Data-driven Approaches to Surrogate Machine Learning Model Development
Abstract
We demonstrate the adaption of three established methods to the field of surrogate machine learning model development. These methods are data augmentation, custom loss functions and transfer learning. Each of these methods have seen widespread use in the field of machine learning, however, here we apply them specifically to surrogate machine learning model development. The machine learning model that forms the basis behind this work was intended to surrogate a traditional engineering model used in the UK nuclear industry. Previous performance of this model has been hampered by poor performance due to limited training data. Here, we demonstrate that through a combination of additional techniques, model performance can be significantly improved. We show that each of the aforementioned techniques have utility in their own right and in combination with one another. However, we see them best applied as part of a transfer learning operation. Five pre-trained surrogate models produced prior to this research were further trained with an augmented dataset and with our custom loss function. Through the combination of all three techniques, we see an improvement of at least in performance across the five models.
keywords:
Nuclear , Machine Learning , Graphite , Advanced Gas-cooled Reactor , Data Science , Data Analysis , Surrogate Model , Convolutional Neural Network , Regression , Supervised Learning , Data Augmentation , Transfer Learning , Loss Function ,This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible.
1 Introduction
A machine learning surrogate (MLS) is a model which aims to explain natural or mathematical phenomena which can already be explained using an existing model. Using data from the original model, machine learning techniques are used to produce an optimised MLS model. The advantages of an MLS include increased computational efficiency when generating model outputs, with the trade-off being reduced accuracy. Once developed and trained, machine learning models (including an MLS) can produce new data instances almost instantly using a standard computer, whereas generating the same information using the original model and equivalent hardware may require hours or days of computational effort. The reduction in accuracy between an MLS and an original model must be quantified on a case-by-case basis and assessed on whether it is acceptable for practical use.
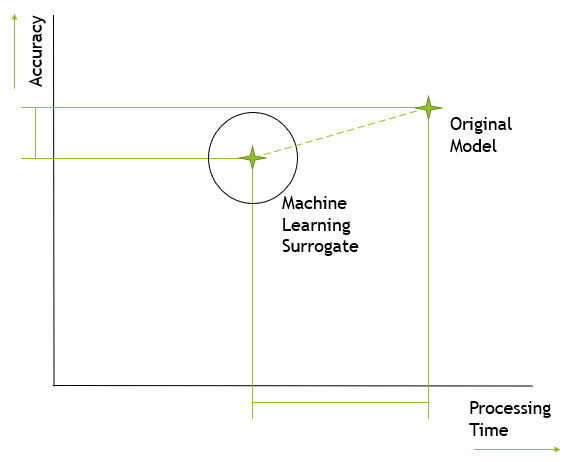
Previous research works have dealt with the production of MLS in areas such as material properties prediction [Nyshadham et al. (2019)] and [Asteris et al. (2021)], with a recent work [Jones et al. (2022)] focusing on seismic analysis for nuclear graphite cores. It is the MLS model from this latest research work that will be focused on in this paper. In the afforementioned works, a strong focus on neural networks [Gurney (1997)] is seen, including convolutional neural networks (CNNs).
Despite the motivation for the production of MLS models being to reduce the need for expensive production of data, a large amount of this data is required to train such a model. A machine learning model trained on an insufficient number of data instances may result in overfitting [Hawkins (2004)]. Some techniques were employed in the aforementioned paper, including randomised layer dropout [Srivastava et al. (2014)], to counteract the effects of overfitting .
A common technique used to improve model performance given a limited dataset is to manipulate existing data instances in a process known as data augmentation [Perez and Wang (2017)]. This approach is commonly employed in machine learning applications involving image recognition and analysis [Hansen (2015)], with techniques such as mirroring and rotation used to increase the number of data instances in a dataset.
Another commonly encountered problem during machine learning model development is dataset bias. In this situation, the dataset used to train the model is weighted towards a particular region of the input and/or output space. Alternatively, the dataset may be sparse in a particular region of the data space i.e. there may only be few data examples for a part of the data input or output continuum. Several methods can be employed to counteract the problem of dataset bias, including emphasising underrepresented data samples to a greater degree. We may instead use a loss function during model training which is designed to correct for dataset bias.
A third problem encountered when training neural networks is the computational cost associated with their development and optimisation. This is particularly problematic when the problem space is complex - such as it is in this research. Instead of starting from scratch, we may use models produced from previous research works as a starting point during the development of neural networks for our own research. Through a process of transfer learning [Torrey and Shavlik (2010)] we can adapt the model architecture, as well as the optimised weights, generated during previous works. By using transfer learning we may be able to make our model development process more efficient by reducing the time and computational resource needed to optimise a model for our purposes.
A research question to be investigated and answered by this paper is whether data augmentation can be applied to problems such as machine learning surrogates. To this end, a framework will be developed to apply image manipulation techniques to the dataset used in the aforementioned graphite core model. In addition, we will investigate whether the use of custom loss functions and transfer learning can improve model performance.
2 Background
2.1 Advanced Gas-cooled Reactors and the Parmec Model
The computational model Parmec [Koziara (2019)] is the underlying model which was the subject of a MLS model in [Jones et al. (2022)] and the same problem and base dataset is considered in this work. Parmec is employed to simulate the seismic response of the graphite core within the UK’s advanced gas-cooled reactor (AGR). This model consists of a simplified 3-dimensional representation of the AGR graphite core, including the positional arrangement of the graphite bricks and other components. Parmec can be used to simulate a range of different seismic scenarios with the resulting component translation, rotation etc. being calculated by the model.
In addition to the seismic configuration, another input to the Parmec model is configuration of cracked fuel bricks within the graphite core. Due to years of exposure to high temperatures and irradiation, some of the fuel bricks within the reactor are cracking, causing them to break into two pieces. The presence and configuration of these cracks has an impact on the reaction of the core to seismic loading. It is possible that up to 40% of the fuel bricks will eventually crack, although it is difficult to determine or predict where and when cracks will occur.
The relationship between crack configuration and seismic response of core components is complex, hence the Parmec model consists of many thousands of parameters and equations. In addition, there are over possible permutations of crack configuration, assuming 40% cracking. With each configuration requiring around 2 hours to compute the seismic response via Parmec, it is clearly impractical to generate data for even a small percentage of them. Instead, industry practice is to generate random configurations of cracks, passing each through Parmec in order to build up a stochastic distribution of the seismic response.
2.2 Previous Machine Learning Surrogate Model of Parmec
In previous machine learning assessments of AGR graphite core seismic analysis [Jones et al. (2022)], each crack configuration is considered an individual data instance, with the encoding of cracked bricks being the input features and the response of core components to the earthquake being the output labels. The Parmec software generates a time-history of the earthquake response for all of the thousands of components within the core. For the sake of simplicity and focus, the MLS model was trained to predict the earthquake response for a single interstitial brick at a single time frame - see Figure 2.
To summarise the features of the MLS, each instance has an input size of 1988 with this being the number of fuel bricks within the AGR graphite. This input was arranged into a 3D tensor which retains physical positional relationships within the actual AGR graphite core (Figure 3). Each element is either a 1, -1 or 0 representing a cracked brick, uncracked brick or ‘empty’ position. The 3-dimensional encoding of the input features also allows the dataset to be used with a convolutional neural network [Albawi et al. (2017)] which was found to be the best performing type of machine learning model.
For the aforementioned study, a dataset of approximately 8300 instances was created using the random crack pattern generator and the Parmec software. Out of these instances, 6300 (75%) were used for training with the remaining 2000 samples retained for testing.

2.3 Data Augmentation
Data augmentation is frequently employed in classification problems within the field of machine learning [Shorten and Khoshgoftaar (2019)], where the model predicts a discrete category for each dataset instance. A classic example of classification is in computer vision, where a 2D or 3D tensor representing an image is used to predict a category that is depicted. For example, models trained on the ImageNet dataset [Deng et al. (2009)], which contains millions of images each representing one of 1000 discrete classifications, attempt to categorise the image depicted in an instance it is presented with. Classification is in contrast to regression problems, where there is a continuous, rather than discrete, output variable.
When dealing with problems such as ImageNet classification, performance is constrained by the size of the dataset. Model performance tends to improve with a larger number of training examples. A related constraint is dataset bias: regardless of the overall number of examples in the entire dataset, if one or more classes exhibits a significantly lesser or greater number of examples than the rest, model performance may be inhibited. Should there be a lack of examples for one particular class, not only will the model have difficulty identifying examples of this class, but performance for other classes will also be impacted.
Both of the aforementioned constraints tend to cause the phenomenon known as overfitting [Hawkins (2004)], where the model optimises too closely to the training data, including any noise or unrelated variability. There exist several methods to alleviate the effects of overfitting, including randomised nodal dropout [Srivastava et al. (2014)]. A commonly used solution to overfitting within image classification is data augmentation, where image manipulation techniques are used to generate additional data from existing examples.
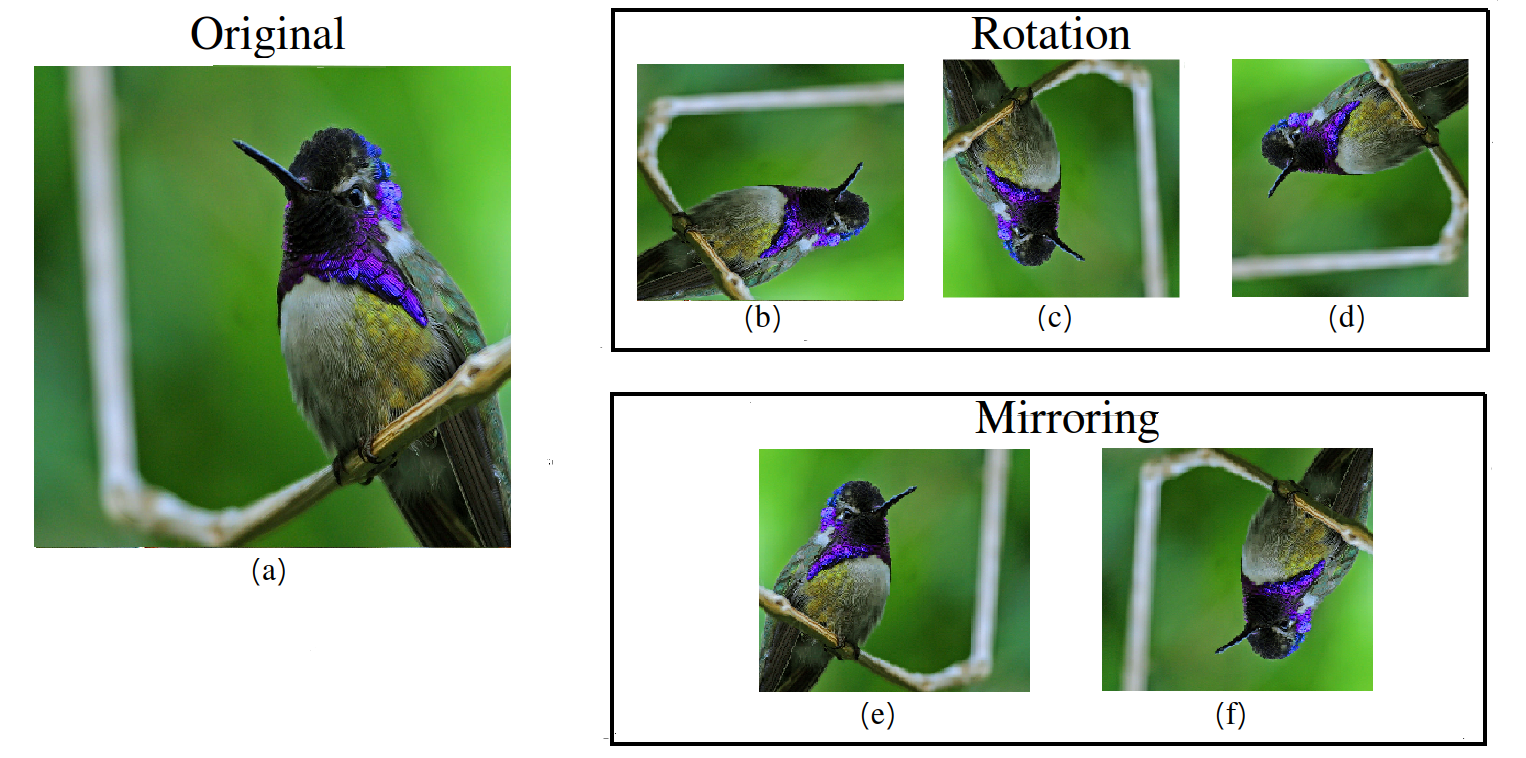
Figure 4 shows an example of a data augmentation process on a single image instance. The image on the left of this figure would correctly be classified as a bird. This image can be used to generate five additional instances of the same class: three by rotation and two by mirroring. By applying this process to all images within a dataset, the number of available training instances can be multiplied by a factor of seven.
From the example, it can be seen that data augmentation techniques are highly suited to problems where the data is structured as a 2D or 3D tensor (such as greyscale or colour images, respectively). By extension, data augmentation is highly effective for applications in which localised or spatial patterns are of importance, for example where CNNs are employed. It should be noted at this point that the research work that we attempt to build on here employs 3D encoding of data as well as CNNs.
2.4 Custom Loss Function
One of the most important model metrics to be selected during machine learning model development is the loss function. This function is used during training to calculate the difference between the ground truth and model prediction (known as the loss rate). Further, the derivative of the loss rate is used to iteratively update the model weights during the training and optimisation process.
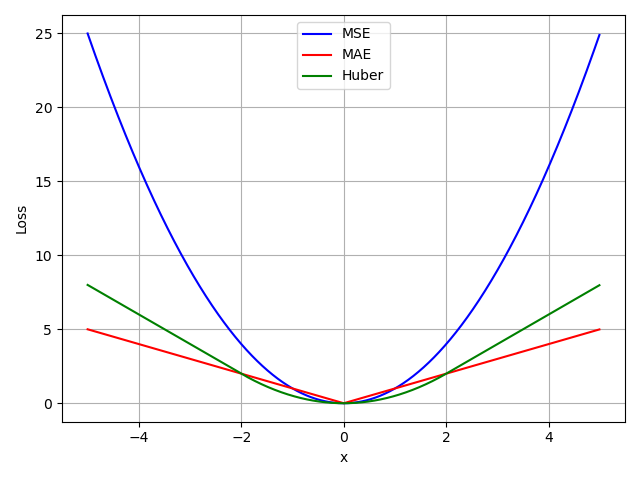
Typically, one of only a few loss functions will be selected for regression model training. A common selection is the mean squared error [Wallach and Goffinet (1989)] or one of its derivatives such as root mean squared error. Other options include mean absolute error [Chai and Draxler (2014)] and Huber loss [Huber (1964)] which was found to be optimal in the preceding research work on this topic [Jones et al. (2022)].
An issue encountered in the aforementioned preceding research was that the data was not evenly distributed throughout the data space. The output data generated by the Parmec model tends to be distributed around a central modal value, with increasingly fewer examples towards the extremes of the data space. This in turn results in a model which tends to over-predict values in the lower part of the data space, and under-predict those in the upper part (Figure 5).
This problem can be compared with the issue of class imbalance encountered in the field of machine learning classification [Johnson and Khoshgoftaar (2019)]. Much literature has been written on the subject of correcting for data imbalance in classification, with a recent work [Sarullo and Mu (2019)] using a weighted loss function.
Conversely, for regression based problems, research attention has been scarce by comparison. Some recent works [Branco et al. (2017)][Yang et al. (2021)] note the lack of research on imbalanced regression have proposed solutions to problems caused by gaps or rarefactions in the data space. The solutions proposed involve the application of smoothing or dataset resampling. We note that the imbalance featured in these research works is not of the relatively smooth trend seen at the bottom of Figure 5.
Whereas the data distribution in the aforementioned research papers contain discontinuities and irregular gaps, our dataset follows a regular pattern. This makes the methods explored previously in this area potentially unsuitable for the research problem at hand. If we wish to counteract the data imbalance problem in the research at hand, a bespoke custom loss function will have to be developed.
2.5 Transfer Learning
Transfer learning is a machine learning technique that focuses on using already trained models to serve a purpose beyond their original intent. Often in machine learning, models are trained from scratch, a process that consumes significant resources in terms of time and computation to achieve optimal performance. Transfer learning can serve to make the process more efficient and less resource intensive by using the knowledge from the pre-trained models in the training process.
In [Jones et al. (2022)], an optimal model architecture was developed for the purpose of surrogation of a nuclear engineering model. Using this architecture and the training data, the parameters of the model were optimised from random starting weights. As training started from random weights, the process of model optimisation was repeated multiple times. The best performing models from this study, along with their pre-trained weights, can be transferred to this study as a starting point for exploitation of the methods described in subsections 2.3 & 2.4.
3 Preparation
3.1 Image Manipulation Techniques

Recall from Figure 3 that the input features for this research problem is a 3D tensor representing the position of cracked fuel bricks within a given instance. This tensor is comparable to that of a colour image such as the one shown in Figure 4. Being a tensor of a similar encoding to that in the aforementioned figure, the same image manipulation techniques can also be applied to the tensor for this research problem.
Recall also from Figure 2 that the output labels for this research problem are continuous values representing displacement in the central brick of the core. Note also from the aforementioned figure that the overall data space from which the output variables are extracted is planar and can be expressed as a 2D tensor. For a given instance i.e. input/output pair, we can apply any of the rotational or mirroring techniques shown in Figure 4. Note that if we rotate or mirror about the vertical axis at the centre-point of the core, the encoding order of the input features will change, but the output label will not (as it represents the top brick in the central channel). Hence, data augmentation for the dataset in this study will create new instances with restructured feature tensors, but the same output label value - see Figure 6.
If we apply rotation (90°, 180°and 270°) and mirroring (vertical and horizontal) to all examples in our dataset, we can multiply the available number of instances by a factor of six.
As mentioned in subsection 2.3, the motivation behind using image manipulation techniques to create an augmented dataset is based on the conjecture that symmetries do exist in the Parmec data space. What is the justification behind the belief that rotational and symmetric manipulations of Parmec inputs would yield similarly transformed outputs? There are three lines of evidence that can be used to support the validity of this process:
-
1.
AGR Design: The design of the AGR (and the Parmec model that is based on it) contains four-fold symmetry [Nonbøl (1996)]. This effectively means that each quarter of the AGR (and Parmec) model is a rotation or mirror of the others. However, this is an incomplete justification as the simulated earthquake always impacts the model on one particular point on its periphery i.e. it is not symmetric.
-
2.
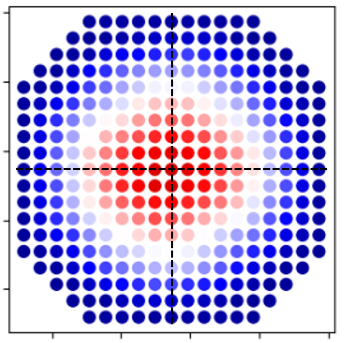
Dataset Observation: Observe Figure 7 which shows the average output value for each brick in the top layer of the Parmec model. It can be seen that there is a symmetry across both the vertical and horizontal centre-lines. This pattern is of the same four-fold symmetry as mentioned in the first bullet-point.
-
3.
Augmented Equivalent Data: Through the Parmec software package, we have the benefit of creating ground truth equivalents of augmented data. For a given ground truth example, we can manipulate the inputs according to one of the transformations shown in Figure 6 and then feed them through the Parmec model. Then we can compare the outputs generated by Parmec and our non-Parmec data augmentation technique.
We performed the process described in bullet point 3 above for two base instances, applying each of the five manipulation techniques on the inputs and then using these to generate labelled examples using Parmec. Simultaneously, we apply all five of our non-Parmec data augmentation techniques to the inputs and outputs of both examples. Comparing the outputs of both techniques, we notice agreement when applying rotation by 180°and when mirroring about the horizontal axis.
The validity of the augmentation technique discussed here will ultimately be tested through an experimental machine learning process. We can train two machine learning models of the exact same architecture and parameters: one with a dataset augmented with and one with the base dataset. A separate testing set of only non-augmented instances will be retained for testing both models which both models can best tested against. The performance of each image manipulation method can be evaluated in this way.
3.2 Weighted Loss Function
In [Jones et al. (2022)], the effectiveness of using three alternative loss functions were compared. These were the mean squared error (MSE), mean absolute error (MAE) and the Huber loss [Huber (1964)]. A model trained using the Huber loss function was found to produce the best performance. However, the other two loss functions produced a similar, albeit poorer, performance. Each of the three loss functions (Figure 8) each have their own strengths and weaknesses, with MSE heavily weighting outlying values, MAE proportionately weighting outliers and Huber being somewhere in between. As mentioned in subsection 2.4, our base dataset is highly centred around a central value with a double tailed distribution. Regardless of the loss function used, the resulting model is biased towards the central region, resulting in difficulty predicting at the upper and lower extremes (Figure 5).
We propose a loss function tailored to this dataset which applies an adjustment factor that is a function of model prediction distance from a central value.
| (1) |
| (2) |
| (3) |
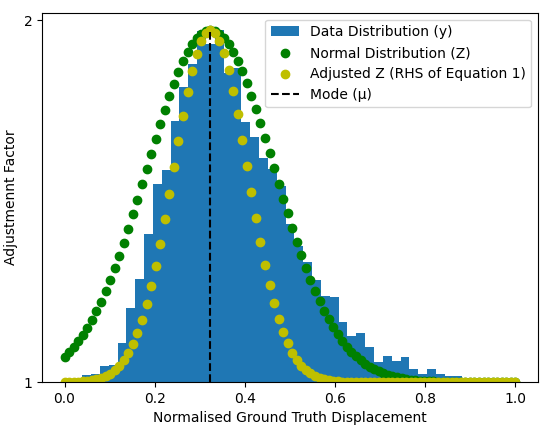
As can be seen from (1), the regular loss, which takes the mean of the square difference between the ground truth and the model prediction . This is then adjusted by the factor , as given by (2) and is calculated for each instance . This term is based on the probability density function which in this case describes a Gaussian distribution. This Gaussian distribution is fit to that of our data distribution (Figure 9) by use of the mode and standard deviation . This summation is scaled through division by the square of , which denotes the maximum such . Also included is the magnitude coefficient which will be optimised experimentally.
This function results in a strong adjustment for predictions made near the mode, quickly dropping off to one as we move away in either direction. This adjusted loss function penalises predictions made near the region where there is a large concentration of training data and instead pushes it towards the extremes. This equation is designed with the intention of counteracting the bias in the data distribution.
3.3 Pre-Trained Model Transfer
In [Jones et al. (2022)], multiple machine learning models were developed and trained on the dataset. In the best performing case, a convolutional neural network was utilised with a refined architecture. Optimal performance was achieved when including inputs representing the cracking status of the top 3 levels of the AGR core. The model was used to predict displacements in a single brick on the top level of the core at a single time point during an earthquake - the distribution of these outputs for the dataset can be seen in Figure 9.
Out of all of the models produced in the aforementioned paper, the best performing five models were obtained as well as their optimised weights. We evaluated each of these models, numbered M1 to M5, against a testing dataset with the results shown in Table 1.
| Model | Test Performance (MSE) |
|---|---|
| M1 | 9.28e-3 |
| M2 | 9.25e-3 |
| M3 | 9.22e-3 |
| M4 | 9.68e-3 |
| M5 | 9.48e-3 |
These models will form the basis of transfer learning experiments through refinement using the methods described in subsections 3.1 & 3.2. As mentioned in subsection 2.5, transfer learning can reduce the time and computational resources required compared to starting from randomised weights. Transferring models and weights in this case will not only reduce resource requirements but also be interesting from a research perspective.
4 Experimental Evaluation Process
4.1 Augmentation
We began by evaluating the effectiveness of each image manipulation technique mentioned in subsection 2.3. To do this, we augmented the base dataset using each of the five image manipulation techniques. This resulted in six available data sets: three using rotation, two using mirroring and the original unaugmented set. A summary of the datasets is shown in Table 2.
| Dataset No. | Description |
|---|---|
| D0 | Original |
| D1 | Rotation 90° |
| D2 | Rotation 180° |
| D3 | Rotation 270° |
| D4 | Mirror Vertical |
| D5 | Mirror Horizontal |
For the purposes of comparison, a model design was selected which is highly simplified compared to that utilised in [Jones et al. (2022)]. This simplification was made in order to reduce computational demands and to allow obtainment of results quickly. As our intention at this point is to compare the effectiveness of using different datasets and not overall optimisation, a simplified model is acceptable for this purpose.
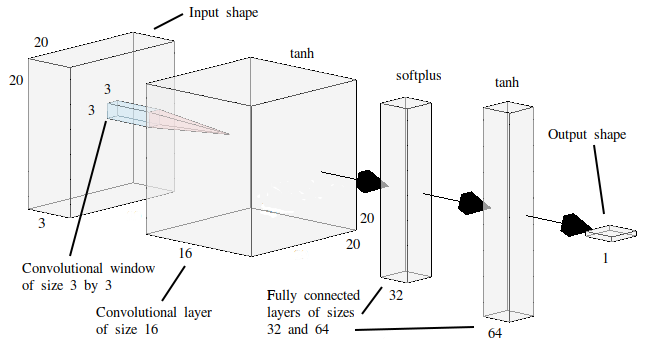
The neural network architecture that was selected for this part of the research can be seen in Figure 10. Between the input and output layers, there is one convolutional layer followed by two dense layers. Activation functions and the use of dropout was utilised based on previous experience. The Huber loss function was used for back propagation and optimisation during training.
| Experiment No. | Included Datasets |
|---|---|
| E1.0 | D0 |
| E1.1 | D0 & D1 |
| E1.2 | D0 & D2 |
| E1.3 | D0 & D3 |
| E1.4 | D0 & D4 |
| E1.5 | D0 & D5 |
Six experiments were performed which involved training the model shown in Figure 10 individually with the datasets listed in Table 3. A 10% sample of the unagumented dataset (D0) was retained for validation and the model was trained until reaching convergence in terms of validation loss. For each experiment, the training process was repeated 32 times, each time initialising with randomised starting weights and dropout nodes. Each model was then evaluated using a separate testing dataset with the results given in subsection 5.1.1.
The datasets from the first phase were combined incrementally in the order of effectiveness as per Table 4. Again, each experiment is repeated 32 times. The results of this experiment are given in subsection 5.1.2.
| Experiment No. | Included Datasets |
|---|---|
| E2.1 | D0, D2 & D4 |
| E2.2 | D0, D2, D4 & D1 |
| E2.3 | D0, D2, D4, D1 & D3 |
| E2.4 | All |
4.2 Custom Loss Function
The purpose of this experiment is to evaluate the bespoke loss function defined in subsection 3.2 and shown in (1) & (2). The simplified architecture used in the previous section and shown in Figure 10 was again used in the experiments in this section. Initially, the unaugmented dataset (D0 from Table 2 was used for training and the same testing set as used in subsection 4.1 for evaluation.
In addition, we will make adjustments to the (1) & (2) and train models using the same parameters. This will not only allow us to refine the function but also understand the impact of each component of it. In this part of the experiment, the alpha coefficient () is set to unity.
| Experiment No. | Loss Function |
|---|---|
| E3.1 | As per (1) & (2) |
| E3.2 | Removing power of 2 |
| from and of (1) | |
| E3.3 | Removing mean term () from |
| from (1) | |
| E3.4 | Combining E3.2 & E3.3 |
The next phase of research involved the use of our custom loss function in combination with the augmented datasets as detailed in subsection 4.1. All experiments outlined in Table 6 use a training set which includes all augmented datasets as per E2.4. Further, we adjust the alpha coefficient in the remaining parts of this experiment, with having a value of unity in E4.0 (as it was in experiment 3). E4.1, E4.2 & E4.3 each increment by unity in turn.
As per experiments 1 & 2, we will repeat each experiment 32 times to account for the stochastic nature of weight initialisation. A summary of the experiments performed in this section is given in Table 5. The results are reported in subsection 5.2.
| Experiment No. | Loss Function |
|---|---|
| E4.0 | Dataset from E2.4 & loss function |
| from E3.1 | |
| E4.1 | As per E4.0 with of 2 |
| E4.2 | As per E4.0 with of 3 |
| E4.3 | As per E4.0 with of 4 |
4.3 Transfer Learning
Subsection 3.3 discusses five pre-trained models obtained using the methodology of a previous research work in this field [Jones et al. (2022)]. The performance of these models against a testing dataset is summarised in Table 1.
The intention of this experiment is to further train these models using the methods detailed in the previous two subsections (4.1 & 4.2). We begin by further training models M1 to M5 using our dataset enlarged by all augmentation methods as per E2.4. We then combine both augmentation and the use of our custom loss function as defined in Equations1 & 2. Finally, we perform the same further training of the transferred models using the conditions of the previous experiment but with an coefficient of two.
This experiment is summarised in Table 7. We repeat the training process six times for each part of the experiment as opposed to the 32 times performed in earlier experiments. This is as only the dropout nodes are randomly selected and we are not initialising he weights. The results of this experiment will be presented in subsection 5.3.
| Experiment | Description |
|---|---|
| No. | |
| E5.1 | Transfer learning with all |
| augmentation datasets added | |
| to training set as per E2.4 | |
| E5.2 | As per E5.1 but with the custom loss |
| function defined by (1) | |
| E5.3 | As per E5.2 but with |
| coefficient of 2 |
5 Results
This section outlines several experiments used to test the hypotheses described in previous sections as well as a summary of the results.
5.1 Augmentation
As mentioned in subsection 4.1, two augmentation experimental approaches are attempted. The first tests each image manipulation technique individually, the second exploits combinations of these techniques. The following two subsections report the results of these approaches, respectively.
5.1.1 Individual Augmentation
The results of this experiment are summarised in Table 8. The experiment which produced the optimal performance (i.e. lowest test loss) out of 32 repeats was E1.4 with 7.10E-3. This experiment also had the lowest mean loss (8.10E-3). All experiments which used an augmented dataset (E1.1 to E1.5) had a lower optimal performance than when using the unaugmented set only (E1.0). The mean values for all augmented experiments excluding E1.5 are below that of E1.0.
| Experiment | Optimal Test | Mean Test |
| No. | Performance | Performance |
| E1.0 | 1.06E-2 | 1.11E-2 |
| E1.1 | 7.70E-3 | 8.60E-3 |
| E1.2 | 7.20E-3 | 8.20E-3 |
| E1.3 | 7.90E-3 | 9.00E-3 |
| E1.4 | 7.10E-3 | 8.10E-3 |
| E1.5 | 1.02E-2 | 1.12E-2 |
5.1.2 Multiple Augmentation
The results of this experiment are summarised in Table 9. All experiments which combine augmented datasets (E2.1 to E2.4) have improved optimal and mean test performances over that of the unagumented experiment (E1.0). As datasets are are incrementally added, both the optimal and mean test performances see improvement.
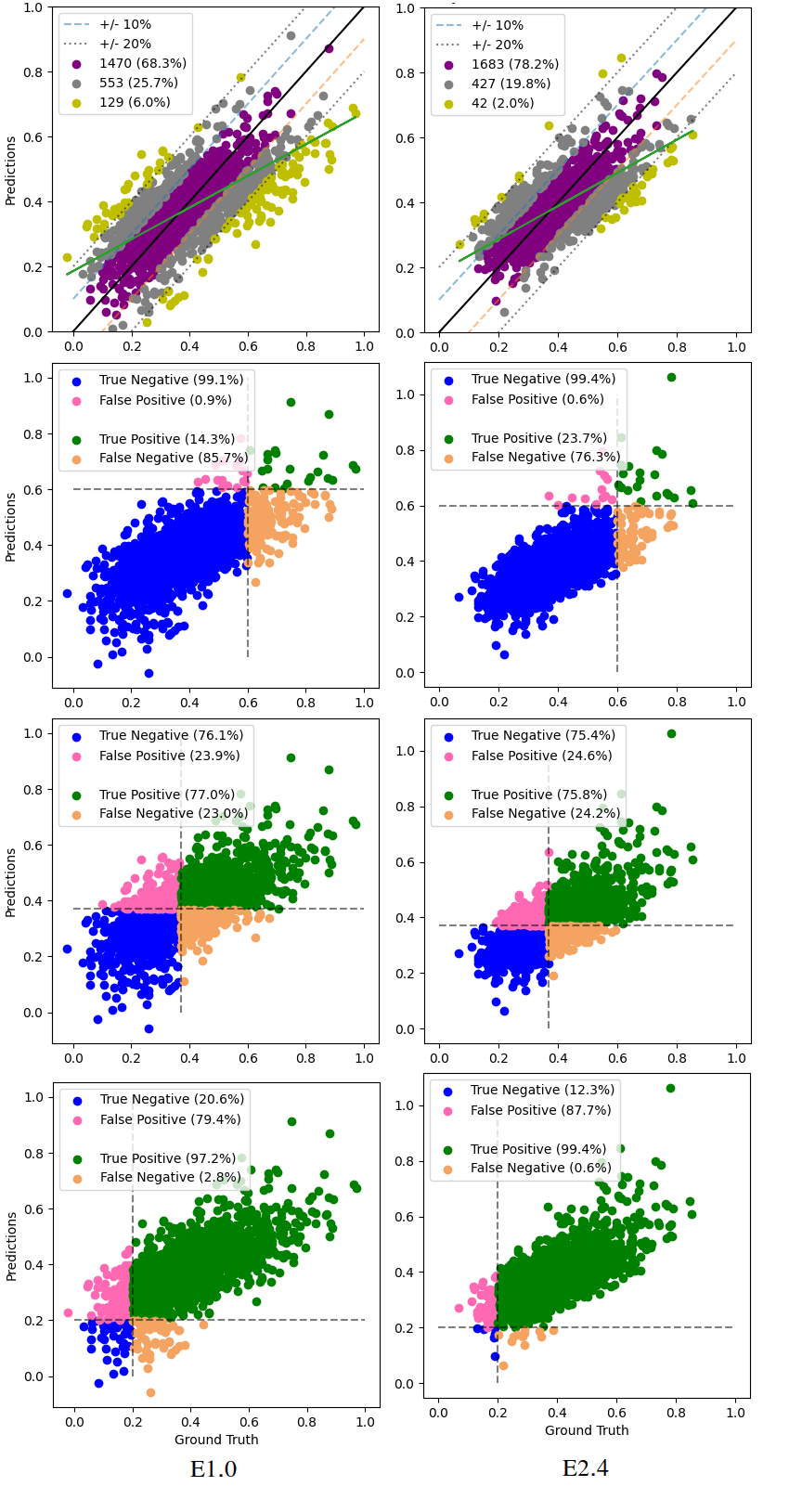
In Figure 11 we see a visualisation and comparison of the test performance of the optimal model from E1.0 & E2.4.
| Experiment | Optimal Test | Mean Test |
| No. | Performance | Performance |
| E1.0 | 1.06E-2 | 1.11E-2 |
| E2.1 | 7.30E-3 | 8.40E-3 |
| E2.2 | 6.60E-3 | 7.70E-3 |
| E2.3 | 6.60E-3 | 7.70E-3 |
| E2.4 | 6.50E-3 | 7.50E-3 |
5.2 Custom Loss Function
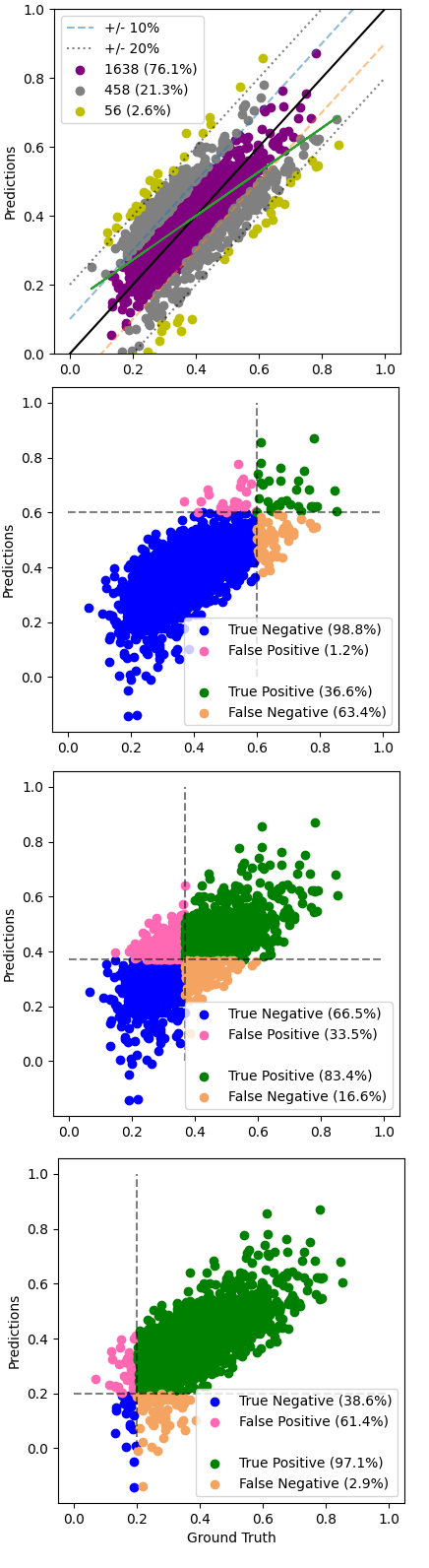
An experimental approach to the development of a loss function customised to the needs of the data problem at hand was discussed in subsection 4.2 with a summary of proposed experiments shown in Tables 5 & 6. The results are summarised in Tables 10 & 11 with a visual summary of E4.1 shown in Figure 12. All parts of experiment 3 show similar mean squared error to that of the baseline case (E1.0) with little variation. The addition of all augmented datasets to the training set (E4.0) yields similar model performance to that of experiment E2.4 which uses the baseline loss function. Increasing the coefficient above unity appears to increase mean squared error.
| Experiment | Optimal Test | Mean Test |
| No. | Performance | Performance |
| E1.0 | 1.06E-2 | 1.11E-2 |
| E3.1 | 1.08E-2 | 1.11E-2 |
| E3.2 | 1.06E-2 | 1.11E-2 |
| E3.3 | 1.08E-2 | 1.11E-2 |
| E3.4 | 1.07E-2 | 1.11E-2 |
| Experiment | Optimal Test | Mean Test |
| No. | Performance | Performance |
| E4.0 | 6.54E-3 | 7.50E-3 |
| E4.1 | 7.31E-3 | 7.88E-3 |
| E4.2 | 8.14E-3 | 9.65E-3 |
| E4.3 | 4.17E-2 | 4.41E-2 |
5.3 Transfer Learning
We discussed in subsection 4.3 that our five existing models with their pre-trained weights (M1 to M5) were further trained using methods developed in this research work. The performance of these models further trained on our augmented training set is shown in Table 12. Comparing these results with the original model performance (Table 1) it can be seen that a significant improvement has been achieved.
Looking next at transfer models trained with the aforementioned augmented dataset and also using our custom loss function, very similar performance results are seen (Table 13).
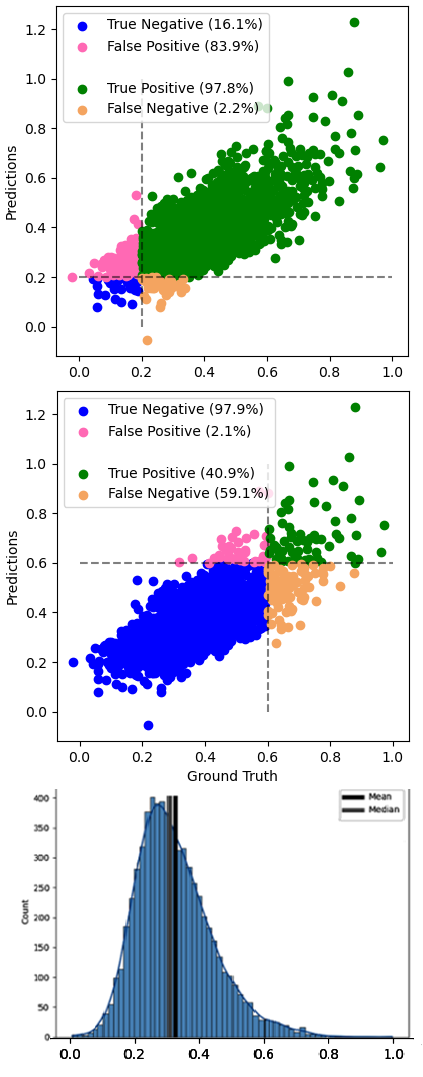
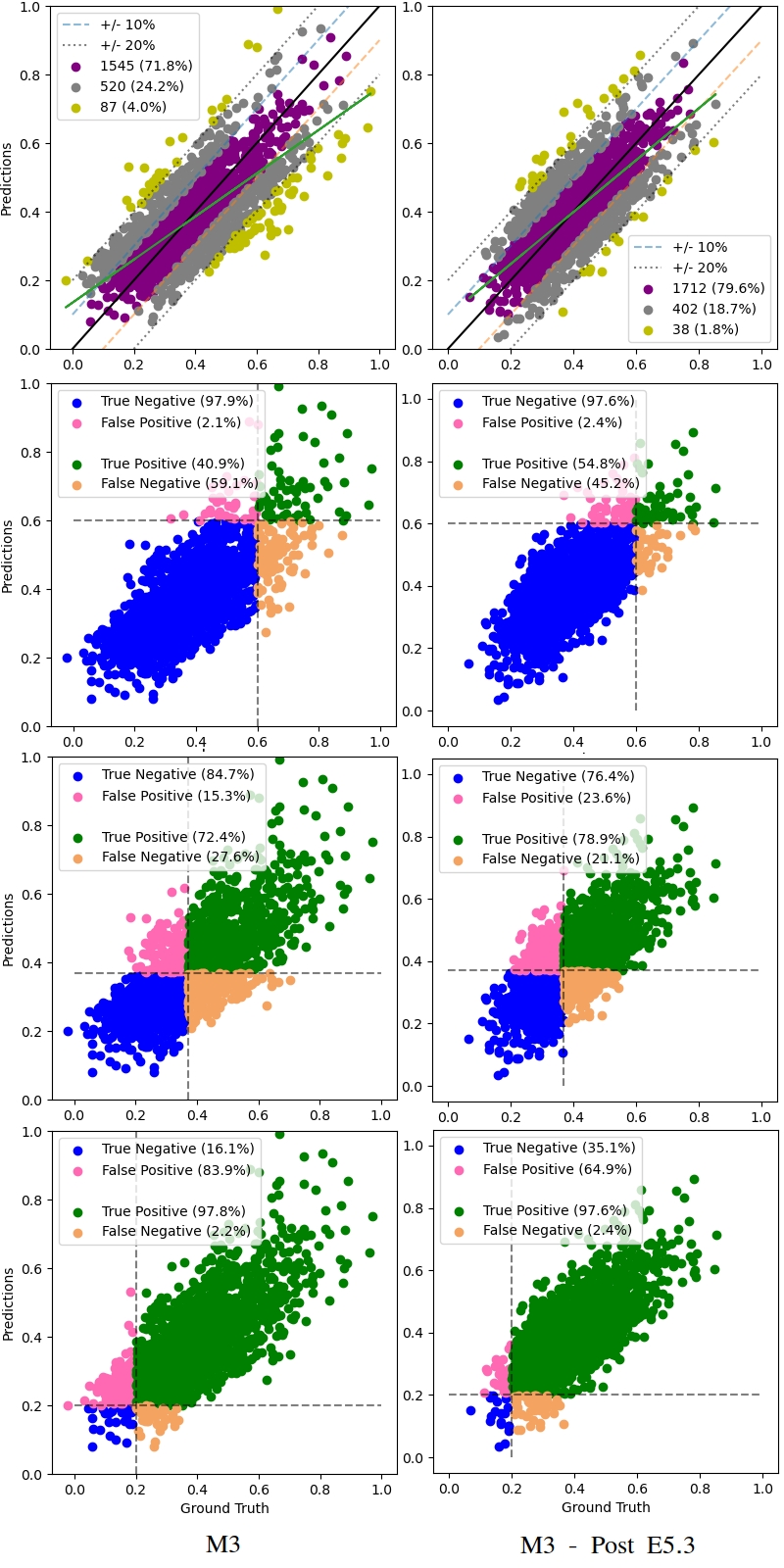
Finally, performing the same process as the aforementioned experiment but with the set to two, we see the performance of the models summarised in Table 14 with a visual comparison with the original M3 model seen in Figure 13 . Comparing E5.1 & E5.2 with E5.3, it initially appears to perform slightly worse in terms of MSE test loss. From the comparison figure, multiple improvements over the original model performance can be seen, including a closer fit with fewer examples falling outside of both the 10 and 20 point margins. Also, the model from E5.3 performs considerably better than its original counterpart at the upper and lower bounds of the data space.
| Model | Optimal Test | Mean Test |
|---|---|---|
| Performance | Performance | |
| M1 | 5.70E-3 | 6.20E-3 |
| M2 | 5.70E-3 | 6.20E-3 |
| M3 | 5.70E-3 | 6.10E-3 |
| M4 | 5.70E-3 | 6.20E-3 |
| M5 | 5.80E-3 | 6.20E-3 |
| Model | Optimal Test | Previous Test | Reduction |
|---|---|---|---|
| Performance | Performance | % | |
| M1 | 5.70E-3 | 9.28e-3 | 38.5 |
| M2 | 5.70E-3 | 9.25e-3 | 38.0 |
| M3 | 5.70E-3 | 9.22e-3 | 38.0 |
| M4 | 5.70E-3 | 9.68e-3 | 41.0 |
| M5 | 5.80E-3 | 9.48e-3 | 39.0 |
| Model | Optimal Test | Previous Test | Reduction |
|---|---|---|---|
| Performance | Performance | % | |
| M1 | 6.00E-3 | 9.28e-3 | 35.0 |
| M2 | 6.20E-3 | 9.25e-3 | 33.0 |
| M3 | 6.40E-3 | 9.22e-3 | 30.5 |
| M4 | 6.40E-3 | 9.68e-3 | 34.0 |
| M5 | 6.40E-3 | 9.48e-3 | 32.5 |
5.4 Analysis and Discussion
Looking first at the augmentation experiments (see subsection 5.1), we can see that all dataset augmentation has a positive effect on model performance. The results of experiment 1 (Table 8) show that the addition of some augmented datasets have more of an effect than others. For example, experiments E1.4 & E1.2 (rotation by 180°and vertical mirroring) both see about a one third reduction in mean squared error in comparison to the baseline (E1.0). It is interesting that the two best performing augmentations both make adjustments about the vertical axis. Conversely, the least performing augmented dataset (D5, included in E1.5) makes its adjustment about the horizontal axis.
It is clear from experiment 2 (Table 9) that the combination of all augmented datasets to the training set yields the best result (E2.4). A deeper analysis of the performance of the model produced in experiment E2.4 can be made by comparing the left and right parts of Figure 11. It can be seen that a model trained on all augmented datasets produces an overall better fit than when using no augmentation at all. Key indicators include the percentage of data within 20 points of the ground truth - 98% for the best performing model from E2.4 compared with 94% for a similar model from E1.0. The inclusion of all augmented datasets also appears to improve model prediction in the upper part of the data space - compare the second section from the top in Figure 11. However, the best model from E2.4 also performs worse on predictions in the lower part of the data space (compare bottom parts of the aforementioned figure).
Recall that the model architecture used in these experiments is highly simplified compared to previous works in this field. We should note at this point that the results of experiment 2 are an improvement even over those of highly complex models from [Jones et al. (2022)] - compare with the performance of M1 to M5, for example (Table 1). This suggests that dataset size is far more important in this problem space than model complexity and refinement.
From an initial assessment of experiment 3 (Table 10), it appears that the use a custom loss function as defined in Equations 1 & 2 has no advantage compared to the baseline (E1.0). All of the reported mean squared error test values are within a few percent of one another.
Experiment 4 combined our custom loss function with all augmented dataset from experiment 2. A model trained with the combined custom loss function and full augmented data set (E4.0) has a similar performance to that of a model when using the augmented set alone (E2.4). Increasing the value of the coefficient produces an increasing optimal and mean test performance.
So is there any value in the method evaluated in experiments 3 & 4? To answer this question, we must return to the motivation behind this method as detailed in subsections 2.4. We discuss the fact that our data space is concentrated in a central region with increasing rarefaction as we move away from it. Consequently, our models trained on this data performs poorly near the extremes as can be seen from the left part of Figure 11. Comparing the aforementioned figure with a visualisation of the optimal model from experiment E4.1 ( = 2), we can see significant improvements in model performance at the upper and lower extremes of the data space (Figure 12). This advantage comes at the expense of minor reductions in overall performance metrics, for example percentage of examples that are predicted outside of 20 percentage points of the ground truth (rising from 2.0% in E2.4 to 2.6% in E4.1). Whether or not this trade-off is of value will dependent on any practical application of the model. Nonetheless, it is likely that analysis using any such model would value good performance near the extremes as events in these regions are are most likely to impact safety. Therefore, we highlight the potential of this method and carry it forward into experiment 5.
We can see from the results of experiment 5.1 (Table 12) that further training our pre-trained models with an augmented dataset results in a significant performance uplift. For example, M1 sees its test mean squared error drop from 9.28e-3 to a minimum of 5.70e-3 - a performance improvement of about 38.5%. Combining the augmented dataset with our custom loss function and further training our base models appears to have little effect beyond what we saw in E5.1 (Table 13). Repeating E5.3 with an alpha coefficient of 2 initially appears to worsen performance, with test MSE rising from 5.70E-3 to between 6E-3 and 6.40E-3. However, on inspection of the visual results of E5.3 and comparison with those of E5.1 & E5.2, we see significantly improved performance at the upper and lower boundaries (above 0.6 and below 0.2 on the normalised scale of ground truth). Hence, we present the optimal results from E5.3 in Figure 13. Some notable improvements include a halving in the number of predictions that fall outside of the 20 percentage point margin (4.0% in the original M3 against 1.8% post E5.3), an increasing percentage of samples correctly placed over the 0.6 boundary (40.9% in the original M3 against 54.8% post E5.3) and finally a similar improvement below the 0.2 boundary (16.1% against 35.1%). As touched on earlier, in the field of machine learning for nuclear energy, this represents noteworthy progress as safety decisions are likely to concern events at the extremes i.e. very high or very low values.
6 Conclusion
In this research work, we demonstrate the adaption of three established approaches to the field of surrogate machine learning model development. The methods are data augmentation, custom loss functions and transfer learning. Each of these approaches have seen widespread use in the field of machine learning, however, here we apply them specifically to surrogate machine learning model development.
The machine learning model that forms the basis behind this work was intended to surrogate a traditional engineering model used in the UK nuclear industry. This model was built with the intention of increasing computational efficiency over the original model it surrogated. The performance of this model was hampered by poor performance due to limited training data. Here, we demonstrate that through a combination of additional techniques, model performance can be significantly improved.
Through exploitation of symmetry in the data and use of image manipulation techniques, we find that data augmentation techniques that make adjustments about the vertical axis are most effective, when applied individually. The combined use of all proposed augmentation methods in tandem produces the best performance uplift, suggesting that each of the methods provides at least some utility.
The second approach details an experimental refinement of a custom loss function specifically tailored to the training data distribution. We show that our custom loss function can improve performance at the extreme upper and lower parts of the data distribution - areas where previous models had performance difficulties.
We show that each of the aforementioned techniques have utility in their own right and in combination with one another. However, we see them best applied as part of a transfer learning operation. Five pre-trained surrogate models produced prior to this research were further trained with the augmented dataset and with our custom loss function. Through the combination of all three techniques, we see an improvement of at least in performance across the five models.
7 Future Work
Further work will aim to build on the methods developed in this research work. This includes refinement and fine tuning of the custom loss function developed in this paper. In addition, we will look at other techniques that could be used to improve model performance. One area with potential application to our research problem is active learning [Ren et al. (2021)]. This technique uses additional feedback within the learning process and is often employed in situations where training data is in short supply. As we have established in this research work, techniques which compensate for a lack of training data or gaps in training data can be used to improve performance. Therefore, active learning is a worthwhile area to study next.
8 Acknowledgments
The authors would like to acknowledge the assistance given by Research IT and the use of the Computational Shared Facility at The University of Manchester.
References
- Albawi et al. (2017) Albawi, S., Mohammed, T.A., Al-Zawi, S., 2017. Understanding of a convolutional neural network, in: 2017 International Conference on Engineering and Technology (ICET), Ieee. pp. 1–6.
- Asteris et al. (2021) Asteris, P.G., Skentou, A.D., Bardhan, A., Samui, P., Pilakoutas, K., 2021. Predicting concrete compressive strength using hybrid ensembling of surrogate machine learning models. Cement and Concrete Research 145, 106449.
- Branco et al. (2017) Branco, P., Torgo, L., Ribeiro, R.P., 2017. Smogn: a pre-processing approach for imbalanced regression, in: First international workshop on learning with imbalanced domains: Theory and applications, PMLR. pp. 36–50.
- Chai and Draxler (2014) Chai, T., Draxler, R.R., 2014. Root mean square error (rmse) or mean absolute error (mae). Geoscientific Model Development Discussions 7, 1525–1534.
- Deng et al. (2009) Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L., 2009. Imagenet: A large-scale hierarchical image database, in: 2009 IEEE conference on computer vision and pattern recognition, Ieee. pp. 248–255.
- Gurney (1997) Gurney, K., 1997. An introduction to neural networks. CRC press.
- Hansen (2015) Hansen, L., 2015. Tiny imagenet challenge submission. CS 231N .
- Harris et al. (2020) Harris, C.R., Millman, K.J., van der Walt, S.J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N.J., et al., 2020. Array programming with numpy. Nature 585, 357–362.
- Hawkins (2004) Hawkins, D.M., 2004. The problem of overfitting. Journal of chemical information and computer sciences 44, 1–12.
- Huber (1964) Huber, P.J., 1964. Robust estimation of a location parameter: Annals mathematics statistics, 35 .
- Hunter (2007) Hunter, J.D., 2007. Matplotlib: A 2d graphics environment. Computing in Science & Engineering 9, 90–95. doi:10.1109/MCSE.2007.55.
- Johnson and Khoshgoftaar (2019) Johnson, J.M., Khoshgoftaar, T.M., 2019. Survey on deep learning with class imbalance. Journal of Big Data 6, 1–54.
- Jones et al. (2022) Jones, H.R., Mu, T., Kudawoo, D., Brown, G., Martinuzzi, P., McLachlan, N., 2022. A surrogate machine learning model for advanced gas-cooled reactor graphite core safety analysis. Journal of Nuclear Engineering and Design .
- Koziara (2019) Koziara, T., 2019. Parmec documentation. URL: https://parmes.org/parmec/index.html. [Online; accessed 19-November-2020].
- Nonbøl (1996) Nonbøl, E., 1996. Description of the advanced gas cooled type of reactor (AGR). Technical Report. Nordisk Kernesikkerhedsforskning.
- Nyshadham et al. (2019) Nyshadham, C., Rupp, M., Bekker, B., Shapeev, A.V., Mueller, T., Rosenbrock, C.W., Csányi, G., Wingate, D.W., Hart, G.L., 2019. Machine-learned multi-system surrogate models for materials prediction. npj Computational Materials 5, 1–6.
- Perez and Wang (2017) Perez, L., Wang, J., 2017. The effectiveness of data augmentation in image classification using deep learning. arXiv preprint arXiv:1712.04621 .
- Ren et al. (2021) Ren, P., Xiao, Y., Chang, X., Huang, P.Y., Li, Z., Gupta, B.B., Chen, X., Wang, X., 2021. A survey of deep active learning. ACM computing surveys (CSUR) 54, 1–40.
- Sarullo and Mu (2019) Sarullo, A., Mu, T., 2019. On class imbalance and background filtering in visual relationship detection, in: 2019 International Joint Conference on Neural Networks (IJCNN), IEEE. pp. 1–8.
- Shorten and Khoshgoftaar (2019) Shorten, C., Khoshgoftaar, T.M., 2019. A survey on image data augmentation for deep learning. Journal of Big Data 6, 1–48.
- Srivastava et al. (2014) Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R., 2014. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research 15, 1929–1958.
- Torrey and Shavlik (2010) Torrey, L., Shavlik, J., 2010. Transfer learning, in: Handbook of research on machine learning applications and trends: algorithms, methods, and techniques. IGI global, pp. 242–264.
- Wallach and Goffinet (1989) Wallach, D., Goffinet, B., 1989. Mean squared error of prediction as a criterion for evaluating and comparing system models. Ecological modelling 44, 299–306.
- Yang et al. (2021) Yang, Y., Zha, K., Chen, Y., Wang, H., Katabi, D., 2021. Delving into deep imbalanced regression, in: International Conference on Machine Learning, PMLR. pp. 11842–11851.
- Zheng et al. (2015) Zheng, H., Yang, Z., Liu, W., Liang, J., Li, Y., 2015. Improving deep neural networks using softplus units, in: 2015 International Joint Conference on Neural Networks (IJCNN), IEEE. pp. 1–4.