Data-aided Sensing for Distributed Detection
Abstract
In this paper, we study data-aided sensing (DAS) for distributed detection in wireless sensor networks (WSNs) when sensors’ measurements are correlated. In particular, we derive a node selection criterion based on the J-divergence in DAS for reliable decision subject to a decision delay constraint. Based on the proposed J-divergence based DAS, the nodes can be selected to rapidly increase the log-likelihood ratio (LLR), which leads to a reliable decision with a smaller number of the sensors that upload measurements for a shorter decision delay. From simulation results, it is confirmed that the J-divergence based DAS can provide a reliable decision with a smaller number of sensors compared to other approaches.
Distributed Detection; Wireless Sensor Networks; Intelligent Data Collection
I Introduction
In wireless sensor networks (WSNs), a set of sensors are deployed to perform environmental monitoring and send observations or measurements to a fusion center (FC) [1]. The FC is responsible for making a final decision on the physical phenomenon from the reported information. WSNs can be part of the Internet of Things (IoT) [2] [3] to provide data sets collected from sensors to various IoT applications.
In conventional WSNs, various approaches are studied to perform distributed detection with decision fusion rules at the FC [4]. The optimal decision fusion rules in various channel models have been intensively studied in the literature (see references in [5] [6]). In [7], efficient transmissions from sensors to the FC studied using the channel state information (CSI). Furthermore, in [8], cross-layer optimization is considered to maximize the life time of WSN when sensors’ measurements are correlated. In [9], the notion of massive multiple input multiple output (MIMO) [10] is exploited for distributed detection when the FC is equipped with a large number of antennas.
In a number of IoT applications, as in WSNs, devices’ sensing to acquire local measurements or data and uploading to a server in cloud are required. In cellular IoT, sensors are to send their local measurements to an access point (AP). While sensing and uploading can be considered separately, they can also be integrated, which leads to data-aided sensing (DAS) [11] [12]. In general, DAS can be seen as iterative intelligent data collection scheme where an AP is to collect data sets from devices or sensor nodes through multiple rounds. In DAS, the AP chooses a set of nodes at each round based on the data sets that are already available at the AP from previous rounds for efficient data collection. As a result, the AP (actually a server that is connected to the AP) is able to efficiently provide an answer to a given query with a small number of measurements compared to random polling.
In this paper, we apply DAS to distributed detection in WSNs. Due to the nature of DAS where sensor nodes sequentially send their measurements according to a certain order, distributed detection can be seen as sequential detection [13]. Clearly, if sensors’ measurements are independent and identically distributed (iid), the performance of distributed detection is independent of the uploading order. However, for correlated measurements, a certain order can allow an early decision or a reliable decision with a smaller number of sensors’ measurements. Thus, based on DAS, we can provide an efficient way to decide the order of sensor nodes for uploading, which can lead to a reliable decision with a smaller number of measurements. In particular, we derive an objective function based on the J-divergence [14] to decide the next sensor node in DAS for distributed detection.
The paper is organized as follows. The system model is presented in Section II. The notion of DAS is briefly explained and applied to ditributed detection in Sections III and IV. We present simulation results and conclude the paper with some remarks in Sections V and VI.
Notation
Matrices and vectors are denoted by upper- and lower-case boldface letters, respectively. The superscript denotes the transpose. stands for the statistical expectation. In addition, represents the covariance matrix of random vector . represents the distributions of real-valued Gaussian random vectors with mean vector and covariance matrix , respectively.
II System Model
In this section, we present the system model for a WSN that consists of a number of sensor nodes and one AP that is also an FC for distributed detection [4]. Thus, throughout the paper, we assume that AP and FC are interchangeable.
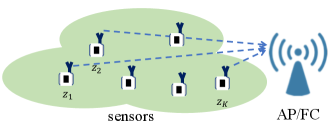
Suppose that there are sensor nodes and denote by the local measurement of node as illustrated in Fig. 1. Each sensor is to send its local measurement to the AP. The AP is to choose one of hypotheses, which are denoted by , based on the received local measurements. Provided that all measurements are available, the AP can make a decision based on the maximum likelihood (ML) principle as follows:
| (1) |
where represents the likelihood function of for given .
For example, suppose that the ’s follow a Gaussian distribution with mean vector and covariance matrix under hypothesis . In this case, (1) can be re-written as
| (2) | ||||
| (3) |
where that is referred to as the complete information.
For a large number of sensor nodes, , while a reliable decision can be made if all the measurements are uploaded to the AP, the time to receive all the measurements can be long due to a limited bandwidth, which results in a long decision delay. In particular, if only one sensor node is allowed to transmit at a slot time (in time division multiple access (TDMA)), the time to make a decision is equivalent to that to receive all the measurements, i.e., -slot time (under the assumption that the processing time to choose a hypothesis according to (3) is negligible). As a result, in order to shorten the decision delay, a fraction of measurements can be used at the cost of degraded decision performance.
III Data-aided Sensing
In this section, we briefly present the notion of DAS for joint sensing and communication to efficiently upload measurements of nodes [12] [15].
Suppose that only one node can upload its measurement at each round. Denote by the set of local measurements that are available at the AP after iteration . Then, for a certain objective function, denoted by , the AP can decide the next node to upload its local information as follows:
| (4) |
where is the index of the node that is to upload its local measurement at round , represents the index set of the nodes associated with , and denotes the complement of . Clearly, it can be shown that . In (4), we can see that the selected node, say , at each round depends on the accumulated measurements from the previous rounds, , which shows the key idea of DAS.
The objective function in (4) varies depending on the application. As an example, let us consider an entropy-based DAS where the AP is to choose the uploading order based on the entropy of measurements. Since is available at the AP after iteration , the entropy or information of the remained measurements becomes , where represents the conditional entropy of for given . Thus, as in [15], the following objective function can be used for the node selection:
| (5) |
which is the entropy gap, where is the amount of information by uploading the measurement from node . Clearly, for fast data collection (or data collection with a small number of nodes), we want to choose the next nodes to minimize the entropy gap.
Note that is independent of . Thus, the next node is to be chosen according to the maximization of conditional entropy is given by
| (6) |
That is, the next node should have the maximum amount of information (in terms of the conditional entropy) given that is already available at the AP.
In [12], the mean squared error (MSE) between the total measurement and its estimate is to be minimized in choosing the node at round , i.e.,
| (7) |
where is the minimum MSE estimator of for given and the expectation is carried out over , which is the subset of measurements that are not available before round . Since the measurements are assumed to be Gaussian in [12], second order statistics can be used for DAS, which is called Gaussian DAS. After some manipulations, it can also be shown that
| (8) |
where is constant and is the conditional mean of for given . Thus, the next node can be selected as follows:
| (9) |
For Gaussian measurements, the MSE, , is proportional to the conditional entropy, . Thus, Gaussian DAS is also to minimize the entropy gap in selecting nodes, i.e., Gaussian DAS is also the entropy-based DAS.
IV Node Selection in Distributed Detection with DAS
In this section, we apply DAS to distributed detection. We first consider the entropy-based DAS to decide the next node in distributed detection. Then, another approach is proposed, which has the objective function based on the J-divergence.
IV-A Entropy-based DAS for Node Selection
Since the entropy-based DAS can allow the AP to estimate or approximate the complete information, , with a small number of measurements, it can be used in distributed detection. That is, under each hypothesis, the AP can collect a subset of measurements and use them to make a decision.
Suppose that the AP has a subset of measurements, i.e., , at the end of round . The AP has the likelihood function, . Under hypothesis , the updated likelihood function with a new measurement from node becomes , where . As in Section III, for each hypothesis , the node selection can be carried out to minimize the entropy gap. Thus, if the ascending order is employed, the node selection becomes
| (10) |
for , where nodes are selected at each . Clearly, we have , and a decision can be made every , i.e., after nodes upload their measurements.
Alternatively, if there are parallel channels, the selected nodes can be given by
| (11) |
IV-B KL Divergence for Node Selection
With known measurements at the end of round , i.e., , the AP can choose the next node to increase the log-likelihood ratio (LLR) for the maximum likelihood (ML) detection. For example, suppose that . Then, with a new measurement, the LLR is given by
| (12) |
Since is unknown, the expectation of LLR can be considered. Under , the expectation of LLR is given by
| (13) |
and can be chosen to maximize the expectation. However, since there is also hypothesis , for uniform prior, the objective function to be maximized can be defined as
| (14) | ||||
| (15) | ||||
| (16) | ||||
| (17) |
where and is the Kullback–Leibler (KL) divergence between two distributions, and [14]. Here, represents the expectation over . In (17), the objective function is the -divergence [14] between and .
In general, for hypotheses, the node selection can be generalized as follows:
| (18) |
The resulting DAS that uses the node selection criterion in (18) is referred to as the J-divergence based DAS (J-DAS).
We now derive more explicit expressions for the objective function in (17) when are jointly Gaussian. For simplicity, consider . Then, the objective function in (17) becomes
| (19) | ||||
| (20) |
where and for notational convenience.
For convenience, let be the column vector consisting of the elements of . In addition, let , , and . Let and , where . Then, under , we have
| (21) |
After some manipulations using the matrix inversion lemma [16], it can be shown that
| (22) | ||||
| (23) |
where and
| (24) | ||||
| (25) |
The second term in (20), i.e., , can also be found by a similar way.
For Gaussian measurements, the complexity of J-DAS mainly depends on the complexity to find the J-divergence or (23). At round , since is the common term for all , the complexity is mainly due to that to find in (25). Again, is independent of , the complexity to find is , while the complexity to find the inverse of from the results in the previous round is . Thus, the complexity at round is . Thus, if the number of iterations is , the total complexity is bounded by .
V Simulation Results
In this section, we present simulation results with LLRs. For each average LLR, the results of 500 independent runs are used. In simulations, we assume that the ’s are jointly Gaussian with and . For comparisons, we consider the three node selection criteria: J-DAS (i.e., (18)), entropy-based DAS (i.e., (10)), and random selection.
For the first simulation, we assume that
| (26) |
where is the amplitude of the mean signal. In addition, the covariance matrix of under is given by
| (27) |
where and , and represents the noise variance. The signal-to-noise ratio (SNR) is defined as . In Fig. 2, the average LLR is shown as a function of iterations. When is correct, it is shown that the LLR increases with the number of samples or iterations. Clearly, the performance of J-DAS outperforms those of entropy-based DAS and random selection. In other words, when a decision is made with a small number of iterations or samples in distributed detection, J-DAS can help provide reliable outcomes compared to the others.
It is interesting to see that the entropy-based DAS does not provide a good performance in distributed detection as shown in Fig. 2. The entropy-based DAS is to choose the node that has the most uncorrelated measurement as shown in (10). In fact, such a measurement needs not contribute to maximizing the difference between the hypotheses.
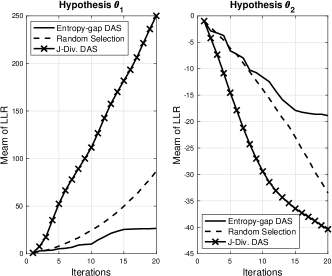
(a) (b)
For the next simulation, we consider the case of iid measurements. That is, for all . In addition, it is assumed that and for all . As mentioned earlier, in this case, the performance is independent of the uploading order, which can be confirmed by the results in Fig. 3.
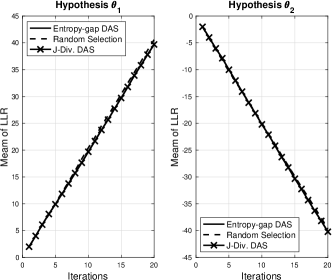
(a) (b)
VI Concluding Remarks
In this paper, the notion of DAS has been exploited to provide a good performance of distributed detection in WSN with a smaller number of sensors that upload their measurements. In particular, a J-divergence based node selection criterion was proposed for DAS, which was referred to as J-DAS, so that the measurement from the next node can maximize LLR. From simulation results, it was shown that LLR increased rapidly as the number of iterations increased when J-DAS was employed.
There would be a number of further research topics. Among those, as in [17], the application of J-DAS to distributed machine learning for classification is interesting. The performance analysis of J-DAS would also be another topic to be studied in the future.
References
- [1] W. Dargie and C. Poellabauer, Fundamentals of Wireless Sensor Networks: Theory and Practice. Wiley Publishing, 2010.
- [2] Q. Zhu, R. Wang, Q. Chen, Y. Liu, and W. Qin, “IOT gateway: Bridging wireless sensor networks into Internet of Things,” in 2010 IEEE/IFIP International Conference on Embedded and Ubiquitous Computing, pp. 347–352, 2010.
- [3] Y. Kuo, C. Li, J. Jhang, and S. Lin, “Design of a wireless sensor network-based IoT platform for wide area and heterogeneous applications,” IEEE Sensors Journal, vol. 18, pp. 5187–5197, June 2018.
- [4] P. K. Varshney, Distributed Detection and Data Fusion. New York: Springer, 1997.
- [5] R. Viswanathan and P. Varshney, “Distributed detection with multiple sensors i. fundamentals,” Proceedings of the IEEE, vol. 85, no. 1, pp. 54–63, 1997.
- [6] J.-F. Chamberland and V. V. Veeravalli, “Decentralized detection in sensor networks,” IEEE Trans. Signal Process., vol. 51, pp. 407–416, feb 2003.
- [7] B. Chen, L. Tong, and P. K. Varshney, “Channel-aware distributed detection in wireless sensor networks,” IEEE Signal Process. Mag., vol. 23, pp. 16–26, jul 2006.
- [8] S. He, J. Chen, D. K. Y. Yau, and Y. Sun, “Cross-layer optimization of correlated data gathering in wireless sensor networks,” in 2010 7th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks (SECON), pp. 1–9, June 2010.
- [9] A. Chawla, A. Patel, A. K. Jagannatham, and P. K. Varshney, “Distributed detection in massive MIMO wireless sensor networks under perfect and imperfect CSI,” IEEE Trans. Signal Processing, vol. 67, no. 15, pp. 4055–4068, 2019.
- [10] T. L. Marzetta, “Noncooperative cellular wireless with unlimited numbers of base station antennas,” IEEE Trans. Wireless Communications, vol. 9, pp. 3590–3600, Nov. 2010.
- [11] J. Choi, “A cross-layer approach to data-aided sensing using compressive random access,” IEEE Internet of Things J., vol. 6, pp. 7093–7102, Aug 2019.
- [12] J. Choi, “Gaussian data-aided sensing with multichannel random access and model selection,” IEEE Internet of Things J., vol. 7, no. 3, pp. 2412–2420, 2020.
- [13] A. Wald, “Sequential tests of statistical hypotheses,” Ann. Math. Statist., vol. 16, pp. 117–186, 06 1945.
- [14] S. Kullback, Information Theory and Statistics. New York: Wiley, 1959.
- [15] J. Choi, “Data-aided sensing where communication and sensing meet: An introduction,” in 2020 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), pp. 1–6, 2020.
- [16] D. A. Harville, Matrix Algebra From a Statistician’s Perspective. New York: Springer, 1997.
- [17] J. Choi and S. R. Pokhrel, “Federated learning with multichannel ALOHA,” IEEE Wireless Communications Letters, vol. 9, no. 4, pp. 499–502, 2020.