Data-and-Knowledge Dual-Driven Automatic Modulation Recognition for Wireless Communication Networks
Abstract
Automatic modulation classification is of crucial importance in wireless communication networks. Deep learning based automatic modulation classification schemes have attracted extensive attention due to the superior accuracy. However, the data-driven method relies on a large amount of training samples and the classification accuracy is poor in the low signal-to-noise radio (SNR). In order to tackle these problems, a novel data-and-knowledge dual-driven automatic modulation classification scheme based on radio frequency machine learning is proposed by exploiting the attribute features of different modulations. The visual model is utilized to extract visual features. The attribute learning model is used to learn the attribute semantic representations. The transformation model is proposed to convert the attribute representation into the visual space. Extensive simulation results demonstrate that our proposed automatic modulation classification scheme can achieve better performance than the benchmark schemes in terms of the classification accuracy, especially in the low SNR. Moreover, the confusion among high-order modulations is reduced by using our proposed scheme compared with other traditional schemes.
Index Terms:
Automatic modulation classification, data-and-knowledge dual-driven, low signal-to-noise radio.I Introduction
Artificial intelligence and intelligent communication are indispensable parts in wireless communication systems. As an indispensable intelligent communication technology in wireless communication systems, automatic modulation classification (AMC) has been widely used in various applications. In military applications, AMC helps to recover the transmitted information and generate interference signals with matching modulation [1]. In civilian applications, AMC is able to determine the appropriate demodulation method to realize the correct recovery of transmitted information [2].
The existing automatic modulation classification (AMC) schemes can be mainly classified into two categories, namely, model-driven AMC and data-driven AMC. The model-driven schemes mainly include likelihood-based (LB) schemes [3] and feature-based (FB) schemes [4]. The LB classifier treats AMC as a hypothesis testing problem. Different test statistics are constructed firstly. Then, the likelihood functions are calculated under the modulation hypothesis by using the constructed test statistics. Lastly, these functions are compared to make the final decision [3]. The FB schemes aim to extract unique characteristics of different types of signals and have robust performance with low implementation complexity [5]. In contrast, data-driven methods, such as support vector machine (SVM) [6], and logistic regression [5], etc., perform modulation classification by learning the difference among data distributions. Moreover, the data-driven deep learning utilize the neural networks to extract the visual features automatically from the original data, such as I/Q samples. The related works are classified as follows.
Model-driven methods: The authors in [7] used the maximum-likelihood method to recognize digital amplitude-phase modulations. It was shown that the maximum-likelihood classifier is capable of classifying any finite set of distinctive constellations with the zero error rate when the number of available symbols goes to infinity. However, the maximum-likelihood method suffers from high computational complexity. With the FB schemes, the authors in [8] utilized the high-order statistical features to realize the modulation classification. It was shown that the FB method can achieve good performance with low computational complexity.
Data-driven methods: A long short-term memory (LSTM) based AMC algorithm was proposed in [9]. LSTM learns the dependency relationship between the current element and the elements before-after through the gating structure. However, its recurrent structure results in high computational complexity. Meanwhile, spatial correlation features are ignored in this scheme. The authors in [10] utilized the CNN-LSTM to efficiently explore the feature interaction and the spatial-temporal properties of raw complex temporal signals. However, the increase of the depth of the network can cause the gradient vanishing and over-fitting problems. A deep residual network (ResNet) was proposed in [11] by using residual learning with skip connection for image classifications, which alleviates the over-fitting problem when training deep networks. Meanwhile, it is able to learn discriminative features for achieving a better performance. However, the complex architecture of deep network needs a lot of computing resources and takes a long time to train. This drawback makes it unrealistic in the practical scenarios since the real-time performance is of crucial importance in practical applications. In [12], the authors designed a lightweight model with smaller model sizes. High computation efficiency was achieved by using model compression. The simulation results demonstrated that the lightweight model reduces the training time significantly with negligible loss in classification accuracy.
All the data-driven AMC schemes mentioned in [9]-[12] require a large amount of training samples, which are difficult to be obtained in practical communication scenarios. Meanwhile, pure data-driven schemes cannot satisfy the classification performance requirements under the dynamically changing communication scenarios. In particular, the classification performance achieved by using those methods is very poor in low SNRs. Recently, radio frequency machine learning (RFML) has been proposed [13],[14] and envisioned to be promising to tackle these problems. It exploits expert knowledge to achieve superior performance. Motivated by RFML, a novel data and knowledge dual-driven AMC scheme is proposed in this paper. Our main contributions are as follows.
-
•
It is the first time that semantic information, e.g., class attributes, is exploited to decrease the required number of training samples, which is of crucial importance in the practical complex and dynamic wireless networks.
-
•
An improved residual network is proposed for attribute learning.
-
•
A novel data and knowledge dual-driven framework for AMC is proposed to construct the classifier to learn the muti-dimensional representations of different modulations from I/Q signals.
-
•
Simulation results demonstrate that our proposed scheme has a better classification performance compared with other DL-based AMC schemes, especially in the low SNR. Moreover, the confusion between 16QAM and 64QAM is reduced significantly.
II Preliminaries
II-A Problem Statement
The modulation classification can be identified as a -class hypothesis test, where denotes the number of modulations. The received signal under the th modulation hypothesis is given as
| (1) |
where and are the transmitted signal and the received signal, respectively. is the number of signal symbols. is the additive white Gaussian noise with mean being zero and variance being .
The in-phase and quadrature (I/Q) parts of the received signal are both utilized. These two parts usually obey an identical independent distribution, which can be input into the neural network without normalization [15]. The I/Q signal samples can be expressed as a vector by turning the received signal into the vector , given as
| (2a) | ||||
| (2b) | ||||
where and represent the in-phase part and the quadrature part of the received signal, respectively, and . and represent the operators of the real and imaginary parts of the signal, respectively. The raw data can be specifically expressed as the form of matrix, given as
| (3) |
II-B Traditional AMC Methods
The DL-based schemes such as CNN and RNN are utilized to extract features from the raw data. Then, a fully connected (FC) layer is utilized to integrate the information and carry out the conversion of feature dimension. The feature learning can be expressed as a process that the raw data is mapped into a -dimensional vector , given as
| (4) |
where mapping function represents the feature learning model with the fully connected layer, and represents the feature vector output from the FC layer.

Finally, the learned feature vectors are classified by another FC layer with the classifier. The number of neurons in the last layer is equal to the number of modulation formats. Thus, each output neuron corresponds to a modulation format. is used to convert the output into the probability that the input signal belongs to each candidate modulation format. The cross-entropy loss function is utilized to measure the gap between the model output and the true label. It can be given as
| (5) |
where represents the number of classes, represents the number of samples. is the output of , which represents the probability when data sample belongs to class . is a indicative variable, which is given as
| (8) |
However, the pure data-driven AMC method requires a large number of samples to complete the training of deep networks. Moreover, the classification accuracy of traditional methods is poor in the practical complex and dynamic scenarios, especially in the low SNRs. Fortunately, the exploitation of expert knowledge is promising to tackle those problems [16]. However, to our best knowledge, few investigations have studied it. Therefore, we propose a novel data and knowledge dual-driven AMC method.
III Proposed AMC Scheme
The architecture of our proposed AMC scheme is shown in Fig. 1. On one branch, the visual model encodes the raw I/Q data into visual vectors. The visual feature space is used as the embedding space where both the visual content and the attribute vector of the class that the modulation format belongs to are embedded. On the other branch, the attribute learning model learns the attribute vectors corresponding to different modulation formats according to the deterministic attribute labels that are set artificially. Then, the transformation model converts the attribute vectors into the visual feature space. Lastly, a least square embedding loss is utilized to minimize the discrepancy between the visual feature vectors and the attribute vectors.
III-A Visual Model
Fig. 2 illustrates the framework of the visual model. The multi-scale convolutional network (MSNet) is employed as the visual model. The MSNet consists of several multiscale (MS) modules, global average-pooling (GAP), FC layers and the classifier. MS modules are used to capture the multi-level feature information by using a convolution layer with stride = 2 to reduce the feature dimension at the top layer of the module. Then, several parallel convolutions with different kernel sizes are utilized to capture multi-level features. Features from different convolutional layers are consolidated together by using the concat operation. After the concat operation, the FC layer of the traditional CNN is replaced by the GAP for aggregating information from the MS modules to average each feature output from the four corresponding channels. Compared with the traditional FC layer, the over-fitting problem is avoided since there is no parameter required to be optimized in GAP. Moreover, another FC layer with rectified linear units (ReLU) is utilized to reduce the feature dimensionality. ReLU function can be expressed as
| (9) |
where represents the operator for obtaining the maximum value.
The values of several neurons are set to be zero, which results in the sparsity of the network and reduces the interdependence among parameters. Therefore, the occurrence of over-fitting problems can be alleviated. Moreover, different from and activation function, ReLU function dose not have the saturation zone. Thus, the gradient vanishing problem can be avoided. The specific architecture of the visual model is shown in Table I.
III-B Attribute Learning Model
The core goal of AMC is to recognize the category of different modulations. Each modulation has its unique characteristics. Thus, modulation can be identified based on the high-level description that is phrased in terms of semantic attributes. Different classes are usually different in the high dimensional feature space. In this case, it is promising to combine semantic attributes and visual features to achieve a higher classification accuracy.
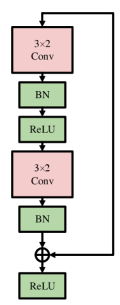
An adaptation of residual network was exploited to learn the attribute representation of different modulations. The residual unit is shown in Fig. 3(a). Two 2D convolution operations with kernel size are performed in the residual unit. Different from ResNet in [15], the batch normalization layer is used to standardize the data in the intermediate layers to avoid the gradient disappearance caused by the saturation of the partial derivative of the intermediate variable. Alongside, ReLU activation is used after the first convolution and after the skip connection to introduce non-linear operations as shown in Fig. 3(a). The residual stack, as shown in Fig. 3(b) consists of a convolution operation with a kernel size of followed by two residual units. The maxpool layer is used to compress features. Moreover, the GAP is used to average the outputs of different channels. Therefore, the parameters are reduced greatly compared with FC in ResNet proposed in [15]. The specific architecture of the attribute learning network is shown in Fig. 3(c). The number of residual stack is decreased from 6 to 3 to reduce the complexity of the model. The kernel size and output dimensions corresponding to different layers of the attribute learning model are shown in Table II.
Since the learning of each attribute transcends the specific classification task, the attribute learning model can be pre-learned independently [16]. In this way, we can perform attribute learning through bigger datasets that are not limited to AMC datasets.



III-C The Visual-Attribute Embedding Model
The visual-attribute embedding model has two branches. One branch is the visual encoding branch adapted from the MSNet in Fig. 1, and the classification layer is removed. The visual encoding branch can output the visual feature vector. It takes the raw data of the signal samples as the input. Then, the MS module is used to extract multi-dimensional features. The GAP is used to flatten multi-channel features. Finally, the FC layer outputs a -dimensional feature vector .
| Input Layers | Kernel Size | Output |
|---|---|---|
| Input | ||
| MS module | ||
| MS module | ||
| GAP | ||
| FC/ReLU | ||
| FC/Softmax |
| Input Layers | Kernel Size | Output Dimensions |
|---|---|---|
| Input | ||
| Conv | ||
| ResUnit | ||
| ResUnit | ||
| Maxpool | ||
| ResUnit | ||
| ResUnit | ||
| Maxpool | ||
| ResUnit | ||
| ResUnit | ||
| Maxpool | ||
| GAP | ||
| FC |
The semantic embedding is achieved by the other branch which is a attribute learning subnet as illustrated in III-B. The subnet outputs a -dimensional feature vector . Moreover, a joint embedding space is learned where both the attribute vectors and the visual feature vectors can be projected. The authors in [16] has proved that the visual feature space is the most appropriate embedding space, which can alleviate the hubness problem [16]. Therefore, a transformation subnet is designed to convert attribute vectors into vectors in the same dimensional space as the visual feature vectors. Specifically, it takes the -dimensional attribute representation vector of the attribute learning subnet as input, and after going through two FC layers and the ReLU activation outputs a D-dimensional semantic embedding vector . In order to show the process of the transformation subnet in detail, the output can be expressed as
| (10) |
where and are the weights to be learned in the first FC layer and the second FC layer. The rectified linear units is used as the activation function to introduce non-linearity into the network.
Each of the FC layer has a parameter regularization loss. The two branches are linked together by a least square embedding loss which aims to minimise the discrepancy between the visual feature vector and its class representation embedding vector in the visual feature space. The loss function is given as
| (11) | ||||
where is the number of training samples and is the hyper-parameter weighting the strengths of the two parameter regularization losses against the embedding loss.
As is shown in Fig. 3, different from the traditional pure data-driven architecture, our proposed scheme constructs a embedding space where both visual features and attribute features can be projected. The integration of attribute features can improve the performance of the model in low SNRs. Meanwhile, the existence of two pre-trained models makes end-to-end training only be required for the transformation model. Therefore, the training speed of our proposed scheme can be extremely high. Moreover, due to the introduction of attribute knowledge, we can reduce the requirements for visual model data. Lastly, different from abstract visual features, the attribute features labels are composed of deterministic binary variables which have clear physical implications.
IV Simulation Results
In this section, simulation results are presented to evaluate the performance of our proposed AMC scheme and compare with the benchmark schemes. The simulation settings are based on the works in [4]. The performance is measured on a system equipped by a 3.00-GHz CPU, 16GB RAM, and a single NVIDIA GeForce GTX 1660SUPER GPU.





For the attribute learning model, we train it by using the stochastic gradient descent (sgd) optimizer with an initial learning rate of 0.01, and a momentum of 0.9 for 40 epochs. Different from the training of visual model, the attribute learning is not a classification problem. Therefore, the mean squared error function is utilized to measure the gap between the model output and the true attribute label.
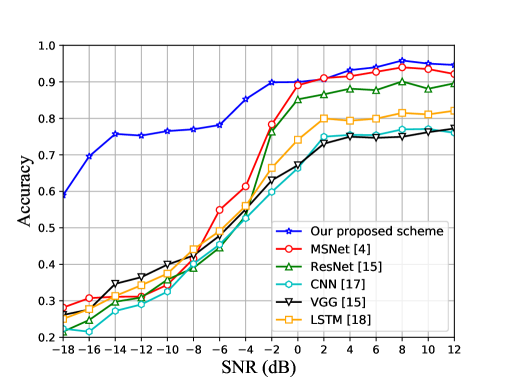
The classification performance is operated on a publicly available dataset, which is presented on the website 111https://www.deepsig.ai/datasets.. Fig. 4 shows the classification performance comparison of our proposed scheme with those achieved by several representative DL-based models for AMC including MSNet [4], ResNet [15], VGG [15] and LSTM [18]. It is evident that the proposed scheme is superior to other traditional models, and it can provide 2% gains over ResNet, 5% gains over MSNet, 17% gains over LSTM and VGG at 12dB. Moreover, our proposed scheme has superior classification performance in low SNRs. It can reach about 60% accuracy when the SNR is -20dB, and it can achieve over 70% accuracy when the SNR is over -14dB, while the performance of ResNet is only about 25% at -20dB and 32% at -14dB.
The comparison of the confusion matrices between MSNet [4] and our proposed scheme is shown in Fig. 5. It is seen that the proposed scheme has less confusion compared to other traditional models. Specifically, two modulation formats perform worse in MSNet, which are 16QAM and 64QAM as shown in Fig. 5(a) and Fig. 5(b), respectively.
Fig. 6 illustrates the training loss of each model for AMC. The proposed scheme can achieve a lower loss in the training set compared to the other models and obtains a higher convergence speed than other models. Specifically, our proposed model can achieve convergence at only about the th epoch. This is reasonable, since the pre-trained subnets can greatly reduce the end-to-end training time.
To further demonstrate the effectiveness of the proposed scheme, we visualize the extracted feature and convert them into a two-dimensional scatter map [19] shown in Fig. 7. It can be seen that 16QAM and 64QAM are mixed together in MSNet [4]. In contrast, the features between 16QAM and 64QAM are much more discriminative in our proposed scheme. This indicates that our proposed scheme can achieve better classification performance for high-order modulations.
V Conclusion
A novel data and knowledge dual-driven AMC scheme based on RFML was proposed by exploiting attribute features and visual features. The attribute learning model was utilized to learn different attribute representations. The transformation model was used to convert attribute features into visual space to embed with the output of visual model. Simulation results demonstrated that our proposed scheme is superior to other benchmark schemes in terms of the classification accuracy especially in the low SNR. Moreover, the confusion between high-order modulations is reduced compared with other benchmark schemes.
References
- [1] Q. Wu, G. Ding, Y. Xu, S. Feng, Z. Du, J. Wang, and K. Long, “Cognitive Internet of Things: A new paradigm beyond connection,” IEEE Internet Things J., vol. 1, no. 2, pp. 129-143, Apr. 2014
- [2] G. Ding, J. Wang, Q. Wu, Y.-D. Yao, F. Song, and T. A. Tsiftsis, “Cellular-base-station-assisted device-to-device communications in TV white space,” IEEE J. Sel. Areas Commun., vol. 34, no. 1, pp. 107-121, Jan. 2016.
- [3] F. Hameed, O. A. Dobre, and D. C. Popescu, “On the likelihood-based approach to modulation classification,” IEEE Trans. Wireless Commun., vol. 8, no. 12, pp. 5884-5892, Dec. 2009.
- [4] H. Zhang, F. Zhou, Q. Wu, W. Wu, and R. Q. Hu, “A novel automatic modulation classification scheme based on multi-scale networks,” IEEE Trans. Cognit. Commun. Netw., pp. 1-1, 2021.
- [5] S. Huang, Y. Yao, Z. Wei, Z. Feng, and P. Zhang, “Automatic modulation classification of overlapped sources using multiple cumulants,” IEEE Trans. Veh. Technol., vol. 66, no. 7, pp. 6089-6101, Jul. 2017.
- [6] F. Cai and V. Cherkassky, “Generalized smo algorithm for svm-based multitask learning,” IEEE Trans. Neural Netw. Learn. Syst., vol. 23, no. 6, pp. 997-1003, Jun. 2012.
- [7] W. Wei and J. Mendel, “Maximum-likelihood classification for digital amplitude-phase modulations,” IEEE Trans. Commun., vol. 48, no. 2, pp. 189-193, Feb. 2000.
- [8] Fuhui Zhou, Yuhang Wu, and Qihui Wu, “Resource allocation based on deep reinforcement learning for wideband cognitive radio networks,” URSI GASS 2021, to be published.
- [9] Y. Chen, W. Shao, J. Liu, L. Yu, and Z. Qian, “Automatic modulation classification scheme based on lstm with random erasing and attention mechanism,” IEEE Access., vol. 8, pp. 154290-154300, Aug. 2020.
- [10] Z. Zhang, H. Luo, C. Wang, C. Gan, and Y. Xiang, “Automatic modulation classification using cnn-lstm based dual-stream structure,” IEEE Trans. Veh. Technol., vol. 69, no. 11, pp. 13521-13531, Nov. 2020.
- [11] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 770-778.
- [12] Y. Wang, J. Yang, M. Liu, and G. Gui, “Lightamc: Lightweight automatic modulation classification via deep learning and compressive sensing,” IEEE Trans. Veh. Technol., vol. 69, no. 3, pp. 3491-3495, Mar. 2020.
- [13] L. J. Wong, W. H. Clark IV, B. Flowers, R. M. Buehrer, A. J. Michaels, and W. C. Headley, “The rfml ecosystem: A look at the unique challenges of applying deep learning to radio frequency applications,” arXiv preprint arXiv:2010.00432, 2020.
- [14] W. H. Clark, V. Arndorfer, B. Tamir, D. Kim, C. Vives, H. Morris, L. J. Wong, and W. C. Headley, “Developing RFML intuition: An automatic modulation classification architecture case study, ” in Proc. IEEE Military Commun. Conf., Oct. 2019, pp. 292-298.
- [15] T. J. OShea, T. Roy, and T. C. Clancy, “Over-the-air deep learning based radio signal classification,” IEEE J. Sel. Topics Signal Process., vol. 12, no. 1, pp. 168-179, Feb. 2018.
- [16] L. Zhang, T. Xiang, and S. Gong, “Learning a deep embedding model for zero-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 2021-2030.
- [17] T. J. OShea, J. Corgan, and T. C. Clancy, “Convolutional radio modulation recognition networks,” in Proc. Int. Conf. Eng. Applications of Neural Networks. Springer, 2016, pp. 213-226.
- [18] S. Rajendran, W. Meert, D. Giustiniano, V. Lenders, and S. Pollin, “Deep learning models for wireless signal classification with distributed low-cost spectrum sensors,” IEEE Trans. Cognit. Commun. Netw., vol. 4, no. 3, pp. 433-445, Sep. 2018.
- [19] Q. Wu, T. Ruan, F. Zhou, Y. Huang, F. Xu, S. Zhao, Y. Liu, and X. Huang, “A unified cognitive learning framework for adapting to dynamic environment and tasks,” IEEE Wireless Commun., to be published, 2021.