexYolo model; and 4) data encoding for communication. As shown in the lower right part of the figure, the Mirror Simulator is also developed based on CARLA and consists of three components: 1) decoding of the communicated data; 2) 3D rebuilding for vehicles and pedestrians, and 3) output interface for CDA applications to readily retrieve the post-perception data.
In this paper, we present the basic concept of CMM and design the concrete workflow of a roadside-sensor-based intersection surveillance scenario. In the following section of co-simulation design and development, we focus on: 1) applying roadside 3D-LiDAR for perception; 2) object detection and classification for vehicles and pedestrians; and 3) multi-vehicle 3D rebuilding for enabling CDA applications.
III-B Real-world Simulator Design
The main purpose of the real-world simulator is to generate a virtual environment based on CARLA to emulate the real-world traffic environment. The main sub-tasks of the development effort are shown as follows.
III-B1 Traffic scenario design
CARLA has provided several well-developed virtual towns with different road maps and textures. In this paper, we implement “town03” as our fundamental traffic map and select a target intersection for research. This is shown in the left part of Figure 3. Additionally, we can generate vehicles and pedestrians via CARLA-based python scripts. The right part of Figure 3 shows a specific top-down view of the traffic scenario with vehicles, pedestrians, and a 3D-LiDAR installed at the target intersection. The traffic is generated via the CARLA interface with respect to certain traffic demands and the traffic signals are controlled by the built-in traffic signal manager in CARLA.
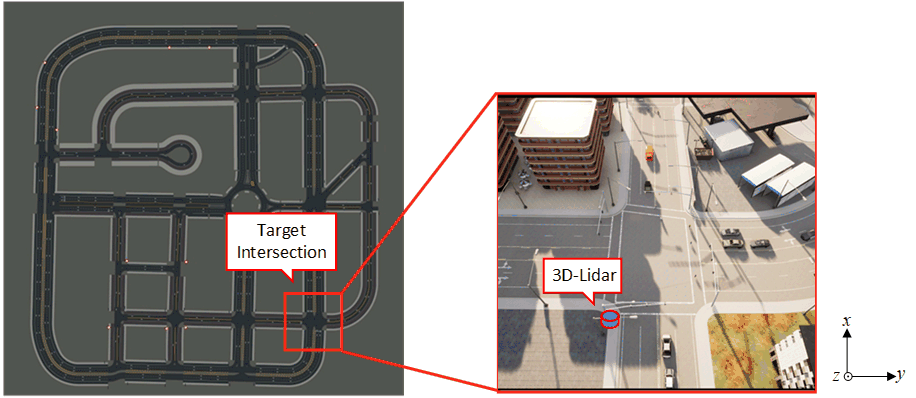
III-B2 Infrastructure based sensor design
In this paper, we implement a roadside 3D-LiDAR as our main sensor. The roadside LiDAR is installed at the southwest corner of the target intersection, which is demonstrated in Figure 3 (the LiDAR is installed below the arm of the traffic signal pole). Specifically, detailed settings about the roadside 3D-LiDAR are described later in Table I. To reduce the concern on transferability of the deployed deep neural network model, we resemble the LiDAR setups as used to obtain the KITTI dataset [40]. This means that the pitch, yaw, and roll of the LiDAR are set as zeros in CARLA global coordinate, as shown in the right part of Figure 3. Specifically, the LiDAR intensity is calculated by the following equation:
| (1) |
where represents the initial intensity value (equals to 1 in this study); represents the attenuation coefficient, depending on the sensor’s wavelength and atmospheric conditions (which can be modified by the LiDAR attribute “atmosphere_attenuation_rate”); and is the distance from the hit point to the sensor. Furthermore, realistic LiDAR features such as random no returns and background noise are also considered [41]. More details about the implemented 3D-LiDAR are described in section IV.
III-B3 Deep Learning-Based Perception Methods
In this paper, we apply the ComplexYolo model [37] as our fundamental 3D object detection method. The basic pipeline of the ComplexYolo model is demonstrated in Figure 4.
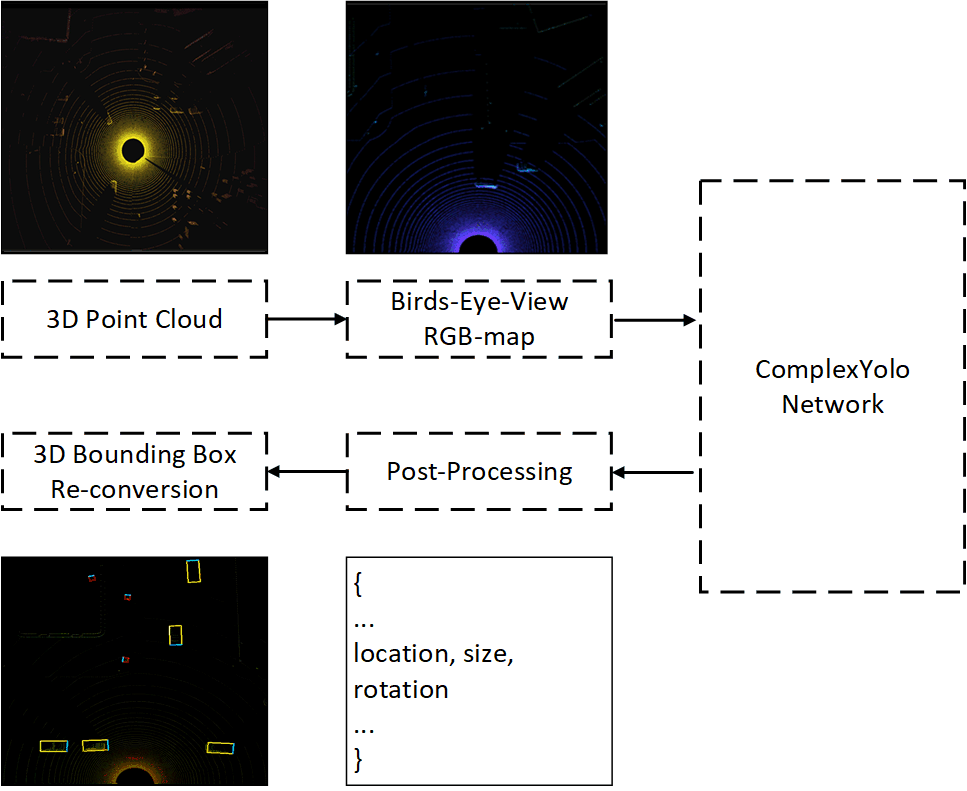
In the ComplexYolo model, raw 3D-LiDAR data is firstly cut into a certain shape with respect to the target region; then the 3D point cloud is processed into Bird’s-Eye-View (BEV) RGB map based on different features; the CNN-based ComplexYolo network generates detection outputs based on the RGB map; moreover, post-processing is implemented to filter detection results with respect to certain thresholds; finally, 3D bounding boxes are calculated and displayed on the RGB map image. The optimization loss functions for ComplexYolo is defined as:
| (2) |
where is defined as the sum of squared errors using the multi-part loss introduced in YOLO [42] and YOLOv2 [43], while the Euler regression part is defined to handle complex numbers, which has a closed mathematical space for angle comparisons [37]. The implementation details of the ComplexYolo model in this paper will be introduced in Section IV.
III-C Mirror Simulator Design
The main purposes of the Mirror Simulator are: 1) performing 3D rebuilding for the perceived objects; and 2) providing a readily used output interface for CDA applications.
In this paper, the Mirror Simulator is also developed based on the CARLA simulator. The same CARLA town, “town03”, is used to build this mobility mirror, as shown on the left in Figure 3. The 3D rebuilding procedure consists of two parts: 1) decoding post-perception data received from the real-world simulator via communication; and 2) generating 3D traffic objects with respect to the decoding data based on CARLA Python APIs (Application Programming Interfaces). Specifically, the message decoding method is further described in the next section.
III-D Co-Simulation Workflow Design
In this paper, TCP protocol [44] is implemented to transmit post-perception data from the Real-world Simulator to the Mirror Simulator. Specifically, before transmitting, object detection results are encoded based on JSON protocol [45], which includes the locations and orientations of the objects. For data encoding at the Mirror Simulator, the JSON data is decomposed according to the data structure in CARLA.
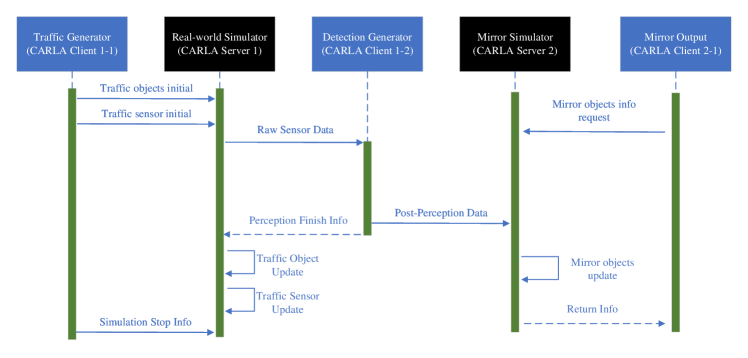
For this co-simulation platform, we design the information flow based on the server-client architecture in CARLA [5]. The sequence diagram for information synchronization among components is demonstrated in Figure 5.
In the CARLA platform, the server runs the simulation (i.e., updates the information), while the client retrieves information. Specifically, as shown in Figure 5, the Traffic Generator (CARLA Client 1-1) is responsible for simulation initialization or stopping requests; the Real-world Simulator (CARLA Server 1) runs the simulation for real-world traffic and the LiDAR sensor; the Detection Generator (CARLA Client 1-2) is designed to generate 3D object detection results by utilizing the ComplexYolo model. The detection results are encoded into post-perception data and transmitted to the Mirror Simulator (CARLA Server 2) via TCP communications. Finally, the Mirror Output (CARLA Client 2-1) can retrieve the mirrored objects’ information, e.g., vehicle center location, bounding box dimension, and orientation, from the Mirror Simulator.
III-E V2X Effect Design
Since Vehicle-to-everything (V2X) communication effects are significant in CDA implementations, this section introduces the V2X effect design from three different perspectives.
III-E1 Communication Delay
Owing to the co-simulation structure, the communication delay is naturally involved in deploying Realworld Simulation and Mirror Simulation on different computers. Furthermore, to support assessment for different delay conditions, an active communication delay (ACD) is designed at Detection Generator shown in Figure 5. ACD aims to provide customized time delays that can be defined according to specific requirements. Hence, the total delay of the co-simulation is designed as:
| (3) |
where , and represent the innate time delay of the co-simulation and the delay from ACD. Specifically, for wireless communication applied in the our case study shown in Section IV, is about and is applied by setting as and respectively.
III-E2 Message Dropping
Considering that message dropping is a common issue in communications systems [46], an Active Message Dropping (AMD) mechanism is designed in our co-simulation system. In the Co-simulation system, AMD is designed by the stochastic process and deployed right after the ACD module. The represents the factor for the message dropping, which is designed by:
| (4) |
For each frame, if is smaller than a certain threshold , the message of this frame will be drooped. Specifically, for experiments in section IV-E, is set as , , and respectively.
IV Case Study: Roadside-LiDAR-Based Vehicle Detection For Enabling CDA
IV-A System Setup
Both the Real-world Simulator and Mirror Simulator run under the synchronous mode of CARLA, which means the server can update the simulator information at the same time step with the clients. In this paper, the simulation frequency is set as 10 Hz. The network traffic demand is set to be 100 vehicles (driving around the town according to the default routing strategy and autopilot method in CARLA) [5]. For the 3D-LiDAR implemented in this paper, attributes of the LiDAR sensor are shown in Table I.
| Parameters | Default | Description | ||
|---|---|---|---|---|
| Channels | 64 | Number of lasers. | ||
| Height | 1.73 | Height with respect to the road surface. | ||
| Range | 100.0 | Maximum distance to measure/ray-cast in meters. | ||
| Rotation_frequency | 10.0 | LiDAR rotation frequency. | ||
| Upper_fov | 2.0 | Angle in degrees of the highest laser beam. | ||
| Lower_fov | -24.9 | Angle in degrees of the lowest laser beam. | ||
| Atmosphere_attenuation_rate | 0.004 | Coefficient that measures the LiDAR intensity loss. | ||
| Noise_stddev | 0.01 | The standard deviation of the noise model of points along its ray-cast. | ||
| Dropoff rate | 45% | General proportion of points that are randomly dropped. | ||
| Dropoff_intensity_limit | 0.8 | The threshold of intensity value for exempting dropoff. | ||
| Dropoff_zero_intensity | 40% | The probability value of dropoff for zero-intensity points. |
IV-B CARTI Dataset
To implement the ComplexYolo model in our co-simulation platform, a well-defined 3D-LiDAR dataset with the ground-truth label is required. Although CARLA provides a comprehensive Python API for data retrieving and object controlling, a built-in dataset generator is still missing. Therefore, based on the existing CARLA Python API and the KITTI dataset structure, we develop a CARLA-based 3D-LiDAR Dataset which is named CARTI Dataset. The code for generating the CARTI dataset is available at https://github.com/zwbai/CARTI_Dataset. Although the LiDAR is running in , the data frame is recorded at to improve the diversity of the dataset, i.e., including more differences in certain frames of data. Specifically, a total of 11,000 frames of data are collected.
IV-C Vehicle Detection
IV-C1 Point Cloud Preprocessing
In this paper, our target range for vehicle detection is defined as a 50 meters by 50 meters area with respect to the location of LiDAR. The square size of the target range is due to the construction mechanism of the BEV feature map which is shown in section IV-C2. The raw point cloud data can be described by:
| (5) |
To reduce the impact from 3D LiDAR points out of the target range, is geo-fenced by:
| (6) |
where represents the 3D point cloud data after geofencing; and and are set as respectively. Considering the calibrated height of the roadside Lidar to be , is set as . Additionally, ground truth labels are collected according to the objects within the target range.
IV-C2 BEV Image Construction
The 3D points within the target range are then normalized by the following equations:
| (7) |
where and represent the range along the x-axis direction and y-axis direction, respectively; and denote the weight and height of the BEV image, respectively. Specifically, and represent the points in and the points after normalization respectively.
Then the three-feature maps, i.e., R-map, G-map, and B-map can be defined according to the density, height, and intensity information, respectively, which is shown below:
| (8) |
where represents a specific grid cell of RGB-map; , and represent three channels for RGB-map; represents the intensity of LiDAR point and describes the number of points mapped from to .
IV-C3 Model Training
Based on the CARTI dataset, we train the ComplexYolo model from scratch via stochastic gradient descent with a weight decay of 0.0005 and momentum of 0.9. For the dataset preparation, we subdivide the training set with 80% for training and 20% for validation. The learning rate is set as 0.001 for initialization and gradually decreased along 1000 training epochs. For regularization, we implement batch normalization. For activation functions, a leaky rectified linear activation function, defined as follows, is used except in the last layer of the convolution neural network (CNN) where a linear activation function is used.
| (9) |
IV-D Functionality for Authentic Perception
IV-D1 Quantitative Performance
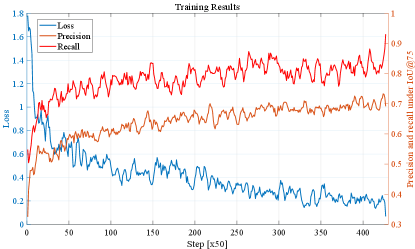
For quantitative results and analysis, Figure 6 demonstrate the overall performance of the training results including the training loss, precision, and recall. Specifically, Precision illustrates the proportion of true positive detection among all predicted detection (i.e., all the bounding boxes generated from the model). The recall is a factor that measures the ability of the detector to find all the relevant cases (i.e., all the ground truths) which is the proportion of true positive detection among all ground truths (i.e., real vehicles and pedestrians). Additionally, the notations of and mean these values are calculated based on the Intersection of Union (IoU) of and , respectively.
The evaluation results of the testing dataset are demonstrated in Table II. Specifically, AP represents the average precision for each class along the different thresholds and F1 is the harmonic mean for precision and recall, which is designed as:
| (10) |
It is notable that the detection results for vehicles are much better than for pedestrians. A hypothesis is that fewer LiDAR points would be reflected from pedestrians than vehicles and pedestrians are more susceptible to occlusion, due to their smaller sizes.
| Evaluation Criteria | Precision | Recall | AP | F1 | |
|---|---|---|---|---|---|
| Class | Car | 84.85 | 95.93 | 95.41 | 90.05 |
| Pedestrian | 35.71 | 42.00 | 21.45 | 38.60 | |
IV-D2 Qualitative Performance
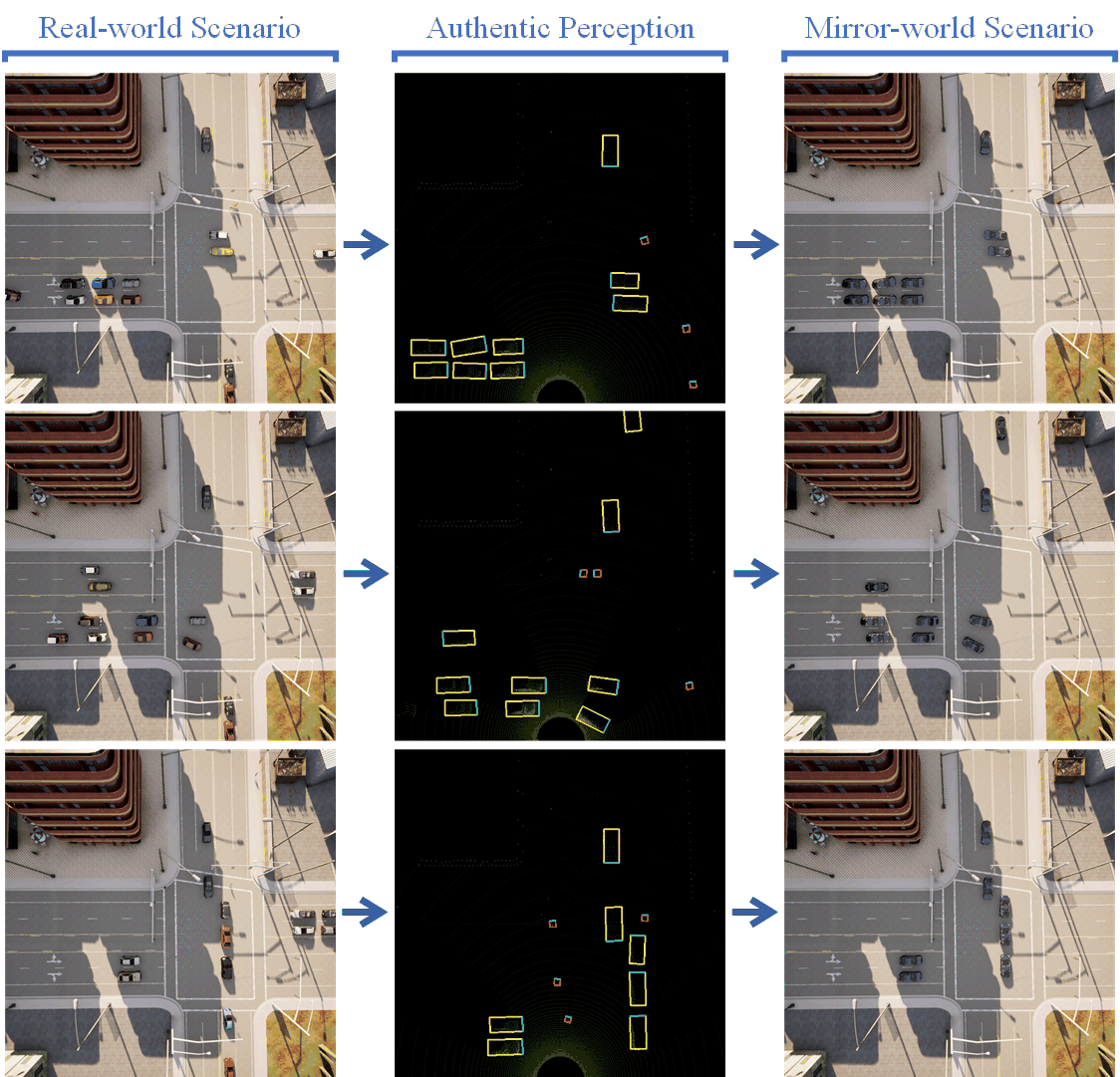
For qualitative results and analysis, Figure 7 demonstrates the key pipeline for the co-simulation system. The left-column images show the top-down view of the “real-world” traffic environment, the authentic perception results are visualized in mid-column images, and the traffic conditions in the “mirror world” are demonstrated by the right-column top-down view images. For detection visualization, vehicles and pedestrians are bounded with yellow and red boxes, respectively. In addition, the blue edges of the bounding boxes represent the forward direction of the objects.
Figure 7 validates the feasibility of our CMM-based co-simulation platform. Vehicles and pedestrians are detected via the roadside-based LiDAR and the associated digital replica is reconstructed in the mobility mirror simulator. Due to the detection range and accuracy of the selected model (i.e., ComplexYolo), some objects will be missed. Nevertheless, our platform is generic and highly compatible with different detection models and the results can be improved with the advances in SOTA detection methods.
In general, Figure 7 validates the core concept of our CMM-based co-simulation platform, i.e., generating authentic detection results based on high-fidelity sensors and rebuilding the traffic objects for external CDA applications, which demonstrates the functionality and feasibility of the co-simulation platform.
IV-E Functionality for Enabling CDA
This section will demonstrate two main aspects of the functionalities of our co-simulation platform in terms of enabling CDA. As shown in Figure 8, a specific CDA application – infrastructure-assisted CACC – is designed in a mixed traffic scenario to illustrate 1) why authentic perception is important for supporting CDA algorithm development and evaluation; and 2) how can the co-simulation platform supports the CDA applications.
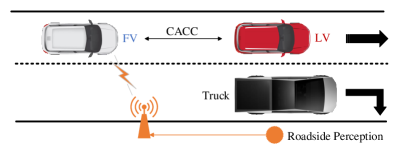
In Figure 8, the ego-vehicle (marked as FV, i.e., the following vehicle), a CV without self-perception capacity, is trying to follow a leading vehicle (LV), a legacy vehicle without connectivity. The location and speed information of the leading vehicle is required for this scenario.
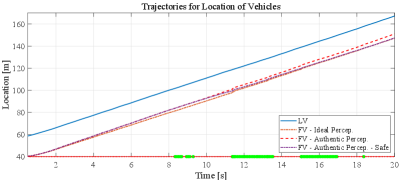
In this paper, different perspectives are considered to make the assessment more comprehensive and realistic: 1)mobile occlusion, e.g., LV in Figure 8 is occluded by the Truck, 2) time delay, and 3) message drop. To be specific, the Intelligent Driver Model (IDM) is applied to act as a basic CACC method, and when miss detection happens, two schemes are designed to generate continuous perception results: 1) there are no leading vehicles; and 2) the LV will keep its location as before. Since scheme #1 represents a progressive CACC style, scheme #2 represents a conservative CACC style. As demonstrated by Figure 9, Ideal Perception (IP) represents the ground truth vehicle location, and Authentic Perception (AP) and AP-Safe (AP-S) are the visualizations for the two schemes mentioned above. Particularly, the time when detection of LV is received is marked by a green “\textcolorgreen” at the bottom of the figures while a red “\textcolorred” is marked for miss detection happens. Based on the three perception results, vehicle trajectories are generated and shown in Figures 10 to 12. In Figure 10, FVs based on different perception results can keep a reasonable distance gap to the LV. In detail, the trajectory of AP-S has a closer fit with the trajectory of Ideal Perception.
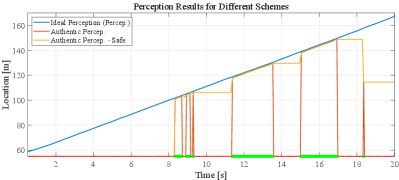
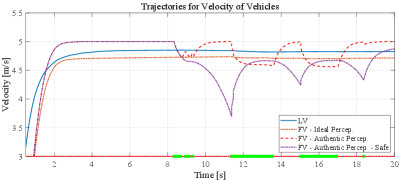
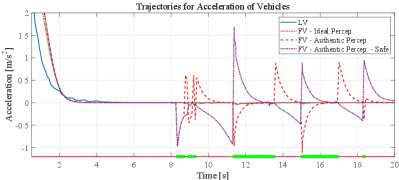
Although three perception schemes can support FV generating feasible location trajectories, the speed and acceleration trajectories generated from authentic perception (i.e., AP and AP-S) have significant differences from the trajectory generated by ideal perception (i.e., IP), which are shown in Figure 11 and 12. For velocity, trajectories generated by AP and AP-S have much more speed fluctuations which are mainly caused by 1) the miss detection caused by occlusion and 2) wrong detection caused by the performance of the detection model itself, such as the detection at shown in Figure 9. Thus, it is quite difficult to model the deficiency of authentic perception in a traditional way, such as the probabilistic model. For acceleration, a similar pattern can be found in Figure 12. The trajectories based on AP and AP-S have more fluctuations compared with the trajectory of IP.
Furthermore, it is notable that the fluctuations are highly correlated with the status of perception results. Specifically, AP will accelerate will the LV is missing and AP-S tends to decelerate until the LV is detected again. These trajectory patterns illustrate that the perception process and results will significantly affect the performance of CACC in this case or similar to other CDA applications, which further demonstrates the necessity to take authentic perception into consideration when designing subsequent CDA algorithms.
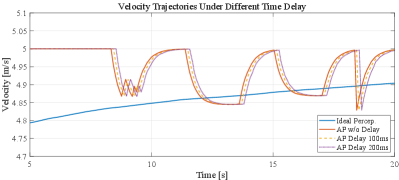
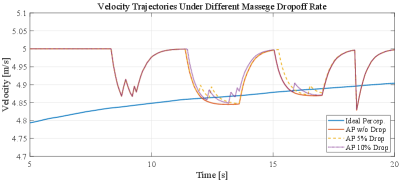
For the functionality of our platform to support the V2X effect, time delay and message drop are considered in section ,III-E, and experiments are conducted accordingly in this section. Figure 13 shows the velocity trajectories based on IP, AP without (w/o) delay, AP with delay, and AP with delay, respectively. Figure 14 shows the velocity trajectories based on IP, AP without message drop (w/o drop), AP with 5% message drop, and AP with 10% message drop, respectively. Results from Figures 13 and 14 demonstrate that our platform can support the analysis of the V2X effect which plays a crucial role in CDA implementation.
V Conclusion and Discussion
To enable cooperative driving automation (CDA), simulators are imperative to comprehensively support the design and assessment of various applications. Moreover, authentic perception based on high-resolution sensors is of great significance for CDA development. To the best of the authors’ knowledge, this paper is the first attempt to design and develop a co-simulation platform to prove the cyber mobility mirror (CMM) concept, which can both emulate high-resolution sensors and provide readily retrieved perception information. Specifically, the co-simulation platform consists of two main sub-simulators: 1) the Real-world Simulator for emulating the real-world traffic environment and (roadside) sensors and generating the authentic perception data; and 2) the Mirror Simulator for 3D reconstructing traffic objects and providing a readily retrieved interface for downstream CDA applications to access the location and orientation information of target traffic objects. A case study is conducted for roadside LiDAR-based vehicle detection in an intersection scenario, which demonstrates the performance of authentic perception as well as the functionality and feasibility of the co-simulation platform for enabling CDA.
In this paper, we develop a preliminary framework for CMM and validate it with simulation. A natural future step would be to realize the system in the real world, but there are some open issues deserving further exploration. For instance, we need to overcome disparities in the features between sensor data from simulators and that in reality. We need to investigate the model transferability issue, i.e., to design a model that can be trained on simulation and implemented in real-world scenarios without the necessity or much effort in re-training the model or fine-tuning parameters.
Acknowledgments
This research was funded by the Toyota Motor North America InfoTech Labs. The contents of this paper reflect the views of the authors, who are responsible for the facts and the accuracy of the data presented herein. The contents do not necessarily reflect the official views of Toyota Motor North America.
References
- [1] D. J. Fagnant and K. Kockelman, “Preparing a nation for autonomous vehicles: opportunities, barriers and policy recommendations,” Transportation Research Part A: Policy and Practice, vol. 77, pp. 167–181, 2015.
- [2] J. A. Misener and S. E. Shladover, “Path investigations in vehicle-roadside cooperation and safety: A foundation for safety and vehicle-infrastructure integration research,” in 2006 IEEE Intelligent Transportation Systems Conference. IEEE, 2006, pp. 9–16.
- [3] R. Stahlmann, A. Festag, A. Tomatis, I. Radusch, and F. Fischer, “Starting european field tests for car-2-x communication: the drive c2x framework,” in 18th ITS World Congress and Exhibition, 2011, p. 12.
- [4] L. Fujitsu, “Fujitsu future mobility accelerator digital twin analyzer,” Available: https://www.fujitsu.com/global/about/resources/news/press-releases/2020/0910-01.html, 2020.
- [5] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “Carla: An open urban driving simulator,” in Conference on robot learning. PMLR, 2017, pp. 1–16.
- [6] G. Rong, B. H. Shin, H. Tabatabaee, Q. Lu, S. Lemke, M. Možeiko, E. Boise, G. Uhm, M. Gerow, S. Mehta et al., “Lgsvl simulator: A high fidelity simulator for autonomous driving,” in 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2020, pp. 1–6.
- [7] P. A. Lopez, M. Behrisch, L. Bieker-Walz, J. Erdmann, Y.-P. Flötteröd, R. Hilbrich, L. Lücken, J. Rummel, P. Wagner, and E. Wießner, “Microscopic traffic simulation using sumo,” in 2018 21st International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2018, pp. 2575–2582.
- [8] Z. Bai, G. Wu, M. J. Barth, Y. Liu, A. Sisbot, and K. Oguchi, “Pillargrid: Deep learning-based cooperative perception for 3d object detection from onboard-roadside lidar,” arXiv preprint arXiv:2203.06319, 2022.
- [9] Z. Bai, W. Shangguan, B. Cai, and L. Chai, “Deep reinforcement learning based high-level driving behavior decision-making model in heterogeneous traffic,” in 2019 Chinese Control Conference (CCC), 2019, pp. 8600–8605.
- [10] J. Barceló et al., Fundamentals of traffic simulation. Springer, 2010, vol. 145.
- [11] M. Fellendorf and P. Vortisch, “Microscopic traffic flow simulator vissim,” in Fundamentals of traffic simulation. Springer, 2010, pp. 63–93.
- [12] J. Barceló and J. Casas, “Dynamic network simulation with aimsun,” in Simulation approaches in transportation analysis. Springer, 2005, pp. 57–98.
- [13] M. Behrisch, L. Bieker, J. Erdmann, and D. Krajzewicz, “Sumo–simulation of urban mobility: an overview,” in Proceedings of SIMUL 2011, The Third International Conference on Advances in System Simulation. ThinkMind, 2011.
- [14] A. Varga, “Omnet++,” in Modeling and tools for network simulation. Springer, 2010, pp. 35–59.
- [15] B. R. Kiran, I. Sobh, V. Talpaert, P. Mannion, A. A. Al Sallab, S. Yogamani, and P. Pérez, “Deep reinforcement learning for autonomous driving: A survey,” IEEE Transactions on Intelligent Transportation Systems, 2021.
- [16] A. Juliani, V.-P. Berges, E. Teng, A. Cohen, J. Harper, C. Elion, C. Goy, Y. Gao, H. Henry, M. Mattar et al., “Unity: A general platform for intelligent agents,” arXiv preprint arXiv:1809.02627, 2018.
- [17] B. Karis and E. Games, “Real shading in unreal engine 4,” Proc. Physically Based Shading Theory Practice, vol. 4, no. 3, 2013.
- [18] S. Shah, D. Dey, C. Lovett, and A. Kapoor, “Airsim: High-fidelity visual and physical simulation for autonomous vehicles,” in Field and service robotics. Springer, 2018, pp. 621–635.
- [19] A. Koubâa, A. Allouch, M. Alajlan, Y. Javed, A. Belghith, and M. Khalgui, “Micro air vehicle link (mavlink) in a nutshell: A survey,” IEEE Access, vol. 7, pp. 87 658–87 680, 2019.
- [20] S. Kato, S. Tokunaga, Y. Maruyama, S. Maeda, M. Hirabayashi, Y. Kitsukawa, A. Monrroy, T. Ando, Y. Fujii, and T. Azumi, “Autoware on board: Enabling autonomous vehicles with embedded systems,” in 2018 ACM/IEEE 9th International Conference on Cyber-Physical Systems (ICCPS). IEEE, 2018, pp. 287–296.
- [21] F. Graf, Apollo. Routledge, 2008.
- [22] Z. Bai, G. Wu, X. Qi, Y. Liu, K. Oguchi, and M. J. Barth, “Infrastructure-based object detection and tracking for cooperative driving automation: A survey,” in 2022 IEEE Intelligent Vehicles Symposium (IV), 2022, pp. 1366–1373.
- [23] J. Guerrero-Ibáñez, S. Zeadally, and J. Contreras-Castillo, “Sensor technologies for intelligent transportation systems,” Sensors, vol. 18, no. 4, p. 1212, 2018.
- [24] S. Aslani and H. Mahdavi-Nasab, “Optical flow based moving object detection and tracking for traffic surveillance,” International Journal of Electrical, Computer, Energetic, Electronic and Communication Engineering, vol. 7, no. 9, pp. 1252–1256, 2013.
- [25] G. Lee, R. Mallipeddi, G.-J. Jang, and M. Lee, “A genetic algorithm-based moving object detection for real-time traffic surveillance,” IEEE signal processing letters, vol. 22, no. 10, pp. 1619–1622, 2015.
- [26] J. Wu, H. Xu, J. Zheng, and J. Zhao, “Automatic vehicle detection with roadside lidar data under rainy and snowy conditions,” IEEE Intelligent Transportation Systems Magazine, vol. 13, no. 1, pp. 197–209, 2020.
- [27] J. Wu, H. Xu, and J. Zhao, “Automatic lane identification using the roadside lidar sensors,” IEEE Intelligent Transportation Systems Magazine, vol. 12, no. 1, pp. 25–34, 2018.
- [28] J. Wu, H. Xu, Y. Tian, Y. Zhang, J. Zhao, and B. Lv, “An automatic lane identification method for the roadside light detection and ranging sensor,” Journal of Intelligent Transportation Systems, vol. 24, no. 5, pp. 467–479, 2020.
- [29] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 9, pp. 1904–1916, 2015.
- [30] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “Yolov4: Optimal speed and accuracy of object detection,” arXiv preprint arXiv:2004.10934, 2020.
- [31] F. Chabot, M. Chaouch, J. Rabarisoa, C. Teuliere, and T. Chateau, “Deep manta: A coarse-to-fine many-task network for joint 2d and 3d vehicle analysis from monocular image,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2040–2049.
- [32] C.-T. Lin, S.-W. Huang, Y.-Y. Wu, and S.-H. Lai, “Gan-based day-to-night image style transfer for nighttime vehicle detection,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 2, pp. 951–963, 2020.
- [33] P.-Y. Chen, J.-W. Hsieh, M. Gochoo, C.-Y. Wang, and H.-Y. M. Liao, “Smaller object detection for real-time embedded traffic flow estimation using fish-eye cameras,” in 2019 IEEE International Conference on Image Processing (ICIP). IEEE, 2019, pp. 2956–2960.
- [34] Z. Bai, S. P. Nayak, X. Zhao, G. Wu, M. J. Barth, X. Qi, Y. Liu, and K. Oguchi, “Cyber mobility mirror: Deep learning-based real-time 3d object perception and reconstruction using roadside lidar,” arXiv preprint arXiv:2202.13505, 2022.
- [35] A. Asvadi, L. Garrote, C. Premebida, P. Peixoto, and U. J. Nunes, “Multimodal vehicle detection: fusing 3d-lidar and color camera data,” Pattern Recognition Letters, vol. 115, pp. 20–29, 2018.
- [36] Y. Zeng, Y. Hu, S. Liu, J. Ye, Y. Han, X. Li, and N. Sun, “Rt3d: Real-time 3-d vehicle detection in lidar point cloud for autonomous driving,” IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 3434–3440, 2018.
- [37] M. Simony, S. Milzy, K. Amendey, and H.-M. Gross, “Complex-yolo: An euler-region-proposal for real-time 3d object detection on point clouds,” in Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018, pp. 0–0.
- [38] Q. Jin, G. Wu, K. Boriboonsomsin, and M. Barth, “Improving traffic operations using real-time optimal lane selection with connected vehicle technology,” in 2014 IEEE Intelligent Vehicles Symposium Proceedings. IEEE, 2014, pp. 70–75.
- [39] Z. Bai, P. Hao, W. Shangguan, B. Cai, and M. J. Barth, “Hybrid reinforcement learning-based eco-driving strategy for connected and automated vehicles at signalized intersections,” IEEE Transactions on Intelligent Transportation Systems, pp. 1–14, 2022.
- [40] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 3354–3361.
- [41] S. Thrun, W. Burgard, and D. Fox, Probabilistic Robotics. MIT Press, 2005.
- [42] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [43] J. Redmon and A. Farhadi, “Yolo9000: Better, faster, stronger,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- [44] C. Hunt, “Tcp/ip network administration, 3rd edition,” Oreilly & Associates Inc, 2002.
- [45] JoeLennon and JoeLennon, Introduction to JSON. Beginning CouchDB, 2009.
- [46] A. Krifa, C. Barakat, and T. Spyropoulos, “Message drop and scheduling in dtns: Theory and practice,” IEEE Transactions on Mobile Computing, vol. 11, no. 9, pp. 1470–1483, 2011.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ae44eac3-8d3e-449b-9af9-bb73c03d317e/zwbai.jpg) |
Zhengwei Bai (Student Member, IEEE) received the B.E. and M.S. degrees from Beijing Jiaotong University, Beijing, China, in 2017 and 2020, respectively. He is currently a Ph.D. candidate in electrical and computer engineering at the University of California at Riverside. His research focuses on object detection and tracking, cooperative perception, decision making, motion planning, and cooperative driving automation (CDA). He serves as a Review Editor in Urban Transportation Systems and Mobility. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ae44eac3-8d3e-449b-9af9-bb73c03d317e/Guoyuan.png) |
Guoyuan Wu (Senior Member, IEEE) received his Ph.D. degree in mechanical engineering from the University of California, Berkeley in 2010. Currently, he holds an Associate Researcher and an Associate Adjunct Professor position at Bourns College of Engineering – Center for Environmental Research & Technology (CE–CERT) and the Department of Electrical & Computer Engineering at the University of California at Riverside. development and evaluation of sustainable and intelligent transportation system (SITS) technologies, including connected and automated transportation systems (CATS), shared mobility, transportation electrification, optimization and control of vehicles, traffic simulation, and emissions measurement and modeling. Dr. Wu serves as Associate Editors for a few journals, including IEEE Transactions on Intelligent Transportation Systems, SAE International Journal of Connected and Automated Vehicles, and IEEE Open Journal of ITS. He is also a member of the Vehicle-Highway Automation Standing Committee (ACP30) of the Transportation Research Board (TRB), a board member of the Chinese Institute of Engineers Southern California Chapter (CIE-SOCAL), and a member of the Chinese Overseas Transportation Association (COTA). He is a recipient of the Vincent Bendix Automotive Electronics Engineering Award. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ae44eac3-8d3e-449b-9af9-bb73c03d317e/Xuewei.png) |
Xuewei Qi (Member, IEEE) received his Ph.D. degree in electrical and computer engineering from the University of California-Riverside in 2016 and his M.S. degree in engineering from the University of Georgia, USA, in 2013. He is a Principle AI Researcher with Toyota North America Research Labs (Silicon Valley). He was with General Motors as an Artificial Intelligence and Machine Learning Research Scientist. He was also working as a Lead Perception Research Engineer at Aeye.ai. His recent research interests include deep learning, autonomous vehicles, perception and sensor fusion, reinforcement learning, and decision making. He is also serving as a member of several standing committees of the Transportation Research Board (TRB). |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ae44eac3-8d3e-449b-9af9-bb73c03d317e/Yongkang.jpg) |
Yongkang Liu received the Ph.D. and M.S. degrees in electrical engineering from the University of Texas at Dallas in 2021 and 2017, respectively. He is currently a Research Engineer at Toyota Motor North America, InfoTech Labs. His current research interests are focused on in-vehicle systems and advancements in intelligent vehicle technologies. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ae44eac3-8d3e-449b-9af9-bb73c03d317e/Kentaro.png) |
Kentaro Oguchi received the M.S. degree in computer science from Nagoya University. He is currently a Director at Toyota Motor North America, InfoTech Labs. Oguchi’s team is responsible for creating intelligent connected vehicle architecture that takes advantage of novel AI technologies to provide real-time services to connected vehicles for smoother and efficient traffic, intelligent dynamic parking navigation, and vehicle guidance to avoid risks from anomalous drivers. His team also creates technologies to form a vehicular cloud using Vehicle-to-Everything technologies. Prior, he worked as a senior researcher at Toyota Central R&D Labs in Japan. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ae44eac3-8d3e-449b-9af9-bb73c03d317e/Matt.png) |
Matthew J. Barth (Fellow, IEEE) received the M.S. and Ph.D. degree in electrical and computer engineering from the University of California at Santa Barbara, in 1985 and 1990, respectively. He is currently the Yeager Families Professor with the College of Engineering, the University of California at Riverside, USA. He is also serving as the Director of the Center for Environmental Research and Technology. His current research interests include ITS and the environment, transportation/emissions modeling, vehicle activity analysis, advanced navigation techniques, electric vehicle technology, and advanced sensing and control. Dr. Barth has been active in the IEEE Intelligent Transportation System Society for many years, serving as a Senior Editor for both the Transactions of ITS and the Transactions on Intelligent Vehicles. He served as the IEEE ITSS President for 2014 and 2015 and is currently the IEEE ITSS Vice President of Education. |