DAPDAG: Domain Adaptation via
Perturbed DAG Reconstruction
Abstract
Leveraging labelled data from multiple domains to enable prediction in another domain without labels is an important, yet challenging problem. To address this problem, we introduce the framework DAPDAG (Domain Adaptation via Perturbed DAG Reconstruction) and propose to learn an auto-encoder that undertakes inference on population statistics given features and reconstructing a directed acyclic graph (DAG) as an auxiliary task. The underlying DAG structure is assumed invariant among observed variables whose conditional distributions are allowed to vary across domains led by a latent environmental variable . The encoder is designed to serve as an inference device on while the decoder reconstructs each observed variable conditioned on its graphical parents in the DAG and the inferred . We train the encoder and decoder jointly through an end-to-end manner and conduct experiments on both synthetic and real datasets with mixed types of variables. Empirical results demonstrate that reconstructing the DAG benefits the approximate inference and furthermore, our approach can achieve competitive performance against other benchmarks in prediction tasks, with better adaptation ability especially in the target domain significantly different from the source domains.
1 Introduction
Domain adaptation (DA) concerns itself with a scenario where one wants to transfer a model learned from one or more labelled source datasets, to a target dataset (which can be labelled or unlabelled) drawn from a different but somehow related distribution. In many settings, a wealth of data may exist, contained in several datasets collected from different sources, such as different hospitals, yet the target domain has few labels available due to possible lag or in-feasibility on data collection. Knowing what information can be transferred across domains and what needs to be adapted becomes the key to leveraging these datasets when presented unlabelled dataset from another domain, which has attracted significant attention in the machine learning community. In this paper, we revisit the problem of unsupervised domain adaptation (UDA), where the target dataset is unlabelled, under the same feature space with multiple source domains. To avoid over repetition, the word “environment” and “domain” are used interchangeably in the following paragraphs.
For UDA, there have been various approaches developed and most of them can be summarised into two main categories - either learning an invariant representation of features with implicit alignment over source domains and the target domain, or utilising the underlying causal assumptions and knowledge that provide clues on the source of distribution shift for better adaptation. Despite the success of invariant representation methods in visual UDA tasks (Wang & Deng, 2018; Deng et al., 2019; Kang et al., 2019; Lee et al., 2019; Liu et al., 2019; Jiang et al., 2020), its black-box nature remains vague locally and causes issue in some situations (Zhao et al., 2019). Exploring the underlying causal structure and properties may help add more interpretability and make predictions across different domains more robust 111Robustness refers to generalisation ability of model to unseen data. In most settings, the causal structure of variables (both the features and the label ) are assumed to remain constant across domains and the label has a fixed conditional distribution given causal features (Schölkopf et al., 2012; Magliacane et al., 2017). In this work, we expect to capture similar invariant structural information but with conditional shift. More specifically, we cast the data generating process of distinct domains as a probability distribution with a continuous latent variable that perturbs the conditional distributions of observed variables. An auto-encoder approach is proposed to capture this latent , utilising structural regularisation to facilitate sparsity and acyclicity among variable relationships. Our model is expected to be able to make inference on , which is further used to adjust for domain shift in prediction. To accomplish this, the encoder structure is designed to approximate the posterior of , drawing insights from methods of deep sets (Zaheer et al., 2017) and Bayesian inference (Maeda et al., 2020), while the decoder aims to reconstruct all observed variables in a DAG taking the inferred .
Contributions
The main contributions of this paper are three-fold:
-
•
We present a framework consisting of a encoder for the approximate inference on domain-specific variable , and a decoder to reconstruct mixed-type data including continuous and binary variables. A novel training strategy is proposed to train our model: weighted stochastic domain selection, which enables inter and intra-domain validation during training.
-
•
We provide a generalisation bound on the decoder in our structure with mixed-type data, validating the training loss form to some extent.
-
•
We validate our method with experiments on both simulated and real-world datasets, demonstrating the effectiveness of DAG reconstruction and performance gain of our approach in prediction tasks against benchmarks.
Related Work
Since we are more interested in causal methods for UDA, review on other UDA methods would not be discussed in this paper. For more detailed reviews on general DA methods, please refer to (Quiñonero-Candela et al., 2009) and (Pan & Yang, 2009). Various approaches have been proposed in causal UDA yet most of them can be categorised into three classes: (1) Correcting distribution shift by different scenarios of UDA according to underlying causal relations between and (e.g. to estimate the target conditional distribution as a linear mixture of source domain conditionals by matching the target-domain feature distribution) (Schölkopf et al., 2012; Zhang et al., 2015; Stojanov et al., 2019); (2) Identifying invariant subset of variables across domains for robust prediction (Magliacane et al., 2017; Rojas-Carulla et al., 2018); (3) Augmenting causal graph by considering interventions or environmental changes as exogenous (context) variables which affect endogenous (system) variables and implementing joint causal inference (JCI) on these augmenting graphs (Mooij et al., 2020; Zhang et al., 2020). Our approach is closest to the third class, by introducing an latent perturbation variable that induces conditional shift of observed variables. The resulting graph may not be causal any more, nevertheless our focus is the DAG representation of the whole distribution, which enforces sparsity and acyclicity for better learning of .
Our entire framework also takes resemblance with meta learning (for a survey on this, please see (Vilalta & Drissi, 2002; Vanschoren, 2018)). In our setting, the objective is to learn an algorithm from different training tasks (domains) and to apply the algorithm to a new task (domain). (Maeda et al., 2020) introduces an auto-encoder model to learn the latent embedding of different tasks under the Bayesian inference framework, which has similar mechanism with ours except that our decoder aims to reconstruct all variables in a DAG instead of only the target variable. There also exist a few works using meta-learning approach to handle variant causal structures across domains (Nair et al., 2019; Dasgupta et al., 2019; Ke et al., 2020; Löwe et al., 2020). Since our approach assumes an invariant DAG structure, we would not dive deeper into those methods although they may provide inspiring reference for our future work.
2 Preliminaries
Learning a casual DAG is a hard problem that needs exhaustive search over a super-exponential combinatorial DAG space, which becomes impossible to deal with in high-dimensional case. However, recent advances in structure learning (Zheng et al., 2018; Yu et al., 2019; Zhang et al., 2019; Lachapelle et al., 2019; Yang et al., 2020; Zheng et al., 2020) reduce the original combinatorial optimisation problem to a continuous optimisation by using a novel acyclicity constraint, which accelerate the learning and provide more inspirations. Some works have been extended to more complex settings including structural learning across non-stationary environments (Ghassami et al., 2018; Bengio et al., 2019; Ke et al., 2019). Despite difference in implementation, above methods use end-to-end optimisation with standard gradient-descent methods that are on-the-shelf. In our work, we take the advantage of continuous optimisation methods and emphasise on NO-TEARS methods (Zheng et al., 2018, 2020) that can be better integrated into the deep learning framework. We consider learning a DAG as a auxiliary task to improve model’s generalisation and robustness (Kyono et al., 2020), contributing to the better learning of latent variable in the meantime.
An example is introduced below to recap the basic idea of the NO-TEARS method. Suppose we want to learn a linear SEM (Structural Equation Model) with the form where is the random noise variable and is the weighted adjacency matrix. Then it can be proved that:
| (1) |
where is the Hadamard product .
For formal proof, please refer to (Zheng et al., 2018). This formulation converts learning a linear DAG into a non-convex optimisation problem:
| (2) |
In (Zheng et al., 2018), they solve the above problem by augmenting quadratic penalty and using Lagrangian method:
| (3) |
where is the penalty coefficient and is the Lagrangian Multiplier. A further extension of this conversion has proposed by (Zheng et al., 2020) to the case of general non-parametric DAGs. Please refer appendix A for a detailed illustration.
3 Methodology
3.1 Formulation
Problem Setting
Let be the target variable and be features. We consider labeled datasets from different source domains, i.e. where represents the domain index, stands for the probability distribution of in domain and is the dataset size of domain . Our objective is to predict given from the target domain without labels.
Basic Assumptions
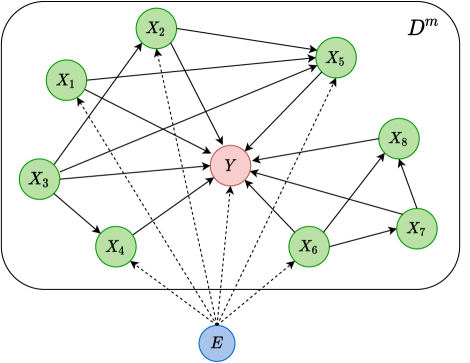
Let be observed variables, we assume:
-
•
Besides , there is a latent environmental variable controlling the distribution shift of observed variables. For each domain, is sampled from its prior and fixed for data generation.
-
•
Observed data are generated according to a perturbed DAG: the conditional distribution of given its parents and follows an exponential family distribution in the form of:
(4) where , and are functions.
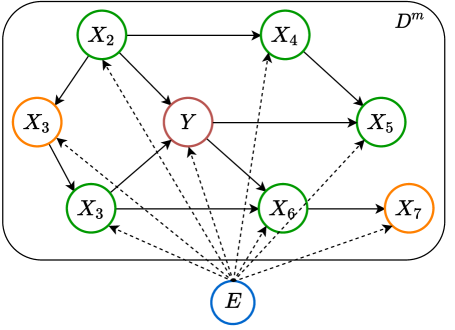
Perturbed DAG
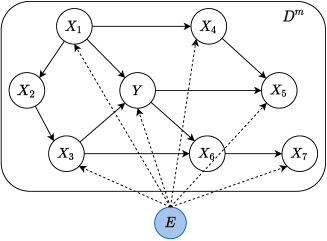
We assume a perturbed DAG where a joint environmental variable will influence the conditional distribution of an observed variable across domains. The illustration of this perturbed DAG is shown in Figure 1.
3.2 Model
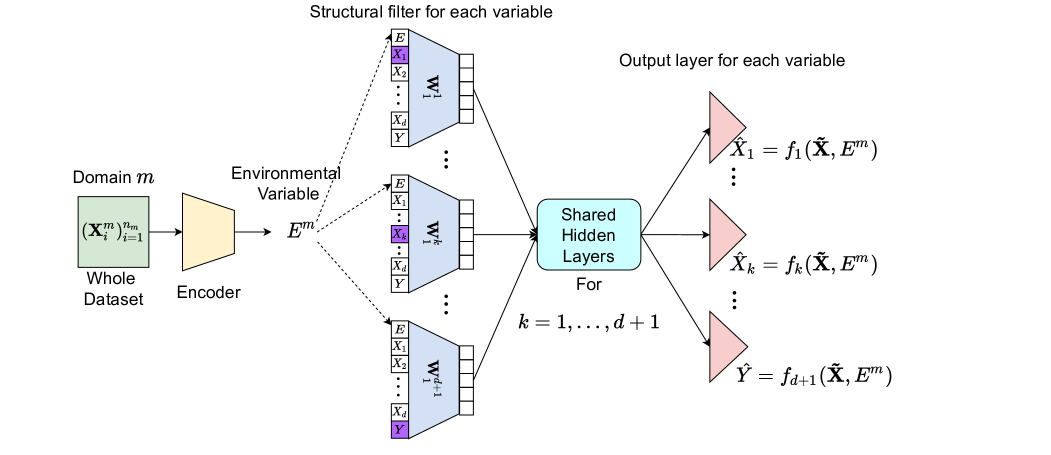
We expect a model that is able to well capture the difference between of different domains, and then adapt to the change accordingly. So how to properly encode an empirical distribution to a statistics becomes the cornerstone of our model. Considering similarity with the goal of classical statistical estimation methods such as Maximum Likelihood Estimation (MLE), our objective is to learn an estimation device that can output the estimated for each domain taking its samples as input. The model has an auto-encoder architecture, with an encoder to take the whole domain sample to approximate and a decoder to reconstruct each feature according its graphical parents and . The latter bears resemblance with CASTLE (Kyono et al., 2020) except that is used for reconstruction. Figure 2 sketches the general model architecture which consists of a domain encoder, a set of structural filters, shared hidden layers and separate output layers. We now explain each part in detail.
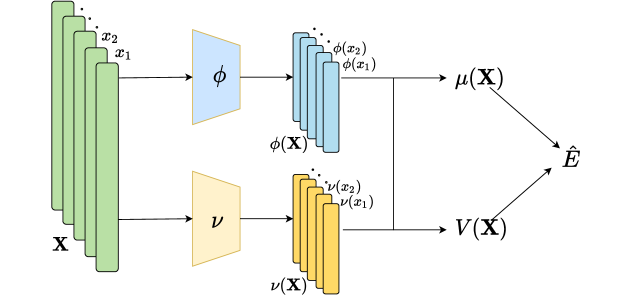
3.2.1 Domain Encoder
An encoder that takes the whole dataset features and outputs an estimated environmental variable neglecting the permutation of sample orders for each specific domain is preferred in our case. According the theory of deep sets (Zaheer et al., 2017) below:
Theorem 3.1.
(Zaheer et al., 2017) A function on a set having countable elements, is a valid set function, i.e. invariant to the permutation of objects in if and only if it can be decomposed as the form for suitable transformations and .
The key to deep sets is to add up all representations and then apply nonlinear transformations. Further inspired by the approximated Bayesian posterior (Maeda et al., 2020) on the variable , we design our encoder structure as shown in Figure 3 where:
| (5) | ||||
| (6) |
For point estimation on , we directly let . For approximate Bayesian inference on , we sample . See more about the intuition on encoder structure design in Appendix B.
3.2.2 Structural Filters
We directly use a weight matrix as each variable’s structural filter, more details about which are shown in Figure 2. As for other hidden layers in the decoder architecture, we keep them shared for all variables and these will be discussed in next sub-section.
3.2.3 Hidden and Output Layers
Shared Hidden Layers
The model is designed to have shared hidden layers out of two purposes: (1) Learning similar basis functions/representations among variables; (2) Saving the computation resource.
As we have mentioned in assumptions, each variable follows a distribution of exponential family conditioned on its parents (and ). Since distributions in exponential family can be represented as a common form of probability density function, the shared hidden layers are expected to learn the similarity of basis representation among these variables that are assumed to follow conditional distributions from the same family.
On the other hand, shared hidden layers can substantially reduce the efforts needed for computation during training the model. Normally, we would have separate hidden layers for each variable. However, this will introduce much more learning parameters, which decrease the model’s scalability in high-dimensional setting and could also aggravate over-fitting facing small dataset.
Separate Output Layers
We have separate output layer for each variable of either a continuous type or binary type. For continuous variables, the output layer is simply a weight matrix without any activation function. For binary variables, the output layer will be a weight matrix with sigmoid activation function.
3.2.4 Loss Function
Denote the parameters of encoder, structural filters, shared hidden layers and output layers respectively (), the model is trained by minimising the below loss function with respect to and for each source domain index :
| (7) |
where for continuous variables:
| (8) |
and for binary variables:
| (9) |
We also regularise the estimated since a small is expected for better generalisation of decoder as shown in Theorem 3.2. The DAG loss takes the form of:
| (10) |
where is the reconstruction loss for all variables including features and the label in domain . We use the mean squared loss (8) for continuous variables and cross entropy loss (9) for binary variables. is the acyclicity constraint of NO-TEARS (Zheng et al., 2020). is the group lasso regularisation on the weight matrix in . , and are the corresponding hyper-parameters.
Generalisation Bound of Decoder
We have derived a generalisation bound of the decoder trained on i.i.d data within the same domain, which validates the form of our loss function (7).
Theorem 3.2.
Let : be a -layer ReLU feed-forward neural network decoder with hidden layer size . Then, under appropriate assumptions C.1, C.2, C.3 and C.4 on the neural network norm and loss functions (refer to Appendix C.1 for more details), , with probability at least on a training domain with i.i.d samples conditioned on a shared , we have:
| (11) |
where , and are constants, is the square of norm on the corresponding parameters and is the DAG constraint on . For more details on the theorem proof, please refer to Appendix C.
3.2.5 Training Strategy
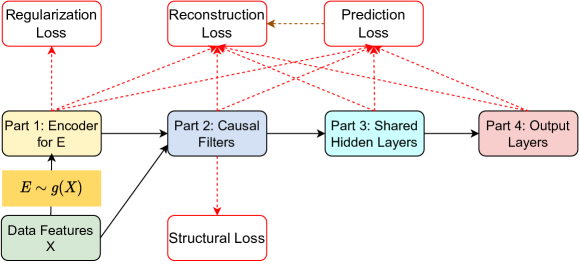
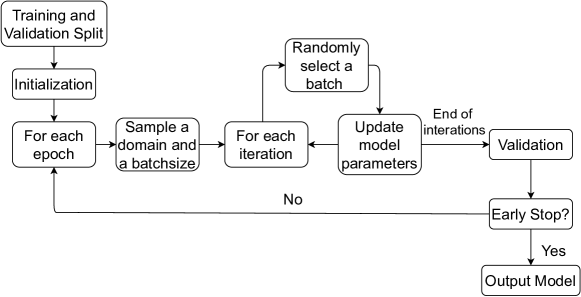
In this section, we introduce a novel algorithm for training our model with multiple domains. The flow chart of the training algorithm is depicted as in Figure 5. For more details, please refer to the Algorithm 1 in supplementary materials D.
Prediction in the Target Domain
To predict the target variable in the target domain, we first feed features of the whole unlabelled dataset into the encoder to get the predicted . Then we go through corresponding model components by order: the last causal filter of , the hidden layers and the last output layer of trained from source domains to get the predicted taking and features as input.
3.2.6 Bayesian Formulation
We can also put the whole framework into Bayesian formulation. The log likelihood of observed data is
| (12) |
By taking the expectation on both sides of (3.2.6) with respect to a variational posterior , the evidence lower bound (ELBO) of the marginal distribution of observed data is derived as below:
| (13) |
Where if we assume . It is easily noticed that this KL term also contains a squared regularisation term on estimated . We can then replace the prediction loss and reconstruction loss in (7) with corresponding ELBO to train the Bayesian predictor.
Prediction
After getting the trained decoder and variational parameters (the encoder parameters), we perform prediction on the target domain by approximate inference via sampling :
| (14) |
where .
4 Experiments
In this section, we empirically evaluate the performance of our method for UDA on synthetic and real-world datasets. To begin with, we will briefly describe experiment settings including evaluation metrics, baselines and benchmarks we compare with. In the second sub-session, we discuss experiments on two made-up datasets which comply with our basic assumptions. We demonstrate the performance improvement of DAPDAG (our method) (Please refer to Appendix E.5 for ablation studies on how each part of the model contributes to the performance gain). In the third section, we introduce real-world datasets - MAGGIC (Meta-Analysis Global Group in Chronic Heart Failure) (Mart´ınez-Sellés et al., 2012) with 30 different studies of patients and test our method on the processed datasets of selected studies against benchmarks.
4.1 Experiment Setups
Benchmarks
We benchmark DAPDAG against the plain MLP, CASTLE and MDAN (Multi-domain Adversarial Networks) (Zhao et al., 2018) and BRM (Meta Learning as Bayesian Risk Minimisation) (Maeda et al., 2020). We set MLP to be our baseline method and train it on merged data by directly combining all source domains. MDAN is representative of a class of well-founded DA methods (Pei et al., 2018; Sebag et al., 2019) to learn an invariant feature representation or implicit distribution alignment across domains. They use an adversarial objective to minimise the training loss over labelled sources and distance of feature representation between each source domain and the target domain at the same time. Despite that this class of methods are usually applied in the field of computer vision with high-dimensional image data, we adapt the structure and transfer the idea to our learning setting where data are generated by a DAG with much fewer variables. While BRM can also be regarded as an auto-encoder that could make inference on latent variable perturbing the conditional distribution of without reconstructing DAG as an auxiliary task.
Implementation and Training
All methods are implemented using PyTorch driven by GPU. We set the same decoder architecture of DAPDAG as CASTLE except that DAPDAG has an extra domain encoder and an extra row for taking inferred in structural filters. Moreover, the DAPDAG decoder has the same number of hidden layers and number neurons in each hidden layer with MLP, BRM decoder and feature extractor of MDAN. We fix the number of hidden layers to be 2 and number of hidden neurons to be 16 for both synthetic and real datasets. For the encoder of DAPDAG and DoAMLP, we use a two-hidden-layer deep-set structure with the same number of neurons as decoder in each hidden layer. The activation function used is ELU and each model is trained using the Adam optimiser (Kingma & Ba, 2014) with an early stopping regime. For the data features with large scales in classification datasets such as ages, BMI (body-mass index), we standardise these variables with a mean of 0 and variance of 1.
4.2 Synthetic Datasets
In this part, we present experiments on synthetic datasets, please refer to E.3 in supplementary materials for more detailed description on synthetic datasets.
Comparison with Benchmarks
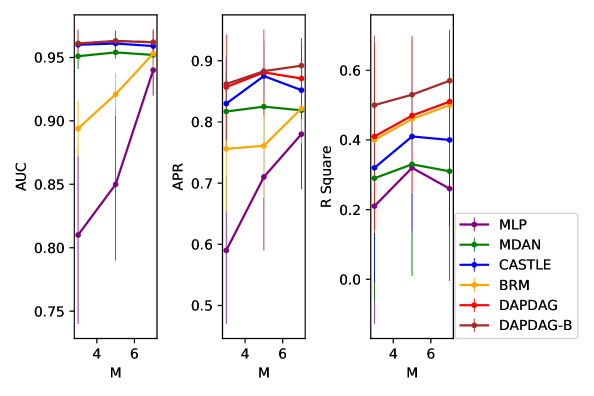
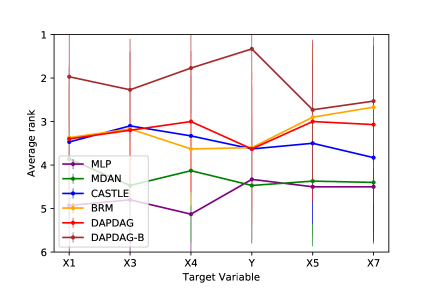
We compare DAPDAG with other benchmarks with variant number of training sources with size of 500 for each domain set. As the results show in Figure 6, DAPDAG outperforms all other benchmarks in both classification and regression datasets. Despite the fact that CASTLE does not have the ability to adjust for domain shift, it achieves better performance than MDAN with the ability of domain adaptation. This validates the intuition that in a causally perturbed system, forcing different distributions to be in a similar representation space may not help much compared to finding invariant causal features for prediction. However, these results only sketch a general performance gain of DAPDAG against other methods over multiple combinations of source and target domains. We also compare DAPDAG against benchmarks with respect to different target variables and average source-target difference. The results are shown in Figure 7. We observe that DAPDAG has apparently better performance in scenarios where target domain is significantly different from sources and the target variable is not a sink node (that has no descendants) in the underlying causal DAG.
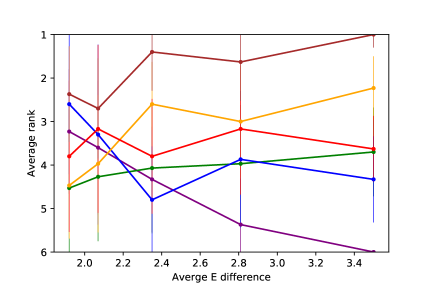
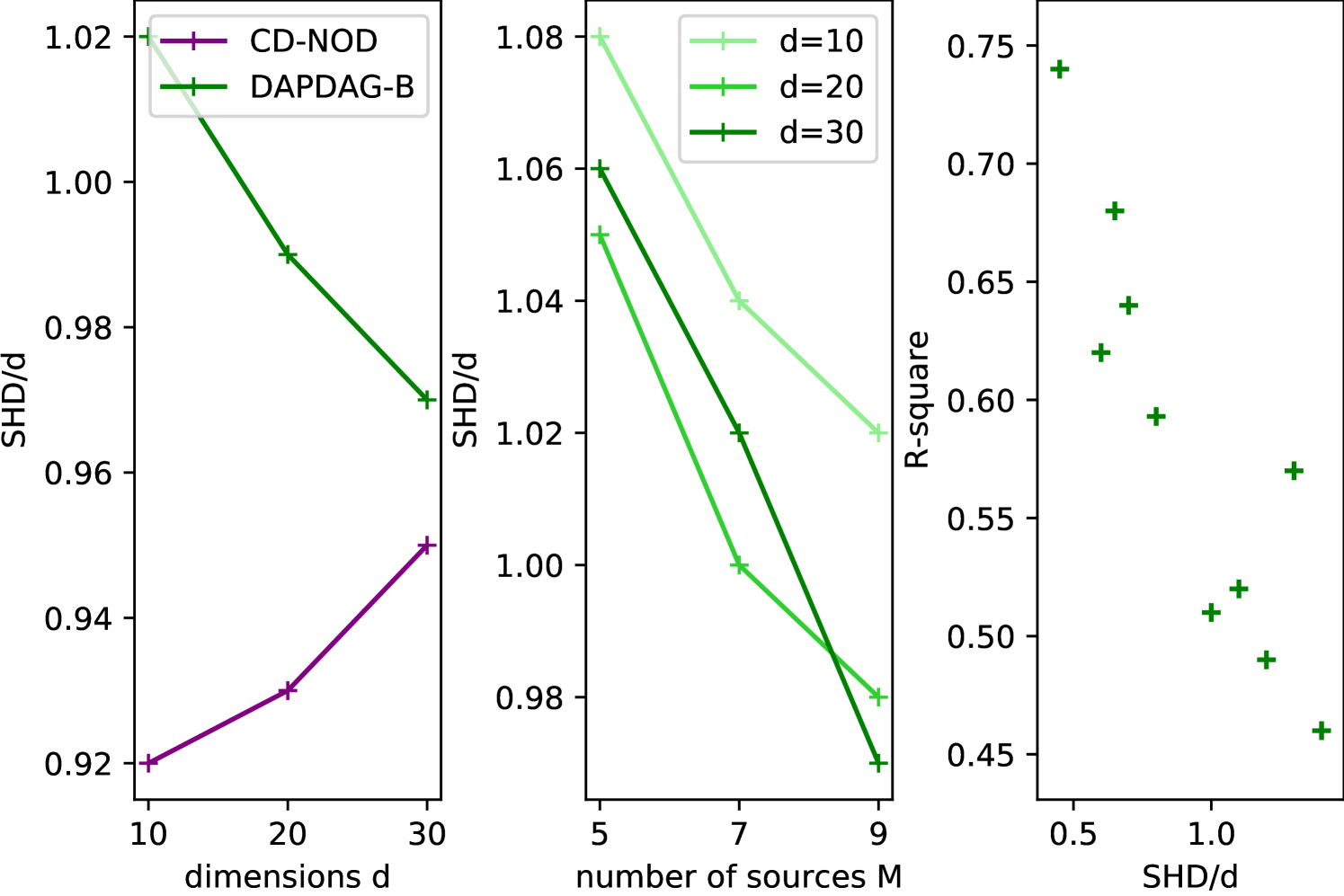
Evaluation of DAG Learning
We have also included a few experiments evaluating the learned causal DAGs from synthetic regression datasets, as shown in Figure 8, where is the number of variables, is the number of training domains and SHD is the structural hamming distance (used to measure the discrepancy between the learned graph and the truth, the lower the better). For generating synthetic datasets with different dimensions , we randomly generate causal graphs and assign non-linear conditionals (For each variable where both and are randomly sampled weight matrices, represent the graphical parents of the variable , is the noise variable and is the activation function) according to the causal order. We compare our method with the baseline CD-NOD (Zhang et al., 2017) in the left plot of Figure 8 (for non-oriented edges, we use the ground-truth directions if possible). Due to an extra prediction loss on the target variable in addition to the reconstruction loss, the learned graphs usually deviate from the truth in terms of mis-specified edges and redundant edges. Yet this prediction loss in the Bayesian formulation will become less important as dimensions increase and then the learned graph will approach the ground truth, which is shown in both the left plot and middle plot of the Figure 8. Meanwhile, the right plot in Figure 8 demonstrates a highly positive relationship between the accuracy of graph learning and prediction performance.
Scalability Analysis: Please refer to part E.6 in the appendix for more details.
4.3 MAGGIC Datasets
In this section, we show experimental results on MAGGIC dataset. Since DAPDAG-B (Bayesian formulation) performs better than DAPDAG on synthetic datasets, we only show the performance of DAPDAG in this part. We also add a benchmark - a data imputation method called MisForest (Stekhoven & Bühlmann, 2012) to impute labels in the target domain as missing values. MAGGIC is a collection of 30 datasets from different medical studies containing patients who experienced heart failure. For the UDA task, we take the 12 shared variables by all studies and set the label as one-year survival indicator.
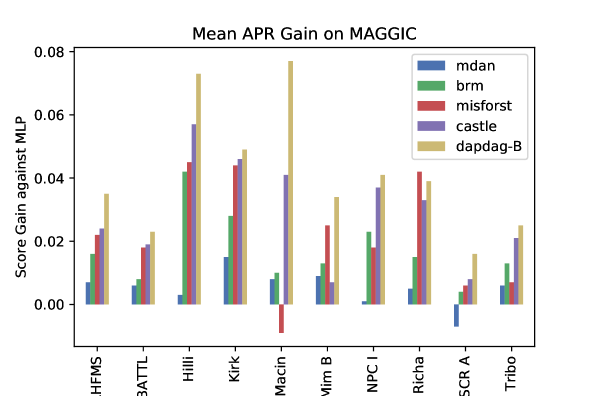
Performance
The experiment results on selected MAGGIC studies are demonstrated in Figure 9. The shown results of our method are obtained using the environmental variable with dimension 3, which is fine-tuned as a hyper-parameter during the model selection.We observe that DAPDAG-B can almost beat other benchmarks on the selected studies in APR scores. Despite the minor improvement against benchmarks in a few studies such as ”BATTL” and ”Kirk” or even worse performance than MissForest in ”Richa”, DAPDAG exhibits significant performance boost in other studies like ”Hilli”, ”Macin” and ”NPC I”, which are found to be more different from rest sources (please refer to E.8 in supplementary materials).
5 Discussion
To sum up, we explore a novel auto-encoder structure that combines estimation of population statistics using deep sets and reconstructing a DAG through a regularised decoder. We prove that under certain assumptions, the loss function has components similar to terms in the generalisation bound of decoder, which validates the form of training loss. Experiments on synthetic and real datasets manifest the performance gain of our method against popular benchmarks in UDA tasks.
Better design of encoder.
Currently, the encoder needs to take the whole dataset from a domain as input, which greatly slows down the training speed when the source dataset size is huge. Meanwhile, a source domain with large sample set is preferred since it will help capture the environmental variable . Therefore, a better encoder should be designed to balance the trade-off from domain sizes.
Theoretical exploration on the encoder.
We have derived a generalisation bound for decoder within the same domain yet haven’t looked into the properties of encoder. We hope to dive deeper into theoretical guarantees on the encoder for inference on .
Extension to DA with Feature Mismatch.
Currently, we only focus on the task of UDA within the same feature space. In reality, it is highly possible to encounter datasets with different features available in each domain, such as the case of missing features across studies in MAGGIC dataset. Although imputation can be a solution, it can fail if there are a large portion of non-overlapped features for each domain. Therefore, it is imperative to develop approaches that can handle feature mismatch in the near future.
References
- Bengio et al. (2019) Bengio, Y., Deleu, T., Rahaman, N., Ke, R., Lachapelle, S., Bilaniuk, O., Goyal, A., and Pal, C. A meta-transfer objective for learning to disentangle causal mechanisms. arXiv preprint arXiv:1901.10912, 2019.
- Cuturi (2013) Cuturi, M. Sinkhorn distances: Lightspeed computation of optimal transport. Advances in neural information processing systems, 26:2292–2300, 2013.
- Dasgupta et al. (2019) Dasgupta, I., Wang, J., Chiappa, S., Mitrovic, J., Ortega, P., Raposo, D., Hughes, E., Battaglia, P., Botvinick, M., and Kurth-Nelson, Z. Causal reasoning from meta-reinforcement learning. arXiv preprint arXiv:1901.08162, 2019.
- Deng et al. (2019) Deng, Z., Luo, Y., and Zhu, J. Cluster alignment with a teacher for unsupervised domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9944–9953, 2019.
- Germain et al. (2016) Germain, P., Bach, F., Lacoste, A., and Lacoste-Julien, S. Pac-bayesian theory meets bayesian inference. In Neural Information Processing Systems (NIPS 2016), pp. 1876–1884, 2016.
- Ghassami et al. (2018) Ghassami, A., Kiyavash, N., Huang, B., and Zhang, K. Multi-domain causal structure learning in linear systems. Advances in neural information processing systems, 31:6266, 2018.
- Jiang et al. (2020) Jiang, X., Lao, Q., Matwin, S., and Havaei, M. Implicit class-conditioned domain alignment for unsupervised domain adaptation. In International Conference on Machine Learning, pp. 4816–4827. PMLR, 2020.
- Kaiser & Sipos (2021) Kaiser, M. and Sipos, M. Unsuitability of notears for causal graph discovery. arXiv preprint arXiv:2104.05441, 2021.
- Kang et al. (2019) Kang, G., Jiang, L., Yang, Y., and Hauptmann, A. G. Contrastive adaptation network for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4893–4902, 2019.
- Ke et al. (2019) Ke, N. R., Bilaniuk, O., Goyal, A., Bauer, S., Larochelle, H., Schölkopf, B., Mozer, M. C., Pal, C., and Bengio, Y. Learning neural causal models from unknown interventions. arXiv preprint arXiv:1910.01075, 2019.
- Ke et al. (2020) Ke, N. R., Wang, J., Mitrovic, J., Szummer, M., Rezende, D. J., et al. Amortized learning of neural causal representations. arXiv preprint arXiv:2008.09301, 2020.
- Kingma & Ba (2014) Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Kyono & van der Schaar (2019) Kyono, T. and van der Schaar, M. Improving model robustness using causal knowledge. arXiv preprint arXiv:1911.12441, 2019.
- Kyono et al. (2020) Kyono, T., Zhang, Y., and van der Schaar, M. Castle: Regularization via auxiliary causal graph discovery. arXiv preprint arXiv:2009.13180, 2020.
- Lachapelle et al. (2019) Lachapelle, S., Brouillard, P., Deleu, T., and Lacoste-Julien, S. Gradient-based neural dag learning. arXiv preprint arXiv:1906.02226, 2019.
- Lee et al. (2019) Lee, S., Kim, D., Kim, N., and Jeong, S.-G. Drop to adapt: Learning discriminative features for unsupervised domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 91–100, 2019.
- Liu et al. (2019) Liu, H., Long, M., Wang, J., and Jordan, M. Transferable adversarial training: A general approach to adapting deep classifiers. In International Conference on Machine Learning, pp. 4013–4022. PMLR, 2019.
- Löwe et al. (2020) Löwe, S., Madras, D., Zemel, R., and Welling, M. Amortized causal discovery: Learning to infer causal graphs from time-series data. arXiv preprint arXiv:2006.10833, 2020.
- Maeda et al. (2020) Maeda, S.-i., Nakanishi, T., and Koyama, M. Meta learning as bayes risk minimization. arXiv preprint arXiv:2006.01488, 2020.
- Magliacane et al. (2017) Magliacane, S., van Ommen, T., Claassen, T., Bongers, S., Versteeg, P., and Mooij, J. M. Domain adaptation by using causal inference to predict invariant conditional distributions. Advances in neural information processing systems, 2017.
- Mart´ınez-Sellés et al. (2012) Martínez-Sellés, M., Doughty, R. N., Poppe, K., Whalley, G. A., Earle, N., Tribouilloy, C., McMurray, J. J., Swedberg, K., Køber, L., Berry, C., et al. Gender and survival in patients with heart failure: interactions with diabetes and aetiology. results from the maggic individual patient meta-analysis. European journal of heart failure, 14(5):473–479, 2012.
- Mooij et al. (2020) Mooij, J. M., Magliacane, S., and Claassen, T. Joint causal inference from multiple contexts. 2020.
- Nair et al. (2019) Nair, S., Zhu, Y., Savarese, S., and Fei-Fei, L. Causal induction from visual observations for goal directed tasks. arXiv preprint arXiv:1910.01751, 2019.
- Pan & Yang (2009) Pan, S. J. and Yang, Q. A survey on transfer learning. IEEE Transactions on knowledge and data engineering, 22(10):1345–1359, 2009.
- Panaretos & Zemel (2019) Panaretos, V. M. and Zemel, Y. Statistical aspects of wasserstein distances. Annual review of statistics and its application, 6:405–431, 2019.
- Pei et al. (2018) Pei, Z., Cao, Z., Long, M., and Wang, J. Multi-adversarial domain adaptation. In Thirty-second AAAI conference on artificial intelligence, 2018.
- Quiñonero-Candela et al. (2009) Quiñonero-Candela, J., Sugiyama, M., Lawrence, N. D., and Schwaighofer, A. Dataset shift in machine learning. Mit Press, 2009.
- Rojas-Carulla et al. (2018) Rojas-Carulla, M., Schölkopf, B., Turner, R., and Peters, J. Invariant models for causal transfer learning. The Journal of Machine Learning Research, 19(1):1309–1342, 2018.
- Schölkopf et al. (2012) Schölkopf, B., Janzing, D., Peters, J., Sgouritsa, E., Zhang, K., and Mooij, J. On causal and anticausal learning. arXiv preprint arXiv:1206.6471, 2012.
- Sebag et al. (2019) Sebag, A. S., Heinrich, L., Schoenauer, M., Sebag, M., Wu, L., and Altschuler, S. Multi-domain adversarial learning. In ICLR 2019-Seventh annual International Conference on Learning Representations, 2019.
- Stekhoven & Bühlmann (2012) Stekhoven, D. J. and Bühlmann, P. Missforest—non-parametric missing value imputation for mixed-type data. Bioinformatics, 28(1):112–118, 2012.
- Stojanov et al. (2019) Stojanov, P., Gong, M., Carbonell, J., and Zhang, K. Data-driven approach to multiple-source domain adaptation. In The 22nd International Conference on Artificial Intelligence and Statistics, pp. 3487–3496. PMLR, 2019.
- Vanschoren (2018) Vanschoren, J. Meta-learning: A survey. arXiv preprint arXiv:1810.03548, 2018.
- Vilalta & Drissi (2002) Vilalta, R. and Drissi, Y. A perspective view and survey of meta-learning. Artificial intelligence review, 18(2):77–95, 2002.
- Wang & Deng (2018) Wang, M. and Deng, W. Deep visual domain adaptation: A survey. Neurocomputing, 312:135–153, 2018.
- Yang et al. (2020) Yang, M., Liu, F., Chen, Z., Shen, X., Hao, J., and Wang, J. Causalvae: Structured causal disentanglement in variational autoencoder. arXiv preprint arXiv:2004.08697, 2020.
- Yu et al. (2019) Yu, Y., Chen, J., Gao, T., and Yu, M. Dag-gnn: Dag structure learning with graph neural networks. In International Conference on Machine Learning, pp. 7154–7163. PMLR, 2019.
- Zaheer et al. (2017) Zaheer, M., Kottur, S., Ravanbakhsh, S., Poczos, B., Salakhutdinov, R. R., and Smola, A. J. Deep sets. Advances in Neural Information Processing Systems, 30, 2017.
- Zhang et al. (2015) Zhang, K., Gong, M., and Schölkopf, B. Multi-source domain adaptation: A causal view. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 29, 2015.
- Zhang et al. (2017) Zhang, K., Huang, B., Zhang, J., Glymour, C., and Schölkopf, B. Causal discovery from nonstationary/heterogeneous data: Skeleton estimation and orientation determination. In IJCAI: Proceedings of the Conference, volume 2017, pp. 1347. NIH Public Access, 2017.
- Zhang et al. (2020) Zhang, K., Gong, M., Stojanov, P., Huang, B., Liu, Q., and Glymour, C. Domain adaptation as a problem of inference on graphical models. Advances in neural information processing systems, 2020.
- Zhang et al. (2019) Zhang, M., Jiang, S., Cui, Z., Garnett, R., and Chen, Y. D-vae: A variational autoencoder for directed acyclic graphs. arXiv preprint arXiv:1904.11088, 2019.
- Zhao et al. (2018) Zhao, H., Zhang, S., Wu, G., Gordon, G. J., et al. Multiple source domain adaptation with adversarial learning. 2018.
- Zhao et al. (2019) Zhao, H., Des Combes, R. T., Zhang, K., and Gordon, G. On learning invariant representations for domain adaptation. In International Conference on Machine Learning, pp. 7523–7532. PMLR, 2019.
- Zheng et al. (2018) Zheng, X., Aragam, B., Ravikumar, P., and Xing, E. P. Dags with no tears: Continuous optimization for structure learning. Advances in neural information processing systems, 2018.
- Zheng et al. (2020) Zheng, X., Dan, C., Aragam, B., Ravikumar, P., and Xing, E. Learning sparse nonparametric dags. In International Conference on Artificial Intelligence and Statistics, pp. 3414–3425. PMLR, 2020.
Appendix A NOTEARS for Learning Non-linear SEM
How to construct a proxy of for a general non-linear SEM? Suppose in graph , there exists a function for the -th variable such that
| (15) |
where if then does not depend on , leading to a result that the function is constant for all . (Zheng et al., 2020) uses partial derivatives to measure the dependence of on . Denote , then it can be shown that
| (16) |
where is the -norm. Denote the matrix with entries . Then becomes an non-linear surrogate of the adjacency matrix in linear models. Now consider using a MLP to approximate the . Suppose the MLP has hidden layers and a single activation :
| (17) |
where and and . It is shown in (Zheng et al., 2020) that if for all , then is independent of the -th input . Let with and define as the norm of -th row of . Then it suffices to solve DAG learning by tacking below problem (Zheng et al., 2020):
| (18) | |||
Appendix B Intuition on the Encoder Design
In this part, we intuitively induce the encoder design drawn from Bayesian posterior of . Our objective is to infer the latent variable from a sample of features. Following the idea of Bayesian inference, the MAP estimate of a latent variable can be obtained by maximising its posterior. In our case, however, we aim to learn a direct but approximate mapping from the features to the key statistics of posterior distribution given those features if its posterior is assumed to have a special form of distribution, e.g. Gaussian.
Consider the observed data in source domain . For notation simplicity, we omit the domain index in following texts. let’s begin with the conditional probability of i.i.d data drawn from the same domain, we have:
| (19) |
For the posterior of given , we have:
| (20) |
If we further assume both and are members of an exponential family, e.g. Gaussian distributions (without loss of generality), which can be expressed (approximately) as:
| (21) | ||||
| (22) |
where , are approximated mappings and is the parameter for the prior variance of . Then we can re-write as:
| (23) |
By completion of squares on (23), we get the approximate posterior with the similar form as in (6) except that the input is in (23) instead of in (6).
Appendix C Generalisation Bound with Mixed Type Data
Our proof of Theorem 3.2 mainly follows the work by (Kyono et al., 2020), except the extension to mixed data type including binary variables and regularisation on the environmental variable . Let and be the expected loss and empirical loss respectively. We further divide each loss into two components - as the loss of continuous variables and as the loss of binary variables. Similar notations of distinguishing variable types are applied to , and .
C.1 Assumptions
Assumption C.1.
For any sample , the continuous variables has bounded norm such that . This can further infer that (Kyono et al., 2020):
| (24) |
where is a constant.
Assumption C.2.
For any sample , we assume
| (25) |
where is a constant.
Assumption C.3.
The squared loss function of continuous variables is sub-Gaussian under the distribution with a proxy-variance factor such that , .
Assumption C.4.
The loss function for binary variables where is the cross-entropy loss function of -th binary variable, is sub-Gaussian under the distribution with a proxy-variance factor such that , .
C.2 Generalisation Bound for the Decoder
Proof. Denote as the parameters of DAPDAG decoder and as perturbed where each parameter in is perturbed by a noise vector .
Step 1.
We first the derive the upper bound for the expected loss over parameter perturbation and data distribution. For each shared within the same domain, we have (for simplicity, we omit the notation of , which serves as an input for , , and ):
| (26) |
Similarly, we can derive:
where is the upper bound of such that . Let and be the distribution and prior distribution of perturbed decoder parameter , and be the distribution and prior distribution of respectively. According to Corollary 4 in (Germain et al., 2016) and original proof of CASTLE, we can trivially transfer their theoretical results to continuous variables in our framework. Given and that are independent of training data in the domain with , we can deduce from the PAC-Bayes theorem that with probability at least , for any i.i.d training samples with the shared :
| (28) |
where and . Combining C.2, C.2 and 28, we get:
| (29) |
For -th binary variable denoted as , we have:
| (30) |
We then upper bound the expected perturbed loss for all binary variables:
| (31) |
where is a constant such that . Similar to C.2, we also have:
| (32) |
Similar to 28, given and that are independent of training data in the domain with , we can deduce from the PAC-Bayes theorem that with probability at least , for any i.i.d training samples with the shared :
| (33) |
where and . Combining results from C.2, C.2 and 28, we get:
| (34) |
Step 2.
Notice that where , and represent the parameter of structural filters, shared hidden layers and output layers, we can further dissemble for and write and in more details. Let be the weight matrix in a neural network layer and be the number of hidden layers, then we denote:
| (35) |
as the decoder parameters of continuous variables. And the similar denotation for binary variables are as below:
| (36) |
Therefore, it is obvious that:
| (37) |
Furthermore, we assume both and can be decomposed into two parts such that:
| (38) |
where and are corresponding prior and probability distributions of structural filters that form a DAG, and are weight parameter distributions of corresponding layer parameters. Without loss of generality, and are assumed to follow normal distributions for simplicity:
| (39) |
and the variable and constant take the form as:
| (40) |
where is a adjacency-proxy matrix such that is the -norm of the -th row of the -th perturbed structural filter matrix and represents the Hadamard product operation. From the introduction of NOTEARS method before, we know that and in fact each element in is non-negative, so using Normal approximation in 40 may not be appropriate for Bayesian Inference. Formally, it is better to consider using truncated normal or exponential priors for better approximation.
And and are given as:
| (41) | ||||
| (42) |
Recall that we also have a shared environmental variable , which can be considered as a parameter independent of each component in the decoder. Despite that the value is obtained from the encoder taking sample features as input, for any i.i.d samples drawn from the same domain, this is fixed as a constant for decoder. Here, we further assume:
| (43) |
Step 3.
By using the fact the that KL of two joint distributions is greater or equal to the KL of two marginal distributions, we can upper bound the KL in 29 and 34 using their versions of joint distributions:
| (44) |
And we can upper bound as follows:
| (45) |
By upper-bounding the 34 and 29 using C.2, we have the final generalisation bound of decoder for mixed-type variables. Given and that are independent of training data within each domain, for any i.i.d training samples with the shared , then with probability at least we have:
| (46) |
where .
Appendix D Training Algorithm
This section looks into more details about the training algorithm of DAPDAG. The sudo-code of the algorithm is shown in Algorithm 1.
Appendix E Experiments
E.1 Metrics
Classification
For classification task, we report two scores: Area Under ROC Curve (AUC) and Average Precision-Recall Score (APR). An ROC curve (receiver operating characteristic curve) plots True Positive Rate (TPR) versus False Positive Rate (FPR) at different classification thresholds, showing the performance of a classifier in a more balanced and robust manner. APR summarises a precision-recall curve as the weighted mean of precision attained at each pre-defined threshold, with the increase in recall from the previous threshold used as the weight:
| (47) |
where and are the precision and recall at the -th threshold. Both AUC and APR are computed using the predicted probabilities from classifier and the true labels in binary classification.
Regression
For regression task, we present the coefficient of determination (), the proportion of the variation in that is predictable from .
E.2 Benchmark: Domain-invariant Representation Methods
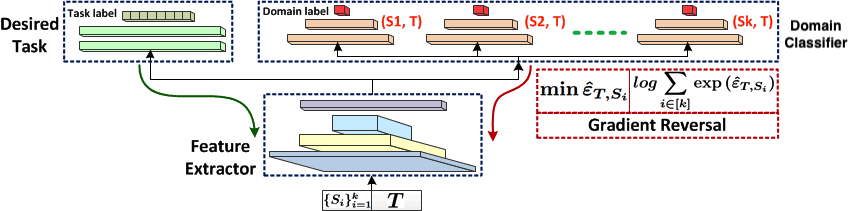
Here we give a more detailed description on adversarial methods for UDA with implicit alignment. Please refer to Figure 10 for a general idea of the class of methods.
We have also added the data-driven unsupervised domain adaptation proposed by (Zhang et al., 2020) in extra comparison experiments. Because it requires a two-stage learning and much more parameters than our approach, we do not include it in the main texts. For more details, please see the Figure 18 for the experiments on synthetic regression datasets.
E.3 Synthetic Dataset Generation
We make two synthetic datasets for classification and regression task respectively: the classification dataset is made up following a DAG learned from MAGGIC dataset and the regression dataset is generated by our own DAG design in Figure 11. The general algorithm of synthetic generation is exhibited in Algorithm 2.
E.3.1 Classification
We refer to the learned causal graph in (Kyono & van der Schaar, 2019) as our ground truth for synthetic classification data (as shown in the right part of Figure 11). The made-up dataset have features that carry explicit meaning in real world thus they are generated compatible with reality to some extent (e.g. design of variable types, range of values, positive and negative causal relations should acknowledge the real-world constraints such as ages can not be negative.). We use 8 features to predict : 5-year survival rate of ”made-up” patients. These features are : Age of patients; : Ethnicity of the patient; : Angina; : Myocardial Infarction; : ACE Inhibitors; : NYHA1; : NYHA2; : NYHA3. Equations 48 below elaborate more details about their distributions and causal relationships.
| (48) |
where is an intermediate variable for deriving , which will not show as a feature in the dataset, stand for the log-normal distribution.
E.3.2 Regression
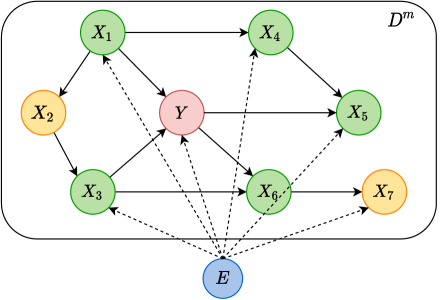
The second dataset for regression task is generated according to the DAG in Figure 11. Its structural equations are sketched below:
| (49) |
E.4 Verifying Intuition on Synthetic Datasets
In this section, we verify the close relationship between difference and Wasserstein distance of two distributions through synthetic causal data and meanwhile dive deeper into how well DAPDAG can learn this and exploit this for domain adaptation.
Wasserstein Distance between two empirical distributions
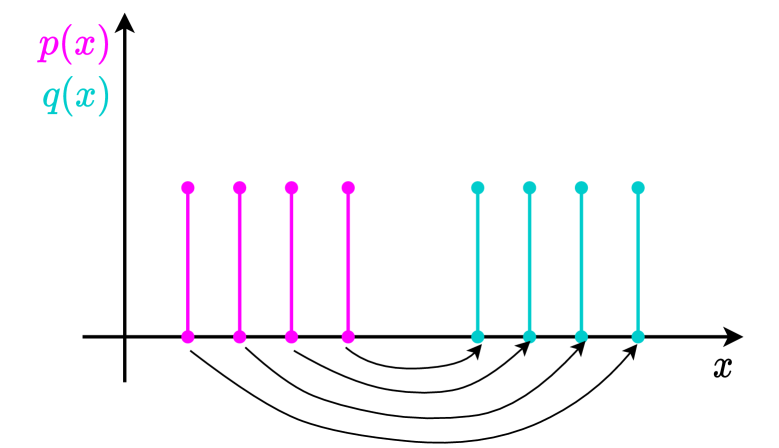
There exist extensive works inspecting distribution distances, e.g. KL-divergence and H-divergence, and how to utilise these metrics for further applications. In our work, we use a distance metric called Wasserstein distance to measure the distance of two empirical distributions (Panaretos & Zemel, 2019). It’s formal mathematical definition is below: The -Wasserstein distance between probability measures and on is defined as
| (50) |
A very high-level understanding of the distance metric from the optimal transport perspective is the minimum effort it would take to move points of mass from one distribution to the other. Let’s consider a simple example in Figure 12 where we want to move the points in to the same places of points in . There can be a lot of ways of moving, and the arrows in the Figure depict one of them. However, what we are interested is the way with the least effort. This can be approximated using a numeric method called Sinkhorn iterations (Cuturi, 2013). Since our focus is on DA, we skip the details of this algorithm and directly apply the method to compute the distance of each pair of synthetic datasets.
Visualisation of Results
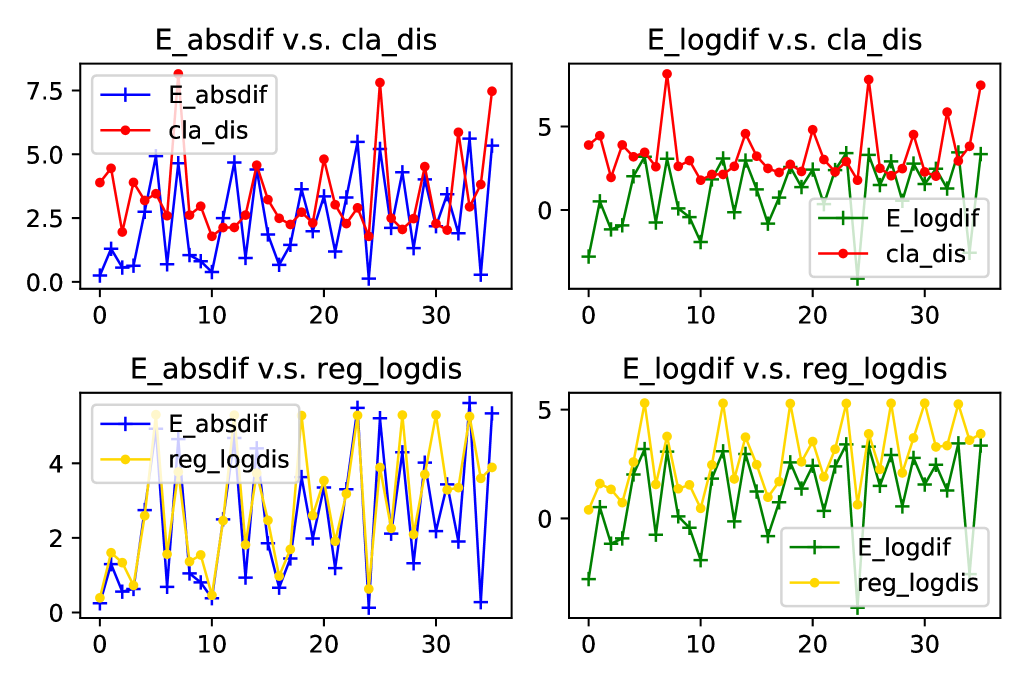
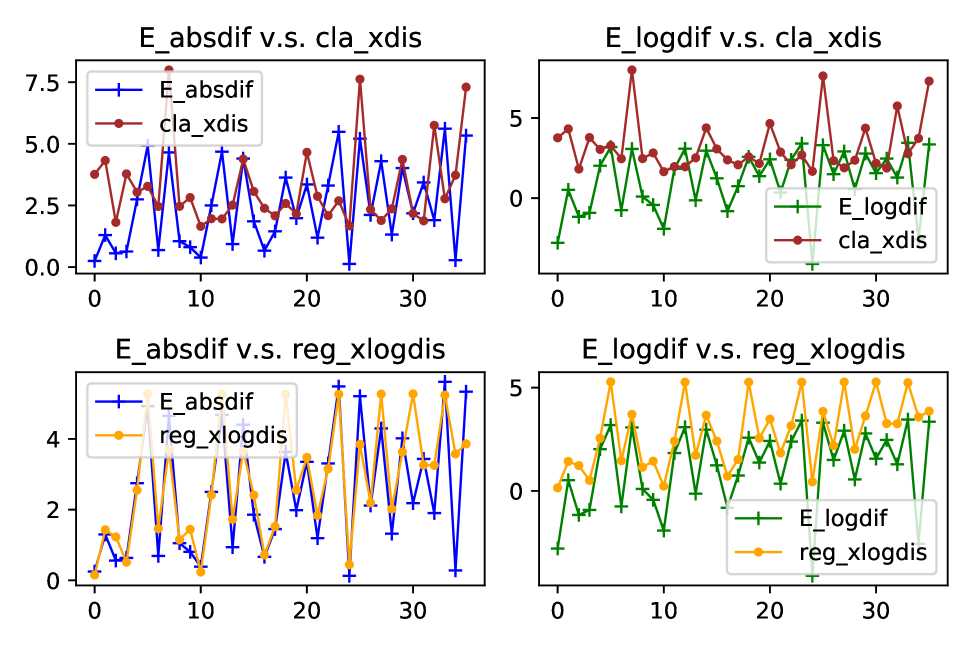
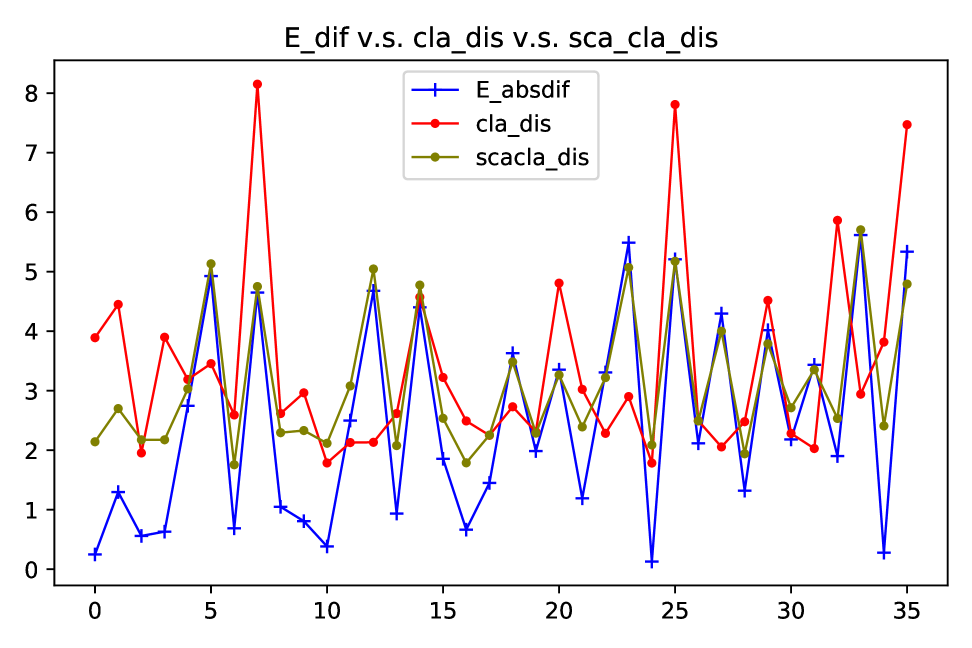
It is an interesting fact from Figure 13 that the difference of s that are used for generating two synthetic datasets can be a regarded as good proxy of Wasserstein distance between these two datasets. For regression data, the absolute difference of s almost fully coincides with the log of Wasserstein distance in terms of both values and fluctuations. Since our method utilises the features in the target domain for adaptation, we also plot the relationship between difference and Wasserstein distance of features in 14. As shown in the plots, ignorance of labels barely affects the relationship. This finding provides a strong evidence for using only features to find the distribution difference and adjust for the shift accordingly.
However, on the classification dataset, we can see that despite of the resemblance on fluctuations, true values of differences deviate to some extent from distances of both full variables and only features. Luckily, we can relieve this issue by standardising the features with large scales. And after standardisation, the distance can better capture the variation of difference, as illustrated in Figure 15.
Capturing the difference
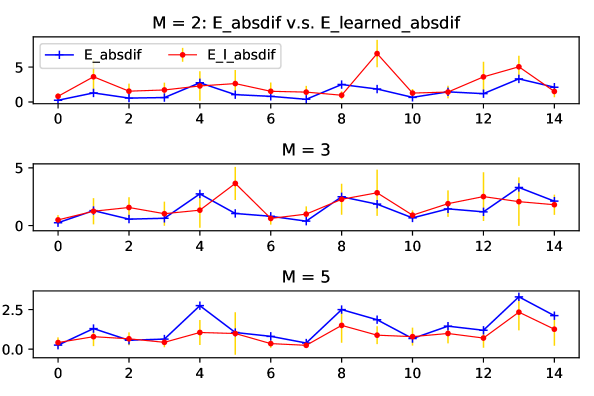
How well can our method learn the difference so as to enable its ability of domain adaptation? We observe that as the number of sources increases, the learned difference catches better the trend of true difference, which is exhibited in Figure 16. This supports the benefit of training more sources for adaptation.
E.5 Ablation Studies
We do ablation studies on various loss components in (4) except for the regularisation loss on to better understand sources of performance gain. It is noticed that the comparison experiment with CASTLE can be considered as an ablation study on the encoder and once this is introduced, the square of should be regularised as proved in C.2 to lower the generalisation bound of decoder during training. Therefore, it is not necessary to do a separate ablation study on the squared regularisation term in 7. Besides, we have shown the comparison with BRM as an ablation study on structural filters. Both DAPDAG and CASTLE have the same number of structural filters as the total number of variables and these filters contribute to the reconstruction of each variable and DAG learning. In BRM, however, there is only one filter that selects features locally for the target variable.
| Methods | M=3 | M=5 | M=7 | |||
| AUC | APR | AUR | APR | AUR | APR | |
| Dag+Spa | 0.947(0.021) | 0.814(0.091) | 0.954(0.017) | 0.820(0.075) | 0.958(0.015) | 0.827(0.063) |
| Rec+Dag | 0.959(0.006) | 0.825(0.072) | 0.961(0.004) | 0.849(0.063) | 0.962(0.004) | 0.872(0.049) |
| Rec+Spa | 0.960(0.005) | 0.845(0.069) | 0.962(0.005) | 0.854(0.055) | 0.963(0.003) | 0.890(0.044) |
| Rec+Dag+Spa | 0.961(0.004) | 0.856(0.036) | 0.964(0.004) | 0.883(0.033) | 0.965(0.003) | 0.893(0.031) |
| Methods | RMSE | ||
|---|---|---|---|
| M=3 | M=5 | M=7 | |
| Dag+Spa | 0.422(0.325) | 0.444(0.306) | 0.495(0.258) |
| Rec+Dag | 0.479(0.254) | 0.508(0.221) | 0.545(0.173) |
| Rec+Spa | 0.486(0.231) | 0.510(0.209) | 0.558(0.166) |
| Rec+Dag+Spa | 0.501(0.200) | 0.533(0.167) | 0.572(0.142) |
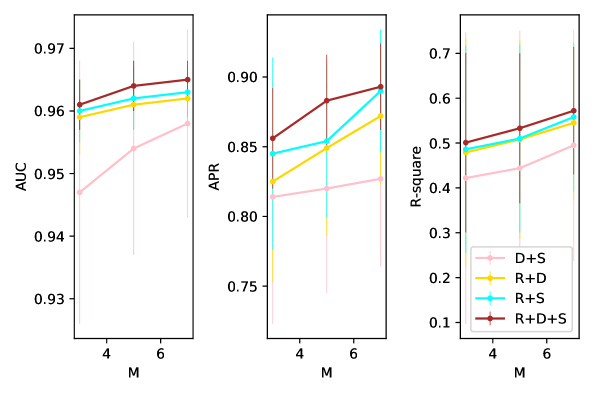
The comparison results in Figure 17 verify the importance of structural filters and the regularisation on these filters as a DAG. On the regression dataset, if we do not reconstruct each variable, the performance of DAPDAG will be even worse than BRM with much simpler structure. Therefore, reconstruction of all variables brings significant benefit to prediction while DAG and sparsity constraint further improves the model’s robustness across different domains.
E.6 Scalability
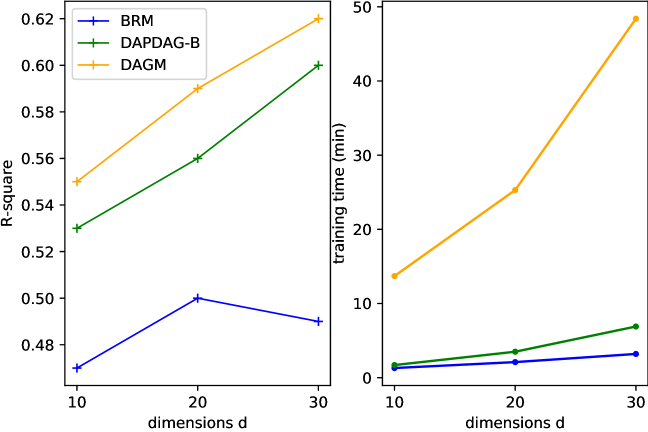
We have extended simulations to cases with higher dimensions, about which you may find more information in Figure 18. In the right plot, we compare our method with two UDA benchmarks in training time versus data dimensions. Despite the minor gap between our approach and (Zhang et al., 2020), ours needs considerately less time for training than theirs in high-dimensional settings.
E.7 Processing of MAGGIC Dataset
It is tricky that data-preprocessing and domain selection can exert considerate influence on testing performance because these datasets have extensive missing values or features in each study while the usual data imputation methods tend to impute those missing values without taking account of domain distinction. And we admit that in this part future work is needed for better data imputation or UDA methodology that can deal with feature mismatch.
Imputation of Missing Values
Despite extensive instances contained by MAGGIC, each study tends to have massive missing values in certain features or even a number of missing features, which significantly violates our assumptions in terms of causal sufficiency and feature match. Hence it is imperative to process these datasets before use. We omit those with missing labels and use MissForest (Stekhoven & Bühlmann, 2012), a non-parametric missing value imputation method for mixed-type data, to impute missing values of features. We first iterate imputation of missing values over studies. During imputing missing entries in each study, we try to rely on other features of that study as much as possible. For missing features that cannot be imputed based on the single study, we resort to other studies that have the features available. For binary features, the imputed values would be fractions between 0 and 1, which are transformed to 0 or 1 with a threshold at 0.5.
Selection of Domains
We then select processed studies with fewest missing features originally for experiments because those studies are supposed to be affected least by data imputation and maintain the distribution shift from other domains. The selected studies are shown in Table 3 with dataset size followed in the parentheses.
Standardisation of Non-binary features
All continuous features are standardised with mean of 0 and variance of 1, just following the same procedure as we do for synthetic classification dataset.
Meanwhile, a recent work (Kaiser & Sipos, 2021) claims that continuous optimisation/differentiable methods of causal discovery such as NO-TEARS may not work well on dataset with variant scales. They observe inconsistent learning results with respect to data scaling - variables with larger scales or variance tend to be the child nodes. Standardising the data with large scales can alleviate the problem to some extent.
E.8 Supporting Experimental Figures and Plots
E.8.1 Comparison against Benchmarks on MAGGIC Datasets
| Target Study | AUC Scores | |||||
|---|---|---|---|---|---|---|
| Deep MLP | MDAN | BRM | MisForest | CASTLE | DAPDAG-B | |
| AHFMS (99.7) | 0.782(0.012) | 0.785(0.013) | 0.811(0.010) | 0.819(0.006) | 0.826(0.019) | 0.854(0.011) |
| BATTL (58.8) | 0.692(0.016) | 0.707(0.020) | 0.735(0.014) | 0.765(0.007) | 0.768(0.013) | 0.790(0.012) |
| Hilli (111.5) | 0.687(0.014) | 0.695(0.020) | 0.699(0.014) | 0.711(0.012) | 0.713(0.005) | 0.730(0.013) |
| Kirk (46.9) | 0.868(0.005) | 0.891(0.009) | 0.931(0.012) | 0.936(0.010) | 0.954(0.008) | 0.970(0.009) |
| Macin (361) | 0.569(0.010) | 0.567(0.007) | 0.619(0.015) | 0.588(0.014) | 0.625(0.017) | 0.646(0.015) |
| Mim B (59.4) | 0.596(0.011) | 0.578(0.014) | 0.612(0.018) | 0.647(0.013) | 0.616(0.024) | 0.659(0.016) |
| NPC I (71.5) | 0.517(0.016) | 0.524(0.011) | 0.540(0.017) | 0.542(0.021) | 0.533(0.011) | 0.571(0.020) |
| Richa (36.6) | 0.712(0.012) | 0.711(0.013) | 0.739(0.013) | 0.782(0.011) | 0.757(0.012) | 0.775(0.017) |
| SCR A (54.9) | 0.706(0.017) | 0.698(0.024) | 0.710(0.019) | 0.675(0.009) | 0.691(0.022) | 0.728(0.018) |
| Tribo (56.6) | 0.760(0.006) | 0.771(0.010) | 0.766(0.016) | 0.769(0.012) | 0.788(0.015) | 0.799(0.010) |
| Target Study | APR Scores | |||||
|---|---|---|---|---|---|---|
| Deep MLP | MDAN | BRM | MisForest | CASTLE | DAPDAG | |
| AHFMS (196) | 0.914(0.011) | 0.921(0.008) | 0.930(0.014) | 0.936(0.007) | 0.938(0.009) | 0.949(0.009) |
| BATTL (363) | 0.947(0.013) | 0.953(0.010) | 0.955(0.009) | 0.965(0.003) | 0.966(0.004) | 0.970(0.006) |
| Hilli (176) | 0.853(0.007) | 0.865(0.013) | 0.866(0.010) | 0.869(0.006) | 0.881(0.002) | 0.897(0.008) |
| Kirk (215) | 0.923(0.007) | 0.938(0.006) | 0.952(0.012) | 0.967(0.004) | 0.969(0.002) | 0.972(0.007) |
| Macin (228) | 0.506(0.012) | 0.514(0.019) | 0.517(0.017) | 0.497(0.017) | 0.547(0.014) | 0.581(0.016) |
| Mim B (282) | 0.812(0.009) | 0.821(0.014) | 0.825(0.016) | 0.837(0.007) | 0.819(0.021) | 0.846(0.013) |
| NPC I (66) | 0.528(0.011) | 0.529(0.019) | 0.551(0.018) | 0.546(0.013) | 0.565(0.023) | 0.569(0.018) |
| Richa (627) | 0.879(0.008) | 0.884(0.011) | 0.894(0.011) | 0.921(0.010) | 0.912(0.006) | 0.918(0.010) |
| SCR A (324) | 0.959(0.011) | 0.952(0.012) | 0.963(0.013) | 0.965(0.008) | 0.967(0.013) | 0.975(0.012) |
| Tribo (663) | 0.914(0.005) | 0.920(0.014) | 0.927(0.012) | 0.921(0.009) | 0.935(0.010) | 0.939(0.011) |